

据统计,互联网数据量正以每三年翻一番的速度膨胀,其中, 95%以上都是非结构化数据,且这个比例仍在不断提升。如今,互联网已全面覆盖大家生活的方方面面,每个人的消费行为、娱乐行为和社交行为都将产生海量的图片、音视频、网络日志等非结构化数据。非结构化数据的持续在线及数据种类的多样对数据的处理提出了很高的要求。作为国内最专业的数据管理平台,七牛已覆盖国内 50%以上的互联网用户。那么,七牛数据处理架构都经过了哪些演变呢?小编带你一探究竟。
七牛云存储的数据处理主要分为实时处理和异步处理,对于较小的文件(如图片),一般推荐使用实时处理的方式。
对于实时处理,用户可简单通过 URL 对已有的文件进行实时处理。当用户将文件上传到七牛 KODO 对象存储平台,会得到相应的 key ,可通过 URL 访问。例如 http://xxx.com/key ,当需要对该文件进行实时处理时,可以通过http://xxx.com/key?<fop>/<param1_value>/<param2_name>/<param2_value>/….进行处理。具体操作参数可以参考七牛官方文档。参数过多过长时可以设置样式,若涉及操作复杂多变可以采用管道技术。
异步请求可以通过 Portal 、命令行工具、 SDK 发起请求。一般适合处理较大文件,比如较大的音视频,这种情况下实时响应的效果并不理想,则可以采用异步持久化处理方式,返回的结果是处理后的文件在七牛云存储中的相关元信息( bucket 、 key 等),用户可以通过设置回调服务器地址,将结果 POST 到自己的接收服务器,也可以主动查询数据处理状态和结果信息。
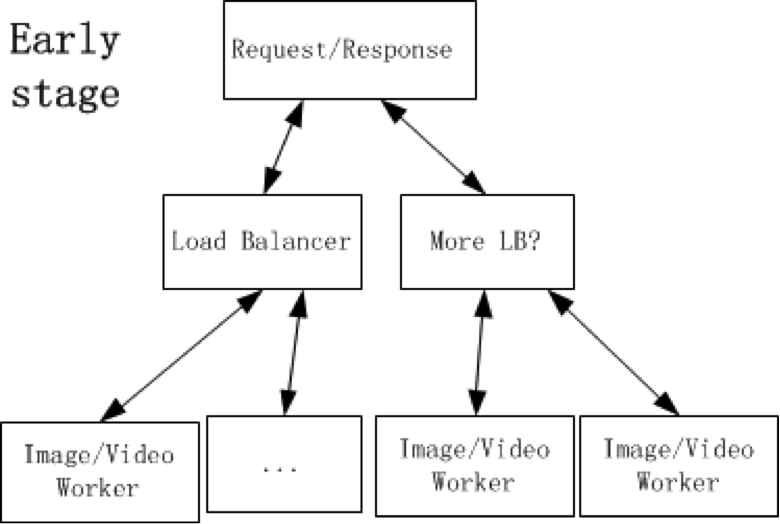
上图描述了简单的实时处理的基本架构,用户可以通过七牛云存储的 I/O 入口发起请求,判断出是合法的数据处理请求后,就会将其传给数据处理调度服务,通过调度分发给计算处理集群。每个 worker 处理的流程为参数检查->下载数据->结合原数据信息对参数进行检查(若数据的相关信息不需要 download 下来就可以获取,那么可以和前面的步骤对调)->自己编写算法实现或者调用工具对数据进行处理,比如转码、图像缩略等操作->结果返回(异步请求一般会持久化保存,通过对象存储服务,将结果上传,得到文件上传后的相关信息,例如 bucket 、 key 等,返回的是文件的相关信息)。这里可以简单的把数据处理调度看做负载均衡器,请求根据接口判断,通过调度指向对应服务,然后将结果原路返回给用户。
上面的结构简单清晰,但同时面临几个问题:
数据处理调度这个服务相对比较重,它不仅仅需要实现负载均衡,还需要对所有处理终端服务进行管理,单台计算型服务器上可能有多个服务 worker (多个图片处理、音视频处理服务 worker ),随着业务发展,管理的 worker 数量是非常多的。
内部实现缓存机制,使得读写缓存的流量全部集中在数据处理调度这个服务。
数据的处理离不开原数据,一般我们可以在 worker 中待前面的步骤顺利通过后,调用七牛的对象存储服务开始下载,那么每个 worker 都必须配置对象存储服务的地址信息,然后才能 download 原数据,这套地址信息对所有 worker 都是共用的。前面提到 1 台物理机器上可能有多个服务 worker ,每个 worker 自身有不同的属性参数(最起码端口号不同),而且可能机器上的服务 worker 有 Image Worker 也有 Video Worker ,共用一套配置显然不能满足,若每个 worker 都将这些普遍共用的信息写入配置,那么维护起来非常不方便。因此,七牛的数据处理架构有了一些演变,就有了如下的架构。
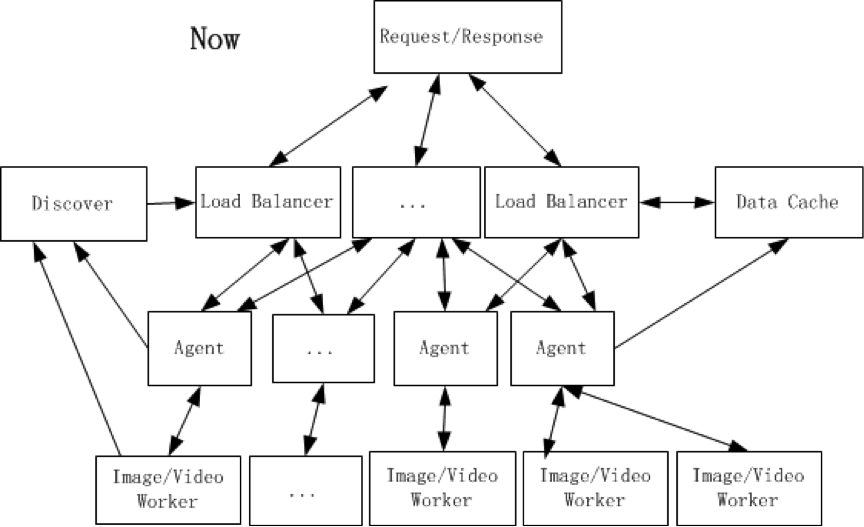
首先,将 Data Cache 独立出来,理由非常简单,在很多环节都需要缓存服务,并且根据缓存数据大小、热度选择是 SSD 或者 HDD 进行缓存,小文件且热度高适合 SSD ,大文件且热度较低适合 HDD 。
