
жҖ§иғҪй—®йўҳе’ҢBugдёҚеҗҢпјҢеҗҺиҖ…зҡ„еҲҶжһҗе’Ңи§ЈеҶіжҖқи·Ҝжӣҙжё…жҷ°пјҢеҫҲеӨҡж—¶еҖҷд»Һеә”з”Ёж—Ҙеҝ—пјҲж–Үдёӯзҡ„еә”з”ЁжҢҮеҲҶеёғејҸжңҚеҠЎдёӢзҡ„еҚ•дёӘиҠӮзӮ№пјүеҚіеҸҜзӣҙжҺҘжүҫеҲ°й—®йўҳж №жәҗпјҢиҖҢжҖ§иғҪй—®йўҳпјҢе…¶жҺ’жҹҘжҖқи·ҜжӣҙдёәеӨҚжқӮдёҖдәӣгҖӮ
еҜ№еә”з”ЁиҝӣиЎҢжҖ§иғҪдјҳеҢ–пјҢжҳҜдёҖдёӘзі»з»ҹжҖ§зҡ„е·ҘзЁӢпјҢеҜ№е·ҘзЁӢеёҲзҡ„жҠҖжңҜе№ҝеәҰе’ҢжҠҖжңҜж·ұеәҰйғҪжңүжүҖиҰҒжұӮгҖӮдёҖдёӘз®ҖеҚ•зҡ„еә”з”ЁпјҢе®ғдёҚд»…еҢ…еҗ«дәҶеә”з”Ёд»Јз Ғжң¬иә«пјҢиҝҳе’Ңе®№еҷЁпјҲиҷҡжӢҹжңәпјүгҖҒж“ҚдҪңзі»з»ҹгҖҒеӯҳеӮЁгҖҒзҪ‘з»ңгҖҒж–Ү件系з»ҹзӯүзҙ§еҜҶзӣёе…іпјҢзәҝдёҠеә”з”ЁдёҖж—ҰеҮәзҺ°дәҶжҖ§иғҪй—®йўҳпјҢйңҖиҰҒжҲ‘们д»ҺеӨҡж–№йқўеҺ»иҖғиҷ‘гҖӮ
дёҺжӯӨеҗҢж—¶пјҢйҷӨдәҶдёҖдәӣдҪҺзә§зҡ„д»Јз ҒйҖ»иҫ‘еј•еҸ‘зҡ„жҖ§иғҪй—®йўҳеӨ–пјҢеҫҲеӨҡжҖ§иғҪй—®йўҳйҡҗи—Ҹзҡ„иҫғж·ұпјҢжҺ’жҹҘиө·жқҘдјҡжҜ”иҫғеӣ°йҡҫпјҢйңҖиҰҒжҲ‘们еҜ№еә”з”Ёзҡ„еҗ„дёӘеӯҗжЁЎеқ—гҖҒеә”з”ЁжүҖдҪҝз”Ёзҡ„жЎҶжһ¶е’Ң组件зҡ„еҺҹзҗҶжңүжүҖдәҶи§ЈпјҢеҗҢж—¶жҺҢжҸЎдёҖе®ҡзҡ„жҖ§иғҪдјҳеҢ–е·Ҙе…·е’Ңз»ҸйӘҢгҖӮ
жң¬ж–ҮжҖ»з»“дәҶжҲ‘们еңЁиҝӣиЎҢжҖ§иғҪдјҳеҢ–ж—¶еёёз”Ёзҡ„дёҖдәӣе·Ҙе…·еҸҠжҠҖе·§пјҢзӣ®зҡ„жҳҜеёҢжңӣйҖҡиҝҮдёҖдёӘе…Ёйқўзҡ„и§Ҷи§’пјҢеҺ»ж„ҹзҹҘжҖ§иғҪдјҳеҢ–зҡ„ж•ҙдҪ“и„үз»ңгҖӮжң¬ж–Үдё»иҰҒеҲҶдёәдёӢйқўдёүдёӘйғЁеҲҶпјҡ
- 第дёҖйғЁеҲҶдјҡд»Ӣз»ҚжҖ§иғҪдјҳеҢ–зҡ„дёҖдәӣиғҢжҷҜзҹҘиҜҶгҖӮ
- 第дәҢйғЁеҲҶдјҡд»Ӣз»ҚжҖ§иғҪдјҳеҢ–зҡ„йҖҡз”ЁжөҒзЁӢд»ҘеҸҠеёёи§Ғзҡ„дёҖдәӣиҜҜеҢәгҖӮ
- 第дёүйғЁеҲҶдјҡд»Һзі»з»ҹеұӮе’ҢдёҡеҠЎеұӮзҡ„и§’еәҰпјҢд»Ӣз»Қй«ҳж•Ҳзҡ„жҖ§иғҪй—®йўҳе®ҡдҪҚе·Ҙе…·е’Ңй«ҳйў‘жҖ§иғҪ瓶йўҲзӮ№еҲҶеёғгҖӮ
жң¬ж–ҮдёӯжҸҗеҲ°зҡ„зәҝзЁӢгҖҒе ҶгҖҒеһғеңҫеӣһ收зӯүеҗҚиҜҚпјҢеҰӮж— зү№еҲ«иҜҙжҳҺпјҢжҢҮзҡ„жҳҜ Java еә”з”Ёдёӯзҡ„зӣёе…іжҰӮеҝөгҖӮ
1.жҖ§иғҪдјҳеҢ–зҡ„иғҢжҷҜ
еүҚйқўжҸҗеҲ°иҝҮпјҢеә”з”ЁеҮәзҺ°жҖ§иғҪй—®йўҳе’Ңеә”з”ЁеӯҳеңЁзјәйҷ·жҳҜдёҚдёҖж ·зҡ„пјҢеҗҺиҖ…еӨ§еӨҡж•°жҳҜз”ұдәҺд»Јз Ғзҡ„иҙЁйҮҸй—®йўҳеҜјиҮҙпјҢдјҡеҜјиҮҙеә”з”ЁеҠҹиғҪжҖ§зҡ„зјәеӨұжҲ–еҮәзҺ°йЈҺйҷ©пјҢдёҖз»ҸеҸ‘зҺ°пјҢдјҡиў«еҸҠж—¶дҝ®еӨҚгҖӮиҖҢжҖ§иғҪй—®йўҳпјҢеҸҜиғҪжҳҜз”ұеӨҡж–№йқўзҡ„еӣ зҙ е…ұеҗҢдҪңз”Ёзҡ„з»“жһңпјҡд»Јз ҒиҙЁйҮҸдёҖиҲ¬гҖҒдёҡеҠЎеҸ‘еұ•еӨӘеҝ«гҖҒеә”з”Ёжһ¶жһ„и®ҫи®ЎдёҚеҗҲзҗҶзӯүпјҢиҝҷдәӣй—®йўҳеӨ„зҗҶиө·жқҘдёҖиҲ¬иҖ—ж—¶иҫғй•ҝгҖҒеҲҶжһҗй“ҫи·ҜеӨҚжқӮпјҢеӨ§е®¶йғҪдёҚж„ҝж„Ҹе№ІпјҢеӣ жӯӨеҸҜиғҪдјҡиў«дёҖдәӣдёҙж—¶жҖ§зҡ„иЎҘж•‘жүӢж®өжүҖжҺ©зӣ–пјҢеҰӮпјҡзі»з»ҹж°ҙдҪҚй«ҳжҲ–иҖ…еҚ•жңәзҡ„зәҝзЁӢжұ йҳҹеҲ—зҲҶзӮёпјҢйӮЈе°ұйӣҶзҫӨжү©е®№еўһеҠ жңәеҷЁпјӣеҶ…еӯҳеҚ з”Ёй«ҳ/й«ҳеі°ж—¶ж®ө OOMпјҢйӮЈе°ұйҮҚеҗҜеҲҶеҲҶй’ҹи§ЈеҶі......
дёҙж—¶жҖ§зҡ„иЎҘж•‘жҺӘж–ҪеҸӘжҳҜеңЁз»ҷеә”з”ЁеҹӢйӣ·пјҢеҗҢж—¶д№ҹеҸӘиғҪи§ЈеҶійғЁеҲҶй—®йўҳгҖӮиӯ¬еҰӮпјҢеңЁеҫҲеӨҡеңәжҷҜдёӢпјҢеҠ жңәеҷЁд№ҹ并дёҚиғҪи§ЈеҶіеә”з”Ёзҡ„жҖ§иғҪй—®йўҳпјҢеҰӮеҜ№ж—¶е»¶жҜ”иҫғж•Ҹж„ҹзҡ„дёҖдәӣеә”з”Ёеҝ…йЎ»жҠҠеҚ•жңәзҡ„жҖ§иғҪдјҳеҢ–еҲ°жһҒиҮҙпјҢдёҺжӯӨеҗҢж—¶пјҢеҠ жңәеҷЁиҝҷз§Қж–№ејҸд№ҹйҖ жҲҗдәҶиө„жәҗзҡ„жөӘиҙ№пјҢй•ҝжңҹжқҘзңӢжҳҜеҫ—дёҚеҒҝеӨұзҡ„гҖӮеҜ№еә”з”ЁиҝӣиЎҢеҗҲзҗҶзҡ„жҖ§иғҪдјҳеҢ–пјҢеҸҜеңЁеә”з”ЁзЁіе®ҡжҖ§гҖҒжҲҗжң¬ж ёз®—иҺ·еҫ—еҫҲеӨ§зҡ„收зӣҠгҖӮ
В

В
дёҠйқўжҲ‘们йҳҗиҝ°дәҶиҝӣиЎҢжҖ§иғҪдјҳеҢ–зҡ„еҝ…иҰҒжҖ§гҖӮеҒҮи®ҫзҺ°еңЁжҲ‘们зҡ„еә”з”Ёе·Із»ҸжңүдәҶжҖ§иғҪй—®йўҳпјҲeg. CPU ж°ҙдҪҚжҜ”иҫғй«ҳпјүпјҢеҮҶеӨҮејҖе§ӢиҝӣиЎҢдјҳеҢ–е·ҘдҪңдәҶпјҢеңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢжҪңеңЁзҡ„з—ӣзӮ№дјҡжңүе“Әдәӣе‘ўпјҹдёӢйқўеҲ—еҮәдёҖдәӣиҫғдёәеёёи§Ғзҡ„пјҡ
- еҜ№жҖ§иғҪдјҳеҢ–зҡ„жөҒзЁӢдёҚжҳҜеҫҲжё…жҷ°гҖӮеҲқжӯҘе®ҡдёәдёҖдёӘ疑似瓶йўҲзӮ№еҗҺпјҢе°ұе…ҙй«ҳйҮҮзғҲең°еҗӯ哧еҗӯ哧ејҖе§Ӣе№ІпјҢжңҖз»Ҳи§ЈеҶізҡ„й—®йўҳе…¶е®һеҸӘжҳҜдёҖдёӘжө…еұӮж¬Ўзҡ„жҖ§иғҪ瓶йўҲпјҢзңҹе®һзҡ„й—®йўҳзҡ„ж №жәҗ并жңӘи§Ұиҫҫпјӣ
- еҜ№жҖ§иғҪ瓶йўҲзӮ№зҡ„еҲҶжһҗжҖқи·ҜдёҚжҳҜеҫҲжё…жҷ°гҖӮCPUгҖҒзҪ‘з»ңгҖҒеҶ…еӯҳ......иҝҷд№ҲеӨҡзҡ„жҖ§иғҪжҢҮж ҮпјҢжҲ‘еҲ°еә•иҜҘе…іжіЁд»Җд№ҲпјҢеә”иҜҘд»Һе“ӘдёҖеқ—е„ҝејҖе§Ӣе…ҘжүӢпјҹ
- еҜ№жҖ§иғҪдјҳеҢ–зҡ„е·Ҙе…·дёҚдәҶи§ЈгҖӮйҒҮеҲ°й—®йўҳеҗҺпјҢдёҚжё…жҘҡиҜҘз”Ёе“ӘдёӘе·Ҙе…·пјҢдёҚзҹҘйҒ“йҖҡиҝҮе·Ҙе…·еҫ—еҲ°зҡ„жҢҮж Үд»ЈиЎЁд»Җд№ҲгҖӮ
2.жҖ§иғҪдјҳеҢ–зҡ„жөҒзЁӢ
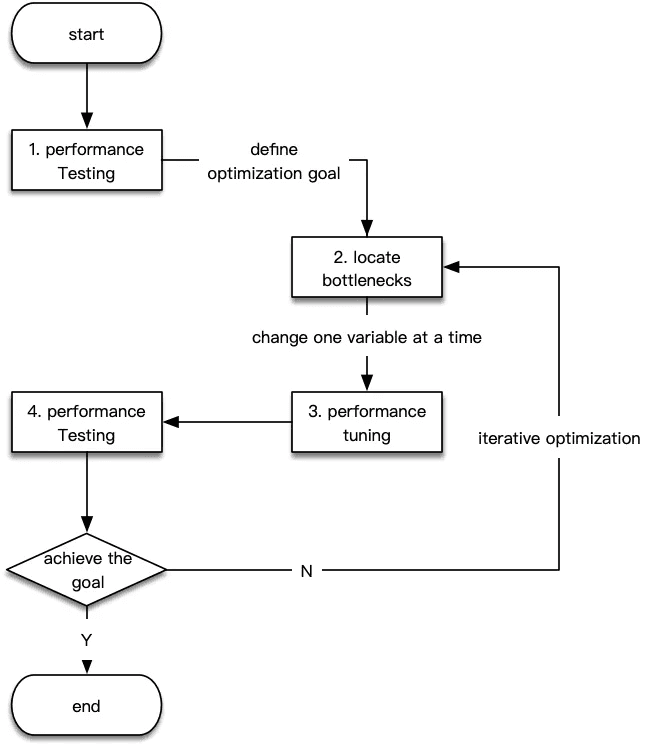
еңЁжҖ§иғҪдјҳеҢ–иҝҷдёӘйўҶеҹҹпјҢ并没жңүдёҖдёӘдёҘж јзҡ„жөҒзЁӢе®ҡд№үпјҢдҪҶжҳҜеҜ№дәҺз»қеӨ§еӨҡж•°зҡ„дјҳеҢ–еңәжҷҜпјҢжҲ‘们еҸҜд»Ҙе°Ҷе…¶иҝҮзЁӢжҠҪиұЎдёәдёӢйқўеӣӣдёӘжӯҘйӘӨгҖӮ
- еҮҶеӨҮйҳ¶ж®өпјҡдё»иҰҒе·ҘдҪңжҳҜжҳҜйҖҡиҝҮжҖ§иғҪжөӢиҜ•пјҢдәҶи§Јеә”з”Ёзҡ„жҰӮеҶөгҖҒ瓶йўҲзҡ„еӨ§жҰӮж–№еҗ‘пјҢжҳҺзЎ®дјҳеҢ–зӣ®ж Үпјӣ
- еҲҶжһҗйҳ¶ж®өпјҡйҖҡиҝҮеҗ„з§Қе·Ҙе…·жҲ–жүӢж®өпјҢеҲқжӯҘе®ҡдҪҚжҖ§иғҪ瓶йўҲзӮ№пјӣ
- и°ғдјҳйҳ¶ж®өпјҡж №жҚ®е®ҡдҪҚеҲ°зҡ„瓶йўҲзӮ№пјҢиҝӣиЎҢеә”з”ЁжҖ§иғҪи°ғдјҳпјӣ
- жөӢиҜ•йҳ¶ж®өпјҡи®©и°ғдјҳиҝҮзҡ„еә”з”ЁиҝӣиЎҢжҖ§иғҪжөӢиҜ•пјҢдёҺеҮҶеӨҮйҳ¶ж®өзҡ„еҗ„йЎ№жҢҮж ҮиҝӣиЎҢеҜ№жҜ”пјҢи§ӮжөӢе…¶жҳҜеҗҰз¬ҰеҗҲйў„жңҹпјҢеҰӮжһң瓶йўҲзӮ№жІЎжңүж¶ҲйҷӨжҲ–иҖ…жҖ§иғҪжҢҮж ҮдёҚз¬ҰеҗҲйў„жңҹпјҢеҲҷйҮҚеӨҚжӯҘйӘӨ2е’Ң3гҖӮ
дёӢеӣҫеҚідёәдёҠиҝ°еӣӣдёӘйҳ¶ж®өзҡ„з®ҖиҰҒжөҒзЁӢгҖӮ
В
В
2.1 йҖҡз”ЁжөҒзЁӢиҜҰи§Ј
