
引用:http://my.oschina.net/zhanyu/blog/86147
部署前准备:
- Solr 4.0 必须运行在Java1.5 或更高版本的Java 虚拟机中,运行标准Solr 服务只需要安装JRE 即可。
- Solr 4.0 : http://www.apache.org/dyn/closer.cgi/lucene/solr/4.0.0
- 本文以Tomcat7.0 进行演示。
- 如果出现错误无法运行,请更换更高版本的JDK,Solr各版本支持JDK的版本不尽相同,可以查阅官方中各个版本的不同。
Solr 4.0 目录:
这里是我的部署方式,Tomcat安装好之后把apache-solr-4.0.0\example\webapps下的solr.war文件拷贝到Tomcat下的Tomcat7.0\webapps目录下,然后启动Tomcat 报错不用管,solr.war会自动解压,之后打开Tomcat7.0\webapps\solr\WEB-INF\web.xml,把下面代码复制进去放到后面:
//这个是指定solrHome所在的目录
|
1
2
3
4
5
|
<env-entry>
<env-entry-name>solr/home</env-entry-name> //这个参数不要换
<env-entry-value>E:\SolrHome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
|
其中 E:\SolrHome 是存放solr配置文件等,修改为自己文件的位置,为了看着更清晰直观,你可以这样放:
E:\Tomcat7.0
E:\apache-solr-4.0.0
E:\SolrHome
现在可以重新启动Tomcat了,没有报错,通过这个地址进入Solr4.0页面:http://localhost:8080/solr
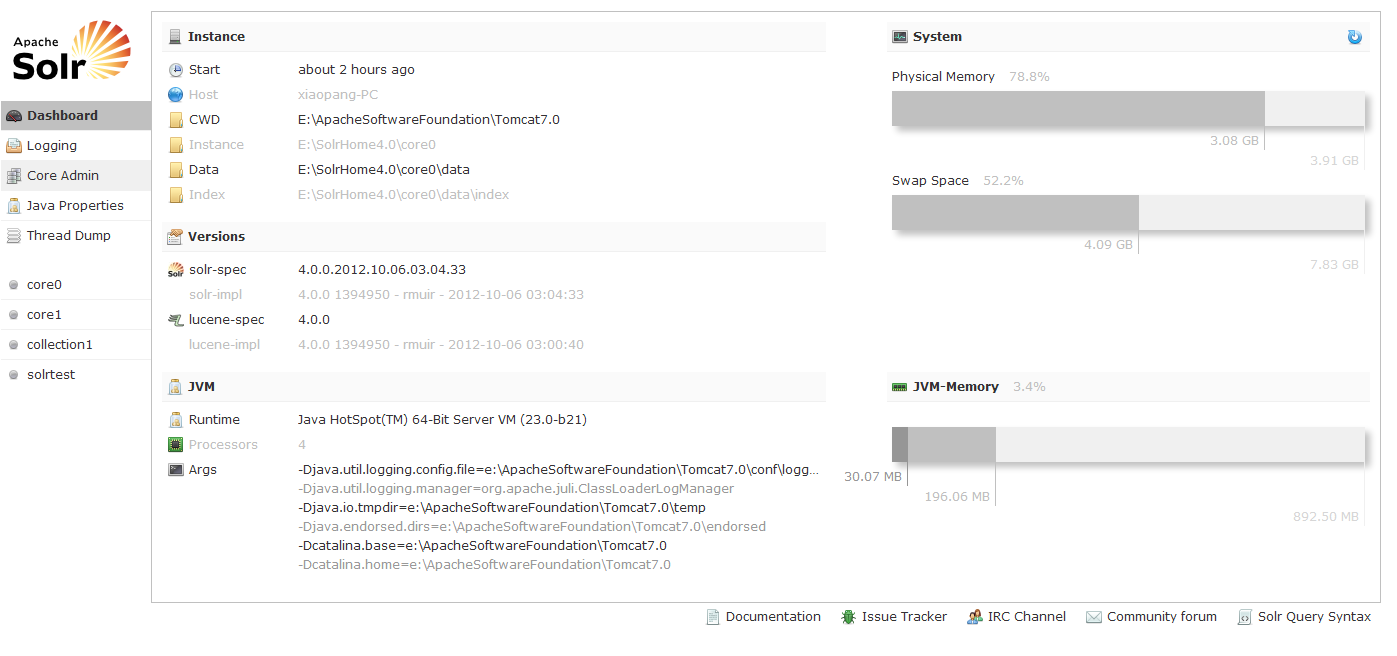
如果进入以上界面说明成功了,没有成功的话页面会有ERROR提示。
如图:左侧core0,core1等是solr 4.0中的示例,core0和core1位于apache-solr-4.0.0\example\multicore所有文件都下拷贝到E:\SoleHome下,core0和core1可以理解为两个库,都是独立的,用来存放索引以及生成这些索引文件所需要的配置文件,solrtest是我测试建立的目录,如图:

没添加一个库都需要在solr.xml里面进行配置,这个比较简单
|
1
2
3
4
5
6
7
8
|
<solr persistent="false">
<cores adminPath="/admin/cores" host="${host:}" hostPort="${jetty.port:}">
<core name="core0" instanceDir="core0" />
<core name="core1" instanceDir="core1" />
<core name="collection1" instanceDir="collection1" />
<core name="solrtest" instanceDir="solrtest"/>
</cores>
</solr>
|
|
1
|
name="",是库的名字,instanceDir="",是目录 |
每个目录下包含两个文件夹conf和data,data下有两个文件夹index和tlog,index是存放生成的索引文件,tlog存放log,conf下是必要的配置文件schema.xml和solrconfig.xml,可以参考官方或者core里面的配置文件:
这里是schema文件,用于定义索引字段的type类型和字段名字.也可以定义“中文分词”类型的。一般中文分词的索引我们用的是,text_ika,所以需要引入jar包。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
<?xml version="1.0" ?>
<schema name="example solr test" version="1.1">
<types>
<fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
</types>
<fields>
<!-- general -->
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="type" type="string" indexed="true" stored="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" multiValued="false" />
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
<!-- field to use to determine and enforce document uniqueness. -->
<uniqueKey>id</uniqueKey>
<!-- field for the QueryParser to use when an explicit fieldname is absent -->
<defaultSearchField>name</defaultSearchField>
<!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
<solrQueryParser defaultOperator="OR"/>
</schema>
|
solrconfig.xml我还不是很懂,在这里就不讲了,但是必须配置(好像是必须配):
这个基本上维持原样即可,不做改变。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 可以从core文件中copy过来 --><config>
<luceneMatchVersion>LUCENE_40</luceneMatchVersion>
<directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.StandardDirectoryFactory}"/>
<dataDir>${solr.solrtest.data.dir:}</dataDir> solr.solrtest.data.dir存放的是索引目录
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.solrtest.data.dir:}</str>
</updateLog>
</updateHandler>
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
</lst>
</requestHandler>
<requestHandler name="/replication" class="solr.ReplicationHandler" startup="lazy" />
<requestDispatcher handleSelect="true" >
<requestParsers enableRemoteStreaming="false" multipartUploadLimitInKB="2048" />
