
еЬ®еИЖеЄГеЉПжЬНеК°жЮґжЮДдЄ≠пЉМйЬАи¶БеѓєеИЖеЄГеЉПжЬНеК°ињЫи°Мж≤їзРЖвАФвАФеЬ®еИЖеЄГеЉПжЬНеК°еНПеРМеРСзФ®жИЈжПРдЊЫжЬНеК°жЧґпЉМжѓПдЄ™иѓЈж±ВйÚ襀еУ™дЇЫжЬНеК°е§ДзРЖпЉЯеЬ®йБЗеИ∞йЧЃйҐШжЧґпЉМеЬ®и∞ГзФ®еУ™дЄ™жЬНеК°дЄКеПСзФЯдЇЖйЧЃйҐШпЉЯеЬ®еИЖжЮРжАІиГљжЧґпЉМи∞ГзФ®еРДдЄ™жЬНеК°йГљиК±дЇЖе§ЪйХњжЧґйЧіпЉЯеУ™дЇЫи∞ГзФ®еПѓдї•еєґи°МжЙІи°МпЉЯвА¶вА¶ дЄЇж≠§пЉМеИЖеЄГеЉПжЬНеК°еє≥еП∞е∞±йЬАи¶БжПРдЊЫињЩж†ЈдЄАзІНеЯЇз°АжЬНеК°вАФвАФеПѓдї•иЃ∞ељХжѓПдЄ™иѓЈж±ВзЪДи∞ГзФ®йУЊпЉЫи∞ГзФ®йУЊдЄКи∞ГзФ®жѓПдЄ™жЬНеК°зЪДжЧґйЧіпЉЫеРДдЄ™жЬНеК°дєЛйЧізЪДжЛУжЙСеЕ≥з≥ївА¶вА¶ жИСдїђжККињЩзІНи°МдЄЇзІ∞дЄЇвАЬеИЖеЄГеЉПжЬНеК°иЈЯиЄ™вАЭгАВпЉИдЇЖиІ£жЇРз†БеПѓ+ж±Вж±В: 1791743380пЉЙ
1. иГМжЩѓ
зО∞дїКдЄЪзХМеИЖеЄГеЉПжЬНеК°иЈЯиЄ™зЪДзРЖиЃЇеЯЇз°АдЄїи¶БжЭ•иЗ™дЇО Google зЪДдЄАзѓЗиЃЇжЦЗгАКDapper, a Large-Scale Distributed Systems Tracing InfrastructureгАЛпЉМдљњзФ®жЬАдЄЇеєњж≥ЫзЪДеЉАжЇРеЃЮзО∞жШѓ Twitter зЪД ZipkinпЉМдЄЇдЇЖеЃЮзО∞еє≥еП∞жЧ†еЕ≥гАБеОВеХЖжЧ†еЕ≥зЪДеИЖеЄГеЉПжЬНеК°иЈЯиЄ™пЉМCNCF еПСеЄГдЇЖеЄГеЉПжЬНеК°иЈЯиЄ™ж†ЗеЗЖ Open TracingгАВеЫљеЖЕпЉМжЈШеЃЭзЪДвАЬйє∞зЬЉвАЭгАБдЇђдЄЬзЪДвАЬHydraвАЭгАБе§ІдЉЧзВєиѓДзЪДвАЬCATвАЭгАБжЦ∞жµ™зЪДвАЬWatchmanвАЭгАБеФѓеУБдЉЪзЪДвАЬMicroscopeвАЭгАБз™Эз™ЭзљСзЪДвАЬTracingвАЭйГљжШѓињЩж†ЈзЪДз≥їзїЯгАВ
2. Spring Cloud Sleuth
дЄАиИђзЪДпЉМдЄАдЄ™еИЖеЄГеЉПжЬНеК°иЈЯиЄ™з≥їзїЯпЉМдЄїи¶БжЬЙдЄЙйГ®еИЖпЉЪжХ∞жНЃжФґйЫЖгАБжХ∞жНЃе≠ШеВ®еТМжХ∞жНЃе±Хз§ЇгАВж†єжНЃз≥їзїЯе§Іе∞ПдЄНеРМпЉМжѓПдЄАйГ®еИЖзЪДзїУжЮДеПИжЬЙдЄАеЃЪеПШеМЦгАВи≠ђе¶ВпЉМеѓєдЇОе§ІиІДж®°еИЖеЄГеЉПз≥їзїЯпЉМжХ∞жНЃе≠ШеВ®еПѓеИЖдЄЇеЃЮжЧґжХ∞жНЃеТМеЕ®йЗПжХ∞жНЃдЄ§йГ®еИЖпЉМеЃЮжЧґжХ∞жНЃзФ®дЇОжХЕйЪЬжОТжЯ•пЉИtroubleshootingпЉЙпЉМеЕ®йЗПжХ∞жНЃзФ®дЇОз≥їзїЯдЉШеМЦпЉЫжХ∞жНЃжФґйЫЖйЩ§дЇЖжФѓжМБеє≥еП∞жЧ†еЕ≥еТМеЉАеПСиѓ≠и®АжЧ†еЕ≥з≥їзїЯзЪДжХ∞жНЃжФґйЫЖпЉМињШеМЕжЛђеЉВж≠•жХ∞жНЃжФґйЫЖпЉИйЬАи¶БиЈЯиЄ™йШЯеИЧдЄ≠зЪДжґИжБѓпЉМдњЭиѓБи∞ГзФ®зЪДињЮиіѓжАІпЉЙпЉМдї•еПКз°ЃдњЭжЫіе∞ПзЪДдЊµеЕ•жАІпЉЫжХ∞жНЃе±Хз§ЇеПИжґЙеПКеИ∞жХ∞жНЃжМЦжОШеТМеИЖжЮРгАВиЩљзДґжѓПдЄАйГ®еИЖйГљеПѓиГљеПШеЊЧеЊИе§НжЭВпЉМдљЖеЯЇжЬђеОЯзРЖйГљз±їдЉЉгАВ
 
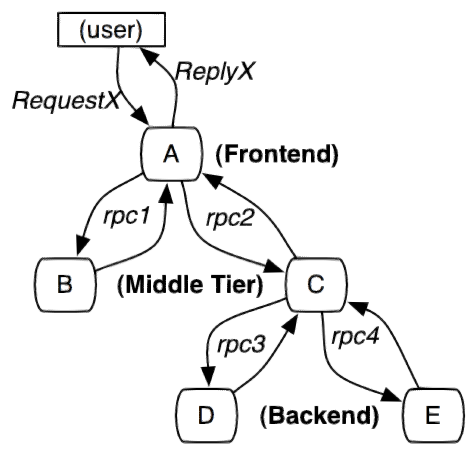
 
жЬНеК°ињљиЄ™зЪДињљиЄ™еНХеЕГжШѓдїОеЃҐжИЈеПСиµЈиѓЈж±ВпЉИrequestпЉЙжʵ茌襀蜚誙з≥їзїЯзЪДиЊєзХМеЉАеІЛпЉМеИ∞襀蜚誙з≥їзїЯеРСеЃҐжИЈињФеЫЮеУНеЇФпЉИresponseпЉЙдЄЇж≠ҐзЪДињЗз®ЛпЉМзІ∞дЄЇдЄАдЄ™вАЬtraceвАЭгАВжѓПдЄ™ trace дЄ≠дЉЪи∞ГзФ®иЛ•еє≤дЄ™жЬНеК°пЉМдЄЇдЇЖиЃ∞ељХи∞ГзФ®дЇЖеУ™дЇЫжЬНеК°пЉМдї•еПКжѓПжђ°и∞ГзФ®зЪДжґИиАЧжЧґйЧіз≠Йдњ°жБѓпЉМеЬ®жѓПжђ°и∞ГзФ®жЬНеК°жЧґпЉМеЯЛеЕ•дЄАдЄ™и∞ГзФ®иЃ∞ељХпЉМзІ∞дЄЇдЄАдЄ™вАЬspanвАЭгАВињЩж†ЈпЉМиЛ•еє≤дЄ™жЬЙеЇПзЪД span е∞±зїДжИРдЇЖдЄАдЄ™ traceгАВеЬ®з≥їзїЯеРСе§ЦзХМжПРдЊЫжЬНеК°зЪДињЗз®ЛдЄ≠пЉМдЉЪдЄНжЦ≠еЬ∞жЬЙиѓЈж±ВеТМеУНеЇФеПСзФЯпЉМдєЯе∞±дЉЪдЄНжЦ≠зФЯжИР traceпЉМжККињЩдЇЫеЄ¶жЬЙspan зЪД trace иЃ∞ељХдЄЛжЭ•пЉМе∞±еПѓдї•жППзїШеЗЇдЄАеєЕз≥їзїЯзЪДжЬНеК°жЛУжЙСеЫЊгАВйЩДеЄ¶дЄК span дЄ≠зЪДеУНеЇФжЧґйЧіпЉМдї•еПКиѓЈж±ВжИРеКЯдЄОеР¶з≠Йдњ°жБѓпЉМе∞±еПѓдї•еЬ®еПСзФЯйЧЃйҐШзЪДжЧґеАЩпЉМжЙЊеИ∞еЉВеЄЄзЪДжЬНеК°пЉЫж†єжНЃеОЖеП≤жХ∞жНЃпЉМињШеПѓдї•дїОз≥їзїЯжХідљУе±ВйЭҐеИЖжЮРеЗЇеУ™йЗМжАІиГљеЈЃпЉМеЃЪдљНжАІиГљдЉШеМЦзЪДзЫЃж†ЗгАВ
 
