Hashtableзҡ„з»“жһ„пјҢйҮҮз”Ёзҡ„жҳҜж•°жҚ®з»“жһ„дёӯжүҖиҜҙзҡ„й“ҫең°еқҖжі•еӨ„зҗҶеҶІзӘҒзҡ„ж–№жі•
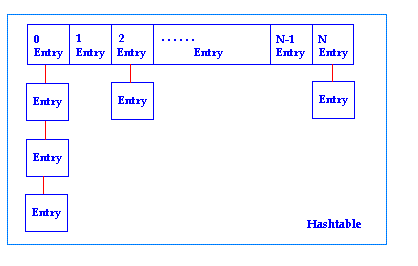
д»ҺдёҠйқўзҡ„з»“жһ„еӣҫеҸҜд»ҘзңӢеҮәпјҢHashtableзҡ„е®һиҙЁе°ұжҳҜдёҖдёӘж•°з»„пјӢй“ҫиЎЁгҖӮеӣҫдёӯзҡ„Entryе°ұжҳҜй“ҫиЎЁзҡ„е®һзҺ°пјҢEntryзҡ„з»“жһ„дёӯеҢ…еҗ«дәҶеҜ№иҮӘе·ұзҡ„еҸҰдёҖдёӘе®һдҫӢзҡ„еј•з”ЁnextпјҢз”Ёд»ҘжҢҮеҗ‘еҸҰеӨ–дёҖдёӘEntryгҖӮиҖҢеӣҫдёӯж Үжңүж•°еӯ—зҡ„йғЁеҲҶжҳҜдёҖдёӘEntryж•°з»„пјҢж•°еӯ—е°ұжҳҜиҝҷдёӘEntryж•°з»„зҡ„indexгҖӮйӮЈд№ҲеҫҖ HashtableеўһеҠ й”®еҖјеҜ№зҡ„ж—¶еҖҷпјҢindexдјҡж №жҚ®й”®зҡ„hashcodeгҖҒEntryж•°з»„зҡ„й•ҝеәҰе…ұеҗҢеҶіе®ҡпјҢд»ҺиҖҢеҶіе®ҡй”®еҖјеҜ№еӯҳж”ҫеңЁEntryж•°з»„зҡ„е“ӘдёӘдҪҚзҪ®гҖӮд»Һиҝҷз§Қж„Ҹд№үжқҘиҜҙпјҢеҪ“й”®дёҖе®ҡпјҢEntryж•°з»„зҡ„й•ҝеәҰдёҖе®ҡзҡ„жғ…еҶөдёӢпјҢжүҖеҫ—еҲ°зҡ„indexиӮҜе®ҡжҳҜзӣёеҗҢзҡ„пјҢд№ҹе°ұжҳҜиҜҙжҸ’е…ҘйЎәеәҸеә”иҜҘдёҚдјҡеҪұе“Қиҫ“еҮәзҡ„йЎәеәҸжүҚеҜ№гҖӮ然иҖҢпјҢиҝҳжңүдёҖдёӘйҮҚиҰҒзҡ„еӣ зҙ жІЎжңүиҖғиҷ‘пјҢе°ұжҳҜи®Ўз®—indexеҮәзҺ°зӣёеҗҢеҖјзҡ„жғ…еҶөгҖӮиӯ¬еҰӮд»Јз Ғдёӯ "sichuan" е’Ң "anhui"пјҢжүҖеҫ—еҲ°зҡ„indexжҳҜзӣёеҗҢзҡ„пјҢеңЁиҝҷдёӘж—¶еҖҷпјҢEntryзҡ„й“ҫиЎЁеҠҹиғҪе°ұеҸ‘жҢҘдҪңз”ЁдәҶпјҡputж–№жі•йҖҡиҝҮEntryзҡ„nextеұһжҖ§иҺ·еҫ—еҜ№еҸҰеӨ–дёҖдёӘ Entryзҡ„еј•з”ЁпјҢ然еҗҺе°ҶеҗҺжқҘиҖ…ж”ҫе…Ҙе…¶дёӯгҖӮж №жҚ®debugеҫ—еҮәзҡ„з»“жһңпјҢ"sichuan", "anhui"зҡ„indexеҗҢдёә2пјҢ"hunan"зҡ„indexдёә6пјҢ"beijing"зҡ„indexдёә1пјҢеңЁиҫ“еҮәзҡ„ж—¶еҖҷпјҢдјҡд»ҘindexйҖ’еҮҸзҡ„ж–№ејҸиҺ·еҫ—й”®еҖјеҜ№гҖӮеҫҲжҳҺжҳҫпјҢдјҡж”№еҸҳзҡ„иҫ“еҮәйЎәеәҸеҸӘжңү"sichuan"е’Ң"anhui"дәҶпјҢд№ҹе°ұжҳҜиҜҙиҫ“еҮәеҸӘжңүдёӨз§ҚеҸҜиғҪпјҡ"hunan" - "sichuan" - "anhui" - "beijing"е’Ң"hunan" - "anhui" - "sichuan" - "beijing"гҖӮд»ҘдёӢжҳҜиҝҗиЎҢдәҶзӨәдҫӢд»Јз Ғд№ӢеҗҺпјҢHashtableзҡ„з»“жһңпјҡ

