- жµПиІИ: 240299 жђ°
- жАІеИЂ:

- жЭ•иЗ™: дЄКжµЈ
-

жЦЗзЂ†еИЖз±ї
- еЕ®йГ®еНЪеЃҐ (119)
- Eclipse (2)
- java (16)
- Hibernate (2)
- jdbc (5)
- io (4)
- JUnit (1)
- JavaиЃЊиЃ°ж®°еЉП (6)
- ant (2)
- mysql (13)
- struts 2 (4)
- Guice (2)
- js (3)
- linux (10)
- йАЪиЃѓ (1)
- sybase (5)
- жК•и°® (2)
- db2 (3)
- oracle (4)
- lucene (4)
- gwt (1)
- жХ∞жНЃдїУеЇУ (4)
- й°єзЫЃзЃ°зРЖ (2)
- еИЖеЄГеЉПйЫЖзЊ§ (3)
- Hadoop (1)
- GREENPLUM (2)
- spring (1)
- Hbase (1)
- еЙНзЂѓзЫЄеЕ≥ (7)
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 15)
- жИСзЪДйЧЃз≠Ф ( 1)
е≠Шж°£еИЖз±ї
- 2013-02 ( 1)
- 2012-07 ( 1)
- 2012-06 ( 2)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
rq2_79пЉЪ
Solr DataImportHandlerеҐЮйЗПжЦєеЉПеѓЉеЕ•жЧґпЉМжЬЙ ...
solr Data Import Request Handler -
rq2_79пЉЪ
http://developer.51cto.com/col/ ...
JVMеК†иљљClassињЗз®ЛеИЖжЮР -
chenfei3306пЉЪ
жДЯи∞Ґж•ЉдЄїзЪДеИЖжЮРпЉМзО∞еЬ®еѓєhqlзЪДиІ£жЮРжЬЙдЇЖе§ІдљУзЪДиЃ§иѓЖдЇЖ
hibernate зЪДHQLжЇРз†БеИЖжЮР -
еЫЫдЄ™зЯ≥е§іпЉЪ
...
иѓХзФ®log4jdbc -
dongbiyingпЉЪ
зЬЯиЃ©дЇЇжЧ†иАРеСАпЉБдљ†иІЙеЊЧжШѓдЄНжШѓjarзЪДйЧЃйҐШеСАпЉБ
RetroGuardе≠¶дє†жМЗеНЧ
е§ІеЮЛзљСзЂЩжЮґжЮДжЉФеПШеТМзЯ•иѓЖдљУз≥ї
- еНЪеЃҐеИЖз±їпЉЪ
- JavaиЃЊиЃ°ж®°еЉП
дєЛеЙНдєЯжЬЙдЄАдЇЫдїЛзїНе§ІеЮЛзљСзЂЩжЮґжЮДжЉФеПШзЪДжЦЗзЂ†пЉМдЊЛе¶ВLiveJournalзЪДгАБebayзЪДпЉМйГљжШѓйЭЮеЄЄеАЉеЊЧеПВиАГзЪДпЉМдЄНињЗжДЯиІЙдїЦдїђиЃ≤зЪДжЫіе§ЪзЪДжШѓжѓПжђ°жЉФеПШзЪДзїУжЮЬпЉМиАМ
ж≤°жЬЙеЊИиѓ¶зїЖзЪДиЃ≤дЄЇдїАдєИйЬАи¶БеБЪињЩж†ЈзЪДжЉФеПШпЉМеЖНеК†дЄКињСжЭ•жДЯиІЙжЬЙдЄНе∞СеРМе≠¶йГљеЊИйЪЊжШОзЩљдЄЇдїАдєИдЄАдЄ™зљСзЂЩйЬАи¶БйВ£дєИе§НжЭВзЪДжКАжЬѓпЉМдЇОжШѓжЬЙдЇЖеЖЩињЩзѓЗжЦЗзЂ†зЪДжГ≥ж≥ХпЉМеЬ®ињЩзѓЗжЦЗзЂ†дЄ≠
е∞ЖйШРињ∞дЄАдЄ™жЩЃйАЪзЪДзљСзЂЩеПСе±ХжИРе§ІеЮЛзљСзЂЩињЗз®ЛдЄ≠зЪДдЄАзІНиЊГдЄЇеЕЄеЮЛзЪДжЮґжЮДжЉФеПШеОЖз®ЛеТМжЙАйЬАжОМжП°зЪДзЯ•иѓЖдљУз≥їпЉМеЄМжЬЫиГљзїЩжГ≥дїОдЇЛдЇТиБФзљСи°МдЄЪзЪДеРМе≠¶дЄАзВєеИЭж≠•зЪДж¶ВењµпЉМ:)пЉМжЦЗ
дЄ≠зЪДдЄНеѓєдєЛе§ДдєЯиѓЈеРДдљНе§ЪзїЩзВєеїЇиЃЃпЉМиЃ©жЬђжЦЗзЬЯж≠£иµЈеИ∞жКЫз†ЦеЉХзОЙзЪДжХИжЮЬгАВ
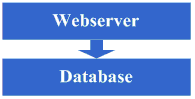
жЮґжЮДжЉФеПШзђђдЄАж≠•пЉЪзЙ©зРЖеИЖз¶їwebserverеТМжХ∞жНЃеЇУ
жЬАеЉАеІЛпЉМзФ±дЇОжЯРдЇЫжГ≥ж≥ХпЉМдЇОжШѓеЬ®дЇТиБФзљСдЄКжР≠еїЇдЇЖдЄАдЄ™зљСзЂЩпЉМињЩдЄ™жЧґеАЩзФЪиЗ≥жЬЙеПѓиГљдЄїжЬЇйГљжШѓзІЯеАЯзЪДпЉМдљЖзФ±дЇОињЩзѓЗжЦЗзЂ†жИСдїђеП™еЕ≥ж≥®жЮґжЮДзЪДжЉФеПШеОЖз®ЛпЉМеЫ†ж≠§е∞±еБЗиЃЊињЩдЄ™жЧґеАЩ
еЈ≤зїПжШѓжЙШзЃ°дЇЖдЄАеП∞дЄїжЬЇпЉМеєґдЄФжЬЙдЄАеЃЪзЪДеЄ¶еЃљдЇЖпЉМињЩдЄ™жЧґеАЩзФ±дЇОзљСзЂЩеЕЈе§ЗдЇЖдЄАеЃЪзЪДзЙєиЙ≤пЉМеРЄеЉХдЇЖйГ®еИЖдЇЇиЃњйЧЃпЉМйАРжЄРдљ†еПСзО∞з≥їзїЯзЪДеОЛеКЫиґКжЭ•иґКйЂШпЉМеУНеЇФйАЯеЇ¶иґКжЭ•иґКжЕҐпЉМиАМ
ињЩдЄ™жЧґеАЩжѓФиЊГжШОжШЊзЪДжШѓжХ∞жНЃеЇУеТМеЇФзФ®дЇТзЫЄељ±еУНпЉМеЇФзФ®еЗЇйЧЃйҐШдЇЖпЉМжХ∞жНЃеЇУдєЯеЊИеЃєжШУеЗЇзО∞йЧЃйҐШпЉМиАМжХ∞жНЃеЇУеЗЇйЧЃйҐШзЪДжЧґеАЩпЉМеЇФзФ®дєЯеЃєжШУеЗЇйЧЃйҐШпЉМдЇОжШѓињЫеЕ•дЇЖзђђдЄАж≠•жЉФеПШйШґ
жЃµпЉЪе∞ЖеЇФзФ®еТМжХ∞жНЃеЇУдїОзЙ©зРЖдЄКеИЖз¶їпЉМеПШжИРдЇЖдЄ§еП∞жЬЇеЩ®пЉМињЩдЄ™жЧґеАЩжКАжЬѓдЄКж≤°жЬЙдїАдєИжЦ∞зЪДи¶Бж±ВпЉМдљЖдљ†еПСзО∞з°ЃеЃЮиµЈеИ∞жХИжЮЬдЇЖпЉМз≥їзїЯеПИжБҐе§НеИ∞дї•еЙНзЪДеУНеЇФйАЯеЇ¶дЇЖпЉМеєґдЄФжФѓжТСдљП
дЇЖжЫійЂШзЪДжµБйЗПпЉМеєґдЄФдЄНдЉЪеЫ†дЄЇжХ∞жНЃеЇУеТМеЇФзԮ嚥жИРдЇТзЫЄзЪДељ±еУНгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
ињЩдЄАж≠•жЮґжЮДжЉФеПШеѓєжКАжЬѓдЄКзЪДзЯ•иѓЖдљУз≥їеЯЇжЬђж≤°жЬЙи¶Бж±ВгАВ
жЮґжЮДжЉФеПШзђђдЇМж≠•пЉЪеҐЮеК†й°µйЭҐзЉУе≠Ш
е•љжЩѓдЄНйХњпЉМйЪПзЭАиЃњйЧЃзЪДдЇЇиґКжЭ•иґКе§ЪпЉМдљ†еПСзО∞еУНеЇФйАЯеЇ¶еПИеЉАеІЛеПШжЕҐдЇЖпЉМжЯ•жЙЊеОЯеЫ†пЉМеПСзО∞жШѓиЃњйЧЃжХ∞жНЃеЇУзЪДжУНдљЬ姙е§ЪпЉМеѓЉиЗіжХ∞жНЃињЮжО•зЂЮдЇЙжњАзГИпЉМжЙАдї•еУНеЇФеПШжЕҐпЉМдљЖжХ∞жНЃеЇУињЮ
жО•еПИдЄНиГљеЉА姙е§ЪпЉМеР¶еИЩжХ∞жНЃеЇУжЬЇеЩ®еОЛеКЫдЉЪеЊИйЂШпЉМеЫ†ж≠§иАГиЩСйЗЗзФ®зЉУе≠ШжЬЇеИґжЭ•еЗПе∞СжХ∞жНЃеЇУињЮжО•иµДжЇРзЪДзЂЮдЇЙеТМеѓєжХ∞жНЃеЇУиѓїзЪДеОЛеКЫпЉМињЩдЄ™жЧґеАЩй¶ЦеЕИдєЯиЃЄдЉЪйАЙжЛ©йЗЗзФ®squid
