- 浏览: 314217 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
-
zhou363667565:
看到你的这个配置 有个地方有点问题:
< aop:po ...
spring ibatis 事务配置 -
wo17796452:
[b][/b][i][/i][u][/u]引用[*][img] ...
crowd Jira confluence 集成 -
wo17796452:
<input type="button&quo ...
crowd Jira confluence 集成 -
benbear2008:
这些类图呢?
Spring MVC框架类图与顺序图 -
TTLtry:
谢了 最近学习spring时候 却总是登不上官方网站 很多 ...
Spring 2.5.5 api 帮助文档 chm格式 下载
2 MapReduce框架结构
Map/Reduce是一个用于大规模数据处理的分布式计算模型,它最初是由Google工程师设计并实现的,Google已经将它完整的MapReduce论文公开发布了。其中对它的定义是,Map/Reduce是一个编程模型(programming model),是一个用于处理和生成大规模数据集(processing and generating large data sets)的相关的实现。用户定义一个map函数来处理一个key/value对以生成一批中间的key/value对,再定义一个reduce函数将所有这些中间的有着相同key的values合并起来。很多现实世界中的任务都可用这个模型来表达。
Hadoop的Map/Reduce框架也是基于这个原理实现的,下面简要介绍一下Map/Reduce框架主要组成及相互的关系。
2.1 总体结构
2.1.1 Mapper和Reducer
运行于Hadoop的MapReduce应用程序最基本的组成部分包括一个Mapper和一个Reducer类,以及一个创建JobConf的执行程序,在一些应用中还可以包括一个Combiner类,它实际也是Reducer的实现。
2.1.2 JobTracker和TaskTracker
它们都是由一个master服务JobTracker和多个运行于多个节点的slaver服务TaskTracker两个类提供的服务调度的。master负责调度job的每一个子任务task运行于slave上,并监控它们,如果发现有失败的task就重新运行它,slave则负责直接执行每一个task。TaskTracker都需要运行在HDFS的DataNode上,而JobTracker则不需要,一般情况应该把JobTracker部署在单独的机器上。
2.1.3 JobClient
每一个job都会在用户端通过JobClient类将应用程序以及配置参数Configuration打包成jar文件存储在HDFS,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask)将它们分发到各个TaskTracker服务中去执行。
2.1.4 JobInProgress
JobClient提交job后,JobTracker会创建一个JobInProgress来跟踪和调度这个job,并把它添加到job队列里。JobInProgress会根据提交的job jar中定义的输入数据集(已分解成FileSplit)创建对应的一批TaskInProgress用于监控和调度MapTask,同时在创建指定数目的TaskInProgress用于监控和调度ReduceTask,缺省为1个ReduceTask。
2.1.5 TaskInProgress
JobTracker启动任务时通过每一个TaskInProgress来launchTask,这时会把Task对象(即MapTask和ReduceTask)序列化写入相应的TaskTracker服务中,TaskTracker收到后会创建对应的TaskInProgress(此TaskInProgress实现非JobTracker中使用的TaskInProgress,作用类似)用于监控和调度该Task。启动具体的Task进程是通过TaskInProgress管理的TaskRunner对象来运行的。TaskRunner会自动装载job jar,并设置好环境变量后启动一个独立的java child进程来执行Task,即MapTask或者ReduceTask,但它们不一定运行在同一个TaskTracker中。
