
在分布式服务架构中,需要对分布式服务进行治理——在分布式服务协同向用户提供服务时,每个请求都被哪些服务处理?在遇到问题时,在调用哪个服务上发生了问题?在分析性能时,调用各个服务都花了多长时间?哪些调用可以并行执行?…… 为此,分布式服务平台就需要提供这样一种基础服务——可以记录每个请求的调用链;调用链上调用每个服务的时间;各个服务之间的拓扑关系…… 我们把这种行为称为“分布式服务跟踪”。(了解源码可+求求: 1791743380)
1. 背景
现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最为广泛的开源实现是 Twitter 的 Zipkin,为了实现平台无关、厂商无关的分布式服务跟踪,CNCF 发布了布式服务跟踪标准 Open Tracing。国内,淘宝的“鹰眼”、京东的“Hydra”、大众点评的“CAT”、新浪的“Watchman”、唯品会的“Microscope”、窝窝网的“Tracing”都是这样的系统。
2. Spring Cloud Sleuth
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
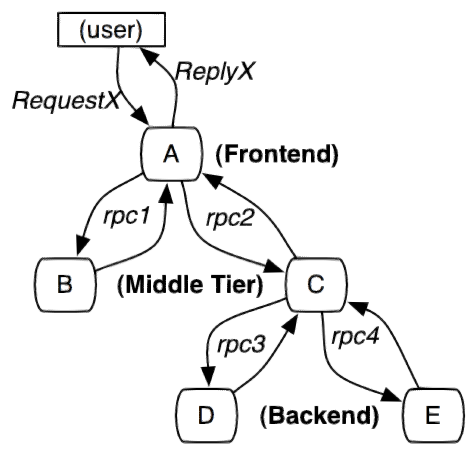
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
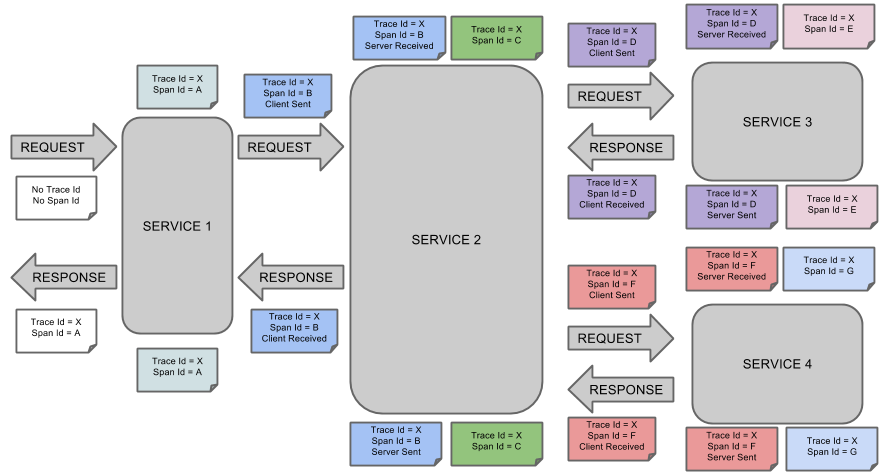
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
2. ZipKin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
3. 快速上手
3.1 zipkin
3.1.1 zipkin下载
根据全球最大同性交友网站(github)搜索zipkin后发现,zipkin现在已经不在推荐使用maven引入jar的方式构建了,目前推荐的方案是直接down他们打好包的jar,用java -jar的方式启动,传送门在这里:https://github.com/openzipkin/zipkin。
The quickest way to get started is to fetch the latest released server as a self-contained executable jar. Note that the Zipkin server requires minimum JRE 8. For example:
- curl -sSL https://zipkin.io/quickstart.sh | bash -s
- java -jar zipkin.jar
You can also start Zipkin via Docker.
- docker run -d -p 9411:9411 openzipkin/zipkin
Once the server is running, you can view traces with the Zipkin UI at http://your_host:9411/zipkin/.
If your applications aren’t sending traces, yet, configure them with Zipkin instrumentation or try one of our examples.
Check out the zipkin-server documentation for configuration details, or docker-zipkin for how to use docker-compose.