еңЁдёҠиҝ°йҖҡз”ЁжөҒзЁӢзҡ„еӣӣдёӘжӯҘйӘӨеҪ“дёӯпјҢжӯҘйӘӨ2е’Ң3жҲ‘们дјҡеңЁжҺҘдёӢжқҘдёӨдёӘйғЁеҲҶйҮҚзӮ№иҝӣиЎҢд»Ӣз»ҚгҖӮйҰ–е…ҲжҲ‘们жқҘзңӢдёҖдёӢпјҢеңЁеҮҶеӨҮйҳ¶ж®өе’ҢжөӢиҜ•йҳ¶ж®өпјҢжҲ‘们йңҖиҰҒеҒҡдёҖдәӣд»Җд№ҲгҖӮ
| 2.1.1 еҮҶеӨҮйҳ¶ж®ө
еҮҶеӨҮйҳ¶ж®өжҳҜйқһеёёе…ій”®зҡ„дёҖжӯҘпјҢдёҚиғҪзңҒз•ҘгҖӮ
йҰ–е…ҲпјҢйңҖиҰҒеҜ№жҲ‘们иҝӣиЎҢи°ғдјҳзҡ„еҜ№иұЎиҝӣиЎҢиҜҰе°Ҫзҡ„дәҶи§ЈпјҢжүҖи°“зҹҘе·ұзҹҘеҪјпјҢзҷҫжҲҳдёҚж®ҶгҖӮ
- еҜ№жҖ§иғҪй—®йўҳиҝӣиЎҢзІ—з•ҘиҜ„дј°пјҢиҝҮж»ӨдёҖдәӣеӣ дёәдҪҺзә§зҡ„дёҡеҠЎйҖ»иҫ‘еҜјиҮҙзҡ„жҖ§иғҪй—®йўҳгҖӮиӯ¬еҰӮпјҢзәҝдёҠеә”з”Ёж—Ҙеҝ—зә§еҲ«дёҚеҗҲзҗҶпјҢеҸҜиғҪдјҡеңЁеӨ§жөҒйҮҸж—¶еҜјиҮҙ CPU е’ҢзЈҒзӣҳзҡ„иҙҹиҪҪйЈҷй«ҳпјҢиҝҷз§Қжғ…еҶөи°ғж•ҙж—Ҙеҝ—зә§еҲ«еҚіеҸҜпјӣ
- дәҶи§Јеә”з”Ёзҡ„зҡ„жҖ»дҪ“жһ¶жһ„пјҢжҜ”еҰӮеә”з”Ёзҡ„еӨ–йғЁдҫқиө–е’Ңж ёеҝғжҺҘеҸЈжңүе“ӘдәӣпјҢдҪҝз”ЁдәҶе“Әдәӣ组件е’ҢжЎҶжһ¶пјҢе“ӘдәӣжҺҘеҸЈгҖҒжЁЎеқ—зҡ„дҪҝз”ЁзҺҮиҫғй«ҳпјҢдёҠдёӢжёёзҡ„ж•°жҚ®й“ҫи·ҜжҳҜжҖҺд№Ҳж ·зҡ„зӯүпјӣ
- дәҶи§Јеә”з”ЁеҜ№еә”зҡ„жңҚеҠЎеҷЁдҝЎжҒҜпјҢеҰӮжңҚеҠЎеҷЁжүҖеңЁзҡ„йӣҶзҫӨдҝЎжҒҜгҖҒжңҚеҠЎеҷЁзҡ„ CPU/еҶ…еӯҳдҝЎжҒҜгҖҒе®үиЈ…зҡ„ Linux зүҲжң¬дҝЎжҒҜгҖҒжңҚеҠЎеҷЁжҳҜе®№еҷЁиҝҳжҳҜиҷҡжӢҹжңәгҖҒжүҖеңЁе®ҝдё»жңәж··йғЁеҗҺжҳҜеҗҰеҜ№еҪ“еүҚеә”з”Ёжңүе№Іжү°зӯүпјӣ
е…¶ж¬ЎпјҢжҲ‘们йңҖиҰҒиҺ·еҸ–еҹәеҮҶж•°жҚ®пјҢ然еҗҺз»“еҗҲеҹәеҮҶж•°жҚ®е’ҢеҪ“еүҚзҡ„дёҖдәӣдёҡеҠЎжҢҮж ҮпјҢзЎ®е®ҡжӯӨж¬ЎжҖ§иғҪдјҳеҢ–зҡ„жңҖз»Ҳзӣ®ж ҮгҖӮ
- дҪҝз”ЁеҹәеҮҶжөӢиҜ•е·Ҙе…·иҺ·еҸ–зі»з»ҹз»ҶзІ’еәҰжҢҮж ҮгҖӮеҸҜд»ҘдҪҝз”ЁиӢҘе№І Linux еҹәеҮҶжөӢиҜ•е·Ҙе…·пјҲeg. jmeterгҖҒabгҖҒloadrunnerwrkгҖҒwrkзӯүпјүпјҢеҫ—еҲ°ж–Ү件系з»ҹгҖҒзЈҒзӣҳ I/OгҖҒзҪ‘з»ңзӯүзҡ„жҖ§иғҪжҠҘе‘ҠгҖӮйҷӨжӯӨд№ӢеӨ–пјҢзұ»дјј GCгҖҒWeb жңҚеҠЎеҷЁгҖҒзҪ‘еҚЎжөҒйҮҸзӯүдҝЎжҒҜпјҢеҰӮжңүеҝ…иҰҒд№ҹжҳҜйңҖиҰҒдәҶи§Ји®°еҪ•зҡ„пјӣ
- йҖҡиҝҮеҺӢжөӢе·Ҙе…·жҲ–иҖ…еҺӢжөӢе№іеҸ°пјҲеҰӮжһңжңүзҡ„иҜқпјүпјҢеҜ№еә”з”ЁиҝӣиЎҢеҺӢеҠӣжөӢиҜ•пјҢиҺ·еҸ–еҪ“еүҚеә”з”Ёзҡ„е®Ҹи§ӮдёҡеҠЎжҢҮж ҮпјҢиӯ¬еҰӮпјҡе“Қеә”ж—¶й—ҙгҖҒеҗһеҗҗйҮҸгҖҒTPSгҖҒQPSгҖҒж¶Ҳиҙ№йҖҹзҺҮпјҲеҜ№дәҺжңү MQ зҡ„еә”з”ЁпјүзӯүгҖӮеҺӢеҠӣжөӢиҜ•д№ҹеҸҜд»ҘзңҒз•ҘпјҢеҸҜд»Ҙз»“еҗҲеҪ“еүҚзҡ„е®һйҷ…дёҡеҠЎе’ҢиҝҮеҫҖзҡ„зӣ‘жҺ§ж•°жҚ®пјҢеҺ»з»ҹи®ЎеҪ“еүҚзҡ„дёҖдәӣж ёеҝғдёҡеҠЎжҢҮж ҮпјҢеҰӮеҚҲй«ҳеі°зҡ„жңҚеҠЎ TPSгҖӮ
| 2.1.2 жөӢиҜ•йҳ¶ж®ө
иҝӣе…ҘеҲ°иҝҷдёҖйҳ¶ж®өпјҢиҜҙжҳҺжҲ‘们已з»ҸеҲқжӯҘзЎ®е®ҡдәҶеә”з”ЁжҖ§иғҪ瓶йўҲзҡ„жүҖеңЁпјҢиҖҢдё”е·Із»ҸиҝӣиЎҢеҲқжӯҘзҡ„и°ғдјҳдәҶгҖӮжЈҖжөӢжҲ‘们и°ғдјҳжҳҜеҗҰжңүж•Ҳзҡ„ж–№ејҸпјҢе°ұжҳҜеңЁд»ҝзңҹзҡ„жқЎд»¶дёӢпјҢеҜ№еә”з”ЁиҝӣиЎҢеҺӢеҠӣжөӢиҜ•гҖӮжіЁж„Ҹпјҡз”ұдәҺ Java жңү JITпјҲjust-in-time compilationпјүиҝҮзЁӢпјҢеӣ жӯӨеҺӢеҠӣжөӢиҜ•ж—¶еҸҜиғҪйңҖиҰҒиҝӣиЎҢеүҚжңҹйў„зғӯгҖӮ
еҰӮжһңеҺӢеҠӣжөӢиҜ•зҡ„з»“жһңз¬ҰеҗҲдәҶйў„жңҹзҡ„и°ғдјҳзӣ®ж ҮпјҢжҲ–иҖ…дёҺеҹәеҮҶж•°жҚ®зӣёжҜ”пјҢжңүеҫҲеӨ§зҡ„ж”№е–„пјҢеҲҷжҲ‘们еҸҜд»Ҙ继з»ӯйҖҡиҝҮе·Ҙе…·е®ҡдҪҚдёӢдёҖдёӘ瓶йўҲзӮ№пјҢеҗҰеҲҷпјҢеҲҷйңҖиҰҒжҡӮж—¶жҺ’йҷӨиҝҷдёӘ瓶йўҲзӮ№пјҢ继з»ӯеҜ»жүҫдёӢдёҖдёӘеҸҳйҮҸгҖӮ
В

В
2.2 жіЁж„ҸдәӢйЎ№
еңЁиҝӣиЎҢжҖ§иғҪдјҳеҢ–ж—¶пјҢдәҶи§ЈдёӢйқўиҝҷдәӣжіЁж„ҸдәӢйЎ№еҸҜд»Ҙи®©жҲ‘们少иө°дёҖдәӣејҜи·ҜгҖӮ
- жҖ§иғҪ瓶йўҲзӮ№йҖҡеёёе‘ҲзҺ° 2/8 еҲҶеёғпјҢеҚі80%зҡ„жҖ§иғҪй—®йўҳйҖҡеёёжҳҜз”ұ20%зҡ„жҖ§иғҪ瓶йўҲзӮ№еҜјиҮҙзҡ„пјҢ2/8 еҺҹеҲҷд№ҹж„Ҹе‘ізқҖ并дёҚжҳҜжүҖжңүзҡ„жҖ§иғҪй—®йўҳйғҪеҖјеҫ—еҺ»дјҳеҢ–пјӣ
- жҖ§иғҪдјҳеҢ–жҳҜдёҖдёӘжёҗиҝӣгҖҒиҝӯд»Јзҡ„иҝҮзЁӢпјҢйңҖиҰҒйҖҗжӯҘгҖҒеҠЁжҖҒең°иҝӣиЎҢгҖӮи®°еҪ•еҹәеҮҶеҗҺпјҢжҜҸж¬Ўж”№еҸҳдёҖдёӘеҸҳйҮҸпјҢеј•е…ҘеӨҡдёӘеҸҳйҮҸдјҡз»ҷжҲ‘们зҡ„и§ӮжөӢгҖҒдјҳеҢ–иҝҮзЁӢйҖ жҲҗе№Іжү°пјӣ
- дёҚиҰҒиҝҮеәҰиҝҪжұӮеә”з”Ёзҡ„еҚ•жңәжҖ§иғҪпјҢеҰӮжһңеҚ•жңәиЎЁзҺ°иүҜеҘҪпјҢеҲҷеә”иҜҘд»Һзі»з»ҹжһ¶жһ„зҡ„и§’еәҰеҺ»жҖқиҖғ; дёҚиҰҒиҝҮеәҰиҝҪжұӮеҚ•дёҖз»ҙеәҰдёҠзҡ„жһҒиҮҙдјҳеҢ–пјҢеҰӮиҝҮеәҰиҝҪжұӮ CPU зҡ„жҖ§иғҪиҖҢеҝҪз•ҘдәҶеҶ…еӯҳж–№йқўзҡ„瓶йўҲпјӣ
- йҖүжӢ©еҗҲйҖӮзҡ„жҖ§иғҪдјҳеҢ–е·Ҙе…·пјҢеҸҜд»ҘдҪҝеҫ—жҖ§иғҪдјҳеҢ–еҸ–еҫ—дәӢеҚҠеҠҹеҖҚзҡ„ж•Ҳжһңпјӣ
- ж•ҙдёӘеә”з”Ёзҡ„дјҳеҢ–пјҢеә”иҜҘдёҺзәҝдёҠзі»з»ҹйҡ”зҰ»пјҢж–°зҡ„д»Јз ҒдёҠзәҝеә”иҜҘжңүйҷҚзә§ж–№жЎҲгҖӮ
3.瓶йўҲзӮ№еҲҶжһҗе·Ҙе…·з®ұ
жҖ§иғҪдјҳеҢ–е…¶е®һе°ұжҳҜжүҫеҮәеә”з”ЁеӯҳеңЁжҖ§иғҪ瓶йўҲзӮ№пјҢ然еҗҺи®ҫжі•йҖҡиҝҮдёҖдәӣи°ғдјҳжүӢж®өеҺ»зј“и§ЈгҖӮжҖ§иғҪ瓶йўҲзӮ№зҡ„е®ҡдҪҚжҳҜиҫғеӣ°йҡҫзҡ„пјҢеҝ«йҖҹгҖҒзӣҙжҺҘең°е®ҡдҪҚеҲ°з“¶йўҲзӮ№пјҢйңҖиҰҒе…·еӨҮдёӢйқўдёӨдёӘжқЎд»¶пјҡ
- жҒ°еҲ°еҘҪеӨ„зҡ„е·Ҙе…·пјӣ
- дёҖе®ҡзҡ„жҖ§иғҪдјҳеҢ–з»ҸйӘҢгҖӮ
е·Ҙж¬Іе–„е…¶дәӢпјҢеҝ…е…ҲеҲ©е…¶еҷЁпјҢжҲ‘们иҜҘеҰӮдҪ•йҖүжӢ©еҗҲйҖӮзҡ„е·Ҙе…·е‘ўпјҹдёҚеҗҢзҡ„дјҳеҢ–еңәжҷҜдёӢпјҢеҸҲиҜҘйҖүжӢ©йӮЈдәӣе·Ҙе…·е‘ўпјҹ
йҰ–йҖүпјҢжҲ‘们жқҘзңӢдёҖдёӢеӨ§еҗҚйјҺйјҺзҡ„гҖҢжҖ§иғҪе·Ҙе…·(Linux Performance Tools-full)еӣҫгҖҚпјҢжғіеҝ…еҫҲеӨҡе·ҘзЁӢеёҲйғҪзҹҘйҒ“пјҢе®ғеҮәиҮӘзі»з»ҹжҖ§иғҪ专家 Brendan GreggгҖӮиҜҘеӣҫд»Һ Linux еҶ…ж ёзҡ„еҗ„дёӘеӯҗзі»з»ҹеҮәеҸ‘пјҢеҲ—еҮәдәҶжҲ‘们еңЁеҜ№еҗ„дёӘеӯҗзі»з»ҹиҝӣиЎҢжҖ§иғҪеҲҶжһҗж—¶пјҢеҸҜдҪҝз”Ёзҡ„е·Ҙе…·пјҢж¶өзӣ–дәҶзӣ‘жөӢгҖҒеҲҶжһҗгҖҒи°ғдјҳзӯүжҖ§иғҪдјҳеҢ–зҡ„ж–№ж–№йқўйқўгҖӮйҷӨдәҶиҝҷеј е…ЁжҷҜеӣҫд№ӢеӨ–пјҢBrendan Gregg иҝҳеҚ•зӢ¬жҸҗдҫӣдәҶеҹәеҮҶжөӢиҜ•е·Ҙе…·(Linux Performance Benchmark Tools)еӣҫгҖҒжҖ§иғҪзӣ‘жөӢе·Ҙе…·(Linux Performance Observability Tools)еӣҫзӯүпјҢжӣҙиҜҰз»Ҷзҡ„еҶ…е®№иҜ·еҸӮиҖғ Brendan Gregg зҡ„зҪ‘з«ҷиҜҙжҳҺгҖӮ
