
s
http://chengyue2007.iteye.com/blog/1852095
java中URL 的编码和解码函数
java.net.URLEncoder.encode(String s)和java.net.URLDecoder.decode(String s);
在javascript 中URL 的编码和解码函数
escape(String s)和unescape(String s) ;
在前台:
var url="test.jsp?param="+escape('this%is#te=st&o k?+/');
在后台:
String param=request.getParameter("param");
System.out.println(URLDecoder.decode(param,"UTF-8"));
character_code字符编码器.exe
http://dl.iteye.com/topics/download/d989e537-2f04-36e3-8e14-16f13b585c39
vi vim gvim 十进制转换成 十 六 进制
vi 命令 :%! 其实就是调用外部shell命令,需要注意的是xxd的字节序是big-endian的,不要搞错了。
如果你的Linux系统中找不到xxd命令,那么检查下是否有安装vim-common 包
[root@b2cbbstest ~]# rpm -qa | grep vim
vim-enhanced-6.3.046-0.40E.7
vim-X11-6.3.046-0.40E.7
vim-minimal-6.3.046-0.40E.7
vi 输入 :%!xxd 调用xxd来将 10进制 文件转换成16 进制
vi 再 输入 :%!xxd -r 文件模式 16 进制 转换文件模式10进制
xxd可以实现从16进制反向生成文件,只需要加上-r选现即可。
注意xxd接受的是big-endian格式的16进制值,
如果输入的是little-endian的,则生成的文件字符(包括换行符)是两两颠倒的。
Linux中如何将文件dump成16进制值
http://www.ningoo.net/html/2008/how_to_dump_file_to_hex_and_reverse.html
用Linux/Unix命令把十六进制转换成十进制
http://icelingr.blogbus.com/logs/50889108.html
1) 十六进制的数字转成十进制
[root@b2cbbstest ~]# echo $((0xac))
172
2) 十六进制和十进制互相转换
[root@b2cbbstest ~]# printf %d 0xac
172
[root@b2cbbstest ~]# printf %x 172
ac
3) bc 的作用:十六进制和十进制互转,十进制和二进制之间也可以转换。
// 把十六进制转换成十进制
[root@b2cbbstest ~]# echo 'ibase=16;obase=A; AC'|bc
172
[root@b2cbbstest ~]# echo 'ibase=16;obase=1010; AC'|bc (Linux)
0172
// Aix 机器 十六进制转换成十进制
# pwd
/home/wcs
# oslevel -r
6100-04
# echo 'ibase=16;obase=1010; AC'|bc
0172
注意这里:在 Unix 里面执行的时候会报这么个错误,但还是会有结果。
]$ echo 'ibase=16;AC' | bc
172
把十进制转换成十六进制
]$ echo 'ibase=10;obase=16;172'|bc
AC
]$ echo 'obase=16;172'|bc
AC
把十进制转换成二进制
]$ echo 'obase=2;172'|bc
10101100
把二进制转换成十进制
]$ echo 'ibase=2;10101100'|bc
172
貌似 ibase 和 obase 这两个参数的 default 值就是10(十进制),所以似乎如果不写的话,ibase 代表输入的参数是十进制,obase 代表输出的值是十进制。也就是说,不是十进制的时候才注明,似乎这样就不会错了。
RedHat Linux hexdump,od,xxd
http://hi.baidu.com/system_exp/blog/item/074c258e198117e4f11f3610.html
[root@b2cbbstest ~]# echo test.txt | xxd
0000000: 7465 7374 2e74 7874 0a test.txt.
[root@b2cbbstest ~]# echo test.txt | hexdump
0000000 6574 7473 742e 7478 000a
0000009
[root@b2cbbstest ~]# echo test.txt | od -x
0000000 6574 7473 742e 7478 000a
0000011
[root@b2cbbstest ~]# more test.txt
0
hexdump 和od 出来的结果都是按实际存储的字节序,因为基于x86的linux是little-endian 的,也就是高低字节是颠倒了的。但是xxd 的结果是将字节序调整过了的
ASCII码查询器 汉字反查
| 10进制 | 16进制 | 8进制 | 2进制 | |
| 唐 | 21776 | 5510 | 52420 | 101010100010000 |
| 修 | 20462 | 4FEE | 47756 | 100111111101110 |
| 进 | 36827 | 8FDB | 107733 | 1000111111011011 |
ASCII码由美国国家标准局制定的(美国标准信息交换码),它已被国际标准化组织(ISO)定为国际标准。
UTF-8 和 UTF-16 的 区别
http://bbs.51testing.com/viewthread.php?tid=200993
UTF-8, 8bit编码, ASCII不作变换, 其他字符做变长编码, 每个字符1-3 byte. 通常作为外码. 有以下优点:
* 与CPU字节顺序无关, 可以在不同平台之间交流
* 容错能力高, 任何一个字节损坏后, 最多只会导致一个编码码位损失, 不会链锁错误(如GB码错一个字节就会整行乱码)
UTF-16, 16bit编码, 是变长码, 大致相当于20位编码, 值在0到0x10FFFF之间, 基本上就是unicode编码的实现. 它是变长码, 与CPU字序有关, 但因为最省空间, 常作为网络传输的外码.
JAVA字符编码系列一:Unicode,GBK,GB2312,UTF-8概念基础
http://blog.csdn.net/qinysong/article/details/1179480
二进制转换表 [XML] ASCII 2007年08月25日 05:35

package com.javaeye.lindows.test;
public class TestAscii {
//ascii码值转换成字符串
static int y = 97;
static char x = (char) y;
//字符串转换成ascii码值
static char b = 'a';
static int a = (int)b;
public static void main(String[] args) {
System.out.println(x);
System.out.println(a);
}
}
http://stephen830.iteye.com/blog/258929
http://www.netfetch.cn/netfetch/article.asp?id=676
Utf-8编码在国外应用普遍,为什么在国内应用却不多呢?
尤其各大门户网站采用Utf-8的几乎没有。
是否采用Utf-8,这个问题大家争论已久,但是很少有人系统地解说为什么要采用Utf-8编码?
