
1. 环境描述
本次测试基于JeecgBoot 2.4.6,测试代码在Jeecg-boot-module-system中编写。
2. 引入坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
3. 配置yml文件
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
allow:
web-stat-filter:
enabled: true
dynamic:
druid: # 全局druid参数,绝大部分值和默认保持一致。(现已支持的参数如下,不清楚含义不要乱设置)
# 连接池的配置信息
# 初始化大小,最小,最大
initial-size: 5
min-idle: 5
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
primary: master # 设置默认的数据源或者数据源组,默认值即为master
strict: false # 严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master:
url: jdbc:mysql://127.0.0.1:3306/jeecg-boot?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
# 多数据源配置
#multi-datasource1:
#url: jdbc:mysql://localhost:3306/jeecg-boot2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
#username: root
#password: root
#driver-class-name: com.mysql.cj.jdbc.Driver
# 指定默认数据源名称
shardingsphere:
props:
sql:
show: true
dataSource:
names: ds0
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/jeecg-boot?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: root
password: root
sharding:
tables:
sys_log:
logicTable: sys_log
actualDataNodes: ds0.sys_log$->{1..2}
tableStrategy:
inline:
shardingColumn: id
algorithmExpression: sys_log$->{id % 2 + 1}
keyGenerator:
type: SNOWFLAKE
column: id
worker:
id: 1
注意:在jeecgboot原有数据源的基础上,增加了primary节点,用来设置默认的数据源。
4. 建立数据表
在jeecgboot默认的数据库中,将sys_log表复制两份,分别命名为sys_log1和sys_log2
5. 添加配置类
在config目录下,添加配置类DataSourceConfiguration和DataSourceHealthConfig
其中DataSourceConfiguration.java配置类代码如下:
package org.jeecg.config;
import com.baomidou.dynamic.datasource.DynamicRoutingDataSource;
import com.baomidou.dynamic.datasource.provider.AbstractDataSourceProvider;
import com.baomidou.dynamic.datasource.provider.DynamicDataSourceProvider;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DataSourceProperty;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceAutoConfiguration;
import com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceProperties;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.boot.autoconfigure.AutoConfigureBefore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Lazy;
import org.springframework.context.annotation.Primary;
import javax.annotation.Resource;
import javax.sql.DataSource;
import java.util.Map;
@Configuration
@AutoConfigureBefore({DynamicDataSourceAutoConfiguration.class, SpringBootConfiguration.class})
public class DataSourceConfiguration {
/**
* 分表数据源名称
*/
public static final String SHARDING_DATA_SOURCE_NAME = "sharding";
/**
* 动态数据源配置项
*/
@Autowired
private DynamicDataSourceProperties dynamicDataSourceProperties;
@Lazy
@Resource
DataSource shardingDataSource;
/**
* 将shardingDataSource放到了多数据源(dataSourceMap)中
* 注意有个版本的bug,3.1.1版本 不会进入loadDataSources 方法,这样就一直造成数据源注册失败
*/
@Bean
public DynamicDataSourceProvider dynamicDataSourceProvider() {
Map<String, DataSourceProperty> datasourceMap = dynamicDataSourceProperties.getDatasource();
return new AbstractDataSourceProvider() {
@Override
public Map<String, DataSource> loadDataSources() {
Map<String, DataSource> dataSourceMap = createDataSourceMap(datasourceMap);
// 将 shardingjdbc 管理的数据源也交给动态数据源管理
dataSourceMap.put(SHARDING_DATA_SOURCE_NAME, shardingDataSource);
return dataSourceMap;
}
};
}
/**
* 将动态数据源设置为首选的
* 当spring存在多个数据源时, 自动注入的是首选的对象
* 设置为主要的数据源之后,就可以支持shardingjdbc原生的配置方式了
*
* @return
*/
@Primary
@Bean
public DataSource dataSource(DynamicDataSourceProvider dynamicDataSourceProvider) {
DynamicRoutingDataSource dataSource = new DynamicRoutingDataSource();
dataSource.setPrimary(dynamicDataSourceProperties.getPrimary());
dataSource.setStrict(dynamicDataSourceProperties.getStrict());
dataSource.setStrategy(dynamicDataSourceProperties.getStrategy());
dataSource.setProvider(dynamicDataSourceProvider);
dataSource.setP6spy(dynamicDataSourceProperties.getP6spy());
dataSource.setSeata(dynamicDataSourceProperties.getSeata());
return dataSource;
}
}
DataSourceHealthConfig.java配置类代码如下:
package org.jeecg.config;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.actuate.autoconfigure.jdbc.DataSourceHealthContributorAutoConfiguration;
import org.springframework.boot.actuate.health.AbstractHealthIndicator;
import org.springframework.boot.actuate.jdbc.DataSourceHealthIndicator;
import org.springframework.boot.jdbc.metadata.DataSourcePoolMetadataProvider;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
import javax.sql.DataSource;
import java.util.Map;
@Configuration
public class DataSourceHealthConfig extends DataSourceHealthContributorAutoConfiguration {
@Value("${spring.datasource.dbcp2.validation-query:select 1}")
private String defaultQuery;
public DataSourceHealthConfig(Map<String, DataSource> dataSources, ObjectProvider<DataSourcePoolMetadataProvider> metadataProviders) {
super(dataSources, metadataProviders);
}
@Override
protected AbstractHealthIndicator createIndicator(DataSource source) {
DataSourceHealthIndicator indicator = (DataSourceHealthIndicator) super.createIndicator(source);
if (!StringUtils.hasText(indicator.getQuery())) {
indicator.setQuery(defaultQuery);
}
return indicator;
}
}
6. 接口编写
Mapper
package org.jeecg.modules.shardingjdbc.mapper;
import com.baomidou.dynamic.datasource.annotation.DS;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Map;
/**
* Created by sunh.
