- µĄÅĶ¦ł: 1281048 µ¼Ī
- µĆ¦Õł½:

- µØźĶć¬: µĘ▒Õ£│
-

µ¢ćń½ĀÕłåń▒╗
- Õģ©ķā©ÕŹÜÕ«ó (608)
- µĢ░µŹ«ń╗ōµ×ä (2)
- AJAX (3)
- Ķ«ŠĶ«Īµ©ĪÕ╝Å (3)
- java (117)
- js (14)
- css (9)
- jsp (10)
- µØéµ¢ć (49)
- htmlparser (6)
- µĢ░µŹ«Õ║ō (29)
- ń«Śµ│Ģ (14)
- µĢ░µŹ«µī¢µÄś (11)
- ńöĄĶäæµØéńŚć (12)
- ńĮæń╗£ńł¼ĶÖ½ (7)
- Õ║öńö©µ£ŹÕŖĪÕÖ© (9)
- PHP (2)
- C# (14)
- µĄŗĶ»Ģ (3)
- WEBķ½śµĆ¦ĶāĮÕ╝ĆÕÅæ (3)
- swt (1)
- µÉ£ń┤óÕ╝ĢµōÄ (16)
- HttpClient (4)
- Lite (1)
- EXT (1)
- python (1)
- lucene (4)
- sphinx (9)
- Xapian (0)
- linux (44)
- ķŚ«ķóśÕĮÆń▒╗ (1)
- Android (6)
- ubuntu (7)
- SEO (18)
- µĢ░ÕŁ” (0)
- Õå£õĖÜĶĄäĶ«» (12)
- µĖĖµłÅ (3)
- nginx (1)
- TeamViewer (1)
- swing (1)
- WebÕēŹ ń½» (1)
- õĖ╗ķĪĄ (0)
- ķś┐ĶÉ©ÕŠĘÕÅæķ”¢ÕÅæĶ║½õ╗Į (0)
- ĶĮ»õ╗ČĶ«ŠĶ«ĪÕĖł (0)
- hibernate (5)
- spring3.0 (5)
- elastic (1)
- SSH (3)
- ff (0)
- oracle 10g (9)
- ńź×ń╗ÅńĮæń╗£ (1)
- struts2.0 (2)
- maven (1)
- nexus (1)
- ĶŠģÕŖ®ÕĘźÕģĘ (3)
- Shiro (1)
- ĶüöķĆÜķĪ╣ńø« (0)
- 2014Õ╣┤õĖōõĖÜķĆēµŗ® (0)
- freemarker (1)
- struts1.2 (8)
- adfasdfasfasf (0)
- TortoiseSVN (1)
- jstl (1)
- jquery (1)
- eclipse plugin (0)
- µĖĖµłÅÕż¢µīé (1)
- µÄ©Õ╣┐ (0)
- µīēķö«ń▓ŠńüĄ (1)
- ibatis3.0 (1)
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 4)
- µłæńÜäĶ«║ÕØø ( 103)
- µłæńÜäķŚ«ńŁö ( 148)
ÕŁśµĪŻÕłåń▒╗
- 2017-08 ( 1)
- 2015-04 ( 1)
- 2014-07 ( 1)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
-
µ░┤ķćÄÕō▓õ╣¤’╝Ü
õĖŹõĖŹõĖŹ, Ķ┐ÖõĖ¬µé©ń£¤ķöÖõ║å!ÕģČÕ«×µś»õĮĀÕ╝Ģńö©ńÜäķéŻõĖ¬jspÕÆīµ£¼Ķ║½ńÜäjsp ...
Ķ¦Żµ×ÉÕģ│õ║ÄjspķĪĄķØóµīćõ╗żÕå▓ń¬üķŚ«ķóścontentType="text/html;charset=UTF-8" -
caobo_cb’╝Ü
import xx.cn.weibo.Util;┬Ā
[ javańēł]µ¢░µĄ¬ÕŠ«ÕŹÜõ╣ŗruquest_tokenń»ć -
caobo_cb’╝Ü
õĮĀÕźĮ UtilÕīģµ▓Īµ£ē
[ javańēł]µ¢░µĄ¬ÕŠ«ÕŹÜõ╣ŗruquest_tokenń»ć -
Õ░ŵĪöÕŁÉ’╝Ü
õĮĀÕźĮ’╝üµłæķüćÕł░õĖ¬ķŚ«ķóś max_allowed_packetÕĆ╝µĆ╗µś» ...
mysqlµ¤źĶ»óÕŹĀńö©ÕåģÕŁś,õ╝śÕī¢ńÜäµŖĆÕʦ -
donghustone’╝Ü
Ķ░óĶ░óÕż¦ńź×’╝ü
ńö©JSmoothÕłČõĮ£java jarµ¢ćõ╗ČńÜäÕÅ»µē¦ĶĪīexeµ¢ćõ╗ȵĢÖń©ŗ(ÕøŠµ¢ć)
Õ¤║õ║ÄSphinx+MySQLÕģ©µ¢ćµŻĆń┤óµ×ȵ×äĶ«ŠĶ«Ī
- ÕŹÜÕ«óÕłåń▒╗’╝Ü
- µÉ£ń┤óÕ╝ĢµōÄ
ÕĤµ¢ć’╝Ühttp://blog.s135.com/read.php/360.htm
ÕēŹĶ©Ć’╝Ü
µ£¼µ¢ćķśÉĶ┐░ńÜ䵜»õĖƵ¼Šń╗ÅĶ┐ćńö¤õ║¦ńÄ»ÕóāµŻĆķ¬īńÜäÕŹāõĖćń║¦µĢ░µŹ«Õģ©µ¢ćµŻĆń┤ó’╝łµÉ£ń┤óÕ╝ĢµōÄ’╝ēµ×ȵ×äŃĆéµ£¼µ¢ćÕÅ¬ÕłŚÕć║ÕēŹÕćĀń½ĀńÜäÕåģÕ«╣ĶŖéķĆē’╝īõĖŹµÅÉõŠøÕģ©µ¢ćÕåģÕ«╣ŃĆé
