- 浏览: 867465 次
- 性别:

- 来自: lanzhou
-

文章分类
最新评论
-
liu346435400:
楼主讲了实话啊,中国程序员的现状,也是只见中国程序员拼死拼活的 ...
中国的程序员为什么这么辛苦 -
qw8226718:
国内ASP.NET下功能比较完善,优化比较好的Spacebui ...
国内外开源sns源码大全 -
dotjar:
敢问兰州的大哥,Prism 现在在12.04LTS上可用么?我 ...
最佳 Ubuntu 下 WebQQ 聊天体验 -
coralsea:
兄弟,卫星通信不是这么简单的,单向接收卫星广播信号不需要太大的 ...
Google 上网 -
txin0814:
我成功安装chrome frame后 在IE地址栏前加上cf: ...
IE中使用Google Chrome Frame运行HTML 5
 Web app developers spend most of our time not thinking about how data is actually transmitted through the bowels of the network stack. Abstractions at the application layer let us pretend that networks read and write whole messages as smooth streams of bytes. Generally this is a good thing. But knowing what's going underneath is crucial to performance tuning and application design. The character of our users' internet connections is changing and some of the rules of thumb we rely on may need to be revised.
Web app developers spend most of our time not thinking about how data is actually transmitted through the bowels of the network stack. Abstractions at the application layer let us pretend that networks read and write whole messages as smooth streams of bytes. Generally this is a good thing. But knowing what's going underneath is crucial to performance tuning and application design. The character of our users' internet connections is changing and some of the rules of thumb we rely on may need to be revised.
In reality, the Internet is more like a giant cascading multiplayer game of pachinko. You pour some balls in, they bounce around, lights flash and —usually— they come out in the right order on the other side of the world.
What we talk about, when we talk about bandwidth
It's common to talk about network connections solely in terms of "bandwidth". Users are segmented into the high-bandwidth who get the best experience, and low-bandwidth users in the backwoods. We hope some day everyone will be high-bandwidth and we won't have to worry about it anymore.
That mental shorthand served when users had reasonably consistent wired connections and their computers ran one application at a time. But it's like talking only about the top speed of a car or the MHz of a computer. Latency and asymmetry matter at least as much as the notional bits-per-second and I argue that they are becoming even more important. The quality of the "last mile" of network between users and the backbone is in some ways getting worse as people ditch their copper wires for shared wifi and mobile towers, and clog their uplinks with video chat.
It's a rough world out there, and we need to to a better job of thinking about and testing under realistic network conditions. A better mental model of bandwidth should include:
- packets-per-second
- packet latency
- upstream vs downstream
Packets, not bytes
The quantum of internet transmission is not the bit or the byte, it's the packet. Everything that happens on the 'net happens as discrete pachinko balls of regular sizes. A message of N bytes is chopped into ceil(N / 1460) packets [1] which are then sent willy-nilly. That means there is little to no difference between sending 1 byte or 1,000. It also means that sending 1,461 bytes is twice the work of sending 1,460: two packets have to be sent, received, reassembled, and acknowledged.
Packet #1 Payload
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
.....................................................................
...........................................................
Packet #2 Payload
.
Listing 0: Byte 1,461 aka The Byte of Doom
Crossing the packet line in HTTP is very easy to do without knowing it. Suppose your application uses a third-party web analytics library which, like most analytics libraries, stores a big hunk of data about the user inside long-lived cookie tied to your domain. Suppose you also stuff a little bit of data into the cookie too. This cookie data is thereafter echoed back to your web server upon each request. The boilerplate HTTP headers (Accept, User-agent, etc) sent by every modern browser take up a few hundred more bytes. Add in the actual URL, Referer header, query parameters... and you're dead. There is also the little-known fact that browsers split certain POST requests into at least two packets regardless of the size of the message.
One packet, more or less, who cares? For one, none of your fancy caching and CDNs can help the client send data upstream. TCP slow-start means that the client will wait for acknowledgement of the first packet before sending the second. And as we'll see below, that extra packet can make a large difference in the responsiveness of your app when it's compounded by latency and narrow upstream connections.
