
ж–Үз« жқҘжәҗпјҡhttp://www.cnblogs.com/smyhvae/p/4810168.html
В
В
гҖҗжӯЈж–ҮгҖ‘
еЈ°жҳҺпјҡжң¬ж–ҮеҸӘжҳҜеҒҡдёҖдёӘжҖ»з»“пјҢжңүе…іjvmзҡ„иҜҰз»ҶзҹҘиҜҶеҸҜд»ҘеҸӮиҖғжң¬дәәд№ӢеүҚзҡ„зі»еҲ—ж–Үз« пјҢе°Өе…¶жҳҜйӮЈзҜҮпјҡJavaиҷҡжӢҹжңәиҜҰи§Ј04----GCз®—жі•е’Ңз§Қзұ»гҖӮйӮЈзҜҮж–Үз« е’Ңжң¬ж–ҮжҳҜйқўиҜ•ж—¶зҡ„йҮҚзӮ№гҖӮ
йқўиҜ•еҝ…й—®е…ій”®иҜҚпјҡJVMеһғеңҫеӣһ收гҖҒзұ»еҠ иҪҪжңәеҲ¶гҖӮ
В
е…ҲжҠҠжң¬ж–Үзҡ„зӣ®еҪ•з”»дёҖдёӘжҖқз»ҙеҜјеӣҫпјҡпјҲеӣҫзҡ„жәҗж–Ү件еңЁжң¬ж–Үжң«е°ҫпјү
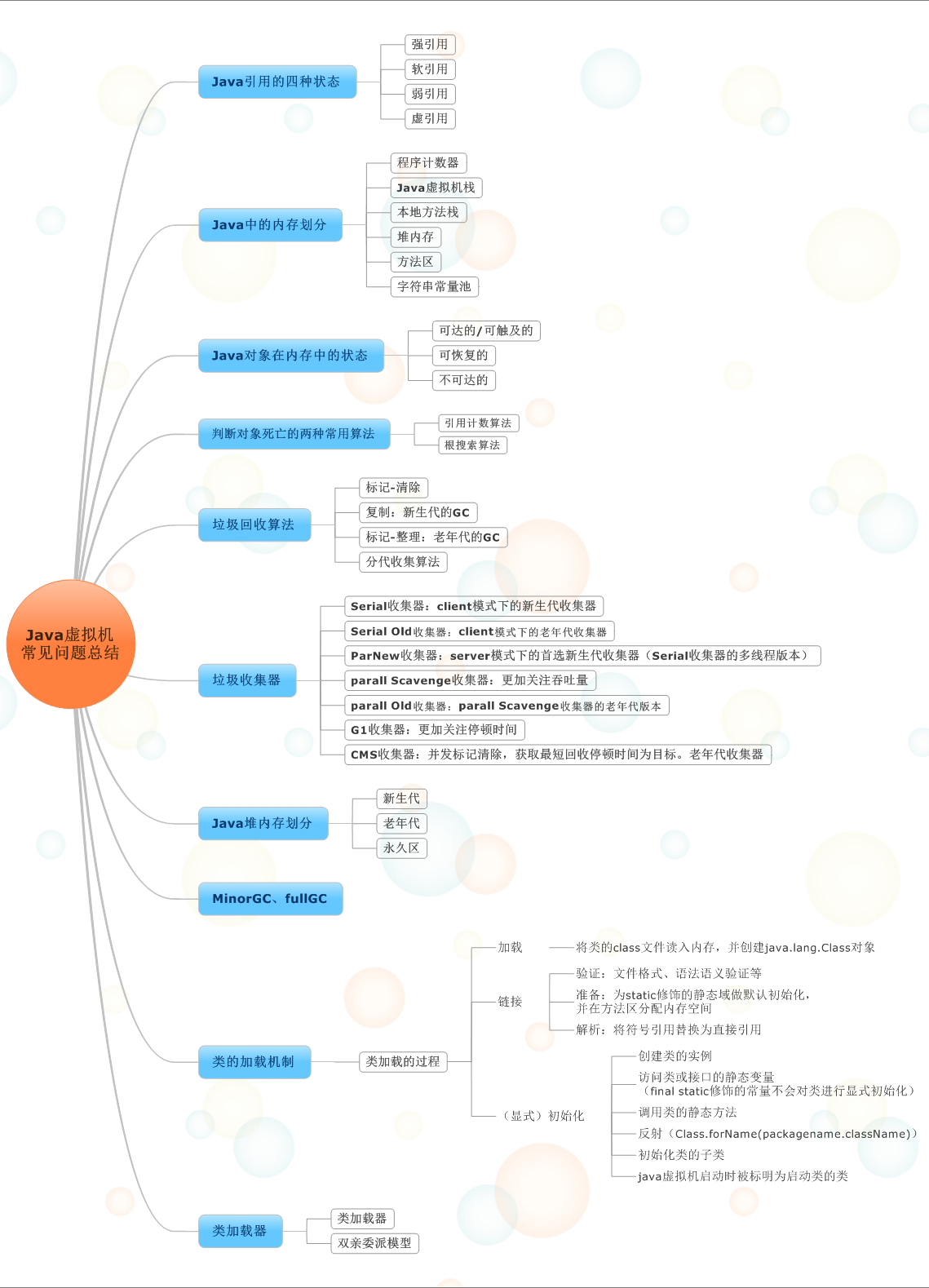
В
дёҖгҖҒJavaеј•з”Ёзҡ„еӣӣз§ҚзҠ¶жҖҒпјҡ
javaдёӯеј•з”Ёзҡ„е®ҡд№үпјҡеҰӮжһңreferenceзұ»еһӢзҡ„ж•°жҚ®дёӯеӯҳеӮЁзҡ„ж•°еҖјд»ЈиЎЁзҡ„жҳҜеҸҰеӨ–дёҖеқ—еҶ…еӯҳзҡ„иө·е§Ӣең°еқҖпјҢе°ұжҲҗиҝҷеқ—еҶ…еӯҳд»ЈиЎЁзқҖдёҖдёӘеј•з”ЁгҖӮ
В
ејәеј•з”Ёпјҡ
гҖҖгҖҖз”Ёзҡ„жңҖе№ҝгҖӮжҲ‘们平时еҶҷд»Јз Ғж—¶пјҢnewдёҖдёӘObjectеӯҳж”ҫеңЁе ҶеҶ…еӯҳпјҢ然еҗҺз”ЁдёҖдёӘеј•з”ЁжҢҮеҗ‘е®ғпјҢиҝҷе°ұжҳҜејәеј•з”ЁгҖӮ
гҖҖгҖҖеҰӮжһңдёҖдёӘеҜ№иұЎе…·жңүејәеј•з”ЁпјҢйӮЈеһғеңҫеӣһ收еҷЁз»қдёҚдјҡеӣһ收е®ғгҖӮеҪ“еҶ…еӯҳз©әй—ҙдёҚи¶іпјҢJavaиҷҡжӢҹжңәе®Ғж„ҝжҠӣеҮәOutOfMemoryErrorй”ҷиҜҜпјҢдҪҝзЁӢеәҸејӮеёёз»ҲжӯўпјҢд№ҹдёҚдјҡйқ йҡҸж„Ҹеӣһ收具жңүејәеј•з”Ёзҡ„еҜ№иұЎжқҘи§ЈеҶіеҶ…еӯҳдёҚи¶ізҡ„й—®йўҳгҖӮ
иҪҜеј•з”Ёпјҡ
гҖҖгҖҖеҰӮжһңдёҖдёӘеҜ№иұЎеҸӘе…·жңүиҪҜеј•з”ЁпјҢеҲҷеҶ…еӯҳз©әй—ҙи¶іеӨҹж—¶пјҢеһғеңҫеӣһ收еҷЁе°ұдёҚдјҡеӣһ收е®ғпјӣеҰӮжһңеҶ…еӯҳз©әй—ҙдёҚи¶ідәҶпјҢе°ұдјҡеӣһ收иҝҷдәӣеҜ№иұЎзҡ„еҶ…еӯҳгҖӮпјҲеӨҮжіЁпјҡеҰӮжһңеҶ…еӯҳдёҚи¶іпјҢйҡҸж—¶жңүеҸҜиғҪиў«еӣһ收гҖӮпјү
гҖҖгҖҖеҸӘиҰҒеһғеңҫеӣһ收еҷЁжІЎжңүеӣһ收е®ғпјҢиҜҘеҜ№иұЎе°ұеҸҜд»Ҙиў«зЁӢеәҸдҪҝз”ЁгҖӮиҪҜеј•з”ЁеҸҜз”ЁжқҘе®һзҺ°еҶ…еӯҳж•Ҹж„ҹзҡ„й«ҳйҖҹзј“еӯҳгҖӮ
жҸҗдҫӣSoftReferenceзұ»жқҘе®һзҺ°иҪҜеј•з”ЁгҖӮ
ејұеј•з”Ёпјҡ
гҖҖгҖҖејұеј•з”ЁдёҺиҪҜеј•з”Ёзҡ„еҢәеҲ«еңЁдәҺпјҡеҸӘе…·жңүејұеј•з”Ёзҡ„еҜ№иұЎжӢҘжңүжӣҙзҹӯжҡӮзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮ
гҖҖгҖҖжҜҸж¬Ўжү§иЎҢGCзҡ„ж—¶еҖҷпјҢдёҖж—ҰеҸ‘зҺ°дәҶеҸӘе…·жңүејұеј•з”Ёзҡ„еҜ№иұЎпјҢдёҚз®ЎеҪ“еүҚеҶ…еӯҳз©әй—ҙи¶іеӨҹдёҺеҗҰпјҢйғҪдјҡеӣһ收е®ғзҡ„еҶ…еӯҳгҖӮдёҚиҝҮпјҢз”ұдәҺеһғеңҫеӣһ收еҷЁжҳҜдёҖдёӘдјҳе…Ҳзә§еҫҲдҪҺзҡ„зәҝзЁӢпјҢеӣ жӯӨдёҚдёҖе®ҡдјҡеҫҲеҝ«еҸ‘зҺ°йӮЈдәӣеҸӘе…·жңүејұеј•з”Ёзҡ„еҜ№иұЎгҖӮ
иў«ејұеј•з”Ёе…іиҒ”зҡ„еҜ№иұЎеҸӘиғҪз”ҹеӯҳеҲ°дёӢдёҖж¬Ўеһғеңҫ收йӣҶеҸ‘з”ҹд№ӢеүҚгҖӮ
жҸҗдҫӣWeakReferenceзұ»жқҘе®һзҺ°ејұеј•з”ЁгҖӮ
иҷҡеј•з”Ёпјҡ
гҖҖгҖҖвҖңиҷҡеј•з”ЁвҖқйЎҫеҗҚжҖқд№үпјҢе°ұжҳҜеҪўеҗҢиҷҡи®ҫпјҢдёҺе…¶д»–еҮ з§Қеј•з”ЁйғҪдёҚеҗҢпјҢиҷҡ引用并дёҚдјҡеҶіе®ҡеҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮеҰӮжһңдёҖдёӘеҜ№иұЎд»…жҢҒжңүиҷҡеј•з”ЁпјҢйӮЈд№Ҳе®ғе°ұе’ҢжІЎжңүд»»дҪ•еј•з”ЁдёҖж ·пјҢеңЁд»»дҪ•ж—¶еҖҷйғҪеҸҜиғҪиў«еһғеңҫеӣһ收еҷЁеӣһ收гҖӮ
гҖҖгҖҖиҷҡеј•з”Ёдё»иҰҒз”ЁжқҘи·ҹиёӘеҜ№иұЎиў«еһғеңҫеӣһ收еҷЁеӣһ收зҡ„жҙ»еҠЁгҖӮ
дёәдёҖдёӘеҜ№иұЎи®ҫзҪ®иҷҡеј•з”Ёе…іиҒ”зҡ„е”ҜдёҖзӣ®зҡ„е°ұжҳҜиғҪеңЁиҝҷдёӘеҜ№иұЎиў«ж”¶йӣҶеҷЁеӣһ收时еҸ—еҲ°дёҖдёӘзі»з»ҹйҖҡзҹҘгҖӮ
жҸҗдҫӣPhantomRefenceзұ»жқҘе®һзҺ°иҷҡеј•з”ЁгҖӮ
жіЁпјҡе…ідәҺеҗ„з§Қеј•з”Ёзҡ„иҜҰи§ЈпјҢеҸҜд»ҘеҸӮиҖғиҝҷзҜҮеҚҡе®ўпјҡ
http://zhangjunhd.blog.51cto.com/113473/53092
В
дәҢгҖҒJavaдёӯзҡ„еҶ…еӯҳеҲ’еҲҶпјҡ
JavaзЁӢеәҸеңЁиҝҗиЎҢж—¶пјҢйңҖиҰҒеңЁеҶ…еӯҳдёӯзҡ„еҲҶй…Қз©әй—ҙгҖӮдёәдәҶжҸҗй«ҳиҝҗз®—ж•ҲзҺҮпјҢе°ұеҜ№ж•°жҚ®иҝӣиЎҢдәҶдёҚеҗҢз©әй—ҙзҡ„еҲ’еҲҶпјҢеӣ дёәжҜҸдёҖзүҮеҢәеҹҹйғҪжңүзү№е®ҡзҡ„еӨ„зҗҶж•°жҚ®ж–№ејҸе’ҢеҶ…еӯҳз®ЎзҗҶж–№ејҸгҖӮ

