- µÁÅÞºê: 229656 µ¼í
- µÇºÕê½:

- µØÑÞç¬: µ▓êÚÿ│
-

µûçþ½áÕêåþ▒╗
- Õà¿Úâ¿ÕìÜÕ«ó (105)
- java (30)
- linux unix (19)
- þëêµ£¼µÄºÕê (15)
- ajax (2)
- Õ╝ÇÕÅæÕÀÑÕàÀÕÅèÞ¥àÕè®ÕÀÑÕàÀ (3)
- database (2)
- flex (10)
- ÕàÂÕ«â (2)
- windows (1)
- Õ╝ǵ║Éõ╝üõ©ÜÕ║öþö¿ (6)
- Õ╝ǵ║Éerp (4)
- Õ╝ǵ║Écms (0)
- Õ╝ǵ║ÉÚù¿µêÀ (0)
- php (1)
- ofbiz&opentaps (4)
- Þ┐Éþ╗┤þ«íþÉå (0)
- MOQUI (3)
- linux unix mysql (0)
- mysql (2)
- hadoop (3)
- android (0)
- Õ¥«õ┐íÕà¼õ╝ùÕÅÀ (1)
- java cassandra nosql (0)
- Nosql (1)
- socket (1)
- tcp (1)
- udp (1)
- ÕìüÕà¡Þ┐øÕê (1)
- ofbiz (1)
- docker (1)
- ÞÖܵïƒÕîû (0)
- ÕêåÕ©âÕ╝Å (0)
þñ¥Õî║þëêÕØù
- µêæþÜäÞÁäÞ«» ( 0)
- µêæþÜäÞ«║ÕØø ( 26)
- µêæþÜäÚù«þ¡ö ( 5)
Õ¡ÿµíúÕêåþ▒╗
- 2017-01 ( 1)
- 2016-04 ( 1)
- 2015-08 ( 1)
- µø┤ÕñÜÕ¡ÿµíú...
µ£Çµû░Þ»äÞ«║
-
w87848608´╝Ü
þö¿phpunit --coverage-htmlÕæ¢õ╗ñõ©ÇµáÀÕç║þÄ░õ║å ...
Õà│õ║Äphpunitõ©ÄSeleniumÕÅûcoverageþÜäÚàìþ¢«(ÕăÕêø) -
surpass_li´╝Ü
ÕÑ¢õ╣àµ▓íµØÑÞ┐Öõ║å´╝îõ©ìÕÑ¢µäŵÇØ´╝îõ¢áÕÅéþàºDeploying OFBiz ...
ofibz10.04Úâ¿þ¢▓Õê░ jboss5.1.0µêÉÕèƒ -
tide2046´╝Ü
µ▒éÚâ¿þ¢▓µûçµíúÒÇéÞ░óÞ░óÒÇé
ofibz10.04Úâ¿þ¢▓Õê░ jboss5.1.0µêÉÕèƒ -
Romotc´╝Ü
Õ¥üµûç +1´╝î1µÑ╝þÜäµû╣µ│òÞ┐ÿµÿ»µ£ëþé╣Úù«ÚóÿÒÇé
eclipseþ╝ûÞ»æµùÂÞ┐çµ╗ñSVNþëêµ£¼µÄºÕêÂõ┐íµü»µû╣µ│ò -
µêæµö╣ÕÉìõ║å´╝Ü
Þ░óÞ░ó´╝îµö ÞùÅ õ║å´╝îÕñçþö¿ÒÇé
JavaÞÄÀÕÅûÕ«óµêÀþ½»þ£ƒÕ«×IPÕ£░ÕØÇþÜäõ©ñþºìµû╣µ│ò(Þ¢¼)
Þ┐ÖÚçîÕàêÕñºÞç┤õ╗ïþ╗ìõ©Çõ©ïHadoop.
┬á┬á┬á µ£¼µûçÕñºÚâ¿ÕêåÕåàÕ«╣Ú⢵ÿ»õ╗ÄÕ«ÿþ¢æ
Hadoop
õ©èµØÑþÜäÒÇéÕàÂõ©¡µ£ëõ©Çþ»ç
õ╗ïþ╗ìHDFSþÜäpdfµûçµíú