2.1.6 MapTask和ReduceTask
一个完整的job会自动依次执行Mapper、Combiner(在JobConf指定了Combiner时执行)和Reducer,其中Mapper和Combiner是由MapTask调用执行,Reducer则由ReduceTask调用,Combiner实际也是Reducer接口类的实现。Mapper会根据job jar中定义的输入数据集按<key1,value1>对读入,处理完成生成临时的<key2,value2>对,如果定义了Combiner,MapTask会在Mapper完成调用该Combiner将相同key的值做合并处理,以减少输出结果集。MapTask的任务全完成即交给ReduceTask进程调用Reducer处理,生成最终结果<key3,value3>对。这个过程在下一部分再详细介绍。
下图描述了Map/Reduce框架中主要组成和它们之间的关系:
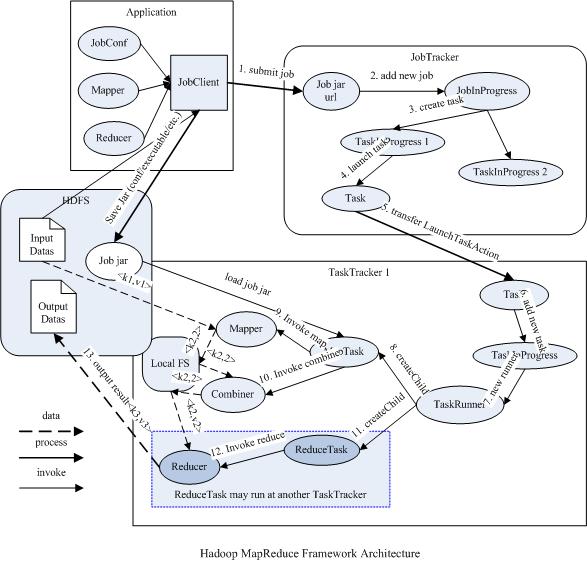
2.2 Job创建过程
2.2.1 JobClient.runJob() 开始运行job并分解输入数据集
一个MapReduce的Job会通过JobClient类根据用户在JobConf类中定义的InputFormat实现类来将输入的数据集分解成一批小的数据集,每一个小数据集会对应创建一个MapTask来处理。JobClient会使用缺省的FileInputFormat类调用FileInputFormat.getSplits()方法生成小数据集,如果判断数据文件是isSplitable()的话,会将大的文件分解成小的FileSplit,当然只是记录文件在HDFS里的路径及偏移量和Split大小。这些信息会统一打包到jobFile的jar中并存储在HDFS中,再将jobFile路径提交给JobTracker去调度和执行。
2.2.2 JobClient.submitJob() 提交job到JobTracker
jobFile的提交过程是通过RPC模块(有单独一章来详细介绍)来实现的。大致过程是,JobClient类中通过RPC实现的Proxy接口调用JobTracker的submitJob()方法,而JobTracker必须实现JobSubmissionProtocol接口。JobTracker则根据获得的jobFile路径创建与job有关的一系列对象(即JobInProgress和TaskInProgress等)来调度并执行job。
JobTracker创建job成功后会给JobClient传回一个JobStatus对象用于记录job的状态信息,如执行时间、Map和Reduce任务完成的比例等。JobClient会根据这个JobStatus对象创建一个NetworkedJob的RunningJob对象,用于定时从JobTracker获得执行过程的统计数据来监控并打印到用户的控制台。
与创建Job过程相关的类和方法如下图所示
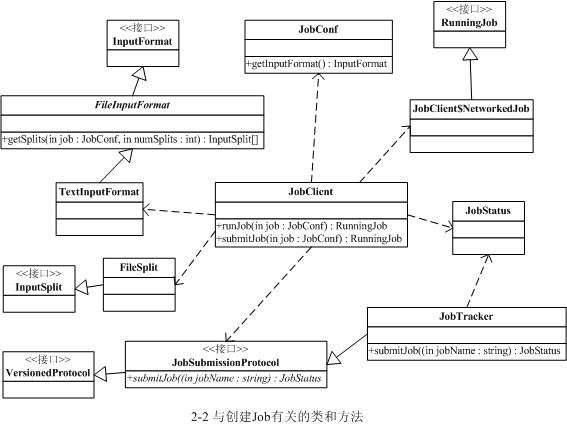
2.3 Job执行过程
上面已经提到,job是统一由JobTracker来调度的,具体的Task分发给各个TaskTracker节点来执行。下面通过源码来详细解析执行过程,首先先从JobTracker收到JobClient的提交请求开始。
2.3.1 JobTracker初始化Job和Task队列过程
2.3.1.1 JobTracker.submitJob() 收到请求
当JobTracker接收到新的job请求(即submitJob()函数被调用)后,会创建一个JobInProgress对象并通过它来管理和调度任务。JobInProgress在创建的时候会初始化一系列与任务有关的参数,如job jar的位置(会把它从HDFS复制本地的文件系统中的临时目录里),Map和Reduce的数据,job的优先级别,以及记录统计报告的对象等。
