Ķ┐ÖÕćĀÕż®õĖĆńø┤ń£ŗÕł░bloom filterĶ┐ÖõĖ¬ń«Śµ│ĢŃĆéńĮæõĖŖńÜäĶĄäµ¢ÖÕŠłõĖŹķöÖõ║å’╝īÕģłµæśÕĮĢõĖŗ’╝īµ£ĆÕÉÄĶć¬ÕĘ▒ń╗ÖÕć║õĖĆõĖ¬ÕģĘõĮōńÜäÕ║öńö©ŃĆé
┬Ā
bloom filterńÜäwiki
┬Ā
ÕćĀõĖ¬Õ║öńö©
ķŚ«ķóś ÕåÖķüō
AÕÆīBõĖŁÕÉäÕŁśµöŠńØĆõĖĆõ║┐µØĪõĖŹķćŹÕżŹńÜäURL’╝īURLÕŁśµöŠµŚČµŚĀÕ║ÅńÜä’╝īõĖöURLµś»µ▓Īµ£ēńē╣ÕŠüńÜä’╝īAÕÆīBÕÅ»õ╗źĶ»Ģõ╗╗µäŵĢ░µŹ«ń╗ōµ×ä’╝īõ╣¤ÕÅ»õ╗źµś»ÕŁśÕ£©µĢ░µŹ«Õ║ōõĖŁŃĆé
Õ”éõĮĢµēŠÕć║AõĖŁµ£ēĶĆīBõĖŁµ▓Īµ£ēńÜäURLŃĆé
ķŚ«ķóś ÕåÖķüō
ń╗ÖõĮĀA,BõĖżõĖ¬µ¢ćõ╗Č’╝īÕÉäÕŁśµöŠ50õ║┐µØĪURL’╝īµ»ÅµØĪURLÕŹĀńö©64ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČµś»4G’╝īĶ«®õĮĀµēŠÕć║A,Bµ¢ćõ╗ČÕģ▒ÕÉīńÜäURLŃĆéÕ”éµ×£µś»õĖēõĖ¬õ╣āĶć│nõĖ¬µ¢ćõ╗ČÕæó’╝¤
┬Ā
┬Ā
Õģ│õ║Äbloom filter
┬ĀÕåÖķüō
Bloom Filterµś»õĖĆń¦Źń®║ķŚ┤µĢłńÄćÕŠłķ½śńÜäķÜŵ£║µĢ░µŹ«ń╗ōµ×ä’╝īÕ«āÕł®ńö©õĮŹµĢ░ń╗äÕŠłń«Ćµ┤üÕ£░ĶĪ©ńż║õĖĆõĖ¬ķøåÕÉł’╝īÕ╣ČĶāĮÕłżµ¢ŁõĖĆõĖ¬Õģāń┤Āµś»ÕÉ”Õ▒×õ║ÄĶ┐ÖõĖ¬ķøåÕÉłŃĆéBloom FilterńÜäĶ┐Öń¦Źķ½śµĢłµś»µ£ēõĖĆÕ«Üõ╗Żõ╗ĘńÜä’╝ÜÕ£©Õłżµ¢ŁõĖĆõĖ¬Õģāń┤Āµś»ÕÉ”Õ▒×õ║ĵ¤ÉõĖ¬ķøåÕÉłµŚČ’╝īµ£ēÕÅ»ĶāĮõ╝ܵŖŖõĖŹÕ▒×õ║ÄĶ┐ÖõĖ¬ķøåÕÉłńÜäÕģāń┤ĀĶ»»Ķ«żõĖ║Õ▒×õ║ÄĶ┐ÖõĖ¬ķøåÕÉł’╝łfalse positive’╝ēŃĆéÕøĀµŁż’╝īBloom FilterõĖŹķĆéÕÉłķéŻõ║øŌĆ£ķøČķöÖĶ»»ŌĆØńÜäÕ║öńö©Õ£║ÕÉłŃĆéĶĆīÕ£©ĶāĮÕ«╣Õ┐ŹõĮÄķöÖĶ»»ńÄćńÜäÕ║öńö©Õ£║ÕÉłõĖŗ’╝īBloom FilterķĆÜĶ┐ćµ×üÕ░æńÜäķöÖĶ»»µŹóÕÅ¢õ║åÕŁśÕé©ń®║ķŚ┤ńÜäµ×üÕż¦ĶŖéń£üŃĆé
┬ĀÕåÖķüō
Bloom FilterŃĆéÕ«āµś»õĖĆń¦ŹÕ¤║õ║ÄķÜŵ£║µĢ░(µł¢Hash)ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ«āµö»µīüÕ»╣µłÉÕæśõĮ┐ńö©ĶŠāÕ░æń®║ķŚ┤µØźÕŁśÕé©’╝īÕŹ┤ĶāĮÕŠŚÕł░ĶŠāķ½śµĢłńÄćńÜ䵤źĶ»óŃĆ鵏óÕÅźĶ»ØĶ»┤’╝ÜÕ£©Bloom Filter ÕÅ»õ╗źńö©õ║ĵŻĆń┤óõĖĆõĖ¬Õģāń┤Āµś»Õɔգ©õĖĆõĖ¬ķøåÕÉłõĖŁŃĆé
┬Ā
┬Ā
ÕĤńÉå