з≠Йз±їдЉЉзЪДжЬЇеИґжЭ•е∞Жз≥їзїЯдЄ≠зЫЄеѓєйЭЩжАБзЪДй°µйЭҐпЉИдЊЛе¶ВдЄА䪧姩жЙНдЉЪжЬЙжЫіжЦ∞зЪДй°µйЭҐпЉЙињЫи°МзЉУе≠ШпЉИељУзДґпЉМдєЯеПѓдї•йЗЗзФ®е∞Жй°µйЭҐйЭЩжАБеМЦзЪДжЦєж°ИпЉЙпЉМињЩж†Јз®ЛеЇПдЄКеПѓдї•дЄНеБЪдњЃжФєпЉМе∞±иГље§Я
еЊИе•љзЪДеЗПе∞СеѓєwebserverзЪДеОЛеКЫдї•еПКеЗПе∞СжХ∞жНЃеЇУињЮжО•иµДжЇРзЪДзЂЮдЇЙпЉМOKпЉМдЇОжШѓеЉАеІЛйЗЗзФ®squidжЭ•еБЪзЫЄеѓєйЭЩжАБзЪДй°µйЭҐзЪДзЉУе≠ШгАВ
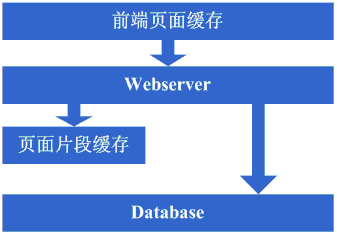
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ

ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
еЙНзЂѓй°µйЭҐзЉУе≠ШжКАжЬѓпЉМдЊЛе¶ВsquidпЉМе¶ВжГ≥зФ®е•љзЪДиѓЭињШеЊЧжЈ±еЕ•жОМжП°дЄЛsquidзЪДеЃЮзО∞жЦєеЉПдї•еПКзЉУе≠ШзЪД姱жХИзЃЧж≥Хз≠ЙгАВ
жЮґжЮДжЉФеПШзђђдЄЙж≠•пЉЪеҐЮеК†й°µйЭҐзЙЗжЃµзЉУе≠Ш
еҐЮеК†дЇЖsquidеБЪзЉУе≠ШеРОпЉМжХідљУз≥їзїЯзЪДйАЯеЇ¶з°ЃеЃЮжШѓжПРеНЗдЇЖпЉМwebserverзЪДеОЛеКЫдєЯеЉАеІЛдЄЛйЩНдЇЖпЉМдљЖйЪПзЭАиЃњйЧЃйЗПзЪДеҐЮеК†пЉМеПСзО∞з≥їзїЯеПИеЉАеІЛеПШзЪДжЬЙдЇЫжЕҐдЇЖпЉМеЬ®е∞Э
еИ∞дЇЖsquidдєЛз±їзЪДеК®жАБзЉУе≠ШеЄ¶жЭ•зЪДе•ље§ДеРОпЉМеЉАеІЛжГ≥иГљдЄНиГљиЃ©зО∞еЬ®йВ£дЇЫеК®жАБй°µйЭҐйЗМзЫЄеѓєйЭЩжАБзЪДйГ®еИЖдєЯзЉУе≠ШиµЈжЭ•еСҐпЉМеЫ†ж≠§иАГиЩСйЗЗзФ®з±їдЉЉESIдєЛз±їзЪДй°µйЭҐзЙЗжЃµзЉУе≠Шз≠Ц
зХ•пЉМOKпЉМдЇОжШѓеЉАеІЛйЗЗзФ®ESIжЭ•еБЪеК®жАБй°µйЭҐдЄ≠зЫЄеѓєйЭЩжАБзЪДзЙЗжЃµйГ®еИЖзЪДзЉУе≠ШгАВ
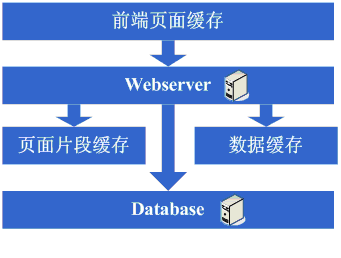
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
й°µйЭҐзЙЗжЃµзЉУе≠ШжКАжЬѓпЉМдЊЛе¶ВESIз≠ЙпЉМжГ≥зФ®е•љзЪДиѓЭеРМж†ЈйЬАи¶БжОМжП°ESIзЪДеЃЮзО∞жЦєеЉПз≠ЙпЉЫ
жЮґжЮДжЉФеПШзђђеЫЫж≠•пЉЪжХ∞жНЃзЉУе≠Ш
еЬ®йЗЗзФ®ESIдєЛз±їзЪДжКАжЬѓеЖНжђ°жПРйЂШдЇЖз≥їзїЯзЪДзЉУе≠ШжХИжЮЬеРОпЉМз≥їзїЯзЪДеОЛеКЫз°ЃеЃЮињЫдЄАж≠•йЩНдљОдЇЖпЉМдљЖеРМж†ЈпЉМйЪПзЭАиЃњйЧЃйЗПзЪДеҐЮеК†пЉМз≥їзїЯињШжШѓеЉАеІЛеПШжЕҐпЉМзїПињЗжЯ•жЙЊпЉМеПѓиГљдЉЪеПСзО∞з≥ї
зїЯдЄ≠е≠ШеЬ®дЄАдЇЫйЗНе§НиОЈеПЦжХ∞жНЃдњ°жБѓзЪДеЬ∞жЦєпЉМеГПиОЈеПЦзФ®жИЈдњ°жБѓз≠ЙпЉМињЩдЄ™жЧґеАЩеЉАеІЛиАГиЩСжШѓдЄНжШѓеПѓдї•е∞ЖињЩдЇЫжХ∞жНЃдњ°жБѓдєЯзЉУе≠ШиµЈжЭ•еСҐпЉМдЇОжШѓе∞ЖињЩдЇЫжХ∞жНЃзЉУе≠ШеИ∞жЬђеЬ∞еЖЕе≠ШпЉМжФєеПШеЃМ
жѓХеРОпЉМеЃМеЕ®зђ¶еРИйҐДжЬЯпЉМз≥їзїЯзЪДеУНеЇФйАЯеЇ¶еПИжБҐе§НдЇЖпЉМжХ∞жНЃеЇУзЪДеОЛеКЫдєЯеЖНеЇ¶йЩНдљОдЇЖдЄНе∞СгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
зЉУе≠ШжКАжЬѓпЉМеМЕжЛђеГПMapжХ∞жНЃзїУжЮДгАБзЉУе≠ШзЃЧж≥ХгАБжЙАйАЙзФ®зЪДж°ЖжЮґжЬђиЇЂзЪДеЃЮзО∞жЬЇеИґз≠ЙгАВ
жЮґжЮДжЉФеПШзђђдЇФж≠•пЉЪ еҐЮеК†webserver
е•љжЩѓдЄНйХњпЉМеПСзО∞йЪПзЭАз≥їзїЯиЃњйЧЃйЗПзЪДеЖНеЇ¶еҐЮеК†пЉМwebserverжЬЇеЩ®зЪДеОЛеКЫеЬ®йЂШе≥∞жЬЯдЉЪдЄКеНЗеИ∞жѓФиЊГйЂШпЉМињЩдЄ™жЧґеАЩеЉАеІЛиАГиЩСеҐЮеК†дЄАеП∞webserverпЉМињЩдєЯжШѓдЄЇ
дЇЖеРМжЧґиІ£еЖ≥еПѓзФ®жАІзЪДйЧЃйҐШпЉМйБњеЕНеНХеП∞зЪДwebserver
downжЬЇзЪДиѓЭе∞±ж≤°ж≥ХдљњзФ®дЇЖпЉМеЬ®еБЪдЇЖињЩдЇЫиАГиЩСеРОпЉМеЖ≥еЃЪеҐЮеК†дЄАеП∞webserverпЉМеҐЮеК†дЄАеП∞webserverжЧґпЉМдЉЪзҐ∞еИ∞дЄАдЇЫйЧЃйҐШпЉМеЕЄеЮЛзЪДжЬЙпЉЪ
1гАБе¶ВдљХиЃ©иЃњйЧЃеИЖйЕНеИ∞ињЩдЄ§еП∞жЬЇеЩ®дЄКпЉМињЩдЄ™жЧґеАЩйАЪеЄЄдЉЪиАГиЩСзЪДжЦєж°ИжШѓApacheиЗ™еЄ¶зЪДиіЯиљљеЭЗи°°жЦєж°ИпЉМжИЦLVSињЩз±їзЪДиљѓдїґиіЯиљљеЭЗи°°жЦєж°ИпЉЫ
2гАБе¶ВдљХдњЭжМБзКґжАБдњ°жБѓзЪДеРМж≠•пЉМдЊЛе¶ВзФ®жИЈsessionз≠ЙпЉМињЩдЄ™жЧґеАЩдЉЪиАГиЩСзЪДжЦєж°ИжЬЙеЖЩеЕ•жХ∞жНЃеЇУгАБеЖЩеЕ•е≠ШеВ®гАБcookieжИЦеРМж≠•sessionдњ°жБѓз≠ЙжЬЇеИґз≠ЙпЉЫ
3гАБе¶ВдљХдњЭжМБжХ∞жНЃзЉУе≠Шдњ°жБѓзЪДеРМж≠•пЉМдЊЛе¶ВдєЛеЙНзЉУе≠ШзЪДзФ®жИЈжХ∞жНЃз≠ЙпЉМињЩдЄ™жЧґеАЩйАЪеЄЄдЉЪиАГиЩСзЪДжЬЇеИґжЬЙзЉУе≠ШеРМж≠•жИЦеИЖеЄГеЉПзЉУе≠ШпЉЫ
4гАБе¶ВдљХиЃ©дЄКдЉ†жЦЗдїґињЩдЇЫз±їдЉЉзЪДеКЯиГљзїІзї≠ж≠£еЄЄпЉМињЩдЄ™жЧґеАЩйАЪеЄЄдЉЪиАГиЩСзЪДжЬЇеИґжШѓдљњзФ®еЕ±дЇЂжЦЗдїґз≥їзїЯжИЦе≠ШеВ®з≠ЙпЉЫ
еЬ®иІ£еЖ≥дЇЖињЩдЇЫйЧЃйҐШеРОпЉМзїИдЇОжШѓжККwebserverеҐЮеК†дЄЇдЇЖдЄ§еП∞пЉМз≥їзїЯзїИдЇОжШѓеПИжБҐе§НеИ∞дЇЖдї•еЊАзЪДйАЯеЇ¶гАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