Packet Latency
Packet latency is the time it takes a packet to wind through the wires and hops between points A and B. It is roughly a function of the physical distance (at 2/3 of the speed of light) plus the time the packet spends queued up inside various network devices along the way. A typical packet sent on the 'net backbone between San Francisco and New York will take about 60 milliseconds. But the latency of a user's last-mile internet connection can vary enormously [2]. Maybe it's a hot day and their router is running slowly. The EDGE mobile network has a best-case latency of 150msec and a real-world average of 500msec. There is a semi-famous rant from 1996 complaining about 100msec latency from substandard telephone modems. If only.
Packet loss
Packet loss manifests as packet latency. The odds are decent that a couple packets that made up the copy of this article you are reading got lost along the way. Maybe they had a collision, maybe they stopped to have a beer and forgot. The sending end then has to notice that a packet has not been acknowledged and re-transmit.
Wireless home networks are becoming the norm and they are unfortunately very susceptible to interference from devices sitting on the 2.4GHz band, like microwaves and baby monitors. They are also notorious for cross-vendor incompatibilities. Another dirty secret is that consumer-grade wifi devices you'll find in cafés and small offices don't do traffic shaping. All it takes is one user watching a video to flood the uplink.
Upstream < Downstream
Internet providers lie. That "6 Megabit" cable internet connection is actually 6mbps down and 1mbps up. The bandwidth reserved for upstream transmission is often 20% or less of the total available. This was an almost defensible thing to do until users started file sharing, VOIPing, video chatting, etc en masse. Even though users still pull more information down than they send up, the asymmetry of their connections means that the upstream is a chokepoint that will probably get worse for a long time.
A Dismal Testing Harness

Figure 0: It's popcorn for dinner tonight, my love. I'm doing science!
We need a way to simulate high latency, variable latency, limited packet rate, and packet loss. In the olden days a good way to test the performance of a system through a bad connection was to configure the switch port to run at half-duplex. Sometimes we even did such testing on purpose. :) Tor is pretty good for simulating a crappy connection but it only works for publicly-accessible sites. Microwave ovens consistently cause packet loss (my parents' old monster kills wifi at 20 paces) but it's a waste of electricity.
The ipfw on Mac and FreeBSD comes in handy for local testing. The command below will approximate an iPhone on the EDGE network with a 350kbit/sec throttle, 5% packet loss rate and 500msecs latency. Use sudo ipfw flush to deactivate the rules when you are done.
$ sudo ipfw pipe 1 config bw 350kbit/s plr 0.05 delay 500ms
$ sudo ipfw add pipe 1 dst-port http
Here's another that will randomly drop half of all DNS requests. Have fun with that one.
$ sudo ipfw pipe 2 config plr 0.5
$ sudo ipfw add pipe 2 dst-port 53
To measure the effects of latency and packet loss I chose a highly-cached 130KB file from Yahoo's servers. I ran a script to download it as many times as possible in 5 minutes under various ipfw rules [3]. The "baseline" runs were the control with no ipfw restrictions or interference.
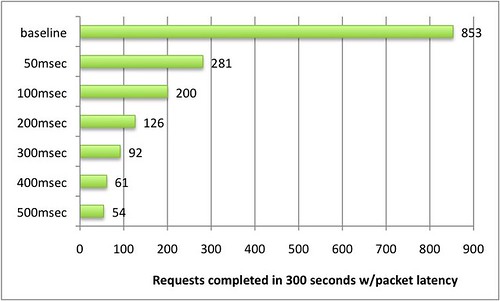
Figure 1: The effect of packet latency on download speed
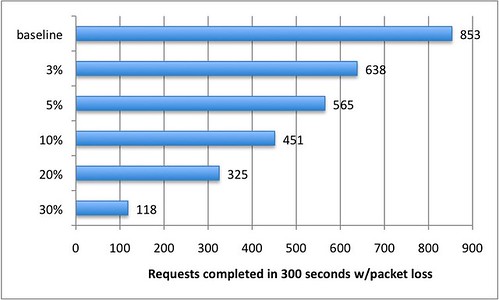
Figure 2: Effect of packet loss on download speed
Just 100 milliseconds of packet latency is enough to cause a smallish file to download in an average of 1500 milliseconds instead of 350 milliseconds. And that's not the worst part: the individual download times ranged from 1,000 to 3,000 milliseconds. Software that's consistently slow can be endured. Software that halts for no obvious reason is maddening.
