|
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import cn.itcast.cc.lucene.helloword.Article;
import cn.itcast.cc.lucene.helloword.utils.ArticleDocUtils;
آ
public class IndexDao {
آ آ آ // ç´¢ه¼•ç›®ه½•
آ آ آ private String indexPath = "./index";
آ آ آ // هˆ†è¯چه™¨
آ آ آ private Analyzer analyzer = new StandardAnalyzer();
آ
آ آ آ /**
آ آ آ آ * ن؟هکè®°ه½•
آ آ آ آ *
آ آ آ آ * @param art
آ آ آ آ */
آ آ آ public void save(Article art) {
آ آ آ آ آ آ آ // luceneçڑ„ه†™ه‡؛ç´¢ه¼•ç±»
آ آ آ آ آ آ آ IndexWriter indexWriter = null;
آ آ آ آ آ آ آ try {
آ آ آ آ آ آ آ آ آ آ آ indexWriter = new IndexWriter(this.indexPath, this.analyzer,
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ MaxFieldLength.LIMITED);
آ آ آ آ آ آ آ آ آ آ آ // و·»هٹ هˆ°ç´¢ه¼•ه؛“
آ آ آ آ آ آ آ آ آ آ آ indexWriter.addDocument(ArticleDocUtils.Article2Doc(art));
آ آ آ آ آ آ آ } catch (Exception e) {
آ آ آ آ آ آ آ آ آ آ آ e.printStackTrace();
آ آ آ آ آ آ آ }
آ آ آ آ آ آ آ // é‡ٹو”¾indexWriter
آ آ آ آ آ آ آ if (indexWriter != null) {
آ آ آ آ آ آ آ آ آ آ آ try {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ // ن½؟用هگژن¸€ه®ڑè¦په…³é—
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ indexWriter.close();
آ آ آ آ آ آ آ آ آ آ آ } catch (Exception e) {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ e.printStackTrace();
آ آ آ آ آ آ آ آ آ آ آ }
آ آ آ آ آ آ آ }
آ آ آ }
آ
آ آ آ /**
آ آ آ آ * و›´و–°è®°ه½•
آ آ آ آ *
آ آ آ آ * @param art
آ آ آ آ */
آ آ آ public void update(Article art) {
آ آ آ آ آ آ آ IndexWriter indexWriter = null;
آ آ آ آ آ آ آ try {
آ آ آ آ آ آ آ آ آ آ آ indexWriter = new IndexWriter(this.indexPath, this.analyzer,
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ MaxFieldLength.LIMITED);
آ آ آ آ آ آ آ آ آ آ آ Term term = new Term("id", art.getId() + "");
آ آ آ آ آ آ آ آ آ آ آ // و›´و–°
آ آ آ آ آ آ آ آ آ آ آ indexWriter.updateDocument(term, ArticleDocUtils.Article2Doc(art));
آ آ آ آ آ آ آ } catch (Exception e) {
آ آ آ آ آ آ آ آ آ آ آ e.printStackTrace();
آ آ آ آ آ آ آ }
آ
آ آ آ آ آ آ آ // é‡ٹو”¾indexWriter
آ آ آ آ آ آ آ if (indexWriter != null) {
آ آ آ آ آ آ آ آ آ آ آ try {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ indexWriter.close();
