- 浏览: 963453 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (385)
- 搜索引擎学习 (62)
- 算法 (1)
- 数据库 (15)
- web开发 (38)
- solr开发 (17)
- nutch 1.2 系统学习 (8)
- cms (1)
- 系统架构 (11)
- linux 与 unix 编程 (16)
- android (15)
- maven (1)
- 关注物流 (1)
- 网址收集 (1)
- 分布式,集群 (1)
- mysql (5)
- apache (1)
- 资料文档备份 (7)
- 上班有感 (0)
- 工作流 (15)
- javascript (1)
- weblogic (1)
- eclipse 集成 (1)
- JMS (7)
- Hibernate (1)
- 性能测试 (1)
- spring (6)
- 缓存cache (1)
- mongodb (2)
- webservice (1)
- HTML5 COCOS2D-HTML5 (1)
- BrowserQuest (2)
最新评论
-
avi9111:
内陷到android, ios, winphone里面也是随便 ...
【HTML5游戏开发】二次开发 BrowserQuest 第一集 -
avi9111:
呵呵,做不下去了吧,没有第二集了吧,游戏是个深坑,谨慎进入,其 ...
【HTML5游戏开发】二次开发 BrowserQuest 第一集 -
excaliburace:
方案3亲测完全可用,顺便解决了我其他方面的一些疑问,非常感谢
spring security 2添加用户验证码 -
yuanliangding:
Spring太强大了。
Spring Data JPA 简单介绍 -
小高你好:
什么是hibernate懒加载?什么时候用懒加载?为什么要用懒加载?
当我们以Web UI方式使用Heritrix时,点击任务开始(start)按钮时,Heritrix就开始了它的爬取工作.但它的内部
执行流程是怎样的呢?别急,下面将慢慢道来.
(一)CrawlJobHandler
当点击任务开始(start)按钮时,将执行它的startCrawler()方法:
if(sAction.equalsIgnoreCase("start"))
{
// Tell handler to start crawl job
handler.startCrawler();
}
再来看看startCrawler()方法的执行:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->public class CrawlJobHandler implements CrawlStatusListener {
public void startCrawler() {
running = true;
if (pendingCrawlJobs.size() > 0 && isCrawling() == false) {
// Ok, can just start the next job
startNextJob();
}
}
protected final void startNextJob() {
synchronized (this) {
if(startingNextJob != null) {
try {
startingNextJob.join();
} catch (InterruptedException e) {
e.printStackTrace();
return;
}
}
startingNextJob = new Thread(new Runnable() {
public void run() {
startNextJobInternal();
}
}, "StartNextJob");
//当前任务线程开始执行
startingNextJob.start();
}
}
protected void startNextJobInternal() {
if (pendingCrawlJobs.size() == 0 || isCrawling()) {
// No job ready or already crawling.
return;
}
//从待处理的任务列表取出一个任务
this.currentJob = (CrawlJob)pendingCrawlJobs.first();
assert pendingCrawlJobs.contains(currentJob) :
"pendingCrawlJobs is in an illegal state";
//从待处理列表中删除
pendingCrawlJobs.remove(currentJob);
try {
this.currentJob.setupForCrawlStart();
// This is ugly but needed so I can clear the currentJob
// reference in the crawlEnding and update the list of completed
// jobs. Also, crawlEnded can startup next job.
this.currentJob.getController().addCrawlStatusListener(this);
// now, actually start
//控制器真正开始执行的地方
this.currentJob.getController().requestCrawlStart();
} catch (InitializationException e) {
loadJob(getStateJobFile(this.currentJob.getDirectory()));
this.currentJob = null;
startNextJobInternal(); // Load the next job if there is one.
}
}
}
由以上代码不难发现整个流程如下:
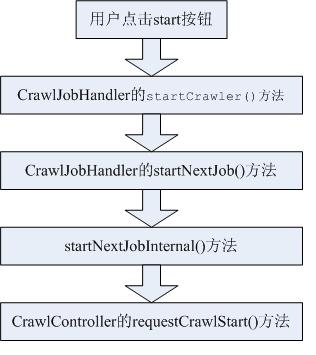
可以看出,最终将启动CrawlController的requestCrawlStart()方法.
(二)CrawlController
该类是一次抓取任务中的核心组件。它将决定整个抓取任务的开始和结束.
