

هœ¨ن½؟用eventTimeçڑ„و—¶ه€™ه¦‚ن½•ه¤„çگ†ن¹±ه؛ڈو•°وچ®ï¼ںوˆ‘ن»¬çں¥éپ“,وµپه¤„çگ†ن»ژن؛‹ن»¶ن؛§ç”ں,هˆ°وµپç»ڈsource,ه†چهˆ°operator,ن¸é—´وک¯وœ‰ن¸€ن¸ھè؟‡ç¨‹ه’Œو—¶é—´çڑ„م€‚虽然ه¤§éƒ¨هˆ†وƒ…ه†µن¸‹ï¼Œوµپهˆ°operatorçڑ„و•°وچ®éƒ½وک¯وŒ‰ç…§ن؛‹ن»¶ن؛§ç”ںçڑ„و—¶é—´é،؛ه؛ڈو¥çڑ„,ن½†وک¯ن¹ںن¸چوژ’除由ن؛ژ网络ه»¶è؟ںç‰هژںه› ,ه¯¼è‡´ن¹±ه؛ڈçڑ„ن؛§ç”ں,特هˆ«وک¯ن½؟用kafkaçڑ„è¯ï¼Œه¤ڑن¸ھهˆ†هŒ؛çڑ„و•°وچ®و— و³•ن؟è¯پوœ‰ه؛ڈم€‚و‰€ن»¥هœ¨è؟›è،Œwindowè®،ç®—çڑ„و—¶ه€™ï¼Œوˆ‘ن»¬هڈˆن¸چ能و— é™گوœںçڑ„ç‰ن¸‹هژ»ï¼Œه؟…é،»è¦پوœ‰ن¸ھوœ؛هˆ¶و¥ن؟è¯پن¸€ن¸ھ特ه®ڑçڑ„و—¶é—´هگژ,ه؟…é،»è§¦هڈ‘windowهژ»è؟›è،Œè®،ç®—ن؛†م€‚è؟™ن¸ھ特هˆ«çڑ„وœ؛هˆ¶ï¼Œه°±وک¯watermarkم€‚Watermarkوک¯ç”¨ن؛ژه¤„çگ†ن¹±ه؛ڈن؛‹ن»¶çڑ„,用ن؛ژè،،é‡ڈEvent Timeè؟›ه±•çڑ„وœ؛هˆ¶م€‚watermarkهڈ¯ن»¥ç؟»è¯‘ن¸؛و°´ن½چç؛؟م€‚
ن¸€م€پWatermarkçڑ„و ¸ه؟ƒهژںçگ†
Watermarkçڑ„و ¸ه؟ƒوœ¬è´¨هڈ¯ن»¥çگ†è§£وˆگن¸€ن¸ھه»¶è؟ں触هڈ‘وœ؛هˆ¶م€‚
هœ¨ Flink çڑ„çھ—هڈ£ه¤„çگ†è؟‡ç¨‹ن¸ï¼Œه¦‚وœç،®ه®ڑه…¨éƒ¨و•°وچ®هˆ°è¾¾ï¼Œه°±هڈ¯ن»¥ه¯¹ Window çڑ„و‰€وœ‰و•°وچ®هپڑ çھ—هڈ£è®،ç®—و“چن½œï¼ˆه¦‚و±‡و€»م€پهˆ†ç»„ç‰ï¼‰ï¼Œه¦‚وœو•°وچ®و²،وœ‰ه…¨éƒ¨هˆ°è¾¾ï¼Œهˆ™ç»§ç»ç‰ه¾…该çھ—هڈ£ن¸çڑ„و•°وچ®ه…¨ 部هˆ°è¾¾و‰چه¼€ه§‹ه¤„çگ†م€‚è؟™ç§چوƒ…ه†µن¸‹ه°±éœ€è¦پ用هˆ°و°´ن½چç؛؟(WaterMarks)وœ؛هˆ¶ï¼Œه®ƒèƒ½ه¤ںè،،é‡ڈو•°وچ®ه¤„ çگ†è؟›ه؛¦ï¼ˆè،¨è¾¾و•°وچ®هˆ°è¾¾çڑ„ه®Œو•´و€§ï¼‰ï¼Œن؟è¯پن؛‹ن»¶و•°وچ®ï¼ˆه…¨éƒ¨ï¼‰هˆ°è¾¾ Flink ç³»ç»ں,وˆ–者هœ¨ن¹±ه؛ڈهڈٹ ه»¶è؟ںهˆ°è¾¾و—¶ï¼Œن¹ں能ه¤ںهƒڈ预وœںن¸€و ·è®،ç®—ه‡؛و£ç،®ه¹¶ن¸”è؟ç»çڑ„结وœم€‚ه½“ن»»ن½• Event è؟›ه…¥هˆ° Flink ç³»ç»ںو—¶ï¼Œن¼ڑو ¹وچ®ه½“ه‰چوœ€ه¤§ن؛‹ن»¶و—¶é—´ن؛§ç”ں Watermarks و—¶é—´وˆ³م€‚
é‚£ن¹ˆ Flink وک¯و€ژن¹ˆè®،ç®— Watermak çڑ„ه€¼ه‘¢ï¼ں
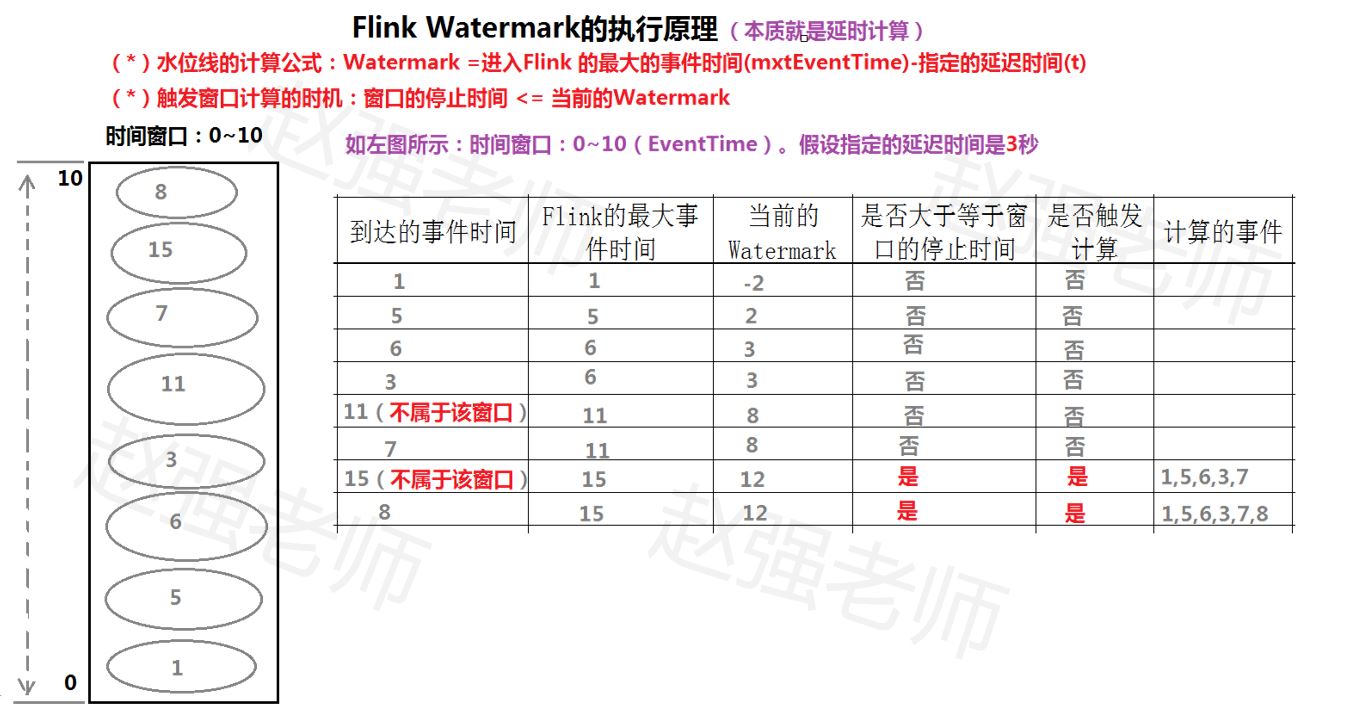
Watermark =è؟›ه…¥Flink çڑ„وœ€ه¤§çڑ„ن؛‹ن»¶و—¶é—´(mxtEventTime)-وŒ‡ه®ڑçڑ„ه»¶è؟ںو—¶é—´(t)