дёҠйқўиҝҷеј еӣҫе°ұжҳҜjvmиҝҗиЎҢж—¶зҡ„зҠ¶жҖҒгҖӮе…·дҪ“еҲ’еҲҶдёәеҰӮдёӢ5дёӘеҶ…еӯҳз©әй—ҙпјҡпјҲйқһеёёйҮҚиҰҒпјү
- зЁӢеәҸи®Ўж•°еҷЁпјҡдҝқиҜҒзәҝзЁӢеҲҮжҚўеҗҺиғҪжҒўеӨҚеҲ°еҺҹжқҘзҡ„жү§иЎҢдҪҚзҪ®
- иҷҡжӢҹжңәж ҲпјҡпјҲж ҲеҶ…еӯҳпјүдёәиҷҡжӢҹжңәжү§иЎҢjavaж–№жі•жңҚеҠЎпјҡж–№жі•иў«и°ғз”Ёж—¶еҲӣе»әж Ҳеё§-->еұҖйғЁеҸҳйҮҸиЎЁ->еұҖйғЁеҸҳйҮҸгҖҒеҜ№иұЎеј•з”Ё
- жң¬ең°ж–№жі•ж ҲпјҡдёәиҷҡжӢҹжңәжү§дҪҝз”ЁеҲ°зҡ„Nativeж–№жі•жңҚеҠЎ
- е ҶеҶ…еӯҳпјҡеӯҳж”ҫжүҖжңүnewеҮәжқҘзҡ„дёңиҘҝ
- ж–№жі•еҢәпјҡеӯҳеӮЁиў«иҷҡжӢҹжңәеҠ иҪҪзҡ„зұ»дҝЎжҒҜгҖҒеёёйҮҸгҖҒйқҷжҖҒеёёйҮҸгҖҒйқҷжҖҒж–№жі•зӯүгҖӮ
- иҝҗиЎҢж—¶еёёйҮҸжұ пјҲж–№жі•еҢәзҡ„дёҖйғЁеҲҶпјү
GCеҜ№е®ғ们зҡ„еӣһ收пјҡ
еҶ…еӯҳеҢәеҹҹдёӯзҡ„зЁӢеәҸи®Ўж•°еҷЁгҖҒиҷҡжӢҹжңәж ҲгҖҒжң¬ең°ж–№жі•ж Ҳиҝҷ3дёӘеҢәеҹҹйҡҸзқҖзәҝзЁӢиҖҢз”ҹпјҢзәҝзЁӢиҖҢзҒӯпјӣж Ҳдёӯзҡ„ж Ҳеё§йҡҸзқҖж–№жі•зҡ„иҝӣе…Ҙе’ҢйҖҖеҮәиҖҢжңүжқЎдёҚзҙҠең°жү§иЎҢзқҖеҮәж Ҳе’Ңе…Ҙж Ҳзҡ„ж“ҚдҪңпјҢжҜҸдёӘж Ҳеё§дёӯеҲҶй…ҚеӨҡе°‘еҶ…еӯҳеҹәжң¬жҳҜеңЁзұ»з»“жһ„зЎ®е®ҡдёӢжқҘж—¶е°ұе·ІзҹҘзҡ„гҖӮеңЁиҝҷеҮ дёӘеҢәеҹҹдёҚйңҖиҰҒиҝҮеӨҡиҖғиҷ‘еӣһ收зҡ„й—®йўҳпјҢеӣ дёәж–№жі•з»“жқҹжҲ–иҖ…зәҝзЁӢз»“жқҹж—¶пјҢеҶ…еӯҳиҮӘ然е°ұи·ҹзқҖеӣһ收дәҶгҖӮ
GCеӣһ收зҡ„дё»иҰҒеҜ№иұЎпјҡиҖҢJavaе Ҷе’Ңж–№жі•еҢәеҲҷдёҚеҗҢпјҢдёҖдёӘжҺҘеҸЈдёӯзҡ„еӨҡдёӘе®һзҺ°зұ»йңҖиҰҒзҡ„еҶ…еӯҳеҸҜиғҪдёҚеҗҢпјҢдёҖдёӘж–№жі•дёӯзҡ„еӨҡдёӘеҲҶж”ҜйңҖиҰҒзҡ„еҶ…еӯҳд№ҹеҸҜиғҪдёҚдёҖж ·пјҢжҲ‘们еҸӘжңүеңЁзЁӢеәҸеӨ„дәҺиҝҗиЎҢжңҹй—ҙж—¶жүҚиғҪзҹҘйҒ“дјҡеҲӣе»әе“ӘдәӣеҜ№иұЎпјҢиҝҷйғЁеҲҶеҶ…еӯҳзҡ„еҲҶй…Қе’Ңеӣһ收йғҪжҳҜеҠЁжҖҒзҡ„пјҢGCе…іжіЁзҡ„д№ҹжҳҜиҝҷйғЁеҲҶеҶ…еӯҳпјҢеҗҺйқўзҡ„ж–Үз« дёӯеҰӮжһңж¶үеҸҠеҲ°вҖңеҶ…еӯҳвҖқеҲҶй…ҚдёҺеӣһ收д№ҹд»…жҢҮзқҖдёҖйғЁеҲҶеҶ…еӯҳгҖӮ
В
1гҖҒзЁӢеәҸи®Ўж•°еҷЁпјҡпјҲзәҝзЁӢз§Ғжңүпјү
жҜҸдёӘзәҝзЁӢжӢҘжңүдёҖдёӘзЁӢеәҸи®Ўж•°еҷЁпјҢеңЁзәҝзЁӢеҲӣе»әж—¶еҲӣе»әпјҢ
жҢҮеҗ‘дёӢдёҖжқЎжҢҮд»Өзҡ„ең°еқҖ
жү§иЎҢжң¬ең°ж–№жі•ж—¶пјҢе…¶еҖјдёәundefined
иҜҙзҡ„йҖҡдҝ—дёҖзӮ№пјҢжҲ‘们зҹҘйҒ“пјҢJavaжҳҜж”ҜжҢҒеӨҡзәҝзЁӢзҡ„пјҢзЁӢеәҸе…ҲеҺ»жү§иЎҢAзәҝзЁӢпјҢжү§иЎҢеҲ°дёҖеҚҠпјҢ然еҗҺе°ұеҺ»жү§иЎҢBзәҝзЁӢпјҢ然еҗҺеҸҲи·‘еӣһжқҘжҺҘзқҖжү§иЎҢAзәҝзЁӢпјҢйӮЈзЁӢеәҸжҳҜжҖҺд№Ҳи®°дҪҸAзәҝзЁӢе·Із»Ҹжү§иЎҢеҲ°е“ӘйҮҢдәҶе‘ўпјҹиҝҷе°ұйңҖиҰҒзЁӢеәҸи®Ўж•°еҷЁдәҶгҖӮеӣ жӯӨпјҢдёәдәҶзәҝзЁӢеҲҮжҚўеҗҺиғҪеӨҹжҒўеӨҚеҲ°жӯЈзЎ®зҡ„жү§иЎҢдҪҚзҪ®пјҢжҜҸжқЎзәҝзЁӢйғҪжңүдёҖдёӘзӢ¬з«Ӣзҡ„зЁӢеәҸи®Ўж•°еҷЁпјҢиҝҷеқ—е„ҝеұһдәҺвҖңзәҝзЁӢз§ҒжңүвҖқзҡ„еҶ…еӯҳгҖӮ
В
2гҖҒJavaиҷҡжӢҹжңәж ҲпјҡпјҲзәҝзЁӢз§Ғжңүпјү
жҜҸдёӘж–№жі•иў«и°ғз”Ёзҡ„ж—¶еҖҷйғҪдјҡеҲӣе»әдёҖдёӘж Ҳеё§пјҢз”ЁдәҺеӯҳеӮЁеұҖйғЁеҸҳйҮҸиЎЁгҖҒж“ҚдҪңж ҲгҖҒеҠЁжҖҒй“ҫжҺҘгҖҒж–№жі•еҮәеҸЈзӯүдҝЎжҒҜгҖӮеұҖйғЁеҸҳйҮҸиЎЁеӯҳж”ҫзҡ„жҳҜпјҡзј–иҜ‘жңҹеҸҜзҹҘзҡ„еҹәжң¬ж•°жҚ®зұ»еһӢгҖҒеҜ№иұЎеј•з”Ёзұ»еһӢгҖӮ
В В В жҜҸдёӘж–№жі•иў«и°ғз”ЁзӣҙеҲ°жү§иЎҢе®ҢжҲҗзҡ„иҝҮзЁӢпјҢе°ұеҜ№еә”зқҖдёҖдёӘж Ҳеё§еңЁиҷҡжӢҹжңәдёӯд»Һе…Ҙж ҲеҲ°еҮәж Ҳзҡ„иҝҮзЁӢгҖӮ
еңЁJavaиҷҡжӢҹжңә规иҢғдёӯпјҢеҜ№иҝҷдёӘеҢәеҹҹ规е®ҡдәҶдёӨз§ҚејӮеёёжғ…еҶөпјҡ
гҖҖгҖҖпјҲ1пјүеҰӮжһңзәҝзЁӢиҜ·жұӮзҡ„ж Ҳж·ұеәҰеӨӘж·ұпјҢи¶…еҮәдәҶиҷҡжӢҹжңәжүҖе…Ғи®ёзҡ„ж·ұеәҰпјҢе°ұдјҡеҮәзҺ°StackOverFlowErrorпјҲжҜ”еҰӮж— йҷҗйҖ’еҪ’гҖӮеӣ дёәжҜҸдёҖеұӮж Ҳеё§йғҪеҚ з”ЁдёҖе®ҡз©әй—ҙпјҢиҖҢ Xss 规е®ҡдәҶж Ҳзҡ„жңҖеӨ§з©әй—ҙпјҢи¶…еҮәиҝҷдёӘеҖје°ұдјҡжҠҘй”ҷпјү
гҖҖгҖҖпјҲ2пјүиҷҡжӢҹжңәж ҲеҸҜд»ҘеҠЁжҖҒжү©еұ•пјҢеҰӮжһңжү©еұ•еҲ°ж— жі•з”іиҜ·и¶іеӨҹзҡ„еҶ…еӯҳз©әй—ҙпјҢдјҡеҮәзҺ°OOM
В
3гҖҒжң¬ең°ж–№жі•ж Ҳпјҡ
пјҲ1пјүжң¬ең°ж–№жі•ж ҲдёҺjavaиҷҡжӢҹжңәж ҲдҪңз”Ёйқһеёёзұ»дјјпјҢе…¶еҢәеҲ«жҳҜпјҡjavaиҷҡжӢҹжңәж ҲжҳҜдёәиҷҡжӢҹжңәжү§иЎҢjavaж–№жі•жңҚеҠЎзҡ„пјҢиҖҢжң¬ең°ж–№жі•ж ҲеҲҷдёәиҷҡжӢҹжңәжү§дҪҝз”ЁеҲ°зҡ„Nativeж–№жі•жңҚеҠЎгҖӮ
пјҲ2пјүJavaиҷҡжӢҹжңәжІЎжңүеҜ№жң¬ең°ж–№жі•ж Ҳзҡ„дҪҝз”Ёе’Ңж•°жҚ®з»“жһ„еҒҡејәеҲ¶и§„е®ҡпјҢSun HotSpotиҷҡжӢҹжңәе°ұжҠҠjavaиҷҡжӢҹжңәж Ҳе’Ңжң¬ең°ж–№жі•ж ҲеҗҲдәҢдёәдёҖгҖӮ
пјҲ3пјүжң¬ең°ж–№жі•ж Ҳд№ҹдјҡжҠӣеҮәStackOverFlowErrorе’ҢOutOfMemoryErrorгҖӮ
В
4гҖҒJavaе ҶпјҡеҚіе ҶеҶ…еӯҳпјҲзәҝзЁӢе…ұдә«пјү
пјҲ1пјүе ҶжҳҜjavaиҷҡжӢҹжңәжүҖз®ЎзҗҶзҡ„еҶ…еӯҳеҢәеҹҹдёӯжңҖеӨ§зҡ„дёҖеқ—пјҢjavaе ҶжҳҜиў«жүҖжңүзәҝзЁӢе…ұдә«зҡ„еҶ…еӯҳеҢәеҹҹпјҢеңЁjavaиҷҡжӢҹжңәеҗҜеҠЁж—¶еҲӣе»әпјҢе ҶеҶ…еӯҳзҡ„е”ҜдёҖзӣ®зҡ„е°ұжҳҜеӯҳж”ҫеҜ№иұЎе®һдҫӢеҮ д№ҺжүҖжңүзҡ„еҜ№иұЎе®һдҫӢйғҪеңЁе ҶеҶ…еӯҳеҲҶй…ҚгҖӮ
пјҲ2пјүе ҶжҳҜGCз®ЎзҗҶзҡ„дё»иҰҒеҢәеҹҹпјҢд»Һеһғеңҫеӣһ收зҡ„и§’еәҰзңӢпјҢз”ұдәҺзҺ°еңЁзҡ„еһғеңҫ收йӣҶеҷЁйғҪжҳҜйҮҮз”Ёзҡ„еҲҶ代收йӣҶз®—жі•пјҢеӣ жӯӨjavaе ҶиҝҳеҸҜд»ҘеҲқжӯҘз»ҶеҲҶдёәж–°з”ҹд»Је’ҢиҖҒе№ҙд»ЈгҖӮ
пјҲ3пјүJavaиҷҡжӢҹжңә规е®ҡпјҢе ҶеҸҜд»ҘеӨ„дәҺзү©зҗҶдёҠдёҚиҝһз»ӯзҡ„еҶ…еӯҳз©әй—ҙдёӯпјҢеҸӘиҰҒйҖ»иҫ‘дёҠиҝһз»ӯзҡ„еҚіеҸҜгҖӮеңЁе®һзҺ°дёҠж—ўеҸҜд»ҘжҳҜеӣәе®ҡзҡ„пјҢд№ҹеҸҜд»ҘжҳҜеҸҜеҠЁжҖҒжү©еұ•зҡ„гҖӮеҰӮжһңеңЁе ҶеҶ…еӯҳжІЎжңүе®ҢжҲҗе®һдҫӢеҲҶй…ҚпјҢ并且е ҶеӨ§е°Ҹд№ҹж— жі•жү©еұ•пјҢе°ұдјҡжҠӣеҮәOutOfMemoryErrorејӮеёёгҖӮ
В
5гҖҒж–№жі•еҢәпјҡпјҲзәҝзЁӢе…ұдә«пјү
пјҲ1пјүз”ЁдәҺеӯҳеӮЁе·Іиў«иҷҡжӢҹжңәеҠ иҪҪзҡ„зұ»дҝЎжҒҜгҖҒеёёйҮҸгҖҒйқҷжҖҒеҸҳйҮҸгҖҒеҚіж—¶зј–иҜ‘еҷЁзј–иҜ‘еҗҺзҡ„д»Јз Ғзӯүж•°жҚ®гҖӮ
пјҲ2пјүSun HotSpotиҷҡжӢҹжңәжҠҠж–№жі•еҢәеҸ«еҒҡж°ёд№…д»ЈпјҲPermanent GenerationпјүпјҢж–№жі•еҢәдёӯжңҖйҮҚиҰҒзҡ„йғЁеҲҶжҳҜиҝҗиЎҢж—¶еёёйҮҸжұ гҖӮж°ёд№…д»Јзҡ„еһғеңҫ收йӣҶеӣһ收дёӨйғЁеҲҶеҶ…е®№пјҡеәҹејғеёёйҮҸе’Ңж— з”Ёзҡ„зұ»гҖӮ
еәҹејғеёёйҮҸпјҡеҰӮеёёйҮҸжұ дёӯеӯ—йқўйҮҸпјҢжІЎжңүд»»дҪ•дёҖдёӘеҜ№иұЎеј•з”ЁеёёйҮҸжұ дёӯзҡ„еёёйҮҸ
ж— з”Ёзҡ„зұ»пјҡ
1гҖҒиҜҘзұ»жүҖжңүзҡ„е®һдҫӢйғҪе·Із»Ҹиў«еӣһ收пјҢд№ҹе°ұжҳҜjavaе ҶдёӯдёҚеӯҳеңЁиҜҘзұ»зҡ„д»»дҪ•е®һдҫӢпјӣ
2гҖҒеҠ иҪҪиҜҘзұ»зҡ„ClassLoaderе·Із»Ҹиў«еӣһ收пјӣ
3гҖҒиҜҘзұ»еҜ№еә”зҡ„java.lang.ClassеҜ№иұЎжІЎжңүеңЁд»»дҪ•ең°ж–№иў«еј•з”ЁпјҢж— жі•еҶҚд»»дҪ•ең°ж–№йҖҡиҝҮеҸҚе°„и®ҝй—®иҜҘзұ»зҡ„ж–№жі•гҖӮ
В
6гҖҒиҝҗиЎҢж—¶еёёйҮҸжұ пјҡ
пјҲ1пјүиҝҗиЎҢж—¶еёёйҮҸжұ жҳҜж–№жі•еҢәзҡ„дёҖйғЁеҲҶпјҢиҮӘ然еҸ—еҲ°ж–№жі•еҢәеҶ…еӯҳзҡ„йҷҗеҲ¶пјҢеҪ“еёёйҮҸжұ ж— жі•еҶҚз”іиҜ·еҲ°еҶ…еӯҳж—¶е°ұдјҡжҠӣеҮәOutOfMemoryErrorејӮеёёгҖӮВ
жіЁпјҡе…ідәҺжң¬ж®өзҡ„иҜҰз»ҶеҶ…е®№пјҢеҸҜд»ҘеҸӮиҖғжң¬дәәзҡ„еҸҰеӨ–дёҖзҜҮеҚҡе®ўпјҡJavaиҷҡжӢҹжңәиҜҰи§Ј02----JVMеҶ…еӯҳз»“жһ„
В
7гҖҒзӣҙжҺҘеҶ…еӯҳпјҲDirect Memoryпјүпјҡ
зӣҙжҺҘеҶ…еӯҳпјҲDirectMemoryпјү并дёҚжҳҜиҷҡжӢҹжңәиҝҗиЎҢж—¶ж•°жҚ®еҢәзҡ„дёҖйғЁеҲҶпјҢд№ҹдёҚжҳҜJavaиҷҡжӢҹжңә规иҢғдёӯе®ҡд№үзҡ„еҶ…еӯҳеҢәеҹҹпјҢдҪҶжҳҜиҝҷйғЁеҲҶеҶ…еӯҳд№ҹиў«йў‘з№Ғең°дҪҝз”ЁпјҢиҖҢдё”д№ҹеҸҜиғҪеҜјиҮҙOutOfMemoryErrorејӮеёёеҮәзҺ°гҖӮJDK1.4еҠ зҡ„NIOдёӯпјҢByteBufferжңүдёӘж–№жі•жҳҜallocateDirect(intcapacity) пјҢиҝҷжҳҜдёҖз§ҚеҹәдәҺйҖҡйҒ“пјҲChannelпјүдёҺзј“еҶІеҢәпјҲBufferпјүзҡ„I/Oж–№ејҸпјҢе®ғеҸҜд»ҘдҪҝз”ЁNativeеҮҪж•°еә“зӣҙжҺҘеҲҶй…Қе ҶеӨ–еҶ…еӯҳпјҢ然еҗҺйҖҡиҝҮдёҖдёӘеӯҳеӮЁеңЁJavaе ҶйҮҢйқўзҡ„DirectByteBufferеҜ№иұЎдҪңдёәиҝҷеқ—еҶ…еӯҳзҡ„еј•з”ЁиҝӣиЎҢж“ҚдҪңгҖӮиҝҷж ·иғҪеңЁдёҖдәӣеңәжҷҜдёӯжҳҫи‘—жҸҗй«ҳжҖ§иғҪпјҢеӣ дёәйҒҝе…ҚдәҶеңЁJavaе Ҷе’ҢNativeе ҶдёӯжқҘеӣһеӨҚеҲ¶ж•°жҚ®гҖӮжҳҫ然пјҢжң¬жңәзӣҙжҺҘеҶ…еӯҳзҡ„еҲҶй…ҚдёҚдјҡеҸ—еҲ°Javaе ҶеӨ§е°Ҹзҡ„йҷҗеҲ¶пјҢдҪҶжҳҜпјҢ既然жҳҜеҶ…еӯҳпјҢеҲҷиӮҜе®ҡиҝҳжҳҜдјҡеҸ—еҲ°жң¬жңәжҖ»еҶ…еӯҳпјҲеҢ…жӢ¬RAMеҸҠSWAPеҢәжҲ–иҖ…еҲҶйЎөж–Ү件пјүзҡ„еӨ§е°ҸеҸҠеӨ„зҗҶеҷЁеҜ»еқҖз©әй—ҙзҡ„йҷҗеҲ¶гҖӮжңҚеҠЎеҷЁз®ЎзҗҶе‘ҳй…ҚзҪ®иҷҡжӢҹжңәеҸӮж•°ж—¶пјҢдёҖиҲ¬дјҡж №жҚ®е®һйҷ…еҶ…еӯҳи®ҫзҪ®-XmxзӯүеҸӮж•°дҝЎжҒҜпјҢдҪҶз»ҸеёёдјҡеҝҪз•ҘжҺүзӣҙжҺҘеҶ…еӯҳпјҢдҪҝеҫ—еҗ„дёӘеҶ…еӯҳеҢәеҹҹзҡ„жҖ»е’ҢеӨ§дәҺзү©зҗҶеҶ…еӯҳйҷҗеҲ¶пјҲеҢ…жӢ¬зү©зҗҶдёҠзҡ„е’Ңж“ҚдҪңзі»з»ҹзә§зҡ„йҷҗеҲ¶пјүпјҢд»ҺиҖҢеҜјиҮҙеҠЁжҖҒжү©еұ•ж—¶еҮәзҺ°OutOfMemoryErrorејӮеёёгҖӮ
В
еҸӘиғҪзӯүеҫ…иҖҒе№ҙд»Јж»ЎдәҶеҗҺFull GCпјҢ然еҗҺвҖңйЎәдҫҝең°вҖқеё®е®ғжё…зҗҶжҺүеҶ…еӯҳзҡ„еәҹејғеҜ№иұЎгҖӮ
В
дёүгҖҒJavaеҜ№иұЎеңЁеҶ…еӯҳдёӯзҡ„зҠ¶жҖҒпјҡ
еҸҜиҫҫзҡ„/еҸҜи§ҰеҸҠзҡ„пјҡ
гҖҖгҖҖJavaеҜ№иұЎиў«еҲӣе»әеҗҺпјҢеҰӮжһңиў«дёҖдёӘжҲ–еӨҡдёӘеҸҳйҮҸеј•з”ЁпјҢйӮЈе°ұжҳҜеҸҜиҫҫзҡ„гҖӮеҚід»Һж №иҠӮзӮ№еҸҜд»Ҙи§ҰеҸҠеҲ°иҝҷдёӘеҜ№иұЎгҖӮ
гҖҖгҖҖе…¶е®һе°ұжҳҜд»Һж №иҠӮзӮ№жү«жҸҸпјҢеҸӘиҰҒиҝҷдёӘеҜ№иұЎеңЁеј•з”Ёй“ҫдёӯпјҢйӮЈе°ұжҳҜеҸҜи§ҰеҸҠзҡ„гҖӮ
еҸҜжҒўеӨҚзҡ„пјҡ
гҖҖгҖҖJavaеҜ№иұЎдёҚеҶҚиў«д»»дҪ•еҸҳйҮҸеј•з”Ёе°ұиҝӣе…ҘдәҶеҸҜжҒўеӨҚзҠ¶жҖҒгҖӮ
гҖҖгҖҖеңЁеӣһ收иҜҘеҜ№иұЎд№ӢеүҚпјҢиҜҘеҜ№иұЎзҡ„finalize()ж–№жі•иҝӣиЎҢиө„жәҗжё…зҗҶгҖӮеҰӮжһңеңЁfinalize()ж–№жі•дёӯйҮҚж–°и®©еҸҳйҮҸеј•з”ЁиҜҘеҜ№иұЎпјҢеҲҷиҜҘеҜ№иұЎеҶҚж¬ЎеҸҳдёәеҸҜиҫҫзҠ¶жҖҒпјҢеҗҰеҲҷиҜҘеҜ№иұЎиҝӣе…ҘдёҚеҸҜиҫҫзҠ¶жҖҒ
д»»дҪ•дёҖдёӘеҜ№иұЎзҡ„finalize()ж–№жі•йғҪеҸӘдјҡиў«зі»з»ҹиҮӘеҠЁи°ғз”ЁдёҖж¬Ў
дёҚеҸҜиҫҫзҡ„пјҡ
гҖҖгҖҖJavaеҜ№иұЎдёҚиў«д»»дҪ•еҸҳйҮҸеј•з”ЁпјҢдё”зі»з»ҹеңЁи°ғз”ЁеҜ№иұЎзҡ„finalize()ж–№жі•еҗҺдҫқ然没жңүдҪҝиҜҘеҜ№иұЎеҸҳжҲҗеҸҜиҫҫзҠ¶жҖҒпјҲиҜҘеҜ№иұЎдҫқ然没жңүиў«еҸҳйҮҸеј•з”ЁпјүпјҢйӮЈд№ҲиҜҘеҜ№иұЎе°ҶеҸҳжҲҗдёҚеҸҜиҫҫзҠ¶жҖҒгҖӮ
гҖҖгҖҖеҪ“JavaеҜ№иұЎеӨ„дәҺдёҚеҸҜиҫҫзҠ¶жҖҒж—¶пјҢзі»з»ҹжүҚдјҡзңҹжӯЈеӣһ收иҜҘеҜ№иұЎжүҖеҚ жңүзҡ„иө„жәҗгҖӮ
В
еӣӣгҖҒеҲӨж–ӯеҜ№иұЎжӯ»дәЎзҡ„дёӨз§Қеёёз”Ёз®—жі•пјҡ
В В В еҪ“еҜ№иұЎдёҚиў«еј•з”Ёзҡ„ж—¶еҖҷпјҢиҝҷдёӘеҜ№иұЎе°ұжҳҜжӯ»дәЎзҡ„пјҢзӯүеҫ…GCиҝӣиЎҢеӣһ收гҖӮ
1гҖҒеј•з”Ёи®Ўж•°з®—жі•пјҡ
жҰӮеҝөпјҡ
гҖҖгҖҖз»ҷеҜ№иұЎдёӯж·»еҠ дёҖдёӘеј•з”Ёи®Ўж•°еҷЁпјҢжҜҸеҪ“жңүдёҖдёӘең°ж–№еј•з”Ёе®ғж—¶пјҢи®Ўж•°еҷЁеҖје°ұеҠ 1пјӣеҪ“еј•з”ЁеӨұж•Ҳж—¶пјҢи®Ўж•°еҷЁеҖје°ұеҮҸ1пјӣд»»дҪ•ж—¶еҲ»и®Ўж•°еҷЁдёә0зҡ„еҜ№иұЎе°ұжҳҜдёҚеҸҜиғҪеҶҚиў«дҪҝз”Ёзҡ„гҖӮ
дҪҶжҳҜпјҡ
гҖҖгҖҖдё»жөҒзҡ„javaиҷҡжӢҹжңә并没жңүйҖүз”Ёеј•з”Ёи®Ўж•°з®—жі•жқҘз®ЎзҗҶеҶ…еӯҳпјҢе…¶дёӯжңҖдё»иҰҒзҡ„еҺҹеӣ жҳҜпјҡе®ғеҫҲйҡҫи§ЈеҶіеҜ№иұЎд№Ӣй—ҙзӣёдә’еҫӘзҺҜеј•з”Ёзҡ„й—®йўҳгҖӮ
дјҳзӮ№пјҡ
гҖҖгҖҖз®—жі•зҡ„е®һзҺ°з®ҖеҚ•пјҢеҲӨе®ҡж•ҲзҺҮд№ҹй«ҳпјҢеӨ§йғЁеҲҶжғ…еҶөдёӢжҳҜдёҖдёӘдёҚй”ҷзҡ„з®—жі•гҖӮеҫҲеӨҡең°ж–№еә”з”ЁеҲ°е®ғ
зјәзӮ№пјҡ
еј•з”Ёе’ҢеҺ»еј•з”ЁдјҙйҡҸеҠ жі•е’ҢеҮҸжі•пјҢеҪұе“ҚжҖ§иғҪ
иҮҙе‘Ҫзҡ„зјәйҷ·пјҡеҜ№дәҺеҫӘзҺҜеј•з”Ёзҡ„еҜ№иұЎж— жі•иҝӣиЎҢеӣһ收
2гҖҒж №жҗңзҙўз®—жі•пјҡпјҲjvmйҮҮз”Ёзҡ„з®—жі•пјҢд№ҹеҸ«еҸҜиҫҫжҖ§еҲҶжһҗз®—жі•пјү
жҰӮеҝөпјҡ
гҖҖгҖҖи®ҫз«ӢиӢҘе№Із§Қж №еҜ№иұЎпјҢеҪ“д»»дҪ•дёҖдёӘж №еҜ№иұЎпјҲGC RootпјүеҲ°жҹҗдёҖдёӘеҜ№иұЎеқҮдёҚеҸҜиҫҫж—¶пјҢеҲҷи®ӨдёәиҝҷдёӘеҜ№иұЎжҳҜеҸҜд»Ҙиў«еӣһ收зҡ„гҖӮ
жіЁпјҡиҝҷйҮҢжҸҗеҲ°пјҢи®ҫз«ӢиӢҘе№Із§Қж №еҜ№иұЎпјҢеҪ“д»»дҪ•дёҖдёӘж №еҜ№иұЎеҲ°жҹҗдёҖдёӘеҜ№иұЎеқҮдёҚеҸҜиҫҫж—¶пјҢеҲҷи®ӨдёәиҝҷдёӘеҜ№иұЎжҳҜеҸҜд»Ҙиў«еӣһ收зҡ„гҖӮжҲ‘们еңЁеҗҺйқўд»Ӣз»Қж Үи®°-жё…зҗҶз®—жі•/ж Үи®°ж•ҙзҗҶз®—жі•ж—¶пјҢд№ҹдјҡдёҖзӣҙејәи°ғд»Һж №иҠӮзӮ№ејҖе§ӢпјҢеҜ№жүҖжңүеҸҜиҫҫеҜ№иұЎеҒҡдёҖж¬Ўж Үи®°пјҢйӮЈд»Җд№ҲеҸ«еҒҡеҸҜиҫҫе‘ўпјҹ
еҸҜиҫҫжҖ§еҲҶжһҗпјҡ
гҖҖгҖҖд»Һж №пјҲGC Rootsпјүзҡ„еҜ№иұЎдҪңдёәиө·е§ӢзӮ№пјҢејҖе§Ӣеҗ‘дёӢжҗңзҙўпјҢжҗңзҙўжүҖиө°иҝҮзҡ„и·Ҝеҫ„з§°дёәвҖңеј•з”Ёй“ҫвҖқпјҢеҪ“дёҖдёӘеҜ№иұЎеҲ°GC RootsжІЎжңүд»»дҪ•еј•з”Ёй“ҫзӣёиҝһпјҲз”Ёеӣҫи®әзҡ„жҰӮеҝөжқҘи®ІпјҢе°ұжҳҜд»ҺGC RootsеҲ°иҝҷдёӘеҜ№иұЎдёҚеҸҜиҫҫпјүж—¶пјҢеҲҷиҜҒжҳҺжӯӨеҜ№иұЎжҳҜдёҚеҸҜз”Ёзҡ„гҖӮ