先看看它的源代码:在构造 CrawlController实例,需要先做以下工作:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->package org.archive.crawler.framework;
public class CrawlController implements Serializable, Reporter {

// key subcomponents which define and implement a crawl in progress
private transient CrawlOrder order;
private transient CrawlScope scope;
private transient ProcessorChainList processorChains;
private transient Frontier frontier;
private transient ToePool toePool;
private transient ServerCache serverCache;
// This gets passed into the initialize method.
private transient SettingsHandler settingsHandler;
}
CrawlOrder:它保存了对该次抓取任务中order.xml的属性配置。
CrawlScope:决定当前抓取范围的一个组件。
ProcessorChainList:从名称上可知,其表示处理器链。
Frontier:它是一个URL的处理器,决定下一个要被处理的URL是什么。
ToePool:它表示一个线程池,管理了所有该抓取任务所创建的子线程。
ServerCache:它表示一个缓冲池,保存了所有在当前任务中,抓取过的Host名称和Server名称。
(1)首先构造一个XMLSettingsHandler对象,将order.xml内的属性信息装入,并调用它的initialize方法进行初始化。
(2)调用CrawlController构造函数,构造一个CrawlController实例
(3)调用CrawlController的initilize(SettingsHandler)方法,初始化CrawlController实例。其中,传入的参数就是
在第一步里构造的XMLSettingsHandler实例。
(4 )当上述3步完成后,CrawlController就具备了运行的条件。此时,只需调用它的requestCrawlStart()方法,就
可以启动线程池和Frontier,然后开始不断的抓取网页。
先来看看initilize(SettingsHandler)方法:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->public void initialize(SettingsHandler sH)
throws InitializationException {
sendCrawlStateChangeEvent(PREPARING, CrawlJob.STATUS_PREPARING);
this.singleThreadLock = new ReentrantLock();
this.settingsHandler = sH;
//从XMLSettingsHandler中取出Order
this.order = settingsHandler.getOrder();
this.order.setController(this);
this.bigmaps = new Hashtable<String,CachedBdbMap<?,?>>();
sExit = "";
this.manifest = new StringBuffer();
String onFailMessage = "";
try {
onFailMessage = "You must set the User-Agent and From HTTP" +
" header values to acceptable strings. \n" +
" User-Agent: [software-name](+[info-url])[misc]\n" +
" From: [email-address]\n";
//检查了用户设定的UserAgent等信息,看是否符合格式
order.checkUserAgentAndFrom();
onFailMessage = "Unable to setup disk";
if (disk == null) {
setupDisk(); //设定了开始抓取后保存文件信息的目录结构
}
onFailMessage = "Unable to create log file(s)";
//初始化了日志信息的记录工具
setupLogs();
onFailMessage = "Unable to test/run checkpoint recover";
this.checkpointRecover = getCheckpointRecover();
if (this.checkpointRecover == null) {
this.checkpointer =
new Checkpointer(this, this.checkpointsDisk);
} else {
setupCheckpointRecover();
}
onFailMessage = "Unable to setup bdb environment.";
//初始化使用Berkley DB的一些工具
setupBdb();
onFailMessage = "Unable to setup statistics";
setupStatTracking();
onFailMessage = "Unable to setup crawl modules";
//初始化了Scope、Frontier以及ProcessorChain
setupCrawlModules();
} catch (Exception e) {
String tmp = "On crawl: "
+ settingsHandler.getSettingsObject(null).getName() + " " +
onFailMessage;
LOGGER.log(Level.SEVERE, tmp, e);
throw new InitializationException(tmp, e);
}
Lookup.getDefaultCache(DClass.IN).setMaxEntries(1);
//dns.getRecords("localhost", Type.A, DClass.IN);
//实例化线程池
setupToePool();
setThresholds();
reserveMemory = new LinkedList<char[]>();
for(int i = 1; i < RESERVE_BLOCKS; i++) {
reserveMemory.add(new char[RESERVE_BLOCK_SIZE]);
}
}
可以看出在initilize()方法中主要做一些初始化工作,但这些对于Heritrix的运行是必需的.
