English:http://www.theserverside.com/news/1363855/Spring-Batch-Overview
遗漏的企业功能
尽管成长势头落后于SOA和实时集成(real-time integration),但企业中许多接口还是基于文本文件,并且最好的处理方式是批处理方式。不过,基于Java的批处理架构还没有事实标准或工业标准。在企业市场中,批处理却似是一关键的并被遗漏的架构和功能。
想一下:
- 每天,批处理都被用于在关键企业应用中用来处理百万级的业务数据
- 尽管批处理任务是大多数IT项目的一部分,但没有广泛被采用的商业或开源软件框架去提供一个健全的企业级解决方案
- 缺乏标准架构导致了昂贵的内部定制的一次性方案
- 尽管缺乏标准的批处理架构,但却已经拥有构建高性能批处理方案的几十年经验
Spring Batch开始的时候就是关注于这些遗漏的功能,通过创建一个开源项目在Java社区中提供一个有益的批处理标准。
Spring Batch的架构
Spring Batch架构是在于提供一个富有自由度的应用框架,同时提供批运行环境。下边是例图:
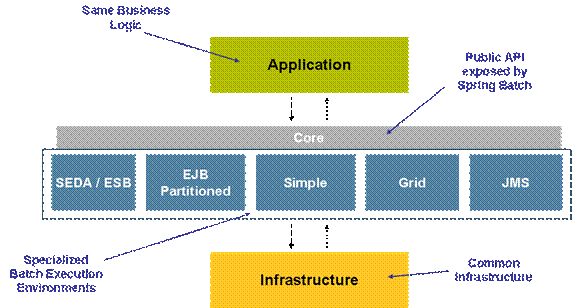
图 1 – 基于公共基础架构的专属执行环境
从依赖关系来讲,被描述的各层很好地被隔离开,并且每层仅仅依赖(在编译时)它的下一层。它们是:
-
应用(Application)
- 商业逻辑由应用开发人员编写(Spring Batch的客户端),它仅依赖于其他编译和配置的核心接口
-
核心(Core)
- Sping Batch的公共程序接口包括任务,步骤,配置和执行接口的批处理领域语言。
-
执行(Execution)
- 部署环境和管理的关注内容。不同的执行环境(e.g. SEDA/ESB,
EJB Partitioned, Simple, Grid and JMS) 被不同地配置却可以执行相同的应用商业逻辑。
-
基础架构(Infrastructure)
- 一组底端的用于实现运行工具和部分核心层。
执行层为来自社区和业内项目的协作和贡献提供了丰富的土壤。对于此接口的多重实现提供了不同的架构模式和发布不同层次的可扩展性和稳定性而无需改变商业逻辑或任务配置。
Spring Batch架构提供核心服务用于构建批运行环境,列于图1。这些提供于初始发布的Spring Batch1.0版本的简单的执行服务是一个单一JVM配置 (带有多线程能力)。它可处理多个格式的输入源(e.g. fixed length records,
delimited records, xml records, database, etc.) 并输出到不同格式的目标 (e.g. other flat files, database, queues, etc).
简单的批运行环境例子
批任务常常通过管道和过滤模式实现。Spring Batch并没有不同。看例图 2.
