- 浏览: 1052877 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (538)
- 奇文共赏 (36)
- spring (13)
- hibernate (10)
- AOP/Aspectj (9)
- spring security (7)
- lucence (5)
- compass (3)
- jbmp (2)
- jboss rule(drools) (0)
- birt (1)
- jasper (1)
- cxf (3)
- flex (98)
- webgis (6)
- 设计模式 (1)
- 代码重构 (2)
- log4j (1)
- tomcat (9)
- 神品音乐 (1)
- 工作计划 (2)
- appfuse (1)
- svn (4)
- 寻章摘句 (3)
- eclipse (10)
- arcgis api for flex (1)
- 算法 (5)
- opengis-cs (1)
- bug心得 (13)
- 图标 (1)
- software&key (14)
- java (17)
- 搞笑视频 (13)
- sqlserver (9)
- postgresql (1)
- postgis (0)
- geoserver (5)
- 日子 (50)
- 水晶报表 (1)
- 绝对电影 (3)
- Alternativa3D (1)
- 酷站大全 (10)
- c++ (5)
- oracle (17)
- oracle spatial (25)
- flashbuilder4 (3)
- TweenLite (1)
- DailyBuild (6)
- 华山论贱 (5)
- 系统性能 (5)
- 经典古文 (6)
- SOA/SCA/OSGI (6)
- jira (2)
- Hadoop生态圈(hadoop/hbase/pig/hive/zookeeper) (37)
- 风水 (1)
- linux操作基础 (17)
- 经济 (4)
- 茶 (3)
- JUnit (1)
- C# dotNet (1)
- netbeans (1)
- Java2D (1)
- QT4 (1)
- google Test/Mock/AutoTest (3)
- maven (1)
- 3d/OSG (1)
- Eclipse RCP (3)
- CUDA (1)
- Access control (0)
- http://linux.chinaunix.net/techdoc/beginner/2008/01/29/977725.shtml (1)
- redis (1)
最新评论
-
dove19900520:
朋友,你确定你的标题跟文章内容对应???
tomcat控制浏览器不缓存 -
wussrc:
我只想说牛逼,就我接触过的那点云计算的东西,仔细想想还真是这么 ...
别样解释云计算,太TM天才跨界了 -
hw_imxy:
endpoint="/Hello/messagebr ...
flex+java代码分两个工程 -
gaohejie:
rsrsdgrfdh坎坎坷坷
Flex 与 Spring 集成 -
李涤尘:
谢谢。不过说得有点太罗嗦了。
Oracle数据库数据的导入及导出(转)
http://www.cnblogs.com/chenjingjing/archive/2010/01/26/1656869.html
最适合使用Hbase存储的数据是非常稀疏的数据(非结构化或者半结构化的数据)。Hbase之所以擅长存储这类数据,是因为Hbase是column-oriented列导向的存储机制,而我们熟知的RDBMS都是row- oriented行导向的存储机制(郁闷的是我看过N本关于关系数据库的介绍从来没有提到过row-
oriented行导向存储这个概念)。在列导向的存储机制下对于Null值得存储是不占用任何空间的。比如,如果某个表
UserTable有10列,但在存储时只有一列有数据,那么其他空值的9列是不占用存储空间的(普通的数据库MySql是如何占用存储空间的呢?)。
Hbase适合存储非结构化的稀疏数据的另一原因是他对列集合 column families 处理机制。
打个比方,ruby和python这样的动态语言和c++、java类的编译语言有什么不同? 对于我来说,最显然的不同就是你不需要为变量预先指定一个类型。Ok
,现在Hbase为未来的DBA也带来了这个激动人心的特性,你只需要告诉你的数据存储到Hbase的那个column families
就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。
Hbase还有很多特性,比如不支持join查询,但你存储时可以用:parent-child tuple(不是很懂) 的方式来变相解决。
由于它是Google BigTable的 Java 实现,你可以参考一下:google bigtable 。