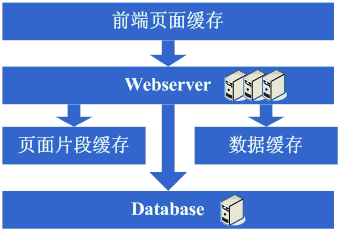
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
иіЯиљљеЭЗи°°жКАжЬѓпЉИеМЕжЛђдљЖдЄНйЩРдЇОз°ђдїґиіЯиљљеЭЗи°°гАБиљѓдїґиіЯиљљеЭЗи°°гАБиіЯиљљзЃЧж≥ХгАБlinuxиљђеПСеНПиЃЃгАБжЙАйАЙзФ®зЪДжКАжЬѓзЪДеЃЮзО∞зїЖиКВз≠ЙпЉЙгАБдЄїе§ЗжКАжЬѓпЉИеМЕжЛђдљЖдЄНйЩРдЇОARPжђЇ
й™ЧгАБlinux
heart-beatз≠ЙпЉЙгАБзКґжАБдњ°жБѓжИЦзЉУе≠ШеРМж≠•жКАжЬѓпЉИеМЕжЛђдљЖдЄНйЩРдЇОCookieжКАжЬѓгАБUDPеНПиЃЃгАБзКґжАБдњ°жБѓеєњжТ≠гАБжЙАйАЙзФ®зЪДзЉУе≠ШеРМж≠•жКАжЬѓзЪДеЃЮзО∞зїЖиКВз≠ЙпЉЙгАБеЕ±
дЇЂжЦЗдїґжКАжЬѓпЉИеМЕжЛђдљЖдЄНйЩРдЇОNFSз≠ЙпЉЙгАБе≠ШеВ®жКАжЬѓпЉИеМЕжЛђдљЖдЄНйЩРдЇОе≠ШеВ®иЃЊе§Зз≠ЙпЉЙгАВ
жЮґжЮДжЉФеПШзђђеЕ≠ж≠•пЉЪеИЖеЇУ
дЇЂеПЧдЇЖдЄАжЃµжЧґйЧізЪДз≥їзїЯиЃњйЧЃйЗПйЂШйАЯеҐЮйХњзЪДеєЄз¶ПеРОпЉМеПСзО∞з≥їзїЯеПИеЉАеІЛеПШжЕҐдЇЖпЉМињЩжђ°еПИжШѓдїАдєИзКґеЖµеСҐпЉМзїПињЗжЯ•жЙЊпЉМеПСзО∞жХ∞жНЃеЇУеЖЩеЕ•гАБжЫіжЦ∞зЪДињЩдЇЫжУНдљЬзЪДйГ®еИЖжХ∞жНЃеЇУињЮжО•зЪД
иµДжЇРзЂЮдЇЙйЭЮеЄЄжњАзГИпЉМеѓЉиЗідЇЖз≥їзїЯеПШжЕҐпЉМињЩдЄЛжАОдєИеКЮеСҐпЉМж≠§жЧґеПѓйАЙзЪДжЦєж°ИжЬЙжХ∞жНЃеЇУйЫЖзЊ§еТМеИЖеЇУз≠ЦзХ•пЉМйЫЖзЊ§жЦєйЭҐеГПжЬЙдЇЫжХ∞жНЃеЇУжФѓжМБзЪДеєґдЄНжШѓеЊИе•љпЉМеЫ†ж≠§еИЖеЇУдЉЪжИРдЄЇжѓФиЊГжЩЃ
йБНзЪДз≠ЦзХ•пЉМеИЖеЇУдєЯе∞±жДПеС≥зЭАи¶БеѓєеОЯжЬЙз®ЛеЇПињЫи°МдњЃжФєпЉМдЄАйАЪдњЃжФєеЃЮзО∞еИЖеЇУеРОпЉМдЄНйФЩпЉМзЫЃж†ЗиЊЊеИ∞дЇЖпЉМз≥їзїЯжБҐе§НзФЪиЗ≥йАЯеЇ¶жѓФдї•еЙНињШењЂдЇЖгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
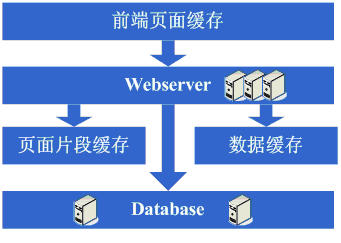
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
ињЩдЄАж≠•жЫіе§ЪзЪДжШѓйЬАи¶БдїОдЄЪеК°дЄКеБЪеРИзРЖзЪДеИТеИЖпЉМдї•еЃЮзО∞еИЖеЇУпЉМеЕЈдљУжКАжЬѓзїЖиКВдЄКж≤°жЬЙеЕґдїЦзЪДи¶Бж±ВпЉЫ
дљЖеРМжЧґйЪПзЭАжХ∞жНЃйЗПзЪДеҐЮе§ІеТМеИЖеЇУзЪДињЫи°МпЉМеЬ®жХ∞жНЃеЇУзЪДиЃЊиЃ°гАБи∞ГдЉШдї•еПКзїіжК§дЄКйЬАи¶БеБЪзЪДжЫіе•љпЉМеЫ†ж≠§еѓєињЩдЇЫжЦєйЭҐзЪДжКАжЬѓињШжШѓжПРеЗЇдЇЖеЊИйЂШзЪДи¶Бж±ВзЪДгАВ
жЮґжЮДжЉФеПШзђђдЄГж≠•пЉЪеИЖи°®гАБDALеТМеИЖеЄГеЉПзЉУе≠Ш
йЪПзЭАз≥їзїЯзЪДдЄНжЦ≠ињРи°МпЉМжХ∞жНЃйЗПеЉАеІЛе§ІеєЕеЇ¶еҐЮйХњпЉМињЩдЄ™жЧґеАЩеПСзО∞еИЖеЇУеРОжߕ胥дїНзДґдЉЪжЬЙдЇЫжЕҐпЉМдЇОжШѓжМЙзЕІеИЖеЇУзЪДжАЭжГ≥еЉАеІЛеБЪеИЖи°®зЪДеЈ•дљЬпЉМељУзДґпЉМињЩдЄНеПѓйБњеЕНзЪДдЉЪйЬАи¶Беѓєз®ЛеЇП
ињЫи°МдЄАдЇЫдњЃжФєпЉМдєЯиЃЄеЬ®ињЩдЄ™жЧґеАЩе∞±дЉЪеПСзО∞еЇФзФ®иЗ™еЈ±и¶БеЕ≥ењГеИЖеЇУеИЖи°®зЪДиІДеИЩз≠ЙпЉМињШжШѓжЬЙдЇЫе§НжЭВзЪДпЉМдЇОжШѓиРМзФЯиГљеР¶еҐЮеК†дЄАдЄ™йАЪзФ®зЪДж°ЖжЮґжЭ•еЃЮзО∞еИЖеЇУеИЖи°®зЪДжХ∞жНЃиЃњйЧЃпЉМињЩдЄ™
еЬ®ebayзЪДжЮґжЮДдЄ≠еѓєеЇФзЪДе∞±жШѓDALпЉМињЩдЄ™жЉФеПШзЪДињЗз®ЛзЫЄеѓєиАМи®АйЬАи¶БиК±иієиЊГйХњзЪДжЧґйЧіпЉМељУзДґпЉМдєЯжЬЙеПѓиГљињЩдЄ™йАЪзФ®зЪДж°ЖжЮґдЉЪз≠ЙеИ∞еИЖи°®еБЪеЃМеРОжЙНеЉАеІЛеБЪпЉМеРМжЧґпЉМеЬ®ињЩдЄ™
йШґжЃµеПѓ
иГљдЉЪеПСзО∞дєЛеЙНзЪДзЉУе≠ШеРМж≠•жЦєж°ИеЗЇзО∞йЧЃйҐШпЉМеЫ†дЄЇжХ∞жНЃйЗП姙姲пЉМеѓЉиЗізО∞еЬ®дЄН姙еПѓиГље∞ЖзЉУе≠Ше≠ШеЬ®жЬђеЬ∞пЉМзДґеРОеРМж≠•зЪДжЦєеЉПпЉМйЬАи¶БйЗЗзФ®еИЖеЄГеЉПзЉУе≠ШжЦєж°ИдЇЖпЉМдЇОжШѓпЉМеПИжШѓдЄАйАЪиАГеѓЯ
еТМжКШз£®пЉМзїИдЇОжШѓе∞Же§ІйЗПзЪДжХ∞жНЃзЉУе≠ШиљђзІїеИ∞еИЖеЄГеЉПзЉУе≠ШдЄКдЇЖгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ

ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
еИЖи°®жЫіе§ЪзЪДеРМж†ЈжШѓдЄЪеК°дЄКзЪДеИТеИЖпЉМжКАжЬѓдЄКжґЙеПКеИ∞зЪДдЉЪжЬЙеК®жАБhashзЃЧж≥ХгАБconsistent hashзЃЧж≥Хз≠ЙпЉЫ
DALжґЙеПКеИ∞жѓФиЊГе§ЪзЪДе§НжЭВжКАжЬѓпЉМдЊЛе¶ВжХ∞жНЃеЇУињЮжО•зЪДзЃ°зРЖпЉИиґЕжЧґгАБеЉВеЄЄпЉЙгАБжХ∞жНЃеЇУжУНдљЬзЪДжОІеИґпЉИиґЕжЧґгАБеЉВеЄЄпЉЙгАБеИЖеЇУеИЖи°®иІДеИЩзЪДе∞Би£Ез≠ЙпЉЫ
жЮґжЮДжЉФеПШзђђеЕЂж≠•пЉЪеҐЮеК†жЫіе§ЪзЪДwebserver
еЬ®еБЪеЃМеИЖеЇУеИЖи°®ињЩдЇЫеЈ•дљЬеРОпЉМжХ∞жНЃеЇУдЄКзЪДеОЛеКЫеЈ≤зїПйЩНеИ∞жѓФиЊГдљОдЇЖпЉМеПИеЉАеІЛињЗзЭАжѓП姩зЬЛзЭАиЃњйЧЃйЗПжЪіеҐЮзЪДеєЄз¶ПзФЯжіїдЇЖпЉМз™БзДґжЬЙдЄА姩пЉМеПСзО∞з≥їзїЯзЪДиЃњйЧЃеПИеЉАеІЛжЬЙеПШжЕҐзЪДиґЛеКњ