凡事皆有正反!采用Utf-8编码同样有其利弊,当利大于弊,我们当然就采用Utf-8?
关于UTF-8编码和中文字符集
中文有三种字符集,统一文字的编码将是进一步交流的基础。
·国内网站和BLOG较多使用简体中文编码GB2312 字符集;
·港澳台地区网站和部落格使用繁体中文网页编码BIG5字符集;
·UTF-8 包含了简体和繁体中文字符,能正确显示多种语言文字.
统一编码带来的交流便利将在trackback等功能上体现出。
计算机对多国语言的支持
通常在文档只需支持一种语言的情况下,编码只需收录该语言内的字元。最常见的就是拉丁字母用ASCII、简体中文用GB2312、繁体中文用BIG5等。
在越来越国际化的环境下,多语言支持对于软件开发已不再是个可有可无的而是必须的功能。UTF-8就提供了可在同文档同时支持多语言。例如,
汉字:简体字,繁體字
韩文:한국어
阿拉伯文:العربيه
目前很多软件对UTF-8的支持都不太好、开发工具对UTF-8的支持也不全、程序员对UTF-8的了解不深,所以用UTF-8时会碰见许多问题。但我们坚信UTF8是对于多语言支持的趋势也是基础。
Unicode 问答集
问:什么是Unicode?
答:Unicode 给每个字符提供了一个唯一的数字,不论是什么平台,不论是什么程序,不论什么语言。Unicode标准已经被这些工业界的领导们所采用,例 如:Apple, HP, IBM, JustSystem, Microsoft, oracle, SAP, Sun, Sybase, Unisys和其它许多公司。最新的标准都需要Unicode,例如XML, Java, ECMAScript (JavaScript), LDAP, CORBA 3.0, WML等等,并且,Unicode是实现ISO/IEC 10646的正规方式。许多操作系统,所有最新的浏览器和许多其他产品都支持它。Unicode标准的出现和支持它工具的存在,是近来全球软件技术最重要 的发展趋势。
问:为什么使用Unicode?
答:基本上,计算机只是处理数字。它们指定一个数字,来储存字母或其他字符。在创造Unicode之前,有数百种指定这些数字的编码系统。没有一 个编码可以包含足够的字符:例如,单单欧州共同体就需要好几种不同的编码来包括所有的语言。即使是单一种语言,例如英语,也没有哪一个编码可以适用于所有 的字母,标点符号,和常用的技术符号。这些编码系统也会互相冲突。也就是说,两种编码可能使用相同的数字代表两个不同的字符,或使用不同的数字代表相同的 字符。任何一台特定的计算机(特别是服务器)都需要支持许多不同的编码,但是,不论什么时候数据通过不同的编码或平台之间,那些数据总会有损坏的危险。
问:举个例子吧。
答:比如,简体中文(GB)、繁体中文(BIG5)、日文中,“赵”都是一个字,但是编码不同。在不同的编码下,BIG5的赵是0xBBAF,而 0xBBAF在GB里面就被显示为“化”,这就是乱码。而Unicode采用统一的编码,“赵”只有一个,不必管他在哪种文字里。
问:Unicode的优点是什么?
答:举一个最明显的例子就是Windows 2000/XP以及微软Office2000及其后的产品。因为这些软件都是Unicode内核,因此,无论何种文字,都可以在上面正常显示,而且是同屏 显示。以前,简体中文的Word文件拿到英文版打开就会是乱码,简体中文的程序在Windows英文版上运行会出现乱码,而现在一切都解决了。
问:中国京剧戏考为什么使用Unicode?
答:因为有些剧本中的生僻字,只在扩展字库或繁体字库中才有,有的甚至没有。而Unicode不仅包含了所有常用字和大部分生僻字,而且因为其可 扩展,在现在没有的情况下,将来也是可以扩充的。例如最新的Unicode 4.0标准,较3.0增加了很多生僻字。目前有70207个汉字。再有一点就是Unicode在将来会取代现有的GBK及BIG5。
什么是 UCS 和 ISO 10646?
国际标准 ISO 10646 定义了 通用字符集 (Universal Character Set, UCS). UCS 是所有其他字符集标准的一个超集. 它保证与其他字符集是双向兼容的. 就是说, 如果你将任何文本字符串翻译到 UCS格式, 然后再翻译回原编码, 你不会丢失任何信息.
在 Unix 下使用 UCS-2 (或 UCS-4) 会导致非常严重的问题. 用这些编码的字符串会包含一些特殊的字符, 比如 '' 或 '/', 它们在 文件名和其他 C 库函数参数里都有特别的含义. 另外, 大多数使用 ASCII 文件的 UNIX 下的工具, 如果不进行重大修改是无法读取 16 位的字符的. 基于这些原因, 在文件名, 文本文件, 环境变量等地方, UCS-2 不适合作为 Unicode 的外部编码.