下面3副图是Hbase的架构、数据模型和一个表格例子,你也可以从:Hadoop summit
上 获取更多的信息。
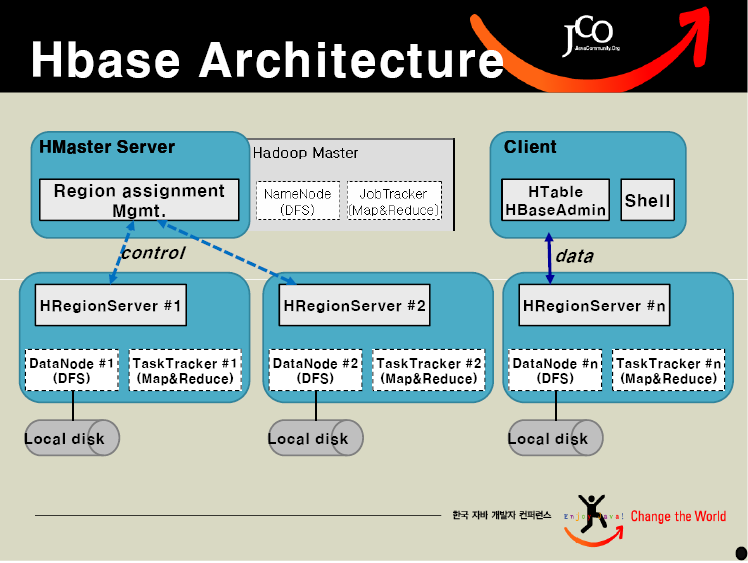




发表评论

-
一网打尽当下NoSQL类型、适用场景及使用公司
2014-12-28 20:56 975一网打尽当下NoSQL类型、适用场景及使用公司 http:// ... -
别样解释云计算,太TM天才跨界了
2014-02-25 09:41 2447http://mp.weixin.qq.com/s?__bi ... -
Build, Install, Configure and Run Apache Hadoop 2.2.0 in Microsoft Windows OS
2013-12-09 11:17 2546http://www.srccodes.com/p/arti ... -
hadoop的超时设置
2013-06-23 11:47 2432from http://blog.163.com/zheng ... -
hadoop与panasas
2012-12-26 09:53 887在应用的场景中,hadoop当然希望使用全部的本地硬盘,但是对 ... -
程序开过多线程,导致hadoop作业无法运行成功
2012-10-23 16:14 7070Exception in thread "Threa ... -
mount盘异常,导致hadoop作业无法发送
2012-10-23 16:12 961异常信息 2012-10-23 21:10:42,18 ... -
HDFS quota 設定
2012-08-02 16:22 5538http://fenriswolf.me/2012/04/04 ... -
hadoop常用的指令
2011-10-09 16:50 1709hadoop job -kill jobid 可以整个的杀掉 ... -
Hadoop基准测试
2011-08-08 10:04 1284http://www.michael-noll.com/ ... -
Hadoop Job Scheduler作业调度器
2011-05-21 11:02 2532http://hi.baidu.com/zhengxiang3 ... -
hadoop指定某个文件的blocksize,而不改变整个集群的blocksize
2011-03-20 17:20 2114文件上传的时候,使用下面的命令即可 hadoop f ... -
Hadoop Job Tuning
2011-02-28 15:53 824http://www.searchtb.com/2010/12 ... -
如何在不重启整个hadoop集群的情况下,增加新的节点
2011-02-25 10:12 14171.在namenode 的conf/slaves文件中增加新的 ... -
对hadoop task进行profiling的几种方法整理
2011-02-10 21:57 1661对hadoop task进行profiling的几种方法整 ... -
如何对hadoop作业的某个task进行debug单步跟踪
2011-02-10 21:56 2087http://blog.csdn.net/AE86_FC/ar ... -
hadoop 0.20 程式開發 eclipse plugin
2011-01-26 19:36 2269http://trac.nchc.org.tw/cloud/w ... -
hadoop-0.21.0-eclipse-plugin无法在eclipse中运行解决方案
2011-01-26 09:47 3609LINUX下将hadoop-0.21自带的hadoop ecl ... -
How to Benchmark a Hadoop Cluster
2011-01-19 22:15 2860How to Benchmark a Hadoop Clu ... -
json在线格式化
2010-12-21 16:23 2439http://jsonformatter.curiouscon ...
相关推荐
Hadoop和HBase是大数据处理领域中的重要组件,它们在分布式存储和实时数据访问方面扮演着关键角色。Hadoop是一个开源框架,主要用于处理和存储大量数据,而HBase是建立在Hadoop之上的非关系型数据库,提供高可靠性、...
HBase 是一个高性能、分布式、面向列的 NoSQL 数据库,通常用来存储结构化和半结构化数据。HBase 的安装配置与 Hadoop 相似,这里不再详细介绍。 三、Hive 集群环境搭建 Hive 是一个基于 Hadoop 的数据仓库工具,...
在Mapper类中,通过解析文本数据并将其转换为KeyValue对象,MapReduce作业能够输出适合HBase存储的数据格式。 HDFS中的数据行表示了如何组织数据以便于转换为HFile格式。每一行包含行键(rowkey)、列族、列限定符...