дЇЖпЉМињЩдЄ™жЧґеАЩй¶ЦеЕИжЯ•зЬЛжХ∞жНЃеЇУпЉМеОЛеКЫдЄАеИЗж≠£еЄЄпЉМдєЛеРОжЯ•зЬЛwebserverпЉМеПСзО∞apacheйШїе°ЮдЇЖеЊИе§ЪзЪДиѓЈж±ВпЉМиАМеЇФзФ®жЬНеК°еЩ®еѓєжѓПдЄ™иѓЈж±ВдєЯжШѓжѓФиЊГењЂзЪДпЉМзЬЛжЭ•
жШѓиѓЈж±ВжХ∞姙йЂШеѓЉиЗійЬАи¶БжОТйШЯз≠ЙеЊЕпЉМеУНеЇФйАЯеЇ¶еПШжЕҐпЉМињЩињШе•љеКЮпЉМдЄАиИђжЭ•иѓіпЉМињЩдЄ™жЧґеАЩдєЯдЉЪжЬЙдЇЫйТ±дЇЖпЉМдЇОжШѓжЈїеК†дЄАдЇЫwebserverжЬНеК°еЩ®пЉМеЬ®ињЩдЄ™жЈїеК†
webserverжЬНеК°еЩ®зЪДињЗз®ЛпЉМжЬЙеПѓиГљдЉЪеЗЇзО∞еЗ†зІНжМСжИШпЉЪ
1гАБApacheзЪДиљѓиіЯиљљжИЦLVSиљѓиіЯиљљз≠ЙжЧ†ж≥ХжЙњжЛЕеЈ®е§ІзЪДwebиЃњйЧЃйЗПпЉИиѓЈж±ВињЮжО•жХ∞гАБзљСзїЬжµБйЗПз≠ЙпЉЙзЪДи∞ГеЇ¶дЇЖпЉМињЩдЄ™жЧґеАЩе¶ВжЮЬзїПиієеЕБиЃЄзЪДиѓЭпЉМдЉЪйЗЗеПЦзЪДжЦєж°ИжШѓиі≠
дє∞з°ђдїґиіЯиљљпЉМдЊЛе¶ВF5гАБNetsclarгАБAthelonдєЛз±їзЪДпЉМе¶ВзїПиієдЄНеЕБиЃЄзЪДиѓЭпЉМдЉЪйЗЗеПЦзЪДжЦєж°ИжШѓе∞ЖеЇФзФ®дїОйАїиЊСдЄКеБЪдЄАеЃЪзЪДеИЖз±їпЉМзДґеРОеИЖжХ£еИ∞дЄНеРМзЪДиљѓиіЯиљљ
йЫЖзЊ§дЄ≠пЉЫ
2гАБеОЯжЬЙзЪДдЄАдЇЫзКґжАБдњ°жБѓеРМж≠•гАБжЦЗдїґеЕ±дЇЂз≠ЙжЦєж°ИеПѓиГљдЉЪеЗЇзО∞зУґйҐИпЉМйЬАи¶БињЫи°МжФєињЫпЉМдєЯиЃЄињЩдЄ™жЧґеАЩдЉЪж†єжНЃжГЕеЖµзЉЦеЖЩзђ¶еРИзљСзЂЩдЄЪеК°йЬАж±ВзЪДеИЖеЄГеЉПжЦЗдїґз≥їзїЯз≠ЙпЉЫ
еЬ®еБЪеЃМињЩдЇЫеЈ•дљЬеРОпЉМеЉАеІЛињЫеЕ•дЄАдЄ™зЬЛдЉЉеЃМзЊОзЪДжЧ†йЩРдЉЄзЉ©зЪДжЧґдї£пЉМељУзљСзЂЩжµБйЗПеҐЮеК†жЧґпЉМеЇФеѓєзЪДиІ£еЖ≥жЦєж°Ие∞±жШѓдЄНжЦ≠зЪДжЈїеК†webserverгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
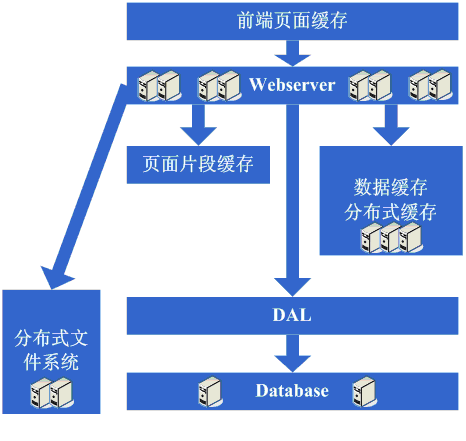
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
еИ∞дЇЖињЩдЄАж≠•пЉМйЪПзЭАжЬЇеЩ®жХ∞зЪДдЄНжЦ≠еҐЮйХњгАБжХ∞жНЃйЗПзЪДдЄНжЦ≠еҐЮйХњеТМеѓєз≥їзїЯеПѓзФ®жАІзЪДи¶Бж±ВиґКжЭ•иґКйЂШпЉМињЩдЄ™жЧґеАЩи¶Бж±ВеѓєжЙАйЗЗзФ®зЪДжКАжЬѓйГљи¶БжЬЙжЫідЄЇжЈ±еЕ•зЪДзРЖиІ£пЉМеєґйЬАи¶Бж†єжНЃзљСзЂЩзЪДйЬАж±ВжЭ•еБЪжЫіеК†еЃЪеИґжАІиі®зЪДдЇІеУБгАВ
жЮґжЮДжЉФеПШзђђдєЭж≠•пЉЪжХ∞жНЃиѓїеЖЩеИЖз¶їеТМеїЙдїЈе≠ШеВ®жЦєж°И
з™БзДґжЬЙдЄА姩пЉМеПСзО∞ињЩдЄ™еЃМзЊОзЪДжЧґдї£дєЯи¶БзїУжЭЯдЇЖпЉМжХ∞жНЃеЇУзЪДе٩楶еПИдЄАжђ°еЗЇзО∞еЬ®зЬЉеЙНдЇЖпЉМзФ±дЇОжЈїеК†зЪДwebserver姙е§ЪдЇЖпЉМеѓЉиЗіжХ∞жНЃеЇУињЮжО•зЪДиµДжЇРињШжШѓдЄНе§ЯзФ®пЉМиАМ
ињЩдЄ™жЧґеАЩеПИеЈ≤зїПеИЖеЇУеИЖи°®дЇЖпЉМеЉАеІЛеИЖжЮРжХ∞жНЃеЇУзЪДеОЛеКЫзКґеЖµпЉМеПѓиГљдЉЪеПСзО∞жХ∞жНЃеЇУзЪДиѓїеЖЩжѓФеЊИйЂШпЉМињЩдЄ™жЧґеАЩйАЪеЄЄдЉЪжГ≥еИ∞жХ∞жНЃиѓїеЖЩеИЖз¶їзЪДжЦєж°ИпЉМељУзДґпЉМињЩдЄ™жЦєж°Ии¶БеЃЮзО∞еєґдЄН
еЃєжШУпЉМеП¶е§ЦпЉМеПѓиГљдЉЪеПСзО∞дЄАдЇЫжХ∞жНЃе≠ШеВ®еЬ®жХ∞жНЃеЇУдЄКжЬЙдЇЫжµ™иієпЉМжИЦиАЕиѓіињЗдЇОеН†зФ®жХ∞жНЃеЇУиµДжЇРпЉМеЫ†ж≠§еЬ®ињЩдЄ™йШґжЃµеПѓиГљдЉЪ嚥жИРзЪДжЮґжЮДжЉФеПШжШѓеЃЮзО∞жХ∞жНЃиѓїеЖЩеИЖз¶їпЉМеРМжЧґзЉЦеЖЩдЄА
дЇЫжЫідЄЇеїЙдїЈзЪДе≠ШеВ®жЦєж°ИпЉМдЊЛе¶ВBigTableињЩзІНгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
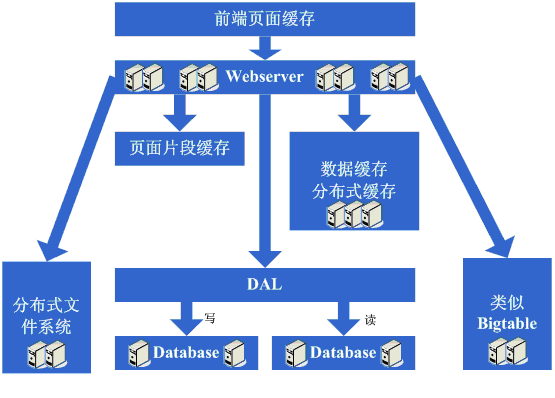
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
жХ∞жНЃиѓїеЖЩеИЖз¶їи¶Бж±ВеѓєжХ∞жНЃеЇУзЪДе§НеИґгАБstandbyз≠Йз≠ЦзХ•жЬЙжЈ±еЕ•зЪДжОМжП°еТМзРЖиІ£пЉМеРМжЧґдЉЪи¶Бж±ВеЕЈе§ЗиЗ™и°МеЃЮзО∞зЪДжКАжЬѓпЉЫ
еїЙдїЈе≠ШеВ®жЦєж°Ии¶Бж±ВеѓєOSзЪДжЦЗдїґе≠ШеВ®жЬЙжЈ±еЕ•зЪДжОМжП°еТМзРЖиІ£пЉМеРМжЧґи¶Бж±ВеѓєйЗЗзФ®зЪДиѓ≠и®АеЬ®жЦЗдїґињЩеЭЧзЪДеЃЮзО∞жЬЙжЈ±еЕ•зЪДжОМжП°гАВ
жЮґжЮДжЉФеПШзђђеНБж≠•пЉЪињЫеЕ•е§ІеЮЛеИЖеЄГеЉПеЇФзФ®жЧґдї£еТМеїЙдїЈжЬНеК°еٮ猧楶жГ≥жЧґдї£
зїПињЗдЄКйЭҐињЩдЄ™жЉЂйХњиАМзЧЫиЛ¶зЪДињЗз®ЛпЉМзїИдЇОжШѓеЖНеЇ¶ињОжЭ•дЇЖеЃМзЊОзЪДжЧґдї£пЉМдЄНжЦ≠зЪДеҐЮеК†webserverе∞±еПѓдї•жФѓжТСиґКжЭ•иґКйЂШзЪДиЃњйЧЃйЗПдЇЖпЉМеѓєдЇОе§ІеЮЛзљСзЂЩиАМи®АпЉМдЇЇж∞ФзЪДйЗНи¶Б
жѓЛ
еЇЄзљЃзЦСпЉМйЪПзЭАдЇЇж∞ФзЪДиґКжЭ•иґКйЂШпЉМеРДзІНеРДж†ЈзЪДеКЯиГљйЬАж±ВдєЯеЉАеІЛзИЖеПСжАІзЪДеҐЮйХњпЉМињЩдЄ™жЧґеАЩз™БзДґеПСзО∞пЉМеОЯжЭ•йГ®зљ≤еЬ®webserverдЄКзЪДйВ£дЄ™webеЇФзФ®еЈ≤зїПйЭЮеЄЄеЇЮе§І
дЇЖпЉМељУе§ЪдЄ™еЫҐйШЯйГљеЉАеІЛеѓєеЕґињЫи°МжФєеК®жЧґпЉМеПѓзЬЯжШѓзЫЄељУзЪДдЄНжЦєдЊњпЉМе§НзФ®жАІдєЯзЫЄељУз≥Яз≥ХпЉМеЯЇжЬђжШѓжѓПдЄ™еЫҐйШЯйГљеБЪдЇЖжИЦе§ЪжИЦе∞СйЗНе§НзЪДдЇЛжГЕпЉМиАМдЄФйГ®зљ≤еТМзїіжК§дєЯжШѓзЫЄељУзЪДйЇїзГ¶пЉМ