再来看看CrawlController的核心,requestCrawlStart()方法:
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />--> public void requestCrawlStart() {
//初始化处理器链
runProcessorInitialTasks();
sendCrawlStateChangeEvent(STARTED, CrawlJob.STATUS_PENDING);
String jobState;
state = RUNNING;
jobState = CrawlJob.STATUS_RUNNING;
sendCrawlStateChangeEvent(this.state, jobState);
// A proper exit will change this value.
this.sExit = CrawlJob.STATUS_FINISHED_ABNORMAL;
Thread statLogger = new Thread(statistics);
statLogger.setName("StatLogger");
//开始日志线程
statLogger.start();
//启运Frontier,抓取工作开始
frontier.start();
}
可以看出,做了那么多工作,最终将启动Frontier的start方法,而Frontier将为线程池的线程提供URI,真正开始
抓取任务.至此,抓取任务开始.
主要参考:开发自己的搜索引擎—Lucene 2.0+Heritrix


发表评论

-
nutch1.4 环境变量设置
2012-04-06 12:52 1741Exception in thread "main& ... -
正则使用
2010-06-18 00:19 1159java正则表达式(java.Regex)HtmlParser ... -
nutch 1.0 读源码,过滤掉不正确的URL实现方法
2010-06-18 00:17 3418nutch 1.0 读源码,过滤掉不正确的URL实现方法: ... -
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputExnutch新发现,为以后备忘
2010-06-16 23:16 2303urls -dir mycrawl -depth 3 -top ... -
HTMLParser 解析html字符串,提取纯文本
2010-05-14 09:59 8334今天在群里问别人怎么提取文本,也没有具体告诉我用什么,只是说用 ... -
HTMLParser的两种使用方法[转]
2010-05-13 23:37 1959HTMLParser的两种使用方法 文章分类:Java编程 ... -
搜索引擎术语
2010-05-05 11:40 1445附录. 术语 B: 半结构化� ... -
影响Lucene索引速度原因以及提高索引速度技巧[转]
2010-04-25 00:11 2751影响Lucene索引速度原因以及提高索引速度技巧 关键字: ... -
如何配置compass的索引位置为相对路径
2009-09-01 19:28 1513Compass是对lucene进行封装 ... -
heritrix 基本介绍
2009-08-01 10:35 3924Heritrix使用小结 1. H ... -
我对HtmlParser 提取网页各属性的总结及示例说明
2009-07-08 13:50 1955/** * 属性过滤器 * @param parser ... -
数学之美 系列十三 信息指纹及其应用
2009-06-25 22:34 10472006年8月3日 上午 11:17:00 ... -
数学之美系列二十一 - 布隆过滤器(Bloom Filter)
2009-06-25 22:27 15222007年7月3日 上午 09:35:00 ... -
用HTMLParser提取URL页面超链接的一段代码(小试牛刀)
2009-06-06 16:54 7101用HTMLParser提取URL页面超 ... -
深入学习Heritrix---解析处理器(Processor)
2009-06-06 13:17 1636键字: heritrix processor 本节解析与 ... -
深入学习Heritrix---解析Frontier(链接工厂)
2009-06-06 10:02 1229Frontier是Heritrix最核心的组成部分之一,也是最 ... -
深入学习Heritrix---解析Frontier(链接工厂)
2009-06-03 21:50 1527原创作者: pengranxiang 阅读:231次 ... -
lucene2.0+heritrix示例补充
2009-06-03 21:31 1556由于lucene2.0+heritrix一书示例用的网站( ... -
htmlparser 使用手册
2009-05-30 16:47 29322009-05-08 14:20 需要做一 ... -
Nutch插件机制和Nutch一个插件实例
2009-05-25 23:54 18772007年06月16日 星期六 15:07 Pl ...
相关推荐
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。官网下载好像要翻墙,我下下来方便大家使用,这是3.4版本,配合heritrix-3.4.0-SNAPSHOT-dist.zip使用
Heritrix 1.14.4是该工具的一个版本,提供了两个压缩包:`heritrix-1.14.4.zip`和`heritrix-1.14.4-src.zip`。这两个文件分别包含了不同的内容,便于用户根据需求进行使用和开发。 `heritrix-1.14.4.zip` 包含了...
总的来说,Heritrix-1.14.4-src提供了深入了解网络爬虫工作原理的机会,同时也让用户有机会自定义和优化爬虫行为,以满足特定的业务需求。虽然这个版本可能没有最新版的特性,但对于学习和理解爬虫技术来说,仍然是...
在提供的压缩包中,有两个主要文件:"heritrix-1.14.4.zip" 和 "heritrix-1.14.4-src.zip"。前者是Heritrix的编译后的二进制版本,可以直接运行,而后者包含了源代码,对于希望定制或深入理解Heritrix工作原理的...