Õ╗║ń½ŗõĖĆõĖ¬Õ«╣ķćÅõĖ║500õĖćńÜäBit Arrayń╗ōµ×ä’╝łBit ArrayńÜäÕż¦Õ░ÅÕÆīkeywordńÜäµĢ░ķćÅÕå│Õ«Üõ║åĶ»»ÕłżńÜäÕćĀńÄć’╝ē’╝īÕ░åķøåÕÉłõĖŁńÜäµ»ÅõĖ¬keywordķĆÜĶ┐ć32õĖ¬hashÕćĮµĢ░ÕłåÕł½Ķ«Īń«ŚÕć║32õĖ¬µĢ░ÕŁŚ’╝īńäČÕÉÄÕ»╣Ķ┐Ö32õĖ¬µĢ░ÕŁŚÕłåÕł½ńö©500õĖćÕÅ¢µ©Ī’╝īńäČÕÉÄÕ░åBit ArrayõĖŁÕ»╣Õ║öńÜäõĮŹńĮ«õĖ║1’╝īµłæõ╗¼Õ░åÕģČń¦░õĖ║ńē╣ÕŠüÕĆ╝ŃĆéń«ĆÕŹĢńÜäĶ»┤Õ░▒µś»Õ░åµ»ÅõĖ¬keywordÕ»╣Õ║öÕł░Bit ArrayõĖŁńÜä32õĖ¬õĮŹńĮ«õĖŖ’╝īĶ¦üõĖŗÕøŠ’╝Ü

ÕĮōķ£ĆĶ”üÕ┐½ķƤµ¤źµēŠµ¤ÉõĖ¬keywordµŚČ’╝īÕŬĶ”üÕ░åÕģČķĆÜĶ┐ćÕÉīµĀĘńÜä32õĖ¬hashÕćĮµĢ░Ķ┐Éń«Ś’╝īńäČÕÉĵśĀÕ░äÕł░Bit ArrayõĖŁńÜäÕ»╣Õ║öõĮŹ’╝īÕ”éµ×£Bit ArrayõĖŁńÜäÕ»╣Õ║öõĮŹÕģ©ķā©µś»1’╝īķéŻõ╣łĶ»┤µśÄĶ»źkeywordÕī╣ķģŹµłÉÕŖ¤ŃĆé
┬Ā
ķĆéńö©ĶīāÕø┤
ÕÅ»õ╗źńö©µØźÕ«×ńÄ░µĢ░µŹ«ÕŁŚÕģĖ’╝īĶ┐øĶĪīµĢ░µŹ«ńÜäÕłżķ插╝īµł¢ĶĆģķøåÕÉłµ▒éõ║żķøå┬Ā
µē®Õ▒Ģ
Bloom filterÕ░åķøåÕÉłõĖŁńÜäÕģāń┤ĀµśĀÕ░äÕł░õĮŹµĢ░ń╗äõĖŁ’╝īńö©k’╝łkõĖ║ÕōłÕĖīÕćĮµĢ░õĖ¬µĢ░’╝ēõĖ¬µśĀÕ░äõĮŹµś»ÕÉ”Õģ©1ĶĪ©ńż║Õģāń┤ĀÕ£©õĖŹÕ£©Ķ┐ÖõĖ¬ķøåÕÉłõĖŁŃĆéCounting bloom filter’╝łCBF’╝ēÕ░åõĮŹµĢ░ń╗äõĖŁńÜäµ»ÅõĖĆõĮŹµē®Õ▒ĢõĖ║õĖĆõĖ¬counter’╝īõ╗ÄĶĆīµö»µīüõ║åÕģāń┤ĀńÜäÕłĀķÖżµōŹõĮ£ŃĆéSpectral Bloom Filter’╝łSBF’╝ēÕ░åÕģČõĖÄķøåÕÉłÕģāń┤ĀńÜäÕć║ńÄ░µ¼ĪµĢ░Õģ│ĶüöŃĆéSBFķććńö©counterõĖŁńÜäµ£ĆÕ░ÅÕĆ╝µØźĶ┐æõ╝╝ĶĪ©ńż║Õģāń┤ĀńÜäÕć║ńÄ░ķóæńÄćŃĆé┬Ā
Õģ│õ║ÄķöÖĶ»»ńÄć
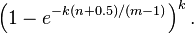
┬Ā
ÕģČõĖŁ’╝ÜkµĀćńż║hashÕćĮµĢ░ńÜäõĖ¬µĢ░’╝īmĶĪ©ńż║bit arrayńÜäķĢ┐Õ║”’╝łõĮŹµĢ░’╝ē’╝īnĶĪ©ńż║Õ«×ķÖģµĢ░µŹ«ńÜäõĖ¬µĢ░ŃĆé
┬Ā
ÕģĘõĮōõŠŗÕŁÉ
µ│©µäÅ’╝ÜÕ”éµ×£Ķ”üµĄŗĶ»Ģ’╝īµ»öĶŠāķĢ┐ńÜäµĢ░µŹ«’╝īķ£ĆĶ”üĶ░āĶŖéjvmÕÅéµĢ░
┬Ā
-server -Xms800m -Xmx800m┬Ā┬Ā -XX:MaxNewSize=256m
//ÕŠģµ»öĶŠāńÜäµĢ░µŹ«ķĢ┐Õ║”---Õ»╣Õ║öÕģ¼Õ╝ÅõĖŁńÜäN
private static final Integer dataLength = 400;
