转自:http://www.cnblogs.com/ipointer/archive/2006/11/16/246251.html
通过一周左右的研究,对规则引擎有了一定的了解。现在写点东西跟大家一起交流,本文主要针对
RETE
算法进行描述。我的文笔不太好,如
果有什么没讲明白的或是说错的地方,请给我留言。
首先申明,我的帖子借鉴了网上很流行的一篇帖子,好像是来自
CSDN
;还有一点,我不想做太多的名词解
释,因为我也不是个研究很深的人,定义的不好怕被笑话。
好现在我们开始。
首先介绍一些网上对于规则引擎比较好的帖子。
1、
来自
JAVA
视频网
http://forum.iteye.com/viewtopic.php?t=7803&postdays=0&postorder=asc&start=0
2、
RETE
算法的最原始的描述,我不知道在哪里找到的,想要的人可以留下
E-mail
3、
CMU
的一位博士生的毕业论文,个人觉得非常好,我的很多观点都是来自这里的,要的人也可以给我发
mail
mailto:ipointer@163.com
接着统一一下术语,很多资料里的术语都非常混乱。
1、
facts
事实,我们实现的时候,会有一个事实库。用
F
表示。
2、
patterns
模板,事实的一个模型,所有事实库中的事实都必须满足模板中的一个。用
P
表示。
3、
conditions
条件
,
规则的组成部分。也必须满足模板库中的一条模板。用
C
表示。我们可以这样理解
facts
、
patterns
、
conditions
之间的关系。
Patterns
是一个接口,
conditions
则是实现这个接口的
类,而
facts
是
这个类的实例。
4、
rules
规则,由一到多个条件构成。一般用
and
或
or
连接
conditions
。用
R
表示。
5、
actions
动作,激活一条
rule
执行的动作。我们这里不作讨论。
6、
还有一些术
语,如:
working-memory
、
production-memory
,跟这里的概念大同小异。
7、
还有一些,
如:
alpha-network
、
beta-network
、
join-node
,我们下面会用到,先放一下,一会讨论。
引用一下网上很流行的例子,我觉得没讲明白,我在用我的想法解释一下。
假设在规则记忆中有下列三条规则
if
A(x) and B(x) and C(y) then add D(x)
if
A(x) and B(y) and D(x) then add E(x)
if
A(x) and B(x) and E(x) then delete A(x)
RETE
算法会先将规则编译成下列的树状架构排序网络
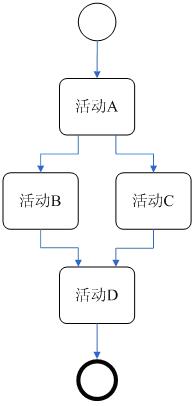
而工作记忆内容及顺序为
{A(1)
,
A(2)
,
B(2)
,
B(3)
,
B(4)
,
C(5)}
,当工作记忆依序进入网络后,会依序储存在符合条件的节点中,直到完全符合条件的推论规则推出推论。
以上述例子而言,
最后推得
D(2)
。
让我们来分析这个例子。
模板库:(这个例子中只有一个模板,算法原描述中有不同的例子
,
一般我们会用
tuple,
元组的形式来定义
facts,patterns,condition
)
P:
(?A , ?x)
其
中的
A
可能代表一
定的操作,如例子中的
A,B,C,D,E ; x
代表操作的参数。看看这个模板是不是已经可以描述所有的事实。
条件库:
(
这里元组的第一项代表实际的操作,第二项代表形参
)
C1:
(A , <x>)
C2:
(B , <x>)
C3:
(C , <y>)
C4:
(D , <x>)
C5:
(E , <x>)
C6:
(B , <y>)
事实库:(第二项代表实参)
F1:
(A,1)
F2:
(A,2)
F3:
(B,2)
F4:
(B,3)
F5:
(B,4)
F6:
(C,5)
规则库:
R1: c1^c2^c3
R2: c1^c2^c4
R3: c1^c2^c5
有人可能会质疑
R1: c1^c2^c3
,没有描述出,原式中:
if A(x) and B(x) and C(y) then add D(x)
,
A=B
的关系。但请仔细看一下,这一点已经在条件库中定义出来了。
下面我来描述一下,规则引擎中
RETE
算法的实现。
首先,我们要定一些规则,根据这些规则,我们的引擎可以编译出一个树状结构,上面的那张图中是一种
简易的表现,其实在实现的时候不是这个样子的。
这就是
beta-network
出场的时候了,根据
rules
我们就可以确定
beta-network
,下面,我就画出本例中的
beta-network
,为了描述方便,我把
alpha-network
也画出来了。
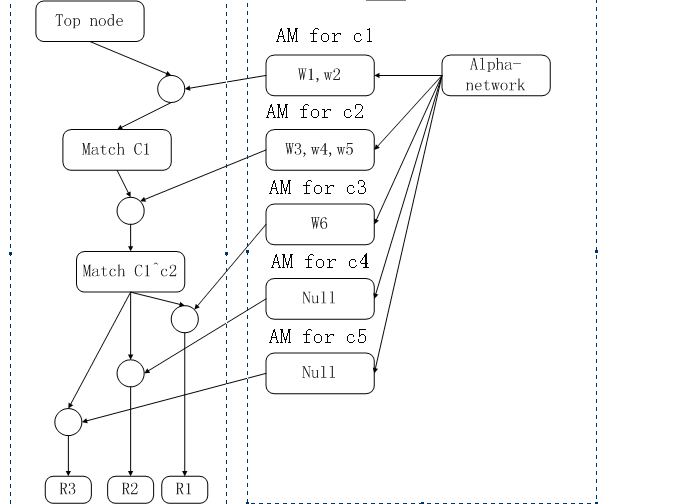
上图中,左边的部分就是
beta-network,
右边是
alpha-network,
圆圈是
join-node.
从上图中,我们可以验证,在
beta-network
中,表现出了
rules
的内容,其中
r1,r2,r3
共享了许多
BM
和
join-node,
这是由于这些规则中有共同的部分,这样能加快
match
的速度。
右边的
alpha-network
是根据事实库构建的,其中除
alpha-network
节点的节点都是根据每一条
condition,
从事实库中
match
过来的,这一过程是静态的,即在编译构建网络的过程中已经建立的。只要事实库是稳定的,即没有大幅
度的变化,
RETE
算
法的执行效率应该是非常高的,其原因就是已经通过静态的编译,构建了
alpha-network
。我们可以验证一下,满足
c1
的事实确实是
w1,w2
。
下面我们就看一下,这个算法是怎么来运行的,即怎么来确定被激活的
rules
的。从
top-node
往下遍历,到一个
join-node,
与
AM for c1
的节点汇合,运行到
match c1
节点。此时,
match c1
节点的内容就是:
w1,w2
。继续往下,与
AM for c2
汇合(所有可能的组合应
该是
w1^w3,w1^w4,w1^w5,w2^w3,w2^w4,w2^w5
),因为
c1^c2
要求参数相同,因此,
match
c1^c2
的内容是:
w2^w3
。再继续,这里有一个扇出(
fan-out
),其中只有一个
join-node
可以被激活,因为旁边的
AM
只有一个非空。因此,也只有
R1
被激活了。
解决扇出带来的效率降低的问题,我们可以使用
hashtable
来解决这个问题。
RETE
算法还有一些问题,如:
facts
库变化,我们怎么才能高效的重建
alpha-network
,同理包括
rules
的变化对
beta-network
的影响。这一部分我还没细看,到时候再贴出来吧。
分享到:





相关推荐
Rete算法是一种用于快速匹配模式的算法,常用于规则引擎和专家系统,而RDF(Resource Description Framework)是描述和链接网络资源的数据模型,广泛应用于语义网和Linked Data。分布式并行推理方法则是指在多节点或...