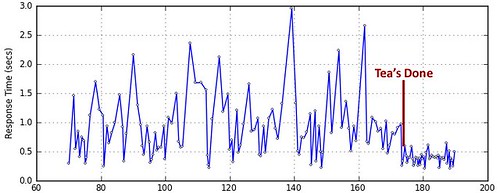
Figure 3: Extreme volatility of response times during packet loss.
So, latency sucks. Now what?
Yahoo's web performance guidelines are still the most complete resource around, and backed up by real-world data. The key advice is to reduce the number of HTTP requests, reduce the amount of data sent, and to order requests in ways that use the observed behavior of browsers to best effect. However there is a simplification which buckets users into high/low/mobile categories. This doesn't necessarily address poor-quality bandwidth across all classes of user. The user's connection quality is often very bad and getting worse, which changes the calculus of what techniques to employ. In particular we should also take into account that:
- Upstream packets are almost always expensive.
- Any client can have high or low overall bandwidth.
- High latency is not an error condition, it's a fact of life.
- TCP connections and DNS lookups are expensive under high latency.
- Variable latency is in some ways worse than low bandwidth.
Assuming that a large but unknown percentage of your users labor under adverse network conditions, here are some things you can do:
- To keep your user's HTTP requests down to one packet, stay within a budget of about 800 bytes for cookies and URLs. Note that every byte of the URL counts twice: once for the URL and once for the Referer header on subsequent clicks. An interesting technique is to store app state that doesn't need to go to the server in fragment identifiers instead of query string parameters, e.g.
/blah#foo=barinstead of/blah?foo=bar. Nothing after the # mark is sent to the server. - If your app sends largish amounts of data upstream (excluding images, which are already compressed), consider implementing client-side compression. It's possible to get 1.5:1 compression with a simple LZW+Base64 function; if you're willing to monkey with ActionScript you could probably do real gzip compression.
-
YSlow says you should flush() early and put Javascript at the bottom. The reasoning is sound: get the HTML <head> portion out as quickly as possible so the browser can start downloading any referenced stylesheets and images. On the other hand, JS is supposed to go on the bottom because script tags halt parallel downloads. The trouble comes when your page arrives in pieces over a long period of time: the HTML and CSS are mostly there, maybe some images, but the JS is lost in the ether. That means the application may look like it's ready to go but actually isn't — the click handlers and logic and ajax includes haven't arrived yet.
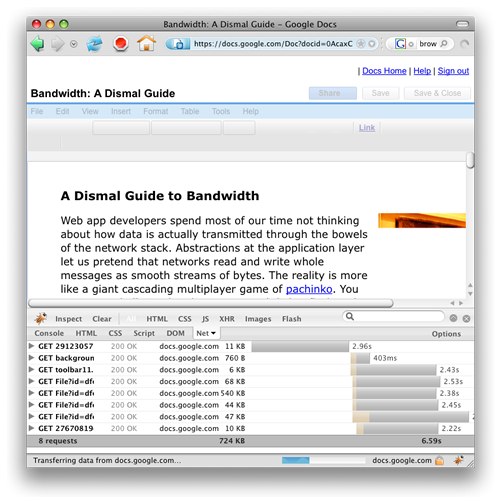
Figure 4: docs is loading slowly... dare I click?Maybe in addition to the CSS/HTML/Javascript sandwich you could stuff a minimal version of the UI into the first 1-3KB, which gets replaced by the full version. Google Docs presents document contents as quickly as possible but disables the buttons until its sanity checks pass. Yahoo's home page does something similar.