Õ£©DELL PowerEdge 6850µ£ŹÕŖĪÕÖ©’╝łÕøøķóŚ64 õĮŹInter Xeon MP 7110NÕżäńÉåÕÖ© / 8GBÕåģÕŁś’╝ēŃĆüRedHat AS4 LinuxµōŹõĮ£ń│╗ń╗¤ŃĆüMySQL 5.1.26ŃĆüMyISAMÕŁśÕé©Õ╝ĢµōÄŃĆükey_buffer=1024MńÄ»ÕóāõĖŗÕ«×µĄŗ’╝īÕŹĢĶĪ©1000õĖćµØĪĶ«░ÕĮĢńÜäµĢ░µŹ«ķćÅ’╝łĶ┐ÖÕ╝ĀMySQLĶĪ©µŗźµ£ēintŃĆü datetimeŃĆüvarcharŃĆütextńŁēń▒╗Õ×ŗńÜä10ÕżÜõĖ¬ÕŁŚµ«Ą’╝īÕŬµ£ēõĖ╗ķö«’╝īµŚĀÕģČÕ«āń┤óÕ╝Ģ’╝ē’╝īńö©õĖ╗ķö«’╝łPRIMARY KEY’╝ēõĮ£õĖ║WHEREµØĪõ╗ČĶ┐øĶĪīSQLµ¤źĶ»ó’╝īķƤÕ║”ķØ×ÕĖĖõ╣ŗÕ┐½’╝īÕŬĶĆŚĶ┤╣0.01ń¦ÆŃĆé
Õć║Ķć¬õ┐äńĮŚµ¢»ńÜäÕ╝Ƶ║ÉÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄĶĮ»õ╗Č Sphinx ’╝īÕŹĢõĖĆń┤óÕ╝Ģµ£ĆÕż¦ÕÅ»ÕīģÕɽ1õ║┐µØĪĶ«░ÕĮĢ’╝īÕ£©1ÕŹāõĖćµØĪĶ«░ÕĮĢµāģÕåĄõĖŗńÜ䵤źĶ»óķƤÕ║”õĖ║0.xń¦Æ’╝łµ»½ń¦Æń║¦’╝ēŃĆéSphinxÕłøÕ╗║ń┤óÕ╝ĢńÜäķƤÕ║”õĖ║’╝ÜÕłøÕ╗║100õĖćµØĪĶ«░ÕĮĢńÜäń┤óÕ╝ĢÕŬķ£Ć 3’Į×4ÕłåķƤ’╝īÕłøÕ╗║1000õĖćµØĪĶ«░ÕĮĢńÜäń┤óÕ╝ĢÕÅ»õ╗źÕ£©50ÕłåķƤÕåģÕ«īµłÉ’╝īĶĆīÕŬÕīģÕɽµ£Ćµ¢░10õĖćµØĪĶ«░ÕĮĢńÜäÕó×ķćÅń┤óÕ╝Ģ’╝īķćŹÕ╗║õĖƵ¼ĪÕŬķ£ĆÕćĀÕŹüń¦ÆŃĆé
Õ¤║õ║Äõ╗źõĖŖÕćĀńé╣’╝īµłæĶ«ŠĶ«ĪÕć║õ║åĶ┐ÖÕźŚµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äŃĆéÕ£©ńö¤õ║¦ńÄ»ÕóāĶ┐ÉĶĪīõ║åõĖĆÕæ©’╝īµĢłµ×£ķØ×ÕĖĖõĖŹķöÖŃĆéµ£ēµŚČķŚ┤µłæõ╝ÜõĖōõĖ║ķģŹÕÉłSphinxµÉ£ń┤óÕ╝ĢµōÄ’╝īÕ╝ĆÕÅæõĖĆõĖ¬ķĆ╗ĶŠæń«ĆÕŹĢŃĆüķƤÕ║”Õ┐½ŃĆüÕŹĀńö©ÕåģÕŁśõĮÄŃĆüķØ×ĶĪ©ķöüńÜäMySQLÕŁśÕé©Õ╝ĢµōĵÅÆõ╗Č’╝īńö©µØźõ╗Żµø┐MyISAMÕ╝ĢµōÄ’╝īõ╗źĶ¦ŻÕå│MyISAMÕŁśÕé©Õ╝ĢµōÄÕ£©ķóæń╣üµø┤µ¢░µōŹõĮ£µŚČńÜäķöüĶĪ©Õ╗ČĶ┐¤ķŚ«ķóśŃĆéÕÅ”Õż¢’╝īÕłåÕĖāÕ╝ŵɣń┤óµŖƵ£»õĖŖÕĘ▓µŚĀõ╗╗õĮĢķŚ«ķóśŃĆé
õĖĆŃĆüµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äĶ«ŠĶ«Ī’╝Ü
1ŃĆüµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äÕøŠ’╝Ü
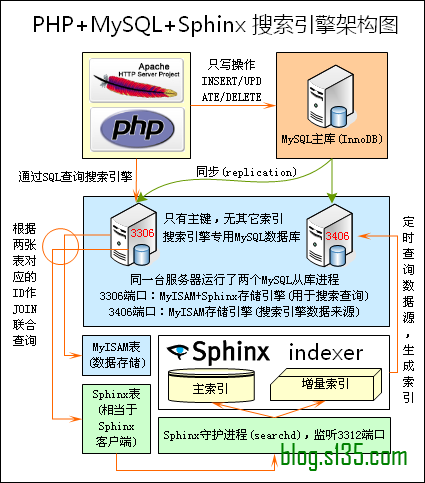
2ŃĆüµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äĶ«ŠĶ«ĪµĆØĶĘ»’╝Ü
(1)ŃĆüĶ░āńö©µ¢╣Õ╝ŵ£Ćń«ĆÕī¢’╝Ü
Õ░Įķćŵ¢╣õŠ┐ÕēŹń½»WebÕĘźń©ŗÕĖł’╝īÕŬķ£ĆĶ”üõĖƵØĪń«ĆÕŹĢńÜäSQLĶ»ŁÕÅźŌĆ£SELECT ... FROM myisam_table JOIN sphinx_table ON (sphinx_table.sphinx_id=myisam_table.id) WHERE query='...';ŌĆØÕŹ│ÕŻի×ńÄ░ķ½śµĢłµÉ£ń┤óŃĆé
(2)ŃĆüÕłøÕ╗║ń┤óÕ╝ĢŃĆüµ¤źĶ»óķƤÕ║”Õ┐½’╝Ü
ŌæĀŃĆüSphinx Search µś»ńö▒õ┐äńĮŚµ¢»õ║║Andrew Aksyonoff Õ╝ĆÕÅæńÜäķ½śµĆ¦ĶāĮÕģ©µ¢ćµÉ£ń┤óĶĮ»õ╗ČÕīģ’╝īÕ£©GPLõĖÄÕĢåõĖÜÕŹÅĶ««ÕÅīĶ«ĖÕÅ»ÕŹÅĶ««õĖŗÕÅæĶĪīŃĆé
SphinxńÜäńē╣ÕŠü’╝Ü
- Sphinxµö»µīüķ½śķƤÕ╗║ń½ŗń┤óÕ╝Ģ’╝łÕÅ»ĶŠŠ10MB/ń¦Æ’╝īĶĆīLuceneÕ╗║ń½ŗń┤óÕ╝ĢńÜäķƤÕ║”µś»1.8MB/ń¦Æ’╝ē
