- µÁÅÞºê: 645662 µ¼í
- µÇºÕê½:

- µØÑÞç¬: µ¡ªµ▒ë
-

µûçþ½áÕêåþ▒╗
þñ¥Õî║þëêÕØù
- µêæþÜäÞÁäÞ«» ( 0)
- µêæþÜäÞ«║ÕØø ( 0)
- µêæþÜäÚù«þ¡ö ( 1)
Õ¡ÿµíúÕêåþ▒╗
- 2010-03 ( 2)
- 2010-01 ( 63)
- 2009-12 ( 79)
- µø┤ÕñÜÕ¡ÿµíú...
µ£Çµû░Þ»äÞ«║
-
lizhuang´╝Ü
Þ┐Öõ©¬µû╣µ│òþÜäÕåàÚâ¿Õ«×þÄ░õ©╗Þªüµÿ»õ¥ØÞÁûõ║Äþ▒╗ÕèáÞ¢¢ÕÖ¿´╝îõ©ÇÞê¼þÜäÞç¬ÕÀ▒Õ«×þÄ░þÜäþ▒╗µÿ»þö¿ ...
Javaõ©¡getResourceAsStreamþÜäþö¿µ│ò -
prince4426´╝Ü
Õø×þ¡öÞ»äÞ«║Úâ¢Õ¥êþ▓¥Õ¢®
Javaõ©¡getResourceAsStreamþÜäþö¿µ│ò -
kexuetou´╝Ü
þ¥Äõ║║ժ鵡ñÕñÜÕ¿ç ÕåÖÚüôÕÅ»Þâ¢Þ┐ÖµáÀµÇ╗þ╗ôµø┤ÕÑ¢´╝îÞÀ»Õ¥äÕëìõ©ìÕ©ª'/'´╝îÕêÖµÿ»þø©Õ»╣ ...
Javaõ©¡getResourceAsStreamþÜäþö¿µ│ò -
guoxin91´╝Ü
...
Javaõ©¡getResourceAsStreamþÜäþö¿µ│ò -
þ¥Äõ║║ժ鵡ñÕñÜÕ¿ç´╝Ü
ÕÅ»Þâ¢Þ┐ÖµáÀµÇ╗þ╗ôµø┤ÕÑ¢´╝îÞÀ»Õ¥äÕëìõ©ìÕ©ª'/'´╝îÕêÖµÿ»þø©Õ»╣ÞÀ»Õ¥ä´╝øÞïÑÕ©ª´╝îÕêÖµÿ»þ╗Ø ...
Javaõ©¡getResourceAsStreamþÜäþö¿µ│ò
µ£¼µûçÚô¥µÄÑ´╝Ühttp://hi.chinaunix.net/?uid-693307-action-viewspace-itemid-12080
Õ£¿µêæÕçáÕ╣┤ÕëìÕ╝ÇÕºïÕåÖÒÇèC++þ╝ûþáüÞºäÞîâõ©ÄµîçÕ»╝ÒÇïõ©Çµûçµù´╝îÕ░▒ÕÀ▓þ╗ÅÞºäÕêÆþØÇÞªüÕèáÕàÑÞ┐ÖµáÀõ©Çþ»çÞ«¿Þ«║ C++ Õ╝éÕ©©µ£║ÕêÂþÜäµûçþ½áõ║åÒÇéµ▓íµâ│Õê░µùÂÚÜöÕçáÕ╣┤õ╗ÑÕÉĵë쵣뵣║õ╝ܵèèÞ┐Öõ©¬Õ░¥ÕÀ┤ÞíÑÕ«î :-)ÒÇé
Þ┐ÿ µÿ»ÚéúÕÅÑÕ╝ÇÕ£║þÖ¢´╝ÜÔÇ£Õ£¿µü░Õ¢ôþÜäÕ£║ÕÉêõ¢┐þö¿µü░Õ¢ôþÜäþë╣µÇºÔÇØ Õ»╣µ»Åõ©¬þº░ÞüîþÜä C++ þ¿ïÕ║ÅÕæÿµØÑÞ»┤Ú⢵ÿ»õ©Çõ©¬Õƒ║µ£¼µáçÕçåÒÇéµâ│ÞªüÕüÜÕê░Þ┐Öþé╣´╝îÕ░▒Õ┐àÚí╗Þªüõ║åÞºúÞ»¡Þ¿Çõ©¡µ»Åõ©¬þë╣µÇºþÜäÕ«×þÄ░µû╣Õ╝ÅÕÅèÕàµùÂþ®║Õ╝ÇÚöÇÒÇéÕ╝éÕ©©ÕñäþÉåþö▒õ║ĵÂëÕÅèÕñºÚçÅÕ║òÕ▒éÕåàÕ«╣´╝îÕÉæµØѵÿ» C++ ÕÉäþºìÚ½ÿþ║ºµ£║ÕêÂõ©¡Þ¥âÚÜ¥þÉåÞºúÕÆîÚÇÅÕ¢╗µÄîµÅíþÜäÚâ¿ÕêåÒÇéµ£¼µûçÕ░åÕ£¿Õ░¢ÚçÅÕ░æÕ╝òÕàÑÕ║òÕ▒éþ╗åÞèéþÜäÕëìµÅÉõ©ï´╝îÞ«¿Þ«║ C++ õ©¡Þ┐Öõ©ÇÕ┤¡µû░þë╣µÇº´╝îÕ╣ÂÕêåµ×ÉÕàÂÕ«×þÄ░Õ╝ÇÚöÇÒÇé
ÒÇÇ
Õà│õ║Äþ║┐þ¿ï Þ┐øþ¿ïÕÆîþ║┐þ¿ïþÜ䵪éÕ┐Áþø©õ┐íÕÉäõ¢ìþ£ïÕ«ÿµù®ÕÀ▓ÞÇ│þåƒÞâ¢Þ»ªÒÇéÕ£¿Þ┐ÖÚçî´╝îµêæÕŬµâ│Õ©ªÕñºÕ«ÂÕø×Õ┐åÕçáþé╣ÚçìÞªüµªéÕ┐Á´╝Ü
Þ┐øþ¿ïÕÆîþ║┐þ¿ïþÜ䵪éÕ┐Áþø©õ┐íÕÉäõ¢ìþ£ïÕ«ÿµù®ÕÀ▓ÞÇ│þåƒÞâ¢Þ»ªÒÇéÕ£¿Þ┐ÖÚçî´╝îµêæÕŬµâ│Õ©ªÕñºÕ«ÂÕø×Õ┐åÕçáþé╣ÚçìÞªüµªéÕ┐Á´╝Ü
- õ©Çõ©¬Þ┐øþ¿ïõ©¡ÕÅ»õ╗ÑÕÉîµùÂÕîàÕɽÕñÜõ©¬þ║┐þ¿ïÒÇé
- µêæõ╗¼ÚÇÜÕ©©Þ«ñõ©║þ║┐þ¿ïµÿ»µôìõ¢£þ│╗þ╗ƒÕŻ޻åÕê½þÜäµ£ÇÕ░ÅÕ╣ÂÕÅæµëºÞíîÕÆîÞ░âÕ║ªÕìòõ¢ì´╝êõ©ìÞªüÞÀƒõ┐║Þ»┤Þ┐ÿµ£ë Green Thread µêûÞÇà Fiber´╝îOS Kernel õ©ìÞ«ñÞ»åõ╣ƒõ©ìÕÅéõ©ÄÞ┐Öõ║øþë®õ╗ÂþÜäÞ░âÕ║ª´╝ëÒÇé
- ÕÉîõ©ÇÞ┐øþ¿ïõ©¡þÜäÕñÜõ©¬þ║┐þ¿ïÕà▒õ║½õ╗úþáüµ«Á´╝êõ╗úþáüÕÆîÕ©©ÚçÅ´╝ëÒÇüµò░µì«µ«Á´╝êÚØÖµÇüÕÆîÕà¿Õ▒ÇÕÅÿÚçÅ´╝ëÕÆîµë®Õ▒òµ«Á´╝êÕáåÕ¡ÿÕé¿´╝ë´╝îõ¢åµÿ»µ»Åõ©¬þ║┐þ¿ïµ£ëÞç¬ÕÀ▒þÜäµá굫ÁÒÇé µá굫ÁÕÅêÕŽÞ┐ÉÞíîµùµáê´╝îþö¿µØÑÕ¡ÿµö¥µëǵ£ëÕ▒ÇÚâ¿ÕÅÿÚçÅÕÆîõ©┤µùÂÕÅÿÚçÅ´╝êÕÅéµò░ÒÇüÞ┐öÕø×ÕÇ╝ÒÇüõ©┤µùµ×äÚÇáþÜäÕÅÿÚçÅþ¡ë´╝ëÒÇéÞ┐Öõ©ÇµØíÕ»╣õ©ïµûçõ©¡þÜ䵃Éõ║øµªéÕ┐ÁµØÑÞ»┤µÿ»ÚØ×Õ©©ÚçìÞªüþÜä´╝îõ¢åµÿ»Þ»Àµ│¿µäÅ´╝îÞ┐ÖÚçîµÅÉ Õê░þÜäÕÉäõ©¬ÔÇ£µ«ÁÔÇØÚ⢵ÿ»ÚÇ╗Þ¥æõ©èþÜäÞ»┤µ│ò´╝îÕ£¿þë®þÉåõ©èµƒÉõ║øþí¼õ╗µ×µ×äµêûÞÇàµôìõ¢£þ│╗þ╗ƒÕÅ»Þâ¢õ©ìõ¢┐þö¿µ«ÁÕ╝ÅÕ¡ÿÕé¿ÒÇéõ©ìÞ┐çµ▓íÕà│þ│╗´╝îþ╝ûÞ»æÕÖ¿õ╝Üõ┐ØÞ»üÞ┐Öõ║øÚÇ╗ޥ浪éÕ┐ÁÕÆîÕüçÞ«¥þÜäÕëìµÅɵØíõ╗ÂÕ»╣µ»Åõ©¬ C/C++ þ¿ïÕ║ÅÕæÿµØÑÞ»┤Õºïþ╗êµÿ»µêÉþ½ïþÜäÒÇé
- þö▒õ║ÄÕà▒õ║½õ║åÚÖñµáêõ╗ÑÕñûþÜäµëǵ£ëÕåàÕ¡ÿÕ£░ÕØǵ«Á´╝îþ║┐þ¿ïõ©ìÕÅ»õ╗ѵ£ëÞç¬ÕÀ▒þÜäÔÇ£ÚØÖµÇüÔÇصêûÔÇ£Õà¿Õ▒ÇÔÇØÕÅÿÚçÅ´╝îõ©║õ║åÕ╝ÑÞíÑÞ┐Öõ©Çþ╝║µå¥´╝îµôìõ¢£þ│╗þ╗ƒÚÇÜÕ©©õ╝ܵÅÉõ¥øõ©Çþºìþº░õ©║TLS´╝êThread Local Storage´╝îÕì│´╝ÜÔÇ£þ║┐þ¿ïµ£¼Õ£░Õ¡ÿÕé¿ÔÇØ´╝ëþÜäµ£║ÕêÂÒÇéÚÇÜÞ┐ç޻ѵ£║ÕêÂÕÅ»õ╗ÑÕ«×þÄ░þ▒╗õ╝╝þÜäÕèƒÞâ¢ÒÇéTLS ÚÇÜÕ©©µÿ»þ║┐þ¿ïµÄºÕêÂÕØù´╝êTCB´╝ëõ©¡þÜ䵃Éõ©¬µîçÚÆêµëǵîçÕÉæþÜäõ©Çõ©¬µîçÚÆêµò░þ╗ä´╝îµò░þ╗äõ©¡þÜäµ»Åõ©¬Õàâþ┤áþº░õ©║õ©Çõ©¬µº¢´╝êSlot´╝ë´╝îµ»Åõ©¬µº¢õ©¡þÜäµîçÚÆêþö▒õ¢┐þö¿ÞÇàÕ«Üõ╣ë´╝îÕÅ»õ╗ѵîçÕÉæõ╗╗µäÅõ¢ìþ¢«´╝êõ¢åÚÇÜÕ©©µÿ»µîçÕÉæÕáåÕ¡ÿÕé¿õ©¡þÜ䵃Éõ©¬ÕüÅþº╗´╝ëÒÇé