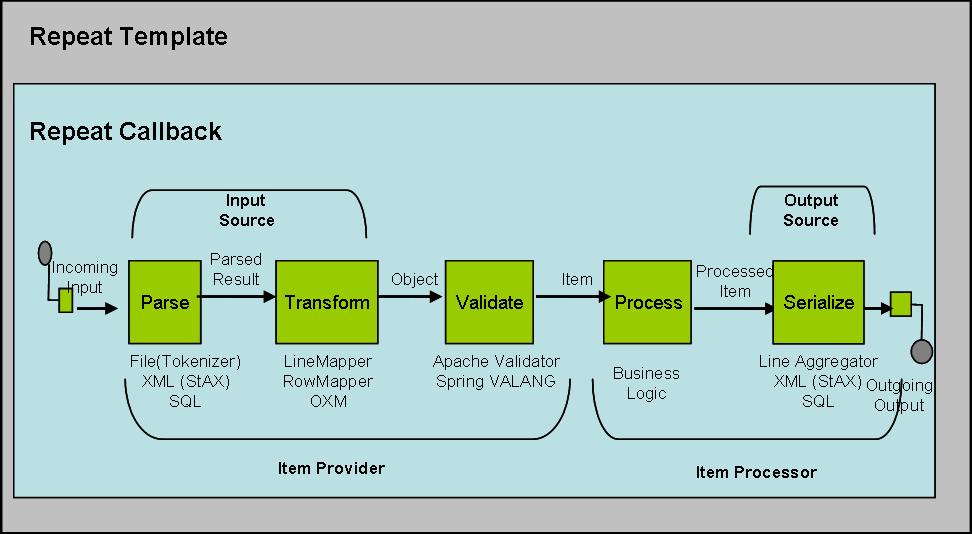
图2 - Spring Batch 的管道和过滤器
在Spring Batch机构的例子模块中有许多批处理任务的例子。简单批运行环境和其对Spring Batch的依赖性可以通过一个例子来展示。尽管这个例子是人为的,但它展示了一个有多个步骤的任务。任务是一个橄榄球(美式足球)统计的导入任务,在配置文件中的id是football。
开支批处理任务之前,先看一个两个需要导入的输入文件。第一个是 ‘player.csv’,它可以在例子项目的 src/main/resources/data/footballjob/input/目录中找到. 文件中的每一行代表一个玩家,有唯一的ID,名字和位置等:
AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996
AbduRa00,Abdullah,Rabih,rb,1975,1999
AberWa00,Abercrombie,Walter,rb,1959,1982
AbraDa00,Abramowicz,Danny,wr,1945,1967
AdamBo00,Adams,Bob,te,1946,1969
AdamCh00,Adams,Charlie,wr,1979,2003
首要需要注意的字符是逗号用来分割每个元素,这种格式是大家熟知的‘CSV’。其他的分隔符如竖线和分号也可以用于分割字段。普通文本文件也可以是拥有固定长度的记录而不是带分隔符的记录。因为例子中的两个输入文件都是逗号分隔的,当前我们会跳过固定长度的情况,但会讲两中类型之间的不同是固定长度格式指定每个字段一个固定长度标识而不是通过一个分隔符来分割独立单元。
第二个文件是 ‘games.csv’,是一个位于同一目录同样格式的文件:
AbduKa00,1996,mia,10,nwe,0,0,0,0,0,29,104,,16,2
AbduKa00,1996,mia,11,clt,0,0,0,0,0,18,70,,11,2
AbduKa00,1996,mia,12,oti,0,0,0,0,0,18,59,,0,0
AbduKa00,1996,mia,13,pit,0,0,0,0,0,16,57,,0,0
AbduKa00,1996,mia,14,rai,0,0,0,0,0,18,39,,7,0
AbduKa00,1996,mia,15,nyg,0,0,0,0,0,17,96,,14,0
文件中每行代表一个独立玩家在特定游戏中的成绩,包括通过场地,接球,冲刺和总的触底统计。
批处理任务将导入两个文件到数据库,然后整合他们来总结每个玩家在一个指定年度的成绩如何。虽然这个例子有点微不足道,但它展示了对各类型的输入和常见的方式格式是一个很平常的批处理场景。 这就是, 汇总一个巨大的数据集,使它可以通过一个在线web应用更容易的被处理和查看。在一个企业方案中,第三步,报表,可以通过使用Eclipse的BIRT来实现或通过Java报表引擎。给出描述,批处理任务可以容易地被分到三个步骤中:玩家数据导入,游戏数据导入和汇总报表。
注意到Spring的一个好的特性的叫Spring IDE项目是会有帮助的。Spring IDE(译者注:目前已经整合到STS - SpringSource Tool Suite)可以在下载时被安装,并且Spring配置可以添加到IDE项目中。在理解一个任务配置的结构中,可视化地Spring beans视图是有帮助的。Spring IDE 生成的关系图显示在图3中:
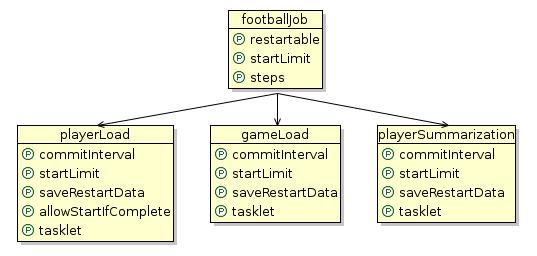
Figure 3 - Spring Bean Job Configuration
它是与footballJob.xml的任务配置文件一致的。该文件可在src/main/resources中找到。footballjob的处理步骤配置如下:
<property name="steps">
<list>
<bean id="playerload"> ... </bean>
<bean id="gameLoad"> ... </bean
<bean id="playerSummarization"> ... </bean>
</list>
</property>
每一步一直运行到没有输入数据需要处理为止。这意味这每个相应文件已经完全处理完毕。第一步,玩家导入,通过从文件读取一行并解析成一个领域对象开始执行。该对象然后被出入到一个DAO,并通过它写入PLAYERS表。此动作会被重复直至没有任何记录在文件中,并导致playerLoad处理步骤完成。接下来,gameLoad处理步骤做相同工作将游戏输入文件导入到GAMES表。一旦完成,playerSummarization处理步骤就可以开始了。不像前两步,playerSummarization的输入是来之数据库,通过SQL语句来合并GAMES和PLAYERS表。每个返回的行被包装成一个领域对象,然后写入到PLAYER_SUMMARY表。
现在,我们讨论了整个批处理任务流程,可以进一步深入探究第一步: playerLoad。
<bean id="playerload" class="org.springframework.batch...SimpleStepConfiguration">
<property name="commitInterval" value="100" />
<property name="tasklet">
<bean class="org.springframework...RestartableItemProviderTasklet">
<property name="itemProvider">...</property>