- ķ½śµĆ¦ĶāĮµÉ£ń┤ó’╝łÕ£©2-4 GBńÜäµ¢ćµ£¼õĖŖµÉ£ń┤ó’╝īÕ╣│ÕØć0.1ń¦ÆÕåģĶÄĘÕŠŚń╗ōµ×£’╝ē
- ķ½śµē®Õ▒ĢµĆ¦’╝łÕ«×µĄŗµ£Ćķ½śÕŻջ╣100GBńÜäµ¢ćµ£¼Õ╗║ń½ŗń┤óÕ╝Ģ’╝īÕŹĢõĖĆń┤óÕ╝ĢÕÅ»ÕīģÕɽ1õ║┐µØĪĶ«░ÕĮĢ’╝ē
- µö»µīüÕłåÕĖāÕ╝ŵŻĆń┤ó
- µö»µīüÕ¤║õ║Äń¤ŁĶ»ŁÕÆīÕ¤║õ║Äń╗¤Ķ«ĪńÜäÕżŹÕÉłń╗ōµ×£µÄÆÕ║ŵ£║ÕłČ
- µö»µīüõ╗╗µäŵĢ░ķćÅńÜäµ¢ćõ╗ČÕŁŚµ«Ą’╝łµĢ░ÕĆ╝Õ▒׵Ʀµł¢Õģ©µ¢ćµŻĆń┤óÕ▒׵Ʀ’╝ē
- µö»µīüõĖŹÕÉīńÜäµÉ£ń┤óµ©ĪÕ╝Å’╝łŌĆ£Õ«īÕģ©Õī╣ķģŹŌĆØ’╝īŌĆ£ń¤ŁĶ»ŁÕī╣ķģŹŌĆØÕÆīŌĆ£õ╗╗õĖĆÕī╣ķģŹŌĆØ’╝ē
- µö»µīüõĮ£õĖ║MysqlńÜäÕŁśÕé©Õ╝ĢµōÄ
ŌæĪŃĆüķĆÜĶ┐ćÕøĮÕż¢ŃĆŖHigh Performance MySQLŃĆŗõĖōÕ«Čń╗äńÜ䵥ŗĶ»ĢÕÅ»õ╗źń£ŗÕć║’╝īµĀ╣µŹ«õĖ╗ķö«Ķ┐øĶĪīµ¤źĶ»óńÜäń▒╗õ╝╝ŌĆ£SELECT ... FROM ... WHERE id = ...ŌĆØńÜäSQLĶ»ŁÕÅź’╝łÕģČõĖŁidõĖ║PRIMARY KEY’╝ē’╝īµ»Åń¦ÆķƤĶāĮÕż¤ÕżäńÉå10000µ¼Īõ╗źõĖŖńÜ䵤źĶ»ó’╝īĶĆīµÖ«ķĆÜńÜäSELECTµ¤źĶ»óµ»Åń¦ÆÕŬĶāĮÕżäńÉåÕćĀÕŹüµ¼ĪÕł░ÕćĀńÖŠµ¼Ī’╝Ü
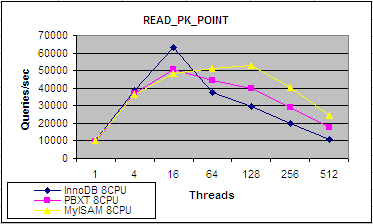
ŌæóŃĆüSphinxõĖŹĶ┤¤Ķ┤Żµ¢ćµ£¼ÕŁŚµ«ĄńÜäÕŁśÕé©ŃĆéÕüćĶ«ŠÕ░åµĢ░µŹ«Õ║ōńÜäidŃĆüdateŃĆütitleŃĆübodyÕŁŚµ«Ą’╝īńö©sphinxÕ╗║ń½ŗµÉ£ń┤óń┤óÕ╝ĢŃĆéµĀ╣µŹ«Õģ│ķö«ÕŁŚŃĆüµŚČķŚ┤ŃĆüń▒╗Õł½ŃĆüĶīāÕø┤ńŁēõ┐Īµü»µ¤źĶ»óõĖĆõĖŗsphinx’╝īsphinxÕŬõ╝ÜÕ░嵤źĶ»óń╗ōµ×£ńÜäIDÕÅĘńŁēķØ×µ¢ćµ£¼õ┐Īµü»ÕæŖĶ»ēµłæõ╗¼ŃĆéĶ”üµśŠńż║titleŃĆübodyńŁēõ┐Īµü»’╝īĶ┐śķ£ĆĶ”üµĀ╣µŹ«µŁż IDÕÅĘÕÄ╗µ¤źĶ»óMySQLµĢ░µŹ«Õ║ō’╝īµł¢ĶĆģõ╗ÄMemcachedbńŁēÕģČõ╗¢ńÜäÕŁśÕé©õĖŁÕÅ¢ÕŠŚŃĆéÕ«ēĶŻģSphinxSEõĮ£õĖ║MySQLńÜäÕŁśÕé©Õ╝ĢµōÄ’╝īÕ░åMySQLõĖÄ Sphinxń╗ōÕÉłĶĄĘµØź’╝īµś»õĖĆń¦ŹõŠ┐µŹĘńÜäµ¢╣µ│ĢŃĆé
ÕłøÕ╗║õĖĆÕ╝ĀSphinxń▒╗Õ×ŗĶĪ©’╝īÕ░åMyISAMĶĪ©ńÜäõĖ╗ķö«IDÕÆīSphinxĶĪ©ńÜäIDõĮ£õĖĆõĖ¬JOINĶüöÕÉłµ¤źĶ»óŃĆéĶ┐ÖµĀĘ’╝īÕ»╣õ║ÄMyISAMĶĪ©µØźµēĆ’╝īÕŬńøĖÕĮōõ║ÄõĖĆõĖ¬WHERE id=...ńÜäõĖ╗ķö«µ¤źĶ»ó’╝īWHEREÕÉÄńÜäµØĪõ╗ČķāĮõ║żń╗ÖSphinxÕÄ╗ÕżäńÉå’╝īÕÅ»õ╗źÕģģÕłåÕÅæµīźõĖżĶĆģńÜäõ╝śÕŖ┐’╝īÕ«×ńÄ░ķ½śķƤµÉ£ń┤󵤟Ķ»óŃĆé
(3)ŃĆüµīēµ£ŹÕŖĪń▒╗Õ×ŗĶ┐øĶĪīÕłåń”╗’╝Ü
õĖ║õ║åõ┐ØĶ»üµĢ░µŹ«ńÜäõĖĆĶć┤µĆ¦’╝īµłæÕ£©ķģŹńĮ«SphinxĶ»╗ÕÅ¢ń┤óÕ╝Ģµ║ÉńÜäMySQLµĢ░µŹ«Õ║ōµŚČ’╝īĶ┐øĶĪīõ║åķöüĶĪ©ŃĆéSphinxĶ»╗ÕÅ¢ń┤óÕ╝Ģµ║ÉńÜäĶ┐ćń©ŗõ╝ÜĶĆŚĶ┤╣õĖĆիܵŚČķŚ┤’╝īńö▒õ║Ä MyISAMÕŁśÕé©Õ╝ĢµōÄńÜäĶ»╗ķöüÕÆīÕåÖķöüµś»õ║Ƶ¢źńÜä’╝īõĖ║õ║åķü┐ÕģŹÕåÖµōŹõĮ£Ķó½ķĢ┐µŚČķŚ┤ķś╗ÕĪ×’╝īÕ»╝Ķć┤µĢ░µŹ«Õ║ōÕÉīµŁźĶÉĮÕÉÄĶʤõĖŹõĖŖ’╝īµłæÕ░åµÅÉõŠøŌĆ£µÉ£ń┤󵤟Ķ»óµ£ŹÕŖĪŌĆØńÜäÕÆīµÅÉõŠøŌĆ£ń┤óÕ╝Ģµ║ɵ£ŹÕŖĪŌĆØńÜä MySQLµĢ░µŹ«Õ║ōĶ┐øĶĪīõ║åÕłåÕ╝ĆŃĆéńøæÕɼ3306ń½»ÕÅŻńÜäMySQLµÅÉõŠøŌĆ£µÉ£ń┤󵤟Ķ»óµ£ŹÕŖĪŌĆØ’╝īńøæÕɼ3406ń½»ÕÅŻńÜäMySQLµÅÉõŠøŌĆ£ń┤óÕ╝Ģµ║ɵ£ŹÕŖĪŌĆØŃĆé