еҰӮдёҠеӣҫжүҖзӨәпјҢObjectDе’ҢObjectEжҳҜдә’зӣёе…іиҒ”зҡ„пјҢдҪҶжҳҜз”ұдәҺGC rootsеҲ°иҝҷдёӨдёӘеҜ№иұЎдёҚеҸҜиҫҫпјҢжүҖд»ҘжңҖз»ҲDе’ҢEиҝҳжҳҜдјҡиў«еҪ“еҒҡGCзҡ„еҜ№иұЎпјҢдёҠеӣҫиӢҘжҳҜйҮҮз”Ёеј•з”Ёи®Ўж•°жі•пјҢеҲҷA-Eдә”дёӘеҜ№иұЎйғҪдёҚдјҡиў«еӣһ收гҖӮ
В
ж №пјҲGC Rootsпјүпјҡ
иҜҙеҲ°GC rootsпјҲGCж №пјүпјҢеңЁJAVAиҜӯиЁҖдёӯпјҢеҸҜд»ҘеҪ“еҒҡGC rootsзҡ„еҜ№иұЎжңүд»ҘдёӢеҮ з§Қпјҡ
1гҖҒж ҲпјҲж Ҳеё§дёӯзҡ„жң¬ең°еҸҳйҮҸиЎЁпјүдёӯеј•з”Ёзҡ„еҜ№иұЎгҖӮ
2гҖҒж–№жі•еҢәдёӯзҡ„йқҷжҖҒжҲҗе‘ҳгҖӮ
3гҖҒж–№жі•еҢәдёӯзҡ„еёёйҮҸеј•з”Ёзҡ„еҜ№иұЎпјҲе…ЁеұҖеҸҳйҮҸпјү
4гҖҒжң¬ең°ж–№жі•ж ҲдёӯJNIпјҲдёҖиҲ¬иҜҙзҡ„Nativeж–№жі•пјүеј•з”Ёзҡ„еҜ№иұЎгҖӮ
жіЁпјҡ第дёҖе’Ң第еӣӣз§ҚйғҪжҳҜжҢҮзҡ„ж–№жі•зҡ„жң¬ең°еҸҳйҮҸиЎЁпјҢ第дәҢз§ҚиЎЁиҫҫзҡ„ж„ҸжҖқжҜ”иҫғжё…жҷ°пјҢ第дёүз§Қдё»иҰҒжҢҮзҡ„жҳҜеЈ°жҳҺдёәfinalзҡ„еёёйҮҸеҖјгҖӮ
еңЁж №жҗңзҙўз®—жі•зҡ„еҹәзЎҖдёҠпјҢзҺ°д»ЈиҷҡжӢҹжңәзҡ„е®һзҺ°еҪ“дёӯпјҢеһғеңҫжҗңйӣҶзҡ„з®—жі•дё»иҰҒжңүдёүз§ҚпјҢеҲҶеҲ«жҳҜж Үи®°-жё…йҷӨз®—жі•гҖҒеӨҚеҲ¶з®—жі•гҖҒж Үи®°-ж•ҙзҗҶз®—жі•гҖӮиҝҷдёүз§Қз®—жі•йғҪжү©е……дәҶж №жҗңзҙўз®—жі•пјҢдёҚиҝҮе®ғ们зҗҶи§Јиө·жқҘиҝҳжҳҜйқһеёёеҘҪзҗҶи§Јзҡ„гҖӮ
В
дә”гҖҒеһғеңҫеӣһ收算法пјҡ
В
еһғеңҫеӣһ收еҠЁдҪңеҸ‘з”ҹзҡ„еҗҢж—¶пјҢзЁӢеәҸе°Ҷдјҡиў«жҡӮеҒңпјҒпјҒпјҒпјҒпјҒпјҒпјҒпјҒ
В
1гҖҒж Үи®°-жё…йҷӨз®—жі•пјҡ
жҰӮеҝөпјҡ
ж Үи®°йҳ¶ж®өпјҡе…ҲйҖҡиҝҮж №иҠӮзӮ№пјҢж Үи®°жүҖжңүд»Һж №иҠӮзӮ№ејҖе§Ӣзҡ„еҸҜиҫҫеҜ№иұЎгҖӮеӣ жӯӨпјҢжңӘиў«ж Үи®°зҡ„еҜ№иұЎе°ұжҳҜжңӘиў«еј•з”Ёзҡ„еһғеңҫеҜ№иұЎпјӣ
жё…йҷӨйҳ¶ж®өпјҡжё…йҷӨжүҖжңүжңӘиў«ж Үи®°зҡ„еҜ№иұЎгҖӮ
зјәзӮ№пјҡ
ж Үи®°е’Ңжё…йҷӨзҡ„иҝҮзЁӢж•ҲзҺҮдёҚй«ҳпјҲж Үи®°е’Ңжё…йҷӨйғҪйңҖиҰҒд»ҺеӨҙйҒҚеҺҶеҲ°е°ҫпјү
ж Үи®°жё…йҷӨеҗҺдјҡдә§з”ҹеӨ§йҮҸдёҚиҝһз»ӯзҡ„зўҺзүҮгҖӮ
2гҖҒеӨҚеҲ¶з®—жі•пјҡпјҲж–°з”ҹд»Јзҡ„GCпјү
жҰӮеҝөпјҡ
гҖҖгҖҖе°ҶеҺҹжңүзҡ„еҶ…еӯҳз©әй—ҙеҲҶдёәдёӨеқ—пјҢжҜҸж¬ЎеҸӘдҪҝз”Ёе…¶дёӯдёҖеқ—пјҢеңЁеһғеңҫеӣһ收时пјҢе°ҶжӯЈеңЁдҪҝз”Ёзҡ„еҶ…еӯҳдёӯзҡ„еӯҳжҙ»еҜ№иұЎеӨҚеҲ¶еҲ°жңӘдҪҝз”Ёзҡ„еҶ…еӯҳеқ—дёӯпјҢ然еҗҺжё…йҷӨжӯЈеңЁдҪҝз”Ёзҡ„еҶ…еӯҳеқ—дёӯзҡ„жүҖжңүеҜ№иұЎгҖӮ
дјҳзӮ№пјҡ
иҝҷж ·дҪҝеҫ—жҜҸж¬ЎйғҪжҳҜеҜ№ж•ҙдёӘеҚҠеҢәиҝӣиЎҢеӣһ收пјҢеҶ…еӯҳеҲҶй…Қж—¶д№ҹе°ұдёҚз”ЁиҖғиҷ‘еҶ…еӯҳзўҺзүҮзӯүжғ…еҶө
еҸӘиҰҒ移еҠЁе ҶйЎ¶жҢҮй’ҲпјҢжҢүйЎәеәҸеҲҶй…ҚеҶ…еӯҳеҚіеҸҜпјҢе®һзҺ°з®ҖеҚ•пјҢиҝҗиЎҢж•ҲзҺҮй«ҳ
зјәзӮ№пјҡз©әй—ҙзҡ„жөӘиҙ№
гҖҖгҖҖд»Һд»ҘдёҠжҸҸиҝ°дёҚйҡҫзңӢеҮәпјҢеӨҚеҲ¶з®—жі•иҰҒжғідҪҝз”ЁпјҢжңҖиө·з ҒеҜ№иұЎзҡ„еӯҳжҙ»зҺҮиҰҒйқһеёёдҪҺжүҚиЎҢгҖӮ
гҖҖгҖҖзҺ°еңЁзҡ„е•ҶдёҡиҷҡжӢҹжңәйғҪйҮҮз”Ёиҝҷз§Қ收йӣҶз®—жі•жқҘеӣһ收新з”ҹд»ЈпјҢж–°з”ҹд»Јдёӯзҡ„еҜ№иұЎ98%йғҪжҳҜвҖңжңқз”ҹеӨ•жӯ»вҖқзҡ„пјҢжүҖд»Ҙ并дёҚйңҖиҰҒжҢүз…§1:1зҡ„жҜ”дҫӢжқҘеҲ’еҲҶеҶ…еӯҳз©әй—ҙпјҢиҖҢжҳҜе°ҶеҶ…еӯҳеҲҶдёәдёҖеқ—жҜ”иҫғеӨ§зҡ„Edenз©әй—ҙе’ҢдёӨеқ—иҫғе°Ҹзҡ„Survivorз©әй—ҙпјҢжҜҸж¬ЎдҪҝз”ЁEdenе’Ңе…¶дёӯдёҖеқ—SurvivorгҖӮеҪ“еӣһ收时пјҢе°ҶEdenе’ҢSurvivorдёӯиҝҳеӯҳжҙ»зқҖзҡ„еҜ№иұЎдёҖж¬ЎжҖ§ең°еӨҚеҲ¶еҲ°еҸҰеӨ–дёҖеқ—Survivorз©әй—ҙдёҠпјҢжңҖеҗҺжё…зҗҶжҺүEdenе’ҢеҲҡжүҚз”ЁиҝҮзҡ„Survivorз©әй—ҙгҖӮHotSpotиҷҡжӢҹжңәй»ҳи®ӨEdenе’ҢSurvivorзҡ„еӨ§е°ҸжҜ”дҫӢжҳҜ8:1пјҢд№ҹе°ұжҳҜиҜҙпјҢжҜҸж¬Ўж–°з”ҹд»ЈдёӯеҸҜз”ЁеҶ…еӯҳз©әй—ҙдёәж•ҙдёӘж–°з”ҹд»Је®№йҮҸзҡ„90%пјҲ80%+10%пјүпјҢеҸӘжңү10%зҡ„з©әй—ҙдјҡиў«жөӘиҙ№гҖӮ
еҪ“然пјҢ98%зҡ„еҜ№иұЎеҸҜеӣһ收еҸӘжҳҜдёҖиҲ¬еңәжҷҜдёӢзҡ„ж•°жҚ®пјҢжҲ‘们没жңүеҠһжі•дҝқиҜҒжҜҸж¬Ўеӣһ收йғҪеҸӘжңүдёҚеӨҡдәҺ10%зҡ„еҜ№иұЎеӯҳжҙ»пјҢеҪ“Survivorз©әй—ҙдёҚеӨҹз”Ёж—¶пјҢйңҖиҰҒдҫқиө–дәҺиҖҒе№ҙд»ЈиҝӣиЎҢеҲҶй…ҚжӢ…дҝқпјҢжүҖд»ҘеӨ§еҜ№иұЎзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮж•ҙдёӘиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ

В
В
3гҖҒж Үи®°-ж•ҙзҗҶз®—жі•пјҡпјҲиҖҒе№ҙд»Јзҡ„GCпјү
В В В еӨҚеҲ¶з®—жі•еңЁеҜ№иұЎеӯҳжҙ»зҺҮй«ҳзҡ„ж—¶еҖҷиҰҒиҝӣиЎҢиҫғеӨҡзҡ„еӨҚеҲ¶ж“ҚдҪңпјҢж•ҲзҺҮе°ҶдјҡйҷҚдҪҺпјҢжүҖд»ҘеңЁиҖҒе№ҙд»ЈдёӯдёҖиҲ¬дёҚиғҪзӣҙжҺҘйҖүз”Ёиҝҷз§Қз®—жі•гҖӮ
жҰӮеҝөпјҡ
ж Үи®°йҳ¶ж®өпјҡе…ҲйҖҡиҝҮж №иҠӮзӮ№пјҢж Үи®°жүҖжңүд»Һж №иҠӮзӮ№ејҖе§Ӣзҡ„еҸҜиҫҫеҜ№иұЎгҖӮеӣ жӯӨпјҢжңӘиў«ж Үи®°зҡ„еҜ№иұЎе°ұжҳҜжңӘиў«еј•з”Ёзҡ„еһғеңҫеҜ№иұЎ
ж•ҙзҗҶйҳ¶ж®өпјҡе°Ҷе°ҶжүҖжңүзҡ„еӯҳжҙ»еҜ№иұЎеҺӢзј©еҲ°еҶ…еӯҳзҡ„дёҖз«Ҝпјӣд№ӢеҗҺпјҢжё…зҗҶиҫ№з•ҢеӨ–жүҖжңүзҡ„з©әй—ҙ
дјҳзӮ№пјҡ
гҖҖгҖҖдёҚдјҡдә§з”ҹеҶ…еӯҳзўҺзүҮгҖӮ
зјәзӮ№пјҡ
гҖҖгҖҖеңЁж Үи®°зҡ„еҹәзЎҖд№ӢдёҠиҝҳйңҖиҰҒиҝӣиЎҢеҜ№иұЎзҡ„移еҠЁпјҢжҲҗжң¬зӣёеҜ№иҫғй«ҳпјҢж•ҲзҺҮд№ҹдёҚй«ҳгҖӮ
В
е®ғ们зҡ„еҢәеҲ«еҰӮдёӢпјҡпјҲ>иЎЁзӨәеүҚиҖ…иҰҒдјҳдәҺеҗҺиҖ…пјҢ=иЎЁзӨәдёӨиҖ…ж•ҲжһңдёҖж ·пјү
пјҲ1пјүж•ҲзҺҮпјҡеӨҚеҲ¶з®—жі• > ж Үи®°/ж•ҙзҗҶз®—жі• > ж Үи®°/жё…йҷӨз®—жі•пјҲжӯӨеӨ„зҡ„ж•ҲзҺҮеҸӘжҳҜз®ҖеҚ•зҡ„еҜ№жҜ”ж—¶й—ҙеӨҚжқӮеәҰпјҢе®һйҷ…жғ…еҶөдёҚдёҖе®ҡеҰӮжӯӨпјүгҖӮ
пјҲ2пјүеҶ…еӯҳж•ҙйҪҗеәҰпјҡеӨҚеҲ¶з®—жі•=ж Үи®°/ж•ҙзҗҶз®—жі•>ж Үи®°/жё…йҷӨз®—жі•гҖӮ
пјҲ3пјүеҶ…еӯҳеҲ©з”ЁзҺҮпјҡж Үи®°/ж•ҙзҗҶз®—жі•=ж Үи®°/жё…йҷӨз®—жі•>еӨҚеҲ¶з®—жі•гҖӮ
жіЁ1пјҡж Үи®°-ж•ҙзҗҶз®—жі•дёҚд»…еҸҜд»ҘејҘиЎҘж Үи®°-жё…йҷӨз®—жі•еҪ“дёӯпјҢеҶ…еӯҳеҢәеҹҹеҲҶж•Јзҡ„зјәзӮ№пјҢд№ҹж¶ҲйҷӨдәҶеӨҚеҲ¶з®—жі•еҪ“дёӯпјҢеҶ…еӯҳеҮҸеҚҠзҡ„й«ҳйўқд»Јд»·гҖӮ
жіЁ2пјҡеҸҜд»ҘзңӢеҲ°ж Үи®°/жё…йҷӨз®—жі•жҳҜжҜ”иҫғиҗҪеҗҺзҡ„з®—жі•дәҶпјҢдҪҶжҳҜеҗҺдёӨз§Қз®—жі•еҚҙжҳҜеңЁжӯӨеҹәзЎҖдёҠе»әз«Ӣзҡ„гҖӮ
жіЁ3пјҡж—¶й—ҙдёҺз©әй—ҙдёҚеҸҜе…јеҫ—гҖӮ
В
4гҖҒеҲҶ代收йӣҶз®—жі•пјҡ
гҖҖгҖҖеҪ“еүҚе•ҶдёҡиҷҡжӢҹжңәзҡ„GCйғҪжҳҜйҮҮз”Ёзҡ„вҖңеҲҶ代收йӣҶз®—жі•вҖқпјҢиҝҷ并дёҚжҳҜд»Җд№Ҳж–°зҡ„жҖқжғіпјҢеҸӘжҳҜж №жҚ®еҜ№иұЎзҡ„еӯҳжҙ»е‘Ёжңҹзҡ„дёҚеҗҢе°ҶеҶ…еӯҳеҲ’еҲҶдёәеҮ еқ—е„ҝгҖӮдёҖиҲ¬жҳҜжҠҠJavaе ҶеҲҶдёәж–°з”ҹд»Је’ҢиҖҒе№ҙд»Јпјҡзҹӯе‘ҪеҜ№иұЎеҪ’дёәж–°з”ҹд»ЈпјҢй•ҝе‘ҪеҜ№иұЎеҪ’дёәиҖҒе№ҙд»ЈгҖӮ
- еӯҳжҙ»зҺҮдҪҺпјҡе°‘йҮҸеҜ№иұЎеӯҳжҙ»пјҢйҖӮеҗҲеӨҚеҲ¶з®—жі•пјҡеңЁж–°з”ҹд»ЈдёӯпјҢжҜҸж¬ЎGCж—¶йғҪеҸ‘зҺ°жңүеӨ§жү№еҜ№иұЎжӯ»еҺ»пјҢеҸӘжңүе°‘йҮҸеӯҳжҙ»пјҲж–°з”ҹд»Јдёӯ98%зҡ„еҜ№иұЎйғҪжҳҜвҖңжңқз”ҹеӨ•жӯ»вҖқпјүпјҢйӮЈе°ұйҖүз”ЁеӨҚеҲ¶з®—жі•пјҢеҸӘйңҖиҰҒд»ҳеҮәе°‘йҮҸеӯҳжҙ»еҜ№иұЎзҡ„еӨҚеҲ¶жҲҗжң¬е°ұеҸҜд»Ҙе®ҢжҲҗGCгҖӮ
- еӯҳжҙ»зҺҮй«ҳпјҡеӨ§йҮҸеҜ№иұЎеӯҳжҙ»пјҢйҖӮеҗҲз”Ёж Үи®°-жё…зҗҶ/ж Үи®°-ж•ҙзҗҶпјҡеңЁиҖҒе№ҙд»ЈдёӯпјҢеӣ дёәеҜ№иұЎеӯҳжҙ»зҺҮй«ҳгҖҒжІЎжңүйўқеӨ–з©әй—ҙеҜ№д»–иҝӣиЎҢеҲҶй…ҚжӢ…дҝқпјҢе°ұеҝ…йЎ»дҪҝз”ЁвҖңж Үи®°-жё…зҗҶвҖқ/вҖңж Үи®°-ж•ҙзҗҶвҖқз®—жі•иҝӣиЎҢGCгҖӮ
жіЁпјҡиҖҒе№ҙд»Јзҡ„еҜ№иұЎдёӯпјҢжңүдёҖе°ҸйғЁеҲҶжҳҜеӣ дёәеңЁж–°з”ҹд»Јеӣһ收时пјҢиҖҒе№ҙд»ЈеҒҡжӢ…дҝқпјҢиҝӣжқҘзҡ„еҜ№иұЎпјӣз»қеӨ§йғЁеҲҶеҜ№иұЎжҳҜеӣ дёәеҫҲеӨҡж¬ЎGCйғҪжІЎжңүиў«еӣһ收жҺүиҖҢиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮ
В
е…ӯгҖҒеһғеңҫ收йӣҶеҷЁпјҡ
GCиҝӣиЎҢж—¶еҝ…йЎ»еҒңйЎҝжүҖжңүзҡ„Javaжү§иЎҢзәҝзЁӢ----Stop The Worldпјӣ
В
зЁӢеәҸжү§иЎҢ时并йқһеңЁжүҖжңүең°ж–№йғҪиғҪеҒңйЎҝдёӢжқҘејҖе§ӢGCпјҢеҸӘжңүеңЁеҲ°иҫҫе®үе…ЁзӮ№ж—¶жүҚиғҪжҡӮеҒң--SagepointгҖӮ
В
е®үе…ЁзӮ№зҡ„йҖүе®ҡпјҡжҳҜеҗҰе…·жңүи®©зЁӢеәҸй•ҝж—¶й—ҙжү§иЎҢзҡ„зү№еҫҒдёәж ҮеҮҶгҖӮж–№жі•и°ғз”ЁгҖҒеҫӘзҺҜи·іиҪ¬гҖҒејӮеёёи·іиҪ¬зӯүиҝҷдәӣеҠҹиғҪзҡ„жҢҮд»ӨжүҚдјҡдә§з”ҹSafepointгҖӮ
В
GCеҸ‘з”ҹж—¶и®©жүҖжңүзәҝзЁӢйғҪвҖңи·‘вҖқеҲ°жңҖиҝ‘зҡ„е®үе…ЁзӮ№еҒңйЎҝдёӢжқҘпјҢдёӨз§Қж–№жЎҲпјҡ
1гҖҒжҠўе…ҲејҸдёӯж–ӯпјҡдёҚйңҖиҰҒзәҝзЁӢзҡ„жү§иЎҢд»Јз Ғдё»еҠЁеҺ»й…ҚеҗҲпјҢеңЁGCеҸ‘з”ҹж—¶пјҢйҰ–е…ҲжҠҠжүҖжңүзәҝзЁӢе…ЁйғЁдёӯж–ӯпјҢеҰӮжһңеҸ‘зҺ°жңүзәҝзЁӢдёӯж–ӯзҡ„ең°ж–№дёҚеңЁе®үе…ЁзӮ№дёҠпјҢи®©е®ғвҖңи·‘вҖқеҲ°е®үе…ЁзӮ№дёҠгҖӮ
2гҖҒдё»еҠЁејҸдёӯж–ӯпјҡGCйңҖиҰҒдёӯж–ӯзәҝзЁӢзҡ„ж—¶еҖҷпјҢдёҚйңҖиҰҒеҜ№зәҝзЁӢж“ҚдҪңпјҢд»…д»…з®ҖеҚ•зҡ„и®ҫзҪ®дёҖдёӘж Үеҝ—пјҢеҗ„дёӘзәҝзЁӢжү§иЎҢж—¶дё»еҠЁеҺ»иҪ®иҜўиҝҷдёӘж Үеҝ—пјҢеҸ‘зҺ°дёӯж–ӯж Үеҝ—дёәзңҹж—¶е°ұиҮӘе·ұдёӯж–ӯжҢӮиө·гҖӮиҪ®иҜўж Үеҝ—зҡ„ең°ж–№е’Ңе®үе…ЁзӮ№жҳҜйҮҚеҗҲзҡ„гҖӮ
В
зәҝзЁӢеӨ„дәҺSleepзҠ¶жҖҒжҲ–BlockedзҠ¶жҖҒпјҢж— жі•е“Қеә”JVMзҡ„дёӯж–ӯиҜ·жұӮпјҢиө°еҲ°е®үе…ЁзӮ№зҡ„ең°ж–№дёӯж–ӯжҢӮиө·---йңҖиҰҒе®үе…ЁеҢәеҹҹи§ЈеҶіпјҡеңЁдёҖж®өд»Јз ҒзүҮж®өд№ӢеҗҺпјҢеј•з”Ёе…ізі»дёҚдјҡеҸ‘з”ҹеҸҳеҢ–гҖӮеңЁиҝҷдёӘеҢәеҹҹдёӯзҡ„д»»ж„Ҹең°ж–№ејҖе§ӢGCйғҪжҳҜе®үе…Ёзҡ„гҖӮ
В
В
еҰӮжһңиҜҙ收йӣҶз®—жі•жҳҜеҶ…еӯҳеӣһ收зҡ„ж–№жі•и®әпјҢйӮЈд№Ҳеһғеңҫ收йӣҶеҷЁе°ұжҳҜеҶ…еӯҳеӣһ收зҡ„е…·дҪ“е®һзҺ°гҖӮ
иҷҪ然жҲ‘们еңЁеҜ№еҗ„з§Қ收йӣҶеҷЁиҝӣиЎҢжҜ”иҫғпјҢдҪҶ并йқһдёәдәҶжҢ‘еҮәдёҖдёӘжңҖеҘҪзҡ„收йӣҶеҷЁгҖӮеӣ дёәзӣҙеҲ°зҺ°еңЁдёәжӯўиҝҳжІЎжңүжңҖеҘҪзҡ„收йӣҶеҷЁеҮәзҺ°пјҢжӣҙеҠ жІЎжңүдёҮиғҪзҡ„收йӣҶеҷЁпјҢжүҖд»ҘжҲ‘们йҖүжӢ©зҡ„еҸӘжҳҜеҜ№е…·дҪ“еә”з”ЁжңҖеҗҲйҖӮзҡ„收йӣҶеҷЁгҖӮ
1гҖҒSerial收йӣҶеҷЁпјҡпјҲдёІиЎҢ收йӣҶеҷЁпјү
иҝҷдёӘ收йӣҶеҷЁжҳҜдёҖдёӘеҚ•зәҝзЁӢзҡ„收йӣҶеҷЁпјҢдҪҶе®ғзҡ„еҚ•зәҝзЁӢзҡ„ж„Ҹд№ү并дёҚд»…д»…иҜҙжҳҺе®ғеҸӘдјҡдҪҝз”ЁдёҖдёӘCPUжҲ–дёҖжқЎж”¶йӣҶзәҝзЁӢеҺ»е®ҢжҲҗеһғеңҫ收йӣҶе·ҘдҪңпјҢжӣҙйҮҚиҰҒзҡ„жҳҜеңЁе®ғиҝӣиЎҢеһғеңҫ收йӣҶж—¶пјҢеҝ…йЎ»жҡӮеҒңе…¶д»–жүҖжңүзҡ„е·ҘдҪңзәҝзЁӢпјҲStop-The-Worldпјҡе°Ҷз”ЁжҲ·жӯЈеёёе·ҘдҪңзҡ„зәҝзЁӢе…ЁйғЁжҡӮеҒңжҺүпјүпјҢзӣҙеҲ°е®ғ收йӣҶз»“жқҹгҖӮ收йӣҶеҷЁзҡ„иҝҗиЎҢиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ

дёҠеӣҫдёӯпјҡ
- ж–°з”ҹд»ЈйҮҮз”ЁеӨҚеҲ¶з®—жі•пјҢStop-The-World
- иҖҒе№ҙд»ЈйҮҮз”Ёж Үи®°-ж•ҙзҗҶз®—жі•пјҢStop-The-World
еҪ“е®ғиҝӣиЎҢGCе·ҘдҪңзҡ„ж—¶еҖҷпјҢиҷҪ然дјҡйҖ жҲҗStop-The-WorldпјҢдҪҶе®ғеӯҳеңЁжңүеӯҳеңЁзҡ„еҺҹеӣ пјҡжӯЈжҳҜеӣ дёәе®ғзҡ„з®ҖеҚ•иҖҢй«ҳж•ҲпјҲдёҺ其他收йӣҶеҷЁзҡ„еҚ•зәҝзЁӢжҜ”пјүпјҢеҜ№дәҺйҷҗе®ҡеҚ•дёӘCPUзҡ„зҺҜеўғжқҘиҜҙпјҢжІЎжңүзәҝзЁӢдәӨдә’зҡ„ејҖй”ҖпјҢдё“еҝғеҒҡGCпјҢиҮӘ然еҸҜд»ҘиҺ·еҫ—жңҖй«ҳзҡ„еҚ•зәҝзЁӢжүӢжңәж•ҲзҺҮгҖӮжүҖд»ҘSerial收йӣҶеҷЁеҜ№дәҺиҝҗиЎҢеңЁclientжЁЎејҸдёӢжҳҜдёҖдёӘеҫҲеҘҪзҡ„йҖүжӢ©пјҲе®ғдҫқ然жҳҜиҷҡжӢҹжңәиҝҗиЎҢеңЁclientжЁЎејҸдёӢзҡ„й»ҳи®Өж–°з”ҹ代收йӣҶеҷЁпјүгҖӮ
В
2гҖҒParNew收йӣҶеҷЁпјҡSerial收йӣҶеҷЁзҡ„еӨҡзәҝзЁӢзүҲжң¬пјҲдҪҝз”ЁеӨҡжқЎзәҝзЁӢиҝӣиЎҢGCпјү
гҖҖгҖҖParNew收йӣҶеҷЁжҳҜSerial收йӣҶеҷЁзҡ„еӨҡзәҝзЁӢзүҲжң¬гҖӮ
гҖҖгҖҖе®ғжҳҜиҝҗиЎҢеңЁserverжЁЎејҸдёӢзҡ„йҰ–йҖүж–°з”ҹ代收йӣҶеҷЁпјҢйҷӨдәҶSerial收йӣҶеҷЁеӨ–пјҢзӣ®еүҚеҸӘжңүе®ғиғҪдёҺCMS收йӣҶеҷЁй…ҚеҗҲе·ҘдҪңгҖӮCMS收йӣҶеҷЁжҳҜдёҖдёӘиў«и®Өдёәе…·жңүеҲ’ж—¶д»Јж„Ҹд№үзҡ„并еҸ‘收йӣҶеҷЁпјҢеӣ жӯӨеҰӮжһңжңүдёҖдёӘеһғеңҫ收йӣҶеҷЁиғҪе’Ңе®ғдёҖиө·жҗӯй…ҚдҪҝз”Ёи®©е…¶жӣҙеҠ е®ҢзҫҺпјҢйӮЈиҝҷдёӘ收йӣҶеҷЁеҝ…然д№ҹжҳҜдёҖдёӘдёҚеҸҜжҲ–зјәзҡ„йғЁеҲҶдәҶгҖӮ收йӣҶеҷЁзҡ„иҝҗиЎҢиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ

дёҠеӣҫдёӯпјҡ
- ж–°з”ҹд»ЈйҮҮз”ЁеӨҚеҲ¶з®—жі•пјҢStop-The-World
- иҖҒе№ҙд»ЈйҮҮз”Ёж Үи®°-ж•ҙзҗҶз®—жі•пјҢStop-The-World
В
3гҖҒParNew Scanvenge收йӣҶеҷЁпјҲж–°з”ҹ代收йӣҶеҷЁпјү
гҖҖгҖҖзұ»дјјParNewпјҢдҪҶжӣҙеҠ е…іжіЁеҗһеҗҗйҮҸгҖӮзӣ®ж ҮжҳҜпјҡиҫҫеҲ°дёҖдёӘеҸҜжҺ§еҲ¶еҗһеҗҗйҮҸзҡ„收йӣҶеҷЁгҖӮ
еҗһеҗҗйҮҸпјҡCPUз”ЁдәҺиҝҗиЎҢз”ЁжҲ·д»Јз Ғзҡ„ж—¶й—ҙдёҺCPUжҖ»ж¶ҲиҖ—ж—¶й—ҙзҡ„жҜ”еҖјгҖӮ
еҒңйЎҝж—¶й—ҙе’ҢеҗһеҗҗйҮҸдёҚеҸҜиғҪеҗҢж—¶и°ғдјҳгҖӮжҲ‘们дёҖж–№д№°еёҢжңӣеҒңйЎҝж—¶й—ҙе°‘пјҢеҸҰеӨ–дёҖж–№йқўеёҢжңӣеҗһеҗҗйҮҸй«ҳпјҢе…¶е®һиҝҷжҳҜзҹӣзӣҫзҡ„гҖӮеӣ дёәпјҡеңЁGCзҡ„ж—¶еҖҷпјҢеһғеңҫеӣһ收зҡ„е·ҘдҪңжҖ»йҮҸжҳҜдёҚеҸҳзҡ„пјҢеҰӮжһңе°ҶеҒңйЎҝж—¶й—ҙеҮҸе°‘пјҢйӮЈйў‘зҺҮе°ұдјҡжҸҗй«ҳпјӣ既然频зҺҮжҸҗй«ҳдәҶпјҢиҜҙжҳҺе°ұдјҡйў‘з№Ғзҡ„иҝӣиЎҢGCпјҢйӮЈеҗһеҗҗйҮҸе°ұдјҡеҮҸе°‘пјҢжҖ§иғҪе°ұдјҡйҷҚдҪҺгҖӮ
еҗһеҗҗйҮҸпјҡCPUз”ЁдәҺз”ЁжҲ·д»Јз Ғзҡ„ж—¶й—ҙ/CPUжҖ»ж¶ҲиҖ—ж—¶й—ҙзҡ„жҜ”еҖјпјҢеҚі=иҝҗиЎҢз”ЁжҲ·д»Јз Ғзҡ„ж—¶й—ҙ/(иҝҗиЎҢз”ЁжҲ·д»Јз Ғж—¶й—ҙ+еһғеңҫ收йӣҶж—¶й—ҙ)гҖӮжҜ”еҰӮпјҢиҷҡжӢҹжңәжҖ»е…ұиҝҗиЎҢдәҶ100еҲҶй’ҹпјҢе…¶дёӯеһғеңҫ收йӣҶиҠұжҺү1еҲҶй’ҹпјҢйӮЈеҗһеҗҗйҮҸе°ұжҳҜ99%гҖӮ
В
4гҖҒG1收йӣҶеҷЁпјҡ
гҖҖгҖҖжҳҜеҪ“д»Ҡ收йӣҶеҷЁеҸ‘еұ•зҡ„жңҖеүҚиЁҖжҲҗжһңд№ӢдёҖпјҢзҹҘйҒ“jdk1.7пјҢsunе…¬еҸёжүҚи®Өдёәе®ғиҫҫеҲ°дәҶи¶іеӨҹжҲҗзҶҹзҡ„е•Ҷз”ЁзЁӢеәҰгҖӮ
дјҳзӮ№пјҡ
гҖҖгҖҖе®ғжңҖеӨ§зҡ„дјҳзӮ№жҳҜз»“еҗҲдәҶз©әй—ҙж•ҙеҗҲпјҢдёҚдјҡдә§з”ҹеӨ§йҮҸзҡ„зўҺзүҮпјҢд№ҹйҷҚдҪҺдәҶиҝӣиЎҢgcзҡ„йў‘зҺҮгҖӮ
гҖҖгҖҖдәҢжҳҜеҸҜд»Ҙи®©дҪҝз”ЁиҖ…жҳҺзЎ®жҢҮе®ҡжҢҮе®ҡеҒңйЎҝж—¶й—ҙгҖӮпјҲеҸҜд»ҘжҢҮе®ҡдёҖдёӘжңҖе°Ҹж—¶й—ҙпјҢи¶…иҝҮиҝҷдёӘж—¶й—ҙпјҢе°ұдёҚдјҡиҝӣиЎҢеӣһ收дәҶпјү
е®ғжңүдәҶиҝҷд№Ҳй«ҳж•ҲзҺҮзҡ„еҺҹеӣ д№ӢдёҖе°ұжҳҜпјҡеҜ№еһғеңҫеӣһ收иҝӣиЎҢдәҶеҲ’еҲҶдјҳе…Ҳзә§зҡ„ж“ҚдҪңпјҢиҝҷз§Қжңүдјҳе…Ҳзә§зҡ„еҢәеҹҹеӣһ收方ејҸдҝқиҜҒдәҶе®ғзҡ„й«ҳж•ҲзҺҮгҖӮ
еҰӮжһңдҪ зҡ„еә”з”ЁиҝҪжұӮеҒңйЎҝпјҢйӮЈG1зҺ°еңЁе·Із»ҸеҸҜд»ҘдҪңдёәдёҖдёӘеҸҜе°қиҜ•зҡ„йҖүжӢ©пјӣеҰӮжһңдҪ зҡ„еә”з”ЁиҝҪжұӮеҗһеҗҗйҮҸпјҢйӮЈG1并дёҚдјҡдёәдҪ еёҰжқҘд»Җд№Ҳзү№еҲ«зҡ„еҘҪеӨ„гҖӮ
жіЁпјҡд»ҘдёҠжүҖжңүзҡ„收йӣҶеҷЁеҪ“дёӯпјҢеҪ“жү§иЎҢGCж—¶пјҢйғҪдјҡstop the worldпјҢдҪҶжҳҜдёӢйқўзҡ„CMS收йӣҶеҷЁеҚҙдёҚдјҡиҝҷж ·гҖӮ
В
5гҖҒCMS收йӣҶеҷЁпјҡпјҲиҖҒе№ҙ代收йӣҶеҷЁпјү
CMS收йӣҶеҷЁпјҲConcurrent Mark Sweepпјҡ并еҸ‘ж Үи®°жё…йҷӨпјүпјҡжҳҜHotSpotиҷҡжӢҹжңәдёӯ第дёҖж¬ҫзңҹжӯЈж„Ҹд№үдёҠзҡ„并еҸ‘收йӣҶеҷЁпјҢе®ғ第дёҖж¬Ўе®һзҺ°дәҶи®©еһғеңҫ收йӣҶзәҝзЁӢдёҺз”ЁжҲ·зәҝзЁӢеҹәжң¬дёҠеҗҢж—¶е·ҘдҪңгҖӮ
В
В
жҳҜдёҖз§Қд»ҘиҺ·еҸ–жңҖзҹӯеӣһ收еҒңйЎҝж—¶й—ҙдёәзӣ®ж Үзҡ„收йӣҶеҷЁгҖӮйҖӮеҗҲеә”з”ЁеңЁдә’иҒ”зҪ‘з«ҷжҲ–иҖ…B/Sзі»з»ҹзҡ„жңҚеҠЎеҷЁдёҠпјҢиҝҷзұ»еә”з”Ёе°Өе…¶йҮҚи§ҶжңҚеҠЎеҷЁзҡ„е“Қеә”йҖҹеәҰпјҢеёҢжңӣзі»з»ҹеҒңйЎҝж—¶й—ҙжңҖзҹӯгҖӮ
CMS收йӣҶеҷЁиҝҗиЎҢиҝҮзЁӢпјҡпјҲзқҖйҮҚе®һзҺ°дәҶж Үи®°зҡ„иҝҮзЁӢпјү
пјҲ1пјүеҲқе§Ӣж Үи®°
гҖҖгҖҖж №еҸҜд»ҘзӣҙжҺҘе…іиҒ”еҲ°зҡ„еҜ№иұЎ
гҖҖгҖҖйҖҹеәҰеҝ«
пјҲ2пјү并еҸ‘ж Үи®°пјҲе’Ңз”ЁжҲ·зәҝзЁӢдёҖиө·пјү
гҖҖгҖҖдё»иҰҒж Үи®°иҝҮзЁӢпјҢж Үи®°е…ЁйғЁеҜ№иұЎ
пјҲ3пјүйҮҚж–°ж Үи®°
гҖҖгҖҖз”ұдәҺ并еҸ‘ж Үи®°ж—¶пјҢз”ЁжҲ·зәҝзЁӢдҫқ然иҝҗиЎҢпјҢеӣ жӯӨеңЁжӯЈејҸжё…зҗҶеүҚпјҢеҶҚеҒҡдҝ®жӯЈ
пјҲ4пјү并еҸ‘жё…йҷӨпјҲе’Ңз”ЁжҲ·зәҝзЁӢдёҖиө·пјү
гҖҖгҖҖеҹәдәҺж Үи®°з»“жһңпјҢзӣҙжҺҘжё…зҗҶеҜ№иұЎ
ж•ҙдёӘиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ

дёҠеӣҫдёӯпјҢеҲқе§Ӣж Үи®°е’ҢйҮҚж–°ж Үи®°ж—¶пјҢйңҖиҰҒstop the worldгҖӮж•ҙдёӘиҝҮзЁӢдёӯиҖ—ж—¶жңҖй•ҝзҡ„жҳҜ并еҸ‘ж Үи®°е’Ң并еҸ‘жё…йҷӨпјҢиҝҷдёӨдёӘиҝҮзЁӢйғҪеҸҜд»Ҙе’Ңз”ЁжҲ·зәҝзЁӢдёҖиө·е·ҘдҪңгҖӮ
В
дјҳзӮ№пјҡ
гҖҖгҖҖ并еҸ‘收йӣҶпјҢдҪҺеҒңйЎҝ
зјәзӮ№пјҡ
пјҲ1пјүеҜјиҮҙз”ЁжҲ·зҡ„жү§иЎҢйҖҹеәҰйҷҚдҪҺгҖӮ
пјҲ2пјүж— жі•еӨ„зҗҶжө®еҠЁеһғеңҫгҖӮеӣ дёәе®ғйҮҮз”Ёзҡ„жҳҜж Үи®°-жё…йҷӨз®—жі•гҖӮжңүеҸҜиғҪжңүдәӣеһғеңҫеңЁж Үи®°д№ӢеҗҺпјҢйңҖиҰҒзӯүеҲ°дёӢдёҖж¬ЎGCжүҚдјҡиў«еӣһ收гҖӮеҰӮжһңCMSиҝҗиЎҢжңҹй—ҙж— жі•ж»Ўи¶ізЁӢеәҸйңҖиҰҒпјҢйӮЈд№Ҳе°ұдјҡдёҙж—¶еҗҜз”ЁSerial Old收йӣҶеҷЁжқҘйҮҚж–°иҝӣиЎҢиҖҒе№ҙд»Јзҡ„жүӢжңәгҖӮ
пјҲ3пјүз”ұдәҺйҮҮз”Ёзҡ„жҳҜж Үи®°-жё…йҷӨз®—жі•пјҢйӮЈд№Ҳе°ұдјҡдә§з”ҹеӨ§йҮҸзҡ„зўҺзүҮгҖӮеҫҖеҫҖдјҡеҮәзҺ°иҖҒе№ҙд»ЈиҝҳжңүеҫҲеӨ§зҡ„з©әй—ҙеү©дҪҷпјҢдҪҶжҳҜж— жі•жүҫеҲ°и¶іеӨҹеӨ§зҡ„иҝһз»ӯз©әй—ҙжқҘеҲҶй…ҚеҪ“еүҚеҜ№иұЎпјҢдёҚеҫ—дёҚжҸҗеүҚи§ҰеҸ‘дёҖж¬Ўfull GC
В
з–‘й—®пјҡ既然ж Үи®°-жё…йҷӨз®—жі•дјҡйҖ жҲҗеҶ…еӯҳз©әй—ҙзҡ„зўҺзүҮеҢ–пјҢCMS收йӣҶеҷЁдёәд»Җд№ҲдҪҝз”Ёж Үи®°жё…йҷӨз®—жі•иҖҢдёҚжҳҜдҪҝз”Ёж Үи®°ж•ҙзҗҶз®—жі•пјҡ
зӯ”жЎҲпјҡ
гҖҖгҖҖCMS收йӣҶеҷЁжӣҙеҠ е…іжіЁеҒңйЎҝпјҢе®ғеңЁеҒҡGCзҡ„ж—¶еҖҷжҳҜе’Ңз”ЁжҲ·зәҝзЁӢдёҖиө·е·ҘдҪңзҡ„пјҲ并еҸ‘жү§иЎҢпјүпјҢеҰӮжһңдҪҝз”Ёж Үи®°ж•ҙзҗҶз®—жі•зҡ„иҜқпјҢйӮЈд№ҲеңЁжё…зҗҶзҡ„ж—¶еҖҷе°ұдјҡеҺ»з§»еҠЁеҸҜз”ЁеҜ№иұЎзҡ„еҶ…еӯҳз©әй—ҙпјҢйӮЈд№Ҳеә”з”ЁзЁӢеәҸзҡ„зәҝзЁӢе°ұеҫҲжңүеҸҜиғҪжүҫдёҚеҲ°еә”з”ЁеҜ№иұЎеңЁе“ӘйҮҢгҖӮ
дёғгҖҒJavaе ҶеҶ…еӯҳеҲ’еҲҶпјҡ
ж №жҚ®еҜ№иұЎзҡ„еӯҳжҙ»зҺҮпјҲе№ҙйҫ„пјүпјҢJavaеҜ№еҶ…еӯҳеҲ’еҲҶдёә3з§Қпјҡж–°з”ҹд»ЈгҖҒиҖҒе№ҙд»ЈгҖҒж°ёд№…д»Јпјҡ
1гҖҒж–°з”ҹд»Јпјҡ
жҜ”еҰӮжҲ‘们еңЁж–№жі•дёӯеҺ»newдёҖдёӘеҜ№иұЎпјҢйӮЈиҝҷж–№жі•и°ғз”Ёе®ҢжҜ•еҗҺпјҢеҜ№иұЎе°ұдјҡиў«еӣһ收пјҢиҝҷе°ұжҳҜдёҖдёӘе…ёеһӢзҡ„ж–°з”ҹд»ЈеҜ№иұЎгҖӮВ
зҺ°еңЁзҡ„е•ҶдёҡиҷҡжӢҹжңәйғҪйҮҮз”Ёиҝҷз§Қ收йӣҶз®—жі•жқҘеӣһ收新з”ҹд»ЈпјҢж–°з”ҹд»Јдёӯзҡ„еҜ№иұЎ98%йғҪжҳҜвҖңжңқз”ҹеӨ•жӯ»вҖқзҡ„пјҢжүҖд»Ҙ并дёҚйңҖиҰҒжҢүз…§1:1зҡ„жҜ”дҫӢжқҘеҲ’еҲҶеҶ…еӯҳз©әй—ҙпјҢиҖҢжҳҜе°ҶеҶ…еӯҳеҲҶдёәдёҖеқ—жҜ”иҫғеӨ§зҡ„Edenз©әй—ҙе’ҢдёӨеқ—иҫғе°Ҹзҡ„Survivorз©әй—ҙпјҢжҜҸж¬ЎдҪҝз”ЁEdenе’Ңе…¶дёӯдёҖеқ—SurvivorгҖӮеҪ“еӣһ收时пјҢе°ҶEdenе’ҢSurvivorдёӯиҝҳеӯҳжҙ»зқҖзҡ„еҜ№иұЎдёҖж¬ЎжҖ§ең°еӨҚеҲ¶еҲ°еҸҰеӨ–дёҖеқ—Survivorз©әй—ҙдёҠпјҢжңҖеҗҺжё…зҗҶжҺүEdenе’ҢеҲҡжүҚз”ЁиҝҮзҡ„Survivorз©әй—ҙгҖӮHotSpotиҷҡжӢҹжңәй»ҳи®ӨEdenе’ҢSurvivorзҡ„еӨ§е°ҸжҜ”дҫӢжҳҜ8:1пјҢд№ҹе°ұжҳҜиҜҙпјҢжҜҸж¬Ўж–°з”ҹд»ЈдёӯеҸҜз”ЁеҶ…еӯҳз©әй—ҙдёәж•ҙдёӘж–°з”ҹд»Је®№йҮҸзҡ„90%пјҲ80%+10%пјүпјҢеҸӘжңү10%зҡ„з©әй—ҙдјҡиў«жөӘиҙ№гҖӮ
еҪ“然пјҢ98%зҡ„еҜ№иұЎеҸҜеӣһ收еҸӘжҳҜдёҖиҲ¬еңәжҷҜдёӢзҡ„ж•°жҚ®пјҢжҲ‘们没жңүеҠһжі•дҝқиҜҒжҜҸж¬Ўеӣһ收йғҪеҸӘжңүдёҚеӨҡдәҺ10%зҡ„еҜ№иұЎеӯҳжҙ»пјҢеҪ“Survivorз©әй—ҙдёҚеӨҹз”Ёж—¶пјҢйңҖиҰҒдҫқиө–дәҺиҖҒе№ҙд»ЈиҝӣиЎҢеҲҶй…ҚжӢ…дҝқпјҢжүҖд»ҘеӨ§еҜ№иұЎзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮеҗҢж—¶пјҢй•ҝжңҹеӯҳжҙ»зҡ„еҜ№иұЎе°Ҷиҝӣе…ҘиҖҒе№ҙд»ЈпјҲиҷҡжӢҹжңәз»ҷжҜҸдёӘеҜ№иұЎе®ҡд№үдёҖдёӘе№ҙйҫ„и®Ўж•°еҷЁпјүгҖӮ
жқҘзңӢдёӢйқўиҝҷеј еӣҫпјҡ

