
C&R Tree全称是Classification and Regression Tree,即分类及回归树,它是由美国斯坦福大学和加州大学伯克利分校的Breiman等人于1984年提出的,从名称中不难理解,它包含了分类树和回归树,分类树用于目标变量是分类型的,回归树用于目标变量是连续型的。
该算法分割的核心技术取决于目标变量的类型,如果是分类变量,可以选择使用Gini或者是Twoing.如果是连续变量,会自动选择LSD(Least-squared deviation)。
C&R Tree的生长是二叉树, 前面我们讲过的C5.0和CHAID分别是以信息增益率和卡方为标准来选择最佳分组变量和分割点,今天我们讲的C&R Tree,如果目标变量是分类型,则以Gini系数来确认分割点,如果目标变量是数值型,则以方差来确认分割点。
我们先来讲目标变量是分类型的情况,我们称之为分类树:
在C&R Tree算法中,Gini系数反映的是目标变量组间差异程度,系数越小,组间差异越大。Gini系数计算公式如下:
G(t)=1-(t1/T)^2-(t2/T)^2-(t3/T)^2-(tn/T)^2
其中T为总记录数,t1,t2,t3,tn…..分别为输出变量每个类别的记录数
为了比较好理解这个公式,我们以分析结果来理解公式内容,如下图:
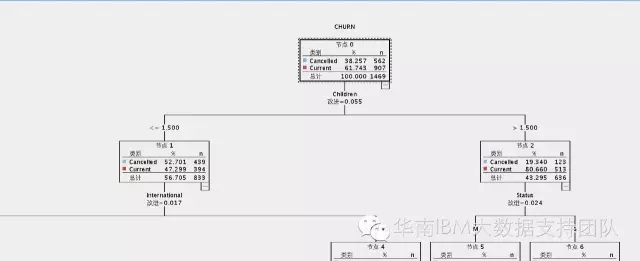
该决策树分析结果,是分析客户的流失为目标,影响的因素有小朋友个数(children),婚姻状态(Status),年龄(age)等,我们先从根节点开始看。
根节点的G(t)=1-(562/1469) ^2-(907/1469)^2=0.472421883
左边节点G(t1)=1-(439/833) ^2-(394/833) ^2=0.498540833
右边节点G(t2)=1-(123/636) ^2-(513/636) ^2=0.311988252
C&R Tree采用Gini系数的减少量来测量异质性下降,因此
ΔG(t)=G(t)-n1/N*G(t1)-n2/N*G(t2)=0.472421883-833/(833+636)* 0.498540833-636/(833+636)* 0.311988252=0.05464854
其中n1是左节点的记录数833,n2是右节点的记录数636,N是根节点的记录数833+636=1469。
计算最终得到的ΔG(t)=0.05464854就是上图中显示的改进=0.055(四舍五入),那么为什么选择这个children<-1.5和children>1/5作为分割点,是因为与其它影响因素相比较,这里计算得到的ΔG(t)最大。所以在整个决策树生长中,可以看到,越往下生长,ΔG(t)越小。
针对连续变量,先对变量按升序排列,然后,从小到大依次以相邻数值的中间值作为将样本分为两组,然后分别计算其ΔG(t)。针对分类变量,由于C&R Tree只能建立二叉树(即只能有两个分支),首先需将多类别合并成两个类别,形成“超类”,然后计算两“超类”下样本输出变量取值的异质性。
在IBM SPSS Modeler中,除了使用Gini系数的减少量作为标准,还可以选择另外两种标准,分别是Twoing(两分法)和Ordered(有序),如下图:
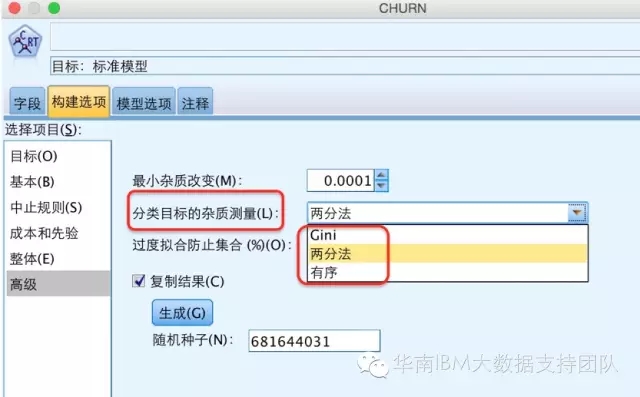
Twoing策略中,输出变量的差异性测度仍采用Gini系数,不同的是,不再以使用Gini系数减少最快为原则,而是要找到使合并形成的左右子节点(两个超类)中分布差异足够大的合并点s,计算公式为:

仍以下图决策树结果为例:
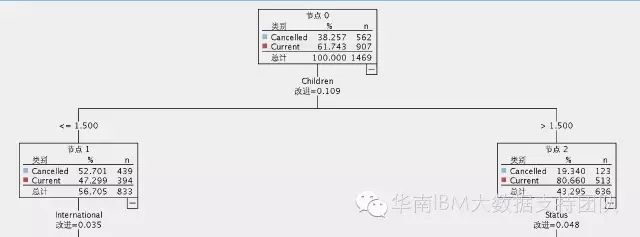

因此

该数值对应着上图第一个根节点的改进=0.109(四舍五入)

可以看到,越是靠近根节点,该值越大。
Order策略适用于有序型输入变量的情况 ,它只限定只有两个连续的类别才可以合并成超类,最终得到最理想的两个超类。
接下来我们来看目标变量是数值型的情况,我们称为回归树。 回归树确定最佳分组变量的策略与分类树相同,主要不同是测试输出变量异质性的指标,
回归树使用的是方差,因此异质性下降的测度指标为方差的减少量,其数学定义为:

其中R(t)和N分别为分组前输出变量的方差和样本量,R(t1),Nt1和R(t2),Nt2分别为分组后左右子树的方差和样本量。使ΔR(t)达到最大的变量应为当前最佳分组变量。我们通过实际例子的结果倒推来理解这个计算公式。
我们使用SPSS Modeler做一个男装销售额(men)预测的场景,因为销售额是数值型,我们选择C&R Tree来实现,那么影响男装销售的输入影响因素有女装销售(women)、电话营销成本(phone)等,得到的决策树分析结果如下:
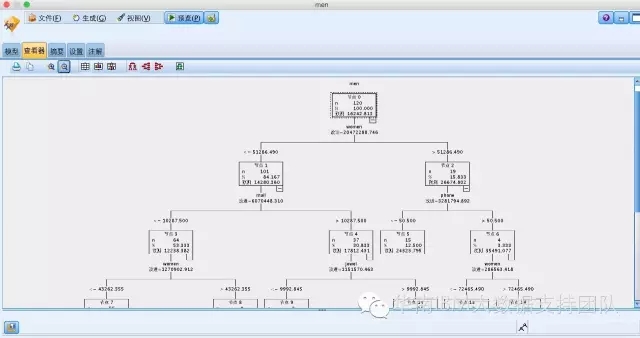
那么为什么生成的决策树会以woman作为最佳分组变量,以51286.490作为分割点呢,因这它计算出来的ΔR(t)最大,大家可以尝试找个例子自己计算看看,这里不再赘述。
最佳分割点的确定方法与最佳分组亦是的确定方法相同。
在IBM SPSSModeler里面,针对 C&R Tree算法,以上介绍的内容是确定分割点的核心标准,对于该算法,还有其它的内容,比如剪枝,交互树建模等,感兴趣的话,可以点击以下链接到官网下载试用!