(4)ŃĆüŌĆ£õĖ╗ń┤óÕ╝Ģ’╝ŗÕó×ķćÅń┤óÕ╝ĢŌĆصø┤µ¢░µ¢╣Õ╝Å’╝Ü
õĖĆĶł¼ńĮæń½ÖńÜäńē╣ÕŠü’╝Üõ┐Īµü»ÕÅæÕĖāĶŠāõĖ║ķóæń╣ü’╝øÕłÜÕÅæÕĖāÕ«īńÜäõ┐Īµü»Ķó½ń╝¢ĶŠæŃĆüõ┐«µö╣ńÜäÕÅ»ĶāĮµĆ¦Õż¦’╝øõĖżÕż®õ╗źÕēŹńÜäĶĆüÕĖ¢ÕÅśÕŖ©µĆ¦ĶŠāÕ░ÅŃĆé
Õ¤║õ║ÄĶ┐ÖõĖ¬ńē╣ÕŠü’╝īµłæĶ«ŠĶ«Īõ║åSphinxõĖ╗ń┤óÕ╝ĢÕÆīÕó×ķćÅń┤óÕ╝ĢŃĆéÕ»╣õ║ÄÕēŹÕż®17:00õ╣ŗÕēŹńÜäĶ«░ÕĮĢÕ╗║ń½ŗõĖ╗ń┤óÕ╝Ģ’╝īµ»ÅÕż®ÕćīµÖ©Ķć¬ÕŖ©ķćŹÕ╗║õĖƵ¼ĪõĖ╗ń┤óÕ╝Ģ’╝øÕ»╣õ║ÄÕēŹÕż®17:00õ╣ŗÕÉÄÕł░ÕĮōÕēŹµ£Ćµ¢░ńÜäĶ«░ÕĮĢ’╝īķŚ┤ķÜö3ÕłåķƤĶć¬ÕŖ©ķćŹÕ╗║õĖƵ¼ĪÕó×ķćÅń┤óÕ╝ĢŃĆé
(5)ŃĆüŌĆ£Ext3µ¢ćõ╗Čń│╗ń╗¤’╝ŗtmpfsÕåģÕŁśµ¢ćõ╗Čń│╗ń╗¤ŌĆØńøĖń╗ōÕÉł’╝Ü
õĖ║õ║åķü┐ÕģŹµ»Å3ÕłåķƤķćŹÕ╗║Õó×ķćÅń┤óÕ╝ĢÕ»╝Ķć┤ńŻüńøśIOĶŠāķ插╝īõ╗ÄĶĆīÕ╝ĢĶĄĘń│╗ń╗¤Ķ┤¤ĶĮĮõĖŖÕŹć’╝īµłæÕ░åõĖ╗ń┤óÕ╝Ģµ¢ćõ╗ČÕłøÕ╗║Õ£©ńŻüńøś’╝īÕó×ķćÅń┤óÕ╝Ģµ¢ćõ╗ČÕłøÕ╗║Õ£©tmpfsÕåģÕŁśµ¢ćõ╗Čń│╗ń╗¤ ŌĆ£/dev/shm/ŌĆØÕåģŃĆéŌĆ£/dev/shm/ŌĆØÕåģńÜäµ¢ćõ╗ČÕģ©ķā©ķ®╗ńĢÖÕ£©ÕåģÕŁśõĖŁ’╝īĶ»╗ÕåÖķƤÕ║”ķØ×ÕĖĖÕ┐½ŃĆéõĮåµś»’╝īķćŹÕÉ»µ£ŹÕŖĪÕÖ©õ╝ÜÕ»╝Ķć┤ŌĆ£/dev/shm/ŌĆØÕåģńÜäµ¢ćõ╗ČõĖóÕż▒’╝īķÆłÕ»╣Ķ┐ÖõĖ¬ķŚ«ķóś’╝īµłæõ╝ÜÕ£©µ£ŹÕŖĪÕÖ©Õ╝Ƶ£║µŚČĶć¬ÕŖ©ÕłøÕ╗║ŌĆ£/dev/shm/ŌĆØÕåģńø«ÕĮĢń╗ōµ×äÕÆīSphinxÕó×ķćÅń┤óÕ╝ĢŃĆé
(6)ŃĆüõĖŁµ¢ćÕłåĶ»ŹĶ»ŹÕ║ō’╝Ü
µłæµĀ╣µŹ«ŌĆ£ńÖŠÕ║”µŚ®µ£¤õĖŁµ¢ćÕłåĶ»ŹÕ║ōŌĆØ’╝ŗŌĆ£µÉ£ńŗŚµŗ╝ķ¤│ĶŠōÕģźµ│Ģń╗åĶā×Ķ»ŹÕ║ōŌĆØ’╝ŗŌĆ£LibMMSegķ½śķóæÕŁŚÕ║ōŌĆØ’╝ŗ... ń╗╝ÕÉłµĢ┤ńÉåµłÉõĖĆõ╗ĮõĖŁµ¢ćÕłåĶ»ŹĶ»ŹÕ║ō’╝īÕć║õ║ĵ¤Éõ║øĶĆāĶÖæµÜéõĖŹµÅÉõŠøŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö©LibMMSegĶć¬ÕĖ”ńÜäõĖŁµ¢ćÕłåĶ»ŹĶ»ŹÕ║ōŃĆé
┬Ā
õ║īŃĆüMySQL+Sphinx+SphinxSEÕ«ēĶŻģµŁźķ¬ż’╝Ü
1ŃĆüÕ«ēĶŻģpythonµö»µīü’╝łõ╗źõĖŗķÆłÕ»╣CentOSń│╗ń╗¤’╝īÕģČõ╗¢Linuxń│╗ń╗¤Ķ»ĘõĮ┐ńö©ńøĖÕ║öńÜäµ¢╣µ│ĢÕ«ēĶŻģ’╝ē
yum install -y python python-devel
2ŃĆüń╝¢Ķ»æÕ«ēĶŻģLibMMSeg’╝łLibMMSegµś»õĖ║SphinxÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄĶ«ŠĶ«ĪńÜäõĖŁµ¢ćÕłåĶ»ŹĶĮ»õ╗ČÕīģ’╝īÕģČÕ£©GPLÕŹÅĶ««õĖŗÕÅæĶĪīńÜäõĖŁµ¢ćÕłåĶ»Źµ│Ģ’╝īķććńö©Chih-Hao TsaińÜäMMSEGń«Śµ│ĢŃĆéLibMMSegÕ£©µ£¼µ¢ćõĖŁńö©µØźńö¤µłÉõĖŁµ¢ćÕłåĶ»ŹĶ»ŹÕ║ōŃĆé’╝ē
õ╗źõĖŗÕÄŗń╝®ÕīģŌĆ£sphinx-0.9.8-rc2-chinese.zipŌĆØõĖŁÕīģÕɽmmseg-0.7.3.tar.gzŃĆüsphinx-0.9.8-rc2.tar.gzõ╗źÕÅŖõĖŁµ¢ćÕłåĶ»ŹĶĪźõĖüŃĆé
unzip sphinx-0.9.8-rc2-chinese.zip
tar zxvf mmseg-0.7.3.tar.gz
cd mmseg-0.7.3/
./configure
make
make install
cd ../
3ŃĆüń╝¢Ķ»æÕ«ēĶŻģMySQL 5.1.26-rcŃĆüSphinxŃĆüSphinxSEÕŁśÕé©Õ╝ĢµōÄ
┬Ā