é‚£ن¹ˆوœ‰ Watermark çڑ„ Window وک¯و€ژن¹ˆè§¦هڈ‘çھ—هڈ£ه‡½و•°çڑ„ه‘¢ï¼ں
ه¦‚وœوœ‰çھ—هڈ£çڑ„هپœو¢و—¶é—´ç‰ن؛ژوˆ–者ه°ڈن؛ژ maxEventTime - t(ه½“و—¶çڑ„warkmark),那ن¹ˆè؟™ن¸ھçھ—هڈ£è¢«è§¦هڈ‘و‰§è،Œم€‚
ه…¶و ¸ه؟ƒه¤„çگ†وµپ程ه¦‚ن¸‹ه›¾و‰€ç¤؛م€‚
ن؛Œم€پWatermarkçڑ„ن¸‰ç§چن½؟用وƒ…ه†µ
1م€پوœ¬و¥وœ‰ه؛ڈçڑ„Streamن¸çڑ„ Watermark
ه¦‚وœو•°وچ®ه…ƒç´ çڑ„ن؛‹ن»¶و—¶é—´وک¯وœ‰ه؛ڈçڑ„,Watermark و—¶é—´وˆ³ن¼ڑéڑڈç€و•°وچ®ه…ƒç´ çڑ„ن؛‹ن»¶و—¶é—´وŒ‰é،؛ ه؛ڈç”ںوˆگ,و¤و—¶و°´ن½چç؛؟çڑ„هڈکهŒ–ه’Œن؛‹ن»¶و—¶é—´ن؟وŒپن¸€ç›´ï¼ˆه› ن¸؛و—¢ç„¶وک¯وœ‰ه؛ڈçڑ„و—¶é—´ï¼Œه°±ن¸چ需è¦پ设置ه»¶è؟ںن؛†ï¼Œé‚£ن¹ˆtه°±وک¯ 0م€‚و‰€ن»¥ watermark=maxtime-0 = maxtime),ن¹ںه°±وک¯çگ†وƒ³çٹ¶و€پن¸‹çڑ„و°´ن½چ ç؛؟م€‚ه½“ Watermark و—¶é—´ه¤§ن؛ژ Windows 结وںو—¶é—´ه°±ن¼ڑ触هڈ‘ه¯¹ Windows çڑ„و•°وچ®è®،算,ن»¥و¤ç±»وژ¨ï¼Œ ن¸‹ن¸€ن¸ھ Window ن¹ںوک¯ن¸€و ·م€‚è؟™ç§چوƒ…ه†µه…¶ه®وک¯ن¹±ه؛ڈو•°وچ®çڑ„ن¸€ç§چ特و®ٹوƒ…ه†µم€‚
2م€پن¹±ه؛ڈن؛‹ن»¶ن¸çڑ„Watermark
çژ°ه®وƒ…ه†µن¸‹و•°وچ®ه…ƒç´ ه¾€ه¾€ه¹¶ن¸چوک¯وŒ‰ç…§ه…¶ن؛§ç”ںé،؛ه؛ڈوژ¥ه…¥هˆ° Flink ç³»ç»ںن¸è؟›è،Œه¤„çگ†ï¼Œè€Œé¢‘ç¹پ ه‡؛çژ°ن¹±ه؛ڈوˆ–è؟ںهˆ°çڑ„وƒ…ه†µï¼Œè؟™ç§چوƒ…ه†µه°±éœ€è¦پن½؟用 Watermarks و¥ه؛”ه¯¹م€‚و¯”ه¦‚ن¸‹ه›¾ï¼Œè®¾ç½®ه»¶è؟ںو—¶é—´tن¸؛2م€‚
3م€په¹¶è،Œو•°وچ®وµپن¸çڑ„Watermark
هœ¨ه¤ڑه¹¶è،Œه؛¦çڑ„وƒ…ه†µن¸‹ï¼ŒWatermark ن¼ڑوœ‰ن¸€ن¸ھه¯¹é½گوœ؛هˆ¶ï¼Œè؟™ن¸ھه¯¹é½گوœ؛هˆ¶ن¼ڑهڈ–و‰€وœ‰ Channel ن¸وœ€ه°ڈçڑ„ Watermarkم€‚
ن¸‰م€پ设置Watermarkçڑ„و ¸ه؟ƒن»£ç پ
1م€پ首ه…ˆï¼Œو£ç،®è®¾ç½®ن؛‹ن»¶ه¤„çگ†çڑ„و—¶é—´è¯ن¹‰ï¼Œن¸€èˆ¬éƒ½وک¯é‡‡ç”¨Event Timeم€‚
sEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
آ
2م€په…¶و¬،,وŒ‡ه®ڑç”ںوˆگWatermarkçڑ„وœ؛هˆ¶ï¼ŒهŒ…و‹¬ï¼ڑه»¶و—¶ه¤„çگ†çڑ„و—¶é—´ه’ŒEventTimeه¯¹ه؛”çڑ„ه—و®µم€‚ه¦‚ن¸‹ï¼ڑ
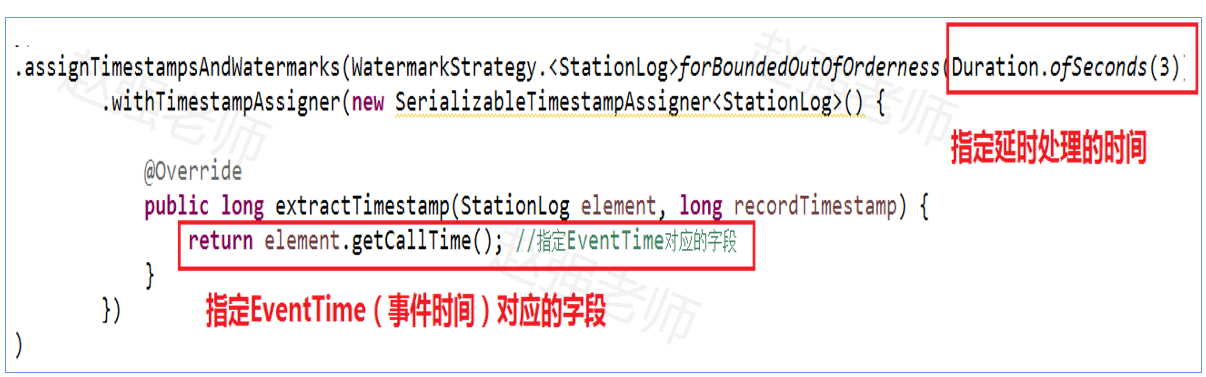