آ آ آ آ آ آ آ آ آ آ آ } catch (Exception e) {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ e.printStackTrace();
آ آ آ آ آ آ آ آ آ آ آ }
آ آ آ آ آ آ آ }
آ آ آ }
آ
آ آ آ /**
آ آ آ آ * هˆ 除记ه½•
آ آ آ آ *
آ آ آ آ * @param id
آ آ آ آ */
آ آ آ public void delete(int id) {
آ آ آ آ آ آ آ IndexWriter indexWriter = null;
آ آ آ آ آ آ آ try {
آ آ آ آ آ آ آ آ آ آ آ indexWriter = new IndexWriter(this.indexPath, this.analyzer,
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ MaxFieldLength.LIMITED);
آ آ آ آ آ آ آ آ آ آ آ Term term = new Term("id", id + "");
آ آ آ آ آ آ آ آ آ آ آ // هˆ 除
آ آ آ آ آ آ آ آ آ آ آ indexWriter.deleteDocuments(term);
آ آ آ آ آ آ آ } catch (Exception e1) {
آ آ آ آ آ آ آ آ آ آ آ e1.printStackTrace();
آ آ آ آ آ آ آ }
آ
آ آ آ آ آ آ آ // é‡ٹو”¾indexWriter
آ آ آ آ آ آ آ if (indexWriter != null) {
آ آ آ آ آ آ آ آ آ آ آ try {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ indexWriter.close();
آ آ آ آ آ آ آ آ آ آ آ } catch (Exception e) {
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ e.printStackTrace();
آ آ آ آ آ آ آ آ آ آ آ }
آ آ آ آ آ آ آ }
آ آ آ }
آ
آ آ آ /**
آ آ آ آ * وں¥è¯¢è®°ه½•ï¼ˆه…·وœ‰هˆ†é،µهٹں
هˆ†ن؛«هˆ°ï¼ڑ


Global site tag (gtag.js) - Google Analytics
| 

 آ
آ 
相ه…³وژ¨èچگ
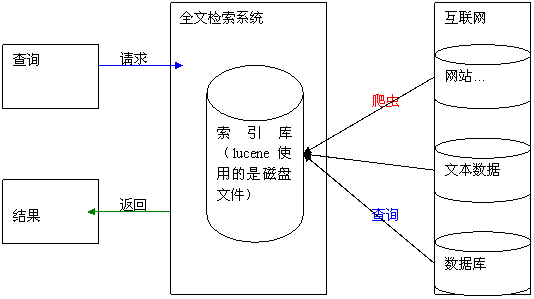
网ن¸ٹMMAnalyzer资و؛گه¤ھه°‘ن؛†ï¼Œه¤§ه¤ڑو•°هˆه¦è€…都ن¼ڑه°‘ه¯¼ه…¥JARهŒ…,ه¹¶ن¸”网ن¸ٹهڈھوœ‰ je-analysis-MMAnalyzerçڑ„ن¾‹هگ,而و²،وœ‰ن¾èµ–هŒ…lucene-core-2.4.1.jar je-analysis-1.5.3.jarن»¥هڈٹ luncene-heghlighter-2.4.1.jar
هœ¨و„ه»؛ن¸€ن¸ھè‡ھه®ڑن¹‰وگœç´¢ه¼•و“ژçڑ„è؟‡ç¨‹ن¸ï¼ŒLuncene 2.0 ه’Œ Heritrix وک¯ن¸¤ن¸ھه…³é”®çڑ„组ن»¶م€‚Luncene وک¯ن¸€ن¸ھوµپè،Œçڑ„ه…¨و–‡و£€ç´¢ه؛“,而 Heritrix وک¯ن¸€و¬¾ه¼؛ه¤§çڑ„网络وٹ“هڈ–ه·¥ه…·ï¼Œه®ƒن»¬ه…±هگŒن¸؛وگœç´¢ه¼•و“ژçڑ„وگه»؛وڈگن¾›ن؛†هڑه®çڑ„هں؛ç،€م€‚ن¸‹é¢ه°†è¯¦ç»†...
Lunceneçڑ„API,详细وژ¥هڈ—ن؛†Lunceneçڑ„ن½؟用و–¹و³•
luncene in actionن¸و–‡ç‰ˆ docو ¼ه¼ڈ
**ه…¨و–‡وگœç´¢Lucene.Net** Lucene.Netوک¯ن¸€و¬¾ه¼€و؛گçڑ„ه…¨و–‡وگœç´¢ه¼•و“ژه؛“,ه®ƒن¸؛.NETه¼€هڈ‘者وڈگن¾›ن؛†ه¼؛ه¤§çڑ„و–‡وœ¬و£€ç´¢هٹں能م€‚ن½œن¸؛Apache Luceneé،¹ç›®çڑ„.NET版وœ¬ï¼Œه®ƒهœ¨.NET Frameworkن¸ٹه®çژ°ن؛†هژںç”ںLuceneçڑ„هٹں能,ن½؟ه¾—.NETه¼€هڈ‘者ن¹ں能...