ÒÇÇ
Õ碵ò░þÜäÞ░âþö¿ÕÆîÞ┐öÕø×µÄÑþØǵêæõ╗¼µØÑÕø×Úí¥õ©ïõ©Çõ©¬ÚóäÕñçþƒÑÞ»å´╝Üþ╝ûÞ»æÕÖ¿Õªéõ¢òÕ«×þÄ░Õ碵ò░þÜäÞ░âþö¿ÕÆîÞ┐öÕø×ÒÇéõ©ÇÞê¼µØÑÞ»┤´╝îþ╝ûÞ»æÕÖ¿õ╝Üõ©║Õ¢ôÕëìÞ░âþö¿µáêÚçîþÜäµ»Åõ©¬Õ碵ò░Õ╗║þ½ïõ©Çõ©¬µáêµíåµ×´╝êStack Frame´╝ëÒÇéÔÇ£µáêµíåµ×ÂÔÇصïàÞ┤ƒþØÇõ╗Ñõ©ïÚçìÞªüõ╗╗Õèí
- õ╝áÚÇÆÕÅéµò░´╝ÜÚÇÜÕ©©´╝îÕ碵ò░þÜäÞ░âþö¿ÕÅéµò░µÇ╗µÿ»Õ£¿Þ┐Öõ©¬Õ碵ò░µáêµíåµ×ÂþÜäµ£ÇÚíÂþ½»ÒÇé
- õ╝áÚÇÆÞ┐öÕø×Õ£░ÕØÇ´╝ÜÕæèÞ»ëÞó½Þ░âþö¿ÞÇàþÜä return Þ»¡ÕÅÑÕ║öÞ»Ñ return Õê░Õô¬ÚçîÕÄ╗´╝îÚÇÜÕ©©µîçÕÉæÞ»ÑÕ碵ò░Þ░âþö¿þÜäõ©ïõ©ÇµØíÞ»¡ÕÅÑÒÇé
- Þ░âþö¿ÞÇàþÜäÕ¢ôÕëìµáêµîçÚÆê´╝Üõ¥┐õ║ĵ©àþÉåÞó½Þ░âþö¿ÞÇàþÜäµëǵ£ëÕ▒ÇÚâ¿ÕÅÿÚçÅÒÇüÕ╣µüóÕñìÞ░âþö¿ÞÇàþÜäþÄ░Õ£║ÒÇé
- Õ¢ôÕëìÕ碵ò░ÕåàþÜäµëǵ£ëÕ▒ÇÚâ¿ÕÅÿÚçÅ´╝ÜÞ«░Õ¥ùÕÉù´╝ƒÕêܵëìÞ»┤Þ┐çµëǵ£ëÕ▒ÇÚâ¿ÕÆîõ©┤µùÂÕÅÿÚçÅÚ⢵ÿ»Õ¡ÿÕé¿Õ£¿µáêõ©èþÜäÒÇé
µ£ÇÕÉÄÕåìÕñìõ╣áõ©Çþé╣´╝ܵáêµÿ»õ©ÇþºìÔÇ£ÕÉÄÞ┐øÕàêÕç║ÔÇØ´╝êLIFO´╝ëþÜäµò░µì«þ╗ôµ×ä´╝îõ©ìÞ┐çÕ«×ÚÖàõ©èÕñºÚâ¿ÕêåµáêþÜäÕ«×þÄ░Ú⢵ö»µîüÚÜŵ£║Þ«┐Úù«ÒÇé
õ©ïÚØóµêæõ╗¼µØÑþ£ïõ©¬ÕàÀõ¢ôõ¥ïÕ¡É´╝Ü
ÕüçÞ«¥µ£ë FuncAÒÇüFuncB ÕÆî FuncC õ©ëõ©¬Õ碵ò░´╝îµ»Åõ©¬Õ碵ò░ÕØçµÄѵöÂõ©ñõ©¬µò┤Õ¢óÕÇ╝õ¢£õ©║ÕàÂÕÅéµò░ÒÇéÕ£¿µƒÉþ║┐þ¿ïõ©èþÜ䵃Éõ©ÇµùÂÚù┤µ«ÁÕåà´╝îFuncA Þ░âþö¿õ║å FuncB´╝îÞÇî FuncB ÕÅêÞ░âþö¿õ║å FuncCÒÇéÕêÖ´╝îÕ«âõ╗¼þÜäµáêµíåµ×Âþ£ïÞÁÀµØÑÕ║öÞ»ÑÕâÅÞ┐ÖµáÀ´╝Ü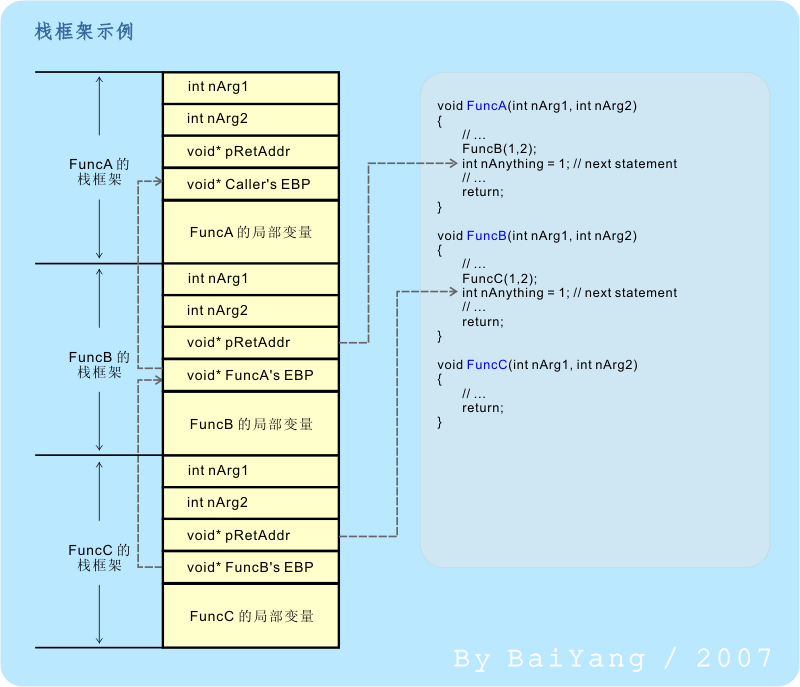
Õø¥1 Õ碵ò░Þ░âþö¿µáêµíåµ×Âþñ║õ¥ï
µ¡úÕªéõ©èÕø¥µëÇþñ║þÜäÚéúµáÀ´╝îÚÜÅþØÇÕ碵ò░Þó½ÚÇÉþ║ºÞ░âþö¿´╝îþ╝ûÞ»æÕÖ¿õ╝Üõ©║µ»Åõ©Çõ©¬Õ碵ò░Õ╗║þ½ïÞç¬ÕÀ▒þÜäµáêµíåµ×´╝îµáêþ®║Úù┤ÚÇɵ©ÉµÂêÞÇùÒÇéÚÜÅþØÇÕ碵ò░þÜäÚÇÉþ║ºÞ┐öÕø×´╝îÞ»ÑÕ碵ò░þÜäµáêµíåµ×Âõ╣ƒÕ░åÞó½ÚÇÉþ║ºÚöǵ»ü´╝îµáêþ®║Úù┤Õ¥ùõ╗ÑÚÇɵ¡ÑÚçèµö¥ÒÇéÚí║õ¥┐Þ»┤õ©ÇÕÅÑ´╝î ÚÇÆÕ¢ÆÕ碵ò░þÜäÕÁîÕÑùÞ░âþö¿µÀ▒Õ║ªÚÇÜÕ©©õ╣ƒµÿ»ÕÅûÕå│õ║ÄÞ┐ÉÞíîµùµáêþ®║Úù┤þÜäÕë®õ¢ÖÕ░║Õ»©ÒÇé
Þ┐ÖÚçîÚí║õ¥┐ÞºúÚçèÕŪõ©Çõ©¬µ£»Þ»¡´╝ÜÞ░âþö¿þ║ªÕ«Ü´╝êcalling convention´╝ëÒÇéÞ░âþö¿þ║ªÕ«ÜÚÇÜÕ©©µîç´╝ÜÞ░âþö¿ÞÇàÕ░åÕÅéµò░ÕÄïÕàѵáêõ©¡´╝êµêûµö¥ÕàÑÕ»äÕ¡ÿÕÖ¿õ©¡´╝ëþÜäÚí║Õ║Å´╝îõ╗ÑÕÅèÞ┐öÕø×µùÂþö▒Þ░ü´╝êÞ░âþö¿ÞÇàÞ┐ÿµÿ»Þó½Þ░âþö¿ÞÇà´╝ëµØѵ©àþÉåÞ┐Öõ║øÕÅéµò░þ¡ëþ╗åÞèéÞºäþ¿ïµû╣ÚØóþÜäþ║ªÕ«ÜÒÇé
µ£ÇÕÉÄÕåìÞ»┤õ©ÇÕÅÑ´╝îÞ┐ÖÚçîµëÇÕ▒òþñ║þÜäÕ碵ò░Þ░âþö¿õ╣âµÿ»µ£ÇÔÇ£þ╗ÅÕà©ÔÇØþÜäµû╣Õ╝ÅÒÇéÕ«×ÚÖàµâàÕåÁµÿ»´╝ÜÕ£¿Õ╝ÇÕÉ»õ║åõ╝ÿÕîûÚÇëÚí╣ÕÉÄ´╝îþ╝ûÞ»æÕÖ¿ÕÅ»Þâ¢õ©ìõ╝Üõ©║õ©Çõ©¬ÕåàÞüöþöÜÞç│ÚØ×ÕåàÞüöþÜäÕ碵ò░þöƒµêɵáêµíåµ×´╝îþ╝ûÞ»æÕÖ¿ÕÅ»Þâ¢õ¢┐þö¿Õ¥êÕñÜõ╝ÿÕîûµèǵ£»µÂêÚÖñÞ┐Öõ©¬µ×äÚÇáÒÇéõ©ìÞ┐çÕ»╣õ║Äõ©Çõ©¬ C/C++ þ¿ïÕ║ÅÕæÿµØÑÞ»┤´╝îÞ¥¥Õê░Þ┐ÖµáÀþÜäþÉåÞºúþ¿ïÕ║ªÚÇÜÕ©©Õ░▒ÞÂ│Õñƒõ║åÒÇé
C++ Õ碵ò░þÜäÞ░âþö¿ÕÆîÞ┐öÕø×ÚªûÕà굥䵩àõ©Çþé╣´╝îÞ┐ÖÚçîÞ»┤þÜä ÔÇ£C++ Õ碵ò░ÔÇصÿ»µîç´╝Ü
- Þ»ÑÕ碵ò░ÕÅ»Þâ¢õ╝Üþø┤µÄѵêûÚù┤µÄÑÕ£░µèøÕç║õ©Çõ©¬Õ╝éÕ©©´╝ÜÕì│Þ»ÑÕ碵ò░þÜäÕ«Üõ╣ëÕ¡ÿµö¥Õ£¿õ©Çõ©¬ C++ þ╝ûÞ»æ´╝êÞÇîõ©ìµÿ»õ╝áþ╗ƒ C´╝ëÕìòÕàâÕåà´╝îÕ╣Âõ©öÞ»ÑÕ碵ò░µ▓íµ£ëõ¢┐þö¿ÔÇ£throw()ÔÇØÕ╝éÕ©©Þ┐çµ╗ñÕÖ¿ÒÇé
- µêûÞÇàÞ»ÑÕ碵ò░þÜäÕ«Üõ╣ëÕåàõ¢┐þö¿ try ÕØùÒÇé
õ╗Ñõ©èõ©ñÞÇàµ╗íÞÂ│ÕàÂõ©ÇÕì│ÕÅ»ÒÇéõ©║õ║åÞâ¢ÕñƒµêÉÕèƒÕ£░µìòÞÄÀÕ╝éÕ©©ÕÆúþí«Õ£░Õ«îµêɵáêÕø×ÚÇÇ´╝êstack unwind´╝ë´╝îþ╝ûÞ»æÕÖ¿Õ┐àÚí╗ÞªüÕ╝òÕàÑõ©Çõ║øÚóØÕñûþÜäµò░µì«þ╗ôµ×äÕÆîþø©Õ║öþÜäÕñäþÉåµ£║ÕêÂÒÇéµêæõ╗¼ÚªûÕàêµØÑþ£ïþ£ïÕ╝òÕàÑõ║åÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂþÜäµáêµíåµ×ÂÕñºµªéµÿ»õ╗Çõ╣êµáÀÕ¡É´╝Ü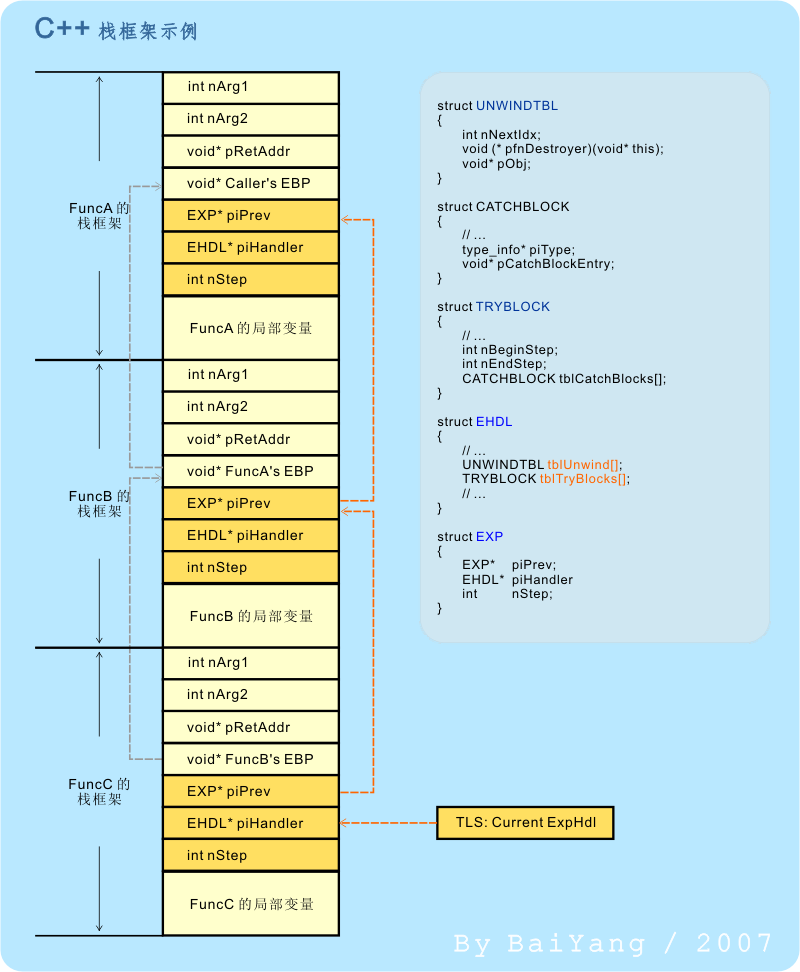
Õø¥2 C++Õ碵ò░Þ░âþö¿µáêµíåµ×Âþñ║õ¥ï