相关推荐
常用的算法包括决策树(C&R Tree、QUEST、CHAID、C5.0)、回归(线性、逻辑、广义线性、Cox回归)、神经网络、支持向量机(Support Vector Machine, SVM)、贝叶斯网络等。 2. **关联(Association)**:发现数据中的关联...
在 IBM SPSS Modeler 中,主要提供了四种常用的决策树演算法供使用者选择,分别为:C5.0、CHAID、QUEST 以及 C&R Tree 四种。 C5.0 是一种常用的决策树演算法,通过资讯衡量标准 (Information Measure) 来构建决策...
qtz40塔式起重机总体及塔身有限元分析法设计().zip
Elasticsearch是一个基于Lucene的搜索服务器
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
美国纽约HVAC(暖通空调)数据示例,谷歌地图数据包括:时间戳、名称、类别、地址、描述、开放网站、电话号码、开放时间、更新开放时间、评论计数、评级、主图像、评论、url、纬度、经度、地点id、国家等。 在地理位置服务(LBS)中,谷歌地图数据采集尤其受到关注,因为它提供了关于各种商业实体的详尽信息,这对于消费者和企业都有极大的价值。本篇文章将详细介绍美国纽约地区的HVAC(暖通空调)系统相关数据示例,此示例数据是通过谷歌地图抓取得到的,展示了此技术在商业和消费者领域的应用潜力。 无需外网,无需任何软件抓取谷歌地图数据:wmhuoke.com
2023-04-06-项目笔记-第四百五十五阶段-课前小分享_小分享1.坚持提交gitee 小分享2.作业中提交代码 小分享3.写代码注意代码风格 4.3.1变量的使用 4.4变量的作用域与生命周期 4.4.1局部变量的作用域 4.4.2全局变量的作用域 4.4.2.1全局变量的作用域_1 4.4.2.453局变量的作用域_453- 2025-04-01
1_实验三 扰码、卷积编码及交织.ppt
北京交通大学901软件工程导论必备知识点.pdf
内容概要:本文档总结了 MyBatis 的常见面试题,涵盖了 MyBatis 的基本概念、优缺点、适用场合、SQL 语句编写技巧、分页机制、主键生成、参数传递方式、动态 SQL、缓存机制、关联查询及接口绑定等内容。通过对这些问题的解答,帮助开发者深入理解 MyBatis 的工作原理及其在实际项目中的应用。文档不仅介绍了 MyBatis 的核心功能,还详细解释了其在不同场景下的具体实现方法,如通过 XML 或注解配置 SQL 语句、处理复杂查询、优化性能等。 适合人群:具备一定 Java 开发经验,尤其是对 MyBatis 有初步了解的研发人员,以及希望深入了解 MyBatis 框架原理和最佳实践的开发人员。 使用场景及目标:①理解 MyBatis 的核心概念和工作原理,如 SQL 映射、参数传递、结果映射等;②掌握 MyBatis 在实际项目中的应用技巧,包括 SQL 编写、分页、主键生成、关联查询等;③学习如何通过 XML 和注解配置 SQL 语句,优化 MyBatis 性能,解决实际开发中的问题。 其他说明:文档内容详尽,涵盖面广,适合用于面试准备和技术学习。建议读者在学习过程中结合实际项目进行练习,以更好地掌握 MyBatis 的使用方法和技巧。此外,文档还提供了丰富的示例代码和配置细节,帮助读者加深理解和应用。
《基于YOLOv8的智能电网设备锈蚀评估系统》(包含源码、可视化界面、完整数据集、部署教程)简单部署即可运行。功能完善、操作简单,适合毕设或课程设计
插头模具 CAD图纸.zip
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
《基于YOLOv8的智慧农业水肥一体化控制系统》(包含源码、可视化界面、完整数据集、部署教程)简单部署即可运行。功能完善、操作简单,适合毕设或课程设计
python爬虫;智能切换策略,反爬检测机制
台区终端电科院送检文档
e235d-main.zip
丁祖昱:疫情对中国房地产市场影响分析及未来展望
MCP快速入门实战,详细的实战教程
YD5141SYZ后压缩式垃圾车的上装箱体设计.zip