В

В
дёҠйқўиҝҷеј еӣҫйқһеёёз»Ҹе…ёпјҢжҳҜжҲ‘们еҒҡжҖ§иғҪдјҳеҢ–ж—¶йқһеёёеҘҪзҡ„еҸӮиҖғиө„ж–ҷпјҢдҪҶдәӢе®һдёҠпјҢжҲ‘们еңЁе®һйҷ…иҝҗз”Ёзҡ„ж—¶еҖҷпјҢдјҡеҸ‘зҺ°еҸҜиғҪе®ғ并дёҚжҳҜжңҖеҗҲйҖӮзҡ„пјҢеҺҹеӣ дё»иҰҒжңүдёӢйқўдёӨзӮ№пјҡ
1пјүеҜ№еҲҶжһҗз»ҸйӘҢиҰҒжұӮиҫғй«ҳгҖӮдёҠйқўиҝҷеј еӣҫе…¶е®һжҳҜд»Һ Linux зі»з»ҹиө„жәҗзҡ„и§’еәҰеҺ»и§ӮжөӢжҖ§иғҪжҢҮж Үзҡ„пјҢиҝҷиҰҒжұӮжҲ‘们еҜ№ Linux еҗ„дёӘеӯҗзі»з»ҹзҡ„еҠҹиғҪгҖҒеҺҹзҗҶиҰҒжңүжүҖдәҶи§ЈгҖӮдёҫдҫӢпјҡйҒҮеҲ°жҖ§иғҪй—®йўҳдәҶпјҢжҲ‘们дёҚдјҡжӢҝжҜҸдёӘеӯҗзі»з»ҹдёӢзҡ„е·Ҙе…·йғҪеҺ»иҜ•дёҖйҒҚпјҢеӨ§еӨҡж•°жғ…еҶөжҳҜпјҡжҲ‘们жҖҖз–‘жҹҗдёӘеӯҗзі»з»ҹжңүй—®йўҳпјҢ然еҗҺж №жҚ®иҝҷеј еӣҫдёҠеҲ—дёҫзҡ„е·Ҙе…·пјҢеҺ»и§ӮжөӢжҲ–иҖ…йӘҢиҜҒжҲ‘们зҡ„зҢңжғіпјҢиҝҷж— з–‘жӢ”й«ҳдәҶеҜ№жҖ§иғҪдјҳеҢ–з»ҸйӘҢзҡ„иҰҒжұӮпјӣ
2пјүйҖӮз”ЁжҖ§е’Ңе®Ңж•ҙжҖ§дёҚжҳҜеҫҲеҘҪгҖӮжҲ‘们еңЁеҲҶжһҗжҖ§иғҪй—®йўҳж—¶пјҢд»Һзі»з»ҹеә•еұӮиҮӘеә•еҗ‘дёҠең°еҲҶжһҗжҳҜиҫғдҪҺж•Ҳзҡ„пјҢеӨ§еӨҡж•°ж—¶еҖҷпјҢд»Һеә”з”ЁеұӮйқўеҺ»еҲҶжһҗдјҡжӣҙеҠ жңүж•ҲгҖӮжҖ§иғҪе·Ҙе…·(Linux Performance Tools-full)еӣҫеҸӘжҳҜд»Һзі»з»ҹеұӮдёҖдёӘи§’еәҰз»ҷеҮәдәҶе·Ҙе…·йӣҶпјҢеҰӮжһңд»Һеә”з”ЁеұӮејҖе§ӢеҲҶжһҗпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ёе“Әдәӣе·Ҙе…·пјҹе“ӘдәӣзӮ№жҳҜжҲ‘们йҰ–е…ҲйңҖиҰҒе…іжіЁзҡ„пјҹ
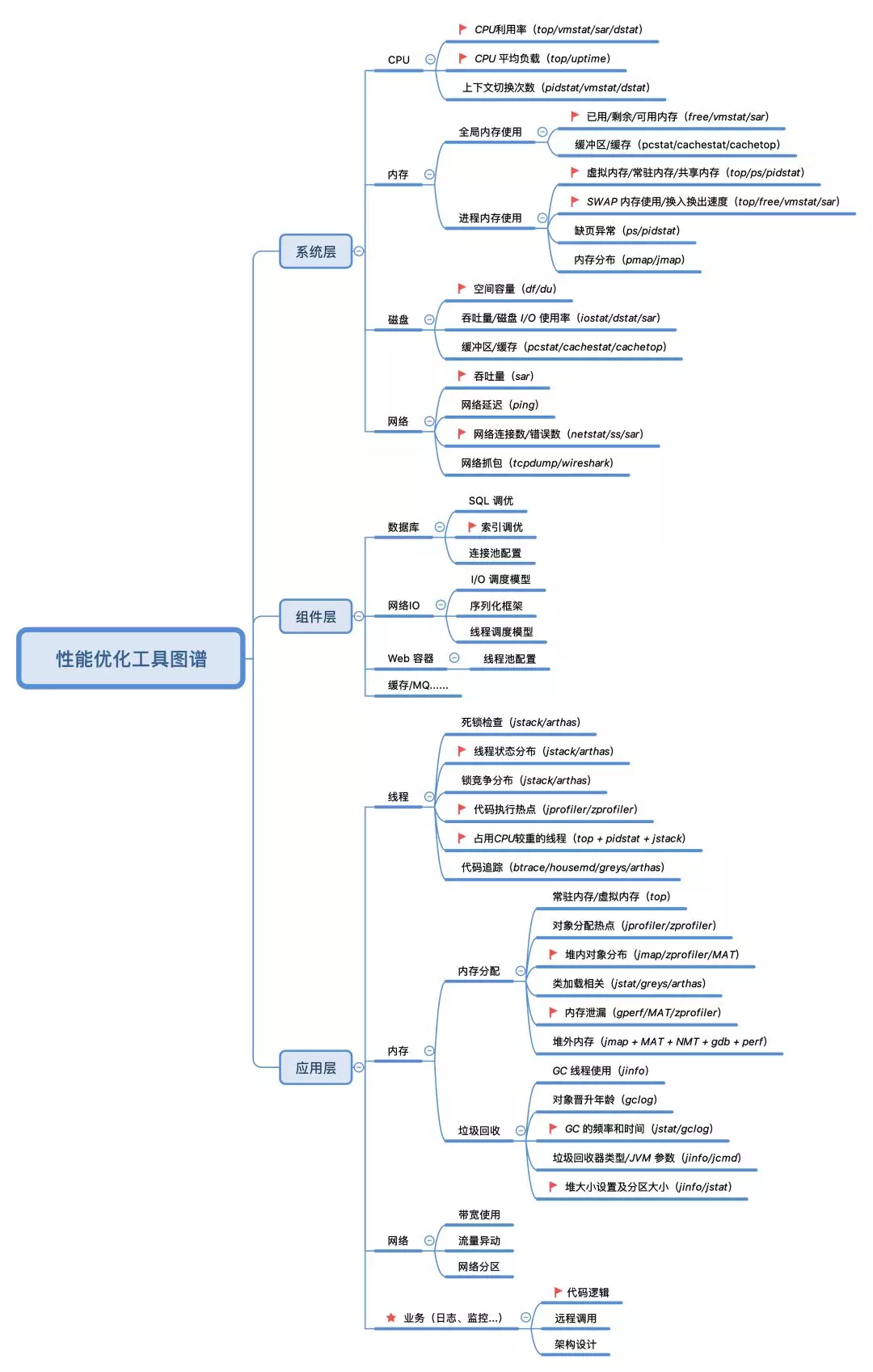
йүҙдәҺдёҠйқўиӢҘе№Із—ӣзӮ№пјҢдёӢйқўз»ҷеҮәдәҶдёҖеј жӣҙдёәе®һз”Ёзҡ„гҖҢжҖ§иғҪдјҳеҢ–е·Ҙе…·еӣҫи°ұгҖҚпјҢиҜҘеӣҫеҲҶеҲ«д»Һзі»з»ҹеұӮгҖҒеә”з”ЁеұӮпјҲеҗ«з»„件еұӮпјүзҡ„и§’еәҰеҮәеҸ‘пјҢеҲ—дёҫдәҶжҲ‘们еңЁеҲҶжһҗжҖ§иғҪй—®йўҳж—¶йҰ–е…ҲйңҖиҰҒе…іжіЁзҡ„еҗ„йЎ№жҢҮж ҮпјҲе…¶дёӯ?ж ҮжіЁзҡ„жҳҜжңҖйңҖиҰҒе…іжіЁзҡ„пјүпјҢиҝҷдәӣзӮ№жҳҜжңҖжңүеҸҜиғҪеҮәзҺ°жҖ§иғҪ瓶йўҲзҡ„ең°ж–№гҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢдёҖдәӣдҪҺйў‘зҡ„жҢҮж ҮжҲ–е·Ҙе…·пјҢеңЁеӣҫдёӯ并没жңүеҲ—еҮәжқҘпјҢеҰӮ CPU дёӯж–ӯгҖҒзҙўеј•иҠӮзӮ№дҪҝз”ЁгҖҒI/OдәӢ件и·ҹиёӘзӯүпјҢиҝҷдәӣдҪҺйў‘зӮ№зҡ„жҺ’жҹҘжҖқи·ҜиҫғеӨҚжқӮпјҢдёҖиҲ¬йҒҮеҲ°зҡ„жңәдјҡд№ҹдёҚеӨҡпјҢеңЁиҝҷйҮҢжҲ‘们иҒҡз„ҰжңҖеёёи§Ғзҡ„дёҖдәӣе°ұеҸҜд»ҘдәҶгҖӮ
еҜ№жҜ”дёҠйқўзҡ„жҖ§иғҪе·Ҙе…·(Linux Performance Tools-full)еӣҫпјҢдёӢеӣҫзҡ„дјҳеҠҝеңЁдәҺпјҡжҠҠе…·дҪ“зҡ„е·Ҙе…·еҗҢжҖ§иғҪжҢҮж Үз»“еҗҲдәҶиө·жқҘпјҢеҗҢж—¶д»ҺдёҚеҗҢзҡ„еұӮж¬ЎеҺ»жҸҸиҝ°дәҶжҖ§иғҪ瓶йўҲзӮ№зҡ„еҲҶеёғпјҢе®һз”ЁжҖ§е’ҢеҸҜж“ҚдҪңжҖ§жӣҙејәдёҖдәӣгҖӮзі»з»ҹеұӮзҡ„е·Ҙе…·еҲҶдёәCPUгҖҒеҶ…еӯҳгҖҒзЈҒзӣҳпјҲеҗ«ж–Ү件系з»ҹпјүгҖҒзҪ‘з»ңеӣӣдёӘйғЁеҲҶпјҢе·Ҙе…·йӣҶеҗҢжҖ§иғҪе·Ҙе…·(Linux Performance Tools-full)еӣҫдёӯзҡ„е·Ҙе…·еҹәжң¬дёҖиҮҙгҖӮ组件еұӮе’Ңеә”з”ЁеұӮдёӯзҡ„е·Ҙе…·жһ„жҲҗдёәпјҡJDK жҸҗдҫӣзҡ„дёҖдәӣе·Ҙе…· + Trace е·Ҙе…· + dump еҲҶжһҗе·Ҙе…· + Profiling е·Ҙе…·зӯүгҖӮ
иҝҷйҮҢе°ұдёҚе…·дҪ“д»Ӣз»Қиҝҷдәӣе·Ҙе…·зҡ„е…·дҪ“з”Ёжі•дәҶпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ё man е‘Ҫд»Өеҫ—еҲ°е·Ҙе…·иҜҰе°Ҫзҡ„дҪҝз”ЁиҜҙжҳҺпјҢйҷӨжӯӨд№ӢеӨ–пјҢиҝҳжңүеҸҰеӨ–дёҖдёӘжҹҘиҜўе‘Ҫд»ӨжүӢеҶҢзҡ„ж–№жі•пјҡinfoгҖӮinfo еҸҜд»ҘзҗҶи§Јдёә man зҡ„иҜҰз»ҶзүҲжң¬пјҢеҰӮжһң man зҡ„иҫ“еҮәдёҚеӨӘеҘҪзҗҶи§ЈпјҢеҸҜд»ҘеҺ»еҸӮиҖғ info ж–ҮжЎЈпјҢе‘Ҫд»ӨеӨӘеӨҡпјҢи®°дёҚдҪҸд№ҹжІЎеҝ…иҰҒи®°дҪҸгҖӮ
В
В
дёҠйқўиҝҷеј еӣҫиҜҘеҰӮдҪ•дҪҝз”Ёпјҹ
йҰ–е…ҲпјҢиҷҪ然д»Һзі»з»ҹгҖҒ组件гҖҒеә”з”ЁдёӨдёӘдёүдёӘи§’еәҰеҺ»жҸҸиҝ°з“¶йўҲзӮ№зҡ„еҲҶеёғпјҢдҪҶеңЁе®һйҷ…иҝҗиЎҢж—¶пјҢиҝҷдёүиҖ…еҫҖеҫҖжҳҜзӣёиҫ…зӣёжҲҗгҖҒзӣёдә’еҪұе“Қзҡ„гҖӮзі»з»ҹжҳҜдёәеә”з”ЁжҸҗдҫӣдәҶиҝҗиЎҢж—¶зҺҜеўғпјҢжҖ§иғҪй—®йўҳзҡ„жң¬иҙЁе°ұжҳҜзі»з»ҹиө„жәҗиҫҫеҲ°дәҶдҪҝз”Ёзҡ„дёҠйҷҗпјҢеҸҚжҳ еңЁеә”з”ЁеұӮпјҢе°ұжҳҜеә”з”Ё/组件зҡ„еҗ„йЎ№жҢҮж ҮејҖе§ӢдёӢйҷҚпјӣиҖҢеә”з”Ё/组件зҡ„дёҚеҗҲзҗҶдҪҝз”Ёе’Ңи®ҫи®ЎпјҢд№ҹдјҡеҠ йҖҹзі»з»ҹиө„жәҗзҡ„иҖ—е°ҪгҖӮеӣ жӯӨпјҢеҲҶжһҗ瓶йўҲзӮ№ж—¶пјҢйңҖиҰҒжҲ‘们结еҗҲд»ҺдёҚеҗҢи§’еәҰеҲҶжһҗеҮәзҡ„з»“жһңпјҢжҠҪеҮәе…ұжҖ§пјҢеҫ—еҲ°жңҖз»Ҳзҡ„з»“и®әгҖӮ
е…¶ж¬ЎпјҢе»әи®®е…Ҳд»Һеә”з”ЁеұӮе…ҘжүӢпјҢеҲҶжһҗеӣҫдёӯж ҮжіЁзҡ„й«ҳйў‘жҢҮж ҮпјҢжҠ“еҮәжңҖйҮҚиҰҒзҡ„гҖҒжңҖеҸҜз–‘зҡ„гҖҒжңҖжңүеҸҜиғҪеҜјиҮҙжҖ§иғҪзҡ„зӮ№пјҢеҫ—еҲ°еҲқжӯҘзҡ„з»“и®әеҗҺпјҢеҶҚеҺ»зі»з»ҹеұӮиҝӣиЎҢйӘҢиҜҒгҖӮиҝҷж ·еҒҡзҡ„еҘҪеӨ„жҳҜпјҡеҫҲеӨҡжҖ§иғҪ瓶йўҲзӮ№дҪ“зҺ°еңЁзі»з»ҹеұӮпјҢдјҡжҳҜеӨҡеҸҳйҮҸе‘ҲзҺ°зҡ„пјҢиӯ¬еҰӮпјҢеә”з”ЁеұӮзҡ„еһғеңҫеӣһ收пјҲGCпјүжҢҮж ҮеҮәзҺ°дәҶејӮеёёпјҢйҖҡиҝҮ JDK иҮӘеёҰзҡ„е·Ҙе…·еҫҲе®№жҳ“и§ӮжөӢеҲ°пјҢдҪҶжҳҜдҪ“зҺ°еңЁзі»з»ҹеұӮдёҠпјҢдјҡеҸ‘зҺ°зі»з»ҹеҪ“еүҚзҡ„ CPU еҲ©з”ЁзҺҮгҖҒеҶ…еӯҳжҢҮж ҮйғҪдёҚеӨӘжӯЈеёёпјҢиҝҷе°ұз»ҷжҲ‘们зҡ„еҲҶжһҗжҖқи·ҜеёҰжқҘдәҶеӣ°жү°гҖӮ