This won't do for heavier applications, or those that don't have a lot of passive text to distract the user with while frantic work happens offstage. Gmail compromises with a loading screen which times out after X seconds. On timeout it asks the user to choose whether to reload or use their lite version.
- Have a plan for disaster: what should happen when one of your scripts or styles or data blobs never arrives? Worse, what if the user's cached copy is corrupted? How do you detect it? Do you retry or fail? A quick win might be to add a checksum/eval step to your javascript and stylesheets.
- We also recommend that you should make as much CSS and Javascript as possible external and to parallelize HTTP requests. But is it wise to do more DNS lookups and open new TCP connections under very high latency? If each new connection takes a couple seconds to establish, it may be better to inline as much as possible.
- The trick is how to decide that an arbitrary user is suffering high latency. For mobile users you can pretty much take high latency as a given [4]. Armed with per-IP statistics on client network latency from bullet #4 above, you can build a lookup table of high-latency subnets and handle requests from those subnets differently. For example if your servers are in Seattle it's a good bet that clients in the 200.0.0.0/8 subnet will be slow. 200.* is for Brasil but the point is that you don't need to know it's for Brasil or iPhone or whatever — you're just acting on observed behavior. Handling individual users from "fast" subnets who happen to have high latency is a taller order. It may be possible to get information from the socket layer about how long it took to establish the initial connection. I don't know the answer yet but there is promising research here and there.
- A good technique that seems to go in and out of fashion is KeepAlive. Modern high-end load balancers will try to keep the TCP connection alive between themselves and the client, no matter what, while also honoring whatever KeepAlive behavior the webserver asks for. This saves expensive TCP connection setup and teardown without tying up expensive webserver processes (the reason why some people turn it off). There's no reason why you couldn't do the same with a software load balancer / proxy like Varnish.
This article is the first in a series and part of ongoing research on bandwidth and web app performance. It's still early in our research, but we chose to share what we've found early so you can join us on our journey of discovery. Next, we will dig deeper into some of the open questions we've posed, examine real-world performance in the face of high latency and packet loss, and suggest more techniques on how to make your apps work better in adverse conditions based on the data we collect.
Carlos Bueno
Software Engineer, Yahoo! Mail
Read more about how to optimize your web site performance with the Yahoo! performance guidelines.


发表评论

-
十八个绝招把你从压力中营救出来
2010-03-08 10:34 1025面对目前的工作与生活,你是否感觉到快要被逼疯了,来自工作的,家 ... -
Chrome扩展页面无法访问的解决办法
2010-03-03 09:04 1370Google推出Chrome扩展页面后有些中国的网友可能访 ... -
程序员礼仪小知识
2010-02-28 18:37 981常用应酬语: ... -
How GitHub Works
2010-02-22 07:53 779Ryan wrote a really great comme ... -
XXXX对80后的30个忠告
2010-02-09 11:10 8181、一个年轻人,如果 ... -
汇总Windows7系统常见5个问题和解决方法
2010-01-27 10:08 9901、DVD音频问题 微软改进了Windows7的硬件 ... -
MHDD找不到硬盘的解决方案
2010-01-27 09:48 4594硬盘要接在SATA0和SATA1上, 只认两个通道. 并且 ... -
NetBeans中文乱码解决办法
2010-01-15 07:56 2249在Windows 和Linux(Fedora/Ubuntu/ ... -
时间管理的6条黄金法则
2009-11-22 06:52 1151“时间就是金钱,效� ... -
从15个小动作猜准上司心思
2009-11-22 06:44 994察言观色是一切人情往� ... -
Fixing Poor MySQL Default Configuration Values
2009-11-15 13:24 987I've recently been accumulating ... -
100 Terrific Tips & Tools for Blogging Librarians
2009-11-14 09:43 2253As you prepare for a career as ... -
基本交际用语
2009-11-10 13:04 827日常生活中少不了要面对各种各样的场景和形 ... -
送你一副巧嘴——实用交际用语
2009-11-10 13:02 1695送你一副巧嘴 现代中� ... -
职场红人必读超级商务英语句子
2009-11-09 23:29 8911 I've come to make sure tha ... -
7 Things To Do After Installing Windows 7
2009-11-09 08:38 8671. Reinstall 7 if you purchased ... -
做个给WIN7减肥的批处理的想法,方便去实施
2009-11-08 09:34 2442首先 开启 Administrator 用户 删除其他用户!这 ... -
Windows 7超级实用的快速操作技巧
2009-11-08 07:35 1018如果你已经升级到 Window ... -
使windows7更好用,10个很有用的Win7技巧
2009-11-08 07:29 1237没错,这些都是Windows 7带给我们的新东西,而且你很有必 ... -
电脑利用firefox模拟访问WAP版网站
2009-11-05 11:27 4742最近由于一些项目的原因,需要使用手机访问一些wap网站,从而参 ...