þö▒Õø¥2ÕŻ޺ü´╝îÕ£¿µ»Åõ©¬ C++ Õ碵ò░þÜäµáêµíåµ×Âõ©¡Úâ¢ÕñÜõ║åõ©Çõ║øõ©£ÞÑ┐ÒÇéõ╗öþ╗åÞºéÕ»ƒþÜä޻ش╝îõ¢áõ╝ÜÕÅæþÄ░´╝îÕñÜÕç║µØÑþÜäõ©£ÞÑ┐µ¡úÕÑ¢µÿ»õ©Çõ©¬ EXP þ▒╗Õ×ïþÜäþ╗ôµ×äõ¢ôÒÇéÞ┐øõ©Çµ¡ÑÕêåµ×ÉÕ░▒õ╝ÜÕÅæþÄ░´╝îÞ┐Öµÿ»õ©Çõ©¬Õà©Õ×ïþÜäÕìòÕÉæÚô¥Þí¿Õ╝Åþ╗ôµ×ä´╝Ü
µ£ÇÕÉÄ´╝îÞ»ÀÕåìþ£ïõ©ÇÚüìÕø¥2´╝îÕ╣ÂÞç│Õ░æÕ»╣ÕàÂõ©¡þÜäµò░µì«þ╗ôµ×äþòÖõ©ïõ©Çõ©¬Õñºõ¢ôÕì░Þ▒íÒÇéµêæõ╗¼õ╝ÜÕ£¿ÕÉÄÚØóÕñÜõ©¬Õ░ÅÞèéõ©¡Þ»ªþ╗åÞ«¿Þ«║Õ«âõ╗¼ÒÇé
µ│¿µäÅ´╝Üõ©║õ║åþ«ÇÕîûÞÁÀÞºü´╝îµ£¼µûçõ©¡µÅÅÞ┐░þÜäµò░µì«þ╗ôµ×äÕåà´╝îÕñºÕñÜþ£üþòÑõ║åõ©Çõ║øõ©ÄÞ»ØÚóÿµùáÕà│þÜäµêÉÕæÿÒÇé
ÒÇÇ
µáêÕø×ÚÇÇ´╝êStack Unwind´╝ëµ£║ÕêÂÔÇ£µáêÕø×ÚÇÇÔÇصÿ»õ╝┤ÚÜÅÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂÕ╝òÕàÑ C++ õ©¡þÜäõ©Çõ©¬µû░µªéÕ┐Á´╝îõ©╗Þªüþö¿µØÑþí«õ┐ØÕ£¿Õ╝éÕ©©Þó½µèøÕç║ÒÇüµìòÞÄÀÕ╣ÂÕñäþÉåÕÉÄ´╝îµëǵ£ëþöƒÕ梵£ƒÕÀ▓þ╗ôµØƒþÜäÕ»╣Þ▒íÚâ¢õ╝ÜÞ󽵡úþí«Õ£░µ×ɵ×ä´╝îÕ«âõ╗¼µëÇÕìáþö¿þÜäþ®║Úù┤õ╝ÜÞ󽵡úþí«Õ£░Õø×µöÂÒÇé ÕÅùþøèõ║ĵáêÕø×ÚÇǵ£║ÕêÂþÜäÕ╝òÕàÑ´╝îõ╗ÑÕÅè C++ þ▒╗µëǵö»µîüþÜäÔÇ£ÞÁäµ║Éþö│Þ»ÀÕì│ÕêØÕºïÕîûÔÇØÞ»¡µäÅ´╝îõ¢┐Õ¥ùµêæõ╗¼þ╗êõ║ÄÞâ¢ÕñƒÕ¢╗Õ║òÕæèÕê½µùóõ©ìõ╝ÿÚøàõ╣ƒõ©ìÕ«ëÕà¿þÜä setjmp/longjmp Þ░âþö¿´╝îþ«Çõ¥┐ÕÅêÕ«ëÕà¿Õ£░Õ«×þÄ░Þ┐£þ¿ïÞÀ│Þ¢¼õ║åÒÇéµêæµâ│Þ┐Öõ╣ƒµÿ» C++ Õ╝éÕ©©ÕñäþÉåµ£║ÕêÂÕ£¿ÚöÖÞ»»ÕñäþÉåõ╗ÑÕñûÕö»õ©Çõ©ÇþºìÕÉêþÉåþÜäÕ║öþö¿µû╣Õ╝Åõ║åÒÇé
õ©ïÚØóµêæõ╗¼Õ░▒µØÑÕàÀõ¢ôþ£ïþ£ïþ╝ûÞ»æÕÖ¿µÿ»Õªéõ¢òÕ«×þÄ░µáêÕø×ÚÇǵ£║ÕêÂþÜä´╝Ü
Õø¥3 C++ µáêÕø×ÚÇǵ£║ÕêÂ
Õø¥3õ©¡þÜäÔÇ£FuncUnWindÔÇØÕ碵ò░Õåà´╝îµëǵ£ëþ£ƒÕ«×õ╗úþáüÕØçõ╗ÑÚ╗æÞë▓ÕÆîÞôØÞë▓Õ¡ùõ¢ôµáçþñ║´╝îþ╝ûÞ»æÕÖ¿þöƒµêÉþÜäõ╗úþáüÕêÖþö▒þü░Þë▓ÕÆîµ®ÖÞë▓Õ¡ùõ¢ôµáçµÿÄÒÇ鵡ñµù´╝îÕ£¿Õø¥2Úçîþ╗ÖÕç║þÜä nStep ÕÅÿÚçÅÕÆî tblUnwind µêÉÕæÿõ¢£þö¿Õ░▒ÕìüÕêåµÿĵÿ¥õ║åÒÇé
nStep ÕÅÿÚçÅþö¿õ║ÄÞÀƒÞ©¬Õ碵ò░ÕåàÕ▒ÇÚâ¿Õ»╣Þ▒íþÜäµ×äÚÇáÒÇüµ×ɵ×äÚÿµ«ÁÒÇéÕåìÚàìÕÉêþ╝ûÞ»æÕÖ¿õ©║µ»Åõ©¬Õ碵ò░þöƒµêÉþÜä tblUnwind Þí¿´╝îÕ░▒ÕÅ»õ╗ÑÕ«îµêÉÚÇǵáêµ£║ÕêÂÒÇéÞí¿õ©¡þÜäpfnDestroyerÕ¡ùµ«ÁÞ«░Õ¢òõ║åÕ»╣Õ║öÚÿµ«ÁÕ║öÕ¢ôµëºÞíîþÜäµ×ɵ×äµôìõ¢£´╝êµ×ɵ×äÕ碵ò░µîçÚÆê´╝ë´╝øpObjÕ¡ùµ«ÁÕêÖÞ«░Õ¢òõ║å޻ѵ¡ÑÕ║öÕ¢ôµ×ɵ×äþÜäÕ»╣Þ▒í this µîçÚÆêÕüÅþº╗ÒÇéÕ░å pObj µëǵîçÕ»╣Þ▒íõ╗úÕàÑ pfnDestroyer µëǵîçµ×ɵ×äÕ碵ò░Õì│ÕŻիîµêÉÕ»╣Þ»ÑÕ»╣Þ▒íþÜäµ×ɵ×äÕÀÑõ¢£ÒÇéÞÇînNextIdxÕ¡ùµ«ÁÕêÖµîçÕÉæõ©ïõ©Çõ©¬Ú£ÇÞªüµ×ɵ×äÕ»╣Þ▒íµëÇÕ£¿þÜäÞíî´╝êõ©ïµáç´╝ëÒÇé
Õ£¿ÕÅæþöƒÕ╝éÕ©©µù´╝îÕ╝éÕ©©ÕñäþÉåÕÖ¿ÚªûÕàêµúǵƒÑÕ¢ôÕëìÕ碵ò░µáêµíåµ×ÂÕåàþÜänStepÕÇ╝´╝îÕ╣ÂÚÇÜÞ┐çpiHandlerÕÅûÕ¥ùtblUnwind[]Þí¿ÒÇéþäÂÕÉÄÕ░å nStep õ¢£õ©║õ©ïµáçÕ©ªÕàÑÞí¿õ©¡´╝îµëºÞíîÞ»ÑÞíîÕ«Üõ╣ëþÜäµ×ɵ×äµôìõ¢£´╝îþäÂÕÉÄÞ¢¼ÕÉæþö▒ nNextIdx µîçÕÉæþÜäõ©ïõ©ÇÞíî´╝îþø┤Õê░ nNextIdx õ©║ -1 õ©║µ¡óÒÇéÕ£¿Õ¢ôÕëìÕ碵ò░þÜäµáêÕø×ÚÇÇÕÀÑõ¢£þ╗ôµØƒÕÉÄ´╝îÕ╝éÕ©©ÕñäþÉåÕÖ¿ÕÅ»µ▓┐Õ¢ôÕëìÕ碵ò░µáêµíåµ×ÂÕåàpiPrevþÜäÕÇ╝Õø×µ║»Õê░Õ╝éÕ©©ÕñäþÉåÚô¥õ©¡þÜäõ©èõ©ÇÞèéþé╣ÚçìÕñìõ©èÞ┐░µôìõ¢£´╝îþø┤Õê░µëǵ£ëÕø×ÚÇÇÕÀÑõ¢£Õ«îµêÉõ©║µ¡óÒÇé
ÕÇ╝Õ¥ùõ©ÇµÅÉþÜäµÿ»´╝înStep þÜäÕÇ╝Õ«îÕà¿Õ£¿þ╝ûÞ»æµùÂÕå│Õ«Ü´╝îÞ┐ÉÞíîµùÂõ╗àڣǵëºÞíîÞïÑÕ╣▓µ¼íþ«ÇÕìòþÜäµò┤Õ¢óþ½ïÕì│µò░ÞÁïÕÇ╝ÒÇ鵡ñÕñû´╝îÕ»╣õ║ĵëǵ£ëÕåàÚâ¿þ▒╗Õ×ïõ╗ÑÕÅèõ¢┐þö¿õ║åÚ╗ÿÞ«ñµ×äÚÇáÒÇüµ×ɵ×äµû╣µ│ò´╝êÕ╣Âõ©öÕ«âþÜäµëǵ£ëµêÉÕæÿÕÆîÕƒ║þ▒╗õ╣ƒõ¢┐þö¿õ║åÚ╗ÿÞ«ñµû╣µ│ò´╝ëþÜäþ▒╗Õ×ï´╝îÕàÂÕêøÕ╗║ÕÆîÚöǵ»üÕØçõ©ìÕ¢▒Õôì nStep þÜäÕÇ╝ÒÇé
µ│¿µäÅ´╝Ü Õªéµ×£Õ£¿µáêÕø×ÚÇÇþÜäÞ┐çþ¿ïõ©¡´╝îþö▒õ║ĵ×ɵ×äÕ碵ò░þÜäÞ░âþö¿ÞÇîÕåìµ¼íÕ╝òÕÅæõ║åÕ╝éÕ©©´╝êÕ╝éÕ©©õ©¡þÜäÕ╝éÕ©©´╝ë´╝îÕêÖÞó½Þ«ñõ©║µÿ»õ©Çµ¼íÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂþÜäõ©ÑÚçìÕñ▒Þ┤ÑÒÇ鵡ñµùÂÞ┐øþ¿ïÕ░åÞó½Õ╝║Þíîþªüµ¡óÒÇéõ©║Úÿ▓µ¡óÕç║þÄ░ Þ┐ÖþºìµâàÕåÁ´╝îÕ║öÕ£¿µëǵ£ëÕÅ»Þ⢵èøÕç║Õ╝éÕ©©þÜäµ×ɵ×äÕ碵ò░õ©¡õ¢┐þö¿ÔÇ£std::uncaught_exception()ÔÇصû╣µ│òÕêñµû¡Õ¢ôÕëìµÿ»Õɪµ¡úÕ£¿Þ┐øÞíîµáêÕø×ÚÇÇ´╝êÕì│´╝ÜÕ¡ÿÕ£¿õ©Çõ©¬ µ£¬µìòÞÄÀµêûµ£¬Õ«îÕà¿ÕñäþÉåÕ«îµ»òþÜäÕ╝éÕ©©´╝ëÒÇéÕªéµÿ»´╝îÕêÖÕ║öµèæÕêÂÕ╝éÕ©© þÜäÕåìµ¼íµèøÕç║ÒÇé