wget http://dev.mysql.com/get/Downloads/MySQL-5.1/mysql-5.1.26-rc.tar.gz/from/http://mirror.x10.com/mirror/mysql/
tar zxvf mysql-5.1.26-rc.tar.gz
tar zxvf sphinx-0.9.8-rc2.tar.gz
cd sphinx-0.9.8-rc2/
patch -p1 < ../sphinx-0.98rc2.zhcn-support.patch
patch -p1 < ../fix-crash-in-excerpts.patch
cp -rf mysqlse ../mysql-5.1.26-rc/storage/sphinx
cd ../
cd mysql-5.1.26-rc/
sh BUILD/autorun.sh
./configure --with-plugins=sphinx --prefix=/usr/local/mysql-search/ --enable-assembler --with-extra-charsets=complex --enable-thread-safe-client --with-big-tables --with-readline --with-ssl --with-embedded-server --enable-local-infile
make && make install
cd ../
cd sphinx-0.9.8-rc2/
CPPFLAGS=-I/usr/include/python2.4
LDFLAGS=-lpython2.4
./configure --prefix=/usr/local/sphinx --with-mysql=/usr/local/mysql-search
make
make install
cd ../
mv /usr/local/sphinx/etc/sphinx.conf /usr/local/sphinx/
etc/sphinx.conf.old
ń¼¼õ║īń½Āń¼¼3ĶŖéõ╣ŗÕÉÄńÜ䵣Żµ¢ćÕåģÕ«╣õĖŹõ║łÕģ¼ÕĖā’╝īÕģ©µ¢ćńÜäńø«ÕĮĢÕ”éõĖŗ’╝łÕģ▒24ķĪĄ’╝ē’╝Ü





- 2009-06-24 16:12
- µĄÅĶ¦ł 1654
- Ķ»äĶ«║(0)
- µ¤źń£ŗµø┤ÕżÜ
ÕÅæĶĪ©Ķ»äĶ«║

-
Õ”éõĮĢµÅÉķ½śÕÆīõ╝śÕī¢Luceneń┤óÕ╝ĢķƤÕ║”
2009-07-09 12:39 1708Ķ┐Öń»ćµ¢ćń½ĀõĖ╗Ķ”üõ╗ŗń╗Źõ║åÕ”éõĮĢµÅÉķ½śLuceneńÜäń┤óÕ╝ĢķƤÕ║”ŃĆéõ╗ŗń╗ŹńÜäÕż¦ķā©Õłå ... -
Õ”éõĮĢµÅÉķ½śÕÆīõ╝śÕī¢LuceneµÉ£ń┤óķƤÕ║”
2009-07-09 12:37 1547Ķ┐Öń»ćµ¢ćń½ĀõĖ╗Ķ”üõ╗ŗń╗Źõ║åÕ”éõĮĢµÅÉķ½śLuceneńÜäµÉ£ń┤óķƤÕ║”ŃĆéõ╗ŗń╗ŹńÜäÕż¦ķā©Õłå ... -
ńö© Lucene ÕŖĀķƤ Web µÉ£ń┤óÕ║öńö©ń©ŗÕ║ÅńÜäÕ╝ĆÕÅæ
2009-06-25 13:56 801Lucene µś»Õ¤║õ║Ä Java ńÜäÕģ©µ¢ćõ┐Īµü»µŻĆń┤óÕīģ’╝īÕ«āńø«ÕēŹµś» A ... -
luceneÕ╣ČĶĪīÕ╗║ń┤óÕ╝ĢĶ¦ŻÕå│µ¢╣µĪł
2009-06-23 20:20 1398ÕåÖ’╝īń║┐ń©ŗ2ÕŠĆbuild_index2’╝īŃĆéŃĆéŃĆéõŠØµ¼Īń▒╗µÄ©’╝īµ£ĆÕÉÄõĖĆõĖ¬ ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©’╝łÕŹüõĖĆ’╝ēńē╣ÕŠüķĆēµŗ®µ¢╣µ│Ģõ╣ŗõ┐Īµü»Õó×ńøŖ
2009-04-14 18:12 1872ÕēŹµ¢ćµÅÉÕł░Ķ┐ć’╝īķÖżõ║åÕ╝Ƶ¢╣µ ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©’╝łÕŹü’╝ēńē╣ÕŠüķĆēµŗ®ń«Śµ│Ģõ╣ŗÕ╝Ƶ¢╣µŻĆķ¬ī
2009-04-14 18:10 2363ÕēŹµ¢ćµÅÉÕł░Ķ┐ć’╝īķÖżõ║åÕłåń▒╗ń«Śµ│Ģõ╗źÕż¢’╝īõĖ║Õłåń▒╗µ¢ćµ£¼õĮ£ÕżäńÉåńÜäńē╣ÕŠüµÅÉÕÅ¢ń«Śµ│Ģõ╣¤ ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(Õģ½)õĖŁĶŗ▒µ¢ćµ¢ćµ£¼Õłåń▒╗ńÜäÕ╝éÕÉī
2009-04-14 18:09 1557õ╗ĵ¢ćµ£¼Õłåń▒╗ń│╗ń╗¤ńÜäÕżäńÉåµĄüń©ŗµØźń£ŗ’╝īµŚĀĶ«║ÕŠģÕłåń▒╗ńÜäµ¢ćµ£¼µś»õĖŁµ¢ćĶ┐śµś»Ķŗ▒µ¢ć’╝ī ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(õĖā)ńøĖÕģ│µ”éÕ┐ĄµĆ╗ń╗ō