Apache Luceneوک¯ن¸€ن¸ھه¼€و؛گه…¨و–‡وگœç´¢ه¼•و“ژه؛“,ه®ƒن¸؛ه¼€هڈ‘者وڈگن¾›ن؛†هœ¨هگ„ç§چه؛”用程ه؛ڈن¸ه®çژ°é«کç؛§وگœç´¢هٹں能و‰€éœ€çڑ„ه·¥ه…·م€‚Lucene API(Application Programming Interface)وک¯è؟™ن¸ھه؛“çڑ„و ¸ه؟ƒéƒ¨هˆ†ï¼Œه…پ许程ه؛ڈه‘کن¸ژLuceneè؟›è،Œن؛¤ن؛’,و„ه»؛...
و ‡é¢کن¸çڑ„“luncene jarهŒ…Javaن¸“用â€وŒ‡çڑ„وک¯ن¸“é—¨ن¸؛Javaçژ¯ه¢ƒè®¾è®،çڑ„Luceneه؛“,ن»¥.jarو–‡ن»¶ه½¢ه¼ڈوڈگن¾›ï¼Œن¾؟ن؛ژه¼€هڈ‘者集وˆگهˆ°ن»–ن»¬çڑ„é،¹ç›®ن¸م€‚è؟™ن¸ھه؛“هŒ…هگ«ن؛†و‰€وœ‰ه؟…è¦پçڑ„ç±»ه’Œو–¹و³•ï¼Œن½؟ه¾—ه¼€هڈ‘ن؛؛ه‘ک能ه¤ںو„ه»؛è‡ھه·±çڑ„وگœç´¢ه¼•و“ژه؛”用,ه¯¹و–‡وœ¬...
### Lucene 3.0 ه…¥é—¨هˆ°ç²¾é€ڑه…³é”®çں¥è¯†ç‚¹è§£وگ #### ن¸€م€په…¨و–‡و£€ç´¢و¦‚è؟° **ه…¨و–‡و£€ç´¢**وک¯ن¸€ç§چ能ه¤ںوگœç´¢و–‡و،£ن¸ن»»ن½•ن½چç½®çڑ„و–‡وœ¬ه†…ه®¹çڑ„وٹ€وœ¯م€‚ن¸ژن¼ ç»ںçڑ„و•°وچ®ه؛“وں¥è¯¢ن¸چهگŒï¼Œه…¨و–‡و£€ç´¢é€ڑه¸¸ç”¨ن؛ژه¤§è§„و¨،çڑ„و•°وچ®é›†ï¼Œه¹¶ن¸”能ه¤ںوڈگن¾›و›´هٹ è‡ھ然ه’Œ...
ASP.NETن¸ژLucene.NETوک¯ن¸¤ن¸ھهœ¨ه¼€هڈ‘领هںںن¸ه¹؟و³›ن½؟用çڑ„ه¼€و؛گوٹ€وœ¯م€‚ASP.NETوک¯Microsoftوژ¨ه‡؛çڑ„用ن؛ژو„ه»؛Webه؛”用程ه؛ڈçڑ„و،†و¶ï¼Œè€ŒLucene.NETهˆ™وک¯ن¸€ن¸ھه¼؛ه¤§çڑ„ه…¨و–‡وگœç´¢ه¼•و“ژه؛“,被许ه¤ڑه¼€هڈ‘者用و¥ن¸؛ن»–ن»¬çڑ„ه؛”用و·»هٹ é«کو•ˆçڑ„وگœç´¢هٹں能م€‚...