*/
@Mapper
@Repository
public interface SysLogShardingMapper {
/**
* 插入日志
* @param type
* @param content
* @param operateType
* @return
*/
@Insert("insert into sys_log(log_type,log_content,operate_type)values( #{type},#{content},#{operateType})")
int insertLog( @Param("type") int type, @Param("content") String content, @Param("operateType") int operateType);
}
Service
package org.jeecg.modules.shardingjdbc.service;
public interface SysLogShardingService {
int insertLog( int type, String content, int operateType);
}
ServiceImpl
package org.jeecg.modules.shardingjdbc.service.Impl;
import com.baomidou.dynamic.datasource.annotation.DS;
import lombok.extern.slf4j.Slf4j;
import org.jeecg.config.DataSourceConfiguration;
import org.jeecg.modules.shardingjdbc.mapper.SysLogShardingDao;
import org.jeecg.modules.shardingjdbc.service.SysLogShardingService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Slf4j
@Service
@DS(DataSourceConfiguration.SHARDING_DATA_SOURCE_NAME)
public class SysLogShardingServiceImpl implements SysLogShardingService {
@Autowired
private SysLogShardingDao sysLogShardingDao;
@Override
public int insertLog(int type, String content, int operateType) {
int affectedRows = sysLogShardingDao.insertLog( type,content, operateType);
return affectedRows;
}
}
7. 测试用例
package org.jeecg.modules.shardingjdbc.controller;
import org.jeecg.common.api.vo.Result;
import org.jeecg.modules.shardingjdbc.mapper.SysLogShardingDao;
import org.jeecg.modules.shardingjdbc.service.SysLogShardingService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 测试sharding-jdbc
*/
@RestController
@RequestMapping("/sys_log")
public class SysLogShardingController {
@Autowired
private SysLogShardingService sysLogShardingService;
@GetMapping("/test1")
public Result<?> TestMongoDb(){
for(int i=1;i<20;i++){
sysLogShardingService.insertLog( i,"jeecgboot",i);
}
return Result.OK("存入成功");
}
}
8. 测试结果
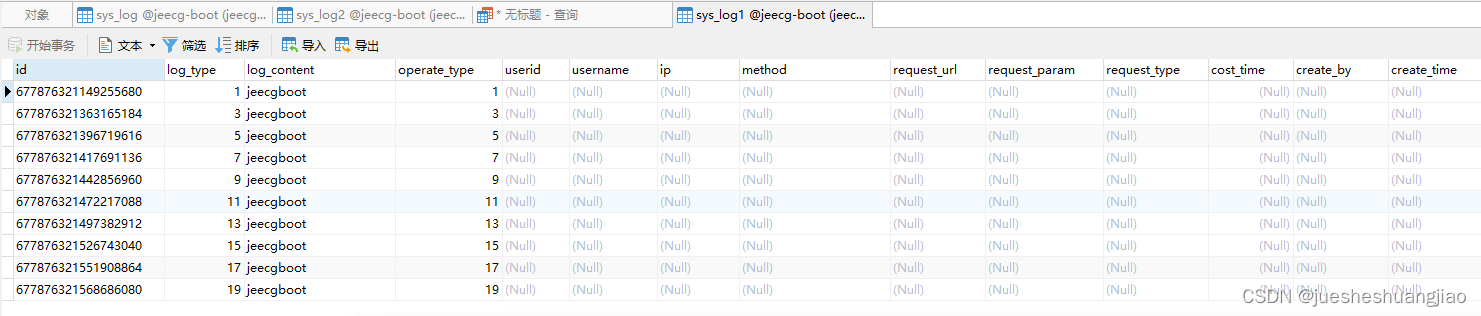

本文转载自:https://blog.csdn.net/u013473447/article/details/121951020



相关推荐
在这个"集成sharding-jdbc实现分库分表.zip"的压缩包中,我们可以深入学习如何将Sharding-JDBC应用于实际项目,以提升系统的性能和可扩展性。 1. **Sharding-JDBC简介** Sharding-JDBC是Java语言实现的,它工作在...