<property name="itemProcessor">...</property>
</bean>
</property>
</bean>
此例程中的主Bean是一个步骤配置(StepConfiguration),可将其看作是一个蓝图展示给你关于批处理任务应该如何被执行的运行环境基础详细信息。它包含两个属性(为了更清楚,其他的已经被移除):Tasklet 和
commitInterval。Tasklet是一个主抽象,代表了在批处理任务中的开发人员的业务逻辑。在执行了所有需要的启动之后,框架会定期将执行委托给该Tasklet。通过此,开发人员可以保持将仅有的关注放在商业逻辑上。此例中,该处理是相当典型的,Tasklet已经被分解成两个类:
- Item Provider – 信息管道源。在对数的基础层次,输入是读取从一个输入源,解析成一个领域对象并返回。以此, 通过提供一个可能的重用途径,用以保证所有数据在处理之前已经被读取的良好的批处理架构实践得以实施。
- Item Processor – 商业逻辑。在高层次,ItemProcessor接受从ItemProvider返回的条目并处理它。在我们的实例中,它是一个数据访问对象,简单地用以处理向PLAYERS表插入数据。
很明确,开发人员做很少的一点。其中有一个带有可配置多少步骤的任务配置,一个与某些类型数据源有关的ItemProvider,和有某些输出源相关的ItemProcessor,同时,一些来自普通记录到对象的数据映射。
StepConfiguration的其他的属性,commitInterval指定框架的如何控制批处理事务的重要信息。在大数据量的处理中,将多个逻辑单元的工作统一到一个事物中的批处理是非常有利的。这是因为启动和提交一个事务消耗是相当大的。例如,在 playerLoad步骤中,框架调用Tasklet上的execute()方法,然后调用ItemProcider的next()方法。ItemProvider从文件中读取一个记录,然后返回一个会传递给Processor的领域对象代表。Processor然后写一条记录到数据库。它可以讲作一个操作 = 一次调用Tasklet.execute() = 文件的一行。因此,设置commitInterval为5会使得框架每从文件中读取5条提交一次事务,产生5条记录在PLAYERS表。
沿着通常的批处理流程,下一步是描述如何将文件中的一行解析为一个领域对象。第一件事,Provider会需要一个输入源,它是最为Spring Batch基础框架的一部分提供的。因为输入是基于普通文件的,一个FlatFileInputSource会用于此:
<bean id="playerFileInputSource"
class="org.springframework.batch.io.file.support.DefaultFlatFileInputSource">
<property name="resource">
<bean class="org.springframework.core.io.ClassPathResource">
<constructor-arg value="data/footballjob/input/player.csv" />
</bean>
</property>
<property name="tokenizer">
<bean class = "org.springframework.batch.io.file.support.transform.DelimitedLineTokenizer">
<property name="names"
value="ID,lastName,firstName,position,birthYear,debutYear" />
</bean>
</property>
</bean>
输入源有有两个需要的依赖。第一个是从中读取数据的资源(待处理文件),第二个是LineTokenizer。LineTokenizer的接口是很简单的,只提供一个字符串。它会返回一个包装了解析完字符串获得结果的FieldSet。FieldSet是Spring Batch的一个普通文件数据的抽象。它允许开发人员使用相同方式处理输入文件,就像于数据库输入打交道一样。开发人员所需要提供的是一个FieldSetMapper (类似于Spring
RowMapper),它可以将FieldSet中的数据映射到一个对象。通过简单地提供每个标记的名字给LineTokenizer,ItemProvider可以传递FieldSet到实现了FieldSetMapper 接口的PlayerMapper里。一个单一的方法mapLine()可以通过通过索引或字段名象开发人员熟悉的SQL结果集一样的方式映射FieldSets到一个Java对象。这种行为有意地被设计的和RowMapper传递给JdbcTemplate相似。看下面的例子:
public class PlayerMapper implements FieldSetMapper {
public Object mapLine(FieldSet fs) {
if(fs == null){
return null;
}
Player player = new Player();
player.setID(fs.readString("ID"));
player.setLastName(fs.readString("lastName"));
player.setFirstName(fs.readString("firstName"));
player.setPosition(fs.readString("position"));