2.3.1.2 JobTracker.resortPriority() 加入队列并按优先级排序
JobInProgress创建后,首先将它加入到jobs队列里,分别用一个map成员变量jobs用来管理所有jobs对象,一个list成员变量jobsByPriority用来维护jobs的执行优先级别。之后JobTracker会调用resortPriority()函数,将jobs先按优先级别排序,再按提交时间排序,这样保证最高优先并且先提交的job会先执行。
2.3.1.3 JobTracker.JobInitThread 通知初始化线程
然后JobTracker会把此job加入到一个管理需要初始化的队列里,即一个list成员变量jobInitQueue里。通过此成员变量调用notifyAll()函数,会唤起一个用于初始化job的线程JobInitThread来处理(JobTracker会有几个内部的线程来维护jobs队列,它们的实现都在JobTracker代码里,稍候再详细介绍)。JobInitThread收到信号后即取出最靠前的job,即优先级别最高的job,调用JobInProgress的initTasks()函数执行真正的初始化工作。
2.3.1.4 JobInProgress.initTasks() 初始化TaskInProgress
Task的初始化过程稍复杂些,首先步骤JobInProgress会创建Map的监控对象。在initTasks()函数里通过调用JobClient的readSplitFile()获得已分解的输入数据的RawSplit列表,然后根据这个列表创建对应数目的Map执行管理对象TaskInProgress。在这个过程中,还会记录该RawSplit块对应的所有在HDFS里的blocks所在的DataNode节点的host,这个会在RawSplit创建时通过FileSplit的getLocations()函数获取,该函数会调用DistributedFileSystem的getFileCacheHints()获得(这个细节会在HDFS模块中讲解)。当然如果是存储在本地文件系统中,即使用LocalFileSystem时当然只有一个location即“localhost”了。
其次JobInProgress会创建Reduce的监控对象,这个比较简单,根据JobConf里指定的Reduce数目创建,缺省只创建1个Reduce任务。监控和调度Reduce任务的也是TaskInProgress类,不过构造方法有所不同,TaskInProgress会根据不同参数分别创建具体的MapTask或者ReduceTask。
JobInProgress创建完TaskInProgress后,最后构造JobStatus并记录job正在执行中,然后再调用JobHistory.JobInfo.logStarted()记录job的执行日志。到这里JobTracker里初始化job的过程全部结束,执行则是通过另一异步的方式处理的,下面接着介绍它。
与初始化Job过程相关的类和方法如下图所示
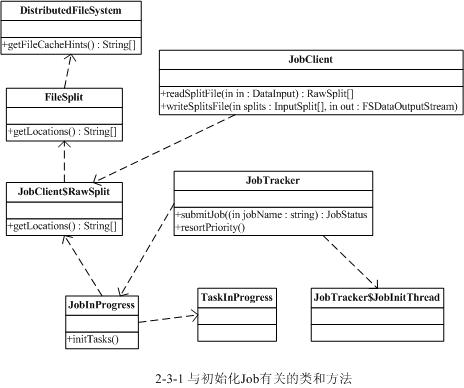
2.3.2 TaskTracker执行Task的过程
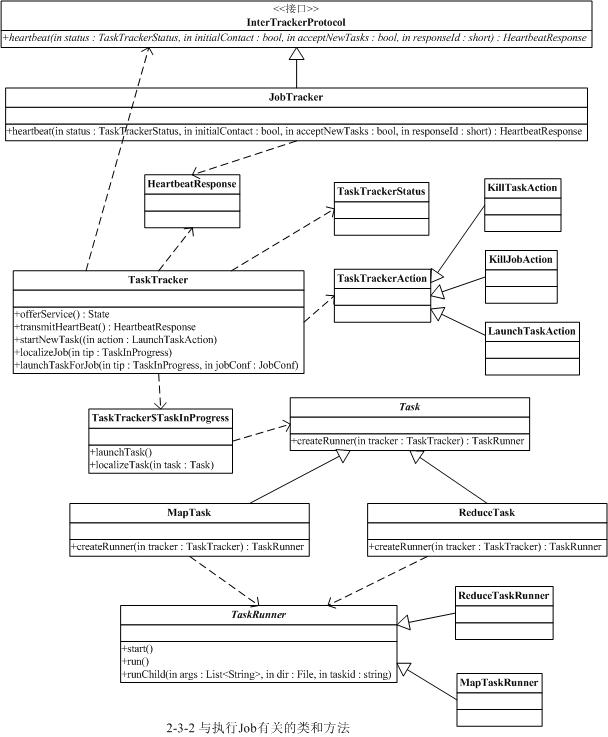
Task的执行实际是由TaskTracker发起的,TaskTracker会定期(缺省为10秒钟,参见MRConstants类中定义的HEARTBEAT_INTERVAL变量)与JobTracker进行一次通信,报告自己Task的执行状态,接收JobTracker的指令等。如果发现有自己需要执行的新任务也会在这时启动,即是在TaskTracker调用JobTracker的heartbeat()方法时进行,此调用底层是通过IPC层调用Proxy接口(在IPC章节详细介绍)实现。这个过程实际比较复杂,下面一一简单介绍下每个步骤。
2.3.2.1 TaskTracker.run() 连接JobTracker