这个"heritrix-1.14.4"版本是Heritrix的特定发行版,提供了对互联网资源进行系统性抓取的功能,帮助用户构建自己的网络存档。 标题"heritrix-1.14.4"表明这是Heritrix的1.14.4版本,这是一个重要的标识,因为每个...
通过深入研究Heritrix-1.14.4的源代码,你可以学习到网络爬虫的基本架构,了解HTTP通信、网页解析、链接处理和数据存储等相关技术,这对于提升你的Web开发和数据抓取能力大有裨益。同时,这也是一个实践软件工程和...
1. **heritrix-3.1.0-dist.zip**:这是Heritrix的发行版,包含运行所需的所有文件,如Java可执行文件(JARs)、配置文件和文档。用户可以直接下载并运行此版本来启动爬虫服务,无需构建源代码。其中,`heritrix-...
heritrix-1.12.1-src.zip与heritrix 配置文档
这个软件项目的标题"heritrix-1.12.1"表明我们正在讨论Heritrix的一个特定版本,即1.12.1版。这个版本可能包含了一些修复、改进或新功能,以提升其性能和适应性。 在描述中提到,Heritrix被誉为Lucene的黄金搭档,...
- `heritrix-3.4.0-SNAPSHOT`目录:这是Heritrix的主目录,包含了所有运行所需的基本文件,如jar包、配置文件、文档等。 - `bin`子目录:存放启动和停止Heritrix的脚本,通常在Unix/Linux环境下使用`start.sh`和`...
近期需要使用heritrix-1.14.4,配了半天才配好,这个是控制台执行版本. 注意:解压到相关目录,之后配置系统环境变量"HERITRIX_HOME"到该解压目录(Java环境已经配置好)。 使用控制台命令启动 : heritrix --admin=...
在提供的压缩包文件中,有两个主要的文件:`heritrix-3.1.0-dist.tar.gz`和`heritrix-3.1.0-src.tar.gz`。这两个文件分别包含了Heritrix的二进制发行版和源代码。 1. `heritrix-3.1.0-dist.tar.gz`: 这个文件是...
Heritrix的压缩包"heritrix-1.14.2.zip"包含以下组件和文件: 1. **源代码**:包含了Heritrix的Java源代码,用户可以查看和修改这些代码以适应自己的需求。 2. **构建脚本**:如Ant或Maven脚本,用于编译和打包项目...
标题"heritrix-1.14.4 for linux"表明这是Heritrix的Linux兼容版本,版本号为1.14.4。在Linux操作系统上运行Heritrix,用户可以利用Linux系统的稳定性和高效性来处理大量的网络抓取任务。 描述中的"heritrix-1.14.4...
"heritrix-1.14.4-docs.rar"这个压缩包包含了该版本的文档,帮助用户理解和使用Heritrix。 文档通常包括用户手册、开发者指南、API参考等,这些内容对于熟悉Heritrix的架构、配置和编程接口至关重要。由于文件较大...
这个版本的源码和编译后的二进制文件分别以"heritrix-1.14.4.zip"和"heritrix-1.14.4-src.zip"的名义提供,允许用户进行深入研究、学习或二次开发。 在Heritrix中,爬虫的主要工作流程包括种子管理、URL过滤、内容...
在“heritrix-1.12.1.zip”这个压缩包中,用户可以找到Heritrix的1.12.1版本的源代码和其他相关文件,这为学习和自定义网络爬虫提供了宝贵的资源。 Heritrix的核心功能是模拟浏览器行为,遍历互联网上的链接,系统...
"heritrix-1.14.3-src.zip"是一个包含了Heritrix 1.14.3版本源代码的压缩文件,对于那些希望深入理解其工作原理或者想要自定义功能的开发者来说,这是一个宝贵的资源。 Heritrix的核心设计基于模块化架构,允许...
这个名为"Heritrix-User-Manual.rar_heritrix"的压缩包包含了Heritrix用户手册的PDF版本,是学习和操作Heritrix的重要资源。下面将详细介绍Heritrix的基本概念、安装步骤、任务创建以及任务分析。 1. **Heritrix...
在深入理解Heritrix-1.14.3之前,我们首先需要了解什么是网络爬虫以及它的工作原理。 网络爬虫,又称为网页蜘蛛,是一种自动化程序,它按照预设的规则在网络(尤其是万维网)上遍历并抓取信息。它通常从一个或几个...