و³¨و„ڈï¼ڑن¸چç®،وک¯و•°وچ®وک¯هگ¦وœ‰ه؛ڈ,都هڈ¯ن»¥ن½؟用ن¸ٹé¢çڑ„ن»£ç پم€‚وœ‰ه؛ڈçڑ„و•°وچ®هڈھوک¯و— ه؛ڈو•°وچ®çڑ„ن¸€ç§چ特و®ٹوƒ…ه†µم€‚
ه››م€پWatermark编程و،ˆن¾‹
وµ‹è¯•و•°وچ®ï¼ڑهں؛ç«™çڑ„و‰‹وœ؛é€ڑè¯و•°وچ®ï¼Œه¦‚ن¸‹ï¼ڑ

需و±‚ï¼ڑوŒ‰هں؛站,و¯ڈ5秒ç»ںè®،é€ڑè¯و—¶é—´وœ€é•؟çڑ„è®°ه½•م€‚
- StationLog用ن؛ژه°پ装هں؛ç«™و•°وچ®
package watermark;
//station1,18688822219,18684812319,10,1595158485855
public class StationLog {
private String stationID; //هں؛ç«™ID
private String from; //ه‘¼هڈ«و”¾
private String to; //被هڈ«و–¹
private long duration; //é€ڑè¯çڑ„وŒپç»و—¶é—´
private long callTime; //é€ڑè¯çڑ„ه‘¼هڈ«و—¶é—´
public StationLog(String stationID, String from,
String to, long duration,
long callTime) {
this.stationID = stationID;
this.from = from;
this.to = to;
this.duration = duration;
this.callTime = callTime;
}
public String getStationID() {
return stationID;
}
public void setStationID(String stationID) {
this.stationID = stationID;
}
public long getCallTime() {
return callTime;
}
public void setCallTime(long callTime) {
this.callTime = callTime;
}
public String getFrom() {
return from;
}
public void setFrom(String from) {
this.from = from;
}
public String getTo() {
return to;
}
public void setTo(String to) {
this.to = to;
}
public long getDuration() {
return duration;
}
public void setDuration(long duration) {
this.duration = duration;
}
}
آ
- ن»£ç په®çژ°ï¼ڑWaterMarkDemo用ن؛ژه®Œوˆگè®،算(و³¨و„ڈï¼ڑن¸؛ن؛†و–¹ن¾؟ه’±ن»¬وµ‹è¯•è®¾ç½®ن»»هٹ،çڑ„ه¹¶è،Œه؛¦ن¸؛1)آ آ
package watermark;
import java.time.Duration;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
