
Join Vs select 结果集作列 有时候我们需要关联很多表统计: select f1, f2, count(*) from a join b join c join d join e …… 如果结果集很小,只统计出几条数据来,那么可以换成这样写 Select f1, f2, (select count(*) from a join b ) from c…… 比如下面的例子: 改写成下面的,速度由0.625秒优化到: 0.032
2 t2.subject_name subjectName,
3 t3.dict_name assignType,
4 t1.assign_date assignDate,
5 t4.totalcount totalCount,
6 (select dict_name from bas_diction where dict_id = t5.assign_marks) as assignMarks,
7 (case t5.if_submit when 1 then '是' else '否' end) as ifSubmit,
8 t6.errorcount errorCount,
9 t6.nocheckCount,
10 case t1.online_assignment when 1 then '是' else '否' end as ifOnline,
11 (select dict_name from bas_diction where dict_id = t5.write_appraise) as writeAppraise
12 from hom_assignmentinfo t1,bas_subject t2,bas_diction t3,
13 (select t1.assignment_id,count(*) as totalcount from hom_assignmentinfo t1,hom_assignment t2
14 where t1.assignment_id = t2.hom_assignment_id
15 group by t1.assignment_id) t4,hom_assignment_appraise t5 left join
16 (select t1.assignment_id,t3.appraise_id,
17 sum(case t3.check_result when 3003001 then 0 else 1 end) as errorcount,
18 sum(case when t3.check_result=3003001 or t3.recheck_result=3003001 then 0 else 1 end)as nocheckCount
19 from hom_assignmentinfo t1,hom_check_assignment t3
20 where t1.assignment_id = t3.assignment_id
21 and t1.person_id='13042'
22 group by t1.assignment_id,t3.appraise_id) t6 on (t5.appraise_id=t6.appraise_id)
23 where t1.subject_id = t2.subject_id
24 and t1.assign_type = t3.dict_id
25 and t1.assignment_id = t4.assignment_id
26 and t1.assignment_id = t5.assignment_id
27 and not exists (select 1 from hom_assignmentinfo t11,hom_assignment_appraise t12
28 where t11.assignment_id=t12.assignment_id and
29 t11.online_assignment = 0 and
30 t12.person_id='13042' and
31 t11.subject_id = t1.subject_id and t11.assign_date > t1.assign_date)
32 and t1.assign_date is not null
33 and t5.person_id='13042'
34 order by t1.assign_date desc;
35
2 t2.subject_name subjectName,
3 t3.dict_name assignType,
4 t1.assign_date assignDate,
5 (select count(*) as totalcount from hom_assignmentinfo where assignment_id=t1.assignment_id) totalcnt,
6 (
7 select sum(case t3.check_result when 3003001 then 0 else 1 end)
8 from hom_check_assignment t3
9 where t1.assignment_id = t3.assignment_id
10 ) errorcount,
11 (
12 select sum(case when t3.check_result=3003001 or t3.recheck_result=3003001 then 0 else 1 end)as nocheckCount
13 from hom_check_assignment t3
14 where t1.assignment_id = t3.assignment_id
15 ) nocheckCount,
16 (select dict_name from bas_diction where dict_id = t5.assign_marks) as assignMarks,
17 (case t5.if_submit when 1 then '是' else '否' end) as ifSubmit,
18 case t1.online_assignment when 1 then '是' else '否' end as ifOnline,
19 (select dict_name from bas_diction where dict_id = t5.write_appraise) as writeAppraise
20 from hom_assignmentinfo t1,bas_subject t2,bas_diction t3, hom_assignment_appraise t5
21 where t1.subject_id = t2.subject_id
22 and t1.assign_type = t3.dict_id
23 and t1.assignment_id = t5.assignment_id
24 and not exists (select 1 from hom_assignmentinfo t11,hom_assignment_appraise t12
25 where t11.assignment_id=t12.assignment_id and
26 t11.online_assignment = 0 and
27 t12.person_id='13042' and
28 t11.subject_id = t1.subject_id and t11.assign_date > t1.assign_date)
29 and t1.assign_date is not null
30 and t5.person_id='13042'
31 order by t1.assign_date desc;