UCS只是规定如何编码,并没有规定如何传输、保存这个编码。例如“汉”字的UCS编码是6C49,我可以用4个ascii数字来传输、保存这个编码;也可以用utf-8编码:3个连续的字节E6 B1 89来表示它。
UTF-8就是以8位为单元对UCS进行编码。从UCS-2到UTF-8的编码方式如下:
UCS-2编码(16进制) UTF-8 字节流(二进制)
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
UTF-16
UTF-16是Unicode的其中一个使用方式。 UTF是 Unicode Translation Format,即把Unicode转做某种格式的意思。
它定义于ISO/IEC 10646-1的附录Q,而RFC2781也定义了相似的做法。
在Unicode基本多文种平面定义的字符(无论是拉丁字母、汉字或其他文字或符号),一律使用2字节储存。而在辅助平面定义的字符,会以代理对(surrogate pair)的形式,以两个2字节的值来储存。
UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节 (2字节) 储存,但UTF-16却无法兼容于ASCII编码。
多语言编码
多语言编码的优点是可以在一个页面里同时显示多种语言。像这样,“アメリカ”、“검색센터”、“กองทัพอากาศ”。但是本地编码的方式通常只能显示一种语言的文字,其他语言的文字就乱码了。
为什么在一个页面里会要多种文字呢?举个例子,blog经常引用别人的网站吧,那么我现在引用了这个“http://www.콘테이너시공테 크.com”,还有这个名称比较有趣的“http://www.♣.com”。这就需要多语言的编码了。(这些网站在支持punycode的浏览器里,如 mozilla, firefox,是可以直接访问的)
再举个例子,我有一个webmail,界面是中文的,编码是GBK。朋友给我发邮件,中文的、英文的都没有问题,正常显示。可我还有朋友是以色列 的,用的是希伯来语给我发的邮件。完蛋,邮件内容都是乱码了。我得手工选择浏览器的编码才能看明白邮件的内容。遗憾的是,这时界面的“回复”按钮又成了乱 码,搞得我看不出哪个按钮是回复了。如果webmail是多语言的编码,比如UTF-8,就不会有这样了。
UTF-8对中文为主的网站有个缺点是,页面变长了。不是内容显示变长了,而是文件的size变长了。UTF-8对一个中文字符的编码通常是3个byte,而GB2312是2个byte。
使用UTF-8的原因
由于要使文字档案之中的文字与ASCII兼容,故此 UTF-8 选择了使用可变长度字节来储存 Unicode ,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。
对 UTF-8 的批评
UTF-8 使用可变长度字节储存,使电脑程序设计变得复杂。 (故此,在电脑程序或操作系统内部,多采用UCS-2编码。)
在旧式的中文、日文及韩文编码之中,每字符都使用2字节储存,而UTF-8须使用3字节。 (采用UTF-16编码则可只使用2字节储存。)
泰语以往使用的ISO 8859-11,每字符只使用1字节储存,而UTF-8须使用3字节。
此外,在Windows XP版本中的记事本程序如果保存的是编码类似于UTF-8的GB2312字符,保存重新打开后将错误显示。例如:使用记事本输入“联通”两个字或“毛”字 保存后再打开显示错误,如果不全是编码类似于UTF-8的GB2312字符则不会出现这种情况。
下边列出一些Utf-8相关讨论:
xdanger说:”地区编码gb2312的好处就是对于搜索引擎比较友好,特别是baidu的网页快照都是gb2312的,Google搜utf-8的效果也不如gb2312。”
我们盲目的向utf-8靠齐是不明智的,因为使用utf-8 用英文的老外没有增加成本,但是我们为了所谓的兼容却要增加成本。
因为如果是全英文的话,数据库根本不会增加,什么意思呢,就是说如果英文站点换成utf8,只是编码方式变了一下,其他的基本上一点影响都没有, 但是带来的好处是鲜见的。其他文字已经在utf-8编码里面了,所以可以任意使用。(例如在英文站点上如果用utf-8,汉字就可以使用了,但是使用3个 字节编码,但是汉字毕竟是少数!所以他们不是很在乎。)
但是如果在国内,情况就不同了,大部分都是汉字,用GB2312(国家标准GB18030-2000)编码,两个字节编码,如果换成utf-8 后,就变成了3个字节,数据明显增大,有人会说utf-8解决了兼容问题,你试想一下,来中文站点的有几个是使用英文以外语言的!!如果他用英文,恭喜 你,只要你装上了GB编码,你就可以自由的使用了,因为GB中是有英文字体的!如果你担心他看不懂中文,那你用utf-8编码的中文他也是看不懂的!
数字图书馆,也就是图书数字化,推荐使用iso 10646 (4byte编码)
特别需要注意的是,ISO 10646 / Unicode也有多种变换形式,UTF-8和UTF-16。新近又增加了UTF-32。从数字化的发展来看,最好直接使用UCS-2而不要涉及这些变换 形式,以免造成今后转换的负担。UTF-8看来已经落后;而UTF-16(Surrogate)还不够成熟。UTF-32正处在发展当中。
utf-8是一种歧视性的编码,采用gb2312一个汉字只需要两个字节,而utf-8要三个字节,平白无故的就要多出一个字节来,你想想这样中文文档的存储,网络传输平白又要多出多少浪费来。老外自己都承认了:
Let’s address the problem first: UTF-8 is kind of racist. It allows us
round-eye paleface anglophone types to tuck our characters neatly into one byte, lets most people whose languages are headquartered west of the Indus river get away with two bytes per, and penalizes India and points east by requiring them to use three bytes per character.
就算要统一编码,作为中国人那也只能支持utf-16,而不是utf-8
当世界需要沟通时,请用Unicode!
