问题
某海量用户网站,用户拥有积分,积分可能会在使用过程中随时更新。现在要为该网站设计一种算法,在每次用户登录时显示其当前积分排名。用户最大规模为2亿;积分为非负整数,且小于100万。
PS: 据说这是迅雷的一道面试题,不过问题本身具有很强的真实性,所以本文打算按照真实场景来考虑,而不局限于面试题的理想环境。
存储结构
首先,我们用一张用户积分表user_score来保存用户的积分信息。
表结构:
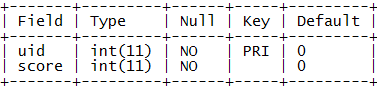
示例数据:
下面的算法会基于这个基本的表结构来进行。
算法1:简单SQL查询
首先,我们很容易想到用一条简单的SQL语句查询出积分大于该用户积分的用户数量:
select 1 + count(t2.uid) as rank
from user_score t1, user_score t2
where t1.uid = @uid and t2.score > t1.score
对于4号用户我们可以得到下面的结果:

算法特点
优点:简单,利用了SQL的功能,不需要复杂的查询逻辑,也不引入额外的存储结构,对小规模或性能要求不高的应用不失为一种良好的解决方案。
缺点:需要对user_score表进行全表扫描,还需要考虑到查询的同时若有积分更新会对表造成锁定,在海量数据规模和高并发的应用中,性能是无法接受的。
算法2:均匀分区设计
在许多应用中缓存是解决性能问题的重要途径,我们自然会想能不能把用户排名用Memcached缓存下来呢?不过再一想发现缓存似乎帮不上什么忙,因为用户排名是一个全局性的统计性指标,而并非用户的私有属性,其他用户的积分变化可能会马上影响到本用户的排名。然而,真实的应用中积分的变化其实也是有一定规律的,通常一个用户的积分不会突然暴增暴减,一般用户总是要在低分区混迹很长一段时间才会慢慢升入高分区,也就是说用户积分的分布总体说来是有区段的,我们进一步注意到高分区用户积分的细微变化其实对低分段用户的排名影响不大。于是,我们可以想到按积分区段进行统计的方法,引入一张分区积分表score_range:
表结构:

数据示例:
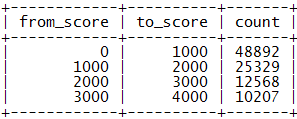
表示[from_score, to_score)区间有count个用户。若我们按每1000分划分一个区间则有[0, 1000), [1000, 2000), …, [999000, 1000000)这1000个区间,以后对用户积分的更新要相应地更新score_range表的区间值。在分区积分表的辅助下查询积分为s的用户的排名,可以首先确定其所属区间,把高于s的积分区间的count值累加,然后再查询出该用户在本区间内的排名,二者相加即可获得用户的排名。
乍一看,这个方法貌似通过区间聚合减少了查询计算量,实则不然。最大的问题在于如何查询用户在本区间内的排名呢?如果是在算法1中的SQL中加上积分条件:
select 1 + count(t2.uid) as rank
from user_score t1, user_score t2
where t1.uid = @uid and t2.score > t1.score and t2.score < @to_score
在理想情况下,由于把t2.score的范围限制在了1000以内,如果对score字段建立索引,我们期望本条SQL语句将通过索引大大减少扫描的user_score表的行数。不过真实情况并非如此,t2.score的范围在1000以内并不意味着该区间内的用户数也是1000,因为这里有积分相同的情况存在!二八定律告诉我们,前20%的低分区往往集中了80%的用户,这就是说对于大量低分区用户进行区间内排名查询的性能远不及对少数的高分区用户,所以在一般情况下这种分区方法不会带来实质性的性能提升。
算法特点
优点:注意到了积分区间的存在,并通过预先聚合消除查询的全表扫描。
缺点:积分非均匀分布的特点使得性能提升并不理想。
算法3:树形分区设计
均匀分区查询算法的失败是由于积分分布的非均匀性,那么我们自然就会想,能不能按二八定律,把score_range表设计为非均匀区间呢?比如,把低分区划密集一点,10分一个区间,然后逐渐变成100分,1000分,10000分 … 当然,这不失为一种方法,不过这种分法有一定的随意性,不容易把握好,而且整个系统的积分分布会随着使用而逐渐发生变化,最初的较好的分区方法可能会变得不适应未来的情况了。我们希望找到一种分区方法,既可以适应积分非均匀性,又可以适应系统积分分布的变化,这就是树形分区。