TaskTracker的启动过程会初始化一系列参数和服务(另有单独的一节介绍),然后尝试连接JobTracker服务(即必须实现InterTrackerProtocol接口),如果连接断开,则会循环尝试连接JobTracker,并重新初始化所有成员和参数,此过程参见run()方法。
2.3.2.2 TaskTracker.offerService() 主循环
如果连接JobTracker服务成功,TaskTracker就会调用offerService()函数进入主执行循环中。这个循环会每隔10秒与JobTracker通讯一次,调用transmitHeartBeat()获得HeartbeatResponse信息。然后调用HeartbeatResponse的getActions()函数获得JobTracker传过来的所有指令即一个TaskTrackerAction数组。再遍历这个数组,如果是一个新任务指令即LaunchTaskAction则调用startNewTask()函数执行新任务,否则加入到tasksToCleanup队列,交给一个taskCleanupThread线程来处理,如执行KillJobAction或者KillTaskAction等。
2.3.2.3 TaskTracker.transmitHeartBeat() 获取JobTracker指令
在transmitHeartBeat()函数处理中,TaskTracker会创建一个新的TaskTrackerStatus对象记录目前任务的执行状况,然后通过IPC接口调用JobTracker的heartbeat()方法发送过去,并接受新的指令,即返回值TaskTrackerAction数组。在这个调用之前,TaskTracker会先检查目前执行的Task数目以及本地磁盘的空间使用情况等,如果可以接收新的Task则设置heartbeat()的askForNewTask参数为true。操作成功后再更新相关的统计信息等。
2.3.2.4 TaskTracker.startNewTask() 启动新任务
此函数的主要任务就是创建TaskTracker$TaskInProgress对象来调度和监控任务,并把它加入到runningTasks队列中。完成后则调用localizeJob()真正初始化Task并开始执行。
2.3.2.5 TaskTracker.localizeJob() 初始化job目录等
此函数主要任务是初始化工作目录workDir,再将job jar包从HDFS复制到本地文件系统中,调用RunJar.unJar()将包解压到工作目录。然后创建一个RunningJob并调用addTaskToJob()函数将它添加到runningJobs监控队列中。完成后即调用launchTaskForJob()开始执行Task。
2.3.2.6 TaskTracker.launchTaskForJob() 执行任务
启动Task的工作实际是调用TaskTracker$TaskInProgress的launchTask()函数来执行的。
2.3.2.7 TaskTracker$TaskInProgress.launchTask() 执行任务
执行任务前先调用localizeTask()更新一下jobConf文件并写入到本地目录中。然后通过调用Task的createRunner()方法创建TaskRunner对象并调用其start()方法最后启动Task独立的java执行子进程。
2.3.2.8 Task.createRunner() 创建启动Runner对象
Task有两个实现版本,即MapTask和ReduceTask,它们分别用于创建Map和Reduce任务。MapTask会创建MapTaskRunner来启动Task子进程,而ReduceTask则创建ReduceTaskRunner来启动。
2.3.2.9 TaskRunner.start() 启动子进程真正执行Task