以上内容来自zipkin官方github摘录。简单解释就是可以使用https下载的方式下载zipkin.jar,并使用java -jar的方式启动,还有一种就是使用docker的方式进行启动。
具体搭建过程我这里就不在赘述,有不懂的可以私信或者关注公众号留言问我。
3.1.2 zipkin启动
zipkin的启动命令就比较谜了。
最简单的启动命令为:nohup java -jar zipkin.jar >zipkin.out 2>&1 &,这时,我们使用的是zipkin的In-Memory,含义是所有的数据都保存在内存中,一旦重启数据将全部清空,这肯定不是我们想要的,我们更想数据可以保存在磁盘中,可以被抽取到大数据平台上,方便我们后续的相关性能、服务状态分析、实时报警等功能。
这里我把使用mysql的启动语句分享出来,有关ES的启动语句基本相同:
- STORAGE_TYPE=mysql MYSQL_DB=zipkin MYSQL_USER=name MYSQL_PASS=password MYSQL_HOST=172.19.237.44 MYSQL_TCP_PORT=3306 MYSQL_USE_SSL=false nohup java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=localhost --zipkin.collector.rabbitmq.username=username --zipkin.collector.rabbitmq.password=password --logging.level.zipkin2=DEBUG >zipkin.out 2>&1 &
-
注意: 因为链路追踪的数据上报量是非常大的,如果上报数据直接使用http请求的方式推送到zipkin中,很有可能会把zipkin服务或者数据库冲崩掉,所以我在这里增加了rabbitmq的相关配置,上报数据先推送至rabbitmq中,再由rabbitmq讲数据推送至zipkin服务,这样达到一个请求削峰填谷的作用。
