
1.标准偏差概念
标准偏差(Std Dev,Standard Deviation) -统计学名词。一种度量数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。标准偏差的大小可通过标准偏差与平均值的倍率关系来衡量。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差应该是17.078分,B组的标准差应该是2.160分,说明A组学生之间的差距要比B组学生之间的差距大得多。
标准偏差又分为总体标准偏差与样本标准偏差
总体标准偏差:针对总体数据的偏差,所以要平均,

样本标准偏差,也称实验标准偏差:针对从总体抽样,利用样本来计算总体偏差,为了使算出的值与总体水平更接近,就必须将算出的标准偏差的值适度放大,即,
 代表总体X的均值。
代表总体X的均值。
 = (200+50+100+200)/4 = 550/4 = 137.5
= (200+50+100+200)/4 = 550/4 = 137.5
 = [(200-137.5)^2+(50-137.5)^2+(100-137.5)^2+(200-137.5)^2]/(4-1)
= [(200-137.5)^2+(50-137.5)^2+(100-137.5)^2+(200-137.5)^2]/(4-1)
2.标准偏差计算公式:

上式为样本标准差,下式为总体标准差,二式差一个自由度,n与n-1。
一个班级学生身高的标准差,50个学生有50个身高数据,如求这个班级学生身高的标准差那么用总体标准差,如这50个身高数据作为全校学生的抽样,那么用样本标准差,因为这50个身高数据是全校学生的样本。
例:有一组数字分别是200、50、100、200,求它们的样本标准偏差。
样本标准偏差 S = Sqrt(S^2)=75, 注:八年级(下册)上海科学技术出版 21.2数据的离散程度中的标准差是总体标准差
3.hive中的标准偏差函数 stddev_pop(),stddev_samp(),stddev()
stddev_pop() 总体标准方差,stddev_samp() 样本标准方差
(1) hive引擎计算标准偏差
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col
from (
select 'A' as col, '1' as num
union all
select 'A' as col, '2' as num
union all
select 'A' as col, '3' as num
union all
select 'B' as col, '1' as num
union all
select 'B' as col, '2' as num
) as a
group by col
;
(2)spark引擎查询标准偏差
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col from ( select 'A' as col, '1' as num union all select 'A' as col, '2' as num union all select 'A' as col, '3' as num union all select 'B' as col, '1' as num union all select 'B' as col, '2' as num ) as a group by col
由上可看出,hive中stddev()函数默认计算总体标准偏差,spark 中stddev()函数默认计算样本标准偏差
4.stddev()也可用于窗口函数
select col, stddev(num) over(partition by col) as stddev_col from ( select 'A' as col, '1' as num union all select 'A' as col, '2' as num union all select 'A' as col, '3' as num union all select 'B' as col, '1' as num union all select 'B' as col, '2' as num ) as a
查询结果:
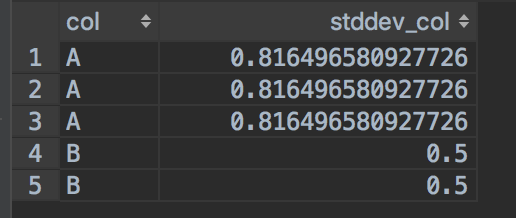
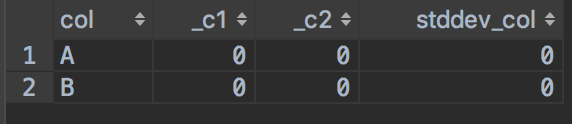
5. 当计算的输入数据只有一行时 ,hive和spark计算标准方差的结果
(1)hive
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col from ( select 'A' as col, '1' as num union all select 'B' as col, '2' as num ) as a group by col ;
查询结果:
(2)spark
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col from ( select 'A' as col, '1' as num union all select 'B' as col, '2' as num ) as a group by col ;