我们可以把[0, 1,000,000)作为一级区间;再把一级区间分为两个2级区间[0, 500,000), [500,000, 1,000,000),然后把二级区间二分为4个3级区间[0, 250,000), [250,000, 500,000), [500,000, 750,000), [750,000, 1,000,000),依此类推,最终我们会得到1,000,000个21级区间[0,1), [1,2) … [999,999, 1,000,000)。这实际上是把区间组织成了一种平衡二叉树结构,根结点代表一级区间,每个非叶子结点有两个子结点,左子结点代表低分区间,右子结点代表高分区间。树形分区结构需要在更新时保持一种不变量(Invariant):非叶子结点的count值总是等于其左右子结点的count值之和。
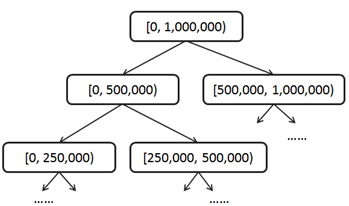
以后,每次用户积分有变化所需要更新的区间数量和积分变化量有关系,积分变化越小更新的区间层次越低。总体上,每次所需要更新的区间数量是用户积分变量的log(n)级别的,也就是说如果用户积分一次变化在百万级,更新区间的数量在二十这个级别。在这种树形分区积分表的辅助下查询积分为s的用户排名,实际上是一个在区间树上由上至下、由粗到细一步步明确s所在位置的过程。比如,对于积分499,000,我们用一个初值为0的排名变量来做累加;首先,它属于1级区间的左子树[0, 500,000),那么该用户排名应该在右子树[500,000, 1,000,000)的用户数count之后,我们把该count值累加到该用户排名变量,进入下一级区间;其次,它属于3级区间的[250,000, 500,000),这是2级区间的右子树,所以不用累加count到排名变量,直接进入下一级区间;再次,它属于4级区间的…;直到最后我们把用户积分精确定位在21级区间[499,000, 499,001),整个累加过程完成,得出排名!
虽然,本算法的更新和查询都涉及到若干个操作,但如果我们为区间的from_score和to_score建立索引,这些操作都是基于键的查询和更新,不会产生表扫描,因此效率更高。另外,本算法并不依赖于关系数据模型和SQL运算,可以轻易地改造为NoSQL等其他存储方式,而基于键的操作也很容易引入缓存机制进一步优化性能。进一步,我们可以估算一下树形区间的数目大约为200,000,000,考虑每个结点的大小,整个结构只占用几十M空间。所以,我们完全可以在内存建立区间树结构,并通过user_score表在O(n)的时间内初始化区间树,然后排名的查询和更新操作都可以在内存进行。一般来讲,同样的算法,从数据库到内存算法的性能提升常常可以达到10^5以上;因此,本算法可以达到非常高的性能。
算法特点
优点:结构稳定,不受积分分布影响;每次查询或更新的复杂度为积分最大值的O(log(n))级别,且与用户规模无关,可以应对海量规模;不依赖于SQL,容易改造为NoSQL或内存数据结构。
缺点:算法相对更复杂。
算法4:积分排名数组
算法3虽然性能较高,达到了积分变化的O(log(n))的复杂度,但是实现上比较复杂。另外,O(log(n))的复杂度只在n特别大的时候才显出它的优势,而实际应用中积分的变化情况往往不会太大,这时和O(n)的算法相比往往没有明显的优势,甚至可能更慢。
考虑到这一情况,仔细观察一下积分变化对排名的具体影响,可以发现某用户的积分从s变为s+n,积分小于s或者大于等于s+n的其他用户排名实际上并不会受到影响,只有积分在[s,s+n)区间内的用户排名会下降1位。我们可以用于一个大小为100,000,000的数组表示积分和排名的对应关系,其中rank[s]表示积分s所对应的排名。初始化时,rank数组可以由user_score表在O(n)的复杂度内计算而来。用户排名的查询和更新基于这个数组来进行。查询积分s所对应的排名直接返回rank[s]即可,复杂度为O(1);当用户积分从s变为s+n,只需要把rank[s]到rank[s+n-1]这n个元素的值增加1即可,复杂度为O(n)。
算法特点
优点:积分排名数组比区间树更简单,易于实现;排名查询复杂度为O(1);排名更新复杂度O(n),在积分变化不大的情况下非常高效。
缺点:当n比较大时,需要更新大量元素,效率不如算法3。
总结
上面介绍了用户积分排名的几种算法,算法1简单易于理解和实现,适用于小规模和低并发应用;算法3引入了更复杂的树形分区结构,但是O(log(n))的复杂度性能优越,可以应用于海量规模和高并发;算法4采用简单的排名数组,易于实现,在积分变化不大的情况下性能不亚于算法3。本问题是一个开放性的问题,相信一定还有其他优秀的算法和解决方案,欢迎探讨!