相关推荐
Often used more narrowly in reference to an external deliverable, which is a deliverable that is subject to approval by the project sponsor or customer” by [PMI, 2000]. Examples of outcomes are a ...
拟阵约束下最大化子模函数的模型及其算法的一种熵聚类方法.pdf
内容概要:本文探讨了在两级电力市场环境中,针对省间交易商的最优购电模型的研究。文中提出了一个双层非线性优化模型,用于处理省内电力市场和省间电力交易的出清问题。该模型采用CVaR(条件风险价值)方法来评估和管理由新能源和负荷不确定性带来的风险。通过KKT条件和对偶理论,将复杂的双层非线性问题转化为更易求解的线性单层问题。此外,还通过实际案例验证了模型的有效性,展示了不同风险偏好设置对购电策略的影响。 适合人群:从事电力系统规划、运营以及风险管理的专业人士,尤其是对电力市场机制感兴趣的学者和技术专家。 使用场景及目标:适用于希望深入了解电力市场运作机制及其风险控制手段的研究人员和技术开发者。主要目标是为省间交易商提供一种科学有效的购电策略,以降低风险并提高经济效益。 其他说明:文章不仅介绍了理论模型的构建过程,还包括具体的数学公式推导和Python代码示例,便于读者理解和实践。同时强调了模型在实际应用中存在的挑战,如数据精度等问题,并指出了未来改进的方向。
内容概要:本文探讨了在MATLAB/Simulink平台上针对四机两区系统的风储联合调频技术。首先介绍了四机两区系统作为经典的电力系统模型,在风电渗透率增加的情况下,传统一次调频方式面临挑战。接着阐述了风储联合调频技术的应用,通过引入虚拟惯性控制和下垂控制策略,提高了系统的频率稳定性。文章展示了具体的MATLAB/Simulink仿真模型,包括系统参数设置、控制算法实现以及仿真加速方法。最终结果显示,在风电渗透率为25%的情况下,通过风储联合调频,系统频率特性得到显著提升,仿真时间缩短至5秒以内。 适合人群:从事电力系统研究、仿真建模的技术人员,特别是关注风电接入电网稳定性的研究人员。 使用场景及目标:适用于希望深入了解风储联合调频机制及其仿真实现的研究人员和技术开发者。目标是掌握如何利用MATLAB/Simulink进行高效的电力系统仿真,尤其是针对含有高比例风电接入的复杂场景。 其他说明:文中提供的具体参数配置和控制算法有助于读者快速搭建类似的仿真环境,并进行相关研究。同时强调了参考文献对于理论基础建立的重要性。
内容概要:本文介绍了永磁同步电机(PMSM)无感控制技术,特别是高频方波注入与滑膜观测器相结合的方法。首先解释了高频方波注入法的工作原理,即通过向电机注入高频方波电压信号,利用电机的凸极效应获取转子位置信息。接着讨论了滑膜观测器的作用,它能够根据电机的电压和电流估计转速和位置,具有较强的鲁棒性。两者结合可以提高无传感器控制系统的稳定性和精度。文中还提供了具体的Python、C语言和Matlab代码示例,展示了如何实现这两种技术。此外,简要提及了正弦波注入的相关论文资料,强调了其在不同工况下的优势。 适合人群:从事电机控制系统设计的研发工程师和技术爱好者,尤其是对永磁同步电机无感控制感兴趣的读者。 使用场景及目标:适用于需要减少传感器依赖、降低成本并提高系统可靠性的情况,如工业自动化设备、电动汽车等领域的电机控制。目标是掌握高频方波注入与滑膜观测器结合的具体实现方法,应用于实际工程项目中。 其他说明:文中提到的高频方波注入和滑膜观测器的结合方式,不仅提高了系统的性能,还在某些特殊情况下表现出更好的适应性。同时,附带提供的代码片段有助于读者更好地理解和实践这一技术。