Unicode官方:
http://www.unicode.org/iuc/iuc10/x-utf8.html
http://www.unicode.org/iuc/iuc10/
|
Java中字符串与ASCII相互转换
JavaScript 汉字转换成ASCII码
文件:alert.js 内容: alert("这里输入文字后,按下'Ctrl+Shift+F'即可转换成ASCII码"); Properties ASCII码转换成汉字 文件:test.properties 内容: "\u8BF7\u8F93\u5165Subscirber" 用MyEclipse Properties Editor(UTF-8编码属性)即可转换,ok... ---------------------------------------------------------------------------------------------- 目前计算机 中用得最广泛的字符集及其编码,是由美国 国家标准 局(ANSI)制定的ASCII码(American Standard Code for Information Interchange,美国标准信息 交换码),它已被国际标准化组织(ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母,ASCII码有7位码和8位码两种形式。 因为1位二进制数可以表示(21 =)2种状态:0、1;而2位二进制数可以表示(22)=4种状态:00 、01、10、11;依次类推,7位二进制数可以表示(27=)128种状态,每种状态都唯一地编为一个7位的二进制码,对应一个字符(或控制码),这些码可以排列成一个十进制序号0~127。所以,7位ASCII码是用七位二进制数进行编码的,可以表示128个字符。 第0~32号及第127号(共34个)是控制字符或通讯专用字符,如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BEL(振铃)等;通讯专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等; 第33~126号(共94个)是字符,其中第48~57号为0~9十个阿拉伯数字;65~90号为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。 注意:在计算机的存储单元中,一个ASCII码值占一个字节(8个二进制位),其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。 为了便于查询,以下列出ASCII码表: 第128~255号为扩展字符(不常用) 在 Web开发时,如下的ASCII码只要加上&#和;就可以变成Web可以辨认的字符了在处理特殊字符的时候特别有用,如:' 单引号在数据库查询的时候是杀手,但是如果转换成'(注意: 转换后的机构 有:&# + 字符的ASCII码值+ ; 三个部分组成)再来存数据库,就没有什么影响了。其他的字符与ASCII码的对照如下表 参考http://hi.baidu.com/lifechipping/blog/item/f2e8b30e7e88f2e637d12259.html |
java native2ascii 基本用法
http://quan-zhao.iteye.com/blog/48097
C:>native2ascii -encoding utf8 ApplicationMessages.properties ApplicationMessages_zh_CN.properties
native2ascii详解
http://www.coderarea.net/html/bianchengyuyan/JAVA/J2SE/2009/0316/81346.html
使用native2ascii来帮助转码
http://www.iteye.com/topic/317286
native2ascii.exe 是 Java 的一个文件转码工具,是将特殊各异的内容 转为 用指定的编码标准文体形式统一的表现出来,它通常位于 JDK_home\bin 目录下,安装好 Java SE 后,可在命令行直接使用 native2ascii 命令进行转码,示例: native2ascii -encoding 8859_1 c:\test.txt c:\temp.txt 将 test.txt 文件内容用 8859_1 转码,另存为 temp.txt 文件 格式:native2ascii -[options] [inputfile [outputfile]] 参数选项 options -reverse:将 Latin-1 或 Unicode 编码转为本地编码 -encoding encoding_name:指定转换时使用的编码 inputfile:要转换的文件 outputfile:转换后的文件 互转(-encoding,非英文内容(如中文)转为编码符 或 编码符之间的转换), 逆转(-reverse,通常是将编码符转为非英文内容,或非英文内容之间的转换), 逆转时被转的文件编码和本地编码需一致,示例: 中文转为 ISO 8859_1 编码后,将 8859_1 码转为中文: native2ascii -encoding 8859_1 c:\a.txt c:\b.txt,将 a 用 8859_1 转码,存为 b (8859_1 码) native2ascii -encoding GBK c:\b.txt c:\c.txt,将 b 用 GBK 转码,存为 c (GBK 码) native2ascii -reverse c:\c.txt c:\d.txt,将 GBK 编码 c 用本地编码转码,存为 d (中文内容) 中文转为 GBK 编码后,将 GBK 码转为中文: native2ascii -encoding GBK c:\a.txt c:\b.txt,将 a 用 GBK 转码,存为 b (GBK 码) native2ascii -reverse c:\b.txt c:\c.txt,将 GBK 编码 b 用本地编码转码,存为 c (中文内容) 例如struts和struts2中的国际化utf-8的转换方式: native2ascii -encoding UTF-8 ApplicationResources_zh_src.properties ApplicationResources_zh.properties
native2ascii unicode 转码成中文
C:\Program Files\Java\jdk1.6.0_25\bin>more a.txt
\u9F50\u9F50\u54C8\u5C14\u914D\u9001\u4E2D\u5FC3
C:\Program Files\Java\jdk1.6.0_25\bin>native2ascii -reverse a.txt b.txt
C:\Program Files\Java\jdk1.6.0_25\bin>more b.txt
齐齐哈尔配送中心
查看本地windows的字符集方法
http://space.itpub.net/?uid-519536-action-viewspace-itemid-580610
1.第一种方法是在cmd命令行界面上通过chcp命令查看
C:\>chcp
Active code page: 936
2.第二种方法是在cmd命令行标题栏右键属性,在弹出对话框内可以看到当前的字符集编码
http://i.msdn.microsoft.com/cc305153.936%28en-us,MSDN.10%29.gif