集成Hadoop和HBase时,通常会将HBase的JAR包添加到Hadoop的类路径中,确保Hadoop集群能够识别并处理HBase的相关操作。这个过程可能涉及到配置Hadoop的环境变量,如HADOOP_CLASSPATH,以及修改HBase的配置文件,如...
Hadoop 是一个分布式计算框架,用于处理大规模数据,而 HBase 是一个基于 Hadoop 的分布式数据库,用于存储和处理大规模数据。在工作中,我们经常需要使用 Hadoop 和 HBase 的 shell 命令来管理和操作数据。下面是 ...
2. HBase:HBase是一个基于Hadoop的分布式数据库,用于存储和处理大规模数据。 3. ZooKeeper:ZooKeeper是一个分布式协调服务,用于管理Hadoop和HBase集群。 二、机器集群结构分布 在本文中,我们将使用8台曙光...
- 例如,使用`HBaseAdmin`类创建和管理表,使用`Table`对象进行数据的put和get,以及`Scan`对象进行表的扫描。 8. **实验环境**: - 实验通常在虚拟机环境中进行,比如VMware Workstation上运行Ubuntu-12.04操作...
在构建大数据处理环境时,Hadoop、HBase、Spark和Hive是四个核心组件,它们协同工作以实现高效的数据存储、处理和分析。本教程将详细介绍如何在Ubuntu系统上搭建这些组件的集群。 1. **Hadoop**:Hadoop是Apache...
【Hadoop Hbase Zookeeper集群配置】涉及到在Linux环境下搭建分布式计算和数据存储系统的流程,主要涵盖以下几个关键知识点: 1. **集群环境设置**:一个基本的Hadoop Hbase Zookeeper集群至少需要3个节点,包括1个...
在大数据处理领域,Hadoop、HBase和Zookeeper是三个至关重要的组件,它们共同构建了一个高效、可扩展的数据处理和存储环境。以下是关于这些技术及其集群配置的详细知识。 首先,Hadoop是一个开源的分布式计算框架,...
HBase则是在Hadoop之上的一个分布式、列族式的NoSQL数据库,它支持实时读写,特别适合处理大规模半结构化或非结构化数据。 首先,让我们深入了解HDFS。HDFS设计的目标是处理PB级别的数据,通过将大文件分割成块并在...
标题 "Hadoop+HBase+Java API" 涉及到三个主要的开源技术:Hadoop、HBase以及Java API,这些都是大数据处理和存储领域的关键组件。以下是对这些技术及其结合使用的详细介绍: **Hadoop** 是一个分布式计算框架,由...
HBase则是基于Hadoop的分布式数据库,尤其适合处理大规模的非结构化数据。下面将详细阐述这两个技术以及它们相关的jar包。 1. Hadoop:Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。...
而HBase,作为Hadoop生态系统中的NoSQL数据库,提供了高效、可伸缩的存储和检索大量结构化数据的能力。 首先,让我们从Hadoop的基础知识开始。Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和...
HBase是一种分布式、高可靠性且高性能的列式存储系统,它基于Hadoop生态体系构建,并且能够支持大规模的数据存储需求。HBase的设计灵感来源于Google的Bigtable论文,通过模仿Bigtable的核心架构和技术特性,HBase...
而HBase是一款基于Hadoop的分布式、高性能、列式存储的NoSQL数据库,适用于实时查询和分析大规模数据。 1. **简介** 在部署Hadoop和HBase时,我们需要构建一个可靠的分布式环境,确保数据的高可用性和容错性。...
通过以上对Hadoop+Hbase搭建云存储的关键知识点的梳理,我们可以清晰地了解到这套技术组合在实际应用中的优势和应用场景,以及如何通过合理的技术选型和部署策略,构建一套既能够高效存储海量数据又能快速访问的云...
在这个系统中,Hadoop提供存储基础,HBase负责实时数据存储和访问,Hive处理复杂的数据分析任务,Lucene实现全文检索,而Memcached则优化了数据访问速度。这种组合可以处理PB级别的数据,并且能够应对各种数据分析...
Hadoop和HBase作为大数据领域的重要工具,为海量数据的存储和分析提供了强大的支持。本文将深入探讨这两个技术以及数据挖掘的相关概念。 Hadoop是Apache软件基金会开发的一个开源框架,主要用于处理和存储大规模...
在大数据领域中,Hadoop、HBase和Hive是重要的组件,它们通常需要协同工作以实现数据存储、管理和分析。随着各个软件的版本不断更新,确保不同组件之间的兼容性成为了一个挑战。本文将介绍Hadoop、HBase、Hive以及...