еңЁHashtableзҡ„е®һзҺ°д»Јз ҒдёӯпјҢжңүдёҖдёӘеҗҚдёәrehashзҡ„ж–№жі•з”ЁдәҺжү©е……Hashtableзҡ„е®№йҮҸгҖӮеҫҲжҳҺжҳҫпјҢеҪ“rehashж–№жі•иў«и°ғз”Ёд»ҘеҗҺпјҢжҜҸдёҖдёӘй”®еҖјеҜ№зӣёеә”зҡ„indexд№ҹдјҡж”№еҸҳпјҢд№ҹе°ұзӯүдәҺе°Ҷй”®еҖјеҜ№йҮҚж–°жҺ’еәҸдәҶгҖӮиҝҷд№ҹжҳҜеҫҖдёҚеҗҢе®№йҮҸзҡ„Hashtableж”ҫе…ҘзӣёеҗҢзҡ„й”®еҖјеҜ№дјҡиҫ“еҮәдёҚеҗҢзҡ„й”®еҖјеҜ№еәҸеҲ—зҡ„еҺҹеӣ гҖӮеңЁJavaдёӯпјҢи§ҰеҸ‘rehashж–№жі•зҡ„жқЎд»¶еҫҲз®ҖеҚ•пјҡhahtableдёӯзҡ„й”®еҖјеҜ№и¶…иҝҮжҹҗдёҖйҳҖеҖјгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢиҜҘйҳҖеҖјзӯүдәҺhashtableдёӯEntryж•°з»„зҡ„й•ҝеәҰГ—0.75гҖӮ
иҮӘ Java 2 е№іеҸ° v1.2 д»ҘжқҘпјҢжӯӨзұ»е·Із»Ҹж”№иҝӣдёәеҸҜд»Ҙе®һзҺ° MapпјҢеӣ жӯӨе®ғеҸҳжҲҗдәҶ Java Collections Framework зҡ„дёҖйғЁеҲҶгҖӮдёҺж–°йӣҶеҗҲзҡ„е®һзҺ°дёҚеҗҢпјҢHashtable жҳҜеҗҢжӯҘзҡ„гҖӮ
з”ұиҝӯд»ЈеҷЁиҝ”еӣһзҡ„ Iterator е’Ңз”ұжүҖжңү Hashtable зҡ„вҖңcollection и§Ҷеӣҫж–№жі•вҖқиҝ”еӣһзҡ„ Collection зҡ„ listIterator ж–№жі•йғҪжҳҜеҝ«йҖҹеӨұиҙҘ зҡ„пјҡеңЁеҲӣе»ә Iterator д№ӢеҗҺпјҢеҰӮжһңд»Һз»“жһ„дёҠеҜ№ Hashtable иҝӣиЎҢдҝ®ж”№пјҢйҷӨйқһйҖҡиҝҮ Iterator иҮӘиә«зҡ„移йҷӨжҲ–ж·»еҠ ж–№жі•пјҢеҗҰеҲҷеңЁд»»дҪ•ж—¶й—ҙд»Ҙд»»дҪ•ж–№ејҸеҜ№е…¶иҝӣиЎҢдҝ®ж”№пјҢIterator йғҪе°ҶжҠӣеҮә ConcurrentModificationExceptionгҖӮеӣ жӯӨпјҢйқўеҜ№е№¶еҸ‘зҡ„дҝ®ж”№пјҢIterator еҫҲеҝ«е°ұдјҡе®Ңе…ЁеӨұиҙҘпјҢиҖҢдёҚеҶ’еңЁе°ҶжқҘжҹҗдёӘдёҚзЎ®е®ҡзҡ„ж—¶й—ҙеҸ‘з”ҹд»»ж„ҸдёҚзЎ®е®ҡиЎҢдёәзҡ„йЈҺйҷ©гҖӮз”ұ Hashtable зҡ„й”®е’ҢеҖјж–№жі•иҝ”еӣһзҡ„ Enumeration дёҚ жҳҜеҝ«йҖҹеӨұиҙҘзҡ„гҖӮ