用java实现native2asscii命令
http://wmj2003.iteye.com/blog/379472
JavaEye与李刚就Struts2中的struts.i18n.encoding的较量
http://blog.csdn.net/diyucity/archive/2009/07/28/4387110.aspx
字体编辑用中日韩汉字Unicode编码表 - 编著:中韩翻译网 金圣镇
http://www.chi2ko.com/tool/CJK.htm
字符编码笔记:ASCII,Unicode和UTF-8
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
Firefox URL Code Version 20.0.1 //firefox 浏览器输入about:config
browser.fixup.use-utf8;true
intl.charsetmenu.browser.cache;UTF-8, gb18030, Big5, windows-1252, gbk
intl.charsetmenu.browser.static;GB18030, GB2312, UTF-8, ISO-8859-1
intl.charsetmenu.mailedit;ISO-8859-1, ISO-8859-15, ISO-8859-6, armscii-8, geostd8, ISO-8859-13, ISO-8859-14, ISO-8859-2, GB2312, GB18030, Big5, KOI8-R, windows-1251, KOI8-U, ISO-8859-7, ISO-8859-8-I, windows-1255, ISO-2022-JP, EUC-KR, ISO-8859-10, ISO-8859-3, TIS-620, ISO-8859-9, UTF-8, VISCII
network.standard-url.encode-utf8;true
network.standard-url.escape-utf8;true
prefs.converted-to-utf8;false
services.aitc.manager.putFreq;10000
关于URL编码
http://www.ruanyifeng.com/blog/2010/02/url_encoding.html
一、问题的由来
URL就是网址,只要上网,就一定会用到。

一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址 “http://www.abc.com”,但是没有希腊字母的网址“http://www.aβγ.com”(读作阿尔法-贝塔-伽玛.com)。这是 因为网络标准RFC 1738做了硬性规定:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致“URL编码”成为了一个混乱的领域。
下面就让我们看看,“URL编码”到底有多混乱。我会依次分析四种不同的情况,在每一种情况中,浏览器的URL编码方法都不一样。把它们的差异解释清楚之后,我再说如何用Javascript找到一个统一的编码方法。
二、情况1:网址路径中包含汉字
打开IE(我用的是8.0版),输入网址“http://zh.wikipedia.org/wiki/春节”。注意,“春节”这两个字此时是网址路径的一部分。

查看HTTP请求的头信息,会发现IE实际查询的网址是“http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82”。也就是说,IE自动将“春节”编码成了“%E6%98%A5%E8%8A%82”。
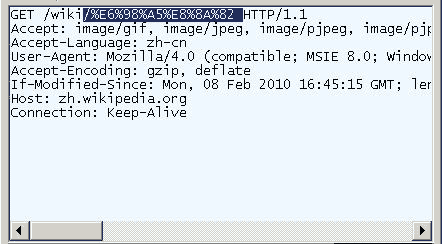
我们知道,“春”和“节”的utf-8编码分别是“E6 98 A5”和“E8 8A 82”,因此,“%E6%98%A5%E8%8A%82”就是按照顺序,在每个字节前加上%而得到的。(具体的转码方法,请参考我写的《字符编码笔记》。)
在Firefox中测试,也得到了同样的结果。所以,结论1就是,网址路径的编码,用的是utf-8编码。
三、情况2:查询字符串包含汉字
在IE中输入网址“http://www.baidu.com/s?wd=春节”。注意,“春节”这两个字此时属于查询字符串,不属于网址路径,不要与情况1混淆。

查看HTTP请求的头信息,会发现IE将“春节”转化成了一个乱码。
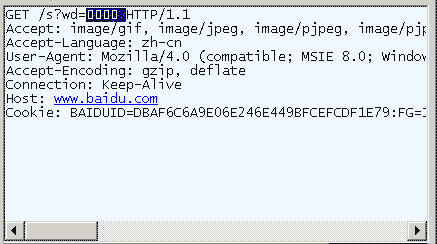
切换到十六进制方式,才能清楚地看到,“春节”被转成了“B4 BA BD DA”。
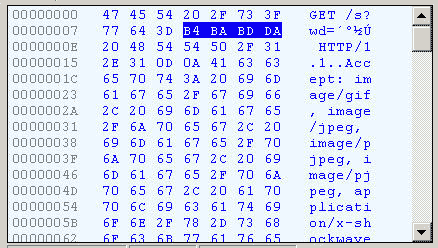
我们知道,“春”和“节”的GB2312编码(我的操作系统“Windows XP”中文版的默认编码)分别是“B4 BA”和“BD DA”。因此,IE实际上就是将查询字符串,以GB2312编码的格式发送出去。
Firefox的处理方法,略有不同。它发送的HTTP Head是“wd=%B4%BA%BD%DA”。也就是说,同样采用GB2312编码,但是在每个字节前加上了%。
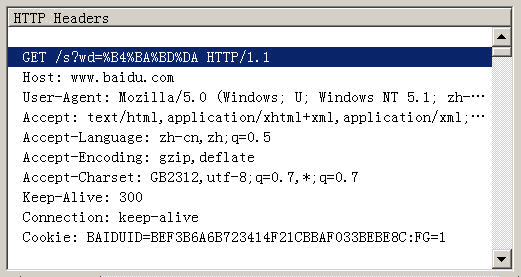
所以,结论2就是,查询字符串的编码,用的是操作系统的默认编码。
四、情况3:Get方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学吕瑞麟老师的试验,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
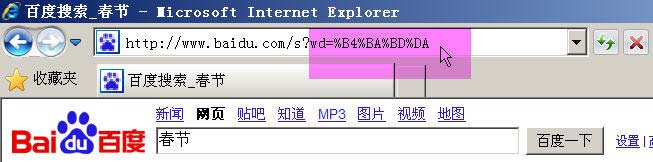
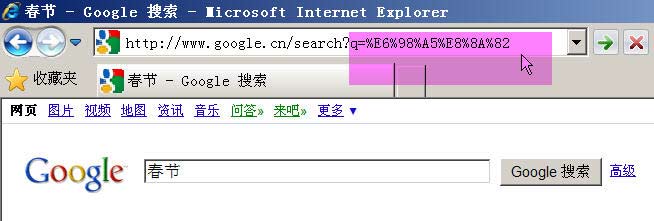
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词“春节”,生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA,这是GB2312编码。
Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。
所以,结论3就是,GET和POST方法的编码,用的是网页的编码。
五、情况4:Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求,最后一种情况则是由Javascript生成HTTP请求,也就是Ajax调用。还是根据吕瑞麟老师的文章,在这种情况下,IE和Firefox的处理方式完全不一样。
举例来说,有这样两行代码:
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是“春节”这两个字
http_request.open('GET', url, true);
那么,无论网页使用什么字符集,IE传送给服务器的总是“q=%B4%BA%BD%DA”,而Firefox传送给服务器的总是“q=%E6%98%A5%E8%8A%82”。也就是说,在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。这就是我们的结论4。
六、Javascript函数:escape()
好了,到此为止,四种情况都说完了。
假定前面你都看懂了,那么此时你应该会感到很头痛。因为,实在太混乱了。不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?