如果什么都做不了,试试全索引扫描
如果一个语句实在不能优化了,那么还有一个方法可以试试:索引覆盖。
如果一个语句可以从索引上获取全部数据,就不需要通过索引再去读表,省了很多I/O。比如这样一个表
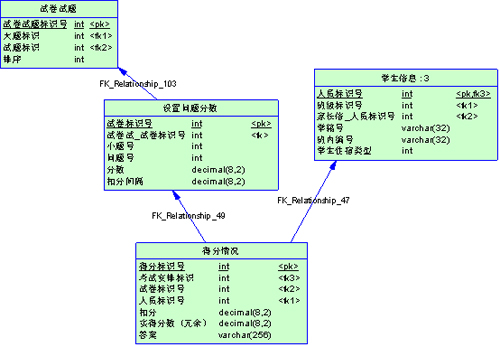
如果我要统计每个学生每道题的得分情况,我们除了要给每个表的主键外键建立索引,还要对【得分情况】的实际得分字段索引,这样,整个查询就可以从索引得到数据了。
Join、In、not in、exist、not exist并不是绝对的
网上很多教程讨论了join、in和exist 的性能差异,其实这不是绝对的,对于效率不理想的语句,还是应该换换写法试试看。
Like
Like毕竟效率太低,必要的话可以试试全文检索。对于中文全文检索,可以结合程序分词来实现。
什么情况下查询用不到索引
参见手册 7.4.3列索引, 7.4.4所列索引, 7.4.5 mysql如何使用索引
去掉不必要的排序,如果必要,尽量用主键排序代替
显而易见却容易被忽视的问题。
数据库参数配置
最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大
# Additional memory pool that is used by InnoDB to store metadata
# information. If InnoDB requires more memory for this purpose it will
# start to allocate it from the OS. As this is fast enough on most
# recent operating systems, you normally do not need to change this
# value. SHOW INNODB STATUS will display the current amount used.
innodb_additional_mem_pool_size = 64M
# InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and
# row data. The bigger you set this the less disk I/O is needed to
# access data in tables. On a dedicated database server you may set this
# parameter up to 80% of the machine physical memory size. Do not set it
# too large, though, because competition of the physical memory may
# cause paging in the operating system. Note that on 32bit systems you
# might be limited to 2-3.5G of user level memory per process, so do not
# set it too high.
innodb_buffer_pool_size = 5G
对于myisam,需要调整key_buffer_size
当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定改调整哪些参数
Cretated_tmp_disk_tables 增加tmp_table_size
Handler_read_key 高表示索引正确 Handler_read_rnd高表示索引不正确
Key_reads/Key_read_requests 应小于0.01 计算缓存损失率,增加Key_buffer_size
Opentables/Open_tables 增加table_cache
select_full_join 没有实用索引的链接的数量。如果不为0,应该检查索引。
select_range_check 如果不为0,该检查表索引。
sort_merge_passes 排序算法已经执行的合并的数量。如果该值较大,应增加sort_buffer_size
table_locks_waited 不能立即获得的表的锁的次数,如果该值较高,应优化查询
Threads_created 创建用来处理连接的线程数。如果Threads_created较大,要增加 thread_cache_size值。
缓存访问率的计算方法Threads_created/Connections。
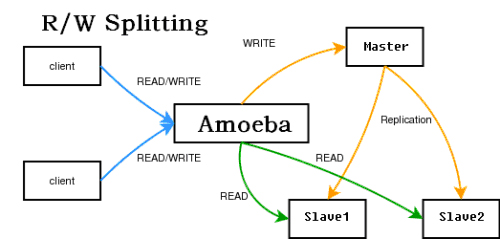
合理的硬件资源和操作系统 如果你的机器内存超过4G,那么毋庸置疑应当采用64位操作系统和64位mysql 读写分离 如果数据库压力很大,一台机器支撑不了,那么可以用mysql复制实现多台机器同步,将数据库的压力分散。 Master Slave1 Slave2 Slave3 主库master用来写入,slave1—slave3都用来做select,每个数据库分担的压力小了很多。 要实现这种方式,需要程序特别设计,写都操作master,读都操作slave,给程序开发带来了额外负担。当然目前已经有中间件来实现这个代理,对程序来读写哪些数据库是透明的。官方有个mysql-proxy,但是还是alpha版本的。新浪有个amobe for mysql,也可达到这个目的,结构如下 使用方法可以看amobe的手册。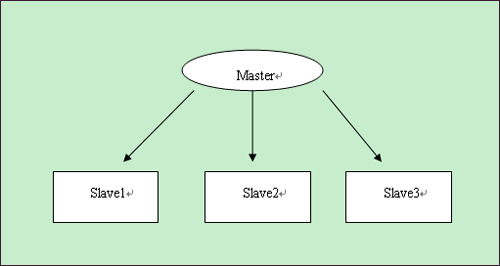


发表评论

-
MySQL 优化总结 (四)
2009-05-31 14:47 767减少不必要的表关联 有时候一个查询需要很 ... -
MySQL 优化总结 (三)
2009-05-31 14:43 866range checked for each rec ... -
MySQL 优化总结 (二)
2009-05-31 14:39 1030Sql语句优化 Sql语句优化工具 ... -
堆排序算法原理以及实例代码
2009-02-17 21:11 29741、 堆排序定义 n个关键 ... -
MyEclipse 6.5 最新下载、注册、汉化
2008-11-11 14:36 12811因最近发现网上很多转� ... -
SCJP 310-055 资料汇总 (不断更新中……)
2008-11-05 17:05 1049SCJP在线练习 http://www.java3z.com ...
