жСШиЗ™пЉЪ
http://www.blogjava.net/zhenandaci/archive/2009/03/17/260315.html
жО•дЄЛжЭ•и¶БиѓізЪДдЄЬи•њеЕґеЃЮдЄНжШѓжЭЊеЉЫеПШйЗПжЬђиЇЂпЉМдљЖзФ±дЇОжШѓдЄЇдЇЖдљњзФ®жЭЊеЉЫеПШйЗПжЙНеЉХеЕ•зЪДпЉМеЫ†ж≠§жФЊеЬ®ињЩйЗМдєЯзЃЧеРИйАВпЉМйВ£е∞±жШѓжГ©зљЪеЫ†е≠РCгАВеЫЮе§ізЬЛдЄАзЬЉеЉХеЕ•дЇЖжЭЊеЉЫеПШйЗПдї•еРОзЪДдЉШеМЦйЧЃйҐШпЉЪ

ж≥®жДПеЕґдЄ≠CзЪДдљНзљЃпЉМдєЯеПѓдї•еЫЮжГ≥дЄАдЄЛCжЙАиµЈзЪДдљЬзФ®пЉИи°®еЊБдљ†жЬЙе§ЪдєИйЗНиІЖз¶їзЊ§зВєпЉМCиґКе§ІиґКйЗНиІЖпЉМиґКдЄНжГ≥дЄҐжОЙеЃГдїђпЉЙгАВињЩдЄ™еЉПе≠РжШѓдї•еЙНеБЪSVMзЪДдЇЇеЖЩзЪДпЉМе§ІеЃґдєЯе∞±ињЩдєИзФ®пЉМдљЖж≤°жЬЙдїїдљХиІДеЃЪиѓіењЕй°їеѓєжЙАжЬЙзЪДжЭЊеЉЫеПШйЗПйГљдљњзФ®еРМдЄАдЄ™жГ©зљЪеЫ†е≠РпЉМжИСдїђеЃМеЕ®еПѓдї•зїЩжѓПдЄАдЄ™з¶їзЊ§зВєйГљдљњзФ®дЄНеРМзЪДCпЉМињЩжЧґе∞±жДПеС≥зЭАдљ†еѓєжѓПдЄ™ж†ЈжЬђзЪДйЗНиІЖз®ЛеЇ¶йГљдЄНдЄАж†ЈпЉМжЬЙдЇЫж†ЈжЬђдЄҐдЇЖдєЯе∞±дЄҐдЇЖпЉМйФЩдЇЖдєЯе∞±йФЩдЇЖпЉМињЩдЇЫе∞±зїЩдЄАдЄ™жѓФиЊГе∞ПзЪДCпЉЫиАМжЬЙдЇЫж†ЈжЬђеЊИйЗНи¶БпЉМеЖ≥дЄНиГљеИЖз±їйФЩиѓѓпЉИжѓФе¶ВдЄ≠е§ЃдЄЛиЊЊзЪДжЦЗдїґеХ•зЪДпЉМзђСпЉЙпЉМе∞±зїЩдЄАдЄ™еЊИе§ІзЪДCгАВ
ељУзДґеЃЮйЩЕдљњзФ®зЪДжЧґеАЩеєґж≤°жЬЙињЩдєИжЮБзЂѓпЉМдљЖдЄАзІНеЊИеЄЄзФ®зЪДеПШ嚥еПѓдї•зФ®жЭ•иІ£еЖ≥еИЖз±їйЧЃйҐШдЄ≠ж†ЈжЬђзЪДвАЬеБПжЦЬвАЭйЧЃйҐШгАВ
еЕИжЭ•иѓіиѓіж†ЈжЬђзЪДеБПжЦЬйЧЃйҐШпЉМдєЯеПЂжХ∞жНЃйЫЖеБПжЦЬпЉИunbalancedпЉЙпЉМеЃГжМЗзЪДжШѓеПВдЄОеИЖз±їзЪДдЄ§дЄ™з±їеИЂпЉИдєЯеПѓдї•жМЗе§ЪдЄ™з±їеИЂпЉЙж†ЈжЬђжХ∞йЗПеЈЃеЉВеЊИе§ІгАВжѓФе¶Виѓіж≠£з±їжЬЙ10пЉМ000дЄ™ж†ЈжЬђпЉМиАМиіЯз±їеП™зїЩдЇЖ100дЄ™пЉМињЩдЉЪеЉХиµЈзЪДйЧЃйҐШжШЊиАМжШУиІБпЉМеПѓдї•зЬЛзЬЛдЄЛйЭҐзЪДеЫЊпЉЪ
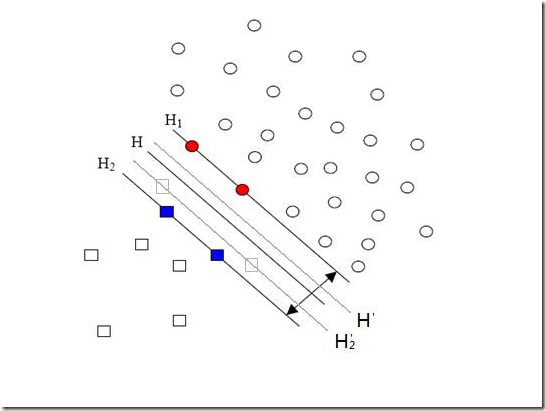
жֺ嚥зЪДзВєжШѓиіЯз±їгАВHпЉМH1пЉМH2жШѓж†єжНЃзїЩзЪДж†ЈжЬђзЃЧеЗЇжЭ•зЪДеИЖз±їйЭҐпЉМзФ±дЇОиіЯз±їзЪДж†ЈжЬђеЊИе∞СеЊИе∞СпЉМжЙАдї•жЬЙдЄАдЇЫжЬђжЭ•жШѓиіЯз±їзЪДж†ЈжЬђзВєж≤°жЬЙжПРдЊЫпЉМжѓФе¶ВеЫЊдЄ≠дЄ§дЄ™зБ∞иЙ≤зЪДжֺ嚥зВєпЉМе¶ВжЮЬињЩдЄ§дЄ™зВєжЬЙжПРдЊЫзЪДиѓЭпЉМйВ£зЃЧеЗЇжЭ•зЪДеИЖз±їйЭҐеЇФиѓ•жШѓHвАЩпЉМH2вАЩеТМH1пЉМдїЦдїђжШЊзДґеТМдєЛеЙНзЪДзїУжЮЬжЬЙеЗЇеЕ•пЉМеЃЮйЩЕдЄКиіЯз±їзїЩзЪДж†ЈжЬђзВєиґКе§ЪпЉМе∞±иґКеЃєжШУеЗЇзО∞еЬ®зБ∞иЙ≤зВєйЩДињСзЪДзВєпЉМжИСдїђзЃЧеЗЇзЪДзїУжЮЬдєЯе∞±иґКжО•ињСдЇОзЬЯеЃЮзЪДеИЖз±їйЭҐгАВдљЖзО∞еЬ®зФ±дЇОеБПжЦЬзЪДзО∞и±°е≠ШеЬ®пЉМдљњеЊЧжХ∞йЗПе§ЪзЪДж≠£з±їеПѓдї•жККеИЖз±їйЭҐеРСиіЯз±їзЪДжЦєеРСвАЬжО®вАЭпЉМеЫ†иАМељ±еУНдЇЖзїУжЮЬзЪДеЗЖз°ЃжАІгАВ
еѓєдїШжХ∞жНЃйЫЖеБПжЦЬйЧЃйҐШзЪДжЦєж≥ХдєЛдЄАе∞±жШѓеЬ®жГ©зљЪеЫ†е≠РдЄКдљЬжЦЗзЂ†пЉМжГ≥ењЕе§ІеЃґдєЯзМЬеИ∞дЇЖпЉМйВ£е∞±жШѓзїЩж†ЈжЬђжХ∞йЗПе∞СзЪДиіЯз±їжЫіе§ІзЪДжГ©зљЪеЫ†е≠РпЉМи°®з§ЇжИСдїђйЗНиІЖињЩйГ®еИЖж†ЈжЬђпЉИжЬђжЭ•жХ∞йЗПе∞±е∞СпЉМеЖНжКЫеЉГдЄАдЇЫпЉМйВ£дЇЇеЃґиіЯз±їињШжіїдЄНжіїдЇЖпЉЙпЉМеЫ†ж≠§жИСдїђзЪДзЫЃж†ЗеЗљжХ∞дЄ≠еЫ†жЭЊеЉЫеПШйЗПиАМжНЯ姱зЪДйГ®еИЖе∞±еПШжИРдЇЖпЉЪ

еЕґдЄ≠i=1вА¶pйГљжШѓж≠£ж†ЈжЬђпЉМj=p+1вА¶p+qйГљжШѓиіЯж†ЈжЬђгАВlibSVMињЩдЄ™зЃЧж≥ХеМЕеЬ®иІ£еЖ≥еБПжЦЬйЧЃйҐШзЪДжЧґеАЩзФ®зЪДе∞±жШѓињЩзІНжЦєж≥ХгАВ