жіЁж„ҸпјҢиҝӯд»ЈеҷЁзҡ„еҝ«йҖҹеӨұиҙҘиЎҢдёәж— жі•еҫ—еҲ°дҝқиҜҒпјҢеӣ дёәдёҖиҲ¬жқҘиҜҙпјҢдёҚеҸҜиғҪеҜ№жҳҜеҗҰеҮәзҺ°дёҚеҗҢжӯҘ并еҸ‘дҝ®ж”№еҒҡеҮәд»»дҪ•зЎ¬жҖ§дҝқиҜҒгҖӮеҝ«йҖҹеӨұиҙҘиҝӯд»ЈеҷЁдјҡе°ҪжңҖеӨ§еҠӘеҠӣжҠӣеҮә ConcurrentModificationExceptionгҖӮеӣ жӯӨпјҢдёәжҸҗй«ҳиҝҷзұ»иҝӯд»ЈеҷЁзҡ„жӯЈзЎ®жҖ§иҖҢзј–еҶҷдёҖдёӘдҫқиө–дәҺжӯӨејӮеёёзҡ„зЁӢеәҸжҳҜй”ҷиҜҜеҒҡжі•пјҡиҝӯд»ЈеҷЁзҡ„еҝ«йҖҹеӨұиҙҘиЎҢдёәеә”иҜҘд»…з”ЁдәҺжЈҖжөӢзЁӢеәҸй”ҷиҜҜгҖӮ
зӣҙжҺҘзңӢHashTable.java
и§ЈеҶіе“ҲеёҢиЎЁзҡ„еҶІзӘҒ-ејҖж”ҫең°еқҖжі•е’Ңй“ҫең°еқҖжі•
еңЁе®һйҷ…еә”з”ЁдёӯпјҢж— и®әеҰӮдҪ•жһ„йҖ е“ҲеёҢеҮҪж•°пјҢеҶІзӘҒжҳҜж— жі•е®Ңе…ЁйҒҝе…Қзҡ„гҖӮ
1 ејҖж”ҫең°еқҖжі•
иҝҷдёӘж–№жі•зҡ„еҹәжң¬жҖқжғіжҳҜпјҡеҪ“еҸ‘з”ҹең°еқҖеҶІзӘҒж—¶пјҢжҢүз…§жҹҗз§Қ方法继з»ӯжҺўжөӢе“ҲеёҢиЎЁдёӯзҡ„е…¶д»–еӯҳеӮЁеҚ•е…ғпјҢзӣҙеҲ°жүҫеҲ°з©әдҪҚзҪ®дёәжӯўгҖӮиҝҷдёӘиҝҮзЁӢеҸҜз”ЁдёӢејҸжҸҸиҝ°пјҡ
H i ( key ) = ( H ( key )+ d i ) mod m ( i = 1,2,вҖҰвҖҰ пјҢ k ( k вүӨ m вҖ“ 1))
е…¶дёӯпјҡ H ( key ) дёәе…ій”®еӯ— key зҡ„зӣҙжҺҘе“ҲеёҢең°еқҖпјҢ m дёәе“ҲеёҢиЎЁзҡ„й•ҝеәҰпјҢ di дёәжҜҸж¬ЎеҶҚжҺўжөӢж—¶зҡ„ең°еқҖеўһйҮҸгҖӮ
йҮҮз”Ёиҝҷз§Қж–№жі•ж—¶пјҢйҰ–е…Ҳи®Ўз®—еҮәе…ғзҙ зҡ„зӣҙжҺҘе“ҲеёҢең°еқҖ H ( key ) пјҢеҰӮжһңиҜҘеӯҳеӮЁеҚ•е…ғе·Іиў«е…¶д»–е…ғзҙ еҚ з”ЁпјҢеҲҷ继з»ӯжҹҘзңӢең°еқҖдёә H ( key ) + d 2 зҡ„еӯҳеӮЁеҚ•е…ғпјҢеҰӮжӯӨйҮҚеӨҚзӣҙиҮіжүҫеҲ°жҹҗдёӘеӯҳеӮЁеҚ•е…ғдёәз©әж—¶пјҢе°Ҷе…ій”®еӯ—дёә key зҡ„ж•°жҚ®е…ғзҙ еӯҳж”ҫеҲ°иҜҘеҚ•е…ғгҖӮ
еўһйҮҸ d еҸҜд»ҘжңүдёҚеҗҢзҡ„еҸ–жі•пјҢе№¶ж №жҚ®е…¶еҸ–жі•жңүдёҚеҗҢзҡ„з§°е‘јпјҡ
пјҲ 1 пјү d i пјқ 1 пјҢ 2 пјҢ 3 пјҢ вҖҰвҖҰ зәҝжҖ§жҺўжөӢеҶҚж•ЈеҲ—пјӣ
пјҲ 2 пјү d i пјқ 1^2 пјҢпјҚ 1^2 пјҢ 2^2 пјҢпјҚ 2^2 пјҢ k^2пјҢ -k^2вҖҰвҖҰ дәҢж¬ЎжҺўжөӢеҶҚж•ЈеҲ—пјӣ
пјҲ 3 пјү d i пјқ дјӘйҡҸжңәеәҸеҲ— дјӘйҡҸжңәеҶҚж•ЈеҲ—пјӣ