Minor GCе’ҢFull GCпјҡ
GCеҲҶдёәдёӨз§ҚпјҡMinor GCе’ҢFull GC
Major GCпјҡиҖҒе№ҙд»Јеӣһ收
Minor GCпјҡд»Һж–°з”ҹд»Јеӣһ收еҶ…еӯҳ
гҖҖгҖҖMinor GCжҳҜеҸ‘з”ҹеңЁж–°з”ҹд»Јдёӯзҡ„еһғеңҫ收йӣҶеҠЁдҪңпјҢйҮҮз”Ёзҡ„жҳҜеӨҚеҲ¶з®—жі•гҖӮ
еҜ№иұЎеңЁEdenе’ҢFromеҢәеҮәз”ҹеҗҺпјҢеңЁз»ҸиҝҮдёҖж¬ЎMinor GCеҗҺпјҢеҰӮжһңеҜ№иұЎиҝҳеӯҳжҙ»пјҢ并且иғҪеӨҹиў«toеҢәжүҖе®№зәіпјҢйӮЈд№ҲеңЁдҪҝз”ЁеӨҚеҲ¶з®—жі•ж—¶иҝҷдәӣеӯҳжҙ»еҜ№иұЎе°ұдјҡиў«еӨҚеҲ¶еҲ°toеҢәеҹҹпјҢ然еҗҺжё…зҗҶжҺүEdenеҢәе’ҢfromеҢәпјҢ并е°ҶиҝҷдәӣеҜ№иұЎзҡ„е№ҙйҫ„и®ҫзҪ®дёә1пјҢд»ҘеҗҺеҜ№иұЎеңЁSurvivorеҢәжҜҸзҶ¬иҝҮдёҖж¬ЎMinor GCпјҢе°ұе°ҶеҜ№иұЎзҡ„е№ҙйҫ„+1пјҢеҪ“еҜ№иұЎзҡ„е№ҙйҫ„иҫҫеҲ°жҹҗдёӘеҖјж—¶пјҲй»ҳи®ӨжҳҜ15еІҒпјҢеҸҜд»ҘйҖҡиҝҮеҸӮж•° --XX:MaxTenuringThresholdи®ҫзҪ®пјүпјҢиҝҷдәӣеҜ№иұЎе°ұдјҡжҲҗдёәиҖҒе№ҙд»ЈгҖӮ
дҪҶиҝҷд№ҹжҳҜдёҚдёҖе®ҡзҡ„пјҢеҜ№дәҺдёҖдәӣиҫғеӨ§зҡ„еҜ№иұЎпјҲеҚійңҖиҰҒеҲҶй…ҚдёҖеқ—иҫғеӨ§зҡ„иҝһз»ӯеҶ…еӯҳз©әй—ҙпјүеҲҷжҳҜзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»Ј
В
еҸ‘з”ҹж—¶й—ҙпјҡ
еҪ“EdenеҢәжІЎжңүи¶іеӨҹз©әй—ҙиҝӣиЎҢеҲҶй…Қж—¶пјҢиҷҡжӢҹжңәе°ҶеҸ‘иө·дёҖж¬ЎMinor GCгҖӮ
В
Full GCпјҡеҜ№ж•ҙдёӘе Ҷеӣһ收
гҖҖгҖҖFull GCжҳҜеҸ‘з”ҹеңЁиҖҒе№ҙд»Јзҡ„еһғеңҫ收йӣҶеҠЁдҪңпјҢйҮҮз”Ёзҡ„жҳҜж Үи®°-жё…йҷӨ/ж•ҙзҗҶз®—жі•гҖӮ
иҖҒе№ҙд»ЈйҮҢзҡ„еҜ№иұЎеҮ д№ҺйғҪжҳҜеңЁSurvivorеҢәзҶ¬иҝҮжқҘзҡ„пјҢдёҚдјҡйӮЈд№Ҳе®№жҳ“жӯ»жҺүгҖӮеӣ жӯӨFull GCеҸ‘з”ҹзҡ„ж¬Ўж•°дёҚдјҡжңүMinor GCйӮЈд№Ҳйў‘з№ҒпјҢ并且еҒҡдёҖж¬ЎFull GCиҰҒжҜ”еҒҡдёҖж¬ЎMinor GCзҡ„ж—¶й—ҙиҰҒй•ҝгҖӮ
еҸҰеӨ–пјҢеҰӮжһңйҮҮз”Ёзҡ„жҳҜж Үи®°-жё…йҷӨз®—жі•зҡ„иҜқдјҡдә§з”ҹи®ёеӨҡзўҺзүҮпјҢжӯӨеҗҺеҰӮжһңйңҖиҰҒдёәиҫғеӨ§зҡ„еҜ№иұЎеҲҶй…ҚеҶ…еӯҳз©әй—ҙж—¶пјҢиӢҘж— жі•жүҫеҲ°и¶іеӨҹзҡ„иҝһз»ӯзҡ„еҶ…еӯҳз©әй—ҙпјҢе°ұдјҡжҸҗеүҚи§ҰеҸ‘дёҖж¬ЎGCгҖӮ
В
еҸ‘з”ҹж—¶й—ҙпјҡ
1гҖҒsystem.gc()е»әи®®JVMиҝӣиЎҢFull GC,иҷҪ然еҸӘжҳҜе»әи®®иҖҢйқһдёҖе®ҡ,дҪҶеҫҲеӨҡжғ…еҶөдёӢе®ғдјҡи§ҰеҸ‘ Full GC,
2гҖҒиҖҒе№ҙд»Јз©әй—ҙдёҚи¶ігҖӮ
3гҖҒж–№жі•еҢәз©әй—ҙдёҚи¶ігҖӮ
4гҖҒеңЁеҸ‘з”ҹMinor GCж—¶пјҢиҷҡжӢҹжңәдјҡжЈҖжҹҘжҜҸж¬ЎжҷӢеҚҮиҝӣе…ҘиҖҒе№ҙд»Јзҡ„еӨ§е°ҸжҳҜеҗҰеӨ§дәҺиҖҒе№ҙд»Јзҡ„еү©дҪҷз©әй—ҙеӨ§е°ҸпјҢеҰӮжһңеӨ§дәҺпјҢеҲҷзӣҙжҺҘи§ҰеҸ‘дёҖж¬ЎFull GC
В
2гҖҒиҖҒе№ҙд»Јпјҡ
В В В еңЁж–°з”ҹд»Јдёӯз»ҸеҺҶдәҶNж¬Ўеһғеңҫеӣһ收еҗҺд»Қ然еӯҳжҙ»зҡ„еҜ№иұЎе°ұдјҡиў«ж”ҫеҲ°иҖҒе№ҙд»ЈдёӯгҖӮиҖҢдё”еӨ§еҜ№иұЎзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮ
В
иҝӣе…ҘиҖҒе№ҙд»Јзҡ„жғ…еҶөпјҡ
1гҖҒminor GCд№ӢеҗҺеҜ№иұЎж— жі•ж”ҫе…ҘSurvivorз©әй—ҙпјҢйҖҡиҝҮеҲҶй…ҚжӢ…дҝқжңәеҲ¶жҸҗеүҚиҪ¬з§»еҲ°иҖҒе№ҙд»ЈгҖӮ
2гҖҒеӨ§еҜ№иұЎзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮ
3гҖҒй•ҝжңҹеӯҳжҙ»зҡ„еҜ№иұЎе°Ҷиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮиҷҡжӢҹжңәз»ҷжҜҸдёӘеҜ№иұЎе®ҡд№үдәҶдёҖдёӘеҜ№иұЎе№ҙйҫ„и®Ўж•°еҷЁпјҢеҰӮжһңеҜ№иұЎеңЁEdenеҮәз”ҹ并з»ҸиҝҮ第дёҖж¬ЎMinor GCеҗҺд»Қ然еӯҳжҙ»пјҢ并且иғҪиў«Survivorе®№зәізҡ„иҜқпјҢе°Ҷ被移еҠЁеҲ°Survivorз©әй—ҙдёӯпјҢ并且еҜ№иұЎе№ҙйҫ„и®ҫдёә1.еҜ№иұЎеңЁSurvivorеҢәдёӯжҜҸвҖңзҶ¬иҝҮвҖқдёҖж¬ЎMinor GCпјҢе№ҙйҫ„е°ұеўһеҠ 1еІҒпјҢеҪ“е®ғзҡ„е№ҙйҫ„еўһеҠ еҲ°дёҖе®ҡзЁӢеәҰпјҢе°ұе°Ҷдјҡиў«жҷӢеҚҮеҲ°иҖҒе№ҙд»ЈдёӯгҖӮеҜ№иұЎжҷӢеҚҮиҖҒе№ҙд»Јзҡ„е№ҙйҫ„йҳҲеҖјпјҢеҸҜд»ҘйҖҡиҝҮеҸӮж•°и®ҫзҪ®-XX:MaxTenuringThresholdгҖӮ
4гҖҒеҰӮжһңеңЁSurvivorз©әй—ҙдёӯзӣёеҗҢе№ҙйҫ„жүҖжңүеҜ№иұЎеӨ§е°Ҹзҡ„жҖ»е’ҢеӨ§дәҺSurvivorз©әй—ҙзҡ„дёҖеҚҠпјҢе№ҙйҫ„еӨ§дәҺжҲ–зӯүдәҺиҜҘе№ҙйҫ„зҡ„еҜ№иұЎе°ұеҸҜд»ҘзӣҙжҺҘиҝӣе…ҘиҖҒе№ҙд»ЈпјҢж— йңҖзӯүеҲ°MaxTenuringThresholdдёӯиҰҒжұӮзҡ„е№ҙйҫ„гҖӮ
В
3гҖҒж°ёд№…д»Јпјҡ
В В В еҚіж–№жі•еҢәгҖӮ
В
е…«гҖҒзұ»еҠ иҪҪжңәеҲ¶пјҡ
В
зұ»зҡ„еҠ иҪҪжҢҮзҡ„жҳҜе°Ҷзұ»зҡ„.classж–Ү件дёӯзҡ„дәҢиҝӣеҲ¶ж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳдёӯпјҢе°Ҷе…¶ж”ҫеңЁиҝҗиЎҢж—¶ж•°жҚ®еҢәзҡ„ж–№жі•еҢәеҶ…пјҢ然еҗҺеңЁе ҶеҢәеҲӣе»әдёҖдёӘиҝҷдёӘзұ»зҡ„Java.lang.ClassеҜ№иұЎпјҢз”ЁжқҘе°ҒиЈ…зұ»еңЁж–№жі•еҢәзұ»зҡ„еҜ№иұЎгҖӮ
В
В В В иҷҡжӢҹжңәжҠҠжҸҸиҝ°зұ»зҡ„ж•°жҚ®д»ҺClassж–Ү件еҠ иҪҪеҲ°еҶ…еӯҳпјҢ并еҜ№ж•°жҚ®иҝӣиЎҢж ЎйӘҢгҖҒиҪ¬жҚўи§Јжһҗе’ҢеҲқе§ӢеҢ–пјҢжңҖз»ҲеҪўжҲҗеҸҜд»Ҙиў«иҷҡжӢҹжңәзӣҙжҺҘдҪҝз”Ёзҡ„Javaзұ»еһӢпјҢиҝҷе°ұжҳҜиҷҡжӢҹжңәзҡ„зұ»еҠ иҪҪжңәеҲ¶гҖӮ
зұ»еҠ иҪҪзҡ„иҝҮзЁӢпјҡ
В В В еҢ…жӢ¬еҠ иҪҪгҖҒй“ҫжҺҘпјҲеҗ«йӘҢиҜҒгҖҒеҮҶеӨҮгҖҒи§ЈжһҗпјүгҖҒеҲқе§ӢеҢ–
еҰӮдёӢеӣҫжүҖзӨәпјҡ