//bloom filterńÜäbitArrayĶŠģÕŖ®Õ»╣Ķ▒ĪķĢ┐Õ║”’╝īÕ»╣Õ║öÕģ¼Õ╝ÅõĖŁM
private static final Integer bitArrayLength = 5000;
//ĶŠģÕŖ®Õ»╣Ķ▒Ī’╝ī
//Õ░å µ¤źµēŠńø«µĀćhashÕÉÄńÜäÕĆ╝ńö©bitArrayLengrhÕÅ¢µ©ĪÕÉÄńÜäń╗ōµ×£ ńÜäõĮŹńĮ« ńĮ«õĖ║ true
private boolean[] bitArray = new boolean[bitArrayLength];
//µ£¼Õ£░µĢ░µŹ«ķøå’╝īÕÅ»õ╗źÕŁśÕé©Õ£©ÕåģÕŁśõĖŁ’╝īµ¢ćõ╗Č’╝īµĢ░µŹ«Õ║ōõĖŁ
//Õ£©ń│╗ń╗¤ÕłØÕ¦ŗÕī¢µŚČ’╝īķ£ĆĶ”üÕ░åµ»ÅõĖ¬ÕĆ╝ Ķ┐øĶĪībloom filterÕżäńÉå’╝īÕłØÕ¦ŗÕī¢bitArray
//Ķ┐ÖµĀĘ’╝ībitArrayÕ░▒ńøĖÕĮōõ║ĵłÉõĖ║õ║åõĖĆõĖ¬ÕĖ”µ£ēŌĆ£õ┐Īµü»µæśĶ”üŌĆØńÜäÕ»åńĀüµ£¼
private Integer[] data = new Integer[dataLength];
//hashÕćĮµĢ░Õ║ō
private HashFunction hashFunction = new HashFunction();
/**
* @param args
*/
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter();
bloomFilter.init();
Scanner in = new Scanner(System.in);
while(in.hasNext()) {
int n = in.nextInt();
long old = System.currentTimeMillis();
boolean exsist = bloomFilter.check(n);
long nl = System.currentTimeMillis();
if(exsist) {
System.out.println("exsist " + (nl - old));
} else {
System.out.println("not exsist " + (nl - old));
}
}
}
private void init() {
//ÕłØÕ¦ŗÕī¢µĢ░µŹ«
//Õ£©Ķ┐ÖķćīÕŬµś»ń«ĆÕŹĢńÜäĶ┐øĶĪīµĢ░ÕŁŚĶĄŗÕĆ╝’╝īÕģĘõĮōÕ║öńö©ÕÅ»õ╗źõ╗ĵĢ░µŹ«µ║ÉĶ»╗ÕÅ¢
for(int i =0,j=0; i<dataLength; i++,j+=2) {
data[i] = j;//ĶĄŗÕĆ╝
//bloom filter µĀĖÕ┐āń«Śµ│Ģ
APHash(data[i]);
RSHash(data[i]);
JSHash(data[i]);
PJWHash(data[i]);
ELFHash(data[i]);
BKDRHash(data[i]);
SDBMHash(data[i]);
DJBHash(data[i]);
DEKHash(data[i]);
BPHash(data[i]);
}
}
//1.ÕŠŚÕł░datańÜähashÕĆ╝
//2.Õ░åhashÕĆ╝õĖÄbitArrayLengthµ©ĪĶ┐Éń«Ś