player.setDebutYear(fs.readInt("debutYear"));
player.setBirthYear(fs.readInt("birthYear"));
return player;
}
}
在此例中,ItemProvider的流程开始于一个在输入源
readFieldSet 的调用。下一行是读入一个字符串并传给预先提供的LineTokenizer。LineTokenizer通过逗号来拆分数据为字符数组和传入的字段名称来创建一个FieldSet。值得注意,如果你要通过名字访问字段,仅需要提供名字而不是索引。
一旦数据领域代表被Provider返回(如 一个Player对象),它会被传给ItemProcessor。此处是一个使用了Spring JdbcTemplate来插入一个新记录到PLAYERS表的DAO。
下一步,仅使用的文件是一个游戏文件的区别之外,gameLoad采用几乎与
playerLoad 步骤同样的方式。
最后一步,playerSummarization更像前两步。它分解为一个读取输入源的Provider和返回一个领域对象的Processor。然而,在此,输入源是数据库而不是一个文件:
<property name="dataSource" ref="dataSource" />
<property name="mapper">
<bean class="sample.mapping.PlayerSummaryMapper" />
</property>
<property name="sql">
<value>
SELECT games.player_id, games.year, SUM(COMPLETES),
SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD),
SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS),
SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD)
from games, players where players.player_id =
games.player_id group by games.player_id, games.year
</value>
</property>
</bean>
SqlCursorInputSource依赖于下列三项:
- 一个DataSource
- 用于每行的SqlRowMapper
- 用于创建Cursor的SQL语句
当步骤一开始,一个查询会运行并打开一个Cursor。每个inputSource.read()调用会将游标设置到下一行。通过提供的RowMapper来返回一个正确的对象。像上两步,每个由Provider返回的记录会被写到数据库的PLAYER_SUMMARY表。
最后,运行此例程,执行JUnit的测试“FootballJobFunctionalTests”,看一下每行记录被处理的输出。ItemProcessors (通过AoP的拦截器)输出每个被处理记录到日志中。这会影响运行效率,但这仅仅是举例只用而已。
总结
Spring Batch是一个非常老的想法的新实现。它将一个在IT组织中非常老的编程模型通过一个流行的开源框架Spring带回到主流。它使一个批处理项目可以享用于任何Spring项目同样干净的架构和轻量级的编程模型,拥有被业界证实的模式,处理,模板,回调和其他想法。 Spring Batch是一个令人兴奋的开始。它提供了一个潜在的标准批处理架构,在成长中的Spring社区和更多。
请通过访问下列网站共享你使用Spring Batch的经验。
附加关键资源
:
[1] Spring Batch Home Page: http://www.springframework.org/spring-batch
[2] Spring Batch Source Code (Subversion repository): https://springframework.svn.sourceforge.net/svnroot/springframework/spring-batch/trunk/
[3] Spring Batch Forum: http://forum.springframework.org/forumdisplay.php?f=41
[4] Spring Batch Jira Page: http://opensource.atlassian.com/projects/spring/browse/BATCH
.
[5] Spring Batch Mailing List: http://lists.interface21.com/listmanager/listinfo/spring-batch-announce
作者简介
Dr David Syer
是一个富有经验的关注交付的架构师和开发主管,隶属Interface21。它设计并成功构建了企业Spring软件方案,并在世界主要的金融机构实现。David由于特的清晰的和富有知识的培训方式而知名。 他有着在各个方面深厚的在现实中使用Spring框架的知识和经验。他喜欢从应用中创建商业价值的简单原则到企业架构。David从一个与Interface21有多个项目交往甚密的领先的风险管理软件提供商投身于Interface21。
Lucas Ward
是一个Accenture的Java架构师,关注于批处理架构并拥有创新和架构实践。过去两年中,他已经工作在 Accenture的方法论和架构最佳实践中。尤其关注使用开源软件。Lucas是Spring
Batch开发的合作领队,借鉴了来自多个Accenture批处理架构的经验。