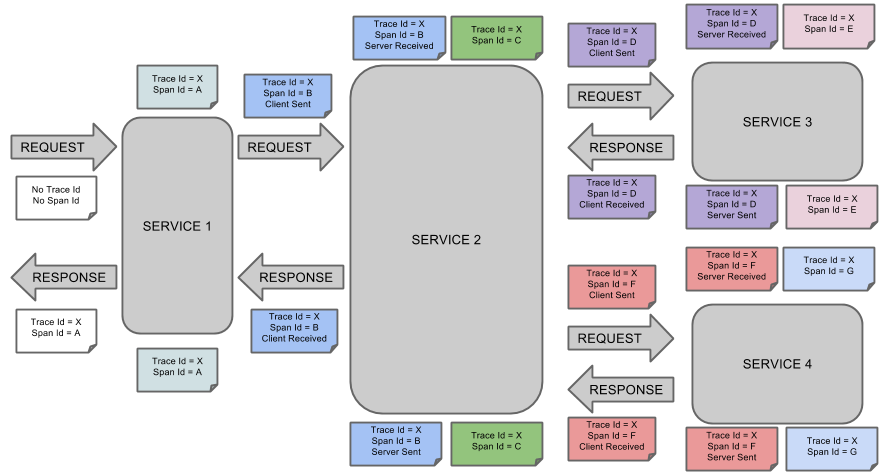
 
Spring Cloud SleuthдЄЇжЬНеК°дєЛйЧіи∞ГзФ®жПРдЊЫйУЊиЈѓињљиЄ™гАВйАЪињЗSleuthеПѓдї•еЊИжЄЕж•ЪзЪДдЇЖиІ£еИ∞дЄАдЄ™жЬНеК°иѓЈж±ВзїПињЗдЇЖеУ™дЇЫжЬНеК°пЉМжѓПдЄ™жЬНеК°е§ДзРЖиК±иієдЇЖе§ЪйХњгАВдїОиАМиЃ©жИСдїђеПѓдї•еЊИжЦєдЊњзЪДзРЖжЄЕеРДеЊЃжЬНеК°йЧізЪДи∞ГзФ®еЕ≥з≥їгАВж≠§е§ЦSleuthеПѓдї•еЄЃеК©жИСдїђпЉЪ
- иАЧжЧґеИЖжЮР: йАЪињЗSleuthеПѓдї•еЊИжЦєдЊњзЪДдЇЖиІ£еИ∞жѓПдЄ™йЗЗж†ЈиѓЈж±ВзЪДиАЧжЧґпЉМдїОиАМеИЖжЮРеЗЇеУ™дЇЫжЬНеК°и∞ГзФ®жѓФиЊГиАЧжЧґ;
- еПѓиІЖеМЦйФЩиѓѓ: еѓєдЇОз®ЛеЇПжЬ™жНХжНЙзЪДеЉВеЄЄпЉМеПѓдї•йАЪињЗйЫЖжИРZipkinжЬНеК°зХМйЭҐдЄКзЬЛеИ∞;
- йУЊиЈѓдЉШеМЦ: еѓєдЇОи∞ГзФ®жѓФиЊГйҐСзєБзЪДжЬНеК°пЉМеПѓдї•йТИеѓєињЩдЇЫжЬНеК°еЃЮжЦљдЄАдЇЫдЉШеМЦжО™жЦљгАВ
spring cloud sleuthеПѓдї•зїУеРИzipkinпЉМе∞Ждњ°жБѓеПСйАБеИ∞zipkinпЉМеИ©зФ®zipkinзЪДе≠ШеВ®жЭ•е≠ШеВ®дњ°жБѓпЉМеИ©зФ®zipkin uiжЭ•е±Хз§ЇжХ∞жНЃгАВ
2. ZipKin
Zipkin жШѓдЄАдЄ™еЉАжФЊжЇРдї£з†БеИЖеЄГеЉПзЪДиЈЯиЄ™з≥їзїЯпЉМзФ±TwitterеЕђеПЄеЉАжЇРпЉМеЃГиЗіеКЫдЇОжФґйЫЖжЬНеК°зЪДеЃЪжЧґжХ∞жНЃпЉМдї•иІ£еЖ≥еЊЃжЬНеК°жЮґжЮДдЄ≠зЪДеїґињЯйЧЃйҐШпЉМеМЕжЛђжХ∞жНЃзЪДжФґйЫЖгАБе≠ШеВ®гАБжЯ•жЙЊеТМе±ХзО∞гАВ
жѓПдЄ™жЬНеК°еРСzipkinжК•еСКиЃ°жЧґжХ∞жНЃпЉМzipkinдЉЪж†єжНЃи∞ГзФ®еЕ≥з≥їйАЪињЗZipkin UIзФЯжИРдЊЭиµЦеЕ≥з≥їеЫЊпЉМжШЊз§ЇдЇЖе§Ъе∞СиЈЯиЄ™иѓЈж±ВйАЪињЗжѓПдЄ™жЬНеК°пЉМиѓ•з≥їзїЯиЃ©еЉАеПСиАЕеПѓйАЪињЗдЄАдЄ™ Web еЙНзЂѓиљїжЭЊзЪДжФґйЫЖеТМеИЖжЮРжХ∞жНЃпЉМдЊЛе¶ВзФ®жИЈжѓПжђ°иѓЈж±ВжЬНеК°зЪДе§ДзРЖжЧґйЧіз≠ЙпЉМеПѓжЦєдЊњзЪДзЫСжµЛз≥їзїЯдЄ≠е≠ШеЬ®зЪДзУґйҐИгАВ