´╝îÚçîÚØóÕ»╣Hadoopõ╗ïþ╗ìþÜäµ»öÞ¥âÕà¿ÚØóõ║åÒÇéµêæþÜäÞ┐Öõ©Çõ©¬þ│╗ÕêùþÜäHadoopÕ¡ªõ╣áþ¼öÞ«░õ╣ƒµÿ»õ╗Ä
Þ┐ÖÚçî
õ©Çµ¡Ñõ©Çµ¡ÑÞ┐øÞíîõ©ïµØÑþÜä´╝îÕÉîµùÂÕÅêÕÅéÞÇâõ║åþ¢æõ©èþÜäÕ¥êÕñܵûçþ½á´╝îÕ»╣Õ¡ªõ╣áHadoopõ©¡ÚüçÕê░þÜäÚù«ÚóÿÞ┐øÞíîõ║åÕ¢Æþ║│µÇ╗þ╗ôÒÇé
┬á┬á┬á Þ¿ÇբƵ¡úõ╝á´╝îÕàêÞ»┤õ©Çõ©ïHadoopþÜäµØÑÚ¥ÖÕÄ╗ÞäëÒÇéÞ░êÕê░HadoopÕ░▒õ©ìÕ¥ùõ©ìµÅÉÕê░
Lucene
ÕÆî
Nutch
ÒÇéÚªûÕàê´╝îLuceneÕ╣Âõ©ìµÿ»õ©Çõ©¬Õ║öþö¿þ¿ïÕ║Å´╝îÞÇîµÿ»µÅÉõ¥øõ║åõ©Çõ©¬þ║»JavaþÜäÚ½ÿµÇºÞâ¢Õ࿵ûçþ┤óÕ╝òÕ╝òµôÄÕÀÑÕàÀÕîà
´╝îÕ«âÕÅ»õ╗ѵû╣õ¥┐þÜäÕÁîÕàÑÕê░ÕÉäþºìÕ«×ÚÖàÕ║öþö¿õ©¡Õ«×þÄ░Õ࿵ûçµÉ£þ┤ó/þ┤óÕ╝òÕèƒÞâ¢ÒÇéNutchµÿ»õ©Çõ©¬Õ║öþö¿þ¿ïÕ║Å´╝îµÿ»õ©Çõ©¬õ╗ÑLuceneõ©║Õƒ║þíÇÕ«×þÄ░þÜäµÉ£þ┤óÕ╝òµôÄÕ║öþö¿
´╝îLucene
õ©║NutchµÅÉõ¥øõ║åµûçµ£¼µÉ£þ┤óÕÆîþ┤óÕ╝òþÜäAPI´╝îNutchõ©ìÕàëµ£ëµÉ£þ┤óþÜäÕèƒÞ⢴╝îÞ┐ÿµ£ëµò░µì«µèôÕÅûþÜäÕèƒÞâ¢ÒÇéÕ£¿nutch0.8.0þëêµ£¼õ╣ïÕëì´╝îHadoopÞ┐ÿÕ▒×õ║Ä
NutchþÜäõ©ÇÚâ¿Õêå´╝îÞÇîõ╗Änutch0.8.0Õ╝ÇÕºï´╝îÕ░åÕàÂõ©¡Õ«×þÄ░þÜäNDFSÕÆîMapReduceÕëÑþª╗Õç║µØѵêÉþ½ïõ©Çõ©¬µû░þÜäÕ╝ǵ║ÉÚí╣þø«´╝îÞ┐ÖÕ░▒µÿ»Hadoop´╝îÞÇî
nutch0.8.0þëêµ£¼Þ¥âõ╣ïõ╗ÑÕëìþÜäNutchÕ£¿µ×µ×äõ©èµ£ëõ║åµá╣µ£¼µÇºþÜäÕÅÿÕîû´╝îÚéúÕ░▒µÿ»Õ«îÕ࿵×äÕ╗║Õ£¿HadoopþÜäÕƒ║þíÇõ╣ïõ©èõ║åÒÇéÕ£¿Hadoopõ©¡Õ«×þÄ░õ║å
GoogleþÜäGFSÕÆîMapReduceþ«ùµ│ò´╝îõ¢┐HadoopµêÉõ©║õ║åõ©Çõ©¬ÕêåÕ©âÕ╝ÅþÜäÞ«íþ«ùÕ╣│ÕÅ░ÒÇé
┬á┬á┬áÕàÂÕ«×´╝îHadoopÕ╣Âõ©ìõ╗àõ╗àµÿ»õ©Çõ©¬þö¿õ║ÄÕ¡ÿÕé¿þÜäÕêåÕ©âÕ╝ŵûçõ╗Âþ│╗þ╗ƒ´╝îÞÇîµÿ»Þ«¥Þ«íþö¿µØÑÕ£¿þö▒ÚÇÜþö¿Þ«íþ«ùÞ«¥Õñçþ╗äµêÉþÜäÕñºÕ×ïÚøåþ¥ñõ©èµëºÞíîÕêåÕ©âÕ╝ÅÕ║öþö¿þÜäµíåµ×ÂÒÇé
┬á┬á┬áHadoopÕîàÕɽõ©ñõ©¬Úâ¿Õêå´╝Ü
┬á┬á┬á1ÒÇüHDFS
┬á┬á┬á┬á┬á┬áÕì│Hadoop Distributed File System (HadoopÕêåÕ©âÕ╝ŵûçõ╗Âþ│╗þ╗ƒ)
      HDFS