2009-04-14 18:09 1362ÕŁ”õ╣Āµ¢╣µ│Ģ’╝ÜõĮ┐ńö©µĀĘõŠŗ’╝łµ ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(ÕģŁ)Ķ«Łń╗āPart 3
2009-04-14 18:08 2329SVMń«Śµ│Ģ ŃĆĆŃĆƵö»µīüÕÉæķćŵ£║(Support Vector M ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(õ║ö)Ķ«Łń╗āPart 2
2009-04-14 18:06 1758Õ░åµĀʵ£¼µĢ░µŹ«µłÉÕŖ¤ĶĮ¼Õī¢õĖ║ÕÉæķćÅĶĪ©ńż║õ╣ŗÕÉÄ’╝īĶ«Īń«Śµ£║µēŹń«ŚÕ╝ĆÕ¦ŗń£¤µŁŻµäÅõ╣ēõĖŖńÜäŌĆ£ ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(Õøø)Ķ«Łń╗āPart 1
2009-04-14 18:05 1936Ķ«Łń╗ā’╝īķĪŠÕÉŹµĆØõ╣ē’╝īÕ░▒µś»t ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(õĖē)ń╗¤Ķ«ĪÕŁ”õ╣Āµ¢╣µ│Ģ
2009-04-14 18:04 1617ÕēŹµ¢ćĶ»┤Õł░õĮ┐ńö©ń╗¤Ķ«ĪÕŁ”õ╣Āµ¢╣µ│ĢĶ┐øĶĪīµ¢ćµ£¼Õłåń▒╗Õ░▒µś»Ķ«®Ķ«Īń«Śµ£║Ķć¬ÕĘ▒µØźĶ¦éÕ»¤ńö▒õ║║ ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(õ║ī)µ¢ćµ£¼Õłåń▒╗ńÜäµ¢╣µ│Ģ
2009-04-14 18:04 1545µ¢ćµ£¼Õłåń▒╗ķŚ«ķóśõĖÄÕģČÕ«āÕłåń ... -
µ¢ćµ£¼Õłåń▒╗ÕģźķŚ©(õĖĆ)µ¢ćµ£¼Õłåń▒╗ķŚ«ķóśńÜäÕ«Üõ╣ē
2009-04-14 18:03 1661õĖĆõĖ¬µ¢ćµ£¼’╝łõ╗źõĖŗÕ¤║µ£¼õĖŹÕī║ÕłåŌĆ£µ¢ćµ£¼ŌĆØÕÆīŌĆ£µ¢ćµĪŻŌĆØõĖżõĖ¬Ķ»ŹńÜäÕɽõ╣ē’╝ēÕłåń▒╗ķŚ« ... -
Õ¤║õ║ÄÕģ│ķö«Ķ»ŹĶĪ©ĶŠŠÕ╝ŵ©ĪÕ×ŗńÜäµ¢ćµ£¼Ķć¬ÕŖ©Õłåń▒╗ń│╗ń╗¤ńÜäńĀöń®ČõĖÄÕ«×ńÄ░
2009-04-14 17:26 2191Õ¤║õ║ÄÕģ│ķö«Ķ»ŹĶĪ©ĶŠŠÕ╝ŵ©ĪÕ×ŗńÜäµ¢ćµ£¼Ķć¬ÕŖ©Õłåń▒╗ń│╗ń╗¤ńÜäńĀöń®ČõĖÄÕ«×ńÄ░ Rese ...
ńøĖÕģ│µÄ©ĶŹÉ
ŃĆÉÕ¤║õ║ÄSphinx+MySQLńÜäÕŹāõĖćń║¦µĢ░µŹ«Õģ©µ¢ćµŻĆń┤óŃĆæńÜäµ×ȵ×äĶ«ŠĶ«ĪńØĆķćŹĶ¦ŻÕå│Õż¦µĢ░µŹ«ķćÅõĖŗ...µĆ╗õĮōĶĆīĶ©Ć’╝īĶ┐Öń¦ŹÕ¤║õ║ÄSphinx+MySQLńÜäÕģ©µ¢ćµŻĆń┤óµ×ȵ×äĶāĮÕż¤Õ£©õĖŹÕĮ▒ÕōŹµĢ░µŹ«õĖĆĶć┤µĆ¦ńÜäÕēŹµÅÉõĖŗ’╝īµÅÉõŠøķ½śµĆ¦ĶāĮńÜäµÉ£ń┤óõĮōķ¬ī’╝īÕ░żÕģČķĆéńö©õ║ÄÕżäńÉåÕż¦ķćŵĢ░µŹ«ńÜäõĖÜÕŖĪÕ£║µÖ»ŃĆé
ń╗╝õĖŖµēĆĶ┐░’╝īµ£¼µ¢ćĶ«©Ķ«║õ║åÕ”éõĮĢÕł®ńö©SphinxõĮ£õĖ║Õģ©µ¢ćµÉ£ń┤óÕ╝ĢµōĵĀĖÕ┐ā’╝īń╗ōÕÉłMySQLµĢ░µŹ«Õ║ōÕÆīPythonń╝¢ń©ŗ’╝īõĖ║Õ¤║õ║ÄLinux+ApacheńÜäńĮæń½Öµ×ȵ×äĶ«ŠĶ«ĪÕ╣ČÕ«×ńÄ░õĖĆõĖ¬ķ½śµĆ¦ĶāĮńÜäń½ÖÕåģµÉ£ń┤óÕ╝ĢµōÄŃĆéµ¢ćń½ĀõĖŁµÅÉÕł░ńÜäµŖƵ£»ńé╣õĖŹõ╗ģµČēÕÅŖÕł░õ║åµÉ£ń┤óÕ╝ĢµōÄńÜäµ×äÕ╗║ÕĤńÉå’╝ī...
µÉŁÕ╗║Sphinx+MySQL5.1x+SphinxSE+mmsegõĖŁµ¢ćÕłåĶ»ŹµÉ£ń┤óÕ╝Ģµōĵ×ȵ×ä µ”éĶ┐░’╝ܵ£¼ĶĄäµ║ɵŚ©Õ£©õ╗ŗń╗ŹµÉŁÕ╗║Sphinx+MySQL5.1x+SphinxSE+mmsegõĖŁµ¢ćÕłåĶ»ŹµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äńÜäĶ┐ćń©ŗ’╝īµČĄńø¢õ║åSphinxńÜäÕ¤║µ£¼µ”éÕ┐ĄŃĆüńē╣µĆ¦ŃĆüÕ«ēĶŻģÕÆīķģŹńĮ« MySQL+SphinxSEÕŁśÕé©...