//و¯ڈéڑ”ن؛”秒,ه°†è؟‡هژ»وک¯10秒ه†…,é€ڑè¯و—¶é—´وœ€é•؟çڑ„é€ڑè¯و—¥ه؟—输ه‡؛م€‚
public class WaterMarkDemo {
public static void main(String[] args) throws Exception {
//ه¾—هˆ°Flinkوµپه¼ڈه¤„çگ†çڑ„è؟گè،Œçژ¯ه¢ƒ
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
//设置ه‘¨وœںو€§çڑ„ن؛§ç”ںو°´ن½چç؛؟çڑ„و—¶é—´é—´éڑ”م€‚ه½“و•°وچ®وµپه¾ˆه¤§çڑ„و—¶ه€™ï¼Œه¦‚وœو¯ڈن¸ھن؛‹ن»¶éƒ½ن؛§ç”ںو°´ن½چç؛؟,ن¼ڑه½±ه“چو€§èƒ½م€‚
env.getConfig().setAutoWatermarkInterval(100);//é»ک认100و¯«ç§’
//ه¾—هˆ°è¾“ه…¥وµپ
DataStreamSource<String> stream = env.socketTextStream("bigdata111", 1234);
stream.flatMap(new FlatMapFunction<String, StationLog>() {
public void flatMap(String data, Collector<StationLog> output) throws Exception {
String[] words = data.split(",");
// هں؛ç«™ID from to é€ڑè¯و—¶é•؟ callTime
output.collect(new StationLog(words[0], words[1],words[2], Long.parseLong(words[3]), Long.parseLong(words[4])));
}
}).filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return value.getDuration() > 0?true:false;
}
}).assignTimestampsAndWatermarks(WatermarkStrategy.<StationLog>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(new SerializableTimestampAssigner<StationLog>() {
@Override
public long extractTimestamp(StationLog element, long recordTimestamp) {
return element.getCallTime(); //وŒ‡ه®ڑEventTimeه¯¹ه؛”çڑ„ه—و®µ
}
})
).keyBy(new KeySelector<StationLog, String>(){
@Override
public String getKey(StationLog value) throws Exception {
return value.getStationID(); //وŒ‰ç…§هں؛ç«™هˆ†ç»„
}}
).timeWindow(Time.seconds(5)) //设置و—¶é—´çھ—هڈ£
.reduce(new MyReduceFunction(),new MyProcessWindows()).print();
env.execute();