ÕàÀµ£ëÚ½ÿÕ«╣ÚöֵǺ´╝îÕ╣Âõ©öÕÅ»õ╗ÑÞó½Úâ¿þ¢▓Õ£¿õ¢Äõ╗ÀþÜäþí¼õ╗ÂÞ«¥Õñçõ╣ïõ©èÒÇéHDFSÕ¥êÚÇéÕÉêÚéúõ║øµ£ëÕñºµò░µì«ÚøåþÜäÕ║öþö¿´╝îÕ╣Âõ©öµÅÉõ¥øõ║åÕ»╣µò░µì«Þ»╗ÕåÖþÜäÚ½ÿÕÉ×ÕÉÉþÄçÒÇéHDFSµÿ»õ©Çõ©¬
master/slaveþÜäþ╗ôµ×ä´╝îÕ░▒ÚÇÜÕ©©þÜäÚâ¿þ¢▓µØÑÞ»┤´╝îÕ£¿masterõ©èÕŬÞ┐ÉÞíîõ©Çõ©¬Namenode´╝îÞÇîÕ£¿µ»Åõ©Çõ©¬slaveõ©èÞ┐ÉÞíîõ©Çõ©¬DatanodeÒÇé
      HDFS
µö»µîüõ╝áþ╗ƒþÜäÕ▒éµ¼íµûçõ╗Âþ╗äþ╗çþ╗ôµ×ä´╝îÕÉîþÄ░µ£ëþÜäõ©Çõ║øµûçõ╗Âþ│╗þ╗ƒÕ£¿µôìõ¢£õ©èÕ¥êþ▒╗õ╝╝´╝îµ»öÕªéõ¢áÕÅ»õ╗ÑÕêøÕ╗║ÕÆîÕêáÚÖñõ©Çõ©¬µûçõ╗´╝îµèèõ©Çõ©¬µûçõ╗Âõ╗Äõ©Çõ©¬þø«Õ¢òþº╗Õê░ÕŪõ©Çõ©¬þø«Õ¢ò´╝îÚçìÕæ¢ÕÉìþ¡ëþ¡ëµôì
õ¢£ÒÇéNamenodeþ«íþÉåþØǵò┤õ©¬ÕêåÕ©âÕ╝ŵûçõ╗Âþ│╗þ╗ƒ´╝îÕ»╣µûçõ╗Âþ│╗þ╗ƒþÜäµôìõ¢£´╝êÕªéÕ╗║þ½ïÒÇüÕêáÚÖñµûçõ╗ÂÕÆîµûçõ╗ÂÕñ╣´╝ëÚ⢵ÿ»ÚÇÜÞ┐çNamenodeµØѵĺÕêÂÒÇé┬á
┬á┬á┬á┬á┬áõ©ïÚØóµÿ»HDFSþÜäþ╗ôµ×ä´╝Ü
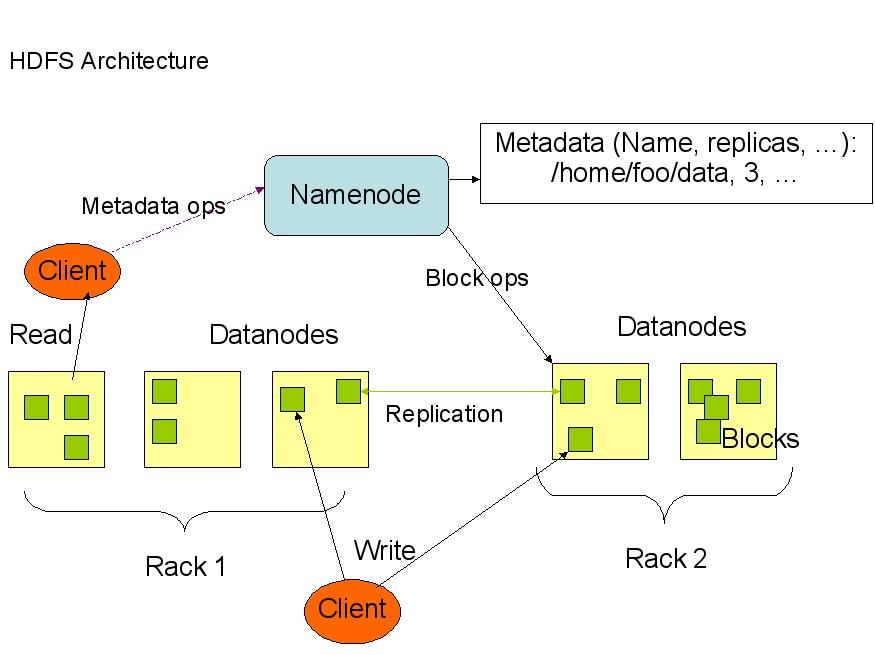
┬á┬á┬á┬á┬á┬áõ╗Äõ©èÚØóþÜäÕø¥õ©¡ÕÅ»õ╗Ñþ£ï
Õç║´╝îNamenode´╝îDatanode´╝îClientõ╣ïÚù┤þÜäÚÇÜõ┐íÚ⢵ÿ»Õ╗║þ½ïÕ£¿TCP/IPþÜäÕƒ║þíÇõ╣ïõ©èþÜäÒÇéÕ¢ôClientÞªüµëºÞíîõ©Çõ©¬ÕåÖÕàÑþÜäµôìõ¢£þÜäµùÂÕÇÖ´╝îÕæ¢õ╗ñ
õ©ìµÿ»Ú®¼õ©èÕ░▒ÕÅæÚÇüÕê░Namenode´╝îClientÚªûÕàêÕ£¿µ£¼µ£║õ©èõ©┤µùµûçõ╗ÂÕñ╣õ©¡þ╝ôÕ¡ÿÞ┐Öõ║øµò░µì«´╝îÕ¢ôõ©┤µùµûçõ╗ÂÕñ╣õ©¡þÜäµò░µì«ÕØùÞ¥¥Õê░õ║åÞ«¥Õ«ÜþÜäBlockþÜäÕÇ╝´╝êÚ╗ÿÞ«ñµÿ»
64M´╝ëµù´╝îClientõ¥┐õ╝ÜÚÇÜþƒÑNamenode´╝îNamenodeõ¥┐ÕôìÕ║öClientþÜäRPCÞ»Àµ▒é´╝îÕ░åµûçõ╗ÂÕÉìµÅÆÕàѵûçõ╗Âþ│╗þ╗ƒÕ▒éµ¼íõ©¡Õ╣Âõ©öÕ£¿
Datanodeõ©¡µë¥Õê░õ©ÇÕØùÕ¡ÿµö¥Þ»Ñµò░µì«þÜäblock´╝îÕÉîµùÂÕ░åÞ»ÑDatanodeÕÅèÕ»╣Õ║öþÜäµò░µì«ÕØùõ┐íµü»ÕæèÞ»ëClient´╝îClientõ¥┐Þ┐Öõ║øµ£¼Õ£░õ©┤µùµûçõ╗ÂÕñ╣õ©¡
þÜäµò░µì«ÕØùÕåÖÕàѵîçÕ«ÜþÜäµò░µì«Þèéþé╣ÒÇé
