
【友情提示】新的编写教程参考这里文章
http://2879835984.iteye.com/admin/blogs/2308297
摘要
上一篇博客跟大家详细介绍了如何写出《黄焖鸡米饭是怎么火起来的》这样的数据分析类的文章,相信很多人都对数据来源也就是如何爬取到黄焖鸡米饭商家信息很感兴趣。那么今天我就跟大家具体讲一讲怎么使用神箭手云爬虫写爬虫,以上篇博客的黄焖鸡米饭的代码为例。
首先我们先看一下这段从大众点评网上爬取黄焖鸡米饭商户信息的脚本代码:
// 大众点评上爬取所有"黄焖鸡米饭"的商户信息
var keywords = "黄焖鸡米饭";
var scanUrls = ["http://www.dianping.com/search/keyword/1/0_"+keywords];
//国内的城市id到2323,意味着种子url有2323个
//作为sample,这里改成1,只爬取上海的黄焖鸡米饭门店
//for (var i = 1; i <= 2323; i++) {
for (var i = 1; i <= 1; i++) {
scanUrls.push("http://www.dianping.com/search/keyword/"+i+"/0_"+keywords);
}
var configs = {
domains: ["dianping.com"],
scanUrls: scanUrls,
helperUrlRegexes: ["http://www.dianping.com/search/keyword/\\d+/0_.*"],
contentUrlRegexes: ["http://www.dianping.com/shop/\\d+/editmember"],
enableProxy: true,
interval: 5000,
fields: [
{
name: "shop_name",
selector: "//div[contains(@class,'shop-review-wrap')]/div/h3/a/text()"
},
{
name: "id",
selector: "//div[contains(@class,'shop-review-wrap')]/div/h3/a/@href"
},
{
name: "create_time",
selector: "//div[contains(@class,'block raw-block')]/ul/li[1]/span"
},
{
name: "region_name",
selector: "//div[@class='breadcrumb']/b[1]/a/span/text()",
required: true
},
{
name: "province_name",
selector: "//div[@class='breadcrumb']/b[1]/a/span/text()"
}
]
};
configs.onProcessHelperUrl = function(url, content) {
var urls = extractList(content, "//div[@class='tit']/a[not(contains(@class,'shop-branch'))]/@href");
for (var i = 0; i < urls.length; i++) {
addUrl(urls[i]+"/editmember");
}
var nextPage = extract(content,"//div[@class='page']/a[@class='next']/@href");
if (nextPage) {
addUrl(nextPage);
var result = /\d+$/.exec(nextPage);
if (result) {
var data = result[0];
var count = nextPage.length-data.length;
var lll = nextPage.substr(0, count)+(parseInt(data)+1);
addUrl(nextPage.substr(0, count)+(parseInt(data)+1));
addUrl(nextPage.substr(0, count)+(parseInt(data)+2));
}
}
return false;
}
configs.afterExtractField = function(fieldName, data) {
if (fieldName == "id") {
var result = /\d+$/.exec(data);
if (result) {
data = result[0];
}
}
else if (fieldName == "shop_name") {
if (data.indexOf("黄焖鸡米饭") == -1) {
skip();
}
}
else if (fieldName == "create_time") {
var result = /\d{2}-\d{2}-\d{2}$/.exec(data);
data = "20"+result[0];
}
else if (fieldName == "province_name" || fieldName == "region_name") {
var position = data.indexOf("县");
if (position != -1 && position < data.length -1) {
data = data.substr(0,position+1);
}
position = data.indexOf("市");