ÒÇÇ
Õ╝éÕ©©µìòÞÄÀµ£║ÕêÂõ©Çõ©¬Õ╝éÕ©©Þó½µèøÕç║µù´╝îÕ░▒õ╝Üþ½ïÕì│Õ╝òÕÅæ C++ þÜäÕ╝éÕ©©µìòÞÄÀµ£║Õê´╝Ü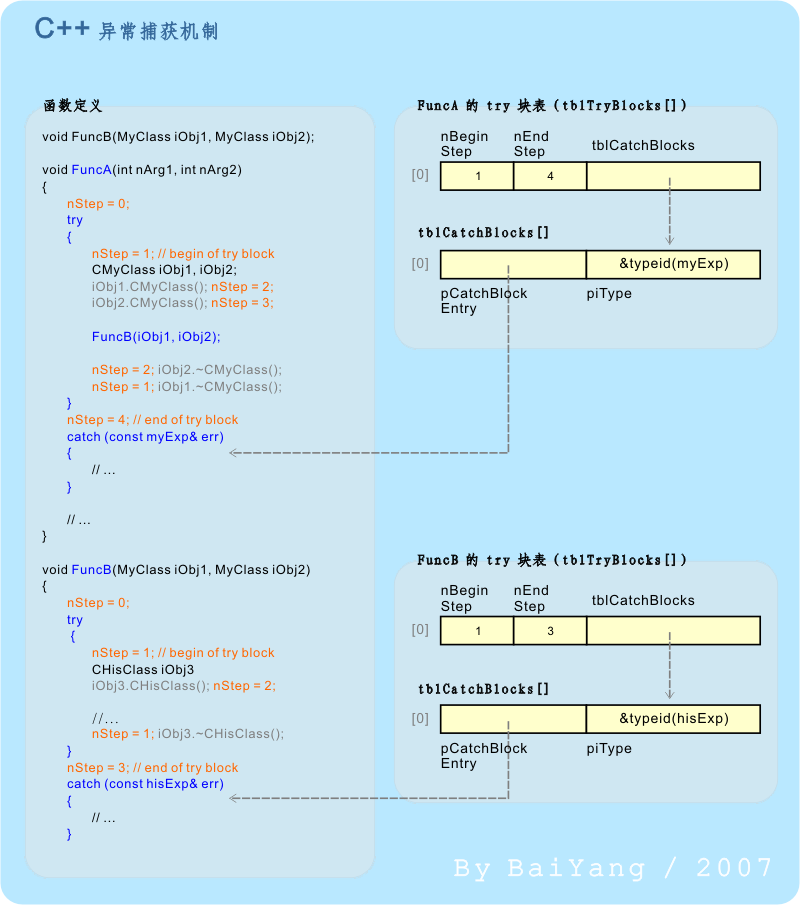
Õø¥4 C++ Õ╝éÕ©©µìòÞÄÀµ£║ÕêÂ
Õ£¿õ©èõ©ÇÕ░ÅÞèéõ©¡´╝îµêæõ╗¼ÕÀ▓þ╗Åþ£ïÕê░õ║ånStepÕÅÿ ÚçÅÕ£¿ÞÀƒÞ©¬Õ»╣Þ▒íµ×äÚÇáÒÇüµ×ɵ×äµû╣ÚØóþÜäõ¢£þö¿ÒÇéÕ«×ÚÖàõ©è nStep ÚÖñõ║åÞâ¢ÕñƒÞÀƒÞ©¬Õ»╣Þ▒íÕêøÕ╗║ÒÇüÚöǵ»üÚÿµ«Áõ╗ÑÕñû´╝îÞ┐ÿÞâ¢ÕñƒµáçÞ»åÕ¢ôÕëìµëºÞíîþé╣µÿ»Õɪգ¿ try ÕØùõ©¡´╝îõ╗ÑÕÅè´╝êÕªéµ×£Õ¢ôÕëìÕ碵ò░µ£ëÕñÜõ©¬ try ÕØùþÜä޻ش╝ëþ®Âþ½ƒÕ£¿Õô¬õ©¬ try ÕØùõ©¡ÒÇéÞ┐Öµÿ»ÚÇÜÞ┐çÕ£¿µ»Åõ©Çõ©¬ try ÕØùþÜäÕàÑÕÅúÕÆîÕç║ÕÅúÕÉäõ©║ nStep ÞÁïõ║êõ©Çõ©¬Õö»õ©Ç ID ÕÇ╝´╝îÕ╣Âþí«õ┐Ø nStep Õ£¿Õ»╣Õ║ö try ÕØùÕåàþÜäÕÅÿÕîûµü░Õ£¿µ¡ñÞîâÕø┤õ╣ïÕåàµØÑÕ«×þÄ░þÜäÒÇé
Õ£¿ÕàÀõ¢ôÕ«×þÄ░Õ╝éÕ©©µìòÞÄÀµù´╝îÚªûÕàê´╝îC++ Õ╝éÕ©©ÕñäþÉåÕÖ¿µúǵƒÑÕÅæþöƒÕ╝éÕ©©þÜäõ¢ìþ¢«µÿ»Õɪգ¿Õ¢ôÕëìÕ碵ò░þÜ䵃Éõ©¬ try ÕØùõ╣ïÕåàÒÇéÞ┐ÖÚí╣ÕÀÑõ¢£ÕÅ»õ╗ÑÚÇÜÞ┐çÕ░åÕ¢ôÕëìÕ碵ò░þÜä nStep ÕÇ╝õ¥Øµ¼íÕ£¿piHandlerµîçÕÉætblTryBlocks[]Þí¿þÜäµØíþø«õ©¡Þ┐øÞíîÞîâÕø┤õ©║ [nBeginStep, nEndStep) þÜäµ»öÕ»╣µØÑÕ«îµêÉÒÇé
õ¥ïÕªé´╝ÜÞïÑÕø¥4 õ©¡þÜä FuncB Õ£¿ nStep == 2 µùÂÕÅæþöƒõ║åÕ╝éÕ©©´╝îÕêÖÚÇÜÞ┐çµ»öÕ»╣ FuncB þÜä tblTryBlocks[] Þí¿ÕÅæþÄ░ 2Ôêê[1, 3)´╝îµòàÞ»ÑÕ╝éÕ©©ÕÅæþöƒÕ£¿ FuncB ÕåàþÜäþ¼¼õ©Çõ©¬ try ÕØùõ©¡ÒÇé
Õർí´╝îÕªéµ×£Õ╝éÕ©©ÕÅæþöƒþÜäõ¢ìþ¢«Õ£¿Õ¢ôÕëìÕ碵ò░õ©¡þÜ䵃Éõ©¬ try ÕØùÕåà´╝îÕêÖÕ░ØÞ»òÕî╣ÚàìÞ»ÑtblTryBlocks[]þø©Õ║öµØíþø«õ©¡þÜätblCatchBlocks[]Þí¿ÒÇétblCatchBlocks[]Þí¿õ©¡Þ«░Õ¢òõ║åõ©ÄµîçÕ«Ü try ÕØùÚàìÕÑùÕç║þÄ░þÜäµëǵ£ë catch ÕØùþø©Õà│õ┐íµü»´╝îÕîàµï¼Þ┐Öõ©¬ catch ÕØùµëÇÞ⢵ìòÞÄÀþÜäÕ╝éÕ©©þ▒╗Õ×ïÕÅèÕàÂÞÁÀÕºïÕ£░ÕØÇþ¡ëõ┐íµü»ÒÇé
Þïѵë¥Õê░õ║åõ©Çõ©¬Õî╣ÚàìþÜä catch ÕØù´╝îÕêÖÕñìÕêÂÕ¢ôÕëìÕ╝éÕ©©Õ»╣Þ▒íÕê░µ¡ñ catch ÕØù´╝îþäÂÕÉÄÞÀ│Þ¢¼Õê░ÕàÂÕàÑÕÅúÕ£░ÕØǵëºÞíîÕØùÕåàõ╗úþáüÒÇé
ÕɪÕêÖ´╝îÕêÖÞ»┤µÿÄÕ╝éÕ©©ÕÅæþöƒõ¢ìþ¢«õ©ìÕ£¿Õ¢ôÕëìÕ碵ò░þÜä try ÕØùÕåà´╝îµêûÞÇàÞ┐Öõ©¬ try ÕØùõ©¡µ▓íµ£ëõ©ÄÕ¢ôÕëìÕ╝éÕ©©þø©Õî╣ÚàìþÜä catch ÕØù´╝ñµùÂÕêÖµ▓┐þØÇÕ碵ò░µáêµíåµ×Âõ©¡piPrevµëǵîçÕ£░ÕØÇ´╝êÕì│´╝ÜÕ╝éÕ©©ÕñäþÉåÚô¥õ©¡þÜäõ©èõ©Çõ©¬Þèéþé╣´╝ëÚÇÉþ║ºÚçìÕñìõ╗Ñõ©èÞ┐çþ¿ï´╝îþø┤Þç│µë¥Õê░õ©Çõ©¬Õî╣ÚàìþÜä catch ÕØùµêûÕê░Þ¥¥Õ╝éÕ©©ÕñäþÉåÚô¥þÜäÚªûÞèéþé╣ÒÇéÕ»╣õ║ÄÕÉÄÞÇà´╝îµêæõ╗¼þº░õ©║ÕÅæþöƒõ║åµ£¬µìòÞÄÀþÜäÕ╝éÕ©©´╝îÕ»╣õ║Ä C++ Õ╝éÕ©©ÕñäþÉåÕÖ¿ÞÇîÞ¿Ç´╝îµ£¬µìòÞÄÀþÜäÕ╝éÕ©©µÿ»õ©Çõ©¬õ©ÑÚçìÚöÖÞ»»´╝îÕ░åÕ»╝Þç┤µØƒÕ¢ôÕëìÞ┐øþ¿ïÞó½Õ╝║ÕêÂþ╗ôµØƒÒÇé
µ│¿µäÅ´╝Ü ÞÖ¢þäÂÕ£¿Õø¥4þñ║õ¥ïõ©¡þÜä tblTryBlocks[] ÕŬµ£ëõ©Çõ©¬µØíþø«´╝îÞ┐Öõ©¬µØíþø«õ©¡þÜä tblCatchBlocks[] õ╣ƒÕŬµ£ëõ©ÇÞíîÒÇéõ¢åµÿ»Õ£¿Õ«×ÚÖàµâàÕåÁõ©¡´╝îÞ┐Öõ©ñõ©¬Þí¿õ©¡Úâ¢ÕàüÞ«©þö¿ÕñܵØíÞ«░Õ¢òÒÇéµäÅÕì│´╝Üõ©Çõ©¬Õ碵ò░õ©¡ÕÅ»õ╗ѵ£ëÕñÜõ©¬ try ÕØù´╝îµ»Åõ©¬ try ÕØùÕÉÄÕØçÕÅ»ÞÀƒÚÜÅÕñÜõ©¬õ©Äõ╣ïÚàìÕÑùþÜä catch ÕØùÒÇé
µ│¿µäÅ´╝ܵîëþີáçÕçåµäÅõ╣ëõ©èþÜäþÉåÞºú´╝îÕ╝éÕ©©µùÂþÜäµáêÕø×ÚÇǵÿ»õ╝┤ÚÜÅþØÇÕ╝éÕ©©µìòÞÄÀÞ┐çþ¿ïµ▓┐þØÇÕ╝éÕ©©ÕñäþÉå Úô¥ÚÇÉÕ▒éÕÉæõ©èÞ┐øÞíîþÜäÒÇéõ¢åµÿ»µ£ëõ║øþ╝ûÞ»æÕÖ¿µÿ»Õ£¿ÕàêÕ«îµêÉÕ╝éÕ©©µìòÞÄÀÕÉÄÕåìõ©Çµ¼íµÇºÞ┐øÞíîµáêÕø×ÚÇÇþÜäÒÇéµùáÞ«║ÕàÀõ¢ôÕ«×þÄ░õ¢┐þö¿õ║åÕô¬þºìµû╣Õ╝Å´╝îÚÖñÚØ×µ¡úÕ£¿Õ╝ÇÕÅæõ©Çõ©¬ÕåàÕ¡ÿõ©Ñµá╝ÕÅùÚÖÉþÜäÕÁîÕàÑÕ╝ÅÕ║öþö¿´╝î ÚÇÜÕ©©µêæõ╗¼µîëþີáçÕçåÞ»¡µäŵØÑþÉåÞºúÚâ¢õ©ìõ╝Üõ║ºþöƒõ╗Çõ╣êÚù«ÚóÿÒÇé