内容概要:本文深入探讨了MATLAB中扩展卡尔曼滤波(EKF)和双扩展卡尔曼滤波(DEKF)在电池参数辨识中的应用。首先介绍了EKF的基本原理和代码实现,包括状态预测和更新步骤。接着讨论了DEKF的工作机制,即同时估计系统状态和参数,解决了参数和状态耦合估计的问题。文章还详细描述了电池参数辨识的具体应用场景,特别是针对电池管理系统中的荷电状态(SOC)估计。此外,提到了一些实用技巧,如雅可比矩阵的计算、参数初始值的选择、数据预处理方法等,并引用了几篇重要文献作为参考。 适合人群:从事电池管理系统开发的研究人员和技术人员,尤其是对状态估计和参数辨识感兴趣的读者。 使用场景及目标:适用于需要精确估计电池参数的实际项目,如电动汽车、储能系统等领域。目标是提高电池管理系统的性能,确保电池的安全性和可靠性。 其他说明:文章强调了实际应用中的注意事项,如数据处理、参数选择和模型优化等方面的经验分享。同时提醒读者关注最新的研究成果和技术进展,以便更好地应用于实际工作中。
内容概要:本文详细介绍了在无电子凸轮功能情况下,利用三菱FX3U系列PLC和威纶通触摸屏实现分切机上下收放卷张力控制的方法。主要内容涵盖硬件连接、程序框架设计、张力检测与读取、PID控制逻辑以及触摸屏交互界面的设计。文中通过具体代码示例展示了如何初始化寄存器、读取张力传感器数据、计算张力偏差并实施PID控制,最终实现稳定的张力控制。此外,还讨论了卷径计算、速度同步控制等关键技术点,并提供了现场调试经验和优化建议。 适合人群:从事自动化生产设备维护和技术支持的专业人士,尤其是熟悉PLC编程和触摸屏应用的技术人员。 使用场景及目标:适用于需要对分切机进行升级改造的企业,旨在提高分切机的张力控制精度,确保材料切割质量,降低生产成本。通过本方案可以实现±3%的张力控制精度,满足基本生产需求。 其他说明:本文不仅提供详细的程序代码和硬件配置指南,还分享了许多实用的调试技巧和经验,帮助技术人员更好地理解和应用相关技术。
内容概要:本文详细介绍了一种基于西门子S7-200和S7-300 PLC以及组态王软件的三泵变频恒压供水系统。主要内容涵盖IO分配、接线图原理图、梯形图程序编写和组态画面设计四个方面。通过合理的硬件配置和精确的编程逻辑,确保系统能够在不同负载情况下保持稳定的供水压力,同时实现节能和延长设备使用寿命的目标。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是熟悉PLC编程和组态软件使用的专业人士。 使用场景及目标:适用于需要稳定供水的各种场合,如住宅小区、工厂等。目标是通过优化控制系统,提升供水效率,减少能源消耗,并确保系统的可靠性和安全性。 其他说明:文中提供了详细的实例代码和调试技巧,帮助读者更好地理解和实施该项目。此外,还分享了一些实用的经验教训,有助于避免常见的错误和陷阱。