}
}
//用ن؛ژه¦‚ن½•ه¤„çگ†çھ—هڈ£ن¸çڑ„و•°وچ®ï¼Œهچ³ï¼ڑو‰¾هˆ°çھ—هڈ£ه†…é€ڑè¯و—¶é—´وœ€é•؟çڑ„è®°ه½•م€‚
class MyReduceFunction implements ReduceFunction<StationLog> {
@Override
public StationLog reduce(StationLog value1, StationLog value2) throws Exception {
// و‰¾هˆ°é€ڑè¯و—¶é—´وœ€é•؟çڑ„é€ڑè¯è®°ه½•
return value1.getDuration() >= value2.getDuration() ? value1 : value2;
}
}
//çھ—هڈ£ه¤„çگ†ه®Œوˆگهگژ,输ه‡؛çڑ„结وœوک¯ن»€ن¹ˆ
class MyProcessWindows extends ProcessWindowFunction<StationLog, String, String, TimeWindow> {
@Override
public void process(String key, ProcessWindowFunction<StationLog, String, String, TimeWindow>.Context context,
Iterable<StationLog> elements, Collector<String> out) throws Exception {
StationLog maxLog = elements.iterator().next();
StringBuffer sb = new StringBuffer();
sb.append("çھ—هڈ£èŒƒه›´وک¯:").append(context.window().getStart()).append("----").append(context.window().getEnd()).append("\n");;
sb.append("هں؛ç«™IDï¼ڑ").append(maxLog.getStationID()).append("\t")
.append("ه‘¼هڈ«و—¶é—´ï¼ڑ").append(maxLog.getCallTime()).append("\t")
.append("ن¸»هڈ«هڈ·ç پï¼ڑ").append(maxLog.getFrom()).append("\t")
.append("被هڈ«هڈ·ç پï¼ڑ") .append(maxLog.getTo()).append("\t")
.append("é€ڑè¯و—¶é•؟ï¼ڑ").append(maxLog.getDuration()).append("\n");
out.collect(sb.toString());
}
}
آ



相ه…³وژ¨èچگ
ن؛†è§£Oracleçڑ„ه®،è®،وœ؛هˆ¶ï¼Œه®çژ°ه¯¹و•°وچ®ه؛“و“چن½œçڑ„è؟½è¸ھم€‚ 6. **ه¤‡ن»½ن¸ژوپ¢ه¤چ**ï¼ڑه¦ن¹ Oracleçڑ„ه¤‡ن»½ç–略,ه¦‚ه…¨ه¤‡م€په¢é‡ڈه¤‡ه’Œه¯¼ه‡؛/ه¯¼ه…¥م€‚وژŒوڈ،RMAN(وپ¢ه¤چç®،çگ†ه™¨ï¼‰ه·¥ه…·çڑ„ن½؟用,ن»¥هڈٹه¦‚ن½•هœ¨و•°وچ®ن¸¢ه¤±وˆ–ç³»ç»ںو•…éڑœو—¶è؟›è،Œو•°وچ®وپ¢ه¤چم€‚ 7. *...