┬á┬á┬á┬á┬á┬áHDFSÚççÕÅûõ║åÕ뻵£¼þ¡ûþòÑ´╝îÕàÂþø«þÜäµÿ»õ©║õ║åµÅÉÚ½ÿþ│╗þ╗ƒþÜäÕÅ»ÚØáµÇº´╝îÕÅ»þö¿µÇºÒÇéHDFSþÜäÕ뻵£¼µö¥þ¢«þ¡ûþòѵÿ»õ©ëõ©¬Õ뻵£¼´╝î
õ©Çõ©¬µö¥Õ£¿µ£¼Þèéþé╣õ©è´╝îõ©Çõ©¬µö¥Õ£¿ÕÉîõ©Çµ£║µ×Âõ©¡þÜäÕŪõ©Çõ©¬Þèéþé╣õ©è´╝îÞ┐ÿµ£ëõ©Çõ©¬Õ뻵£¼µö¥Õ£¿ÕŪõ©Çõ©¬õ©ìÕÉîþÜäµ£║µ×Âõ©¡þÜäõ©Çõ©¬Þèéþé╣õ©èÒÇéÕ¢ôÕëìþëêµ£¼þÜähadoop0.12.0õ©¡Þ┐ÿµ▓íµ£ëÕ«×
þÄ░´╝îõ¢åµÿ»µ¡úÕ£¿Þ┐øÞíîõ©¡´╝îþø©õ┐íõ©ìõ╣àÕ░▒ÕÅ»õ╗ÑÕç║µØÑõ║åÒÇé
┬á┬á┬á2ÒÇüMapReduceþÜäÕ«×þÄ░
      
MapReduce
µÿ»Google
þÜäõ©ÇÚí╣ÚçìÞªüµèǵ£»´╝îÕ«âµÿ»õ©Çõ©¬þ╝ûþ¿ïµ¿íÕ×ï´╝îþö¿õ╗ÑÞ┐øÞíîÕñºµò░µì«ÚçÅþÜäÞ«íþ«ùÒÇéÕ»╣õ║ÄÕñºµò░µì«ÚçÅþÜäÞ«íþ«ù´╝îÚÇÜÕ©©Úççþö¿þÜäÕñäþÉåµëïµ│òÕ░▒µÿ»Õ╣ÂÞíîÞ«íþ«ùÒÇéÞç│Õ░æþÄ░Úÿµ«ÁÞÇîÞ¿Ç´╝îÕ»╣Þ«©ÕñÜÕ╝ÇÕÅæõ║║ÕæÿµØÑ
Þ»┤´╝îÕ╣ÂÞíîÞ«íþ«ùÞ┐ÿµÿ»õ©Çõ©¬µ»öÞ¥âÚüÑÞ┐£þÜäõ©£ÞÑ┐ÒÇéMapReduceÕ░▒µÿ»õ©Çþºìþ«ÇÕîûÕ╣ÂÞíîÞ«íþ«ùþÜäþ╝ûþ¿ïµ¿íÕ×ï´╝îÕ«âÞ«®Úéúõ║øµ▓íµ£ëÕñÜÕ░æÕ╣ÂÞíîÞ«íþ«ùþ╗ÅÚ¬îþÜäÕ╝ÇÕÅæõ║║Õæÿõ╣ƒÕÅ»õ╗ÑÕ╝ÇÕÅæÕ╣ÂÞíîÕ║öþö¿ÒÇé
┬á┬á┬á┬á┬á┬áMapReduceþÜäÕÉìÕ¡ùµ║Éõ║ÄÞ┐Öõ©¬µ¿íÕ×ïõ©¡þÜäõ©ñÚí╣µá©Õ┐âµôìõ¢£´╝ÜMapÕÆî ReduceÒÇéõ╣ƒÞ«©þ僵éëFunctional Programming´╝ê
Õ碵ò░Õ╝Åþ╝ûþ¿ï
´╝ë
þÜäõ║║ÞºüÕê░Þ┐Öõ©ñõ©¬Þ»ìõ╝ÜÕÇìµäƒõ║▓ÕêçÒÇéþ«ÇÕìòþÜäÞ»┤µØÑ´╝îMapµÿ»µèèõ©Çþ╗äµò░µì«õ©ÇÕ»╣õ©ÇþÜäµÿáÕ░äõ©║ÕŪÕñûþÜäõ©Çþ╗äµò░µì«´╝îÕàµÿáÕ░äþÜäÞºäÕêÖþö▒õ©Çõ©¬Õ碵ò░µØѵîçÕ«Ü´╝îµ»öÕªéÕ»╣[1, 2, 3,
4]Þ┐øÞíîõ╣ÿ2þÜäµÿáÕ░äÕ░▒ÕÅÿµêÉõ║å[2, 4, 6, 8]ÒÇéReduceµÿ»Õ»╣õ©Çþ╗äµò░µì«Þ┐øÞíîÕ¢Æþ║ª´╝îÞ┐Öõ©¬Õ¢Æþ║ªþÜäÞºäÕêÖþö▒õ©Çõ©¬Õ碵ò░µîçÕ«Ü´╝îµ»öÕªéÕ»╣[1, 2, 3,
4]Þ┐øÞíîµ▒éÕÆîþÜäÕ¢Æþ║ªÕ¥ùÕê░þ╗ôµ×£µÿ»10´╝îÞÇîÕ»╣Õ«âÞ┐øÞíîµ▒éþº»þÜäÕ¢Æþ║ªþ╗ôµ×£µÿ»24ÒÇé
┬á┬á┬á┬á┬á┬áÕà│õ║ÄMapReduceþÜäÕåàÕ«╣´╝îÕ╗║Þ««þ£ïþ£ïÕ¡ƒÕ▓®þÜäÞ┐Öþ»ç
MapReduce:The Free Lunch Is Not Over!