</requestDispatcher>
<requestHandler name="standard" class="solr.StandardRequestHandler" default="true" />
<requestHandler name="/analysis/field" startup="lazy" class="solr.FieldAnalysisRequestHandler" />
<requestHandler name="/update" class="solr.UpdateRequestHandler" />
<requestHandler name="/admin/" class="org.apache.solr.handler.admin.AdminHandlers" />
<requestHandler name="/admin/ping" class="solr.PingRequestHandler">
<lst name="invariants">
<str name="q">solrpingquery</str>
</lst>
<lst name="defaults">
<str name="echoParams">all</str>
</lst>
</requestHandler>
<!-- config for the admin interface -->
<admin>
<defaultQuery>solr</defaultQuery>
</admin>
</config>
|
之后在exampledocs目录下手动创建一个solr1.xml文件://这个也可以是数据库的数据源,这里只是提供xml的数据源,用于提交,形成solr的索引。
|
1
2
3
4
5
6
7
8
|
<?xml version="1.0" ?>
<add>
<doc>
<field name="id">solr1</field>
<field name="type">type1</field>
<field name="name">my solr test</field>
</doc>
</add>
|
跟schema.xml中的字段对应,好了现在可以提交数据了,这里在window命令窗口提交数据,把E:\apache-solr-4.0.0\example\exampledocs下的post.jar复制到 E:\SolrHome\exampledocs下
打开命令窗口CD 到E:\SolrHome\exampledocs下使用命令,Tomcat不要忘了开:
java -Durl=http://localhost:8080/solr/solrtest/update -Ddata=files -jar post.jar solr1.xml
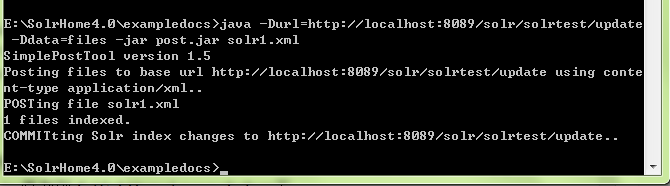
如图成功的添加的索引,看下E:\SolrHome\solrtest\data\index下的文件:
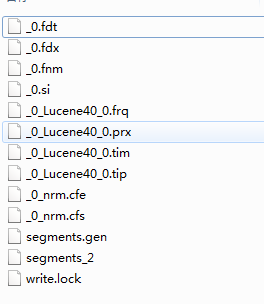
进入solr页面:
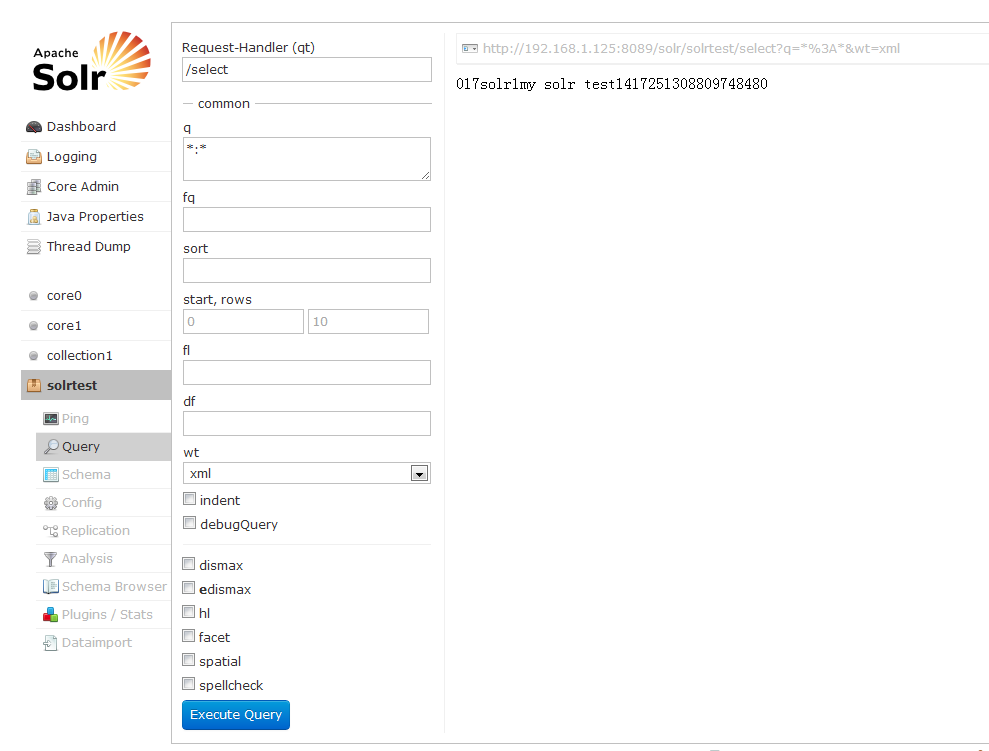
点击Executu Query查询,右侧生成了地址可以打开查看,到此结束。



相关推荐
它适用于Lucene和Solr等全文检索引擎,为这些平台提供高效的中文分词支持。IKAnalyzer的设计目标是:简单易用、高度可配置、持续优化,并且支持扩展。 **IKAnalyzer 的主要特点** 1. **灵活性**:IKAnalyzer 支持...