分享到:




相关推荐
在C#中,使用二叉树实现实时计算海量用户积分排名是一种高效的方法,尤其适用于需要频繁更新和查询排名的场景。传统的解决方案通常涉及定时批量处理积分计算,将结果存储在中间表中,或者仅显示顶级用户的排行榜。...
时域积分方程混合与快速算法结合了积分方程和快速算法的优势,既保留了积分方程在处理电磁问题上的精确性,又通过快速算法显著提高了求解速度,大幅度减少了计算资源的消耗。这对于需要处理海量数据的大数据环境来说...
《大数据-算法-模糊Choquet可积函数空间与集值模糊积分》这篇论文,正是针对大数据背景下的模糊信息处理问题,给出了系统的理论分析与算法设计,从而在不确定性的环境中寻求更精准的数据分析方法。 首先,论文探讨...
在这本书《大数据应用中的次线性算法》中,作者Dan Wang和Zhu Han深入探讨了次线性算法在大数据应用中的各个方面。本书由Springer出版社出版,属于SpringerBriefs in Computer Science系列书籍,这意味着它旨在为...
以ENIAC为例,这是1946年由美国宾夕法尼亚大学研制的第一台电子积分计算机,它的出现标志着电子计算机时代的开始。ENIAC的巨大规模和处理速度展示了计算机相对于传统计算工具的巨大优势。 计算机的特点主要体现在...
【基于云计算的Web数据挖掘免积分】文档主要探讨了如何利用云计算技术解决Web数据挖掘中的挑战,特别是面对互联网上海量、分布式、异构和动态的数据。传统的集中式数据挖掘方法在处理这些复杂情况时往往力不从心。...
大数据时代,算法已成为理解和处理海量信息的关键工具。在数值逼近领域,这些算法被用来解决复杂问题,如最佳逼近、数值积分和微分方程的稀疏解法。本论文针对这些问题进行了深入研究。 一、多元样条函数的最佳逼近...
6. **积分与积分方程**:探讨MATLAB在积分计算和积分方程求解上的方法,包括定积分、不定积分、微分方程组的数值解等。 7. **优化与非线性方程求解**:涵盖MATLAB的优化工具箱,讲解线性和非线性方程组的解法,以及...
- **积分系统**:用户通过参与社区活动获取积分,积分可用于提升用户等级、兑换奖励等。 - **声誉系统**:根据用户的贡献度(如优质回答、受欢迎的帖子等)设置声誉值,激励用户积极参与。 7. **安全防护** - **...
5. **积分与积分方程案例**:针对科学计算中的积分问题,书中提供了实例,介绍了MATLAB的积分计算方法,包括定积分、不定积分和积分方程的求解。 6. **优化与非线性方程(组)求解**:书中包含多个关于优化算法和非...
另一方面,“秒数据直接积分算法”的提出,旨在提升大气可降水量的计算准确性。该算法抛弃了以往基于规定层探空资料计算可降水量的传统方法,而是直接利用探空系统获取的秒级观测数据进行积分处理。经过与GPS反演...
比如,PID(比例-积分-微分)控制器是一种广泛应用的控制算法,能有效稳定系统性能,减少波动。随着计算机技术的进步,现代化工自动化系统更加复杂,包括了SCADA(监督控制和数据采集)、DCS(分布式控制系统)以及...
在高性能计算方向,学生将学习《数值计算方法》,这门课程关注的是科学计算和工程问题的数值解法,包括非线性方程、线性方程组、插值法、数值微分与积分以及常微分方程的数值解。目的是让学生理解和掌握数值计算的...
根据提供的文档内容,我们可以归纳并深入探讨以下几个关键的知识点: ### 1. 计算机的产生与发展 #### 1.1 第一台计算机——ENIAC - **名称**: ENIAC (Electronic Numerical Integrator And Computer),意为电子...
描述中的"大数据-算法"关键词指出该研究与大数据处理和算法设计有关,可能涉及如何在海量数据环境中有效地运用特定算法来处理复杂的科学计算问题。 虽然标签部分为空,但根据标题和描述,我们可以推断出该研究可能...
商品查找功能则需优化搜索算法,降低用户在海量信息中的查找难度;留言板功能促进用户互动,增强社区氛围;商品推荐功能则依据用户行为和偏好,推送相关商品,提高转化率。 系统总体结构图描绘了网站的主要组成部分...