public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
/**
* Class String is special cased within the Serialization Stream Protocol.
*
* A String instance is written into an ObjectOutputStream according to
* <a href="{@docRoot}/../platform/serialization/spec/output.html">
* Object Serialization Specification, Section 6.2, "Stream Elements"</a>
*/
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
/**
* Initializes a newly created {@code String} object so that it represents
* an empty character sequence. Note that use of this constructor is
* unnecessary since Strings are immutable.
*/
public String() {
this.value = "".value;
}
}
以上是jdk1.8中对String类的定义,看得出以下几个结论:
- String 类被final关键字修饰,因此String类不能被继承,并且它的成员方法都默认为final方法;字符串一旦创建就不能再修改。
- String 类实现了Serializable、CharSequence、 Comparable接口。
- String 实例的值是通过字符数组实现字符串存储的。
可变的字符序列,StringBuffer的append方法使用了synchronized,所以是线程安全的,StringBuilder的效率比StringBuffer快。
可变的字符序列,StringBuffer是线程不安全的。,StringBuffer的效率比StringBuffer慢。
- 在java中 当"+" 前后出现字符串时表示字符串拼接的操作,因为String是final修饰的,创建后就不可变,所以“+”底层实际是创建了一个StringBuilder对象,然后调用append方法去拼接字符串,再调用toString方法生成一个新的String。
- 只有使用引号包含文本的方式创建的String对象之间使用 “+” 连接产生的新对象才会被加入字符串池中。
例如:
String s5 = "a" + "b";直接在堆内存中的字符串池创建b这个对象
- 所有包含new方式新建对象(包括null)的 “+” 连接表达式,它所产生的新对象都不会被加入字符串池中。
例如:
String s3 = new String("a");
String s4 = new String("b");
String s5 = s3 + s4;
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
intern方法是一个本地方法。作用就是调用该方法时先去字符串常量池中查找是否有相等的(equals)值,有就直接返回常量池中的引用。没有就将该字符串存入字符串常量池,再返回字符串常量池中的引用。
注意:jkd1.6之前常量池和堆是分开的,所以这里是在常量池里存的的具体的值。jdk1.6之后常量池和堆在一起,这里常量池中保存的是堆中对象的引用。
- String 创建对象在内存结构以及常见的对象数量问题解析
创建对象有2种方式
- 通过常量池创建
JVM会首先检查在字符串常量池,如果在字符串常量池中存在了该字符串 ,则将该字符串对象的地址值赋值给引用。如果字符串不在常量池中,就会在常量池中创建字符串,然后将字符串对象的地址值交给引用。所以最多只会创建一个对象。
实例分析
String s1 = "a";
String s3 = new String("a");
String s4 = new String("b");
String s2 = "b";
String s5 = "a" + "b";
String s6 = "a" + s4;
String s7 = s1 + s2;
String s8 = "ab";
final String s9 = "e";
final String s10 = "f";
String s11 = s9 + s10;
String s12 = "ef";
System.out.println(s1 == s3); // false
System.out.println(s1.equals(s3)); // true
System.out.println(s5 == s6); // false
System.out.println(s5 == s7); // false