这里是真正启动子进程并执行Task的地方。它会调用run()函数来处理。执行的过程比较复杂,主要的工作就是初始化启动java子进程的一系列环境变量,包括设定工作目录workDir,设置CLASSPATH环境变量等(需要将TaskTracker的环境变量以及job jar的路径合并起来)。然后装载job jar包,调用runChild()方法启动子进程,即通过ProcessBuilder来创建,同时子进程的stdout/stdin/syslog的输出定向到该Task指定的输出日志目录中,具体的输出通过TaskLog类来实现。这里有个小问题,Task子进程只能输出INFO级别日志,而且该级别是在run()函数中直接指定,不过改进也不复杂。
与Job执行过程相关的类和方法如下图所示
2.4 JobTracker和TaskTracker
如上面所述,JobTracker和TaskTracker是MapReduce框架最基本的两个服务,其他所有处理均由它们调度执行,下面简单介绍它们内部提供的服务及创建的线程,详细过程下回分解J
2.4.1 JobTracker的服务和线程
JobTracker是MapReduce框架中最主要的类之一,所有job的执行都由它来调度,而且Hadoop系统中只配置一个JobTracker应用。启动JobTracker后它会初始化若干个服务以及若干个内部线程用来维护job的执行过程和结果。下面简单介绍一下它们。
首先,JobTracker会启动一个interTrackerServer,端口配置在Configuration中的"mapred.job.tracker"参数,缺省是绑定8012端口。它有两个用途,一是用于接收和处理TaskTracker的heartbeat等请求,即必须实现InterTrackerProtocol接口及协议。二是用于接收和处理JobClient的请求,如submitJob,killJob等,即必须实现JobSubmissionProtocol接口及协议。
其次,它会启动一个infoServer,运行StatusHttpServer,缺省监听50030端口。是一个web服务,用于给用户提供web界面查询job执行状况的服务。
JobTracker还会启动多个线程,ExpireLaunchingTasks线程用于停止那些未在超时时间内报告进度的Tasks。ExpireTrackers线程用于停止那些可能已经当掉的TaskTracker,即长时间未报告的TaskTracker将不会再分配新的Task。RetireJobs线程用于清除那些已经完成很长时间还存在队列里的jobs。JobInitThread线程用于初始化job,这在前面章节已经介绍。TaskCommitQueue线程用于调度Task的那些所有与FileSystem操作相关的处理,并记录Task的状态等信息。
2.4.2 TaskTracker的服务和线程
TaskTracker也是MapReduce框架中最主要的类之一,它运行于每一台DataNode节点上,用于调度Task的实际运行工作。它内部也会启动一些服务和线程。
TaskTracker也会启动一个StatusHttpServer服务来提供web界面的查询Task执行状态的工具。
其次,它还会启动一个taskReportServer服务,这个用于提供给它的子进程即TaskRunner启动的MapTask或者ReduceTask向它报告状况,子进程的启动命令实现在TaskTracker$Child类中,由TaskRunner.run()通过命令行参数传入该服务地址和端口,即调用TaskTracker的getTaskTrackerReportAddress(),这个地址会在taskReportServer服务创建时获得。
TaskTracker也会启动一个MapEventsFetcherThread线程用于获取Map任务的输出数据信息。
2.5 Job状态监控
未完待


发表评论

-
git macos 配置
2011-10-04 12:33 1760git有4种协议方式建git服务器,分别是本地协议、SSH协议 ... -
Java加密技术(十)
2011-05-08 22:31 919在Java 加密技术(九)中,我们使用自签名证书完成了认证。接 ... -
Java加密技术(九)