相关推荐
本文主要讲解了 Hive 中自定义 UDF 函数的编写方法,包括创建 UDF 类、实现自定义函数逻辑、编译和打包 UDF jar 包、上传至 Hive 服务器并注册自定义函数。 一、创建 UDF 类 为了实现自定义 UDF 函数,需要创建一...
9. 样本标准偏离函数: stddev_samp 31 10.中位数函数: percentile 31 11. 中位数函数: percentile 31 12. 近似中位数函数: percentile_approx 32 13. 近似中位数函数: percentile_approx 32 14. 直方图: histogram_...
通过学习将Oracle和Hive的常用函数整理出来做了个对比,提供他们各自支持的常用函数。
本篇文章将详细解析Hive中的各种函数,帮助你更好地理解和应用这些功能。 一、关系运算 关系运算用于比较两个或多个表达式,确定它们之间的逻辑关系。以下是Hive支持的关系运算符: 1. 等值比较:`=` - 用于判断...
hive和oracle常用函数对照,包含常用的函数分类 字符函数 数值函数 日期函数 聚合函数 转换函数 其他 增加的hive函数对比,只需要2个积分喔
本文档将详细介绍Hive中各种常用的函数,包括关系运算、数学运算、逻辑运算、数值计算、日期函数、条件函数、字符串函数以及集合统计函数。 #### 一、关系运算 这些运算符用于进行基本的关系比较。 1. **等值比较...
- 总体标准偏离函数“stddev_pop”,样本标准偏离函数“stddev_samp”。 - 中位数函数未提供具体信息,但通常用于统计学中表示一组数据的中间值。 由于文本中未提供完整的第七部分“字符串函数”和第八部分“集合...
hive、oracle常用函数对照表
包含hive和oracle的常用函数对比关系表,可以用于查询hive函数转换成oracle函数,或者oracle函数转换hive函数之间的相互转换。
Hive 函数大全是 Hive 中各种常用函数的集合,涵盖了日期函数、集合统计函数、字符串函数、条件函数、复合类型构建操作等多个方面。下面是一些常用的 Hive 函数: 关系运算 关系运算是 Hive 中最基本的操作之一,...
Hive 的函数和语法是其核心组件之一,本文将对 Hive 的函数和语法进行详细的说明。 内置函数 Hive提供了一些内置函数,用于执行数学运算、字符串处理、日期处理等操作。这些函数可以在 Hive 的查询语句中使用,...
Hive 函数大全是 Hive 中的关系运算符和条件判断函数的集合,用于对数据进行比较、判断和过滤。下面是 Hive 函数大全的详细说明: 一、关系运算符 关系运算符用于比较两个表达式的值,包括等值比较、不等值比较、...
本篇文章将详细介绍Hive中的一些主要函数,包括数学函数、类型转换函数、条件函数、字符函数、聚合函数以及表生成函数。 一、关系运算 关系运算是查询语言的基础,用于比较和筛选数据。在Hive中,主要有以下几种...
本文将详细介绍Hive中常见的几类函数及其用法,包括关系运算、数学运算、逻辑运算、数值计算、日期函数、条件函数、字符串函数以及集合统计函数等。 #### 一、关系运算 1. **等值比较(=)**: 用于判断两个值是否...
- **可重用性**:一旦编写并部署,可以在多个Hive查询中重复使用这些自定义函数,提高代码复用率。 ##### 2.2 UDF的编写步骤 1. **继承UDF类**:所有Hive UDF都必须继承自`org.apache.hadoop.hive.ql.exec.UDF`类。...
本文将详细探讨如何在Hive中自定义User Defined Function(UDF)来实现Base64的加密和解密。 首先,我们需要了解Base64的基本原理。Base64是一种将任意二进制数据转化为ASCII字符集的方法,它通过将每3个字节转换为...
包含个数统计count、总和统计sum、平均值统计avg、最小值统计min、最大值统计max、非空集合总体变量var_pop和样本变量var_samp函数、总体标准偏离stddev_pop和样本标准偏离stddev_samp函数以及中位数percentile函数...
在Hive中,UDF分为三种类型:UDF(单行函数)、UDAF(累积聚合函数)和UDTF(多行转换函数)。在这里,我们只需要UDF,因为它适用于处理单行数据。 1. **编写Java类**: 要创建一个UDF,你需要编写一个Java类,该...
本文主要介绍Hive中的窗口函数,特别是SUM、AVG、MIN、MAX等基础函数的应用场景及其具体用法。 #### 二、窗口函数应用场景 ##### 1. 分区排序 窗口函数可以基于分区内的记录进行排序,从而实现对特定分区内数据的...
然而,在实际应用中,开发人员可能会遇到一个常见问题——Spark 无法直接使用 Hive 中定义的自定义函数(UDF)。本文将深入探讨这一问题,并提供解决方案。 #### 一、问题背景 当开发者尝试在 Spark 应用程序中...