回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致的,所以就保证了服务器得到的数据是格式统一的。
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果 是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
所以,“Hello World”的escape()编码就是“Hello%20World”。因为空格的Unicode值是20(十六进制)。

还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
七、Javascript函数:encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
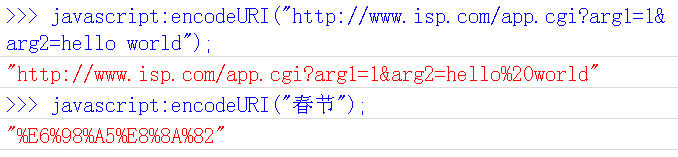
它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
八、Javascript函数:encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。
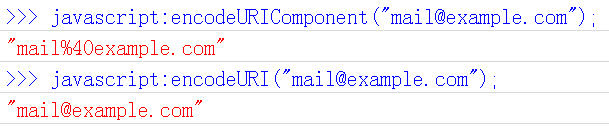
它对应的解码函数是decodeURIComponent()。
(完)
使用URL Decoder和URL Encoder对中文进行处理
http://asflex.iteye.com/blog/356028
一 URLEncoder
HTML 格式编码的实用工具类。该类包含了将 String 转换为 application/x-www-form-urlencoded MIME 格式的静态方法。有关 HTML 格式编码的更多信息,请参阅 HTML 规范。
对 String 编码时,使用以下规则:
字母数字字符 "a" 到 "z"、"A" 到 "Z" 和 "0" 到 "9" 保持不变。
特殊字符 "."、"-"、"*" 和 "_" 保持不变。
空格字符 " " 转换为一个加号 "+"。
所有其他字符都是不安全的,因此首先使用一些编码机制将它们转换为一个或多个字节。然后每个字节用一个包含 3 个字符的字符串 "%xy" 表示,其中 xy 为该字节的两位十六进制表示形式。推荐的编码机制是 UTF-8。但是,出于兼容性考虑,如果未指定一种编码,则使用相应平台的默认编码。
例如,使用 UTF-8 编码机制,字符串 "The string ü@foo-bar" 将转换为 "The+string+%C3%BC%40foo-bar",因为在 UTF-8 中,字符 ü 编码为两个字节,C3 (十六进制)和 BC (十六进制),字符 @ 编码为一个字节 40 (十六进制)。
二 URLDecoder
该类包含了将 String 从 application/x-www-form-urlencoded MIME 格式解码的静态方法。
该转换过程正好与 URLEncoder 类使用的过程相反。假定已编码的字符串中的所有字符为下列之一:"a" 到 "z"、"A" 到 "Z"、"0" 到 "9" 和 "-"、"_"、"." 以及 "*"。允许有 "%" 字符,但是将它解释为特殊转义序列的开始。
转换中使用以下规则:
字母数字字符 "a" 到 "z"、"A" 到 "Z" 和 "0" 到 "9" 保持不变。
特殊字符 "."、"-"、"*" 和 "_" 保持不变。
加号 "+" 转换为空格字符 " "。
将把 "%xy" 格式序列视为一个字节,其中 xy 为 8 位的两位十六进制表示形式。然后,所有连续包含一个或多个这些字节序列的子字符串,将被其编码可生成这些连续字节的字符所代替。可以指定对这些字符进行解 码的编码机制,或者如果未指定的话,则使用平台的默认编码机制。
该解码器处理非法字符串有两种可能的方法。一种方法是不管该非法字符,另一种方法是抛出 IllegalArgumentException 异常
简单示例:
- try {
- String encodeStr = URLEncoder.encode("中国", "utf-8");
- System.out.println("处理后:" + encodeStr);
- String decodeStr = URLDecoder.decode(encodeStr, "utf-8");
- System.out.println("解码:" + decodeStr);
- } catch (UnsupportedEncodingException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
运行结果:
- 处理后:%E4%B8%AD%E5%9B%BD
- 解码:中国
TestCode.java
- package com.javaeye.lindows.net;
- //java.net.URLEncoder和java.net.URLDecoder的使用2008-12-05 09:29
- public class TestCode {
- public static void main(String[] args) {
- String str = "你好吗";
- try {
- // 将 String 转换为 application/x-www-form-urlencoded MIME 格式
- // 使用指定的编码机制将字符串转换为 application/x-www-form-urlencoded 格式。
- String codestr = java.net.URLEncoder.encode(str, "UTF-8");
- System.out.println("codestr:" + codestr);
- // 使用指定的编码机制对 application/x-www-form-urlencoded 字符串解码。
- String decodeStr = java.net.URLDecoder.decode(codestr, "UTF-8");
- System.out.println("decodestr:" + decodeStr);
- str = "你小子好嚣张呀?";
- codestr = java.net.URLEncoder.encode(str, "gbk");
- System.out.println("codestr:" + codestr);
- decodeStr = java.net.URLDecoder.decode(codestr, "gbk");
- System.out.println("decodestr:" + decodeStr);
- str = "你小子好帅呀!";
- codestr = java.net.URLEncoder.encode(str, "gb2312");
- System.out.println("codestr:" + codestr);
- decodeStr = java.net.URLDecoder.decode(codestr, "gb2312");
- System.out.println("decodestr:" + decodeStr);
- str = "Go,go,快点,车马上要走了!";
- codestr = java.net.URLEncoder.encode(str, "gb18030");
- System.out.println("codestr:" + codestr);
- decodeStr = java.net.URLDecoder.decode(codestr, "gb18030");
- System.out.println("decodestr:" + decodeStr);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
url.java
- package com.javaeye.lindows.net;
- import java.net.URLEncoder;
- import java.net.URLDecoder;
- import java.io.*;
- public class URL {
- /**
- * 将文件名中的汉字转为UTF8编码的串,以便下载时能正确显示另存的文件名
- * @param s
- * 原文件名
- * @return 重新编码后的文件名
- */
- public static String toUtf8String(String s) {
- StringBuffer sb = new StringBuffer();
- for (int i = 0; i < s.length(); i++) {
- char c = s.charAt(i);
- if (c >= 0 && c <= 255) {
- sb.append(c);
- } else {
- byte[] b;
- try {
- b = String.valueOf(c).getBytes("utf-8");
- } catch (Exception ex) {
- System.out.println(ex);
- b = new byte[0];
- }
- for (int j = 0; j < b.length; j++) {
- int k = b[j];
- if (k < 0)
- k += 256;
- sb.append("%" + Integer.toHexString(k).toUpperCase());
- }
- }
- }
- return sb.toString();
- }
- public static void main(String args[]) {
- try {
- String enCode = URLEncoder.encode(
- "http://www.ioby.net/default.jsp?name=哈哈", "UTF-8");
- System.out.println(enCode);
- String deCode = URLDecoder.decode(enCode, "UTF-8");
- } catch (Exception e) {
- e.printStackTrace();
- }
- URL u = new URL();
- String s = "name=哈哈";
- System.out.println("http://www.ioby.net/default.jsp? "+u.toUtf8String(s));
- }
- }
中文文件:address.txt
内容:
中文字符行1
中文字符行2
中文字符行3
、、、
URL编码:TestURLCode.java
- package com.iteye.lindows.url;
- import java.io.BufferedReader;
- import java.io.BufferedWriter;
- import java.io.File;
- import java.io.FileReader;
- import java.io.FileWriter;
- import java.io.UnsupportedEncodingException;
- import java.net.URLEncoder;
- public class TestURLCode {
- /**
- * @param args
- */
- // 批量编码中文字符为 url code
- public static void main(String[] args) {
- BufferedReader reader = null;
- BufferedWriter writer = null;
- try {
- reader = new BufferedReader(new FileReader("E:\\address.txt"));
- File file = new File("E:\\address_url_code.txt");
- if(file.exists()){
- file.delete();
- }
- file.createNewFile();
- writer = new BufferedWriter(new FileWriter(file));
- String line = "";
- while((line = reader.readLine()) != null){
- writer.write(encode(line) +"\r\n");
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- try {
- if(reader != null)reader.close();
- if(writer != null)writer.close();
- } catch (Exception e2) {
- e2.printStackTrace();
- }
- }
- }
- public static String encode(String address){
- try {
- return URLEncoder.encode(address, "UTF-8");
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- return "";
- }
- }
- }
HTTPS安全模式下,讨厌的IE "nosecure" warning
http://cyfgod.iteye.com/blog/435381
https://emall.suningshop.com/webapp/wcs/stores/servlet/ProductDisplay?catalogId=10051&storeId=10052&productId=31249&langId=-7
IE浏览器,在HTTPS安全模式下预览WEB页面,我们经常会碰到下面的warning message:
"This page contains both secure and nonsecure items.