Õñçµ│¿´╝ÜÕ«×ÚÖàõ©è tblCatchBlocks õ©¡Þ┐ÿµ£ëõ©Çõ║øÞ¥âõ©║Õà│Úö«õ¢åÞó½µòàµäÅþ£üþòÑþÜäÕ¡ùµ«ÁÒÇéµ»öÕªéµîçµÿÄÞ»Ñ catch ÕØùÕ╝éÕ©©Õ»╣Þ▒íÕñìÕêµû╣Õ╝Å´╝êõ╝áÕÇ╝´╝êµïÀÞ┤ص×äÚÇá´╝ëµêûõ╝áÕØÇ´╝êÕ╝òþö¿µêûµîçÚÆê´╝ë´╝ëþÜäÕ¡ùµ«Á´╝îõ╗ÑÕÅèÕ£¿õ¢òÕñäÕ¡ÿµö¥Þó½ÕñìÕêÂþÜäÕ╝éÕ©©Õ»╣Þ▒í´╝êþø©Õ»╣õ║ÄÕàÑÕÅúÕ£░ÕØÇþÜäÕüÅþº╗õ¢ìþ¢«´╝ëþ¡ëõ┐íµü»ÒÇé
Õ╝éÕ©©þÜäµèøÕç║µÄÑõ©ïµØÑÞ«¿Þ«║µò┤õ©¬ C++ Õ╝éÕ©©ÕñäþÉåµ£║ÕêÂõ©¡þÜäµ£ÇÕÉÄõ©Çõ©¬þÄ»Þèé´╝îÕ╝éÕ©©þÜäµèøÕç║´╝Ü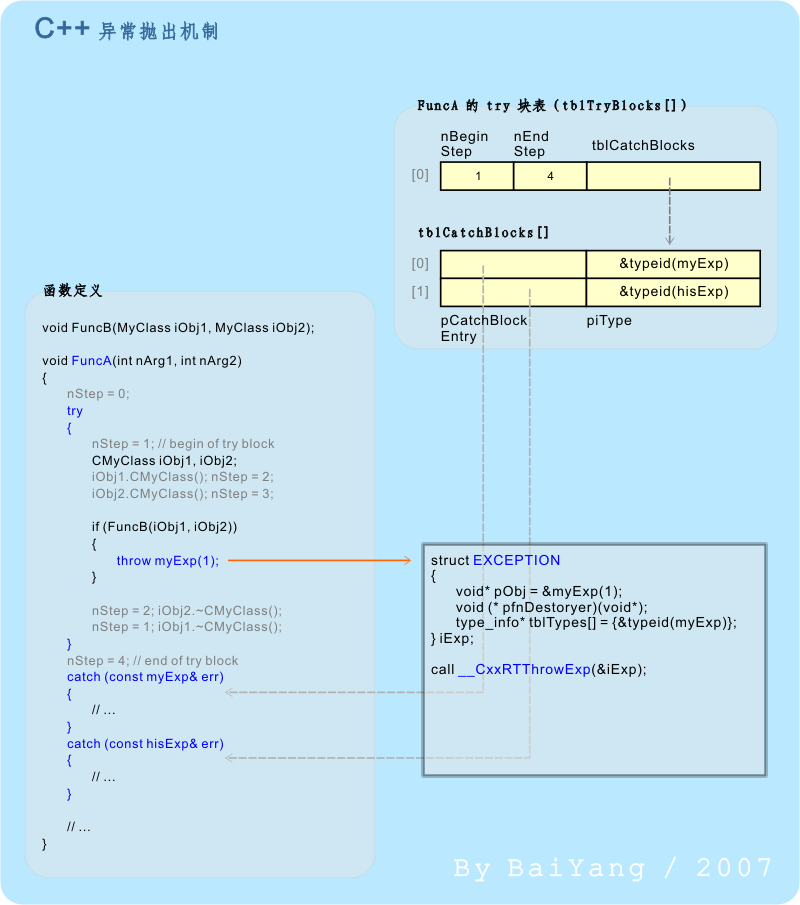
Õø¥5 C++ Õ╝éÕ©©µèøÕç║
Õ£¿þ╝ûÞ»æõ©Çµ«Á C++ õ╗úþáüµù´╝îþ╝ûÞ»æÕÖ¿õ╝ÜÕ░åµëǵ£ë throw Þ»¡ÕÅѵø┐µìóõ©║Õà C++ Þ┐ÉÞíîµùÂÕ║ôõ©¡þÜ䵃Éõ©ÇµîçÕ«ÜÕ碵ò░´╝îÞ┐ÖÚçîµêæõ╗¼ÕŽիâ__CxxRTThrowExp´╝êõ©Äµ£¼µûçµÅÉÕê░þÜäµëǵ£ëÕàÂÕ«âµò░µì«þ╗ôµ×äÕÆîÕ▒׵ǺÕÉìõ©ÇµáÀ´╝îÕ£¿Õ«×ÚÖàÕ║öþö¿õ©¡Õ«âÕÅ»õ╗ѵÿ»õ╗╗µäÅÕÉìþº░´╝ëÒÇéÞ»ÑÕ碵ò░µÄѵöÂõ©Çõ©¬þ╝ûÞ»æÕÖ¿Þ«ñÕÅ»þÜäÕåàÚâ¿þ╗ôµ×ä´╝êµêæõ╗¼ÕŽիâEXCEPTIONþ╗ô µ×ä´╝ëÒÇéÞ┐Öõ©¬þ╗ôµ×äõ©¡ÕîàÕɽõ║åÕ¥àµèøÕç║Õ╝éÕ©©Õ»╣Þ▒íþÜäÞÁÀÕºïÕ£░ÕØÇÒÇüþö¿õ║ÄÚöǵ»üÕ«âþÜäµ×ɵ×äÕ碵ò░´╝îõ╗ÑÕÅèÕ«âþÜä type_info õ┐íµü»ÒÇéÕ»╣õ║ĵ▓íµ£ëÕÉ»þö¿ RTTI µ£║Õê´╝êþ╝ûÞ»æÕÖ¿þªüþö¿õ║å RTTI µ£║Õêµêûµ▓íµ£ëÕ£¿þ▒╗Õ▒éµ¼íþ╗ôµ×äõ©¡õ¢┐þö¿ÞÖÜÞí¿´╝ëþÜäÕ╝éÕ©©þ▒╗Õ▒éµ¼íþ╗ôµ×ä´╝îÕÅ»Þâ¢Þ┐ÿÞªüÕîàÕɽÕàµëǵ£ëÕƒ║þ▒╗þÜä type_info õ┐íµü»´╝îõ╗Ñõ¥┐õ©Äþø©Õ║öþÜä catch ÕØùÞ┐øÞíîÕî╣ÚàìÒÇé
Õ£¿Õø¥5õ©¡þÜäµÀ▒þü░Þë▓µíåÕø¥Õåà´╝îµêæõ╗¼õ¢┐þö¿ C++ õ╝¬õ╗úþáüÕ▒òþñ║õ║åÕ碵ò░ FuncA õ©¡þÜä ÔÇ£throw myExp(1);ÔÇØ Þ»¡ÕÅÑÕ░åÞó½þ╝ûÞ»æÕÖ¿µ£Çþ╗êþ┐╗Þ»æµêÉþÜäµáÀÕ¡ÉÒÇéÕ«×ÚÖàõ©èÕ£¿Õñܵò░µâàÕåÁõ©ï´╝î__CxxRTThrowExpÕ碵ò░Õì│µêæõ╗¼ÕëìÚØóµø¥Õñܵ¼íµÅÉÕê░þÜäÔÇ£Õ╝éÕ©©ÕñäþÉåÕÖ¿ÔÇØ´╝îÕ╝éÕ©©µìòÞÄÀÕÆîµáêÕø×ÚÇÇþ¡ëÕÉäÚí╣ÚçìÞªüÕÀÑõ¢£Úâ¢þö▒Õ«âµØÑÕ«îµêÉÒÇé
__CxxRTThrowExpÚªûÕàêµÄѵö´╝êÕ╣Âõ┐ØÕ¡ÿ´╝ëEXCEPTIONÕ»╣Þ▒í´╝øþäÂÕÉÄõ╗ÄTLS´╝ÜCurrent ExpHdlÕñäµë¥Õê░õ©ÄÕ¢ôÕëìÕ碵ò░Õ»╣Õ║öþÜä piHandlerÒÇünStep þ¡ëÕ╝éÕ©©ÕñäþÉåþø©Õà│µò░µì«´╝øÕ╣µîëþàºÕëìµûçµëÇÞ┐░þÜäµ£║ÕêÂÕ«îµêÉÕ╝éÕ©©µìòÞÄÀÕÆîµáêÕø×ÚÇÇÒÇéþö▒µ¡ñÕ«îµêÉõ║åÕîàµï¼ÔÇ£µèøÕç║ÔÇØ->ÔÇ£µìòÞÄÀÔÇØ->ÔÇ£Õø×ÚÇÇÔÇØþ¡ëµ¡ÑÚ¬ñþÜäµò┤ÕÑùÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂÒÇé
ÒÇÇ
Windowsõ©¡þÜäþ╗ôµ×äÕîûÕ╝éÕ©©ÕñäþÉåMicrosoft Windows Õ©ªµ£ëõ©ÇþºìÕÉìõ©║ÔÇ£þ╗ôµ×äÕîûÕ╝éÕ©©ÕñäþÉåÔÇØþÜäµ£║Õê´╝îÚØ×Õ©©ÞæùÕÉìþÜäÔÇ£ÕåàÕ¡ÿÞ«┐Úù«Þ┐Øõ¥ïÔÇØÕç║ÚöÖÕ»╣޻صíåÕ░▒µÿ»Þ»Ñµ£║ÕêÂþÜäõ©Çþºìõ¢ôþÄ░ÒÇéWindows þ╗ôµ×äÕîûÕ╝éÕ©©ÕñäþÉåõ©ÄÕëìµûçÞ«¿Þ«║þÜä C++ Õ╝éÕ©©ÕñäþÉåµ£║Õêµ£ëµâèõ║║þÜäþø©õ╝╝õ╣ïÕñä´╝îÕÉîµáÀõ¢┐þö¿þ▒╗õ╝╝þÜäÚô¥Õ╝Åþ╗ôµ×äÕ«×þÄ░ÒÇéÕ»╣õ║Ä Windows õ©ïþÜäÕ║öþö¿þ¿ïÕ║Å´╝îÕŬڣÇõ¢┐þö¿ SetUnhandledExceptionFilter API µ│¿ÕåîÕ╝éÕ©©ÕñäþÉåÕÖ¿´╝øþö¿ FS:[0] µø┐õ╗úÕëìµûçµëÇÞ┐░þÜä TLS: Current ExpHdl þ¡ëÕ¥êÕ░æþÜäµö╣Õè¿´╝îÕì│ÕÅ»Õ░嵡ñõ©ñþºìÚöÖÞ»»ÕñäþÉåµ£║ÕêÂÕÉêÞÇîõ©║õ©ÇÒÇéÞ┐ÖµáÀÕüÜþÜäõ╝ÿÕè┐ÕìüÕêåµÿĵÿ¥´╝Ü
Õ╝éÕ©©ÕñäþÉåµ£║ÕêÂþÜäÕ╝ÇÚöÇÕêåµ×ÉÞç│µ¡ñ´╝îµêæõ╗¼ÕÀ▓Õ«îµò┤Õ£░ÚÿÉÞ┐░õ║åµò┤ÕÑù C++ Õ╝éÕ©©ÕñäþÉåµ£║ÕêÂþÜäÕ«×þÄ░ÕăþÉåÒÇéµêæÕ£¿µ£¼µûçþÜäÕ╝ÇÕñ┤µø¥µÅÉÕê░´╝îõ¢£õ©║õ©ÇÕÉì C++ þ¿ïÕ║ÅÕæÿ´╝îõ║åÞºúÕൃÉõ©Çþë╣µÇºþÜäÕ«×þÄ░ÕăþÉåõ©╗Þªüµÿ»õ©║õ║åÚü┐ÕàìÚöÖÞ»»Õ£░õ¢┐þö¿Þ»Ñþë╣µÇºÒÇéÞªüÞ¥¥Õê░Þ┐Öõ©¬þø«þÜä´╝îÞ┐ÿÞªüÕ£¿õ║åÞºúÕ«×þÄ░ÕăþÉåþÜäÕƒ║þíÇõ©èÞ┐øÞíîõ©Çõ║øÚóØÕñûþÜäÕ╝ÇÚöÇÕêåµ×ÉÕÀÑõ¢£´╝Üþë╣µÇºµùÂÚù┤Õ╝ÇÚöÇþ®║Úù┤Õ╝ÇÚöÇEHDLµùáÞ┐ÉÞíîµùÂÕ╝ÇÚöǵ»ÅÔÇ£C++Õ碵ò░ÔÇØõ©Çõ©¬ EHDL Õ»╣Þ▒í´╝îÕàÂõ©¡þÜä tblTryBlocks[] µêÉÕæÿõ╗àÕ£¿Õ碵ò░õ©¡ÕîàÕɽÞç│Õ░æõ©Çõ©¬ try ÕØùµùÂõ¢┐þö¿ÒÇéÕà©Õ×ïµâàÕåÁõ©ïÕ░Åõ║Ä 64 Õ¡ùÞèéÒÇé ÒÇÇ