┬á┬á┬áÕÑ¢õ║å´╝îõ¢£õ©║Þ┐Öõ©¬þ│╗ÕêùþÜäþ¼¼õ©Çþ»çÕ░▒ÕåÖÞ┐Öõ╣êÕñÜõ║å´╝îµêæõ╣ƒµÿ»ÕêÜÕ╝ÇÕºïµÄÑÞºªHadoop´╝îõ©ïõ©Çþ»çÕ░▒µÿ»Þ«▓HadoopþÜäÚâ¿þ¢▓´╝îÞ░êÞ░êµêæÕ£¿Úâ¿þ¢▓HadoopµùÂÚüçÕê░þÜäÚù«Úóÿ´╝îõ╣ƒþ╗ÖÕñºÕ«Âõ©Çõ©¬ÕÅéÞÇâ´╝îÕ░æÞÁ░þé╣Õ╝»ÞÀ»ÒÇé


- 2010-07-14 11:21
- µÁÅÞºê 780
- Þ»äÞ«║(0)
- Õêåþ▒╗:þ╝ûþ¿ïÞ»¡Þ¿Ç
- µƒÑþ£ïµø┤ÕñÜ
ÕÅæÞí¿Þ»äÞ«║

-
Õ£¿ofbizµíåµ×Âõ©¡Õ«×þÄ░httpsÕÅîÕÉæÞ«ñÞ»ü´╝êþ¼öÞ«░´╝ë
2016-04-08 10:16 497ofbizÚ╗ÿÞ«ñþÜäÚàìþ¢«µûçõ╗Âõ©¡µ▓íµ£ëµÅÉõ¥øµ£ìÕèíþ½»õ┐íõ╗╗þÜäÞ»üõ╣ªÚàìþ¢«Úí╣´╝î ... -
hadoop2.4Õ£¿windows7µÉ¡Õ╗║ÕìòÞèéþé╣þÄ»ÕóâþÜäþ«ÇÞªüõ╗ïþ╗ì
2014-05-27 16:18 922µ£¼µûçÕÅéþຠ┬áhadoop2.2Õ£¿window7õ©èµÉ¡Õ╗║ÕìòÞèéþé╣ ... -
Õà│õ║Äofbiz ÚøåµêÉurlrewritefilterÕ«×þÄ░url õ╝¬ÚØÖµÇüÕîû
2013-03-19 12:52 1787Õà│õ║Äofbiz ÚøåµêÉurlrewritefilterÕ«×þÄ░ur ... -
hadoopÕ¡ªõ╣áþ¼öÞ«░´╝êÕ迵ÇüÕêáÚÖñÞèéþé╣´╝ë
2012-09-19 13:41 1080Õ£¿hadoopÚøåþ¥ñþÄ»Õóâõ©ïÚ£ÇÞªüÕ░åõ©ñÕÅ░datanodeÕêáÚÖñ´╝îõ©║õ║åõ©ì ... -
CentOSþ│╗þ╗ƒÕ«ëÞúàTomcatÕêçµìóJDKþÜäµû╣µ│ò
2011-10-14 09:38 1140CentOSþ│╗þ╗ƒÕ«ëÞúàTomcatÕêçµìóJDKþÜäµû╣µ│ò ... -
õ©Çõ©¬õ╗ÄÕ¡ùþ¼ªõ©▓õ©¡µÅÉÕÅûÚçæÚóØþÜ䵡úÕêÖÞí¿Þ¥¥Õ╝Å
2011-05-19 15:44 2175┬á┬á┬á┬á┬á┬á┬á õ©Çõ©¬õ╗ÄÕ¡ùþ¼ªõ©▓õ©¡µÅÉÕÅûÚçæÚóØþÜ䵡úÕêÖÞí¿Þ¥¥Õ╝Å´╝îÕêØ ... -
tomcatÞ┐£þ¿ïÞ░âÞ»ò µû╣µ│ò1´╝ÜÚÇéþö¿õ║Ätomcat6 õ┐«µö╣startup.bat Õ£¿Õ░¥Úâ¿õ┐«µö╣µêÉõ╗Ñõ©ïÕêùµû╣Õ╝ÅÕÉ»Õè¿ set JPDA_ADDRESS=8000 se
2011-01-05 12:37 1514tomcat 6 Þ┐£þ¿ïÞ░âÞ»ò ... -
HadoopÕ¡ªõ╣áþ¼öÞ«░õ║î Õ«ëÞúàÚâ¿þ¢▓
2010-07-14 11:22 751Õăµûç┬á http://www.cnblogs.com ... -
JavaÞÄÀÕÅûÕ«óµêÀþ½»þ£ƒÕ«×IPÕ£░ÕØÇþÜäõ©ñþºìµû╣µ│ò(Þ¢¼)
2010-05-14 15:04 1232Õ£¿JSPÚçî´╝îÞÄÀÕÅûÕ«óµêÀþ½»þÜäIPÕ£░ÕØÇþÜäµû╣µ│òµÿ»´╝Ürequest.ge ... -
20µ¼¥Õ╝ǵ║ɵɣþ┤óÕ╝òµôÄþ│╗þ╗ƒ
2010-04-16 19:32 1246õ©Çõ║øÕ╝ǵ║ɵɣþ┤óÕ╝òµôÄþ│╗þ╗ƒõ╗ïþ╗ì´╝îÕîàÕɽÕ╝ǵ║ÉWebµÉ£þ┤óÕ╝òµôÄÕÆîÕ╝ǵ║ɵíîÚØóµÉ£þ┤ó ... -
Õ£¿JasperReportµèÑÞí¿õ©¡ÕèáÕàÑÕñºÕåÖÚçæÚóØ(þ¼öÞ«░)
2010-04-14 09:06 2668µæÿÞç¬ÒÇÇhttp://www.blogjava.net/hisp ... -
jdkÕÀÑÕàÀkeytoolÕÆîjarsignerÕ©«Õè®Part2(Þ¢¼)
2010-01-08 12:46 2173┬á┬á┬á┬á┬á┬á┬á jdkÕÀÑÕàÀkeytoolÕÆîjarsignerÕ©« ... -
jdkÕÀÑÕàÀkeytoolÕÆîjarsignerÕ©«Õè®Part1
2010-01-08 12:41 1619jdkÕÀÑÕàÀkeytoolÕÆîjarsignerÕ©« ... -
JPA µë╣µ│¿ÕÅéÞÇâ (Þ¢¼Þ¢¢)
2009-03-30 13:27 1029JPAµë╣µ│¿ÕÅéÞÇâ 1 JPA µë╣µ│ ... -
ÚÇÜÞ┐çurlrewriteÕÆîfilterÕ«×þÄ░Õ迵Çüþ¢æþ½ÖþöƒµêÉÚØÖµÇüÚíÁÕ╣Âþ╝ôÕ¡ÿþÜäµû╣µíê
2008-10-06 14:37 3317Õà│õ║ĵö╣ÚÇáÕ迵Çüþ¢æþ½Öõ©║þöƒµêÉÚØÖµÇüÚíÁþÜäµû╣µíê ┬á ┬á url Úçì ... -
jspþöƒµêÉÚ¬îÞ»üþáü
2008-01-15 15:27 916<%@ page contentType="i ... -
tomcatõ©ïÚàìþ¢«õ¢┐þö¿awstatsþ¼öÞ«░
2008-01-10 11:43 4579tomcatõ©ïÚàìþ¢«õ¢┐þö¿awstatsþ¼öÞ«░ 1ÒÇéþÄ»Õóâ õ¢┐þö¿þÜä ... -
ipÕ£░ÕØÇõ©ÄLongÕ×ïµò░µì«Þ┐øÞíîþø©õ║ÆÞ¢¼µìó
2007-12-04 23:17 4532/** * µá╣µì«ipÕ£░ÕØÇÞ«íþ«ùÕç║longÕ×ïþÜäµò░µì« * @ ... -
javaÕ»╣Þ▒íÕêØÕºïÕîûÞ┐çþ¿ï(Þ¢¼)
2007-04-22 22:57 1377java new õ©Çõ©¬Õ«×õ¥ïµùÂÕÇÖ,Õ»╣Þ▒íÕêØÕºïÕîûÞ┐çþ¿ï 1.þêÂþ▒╗ st ... -
java õ©¡ Hashtable µÄÆÕ║Å (Þ¢¼)
2007-04-10 22:41 4767import java.util.Arrays; import ...