System.out.println(s5.equals(s7)); // true
System.out.println(s5 == s8); // true
System.out.println(s11 == s12); // true
画图分析
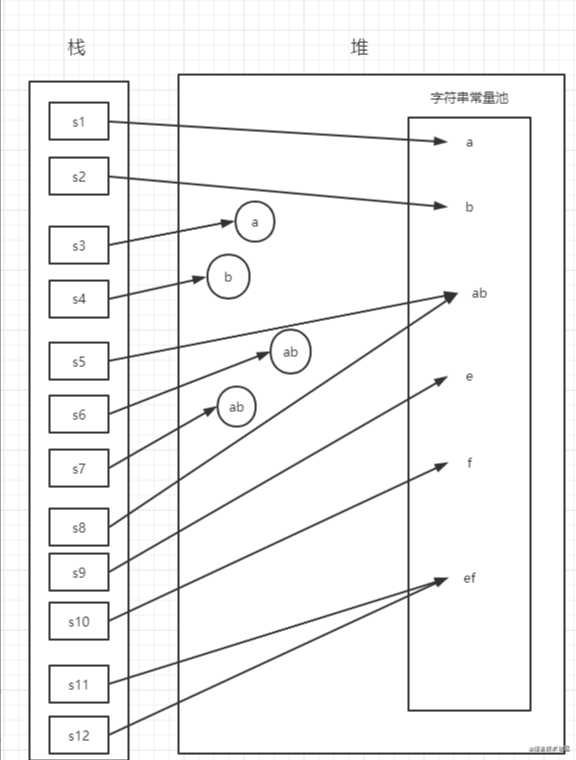
结果分析
s1 在常量池中生成了一个对象
s3 常量池中已经有了,所以只在堆中创建了一个对象
s4 常量池和堆中各创建了一个对象,共两个对象(这两个对象的字符串数组是同一个)
s2 常量池中已经有了,没有重新创建对象
s5 编译时将常量拼接好了,然后在常量池中创建了一个对象
s6 生成一个StringBuilder对象用来拼接,最后toSting在堆中生成一个新的对象,共两个对象
s7 与s6一样
s8 常量池中已经有了,没有重新创建对象
s9,s10都是在常量池中生成一个对象
s11 使用final修饰的变量,在编译时替换成常量了,然后将常量拼接好在常量池中创建了一个对象
- 通过new创建
JVM会首先检查字符串常量池,如果字符串已经存在常量池中,直接复制堆中这个对象的副本,然后将堆中的地址值赋给引用,不会在字符串常量池中创建对象。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,然后在堆中复制该对象的副本,并将对象的地址值交给引用。所以可能生成一个或者两个对象。
实例分析
String s1 = new String("g");
s1.intern();
String s2 = "g";
System.out.println(s1 == s2); // false
System.out.println(s1.intern() == s2); // true
String s3 = new String("h") + new String("i");
s3.intern();
String s4 = "hi";
System.out.println(s3 == s4); // true
System.out.println(s3.intern() == s4); // true
String s5 = new String("j") + new String("k");
String s6 = "jk";
s5.intern();
System.out.println(s5 == s6); // false
System.out.println(s5.intern() == s6); // true
画图分析
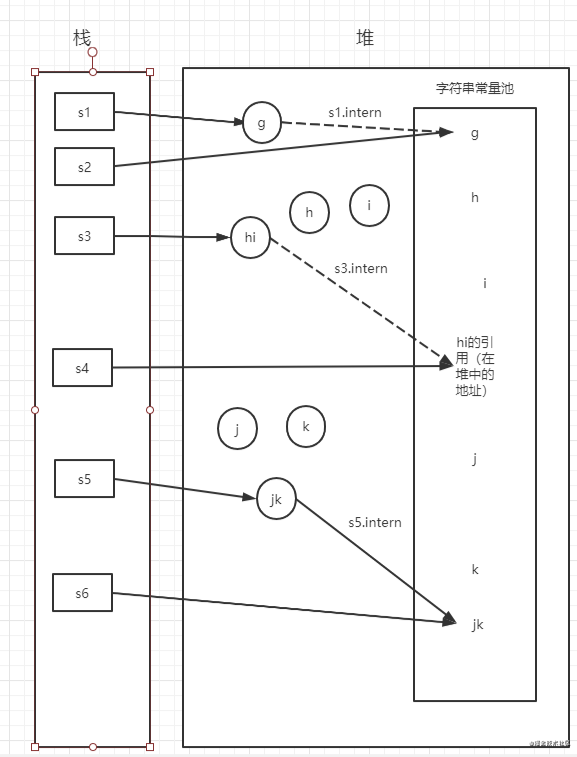
结果分析
s1 在常量池中和堆中各创建了一个对象
s1.intern调用时发现常量池中已经存在“g”了,所以返回常量池中“g”的引用
s2 创建时发现常量池中已经存在了,不会生成新的对象,直接指向常量池的对象
s1和s2指向不同的对象,所以不相等。s1.intern指向常量池的对象,和s2相等
s3 在堆中生成两个匿名对象,一个StringBuilder对象,一个toString生成的对象,常量池中两个对象,共六个对象。最终生成的对象不会存放到字符串常量池中(参考上面“+”的定义)。
s3.intern调用时发现常量池中没有“hi”,将堆中“hi”对象的地址存放在常量池中,所以s3.intern最终还是指向堆中的对象。
s4 创建时发现常量池中已经存在了,直接返回常量池中的引用,所以s4最终也指向了堆中的“hi”对象。所以s3==s4,s3.intern() == s4
s5 创建和s3过程一样
s6 创建时发现常量池中没有,会在常量池中创建一个“jk”对象
s5.intern调用时,发现常量池中已经存在“jk”,直接返回常量池中的对象地址。
所以s5和s6是指向不同的对象
注明:本文参考和引用 "String内存分布和创建时对象生成情况等常见问题详解"这篇文章
“https://www.toutiao.com/i6981781517945111052/?tt_from=weixin&utm_campaign=client_share&wxshare_count=1×tamp=1625616592&app=news_article&utm_source=weixin&utm_medium=toutiao_android&use_new_style=1&req_id=202107070809520101512082132E0BAAEA&share_token=74b9e806-66c2-4911-8763-3585b2b7a411&group_id=6981781517945111052”
分享到:




相关推荐
#### 三、创建String对象的方式及内存分配分析 ##### 1. 使用字符串字面量 当使用字符串字面量创建 `String` 对象时,如 `String s = "abc";`,内存分配过程如下: - JVM 首先检查 **常量池** 中是否已经存在一个...