//3.Õ░åµŁżõĖ║ńÜäbitArrayLengthńĮ«õĖ║true
private void APHash(Integer data) {
int temp = (int)hashFunction.APHash(data.toString());
int l1 = (temp < 0 ? -temp : temp) % bitArrayLength;
bitArray[l1] = true;
}
private boolean check(Integer n) {
if(n > (dataLength-1) * 2 || n < 0)
return false;
//Ķ┐øĶĪīķ¬īĶ»ü’╝īµś»ÕÉ”µēƵ£ēõĮŹÕØćõĖ║true’╝īÕ”éµ×£µ£ēõ╗╗õĮĢõĖĆõĮŹõĖŹµś»trueÕłÖĶĪ©µśÄµ¤źµēŠµĢ░µŹ«õĖŹÕŁśÕ£©
//µ│©µäÅ’╝ībloom filterµś»õ╝ÜÕŁśÕ£©Ķ»»ÕĘ«’╝īÕģĘõĮōńÜäĶ»»ÕĘ«Ķ»Ęń£ŗwikiõĖŖńÜäĶĄäµ¢Ö
if(APHashE(n) && RSHashE(n) && JSHashE(n) && PJWHashE(n) && ELFHashE(n) && BKDRHashE(n)
&& SDBMHashE(n) && DJBHashE(n) && DEKHashE(n) && BPHashE(n)) {
return true;
}
return false;
}
┬Ā
µĆ╗ń╗ō
Õ”éµ×£ĶāĮÕż¤µÄźÕÅŚĶ»»ÕĘ«’╝łÕģĘõĮōńÜäĶ»»ÕĘ«ńÄćÕÅ»õ╗źķĆÜĶ┐ćN,M,KńÜäÕĆ╝µØźĶ«Īń«Ś’╝ē’╝īÕ░▒ÕÅ»õ╗źńö©bloom filterµØźÕżäńÉåÕłżµ¢ŁķøåÕÉłõĖŁµś»ÕÉ”ÕŁśÕ£©µ¤ÉÕģāń┤ĀńÜäķŚ«ķóś’╝īÕÉīµŚČń®║ķŚ┤õĮ┐ńö©ńÄćÕŠłõĮÄ
┬Ā
ÕÅéĶĆā’╝Ü
http://www.hellodba.net/2009/04/bloom_filter.html
http://blog.redfox66.com/post/mass-data-topic-2-bloom-filter.aspx
Õłåõ║½Õł░’╝Ü





ńøĖÕģ│µÄ©ĶŹÉ
bitmap_bloomfilter_t *bbf = create_bitmap_bloomfilter(10000); /* ÕłøÕ╗║õĮŹµĢ░ń╗ä */ long *url[10] = { ... }; /* URLµĢ░ń╗ä */ for (i = 0; i ; ++i) { fprintf(stdout, "%ld -> filtered(%d).\n", url[i], bloom...
Õ£©GoĶ»ŁĶ©ĆõĖŁ’╝īÕ«×ńÄ░Bloom FilterÕÅ»õ╗źÕł®ńö©ÕģČķ½śµĢłÕ╣ČÕÅæÕżäńÉåÕÆīÕåģÕŁśń«ĪńÉåńÜäõ╝śÕŖ┐’╝īõĮ┐ÕŠŚĶ┐Öń¦ŹµĢ░µŹ«ń╗ōµ×äÕ£©Õż¦µĢ░µŹ«Õ£║µÖ»õĖŗµø┤ÕŖĀÕ«×ńö©ŃĆéµ£¼µ¢ćÕ░åµĘ▒ÕģźµÄóĶ«©Bloom FilterńÜäÕ¤║µ£¼ÕĤńÉåŃĆüGoĶ»ŁĶ©ĆõĖŁńÜäÕ«×ńÄ░õ╗źÕÅŖÕģČÕ£©Õ«×ķÖģÕ║öńö©õĖŁńÜäõ╝śń╝║ńé╣ŃĆé ### õĖĆŃĆü...