其次,为每台服务器添加了 agent 服务。一台服务器可能有多个 worker 且可能是不同种的 worker ,数据处理调度服务只需要知道该请求的对应 worker 存在于哪些机器即可,剩下的判断则交由 agent 处理。因为整个计算集群的服务器存在性能差异,采用权重轮询调度,这时某个 worker 对应所在的机器一目了然,也不需要对 worker 整体标记序号,只需要知道某台服务器有哪些 worker 。 agent 可以承担 download 原数据的责任,相当于提取各个 worker 的一些公共操作都可以都交给 Agent ,同时, agent 分担了向 Data Cache 写入数据的任务。
值得一提的是,对于返回失败的数据也可以缓存。假如请求量巨大,每天 100 亿条请求,确认是客户端请求信息不当的错误约占 5%,那么就有 5 亿错误请求,即使服务迭代升级,也会保持原有接口功能不变。那么,若是同一个文件的同一个错误请求,基本上必然重现,这样的请求实际上就可以被缓存,一来用户那边获得快速响应,二来减少计算压力而且减少拖取数据的流量。后来发现这个方案存在一个瑕疵,就是给 Data Cache 造成的压力略微变大,且有部分错误请求响应并没有加快,至少为了获得缓存数据而读盘会有时间消耗。先前 worker 的设计是检查参数是否合法->download 数据->结合原数据信息检查参数是否合法。这里我们对错误请求做了细化,单独屏蔽了 download 数据之前所产生的错误请求,因为这部分响应非常快,本身也没有多少计算,无需写入缓存。
最后,通过 Discover 服务来监控服务情况的变化,所有的 agent 和 worker 都需要向 Discover 上报心跳状态, Load Balancer 会从 Discover 读取各个服务状态、服务相关信息(地址、权重等),同时允许人工通过 Discover 修改各个服务的状态。
异步请求的架构,则是在整个实时处理架构前面加上异步队列服务、异步请求状态服务等,每个 worker 的处理结果需要持久化,返回的是结果文件持久化保存后的相关信息。
现在的整个数据处理架构,看上去中规中矩,同时也存在一些弊端,即使做到了可以对单条请求大致消耗资源的预估,经过多次数据回滚压力测试以及峰值比对确定一台服务器应该部署多少个 worker ,实现较为合理的调度,但机器上的 worker 数量基本上是固定的,无法跨机器实现弹性的实时调度,服务器的资源仍然不能充分利用。例如,当实时处理服务的机器在非峰值阶段,可以将异步请求的服务 worker 迁移到该机器上,分担一部分任务,使得每台机器的负载较为均衡;当实时请求到达峰值的时候,可以迁移部分 worker 到处理公有队列异步请求的机器(付费的私有队列用户不受影响),分担部分压力。

因此,七牛后续将会对整个数据处理的架构做一些关于 Container 的尝试,希望打破原有的一些束缚,带来比较好的效果,可以把 agent 和 worker 放在一个 Container 内部,成为 1:1 的关系。 Container 自身具有隔离性,可以依据系统的资源情况选择这台机器有多少 Container 运行。当某一台服务器资源已经接近饱和时,就会在下一台服务器上启动一个新的 Container 继续接收请求。一旦某台服务器空闲下来,那么这台服务器就属于 Container 待运行的机器,整个计算服务器集群就是个资源池, worker 无需被机器束缚,哪里空闲就启动在哪里,再也不用担心机器资源浪费了。



相关推荐
在余额宝2.0到4.0的发展过程中,数据架构也经历了从传统数据库到大数据处理平台的转变。这不仅包括了从交易数据中提取有价值信息的能力,还包括利用大数据技术对用户行为进行预测,为用户理财提供更加精准的服务。 ...