þø©Õà│µÄ¿ÞìÉ
HadoopÕ¡ªõ╣áþ¼öÞ«░´╝îÞç¬ÕÀ▒µÇ╗þ╗ôþÜäõ©Çõ║øHadoopÕ¡ªõ╣áþ¼öÞ«░´╝îµ»öÞ¥âþ«ÇÕìòÒÇé
ÒÇÉHADOOPÕ¡ªõ╣áþ¼öÞ«░ÒÇæ Hadoopµÿ»ApacheÕƒ║Úçæõ╝ÜÕ╝ÇÕÅæþÜäõ©Çõ©¬Õ╝ǵ║ÉÕêåÕ©âÕ╝ÅÞ«íþ«ùµíåµ×´╝îµÿ»õ║æÞ«íþ«ùÚóåÕƒƒþÜäÚçìÞªüþ╗äµêÉÚâ¿Õêå´╝îÕ░ñÕàÂÕ£¿Õñºµò░µì«ÕñäþÉåµû╣ÚØóµ£ëþØÇÕ╣┐µ│øþÜäÕ║öþö¿ÒÇéµ£¼Õ¡ªõ╣áþ¼öÞ«░Õ░åµÀ▒ÕàѵÄóÞ«¿HadoopþÜäµá©Õ┐âþ╗äõ╗ÂÒÇüµ×µ×äõ╗ÑÕÅèÕªéõ¢òµÉ¡Õ╗║õ║æÞ«íþ«ùÕ╣│ÕÅ░ÒÇé...
Hadoopµÿ»õ©ÇþºìÕ╝ǵ║ÉþÜäÕêåÕ©âÕ╝ÅÕ¡ÿÕé¿ÕÆîÞ«íþ«ùþ│╗þ╗ƒ´╝îÕ«âþö▒ApacheÞ¢»õ╗ÂÕƒ║Úçæõ╝ÜÕ╝ÇÕÅæÒÇéÕ£¿ÕêØÕ¡ªÞÇàþÜäÞºÆÕ║ª´╝îþÉåÞºúHadoopþÜäþ╗äµêÉÚâ¿Õêåõ╗ÑÕÅèÕàµ×µ×äÞ«¥Þ«íµÿ»Õ¡ªõ╣áHadoopþÜäÕƒ║þíÇÒÇé ÚªûÕàê´╝îHadoopþÜäÕêåÕ©âÕ╝ŵûçõ╗Âþ│╗þ╗ƒ´╝êHDFS´╝ëµÿ»Õàµá©Õ┐âþ╗äõ╗Âõ╣ïõ©Ç´╝îÕ«âÕàÀµ£ëÚ½ÿ...
Õ£¿µáçÚóÿµÅÉÕê░þÜäÔÇ£hadoopÕ¡ªõ╣áþ¼öÞ«░´╝êõ║î´╝ëÔÇØõ©¡´╝îµêæõ╗¼þ£ïÕê░õ¢£ÞÇàÚÇÜÞ┐çþ╝ûÕåÖõ©Çõ©¬MapReduceµÁïÞ»òþ▒╗`MyMapReduceSIngleColumnTest`µØÑÕ¡ªõ╣áÕÆîþÉåÞºúHadoop MapReduceþÜäÕƒ║µ£¼ÕÀÑõ¢£ÕăþÉåÒÇéÞ┐Öõ©¬µÁïÞ»òþ▒╗µÿ»Õƒ║õ║Äõ©Çõ©¬þ«ÇÕìòþÜäÕüçÞ«¥´╝îÕì│µêæõ╗¼ÚÇÜÕ©©õ╝ÜÚüçÕê░...
### HadoopÕ¡ªõ╣áþ¼öÞ«░þƒÑÞ»åþé╣µó│þÉå #### õ©ÇÒÇüHadoopþ«Çõ╗ï - **Õ«Üõ╣ë**: Hadoopµÿ»õ©Çõ©¬Õ╝ǵ║ÉþÜäÕêåÕ©âÕ╝ÅÞ«íþ«ùµíåµ×´╝îÞâ¢Õñƒµö»µîüÕñºÞºäµ¿íµò░µì«ÚøåþÜäÕñäþÉåÒÇéÕ«âµ£ÇÕêØþö▒ApacheÞ¢»õ╗ÂÕƒ║Úçæõ╝ÜÕ╝ÇÕÅæ´╝îµù¿Õ£¿µÅÉõ¥øõ©Çþºìþ«ÇÕìòÚ½ÿµòêþÜäÕêåÕ©âÕ╝ÅÞ«íþ«ùÞºúÕå│µû╣µíêÒÇé - ...
ÒÇɵáçÚóÿÒÇæ"Hadoopõ╣ïHBaseÕ¡ªõ╣áþ¼öÞ«░"õ©╗ÞªüÞüÜþäªõ║ÄHadoopþöƒµÇüõ©¡þÜäÕêåÕ©âÕ╝ŵò░µì«Õ║ôHBaseÒÇéHBaseµÿ»õ©Çõ©¬Õƒ║õ║ÄGoogle BigtableþÉåÕ┐ÁÞ«¥Þ«íþÜäÕ╝ǵ║ÉNoSQLµò░µì«Õ║ô´╝îÕ«âÞ┐ÉÞíîÕ£¿Hadoopõ╣ïõ©è´╝îµÅÉõ¥øÚ½ÿµÇºÞâ¢ÒÇüÚ½ÿÕÅ»ÚØáµÇºõ╗ÑÕÅèÕÅ»µ░┤Õ╣│µë®Õ▒òþÜäµò░µì«Õ¡ÿÕé¿Þâ¢Õèø...