дҫӢ1и®ҫжңүе“ҲеёҢеҮҪж•° H ( key ) = key mod 7 пјҢе“ҲеёҢиЎЁзҡ„ең°еқҖз©әй—ҙдёә 0 пҪһ 6 пјҢеҜ№е…ій”®еӯ—еәҸеҲ—пјҲ 32 пјҢ 13 пјҢ 49 пјҢ 55 пјҢ 22 пјҢ 38 пјҢ 21 пјүжҢүзәҝжҖ§жҺўжөӢеҶҚж•ЈеҲ—е’ҢдәҢж¬ЎжҺўжөӢеҶҚж•ЈеҲ—зҡ„ж–№жі•еҲҶеҲ«жһ„йҖ е“ҲеёҢиЎЁгҖӮ
и§Јпјҡ
пјҲ 1 пјүзәҝжҖ§жҺўжөӢеҶҚж•ЈеҲ—пјҡ
32 пј… 7 = 4 пјӣ 13 пј… 7 = 6 пјӣ 49 пј… 7 = 0 пјӣ
55 пј… 7 = 6 еҸ‘з”ҹеҶІзӘҒпјҢдёӢдёҖдёӘеӯҳеӮЁең°еқҖпјҲ 6 пјӢ 1 пјүпј… 7 пјқ 0 пјҢд»Қ然еҸ‘з”ҹеҶІзӘҒпјҢеҶҚдёӢдёҖдёӘеӯҳеӮЁең°еқҖпјҡпјҲ 6 пјӢ 2 пјүпј… 7 пјқ 1 жңӘеҸ‘з”ҹеҶІзӘҒпјҢеҸҜд»Ҙеӯҳе…ҘгҖӮ
22 пј… 7 пјқ 1 еҸ‘з”ҹеҶІзӘҒпјҢдёӢдёҖдёӘеӯҳеӮЁең°еқҖжҳҜпјҡпјҲ 1 пјӢ 1 пјүпј… 7 пјқ 2 жңӘеҸ‘з”ҹеҶІзӘҒпјӣ
38 пј… 7 пјқ 3 пјӣ
21 пј… 7 пјқ 0 еҸ‘з”ҹеҶІзӘҒпјҢжҢүз…§дёҠйқўж–№жі•з»§з»ӯжҺўжөӢзӣҙиҮіз©әй—ҙ 5 пјҢдёҚеҸ‘з”ҹеҶІзӘҒпјҢжүҖеҫ—еҲ°зҡ„е“ҲеёҢиЎЁеҜ№еә”еӯҳеӮЁдҪҚзҪ®пјҡ
дёӢж Үпјҡ 0 1 2 3 4 5 6
49 55 22 38 32 21 13
пјҲ 2 пјүдәҢж¬ЎжҺўжөӢеҶҚж•ЈеҲ—пјҡ
дёӢж Үпјҡ 0 1 2 3 4 5 6
49 22 21 38 32 55 13
жіЁж„ҸпјҡеҜ№дәҺеҲ©з”ЁејҖж”ҫең°еқҖжі•еӨ„зҗҶеҶІзӘҒжүҖдә§з”ҹзҡ„е“ҲеёҢиЎЁдёӯеҲ йҷӨдёҖдёӘе…ғзҙ ж—¶йңҖиҰҒи°Ёж…ҺпјҢдёҚиғҪзӣҙжҺҘең°еҲ йҷӨпјҢеӣ дёәиҝҷж ·е°ҶдјҡжҲӘж–ӯе…¶д»–е…·жңүзӣёеҗҢе“ҲеёҢең°еқҖзҡ„е…ғзҙ зҡ„жҹҘжүҫең°еқҖпјҢжүҖд»ҘпјҢйҖҡеёёйҮҮз”Ёи®ҫе®ҡдёҖдёӘзү№ж®Ҡзҡ„ж Үеҝ—д»ҘзӨәиҜҘе…ғзҙ е·Іиў«еҲ йҷӨгҖӮ
2 й“ҫең°еқҖжі•
й“ҫең°еқҖжі•и§ЈеҶіеҶІзӘҒзҡ„еҒҡжі•жҳҜпјҡеҰӮжһңе“ҲеёҢиЎЁз©әй—ҙдёә 0 пҪһ m - 1 пјҢи®ҫзҪ®дёҖдёӘз”ұ m дёӘжҢҮй’ҲеҲҶйҮҸз»„жҲҗзҡ„дёҖз»ҙж•°з»„ ST[ m ], еҮЎе“ҲеёҢең°еқҖдёә i зҡ„ж•°жҚ®е…ғзҙ йғҪжҸ’е…ҘеҲ°еӨҙжҢҮй’Ҳдёә ST[ i ] зҡ„й“ҫиЎЁдёӯгҖӮиҝҷз§Қж–№жі•жңүзӮ№иҝ‘дјјдәҺйӮ»жҺҘиЎЁзҡ„еҹәжң¬жҖқжғіпјҢдё”иҝҷз§Қж–№жі•йҖӮеҗҲдәҺеҶІзӘҒжҜ”иҫғдёҘйҮҚзҡ„жғ…еҶөгҖӮ