йВ£C+еТМC-жАОдєИз°ЃеЃЪеСҐпЉЯеЃГдїђзЪДе§Іе∞ПжШѓиѓХеЗЇжЭ•зЪДпЉИеПВжХ∞и∞ГдЉШпЉЙпЉМдљЖжШѓдїЦдїђзЪДжѓФдЊЛеПѓдї•жЬЙдЇЫжЦєж≥ХжЭ•з°ЃеЃЪгАВеТ±дїђеЕИеБЗеЃЪиѓіC+жШѓ5ињЩдєИе§ІпЉМйВ£з°ЃеЃЪC-зЪДдЄАдЄ™еЊИзЫіиІВзЪДжЦєж≥Хе∞±жШѓдљњзФ®дЄ§з±їж†ЈжЬђжХ∞зЪДжѓФжЭ•зЃЧпЉМеѓєеЇФеИ∞еИЪжЙНдЄЊзЪДдЊЛе≠РпЉМC-е∞±еПѓдї•еЃЪдЄЇ500ињЩдєИе§ІпЉИеЫ†дЄЇ10пЉМ000пЉЪ100=100пЉЪ1еШЫпЉЙгАВ
дљЖжШѓињЩж†ЈеєґдЄНе§Яе•љпЉМеЫЮзЬЛеИЪжЙНзЪДеЫЊпЉМдљ†дЉЪеПСзО∞ж≠£з±їдєЛжЙАдї•еПѓдї•вАЬжђЇиіЯвАЭиіЯз±їпЉМеЕґеЃЮеєґдЄНжШѓеЫ†дЄЇиіЯз±їж†ЈжЬђе∞СпЉМзЬЯеЃЮзЪДеОЯеЫ†жШѓиіЯз±їзЪДж†ЈжЬђеИЖеЄГзЪДдЄНе§ЯеєњпЉИж≤°жЙ©еЕЕеИ∞иіЯз±їжЬђеЇФиѓ•жЬЙзЪДеМЇеЯЯпЉЙгАВиѓідЄАдЄ™еЕЈдљУзВєзЪДдЊЛе≠РпЉМзО∞еЬ®жГ≥зїЩжФњж≤їз±їеТМдљУиВ≤з±їзЪДжЦЗзЂ†еБЪеИЖз±їпЉМжФњж≤їз±їжЦЗзЂ†еЊИе§ЪпЉМиАМдљУиВ≤з±їеП™жПРдЊЫдЇЖеЗ†зѓЗеЕ≥дЇОзѓЃзРГзЪДжЦЗзЂ†пЉМињЩжЧґеИЖз±їдЉЪжШОжШЊеБПеРСдЇОжФњж≤їз±їпЉМе¶ВжЮЬи¶БзїЩдљУиВ≤з±їжЦЗзЂ†еҐЮеК†ж†ЈжЬђпЉМдљЖеҐЮеК†зЪДж†ЈжЬђдїНзДґеЕ®йГљжШѓеЕ≥дЇОзѓЃзРГзЪДпЉИдєЯе∞±жШѓиѓіпЉМж≤°жЬЙиґ≥зРГпЉМжОТзРГпЉМиµЫиљ¶пЉМжЄЄж≥≥з≠Йз≠ЙпЉЙпЉМйВ£зїУжЮЬдЉЪжАОж†ЈеСҐпЉЯиЩљзДґдљУиВ≤з±їжЦЗзЂ†еЬ®жХ∞йЗПдЄКеПѓдї•иЊЊеИ∞дЄОжФњж≤їз±їдЄАж†Је§ЪпЉМдљЖињЗдЇОйЫЖдЄ≠дЇЖпЉМзїУжЮЬдїНдЉЪеБПеРСдЇОжФњж≤їз±їпЉБжЙАдї•зїЩC+еТМC-з°ЃеЃЪжѓФдЊЛжЫіе•љзЪДжЦєж≥ХеЇФиѓ•жШѓи°°йЗПдїЦдїђеИЖеЄГзЪДз®ЛеЇ¶гАВжѓФе¶ВеПѓдї•зЃЧзЃЧдїЦдїђеЬ®з©ЇйЧідЄ≠еН†жНЃдЇЖе§Ъе§ІзЪДдљУзІѓпЉМдЊЛе¶ВзїЩиіЯз±їжЙЊдЄАдЄ™иґЕзРГвАФвАФе∞±жШѓйЂШзїіз©ЇйЧійЗМзЪДзРГеХ¶вАФвАФеЃГеПѓдї•еМЕеРЂжЙАжЬЙиіЯз±їзЪДж†ЈжЬђпЉМеЖНзїЩж≠£з±їжЙЊдЄАдЄ™пЉМжѓФжѓФдЄ§дЄ™зРГзЪДеНКеЊДпЉМе∞±еПѓдї•е§ІиЗіз°ЃеЃЪеИЖеЄГзЪДжГЕеЖµгАВжШЊзДґеНКеЊДе§ІзЪДеИЖеЄГе∞±жѓФиЊГеєњпЉМе∞±зїЩе∞ПдЄАзВєзЪДжГ©зљЪеЫ†е≠РгАВ
дљЖжШѓињЩж†ЈињШдЄНе§Яе•љпЉМеЫ†дЄЇжЬЙзЪДз±їеИЂж†ЈжЬђз°ЃеЃЮеЊИйЫЖдЄ≠пЉМињЩдЄНжШѓжПРдЊЫзЪДж†ЈжЬђжХ∞йЗПе§Ъе∞СзЪДйЧЃйҐШпЉМињЩжШѓз±їеИЂжЬђиЇЂзЪДзЙєеЊБпЉИе∞±жШѓжЯРдЇЫиѓЭйҐШжґЙеПКзЪДйЭҐеЊИз™ДпЉМдЊЛе¶ВиЃ°зЃЧжЬЇз±їзЪДжЦЗзЂ†е∞±жШОжШЊдЄНе¶ВжЦЗеМЦз±їзЪДжЦЗзЂ†йВ£дєИвАЬ姩驐и°Мз©ЇвАЭпЉЙпЉМињЩдЄ™жЧґеАЩеН≥дЊњиґЕзРГзЪДеНКеЊДеЈЃеЉВеЊИе§ІпЉМдєЯдЄНеЇФиѓ•иµЛдЇИдЄ§дЄ™з±їеИЂдЄНеРМзЪДжГ©зљЪеЫ†е≠РгАВ
зЬЛеИ∞ињЩйЗМиѓїиАЕдЄАеЃЪзЦѓдЇЖпЉМеЫ†дЄЇиѓіжЭ•иѓіеОїпЉМињЩе≤ВдЄНжИРдЇЖдЄАдЄ™иІ£еЖ≥дЄНдЇЖзЪДйЧЃйҐШпЉЯзДґиАМдЇЛеЃЮе¶Вж≠§пЉМеЃМеЕ®зЪДжЦєж≥ХжШѓж≤°жЬЙзЪДпЉМж†єжНЃйЬАи¶БпЉМйАЙжЛ©еЃЮзО∞зЃАеНХеПИеРИзФ®зЪДе∞±е•љпЉИдЊЛе¶ВlibSVMе∞±зЫіжО•дљњзФ®ж†ЈжЬђжХ∞йЗПзЪДжѓФпЉЙгАВ
еИЖдЇЂеИ∞пЉЪ





зЫЄеЕ≥жО®иНР
### SVMеЕ•йЧ®пЉЪSVMзЪДеЕЂиВ°зЃАдїЛ #### 1.1 SVMзЪДеЯЇжЬђж¶Вењµ жФѓжМБеРСйЗПжЬЇпЉИSupport Vector MachineпЉМзЃАзІ∞SVMпЉЙжШѓдЄАзІНзЫСзЭ£е≠¶дє†ж®°еЮЛпЉМдЄїи¶БзФ®дЇОеИЖз±їеТМеЫЮељТеИЖжЮРгАВSVMжЬАжЧ©жШѓзФ±CortesеТМVapnikеЬ®1995еєіжПРеЗЇзЪДгАВеЕґж†ЄењГжАЭжГ≥жШѓеЬ®зЙєеЊБ...