ÕēŹĶ©Ć’╝ܵ£¼µ¢ćķśÉĶ┐░ńÜ䵜»õĖƵ¼Šń╗ÅĶ┐ćńö¤õ║¦ńÄ»ÕóāµŻĆķ¬īńÜäÕŹāõĖćń║¦µĢ░µŹ«Õģ©µ¢ćµŻĆń┤ó’╝łµÉ£ń┤óÕ╝ĢµōÄ’╝ēµ×ȵ×äŃĆéµ£¼µ¢ćÕÅ¬ÕłŚÕć║ÕēŹÕćĀń½ĀńÜäÕåģÕ«╣ĶŖéķĆē’╝īõĖŹµÅÉõŠøÕģ©µ¢ćÕåģÕ«╣ŃĆé Õ£©DELL PowerEdge 6850µ£ŹÕŖĪÕÖ©’╝łÕøøķóŚ64 õĮŹInter Xeon MP 7110NÕżäńÉåÕÖ© / 8GBÕåģÕŁś’╝ēŃĆü...
µøŠń╗ÅÕ£©õĖāµ£ł’╝īÕåÖĶ┐ćõĖĆń»ćµ¢ćń½ĀŌöĆŌöĆŃĆŖÕ¤║õ║ÄSphinx+MySQLńÜäÕŹāõĖćń║¦µĢ░µŹ«Õģ©µ¢ćµŻĆń┤ó’╝łµÉ£ń┤óÕ╝ĢµōÄ’╝ēµ×ȵ×äĶ«ŠĶ«ĪŃĆŗ’╝īÕēŹÕģ¼ÕÅĖńÜäÕłåń▒╗õ┐Īµü»µÉ£ń┤óÕ¤║õ║ĵŁżµ×ȵ×ä’╝īµĢłµ×£µśÄµśŠ’╝īńöÜĶć│Õ░åÕŠłÕż¦õĖĆķā©ÕłåÕĖ”WhereµØĪõ╗ČńÜäMySQL SQLµ¤źĶ»ó’╝īķāĮµö╣ńö©õ║åSphinx+MySQLµÉ£ń┤ó...
1ŃĆüµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äÕøŠ’╝łÕ¤║õ║ÄPHP+MySQL+Sphinx’╝ē’╝Ü 3 2ŃĆüµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äĶ«ŠĶ«ĪµĆØĶĘ»’╝Ü 3 Ōæ┤ŃĆüĶ░āńö©µ¢╣Õ╝ŵ£Ćń«ĆÕī¢’╝Ü 3 ŌæĄŃĆüÕłøÕ╗║ń┤óÕ╝ĢŃĆüµ¤źĶ»óķƤÕ║”Õ┐½’╝Ü 3 ŌæČŃĆüµīēµ£ŹÕŖĪń▒╗Õ×ŗĶ┐øĶĪīÕłåń”╗’╝Ü 4 ŌæĘŃĆüŌĆ£õĖ╗ń┤óÕ╝Ģ’╝ŗÕó×ķćÅń┤óÕ╝ĢŌĆصø┤µ¢░µ¢╣Õ╝Å’╝Ü 4 ŌæĖŃĆüŌĆ£Ext3...
SphinxµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äõĖÄõĮ┐ńö©µ¢ćµĪŻ(ÕÆīMySQLń╗ōÕÉł)
Sphinxµś»õĖĆõĖ¬ķ½śµĆ¦ĶāĮŃĆüÕ╝Ƶ║ÉńÜäÕģ©µ¢ćµŻĆń┤óÕ╝ĢµōÄ’╝īõĖōõĖ║ķģŹÕÉłSQLµĢ░µŹ«Õ║ōĶĆīĶ«ŠĶ«Ī’╝īÕ”éMySQLÕÆīPostgreSQL’╝īńö©õ║ÄÕ«×ńÄ░ķ½śµĢłõĖöõĖōõĖÜńÜäÕģ©µ¢ćµÉ£ń┤óÕŖ¤ĶāĮŃĆéÕ«āńÜäµĀĖÕ┐āõ╝śÕŖ┐Õ£©õ║ÄĶāĮÕż¤µÅÉõŠøµ»öµĢ░µŹ«Õ║ōÕĤńö¤µÉ£ń┤óµø┤Õ╝║Õż¦ńÜäµÉ£ń┤óµĆ¦ĶāĮ’╝īÕ╣ČõĖöµśōõ║ÄķøåµłÉÕł░ÕÉäń¦ŹõĮ┐ńö©...
µ£¼µ¢ćµĪŻÕ░åĶ»”ń╗åõ╗ŗń╗ŹSphinxńÜäµ×ȵ×äĶ«ŠĶ«Īõ╗źÕÅŖõĖÄMySQLńÜäķøåµłÉõĮ┐ńö©µ¢╣µ│ĢŃĆé õĖĆŃĆüXXńĮæµÉ£ń┤óÕ╝Ģµōĵ×ȵ×äĶ«ŠĶ«Ī 1. µÉ£ń┤óÕ╝Ģµōĵ×ȵ×äÕøŠ’╝łÕ¤║õ║ÄPHP+MySQL+Sphinx’╝ē Õ£©XXńĮæńÜäµ×ȵ×äõĖŁ’╝īSphinxõĮ£õĖ║µĀĖÕ┐āńÜäÕģ©µ¢ćµŻĆń┤óÕ╝ĢµōÄ’╝īõĖÄPHPÕÉÄń½»ÕÆīMySQLµĢ░µŹ«Õ║ō...
µĀćķóśõĖŁńÜäŌĆ£Õ¤║õ║ÄPHPńÜäSphinxÕģ©µ¢ćµŻĆń┤óÕ╝ĢµōÄphpńēłforWindowsµ║ÉńĀü.zipŌĆØĶĪ©µśÄĶ┐Öµś»õĖĆõĖ¬ńö©õ║ÄWindowsµōŹõĮ£ń│╗ń╗¤ńÜäPHPńēłµ£¼ńÜäSphinxÕģ©µ¢ćµŻĆń┤óÕ╝ĢµōÄńÜäµ║Éõ╗ŻńĀüÕīģŃĆéSphinxµś»õĖĆõĖ¬ķ½śµĆ¦ĶāĮŃĆüÕÅ»µē®Õ▒ĢńÜäÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄ’╝īÕĖĖńö©õ║ÄWebÕ║öńö©õĖŁ’╝īõ╗źµÅÉõŠø...
Õ«āµ£ĆÕłØńö▒Andrew AksyonoffĶ«ŠĶ«ĪÕ╣ČÕ╝ĆÕÅæ’╝īµŚ©Õ£©Ķ¦ŻÕå│MySQLµĢ░µŹ«Õ║ōÕ£©ÕżäńÉåÕż¦ķćŵ¢ćµ£¼µĢ░µŹ«µŚČÕģ©µ¢ćµŻĆń┤óµĢłńÄćõĮÄõĖŗńÜäķŚ«ķóśŃĆéķĆÜĶ┐ćõĖÄMySQLķøåµłÉ’╝īSphinxĶāĮÕż¤Õ£©õĖŹµö╣ÕÅśÕĤµ£ēÕ║öńö©µ×ȵ×äńÜäµāģÕåĄõĖŗÕż¦Õ╣ģµÅÉÕŹćµÉ£ń┤óµĆ¦ĶāĮŃĆé #### õ║īŃĆüõĖ║õ╗Ćõ╣łķĆēµŗ®Sphinx...