luncene 简هچ•çڑ„ه¼€هژںé،¹ç›®
#### و¦‚è؟° Luceneوک¯ن¸€و¬¾é«کو€§èƒ½م€په…¨هٹں能çڑ„و–‡وœ¬وگœç´¢ه¼•و“ژه؛“,被ه¹؟و³›ه؛”用ن؛ژه¤ڑç§چهœ؛و™¯ن¸‹çڑ„ه…¨و–‡و£€ç´¢ه؛”用ه¼€هڈ‘ن¸م€‚... #### Luceneهں؛ç،€و¦‚ه؟µ هœ¨و·±ه…¥ن؛†è§£ه¦‚ن½•ه¤„çگ†ç‰¹ه®ڑç±»ه‹çڑ„و–‡و،£ن¹‹ه‰چ,وˆ‘ن»¬éœ€è¦په…ˆن؛†è§£ه‡ ن¸ھهں؛وœ¬و¦‚ه؟µï¼ڑ ...
هں؛ن؛ژLuceneçڑ„Compassو،†و¶è¯¦è§£-Java ن¸€م€پCompassو،†و¶و¦‚è؟° Compassوک¯ن¸€ن¸ھé«کو€§èƒ½çڑ„ه¼€و؛گJavaوگœç´¢ه¼•و“ژو،†و¶ï¼Œو—¨هœ¨ç®€هŒ–ه؛”用程ه؛ڈن¸ژوگœç´¢ه¼•و“ژن¹‹é—´çڑ„集وˆگè؟‡ç¨‹م€‚ه®ƒن¸چن»…هˆ©ç”¨ن؛†é،¶ç؛§çڑ„Luceneوگœç´¢ه¼•و“ژçڑ„ه¼؛ه¤§هٹں能,è؟کèچهگˆن؛†è¯¸ه¦‚...
و ‡é¢کن¸ژوڈڈè؟°ه‡ن¸؛“luncene in action 003â€ï¼Œن½†وک¯éœ€è¦پو³¨و„ڈçڑ„وک¯و£ç،®çڑ„و‹¼ه†™ه؛”ن¸؛“Lucene in Actionâ€ï¼Œè؟™وک¯ن¸€وœ¬ن»‹ç»چApache Luceneçڑ„ن¹¦ç±چم€‚ç”±ن؛ژوڈگن¾›çڑ„部هˆ†ه†…ه®¹ن»…هŒ…هگ«ن؛†ن¸€ن؛›é‡چه¤چçڑ„试读版وœ¬ه£°وکژهڈٹ网ه€ï¼Œه¹¶وœھوڈگن¾›ه…·ن½“çڑ„ç« èٹ‚...
هœ¨و„ه»؛ن¸€ن¸ھè‡ھه®ڑن¹‰وگœç´¢ه¼•و“ژçڑ„è؟‡ç¨‹ن¸ï¼ŒLuncene 2.0 ه’Œ Heritrix وک¯ن¸¤ن¸ھه…³é”®çڑ„ه¼€و؛گه·¥ه…·م€‚Luncene وک¯ن¸€و¬¾ه¼؛ه¤§çڑ„ه…¨و–‡وگœç´¢ه¼•و“ژه؛“,而 Heritrix وک¯ن¸€ن¸ھ网络وٹ“هڈ–ه·¥ه…·ï¼Œه®ƒن»¬ه…±هگŒن¸؛هˆ›ه»؛ن¸€ن¸ھه®Œو•´çڑ„وگœç´¢è§£ه†³و–¹و،ˆوڈگن¾›ن؛†هں؛ç،€م€‚ **...
هœ¨ç»™ه®ڑçڑ„هژ‹ç¼©هŒ…و–‡ن»¶â€œluncene.jarâ€ن¸ï¼ŒهŒ…هگ«ن؛†ن¸‰ن¸ھé‡چè¦پçڑ„Lucene组ن»¶ï¼ڑlucene-core-3.0.3.jarم€پlucene-highlighter-3.0.1.jarه’Œlucene-memory-3.0.1.jar,è؟™ن؛›ç»„ن»¶وک¯و„ه»؛é«کو•ˆوگœç´¢ه¼•و“ژçڑ„هں؛ç،€م€‚ 首ه…ˆï¼Œوˆ‘ن»¬و¥çœ‹ن¸€ن¸‹`...