ж≠§жЧґпЉМеПѓдї•йАЪињЗеЉХеЕ•жЭЊеЉЫеПШйЗПеТМжГ©зљЪеЫ†е≠РжЭ•е§ДзРЖињЩзІНжГЕеЖµпЉМеЕБиЃЄжЯРдЇЫж†ЈжЬђзВєдљНдЇОеЖ≥з≠ЦиЊєзХМзФЪиЗ≥йФЩиѓѓеИЖз±їпЉМдїОиАМеЃЮзО∞еѓєе§НжЭВжХ∞жНЃйЫЖзЪДжЬЙжХИеИЖз±їгАВ 3. **ж†ЄжКАеЈІ**пЉЪдЄЇдЇЖе§ДзРЖйЭЮзЇњжАІеПѓеИЖзЪДйЧЃйҐШпЉМSVMйЗЗзФ®дЇЖж†ЄжКАеЈІпЉМеН≥е∞ЖеОЯеІЛжХ∞жНЃ...
- **иљѓйЧійЪФ**пЉЪеЬ®зО∞еЃЮдЄЦзХМдЄ≠пЉМжХ∞жНЃеЊАеЊАдЄНжШѓеЃМеЕ®зЇњжАІеПѓеИЖзЪДпЉМSVMеЉХеЕ•дЇЖ**жЭЊеЉЫеПШйЗП**еТМ**жГ©зљЪй°є**пЉМеЕБиЃЄдЄАеЃЪжХ∞йЗПзЪДж†ЈжЬђеПѓдї•з©њињЗиЊєзХМпЉМдљЖдЉЪеПЧеИ∞зЫЄеЇФжГ©зљЪгАВ - **ж†ЄеЗљжХ∞**пЉЪеѓєдЇОйЭЮзЇњжАІеПѓеИЖзЪДжХ∞жНЃпЉМSVMйАЪињЗ**ж†ЄжКАеЈІ**пЉИе¶В...
дЄЇдЇЖе§ДзРЖињЩзІНжГЕеЖµпЉМSVMеЉХеЕ•дЇЖжЭЊеЉЫеПШйЗПпЉМеЕБиЃЄдЄАеЃЪз®ЛеЇ¶зЪДиѓѓеИЖз±їгАВ #### дЇФгАБж†ЄеЗљжХ∞зЪДдљЬзФ® еЬ®е§ДзРЖйЭЮзЇњжАІеПѓеИЖйЧЃйҐШжЧґпЉМSVMйАЪињЗдљњзФ®ж†ЄеЗљжХ∞е∞ЖдљОзїіз©ЇйЧідЄ≠зЪДйЭЮзЇњжАІйЧЃйҐШиљђжНҐдЄЇйЂШзїіз©ЇйЧідЄ≠зЪДзЇњжАІйЧЃйҐШгАВеЄЄиІБзЪДж†ЄеЗљжХ∞еМЕжЛђе§Ъй°єеЉП...
### SVMеЕ•йЧ®пЉЪжФѓжМБеРСйЗПжЬЇиѓ¶иІ£ #### дЄАгАБSVMзЃАдїЛ жФѓжМБеРСйЗПжЬЇпЉИSupport Vector MachineпЉМзЃАзІ∞SVMпЉЙжШѓзФ±CortesеТМVapnikдЇО1995еєій¶Цжђ°жПРеЗЇзЪДжЬЇеЩ®е≠¶дє†зЃЧж≥ХгАВеЃГжШѓдЄАзІНзЫСзЭ£е≠¶дє†жЦєж≥ХпЉМеЬ®иІ£еЖ≥е∞Пж†ЈжЬђгАБйЭЮзЇњжАІеТМйЂШзїіж®°еЉПиѓЖеИЂз≠Й...
- йАЪињЗеЕБиЃЄдЄАдЇЫжХ∞жНЃзВєиљїеЊЃињЭеПНеИЖз±їиІДеИЩпЉМжЭЊеЉЫеПШйЗПиГље§ЯдљњSVMж®°еЮЛжЫіеЕЈй≤Бж£ТжАІпЉМжПРйЂШеЕґж≥ЫеМЦиГљеКЫгАВ #### дЄЙгАБе§Ъз±їеИЖз±ї - SVMжЬАеИЭиЃЊиЃ°зФ®дЇОдЇМеИЖз±їйЧЃйҐШпЉМдљЖеЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМеЄЄеЄЄйЬАи¶БиІ£еЖ≥е§Ъз±їеИЖз±їйЧЃйҐШгАВ - **иІ£еЖ≥е§Ъз±їеИЖз±їзЪД...