дҫӢ 2 и®ҫжңү 8 дёӘе…ғзҙ { a,b,c,d,e,f,g,h } пјҢйҮҮз”Ёжҹҗз§Қе“ҲеёҢеҮҪж•°еҫ—еҲ°зҡ„ең°еқҖеҲҶеҲ«дёәпјҡ {0 пјҢ 2 пјҢ 4 пјҢ 1 пјҢ 0 пјҢ 8 пјҢ 7 пјҢ 2} пјҢеҪ“е“ҲеёҢиЎЁй•ҝеәҰдёә 10 ж—¶пјҢйҮҮз”Ёй“ҫең°еқҖжі•и§ЈеҶіеҶІзӘҒзҡ„е“ҲеёҢиЎЁеҰӮдёӢеӣҫжүҖзӨәгҖӮ

еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
Javaдёӯзҡ„`Hashtable`зұ»жҳҜJavaйӣҶеҗҲжЎҶжһ¶зҡ„дёҖйғЁеҲҶпјҢе®ғжҳҜдёҖдёӘеҹәдәҺе“ҲеёҢиЎЁзҡ„MapжҺҘеҸЈе®һзҺ°гҖӮиҝҷдёӘж•°жҚ®з»“жһ„е…Ғи®ёжҲ‘们д»Ҙй”®еҖјеҜ№зҡ„еҪўејҸеӯҳеӮЁж•°жҚ®пјҢ并且жҸҗдҫӣдәҶеҝ«йҖҹзҡ„жҸ’е…ҘгҖҒеҲ йҷӨе’ҢжҹҘжүҫж“ҚдҪңгҖӮ`Hashtable`жҳҜзәҝзЁӢе®үе…Ёзҡ„пјҢеӣ жӯӨеҸҜд»ҘеңЁеӨҡ...
гҖҠе®һжҲҳеә”з”ЁJavaз®—жі•еҲҶжһҗдёҺи®ҫи®Ў(й“ҫиЎЁгҖҒдәҢеҸүж ‘гҖҒе“ҲеӨ«жӣјж ‘гҖҒеӣҫгҖҒеҠЁжҖҒ规еҲ’гҖҒHashTableз®—жі•)гҖӢ иҜҫзЁӢз®Җд»Ӣпјҡ з®—жі•еҲҶжһҗдёҺи®ҫи®ЎJavaзүҲпјҢжҳҜдёҖеҘ—е®һз”ЁеһӢз®—жі•иҜҫзЁӢгҖӮйҖҡиҝҮжң¬иҜҫзЁӢзҡ„еӯҰд№ пјҢеӯҰе‘ҳеҸҜд»ҘжҺҢжҸЎд»ҘдёӢжҠҖжңҜзӮ№:зәҝжҖ§з»“жһ„дёҺйЎәеәҸиЎЁ...
йҖҡиҝҮйҳ…иҜ»е’ҢеҲҶжһҗиҝҷд»Ҫд»Јз ҒпјҢжҲ‘们еҸҜд»Ҙж·ұе…ҘдәҶи§Јжҳ“иҜӯиЁҖеҰӮдҪ•еҖҹйүҙJavaзҡ„HashTableе®һзҺ°е“ҲеёҢиЎЁпјҢд»ҘеҸҠжҳ“иҜӯиЁҖзү№жңүзҡ„зј–зЁӢйЈҺж је’ҢжҠҖе·§гҖӮиҝҷжңүеҠ©дәҺжҸҗеҚҮжҲ‘们еҜ№жҳ“иҜӯиЁҖзҡ„зҗҶи§ЈпјҢ并且иғҪеӨҹиҝҗз”ЁеҲ°иҮӘе·ұзҡ„йЎ№зӣ®дёӯпјҢдјҳеҢ–ж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўзҡ„ж•ҲзҺҮгҖӮ
JavaйӣҶеҗҲдё“йўҳжҖ»з»“пјҡHashMapе’ҢHashTableжәҗз ҒеӯҰд№ е’ҢйқўиҜ•жҖ»з»“ жң¬ж–ҮжҖ»з»“дәҶJavaйӣҶеҗҲдё“йўҳдёӯзҡ„HashMapе’ҢHashTableпјҢж¶өзӣ–дәҶе®ғ们зҡ„жәҗз ҒеӯҰд№ е’ҢйқўиҜ•жҖ»з»“гҖӮHashMapжҳҜдёҖз§ҚеҹәдәҺе“ҲеёҢиЎЁзҡ„йӣҶеҗҲзұ»пјҢе®ғзҡ„еӯҳеӮЁз»“жһ„жҳҜдёҖдёӘж•°з»„пјҢжҜҸдёӘе…ғзҙ ...