-
有关zipkin的启动命令可以配置的参数可以看这里:https://github.com/apache/incubator-zipkin/tree/master/zipkin-server
-
有关zipkin配置mysql基础建表语句可以看这里:https://github.com/apache/incubator-zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
-
有关zipkin本身配置文件可以看这里:https://github.com/apache/incubator-zipkin/blob/master/zipkin-server/src/main/resources/zipkin-server-shared.yml
至此,zipkin服务应该已经搭建并完成,现在我们可以访问一下默认端口,看一下zipkin-ui具体长什么样子了。
3.2 Spring Cloud Sleuth 使用
我们先将上一篇用到的zuul-simple、Eureka和producer copy到本篇文章使用的文件夹中。
3.2.1 增加依赖:
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-sleuth</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-stream-rabbit</artifactId>
- </dependency>
在zuul-simple和producer两个项目中增加sleuth和rabbitmq的依赖。
3.2.2 配置文件
增加有关rabbitmq和sleuth的配置,这里我仅给出zuul的配置文件,producer的配置同理。
- server:
- port: 8080
- spring:
- application:
- name: spring-cloud-zuul
- rabbitmq:
- host: host
- port: port
- username: username
- password: password
- sleuth:
- sampler:
- probability: 1.0
- zuul:
- FormBodyWrapperFilter:
- pre:
- disable: true
- eureka:
- client:
- service-url:
- defaultZone: http://localhost:8761/eureka/
- 注:spring.sleuth.sampler.probability的含义是链路追踪采样率,默认是0.1,我这里为了方便测试,将其改成1.0,意思是百分之百采样。
3.2.3 测试
这里我们依次启动Eureka、producer和zuul-simple。
打开浏览器,访问测试连接:http://localhost:8080/spring-cloud-producer/hello?name=spring&token=123
这时我们先看zuul的日志,如下图:
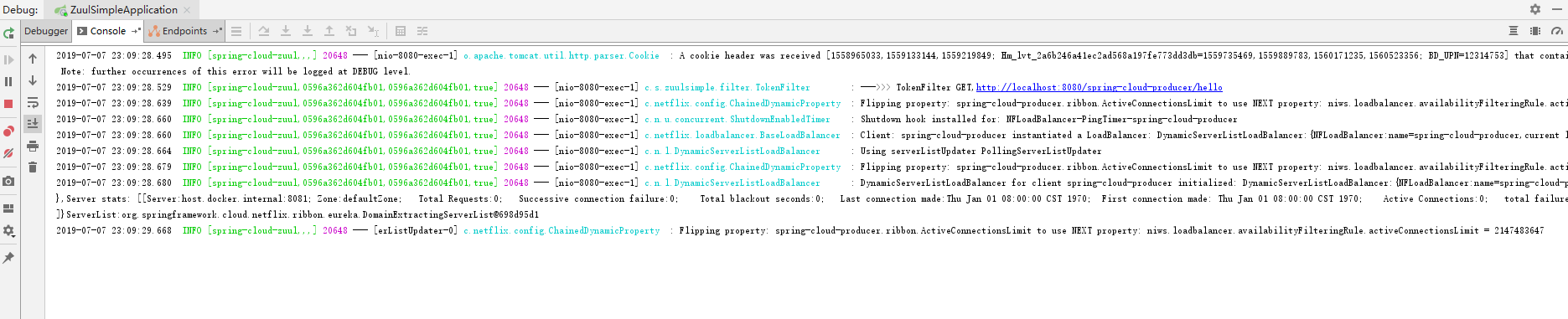
- 2019-07-07 23:09:28.529 INFO [spring-cloud-zuul,0596a362d604fb01,0596a362d604fb01,true] 20648 --- [nio-8080-exec-1] c.s.zuulsimple.filter.TokenFilter