µĆ╗õ╣ŗ’╝īBloom Filterµś»ÕżäńÉåÕż¦µĢ░µŹ«µŚČńÜäõĖĆõĖ¬ķ½śµĢłÕĘźÕģĘ’╝īĶÖĮńäČÕŁśÕ£©Ķ»»ÕłżķŻÄķÖ®’╝īõĮåÕ£©ÕŠłÕżÜÕ£║µÖ»õĖŗ’╝īĶ┐Öń¦ŹķŻÄķÖ®µś»ÕÅ»õ╗źµÄźÕÅŚńÜä’╝īÕøĀõĖ║Õ«āĶāĮµśŠĶæŚķÖŹõĮÄÕŁśÕé©ÕÆīµ¤źĶ»óµłÉµ£¼ŃĆéÕ£©C#ńÄ»ÕóāõĖŁ’╝īÕł®ńö©ÕģČõĖ░Õ»īńÜäÕ║ōÕÆīÕĘźÕģĘ’╝īµłæõ╗¼ÕÅ»õ╗źµ¢╣õŠ┐Õ£░Õ«×ńÄ░ÕÆīÕ║öńö©Bloom ...
ÕĖāķÜåĶ┐ćµ╗żÕÖ©’╝łBloom Filter’╝ēµś»õĖĆń¦Źń®║ķŚ┤µĢłńÄćÕŠłķ½śńÜäµ”éńÄćÕ×ŗµĢ░µŹ«ń╗ōµ×ä’╝īÕ«āńö©õ║ÄÕłżµ¢ŁõĖĆõĖ¬Õģāń┤Āµś»Õɔգ©õĖĆõĖ¬ķøåÕÉłõĖŁŃĆéÕ«āńÜäõ╝śÕŖ┐Õ£©õ║Äń®║ķŚ┤ÕÆīµŚČķŚ┤µĢłńÄć’╝īÕ░żÕģČķĆéńö©õ║ÄÕż¦µĢ░µŹ«Õ£║µÖ»’╝īõĮåń╝║ńé╣µś»µ£ēõĖĆÕ«ÜńÜäĶ»»ÕłżńÄć’╝īÕŹ│ÕÅ»ĶāĮµŖŖõĖŹÕ▒×õ║ÄķøåÕÉłńÜäÕģāń┤ĀķöÖĶ»»...
8. **µ║ÉńĀüĶ¦Żµ×É**’╝ÜÕ£©ÕÉŹõĖ║"Bloom-Filter-master"ńÜäÕÄŗń╝®ÕīģõĖŁ’╝īÕ║öĶ»źÕīģÕɽCĶ»ŁĶ©ĆÕ«×ńÄ░Bloom FilterńÜäµ║Éõ╗ŻńĀüŃĆéķĆÜĶ┐ćķśģĶ»╗ÕÆīÕłåµ×ɵ║ÉńĀü’╝īµłæõ╗¼ÕÅ»õ╗źµø┤µĘ▒ÕģźńÉåĶ¦ŻõĖŖĶ┐░µ”éÕ┐Ąµś»Õ”éõĮĢÕ£©Õ«×ķÖģń©ŗÕ║ÅõĖŁÕ«×ńÄ░ńÜä’╝īõŠŗÕ”éÕ”éõĮĢÕ«Üõ╣ēõĮŹµĢ░ń╗ä’╝īÕ”éõĮĢÕ«Üõ╣ēÕÆī...
6. ńĀöń®ČĶāīµÖ»ÕÆīńø«ńÜä’╝ܵ¢ćń½ĀÕ£©Õ╝ĢĶ©Ćķā©ÕłåÕ╝║Ķ░āõ║åńĀöń®ČńÜäĶāīµÖ»ÕÆīńø«ńÜä’╝īÕŹ│ķØóÕ»╣µĄĘķćŵĢ░µŹ«Õ┐½ķƤÕī╣ķģŹńÜäõĖźÕ│╗ķŚ«ķóś’╝īµÅÉÕć║õ║åõĖĆń¦Źń╗ōÕÉłÕłåÕĖāÕ╝ŵŖƵ£»ÕÆīBloom FilterńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īõ╗źµ£¤µÅÉÕŹćÕż¦µĢ░µŹ«ńÄ»ÕóāõĖŗńÜäµĢ░µŹ«µŻĆń┤óµĆ¦ĶāĮŃĆé 7. õĖŁÕøŠÕłåń▒╗ÕÅĘ’╝ܵ¢ćń½Āń╗Ö...
"õĖĆń¦Źµ¢░ńÜäÕ¤║õ║ÄBloom filterµĢ░µŹ«ń╗ōµ×äńÜäµĢ░µŹ«µČłÕåŚń«Śµ│Ģ" µ£¼µ¢ćµÅÉÕć║õ║åõĖĆń¦Źµ¢░ńÜäÕ¤║õ║ÄBloom filterµĢ░µŹ«ń╗ōµ×äńÜäµĢ░µŹ«µČłÕåŚń«Śµ│Ģ’╝īĶ»źń«Śµ│Ģķ”¢ÕģłÕł®ńö©Õ«īÕģ©µ¢ćõ╗ȵŻĆµĄŗń«Śµ│ĢÕ»╣µĢ░µŹ«Ķ┐øĶĪīµŻĆķ¬īÕī╣ķģŹ’╝īķĆÜĶ┐ćńÜäµĢ░µŹ«ÕØŚÕåŹÕł®ńö©CDCÕłåÕØŚµŻĆµĄŗń«Śµ│ĢĶ┐øĶĪī...