相关推荐
### Spring Batch概览 Spring Batch是Spring框架的一个模块,专门用于处理大量的记录或数据批处理作业。它提供了一种灵活而强大的方法来执行批量数据操作,如数据迁移、报表生成和数据清洗等任务,特别适用于后台...
#### 一、Spring Batch 概览 **Spring Batch** 是一个基于 Java 的批量处理框架,它为开发批量应用程序提供了一种强大的且灵活的方法。该框架旨在帮助开发者构建高性能、健壮的企业级批量处理应用程序。 ##### 1.1...
### ElasticJob与SpringBatch的结合使用 #### 一、引言 随着大数据和微服务架构的兴起,数据处理的需求越来越复杂。在很多场景下,我们需要处理海量数据,并且要保证数据处理的一致性和顺序性。为此,业界发展出了...
《Pro Spring Batch》一书深入探讨了Java Spring Batch框架的核心概念与实际应用,为开发者提供了全面的批处理技术指南。本书由Apress出版,旨在帮助读者掌握Spring Batch框架的精髓,提升在批量数据处理领域的技能...
#### 二、Spring Batch 2.1.8 新特性概览 ##### 2.1 Java 5 支持 这一版本开始支持 Java 5,这为开发者提供了更多的编程语言特性和工具支持,同时也为框架本身的性能和稳定性带来了提升。 ##### 2.2 基于 Chunk ...
- **3.1.2 Spring Batch**:Spring Batch提供了批处理应用程序的框架。 #### 3.2 Spring 与其他技术的集成 - **3.2.1 Spring 与消息队列的集成**:例如与Apache Kafka的集成。 - **3.2.2 Spring 与微服务架构的结合...
- **第十七章:Spring Integration与Spring Batch** —— 讨论了Spring Integration如何与Spring Batch协同工作,实现批处理任务的集成。 - **第十八章:Spring Integration与Web应用** —— 分析了Spring ...
- Spring Batch的大规模批处理任务管理。 9. **阅读源代码的方法论**: - 如何有效地阅读和理解复杂的源代码。 - 分析源代码时需要注意的关键点。 - 通过案例学习如何从源代码中提炼出设计模式和最佳实践。 ##...
- **复杂任务处理**:展示如何使用Spring Batch来管理大型数据集和复杂任务流。 5. **应用集成** - **消息传递系统**:介绍如何利用Spring与其他消息传递系统(如JMS)集成,以实现高效的消息处理。 - **服务...
9. **Spring Batch**:学习Spring的批量处理框架,用于大规模数据处理任务。 10. **Spring Boot**:探讨Spring Boot的快速开发特性,如自动配置、起步依赖和Actuator等。 11. **Spring Security**:了解Spring的...
- **Spring Batch**:介绍 Spring Batch 项目及其在批量处理方面的应用。 - **Spring Integration**:讲解 Spring Integration 项目如何简化企业级应用集成工作。 - **Spring Roo**:介绍 Spring Roo 工具及其在快速...
以上只是Spring框架部分核心知识点的概览,实际上Spring包含的内容远不止这些,如Spring Batch、Spring Integration、Spring AMQP等,都是Spring生态系统的重要组成部分。通过深入学习和实践,开发者能够充分利用...
### Spring Boot 2.0 完整版视频教程知识点概览 #### 一、Spring Boot 简介 - **定义**:Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目标是简化新Spring应用的初始搭建以及开发过程。 - **特点**: - ...
以上只是Spring 3.x部分核心知识点的概览,实际使用中,开发者还需要根据具体需求学习和掌握更多细节,例如国际化支持、WebSocket、RESTful API构建等。随着Spring的不断迭代,Spring 4.x和5.x引入了更多新特性和...
#### 一、Spring框架与JdbcTemplate概览 Spring框架是一个开源的轻量级Java应用开发框架,旨在简化企业级应用的开发。其核心特性包括依赖注入(Dependency Injection,DI)、面向切面编程(Aspect Oriented ...
#### 一、概览 在现代Java Web开发中,Spring框架作为核心,提供了一套完整的解决方案来管理应用程序的各种组件和服务。而MyBatis作为一个优秀的持久层框架,能够方便地进行SQL映射,简化数据库操作。本文档将详细...