1гҖҒеҠ иҪҪпјҡ
гҖҖгҖҖзұ»еҠ иҪҪжҢҮзҡ„жҳҜе°Ҷзұ»зҡ„classж–Ү件иҜ»е…ҘеҶ…еӯҳпјҢ并дёәд№ӢеҲӣе»әдёҖдёӘjava.lang.ClassеҜ№иұЎпјҢдҪңдёәж–№жі•еҢәиҝҷдёӘзұ»зҡ„ж•°жҚ®и®ҝй—®зҡ„е…ҘеҸЈгҖӮ
д№ҹе°ұжҳҜиҜҙпјҢеҪ“зЁӢеәҸдёӯдҪҝз”Ёд»»дҪ•зұ»ж—¶пјҢзі»з»ҹйғҪдјҡдёәд№Ӣе»әз«ӢдёҖдёӘjava.lang.ClassеҜ№иұЎгҖӮе…·дҪ“еҢ…жӢ¬д»ҘдёӢдёүдёӘйғЁеҲҶпјҡ
пјҲ1пјүйҖҡиҝҮзұ»зҡ„е…ЁеҗҚдә§з”ҹеҜ№еә”зұ»зҡ„дәҢиҝӣеҲ¶ж•°жҚ®жөҒгҖӮпјҲж №жҚ®early loadеҺҹзҗҶпјҢеҰӮжһңжІЎжүҫеҲ°еҜ№еә”зҡ„зұ»ж–Ү件пјҢеҸӘжңүеңЁзұ»е®һйҷ…дҪҝз”Ёж—¶жүҚдјҡжҠӣеҮәй”ҷиҜҜпјү
пјҲ2пјүеҲҶжһҗ并е°ҶиҝҷдәӣдәҢиҝӣеҲ¶ж•°жҚ®жөҒиҪ¬жҚўдёәж–№жі•еҢәж–№жі•еҢәзү№е®ҡзҡ„ж•°жҚ®з»“жһ„
пјҲ3пјүеҲӣе»әеҜ№еә”зұ»зҡ„java.lang.ClassеҜ№иұЎпјҢдҪңдёәж–№жі•еҢәзҡ„е…ҘеҸЈпјҲжңүдәҶеҜ№еә”зҡ„ClassеҜ№иұЎпјҢ并дёҚж„Ҹе‘ізқҖиҝҷдёӘзұ»е·Із»Ҹе®ҢжҲҗдәҶеҠ иҪҪй“ҫжҺҘпјү
В
йҖҡиҝҮдҪҝз”ЁдёҚеҗҢзҡ„зұ»еҠ иҪҪеҷЁпјҢеҸҜд»Ҙд»ҺдёҚеҗҢжқҘжәҗеҠ иҪҪзұ»зҡ„дәҢиҝӣеҲ¶ж•°жҚ®пјҢйҖҡеёёжңүеҰӮдёӢеҮ з§ҚжқҘжәҗпјҡ
пјҲ1пјүд»Һжң¬ең°ж–Ү件系з»ҹеҠ иҪҪclassж–Ү件пјҢиҝҷжҳҜз»қеӨ§йғЁеҲҶзЁӢеәҸзҡ„еҠ иҪҪж–№ејҸ
пјҲ2пјүд»ҺjarеҢ…дёӯеҠ иҪҪclassж–Ү件пјҢиҝҷз§Қж–№ејҸд№ҹеҫҲеёёи§ҒпјҢдҫӢеҰӮjdbcзј–зЁӢж—¶з”ЁеҲ°зҡ„ж•°жҚ®еә“й©ұеҠЁзұ»е°ұжҳҜж”ҫеңЁjarеҢ…дёӯпјҢjvmеҸҜд»Ҙд»Һjarж–Ү件дёӯзӣҙжҺҘеҠ иҪҪиҜҘclassж–Ү件
пјҲ3пјүйҖҡиҝҮзҪ‘з»ңеҠ иҪҪclassж–Ү件
пјҲ4пјүжҠҠдёҖдёӘJavaжәҗж–Ү件еҠЁжҖҒзј–иҜ‘гҖҒ并жү§иЎҢеҠ иҪҪ
В
2гҖҒй“ҫжҺҘпјҡ
В В В й“ҫжҺҘжҢҮзҡ„жҳҜе°ҶJavaзұ»зҡ„дәҢиҝӣеҲ¶ж–Ү件еҗҲ并еҲ°jvmзҡ„иҝҗиЎҢзҠ¶жҖҒд№Ӣдёӯзҡ„иҝҮзЁӢгҖӮеңЁй“ҫжҺҘд№ӢеүҚпјҢиҝҷдёӘзұ»еҝ…йЎ»иў«жҲҗеҠҹеҠ иҪҪгҖӮ
зұ»зҡ„й“ҫжҺҘеҢ…жӢ¬йӘҢиҜҒгҖҒеҮҶеӨҮгҖҒи§ЈжһҗиҝҷдёүжӯҘгҖӮе…·дҪ“жҸҸиҝ°еҰӮдёӢпјҡ
2.1В йӘҢиҜҒпјҡ
В В В йӘҢиҜҒжҳҜз”ЁжқҘзЎ®дҝқJavaзұ»зҡ„дәҢиҝӣеҲ¶иЎЁзӨәеңЁз»“жһ„дёҠжҳҜеҗҰе®Ңе…ЁжӯЈзЎ®пјҲеҰӮж–Үд»¶ж јејҸгҖҒиҜӯжі•иҜӯд№үзӯүпјүгҖӮеҰӮжһңйӘҢиҜҒиҝҮзЁӢеҮәй”ҷзҡ„иҜқпјҢдјҡжҠӣеҮәjava.lang.VertifyErrorй”ҷиҜҜгҖӮ
дё»иҰҒйӘҢиҜҒд»ҘдёӢеҶ…е®№пјҡ
- ж–Үд»¶ж јејҸйӘҢиҜҒ
- е…ғж•°жҚ®йӘҢиҜҒпјҡиҜӯд№үйӘҢиҜҒ
- еӯ—иҠӮз ҒйӘҢиҜҒ
2.2В еҮҶеӨҮпјҡ
гҖҖгҖҖеҮҶеӨҮиҝҮзЁӢеҲҷжҳҜеҲӣе»әJavaзұ»дёӯзҡ„йқҷжҖҒеҹҹпјҲstaticдҝ®йҘ°зҡ„еҶ…е®№пјүпјҢ并е°Ҷиҝҷдәӣеҹҹзҡ„еҖји®ҫзҪ®дёәй»ҳи®ӨеҖјпјҢеҗҢж—¶еңЁж–№жі•еҢәдёӯеҲҶй…ҚеҶ…еӯҳз©әй—ҙгҖӮеҮҶеӨҮиҝҮзЁӢ并дёҚдјҡжү§иЎҢд»Јз ҒгҖӮ
жіЁж„ҸиҝҷйҮҢжҳҜеҒҡй»ҳи®ӨеҲқе§ӢеҢ–пјҢдёҚжҳҜеҒҡжҳҫејҸеҲқе§ӢеҢ–гҖӮдҫӢеҰӮпјҡ
public static int value = 12;
дёҠйқўзҡ„д»Јз ҒдёӯпјҢеңЁеҮҶеӨҮйҳ¶ж®өпјҢдјҡз»ҷvalueзҡ„еҖји®ҫзҪ®дёә0пјҲй»ҳи®ӨеҲқе§ӢеҢ–пјүгҖӮеңЁеҗҺйқўзҡ„еҲқе§ӢеҢ–йҳ¶ж®өжүҚдјҡз»ҷvalueзҡ„еҖји®ҫзҪ®дёә12пјҲжҳҫејҸеҲқе§ӢеҢ–пјүгҖӮ
2.3В и§Јжһҗпјҡ
гҖҖгҖҖи§Јжһҗзҡ„иҝҮзЁӢе°ұжҳҜзЎ®дҝқиҝҷдәӣиў«еј•з”Ёзҡ„зұ»иғҪиў«жӯЈзЎ®зҡ„жүҫеҲ°пјҲе°Ҷз¬ҰеҸ·еј•з”ЁжӣҝжҚўдёәзӣҙжҺҘеј•з”ЁпјүгҖӮи§Јжһҗзҡ„иҝҮзЁӢеҸҜиғҪдјҡеҜјиҮҙе…¶е®ғзҡ„Javaзұ»иў«еҠ иҪҪгҖӮ
В
3гҖҒеҲқе§ӢеҢ–пјҡ
гҖҖгҖҖеҲқе§ӢеҢ–йҳ¶ж®өжҳҜзұ»еҠ иҪҪиҝҮзЁӢзҡ„жңҖеҗҺдёҖжӯҘгҖӮеҲ°дәҶеҲқе§ӢеҢ–йҳ¶ж®өпјҢжүҚзңҹжӯЈжү§иЎҢзұ»дёӯе®ҡд№үзҡ„JavaзЁӢеәҸд»Јз ҒпјҲжҲ–иҖ…иҜҙжҳҜеӯ—иҠӮз ҒпјүгҖӮ
еңЁд»ҘдёӢеҮ з§Қжғ…еҶөдёӯпјҢдјҡжү§иЎҢеҲқе§ӢеҢ–иҝҮзЁӢпјҡ
пјҲ1пјүеҲӣе»әзұ»зҡ„е®һдҫӢ
пјҲ2пјүи®ҝй—®зұ»жҲ–жҺҘеҸЈзҡ„йқҷжҖҒеҸҳйҮҸпјҲзү№дҫӢпјҡеҰӮжһңжҳҜз”Ёstatic finalдҝ®йҘ°зҡ„еёёйҮҸпјҢйӮЈе°ұдёҚдјҡеҜ№зұ»иҝӣиЎҢжҳҫејҸеҲқе§ӢеҢ–гҖӮstatic final дҝ®ж”№зҡ„еҸҳйҮҸеҲҷдјҡеҒҡжҳҫејҸеҲқе§ӢеҢ–пјү
пјҲ3пјүи°ғз”Ёзұ»зҡ„йқҷжҖҒж–№жі•
пјҲ4пјүеҸҚе°„пјҲClass.forName(packagename.className)пјү
пјҲ5пјүеҲқе§ӢеҢ–зұ»зҡ„еӯҗзұ»гҖӮжіЁпјҡеӯҗзұ»еҲқе§ӢеҢ–й—®йўҳпјҡж»Ўи¶ідё»еҠЁи°ғз”ЁпјҢеҚізҲ¶зұ»и®ҝй—®еӯҗзұ»дёӯзҡ„йқҷжҖҒеҸҳйҮҸгҖҒж–№жі•пјҢеӯҗзұ»жүҚдјҡеҲқе§ӢеҢ–пјӣеҗҰеҲҷд»…зҲ¶зұ»еҲқе§ӢеҢ–гҖӮ
пјҲ6пјүjavaиҷҡжӢҹжңәеҗҜеҠЁж—¶иў«ж ҮжҳҺдёәеҗҜеҠЁзұ»зҡ„зұ»
жіЁж„Ҹпјҡ
-
йҖҡиҝҮеӯҗзұ»еј•з”ЁзҲ¶зұ»зҡ„йқҷжҖҒеӯ—ж®ө
иҝҷз§Қжғ…еҶөдёҚдјҡеҜјиҮҙеӯҗзұ»зҡ„еҲқе§ӢеҢ–пјҢеӣ дёәеҜ№дәҺйқҷжҖҒеӯ—ж®өпјҢеҸӘжңүзӣҙжҺҘе®ҡд№үйқҷжҖҒеӯ—ж®өзҡ„зұ»жүҚдјҡиў«и§ҰеҸ‘еҲқе§ӢеҢ–пјҢеӯҗзұ»дёҚжҳҜе®ҡд№үиҝҷдёӘйқҷжҖҒеӯ—ж®өзҡ„зұ»пјҢиҮӘ然дёҚиғҪиў«е®һдҫӢеҢ–гҖӮ -
йҖҡиҝҮж•°з»„е®ҡд№үжқҘеј•з”Ёзұ»пјҢдёҚдјҡи§ҰеҸ‘иҜҘзұ»зҡ„еҲқе§ӢеҢ–
дҫӢеҰӮпјҢ Clazz[] arr = new Clazz[10];并дёҚдјҡи§ҰеҸ‘гҖӮ -
еёёйҮҸдёҚдјҡи§ҰеҸ‘е®ҡд№үеёёйҮҸзҡ„зұ»зҡ„еҲқе§ӢеҢ–
еӣ дёәеёёйҮҸеңЁзј–иҜ‘йҳ¶ж®өдјҡеӯҳе…Ҙи°ғз”ЁеёёйҮҸзҡ„зұ»зҡ„еёёйҮҸжұ дёӯпјҢжң¬иҙЁдёҠ并没жңүеј•з”Ёе®ҡд№үиҝҷдёӘеёёйҮҸзҡ„зұ»пјҢжүҖд»ҘдёҚдјҡи§ҰеҸ‘е®ҡд№үиҝҷдёӘеёёйҮҸзҡ„зұ»зҡ„еҲқе§ӢеҢ–гҖӮ
зұ»зҡ„еҲқе§ӢеҢ–зҡ„дё»иҰҒе·ҘдҪңжҳҜдёәйқҷжҖҒеҸҳйҮҸиөӢзЁӢеәҸи®ҫе®ҡзҡ„еҲқеҖјгҖӮеҰӮstatic int a = 100;еңЁеҮҶеӨҮйҳ¶ж®өпјҢaиў«иөӢй»ҳи®ӨеҖј0пјҢеңЁеҲқе§ӢеҢ–йҳ¶ж®өе°ұдјҡиў«иөӢеҖјдёә100гҖӮ
В
йқҷжҖҒиҜӯеҸҘеқ—дёӯеҸӘиғҪи®ҝй—®еҲ°е®ҡд№үеңЁйқҷжҖҒиҜӯеҸҘеқ—д№ӢеүҚзҡ„еҸҳйҮҸпјҢе®ҡд№үеңЁе®ғд№ӢеҗҺзҡ„еҸҳйҮҸпјҢеңЁеүҚйқўзҡ„йқҷжҖҒиҜӯеҸҘеҝ«еҸҜд»ҘиөӢеҖјпјҢдҪҶжҳҜдёҚиғҪи®ҝй—®гҖӮ
еҰӮпјҡ
static {
В В В В В В a=5;
В В В В В В В System.out.println(a);//Cannot reference a field before it is defined
В В В }
В В В public static int a=1;
В
В
зұ»еҠ иҪҪеҷЁпјҡ
JVMи®ҫи®ЎиҖ…жҠҠзұ»еҠ иҪҪйҳ¶ж®өдёӯзҡ„вҖңйҖҡиҝҮ'зұ»е…ЁеҗҚ'жқҘиҺ·еҸ–е®ҡд№үжӯӨзұ»зҡ„дәҢиҝӣеҲ¶еӯ—иҠӮжөҒвҖқиҝҷдёӘеҠЁдҪңж”ҫеҲ°JavaиҷҡжӢҹжңәеӨ–йғЁеҺ»е®һзҺ°пјҢд»Ҙдҫҝи®©еә”з”ЁзЁӢеәҸиҮӘе·ұеҶіе®ҡеҰӮдҪ•еҺ»иҺ·еҸ–жүҖйңҖиҰҒзҡ„зұ»гҖӮе®һзҺ°иҝҷдёӘеҠЁдҪңзҡ„д»Јз ҒжЁЎеқ—з§°дёәвҖңзұ»еҠ иҪҪеҷЁвҖқгҖӮ
В
1.зұ»дёҺзұ»еҠ иҪҪеҷЁ
еҜ№дәҺд»»дҪ•дёҖдёӘзұ»пјҢйғҪйңҖиҰҒз”ұеҠ иҪҪе®ғзҡ„зұ»еҠ иҪҪеҷЁе’ҢиҝҷдёӘзұ»жқҘзЎ®з«Ӣе…¶еңЁJVMдёӯзҡ„е”ҜдёҖжҖ§гҖӮд№ҹе°ұжҳҜиҜҙпјҢдёӨдёӘзұ»жқҘжәҗдәҺеҗҢдёҖдёӘClassж–Ү件пјҢ并且被еҗҢдёҖдёӘзұ»еҠ иҪҪеҷЁеҠ иҪҪпјҢиҝҷдёӨдёӘзұ»жүҚзӣёзӯүгҖӮ
В
зұ»еҠ иҪҪеҷЁпјҡ
1гҖҒbootstrap classloader пјҚеј•еҜјпјҲд№ҹз§°дёәеҺҹе§Ӣпјүзұ»еҠ иҪҪеҷЁпјҢе®ғиҙҹиҙЈеҠ иҪҪJavaзҡ„ж ёеҝғзұ»гҖӮиҙҹиҙЈеҠ иҪҪJAVA_HOME\libзӣ®еҪ•дёӯ并且иғҪиў«иҷҡжӢҹжңәиҜҶеҲ«зҡ„зұ»еә“еҲ°JVMеҶ…еӯҳдёӯпјҢеҰӮжһңеҗҚз§°дёҚз¬ҰеҗҲзҡ„зұ»еә“еҚідҪҝж”ҫеңЁlibзӣ®еҪ•дёӯд№ҹдёҚдјҡиў«еҠ иҪҪгҖӮиҜҘзұ»еҠ иҪҪеҷЁж— жі•иў«JavaзЁӢеәҸзӣҙжҺҘеј•з”ЁгҖӮ
2гҖҒextension classloader пјҚжү©еұ•зұ»еҠ иҪҪеҷЁпјҢе®ғиҙҹиҙЈеҠ иҪҪJREзҡ„жү©еұ•зӣ®еҪ•пјҲJAVA_HOME/jre/lib/extжҲ–иҖ…з”ұjava.ext.dirsзі»з»ҹеұһжҖ§жҢҮе®ҡзҡ„пјүдёӯJARзҡ„зұ»еҢ…гҖӮиҜҘеҠ иҪҪеҷЁеҸҜд»Ҙиў«ејҖеҸ‘иҖ…зӣҙжҺҘдҪҝз”ЁгҖӮ
3гҖҒsystem classloader пјҚзі»з»ҹпјҲд№ҹз§°дёәеә”з”Ёпјүзұ»еҠ иҪҪеҷЁпјҢе®ғиҙҹиҙЈеңЁJVMиў«еҗҜеҠЁж—¶пјҢеҠ иҪҪжқҘиҮӘеңЁе‘Ҫд»Өjavaдёӯзҡ„-classpathжҲ–иҖ…java.class.pathзі»з»ҹеұһжҖ§жҲ–иҖ… CLASSPATHж“ҚдҪңзі»з»ҹеұһжҖ§жүҖжҢҮе®ҡзҡ„JARзұ»еҢ…е’Ңзұ»и·Ҝеҫ„гҖӮ
В
В
жҜҸдёӘClassLoaderеҠ иҪҪClassзҡ„иҝҮзЁӢжҳҜпјҡ
1.жЈҖжөӢжӯӨClassжҳҜеҗҰиҪҪе…ҘиҝҮпјҲеҚіеңЁcacheдёӯжҳҜеҗҰжңүжӯӨClassпјүпјҢеҰӮжһңжңүеҲ°8,еҰӮжһңжІЎжңүеҲ°2
2.еҰӮжһңparent classloaderдёҚеӯҳеңЁпјҲжІЎжңүparentпјҢйӮЈparentдёҖе®ҡжҳҜbootstrap classloaderдәҶпјүпјҢеҲ°4
3.иҜ·жұӮparent classloaderиҪҪе…ҘпјҢеҰӮжһңжҲҗеҠҹеҲ°8пјҢдёҚжҲҗеҠҹеҲ°5
4.иҜ·жұӮjvmд»Һbootstrap classloaderдёӯиҪҪе…ҘпјҢеҰӮжһңжҲҗеҠҹеҲ°8
5.еҜ»жүҫClassж–Ү件пјҲд»ҺдёҺжӯӨclassloaderзӣёе…ізҡ„зұ»и·Ҝеҫ„дёӯеҜ»жүҫпјүгҖӮеҰӮжһңжүҫдёҚеҲ°еҲҷеҲ°7.
6.д»Һж–Ү件дёӯиҪҪе…ҘClassпјҢеҲ°8.
7.жҠӣеҮәClassNotFoundException.
8.иҝ”еӣһClass.
В
В
зұ»еҠ иҪҪеҷЁзҡ„йЎәеәҸжҳҜпјҡ
е…ҲжҳҜbootstrap classloaderпјҢ然еҗҺжҳҜextension classloaderпјҢжңҖеҗҺжүҚжҳҜsystem classloaderгҖӮВ
зұ»еҠ иҪҪеҷЁзҡ„еҸҢдәІе§”жҙҫжңәеҲ¶пјҡеҪ“дёҖдёӘзұ»ж”¶еҲ°дәҶзұ»еҠ иҪҪиҜ·жұӮпјҢд»–йҰ–е…ҲдёҚдјҡе°қиҜ•иҮӘе·ұеҺ»еҠ иҪҪиҝҷдёӘзұ»пјҢиҖҢжҳҜжҠҠиҝҷдёӘиҜ·жұӮ委жҙҫз»ҷзҲ¶зұ»еҺ»е®ҢжҲҗпјҢжҜҸдёҖдёӘеұӮж¬Ўзұ»еҠ иҪҪеҷЁйғҪжҳҜеҰӮжӯӨпјҢеӣ жӯӨжүҖжңүзҡ„еҠ иҪҪиҜ·жұӮйғҪеә”иҜҘдј йҖҒеҲ°еҗҜеҠЁзұ»еҠ иҪҪе…¶дёӯпјҢеҸӘжңүеҪ“зҲ¶зұ»еҠ иҪҪеҷЁеҸҚйҰҲиҮӘе·ұж— жі•е®ҢжҲҗиҝҷдёӘиҜ·жұӮзҡ„ж—¶еҖҷпјҲеңЁе®ғзҡ„еҠ иҪҪи·Ҝеҫ„дёӢжІЎжңүжүҫеҲ°жүҖйңҖеҠ иҪҪзҡ„ClassпјүпјҢеӯҗзұ»еҠ иҪҪеҷЁжүҚдјҡе°қиҜ•иҮӘе·ұеҺ»еҠ иҪҪгҖӮ
В
дё»иҰҒдҪ“зҺ°еңЁClassLoaderзҡ„loadClass()ж–№жі•дёӯпјҢжҖқи·ҜеҫҲз®ҖеҚ•пјҡе…ҲжЈҖжҹҘжҳҜеҗҰе·Із»Ҹиў«еҠ иҪҪиҝҮпјҢиӢҘжІЎжңүеҠ иҪҪеҲҷи°ғз”ЁзҲ¶зұ»еҠ иҪҪеҷЁзҡ„loadClass()ж–№жі•пјҢиӢҘзҲ¶зұ»еҠ иҪҪеҷЁдёәз©әеҲҷй»ҳи®ӨдҪҝз”ЁеҗҜеҠЁзұ»еҠ иҪҪеҷЁдҪңдёәзҲ¶зұ»еҠ иҪҪеҷЁгҖӮеҰӮжһңзҲ¶зұ»еҠ иҪҪеҷЁеҠ иҪҪеӨұиҙҘпјҢжҠӣеҮәClassNotFoundExceptionејӮеёёеҗҺпјҢи°ғз”ЁиҮӘе·ұзҡ„findClass()ж–№жі•иҝӣиЎҢеҠ иҪҪгҖӮ
В
еҸҢдәІе§”жҙҫжЁЎеһӢзҡ„е®һзҺ°
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected synchronized Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
// йҰ–е…ҲеҲӨж–ӯиҜҘзұ»еһӢжҳҜеҗҰе·Іиў«еҠ иҪҪ
Class c = findLoadedClass(name);
if (c == null) {
//еҰӮжһңжІЎжңүиў«еҠ иҪҪпјҢе°ұ委жүҳз»ҷзҲ¶зұ»еҠ иҪҪеҷЁжҲ–еҗҜеҠЁеҠ иҪҪеҷЁеҠ иҪҪ
try {
//еҰӮжһңеӯҳеңЁзҲ¶зұ»еҠ иҪҪеҷЁпјҢе°ұ委жүҳз»ҷзҲ¶зұ»еҠ иҪҪеҷЁеҠ иҪҪ
if (parent != null) {
c = parent.loadClass(name, false);
} else {
//еҰӮжһңдёҚеӯҳеңЁзҲ¶зұ»еҠ иҪҪеҷЁпјҢе°ұжЈҖжҹҘжҳҜеҗҰжҳҜз”ұеҗҜеҠЁеҠ иҪҪеҷЁеҠ иҪҪзҡ„зұ»
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// еҰӮжһңзҲ¶зұ»еҠ иҪҪеҷЁжҠӣеҮәClassNotFoundExceptionпјҢ
//иҜҙжҳҺзҲ¶зұ»еҠ иҪҪеҷЁж— жі•е®ҢжҲҗеҠ иҪҪиҜ·жұӮ
}
if (c == null) {
// еңЁзҲ¶зұ»еҠ иҪҪеҷЁж— жі•еҠ иҪҪзҡ„ж—¶еҖҷпјҢ
//еҶҚи°ғз”Ёжң¬иә«зҡ„findClassж–№жі•жқҘиҝӣиЎҢеҠ иҪҪ
c = findClass(name);
}
}
if (resolve) { //жҳҜеҗҰеҲқе§ӢеҢ–
resolveClass(c);
}
return c;
}
В
В
В
д»Јз ҒдёҫдҫӢ1пјҡ
жҲ‘们еҜ№дёҠйқўзҡ„第пјҲ5пјүз§Қжғ…еҶөеҒҡдёҖдёӘд»Јз ҒдёҫдҫӢгҖӮ
(1)Father.java:

1 public class Father { 2 3 static { 4 System.out.println("*******father init"); 5 } 6 public static int a = 1; 7 }
В
(2)Son.java:
1 public class Son extends Father { 2 static { 3 System.out.println("*******son init"); 4 } 5 public static int b = 2; 6 }
В
(3)JavaTest.java:
1 public class JavaTest { 2 public static void main(String[] args) { 3 System.out.println(Son.a); 4 } 5 }
В
дёҠйқўзҡ„жөӢиҜ•зұ»дёӯпјҢиҷҪ然用дёҠдәҶSonиҝҷдёӘзұ»пјҢдҪҶжҳҜ并没жңүи°ғз”Ёеӯҗзұ»йҮҢзҡ„жҲҗе‘ҳпјҢжүҖд»Ҙ并дёҚдјҡеҜ№еӯҗзұ»иҝӣиЎҢеҲқе§ӢеҢ–гҖӮдәҺжҳҜиҝҗиЎҢж•ҲжһңжҳҜпјҡ

В
еҰӮжһңжҠҠJavaTest.javaж”№жҲҗдёӢйқўиҝҷдёӘж ·еӯҗпјҡ
1 public class JavaTest { 2 public static void main(String[] args) { 3 System.out.println(Son.a); 4 System.out.println(Son.b); 5 } 6 }
В
иҝҗиЎҢж•Ҳжһңпјҡ

В
В
еҰӮжһңжҠҠJavaTest.javaж”№жҲҗдёӢйқўиҝҷдёӘж ·еӯҗпјҡ
JavaTest.java:
1 public class JavaTest { 2 public static void main(String[] args) { 3 System.out.println(Son.b); 4 } 5 }
В
иҝҗиЎҢж•Ҳжһңпјҡ

В
В
д»Јз ҒдёҫдҫӢ2пјҡ
жҲ‘们еҜ№дёҠйқўзҡ„第пјҲ2пјүз§Қжғ…еҶөеҒҡдёҖдёӘд»Јз ҒдёҫдҫӢгҖӮеҚіпјҡеҰӮжһңжҳҜз”Ёstatic finalдҝ®йҘ°зҡ„еёёйҮҸпјҢеҲҷдёҚдјҡиҝӣиЎҢжҳҫејҸеҲқе§ӢеҢ–гҖӮд»Јз ҒдёҫдҫӢеҰӮдёӢпјҡ
(1)Father.java:
1 public class Father { 2 static { 3 System.out.println("*******father init"); 4 } 5 public static int a = 1; 6 }
В
(2)Son.java:
1 public class Son extends Father { 2 static { 3 System.out.println("*******son init"); 4 } 5 6 public static int b = 2; 7 public static final int c = 3; 8 }
В
иҝҷйҮҢйқўзҡ„еҸҳйҮҸcжҳҜдёҖдёӘйқҷжҖҒеёёйҮҸгҖӮ
(3)JavaTest.java:
1 public class JavaTest { 2 public static void main(String[] args) { 3 System.out.println(Son.c); 4 } 5 }
В

дёҠйқўзҡ„иҝҗиЎҢж•ҲжһңжҳҫзӨәпјҢз”ұдәҺcжҳҜfinal staticдҝ®йҘ°зҡ„йқҷжҖҒеёёйҮҸпјҢжүҖд»Ҙж №жң¬е°ұжІЎжңүи°ғз”ЁйқҷжҖҒд»Јз Ғеқ—йҮҢйқўзҡ„еҶ…е®№пјҢд№ҹе°ұжҳҜиҜҙпјҢжІЎжңүеҜ№иҝҷдёӘзұ»иҝӣиЎҢжҳҫејҸеҲқе§ӢеҢ–гҖӮ
зҺ°еңЁпјҢдҝқжҢҒFather.javaзҡ„д»Јз ҒдёҚеҸҳгҖӮе°ҶSon.javaд»Јз ҒеҒҡеҰӮдёӢдҝ®ж”№пјҡ
1 public class Son extends Father { 2 static { 3 System.out.println("*******son init"); 4 } 5 6 public static int b = 2; 7 public static final int c = new Random().nextInt(3); 8 }
В
JavaTest.java:
1 public class JavaTest { 2 public static void main(String[] args) { 3 System.out.println(Son.c); 4 } 5 }
В
иҝҗиЎҢж•ҲжһңеҰӮдёӢпјҡ