C++µáêµíåµ×µ×üÚ½ÿþÜä O(1) µòêþÄç´╝ŵ¼íÞ░âþö¿µùÂÞ┐øÞíî3µ¼íÚóØÕñûþÜäµò┤Õ¢óÞÁïÕÇ╝ÕÆîõ©Çµ¼í TLS Þ«┐Úù«ÒÇ鵻ŠÞ░âþö¿õ©ñõ©¬µîçÚÆêÕÆîõ©Çõ©¬µò┤Õ¢óÕ╝ÇÚöÇÒÇéÕà©Õ×ïµâàÕåÁõ©ïÕ░Åõ║Ä 16 Õ¡ùÞèéÒÇé ÒÇÇ
step ÞÀƒÞ©¬µ×üÚ½ÿþÜä O(1) µòêþÄ絻ŵ¼íÞ┐øÕç║ try ÕØùµêûÕ»╣Þ▒íµ×äÚÇá/µ×ɵ×äõ©Çµ¼íµò┤Õ¢óþ½ïÕì│µò░ÞÁïÕÇ╝ÒÇéµùá´╝êÕÀ▓Þ«░ÕàÑ C++ µáêµíåµ×Âõ©¡þÜäþø©Õ║öÚí╣þø«´╝ëÒÇé ÒÇÇ
Õ╝éÕ©©þÜäµèøÕç║ÒÇüµìòÞÄÀÕÆîµáêÕø×ÚÇÇÕ╝éÕ©©þÜäµèøÕç║µÿ»õ©Çµ¼í O(1) þ║ºµôìõ¢£ÒÇéÕ£¿Õìòõ©¬Õ碵ò░õ©¡Þ┐øÞíîµìòÞÄÀÕÆîµáêÕø×ÚÇÇõ╣ƒÕØçõ©║ O(1) µôìõ¢£ÒÇé õ¢åÕ╝éÕ©©µìòÞÄÀþÜäµÇ╗õ¢ôµêɵ£¼õ©║ O(m)´╝îÕàÂõ©¡ m þ¡ëõ║ÄÕ¢ôÕëìÕ碵ò░Þ░âþö¿µáêõ©¡´╝îõ╗ĵèøÕç║Õ╝éÕ©©þÜäõ¢ìþ¢«Õê░Þ¥¥Õî╣Úàì catch ÕØùõ╣ïÚù┤µëÇþ╗ÅÞ┐çþÜäÕ碵ò░Þ░âþö¿õ©¡´╝îÕîàÕɽ try ÕØù´╝êÕì│´╝ÜÕ«Üõ╣ëõ║åµ£ëµòê tblTryBlocks[]´╝ëþÜäÕ碵ò░õ©¬µò░ÒÇé
µáêÕø×ÚÇÇþÜäµÇ╗µêɵ£¼õ©║ O(n)´╝îÕàÂõ©¡ n þ¡ëõ║ÄÕ¢ôÕëìÕ碵ò░Þ░âþö¿µáêõ©¡´╝îõ╗ĵèøÕç║Õ╝éÕ©©þÜäõ¢ìþ¢«Õê░Þ¥¥Õî╣Úàì catch ÕØùõ╣ïÚù┤µëÇþ╗ÅÞ┐çþÜäÕ碵ò░Þ░âþö¿µò░ÒÇé
Õ£¿Õ╝éÕ©©ÕñäþÉåþ╗ôµØƒÕëì´╝îÚ£Çõ┐ØÕ¡ÿÕ╝éÕ©©Õ»╣Þ▒íÕÅèÕàµ×ɵ×äÕ碵ò░µîçÚÆêÕÆîþø©Õ║öþÜä type_info µÂêµü»ÒÇé ÕàÀõ¢ôµá╣µì«Õ»╣Þ▒íÕ░║Õ»©ÒÇüþ╝ûÞ»æÕÖ¿ÚÇëÚí╣´╝êµÿ»ÕɪÕ╝ÇÕÉ» RTTI´╝ëÕÅèÕ╝éÕ©©µìòÞÄÀÕÖ¿þÜäÕÅéµò░õ╝áÚÇƵû╣Õ╝Å´╝êõ╝áÕÇ╝µêûõ╝áÕØÇ´╝ëþ¡ëÕøáþ┤áµ£ëÞ¥âÕñºÕÅÿÕîûÒÇéÕà©Õ×ïµâàÕåÁõ©ïÕ░Åõ║Ä 256 Õ¡ùÞèéÒÇé
ÒÇÇ
ÕÅ» õ╗Ñþ£ïÕç║´╝îÕ£¿µ▓íµ£ëµèøÕç║Õ╝éÕ©©µù´╝îC++ þÜäÕ╝éÕ©©ÕñäþÉåµ£║Õêµÿ»ÕìüÕêåµ£ëµòêþÜäÒÇéÕ£¿µ£ëÕ╝éÕ©©Þó½µèøÕç║ÕÉÄ´╝îÕÅ»Þâ¢õ╝Üõ¥ØÕ¢ôÕëìÕ碵ò░Þ░âþö¿µáêþÜäµâàÕ¢óÞ┐øÞíîÞïÑÕ╣▓µ¼íµò┤Õ¢óµ»öÞ¥â´╝êtryÕØùÞí¿Õî╣Úàì´╝ëµôìõ¢£´╝îõ¢åÞ┐ÖÚÇÜÕ©©õ©ìõ╝ÜÞÂàÞ┐çÕçáÕìüµ¼íÒÇéÕ»╣õ║Ä ÕñºÕñܵò░ 10 Õ╣┤ÕëìþÜä CPU µØÑÞ»┤´╝îµò┤Õ¢óµ»öÞ¥âõ╣ƒÕÅ¬Ú£Ç 1 µùÂÚƃÕ濵£ƒ´╝îµëÇõ╗ÑÕ╝éÕ©©µìòÞÄÀþÜäµòêþÄçÞ┐ÿµÿ»Õ¥êÚ½ÿþÜäÒÇéµáêÕø×ÚÇÇþÜäµòêþÄçÕêÖõ©Ä return Þ»¡ÕÅÑÕƒ║µ£¼þø©Õ¢ôÒÇé
ÞÇâÞÖæÕê░Õì│õ¢┐µÿ»õ╝áþ╗ƒþÜäÕ碵ò░Þ░âþö¿ÒÇüÚöÖÞ»»ÕñäþÉåÕÆîÚÇÉþ║ºÞ┐öÕø×µ£║ÕêÂõ╣ƒõ©ìµÿ»µ▓íµ£ëõ╗úõ╗ÀþÜäÒÇéÞ┐Öõ║øÕ╝ÇÚöÇÕ£¿þ╗ØÕñºÕñܵò░µâàÕ¢óõ©ïõ╗ìÕÅ»õ╗ѵÄÑÕÅùÒÇéþ®║Úù┤Õ╝ÇÚöǵû╣ÚØó´╝îµ»ÅÔÇ£C++ Õ碵ò░ÔÇØõ©Çõ©¬ EHDL þ╗ôµ×äõ¢ôþÜäÕ╝òÕàÑÕ£¿µƒÉõ║øµ×üþ½»µâàÕ¢óõ©ïõ╝ܵÿĵÿ¥Õó×Õèáþø«µáçµûçõ╗ÂÕ░║Õ»©ÕÆîÕåàÕ¡ÿÕ╝ÇÚöÇÒÇéõ¢åµÿ»Õà©Õ×ïµâàÕåÁõ©ï´╝îÕ«âõ╗¼þÜäÕ¢▒ÕôìÕ╣Âõ©ìÕñº´╝îõ¢åõ╣ƒµ▓íµ£ëÕ░ÅÕê░ÕÅ»õ╗ÑÕ«îÕà¿Õ┐¢þòÑþÜäþ¿ïÕ║ªÒÇéÕªéµ×£ µ¡úÕ£¿õ©║õ©Çõ©¬ÞÁäµ║Éõ©Ñµá╝ÕÅùÚÖÉþÜäþÄ»ÕóâÕ╝ÇÕÅæÕ║öþö¿þ¿ïÕ║Å´╝îõ¢áÕÅ»Þâ¢Ú£ÇÞªüÞÇâÞÖæÕà│Úù¡Õ╝éÕ©©ÕñäþÉåÕÆî RTTI µ£║ÕêÂõ╗ÑÞèéþ║ªÕ¡ÿÕé¿þ®║Úù┤ÒÇé
õ╗Ñõ©èÞ«¿Þ«║þÜäµÿ»õ©ÇþºìÕà©Õ×ïþÜäÕ╝éÕ©©µ£║ÕêÂþÜäÕ«×þÄ░µû╣Õ╝Å´╝îÕÉäÕàÀõ¢ôþ╝ûÞ»æÕÖ¿ÕÄéÕòåÕÅ»Þ⢵£ëÞç¬ÕÀ▒þÜäõ╝ÿÕîûÕÆîµö╣Þ┐øµû╣µíê´╝îõ¢åµÇ╗õ¢ôþÜäÕç║ÕàÑõ©ìõ╝ÜÕ¥êÕñºÒÇé
Õ░ÅÞèéÕ╝é Õ©©ÕñäþÉåµÿ» C++ õ©¡ÕìüÕêåµ£ëþö¿þÜäÕ┤¡µû░þë╣µÇºõ╣ïõ©ÇÒÇéÕ£¿þ╗ØÕñºÕñܵò░µâàÕåÁõ©ï´╝îÕ«âõ╗¼Ú⢵£ëþØÇõ╝ÿÕ╝éþÜäÞí¿þÄ░ÕÆîõ╗ñõ║║µ╗íµäÅþÜäµùÂþ®║µòêþÄçÒÇéÕ╝éÕ©©ÕñäþÉåµ£¼Þ┤¿õ©èµÿ»ÕŪõ©ÇþºìÞ┐öÕø×µ£║ÕêÂÒÇéõ¢åµùáÞ«║õ╗ÄÞ¢»õ╗ÂÕÀÑþ¿ïÒÇüµ¿íÕØùÞ«¥ Þ«íÒÇüþ╝ûþáüõ╣áµâ»Þ┐ÿµÿ»µùÂþ®║µòêþÄçþ¡ëÞºÆÕ║ª µØÑÞ»┤´╝îÚÖñõ║åÕ£¿µ£ëÕààÕêåµûçµíúÞ»┤µÿÄþÜäÕëìµÅÉõ©ï´╝îÕüÂÕ░öÕÅ»þö¿µØѵø┐õ╗úµø┐õ╗úõ╝áþ╗ƒþÜä setjmp/longjmp ÕèƒÞâ¢Õñû´╝îÕ║öõ┐ØÞ»üÕŬÕ░åÕàÂþö¿õ║Äþ¿ïÕ║ÅþÜäÚöÖÞ»»ÕñäþÉåµ£║ÕêÂõ©¡ÒÇé µ¡ñÕñû´╝îþö▒õ║ÄÚò┐ÞÀ│Þ¢¼þÜäõ¢┐þö¿µùóµÿôõ║ÄÕç║ÚöÖ´╝îÕÅêÚÜ¥õ║ÄþÉåÞºúÕÆîþ╗┤µèñÒÇéÕ£¿þ╝ûþáüÞ┐çþ¿ïõ©¡õ╣ƒÕ║öÕ¢ôÕ░¢ÚçÅÚü┐Õàìõ¢┐þö¿ÒÇéÕà│õ║ÄÕ╝éÕ©©þÜäõ©ÇÞ꼵Ǻõ¢┐þö¿Þ»┤µÿÄ´╝îÞ»ÀÕÅéÞÇâ´╝Üõ╗úþáüÚúĵá╝õ©ÄþëêÕ╝Å´╝ÜÕ╝éÕ©©


- 2009-12-07 15:37
- µÁÅÞºê 1737
- Þ»äÞ«║(0)
- µƒÑþ£ïµø┤ÕñÜ
ÕÅæÞí¿Þ»äÞ«║

-
mainõ©¡Þ░âþö¿dllõ©¡þÜäÕ碵ò░´╝îF10Õìòµ¡ÑÕê░mainþÜäÕÅ│ÕñºÕÅúÕÅÀµùÂÕç║þÄ░user breakpoint called...