µá╣µì«2017Õñºµò░µì«ÕÅæÕ▒òÞÂïÕè┐´╝îþ╗ôÕÉêÕø¢ÕåàÕø¢ÕñûþÜäÕñºµò░µì«ÕÅæÕ▒òþÄ░þè´╝îõ╗ÑÕÅèµö┐þ¡ûþ║▓Þªü´╝îµÁàÕ▒éµ¼íþÜäõ╗ïþ╗ìõ║åÕñºµò░µì«ÕÅæÕ▒òþÜäÞÂïÕè┐´╝îõ╗ÑÕÅèþ«ÇÕìòþÜäÕñºµò░µì«µ×µ×äÒÇéµûçþ½áµëÇÞ┐░õ╗àõ╗úÞí¿õ©¬õ║║Þºéþé╣´╝îõ©ìÞÂ│õ╣ïÕñäÞ┐ÿÞ»Àµî絡úÒÇéµûçµíúõ╗àÚÖÉÕ¡ªõ╣áµëÇþö¿´╝îþªüµ¡óõ╗àÚÖÉÕòåõ©ÜÞ¢¼µÆ¡ÒÇé...
- **Õæ¢ÕÉìþö▒µØÑ**´╝ÜHadoopÞ┐Öõ©¬ÕÉìÕ¡ùµØѵ║Éõ║ÄCuttingþÜäÕ¡®Õ¡Éþ╗Öõ©ÇÕñ┤þÄ®ÕàÀÕñºÞ▒íÞÁÀþÜäÕÉìÕ¡ù´╝îÕ«âµÿ»õ©Çõ©¬ÚØ×µ¡úÕ╝ÅþÜäÕÉìþº░´╝îþ«ÇÕìòµÿôÞ«░´╝îµ▓íµ£ëþë╣µ«èÕɽõ╣ëÒÇé - **ÕÅæÕ▒òÕÄåþ¿ï**´╝Ü - **2004Õ╣┤**´╝ÜCuttingÕÆîCafarellaÕ╝ÇÕºïÕ╝ÇÕÅæNutchÚí╣þø«´╝îÞ┐Öµÿ»õ©Çõ©¬...
### HadoopÞ«▓õ╣ëÕƒ║þíÇþ»çþƒÑÞ»åþé╣µªéÞ┐░ #### Õ┐àÕ¡ªÕ┐àõ╝ÜþÜäShellÕæ¢õ╗ñ ShellÕæ¢õ╗ñµÿ»Þ┐øÞíîþ│╗þ╗ƒþ«íþÉåÕÆî...ÚÇÜÞ┐çÕ»╣õ╗Ñõ©èþƒÑÞ»åþé╣þÜäÕ¡ªõ╣á´╝îµêæõ╗¼ÕÅ»õ╗ѵø┤ÕÑ¢Õ£░þÉåÞºúÕÆîµÄîµÅíHadoopþø©Õà│þÜäÕƒ║þíÇþƒÑÞ»åÕÆîµèǵ£»µáê´╝îõ©║Þ┐øõ©Çµ¡ÑµÀ▒ÕàÑÕ¡ªõ╣áHadoopµëôõ©ïÕØÜÕ«×þÜäÕƒ║þíÇÒÇé
### Hadoop Õ«ëÞúàÕÅèÞ»ªþ╗åÕ¡ªõ╣áþ¼öÞ«░ #### Hadoop µªéÞ┐░ Hadoop µÿ»õ©Çõ©¬Þâ¢ÕñƒÕ»╣ÕñºÚçŵò░µì«Þ┐øÞíîÕêåÕ©âÕ╝ÅÕñäþÉåþÜäÞ¢»õ╗µíåµ×´╝îÕ«âµù¿Õ£¿µÅÉõ¥øÚ½ÿµë®Õ▒òµÇºÒÇüÕÅ»ÚØáµÇºÕÆîÚ½ÿµòêµÇº´╝îÚÇéþö¿õ║ÄÕñäþÉåPBþ║ºÕê½þÜäµò░µì«ÚøåÒÇéHadoop þÜäµá©Õ┐âþ╗äõ╗ÂÕîàµï¼ HDFS´╝êHadoop ...
### Hadoop Õ¡ªõ╣áÞÁäµ║ɵªéÞºê #### õ©ÇÒÇüHadoop Õ«ÿµû╣µûçµíú ...õ╗Ñõ©èÞÁäµ║ÉÞªåþøûõ║åHadoopÕ¡ªõ╣áþÜäÕÉäõ©¬µû╣ÚØó´╝îõ╗ÄþÉåÞ«║Õê░Õ«×ÞÀÁ´╝îõ╗ÄÕƒ║þíÇÕê░Ú½ÿþ║º´╝îµù¿Õ£¿Õ©«Õè®ÕêØÕ¡ªÞÇàþ│╗þ╗ƒÕ£░µÄîµÅíHadoopÕÅèÕàÂþø©Õà│µèǵ£»ÒÇéÕ©îµ£øÞ┐Öõ║øÞÁäµ║ÉÞâ¢ÕñƒÕ»╣õ¢áµ£ëµëÇÕ©«Õè®´╝ü
6. **µÁïÞ»òHadoopÚøåþ¥ñ**´╝ÜÚÇÜÞ┐çþ«ÇÕìòþÜäWordCountþ¿ïÕ║ŵêûÕàÂõ╗ûþñ║õ¥ïþ¿ïÕ║ŵÁïÞ»òHadoopÚøåþ¥ñþÜäÕèƒÞâ¢ÒÇé #### Õà¡ÒÇüþ╗ôÞ»¡ µ£¼µûçÞ»ªþ╗åõ╗ïþ╗ìõ║åÕªéõ¢òÕ£¿LinuxþÄ»Õóâõ©ïõ╗ÄÚøÂÕ╝ÇÕºïµÉ¡Õ╗║HadoopÚøåþ¥ñ´╝îÕîàµï¼õ║åJDKÕÆîSSHþÜäÕƒ║þíÇþÄ»ÕóâÚàìþ¢«ÒÇüHadoopþÜäÕ«ëÞúàõ©Ä...
