sealbird
- 浏览: 596480 次
- 性别:

- 来自: 广州
-

最新评论
-
terry07:
java 7 用这个就可以了 Desktop desktop ...
关于java Runtime.getRunTime.exec(String command)的使用 -
HSINKING:
怎么设置打开的dos 窗口是指定的路径下
关于java调用bat文件,不打开窗口 -
liubang201010:
hyperic hq更多参考资料,请访问:http://www ...
hyperic-hq -
^=^:
STDIN_FILENO是unistd.h中定义的一个numb ...
深入理解dup和dup2的用法 -
antor:
留个记号,学习了
[转]用java流方式判断文件类型



相关推荐
O2O 版 Linkedin 线上线下做学生兼职 优你网是一个 O2O 版的职业社交平台,旨在解决学生兼职和企业招聘的痛点问题。通过线上平台和线下团队的结合,优你网提供了一个安全、可靠的兼职交易平台。 知识点: 1. O2O ...
虽然提供的部分内容由于格式问题难以直接解析,但我们可以根据标题、描述和标签来生成相关的知识点。 ### Java分布式应用基础 在分布式系统中,Java是一种广泛使用的编程语言,它提供了丰富的库和框架来支持分布式...
接着,Kafka是由LinkedIn开发并贡献给Apache的流处理平台,它最初设计为日志聚合系统,但后来发展成为一种高效的消息中间件。Kafka的特点是高吞吐量、低延迟以及持久化存储,适合大规模数据流处理。其模型包括生产者...
Pinot是LinkedIn推出的一个分布式OLAP引擎,设计用于实时分析大量数据。 分布式OLAP引擎Pinot的架构设计主要考虑了三个方面:高性能、实时分析和水平扩展。Pinot使用 columnar storage 和 indexing 来提高查询性能...
尽管这个库本身并不直接与Zookeeper或云原生概念相关,但在实际的大型分布式系统中,类似的数据抓取工具可能需要与这些技术结合,以实现高效的数据处理和分析。在使用过程中,了解和掌握这些相关的知识对于开发和...
8. **案例研究**:源代码可能包含对实际项目的分析,如Google的PageRank算法实现,或者LinkedIn的Kafka消息系统的应用。 通过这些源代码,学习者可以亲自动手实践分布式计算的原理,了解各种算法和框架的实际应用,...
LinkedIn API允许开发者访问LinkedIn的数据,包括用户信息、公司数据、职位发布等,以便构建与LinkedIn相关的应用程序和服务。下面,我们将深入探讨这个主题,讲解相关知识点。 1. **LinkedIn API介绍** LinkedIn ...
这个爬虫能够帮助研究人员、数据分析师或者招聘人员批量获取与指定公司相关的LinkedIn用户资料,以便进行数据分析或人才挖掘。下面我们将深入探讨这个项目的工作原理、实现方式以及可能的应用场景。 首先,LinkedIn...
例如,LinkedIn使用了其自有的分布式存储系统,能够存储和处理PB级别的数据。同时,LinkedIn还开发了高效的数据处理和分析框架,比如Kafka,用于实现高吞吐量的数据传输,并且有如Presto这样的查询引擎,用于快速、...
2. **Kafka**:由LinkedIn开发,后来成为Apache项目,Kafka是一款高性能的流处理平台,专注于实时数据流处理和存储。它的设计特点是分布式、持久化、高吞吐量和低延迟。Kafka将消息以日志流的形式存储,允许消费者...
Kafka是一个开源的流处理平台,由LinkedIn开发并贡献给Apache软件基金会。它的核心设计是作为一个高吞吐量、低延迟的消息队列,能够处理海量实时数据。Kafka的主要特点包括消息持久化、支持多消费者和发布/订阅模型...
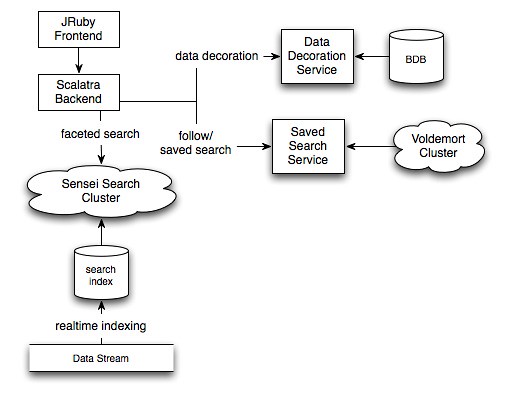
sensei, 分布式实时搜索数据库 什么是 Sensei( http://www.senseidb.com/ )Sensei是一个分布式的弹性实时搜索数据库。维基维基在以下位置可用:http://linkedin.jira.com/wiki/display/SENS
Kafka最初由LinkedIn公司开发,之后于2010年开源,是为处理实时流式数据而设计的分布式消息队列系统。它能够提供高吞吐量,并且在系统可靠性、可伸缩性以及容错性方面表现出色。Kafka使用Scala语言开发,支持多种...
LinkedIn爬网程序连接Linkedin搜寻器搜索并收集我的联系安装$ sudo apt-get update && sudo apt-get upgrade$ sudo apt-get install virtualenv python3 python3-dev python-dev gcc libpq-dev libssl-dev libffi-...
KAFKA是一个高吞吐量的分布式消息系统,由LinkedIn开发并开源,现在是Apache软件基金会的顶级项目。它主要设计用于处理实时流数据,允许应用程序发布和订阅消息,同时提供了一个可扩展且容错的数据总线。本文将详细...
接下来的Kafka是LinkedIn开源的分布式发布-订阅消 息系统,目前这个项目已经属于Apache顶级项目。Kafka的主要特点是基于Pull的模式来处理消息消息,追 求高吞吐量,后面的Kafka学习文档中会详细讲解,这里就不一一...
LinkedIn上的潜在客户开发还可以通过创建和分享相关内容来实现。发布行业洞察、专业知识和有价值的信息可以吸引关注者,并使公司成为行业的思想领导者。这样,当潜在客户在寻找特定解决方案时,他们更可能将目光投向...
LinkedIn API for PHP是一个用于与LinkedIn平台进行数据交互的PHP库,它允许开发者通过编程方式访问LinkedIn的公开或授权用户的数据,如个人资料、职位、公司信息等。在使用这个API时,开发者可以创建各种应用程序,...
- **寻找关注的圈子**:例如,如果您关注采矿设备(mining equipment),可以在搜索框中输入“mining”,加入相关的讨论组。 - **积极参与讨论**:阅读组内话题,发表见解,分享有价值的信息,并留下联系方式。 - **...
分布式OLAP引擎Pinot是LinkedIn开发的一个实时大数据分析平台,专为大规模在线分析处理(OLAP)设计。它能够在亚秒级时间内提供大规模数据的低延迟查询服务,这对于实时业务决策至关重要。Pinot的设计目标是支持高...