- 浏览: 61545 次
- 性别:

- 来自: 北京
-

最新评论
-
scu_cxh:
您好,我在学习hadoop方面的东西,想做一个对task监控的 ...
JobClient应用概述 -
bennie19870116:
看不到图呢...
Eclipse下配置使用Hadoop插件
最近的事确实很多,但大部分精力都放在了项目的设计方面,最近几天才完成了一些初步的编码的工作。在这个阶段,我发现,需要对数据的录入和Job执行的管理做细致的规划,否则在后期的扩展性上将有很大的局限。我设计的框架大体如下:
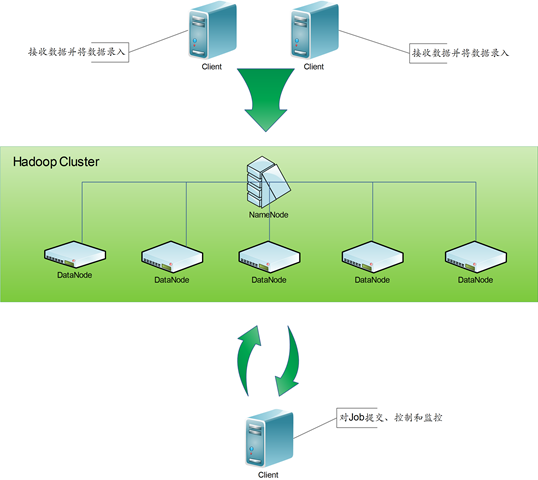
在这个结构里面,可以明显的看到我采用了2种Client,一个是数据录入层,一个是Job管理层。这里我说明一下为什么需要这2种Client。
1、数据录入主要接收数据,数据有多种形式传输,有流模式也有文件模式,为了不影响TaskTracker的性能,我采用Client单独的录入数据。
2、对于Job管理,因为Job任务有先后的顺序管理,而且对于失败的Job需要做重新的尝试,同时还要做到对Job的监控以及执行Job的增删。所以我单独采用一个Client对Job进行管理。实现Job执行的流程控制、状态反馈处理以及Job的热拔插。后面会详细说明。
到这里,可以看到,集群的应用我分成了3个部分。数据录入端、集群以及Job管理端。接下来我说下数据录入和Job管理的内容。
一、数据录入端
在这个部分主要就是对数据进行接收,然后将数据进行简单的时间区分,然后根据指定的时间和条件录入到集群中指定的目录下。例如,时间目录、数据来源目录以及地域目录等等。在这个部分实际上没有什么特别的描述,主要就是接收数据的形式方面,采用了流模式,提升传输的速度。对于一些延迟或是传输失败的数据采用文件搬运的模式。数据接收到本地之后采用Hadoop的API将数据录入到集群中。
二、Job管理端
对于这个部分,主要有以下功能点:
1、Job顺序控制。由于一个业务不可能是一个Job完成,可能需要多个Job来执行,先后存在一些依赖关系,所以通过对Job顺序的控制来完成一组业务。这个通过读取JobList的配置文件来确定先后顺序。
2、Job任务监控。同样,在这个部分主要是采用JobClient来实现。这里就不做细致的代码说明,查看Hadoop的API有详细的说明。如果确实需要代码可以发邮件给我。
3、实现Job的热拔插。由于业务分析的多变,所以需要对Job随时进行一些增删。例如一些Job可能需要新增加,而又有一些Job需要删除不执行。所以这个时候通过配置JobList清单就可以控制Job执行的顺序以及哪些Job执行哪些Job不执行。这样的操作不需要重启任何程序。
4、调度模式。每个业务可能需要多个Job,但是业务之间基本不存在依赖的关系,所以,这个时候,一个业务内的Job就需要实现FIFO模式,也就是顺序执行。但是对于业务之间,我们则需要考虑并发模式,也就是公平调度(公平调度模式需要配置,Hadoop默认是FIFO模式)。在集群支持公平调度模式的情况下,在Job管理端可以实现不同业务下Job的并发执行。

如上图:
1、所有的Business是可以并发的。但是同一个Business下的Job必须是顺序执行,因为存在依赖关系。
2、Job A、Job B、Job C是必须FIFO模式执行。而不同业务下的Job又是可以并发执行。
三、总结
1、分离出来的2种client有利于提升性能,同时具有良好的维护性。
2、Job的管理更加灵活。数据录入相对稳定。集群的计算影响减小。
3、当然,这里还没有提到如何将数据录入到RDBMS中,实际上,一个业务执行完成之后就会将结果数据录入到对应的RDBMS表中。
4、一些代码的编写基本上采用了Java,主要是考虑能更好的调用Hadoop的API。当然中间有些流程也采用了Shell脚本。
5、大体上设计内容如上,如果大家有疑问或是觉得我写的不对的地方欢迎大家发邮件交流。dajuezhao@gmail.com