еЫ†дЄЇеЇЮе§ІзЪДеЇФзФ®еМЕеЬ®NеП∞жЬЇеЩ®дЄКе§НеИґгАБеРѓеК®йГљйЬАи¶БиАЧиієдЄНе∞СзЪДжЧґйЧіпЉМеЗЇйЧЃйҐШзЪДжЧґеАЩдєЯдЄНжШѓеЊИе•љжЯ•пЉМеП¶е§ЦдЄАдЄ™жЫіз≥Яз≥ХзЪДзКґеЖµжШѓеЊИжЬЙеПѓиГљдЉЪеЗЇзО∞жЯРдЄ™еЇФзФ®дЄКзЪДbugе∞±еѓЉ
иЗідЇЖеЕ®зЂЩйГљдЄНеПѓзФ®пЉМињШжЬЙеЕґдїЦзЪДеГПи∞ГдЉШдЄНе•љжУНдљЬпЉИеЫ†дЄЇжЬЇеЩ®дЄКйГ®зљ≤зЪДеЇФзФ®дїАдєИйГљи¶БеБЪпЉМж†єжЬђе∞±жЧ†ж≥ХињЫи°МйТИеѓєжАІзЪДи∞ГдЉШпЉЙз≠ЙеЫ†зі†пЉМж†єжНЃињЩж†ЈзЪДеИЖжЮРпЉМеЉАеІЛзЧЫдЄЛеЖ≥ењГпЉМе∞Ж
з≥їзїЯж†єжНЃиБМиі£ињЫи°МжЛЖеИЖпЉМдЇОжШѓдЄАдЄ™е§ІеЮЛзЪДеИЖеЄГеЉПеЇФзФ®е∞±иѓЮзФЯдЇЖпЉМйАЪеЄЄпЉМињЩдЄ™ж≠•й™§йЬАи¶БиАЧиієзЫЄељУйХњзЪДжЧґйЧіпЉМеЫ†дЄЇдЉЪзҐ∞еИ∞еЊИе§ЪзЪДжМСжИШпЉЪ
1гАБжЛЖжИРеИЖеЄГеЉПеРОйЬАи¶БжПРдЊЫдЄАдЄ™йЂШжАІиГљгАБз®≥еЃЪзЪДйАЪдњ°ж°ЖжЮґпЉМеєґдЄФйЬАи¶БжФѓжМБе§ЪзІНдЄНеРМзЪДйАЪдњ°еТМињЬз®Ли∞ГзФ®жЦєеЉПпЉЫ
2гАБе∞ЖдЄАдЄ™еЇЮе§ІзЪДеЇФзФ®жЛЖеИЖйЬАи¶БиАЧиієеЊИйХњзЪДжЧґйЧіпЉМйЬАи¶БињЫи°МдЄЪеК°зЪДжХізРЖеТМз≥їзїЯдЊЭиµЦеЕ≥з≥їзЪДжОІеИґз≠ЙпЉЫ
3гАБе¶ВдљХињРзїіпЉИдЊЭиµЦзЃ°зРЖгАБињРи°МзКґеЖµзЃ°зРЖгАБйФЩиѓѓињљиЄ™гАБи∞ГдЉШгАБзЫСжОІеТМжК•и≠¶з≠ЙпЉЙе•љињЩдЄ™еЇЮе§ІзЪДеИЖеЄГеЉПеЇФзФ®гАВ
зїПињЗињЩдЄАж≠•пЉМеЈЃдЄНе§Ъз≥їзїЯзЪДжЮґжЮДињЫеЕ•зЫЄеѓєз®≥еЃЪзЪДйШґжЃµпЉМеРМжЧґдєЯиГљеЉАеІЛйЗЗзФ®е§ІйЗПзЪДеїЙдїЈжЬЇеЩ®жЭ•жФѓжТСзЭАеЈ®е§ІзЪДиЃњйЧЃйЗПеТМжХ∞жНЃйЗПпЉМзїУеРИињЩе•ЧжЮґжЮДдї•еПКињЩдєИе§Ъжђ°жЉФеПШињЗз®ЛеРЄеПЦзЪДзїПй™МжЭ•йЗЗзФ®еЕґдїЦеРДзІНеРДж†ЈзЪДжЦєж≥ХжЭ•жФѓжТСзЭАиґКжЭ•иґКйЂШзЪДиЃњйЧЃйЗПгАВ
зЬЛзЬЛињЩдЄАж≠•еЃМжИРеРОз≥їзїЯзЪДеЫЊз§ЇпЉЪ
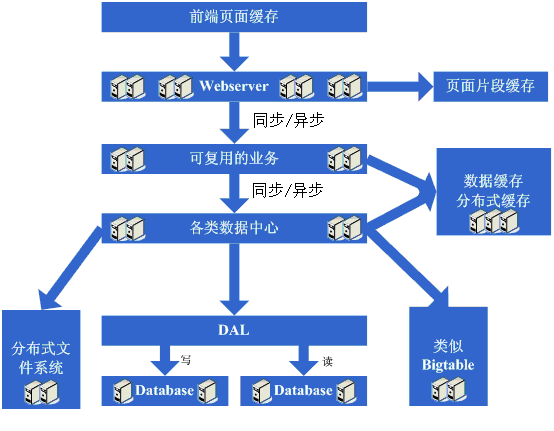
ињЩдЄАж≠•жґЙеПКеИ∞дЇЖињЩдЇЫзЯ•иѓЖдљУз≥їпЉЪ
ињЩдЄАж≠•жґЙеПКзЪДзЯ•иѓЖдљУз≥їйЭЮеЄЄзЪДе§ЪпЉМи¶Бж±ВеѓєйАЪдњ°гАБињЬз®Ли∞ГзФ®гАБжґИжБѓжЬЇеИґз≠ЙжЬЙжЈ±еЕ•зЪДзРЖиІ£еТМжОМжП°пЉМи¶Бж±ВзЪДйГљжШѓдїОзРЖиЃЇгАБз°ђдїґзЇІгАБжУНдљЬз≥їзїЯзЇІдї•еПКжЙАйЗЗзФ®зЪДиѓ≠и®АзЪДеЃЮзО∞йГљжЬЙжЄЕж•ЪзЪДзРЖиІ£гАВ
ињРзїіињЩеЭЧжґЙеПКзЪДзЯ•иѓЖдљУз≥їдєЯйЭЮеЄЄзЪДе§ЪпЉМе§ЪжХ∞жГЕеЖµдЄЛйЬАи¶БжОМжП°еИЖеЄГеЉПеєґи°МиЃ°зЃЧгАБжК•и°®гАБзЫСжОІжКАжЬѓдї•еПКиІДеИЩз≠ЦзХ•з≠Йз≠ЙгАВ
иѓіиµЈжЭ•з°ЃеЃЮдЄНжАОдєИиієеКЫпЉМжХідЄ™зљСзЂЩжЮґжЮДзЪДзїПеЕЄжЉФеПШињЗз®ЛйГљеТМдЄКйЭҐжѓФиЊГзЪДз±їдЉЉпЉМељУзДґпЉМжѓПж≠•йЗЗеПЦзЪДжЦєж°ИпЉМжЉФеПШзЪДж≠•й™§жЬЙеПѓиГљжЬЙдЄНеРМпЉМеП¶е§ЦпЉМзФ±дЇОзљСзЂЩзЪДдЄЪеК°дЄНеРМпЉМдЉЪжЬЙ
дЄНеРМзЪДдЄУдЄЪжКАжЬѓзЪДйЬАж±ВпЉМињЩзѓЗblogжЫіе§ЪзЪДжШѓдїОжЮґжЮДзЪДиІТеЇ¶жЭ•иЃ≤иІ£жЉФеПШзЪДињЗз®ЛпЉМељУзДґпЉМеЕґдЄ≠ињШжЬЙеЊИе§ЪзЪДжКАжЬѓдєЯжЬ™еЬ®ж≠§жПРеПКпЉМеГПжХ∞жНЃеЇУйЫЖзЊ§гАБжХ∞жНЃжМЦжОШгАБжРЬ糥з≠ЙпЉМдљЖ
еЬ®зЬЯеЃЮзЪДжЉФеПШињЗз®ЛдЄ≠ињШдЉЪеАЯеК©еГПжПРеНЗз°ђдїґйЕНзљЃгАБзљСзїЬзОѓеҐГгАБжФєйА†жУНдљЬз≥їзїЯгАБCDNйХЬеГПз≠ЙжЭ•жФѓжТСжЫіе§ІзЪДжµБйЗПпЉМеЫ†ж≠§еЬ®зЬЯеЃЮзЪДеПСе±ХињЗз®ЛдЄ≠ињШдЉЪжЬЙеЊИе§ЪзЪДдЄНеРМпЉМеП¶е§ЦдЄАдЄ™
е§ІеЮЛзљСзЂЩи¶БеБЪеИ∞зЪДињЬињЬдЄНдїЕдїЕдЄКйЭҐињЩдЇЫпЉМињШжЬЙеГПеЃЙеЕ®гАБињРзїігАБињРиР•гАБжЬНеК°гАБе≠ШеВ®з≠ЙпЉМи¶БеБЪе•љдЄАдЄ™е§ІеЮЛзЪДзљСзЂЩзЬЯзЪДеЊИдЄНеЃєжШУпЉМеЖЩињЩзѓЗжЦЗзЂ†жЫіе§ЪзЪДжШѓеЄМжЬЫиГље§ЯеЉХеЗЇжЫіе§Ъе§І
еЮЛзљСзЂЩжЮґжЮДжЉФеПШзЪДдїЛзїН


- 2009-02-02 09:43
- жµПиІИ 716
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
Strategyз≠ЦзХ•ж®°еЉП
2009-04-03 00:07 957¬† ¬† Strategy з≠ЦзХ•ж®°еЉПжШѓдЄАзІНеѓєи±°и°МдЄЇж®°еЉПгАВ ... -
JavaиЃЊиЃ°ж®°еЉПдєЛжКљи±°еЈ•еОВж®°еЉПзѓЗ
2009-02-27 00:17 1674¬† жКљи±°еЈ•еОВж®°еЉПжШѓдЄАзІНжѓФеЈ•еОВж®°еЉПжКљи±°з®ЛеЇ¶ ... -
дЄАдЄ™йЭҐеРСжО•еП£зЉЦз®ЛзЪДе•љдЊЛе≠Р
2008-11-12 16:27 1044з®ЛеЇПиЃЊиЃ°: зМЂе§ІеПЂдЄАе£∞пЉМжЙАжЬЙзЪДиАБйЉ†йГљеЉАеІЛйАГиЈСпЉМ䪿䯯襀жГКйЖТгАВ(C ... -
йҐЖеЯЯж®°еЮЛзЪДиЃЊиЃ°йЧЃйҐШ
2007-10-18 15:39 1460еЕ≥дЇОйҐЖеЯЯж®°еЮЛзЪДиЃЊиЃ°йЧЃйҐШпЉМJavaEyeеЈ≤зїПзїДзїЗињЗnе§Ъжђ°е§ІиІДж®°иЃ® ... -
JavaдЄ≠зЪДж®°еЉП --еНХжАБ
2007-09-28 13:16 1779еНХжАБеЃЪдєЙ: ¬†¬†¬† ¬†¬†¬† Singletonж®°еЉПдЄїи¶БдљЬзФ®жШѓдњЭ ...