- 注:这里的0596a362d604fb01就是这个请求的traceID,0596a362d604fb01是spanID。
我们打开zipkin-ui的界面,如下图:
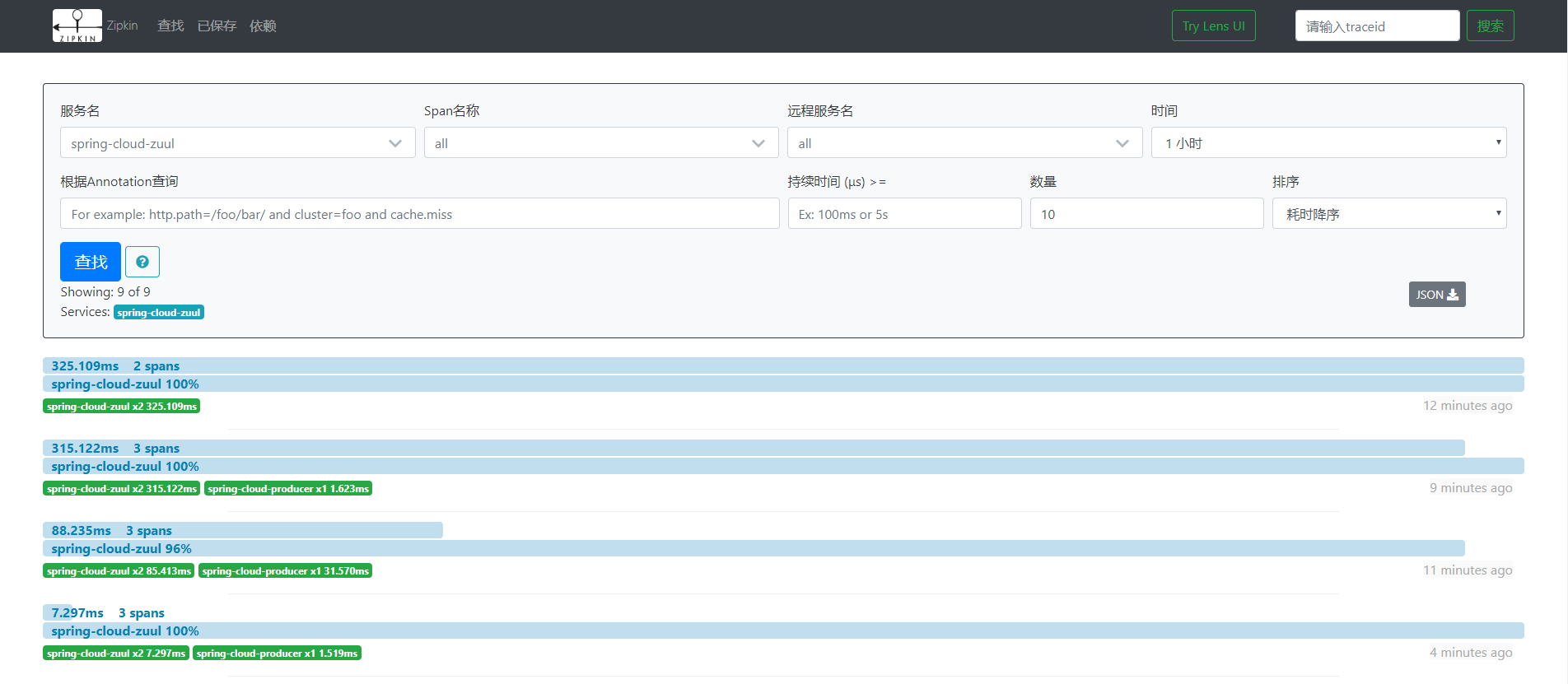
这里我们可以看到这个请求的整体耗时,点击这个请求,可以进入到详情页面,查看每个服务的耗时:
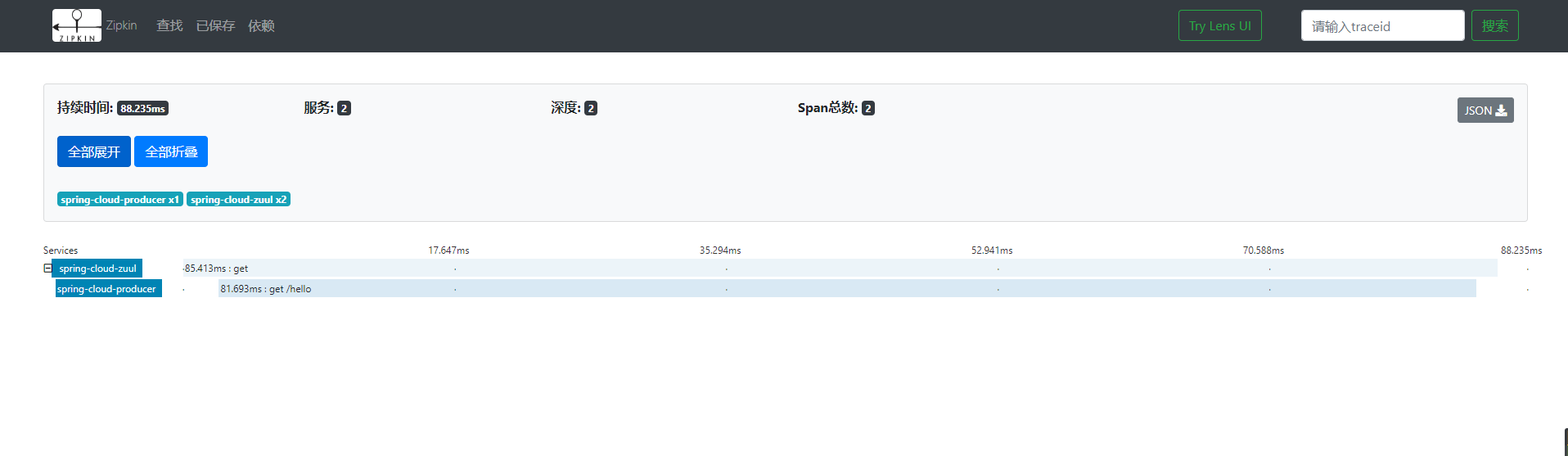
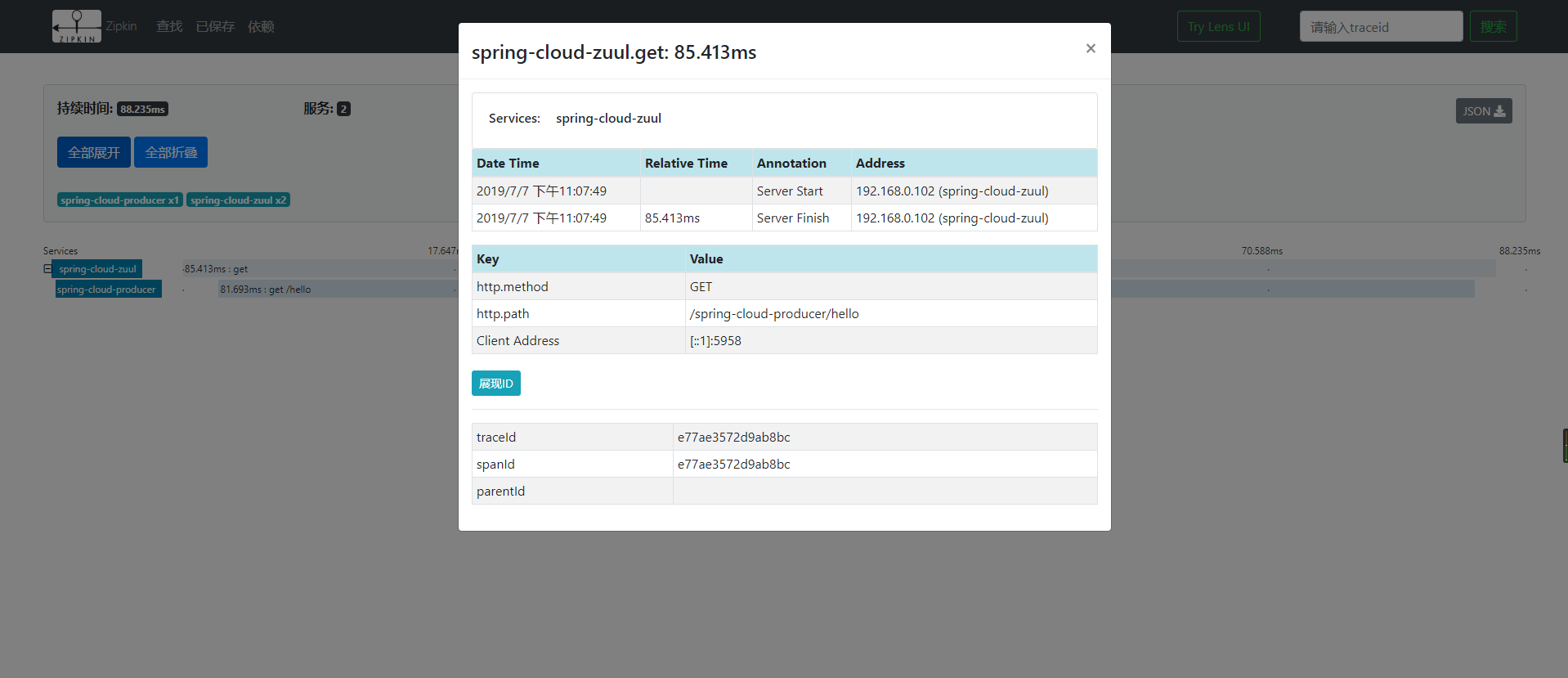
点击对应的服务,我们可以看到相应的访问时间,http请求类型、路径、IP、tranceID、spanId等内容,如下图:



相关推荐
Spring Cloud Sleuth 和 Zipkin 是两个非常流行的工具,用于实现微服务架构中的链路追踪。本篇将详细介绍这两个组件以及如何在Windows环境下进行初步使用。 **Spring Cloud Sleuth** Spring Cloud Sleuth 是一个...
总结来说,Spring Cloud Sleuth+RabbitMQ+Zipkin的结合提供了一套强大的解决方案,帮助我们在微服务环境中实现分布式链路追踪。通过这个Demo程序,我们可以学习如何配置和使用这些工具,以便更好地理解和调试我们的...
Spring Cloud Sleuth:分布式请求链路跟踪 Spring Cloud Sleuth 是一种分布式系统中跟踪服务间调用的工具,它可以直观地展示出一次请求的调用过程。在大型分布式系统中,服务之间的调用关系非常复杂,使用 Spring ...
为了解决这一问题,分布式追踪技术应运而生,其中Spring Cloud Sleuth是Spring Cloud生态系统中的一个关键组件,它与Zipkin等系统配合使用,可以提供强大的分布式追踪能力。本文将详细介绍如何在Spring Boot中配置...