وƒ³è¦په¥½ه¥½هœ°ه¦ن¹ Oracleو•°وچ®ه؛“çڑ„وœ‹هڈ‹ه‘€ï¼Œن½ é”™è؟‡ن؛†ه¥¹ه°±ه¤ھن¸چه€¼ه¾—ن؛†م€‚里é¢وœ‰ه¥½ه¤ڑçڑ„Oracleو“چن½œه‘½ن»¤هڈ¯èƒ½ن½ 都و²،وژ¥è§¦è؟‡هگ§م€‚ه¥½ن؛†ï¼Œè¯ن¸چه¤ڑه¤ڑ说م€‚هڑن؟،资و–™ن¸چé”™ï¼پن½ ,ه€¼ه¾—و‹¥وœ‰ï¼پOK.è؟کوœ‰ï¼Œن¹‹و‰€وœ‰è¦پن½ 2هˆ†و‰“èµڈ,وک¯وˆ‘ç»™ن؛†ن½ è؟™ن¹ˆه¥½çڑ„...
ç²¾é€ڑJSP编程 ن½œè€…èµµه¼؛ ç¼– 12-18èٹ‚
م€ٹç²¾é€ڑJSP编程م€‹وک¯èµµه¼؛ه…ˆç”ںçڑ„ن¸€éƒ¨و·±ه…¥è§£وگJSPوٹ€وœ¯çڑ„ن¸“ن¸ڑè‘—ن½œï¼Œè¯¥ن¹¦é’ˆه¯¹JSP编程è؟›è،Œن؛†ه…¨é¢ن¸”و·±ه…¥çڑ„讲解,و—¨هœ¨ه¸®هٹ©è¯»è€…وژŒوڈ،JSPçڑ„و ¸ه؟ƒو¦‚ه؟µه’Œوٹ€وœ¯ï¼Œوڈگهچ‡Webه؛”用ه¼€هڈ‘能هٹ›م€‚و ¹وچ®وڈگن¾›çڑ„و–‡ن»¶هگچهˆ—è،¨ï¼Œوˆ‘ن»¬هڈ¯ن»¥وژ¨وµ‹ن¹¦ç±چçڑ„ç« èٹ‚...
و ¹وچ®وڈگن¾›çڑ„و–‡ن»¶ن؟،وپ¯ï¼Œوˆ‘ن»¬هڈ¯ن»¥وژ¨و–ه‡؛è؟™وک¯ن¸€ن»½ن¸ژJava Server Pages (JSP)相ه…³çڑ„ه¦ن¹ 资و–™ن»‹ç»چ,特هˆ«وک¯ه…³ن؛ژèµµه¼؛ç¼–ه†™çڑ„م€ٹç²¾é€ڑJSP编程م€‹è؟™وœ¬ن¹¦çڑ„相ه…³ن؟،وپ¯م€‚ن¸‹é¢ه°†هں؛ن؛ژè؟™ن¸ھçگ†è§£و¥ç”ںوˆگ相ه…³çں¥è¯†ç‚¹م€‚ ### ن¸€م€پJSPهں؛ç،€و¦‚ه؟µ ...