### SVMеЕ•йЧ®пЉЪжЬЇеЩ®е≠¶дє†зїПеЕЄиІ£жЮР #### жФѓжМБеРСйЗПжЬЇпЉИSVMпЉЙпЉЪзРЖиЃЇдЄОеЃЮиЈµзЪДж°•жҐБ **жФѓжМБеРСйЗПжЬЇпЉИSupport Vector MachineпЉМзЃАзІ∞SVMпЉЙ**жШѓзФ±CortesеТМVapnikеЬ®1995еєій¶Цжђ°жПРеЗЇзЪДпЉМиЗ™йВ£жЧґиµЈдЊњеЬ®жЬЇеЩ®е≠¶дє†йҐЖеЯЯеН†жНЃдЇЖдЄЊиґ≥иљїйЗНзЪД...
дЄЇж≠§пЉМSVMеЉХеЕ•дЇЖжЭЊеЉЫеПШйЗПпЉМеЕБиЃЄдЄАеЃЪжХ∞йЗПзЪДж†ЈжЬђиРљеЬ®йЧійЪФеЖЕпЉМдї•жПРйЂШж®°еЮЛзЪДж≥ЫеМЦиГљеКЫгАВ 6. е§ЪеИЖз±їйЧЃйҐШпЉЪ SVMжЬАеИЭеП™е§ДзРЖдЇМеИЖз±їйЧЃйҐШпЉМдљЖйАЪињЗдЄАеѓєе§ЪгАБдЄАеѓєдЄАжИЦеРИй°µжНЯ姱з≠ЙжЦєж≥ХеПѓдї•жЙ©е±ХеИ∞е§ЪеИЖз±їйЧЃйҐШгАВ 7. CеПВжХ∞дЄОж≠£еИЩеМЦпЉЪ ...
### SVMеЕ•йЧ®пЉИеЕЂпЉЙпЉЪжЭЊеЉЫеПШйЗПиѓ¶иІ£ #### SVMдЄОжЭЊеЉЫеПШйЗПиГМжЩѓ жФѓжМБеРСйЗПжЬЇпЉИSupport Vector MachineпЉМзЃАзІ∞SVMпЉЙжШѓдЄАзІНеєњж≥ЫеЇФзФ®дЇОжЬЇеЩ®е≠¶дє†йҐЖеЯЯзЪДзЫСзЭ£е≠¶дє†зЃЧж≥ХпЉМдЄїи¶БзФ®дЇОеИЖз±їеТМеЫЮељТдїїеК°гАВSVMзЪДж†ЄењГжАЭжГ≥жШѓеЬ®зЙєеЊБз©ЇйЧідЄ≠...
дЄЇдЇЖе§ДзРЖйЭЮзЇњжАІеПѓеИЖжИЦеЩ™е£∞иЊГе§ІзЪДжГЕеЖµпЉМSVMеЉХеЕ•дЇЖжЭЊеЉЫеПШйЗПеТМжГ©зљЪз≥їжХ∞CпЉМеЕБиЃЄдЄАйГ®еИЖж†ЈжЬђиРљеЬ®йЧійЪФеЖЕпЉМ嚥жИРдЇЖжЙАи∞УзЪДиљѓйЧійЪФгАВеРМжЧґпЉМйАЪињЗж†ЄеЗљжХ∞еПѓдї•е∞ЖеОЯеІЛжХ∞жНЃйЭЮзЇњжАІеЬ∞жШ†е∞ДеИ∞йЂШзїіз©ЇйЧіпЉМдљњеЊЧеЬ®йЂШзїіз©ЇйЧідЄ≠еЃЮзО∞зЇњжАІеПѓеИЖпЉМ...
еЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМSVMињШеЉХеЕ•дЇЖжЭЊеЉЫеПШйЗПпЉИslack variablesпЉЙжЭ•е§ДзРЖйВ£дЇЫйЪЊдї•ж≠£з°ЃеИЖз±їзЪДжХ∞жНЃзВєпЉМеЕБиЃЄдЄАеЃЪжХ∞йЗПзЪДжХ∞жНЃзВєиґКињЗеЖ≥з≠ЦиЊєзХМпЉМдї•еҐЮеЉЇж®°еЮЛзЪДй≤Бж£ТжАІгАВжЭЊеЉЫеПШйЗПзЪДеЉХеЕ•дљњеЊЧSVMжИРдЄЇдЄАзІНиљѓйЧійЪФеИЖз±їеЩ®пЉМиГље§ЯеЃєењНдЄАеЃЪз®ЛеЇ¶зЪД...
### SVMеЕ•йЧ®пЉИдєЭпЉЙпЉЪжЭЊеЉЫеПШйЗПдЄОжГ©зљЪеЫ†е≠РCзЪДеЇФзФ®еПКжХ∞жНЃйЫЖеБПжЦЬйЧЃйҐШе§ДзРЖ #### дЄАгАБжГ©зљЪеЫ†е≠РCзЪДж¶ВењµеПКеЕґйЗНи¶БжАІ еЬ®жФѓжМБеРСйЗПжЬЇ(SVM)зЪДе≠¶дє†ињЗз®ЛдЄ≠пЉМжЭЊеЉЫеПШйЗП(slack variable)еТМжГ©зљЪеЫ†е≠РCжШѓдЄ§дЄ™йЭЮеЄЄйЗНи¶БзЪДж¶ВењµгАВеЬ®дЄКдЄАзѓЗ...
### SVMеЕ•йЧ®пЉИдЇФпЉЙзЇњжАІеИЖз±їеЩ®зЪДж±ВиІ£вАФвАФйЧЃйҐШзЪДжППињ∞Part2 #### йЗНи¶Бж¶ВењµдЄОиГМжЩѓ жЬђжЦЗж°£жЧ®еЬ®еЄЃеК©иѓїиАЕзРЖиІ£жФѓжМБеРСйЗПжЬЇ(SVM)дЄ≠зЪДзЇњжАІеИЖз±їеЩ®ж±ВиІ£ињЗз®ЛеПКеЕґжХ∞е≠¶и°®ињ∞пЉМзЙєеИЂеЕ≥ж≥®дЇОе¶ВдљХе∞ЖзЇњжАІеИЖз±їеЩ®йЧЃйҐШиљђеМЦдЄЇдЉШеМЦйЧЃйҐШпЉМеєґиЃ®иЃЇ...
5. **иљѓйЧійЪФдЄОж≠£еИЩеМЦ**пЉЪиІ£йЗКдЄЇдїАдєИеЬ®еЃЮйЩЕеЇФзФ®дЄ≠еЉХеЕ•жЭЊеЉЫеПШйЗПеТМжГ©зљЪй°єпЉМдї•еПКCеПВжХ∞зЪДжДПдєЙгАВ 6. **е§ЪеИЖз±їйЧЃйҐШ**пЉЪдїЛзїНдЄАеѓєдЄАеТМдЄАеѓєе§ЪдЄ§зІНз≠ЦзХ•иІ£еЖ≥е§ЪеИЖз±їйЧЃйҐШзЪДжЦєж≥ХгАВ 7. **SVMеЬ®еЃЮйЩЕйЧЃйҐШдЄ≠зЪДеЇФзФ®**пЉЪеПѓиГљеМЕеРЂSVMеЬ®...
- **иљѓйЧійЪФ**пЉЪеЬ®еЃЮйЩЕжХ∞жНЃдЄ≠пЉМеЃМеЕ®зЇњжАІеПѓеИЖзЪДжГЕеЖµеЊИе∞СиІБпЉМSVMеЉХеЕ•дЇЖжЭЊеЉЫеПШйЗПеТМжГ©зљЪй°єпЉМеЕБиЃЄдЄАйГ®еИЖж†ЈжЬђзВєвАЬиґКзХМвАЭпЉМдїОиАМеЃЮзО∞иљѓйЧійЪФжЬАе§ІеМЦгАВ - **ж†ЄеЗљжХ∞**пЉЪдЄЇдЇЖиІ£еЖ≥йЭЮзЇњжАІйЧЃйҐШпЉМSVMдљњзФ®ж†ЄеЗљжХ∞е∞ЖеОЯеІЛзЙєеЊБз©ЇйЧіжШ†е∞ДеИ∞...