В
В
д»Јз ҒдёҫдҫӢ3пјҡпјҲеҫҲе®№жҳ“еҮәй”ҷпјү
жҲ‘们жқҘдёӢйқўиҝҷж®өд»Јз Ғзҡ„иҝҗиЎҢз»“жһңжҳҜд»Җд№Ҳпјҡ
1 public class TestInstance { 2 3 public static TestInstance instance = new TestInstance(); 4 public static int a; 5 public static int b = 0; 6 7 public TestInstance() { 8 a++; 9 b++; 10 } 11 12 public static void main(String[] args) { 13 System.out.println(TestInstance.a); 14 System.out.println(TestInstance.b); 15 } 16 }
В
иҝҗиЎҢз»“жһңпјҡ

д№ӢжүҖд»Ҙжңүиҝҷж ·зҡ„иҝҗиЎҢз»“жһңпјҢиҝҷйҮҢж¶үеҸҠеҲ°зұ»еҠ иҪҪзҡ„йЎәеәҸпјҡ
пјҲ1пјүеңЁеҠ иҪҪйҳ¶ж®өпјҢеҠ иҪҪзұ»зҡ„дҝЎжҒҜ
пјҲ2пјүеңЁй“ҫжҺҘзҡ„еҮҶеӨҮйҳ¶ж®өз»ҷinstanceгҖҒaгҖҒbеҒҡй»ҳи®ӨеҲқе§ӢеҢ–并еҲҶй…Қз©әй—ҙпјҢжӯӨж—¶aе’Ңbзҡ„еҖјйғҪдёә0
пјҲ3пјүеңЁеҲқе§ӢеҢ–йҳ¶ж®өпјҢжү§иЎҢжһ„йҖ ж–№жі•пјҢжӯӨж—¶aе’Ңbзҡ„еҖјйғҪдёә1
пјҲ4пјүеңЁеҲқе§ӢеҢ–йҳ¶ж®өпјҢз»ҷйқҷжҖҒеҸҳйҮҸеҒҡжҳҫејҸеҲқе§ӢеҢ–пјҢжӯӨж—¶bзҡ„еҖјдёә0
В
жҲ‘们改дёҖдёӢд»Јз Ғзҡ„жү§иЎҢйЎәеәҸпјҢж”№жҲҗдёӢйқўиҝҷдёӘж ·еӯҗпјҡ
1 public class TestInstance { 2 3 public static int a; 4 public static int b = 0; 5 public static TestInstance instance = new TestInstance(); 6 7 public TestInstance() { 8 a++; 9 b++; 10 } 11 12 public static void main(String[] args) { 13 System.out.println(TestInstance.a); 14 System.out.println(TestInstance.b); 15 16 } 17 }
В
иҝҗиЎҢж•ҲжһңжҳҜпјҡ

д№ӢжүҖд»Ҙжңүиҝҷж ·зҡ„иҝҗиЎҢз»“жһңпјҢиҝҷйҮҢж¶үеҸҠеҲ°зұ»еҠ иҪҪзҡ„йЎәеәҸпјҡ
пјҲ1пјүеңЁеҠ иҪҪйҳ¶ж®өпјҢеҠ иҪҪзұ»зҡ„дҝЎжҒҜ
пјҲ2пјүеңЁй“ҫжҺҘзҡ„еҮҶеӨҮйҳ¶ж®өз»ҷinstanceгҖҒaгҖҒbеҒҡй»ҳи®ӨеҲқе§ӢеҢ–并еҲҶй…Қз©әй—ҙпјҢжӯӨж—¶aе’Ңbзҡ„еҖјйғҪдёә0
пјҲ3пјүеңЁеҲқе§ӢеҢ–йҳ¶ж®өпјҢз»ҷйқҷжҖҒеҸҳйҮҸеҒҡжҳҫејҸеҲқе§ӢеҢ–пјҢжӯӨж—¶bзҡ„еҖјд»Қдёә0
пјҲ4пјүеңЁеҲқе§ӢеҢ–йҳ¶ж®өпјҢжү§иЎҢжһ„йҖ ж–№жі•пјҢжӯӨж—¶aе’Ңbзҡ„еҖјйғҪдёә1
В
жіЁж„ҸпјҢиҝҷйҮҢж¶үеҸҠеҲ°еҸҰеӨ–дёҖдёӘзұ»дјјзҡ„зҹҘиҜҶзӮ№дёҚиҰҒжҗһж··дәҶгҖӮзҹҘиҜҶзӮ№еҰӮдёӢгҖӮ
зҹҘиҜҶзӮ№пјҡзұ»зҡ„еҲқе§ӢеҢ–иҝҮзЁӢпјҲйҮҚиҰҒпјү
Student s = new Student();еңЁеҶ…еӯҳдёӯеҒҡдәҶе“ӘдәӣдәӢжғ…?
- еҠ иҪҪStudent.classж–Ү件иҝӣеҶ…еӯҳ
- еңЁж ҲеҶ…еӯҳдёәsејҖиҫҹз©әй—ҙ
- еңЁе ҶеҶ…еӯҳдёәеӯҰз”ҹеҜ№иұЎејҖиҫҹз©әй—ҙ
- еҜ№еӯҰз”ҹеҜ№иұЎзҡ„жҲҗе‘ҳеҸҳйҮҸиҝӣиЎҢй»ҳи®ӨеҲқе§ӢеҢ–
- еҜ№еӯҰз”ҹеҜ№иұЎзҡ„жҲҗе‘ҳеҸҳйҮҸиҝӣиЎҢжҳҫзӨәеҲқе§ӢеҢ–
- йҖҡиҝҮжһ„йҖ ж–№жі•еҜ№еӯҰз”ҹеҜ№иұЎзҡ„жҲҗе‘ҳеҸҳйҮҸиөӢеҖј
- еӯҰз”ҹеҜ№иұЎеҲқе§ӢеҢ–е®ҢжҜ•пјҢжҠҠеҜ№иұЎең°еқҖиөӢеҖјз»ҷsеҸҳйҮҸ



зӣёе…іжҺЁиҚҗ
JavaиҷҡжӢҹжңәпјҲJVMпјүжҳҜJavaзЁӢеәҸиҝҗиЎҢзҡ„ж ёеҝғ组件пјҢе®ғиҙҹиҙЈи§ЈйҮҠжү§иЎҢеӯ—иҠӮз Ғ并管зҗҶеҶ…еӯҳгҖӮжң¬зҜҮж–Үз« е°Ҷж·ұе…ҘжҺўи®ЁJVMзҡ„дёҖдәӣеёёи§Ғй—®йўҳпјҢиҝҷдәӣеҶ…е®№еҜ№дәҺзҗҶи§Је’ҢдјҳеҢ–Javaеә”з”ЁзЁӢеәҸиҮіе…ійҮҚиҰҒпјҢеҗҢж—¶д№ҹжҳҜйқўиҜ•дёӯзҡ„й«ҳйў‘иҖғеҜҹзӮ№гҖӮ дёҖгҖҒJVMеҶ…еӯҳ...
### JVMеҶ…幕пјҡjavaиҷҡжӢҹжңәиҜҰи§Ј #### дёҖгҖҒжҰӮиҝ° JavaиҷҡжӢҹжңә(JVM)жҳҜиҝҗиЎҢJavaеә”з”ЁзЁӢеәҸзҡ„ж ёеҝғ组件пјҢе®ғжҸҗдҫӣдәҶдёҖдёӘеҸҜ移жӨҚгҖҒе®үе…Ёдё”й«ҳжҖ§иғҪзҡ„зҺҜеўғгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁJVMзҡ„еҶ…йғЁжһ¶жһ„еҸҠе…¶еҗ„дёӘз»„жҲҗйғЁеҲҶзҡ„еҠҹиғҪгҖӮ #### дәҢгҖҒJavaиҷҡжӢҹжңә...
### JavaиҷҡжӢҹжңә(JVM)иҜҰи§Ј #### дёҖгҖҒеј•иЁҖ JavaиҷҡжӢҹжңә(JVM)дҪңдёәJavaзј–зЁӢиҜӯиЁҖзҡ„ж ёеҝғ组件д№ӢдёҖпјҢе…¶йҮҚиҰҒжҖ§дёҚиЁҖиҖҢе–»гҖӮжң¬ж–Үе°Ҷж·ұе…Ҙеү–жһҗJVMзҡ„еҹәжң¬жҰӮеҝөгҖҒжһ¶жһ„еҸҠе…¶еҶ…еӯҳз®ЎзҗҶжңәеҲ¶пјҢйҮҚзӮ№и§ЈиҜ»е Ҷе’Ңж ҲеҶ…еӯҳжәўеҮәзҡ„жғ…еҶөеҸҠжЎҲдҫӢеҲҶжһҗгҖӮ ##...
### jvmиҜҰи§Ј(javaиҷҡжӢҹжңәиҜҰи§Ј) #### JavaдёҺJVMжҰӮи§Ҳ JavaдҪңдёәдёҖз§Қе№ҝжіӣдҪҝз”Ёзҡ„зј–зЁӢиҜӯиЁҖпјҢе…¶ж ёеҝғдјҳеҠҝд№ӢдёҖдҫҝжҳҜвҖңдёҖж¬Ўзј–еҶҷпјҢеҲ°еӨ„иҝҗиЎҢвҖқзҡ„зү№жҖ§пјҢиҝҷиғҢеҗҺзҡ„е…ій”®жҠҖжңҜж”Ҝж’‘еҚідёәJavaиҷҡжӢҹжңәпјҲJVMпјүгҖӮJVMжҳҜдёҖз§ҚжҠҪиұЎи®Ўз®—жЁЎеһӢпјҢе…Ғи®ё...
гҖҠJAVAиҷҡжӢҹжңәи§ЈиҜ»е…Ҙй—ЁгҖӢжҳҜдёҖжң¬йқўеҗ‘еҲқеӯҰиҖ…зҡ„жҢҮеҚ—пјҢж—ЁеңЁеёҰйўҶиҜ»иҖ…ж·ұе…ҘзҗҶи§ЈJavaиҷҡжӢҹжңәпјҲJVMпјүзҡ„е·ҘдҪңеҺҹзҗҶе’ҢеҶ…йғЁжңәеҲ¶гҖӮJVMжҳҜJavaиҜӯиЁҖзҡ„ж ёеҝғз»„жҲҗйғЁеҲҶпјҢе®ғдёәJavaзЁӢеәҸжҸҗдҫӣдәҶдёҖдёӘи·Ёе№іеҸ°зҡ„иҝҗиЎҢзҺҜеўғпјҢдҪҝеҫ—вҖңдёҖж¬Ўзј–еҶҷпјҢеҲ°еӨ„иҝҗиЎҢвҖқ...
### 2024е№ҙJavaйқўиҜ•йўҳпјҡJVMд№ӢJavaиҷҡжӢҹжңәйқўиҜ•йўҳ #### JavaеҶ…еӯҳжЁЎеһӢеҸҠеҹәзЎҖзҹҘиҜҶ **1. Javaд»Јз ҒеҰӮдҪ•иў«и®Ўз®—жңәиҜҶеҲ«** JavaзЁӢеәҸжңҖеҲқз”ұејҖеҸ‘дәәе‘ҳдҪҝз”ЁJavaиҜӯжі•зј–еҶҷпјҢиҝҷдәӣд»Јз Ғдәәзұ»еҸҜиҜ»дҪҶи®Ўз®—жңәж— жі•зӣҙжҺҘзҗҶи§ЈгҖӮдёәдәҶдҪҝи®Ўз®—жңә...
JavaжҠҖжңҜиҮӘиҜһз”ҹд»ҘжқҘе°ұд»Ҙе…¶вҖңдёҖж¬Ўзј–еҶҷпјҢеҲ°еӨ„иҝҗиЎҢвҖқзҡ„зҗҶеҝөиҖҢеӨҮеҸ—иөһиӘүпјҢиҖҢиҝҷдёҖзҗҶеҝөзҡ„ж ёеҝғе®һзҺ°жӯЈжҳҜJavaиҷҡжӢҹжңәпјҲJVMпјүгҖӮдёәдәҶж·ұе…ҘзҗҶи§ЈJavaиҷҡжӢҹжңәзҡ„е·ҘдҪңжңәеҲ¶пјҢжң¬ж–Үе°Ҷд»Һе…¶жһ¶жһ„гҖҒ组件гҖҒжү§иЎҢжөҒзЁӢзӯүи§’еәҰиҜҰз»Ҷйҳҗиҝ°JVMзҡ„иҝҗдҪңеҺҹзҗҶгҖӮ...
### JavaиҷҡжӢҹжңә(JVM)иҜҰи§Ј #### дёҖгҖҒJavaжҠҖжңҜжҰӮи§Ҳ JavaдёҚд»…д»…жҳҜдёҖз§Қзј–зЁӢиҜӯиЁҖпјҢжӣҙжҳҜдёҖйЎ№з”ұеӨҡдёӘз»„жҲҗйғЁеҲҶжһ„жҲҗзҡ„жҠҖжңҜгҖӮиҝҷдәӣз»„жҲҗйғЁеҲҶеҢ…жӢ¬Javaзј–зЁӢиҜӯиЁҖгҖҒJavaзұ»ж–Үд»¶ж јејҸгҖҒJavaиҷҡжӢҹжңә(JVM)д»ҘеҸҠJavaеә”з”ЁзЁӢеәҸжҺҘеҸЈ(API)гҖӮе®ғ们...
第20иҠӮJavaиҷҡжӢҹжңә-й«ҳжҖ§иғҪJavaиҷҡжӢҹжңә00:02:58еҲҶй’ҹ | 第21иҠӮJavaиҷҡжӢҹжңә-TaobaoVM00:03:06еҲҶй’ҹ | 第22иҠӮJavaеҶ…еӯҳеҢәеҹҹ-з®Җд»Ӣ00:07:56еҲҶй’ҹ | 第23иҠӮJavaеҶ…еӯҳеҢәеҹҹ-JavaиҷҡжӢҹжңәж Ҳ00:12:04еҲҶй’ҹ | 第24иҠӮJavaеҶ…еӯҳеҢәеҹҹ-зЁӢеәҸ...
иҜ»д№Ұ笔记пјҡjavaиҷҡжӢҹжңәиҜҰи§Јjvmд»Һе…Ҙй—ЁеҲ°зІҫйҖҡ
### JavaиҷҡжӢҹжңә(JVM)еҶ…еӯҳи®ҫзҪ®дёҺи°ғдјҳиҜҰи§Ј #### еј•иЁҖ еңЁзҺ°д»ЈиҪҜ件ејҖеҸ‘дёӯпјҢJavaиҷҡжӢҹжңә(JVM)дҪңдёәжү§иЎҢJavaеӯ—иҠӮз Ғзҡ„ж ёеҝғ组件пјҢе…¶жҖ§иғҪзӣҙжҺҘеҪұе“ҚеҲ°Javaеә”з”Ёзҡ„иҝҗиЎҢж•ҲзҺҮдёҺзЁіе®ҡжҖ§гҖӮзү№еҲ«жҳҜеңЁеӨ§ж•°жҚ®еӨ„зҗҶеңәжҷҜдёӢпјҢеҗҲзҗҶи®ҫзҪ®JVMеҶ…еӯҳ...
"java-JVM-йқўиҜ•йўҳд»ҺеҹәзЎҖеҲ°й«ҳзә§иҜҰи§Ј-HM"иҝҷдёӘиө„ж–ҷеҫҲеҸҜиғҪжҳҜж¶өзӣ–дәҶд»ҺеҹәзЎҖжҰӮеҝөеҲ°еӨҚжқӮй—®йўҳзҡ„дёҖзі»еҲ—JVMйқўиҜ•йўҳзӣ®пјҢж—ЁеңЁеё®еҠ©жұӮиҒҢиҖ…е…ЁйқўеҮҶеӨҮJVMзӣёе…ізҡ„йқўиҜ•гҖӮ дёҖгҖҒJVMеҹәзЎҖ 1. **JVMжһ¶жһ„**пјҡJVMдё»иҰҒеҢ…жӢ¬зұ»еҠ иҪҪеҷЁгҖҒиҝҗиЎҢж—¶ж•°жҚ®еҢә...
JavaиҷҡжӢҹжңәе·ҘдҪңеҺҹзҗҶиҜҰи§Ј JavaиҷҡжӢҹжңәе·ҘдҪңеҺҹзҗҶиҜҰи§ЈжҳҜ Java зЁӢеәҸжү§иЎҢзҡ„ж ёеҝғ组件д№ӢдёҖгҖӮдәҶи§Ј Java иҷҡжӢҹжңәзҡ„е·ҘдҪңеҺҹзҗҶеҜ№ Java ејҖеҸ‘дәәе‘ҳжқҘиҜҙйқһеёёйҮҚиҰҒгҖӮжң¬ж–Үе°ҶиҜҰз»Ҷд»Ӣз»Қ Java иҷҡжӢҹжңәе·ҘдҪңеҺҹзҗҶзҡ„иҜҰз»ҶиҝҮзЁӢе’Ңзұ»еҠ иҪҪеҷЁзҡ„е·ҘдҪңжңәзҗҶгҖӮ...
JVMпјҲJavaиҷҡжӢҹжңәпјүиҜҰи§Ј дёҖгҖҒJVM жҰӮеҝө JVMпјҲJavaиҷҡжӢҹжңәпјүжҳҜдёҖдёӘжҠҪиұЎзҡ„и®Ўз®—жЁЎеһӢпјҢжҸҗдҫӣдәҶдёҖдёӘиҝҗиЎҢзҺҜеўғпјҢиғҪеӨҹиҝҗиЎҢ Java еӯ—иҠӮз ҒгҖӮJVM еҸҜд»Ҙи§ЈиҜ»жҢҮд»Өд»Јз Ғ并дёҺеә•еұӮиҝӣиЎҢдәӨдә’пјҢеҢ…жӢ¬ж“ҚдҪңзі»з»ҹе№іеҸ°е’Ңжү§иЎҢжҢҮд»Ө并管зҗҶиө„жәҗзҡ„硬件...
### JavaиҷҡжӢҹжңә(JVM)зү№жҖ§JAVA SE 7 #### жҰӮиҝ° гҖҠJavaиҷҡжӢҹжңәзү№жҖ§JAVA SE 7.pdfгҖӢжҳҜдёҖжң¬иҜҰз»Ҷд»Ӣз»ҚJavaиҷҡжӢҹжңә(JVM)规иҢғзҡ„д№ҰзұҚпјҢй’ҲеҜ№Java SE 7зүҲжң¬гҖӮжң¬д№Ұз”ұTim LindholmгҖҒFrank YellinгҖҒGilad Brachaе’ҢAlex Buckleyе…ұеҗҢ...
### Java иҷҡжӢҹжңәJVMеҶ…еӯҳжЁЎеһӢзҹҘиҜҶзӮ№ #### 1. JVMжҰӮиҝ° ##### 1.1 Javaзҡ„зү№жҖ§дёҺJVMзҡ„еә”з”Ё JavaиҜӯиЁҖзҡ„зү№жҖ§еҢ…жӢ¬и·Ёе№іеҸ°жҖ§гҖҒйқўеҗ‘еҜ№иұЎгҖҒе®үе…ЁжҖ§зӯүгҖӮJVMжҳҜJavaзЁӢеәҸиғҪеӨҹи·Ёе№іеҸ°иҝҗиЎҢзҡ„е…ій”®пјҢе®ғиҙҹиҙЈе°ҶJavaжәҗд»Јз ҒиҪ¬жҚўжҲҗдёҺе№іеҸ°ж— е…і...