内容概要:本文详细介绍了三相三线制静止无功发生器(SVG/STATCOM)在Simulink中的仿真模型设计与实现。主要内容涵盖ip-iq检测法用于无功功率检测、dq坐标系下的电流解耦控制、电压电流双闭环控制系统的设计、SVPWM调制技术的应用以及具体的仿真参数设置。文中不仅提供了理论背景,还展示了具体的Matlab代码片段,帮助读者理解各个控制环节的工作原理和技术细节。此外,文章还讨论了实际调试中遇到的问题及解决方案,强调了参数调整的重要性。 适合人群:从事电力系统自动化、电力电子技术研究的专业人士,特别是对SVG/STATCOM仿真感兴趣的工程师和研究人员。 使用场景及目标:适用于希望深入了解SVG/STATCOM工作原理并掌握其仿真方法的研究人员和工程师。目标是在实践中能够正确搭建和优化SVG/STATCOM的仿真模型,提高无功补偿的效果。 其他说明:文章提供了丰富的实例代码和调试技巧,有助于读者更好地理解和应用所学知识。同时,文中提及的一些经验和注意事项来源于实际项目,具有较高的参考价值。
基于SIMULINK的风力机发电效率建模探究.pdf
内容概要:本文介绍了如何将CarSim的动力学模型与Simulink的智能算法相结合,利用模型预测控制(MPC)实现车辆的智能超车换道。主要内容包括MPC控制器的设计、路径规划算法、联合仿真的配置要点以及实际应用效果。文中提供了详细的代码片段和技术细节,如权重矩阵设置、路径跟踪目标函数、安全超车条件判断等。此外,还强调了仿真过程中需要注意的关键参数配置,如仿真步长、插值设置等,以确保系统的稳定性和准确性。 适合人群:从事自动驾驶研究的技术人员、汽车工程领域的研究人员、对联合仿真感兴趣的开发者。 使用场景及目标:适用于需要进行自动驾驶车辆行为模拟的研究机构和企业,旨在提高超车换道的安全性和效率,为自动驾驶技术研发提供理论支持和技术验证。 其他说明:随包提供的案例文件已调好所有参数,可以直接导入并运行,帮助用户快速上手。文中提到的具体参数和配置方法对于初学者非常友好,能够显著降低入门门槛。
内容概要:本文详细介绍了利用MATLAB进行信号与系统实验的具体步骤和技术要点。首先讲解了常见信号(如方波、sinc函数、正弦波等)的生成方法及其注意事项,强调了时间轴设置和参数调整的重要性。接着探讨了卷积积分的两种实现方式——符号运算和数值积分,指出了各自的特点和应用场景,并特别提醒了数值卷积时的时间轴重构和步长修正问题。随后深入浅出地解释了频域分析的方法,包括傅里叶变换的符号计算和快速傅里叶变换(FFT),并给出了具体的代码实例和常见错误提示。最后阐述了离散时间信号与系统的Z变换分析,展示了如何通过Z变换将差分方程转化为传递函数以及如何绘制零极点图来评估系统的稳定性。 适合人群:正在学习信号与系统课程的学生,尤其是需要完成相关实验任务的人群;对MATLAB有一定基础,希望通过实践加深对该领域理解的学习者。 使用场景及目标:帮助学生掌握MATLAB环境下信号生成、卷积积分、频域分析和Z变换的基本技能;提高学生解决实际问题的能力,避免常见的编程陷阱;培养学生的动手能力和科学思维习惯。 其他说明:文中不仅提供了详细的代码示例,还分享了许多实用的小技巧,如如何正确保存实验结果图、如何撰写高质量的实验报告等。同时,作者以幽默风趣的语言风格贯穿全文,使得原本枯燥的技术内容变得生动有趣。
KUKA机器人相关文档