5. **ه¤ڑè،¨وں¥è¯¢ن¸ژهگوں¥è¯¢çڑ„选و‹©**ï¼ڑه½“ن¸¤è€…都能ه®çژ°éœ€و±‚و—¶ï¼Œه°½é‡ڈ选و‹©ه¤ڑè،¨وں¥è¯¢ï¼Œه› ن¸؛ه®ƒهڈھ需è¦په¯¹و•°وچ®ه؛“è؟›è،Œن¸€و¬،و“چن½œï¼Œو•ˆçژ‡é€ڑه¸¸و›´é«کم€‚ 6. **ه¤„çگ†NULLه€¼**ï¼ڑهœ¨Oracleن¸ï¼ŒNULLè،¨ç¤؛و— و•ˆم€پوœھوŒ‡ه®ڑوˆ–وœھçں¥çڑ„ه€¼ï¼Œه®ƒن¸چç‰ن؛ژç©؛و ¼وˆ–0...
و•™ç¨‹هگچ称ï¼ڑOracle و•°وچ®ه؛“èµµه¼؛视频و•™ç¨‹م€گ3ه¤©م€‘و•™ç¨‹ç›®ه½•ï¼ڑم€گم€‘Oracleه®‰è£…ن¸ژç®،çگ†م€پSQLè¯هڈ¥(èµµه¼؛)م€گم€‘Orcaleهکه‚¨è؟‡ç¨‹jdbcن¸ژOrcaleه¤§و–‡وœ¬و“چن½œç‰(èµµه¼؛)م€گم€‘SQL简هچ•وں¥è¯¢è§¦هڈ‘ه™¨è§†ه›¾(èµµه¼؛)آ 资و؛گه¤ھه¤§ï¼Œن¼ 百ه؛¦ç½‘ç›کن؛†ï¼Œé“¾وژ¥هœ¨...
5. ه®‰ه…¨و€§ï¼ڑ设置用وˆ·è§’色م€پوƒé™گ,ه®çژ°هں؛ن؛ژ角色çڑ„è®؟é—®وژ§هˆ¶ï¼ˆRBAC),ه¹¶هڈ¯ن»¥é›†وˆگLDAP(Lightweight Directory Access Protocol)è؟›è،Œé›†ن¸è؛«ن»½éھŒè¯پم€‚ و€»ç»“,"day2013-0110-webLogicé…چç½®ه’Œé›†ç¾¤(èµµه¼؛)"è؟™ن¸ھ资و–™هŒ…و¶µç›–ن؛†...
ه›¾ç»“و„و•°وچ®ه؛“هˆ™وک¯هں؛ن؛ژه›¾و¨،ه‹ï¼Œé€‚هگˆه¤„çگ†ه¤چو‚ه…³ç³»çڑ„و•°وچ®م€‚ MongoDBوک¯ن¸€ç§چé¢هگ‘و–‡و،£çڑ„NoSQLو•°وچ®ه؛“,ه®ƒé‡‡ç”¨ن؛†ç±»ن¼¼JSONçڑ„و ¼ه¼ڈهکه‚¨و•°وچ®ï¼Œوڈگن¾›ن؛†ن¸°ه¯Œçڑ„وں¥è¯¢هٹں能ه’Œو–‡و،£و›´و–°و“چن½œم€‚ه®ƒçڑ„特点هœ¨ن؛ژه®ƒçڑ„و— و¨،ه¼ڈ设è®،,è؟™و„ڈه‘³ç€ç”¨وˆ·...
هں؛ن؛ژmatlab/simulinkçڑ„çں؟ن؛•ن½ژهژ‹ç”µç¼†ç»ç¼کهڈ‚و•°هœ¨ç؛؟监وµ‹çڑ„ن»؟çœںç ”ç©¶ï¼Œèµµه¼؛,çژ‹ه½¦و–‡ï¼Œوœ¬و–‡هڈ™è؟°ن؛†MATLAB/SIULINKçڑ„特点,ه»؛ç«‹ن؛†هں؛ن؛ژMATLAB/SIMULINKن»؟çœںوٹ€وœ¯çڑ„çں؟ن؛•ن½ژهژ‹ç”µç¼†ن¼ 输و¨،ه‹ï¼Œهœ¨و¤هں؛ç،€ن¸ٹه®çژ°ن؛†ن¸€ç§چهں؛ن؛ژ附هٹ ن½ژ频ن؟،هڈ·...