жңҖеҗҺпјҢеҰӮжһң瓶йўҲзӮ№еңЁеә”з”ЁеұӮе’Ңзі»з»ҹеұӮеқҮе‘ҲзҺ°еҮәеӨҡеҸҳйҮҸеҲҶеёғпјҢе»әи®®жӯӨж—¶дҪҝз”Ё ZProfilerгҖҒJProfiler зӯүе·Ҙе…·еҜ№еә”з”ЁиҝӣиЎҢ ProfilingпјҢиҺ·еҸ–еә”з”Ёзҡ„з»јеҗҲжҖ§иғҪдҝЎжҒҜпјҲжіЁпјҡProfiling жҢҮзҡ„жҳҜеңЁеә”з”ЁиҝҗиЎҢж—¶пјҢйҖҡиҝҮдәӢ件пјҲEvent-basedпјүгҖҒз»ҹи®ЎжҠҪж ·пјҲSampling StatisticalпјүжҲ–жӨҚе…Ҙйҷ„еҠ жҢҮд»ӨпјҲByte-Code instrumentationпјүзӯүж–№жі•пјҢ收йӣҶеә”з”ЁиҝҗиЎҢж—¶зҡ„дҝЎжҒҜпјҢжқҘз ”з©¶еә”з”ЁиЎҢдёәзҡ„еҠЁжҖҒеҲҶжһҗж–№жі•пјүгҖӮиӯ¬еҰӮпјҢеҸҜд»ҘеҜ№ CPU иҝӣиЎҢжҠҪж ·з»ҹи®ЎпјҢз»“еҗҲеҗ„з§Қз¬ҰеҸ·иЎЁдҝЎжҒҜпјҢеҫ—еҲ°дёҖж®өж—¶й—ҙеҶ…еә”з”ЁеҶ…зҡ„д»Јз ҒзғӯзӮ№гҖӮ
дёӢйқўд»Ӣз»ҚеңЁдёҚеҗҢзҡ„еҲҶжһҗеұӮж¬ЎпјҢжҲ‘们йңҖиҰҒе…іжіЁзҡ„ж ёеҝғжҖ§иғҪжҢҮж ҮпјҢеҗҢж—¶пјҢд№ҹдјҡд»Ӣз»ҚеҰӮдҪ•еҲқжӯҘж №жҚ®иҝҷдәӣжҢҮж ҮпјҢеҲӨж–ӯзі»з»ҹжҲ–еә”з”ЁжҳҜеҗҰеӯҳеңЁжҖ§иғҪ瓶йўҲзӮ№пјҢиҮідәҺ瓶йўҲзӮ№зҡ„зЎ®и®ӨгҖҒ瓶йўҲзӮ№зҡ„жҲҗеӣ гҖҒи°ғдјҳжүӢж®өпјҢе°ҶдјҡеңЁдёӢдёҖйғЁеҲҶеұ•ејҖгҖӮ
3.1 CPU&&зәҝзЁӢ
е’Ң CPU зӣёе…ізҡ„жҢҮж Үдё»иҰҒжңүд»ҘдёӢеҮ дёӘгҖӮеёёз”Ёзҡ„е·Ҙе…·жңү topгҖҒ psгҖҒuptimeгҖҒ vmstatгҖҒ pidstatзӯүгҖӮ
- CPUеҲ©з”ЁзҺҮпјҲCPU Utilizationпјү
- CPU е№іеқҮиҙҹиҪҪпјҲLoad Averageпјү
- дёҠдёӢж–ҮеҲҮжҚўж¬Ўж•°пјҲContext Switchпјү
top - 12:20:57 up 25 days, 20:49, 2 users, load average: 0.93, 0.97, 0.79
Tasks: 51 total, 1 running, 50 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.6 us, 1.8 sy, 0.0 ni, 89.1 id, 0.1 wa, 0.0 hi, 0.1 si, 7.3 st
KiB Mem : 8388608 total, 476436 free, 5903224 used, 2008948 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
119680 admin 20 0 600908 72332 5768 S 2.3 0.9 52:32.61 obproxy
65877 root 20 0 93528 4936 2328 S 1.3 0.1 449:03.61 alisentry_cli
第дёҖиЎҢжҳҫзӨәзҡ„еҶ…е®№пјҡеҪ“еүҚж—¶й—ҙгҖҒзі»з»ҹиҝҗиЎҢж—¶й—ҙд»ҘеҸҠжӯЈеңЁзҷ»еҪ•з”ЁжҲ·ж•°гҖӮload average еҗҺзҡ„дёүдёӘж•°еӯ—пјҢдҫқж¬ЎиЎЁзӨәиҝҮеҺ» 1 еҲҶй’ҹгҖҒ5 еҲҶй’ҹгҖҒ15 еҲҶй’ҹзҡ„е№іеқҮиҙҹиҪҪпјҲLoad AverageпјүгҖӮе№іеқҮиҙҹиҪҪжҳҜжҢҮеҚ•дҪҚж—¶й—ҙеҶ…пјҢзі»з»ҹеӨ„дәҺеҸҜиҝҗиЎҢзҠ¶жҖҒпјҲжӯЈеңЁдҪҝз”Ё CPU жҲ–иҖ…жӯЈеңЁзӯүеҫ… CPU зҡ„иҝӣзЁӢпјҢR зҠ¶жҖҒпјүе’ҢдёҚеҸҜдёӯж–ӯзҠ¶жҖҒпјҲD зҠ¶жҖҒпјүзҡ„е№іеқҮиҝӣзЁӢж•°пјҢд№ҹе°ұжҳҜе№іеқҮжҙ»и·ғиҝӣзЁӢж•°пјҢCPU е№іеқҮиҙҹиҪҪе’Ң CPU дҪҝз”ЁзҺҮ并没жңүзӣҙжҺҘе…ізі»гҖӮ
第дёүиЎҢзҡ„еҶ…е®№иЎЁзӨә CPU еҲ©з”ЁзҺҮпјҢжҜҸдёҖеҲ—зҡ„еҗ«д№үеҸҜд»ҘдҪҝз”Ё man жҹҘзңӢгҖӮCPU дҪҝз”ЁзҺҮдҪ“зҺ°дәҶеҚ•дҪҚж—¶й—ҙеҶ… CPU дҪҝз”Ёжғ…еҶөзҡ„з»ҹи®ЎпјҢд»ҘзҷҫеҲҶжҜ”зҡ„ж–№ејҸеұ•зӨәгҖӮи®Ўз®—ж–№ејҸдёәпјҡCPU еҲ©з”ЁзҺҮ = 1 - пјҲCPU з©әй—Іж—¶й—ҙпјү/ CPU жҖ»зҡ„ж—¶й—ҙгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢйҖҡиҝҮжҖ§иғҪеҲҶжһҗе·Ҙе…·еҫ—еҲ°зҡ„ CPU зҡ„еҲ©з”ЁзҺҮе…¶е®һжҳҜжҹҗдёӘйҮҮж ·ж—¶й—ҙеҶ…зҡ„ CPU е№іеқҮеҖјгҖӮжіЁпјҡtop е·Ҙе…·жҳҫзӨәзҡ„зҡ„ CPU еҲ©з”ЁзҺҮжҳҜжҠҠжүҖжңү CPU ж ёзҡ„ж•°еҖјеҠ иө·жқҘзҡ„пјҢеҚі 8 ж ё CPU зҡ„еҲ©з”ЁзҺҮжңҖеӨ§еҸҜд»ҘеҲ°иҫҫ800%пјҲеҸҜд»Ҙз”Ё htop зӯүжӣҙж–°дёҖдәӣзҡ„е·Ҙе…·д»Јжӣҝ topпјүгҖӮ
дҪҝз”Ё vmstat е‘Ҫд»ӨпјҢеҸҜд»ҘжҹҘзңӢеҲ°гҖҢдёҠдёӢж–ҮеҲҮжҚўж¬Ўж•°гҖҚиҝҷдёӘжҢҮж ҮпјҢеҰӮдёӢиЎЁжүҖзӨәпјҢжҜҸйҡ”1з§’иҫ“еҮә1з»„ж•°жҚ®пјҡ
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 504804 0 1967508 0 0 644 33377 0 1 2 2 88 0 9
дёҠиЎЁзҡ„ csпјҲcontext switchпјү е°ұжҳҜжҜҸз§’дёҠдёӢж–ҮеҲҮжҚўзҡ„ж¬Ўж•°пјҢжҢүз…§дёҚеҗҢеңәжҷҜпјҢCPU дёҠдёӢж–ҮеҲҮжҚўиҝҳеҸҜд»ҘеҲҶдёәдёӯж–ӯдёҠдёӢж–ҮеҲҮжҚўгҖҒзәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўе’ҢиҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўдёүз§ҚпјҢдҪҶжҳҜж— и®әжҳҜе“ӘдёҖз§ҚпјҢиҝҮеӨҡзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢйғҪдјҡжҠҠ CPU ж—¶й—ҙж¶ҲиҖ—еңЁеҜ„еӯҳеҷЁгҖҒеҶ…ж ёж Ҳд»ҘеҸҠиҷҡжӢҹеҶ…еӯҳзӯүж•°жҚ®зҡ„дҝқеӯҳе’ҢжҒўеӨҚдёҠпјҢд»ҺиҖҢзј©зҹӯиҝӣзЁӢзңҹжӯЈиҝҗиЎҢзҡ„ж—¶й—ҙпјҢеҜјиҮҙзі»з»ҹзҡ„ж•ҙдҪ“жҖ§иғҪеӨ§е№…дёӢйҷҚгҖӮvmstat зҡ„иҫ“еҮәдёӯ usгҖҒsy еҲҶеҲ«з”ЁжҲ·жҖҒе’ҢеҶ…ж ёжҖҒзҡ„ CPU еҲ©з”ЁзҺҮпјҢиҝҷдёӨдёӘеҖјд№ҹйқһеёёе…·жңүеҸӮиҖғж„Ҹд№үгҖӮ
vmstat зҡ„иҫ“еҸӘз»ҷеҮәдәҶзі»з»ҹжҖ»дҪ“зҡ„дёҠдёӢж–ҮеҲҮжҚўжғ…еҶөпјҢиҰҒжғіжҹҘзңӢжҜҸдёӘиҝӣзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўиҜҰжғ…пјҲеҰӮиҮӘж„ҝе’ҢйқһиҮӘж„ҝеҲҮжҚўпјүпјҢйңҖиҰҒдҪҝз”Ё pidstatпјҢиҜҘе‘Ҫд»ӨиҝҳеҸҜд»ҘжҹҘзңӢжҹҗдёӘиҝӣзЁӢз”ЁжҲ·жҖҒе’ҢеҶ…ж ёжҖҒзҡ„ CPU еҲ©з”ЁзҺҮгҖӮ
В

В
CPU зӣёе…іжҢҮж ҮејӮеёёзҡ„еҲҶжһҗжҖқи·ҜжҳҜд»Җд№Ҳпјҹ
1пјүCPU еҲ©з”ЁзҺҮпјҡеҰӮжһңжҲ‘们и§ӮеҜҹжҹҗж®өж—¶й—ҙзі»з»ҹжҲ–еә”з”ЁиҝӣзЁӢзҡ„ CPUеҲ©з”ЁзҺҮдёҖзӣҙеҫҲй«ҳпјҲеҚ•дёӘ core и¶…иҝҮ80%пјүпјҢйӮЈд№Ҳе°ұеҖјеҫ—жҲ‘们иӯҰжғ•дәҶгҖӮжҲ‘们еҸҜд»ҘеӨҡж¬ЎдҪҝз”Ё jstack е‘Ҫд»Ө dump еә”з”ЁзәҝзЁӢж ҲжҹҘзңӢзғӯзӮ№д»Јз ҒпјҢйқһ Java еә”з”ЁеҸҜд»ҘзӣҙжҺҘдҪҝз”Ё perf иҝӣиЎҢ CPU йҮҮйҮҮж ·пјҢзҰ»зәҝеҲҶжһҗйҮҮж ·ж•°жҚ®еҗҺеҫ—еҲ° CPU жү§иЎҢзғӯзӮ№пјҲJava еә”з”ЁйңҖиҰҒз¬ҰеҸ·иЎЁиҝӣиЎҢе Ҷж ҲдҝЎжҒҜжҳ е°„пјҢдёҚиғҪзӣҙжҺҘдҪҝз”Ё perfеҫ—еҲ°з»“жһңпјүгҖӮ