IK中文分词器是一款在Java环境下广泛使用的开源中文分词工具,主要针对Lucene和Solr等全文检索引擎设计。2012FF_u1版本是IK Analyzer的一个重要更新,它增强了对中文词汇的处理能力,同时扩展了对Lucene和Solr的支持...
IKAnalyzer 是一个专门为中文分词设计的开源分析器,它在 Lucene 和 Solr 中广泛使用,以提高中文文本检索的准确性和效率。这个压缩包 "ik-analyzer-solr5.4.0" 显然是针对 Lucene 5.4.0 和 Solr 5.4.0 版本优化的 ...
通过本文的学习,我们不仅了解了Lucene和Solr的基本概念、特点以及工作原理,还对比分析了它们之间的异同之处,并探讨了各自适用的应用场景。无论是对于开发者还是运维人员而言,掌握这两种优秀的搜索引擎技术都将...
Lucene和Solr是两个非常重要的开源搜索引擎工具,它们在大数据处理、信息检索以及网站全文搜索等领域发挥着至关重要的作用。本篇将详细阐述Lucene和Solr的基本概念、工作原理以及如何在实际应用中使用它们。 **1. ...
lucene&solr原理分析,lucene搜索引擎和solr搜索服务器原理分析。
IK分词器是Java开发的一款高效、灵活的中文分词工具,特别适用于Lucene和Solr等全文搜索引擎的中文处理。在对文本进行索引和搜索时,分词器的作用至关重要,它能将中文文本拆分成有意义的词汇,以便进行后续的分析和...
Apache Lucene和Solr是两个在信息技术领域广泛使用的开源搜索技术。Lucene是一个高性能、全文本搜索引擎库,而Solr是基于Lucene构建的一个企业级搜索服务器,提供了更高级别的功能和服务。"lucene-solr-sandbox"是这...
在构建高效的全文搜索引擎时,Apache Lucene 和 Solr 是两个非常重要的开源库。它们提供了强大的信息检索和文本分析功能,但Lucene默认的分词器并不适用于中文处理。因此,对于中文索引和搜索,我们需要引入专门针对...
关于solr和lucene的使用方法,这是传智播客黑马的教学视频
Apache Lucene和Solr Apache Lucene是用Java编写的高性能,功能齐全的文本搜索引擎库。 Apache Solr是使用Java编写并使用Apache Lucene的企业搜索平台。 主要功能包括全文搜索,索引复制和分片以及结果分面和突出...
本篇将深入探讨两款广泛应用的开源搜索引擎技术——Lucene和Solr,揭示它们的核心原理以及发展历程。 首先,Lucene是一个强大的全文索引库,由Doug Cutting于1999年开发,最初是一个Java程序。2001年,Lucene被捐赠...
本文将围绕“lucene solr框架代码实例(可直接运行)”这一主题,深入探讨Lucene和Solr的核心特性,以及如何通过它们构建实际的搜索应用。 首先,Lucene是Apache软件基金会的一个开源项目,它提供了一个高性能、...
标题“lucene简单介绍及solr搭建使用”涉及了两个主要的开源搜索技术:Lucene和Solr。Lucene是Java开发的一个全文检索库,而Solr则是基于Lucene构建的企业级搜索平台,提供了更高级的功能和管理界面。 **Lucene简介...
包含与 lucene 和 solr 一起使用的搜索算法 bbox 查询: 完全删除 solr 索引: curl -H "Content-Type: text/xml" --data-binary ' : ' curl -d ' ' curl -d '' export CLASSPATH="<lucene>/lucene/replicator/...
本人用ant idea命令花了214分钟,35秒编译的lucene-solr源码,可以用idea打开,把项目放在D:\space\study\java\lucene-solr路径下,再用idea打开就行了
5. Solr是一个基于Lucene构建的企业级搜索服务器,它提供了搜索引擎的索引、搜索、排序等功能,并通过RESTful API与各种客户端进行交互。Solr在实现搜索引擎方面,不仅继承了Lucene的强大功能,还提供了分布式搜索、...
lucene solr 全文搜索框架,该教程有助于深入了解lucene solr的用法以及他么们之间的比较