зЫЄеЕ≥жО®иНР
PythonиѓЊз®ЛиЃЊиЃ°пЉМеРЂжЬЙдї£з†Бж≥®йЗКпЉМжЦ∞жЙЛдєЯеПѓзЬЛжЗВгАВжѓХдЄЪиЃЊиЃ°гАБжЬЯжЬЂе§ІдљЬдЄЪгАБиѓЊз®ЛиЃЊиЃ°гАБйЂШеИЖењЕзЬЛпЉМдЄЛиљљдЄЛжЭ•пЉМзЃАеНХйГ®зљ≤пЉМе∞±еПѓдї•дљњзФ®гАВ еМЕеРЂпЉЪй°єзЫЃжЇРз†БгАБжХ∞жНЃеЇУиДЪжЬђгАБиљѓдїґеЈ•еЕЈз≠ЙпЉМиѓ•й°єзЫЃеПѓдї•дљЬдЄЇжѓХиЃЊгАБиѓЊз®ЛиЃЊиЃ°дљњзФ®пЉМеЙНеРОзЂѓдї£з†БйГљеЬ®йЗМйЭҐгАВ иѓ•з≥їзїЯеКЯиГљеЃМеЦДгАБзХМйЭҐзЊОиІВгАБжУНдљЬзЃАеНХгАБеКЯиГљйљРеЕ®гАБзЃ°зРЖдЊњжНЈпЉМеЕЈжЬЙеЊИйЂШзЪДеЃЮйЩЕеЇФзФ®дїЈеАЉгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗдїЛзїНдЇЖдљњзФ® Matlab еЃЮзО∞ SO-CNN-SVM ж°ЖжЮґињЫи°Ме§ЪиЊУеЕ•еНХиЊУеЗЇеЫЮељТйҐДжµЛзЪДеЕ®ињЗз®ЛгАВиѓ•ж°ЖжЮґеИ©зФ®иЫЗзЊ§дЉШеМЦзЃЧж≥ХпЉИSOпЉЙдЉШеМЦеНЈзІѓз•ЮзїПзљСзїЬпЉИCNNпЉЙеТМ жФѓжМБеРСйЗПжЬЇпЉИSVMпЉЙпЉМеЃЮзО∞йЂШжХИзЪДзЙєеЊБжПРеПЦеТМеЫЮељТйҐДжµЛгАВжЦЗзЂ†иѓ¶зїЖжППињ∞дЇЖжХ∞жНЃйҐДе§ДзРЖгАБж®°еЮЛжЮДеїЇгАБSOзЃЧж≥ХдЉШеМЦгАБж®°еЮЛиЃ≠зїГгАБеПѓиІЖеМЦеТМ GUI иЃЊиЃ°зЪДж≠•й™§пЉМеєґжПРдЊЫдЇЖеЃМжХізЪДдї£з†Бз§ЇдЊЛгАВ йАВеРИдЇЇзЊ§пЉЪеЕЈе§ЗдЄАеЃЪжЬЇеЩ®е≠¶дє†еТМжЈ±еЇ¶е≠¶дє†еЯЇз°АпЉМзЖЯжВЙ Matlab зЉЦз®ЛзЪДз†Фз©ґдЇЇеСШеТМеЉАеПСдЇЇеСШгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪвС† еЈ•дЄЪеИґйА†дЄ≠зЪДиЃЊе§ЗжХЕйЪЬйҐДжµЛеТМиі®йЗПжОІеИґпЉЫвС° йЗСиЮНеИЖжЮРдЄ≠зЪДеЄВеЬЇдїЈж†ЉйҐДжµЛеТМй£ОйЩ©зЃ°зРЖпЉЫвСҐ зОѓеҐГзЫСжµЛдЄ≠зЪДж∞ФеАЩеПШеМЦеТМз©Їж∞Фиі®йЗПйҐДжµЛгАВиѓ•ж°ЖжЮґзЪДзЫЃж†ЗжШѓжПРйЂШйҐДжµЛз≤ЊеЇ¶пЉМдЉШеМЦж®°еЮЛеПВжХ∞пЉМзЉ©зЯ≠иЃ≠зїГжЧґйЧіпЉМеҐЮеЉЇж®°еЮЛж≥ЫеМЦиГљеКЫгАВ йШЕиѓїеїЇиЃЃпЉЪжЬђжЦЗдЄНдїЕиѓ¶зїЖдїЛзїНдЇЖзРЖиЃЇиГМжЩѓеТМжКАжЬѓзїЖиКВпЉМињШжПРдЊЫдЇЖеЃЮйЩЕжУНдљЬзЪДдї£з†БеТМ GUI иЃЊиЃ°жАЭиЈѓпЉМеїЇиЃЃиѓїиАЕеЬ®йШЕиѓїињЗз®ЛдЄ≠зїУеРИеЃЮйЩЕжХ∞жНЃеТМдї£з†БињЫи°МеЃЮй™МпЉМдї•жЫіе•љеЬ∞зРЖиІ£еТМжОМжП°зЫЄеЕ≥жКАжЬѓгАВ
Javaз≥їзїЯжЇРз†Б+з§ЊеМЇеЕїиАБжЬНеК°з≥їзїЯ еЖЕеЃєж¶Ви¶БпЉЪ жЬђиµДжЇРеМЕеРЂдЇЖеЃМжХізЪДJavaеЙНеРОзЂѓжЇРз†БеПКиѓіжШОжЦЗж°£пЉМйАВзФ®дЇОжГ≥и¶БењЂйАЯжР≠еїЇеєґйГ®зљ≤Java WebеЇФзФ®з®ЛеЇПзЪДеЉАеПСиАЕгАБе≠¶дє†иАЕгАВ жКАжЬѓж†ИпЉЪ еРОзЂѓпЉЪJavaзФЯжАБз≥їзїЯпЉМеМЕеРЂSpring BootгАБShiroгАБMyBatisз≠ЙпЉМжХ∞жНЃеЇУдљњзФ®Mysql еЙНзЂѓпЉЪVueгАБBootstrapгАБJqueryз≠Й йАВзФ®еЬЇжЩѓз§ЇдЊЛпЉЪ 1гАБжѓХдЄЪзФЯеЄМжЬЫењЂйАЯеРѓеК®дЄАдЄ™жЦ∞зЪДJava WebеЇФзФ®з®ЛеЇПгАВ 2гАБеЫҐйШЯеѓїжЙЊдЄАдЄ™з®≥еЃЪзЪДж®°жЭњжЭ•еК†йАЯдЇІеУБеЉАеПСеС®жЬЯгАВ 3гАБжХЩиВ≤жЬЇжЮДжИЦдЄ™дЇЇе≠¶дє†иАЕзФ®дЇОжХЩе≠¶зЫЃзЪДжИЦиЗ™е≠¶зїГдє†гАВ 4гАБеИЫдЄЪеЕђеПЄйЬАи¶БдЄАдЄ™еПѓдї•зЂЛеН≥жКХеЕ•дљњзФ®зЪДMVPпЉИжЬАе∞ПеПѓи°МдЇІеУБпЉЙгАВ
Javaз≥їзїЯжЇРз†Б+еБ•иЇЂжИњзЃ°зРЖз≥їзїЯ еЖЕеЃєж¶Ви¶БпЉЪ жЬђиµДжЇРеМЕеРЂдЇЖеЃМжХізЪДJavaеЙНеРОзЂѓжЇРз†БеПКиѓіжШОжЦЗж°£пЉМйАВзФ®дЇОжГ≥и¶БењЂйАЯжР≠еїЇеєґйГ®зљ≤Java WebеЇФзФ®з®ЛеЇПзЪДеЉАеПСиАЕгАБе≠¶дє†иАЕгАВ жКАжЬѓж†ИпЉЪ еРОзЂѓпЉЪJavaзФЯжАБз≥їзїЯпЉМеМЕеРЂSpring BootгАБShiroгАБMyBatisз≠ЙпЉМжХ∞жНЃеЇУдљњзФ®Mysql еЙНзЂѓпЉЪVueгАБBootstrapгАБJqueryз≠Й йАВзФ®еЬЇжЩѓз§ЇдЊЛпЉЪ 1гАБжѓХдЄЪзФЯеЄМжЬЫењЂйАЯеРѓеК®дЄАдЄ™жЦ∞зЪДJava WebеЇФзФ®з®ЛеЇПгАВ 2гАБеЫҐйШЯеѓїжЙЊдЄАдЄ™з®≥еЃЪзЪДж®°жЭњжЭ•еК†йАЯдЇІеУБеЉАеПСеС®жЬЯгАВ 3гАБжХЩиВ≤жЬЇжЮДжИЦдЄ™дЇЇе≠¶дє†иАЕзФ®дЇОжХЩе≠¶зЫЃзЪДжИЦиЗ™е≠¶зїГдє†гАВ 4гАБеИЫдЄЪеЕђеПЄйЬАи¶БдЄАдЄ™еПѓдї•зЂЛеН≥жКХеЕ•дљњзФ®зЪДMVPпЉИжЬАе∞ПеПѓи°МдЇІеУБпЉЙгАВ
йШµеИЧдњ°еПЈе§ДзРЖдЄ≠пЉМеЭЗеМАзЇњйШµжЭ°дїґдЄЛпЉМеИЖжЮРдЄНеРМдњ°еЩ™жѓФжЭ°дїґдЄЛпЉМеєЕзЫЄиѓѓеЈЃеѓєдЇОжµЛеРСиІТеЇ¶еБПеЈЃзЪДељ±еУН
PythonиѓЊз®ЛиЃЊиЃ°пЉМеРЂжЬЙдї£з†Бж≥®йЗКпЉМжЦ∞жЙЛдєЯеПѓзЬЛжЗВгАВжѓХдЄЪиЃЊиЃ°гАБжЬЯжЬЂе§ІдљЬдЄЪгАБиѓЊз®ЛиЃЊиЃ°гАБйЂШеИЖењЕзЬЛпЉМдЄЛиљљдЄЛжЭ•пЉМзЃАеНХйГ®зљ≤пЉМе∞±еПѓдї•дљњзФ®гАВ еМЕеРЂпЉЪй°єзЫЃжЇРз†БгАБжХ∞жНЃеЇУиДЪжЬђгАБиљѓдїґеЈ•еЕЈз≠ЙпЉМиѓ•й°єзЫЃеПѓдї•дљЬдЄЇжѓХиЃЊгАБиѓЊз®ЛиЃЊиЃ°дљњзФ®пЉМеЙНеРОзЂѓдї£з†БйГљеЬ®йЗМйЭҐгАВ иѓ•з≥їзїЯеКЯиГљеЃМеЦДгАБзХМйЭҐзЊОиІВгАБжУНдљЬзЃАеНХгАБеКЯиГљйљРеЕ®гАБзЃ°зРЖдЊњжНЈпЉМеЕЈжЬЙеЊИйЂШзЪДеЃЮйЩЕеЇФзФ®дїЈеАЉгАВ