2011-05-08 22:30 886在Java加密技术(八)中,我们模拟了一个基于RSA非对称加密 ... -
Java加密技术(八)
2011-05-08 22:28 888在构建Java代码实现前,我们需要完成证书的制作。 1.生成k ... -
Java加密技术(七)
2011-05-08 22:26 847ECC ECC-Elliptic Curves Cryptog ... -
Java加密技术(六)
2011-05-08 22:24 833接下来我们介绍DSA数字签名,非对称加密的另一种实现。 DSA ... -
Java加密技术(五)
2011-05-08 22:23 751接下来我们分析DH加 ... -
Java加密技术(四)
2011-05-08 22:21 797接下来我们介绍典型的� ... -
Java加密技术(三)
2011-05-08 22:19 990除了DES,我们还知道有DESede(TripleDES,就 ... -
Java加密技术(二)
2011-05-08 22:18 860接下来我们介绍对称加密算法,最常用的莫过于DES数据加密算法 ... -
Java加密技术(一)
2011-05-08 22:16 842加密解密,曾经是我一个毕业设计的重要组件。在工作了多年以后回想 ... -
java并发学习之五:读JSR133笔记(持续更新中)
2011-04-11 07:02 909在写线程池的时候,遇� ... -
java并发学习之四:JSR 133 (Java Memory Model) FAQ【译】
2011-04-11 07:01 882Jsr133地址:http://www ... -
java并发学习之三:非阻塞漫想,关于环岛与地铁
2011-04-11 07:00 876到过北京上地的都会知道,上地城铁往西走有一个很大的上地环岛,旁 ... -
java并发学之二
2011-04-11 06:59 915在看书的时候看到了一个观察死锁的工具TDA(Thread Du ... -
ava并发学习之二:线程池
2011-04-11 06:58 767第二步,是实现一个线程池 因为之前看书的时候留了个心眼,看线程 ... -
java并发学习之一:CountDownLatch
2011-04-11 06:57 732看了几个月的《Java Concurrency in Prac ... -
CAS
2011-04-03 20:08 1142需求描述1:大家知道J2EE应用程序都可以用类型以下形式进行保 ... -
定制TortoiseSVN安装包
2011-03-26 07:05 1116TortoiseSVN的MSI安装包是使用Windows ... -
编译TortoiseSVN源代码
2011-03-26 07:04 1262装编译器软件 A. 你需要 VS.NET2005 (或 ...
相关推荐
The Annotated Turing: A Guided Tour through Alan Turing's Historic Paper on Computability and the Turing Machine Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN ...
在人脸识别领域,数据库的建立是第一步。这些图像通常包含各种人脸的不同角度、表情、光照条件、遮挡情况等,以模拟真实世界中的复杂场景。"Annotated Database"提供的详细标注使开发者能够训练机器学习模型来识别和...
在MySQL中,“原始注解”通常指的是数据库设计者或开发者在SQL语句中添加的自定义注释,这些注释用于提供额外的信息,帮助理解和维护数据库结构或查询。 一、MySQL注释的使用 在MySQL中,有三种主要的注释方式: 1...
annotated_nginx Annotated Nginx Source(中文) 简介 Nginx源码分析,注解代码,帮助学习Nginx。 1.10增加了动态模块、http2、reuseport。 1.11.x里的stream模块的变动较大,完善了阶段处理。 1.14增加了mirror...