实现springcloud微服务之间的调用traceId跟踪,并结合zipkin实现图形化调用链路的展示,以及在rocketmq中传递traceId的实现
Spring Cloud Sleuth是Spring Cloud生态系统的一部分,它实现了分布式追踪的标准——OpenTracing和Zipkin。通过集成Sleuth,开发者可以在不修改代码的情况下,轻松地在微服务架构中实现请求的全链路追踪。 二、核心...
毕业设计基于SpringCloud微服务分布式链路追踪系统源码 追踪实现 使用zipkin+sleuth实现 这个是比较成熟的分布式链路追踪实现方案 拦截器自定义实现 基于Google Dapper 论文,进行自定义实现。 原理: traceId :...
7. **分布式追踪**:Spring Cloud Sleuth与Zipkin或Jaeger集成,提供全链路的请求追踪,帮助开发者分析和调试分布式系统中的问题。 8. **数据库集成**:项目可能会使用MySQL或其他关系型数据库存储书籍信息,通过...
Spring Cloud 分布式整合 Zipkin 的链路跟踪详解 知识点1:为什么使用 Zipkin? 在分布式系统中,服务之间的调用关系非常复杂,导致日志查找和调用关系追踪变得困难。Zipkin 可以解决这个问题,它可以将链路调用...
7. **分布式跟踪**:通过Sleuth和Zipkin实现请求的追踪和监控。 ### Spring Cloud 核心组件介绍 1. **Eureka**:提供服务注册与发现的功能,是Spring Cloud体系中的服务治理解决方案。 2. **Config Server**:集中...
- [springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪](http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html) - [springcloud(十三):Spring Cloud Consul ...
2. Spring Cloud Sleuth与Zipkin:学习如何集成Sleuth进行分布式调用链追踪,通过Zipkin可视化分析调用链路。 第五天:Spring Cloud Stream与消息驱动 1. Spring Cloud Stream:理解消息驱动的设计模式,学习如何...
Spring Cloud Zipkin 是一个流行的链路追踪工具,它与 Spring Boot 和 Spring Cloud 结合使用,可以轻松地在微服务架构中实现分布式系统的可观测性。本教程将介绍如何整合 Spring Cloud 与 Zipkin 来实现链路追踪,...
Spring Cloud Sleuth 和 Zipkin 是两个在分布式系统中用于跟踪微服务之间调用的重要工具。本文将深入探讨如何使用它们来提升系统的可监控性和故障排查能力。 首先,Spring Cloud Sleuth 是一个集成在 Spring Boot ...
在Spring Cloud体系中,链路跟踪的实现一般依赖于Spring Cloud Sleuth与Zipkin。Spring Cloud Sleuth类似于一个中间件,可以在微服务调用过程中,将每个服务的调用记录下来。它会在日志中添加一些特有的标签,如...
3. Spring Cloud Sleuth:分布式追踪解决方案,结合Zipkin或ELK Stack实现全链路监控。 通过对Spring Cloud项目源码的学习,不仅可以加深对微服务架构的理解,还能提升代码调试和问题排查能力,为后续的微服务开发...
7. **Spring Cloud Sleuth**:分布式跟踪,整合Zipkin或ELK Stack进行链路追踪。 8. **Spring Cloud Stream**:处理消息驱动的应用,支持RabbitMQ、Kafka等消息中间件。 这些视频课程结合源码分析和课件学习,可以...
本文将深入探讨如何在Spring Boot项目中集成Spring Cloud Sleuth和Zipkin,以及这两个组件如何协同工作,实现强大的分布式追踪功能。 首先,Spring Cloud Sleuth通过AOP(面向切面编程)技术,自动地在微服务间的...
Spring Cloud Sleuth 是Spring Cloud生态下的一个子项目,它与Zipkin、HTrace等服务追踪系统集成,帮助我们收集和可视化微服务间的调用链路。Sleuth 自动为我们的微服务请求添加独特的跟踪ID,使得我们可以追踪到...
SpringCloud是中国Java开发者广泛使用的微服务框架,它包含了一系列组件,用于构建分布式系统。这个压缩包文件"SpringCloud 15个完整例子"提供了一系列从基础到进阶的示例项目,帮助用户深入理解并实践SpringCloud的...