Õ£©bloom-0.1.0Ķ┐ÖõĖ¬ńēłµ£¼õĖŁ’╝īÕ╝ĆÕÅæĶĆģÕÅ»ĶāĮÕĘ▓ń╗ÅÕ«×ńÄ░õ║åÕ¤║µ£¼ńÜäBloom FilterµōŹõĮ£’╝īÕīģµŗ¼µĘ╗ÕŖĀÕģāń┤ĀŃĆüµ¤źĶ»óÕģāń┤ĀÕŁśÕ£©µĆ¦õ╗źÕÅŖÕÅ»ĶāĮńÜäõ╝śÕī¢ń«Śµ│ĢŃĆéķĆÜÕĖĖ’╝īBloom FilterńÜäõĖ╗Ķ”üõ╝śńé╣Õ£©õ║ÄÕģČń®║ķŚ┤µĢłńÄćÕÆīµ¤źĶ»óķƤÕ║”’╝īõĮåõĖŹÕÅ»ķü┐ÕģŹńÜ䵜»ÕŁśÕ£©õĖĆÕ«ÜńÜäĶ»»Õłż...
**µŁŻµ¢ć** ...µĆ╗ńÜäµØźĶ»┤’╝īÕżÜÕŁŚµ«Ąń¤®ķśĄÕ×ŗBloom Filterµś»õĖĆń¦ŹķĆéńö©õ║ÄÕż¦µĢ░µŹ«ÕÆīÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜäķ½śµĢłµĢ░µŹ«ń╗ōµ×ä’╝īÕ«āķĆÜĶ┐ćµē®Õ▒Ģõ╝Āń╗¤ńÜäBloom FilterµØźÕżäńÉåÕżÜń╗┤Õ║”µĢ░µŹ«’╝īÕ╣ČÕģüĶ«ĖµĀ╣µŹ«ķ£Ćµ▒éĶ┐øĶĪīń®║ķŚ┤õ╝śÕī¢’╝īõ╗źķĆéÕ║öÕÉäń¦Źµ¤źĶ»óÕ£║µÖ»ŃĆé
Õ£©õĖŖĶ┐░õ╗ŻńĀüõĖŁ’╝īµłæõ╗¼Õ«Üõ╣ēõ║åõĖĆõĖ¬`BloomFilter`ń▒╗’╝īµ×äķĆĀÕćĮµĢ░µÄźÕÅŚÕōłÕĖīÕćĮµĢ░ńÜäµĢ░ķćÅÕÆīõĮŹµĢ░ń╗äńÜäÕż¦Õ░ÅõĮ£õĖ║ÕÅéµĢ░ŃĆé`add`µ¢╣µ│Ģńö©õ║ĵĘ╗ÕŖĀÕģāń┤ĀÕł░Bloom FilterõĖŁ’╝īÕ«āķĆÜĶ┐ćÕŠ¬ńÄ»õĮ┐ńö©ÕōłÕĖīÕćĮµĢ░µØźĶ«Īń«ŚÕżÜõĖ¬õĮŹńĮ«Õ╣ȵŖŖÕ«āõ╗¼Ķ«ŠńĮ«õĖ║1ŃĆé`check`µ¢╣µ│Ģ...
õŠŗÕ”é’╝īõĮ┐ńö©ÕĖāķÜåĶ┐ćµ╗żÕÖ©’╝łBloom Filter’╝ēĶ┐øĶĪīÕłØµŁźÕłżµ¢Ł’╝īĶ┐Öµś»õĖĆń¦Źń®║ķŚ┤µĢłńÄćµ×üķ½śńÜäµ”éńÄćÕ×ŗµĢ░µŹ«ń╗ōµ×ä’╝īńö©õ║ĵĄŗĶ»ĢõĖĆõĖ¬Õģāń┤Āµś»Õɔգ©õĖĆõĖ¬ķøåÕÉłõĖŁŃĆéĶÖĮńäČÕÅ»ĶāĮõ╝ܵ£ēÕüćķś│µĆ¦’╝īõĮåõĖŹõ╝ÜÕć║ńÄ░Õüćķś┤µĆ¦’╝īĶ┐ÖÕ£©Õż¦µĢ░µŹ«ÕÄ╗ķćŹõĖŁķØ×ÕĖĖµ£ēńö©ŃĆ鵣żÕż¢’╝īÕłåÕĖāÕ╝Å...