2пјүCPU е№іеқҮиҙҹиҪҪпјҡе№іеқҮиҙҹиҪҪй«ҳдәҺ CPU ж•°йҮҸ 70%пјҢж„Ҹе‘ізқҖзі»з»ҹеӯҳеңЁз“¶йўҲзӮ№пјҢйҖ жҲҗиҙҹиҪҪеҚҮй«ҳзҡ„еҺҹеӣ жңүеҫҲеӨҡпјҢеңЁиҝҷйҮҢе°ұдёҚеұ•ејҖдәҶгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢйҖҡиҝҮзӣ‘жҺ§зі»з»ҹзӣ‘жөӢе№іеқҮиҙҹиҪҪзҡ„еҸҳеҢ–и¶ӢеҠҝпјҢжӣҙе®№жҳ“е®ҡдҪҚй—®йўҳпјҢжңүж—¶еҖҷеӨ§ж–Ү件зҡ„еҠ иҪҪзӯүпјҢд№ҹдјҡеҜјиҮҙе№іеқҮиҙҹиҪҪзһ¬ж—¶еҚҮй«ҳгҖӮеҰӮжһң 1 еҲҶй’ҹ/5 еҲҶй’ҹ/15 еҲҶй’ҹзҡ„дёүдёӘеҖјзӣёе·®дёҚеӨ§пјҢйӮЈиҜҙжҳҺзі»з»ҹиҙҹиҪҪеҫҲе№ізЁіпјҢеҲҷдёҚз”Ёе…іжіЁпјҢеҰӮжһңиҝҷдёүдёӘеҖјйҖҗжёҗйҷҚдҪҺпјҢиҜҙжҳҺиҙҹиҪҪеңЁжёҗжёҗеҚҮй«ҳпјҢйңҖиҰҒе…іжіЁж•ҙдҪ“жҖ§иғҪпјӣ
3пјүCPU дёҠдёӢж–ҮеҲҮжҚўпјҡдёҠдёӢж–ҮеҲҮжҚўиҝҷдёӘжҢҮж ҮпјҢ并没жңүз»ҸйӘҢеҖјеҸҜжҺЁиҚҗпјҲеҮ еҚҒеҲ°еҮ дёҮйғҪжңүеҸҜиғҪпјүпјҢиҝҷдёӘжҢҮж ҮеҖјеҸ–еҶідәҺзі»з»ҹжң¬иә«зҡ„ CPU жҖ§иғҪпјҢд»ҘеҸҠеҪ“еүҚеә”з”Ёе·ҘдҪңзҡ„жғ…еҶөгҖӮдҪҶжҳҜпјҢеҰӮжһңзі»з»ҹжҲ–иҖ…еә”з”Ёзҡ„дёҠдёӢж–ҮеҲҮжҚўж¬Ўж•°еҮәзҺ°ж•°йҮҸзә§зҡ„еўһй•ҝпјҢе°ұжңүеҫҲеӨ§жҰӮзҺҮиҜҙжҳҺеӯҳеңЁжҖ§иғҪй—®йўҳпјҢеҰӮйқһиҮӘж„ҝдёҠдёӢеҲҮжҚўеӨ§е№…еәҰдёҠеҚҮпјҢиҜҙжҳҺжңүеӨӘеӨҡзҡ„зәҝзЁӢеңЁз«һдәү CPUгҖӮ
дёҠйқўиҝҷдёүдёӘжҢҮж ҮжҳҜеҜҶеҲҮзӣёе…ізҡ„пјҢеҰӮйў‘з№Ғзҡ„ CPU дёҠдёӢж–ҮеҲҮжҚўпјҢеҸҜиғҪдјҡеҜјиҮҙе№іеқҮиҙҹиҪҪеҚҮй«ҳгҖӮеҰӮдҪ•ж №жҚ®иҝҷдёүиҖ…д№Ӣй—ҙзҡ„е…ізі»иҝӣиЎҢеә”з”Ёи°ғдјҳпјҢе°ҶеңЁдёӢдёҖйғЁеҲҶд»Ӣз»ҚгҖӮ
CPU дёҠзҡ„зҡ„дёҖдәӣејӮеҠЁпјҢйҖҡеёёд№ҹеҸҜд»Ҙд»ҺзәҝзЁӢдёҠи§ӮжөӢеҲ°пјҢдҪҶйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢзәҝзЁӢй—®йўҳ并дёҚе®Ңе…Ёе’Ң CPU зӣёе…ігҖӮдёҺзәҝзЁӢзӣёе…ізҡ„жҢҮж ҮпјҢдё»иҰҒжңүдёӢйқўеҮ дёӘпјҲеқҮйғҪеҸҜд»ҘйҖҡиҝҮ JDK иҮӘеёҰзҡ„ jstack е·Ҙе…·зӣҙжҺҘжҲ–й—ҙжҺҘеҫ—еҲ°пјүпјҡ
- еә”з”Ёдёӯзҡ„жҖ»зҡ„зәҝзЁӢж•°пјӣ
- еә”з”Ёдёӯеҗ„дёӘзәҝзЁӢзҠ¶жҖҒзҡ„еҲҶеёғпјӣ
- зәҝзЁӢй”Ғзҡ„дҪҝз”Ёжғ…еҶөпјҢеҰӮжӯ»й”ҒгҖҒй”ҒеҲҶеёғзӯүпјӣ
е…ідәҺзәҝзЁӢпјҢеҸҜе…іжіЁзҡ„ејӮеёёжңүпјҡ
1пјүзәҝзЁӢжҖ»ж•°жҳҜеҗҰиҝҮеӨҡгҖӮиҝҮеӨҡзҡ„зәҝзЁӢпјҢдҪ“зҺ°еңЁ CPU дёҠе°ұжҳҜеҜјиҮҙйў‘з№Ғзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢеҗҢж—¶зәҝзЁӢиҝҮеӨҡд№ҹдјҡж¶ҲиҖ—еҶ…еӯҳпјҢзәҝзЁӢжҖ»ж•°еӨ§е°Ҹе’Ңеә”з”Ёжң¬иә«е’ҢжңәеҷЁй…ҚзҪ®зӣёе…іпјӣ
2пјүзәҝзЁӢзҡ„зҠ¶жҖҒжҳҜеҗҰејӮеёёгҖӮи§ӮеҜҹ WAITING/BLOCKED зәҝзЁӢжҳҜеҗҰиҝҮеӨҡпјҲзәҝзЁӢж•°и®ҫзҪ®иҝҮеӨҡжҲ–й”Ғз«һдәүеү§зғҲпјүпјҢз»“еҗҲеә”з”ЁеҶ…йғЁй”ҒдҪҝз”Ёзҡ„жғ…еҶөз»јеҗҲеҲҶжһҗпјӣ
3пјүз»“еҗҲ CPU еҲ©з”ЁзҺҮпјҢи§ӮеҜҹжҳҜеҗҰеӯҳеңЁеӨ§йҮҸж¶ҲиҖ— CPU зҡ„зәҝзЁӢгҖӮ
В

В
3.2 еҶ…еӯҳ&&е Ҷ
е’ҢеҶ…еӯҳзӣёе…ізҡ„жҢҮж Үдё»иҰҒжңүд»ҘдёӢеҮ дёӘпјҢеёёз”Ёзҡ„еҲҶжһҗе·Ҙе…·жңүпјҡtopгҖҒfreeгҖҒvmstatгҖҒpidstat д»ҘеҸҠ JDK иҮӘеёҰзҡ„дёҖдәӣе·Ҙе…·гҖӮ
- зі»з»ҹеҶ…еӯҳзҡ„дҪҝз”Ёжғ…еҶөпјҢеҢ…жӢ¬еү©дҪҷеҶ…еӯҳгҖҒе·Із”ЁеҶ…еӯҳгҖҒеҸҜз”ЁеҶ…еӯҳгҖҒзј“еӯҳ/зј“еҶІеҢәпјӣ
- иҝӣзЁӢпјҲеҗ« Java иҝӣзЁӢпјүзҡ„иҷҡжӢҹеҶ…еӯҳгҖҒеёёй©»еҶ…еӯҳгҖҒе…ұдә«еҶ…еӯҳпјӣ
- иҝӣзЁӢзҡ„зјәйЎөејӮеёёж•°пјҢеҢ…еҗ«дё»зјәйЎөејӮеёёе’Ңж¬ЎзјәйЎөејӮеёёпјӣ
- Swap жҚўе…Ҙе’ҢжҚўеҮәзҡ„еҶ…еӯҳеӨ§е°ҸгҖҒSwap еҸӮж•°й…ҚзҪ®пјӣ
- JVM е Ҷзҡ„еҲҶй…ҚпјҢJVM еҗҜеҠЁеҸӮж•°пјӣ
- JVM е Ҷзҡ„еӣһ收пјҢGC жғ…еҶөгҖӮ
дҪҝз”Ё free еҸҜд»ҘжҹҘзңӢзі»з»ҹеҶ…еӯҳзҡ„дҪҝз”Ёжғ…еҶөе’Ң Swap еҲҶеҢәзҡ„дҪҝз”Ёжғ…еҶөпјҢtop е·Ҙе…·еҸҜд»Ҙе…·дҪ“еҲ°жҜҸдёӘиҝӣзЁӢпјҢеҰӮжҲ‘们еҸҜд»Ҙз”ЁдҪҝз”Ё top е·Ҙе…·жҹҘзңӢ Java иҝӣзЁӢзҡ„еёёй©»еҶ…еӯҳеӨ§е°ҸпјҲRESпјүпјҢиҝҷдёӨдёӘе·Ҙе…·з»“еҗҲиө·жқҘпјҢеҸҜз”ЁиҰҶзӣ–еӨ§еӨҡж•°еҶ…еӯҳжҢҮж ҮгҖӮдёӢйқўжҳҜдҪҝз”Ё freeе‘Ҫд»Өзҡ„иҫ“еҮәпјҡ
$free -h
total used free shared buff/cache available
Mem: 125G 6.8G 54G 2.5M 64G 118G
Swap: 2.0G 305M 1.7G
дёҠиҝ°иҫ“еҮәеҗ„еҲ—зҡ„е…·дҪ“еҗ«д№үеңЁиҝҷйҮҢдёҚеңЁиөҳиҝ°пјҢд№ҹжҜ”иҫғе®№жҳ“зҗҶи§ЈгҖӮйҮҚзӮ№д»Ӣз»ҚдёӢ swap е’Ң buff/cache иҝҷдёӨдёӘжҢҮж ҮгҖӮ
Swap зҡ„дҪңз”ЁжҳҜжҠҠдёҖдёӘжң¬ең°ж–Ү件жҲ–иҖ…дёҖеқ—зЈҒзӣҳз©әй—ҙдҪңдёәеҶ…еӯҳжқҘдҪҝз”ЁпјҢеҢ…жӢ¬жҚўеҮәе’ҢжҚўе…ҘдёӨдёӘиҝҮзЁӢгҖӮSwap йңҖиҰҒиҜ»еҶҷзЈҒзӣҳпјҢжүҖд»ҘжҖ§иғҪдёҚжҳҜеҫҲй«ҳпјҢдәӢе®һдёҠпјҢеҢ…жӢ¬ ElasticSearch гҖҒHadoop еңЁеҶ…з»қеӨ§йғЁеҲҶ Java еә”з”ЁйғҪе»әи®®е…іжҺү SwapпјҢиҝҷжҳҜеӣ дёәеҶ…еӯҳзҡ„жҲҗжң¬дёҖзӣҙеңЁйҷҚдҪҺпјҢеҗҢж—¶иҝҷд№ҹе’Ң JVM зҡ„еһғеңҫеӣһ收иҝҮзЁӢжңүе…іпјҡJVMеңЁ GC зҡ„ж—¶еҖҷдјҡйҒҚеҺҶжүҖжңүз”ЁеҲ°зҡ„е Ҷзҡ„еҶ…еӯҳпјҢеҰӮжһңиҝҷйғЁеҲҶеҶ…еӯҳиў« Swap еҮәеҺ»дәҶпјҢйҒҚеҺҶзҡ„ж—¶еҖҷе°ұдјҡжңүзЈҒзӣҳ I/O дә§з”ҹгҖӮSwap еҲҶеҢәзҡ„еҚҮй«ҳдёҖиҲ¬е’ҢзЈҒзӣҳзҡ„дҪҝз”Ёејәзӣёе…іпјҢе…·дҪ“еҲҶжһҗж—¶пјҢйңҖиҰҒз»“еҗҲзј“еӯҳдҪҝз”Ёжғ…еҶөгҖҒswappiness йҳҲеҖјд»ҘеҸҠеҢҝеҗҚйЎөе’Ңж–Ү件йЎөзҡ„жҙ»и·ғжғ…еҶөз»јеҗҲеҲҶжһҗгҖӮ
buff/cache жҳҜзј“еӯҳе’Ңзј“еҶІеҢәзҡ„еӨ§е°ҸгҖӮзј“еӯҳпјҲcacheпјүпјҡжҳҜд»ҺзЈҒзӣҳиҜ»еҸ–зҡ„ж–Ү件зҡ„жҲ–иҖ…еҗ‘зЈҒзӣҳеҶҷж–Ү件时зҡ„дёҙж—¶еӯҳеӮЁж•°жҚ®пјҢйқўеҗ‘ж–Ү件гҖӮдҪҝз”Ё cachestat еҸҜд»ҘжҹҘзңӢж•ҙдёӘзі»з»ҹзј“еӯҳзҡ„иҜ»еҶҷе‘Ҫдёӯжғ…еҶөпјҢдҪҝз”Ё cachetop еҸҜд»Ҙи§ӮеҜҹжҜҸдёӘиҝӣзЁӢзј“еӯҳзҡ„иҜ»еҶҷе‘Ҫдёӯжғ…еҶөгҖӮзј“еҶІеҢәпјҲbufferпјүжҳҜеҶҷе…ҘзЈҒзӣҳж•°жҚ®жҲ–д»ҺзЈҒзӣҳзӣҙжҺҘиҜ»еҸ–зҡ„ж•°жҚ®зҡ„дёҙж—¶еӯҳеӮЁпјҢйқўеҗ‘еқ—и®ҫеӨҮгҖӮfree е‘Ҫд»Өзҡ„иҫ“еҮәдёӯпјҢиҝҷдёӨдёӘжҢҮж ҮжҳҜеҠ еңЁдёҖиө·зҡ„пјҢдҪҝз”Ё vmstat е‘Ҫд»ӨеҸҜд»ҘеҢәеҲҶзј“еӯҳе’Ңзј“еҶІеҢәпјҢиҝҳеҸҜд»ҘзңӢеҲ° Swap еҲҶеҢәжҚўе…Ҙе’ҢжҚўеҮәзҡ„еҶ…еӯҳеӨ§е°ҸгҖӮ
