
原文链接:https://zhuanlan.zhihu.com/p/78335525
Kafka除了具备消息队列MQ的特性和使用场景外,它还有一个重要用途,就是做存储层。
用kafka做存储层,为什么呢?一大堆可以做数据存储的 MySQL、MongoDB、HDFS……
因为kafka数据是持久化磁盘的,还速度快;还可靠、支持分布式……
啥!用了磁盘,还速度快!!!
没错,kafka就是速度无敌,本文将探究kafka无敌性能背后的秘密。
首先要有个概念,kafka高性能的背后,是多方面协同后、最终的结果,kafka从宏观架构、分布式partition存储、ISR数据同步、以及“无孔不入”的高效利用磁盘/操作系统特性,这些多方面的协同,是kafka成为性能之王的必然结果。
本文将从kafka零拷贝,探究其是如何“无孔不入”的高效利用磁盘/操作系统特性的。
先说说零拷贝
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。通常是说在IO读写过程中。
实际上,零拷贝是有广义和狭义之分,目前我们通常听到的零拷贝,包括上面这个定义减少不必要的拷贝次数都是广义上的零拷贝。其实了解到这点就足够了。
我们知道,减少不必要的拷贝次数,就是为了提高效率。那零拷贝之前,是怎样的呢?
聊聊传统IO流程
比如:读取文件,再用socket发送出去
传统方式实现:
先读取、再发送,实际经过1~4四次copy。
buffer = File.read
Socket.send(buffer)
1、第一次:将磁盘文件,读取到操作系统内核缓冲区;
2、第二次:将内核缓冲区的数据,copy到application应用程序的buffer;
3、第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
4、第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
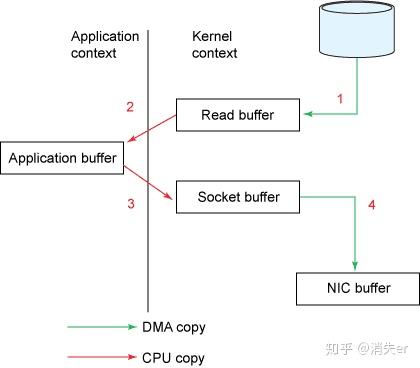
传统方式,读取磁盘文件并进行网络发送,经过的四次数据copy是非常繁琐的。实际IO读写,需要进行IO中断,需要CPU响应中断(带来上下文切换),尽管后来引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。
重新思考传统IO方式,会注意到实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。
显然,第二次和第三次数据copy 其实在这种场景下没有什么帮助反而带来开销,这也正是零拷贝出现的意义。
这种场景:是指读取磁盘文件后,不需要做其他处理,直接用网络发送出去。试想,如果读取磁盘的数据需要用程序进一步处理的话,必须要经过第二次和第三次数据copy,让应用程序在内存缓冲区处理。
为什么Kafka这么快
kafka作为MQ也好,作为存储层也好,无非是两个重要功能,一是Producer生产的数据存到broker,二是 Consumer从broker读取数据;我们把它简化成如下两个过程:
1、网络数据持久化到磁盘 (Producer 到 Broker)
2、磁盘文件通过网络发送(Broker 到 Consumer)
下面,先给出“kafka用了磁盘,还速度快”的结论
1、顺序读写
磁盘顺序读或写的速度400M/s,能够发挥磁盘最大的速度。
随机读写,磁盘速度慢的时候十几到几百K/s。这就看出了差距。
kafka将来自Producer的数据,顺序追加在partition,partition就是一个文件,以此实现顺序写入。
Consumer从broker读取数据时,因为自带了偏移量,接着上次读取的位置继续读,以此实现顺序读。
顺序读写,是kafka利用磁盘特性的一个重要体现。
2、零拷贝 sendfile(in,out)
数据直接在内核完成输入和输出,不需要拷贝到用户空间再写出去。
kafka数据写入磁盘前,数据先写到进程的内存空间。
3、mmap文件映射
虚拟映射只支持文件;
在进程 的非堆内存开辟一块内存空间,和OS内核空间的一块内存进行映射,
kafka数据写入、是写入这块内存空间,但实际这块内存和OS内核内存有映射,也就是相当于写在内核内存空间了,且这块内核空间、内核直接能够访问到,直接落入磁盘。
这里,我们需要清楚的是:内核缓冲区的数据,flush就能完成落盘。
我们来重点探究 kafka两个重要过程、以及是如何利用两个零拷贝技术sendfile和mmap的。
网络数据持久化到磁盘 (Producer 到 Broker)
传统方式实现:
data = socket.read()// 读取网络数据
File file = new File()
file.write(data)// 持久化到磁盘
file.flush()
先接收生产者发来的消息,再落入磁盘。
实际会经过四次copy,如下图的四个箭头。
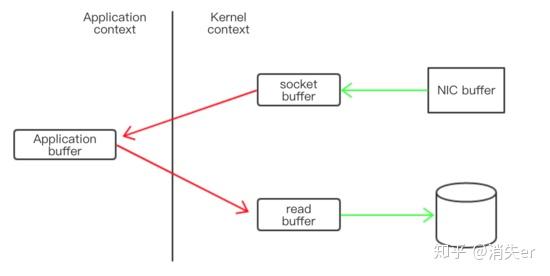
数据落盘通常都是非实时的,kafka生产者数据持久化也是如此。Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
对于kafka来说,Producer生产的数据存到broker,这个过程读取到socket buffer的网络数据,其实可以直接在OS内核缓冲区,完成落盘。并没有必要将socket buffer的网络数据,读取到应用进程缓冲区;在这里应用进程缓冲区其实就是broker,broker收到生产者的数据,就是为了持久化。
在此特殊场景下:接收来自socket buffer的网络数据,应用进程不需要中间处理、直接进行持久化时。——可以使用mmap内存文件映射。