### 小米网架构变迁实践 #### 一、小米网技术架构的发展历程 小米网作为小米公司的官方网站,自诞生之初就面临着巨大的挑战和技术难题。在小米网发展的早期阶段,技术团队仅有三位开发工程师,在短短两个月的时间...
### 互联网时代的架构变迁 #### 单机时代与单体架构 互联网的早期阶段,特别是在资源有限、人力资源紧张的情况下,为了能够快速推出产品或者上线网站,单机模式成为了一个非常实用的选择。在这种模式下,所有的...
豆瓣网技术架构变迁的知识点主要包括以下几个方面: 1. 豆瓣网简介:2005年3月上线,是一个以分享和发现为核心内容的社区,主要内容包括读书、电影、音乐、小组、同城以及九点等板块,同时还有“我的豆瓣”和“友邻...
本压缩包文件“【批量下载】知乎架构变迁史等.zip”可能包含了关于豆瓣、京东、汽车之家以及知乎这四家知名互联网公司的架构演进历程的详细资料。这些公司作为行业内的领军企业,它们的架构变迁对于理解互联网技术的...
《知乎架构变迁史》 知乎,作为中国最大的问答社区,其技术架构的演变历程是一部生动的互联网技术发展史。从2010年最初的初创时期,到如今拥有超过11百万活跃用户(RU 11M+)、80百万月活跃用户(MAU 80M+)以及...
### 知乎架构变迁史概览 #### 一、引言 知乎作为中国最大的问答社区之一,自2010年成立以来经历了多次架构调整和技术迭代。本文将基于《知乎架构变迁史》PDF文档中的信息,深入探讨知乎的技术发展历程及其背后的...
Alpha架构是一种64位RISC(精简指令集计算机)设计,旨在提供比当时主流的CISC(复杂指令集计算机)更高效的数据处理能力。Alpha架构的推出,极大地提升了处理器的运行效率,为大规模数据处理和高性能计算提供了强...
### 途牛网站无线架构变迁概述 #### 一、背景介绍 随着移动互联网技术的快速发展,用户对于在线旅游服务的需求日益增长。途牛作为国内知名的在线旅游服务平台之一,其无线架构经历了多次重大调整与优化,以应对不断...
总之,金融行业数据库架构变迁反映了对数据安全、标准化、自动化和高可用性的追求。随着技术的不断发展,DBA的角色将更加多元化,涵盖更广泛的领域,如云数据库管理、大数据分析等,以应对未来的挑战。
【百度贴吧架构变迁史】是关于互联网产品——百度贴吧在其发展历程中所经历的架构演进的详细介绍。百度贴吧作为中国最大的兴趣社区平台,承载着数百万个兴趣话题,每日吸引数百亿次流量,其架构的演变反映了互联网...
360云查杀服务从零到千亿级PV的架构变迁,不仅反映了技术的迭代和升级,也体现了面对海量用户需求和数据处理压力时,对架构设计和系统优化的高度适应性。通过不断地解决技术债务、优化架构设计、整合资源、提升性能...
去哪儿网数据库架构变迁是一个关于在线旅游平台去哪儿网(Qunar)如何应对业务增长和数据处理挑战的专题。在技术日新月异的今天,数据库架构的演进是确保服务稳定性和性能的关键。本文将深入探讨去哪儿网在数据库...
去哪儿网的数据库架构变迁是一个典型的在线旅游平台在面临高并发、大数据量挑战时的技术演进过程。这篇PPT主要介绍了去哪儿网如何从传统的单机数据库架构逐渐转变为使用Galera集群的多主同步复制架构,以提升系统的...
在互联网浪潮的推动下,知乎自2010年成立以来,其架构经历了从初创时期的简单到如今应对大规模用户需求的复杂演进。在这个过程中,知乎的技术栈和...知乎从0到100的架构变迁史,无疑为行业内外提供了宝贵的经验和启示。
总结来看,Web安全扫描的架构变迁反映了网络安全行业的快速发展。从最初的简单内容爬虫到现在的全网流量分析,扫描器不断进化,以应对Web2.0、云环境和移动应用等新技术带来的安全挑战。未来的扫描架构可能会更加...
TalkingData的数据库技术进化历程为我们揭示了大数据统计分析平台从草根阶段到云端发展的全貌,同时也展示了数据库架构如何适应日益增长的数据处理需求。 TalkingData作为一个专注于移动互联网数据分析的平台,其...
这个演变过程反映了阿里在应对大规模在线交易和数据处理中的挑战,以及对数据库性能、扩展性和可用性的不懈追求。 在淘宝初创时期,阿里依赖单机MySQL,但随着业务增长,单机数据库很快遇到性能瓶颈。为了解决这个...
* 敏感数据的加密和脱敏处理 架构V0.1存在的问题: * 代码可维护性差,新人入职成本太高 * 耦合太紧密,很小的错误也会造成整体的crash * 全部业务都在一个DB实例上,性能扩展性极低 * 日志缺乏和规范不统一,定位...