1. **依赖添加**:在`pom.xml`中引入SpringBoot和Sharding-JDBC的相关依赖,包括`spring-boot-starter-jdbc`和`sharding-jdbc-spring-boot-starter`。 2. **配置ShardingRule**:在`application.properties`或`...
1. **高度兼容性**:Sharding-JDBC能够无缝集成到现有的基于Java的ORM框架中,如JPA、Hibernate、Mybatis、SpringJDBCTemplate等,或者直接使用JDBC进行操作,这极大地降低了代码迁移的成本。 2. **灵活性与扩展性...
<artifactId>sharding-jdbc-spring-boot-starter 对应版本号 ``` 2. 配置数据库连接:在application.properties或application.yml中配置数据库连接信息,包括数据库URL、用户名、密码等。 ```properties spring....
【标题】"sharding-jdbc-boot-demo.zip" 提供了一个示例项目,展示了如何将Sharding-JDBC与Spring Boot框架整合使用。Sharding-JDBC是一个轻量级的Java框架,它允许开发者在不改变现有数据库架构的情况下实现数据分...
【标题】"sharding-jdbc按月分表样例"是一个关于使用Sharding-JDBC进行数据库分片的示例项目,旨在展示如何根据月份动态地将数据分散到不同的表中,以实现数据的水平扩展和负载均衡。Sharding-JDBC是阿里巴巴开源的...
4. **SQL解析与改写**:Sharding-JDBC内部集成了SQL解析引擎,能够识别并改写SQL语句,使其适应分片环境。对于按月分表的场景,SQL查询也需要相应调整,例如,查询2022年2月的订单时,Sharding-JDBC会自动将原SQL...
在这个“使用sharding-jdbc快速实现自动读写分离-demo源码”中,我们将探讨如何利用Sharding-JDBC实现这一功能。 首先,我们需要理解Sharding-JDBC的基本原理。Sharding-JDBC作为一个数据库中间件,工作在JDBC层,...
现在,Spring Boot应用已经集成了Sharding-JDBC,可以像操作单库一样操作分片数据库。在业务代码中,我们可以直接注入`JdbcTemplate`或`JPA`等Spring Boot支持的数据访问层组件进行数据操作。 在实际项目中,我们还...
5. **Sharding-JDBC与Mybatis集成**:集成Sharding-JDBC后,Mybatis的SQL执行将被拦截,分片逻辑会被自动插入,从而实现数据库分片。开发人员可以通过Sharding-JDBC提供的API或者注解来配置分片规则,同时保持...
通过以上步骤,你就可以成功地在项目中集成Sharding-JDBC实现读写分离。这个“Sharding-JDBC实现读写分离demo”将帮助你理解这一过程,并提供实际操作的参考。记得在实际部署时,根据你的业务需求和系统规模,适当...
Sharding-JDBC教程:Spring Boot整合Sharding-JDBC实现分库分表+读写分离 Sharding-JDBC是阿里巴巴开源的关系型数据库中间件,提供了数据库分库分表、读写分离、数据库路由等功能。本教程将指导读者使用Sharding-...
在SpringBoot中集成Sharding-JDBC,可以利用其 starter 机制,只需添加对应的依赖,就能快速启动并配置分片服务。 在压缩包文件“sharding-jdbc-1-master”中,你可能找到以下内容: 1. 项目的主配置文件(如...
一、Sharding-JDBC 与 JOOQ 的兼容性测试 - **测试项** - 不分片时,使用默认数据源的增、删、改、查 - 分片时,使用`ShardingDataSource`数据源的增、删、改、查 - 分片表与不分片表的连表查询...
标题"sharding-jdbc开源分表框架整合mybatis-demo"表明这是一个示例项目,展示了如何将`sharding-jdbc`这个开源的分库分表框架与`MyBatis`持久层框架集成在一起。这通常涉及到数据库水平扩展、数据分布以及事务管理...
8. **扩展性**:Sharding-JDBC不仅可以实现简单的分库分表,还可以配合其他组件如Sharding-Proxy实现服务化,或者与其他中间件如Dubbo、Spring Cloud等集成,构建完整的微服务架构。 以上就是围绕Sharding-JDBC分库...
Sharding-JDBC的一个重要特性是它不需要依赖额外的代理层,直接在应用程序中运行,因此它是轻量级的,并且可以无缝地与应用程序代码集成。这种设计极大地降低了系统的复杂性,并且由于它兼容标准的JDBC驱动,使得...
### SpringBoot+Mybatis-Plus 整合 Sharding-JDBC5.1.1 实现单库分表 #### 一、前言与背景 在现代软件开发中,随着业务量的增长,单一数据库往往难以满足高性能、高并发的需求,因此分库分表成为了一种常见的解决...
【描述】"spring+mybatis+sharding-jdbc实现的一个小demo,仅供参考"说明这是一个用于教学或学习目的的简化版应用,展示了如何集成这三个组件并实现数据库的分库分表功能。在这个demo中,开发者可以了解到如何配置...
Sharding-JDBC, 它定位为轻量级 java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。...