Memory Mapped Files
简称mmap,简单描述其作用就是:将磁盘文件映射到内存, 用户通过修改内存就能修改磁盘文件。
它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
mmap也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。Kafka提供了一个参数——producer.type来控制是不是主动flush;如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
Java NIO对文件映射的支持
Java NIO,提供了一个 MappedByteBuffer 类可以用来实现内存映射。
MappedByteBuffer只能通过调用FileChannel的map()取得,再没有其他方式。
FileChannel.map()是抽象方法,具体实现是在 FileChannelImpl.c 可自行查看JDK源码,其map0()方法就是调用了Linux内核的mmap的API。
使用 MappedByteBuffer类要注意的是:mmap的文件映射,在full gc时才会进行释放。当close时,需要手动清除内存映射文件,可以反射调用sun.misc.Cleaner方法。
磁盘文件通过网络发送(Broker 到 Consumer)
传统方式实现:
先读取磁盘、再用socket发送,实际也是进过四次copy。
buffer = File.read
Socket.send(buffer)而 Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。磁盘数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer(socket buffer),无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件 - 网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。零拷贝过程如下图所示。
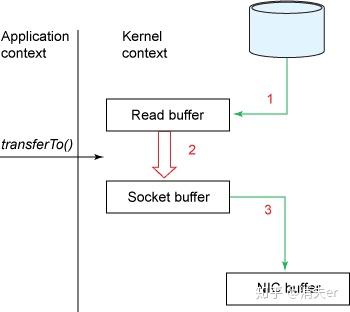
相比于文章开始,对传统IO 4步拷贝的分析,sendfile将第二次、第三次拷贝,一步完成。
其实这项零拷贝技术,直接从内核空间(DMA的)到内核空间(Socket的)、然后发送网卡。
应用的场景非常多,如Tomcat、Nginx、Apache等web服务器返回静态资源等,将数据用网络发送出去,都运用了sendfile。
简单理解 sendfile(in,out)就是,磁盘文件读取到操作系统内核缓冲区后、直接扔给网卡,发送网络数据。
Java NIO对sendfile的支持就是FileChannel.transferTo()/transferFrom()。fileChannel.transferTo( position, count, socketChannel);
把磁盘文件读取OS内核缓冲区后的fileChannel,直接转给socketChannel发送;底层就是sendfile。消费者从broker读取数据,就是由此实现。
具体来看,Kafka 的数据传输通过 TransportLayer 来完成,其子类 PlaintextTransportLayer 通过Java NIO 的 FileChannel 的 transferTo 和 transferFrom 方法实现零拷贝。
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}注: transferTo 和 transferFrom 并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供 sendfile 这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
Kafka总结
总的来说Kafka快的原因:
1、partition顺序读写,充分利用磁盘特性,这是基础;
2、Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入;
3、Customer从broker读取数据,采用sendfile,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
mmap 和 sendfile总结
1、都是Linux内核提供、实现零拷贝的API;
2、sendfile 是将读到内核空间的数据,转到socket buffer,进行网络发送;
3、mmap将磁盘文件映射到内存,支持读和写,对内存的操作会反映在磁盘文件上。
RocketMQ 在消费消息时,使用了 mmap。kafka 使用了 sendFile。



相关推荐
通过ByteBuf对象,Netty能够高效地处理网络I/O,支持零拷贝等优化技术。 2. **消息编码与解码**:在Netty中,我们通常会自定义编解码器来将原始字节流转换为业务对象,以便处理接收到的数据。例如,可以创建一个...
Kafka 使用零拷贝技术来提高 Web Server 静态文件的速度。传统模式下我们从硬盘读取一个文件是这样的先复制到内核空间,然后复制到用户空间;从用户空间重新复制到内核空间,然后发送给网卡。Zero Copy 中直接从内核...
Kafka利用零复制技术,减少了操作系统在内存和磁盘间的数据拷贝,提高了性能。生产者将消息直接写入操作系统缓冲区,然后由操作系统直接发送给网络,减少了CPU的负担。 7. **Kafka Streams**: Kafka 2.13-3.4.0...