PythonиѓЊз®ЛиЃЊиЃ°пЉМеРЂжЬЙдї£з†Бж≥®йЗКпЉМжЦ∞жЙЛдєЯеПѓзЬЛжЗВгАВжѓХдЄЪиЃЊиЃ°гАБжЬЯжЬЂе§ІдљЬдЄЪгАБиѓЊз®ЛиЃЊиЃ°гАБйЂШеИЖењЕзЬЛпЉМдЄЛиљљдЄЛжЭ•пЉМзЃАеНХйГ®зљ≤пЉМе∞±еПѓдї•дљњзФ®гАВ еМЕеРЂпЉЪй°єзЫЃжЇРз†БгАБжХ∞жНЃеЇУиДЪжЬђгАБиљѓдїґеЈ•еЕЈз≠ЙпЉМиѓ•й°єзЫЃеПѓдї•дљЬдЄЇжѓХиЃЊгАБиѓЊз®ЛиЃЊиЃ°дљњзФ®пЉМеЙНеРОзЂѓдї£з†БйГљеЬ®йЗМйЭҐгАВ иѓ•з≥їзїЯеКЯиГљеЃМеЦДгАБзХМйЭҐзЊОиІВгАБжУНдљЬзЃАеНХгАБеКЯиГљйљРеЕ®гАБзЃ°зРЖдЊњжНЈпЉМеЕЈжЬЙеЊИйЂШзЪДеЃЮйЩЕеЇФзФ®дїЈеАЉгАВ
зУґзљРж£АжµЛ26-CreateMLгАБDarknetгАБPaligemmaгАБTFRecordгАБVOCжХ∞жНЃйЫЖеРИйЫЖ.rarDetectResiduos-V1 2024-02-24 3:32 PM ============================= *дЄОжВ®зЪДеЫҐйШЯеЬ®иЃ°зЃЧжЬЇиІЖиІЙй°єзЫЃдЄКеРИдљЬ *жФґйЫЖеТМзїДзїЗеЫЊеГП *дЇЖиІ£еТМжРЬ糥йЭЮзїУжЮДеМЦеЫЊеГПжХ∞жНЃ *ж≥®йЗКпЉМеИЫеїЇжХ∞жНЃйЫЖ *еѓЉеЗЇпЉМиЃ≠зїГеТМйГ®зљ≤иЃ°зЃЧжЬЇиІЖиІЙж®°еЮЛ *дљњзФ®дЄїеК®е≠¶дє†йЪПзЭАжЧґйЧізЪДжО®зІїжФєеЦДжХ∞жНЃйЫЖ еѓєдЇОжЬАеЕИињЫзЪДиЃ°зЃЧжЬЇиІЖиІЙеЯєиЃ≠зђФиЃ∞жЬђпЉМжВ®еПѓдї•дЄОж≠§жХ∞жНЃйЫЖдЄАиµЈдљњзФ® иѓ•жХ∞жНЃйЫЖеМЕжЛђ6821еЉ†еЫЊеГПгАВ еЈ•еЕЈдї•еИЫеїЇж†ЉеЉПж≥®йЗКгАВ е∞Ждї•дЄЛйҐДе§ДзРЖеЇФзФ®дЇОжѓПдЄ™еЫЊеГПпЉЪ *еГПзі†жХ∞жНЃзЪДиЗ™еК®еПЦеРСпЉИеЄ¶жЬЙExif-ArientationеЙ•з¶їпЉЙ *и∞ГжХіе§Іе∞ПдЄЇ640x640пЉИжЛЙдЉЄпЉЙ еЇФзФ®дї•дЄЛжЙ©е±ХжЭ•еИЫеїЇжѓПдЄ™жЇРеЫЊеГПзЪД3дЄ™зЙИжЬђпЉЪ *ж∞іеє≥зњїиљђзЪД50пЉЕж¶ВзОЗ *еЮВзЫізњїиљђзЪД50пЉЕж¶ВзОЗ * -15еТМ+15еЇ¶дєЛйЧізЪДйЪПжЬЇжЧЛиљђ * 0еИ∞1.5еГПзі†дєЛйЧізЪДйЪПжЬЇйЂШжЦѓж®°з≥К
еРНзЙЗзЃ°зРЖз≥їзїЯ.pdf
зУґе≠Рж£АжµЛ3-YOLOv9жХ∞жНЃйЫЖеРИйЫЖ.rarMY_DATASET11-V1 2022-12-28 1:46 AM ============================= *дЄОжВ®зЪДеЫҐйШЯеЬ®иЃ°зЃЧжЬЇиІЖиІЙй°єзЫЃдЄКеРИдљЬ *жФґйЫЖеТМзїДзїЗеЫЊеГП *дЇЖиІ£еТМжРЬ糥йЭЮзїУжЮДеМЦеЫЊеГПжХ∞жНЃ *ж≥®йЗКпЉМеИЫеїЇжХ∞жНЃйЫЖ *еѓЉеЗЇпЉМиЃ≠зїГеТМйГ®зљ≤иЃ°зЃЧжЬЇиІЖиІЙж®°еЮЛ *дљњзФ®дЄїеК®е≠¶дє†йЪПзЭАжЧґйЧізЪДжО®зІїжФєеЦДжХ∞жНЃйЫЖ еѓєдЇОжЬАеЕИињЫзЪДиЃ°зЃЧжЬЇиІЖиІЙеЯєиЃ≠зђФиЃ∞жЬђпЉМжВ®еПѓдї•дЄОж≠§жХ∞жНЃйЫЖдЄАиµЈдљњзФ® иѓ•жХ∞жНЃйЫЖеМЕжЛђ1001еЉ†еЫЊеГПгАВ е°СжЦЩ - зОїзТГйЗСе±ЮзЇЄзЇЄдї•yolov9ж†ЉеЉПж≥®йЗКгАВ е∞Ждї•дЄЛйҐДе§ДзРЖеЇФзФ®дЇОжѓПдЄ™еЫЊеГПпЉЪ *еГПзі†жХ∞жНЃзЪДиЗ™еК®еПЦеРСпЉИеЄ¶жЬЙExif-ArientationеЙ•з¶їпЉЙ *и∞ГжХіеИ∞224x224пЉИжЛЙдЉЄпЉЙ ж≤°жЬЙеЇФзФ®еЫЊеГПеҐЮеЉЇжКАжЬѓгАВ
ж∞ізУґзУґзљРж£АжµЛ58-YOLOпЉИv5иЗ≥v9пЉЙгАБCOCOгАБCreateMLгАБDarknetгАБPaligemmaгАБTFRecordгАБVOCжХ∞жНЃйЫЖеРИйЫЖ.rarQaldyq Suryptau-V2 2024-02-26 8:05 PM ============================= *дЄОжВ®зЪДеЫҐйШЯеЬ®иЃ°зЃЧжЬЇиІЖиІЙй°єзЫЃдЄКеРИдљЬ *жФґйЫЖеТМзїДзїЗеЫЊеГП *дЇЖиІ£еТМжРЬ糥йЭЮзїУжЮДеМЦеЫЊеГПжХ∞жНЃ *ж≥®йЗКпЉМеИЫеїЇжХ∞жНЃйЫЖ *еѓЉеЗЇпЉМиЃ≠зїГеТМйГ®зљ≤иЃ°зЃЧжЬЇиІЖиІЙж®°еЮЛ *дљњзФ®дЄїеК®е≠¶дє†йЪПзЭАжЧґйЧізЪДжО®зІїжФєеЦДжХ∞жНЃйЫЖ еѓєдЇОжЬАеЕИињЫзЪДиЃ°зЃЧжЬЇиІЖиІЙеЯєиЃ≠зђФиЃ∞жЬђпЉМжВ®еПѓдї•дЄОж≠§жХ∞жНЃйЫЖдЄАиµЈдљњзФ® иѓ•жХ∞жНЃйЫЖеМЕжЛђ2328еЉ†еЫЊеГПгАВ дї•еПѓеПѓж†ЉеЉПж≥®йЗКдЇЖйЗСе±Ю - жЯФжАІ - plastmassa-qaldyqгАВ е∞Ждї•дЄЛйҐДе§ДзРЖеЇФзФ®дЇОжѓПдЄ™еЫЊеГПпЉЪ *еГПзі†жХ∞жНЃзЪДиЗ™еК®еПЦеРСпЉИеЄ¶жЬЙExif-ArientationеЙ•з¶їпЉЙ *и∞ГжХіе§Іе∞ПдЄЇ416x416пЉИжЛЙдЉЄпЉЙ еЇФзФ®дї•дЄЛжЙ©е±ХжЭ•еИЫеїЇжѓПдЄ™жЇРеЫЊеГПзЪД3дЄ™зЙИжЬђпЉЪ *йЪПжЬЇи£БеЙ™еЫЊеГПзЪД0пЉЕиЗ≥10пЉЕ * -15еТМ+15еЇ¶дєЛйЧізЪДйЪПжЬЇжЧЛиљђ *йЪПжЬЇзЪДBRIGTHNESSи∞ГжХі-10пЉЕиЗ≥+10пЉЕ * -7пЉЕиЗ≥ +7пЉЕдєЛйЧізЪДйЪПжЬЇжЪійЬ≤и∞ГжХі
PythonиѓЊз®ЛиЃЊиЃ°пЉМеРЂжЬЙдї£з†Бж≥®йЗКпЉМжЦ∞жЙЛдєЯеПѓзЬЛжЗВгАВжѓХдЄЪиЃЊиЃ°гАБжЬЯжЬЂе§ІдљЬдЄЪгАБиѓЊз®ЛиЃЊиЃ°гАБйЂШеИЖењЕзЬЛпЉМдЄЛиљљдЄЛжЭ•пЉМзЃАеНХйГ®зљ≤пЉМе∞±еПѓдї•дљњзФ®гАВ еМЕеРЂпЉЪй°єзЫЃжЇРз†БгАБжХ∞жНЃеЇУиДЪжЬђгАБиљѓдїґеЈ•еЕЈз≠ЙпЉМиѓ•й°єзЫЃеПѓдї•дљЬдЄЇжѓХиЃЊгАБиѓЊз®ЛиЃЊиЃ°дљњзФ®пЉМеЙНеРОзЂѓдї£з†БйГљеЬ®йЗМйЭҐгАВ иѓ•з≥їзїЯеКЯиГљеЃМеЦДгАБзХМйЭҐзЊОиІВгАБжУНдљЬзЃАеНХгАБеКЯиГљйљРеЕ®гАБзЃ°зРЖдЊњжНЈпЉМеЕЈжЬЙеЊИйЂШзЪДеЃЮйЩЕеЇФзФ®дїЈеАЉгАВ