发表评论

-
Hadoop的基准测试工具使用(部分转载)
2011-01-21 11:58 1621一、背景由于以前没有� ... -
分布式集群中的硬件选择
2011-01-21 11:58 1045一、背景最近2个月时间一直在一个阴暗的地下室的角落里工作,主要 ... -
Map/Reduce的内存使用设置
2011-01-21 11:57 1654一、背景今天采用10台� ... -
Hadoop开发常用的InputFormat和OutputFormat(转)
2011-01-21 11:55 1492Hadoop中的Map Reduce框架依 ... -
SecondaryNamenode应用摘记
2010-11-04 15:54 1076一、环境 Hadoop 0.20.2、JDK 1.6、 ... -
Zookeeper分布式安装手册
2010-10-27 09:41 1340一、安装准备1、下载zookeeper-3.3.1,地址:ht ... -
Hadoop分布式安装
2010-10-27 09:41 1021一、安装准备1、下载hadoop 0.20.2,地址:http ... -
Map/Reduce使用杂记
2010-10-27 09:40 973一、硬件环境1、CPU:Intel(R) Core(TM)2 ... -
Hadoop中自定义计数器
2010-10-27 09:40 1543一、环境1、hadoop 0.20.22、操作系统Linux二 ... -
Map/Reduce中的Partiotioner使用
2010-10-27 09:39 923一、环境1、hadoop 0.20.22� ... -
Map/Reduce中的Combiner的使用
2010-10-27 09:38 1205一、作用1、combiner最基本是实现本地key的聚合,对m ... -
Hadoop中DBInputFormat和DBOutputFormat使用
2010-10-27 09:38 2455一、背景 为了方便MapReduce直接访问关系型数据 ... -
Hadoop的MultipleOutputFormat使用
2010-10-27 09:37 1706一、背景 Hadoop的MapReduce中多文件输出默 ... -
Map/Reduce中公平调度器配置
2010-10-27 09:37 1551一、背景一般来说,JOB� ... -
无法启动Datanode的问题
2010-10-27 09:37 2403一、背景早上由于误删namenode上的hadoop文件夹,在 ... -
Map/Reduce的GroupingComparator排序简述
2010-10-27 09:36 1354一、背景排序对于MR来说是个核心内容,如何做好排序十分的重要, ... -
Map/Reduce中分区和分组的问题
2010-10-27 09:35 1146一、为什么写分区和分组在排序中的作用是不一样的,今天早上看书, ... -
关于Map和Reduce最大的并发数设置
2010-10-27 09:34 1254一、环境1、hadoop 0.20.22、操作系统 Linux ... -
关于集群数据负载均衡
2010-10-27 09:33 905一、环境1、hadoop 0.20.22、操作系统 Linux ... -
Map/Reduce执行流程简述
2010-10-27 09:33 994一、背景最近总在弄MR的东西,所以写点关于这个方面的内容,总结 ...
相关推荐
通过阅读Hadoop 2.8.1源码,我们可以深入了解分布式系统的设计理念,理解如何实现数据的高效存储和处理。这不仅可以提升我们的编程技能,也有助于培养解决复杂问题的能力,以及在分布式环境中思考问题的习惯。对于...
在给定文件的信息中,虽然科技情报开发与经济并非与标题“基于Hadoop和Mahout的分布式推荐引擎的设计”直接相关,但其中涉及的一些概念和知识点,例如分布式系统的设计与应用,仍然可以为设计分布式推荐引擎提供重要...
《Hadoop系统搭建及项目实践》课程,正是在这个背景下应运而生,旨在培养学生的Hadoop分布式系统的搭建和应用能力,为学生进入大数据时代打下坚实的基础。 Hadoop作为一个开源框架,能够在普通的硬件上运行,通过...
在SACC2011(Storage and Cloud Computing Conference)上,百度的Hadoop技术领导者马如悦分享了Hadoop的最新进展,特别是Hadoop 2.0版本在社区和百度内部的研发与应用情况,以及对未来发展的思考。 #### 社区...