еңЁJavaзј–зЁӢиҜӯиЁҖдёӯпјҢ`HashMap`е’Ң`HashTable`йғҪжҳҜе®һзҺ°й”®еҖјеҜ№еӯҳеӮЁзҡ„ж•°жҚ®з»“жһ„пјҢдҪҶе®ғ们д№Ӣй—ҙеӯҳеңЁдёҖдәӣжҳҫи‘—зҡ„еҢәеҲ«пјҢиҝҷдәӣеҢәеҲ«дё»иҰҒдҪ“зҺ°еңЁзәҝзЁӢе®үе…ЁжҖ§гҖҒжҖ§иғҪгҖҒnullеҖјеӨ„зҗҶд»ҘеҸҠдёҖдәӣж–№жі•зү№жҖ§дёҠгҖӮд»ҘдёӢжҳҜеҜ№иҝҷдёӨдёӘзұ»зҡ„иҜҰз»ҶеҲҶжһҗпјҡ 1. ...
еңЁJavaзј–зЁӢиҜӯиЁҖдёӯпјҢ`Hashtable`жҳҜдёҖдёӘйқһеёёеҹәзЎҖдё”йҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„пјҢе®ғеұһдәҺйӣҶеҗҲжЎҶжһ¶зҡ„дёҖйғЁеҲҶпјҢжҸҗдҫӣдәҶй”®еҖјеҜ№пјҲkey-value pairsпјүзҡ„еӯҳеӮЁеҠҹиғҪгҖӮ...йҖҡиҝҮеҲҶжһҗеҺӢзј©еҢ…дёӯзҡ„зӨәдҫӢд»Јз ҒпјҢдҪ еҸҜд»ҘжӣҙеҘҪең°жҺҢжҸЎ`Hashtable`зҡ„е®һйҷ…еә”з”ЁгҖӮ
гҖҠе®һжҲҳеә”з”ЁJavaз®—жі•еҲҶжһҗдёҺи®ҫи®Ў(й“ҫиЎЁгҖҒдәҢеҸүж ‘гҖҒе“ҲеӨ«жӣјж ‘гҖҒеӣҫгҖҒеҠЁжҖҒ规еҲ’гҖҒHashTableз®—жі•)гҖӢ з®—жі•еҲҶжһҗдёҺи®ҫи®ЎJavaзүҲпјҢжҳҜдёҖеҘ—е®һз”ЁеһӢз®—жі•иҜҫзЁӢгҖӮйҖҡиҝҮжң¬иҜҫзЁӢзҡ„еӯҰд№ пјҢеӯҰе‘ҳеҸҜд»ҘжҺҢжҸЎд»ҘдёӢжҠҖжңҜзӮ№:зәҝжҖ§з»“жһ„дёҺйЎәеәҸиЎЁгҖҒеҚ•еҗ‘й“ҫиЎЁгҖҒ...
жң¬ж–Үе°ҶйҮҚзӮ№еҲҶжһҗиҝҷдёүз§Қж•°жҚ®з»“жһ„д№Ӣй—ҙзҡ„еҢәеҲ«пјҢзү№еҲ«жҳҜй’ҲеҜ№`HashTable`дёҚж”ҜжҢҒз©әй”®еҖјеҜ№иҖҢ`HashMap`ж”ҜжҢҒиҝҷдёҖзӮ№иҝӣиЎҢж·ұе…ҘжҺўи®ЁгҖӮ #### дәҢгҖҒHashTable `HashTable`жҳҜеҹәдәҺе“ҲеёҢиЎЁе®һзҺ°зҡ„дёҖдёӘзәҝзЁӢе®үе…Ёзҡ„`Map`е®№еҷЁпјҢе®ғдёҚе…Ғи®ё`key`...