дәҶи§ЈеҲ°еёёи§Ғзҡ„еҶ…еӯҳжҢҮж ҮеҗҺпјҢеёёи§Ғзҡ„еҶ…еӯҳй—®йўҳеҸҲжңүе“ӘдәӣпјҹжҖ»з»“еҰӮдёӢпјҡ
- зі»з»ҹеү©дҪҷеҶ…еӯҳ/еҸҜз”ЁдёҚи¶іпјҲжҹҗдёӘиҝӣзЁӢеҚ з”ЁеӨӘеӨҡгҖҒзі»з»ҹжң¬иә«еҶ…еӯҳдёҚи¶іпјүпјҢеҶ…еӯҳжәўеҮәпјӣ
- еҶ…еӯҳеӣһ收ејӮеёёпјҡеҶ…еӯҳжі„жјҸпјҲиҝӣзЁӢеңЁдёҖж®өж—¶й—ҙеҶ…еҶ…еӯҳдҪҝз”ЁжҢҒз»ӯиө°й«ҳпјүгҖҒGC йў‘зҺҮејӮеёёпјӣ
- зј“еӯҳдҪҝз”ЁиҝҮеӨ§пјҲеӨ§ж–Ү件иҜ»еҸ–жҲ–еҶҷе…ҘпјүгҖҒзј“еӯҳе‘ҪдёӯзҺҮдёҚй«ҳпјӣ
- зјәйЎөејӮеёёиҝҮеӨҡпјҲйў‘з№Ғзҡ„ I/O иҜ»пјүпјӣ
- Swap еҲҶеҢәдҪҝз”ЁејӮеёёпјҲдҪҝз”ЁиҝҮеӨ§пјүпјӣ
еҶ…еӯҳзӣёе…іжҢҮж ҮејӮеёёеҗҺпјҢеҲҶжһҗжҖқи·ҜжҳҜжҖҺд№Ҳж ·зҡ„пјҹ
- дҪҝз”Ё free/top жҹҘзңӢеҶ…еӯҳзҡ„е…ЁеұҖдҪҝз”Ёжғ…еҶөпјҢеҰӮзі»з»ҹеҶ…еӯҳзҡ„дҪҝз”ЁгҖҒSwap еҲҶеҢәеҶ…еӯҳдҪҝз”ЁгҖҒзј“еӯҳ/зј“еҶІеҢәеҚ з”Ёжғ…еҶөзӯүпјҢеҲқжӯҘеҲӨж–ӯеҶ…еӯҳй—®йўҳеӯҳеңЁзҡ„ж–№еҗ‘пјҡиҝӣзЁӢеҶ…еӯҳгҖҒзј“еӯҳ/зј“еҶІеҢәгҖҒSwap еҲҶеҢәпјӣ
- и§ӮеҜҹдёҖж®өж—¶й—ҙеҶ…еӯҳзҡ„дҪҝз”Ёи¶ӢеҠҝгҖӮеҰӮйҖҡиҝҮ vmstat и§ӮеҜҹеҶ…еӯҳдҪҝз”ЁжҳҜеҗҰдёҖзӣҙеңЁеўһй•ҝпјӣйҖҡиҝҮ jmap е®ҡж—¶з»ҹи®ЎеҜ№иұЎеҶ…еӯҳеҲҶеёғжғ…еҶөпјҢеҲӨж–ӯжҳҜеҗҰеӯҳеңЁеҶ…еӯҳжі„жјҸпјҢйҖҡиҝҮ cachetop е‘Ҫд»ӨпјҢе®ҡдҪҚзј“еҶІеҢәеҚҮй«ҳзҡ„ж №жәҗзӯүпјӣ
- ж №жҚ®еҶ…еӯҳй—®йўҳзҡ„зұ»еһӢпјҢз»“еҗҲеә”з”Ёжң¬иә«пјҢиҝӣиЎҢиҜҰз»ҶеҲҶжһҗгҖӮ
дёҫдҫӢпјҡдҪҝз”Ё free еҸ‘зҺ°зј“еӯҳ/зј“еҶІеҢәеҚ з”ЁдёҚеӨ§пјҢжҺ’йҷӨзј“еӯҳ/зј“еҶІеҢәеҜ№еҶ…еӯҳзҡ„еҪұе“ҚеҗҺ -> дҪҝз”Ё vmstat жҲ–иҖ… sar и§ӮеҜҹдёҖдёӢеҗ„дёӘиҝӣзЁӢеҶ…еӯҳдҪҝз”ЁеҸҳеҢ–и¶ӢеҠҝ -> еҸ‘зҺ°жҹҗдёӘиҝӣзЁӢзҡ„еҶ…еӯҳж—¶еҖҷз”ЁжҢҒз»ӯиө°й«ҳ -> еҰӮжһңжҳҜ Java еә”з”ЁпјҢеҸҜд»ҘдҪҝз”Ё jmap / VisualVM / heap dump еҲҶжһҗзӯүе·Ҙе…·и§ӮеҜҹеҜ№иұЎеҶ…еӯҳзҡ„еҲҶй…ҚпјҢжҲ–иҖ…йҖҡиҝҮ jstat и§ӮеҜҹ GC еҗҺзҡ„еә”з”ЁеҶ…еӯҳеҸҳеҢ– -> з»“еҗҲдёҡеҠЎеңәжҷҜпјҢе®ҡдҪҚдёәеҶ…еӯҳжі„жјҸ/GCеҸӮж•°й…ҚзҪ®дёҚеҗҲзҗҶ/дёҡеҠЎд»Јз ҒејӮеёёзӯүгҖӮ
3.3 зЈҒзӣҳ&&ж–Ү件
еңЁеҲҶжһҗе’ҢзЈҒзӣҳзӣёе…ізҡ„й—®йўҳж—¶пјҢйҖҡеёёжҳҜе°Ҷе…¶е’Ңж–Ү件系з»ҹеҗҢж—¶иҖғиҷ‘зҡ„пјҢдёӢйқўдёҚеҶҚеҢәеҲҶгҖӮе’ҢзЈҒзӣҳ/ж–Ү件系з»ҹзӣёе…ізҡ„жҢҮж Үдё»иҰҒжңүд»ҘдёӢеҮ дёӘпјҢеёёз”Ёзҡ„и§ӮжөӢе·Ҙе…·дёә iostatе’Ң pidstatпјҢеүҚиҖ…йҖӮз”ЁдәҺж•ҙдёӘзі»з»ҹпјҢеҗҺиҖ…еҸҜи§ӮеҜҹе…·дҪ“иҝӣзЁӢзҡ„ I/OгҖӮ
- зЈҒзӣҳ I/O еҲ©з”ЁзҺҮпјҡжҳҜжҢҮзЈҒзӣҳеӨ„зҗҶ I/O зҡ„ж—¶й—ҙзҷҫеҲҶжҜ”пјӣ
- зЈҒзӣҳеҗһеҗҗйҮҸпјҡжҳҜжҢҮжҜҸз§’зҡ„ I/O иҜ·жұӮеӨ§е°ҸпјҢеҚ•дҪҚдёә KB;
- I/O е“Қеә”ж—¶й—ҙпјҢжҳҜжҢҮ I/O иҜ·жұӮд»ҺеҸ‘еҮәеҲ°ж”¶еҲ°е“Қеә”зҡ„й—ҙйҡ”пјҢеҢ…еҗ«еңЁйҳҹеҲ—дёӯзҡ„зӯүеҫ…ж—¶й—ҙе’Ңе®һйҷ…еӨ„зҗҶж—¶й—ҙпјӣ
- IOPSпјҲInput/Output Per SecondпјүпјҡжҜҸз§’зҡ„ I/O иҜ·жұӮж•°пјӣ
- I/O зӯүеҫ…йҳҹеҲ—еӨ§е°ҸпјҢжҢҮзҡ„жҳҜе№іеқҮ I/O йҳҹеҲ—й•ҝеәҰпјҢйҳҹеҲ—й•ҝеәҰи¶Ҡзҹӯи¶ҠеҘҪпјӣ
дҪҝз”Ё iostat зҡ„иҫ“еҮәз•ҢйқўеҰӮдёӢпјҡ
$iostat -dx
Linux 3.10.0-327.ali2010.alios7.x86_64 (loginhost2.alipay.em14) 10/20/2019В x86_64(32 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.01 15.49 0.05 8.21 3.10 240.49 58.92 0.04 4.38 2.39 4.39 0.09 0.07
дёҠеӣҫдёӯ %util пјҢеҚідёәзЈҒзӣҳ I/O еҲ©з”ЁзҺҮпјҢеҗҢ CPU еҲ©з”ЁзҺҮдёҖж ·пјҢиҝҷдёӘеҖјд№ҹеҸҜиғҪи¶…иҝҮ 100%пјҲеӯҳеңЁе№¶иЎҢ I/OпјүпјӣrkB/s е’Ң wkB/sеҲҶеҲ«иЎЁзӨәжҜҸз§’д»ҺзЈҒзӣҳиҜ»еҸ–е’ҢеҶҷе…Ҙзҡ„ж•°жҚ®йҮҸпјҢеҚіеҗһеҗҗйҮҸпјҢеҚ•дҪҚдёә KBпјӣзЈҒзӣҳ I/OеӨ„зҗҶж—¶й—ҙзҡ„жҢҮж Үдёә r_await е’Ң w_await еҲҶеҲ«иЎЁзӨәиҜ»/еҶҷиҜ·жұӮеӨ„зҗҶе®ҢжҲҗзҡ„е“Қеә”ж—¶й—ҙпјҢsvctm иЎЁзӨәеӨ„зҗҶ I/O жүҖйңҖиҰҒзҡ„е№іеқҮж—¶й—ҙпјҢиҜҘжҢҮж Үе·Іиў«еәҹејғпјҢж— е®һйҷ…ж„Ҹд№үгҖӮr/s + w/s дёә IOPS жҢҮж ҮпјҢеҲҶеҲ«иЎЁзӨәжҜҸз§’еҸ‘йҖҒз»ҷзЈҒзӣҳзҡ„иҜ»иҜ·жұӮж•°е’ҢеҶҷиҜ·жұӮж•°пјӣaqu-sz иЎЁзӨәзӯүеҫ…йҳҹеҲ—зҡ„й•ҝеәҰгҖӮ
pidstat зҡ„иҫ“еҮәеӨ§йғЁеҲҶе’Ң iostat зұ»дјјпјҢеҢәеҲ«еңЁдәҺе®ғеҸҜд»Ҙе®һж—¶жҹҘзңӢжҜҸдёӘиҝӣзЁӢзҡ„ I/O жғ…еҶөгҖӮ
еҰӮдҪ•еҲӨж–ӯзЈҒзӣҳзҡ„жҢҮж ҮеҮәзҺ°дәҶејӮеёёпјҹ
- еҪ“зЈҒзӣҳ I/O еҲ©з”ЁзҺҮй•ҝж—¶й—ҙи¶…иҝҮ 80%пјҢжҲ–иҖ…е“Қеә”ж—¶й—ҙиҝҮеӨ§пјҲеҜ№дәҺ SSDпјҢд»Һ 0.0x жҜ«з§’еҲ° 1.x жҜ«з§’дёҚзӯүпјҢжңәжў°зЈҒзӣҳдёҖиҲ¬дёә5ms~10msпјүпјҢйҖҡеёёж„Ҹе‘ізқҖзЈҒзӣҳ I/O еӯҳеңЁжҖ§иғҪ瓶йўҲпјӣ
- еҰӮжһң %util еҫҲеӨ§пјҢиҖҢ rkB/s е’Ң wkB/s еҫҲе°ҸпјҢдёҖиҲ¬жҳҜеӣ дёәеӯҳеңЁиҫғеӨҡзҡ„зЈҒзӣҳйҡҸжңәиҜ»еҶҷпјҢжңҖеҘҪжҠҠйҡҸжңәиҜ»еҶҷдјҳеҢ–жҲҗйЎәеәҸиҜ»еҶҷпјҢпјҲеҸҜд»ҘйҖҡиҝҮ strace жҲ–иҖ… blktrace и§ӮеҜҹ I/O жҳҜеҗҰиҝһз»ӯеҲӨж–ӯжҳҜеҗҰжҳҜйЎәеәҸзҡ„иҜ»еҶҷиЎҢдёәпјҢйҡҸжңәиҜ»еҶҷеә”еҸҜе…іжіЁ IOPS жҢҮж ҮпјҢйЎәеәҸиҜ»еҶҷеҸҜе…іжіЁеҗһеҗҗйҮҸжҢҮж Үпјүпјӣ
- еҰӮжһң avgqu-sz жҜ”иҫғеӨ§пјҢиҜҙжҳҺжңүеҫҲеӨҡ I/O иҜ·жұӮеңЁйҳҹеҲ—дёӯзӯүеҫ…гҖӮдёҖиҲ¬жқҘиҜҙпјҢеҰӮжһңеҚ•еқ—зЈҒзӣҳзҡ„йҳҹеҲ—й•ҝеәҰжҢҒз»ӯи¶…иҝҮ2пјҢдёҖиҲ¬и®ӨдёәиҜҘзЈҒзӣҳеӯҳеңЁ I/O жҖ§иғҪй—®йўҳгҖӮ
В
В
3.4 зҪ‘з»ң