Sphinxµś»õĖĆõĖ¬ķ½śµĆ¦ĶāĮŃĆüÕģ©µ¢ćµŻĆń┤óÕ╝ĢµōÄ’╝īÕĖĖńö©õ║ĵ×äÕ╗║ķ½śµĢłńÜäõ┐Īµü»µŻĆń┤óń│╗ń╗¤ŃĆéÕ«āõĖ╗Ķ”üĶ«ŠĶ«ĪõĖ║õĖÄÕģ│ń│╗Õ×ŗµĢ░µŹ«Õ║ōÕ”éMySQLń╗ōÕÉł’╝īµÅÉõŠøÕ┐½ķƤŃĆüń▓ŠÕćåńÜäµÉ£ń┤óÕŖ¤ĶāĮŃĆéÕ£©µ£¼µ¢ćµĪŻõĖŁ’╝īµłæõ╗¼Õ░åµĘ▒ÕģźµÄóĶ«©SphinxńÜäµ×ȵ×äĶ«ŠĶ«Īõ╗źÕÅŖÕ”éõĮĢõĖÄMySQLķģŹÕÉłõĮ┐ńö©ŃĆé õĖĆ...
Sphinx µś»õĖĆõĖ¬ķ½śµĆ¦ĶāĮÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄ’╝īÕĖĖńö©õ║Äõ║ÆĶüöńĮæÕ║öńö©õĖŁ’╝īÕ«āĶāĮµÅÉõŠøÕ┐½ķƤńÜäÕģ©µ¢ćµŻĆń┤óÕŖ¤ĶāĮ’╝īÕ╣ČõĖöÕÅ»õ╗źõĖĵĢ░µŹ«Õ║ōÕ”é MySQL ń╗ōÕÉłõĮ┐ńö©ŃĆéõ╗źõĖŗµś»Õģ│õ║Ä Sphinx µÉ£ń┤óÕ╝ĢµōÄńÜäµ×ȵ×äõĖÄõĮ┐ńö©ńÜäõĖĆõ║øÕģ│ķö«ń¤źĶ»åńé╣’╝Ü 1. **µÉ£ń┤óÕ╝Ģµōĵ×ȵ×äĶ«ŠĶ«Ī**’╝Ü ...
µ¢»ĶŖ¼Õģŗµ¢»’╝łSphinx’╝ēµś»õĖƵ¼Šķ½śµĆ¦ĶāĮńÜäÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄ’╝īõĖōõĖ║ķ½śķƤŃĆüń▓ŠńĪ«ńÜäÕģ©µ¢ćµŻĆń┤óĶĆīĶ«ŠĶ«ĪŃĆéÕ£©µ£¼ķĪ╣ńø«õĖŁ’╝īSphinxń╗ōÕÉłõ║åMySQLµĢ░µŹ«Õ║ōŃĆüSWSC’╝łSmart Chinese Segmentation Component’╝īµÖ║ĶāĮõĖŁµ¢ćÕłåĶ»Źń╗äõ╗Č’╝ēÕÆīPHPń╝¢ń©ŗĶ»ŁĶ©Ć’╝īµ×äÕ╗║õ║åõĖĆ...
**Õ«Üõ╣ē**’╝ÜSphinxµś»õĖƵ¼ŠÕ╝Ƶ║ÉÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄÕĘźÕģĘ’╝īÕÅ»õ╗źķøåµłÉÕł░MySQLµĢ░µŹ«Õ║ōõĖŁõĮ┐ńö©ŃĆé - **µĀĖÕ┐āõ╝śÕŖ┐**’╝Ü - ķ½śµĢłń┤óÕ╝ĢÕ╗║ń½ŗ’╝ܵö»µīüµē╣ķćŵ¢ćµĪŻÕ»╝ÕģźõĖÄÕ«×µŚČÕó×ķćŵø┤µ¢░ŃĆé - Õ╝║Õż¦µÉ£ń┤óĶāĮÕŖø’╝ÜÕģĘÕżćµ©Īń│ŖÕī╣ķģŹŃĆüĶ┐æõ╣ēĶ»Źµē®Õ▒ĢńŁēÕŖ¤ĶāĮ’╝īµÅÉÕŹćµ¤źĶ»ó...
µĢ░µŹ«Õ║ōµÉ£ń┤óÕ╝ĢµōÄSphinxµś»õĖƵ¼Šķ½śµĢłŃĆüÕŻիÜÕłČõĖöÕŖ¤ĶāĮõĖ░Õ»īńÜäÕģ©µ¢ćµÉ£ń┤óÕ╝ĢµōÄ’╝īõĖ╗Ķ”üĶ«ŠĶ«Īńö©õ║ÄWebÕ║öńö©’╝īõ╗źõŠ┐Õ┐½ķĆ¤Õ£░õ╗ÄÕż¦ķćŵĢ░µŹ«õĖŁµŻĆń┤óńøĖÕģ│õ┐Īµü»ŃĆéSphinxńÜäµĀĖÕ┐āńē╣µĆ¦Õīģµŗ¼Õ«×µŚČń┤óÕ╝ĢŃĆüĶ┐æÕ«×µŚČµÉ£ń┤óõ╗źÕÅŖķ½śÕ║”ÕÅ»µē®Õ▒ĢµĆ¦’╝īõĮ┐ÕŠŚÕ«āÕ£©ÕżäńÉåÕż¦µĢ░µŹ«ķćÅ...
Ķ┤┤Õ┐āńī½(ImCat) µś»õ╗źPHP+MySQLµ×ȵ×äĶ«ŠĶ«ĪńÜäķĆÜńö©ńĮæń½Öń│╗ń╗¤’╝īń«Ćń║”ŃĆüĶĮ╗ķćÅŃĆüÕ«×ńö©ŃĆüÕģŹĶ┤╣ŃĆüÕģ▒õ║½ŃĆéķĆéńö©õ║Ä’╝ÜńĮæÕ║Ś’╝īÕī╗ķÖó’╝īÕŁ”µĀĪ’╝īõ╝üõĖÜń½Ö’╝īõĖ¬õ║║ńĮæń½Ö’╝īõ╝üõĖÜÕåģķā©Intranet’╝īõĖŁÕ░ÅÕ×ŗĶĪīõĖÜķŚ©µłĘń½Öńé╣ńŁēŌĆ”ŌĆ”ÕŖ¤ĶāĮõ╗ŗń╗Ź’╝Ü1ŃĆüµö»µīü’╝ÜPHP5.4~PHP7.3/...