相关推荐
MySQL性能优化总结.pdf
MySQL性能优化是一个涵盖广泛的主题,涉及数据库设计、SQL查询优化、索引策略等多个方面。以下是对标题和描述中提到的一些关键知识点的详细说明: 1. **表的优化**: - **定长与变长字段的分离**:将定长字段(如...
MySQL 性能优化总结 MySQL 性能优化是数据库管理和开发人员需要掌握的重要技能。性能优化的目标是让查询更快,减少查询所消耗的时间。为了达到这个目标,我们需要从每一个环节入手,包括连接、配置优化、索引优化、...
### MySQL优化技巧总结 #### 一、MySQL慢查询日志(Slow Query Log)与mysqldumpslow工具 **慢查询日志**是MySQL提供的一种非常实用的功能,它能够帮助我们记录并分析那些执行时间较长的SQL语句,进而找出性能瓶颈并...
Mysql基础性能优化思维导向图 (其中包括:mysql基础、mysql性能优化、mysql锁机制和主从复制) 文件名称:MySQL基础与性能优化总结.xmind
课程内容进行了精华的浓缩,有四大内容主旨,MySQL架构与执行流程,MySQL索引原理详解,MySQL事务原理与事务并发,MySQL性能优化总结与MySQL配置优化。课程安排的学习的教程与对应的学习课件,详细的学习笔以及课程...
MySQL优化 MySQL优化是数据库管理中的一个重要...总结而言,MySQL优化是一个涉及多个层面的复杂过程,需要综合考虑配置、索引、查询语句、服务器状态等多方面因素,通过合理配置和优化,以达到提升数据库性能的目的。
### MySQL优化知识点详解 #### 一、MySQL简介 MySQL是一款由MySQL AB公司开发的开源数据库管理系统,后来该公司被Sun Microsystems收购。MySQL因其简单、高效、可靠的特点,在IT行业中迅速崭露头角,成为最受欢迎...
以下是对MySQL优化的详细总结,供您参考学习。 一、查询优化 1. **索引优化**:索引能显著提高查询速度。应为经常用于搜索的列创建索引,特别是主键和外键。复合索引在多条件查询时特别有用,但要注意避免冗余和...
MySQL 5.6 性能优化总结 MySQL 5.6 是一个高性能的关系型数据库管理系统,然而随着数据库规模的增长和复杂度的增加,性能问题开始浮现。因此,性能优化成为 MySQL 数据库管理员和开发者的首要任务。本文将总结 ...
### MySQL优化实战视频课程知识点概览 #### 一、MySQL优化基础 ##### 1.1 数据库优化的重要性 - **背景介绍**:随着互联网技术的发展,数据量呈指数级增长,对数据库系统的性能要求越来越高。 - **核心价值**:...
MySQL优化是数据库管理中至关重要的环节,它关系到系统性能和响应速度。下面将详细介绍MySQL自带的慢查询日志分析工具mysqldumpslow及其使用方法,以及如何使用EXPLAIN来分析SQL查询。 首先,MySQL的慢查询日志...
Mysql数据库优化总结-飞鸿无痕-ChinaUnix博客................................................................................................................
第7课 查询优化技术理论与MySQL实践(五)------外连接消除、嵌套连接消除与连接消除 连接方式有些什么类型?不同类型的连接又是怎么优化的?外连接优化的条件是什么?MySQL中怎么写出可优化的连接语句?MySQL是否...
### 2G内存的MySQL数据库服务器优化 在IT行业中,对于资源有限的环境进行数据库优化是一项挑战性工作,尤其是在仅有2GB内存的情况下对MySQL数据库服务器进行优化。这种优化旨在提高性能的同时确保系统的稳定运行。 ...
#### 一、什么是MySQL优化? MySQL优化是指通过合理安排资源和调整系统参数,使得MySQL运行得更快、更节省资源的过程。优化的目的在于减少系统瓶颈,降低资源消耗,提升系统的响应速度。 #### 二、优化的主要方面 ...
总结,MySQL性能优化与架构设计涵盖了许多方面,包括查询优化、索引策略、数据库设计、缓存利用、并行处理、架构设计、数据分布以及监控与调优工具的使用。理解和掌握这些知识点,能够帮助我们构建高效、稳定的...
#### 五、优化MySQL服务器 在服务器层面上进行优化同样至关重要,这包括但不限于内存配置、磁盘I/O优化以及网络配置等。 - **内存配置**:合理设置缓存和缓冲区大小,比如`innodb_buffer_pool_size`等参数。 - **...