жҺҘдёӢжқҘпјҢжҲ‘们е°ҶиҜҰз»ҶжҺўи®Ё`Hashtable`е’Ң`HashMap`д№Ӣй—ҙзҡ„еҢәеҲ«пјҢ并еҲҶжһҗе®ғ们еҗ„иҮӘзҡ„дјҳзјәзӮ№гҖӮ #### 1. зәҝзЁӢе®үе…ЁжҖ§ - **Hashtable**: жҳҜзәҝзЁӢе®үе…Ёзҡ„гҖӮ`Hashtable`зҡ„жүҖжңүе…ій”®ж“ҚдҪңпјҲеҰӮ`put()`гҖҒ`get()`пјүйғҪжҳҜеҗҢжӯҘзҡ„пјҢиҝҷж„Ҹе‘ізқҖ...
жң¬ж–Үе°ҶиҜҰз»ҶеҲҶжһҗеӣӣз§Қеёёз”Ёзҡ„`Map`е®һзҺ°зұ»пјҡ`HashMap`, `LinkedHashMap`, `TreeMap`д»ҘеҸҠ`HashTable`д№Ӣй—ҙзҡ„еҢәеҲ«гҖӮ #### 1. HashMap `HashMap`жҳҜдёҖз§ҚеҹәдәҺе“ҲеёҢиЎЁе®һзҺ°зҡ„`Map`жҺҘеҸЈпјҢжҸҗдҫӣдәҶдёҖдёӘйқһеҗҢжӯҘзҡ„гҖҒе…Ғи®ёдҪҝз”Ё`null`й”®е’Ң...
гҖҗJavaе®№еҷЁд№ӢHashtableжәҗз ҒеҲҶжһҗгҖ‘ еңЁJavaзј–зЁӢдёӯпјҢ`Hashtable`жҳҜдёҖдёӘеҸӨиҖҒзҡ„е®№еҷЁзұ»пјҢе®ғ继жүҝиҮӘ`Dictionary`жҺҘеҸЈпјҢ并е®һзҺ°дәҶ`Map`жҺҘеҸЈпјҢеҗҢж—¶д№ҹе®һзҺ°дәҶ`Cloneable`е’Ң`Serializable`жҺҘеҸЈгҖӮ`Hashtable`дёҺ`HashMap`зұ»дјјпјҢйғҪжҳҜ...
йҖҡиҝҮдёҠиҝ°еҲҶжһҗпјҢжҲ‘们дәҶи§ЈеҲ°еҰӮдҪ•дҪҝз”ЁJavaеҜ№`HashTable`дёӯзҡ„е…ғзҙ иҝӣиЎҢжҢүй”®жҲ–еҖјзҡ„жҺ’еәҸгҖӮиҝҷйҖҡеёёж¶үеҸҠеҲ°е°Ҷ`Hashtable`зҡ„жқЎзӣ®йӣҶиҪ¬жҚўдёәж•°з»„пјҢ然еҗҺдҪҝз”ЁиҮӘе®ҡд№үжҜ”иҫғеҷЁеҜ№ж•°з»„иҝӣиЎҢжҺ’еәҸгҖӮиҝҷз§Қж–№жі•дёҚд»…йҖӮз”ЁдәҺ`Hashtable`пјҢд№ҹйҖӮз”ЁдәҺ...
Javaдёӯзҡ„`Hashtable`е’Ң`HashMap`йғҪжҳҜ`Map`жҺҘеҸЈзҡ„е®һзҺ°зұ»пјҢе®ғ们йғҪз”ЁдәҺеӯҳеӮЁй”®еҖјеҜ№ж•°жҚ®гҖӮ然иҖҢпјҢиҝҷдёӨдёӘзұ»еңЁи®ҫи®Ўе’ҢеҠҹиғҪдёҠжңүжҳҫи‘—зҡ„е·®ејӮпјҢиҝҷдәӣе·®ејӮдё»иҰҒдҪ“зҺ°еңЁзәҝзЁӢе®үе…ЁжҖ§гҖҒз©әеҖјеӨ„зҗҶгҖҒиҝӯд»ЈеҷЁзұ»еһӢд»ҘеҸҠе“ҲеёҢиЎЁзҡ„еҲқе§ӢеҢ–е’Ңжү©е®№зӯ–з•Ҙ...
в”Ӯ JavaйқўиҜ•йўҳ11.HashMapе’ҢHashTableзҡ„еҢәеҲ«.mp4 в”Ӯ JavaйқўиҜ•йўҳ12.е®һзҺ°дёҖдёӘжӢ·иҙқж–Ү件зҡ„зұ»дҪҝз”Ёеӯ—иҠӮжөҒиҝҳжҳҜеӯ—з¬ҰдёІ.mp4 в”Ӯ JavaйқўиҜ•йўҳ13.зәҝзЁӢзҡ„е®һзҺ°ж–№ејҸ жҖҺд№ҲеҗҜеҠЁзәҝзЁӢжҖҺд№ҲеҢәеҲҶзәҝзЁӢ.mp4 в”Ӯ JavaйқўиҜ•йўҳ14.зәҝзЁӢ并еҸ‘еә“е’ҢзәҝзЁӢжұ ...