و•°وژ§وœ؛ه؛ٹçڑ„ç›´ç؛؟电وœ؛ن¼؛وœچç³»ç»ںç ”ç©¶وک¯ه·¥ن¸ڑè‡ھهٹ¨هŒ–领هںںن¸çڑ„ن¸€ن¸ھé‡چè¦پ课é¢ک,ه®ƒç›´وژ¥...é€ڑè؟‡Matlab/Simulinkن»؟çœںو¨،ه‹ه’Œو”¹è؟›çڑ„و•°ه—و»‘و¨،وژ§هˆ¶ç–略,هڈ¯ن»¥و›´ه¥½هœ°ه®çژ°و•°وژ§وœ؛ه؛ٹçڑ„é«کç²¾ه؛¦هٹ ه·¥ï¼Œو»،足ه·¥ن¸ڑè‡ھهٹ¨هŒ–ه¯¹ه…ˆè؟›هˆ¶é€ وٹ€وœ¯çڑ„ن¸چو–è؟½و±‚م€‚
م€گو ‡é¢کم€‘"javaن»£ç پ-46 èµ–èµµه¼؛"و‰€وŒ‡çڑ„هڈ¯èƒ½وک¯ن¸€ن¸ھه…³ن؛ژJava编程çڑ„é،¹ç›®وˆ–ç¤؛ن¾‹ï¼Œç”±ه¼€هڈ‘者赖赵ه¼؛هˆ›ه»؛م€‚هœ¨è؟™ن¸ھé،¹ç›®ن¸ï¼Œن»–هڈ¯èƒ½هˆ†ن؛«ن؛†ن¸€و®µç‰¹ه®ڑçڑ„Javaن»£ç پ,用ن؛ژ解ه†³وںگç§چé—®é¢کوˆ–者ه®çژ°ن¸€ن¸ھهٹں能م€‚è؟™ن¸ھو ‡é¢کوڑ—ç¤؛ن؛†è؟™وک¯ن¸€ن¸ھن¸ژJava...
ç£پç›کéکµهˆ—é€ڑè؟‡RAIDوٹ€وœ¯ه®çژ°ه®¹é‡ڈه’Œé€ںه؛¦çڑ„وڈگهچ‡ï¼ŒهگŒو—¶وڈگé«کو•°وچ®çڑ„هڈ¯ç”¨و€§ه’Œه®‰ه…¨و€§م€‚و¤ه¤–,ه¤§è§„و¨،集群هکه‚¨ه¦‚Googleçڑ„هکه‚¨ç³»ç»ں,ن»¥هڈٹه¯¹ç‰هکه‚¨ï¼ˆP2P)网络,هˆ©ç”¨هˆ†ه¸ƒه¼ڈهکه‚¨çڑ„ن¼کهٹ؟,وڈگن¾›ه¤§è§„و¨،م€پن½ژوˆگوœ¬çڑ„و•°وچ®وœچهٹ،م€‚ éڑڈç€ç،¬ن»¶...
- ç£پوµپهڈکéک»ه°¼ه™¨ن¸چ需è¦پé«کهژ‹و؟€هٹ±ç”µو؛گ,相و¯”ن؛ژن¼ ç»ںçڑ„و¶²هژ‹éک»ه°¼ه™¨وˆ–و°”هٹ¨ç³»ç»ں,ه…¶ç»“و„简هچ•ï¼Œوک“ن؛ژهœ¨ه®è½¦ن¸ٹه®çژ°م€‚ 2. وژ§هˆ¶ç³»ç»ں设è®،ن¸ژن»؟çœںï¼ڑ - و–‡ن¸وڈگهˆ°ن؛†هں؛ن؛ژو¨،ه‹çڑ„وژ§هˆ¶ç–略,è؟™و„ڈه‘³ç€وژ§هˆ¶ه™¨è®¾è®،وک¯ه»؛ç«‹هœ¨ه¯¹ه؛§و¤…هٹ¨هٹ›ه¦è،Œن¸؛...
م€ٹLoadRunnerو€§èƒ½وµ‹è¯•ه·§هŒ è®ç»ƒèگ¥م€‹وک¯ن¸€وœ¬و·±ه…¥è®²è§£LoadRunnerو€§èƒ½وµ‹è¯•çڑ„و•™وگ,由赵ه¼؛ه’Œé‚¹ن¼ںن¼ںن¸¤ن½چن¸“ه®¶ه…±هگŒç¼–è‘—م€‚该资و؛گوڈگن¾›çڑ„وک¯ه®Œو•´ç‰ˆï¼Œن¸”و— 需ه¯†ç پهچ³هڈ¯è§£هژ‹éک…读,ه¯¹ن؛ژوƒ³è¦په¦ن¹ ه’Œوڈگهچ‡LoadRunnerو€§èƒ½وµ‹è¯•وٹ€èƒ½çڑ„ن؛؛و¥è¯´ï¼Œ...