反思实践,整理学习笔记课后作业(1) 在职教云平台上完成相关练习题(2) 写一篇关于 Hadoop 集群搭建的心得体会教师讲解职教云教师:布置作业,提供指导学生:深入思考,完成作业 【知识点详解】 Hadoop 是一个开源...
1. **Hadoop思考**:探讨Hadoop的设计目标和适用场景,解析其架构,通过MapReduce案例加深理解。 2. **Hadoop安装配置**:包括单机版、伪分布式和分布式Hadoop的安装配置实战。 3. **HDFS实战**:学习HDFS的命令行...
课程总课时为64学时,其中MapReduce和HBase、Hive、Pig章节为重点,分别占据32学时,而Flume、Hadoop应用案例实战等章节也占有一定比例。课程成绩由平时成绩(包括考勤、作业和实验)和期末考试成绩共同决定,各占40...
该系统不仅适用于学习Hadoop的基础知识,还能够帮助开发者理解如何利用Hadoop进行实际应用的开发。 #### 二、关键技术栈与工具 - **Hadoop版本**:1.1.2 - **前端框架**:BootMetro(一个开源CSS框架,用于提升Web...
HADOOP问题和下一代解决方案的知识点涉及的内容非常广泛,包括Hadoop的开源特性、商业支持、架构问题以及...这对于企业来说,意味着能够更加高效和低成本地处理大数据,同时也提出了对传统Hadoop集群架构的重新思考。
### 大数据技术分享:Hadoop的企业应用及GPU数据库 #### Hadoop World 2016 观察 - **大会概况**: - **地点**:硅谷的中心——圣何塞。 - **主题**:围绕Hadoop及其在企业中的应用展开。 - **所见**: - **...
【基于Hadoop的大数据分析】课程规划与设计着重于培养适应大数据时代需求的高素质技术人才,以开源分布式框架Hadoop为核心,旨在让学生掌握大数据分析的原理、技术和方法。Hadoop是Apache基金会开发的一个分布式系统...
课程设计强调实践,通过5周的密集学习,学生不仅能够掌握分布式系统的基本概念,还能通过实际编程,深入理解并应用如Google的分布式系统等真实案例。 #### 二、课程结构与内容 **课程组织:** 整个课程被细分为5次...
【大数据原理与应用课程设计】是一门综合性的实践课程,旨在让学员深入理解和掌握大数据处理的相关技术和流程。课程涵盖了从基础理论到实际操作的多个层面,包括但不限于以下几个方面: 1. **基础知识**:课程要求...
在本教案中,我们将提出一些引导性问题、探究性问题和拓展性问题,以激发学生的思考和讨论。 引导性问题: * 你知道豆瓣影评吗? * 你了解KNN算法吗? * 你知道KNN算法的实现步骤吗? 探究性问题: * 如何使用...
2. **学习Hadoop应用案例**:如阿里巴巴金融利用Hadoop进行小微企业信用评估,通过分析支付宝和淘宝的数据,实现了低坏账率的贷款服务。 3. **掌握Hadoop技术最佳实践**:包括Hadoop数据仓库的构建、Hive报表开发、...
`wordcount`示例:这是Hadoop的典型应用,统计文本中的单词数量。包括创建输入文件、运行MapReduce任务和查看结果。\n\n7. 伪分布式模式配置后,通过`bin/hdfs namenode -format`格式化NameNode,然后分别启动...
Hadoop 和 Spark 两者的异同在于它们的设计目的和应用场景。Hadoop 是一个分布式数据基础设施,而 Spark 是一个专门用来对那些分布式存储的大数据进行处理的工具。选择 Hadoop 还是 Spark,取决于您的需求和应用场景...
### Hadoop集群部署及测试实验知识点总结 ...通过以上详细的实验步骤、注意事项以及实验报告要求的介绍,读者可以全面了解Hadoop集群部署及测试实验的全过程,加深对Hadoop及其MapReduce架构的理解与应用能力。
通过课程设计报告,教师可以了解学生在项目实施过程中的思考过程和所取得的成果,这有助于教师对学生的学习效果进行综合评价。 此外,该教学实施方案还对学生的出勤管理、实验室安全及环境卫生提出了明确要求。课程...
同时,人们对Hadoop的期待过高,希望它能解决所有大数据问题,但Hadoop最初的设计目标仅限于大规模批处理,这导致了实际应用中的满意度下降。 大数据市场的趋势表明,SQL和分布式数据库市场正在快速发展。基础的...