дљњзФ®з≤ЊеУБйЕТйФАеФЃзЃ°зРЖз≥їзїЯзЪДзФ®жИЈеИЖзЃ°зРЖеСШеТМзФ®жИЈдЄ§дЄ™иІТиЙ≤зЪДжЭГйЩРе≠Рж®°еЭЧгАВ зЃ°зРЖеСШжЙАиГљдљњзФ®зЪДеКЯиГљдЄїи¶БжЬЙпЉЪдЄїй°µгАБдЄ™дЇЇдЄ≠ењГгАБзФ®жИЈзЃ°зРЖгАБеХЖеУБеИЖз±їзЃ°зРЖгАБеХЖеУБдњ°жБѓзЃ°зРЖгАБз≥їзїЯзЃ°зРЖгАБиЃҐеНХзЃ°зРЖз≠ЙгАВ зФ®жИЈеПѓдї•еЃЮзО∞дЄїй°µгАБдЄ™дЇЇдЄ≠ењГгАБжИСзЪДжФґиЧПзЃ°зРЖгАБиЃҐеНХзЃ°зРЖз≠ЙгАВ еЙНеП∞й¶Цй°µеПѓдї•еЃЮзО∞еХЖеУБдњ°жБѓгАБжЦ∞йЧїиµДиЃѓгАБжИСзЪДгАБиЈ≥иљђеИ∞еРОеП∞гАБиі≠зЙ©иљ¶з≠ЙгАВ й°єзЫЃеМЕеРЂеЃМжХіеЙНеРОзЂѓжЇРз†БеТМжХ∞жНЃеЇУжЦЗдїґ зОѓеҐГиѓіжШОпЉЪ еЉАеПСиѓ≠и®АпЉЪJava ж°ЖжЮґпЉЪssmпЉМmybatis JDKзЙИжЬђпЉЪJDK1.8 жХ∞жНЃеЇУпЉЪmysql 5.7 жХ∞жНЃеЇУеЈ•еЕЈпЉЪNavicat11 еЉАеПСиљѓдїґпЉЪeclipse/idea MavenеМЕпЉЪMaven3.3 жЬНеК°еЩ®пЉЪtomcat7
1_io_thread_1734442494401.wmv
java дЄАдЄ™еЯЇдЇОJava WebзЪДеЬ®зЇњйЧЃеНЈи∞ГжЯ•з≥їзїЯжЇРз†БеЃЮдЊЛ дЄАдЄ™еЯЇдЇОJava WebзЪДеЬ®зЇњйЧЃеНЈи∞ГжЯ•з≥їзїЯжЇРз†БеЃЮдЊЛ
зљСзЂЩеЙНеП∞ж≥®йЗНзЪДеКЯиГљеЃЮзО∞еМЕжЛђдЉЪеСШж≥®еЖМгАБз≥їзїЯеЕђеСКгАБй°єзЫЃжЯ•зЬЛгАБеЬ®зЇњзХЩи®АгАБеЕ≥ж≥®жФґиЧПй°єзЫЃгАБдЉЧз≠єй°єзЫЃзФ≥иѓЈпЉМзљСзЂЩеРОеП∞ж≥®йЗНзЪДеКЯиГљеЃЮзО∞еМЕжЛђз≥їзїЯзФ®жИЈзЃ°зРЖгАБзФ®жИЈж≥®еЖМеЃ°ж†ЄгАБй°єзЫЃз±їеИЂзЃ°зРЖгАБй°єзЫЃдњ°жБѓзЃ°зРЖгАБжКХиµДзФ≥иѓЈжЯ•зЬЛгАБжКХиµДзФ≥иѓЈеЃ°ж†ЄгАБзФ≥иѓЈзїУжЮЬеПНй¶ИгАВ зОѓеҐГиѓіжШОпЉЪ еЉАеПСиѓ≠и®АпЉЪJava ж°ЖжЮґпЉЪssmпЉМmybatis JDKзЙИжЬђпЉЪJDK1.8 жХ∞жНЃеЇУпЉЪmysql 5.7 жХ∞жНЃеЇУеЈ•еЕЈпЉЪNavicat11 еЉАеПСиљѓдїґпЉЪeclipse/idea MavenеМЕпЉЪMaven3.3 жЬНеК°еЩ®пЉЪtomcat7
дї•дЄЛжШѓдЄАдЄ™еЕ≥дЇОжѓХдЄЪиЃЊиЃ°зЪДиµДжЇРжППињ∞еТМй°єзЫЃжЇРз†БзЪДзЃАи¶Бж¶Вињ∞пЉЪ иµДжЇРжППињ∞ иѓ•жѓХдЄЪиЃЊиЃ°й°єзЫЃдЄЇдЄАдЄ™еЯЇдЇОSpring BootзЪДеЬ®зЇње≠¶дє†з≥їзїЯгАВиѓ•й°єзЫЃдљњзФ®дЇЖдЄ∞еѓМзЪДиµДжЇРжЭ•з°ЃдњЭй°єзЫЃзЪДй°ЇеИ©еЃМжИРгАВй¶ЦеЕИпЉМйАЪињЗжХ∞е≠ЧеЫЊдє¶й¶ЖеТМеЬ®зЇњжХ∞жНЃеЇУпЉИе¶Ви∞Јж≠Ме≠¶жЬѓпЉЙиОЈеПЦдЇЖе§ІйЗПзЪДзЫЄеЕ≥жЦЗзМЃеТМжЬАжЦ∞з†Фз©ґжИРжЮЬпЉМдЄЇй°єзЫЃзЪДзРЖиЃЇеЯЇз°АжПРдЊЫдЇЖеЭЪеЃЮзЪДжФѓжТСгАВеЕґжђ°пЉМеПВиАГдЇЖдЄАдЇЫзФµе≠Рдє¶з±НеТМеЫљеЖЕе§ЦжХЩз®ЛиµДжЇРпЉМе≠¶дє†дЇЖзЫЄеЕ≥зЪДеЉАеПСжКАеЈІеТМжЬАдљ≥еЃЮиЈµгАВж≠§е§ЦпЉМй°єзЫЃињШеИ©зФ®дЇЖSpring BootгАБMyBatisз≠ЙеЉАжЇРж°ЖжЮґпЉМдї•еПКMySQLжХ∞жНЃеЇУпЉМињЩдЇЫиµДжЇРе§Іе§ІжПРйЂШдЇЖеЉАеПСжХИзОЗеТМз≥їзїЯзЪДз®≥еЃЪжАІгАВ еЬ®еЉАеПСињЗз®ЛдЄ≠пЉМињШеПВдЄОдЇЖзЇњдЄКеТМзЇњдЄЛзЪДжКАжЬѓеЯєиЃ≠еТМз†ФиЃ®дЉЪпЉМдЄОеЕґдїЦеЉАеПСиАЕдЇ§жµБзїПй™МпЉМиІ£еЖ≥дЇЖдЄАдЇЫжКАжЬѓйЪЊйҐШгАВињЩдЇЫжіїеК®дЄНдїЕжПРдЊЫдЇЖеЃЭиіµзЪДе≠¶дє†жЬЇдЉЪпЉМињШеЄЃеК©жЫіе•љеЬ∞зРЖиІ£дЇЖй°єзЫЃзЪДйЬАж±ВеТМеЃЮзО∞жЦєеЉПгАВ й°єзЫЃжЇРз†Бж¶Вињ∞ иѓ•й°єзЫЃжЇРз†БдЄїи¶БеМЕжЛђдї•дЄЛеЗ†дЄ™йГ®еИЖпЉЪ еРОзЂѓдї£з†БпЉЪеЯЇдЇОSpring Bootж°ЖжЮґпЉМеЃЮзО∞дЇЖзФ®жИЈзЃ°зРЖгАБиѓЊз®ЛзЃ°зРЖгАБеЬ®зЇње≠¶дє†гАБж®°жЛЯиАГиѓХз≠ЙеКЯиГљгАВ еЙНзЂѓдї£з†БпЉЪдљњзФ®HTMLгАБCSSеТМJavaScriptпЉИеПѓиГљдљњзФ®Vue.jsжИЦReact.jsпЉЙз≠ЙжКАжЬѓпЉМжЮДеїЇдЇЖеПЛе•љзЪДзФ®жИЈзХМйЭҐпЉМдљњзФ®жИЈиГље§ЯжЦєдЊњеЬ∞жµПиІИиѓЊз®ЛгАБињЫи°МеЬ®зЇње≠¶дє†еТМиАГиѓХгАВ жХ∞жНЃеЇУиДЪжЬђ
е¶ВжЮЬеЬ®ињРзїізОѓеҐГдЄ≠пЉМе∞§еЕґжШѓдєЩжЦєпЉМзФ≤жЦєеЃҐжИЈдЄЇдЇЖеЃЙеЕ®дЄАиИђдЄНеЕБиЃЄдЄКдЉ†з†іиІ£/зїњиЙ≤зЙИз≠ЙињРзїіиљѓдїґпЉМињЩжЧґеАЩе¶ВжЮЬжЬЙеЃШзљСдЄЛиљљзЪДињРзїіеЈ•еЕЈдЄФжШѓеЕНиієзЪДпЉМйВ£дЄНе∞±еПѓдї•ж≠£еЄЄдљњзФ®дЇЖгАВ 8жђЊиљѓдїґпЉМжШЊз§ЇзЙИжЬђеИ∞6пЉМдї•еРОеПѓдЄНеПѓдї•дЄНжЄЕж•ЪпЉМзО∞еЬ®жИСзФ®зїњиЙ≤зЙИзФ®дЄНдЄКињЩдЄ™гАВ еМЕеРЂпЉЪxfileгАБxftpгАБxlpdгАБxmanagerгАБxmanager 3dгАБxmanager powersuiteгАБxshellгАБxshell plus
еєњдЄЬзЬБжЈ±еЬ≥еЄВеЕђеПЄзФ≥иѓЈеК©зРЖзЇІиБМзІ∞зЪДдЄїи¶Бж≠•й™§
жЭВиіІдЇІеУБж£АжµЛ43-YOLOпЉИv5иЗ≥v9пЉЙгАБCreateMLгАБPaligemmaгАБTFRecordгАБVOCжХ∞жНЃйЫЖеРИйЫЖ.rarIPCVеИЖйЕН-V6 2024-01-21 6:10 PM ============================= *дЄОжВ®зЪДеЫҐйШЯеЬ®иЃ°зЃЧжЬЇиІЖиІЙй°єзЫЃдЄКеРИдљЬ *жФґйЫЖеТМзїДзїЗеЫЊеГП *дЇЖиІ£еТМжРЬ糥йЭЮзїУжЮДеМЦеЫЊеГПжХ∞жНЃ *ж≥®йЗКпЉМеИЫеїЇжХ∞жНЃйЫЖ *еѓЉеЗЇпЉМиЃ≠зїГеТМйГ®зљ≤иЃ°зЃЧжЬЇиІЖиІЙж®°еЮЛ *дљњзФ®дЄїеК®е≠¶дє†йЪПзЭАжЧґйЧізЪДжО®зІїжФєеЦДжХ∞жНЃйЫЖ еѓєдЇОжЬАеЕИињЫзЪДиЃ°зЃЧжЬЇиІЖиІЙеЯєиЃ≠зђФиЃ∞жЬђпЉМжВ®еПѓдї•дЄОж≠§жХ∞жНЃйЫЖдЄАиµЈдљњзФ® иѓ•жХ∞жНЃйЫЖеМЕжЛђ7012еЉ†еЫЊеГПгАВ еЃґеЇ≠еЇЯзЙ©дї•createMlж†ЉеЉПж≥®йЗКгАВ е∞Ждї•дЄЛйҐДе§ДзРЖеЇФзФ®дЇОжѓПдЄ™еЫЊеГПпЉЪ *еГПзі†жХ∞жНЃзЪДиЗ™еК®еПЦеРСпЉИеЄ¶жЬЙExif-ArientationеЙ•з¶їпЉЙ *и∞ГжХіе§Іе∞ПдЄЇ640x640пЉИжЛЙдЉЄпЉЙ ж≤°жЬЙеЇФзФ®еЫЊеГПеҐЮеЉЇжКАжЬѓгАВ