зҪ‘з»ңиҝҷдёӘжҰӮеҝөж¶өзӣ–зҡ„иҢғеӣҙиҫғе№ҝпјҢеңЁеә”з”ЁеұӮгҖҒдј иҫ“еұӮгҖҒзҪ‘з»ңеұӮгҖҒзҪ‘з»ңжҺҘеҸЈеұӮйғҪжңүдёҚеҗҢзҡ„жҢҮж ҮеҺ»иЎЎйҮҸгҖӮиҝҷйҮҢжҲ‘们讨и®әзҡ„гҖҢзҪ‘з»ңгҖҚпјҢзү№жҢҮеә”з”ЁеұӮзҡ„зҪ‘з»ңпјҢйҖҡеёёдҪҝз”Ёзҡ„жҢҮж ҮеҰӮдёӢ:
- зҪ‘з»ңеёҰе®ҪпјҡиЎЁзӨәй“ҫи·Ҝзҡ„жңҖеӨ§дј иҫ“йҖҹзҺҮпјӣ
- зҪ‘з»ңеҗһеҗҗпјҡиЎЁзӨәеҚ•дҪҚж—¶й—ҙеҶ…жҲҗеҠҹдј иҫ“зҡ„ж•°жҚ®йҮҸеӨ§е°Ҹпјӣ
- зҪ‘з»ң延时пјҡиЎЁзӨәд»ҺзҪ‘з»ңиҜ·жұӮеҸ‘еҮәеҗҺзӣҙеҲ°ж”¶еҲ°иҝңз«Ҝе“Қеә”пјҢжүҖйңҖиҰҒзҡ„ж—¶й—ҙпјӣ
- зҪ‘з»ңиҝһжҺҘж•°е’Ңй”ҷиҜҜж•°пјӣ
дёҖиҲ¬жқҘиҜҙпјҢеә”з”ЁеұӮзҡ„зҪ‘з»ң瓶йўҲжңүеҰӮдёӢеҮ зұ»пјҡ
- йӣҶзҫӨжҲ–жңәеҷЁжүҖеңЁзҡ„жңәжҲҝзҡ„зҪ‘з»ңеёҰе®ҪйҘұе’ҢпјҢеҪұе“Қеә”з”Ё QPS/TPS зҡ„жҸҗеҚҮпјӣ
- зҪ‘з»ңеҗһеҗҗеҮәзҺ°ејӮеёёпјҢеҰӮжҺҘеҸЈеӯҳеңЁеӨ§йҮҸзҡ„ж•°жҚ®дј иҫ“пјҢйҖ жҲҗеёҰе®ҪеҚ з”ЁиҝҮй«ҳпјӣ
- зҪ‘з»ңиҝһжҺҘеҮәзҺ°ејӮеёёжҲ–й”ҷиҜҜпјӣ
- зҪ‘з»ңеҮәзҺ°еҲҶеҢәгҖӮ
еёҰе®Ҫе’ҢзҪ‘з»ңеҗһеҗҗиҝҷдёӨдёӘжҢҮж ҮпјҢдёҖиҲ¬жҲ‘们дјҡе…іжіЁж•ҙдёӘеә”з”Ёзҡ„пјҢйҖҡиҝҮзӣ‘жҺ§зі»з»ҹеҸҜзӣҙжҺҘеҫ—еҲ°пјҢеҰӮжһңдёҖж®өж—¶й—ҙеҶ…еҮәзҺ°дәҶжҳҺжҳҫзҡ„жҢҮж ҮдёҠеҚҮпјҢиҜҙжҳҺеӯҳеңЁзҪ‘з»ңжҖ§иғҪ瓶йўҲгҖӮеҜ№дәҺеҚ•жңәпјҢеҸҜд»ҘдҪҝз”Ё sar еҫ—еҲ°зҪ‘з»ңжҺҘеҸЈгҖҒиҝӣзЁӢзҡ„зҪ‘з»ңеҗһеҗҗгҖӮ
дҪҝз”Ё ping жҲ–иҖ… hping3 еҸҜд»Ҙеҫ—еҲ°жҳҜеҗҰеҮәзҺ°зҪ‘з»ңеҲҶеҢәгҖҒзҪ‘з»ңе…·дҪ“时延гҖӮеҜ№дәҺеә”з”ЁпјҢжҲ‘们жӣҙе…іжіЁж•ҙдёӘй“ҫи·Ҝзҡ„时延пјҢеҸҜд»ҘйҖҡиҝҮдёӯй—ҙ件еҹӢзӮ№еҗҺиҫ“еҮәзҡ„ trace ж—Ҙеҝ—еҫ—еҲ°й“ҫи·ҜдёҠеҗ„дёӘзҺҜиҠӮзҡ„时延дҝЎжҒҜгҖӮ
дҪҝз”Ё netstatгҖҒss е’Ң sar еҸҜд»ҘиҺ·еҸ–зҪ‘з»ңиҝһжҺҘж•°жҲ–зҪ‘з»ңй”ҷиҜҜж•°гҖӮиҝҮеӨҡзҪ‘з»ңй“ҫжҺҘйҖ жҲҗзҡ„ејҖй”ҖжҳҜеҫҲеӨ§зҡ„пјҢдёҖжҳҜдјҡеҚ з”Ёж–Ү件жҸҸиҝ°з¬ҰпјҢдәҢжҳҜдјҡеҚ з”Ёзј“еӯҳпјҢеӣ жӯӨзі»з»ҹеҸҜд»Ҙж”Ҝж’‘зҡ„зҪ‘з»ңй“ҫжҺҘж•°жҳҜжңүйҷҗзҡ„гҖӮ
3.5 е·Ҙе…·жҖ»з»“
еҸҜд»ҘзңӢеҲ°зҡ„жҳҜпјҢеңЁеҲҶжһҗ CPUгҖҒеҶ…еӯҳгҖҒзЈҒзӣҳзӯүзҡ„жҖ§иғҪжҢҮж Үж—¶пјҢжңүеҮ з§Қе·Ҙе…·жҳҜй«ҳйў‘еҮәзҺ°зҡ„пјҢеҰӮ topгҖҒvmstatгҖҒpidstatпјҢиҝҷйҮҢзЁҚеҫ®жҖ»з»“дёҖдёӢ:
- CPUпјҡtopгҖҒvmstatгҖҒpidstatгҖҒsarгҖҒperfгҖҒjstackгҖҒjstatпјӣ
- еҶ…еӯҳпјҡtopгҖҒfreeгҖҒvmstatгҖҒcachetopгҖҒcachestatгҖҒsarгҖҒjmapпјӣ
- зЈҒзӣҳпјҡtopгҖҒiostatгҖҒvmstatгҖҒpidstatгҖҒdu/dfпјӣ
- зҪ‘з»ңпјҡnetstatгҖҒsarгҖҒdstatгҖҒtcpdumpпјӣ
- еә”з”ЁпјҡprofilerгҖҒdumpеҲҶжһҗгҖӮ
дёҠиҝ°зҡ„еҫҲеӨҡе·Ҙе…·пјҢеӨ§йғЁеҲҶжҳҜз”ЁдәҺжҹҘзңӢзі»з»ҹеұӮжҢҮж Үзҡ„пјҢеңЁеә”з”ЁеұӮпјҢйҷӨдәҶжңү JDK жҸҗдҫӣзҡ„дёҖзі»еҲ—е·Ҙе…·пјҢдёҖдәӣе•Ҷз”Ёзҡ„дә§е“ҒеҰӮВ http://gceasy.ioпјҲеҲҶжһҗ GC ж—Ҙеҝ—пјүгҖҒhttp://fastthread.ioпјҲеҲҶжһҗзәҝзЁӢ dump ж—Ҙеҝ—пјүд№ҹжҳҜдёҚй”ҷзҡ„гҖӮ
жҺ’жҹҘ Java еә”з”Ёзҡ„зәҝдёҠејӮеёёжҲ–иҖ…еҲҶжһҗеә”з”Ёд»Јз Ғ瓶йўҲпјҢеҸҜд»ҘдҪҝз”ЁйҳҝйҮҢејҖжәҗзҡ„ Arthas пјҢиҝҷдёӘе·Ҙе…·йқһеёёејәеӨ§пјҢдёӢйқўз®ҖеҚ•д»Ӣз»ҚдёӢгҖӮ
Arthas дё»иҰҒйқўеҗ‘зәҝдёҠеә”з”Ёе®һж—¶иҜҠж–ӯпјҢи§ЈеҶізҡ„жҳҜзұ»дјјгҖҢзәҝдёҠеә”з”ЁејӮеёёдәҶпјҢйңҖиҰҒеңЁзәҝиҝӣиЎҢеҲҶжһҗе’Ңе®ҡдҪҚгҖҚзҡ„й—®йўҳпјҢеҪ“然пјҢArthas жҸҗдҫӣзҡ„дёҖдәӣж–№жі•и°ғз”ЁиҝҪиёӘе·Ҙе…·пјҢеҜ№жҲ‘们жҺ’жҹҘиҜёеҰӮгҖҢж…ўжҹҘиҜўгҖҚзӯүй—®йўҳпјҢд№ҹжҳҜйқһеёёжңүеё®еҠ©зҡ„гҖӮArthas жҸҗдҫӣзҡ„дё»иҰҒеҠҹиғҪжңүпјҡ
- иҺ·еҸ–зәҝзЁӢз»ҹи®ЎпјҢеҰӮзәҝзЁӢжҢҒжңүзҡ„й”Ғз»ҹи®ЎгҖҒCPU еҲ©з”ЁзҺҮз»ҹи®Ўзӯүпјӣ
- зұ»еҠ иҪҪдҝЎжҒҜгҖҒеҠЁжҖҒзұ»еҠ иҪҪгҖҒж–№жі•еҠ иҪҪдҝЎжҒҜпјӣ
- и°ғз”Ёж ҲиҝҪиёӘпјҢи°ғз”ЁиҖ—ж—¶з»ҹи®Ўпјӣ
- ж–№жі•и°ғз”ЁеҸӮж•°гҖҒз»“жһңжЈҖжөӢпјӣ
- зі»з»ҹй…ҚзҪ®гҖҒеә”з”Ёй…ҚзҪ®дҝЎжҒҜпјӣ
- еҸҚзј–иҜ‘еҠ иҪҪзұ»пјӣ
- ....
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢжҖ§иғҪе·Ҙе…·еҸӘжҳҜи§ЈеҶіжҖ§иғҪй—®йўҳзҡ„жүӢж®өпјҢжҲ‘们дәҶи§Јеёёз”Ёе·Ҙе…·зҡ„дёҖиҲ¬з”Ёжі•еҚіеҸҜпјҢдёҚиҰҒеңЁе·Ҙе…·еӯҰд№ дёҠжҠ•е…ҘиҝҮеӨҡзІҫеҠӣгҖӮ



зӣёе…іжҺЁиҚҗ
жҖ§иғҪдјҳеҢ–жүӢеҶҢжҳҜдёҖеҘ—javaжҖ§иғҪеӯҰд№ з ”з©¶е°ҸжҠҖе·§пјҢеҢ…еҗ«еҶ…е®№пјҡJavaжҖ§иғҪдјҳеҢ–гҖҒJVMжҖ§иғҪдјҳеҢ–гҖҒжңҚеҠЎеҷЁжҖ§иғҪдјҳеҢ–гҖҒж•°жҚ®еә“жҖ§иғҪдјҳеҢ–гҖҒеүҚз«ҜжҖ§иғҪдјҳеҢ–зӯүгҖӮ еҶ…е®№еҢ…жӢ¬дҪҶдёҚйҷҗдәҺпјҡ String жҖ§иғҪдјҳеҢ–зҡ„ 3 дёӘе°ҸжҠҖе·§ HashMap 7 з§ҚйҒҚеҺҶж–№ејҸ...
Oracleж•°жҚ®еә“жҖ§иғҪдјҳеҢ–жҳҜзЎ®дҝқзі»з»ҹй«ҳж•ҲиҝҗиЎҢзҡ„е…ій”®зҺҜиҠӮпјҢе°Өе…¶жҳҜеңЁеӨ§ж•°жҚ®йҮҸе’Ңй«ҳ并еҸ‘зҡ„зҺҜеўғдёӯгҖӮOracleж•°жҚ®еә“еӣ е…¶е…ҲиҝӣгҖҒе®Ңж•ҙе’ҢйӣҶжҲҗзҡ„зү№жҖ§пјҢеңЁеёӮеңәдёӯеҚ жҚ®дё»еҜјең°дҪҚпјҢеӣ жӯӨж·ұе…ҘзҗҶи§Је’ҢжҺҢжҸЎOracleзҡ„дјҳеҢ–жҠҖжңҜиҮіе…ійҮҚиҰҒгҖӮ йҰ–е…ҲпјҢ...
C++жҖ§иғҪдјҳеҢ–жҳҜдёҖдёӘеӨҚжқӮзҡ„дё»йўҳпјҢе®ғж¶үеҸҠзј–иҜ‘еҷЁгҖҒз®—жі•гҖҒиҜӯиЁҖзү№жҖ§гҖҒ硬件жһ¶жһ„д»ҘеҸҠж“ҚдҪңзі»з»ҹзӯүеӨҡдёӘеұӮйқўгҖӮжҖ§иғҪдјҳеҢ–зҡ„зӣ®ж ҮжҳҜжҸҗеҚҮиҪҜ件жү§иЎҢж•ҲзҺҮпјҢеҮҸе°‘иө„жәҗж¶ҲиҖ—пјҢзј©зҹӯе“Қеә”ж—¶й—ҙпјҢд»ҘеҸҠжҸҗй«ҳеҗһеҗҗйҮҸгҖӮдёӢйқўе°ҶиҜҰз»Ҷд»Ӣз»ҚиҝҷдәӣжҖ§иғҪдјҳеҢ–зҡ„...
MySQLжҖ§иғҪдјҳеҢ–йҮ‘еӯ—еЎ”жі•еҲҷ MySQLжҖ§иғҪдјҳеҢ–жҳҜжҢҮйҖҡиҝҮи°ғж•ҙMySQLж•°жҚ®еә“зҡ„й…ҚзҪ®гҖҒдјҳеҢ–ж•°жҚ®еә“з»“жһ„е’ҢжҹҘиҜўиҜӯеҸҘзӯүж–№ејҸпјҢжҸҗй«ҳMySQLж•°жҚ®еә“зҡ„жҖ§иғҪе’Ңе“Қеә”йҖҹеәҰпјҢд»Ҙж»Ўи¶іеә”з”ЁзЁӢеәҸзҡ„йңҖжұӮгҖӮMySQLдҪңдёәжңҖжөҒиЎҢзҡ„ејҖжәҗж•°жҚ®еә“д№ӢдёҖпјҢиў«е№ҝжіӣеә”з”Ё...