2010-03-09 18:42 1836Õ£¿dllõ©¡Þ¥ôÕç║õ║åõ©Çõ©¬ÕîàÕɽstringþ▒╗Õ¡ÉÕ»╣Þ▒íþÜäþ▒╗´╝îÕ£¿DEBUG ... -
VCõ©¡Úô¥µÄÑÕ迵ÇüÚô¥µÄÑÕ║ôþÜäµû╣µ│ò
2010-03-06 17:17 1389µû╣µ│òõ©Ç´╝ÜwindowsµÅÉõ¥øõ║åõ©ÇÕÑùÕ碵ò░´╝îþö¿õ║ÄÕèáÞ¢¢Õ迵ÇüÚô¥µÄÑÕ║ôõ©¡þÜäþ¼ª ... -
50õ©¬C/C++µ║Éõ╗úþáüþ¢æþ½Ö
2010-01-30 13:01 3046C/C++µÿ»µ£Çõ©╗ÞªüþÜäþ╝ûþ¿ïÞ»¡Þ¿ÇÒÇéÞ┐ÖÚçîÕêùÕç║õ║å50ÕÉìõ╝ÿþºÇþ¢æþ½ÖÕÆîþ¢æÚíÁµ©à ... -
ÒÇèEffective C++ÒÇïµØíµ¼¥34: Õ░åµûçõ╗ÂÚù┤þÜäþ╝ûÞ»æõ¥ØÞÁûµÇºÚÖìÞç│µ£Çõ¢Ä
2010-01-29 21:04 2186ÕüçÞ«¥µƒÉõ©ÇÕñ®õ¢áµëôÕ╝ÇÞç¬ÕÀ▒þÜäC++þ¿ïÕ║Åõ╗úþáü´╝îþäÂÕÉÄÕ»╣µƒÉõ©¬þ▒╗þÜäÕ«×þÄ░ÕüÜõ║åÕ░Å ... -
QHttp
2010-01-26 17:06 7065QHttpµÿ»QtµëǵÅÉõ¥øµ£ëÕà│þ¢æþ╗£þÜäÚ½ÿÚÿÂAPI´╝îÕÅ»õ╗ÑÕìÅÕ讵êæõ╗¼Þ┐øÞíîH ... -
VCÕ▒ÅÞö¢EnterÕÆîESCÚÇÇÕç║þ¿ïÕ║Å
2010-01-15 21:51 2463ÚçìÞ¢¢PreTranslateMessageÕ碵ò░Õ▒ÅÞö¢Õø×Þ¢ªÕÆîESC ... -
ÒÇèEffective C++ÒÇïµØíµ¼¥22´╝ÜÕ░¢ÚçÅþö¿"õ╝áÕ╝òþö¿"õ╗úµø┐"õ╝áÕÇ╝"
2010-01-13 11:15 2926cÞ»¡Þ¿Çõ©¡´╝îõ╗Çõ╣êÚ⢵ÿ»ÚÇÜÞ┐çõ╝áÕÇ╝µØÑÕ«×þÄ░þÜä´╝îc++þ╗ºµë┐õ║åÞ┐Öõ©Çõ╝áþ╗ƒÕ╣ÂÕ░åÕ«â ... -
ÒÇèÚ½ÿÞ┤¿ÚçÅC++/C þ╝ûþ¿ïµîçÕìùÒÇïõ╣ï ÕåàÕ¡ÿÞÇùÕ░¢µÇÄõ╣êÕè×
2010-01-12 14:20 1635┬á┬á┬á Õªéµ×£Õ£¿þö│Þ»ÀÕ迵ÇüÕåàÕ¡ÿµùµë¥õ©ìÕê░ÞÂ│ÕñƒÕñºþÜäÕåàÕ¡ÿÕØù´╝îmalloc ... -
ÒÇèÚ½ÿÞ┤¿ÚçÅC++/C þ╝ûþ¿ïµîçÕìùÒÇïõ╣ï Õ©©ÞºüþÜäÕåàÕ¡ÿÚöÖÞ»»ÕÅèÕàÂÕ»╣þ¡û
2010-01-12 14:10 1491┬á ÕÅæþöƒÕåàÕ¡ÿÚöÖÞ»»µÿ»õ╗ÂÚØ× ... -
ÒÇèÚ½ÿÞ┤¿ÚçÅC++/C þ╝ûþ¿ïµîçÕìùÒÇïõ╣ï µ£ëõ║åmalloc/freeõ©║õ╗Çõ╣êÞ┐ÿÞªünew/delete
2010-01-12 13:33 1745┬á┬á┬á┬á┬á┬á mallocõ©Äfreeµÿ»C++/CÞ»¡Þ¿ÇþÜäµáçÕçåÕ║ôÕç¢ ... -
ÒÇèÚ½ÿÞ┤¿ÚçÅC++/C þ╝ûþ¿ïµîçÕìùÒÇïõ╣ï freeÕÆîdeleteµèèµîçÚÆêµÇÄõ╣êÕòª´╝ƒ
2010-01-12 11:30 1306Õê½þ£ïfreeÕÆîdeleteþÜäÕÉìÕ¡ùµüÂþïáþïáþÜä´╝êÕ░ñÕàµÿ»delete´╝ë ... -
ÒÇèÚ½ÿÞ┤¿ÚçÅC++/C þ╝ûþ¿ïµîçÕìùÒÇïõ╣ï µØ£þ╗Ø"ÚçĵîçÚÆê"
2010-01-12 11:27 1318ÔÇ£ÚçĵîçÚÆêÔÇØõ©ìµÿ»NULLµîçÚÆê´╝îµÿ»µîçÕÉæÔÇ£Õ×âÕ£¥ÔÇØÕåàÕ¡ÿþÜäµîçÚÆêÒÇéõ║║õ╗¼õ©ÇÞê¼ ... -
ÒÇèEffective C++ÒÇïµØíµ¼¥14: þí«Õ«ÜÕƒ║þ▒╗µ£ëÞÖܵ×ɵ×äÕ碵ò░
2010-01-12 11:18 5204µ£ëµù´╝îõ©Çõ©¬þ▒╗µâ│ÞÀƒÞ©¬Õ«âµ ... -
µò░þ╗äÕÉìõ©ìÕ«îÕà¿þ¡ëõ║ĵîçÚÆê
2010-01-10 19:12 1841µîçÚÆêµÿ»C/C++Þ»¡Þ¿ÇþÜäþë╣Þë▓´╝îÞÇîµò░þ╗äÕÉìõ©ÄµîçÚÆêµ£ëÕñ¬ÕñÜþÜäþø©õ╝╝´╝îþöÜÞç│Õ¥ê ... -
C++Õ¡ùþ¼ªõ©▓Õ«îÕ࿵îçÕ╝òõ╣ïõ║î
2010-01-09 16:16 1567Õ╝òÞ¿ÇÒÇÇÒÇÇÕøáõ©║CÞ»¡Þ¿ÇÚú ... -
C++Õ¡ùþ¼ªõ©▓Õ«îÕ࿵îçÕ╝òõ╣ïõ©Ç
2010-01-08 22:53 1291┬áÕ╝òÞ¿ÇÒÇÇÒÇǵ»½µùáþûæÚù«´╝îµêæõ╗¼Úâ¢þ£ïÕê░Þ┐çÕâÅ TCHAR, st ... -
BMPµûçõ╗µá╝Õ╝Å
2010-01-08 22:15 1889õ©Ç.õ¢ìÕø¥þ╗ôµ×äÕªéõ©ï´╝Ü ┬á---- õ©ÇÒÇüBMPµûçõ╗Âþ╗ôµ×ä ┬á┬á--- ... -
OpenCVÕƒ║þíǵò░µì«þ╗ôµ×ä
2010-01-08 21:56 2186Õø¥Õâŵò░µì«þ╗ôµ×ä´╝Ü 1) IPL ... -
OpenCVÕƒ║µ£¼þƒÑÞ»å
2010-01-08 21:31 29971ÒÇüOpenCVµªéÞ┐░ ┬á 1) õ╗Çõ╣êµÿ»OpenCV┬á Õ╝Ç ... -
calloc(), malloc(), realloc(), free()
2010-01-08 21:08 1444void *calloc(size_t nobj, size_ ...
þø©Õà│µÄ¿ÞìÉ
C++Õ╝éÕ©©µ£║Õêµÿ»C++þ╝ûþ¿ïÞ»¡Þ¿Çõ©¡þö¿õ║ÄÕñäþÉåþ¿ïÕ║ÅÞ┐ÉÞíîµùÂÚöÖÞ»»þÜäõ©ÇþºìÕ╝║ÕñºÕÀÑÕàÀÒÇéÕ«âÕàüÞ«©þ¿ïÕ║ÅÕæÿÕ£¿õ╗úþáüõ©¡Õ«Üõ╣ëÕÅ»Þâ¢Õç║ÚöÖþÜäþé╣´╝îÕ╣ÂÚÇÜÞ┐çÕ╝éÕ©©ÕñäþÉåµØÑõ╝ÿÚøàÕ£░µìòÞÄÀÕÆîÕñäþÉåÞ┐Öõ║øÚöÖÞ»»´╝îÞÇîõ©ìµÿ»Þ«®þ¿ïÕ║Åþ¬üþäÂÕ┤®µ║âÒÇéõ©ïÚØóÕ░åÞ»ªþ╗åõ╗ïþ╗ìC++Õ╝éÕ©©ÕñäþÉåþÜ䵪éÕ┐ÁÒÇü...
C++Õ╝éÕ©©ÕñäþÉåµÇ╗þ╗ô C++Þ»¡Þ¿ÇµÅÉõ¥øõ║åÕ╝éÕ©©ÕñäþÉåµ£║Õê´╝îþö¿õ║ÄÕñäþÉåþ¿ïÕ║Åõ©¡þÜäÚöÖÞ»»ÕÆîÕ╝éÕ©©µâàÕåÁÒÇéÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂÕÅ»õ╗Ñõ¢┐þ¿ïÕ║Åþ╗ôµ×äµø┤µ©àµÖ░ÒÇüµø┤ÕüÑÕú«´╝îÕ╣Âõ©öÕÅ»õ╗ÑÚÿ▓µ¡óþ¿ïÕ║ÅÕ┤®µ║âÒÇéõ©ïÚØóµÿ»C++Õ╝éÕ©©ÕñäþÉåµ£║ÕêÂþÜäµá©Õ┐âÞªüþé╣´╝Ü 1. Õªéµ×£õ¢┐þö¿µÖ«ÚÇÜþÜäÕñäþÉåµû╣Õ╝Å...
Õ£¿CÕÆîC++þ╝ûþ¿ïõ©¡´╝îÕ╝éÕ©©ÕñäþÉåµÿ»õ©ÇþºìÕñäþÉåþ¿ïÕ║ÅÞ┐ÉÞíîµùÂÚöÖÞ»»þÜäÚçìÞªüµ£║ÕêÂÒÇéÕ«âÕàüÞ«©þ¿ïÕ║ÅÕæÿÕ£¿þ¿ïÕ║ŵëºÞíîÞ┐çþ¿ïõ©¡µìòÞÄÀÕÆîÕñäþÉåõ©ìÕ»╗Õ©©þÜäõ║ïõ╗´╝îÚü┐Õàìþ¿ïÕ║ÅÕ┤®µ║âÕ╣µÅÉõ¥øµø┤õ╝ÿÚøàþÜäÚöÖÞ»»ÕñäþÉåµû╣Õ╝ÅÒÇéõ©ïÚØóµêæõ╗¼Õ░åµÀ▒ÕàѵÄóÞ«¿C++þÜäÕ╝éÕ©©ÕñäþÉåµ£║Õê´╝îÕøáõ©║CÞ»¡Þ¿Ç...
ÚÇÜÞ┐çÕêåµ×É`CatchC++ExceptionByReference`Þ┐Öõ©¬Úí╣þø«´╝îõ¢áÕÅ»õ╗ѵÀ▒ÕàÑõ║åÞºúC++Õ╝éÕ©©ÕñäþÉåþÜäþ╗åÞèé´╝îÕ¡ªõ╣áÕªéõ¢òþ╝ûÕåÖµø┤ÕüÑÕú«ÒÇüµø┤ÕàÀÕ«╣ÚöֵǺþÜäõ╗úþáüÒÇéÞ┐Öõ©¬õ¥ïÕ¡ÉÕ░åµ£ëÕè®õ║ĵÅÉÕìçõ¢áÕ»╣Õ╝éÕ©©ÕñäþÉåþÜäþÉåÞºú´╝îÕ╣ÂÞ«®õ¢áÕ£¿Õ«×ÚÖàÚí╣þø«õ©¡µø┤ÕÑ¢Õ£░Õ║öÕ»╣ÕÅ»Þâ¢Õç║þÄ░þÜä...
CÞ»¡Þ¿ÇÕÆîC++Ú⢵ÅÉõ¥øõ║åÕ╝éÕ©©ÕñäþÉåÕèƒÞ⢴╝îõ¢åÕ«âõ╗¼þÜäÕ«×þÄ░µû╣Õ╝ÅÕÆîþÉåÕ┐Áµ£ëµëÇõ©ìÕÉîÒÇé CÞ»¡Þ¿ÇþÜäÕ╝éÕ©©ÕñäþÉåõ©╗Þªüµÿ»ÚÇÜÞ┐çµôìõ¢£þ│╗þ╗ƒµÅÉõ¥øþÜäþ╗ôµ×äÕîûÕ╝éÕ©©ÕñäþÉå´╝êStructured Exception Handling´╝îþ«Çþº░SEH´╝ëµØÑÕ«×þÄ░þÜäÒÇéÕ£¿Windowsµôìõ¢£þ│╗þ╗ƒõ©¡´╝îCÞ»¡Þ¿Ç...