Do you want to display the nonsecure items?"
这个warning真的是很讨厌,虽然可以通过更改浏览器安全设置,禁止弹出这个warning dialog。但对一个成熟的WEB应用产品来说,强制用户去做这种浏览器设置是不友好的,用户体验上也会感觉很差。
哪怎么样才能从程序角度去避免弹出这个warning dialog呢?
我们首先需要了解可能引起这个warning的原因,简单归纳来说,不外乎是以下几点:
1) hard-code了http(或其它非https)的URL访问。
这是一个比较常见的问题,一般来说都不要在WEB页面中硬编码URL,可以采用相对URL。
2) WEB页面中含有没有设置SRC属性的iframe元素。
这个也比较常见,解决也很容易,可以给每个空的iframe设置SRC属性,这个src可以指向一个空的html页面,或是采用src="javascript:void()"这种方式。
3) 调用removeChild()方法去移除一个HTML元素,而这个元素包含一个backgroundImage背景图片的style引用。
这个严格来说,应该是IE的一个bug,可以在Microsoft官方网站上找到这个问题的描述和解决方案。不过即使是最新的IE8, 这个问题好像依然存在。
http://support.microsoft.com/kb/925014
4) 调用innerHTML()方法给一个HTML元素添加内容,之后再把这个元素添加到HTML DOM中。
这个问题可能在一些Ajax应用中会碰到,通过Ajax动态更新HTML内容,如果内容包含image图片等等内容,也会弹出这个warning。
解决方案就是,先将这个元素添加到HTML DOM,然后再调用innerHTML方案, 示例如下:
- // Create DIV element
- var div = document.createElement( "DIV" );
- // Append it to document first
- document.body.appendChild(div);
- // Then call innerHTML to insert HTML content
- div.innerHTML = htmlContent;
- ......
- // Create DIV element
- var div = document.createElement( "DIV" );
- // Append it to document first
- document.body.appendChild(div);
- // Then call innerHTML to insert HTML content
- div.innerHTML = htmlContent;
- ......
在开发过程中,我也只是碰到过这四种情况。还有没有别的原因,就不得而知啦!
statistic sample
- <script type="text/javascript">
- <!--
- var str = "AB4HJYLFNPCRC4CK7N1LZ4ZLFLQI3KRF5K19R53AFFSAVA1X1ZUHYV8X9IYKD1R5SU8YMAZ910HF62V5YKDWK5FJT8GFJGURKFV00CCCD23NWP0RM33FDCCGYIUJN4LLXY6LRK10T0OTV5YEQOEBTYC74Y7JZ0RXFI8NE9LBD5TZDYAL6TLP6MMRC41G7RE6OH3VDW7TLQIGY9WYTD0FI5ZP9FBGANONCQSQY3UJNU5VJZU5MNW2QHZ416G1JKZQ8GAI6L518JO4AIBSPAFZLOTJFKCZL2XU6AJ5YBFFOPFAT1UI5CRCNXH2SPB9FBCD28EH19RBV27SX91Z6902ANLC2J47B67RYNP0ZMWS8D9AWMSX3W8RR9IHPY1BW2QGWC825PAHU5CR754Z9HFX3GA3UQPF25DV2HROSZ2LBVKCQHDX4MKQ60OD3JBM54PJPNXPW13QTWLIO0XG8BL6QS5YOUF9QFLW3REQFLX34FG0JMIB6YCXAWU1G63XR20GN6S50KVDMMPU6Y09MDOJ7INCTSTIHO8SUNN26YUS7IA9R8H3DPC9NZ53OXJ5GNOC8AGDCWJ2EYORSD7L8J24PSK0MPP9NVZRGLPRMQCG9TQ63VPK4UKX5JWBR35H9YZJ6IRM3VAOIRSJTVMU1ZF7PZUTS06TV4PA8B06JX72CDM5H8V92NAAV2QS07KFE9EMFPRDNKJCK4INVCJOC1OBZSP0ADIT3WJ4RQBYYPIUMD4U4AYY4M327CJS02QNG6RF7WVDQBZEGDMWPUKYODZ8H2PZ9PB0DVW6V1LW5JJCNAL5GC5NFJR6PFEWKOU44G01YFMK7OHIB54AGSKWTUQ2G0IF56DJ6YEPPP25O6UA5UO76UXNED9S8JOYQCC1F5HTFWX89JAJH983FSKVSLL2DY6BO6RO2DY5KE63DI8O427DAKZIODYBX9ZYTMYUNLODK2TTBYSLKUHS6PXJUZHRXLVTPES2ZIP813OA7TQQ";
- var count = 0;
- for(var i=0;i<str.length;i++){
- if(str.charAt(i) == 9){
- count++;
- }
- }
- alert(count);
- -->
- </script>
javaScript中URL编码转换,escape() encodeURI() encodeURIC