жң¬иҜҫ件йӣҶеҗҲдё»иҰҒй’ҲеҜ№Javaдёӯзҡ„ж•°жҚ®з»“жһ„еҸҠе…¶з®—жі•иҝӣиЎҢдәҶж·ұе…Ҙзҡ„жҺўи®Ёе’ҢеҲҶжһҗгҖӮ еңЁ"javaж•°жҚ®з»“жһ„иҜҫ件дёҺеҲҶжһҗ"дёӯпјҢжҲ‘们еҸҜд»Ҙжңҹеҫ…еӯҰд№ еҲ°д»ҘдёӢеҮ дёӘе…ій”®зҡ„зҹҘиҜҶзӮ№пјҡ 1. **ж•°з»„**пјҡJavaдёӯзҡ„еҹәзЎҖж•°жҚ®з»“жһ„пјҢз”ЁдәҺеӯҳеӮЁеӣәе®ҡж•°йҮҸзҡ„зӣёеҗҢ...
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»ҶжҺўи®ЁдәҶJava并еҸ‘зҺҜеўғдёӢзҡ„ConcurrentHashMapдёҺHashTableзҡ„е…ій”®е·®ејӮпјҢд»Ӣз»ҚдәҶLinkedHashMapгҖҒHashMapеҸҠе…¶дёҺSetзұ»е®¶ж—ҸжҲҗе‘ҳзҡ„ејӮеҗҢпјҢ并еҲҶжһҗдәҶиҜёеҰӮCollections.sortзӯүйҮҚиҰҒе·Ҙе…·ж–№жі•зҡ„е·ҘдҪңжңәеҲ¶гҖӮжӯӨеӨ–пјҢж–ҮжЎЈ...
2. **йӣҶеҗҲжЎҶжһ¶**пјҡJavaйӣҶеҗҲжЎҶжһ¶жҳҜйқўиҜ•зҡ„йҮҚзӮ№пјҢеҢ…жӢ¬ListпјҲArrayListгҖҒLinkedListгҖҒVectorпјүгҖҒSetпјҲHashSetгҖҒTreeSetпјүе’ҢMapпјҲHashMapгҖҒTreeMapгҖҒHashtableпјүгҖӮдәҶи§Је®ғ们зҡ„зү№зӮ№гҖҒеҢәеҲ«еҸҠеә”з”ЁеңәжҷҜпјҢеҰӮзәҝзЁӢе®үе…ЁгҖҒйҒҚеҺҶж–№ејҸ...
Javaдёӯзҡ„HashMapе’ҢHashTableжҳҜдёӨз§Қеёёи§Ғзҡ„еҹәдәҺе“ҲеёҢиЎЁзҡ„ж•°жҚ®з»“жһ„пјҢе®ғ们еңЁдҪҝз”ЁеңәжҷҜгҖҒзәҝзЁӢе®үе…ЁжҖ§гҖҒж•°жҚ®еӨ„зҗҶж–№ејҸд»ҘеҸҠAPIи®ҫи®Ўзӯүж–№йқўеӯҳеңЁжҳҫи‘—е·®ејӮгҖӮдёӢйқўе°ҶиҜҰз»ҶеҲҶжһҗиҝҷдәӣеҢәеҲ«гҖӮ йҰ–е…ҲпјҢд»Һ继жүҝе…ізі»жқҘзңӢпјҢHashMapе’ҢHashTableзҡ„...
еңЁJavaдёӯе®һзҺ°иҜҚжі•еҲҶжһҗеҷЁпјҢжҲ‘们еҸҜд»ҘеҖҹеҠ©Javaзҡ„ејәеӨ§еҠҹиғҪе’ҢзҒөжҙ»жҖ§пјҢдёәдёҚеҗҢзҡ„зј–зЁӢд»»еҠЎе®ҡеҲ¶и§ЈеҶіж–№жЎҲгҖӮ еңЁдёҠиҝ°Javaе®һзҺ°зҡ„иҜҚжі•еҲҶжһҗеҷЁе®һдҫӢдёӯпјҢжҲ‘们зңӢеҲ°жңүдёӨдёӘдё»иҰҒзұ»пјҡ`Main`е’Ң`Lexer`гҖӮ`Main`зұ»жҳҜзЁӢеәҸзҡ„е…ҘеҸЈзӮ№пјҢе®ғеҲӣе»ә`...