在java语言的所有数据类型中,String类型是比较特殊的一种类型,同时也是面试的时候经常被问到的一个知识点,本文结合java内存分配深度分析关于String的许多令人迷惑的问题。下面是本文将要涉及到的一些问题,...
首先,我们来看Java的内存分配。Java内存主要分为三个区域:栈(Stack)、堆(Heap)和方法区(Method Area)。栈用于存储基本类型变量和对象引用,每个线程都有自己的独立栈空间。当创建一个方法时,栈会为该方法...
Java数组在内存中的分配情况解析主要涉及两种类型的数组:基本类型数组和引用类型数组。这两种类型的数组在内存中存储和管理的方式有所不同。 1. 基本类型数组 基本类型数组,如int、byte、char等,它们的元素直接...
### 模拟内存分配实验知识点总结 #### 实验背景与目的 本次实验是关于操作系统的模拟内存分配实验,旨在帮助学生深入理解操作系统中内存管理的关键技术。通过实践操作,学生可以掌握不同内存分配策略的工作原理及其...
本篇文章将深入探讨`String`对象的内存分析,包括栈、堆、常量池以及静态存储的概念,并通过具体的示例来解析不同情况下`String`对象的创建和内存分配。 首先,了解Java内存的基本结构。Java内存分为以下几个区域:...
Java内存分配全面解析 Java程序在执行过程中,其内存分配主要涉及到JVM(Java Virtual Machine,Java虚拟机)的不同区域。这些区域各自负责不同的任务,共同确保程序的正常运行。以下是对各个内存区域的详细解释: ...
### C语言内存分配详解 #### 一、内存分配机制概览 C语言作为一种低级语言,提供了对内存的直接访问能力。程序运行时使用的内存主要分为五个不同的区域:栈区、堆区、全局区(静态区)、文字常量区以及程序代码区...
接下来我们重点分析Java中字符串的不同声明方式及其内存分配情况: 1. **Strings1;** - **描述**:声明了一个`String`类型的变量`Strings1`,但没有进行初始化,也没有存储任何对象。对于成员变量,由于Java的...
本文旨在深入探讨Java内存分配的基本原理及其在不同内存区域的具体表现,帮助读者更好地理解Java程序运行时内存的使用情况。 #### 二、Java内存区域概述 Java程序在运行时会根据不同的数据类型和生命周期将其分配...
随后重点分析了Basic_String类内部的内存分配机制,特别是其new(extra)方法的作用与实现细节。文中通过实例演示了Basic_String是如何动态管理字符串长度和容量之间的关系,并讨论了内存扩展对性能的影响以及由此引发...
通过上述分析可以看出,Java 中字符串的内存分配涉及多个方面,包括字符串常量池、堆内存以及字符串的拼接方式等。理解这些细节有助于开发者编写出更加高效且易于维护的代码。特别是在处理大量字符串操作时,了解...
#### Java内存分配实例解析 常量池(Constant Pool)是指在编译期间确定并且被保存在`.class`文件中的一些数据。它包含了类、方法、接口等中的常量以及字符串常量。运行时,常量池会被JVM加载,并且可以被扩展。 ...
SSO 允许某些小字符串直接存储在对象内,从而避免了额外的内存分配和指针间接访问开销。 ### 二、多线程环境下的字符串操作 在多线程环境下操作 `std::string` 需要特别注意同步问题。当多个线程尝试同时修改同一...
"JVM内存分配及String常用方法解析" 通过对JVM内存分配和String常用方法的解析,我们可以了解到JVM的内存模型和String类的使用方法。 一、JVM内存分配 JVM将内存分为多个不同的区域,每个区域都有其特定的用途和...
《CUnit动态内存分配与数据结构实用教程》深入解析了C++编程中关于动态内存管理和数据结构的关键概念。动态内存分配是程序运行时根据需要在内存中动态分配空间的技术,主要涉及自由存储区的管理。自由存储区不同于...
标题与描述中提到的知识点是关于C#编程语言中`String`与`string`的区别,以及`string`类型的深入解析。以下是对这些知识点的详细解释: ### `String`与`string`的区别 #### 1. **位置与来源** - `String`是.NET ...
### 深入Java核心:Java内存分配原理精讲 #### 一、Java内存区域概述 在Java程序运行过程中,其内存主要分为以下几个区域: 1. **程序计数器(Program Counter Register)**:线程私有的,是一块较小的内存空间。它...
在C++编程语言中,这些成员函数对于正确地管理动态分配的内存至关重要。 ### 类String的设计 首先,我们来回顾一下`String`类的定义: ```cpp class String { public: String(const char* str = NULL); // 普通...