Þ┐Öõ©¬ÔÇ£hadoopþ¼öÞ«░ÔÇØÕÅ»Þâ¢ÕîàÕɽõ║åÕà│õ║ÄHadoopþöƒµÇüþ│╗þ╗ƒÒÇüHadoopÕêåÕ©âÕ╝ŵûçõ╗Âþ│╗þ╗ƒ´╝êHDFS´╝ëÒÇüMapReduceþ╝ûþ¿ïµ¿íÕ×ïÒÇüYARNÞÁäµ║Éþ«íþÉåÕÖ¿õ╗ÑÕÅèþø©Õà│ÕÀÑÕàÀþÜäÞ»ªþ╗åÕ¡ªõ╣áÞ«░Õ¢òÒÇéþÄ░Õ£¿´╝îÞ«®µêæõ╗¼µÀ▒ÕàѵÄóÞ«¿õ©Çõ©ïÞ┐Öõ║øÕà│Úö«þƒÑÞ»åþé╣ÒÇé 1. HadoopþöƒµÇüþ│╗þ╗ƒ´╝Ü...
### VMwareõ©ïÕ«îÕà¿ÕêåÕ©âÕ╝ÅHadoopÚøåþ¥ñÕ«ëÞúàþ¼öÞ«░ #### õ©ÇÒÇüÕçåÕñçÕÀÑõ¢£õ©ÄþÄ»ÕóâµÉ¡Õ╗║ **1. Õ«ëÞúàVMware** Õ£¿Õ╝ÇÕºïõ╣ïÕëì´╝îÚªûÕàêÚ£ÇÞªüõ©Çõ©¬ÞÖܵïƒÕîûÕ╣│ÕÅ░µØѵ¿íµïƒÕñÜÕÅ░Þ«íþ«ùµ£║õ╣ïÚù┤þÜäõ║ñõ║Æ´╝îÞ┐ÖÚçîÚÇëµï®þÜäµÿ»VMwareÒÇéµá╣µì«µé¿þÜäµôìõ¢£þ│╗þ╗ƒÚÇëµï®ÕÉêÚÇéþÜä...
Þ┐Öõ╗¢ÔÇ£JavaÕ¡ªõ╣áþ¼öÞ«░(Õ┐àþ£ïþ╗ÅÕà©).docÔÇصûçµíúÕ░åµÂÁþøûJavaþÜäµá©Õ┐⵪éÕ┐ÁÕÆîÚçìÞªüþƒÑÞ»åþé╣´╝îÕ»╣õ║ÄÕêØÕ¡ªÞÇàÕÆîµ£ëþ╗ÅÚ¬îþÜäÕ╝ÇÕÅæÞÇàµØÑÞ»┤Ú⢵ÿ»Õ«ØÞ┤ÁþÜäÕÅéÞÇâÞÁäµûÖÒÇé ÚªûÕàê´╝îJavaþÜäÕƒ║þíÇÚâ¿ÕêåÚÇÜÕ©©Õîàµï¼õ╗Ñõ©ïÕçáõ©¬µû╣ÚØó´╝Ü 1. **JavaÞ»¡µ│òÕƒ║þíÇ**´╝ÜÞ┐Öµÿ»µëǵ£ë...
### Õñºµò░µì«Õ¡ªõ╣áþ¼öÞ«░þƒÑÞ»åþé╣µªéÞºê #### þ¼¼õ©ÇÚâ¿Õêå´╝ÜSparkÕ¡ªõ╣á ##### þ¼¼1þ½á´╝ÜSparkõ╗ïþ╗ì - **1.1 Sparkþ«Çõ╗ïõ©ÄÕÅæÕ▒ò** - **ÞâîµÖ»**´╝ÜÚÜÅþØÇÕñºµò░µì«ÕñäþÉåڣǵ▒éþÜäÕó×Úò┐´╝îõ╝áþ╗ƒþÜäHadoop MapReduceµíåµ×ÂÞÖ¢þäµÅÉõ¥øõ║åÕ╝║ÕñºþÜäÞ«íþ«ùÞâ¢Õèø´╝îõ¢å...
RPC´╝êRemote Procedure Call´╝ëÞ┐£þ¿ïÞ┐çþ¿ïÞ░âþö¿µÿ»õ©Çþºìþ¢æþ╗£ÚÇÜõ┐íÕìÅÞ««´╝îÕàüÞ«©õ©ÇÕÅ░Þ«íþ«ùµ£║õ©èþÜäþ¿ïÕ║ÅÞ░âþö¿ÕŪõ©ÇÕÅ░Þ«íþ«ùµ£║õ©èþÜäþ¿ïÕ║Å´╝îÕ░▒ÕâÅÞ░âþö¿µ£¼Õ£░Õ碵ò░õ©ÇµáÀþ«ÇÕìòÒÇéÕ£¿ÕêåÕ©âÕ╝Åþ│╗þ╗ƒõ©¡´╝îRPCµë«µ╝öþØǵá©Õ┐âÞºÆÞë▓´╝îõ¢┐Õ¥ùÕÉäµ£ìÕèíõ╣ïÚù┤Þâ¢Õñƒµû╣õ¥┐Õ£░Þ┐øÞíî...
### PigÕ¡ªõ╣áþ¼öÞ«░þ▓¥Þªü **Pig** µÿ»õ©Çõ©¬Õ£¿ **Hadoop** Õ╣│ÕÅ░õ©èþö¿õ║ĵò░µì«Õêåµ×ÉþÜäÚ½ÿþ║ºÕÀÑÕàÀ´╝îÕ«âµÅÉõ¥øõ║åõ©ÇþºìÚØ×þ¿ïÕ║ÅÕîûþÜäµò░µì«µÁüÞ»¡Þ¿Ç´╝îþº░õ©║ **Pig Latin** ´╝îµØÑÕñäþÉåÕñºÞºäµ¿íþÜäµò░µì«ÚøåÒÇéPig þÜäÞ«¥Þ«íþø«þÜäµÿ»õ©║õ║åþ«ÇÕîû **MapReduce** þÜä...