C++Õ╝éÕ©©ÕñäþÉåµÿ»õ©Çþºìµ£║Õê´╝îµù¿Õ£¿µÅÉÚ½ÿþ¿ïÕ║ÅþÜäÕüÑÕú«µÇºÕÆîÕÅ»ÚØáµÇº´╝îÕ«âÕàüÞ«©þ¿ïÕ║ÅÕæÿÕ£¿þ¿ïÕ║Åõ©¡ÕñäþÉåÕÅ»Þâ¢Õç║þÄ░þÜäÚöÖÞ»»µâàÕåÁ´╝îÞÇîµùáÚ£ÇÕ£¿µ»Åõ©¬ÕÅ»Þâ¢Õç║ÚöÖþÜäÕ£░µû╣Ú⢵ÅÆÕàѵúǵƒÑÕÆîÚöÖÞ»»ÕñäþÉåõ╗úþáü´╝îõ╗ÄÞÇîþ«ÇÕîûõ║åÚöÖÞ»»ÕñäþÉåõ╗úþáüÒÇéC++Õ╝éÕ©©ÕñäþÉåõ©╗Þªüþö▒õ©ëÚâ¿Õêåµ×äµêÉ...
Þ┐Öõ©¬ÕÄïþ╝®Õîàõ©¡þÜäÔÇ£c++Õ╝éÕ©©ÕñäþÉåþÜäÕăþÉåÞ»ªÞºúÕÆîõ╗úþáüþñ║õ¥ï.txtÔÇصûçõ╗ÂÕ¥êÕÅ»Þâ¢ÕîàÕɽõ║åµø┤µÀ▒ÕàÑþÜäþÉåÞ«║ÞºúÚçèÕÆîÕàÀõ¢ôþÜäõ╗úþáüÕ«×õ¥ï´╝îÕ©«Õè®Þ»╗ÞÇàµø┤ÕÑ¢Õ£░þÉåÞºúÕÆîÕ║öþö¿C++þÜäÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂÒÇéÚÇÜÞ┐çÕ¡ªõ╣áÕÆîÕ«×ÞÀÁÞ┐Öõ║øÕåàÕ«╣´╝îÕ╝ÇÕÅæÞÇàÕÅ»õ╗Ñþ╝ûÕåÖÕç║µø┤ÕèáÕüÑÕú«ÒÇüµÿôõ║Ä...
C++Õ╝éÕ©©ÕñäþÉåµÿ»Þ»Ñþ╝ûþ¿ïÞ»¡Þ¿Çõ©¡õ©ÇÚí╣ÚçìÞªüþÜäÚöÖÞ»»ÕñäþÉåµ£║Õê´╝îÕ«âõ¢┐Õ¥ùþ¿ïÕ║ÅÞâ¢ÕñƒÕôìÕ║öÞ┐ÉÞíîµùÂÕç║þÄ░þÜäÕ╝éÕ©©þèÂÕåÁ´╝îÕ╣µîëþàºÚóäÕ«ÜþÜäµû╣Õ╝ÅÞ┐øÞíîÕñäþÉå´╝îÞÇîõ©ìµÿ»þø┤µÄÑÕ┤®µ║âµêûÕ»╝Þç┤µ£¬Õ«Üõ╣ëÞíîõ©║ÒÇéC++õ©¡þÜäÕ╝éÕ©©ÕñäþÉåþø©Þ¥âõ║ÄCÞ»¡Þ¿Çõ¢┐þö¿þÜäÞ┐öÕø×þáüµ£║ÕêÂÕàÀµ£ëµÿĵÿ¥þÜä...
### C++Õ╝éÕ©©ÕñäþÉåµèÇÕÀºÞ»ªÞºú #### õ©ÇÒÇüC++Õ╝éÕ©©ÕñäþÉåþÜäÚçìÞªüµÇº Õ£¿þÄ░õ╗úÞ¢»õ╗ÂÕ╝ÇÕÅæõ©¡´╝îÕ░ñÕàµÿ»Õ»╣õ║ÄÚéúõ║øÚ£ÇÞªüÚò┐µùÂÚù┤þ¿│Õ«ÜÞ┐ÉÞíîþÜäÕ║öþö¿þ¿ïÕ║ŵØÑÞ»┤´╝îþí«õ┐Øõ╗úþáüþÜäÕüÑÕú«µÇºÕÆîþ¿│իܵǺÞç│Õà│ÚçìÞªüÒÇéÕ╝éÕ©©ÕñäþÉåõ¢£õ©║C++Þ»¡Þ¿ÇþÜäõ©ÇÚí╣ÚçìÞªüþë╣µÇº´╝îÞâ¢Õñƒµ£ëµòêÕ£░...
ÕŪÕñû´╝îµ×äÚÇáÕ碵ò░õ©Äµ×ɵ×äÕ碵ò░þÜäÞ░âþö¿Úí║Õ║ÅÒÇüÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂþ¡ëõ╣ƒµÿ»C++Õ║òÕ▒éÕêåµ×ÉþÜäÚçìÞªüþ╗äµêÉÚâ¿ÕêåÒÇé µ¡ñÕñû´╝îC++þÜ䵿íµØ┐Õàâþ╝ûþ¿ïÕÆîSTL´╝êµáçÕç嵿íµØ┐Õ║ô´╝ëµÿ»þÄ░õ╗úC++þ╝ûþ¿ïõ©¡õ©ìÕÅ»µêûþ╝║þÜäÚâ¿ÕêåÒÇéÕ«âõ╗¼þÜäÕ«×þÄ░µ£║ÕêµÂëÕÅèÕê░ÕñìµØéþÜäµ│øÕ×ïþ╝ûþ¿ïµÇصâ│ÕÆîþ╝ûÞ»æµùÂ...
þ║┐þ¿ïµ▒áµÿ»õ©ÇþºìÕñÜþ║┐þ¿ïÕñäþÉåÕ¢óÕ╝Å´╝îÚÇÜÞ┐çþ╗┤µèñõ©Çþ╗äÕÅ»Úçìþö¿þ║┐þ¿ïµØѵÅÉÚ½ÿþ¿ïÕ║ŵëºÞíîµòêþÄçÒÇé...ÚÇÜÞ┐çÕêåµ×ÉÕÆîþÉåÞºúÞ┐Öõ©¬Õ║ôþÜäµ║Éõ╗úþáü´╝îÕ╝ÇÕÅæÞÇàÕÅ»õ╗ÑÕ¡ªõ╣áÕªéõ¢òÕ£¿C++õ©¡Õ«×þÄ░õ©Çõ©¬Ú½ÿµòêÒÇüÞÀ¿Õ╣│ÕÅ░þÜäþ║┐þ¿ïµ▒á´╝îÞ┐ÖÕ£¿ÕñÜþ║┐þ¿ïþ╝ûþ¿ïõ©¡µÿ»ÚØ×Õ©©µ£ëõ╗ÀÕÇ╝þÜäµèÇÞâ¢ÒÇé
C++þÜäÕ╝éÕ©©ÕñäþÉåµ£║ÕêÂÕÅ»õ╗ÑÕ©«Õ讵ìòÞÄÀÕ╣ÂÕñäþÉåÚöÖÞ»»´╝îþí«õ┐Øþ¿ïÕ║ÅÕ£¿Õ╝éÕ©©µâàÕåÁõ©ïÞâ¢þ¿│Õ«ÜÞ┐ÉÞíîÒÇéÕÉîµù´╝îÕìòÕàâµÁïÞ»òµíåµ×ÂÕªéGoogle TestÕŻթ«Õè®Ú¬îÞ»üõ╗úþáüþÜ䵡úþí«µÇºÒÇé 6. **ÕñÜþ║┐þ¿ïÕÆîÕ╣ÂÕÅæ**´╝Üõ©║õ║åµÅÉÚ½ÿµÇºÞâ¢ÕÆîþö¿µêÀõ¢ôÚ¬î´╝îÞ¢»õ╗ÂÕÅ»Þâ¢Ú£ÇÞªüÕ╣ÂÞíîÕñäþÉåÕñÜõ©¬...
ÒÇÉC++Õ╝éÕ©©ÕñäþÉåÞ»ªÞºúÒÇæ Õ╝éÕ©©ÕñäþÉåµÿ»C++þ╝ûþ¿ïõ©¡õ©ÇþºìÚçìÞªüþÜäÚöÖÞ»»ÕñäþÉåµ£║Õê´╝îÕ«âõ¢┐Õ¥ùþ¿ïÕ║ÅÕ£¿ÚüçÕê░Õ╝éÕ©©µâàÕåÁµùÂÞâ¢Õñƒõ╝ÿÚøàÕ£░ÕñäþÉåÚöÖÞ»»´╝îÞÇîÚØ×þ¬üþäÂÕ┤®µ║âÒÇéÕ╝éÕ©©ÕñäþÉåþÜäõ©╗Þªüþø«µáçµÿ»µÅÉÚ½ÿþ¿ïÕ║ÅþÜäÕ«╣ÚöֵǺ´╝îþí«õ┐ØÕ£¿ÚüçÕê░µäÅÕñûµâàÕåÁµù´╝îþ¿ïÕ║ÅÞâ¢ÕñƒÕ░¢ÕÅ»Þâ¢Õ£░...
Õ£¿Þ┐Öõ©¬ÔÇ£Úí║Õ║ÅÞí¿C++þ«ùµ│òÕ«×þÄ░ÔÇØõ©¡´╝îõ¢£ÞÇàµÿ¥þäµÿ»µá╣µì«ÒÇèµò░µì«þ╗ôµ×ä´╝êþö¿ÚØóÕÉæÕ»╣Þ▒íµû╣µ│òõ©ÄC++Þ»¡Þ¿ÇµÅÅÞ┐░´╝ëÒÇï´╝êþ¼¼õ║îþëê´╝ëõ©Çõ╣ªõ©¡þÜ䵪éÕ┐Á´╝îþ╝ûÕåÖõ║åõ©Çõ©¬þ«ÇÕìòþÜäC++þ▒╗´╝îÞ»Ñþ▒╗ÕîàÕɽõ║åÚí║Õ║ÅÞí¿þÜäÕƒ║µ£¼µôìõ¢£´╝îÕªéµÅÆÕàÑÒÇüÕêáÚÖñÕÆîµÄÆÕ║ÅÒÇé ÚªûÕàê´╝îµêæõ╗¼µØÑ...
Þ»Ñþ│╗þ╗ƒþÜäÞ«¥Þ«íÕÆîÕ«×þÄ░µù¿Õ£¿Õ©«Õè®Õ╝ÇÕÅæÞÇàÚóäÚÿ▓ÕÆîÕÅæþÄ░õ╗úþáüõ©¡þÜäµ¢£Õ£¿Õ«ëÕ࿵╝ŵ┤×´╝îÚÇÜÞ┐çÞ┐¢Þ©¬ÕÅ»Þâ¢þÜäÔÇ£µ▒íþé╣ÔÇØ´╝êµ£ëÕ«│µêûõ©ìÕÅ»õ┐íþÜäµò░µì«´╝ëµØÑÕó×Õ╝║Þ¢»õ╗ÂþÜäÕ«ëÕ࿵ǺÒÇé µ▒íþé╣µò░µì«ÚÇÜÕ©©µîçþÜäµÿ»Úéúõ║øµØÑÞç¬õ©ìÕÅ»õ┐íõ╗╗µ║ÉþÜäµò░µì«´╝îõ¥ïÕªéþö¿µêÀÞ¥ôÕàÑÒÇüþ¢æþ╗£Þ»Àµ▒éµêûÞÇà...
Õ£¿C++þ╝ûþ¿ïõ©¡´╝îþ║┐þ¿ïµ▒áµÿ»õ©Çþºìþ«íþÉåþ║┐þ¿ïþÜäµ£ëµòêµ£║Õê´╝îÕ«âÕÅ»õ╗ѵÅÉÚ½ÿþ¿ïÕ║ÅþÜäÕ╣ÂÕÅæµÇºÞ⢴╝îÕçÅÕ░æþ║┐þ¿ïÕêøÕ╗║ÕÆîÚöǵ»üþÜäÕ╝ÇÚöÇÒÇéC++11Õ╝òÕàÑõ║åµáçÕçåÕ║ôõ©¡þÜä`<thread>`´╝î`<future>`ÕÆî`<mutex>`þ¡ëµ¿íÕØù´╝îõ¢┐Õ¥ùÕ£¿C++õ©¡Õ«×þÄ░þ║┐þ¿ïµ▒áµêÉõ©║ÕÅ»Þâ¢ÒÇéµ£¼ÞÁäµ║ɵÿ»...
5. Þ«¥Þ«íÕÆîÕ«×þÄ░õ©Çõ©¬þ«ÇÕìòþÜäþö¿µêÀþòîÚØó´╝îÕàüÞ«©µÀ╗ÕèáÒÇüÕêáÚÖñÕÆÑþ£ïõ║║Õæÿõ┐íµü»ÒÇé 6. Õ¡ÿÕé¿ÕÆîÕèáÞ¢¢õ║║Õæÿµò░µì«Õê░µûçõ╗´╝îÕ«×þÄ░µò░µì«µîüõ╣àÕîûÒÇé ÚÇÜÞ┐çÞ┐Öõ©¬Úí╣þø«´╝îõ¢áõ©ìõ╗àÞâ¢ÕñƒÕÀ®Õø║C++þÜäÕƒ║þíÇþƒÑÞ»å´╝îÞ┐ÿÞâ¢õ║åÞºúÕê░Õªéõ¢òÕ£¿Õ«×ÚÖàþ╝ûþ¿ïõ©¡Þ┐Éþö¿Þ┐Öõ║øµªéÕ┐ÁÒÇéÞ┐ÖÕ░åõ©║...