Õ£©µÅÅĶ┐░õĖŁµÅÉÕł░ńÜä"bloom filter in c language fot atmega micro"’╝īµäÅÕæ│ńØĆĶ┐ÖõĖ¬Õ«×ńÄ░µś»õĖōķŚ©õĖ║ATmegań│╗ÕłŚÕŠ«µÄ¦ÕłČÕÖ©Ķ«ŠĶ«ĪńÜäŃĆéATmegaµś»ArduinoÕĖĖńö©ńÜäõĖĆń¦ŹÕŠ«µÄ¦ÕłČÕÖ©’╝īķĆÜÕĖĖńö©õ║ÄÕĄīÕģźÕ╝Åń│╗ń╗¤Õ╝ĆÕÅæŃĆéÕøĀµŁż’╝īĶ┐ÖõĖ¬ķĪ╣ńø«ÕÅ»ĶāĮµś»õĖ║õ║åÕ£©ĶĄäµ║É...
Õ£©ÕÄŗń╝®ÕīģõĖŁńÜä`BloomFilter_-_Object_Pascal`µ¢ćõ╗ČõĖŁ’╝īÕŠłÕÅ»ĶāĮÕīģÕɽõ║åńö©Delphiń╝¢ÕåÖńÜäÕĖāķÜåĶ┐ćµ╗żÕÖ©ńÜäµ║Éõ╗ŻńĀüńż║õŠŗŃĆéµ║Éõ╗ŻńĀüÕÅ»ĶāĮõ╝ÜÕ«Üõ╣ēõĖĆõĖ¬BloomFilterń▒╗’╝īÕīģÕÉ½ÕłØÕ¦ŗÕī¢ŃĆüµÅÆÕģźÕÆīµ¤źĶ»óńŁēµ¢╣µ│Ģ’╝īÕÉīµŚČÕ«×ńÄ░õ║åÕżÜõĖ¬ÕōłÕĖīÕćĮµĢ░ŃĆéķĆÜĶ┐ćķśģĶ»╗ÕÆī...
Õż¦µĢ░µŹ«ÕżäńÉåń«Śµ│Ģńø«ÕĮĢõĖŁ’╝īõĖ╗Ķ”üõ╗ŗń╗Źõ║åõĖēń¦ŹÕż¦µĢ░µŹ«ÕżäńÉåń«Śµ│Ģ’╝ÜBitmap ń«Śµ│ĢŃĆüBloom Filter ń«Śµ│ĢÕÆīÕłåĶĆīµ▓╗õ╣ŗ/Hash µśĀÕ░ä + Hash ń╗¤Ķ«Ī + ÕĀå/Õ┐½ķƤ/ÕĮÆÕ╣ȵÄÆÕ║ÅŃĆé Õż¦µĢ░µŹ«ÕżäńÉåń«Śµ│ĢõĖĆ’╝ÜBitmap ń«Śµ│Ģ Bitmap ń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖńö©ńÜäÕż¦µĢ░µŹ«...
Õ£©Õż¦µĢ░µŹ«ÕŁśÕé©ÕÆīń«ĪńÉåõĖŁ’╝īBloom Filterµś»õĖĆń¦ŹķØ×ÕĖĖķćŹĶ”üńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ░żÕģČÕ£©ĶŖéń£üÕŁśÕé©ń®║ķŚ┤ÕÆīķ½śµĢłµ¤źĶ»óµ¢╣ķØóÕģʵ£ēµśŠĶæŚõ╝śÕŖ┐ŃĆéBloom Filterńö▒Burton Howard BloomÕ£©1970Õ╣┤µÅÉÕć║’╝īÕ«āµś»õĖĆõĖ¬µ”éńÄćÕ×ŗńÜäµĢ░µŹ«ń╗ōµ×ä’╝īńö©õ║ÄÕłżµ¢ŁõĖĆõĖ¬Õģāń┤Āµś»ÕÉ”...