2. `bin`:可能包含用于处理或分析图像的二进制程序或工具。 3. `src`:可能包含源代码,这些代码可能用于读取、处理或分析数据库中的图像,或者与数据库相关的算法实现。 4. `example`:可能包含示例代码或脚本,...
这本书对于理解计算机科学的基本原理至关重要,尤其是对那些想要深入学习编程语言、编译器设计以及计算机体系结构的人来说。 书中的内容主要围绕以下几个关键知识点展开: 1. **图灵机模型**:图灵机是计算理论的...
python-2.5-annotated 记录阅读代码时的评注. bugfix: 修复svnversion产生的版本信息中包含空格导致无法编译的bug. commit 《Python源码剖析》附书代码: code-reading/pythonympx.rar code-reading/pythonympx.tar....
《Thinking in Java Annotated Solution Guide》是一本针对Bruce Eckel的畅销书《Thinking in Java》的解答指南,主要针对第四版的内容。这本书是Java编程学习者的宝贵资源,它提供了书中练习题的详尽解答,帮助读者...
2. **数据结构**:MATLAB中常用的数据结构,如矩阵、向量、结构数组或细胞数组,如何在RCPR算法中被利用,以及它们如何代表模型的各个方面。 3. **函数和命令**:在MATLAB代码中使用的特定函数和命令,如`fit`...
副标题:他的生平、思想及论文解读原作名: The Annotated Turing作者: Charles Petzold图灵机是英国数学家阿兰·麦席森·图灵提出的一种抽象计算模型,本书深入剖析了图灵这篇描述图灵机和可计算性的原始论文《论可...
《Thinking in C++ Annotated Solution Guide》是一本关于C++编程语言的重要参考资料,它提供了对Bruce Eckel的畅销书《Thinking in C++》的详细解答。这本书深入浅出地介绍了C++的基础概念、语法和高级特性,是学习...
《C# Annotated Standard》是C#编程领域的一本权威参考书籍,由C#语言的设计者之一撰写。这本书深入解析了C#语言的标准,通过详尽的注解和解释,帮助开发者更深入地理解C#的语法、特性以及设计理念。 在C#语言中,...
### 2. μC++ Translator(μC++ 翻译器) #### 2.1 扩展C++ 这部分讲解了μC++如何通过扩展标准C++来引入新的语言特性和语法糖,使程序员能够更自然地表达并发和实时需求。 #### 2.2 编译时结构 介绍了一个μ...
首先,文件标题《Thinking in Java 4th Edition Annotated Solutions Guide》指出了这是一本关于《Thinking in Java》第四版的附有注解的解决方案指南。《Thinking in Java》是由Bruce Eckel编写的Java编程书籍,...
The Annotated C++ Reference Manual 一共四个压缩包
"Thinking in Java 4th Edition + Annotated Solution Guide (代码)英文文字版 带书签 有答案" 指的是该资源包含了《Thinking in Java》第四版的英文文本,同时附带有注解的解决方案指南,这将有助于读者在遇到...
根据提供的文件信息,我们可以推断出此文档主要讨论的是《Annotated C++ Reference Manual》(简称ARM)第十五章的内容,特别关注于异常处理(Exception Handling)。以下是对该章节涉及的关键知识点进行的详细阐述...
redis-3.0-annotated-unstable.zipredis-3.0-annotated-unstable.zipredis-3.0-annotated-unstable.zipredis-3.0-annotated-unstable.zip
《Annotated Lucene 中文版 Lucene源码剖析》是一本深入探讨Apache Lucene的书籍,专注于源码解析,帮助读者理解这个强大的全文搜索引擎库的工作原理。Lucene是一款开源的Java库,它提供了高效的文本搜索功能,被...