3. **零拷贝**:Kafka通过操作系统级别的零拷贝技术,减少了数据在内存和磁盘之间的复制次数,进一步提升了性能。 4. **分区和副本**:每个主题的分区都有多个副本,分布在不同的Broker上,提供冗余和故障恢复能力...
1. **高吞吐量**:Kafka通过使用磁盘顺序写和零拷贝技术实现了极高的吞吐量。 2. **持久性**:Kafka将消息持久化到硬盘,提供了数据持久性和可靠性。 3. **容错性**:通过多副本机制,即使集群中部分节点故障也能...
1. **高吞吐量**:Kafka通过批量发送和零拷贝技术实现了高效的I/O操作,从而达到每秒数十万条消息的处理能力。 2. **持久化**:Kafka将消息写入磁盘,并提供可配置的保留策略,如按时间或大小删除,确保消息不会...
10. **性能优化**:Kafka的高性能得益于其零拷贝机制、内存管理和线程模型。在源码中,可以看到如何优化网络I/O、减少磁盘操作以及有效利用多核处理器。 在深入理解Kafka源码后,开发者能够更好地优化和定制Kafka...
10. **性能优化**:Kafka通过批量发送、零拷贝、内存管理等手段,实现了高吞吐量和低延迟的性能。 11. **Kafka Connect**:允许用户轻松地将Kafka与其他系统(如数据库或Hadoop)集成,实现数据的导入和导出。 12....
6. **性能优化**:Kafka通过批量发送、零拷贝、内存管理等技术实现高性能。批量发送减少了网络I/O次数,零拷贝减少了操作系统层面的数据复制,内存管理优化了消息查找和处理速度。 7. **源码解析**:书中可能会详细...
Kafka的高性能得益于其优化的设计,例如零拷贝(Zero-Copy)技术,减少了数据在内存和磁盘之间的传输次数,提高了消息处理速度。另外,Kafka还支持批处理(Batching),将多条消息打包发送,进一步提升了网络传输...
例如,Kafka使用零拷贝技术来提高数据传输效率,使用分区分片技术来提高数据处理效率。 Kafka是一个功能强大、性能优异的分布式消息系统,被广泛应用于各种大数据处理场景中。Kafka的高可扩展性和高吞吐率使其成为...
4. **高性能**:Kafka使用零拷贝技术,大大减少了数据传输中的CPU开销,从而提高了处理速度。此外,其批量发送和接收消息的能力也提升了效率。 5. **消费者组**:消费者通过加入消费者组来消费消息,同一个组内的...
4. 高吞吐量:Kafka利用批量发送和零拷贝技术,实现了高效的读写性能。 四、C#实战示例 以下是一个简单的C# Kafka生产者和消费者示例: ```csharp using Confluent.Kafka; // 生产者 var producerConfig = new ...
4. **高吞吐量**: Kafka 通过批量发送和批量读取以及零拷贝技术实现高吞吐量。 5. **延迟与时效性**: Kafka 设计时考虑了低延迟,允许实时数据处理和分析。 **应用场景** 1. **日志聚合**: Kafka 常用于收集不同...
- **高性能:** Kafka采用了高效的日志文件存储机制,并利用零拷贝技术提高读写性能。 - **可扩展性:** Kafka支持动态添加和移除Broker,使得系统可以在不停机的情况下扩展或缩小规模。 - **可靠性:** Kafka支持消息...
- **高性能**:通过零拷贝技术,Kafka能实现每秒数十万条消息的处理速度。 - **实时处理**:支持实时数据流处理,使得数据分析更加及时。 - **灵活性**:Kafka可与其他大数据技术(如Hadoop、Spark)无缝集成。 ...
- **零拷贝(Zero-Copy)**: Kafka通过操作系统层面的零拷贝技术提高数据传输效率,减少CPU资源消耗。 - **批量发送(Batching)**: 生产者可以将多条消息打包成一个批次发送,降低网络通信开销。 5. **容错机制*...
- Kafka采用了多路复用技术以及零拷贝技术,大大提高了消息的处理速度。 - 通过并行处理多个Partition,Kafka能够实现非常高的消息吞吐量。 3. **消息保留策略**: - Kafka提供了灵活的消息保留策略,可以根据...
8. **性能优化**:Kafka具有高性能的特点,可以通过批处理、缓存和零拷贝等技术提高吞吐量和降低延迟。 9. **Kafka Streams**:Kafka提供的流处理库,允许开发人员直接在Kafka主题之间进行复杂的计算和转换,实现...
总结来说,KAFKA通过分区、顺序写入、批量处理、内存映射、零拷贝、推拉模型等手段,实现了高效的读写性能,能够在短时间内处理大量消息。同时,其分布式架构和冗余副本策略确保了数据的可靠性和系统的高可用性。...