http://jiangsha.iteye.com/blog/367107
avaScript中URL编码转换,escape() encodeURI() encodeURIComponent
在使用url进行参数传递时, 经常会传递一些中文名的参数或URL地址, 在后台处理时会发生转换错误。在有些传递页面使用GB2312, 而在接收页面使用 UTF8,这样接收到的参数就可能会与原来发生不一致。 使用服务器端的urlEncode函数编码的URL, 与使用客户端javascript的 encodeURI函数编码的URL,结果就不一样。
采用ISO Latin字符集对指定的字符串进行编码。所有的空格符、 标点符号、特殊字符以及其他非ASCII字符都将被转化成% xx格式的字符编码(xx等于该字符 在字符集表里面的编码的16进制数字)。比如, 空格符对应的编码是%20。unescape方法与此相反。 不会被此方法编码的字符: @ * / +
encodeURI() 方法:
encodeURIComponent() 方法:
另外,encodeURI/encodeURIComponent是在javascript1.5之后引进的,escape则在javascript1.0版本就有。
end



相关推荐
在Java中,转换ASCII到其他字符集,如UTF-8,主要通过`java.nio.charset.Charset`类的`newEncoder`和`decode`方法。以下是一个简单的示例: ```java String asciiString = "Hello, ASCII!"; Charset asciiCharset =...
Rocky Linux 8.10内核包
内容概要:本文档详细介绍了如何在Simulink中设计一个满足特定规格的音频带ADC(模数转换器)。首先选择了三阶单环多位量化Σ-Δ调制器作为设计方案,因为这种结构能在音频带宽内提供高噪声整形效果,并且多位量化可以降低量化噪声。接着,文档展示了具体的Simulink建模步骤,包括创建模型、添加各个组件如积分器、量化器、DAC反馈以及连接它们。此外,还进行了参数设计与计算,特别是过采样率和信噪比的估算,并引入了动态元件匹配技术来减少DAC的非线性误差。性能验证部分则通过理想和非理想的仿真实验评估了系统的稳定性和各项指标,最终证明所设计的ADC能够达到预期的技术标准。 适用人群:电子工程专业学生、从事数据转换器研究或开发的技术人员。 使用场景及目标:适用于希望深入了解Σ-Δ调制器的工作原理及其在音频带ADC应用中的具体实现方法的人群。目标是掌握如何利用MATLAB/Simulink工具进行复杂电路的设计与仿真。 其他说明:文中提供了详细的Matlab代码片段用于指导读者完成整个设计流程,同时附带了一些辅助函数帮助分析仿真结果。
内容概要:该题库专为研究生入学考试计算机组成原理科目设计,涵盖名校考研真题、经典教材课后习题、章节题库和模拟试题四大核心模块。名校考研真题精选多所知名高校的计算机组成原理科目及计算机联考真题,并提供详尽解析,帮助考生把握考研命题趋势与难度。经典教材课后习题包括白中英《计算机组成原理》(第5版)和唐朔飞《计算机组成原理》(第2版)的全部课后习题解答,这两部教材被众多名校列为考研指定参考书目。章节题库精选代表性考题,注重基础知识与重难点内容,帮助考生全面掌握考试大纲要求的知识点。模拟试题依据历年考研真题命题规律和热门考点,精心编制两套全真模拟试题,并附标准答案,帮助考生检验学习成果,评估应试能力。 适用人群:计划参加研究生入学考试并报考计算机组成原理科目的考生,尤其是需要系统复习和强化训练的学生。 使用场景及目标:①通过研读名校考研真题,考生可以准确把握考研命题趋势与难度,有效评估复习成效;②通过经典教材课后习题的练习,考生可以巩固基础知识,掌握解题技巧;③通过章节题库的系统练习,考生可以全面掌握考试大纲要求的各个知识点,为备考打下坚实基础;④通过模拟试题的测试,考生可以检验学习成果,评估应试能力,为正式考试做好充分准备。 其他说明:该题库不仅提供详细的题目解析,还涵盖了计算机组成原理的各个方面,包括计算机系统概述、数据表示与运算、存储器分层、指令系统、中央处理器、总线系统和输入输出系统等。考生在使用过程中应结合理论学习与实践操作,注重理解与应用,以提高应试能力和专业知识水平。
__UNI__DB9970A__20250328141034.apk.1
rust for minio
国网台区终端最新规范
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
一个简单的机器学习代码示例,使用的是经典的鸢尾花(Iris)数据集,通过 Scikit-learn 库实现了一个简单的分类模型。这个代码可以帮助你入门机器学习中的分类任务。
pyqt离线包,pyqt-tools离线包
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
SQL常用日期和时间函数整理及在sqlserver测试示例 主要包括 1.查询当前日期GETDATE 2.日期时间加减函数DATEADD 3 返回两个日期中指定的日期部分之间的差值DATEDIFF 4.日期格式转换CONVERT(VARCHAR(10),GETDATE(),120) 5.返回指定日期的年份数值 6.返回指定日期的月份数值 7.返回指定日期的天数数值
GSDML-V2.3-Turck-BL20_E_GW_EN-20160524-010300.xml
T_CPCIF 0225-2022 多聚甲醛.docx
《基于YOLOv8的智能仓储货物堆码倾斜预警系统》(包含源码、可视化界面、完整数据集、部署教程)简单部署即可运行。功能完善、操作简单,适合毕设或课程设计
蚕豆脱壳机设计.zip
台区终端电科院送检文档
Y6一39一No23.6D离心通风机 CAD().zip
django自建博客app