- **支持大规模数据集**:即使是处理成千上万的对象和模式,Rete算法也能保持良好的性能表现。 #### 六、结论 Rete算法是产生式规则系统中一个重要的突破,特别是在处理大规模数据集时表现出了极高的效率。通过对...
`py_rete`可能是一个基于Python实现的Rete算法的库,Rete算法是一种高效的规则引擎实现方式,常用于专家系统和业务规则管理系统。 描述中的"资源来自pypi官网。资源全名:py_rete-0.0.7.dev5.tar.gz"表明这个压缩...
- **Rete算法的核心思想**:Rete算法的核心在于构建一个匹配树结构,用于存储规则中的模式。当新的事实被加入到系统中时,这些事实会沿着匹配树向下传播,以确定哪些规则需要被触发。这种方法可以极大地减少计算量,...
RETE算法是OPS5语言中用于执行模式匹配和推理的核心算法。OPS5是一种人工智能编程语言,主要用于专家系统的构建,它通过一系列的产生式规则(if-then规则)来表达知识并进行推理。OPS5通过RETE网络来处理复杂的模式...
java 源码编辑 虫洞 · 技术栈 | 沉淀、分享、成长,让自己和他人都能有所收获! 作者: 小傅哥,Java Developer, 本文档是作者小傅哥多年从事一线互联网Java开发的学习历程技术汇总,旨在为大家提供一个较清晰详细...
Drools是一个Java语言版本的基于Charles Forgy's Rete算法研究的规则引擎实现。结合Rete到一个面向对象接口中,允许业务对象处理业务表达式。Drools由Java语言开发,但是可以运行在Java环境和.NET环境下。 Drools被...
Drools是由Jboss公司开发的一款高性能开源规则引擎,其核心优势在于完整实现了RETE算法,同时提供了强大的开发支持和自然语言规则描述能力。Drools通过其DSL(领域特定语言),使得非技术人员也能理解并参与规则的...
Drools是Jboss公司旗下一款开源的规则引擎,它完整的实现了Rete算法;提供了强大的EclipsePlugin开发支持;通过使用其中的DSL(DomainSpecificLanguage),可以实现用自然语言方式来描述业务规则,使得业务分析人员也...
其中,Rete算法是最常用的一种算法,它通过构建一个高效的网络结构来实现快速匹配。Rete算法通过预先构建好的网络来减少重复计算,从而大幅提高了匹配速度。尽管Leaps算法是一种实验性质的算法,但其设计理念旨在...
Rete是一种高效匹配算法,专门用于规则引擎,能够高效地处理复杂条件语句,而ReteOO是Rete算法的面向对象版本,PHREAK是Rete算法的进一步优化。 5. **用户指南**:这部分是Drools的实际使用手册,包括了如何使用...
Rete 算法是一种高效的模式匹配算法,用于匹配事实(Facts)和规则。它通过构建 RETE 网络来加速规则的评估,当新的事实被插入到 Working Memory 中时,算法能够迅速找到匹配的规则并执行相应的动作。 **Drools ...
文章提到了Rete算法,这是一种在20世纪70年代末发展起来的模式匹配机制,特别适合处理大量模式数据与数据库的比较,避免数据迭代,提高处理速度。UrsaLeo公司的云分析软件就是利用这种算法,结合Silicon Labs的...
Drools在JBoss应用服务器中作为规则引擎存在,并且是专门为Java语言定制的,基于CharlesForgy的RETE算法的实现。 RETE算法是专家系统领域内用于推理的一种高效算法,它能够高效地处理具有大量规则的系统。Drools...
Drools是一个强大的规则引擎,基于Charles Forgy的Rete算法,特别为Java设计,能够同时在Java和.NET平台上运行。Rete算法的核心优势在于它能够有效地处理面向对象的规则,使得商业对象的规则表达更加直观。Drools...
Drools是Jboss公司旗下一款开源的规则引擎,它完整的实现了Rete 算法;提供了强大的Eclipse Plugin开发支持; 通过使用其中的DSL(Domain Specific Language),可以实现用自然语言方式来描述业务规则,使得业务分析...