гҖҗAndroidжҖ§иғҪдјҳеҢ–гҖ‘жҳҜAndroidејҖеҸ‘дёӯзҡ„йҮҚиҰҒзҺҜиҠӮпјҢж¶өзӣ–дәҶеӨҡдёӘе…ій”®йўҶеҹҹпјҢеҢ…жӢ¬ANRй—®йўҳи§ЈжһҗгҖҒcrashзӣ‘жҺ§ж–№жЎҲгҖҒеҗҜеҠЁйҖҹеәҰдёҺжү§иЎҢж•ҲзҺҮдјҳеҢ–гҖҒеҶ…еӯҳдјҳеҢ–гҖҒиҖ—з”өдјҳеҢ–гҖҒзҪ‘з»ңдј иҫ“дёҺж•°жҚ®еӯҳеӮЁдјҳеҢ–д»ҘеҸҠAPKеӨ§е°ҸдјҳеҢ–гҖӮ **ANRй—®йўҳи§Јжһҗ**жҳҜ...
Sql ServerжҖ§иғҪдјҳеҢ–й«ҳж•Ҳзҙўеј•жҢҮеҚ— Sql ServerжҖ§иғҪдјҳеҢ–й«ҳж•Ҳзҙўеј•жҢҮеҚ—жҳҜжҢҮеңЁSql Serverж•°жҚ®еә“дёӯпјҢйҖҡиҝҮеҗҲзҗҶең°и®ҫи®Ўе’ҢдјҳеҢ–зҙўеј•жқҘжҸҗй«ҳж•°жҚ®еә“жҖ§иғҪзҡ„дёҖзі»еҲ—жҢҮеҚ—е’ҢжңҖдҪіе®һи·өгҖӮжң¬жҢҮеҚ—ж¶өзӣ–дәҶзҙўеј•зҡ„еҹәжң¬жҰӮеҝөгҖҒзҙўеј•зҡ„зұ»еһӢгҖҒзҙўеј•зҡ„...
MySQLжҖ§иғҪдјҳеҢ–жҳҜдёҖдёӘж¶өзӣ–е№ҝжіӣзҡ„дё»йўҳпјҢж¶үеҸҠеӨҡдёӘеұӮйқўпјҢеҢ…жӢ¬SQLиҜӯеҸҘдјҳеҢ–гҖҒзҙўеј•дјҳеҢ–гҖҒж•°жҚ®еә“иЎЁз»“жһ„дјҳеҢ–гҖҒзі»з»ҹзә§й…ҚзҪ®дјҳеҢ–д»ҘеҸҠжңҚеҠЎеҷЁзЎ¬д»¶дјҳеҢ–гҖӮд»ҘдёӢжҳҜеҜ№иҝҷдәӣж–№йқўиҝӣиЎҢиҜҰз»ҶиҜҙжҳҺпјҡ 1. **SQLиҜӯеҸҘдјҳеҢ–** - **ж…ўжҹҘиҜўж—Ҙеҝ—**пјҡ...
гҖҠC++й«ҳж•Ҳзј–зЁӢпјҡеҶ…еӯҳдёҺжҖ§иғҪдјҳеҢ–гҖӢжҳҜдёҖжң¬дё“жіЁдәҺC++зј–зЁӢиҜӯиЁҖеҶ…еӯҳз®ЎзҗҶе’ҢжҖ§иғҪи°ғдјҳзҡ„д№ҰзұҚгҖӮжң¬д№Ұж·ұе…ҘжҺўи®ЁдәҶеҰӮдҪ•еңЁC++зј–зЁӢдёӯй«ҳж•Ҳең°дҪҝз”ЁеҶ…еӯҳиө„жәҗпјҢд»ҘеҸҠеҰӮдҪ•иҝӣиЎҢжҖ§иғҪдјҳеҢ–пјҢд»Ҙзј–еҶҷеҮәж—ўй«ҳж•ҲеҸҲдјҳйӣ…зҡ„д»Јз ҒгҖӮ д№ҰзұҚдҪңиҖ…Rene ...
ж №жҚ®жҸҗдҫӣзҡ„ж–Ү件дҝЎжҒҜпјҢжҲ‘们еҸҜд»ҘжҺЁж–ӯеҮәиҝҷжҳҜдёҖжң¬е…ідәҺJavaзЁӢеәҸжҖ§иғҪдјҳеҢ–зҡ„д№ҰзұҚпјҢдҪңиҖ…жҳҜи‘ӣдёҖйёЈпјҢ并жҸҗдҫӣдәҶиҜҘд№ҰPDFзүҲжң¬зҡ„дёӢиҪҪй“ҫжҺҘгҖӮиҷҪ然没жңүе…·дҪ“зҡ„д№ҰзұҚеҶ…е®№пјҢдҪҶеҹәдәҺж ҮйўҳгҖҒжҸҸиҝ°д»ҘеҸҠйҖҡеёёиҝҷзұ»д№ҰзұҚдјҡж¶үеҸҠзҡ„дё»йўҳпјҢжҲ‘们еҸҜд»ҘжҖ»з»“еҮә...
### MySQLжҖ§иғҪдјҳеҢ–е…ій”®зҹҘиҜҶзӮ№ #### дёҖгҖҒMySQLз®Җд»ӢдёҺеҺҶеҸІжІҝйқ© MySQLжҳҜдёҖдёӘејҖжәҗзҡ„е…ізі»еһӢж•°жҚ®еә“з®ЎзҗҶзі»з»ҹпјҲRDBMSпјүпјҢжңҖеҲқз”ұз‘һе…ёзҡ„MySQL ABе…¬еҸёејҖеҸ‘гҖӮе®ғзҡ„иҪ»йҮҸзә§гҖҒй«ҳж•ҲжҖ§е’ҢдҪҺжҲҗжң¬зү№жҖ§дҪҝе…¶жҲҗдёәдә’иҒ”зҪ‘дёҠдёӯе°ҸеһӢзҪ‘з«ҷзҡ„зҗҶжғі...
ж ҮйўҳдёҺжҸҸиҝ°жҰӮиҝ°зҡ„зҹҘиҜҶзӮ№дё»иҰҒйӣҶдёӯеңЁAIXзі»з»ҹзҡ„жҖ§иғҪдјҳеҢ–зӯ–з•ҘпјҢзү№еҲ«жҳҜй’ҲеҜ№еӨ„зҗҶйҖҹеәҰзҡ„жҸҗеҚҮпјҢйҮҚзӮ№е…іжіЁзҡ„жҳҜCPUжҖ§иғҪгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁиҝҷдәӣзҹҘиҜҶзӮ№пјҢжҸҗдҫӣдёҖдёӘе…Ёйқўзҡ„и§Ҷи§’жқҘзҗҶи§ЈAIXжҖ§иғҪдјҳеҢ–зҡ„е…ій”®ж–№йқўгҖӮ ### AIXжҖ§иғҪдјҳеҢ–еҹәзЎҖжҰӮеҝө...
иө„жәҗеҗҚз§°пјҡSQL ServerжҖ§иғҪдјҳеҢ–дёҺз®ЎзҗҶзҡ„иүәжңҜеҶ…е®№з®Җд»Ӣпјҡжң¬д№Ұе…ұ15з« пјҢеҲҶдёәдёүйғЁеҲҶпјҢ第дёҖйғЁеҲҶпјҲ第1-2з« пјүдёәжҰӮиҝ°йғЁеҲҶпјҢйҳҗиҝ°SQLServerж–№йқўзҡ„вҖңжҖ§иғҪвҖқеҸҠзӣёе…іжҰӮеҝөгҖӮ并з»ҷеҮә常规зҡ„жҖ§иғҪеҸҠжҖ§иғҪзӣёе…ізҡ„й—®йўҳдҫҰжөӢзҡ„вҖңж–№жі•и®әвҖқпјҢиҜ»иҖ…...
гҖҠCSAPPжҖ§иғҪдјҳеҢ–е®һйӘҢгҖӢжҳҜи®Ўз®—жңә科еӯҰдёҺеә”з”ЁпјҲComputer Science and Application ProgrammingпјүиҜҫзЁӢзҡ„дёҖдёӘе®һи·өзҺҜиҠӮпјҢж—ЁеңЁжҸҗеҚҮеӯҰз”ҹеҜ№зЁӢеәҸжҖ§иғҪдјҳеҢ–зҡ„зҗҶи§ЈдёҺжҠҖиғҪгҖӮеңЁиҝҷдёӘе®һйӘҢдёӯпјҢжҲ‘е°ҶиҜҰз»ҶжҺўи®ЁдёүдёӘе…ій”®зҡ„дјҳеҢ–зӯ–з•ҘпјҢ并结еҗҲ...
еҚҺдёә5GжҖ§иғҪдјҳеҢ–жҢҮеҜјжүӢеҶҢ-SAдё»иҰҒе…іжіЁ5GзҪ‘з»ңеңЁжңҚеҠЎиҝһз»ӯжҖ§е’Ңз”ЁжҲ·ж„ҹзҹҘж–№йқўзҡ„дјҳеҢ–пјҢе°Өе…¶еңЁSAпјҲзӢ¬з«Ӣз»„зҪ‘пјүжЁЎејҸдёӢгҖӮиҝҷд»ҪжүӢеҶҢж—ЁеңЁи§ЈеҶізҪ‘з»ңдёӯеӯҳеңЁзҡ„вҖңзӮ№гҖҒзәҝвҖқй—®йўҳпјҢзЎ®дҝқNSAпјҲйқһзӢ¬з«Ӣз»„зҪ‘пјүзҪ‘з»ңзЁіе®ҡиҝҗиЎҢпјҢжҸҗдҫӣдјҳиҙЁзҡ„5GдҪ“йӘҢгҖӮ ...
"MySQLжҖ§иғҪдјҳеҢ–е’Ңй«ҳеҸҜз”Ёжһ¶жһ„е®һи·ө" жң¬д№ҰгҖҠMySQLжҖ§иғҪдјҳеҢ–е’Ңй«ҳеҸҜз”Ёжһ¶жһ„е®һи·өгҖӢжҳҜдёҖжң¬иҜҰз»Ҷд»Ӣз»ҚMySQLжҖ§иғҪдјҳеҢ–е’Ңй«ҳеҸҜз”Ёжһ¶жһ„е®һи·өзҡ„д№ҰзұҚпјҢж—ЁеңЁеё®еҠ©иҜ»иҖ…жҸҗеҚҮMySQLж•°жҚ®еә“зҡ„жҖ§иғҪе’ҢеҸҜйқ жҖ§гҖӮжң¬д№Ұзҡ„еҶ…е®№ж¶өзӣ–дәҶжҹҘиҜўдјҳеҢ–зҡ„еҹәжң¬еҺҹеҲҷе’Ң...
иҫҫжўҰж•°жҚ®еә“жҖ§иғҪдјҳеҢ– иҫҫжўҰж•°жҚ®еә“дҪңдёәеӣҪдә§ж•°жҚ®еә“еёӮеңәеҚ жңүзҺҮ第дёҖзҡ„й«ҳжҖ§иғҪгҖҒй«ҳеҸҜйқ жҖ§гҖҒй«ҳе®үе…ЁжҖ§гҖҒй«ҳе…је®№жҖ§еӨ§еһӢе…ізі»еһӢж•°жҚ®еә“з®ЎзҗҶзі»з»ҹпјҢе·Із»ҸжҲҗеҠҹжӣҝд»ЈдәҶOracleпјҢеңЁз”өеҠӣгҖҒйҮ‘иһҚгҖҒз”өеӯҗж”ҝеҠЎгҖҒж•ҷиӮІзӯүиЎҢдёҡйўҶеҹҹеҫ—еҲ°дәҶе№ҝжіӣзҡ„еә”з”ЁпјҢ...
еҝ«жүӢ APM е№іеҸ°е»әи®ҫдёҺжҖ§иғҪдјҳеҢ– APMпјҲApplication Performance ManagementпјүжҳҜжҢҮеҜ№еә”з”ЁзЁӢеәҸжҖ§иғҪзҡ„зӣ‘жҺ§е’ҢдјҳеҢ–пјҢд»ҘжҸҗй«ҳз”ЁжҲ·дҪ“йӘҢе’Ңж»Ўж„ҸеәҰгҖӮеңЁеҝ«жүӢе№іеҸ°дёӯпјҢAPM зҡ„йҮҚиҰҒжҖ§дёҚиЁҖиҖҢе–»гҖӮжң¬ж–Үе°Ҷд»Һеҝ«жүӢ APM е№іеҸ°е»әи®ҫзҡ„и§’еәҰпјҢжҺўи®Ё...
Oracleж•°жҚ®еә“жҖ§иғҪдјҳеҢ–дёҺж•…йҡңиҜҠж–ӯжҳҜж•°жҚ®еә“з®ЎзҗҶдёӯжһҒдёәйҮҚиҰҒзҡ„дёӨдёӘж–№йқўпјҢе®ғ们зӣҙжҺҘе…ізі»еҲ°дјҒдёҡдёҡеҠЎзі»з»ҹзҡ„зЁіе®ҡиҝҗиЎҢе’ҢжҖ§иғҪиЎЁзҺ°гҖӮеңЁиҝҷзҜҮж–Үз« дёӯпјҢжҲ‘们е°ҶиҜҰз»ҶжҺўи®Ёй’ҲеҜ№Oracleж•°жҚ®еә“жҖ§иғҪй—®йўҳе’Ңж•…йҡңзҡ„иҜҠж–ӯжЎҲдҫӢпјҢ并еҲҶдә«еҰӮдҪ•йҖҡиҝҮжЎҲдҫӢ...
еңЁгҖҠLinuxжҖ§иғҪдјҳеҢ–е®һжҲҳгҖӢжЎҲдҫӢдёӯпјҢжҲ‘们ж·ұе…ҘжҺўи®ЁдәҶеҰӮдҪ•еҲ©з”ЁLinuxзі»з»ҹе·Ҙе…·е’ҢжҠҖжңҜжқҘжҸҗеҚҮзі»з»ҹзҡ„иҝҗиЎҢж•ҲзҺҮе’ҢжҖ§иғҪгҖӮLinuxдҪңдёәдёҖж¬ҫејҖжәҗж“ҚдҪңзі»з»ҹпјҢе…¶ејәеӨ§зҡ„еҸҜе®ҡеҲ¶жҖ§е’Ңдё°еҜҢзҡ„е·Ҙе…·йӣҶдҪҝе…¶жҲҗдёәжҖ§иғҪдјҳеҢ–зҡ„зҗҶжғіе№іеҸ°гҖӮд»ҘдёӢжҳҜдёҖдәӣж ёеҝғ...