- µ¢╣µĪł2’╝ÜÕ╝ĢÕģźBloom Filter’╝īõĖĆõĖ¬µ”éńÄćÕ×ŗµĢ░µŹ«ń╗ōµ×ä’╝īĶāĮÕ£©ÕåģÕŁśÕÅŚķÖÉńÜäµāģÕåĄõĖŗÕ┐½ķĆ¤Õłżµ¢ŁÕģāń┤Āµś»ÕÉ”ÕŁśÕ£©’╝īõĮåÕŁśÕ£©õĖĆÕ«ÜńÜäĶ»»ÕłżńÄćŃĆé 2. **queryķóæÕ║”µÄÆÕ║Å**’╝Ü - µ¢╣µĪł1’╝ÜķĆÜĶ┐ćÕōłÕĖīÕćĮµĢ░Õ░åqueryÕłåµĢŻÕł░µ¢░ńÜäµ¢ćõ╗ČõĖŁ’╝īńäČÕÉÄõĮ┐ńö©ÕåģÕŁśõĖŁńÜä...
õĖ║õ║åµ£ēµĢłÕ║öÕ»╣Ķ┐Öõ║øµīæµłś’╝īńĀöń®ČĶĆģõ╗¼µÅÉÕć║õ║åõĖĆń│╗ÕłŚńÜäń«Śµ│ĢµØźÕżäńÉåÕż¦µĢ░µŹ«ŃĆéµ£¼µ¢ćÕ»╣ÕĖĖńö©ńÜäÕż¦µĢ░µŹ«ÕżäńÉåń«Śµ│ĢĶ┐øĶĪīµĆ╗ń╗ō’╝īÕīģµŗ¼Bloom FilterŃĆüHashingÕÆīBit-MapńŁēŃĆé Bloom Filterµś»õĖĆń¦Źń®║ķŚ┤µĢłńÄćÕŠłķ½śńÜäµ”éńÄćÕ×ŗµĢ░µŹ«ń╗ōµ×ä’╝īńö©õ║ÄÕłżµ¢ŁõĖĆõĖ¬...
Õ£©ńĀöń®ČÕÆīÕ«×ĶĘĄĶ┐ćń©ŗõĖŁ’╝īõĮ£ĶĆģķāæķ╗ĵśÄŃĆüķé╣ķ╣ÅŃĆüķ¤®õ╝¤ń║óŃĆüµØÄńł▒Õ╣│ŃĆüĶ┤Šńä░Õ»╣ķ¬©Õ╣▓ńĮæÕ╝éÕĖĖµŻĆµĄŗńÜäńÉåĶ¦ŻÕÆīĶ¦ŻÕå│µ¢╣µĪł’╝īÕīģµŗ¼õ║åÕ»╣Filter-ary-SketchÕÆīBloom FilterµĢ░µŹ«ń╗ōµ×äńÜäµĘ▒ÕģźÕ║öńö©’╝īõĖ║Õż¦µĢ░µŹ«ńÄ»ÕóāõĖŗńĮæń╗£Õ«ēÕģ©ķŚ«ķóśµÅÉõŠøõ║åµ¢░ńÜäĶ¦ŻÕå│ķĆöÕŠäŃĆé...
Ķ┐Öõ║øń«Śµ│ĢķĆÜÕĖĖÕīģµŗ¼Count-Min SketchŃĆüCount-SketchŃĆüBloom FilterÕÆīTop-K SketchńŁēŃĆéõŠŗÕ”é’╝īCount-Min Sketchńö©õ║Äõ╝░ń«ŚµĢ░µŹ«µĄüõĖŁńÜäÕģāń┤Āķóæµ¼Ī’╝īBloom FilterÕłÖńö©õ║ÄÕ┐½ķĆ¤Õłżµ¢ŁõĖĆõĖ¬Õģāń┤Āµś»ÕÉ”ÕÅ»ĶāĮÕŁśÕ£©õ║ĵĢ░µŹ«ķøåõĖŁ’╝īĶĆīTop-K Sketch...
9. **ÕĖāķÜåĶ┐ćµ╗żÕÖ© (Bloom Filter)**’╝ÜĶÖĮńäȵ¢ćµĪŻõĖŁµ▓Īµ£ēµÅÉÕÅŖ’╝īõĮåÕ«āµś»ÕÅ”õĖĆõĖ¬ń╗ÅÕģĖń«Śµ│Ģ’╝īńö©õ║Äķ½śµĢłÕ£░Õłżµ¢ŁõĖĆõĖ¬Õģāń┤Āµś»ÕÉ”ÕÅ»ĶāĮÕŁśÕ£©õ║ÄÕż¦µĢ░µŹ«ķøåõĖŁ’╝īńē║ńē▓õĖĆÕ«ÜńÜäÕćåńĪ«µĆ¦µØźĶŖéń£üń®║ķŚ┤ŃĆé 10. **Dijkstraµ£Ćń¤ŁĶĘ»ÕŠäń«Śµ│Ģ**’╝ÜÕÉīµĀʵ▓Īµ£ēńø┤µÄźµÅÉÕÅŖ...