内容概要:本文详细介绍了无传感器永磁同步电机(PMSM)控制技术,特别是针对低速和中高速的不同控制策略。低速阶段采用I/F控制,通过固定电流幅值和斜坡加速的方式启动电机,确保平稳启动。中高速阶段则引入滑模观测器进行反电动势估算,从而精确控制电机转速。文中还讨论了两者之间的平滑切换逻辑,强调了参数选择和调试技巧的重要性。此外,提供了具体的伪代码示例,帮助读者更好地理解和实现这一控制方案。 适合人群:从事电机控制系统设计的研发工程师和技术爱好者。 使用场景及目标:适用于需要降低成本并提高可靠性的应用场景,如家用电器、工业自动化设备等。主要目标是掌握无传感器PMSM控制的基本原理及其优化方法。 其他说明:文中提到的实际案例和测试数据有助于加深理解,同时提醒开发者注意硬件参数准确性以及调试过程中可能出现的问题。
智能家居与物联网培训材料.ppt
内容概要:本文详细介绍了使用Matlab解决车辆路径规划问题的四种经典算法:TSP(旅行商问题)、CVRP(带容量约束的车辆路径问题)、CDVRP(带容量和距离双重约束的车辆路径问题)和VRPTW(带时间窗约束的车辆路径问题)。针对每个问题,文中提供了具体的算法实现思路和关键代码片段,如遗传算法用于TSP的基础求解,贪心算法和遗传算法结合用于CVRP的路径分割,以及带有惩罚函数的时间窗约束处理方法。此外,还讨论了性能优化技巧,如矩阵运算替代循环、锦标赛选择、2-opt局部优化等。 适合人群:具有一定编程基础,尤其是对物流调度、路径规划感兴趣的开发者和技术爱好者。 使用场景及目标:适用于物流配送系统的路径优化,旨在提高配送效率,降低成本。具体应用场景包括但不限于外卖配送、快递运输等。目标是帮助读者掌握如何利用Matlab实现高效的路径规划算法,解决实际业务中的复杂约束条件。 其他说明:文中不仅提供了详细的代码实现,还分享了许多实践经验,如参数设置、数据预处理、异常检测等。建议读者在实践中不断尝试不同的算法组合和优化策略,以应对更加复杂的实际问题。
软考网络工程师2010-2014真题及答案完整版 全国计算机软考 适合软考中级人群
包括:源程序工程文件、Proteus仿真工程文件、论文材料、配套技术手册等 1、采用51/52单片机作为主控芯片; 2、采用1602液晶显示:测量酒精值、酒驾阈值、醉驾阈值; 3、采用PCF8591进行AD模数转换; 4、LED指示:正常绿灯、酒驾黄灯、醉驾红灯; 5、可通过按键修改酒驾醉驾阈值;
内容概要:本文详细介绍了利用MATLAB实现约束最优化求解的方法,主要分为两大部分:无约束优化和带约束优化。对于无约束优化,作者首先讲解了梯度下降法的基本原理和实现技巧,如步长搜索和Armijo条件的应用。接着深入探讨了带约束优化问题,特别是序列二次规划(SQP)方法的具体实现,包括拉格朗日函数的Hesse矩阵计算、QP子问题的构建以及拉格朗日乘子的更新策略。文中不仅提供了详细的MATLAB代码示例,还分享了许多调参经验和常见错误的解决办法。 适合人群:具备一定数学基础和编程经验的研究人员、工程师或学生,尤其是对最优化理论和应用感兴趣的读者。 使用场景及目标:适用于需要解决各类优化问题的实际工程项目,如机械臂能耗最小化、化工过程优化等。通过学习本文,读者能够掌握如何将复杂的约束优化问题分解为更易处理的二次规划子问题,从而提高求解效率和准确性。 其他说明:文章强调了优化算法选择的重要性,指出不同的问题结构决定了最适合的算法。此外,作者还分享了一些实用的经验教训,如Hesse矩阵的正定性处理和惩罚因子的动态调整,帮助读者少走弯路。
KUKA机器人相关资料