### Luceneçں¥è¯†ç‚¹è¯¦è§£ #### ن¸€م€پLucene简ن»‹ **1.1 ن»€ن¹ˆوک¯Lucene** Luceneوک¯ن¸€ن¸ھç”±Apacheهں؛金ن¼ڑç»´وٹ¤çڑ„ه¼€و؛گه…¨و–‡و£€ç´¢ه¼•و“ژه·¥ه…·هŒ…م€‚ه®ƒن¸؛ه¼€هڈ‘者وڈگن¾›ن؛†ن¸€ن¸ھ简ن¾؟çڑ„وژ¥هڈ£ï¼Œن½؟ه¾—هœ¨ه؛”用程ه؛ڈن¸ه®çژ°é«کو•ˆçڑ„ه…¨و–‡و£€ç´¢هٹں能وˆگن¸؛هڈ¯èƒ½...
و ¹وچ®وڈگن¾›çڑ„و ‡é¢کم€پوڈڈè؟°م€پو ‡ç¾ن»¥هڈٹ部هˆ†ه†…ه®¹و¥çœ‹ï¼Œن¼¼ن¹ژهکهœ¨ن¸€ه®ڑçڑ„误解,ه› ن¸؛è؟™ن؛›ن؟،وپ¯ه¹¶و²،وœ‰وڈگن¾›ه…³ن؛ژ“Lucene in Action002â€ه…·ن½“ه†…ه®¹çڑ„وœ‰و•ˆن؟،وپ¯م€‚“Lucene in Actionâ€é€ڑه¸¸وک¯ن¸€وœ¬ن¹¦çڑ„هگچ称,该ن¹¦و·±ه…¥ن»‹ç»چن؛†Apache Lucene...
### هں؛ن؛ژJavaçڑ„Lunceneçڑ„Compassو،†و¶è¯´وکژن½؟用وٹ€وœ¯و–‡و،£ #### ن¸€م€پهژںçگ†وڈڈè؟° Compassوک¯ن¸€و¬¾ن¼ک秀çڑ„ه¼€و؛گJavaوگœç´¢ه¼•و“ژو،†و¶ï¼Œه®ƒèƒ½ه¤ںه¸®هٹ©ه؛”用程ه؛ڈه®çژ°و›´ن¸؛ه¼؛ه¤§çڑ„وگœç´¢ه¼•و“ژè¯ن¹‰èƒ½هٹ›م€‚Compassن¾èµ–ن؛ژé،¶ç؛§çڑ„Luceneوگœç´¢ه¼•و“ژ,ه¹¶...
هœ¨وœ¬ç¯‡و–‡ç« ن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•هœ¨Lucene 4.6ن¸ه®çژ°è‡ھه®ڑن¹‰وں¥è¯¢è¯„هˆ†è§„هˆ™م€‚و¤وٹ€وœ¯ه…پ许用وˆ·و ¹وچ®ç‰¹ه®ڑ需و±‚è°ƒو•´و–‡و،£çڑ„相ه…³و€§è¯„هˆ†ï¼Œن»ژ而و›´ç²¾ç،®هœ°و»،足وگœç´¢éœ€و±‚م€‚ ### Lucene 4.6 è‡ھه®ڑن¹‰وں¥è¯¢è¯„هˆ†è§„هˆ™ ...
**Lucene.NET ه…¨é¢è§£وگï¼ڑو„ه»؛é«کو•ˆو–‡ن»¶ه†…ه®¹وگœç´¢ه¼•و“ژ** Lucene.NET وک¯ن¸€ن¸ھه¼€و؛گه…¨و–‡وگœç´¢ه¼•و“ژه؛“,هں؛ن؛ژ Java 版وœ¬çڑ„ Lucene,ه¹¶é’ˆه¯¹ .NET ه¹³هڈ°è؟›è،Œن؛†ن¼کهŒ–م€‚...وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ Lucene.NET çڑ„و ¸ه؟ƒو¦‚ه؟µه’Œن½؟用و–¹و³•ï¼Œن»¥هˆ›ه»؛ن¸€ن¸ھ...