if (position != -1 && position < data.length -1) {
data = data.substr(0,position+1);
}
data = data.replace("餐厅","");
if (fieldName == "province_name") {
data = getProvinceNameByRegion(data);
}
}
return data;
}
start(configs);
可能不懂技术的童鞋表示看不懂,没关系,其实大部分都是一些基本的配置项(比如入口url啊,内容页url啊之类的,具体细节请参考上一篇博客)。现在我就跟大家具体讲一讲怎么在神箭手上运行这段爬虫代码:
1、打开浏览器,输入并打开:http://www.shenjianshou.cn/。
2、登录进入后台。
3、点击后台的“爬虫模板编写”->“新建爬虫模板”。首次进入的开发者需要先申请成为开发者,官方审核速度很快。

4、将代码拷贝到模板脚本里,点击“保存”。
5、点击左侧菜单栏里的“我的任务”->“创建爬虫任务”。
6、选择刚编写的模板后保存,跳转到任务页面后点击启动,等一段时间后爬取的结果就会显示在任务页面。
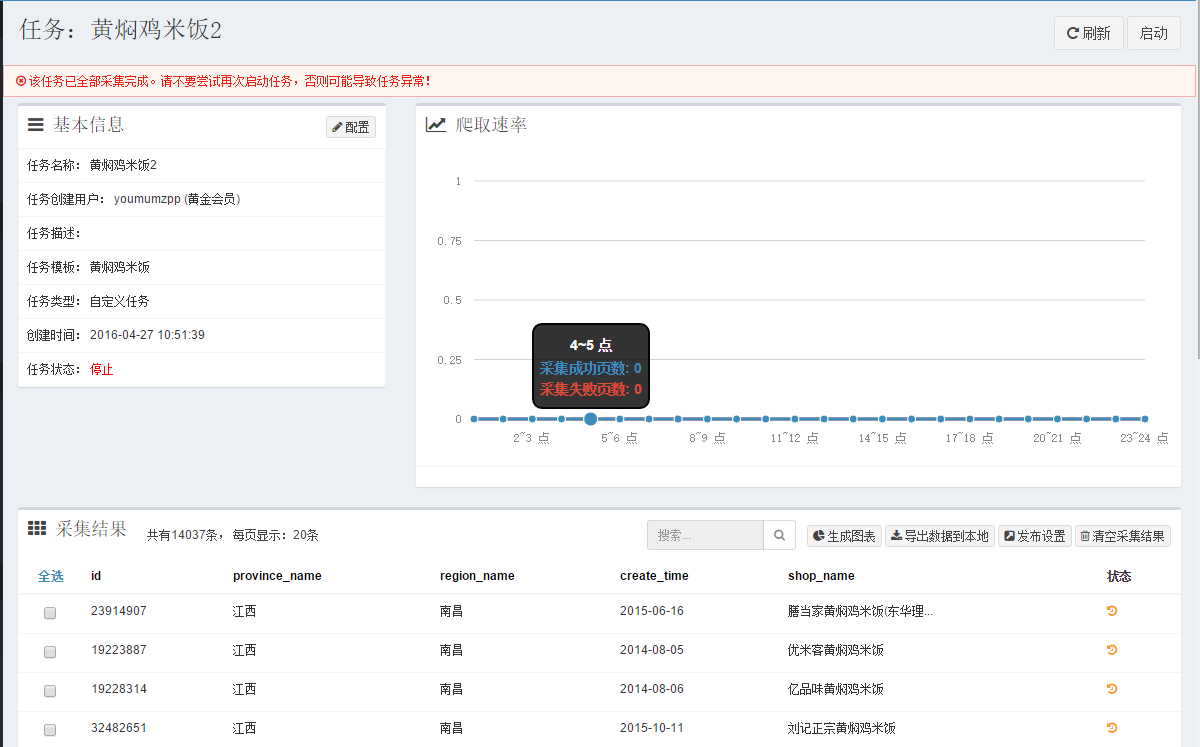
怎么样,很简单吧?想要爬取其他分类(比如大盘鸡啊重庆小面之类的)或者想要爬取其他网站也是没问题的,只需要更改一下爬虫代码就可以了。
具体开发 文档请参考:http://doc.shenjianshou.cn/
神箭手云爬虫开发平台官网链接:http://www.shenjianshou.cn/



相关推荐
神箭手云爬虫API文档是为开发者提供在神箭手云爬虫开发平台上使用JavaScript语言快速开发和配置网络爬虫的详细指南。文档中涵盖了API接口的详细介绍、配置说明以及如何抽取数据的示例代码,以便用户能够直接在平台上...
神箭手云采集Wordpress框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全...
神箭手云采集phpwind框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全在云端...
这里的“神箭手”可能是该插件的品牌或名称,暗示它在数据抓取方面具有高效和精准的特点。描述中再次强调了这是PHP语言编写的源码,这意味着开发者或有技术背景的用户可以查看和修改代码以适应他们的特定需求。 ...
神箭手云采集WeCenter框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全...
神箭手云采集phpwind框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全在云端...
神箭手云采集WeCenter框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全...
神箭手云采集Wordpress框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全...
神箭手云采集(官网地址:www.shenjianshou.cn)discuz框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据...
神箭手云采集Wordpress框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全...
神箭手云采集Discuz框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全在云端...
神箭手云采集(官网地址:www.shenjianshou.cn)Wecenter框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据...
爬取豌豆荚游戏排行榜游戏信息的爬虫程序源码,可以粘贴到神箭手云爬虫上直接跑。
而“神箭手云采集插件”可能是为Dedecms设计的一个功能,用于自动或定时从互联网上抓取、整理和发布数据,例如新闻、博客文章或其他类型的信息。 描述中的“源码学习,压缩包解压密码:www.cqlsoft.com”表明这个...
神箭手云采集插件则涉及到了Web数据抓取和处理。在Web爬虫开发中,通常会用到PHP的cURL库来模拟HTTP请求,获取网页内容;然后使用DOM解析库(如DOMDocument和DOMXPath)或者正则表达式解析HTML,提取所需数据。此外...
帝国CMS是一个广泛使用的开源内容管理系统,而神箭手云采集插件则是用于自动化数据抓取和处理的工具,它可以帮助用户从互联网上批量获取和导入所需信息。 【描述解析】 描述中的信息与标题相吻合,没有提供额外的...
神箭手云采集Wordpress框架插件,云端在线智能爬虫/采集器,基于分布式云计算平台,帮助需要从网页获取信息的客户快速轻松地获取大量规范化数据。操作简单,无需专业知识。降低数据获取成本,提高效率。任务完全...
【标题】"基于PHP的wind神箭手云采集插件源码.zip" 指的是一款使用PHP语言编写的云采集插件,该插件可能是为Wind系统设计的,用于高效地从互联网上抓取和处理数据。在互联网大数据时代,这样的工具对于数据分析、...
【标题】"基于PHP的wind 神箭手云采集插件.zip" 指的是一款使用PHP语言开发的插件,它与“wind 神箭手云采集”服务相结合,用于高效、自动化地从互联网上抓取数据。这款插件可能是为了帮助开发者或者网站管理员更...