ZipkinжПРдЊЫдЇЖеПѓжПТжЛФжХ∞жНЃе≠ШеВ®жЦєеЉПпЉЪIn-MemoryгАБMySqlгАБCassandraдї•еПКElasticsearchгАВжО•дЄЛжЭ•зЪДжµЛиѓХдЄЇжЦєдЊњзЫіжО•йЗЗзФ®In-MemoryжЦєеЉПињЫи°Ме≠ШеВ®пЉМзФЯдЇІжО®иНРElasticsearchгАВ
3. ењЂйАЯдЄКжЙЛ
3.1 zipkin
3.1.1 zipkinдЄЛиљљ
ж†єжНЃеЕ®зРГжЬАе§ІеРМжАІдЇ§еПЛзљСзЂЩпЉИgithubпЉЙжРЬ糥zipkinеРОеПСзО∞пЉМzipkinзО∞еЬ®еЈ≤зїПдЄНеЬ®жО®иНРдљњзФ®mavenеЉХеЕ•jarзЪДжЦєеЉПжЮДеїЇдЇЖпЉМзЫЃеЙНжО®иНРзЪДжЦєж°ИжШѓзЫіжО•downдїЦдїђжЙУе•љеМЕзЪДjarпЉМзФ®java -jarзЪДжЦєеЉПеРѓеК®пЉМдЉ†йАБйЧ®еЬ®ињЩйЗМпЉЪhttps://github.com/openzipkin/zipkinгАВ
The quickest way to get started is to fetch the latest released server as a self-contained executable jar. Note that the Zipkin server requires minimum JRE 8. For example:
curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
 You can also start Zipkin via Docker.
docker run -d -p 9411:9411 openzipkin/zipkin
 Once the server is running, you can view traces with the Zipkin UI at http://your_host:9411/zipkin/.
If your applications arenвАЩt sending traces, yet, configure them with Zipkin instrumentation or try one of our examples.
Check out the zipkin-server documentation for configuration details, or docker-zipkin for how to use docker-compose.
дї•дЄКеЖЕеЃєжЭ•иЗ™zipkinеЃШжЦєgithubжСШељХгАВзЃАеНХиІ£йЗКе∞±жШѓеПѓдї•дљњзФ®httpsдЄЛиљљзЪДжЦєеЉПдЄЛиљљzipkin.jarпЉМеєґдљњзФ®java -jarзЪДжЦєеЉПеРѓеК®пЉМињШжЬЙдЄАзІНе∞±жШѓдљњзФ®dockerзЪДжЦєеЉПињЫи°МеРѓеК®гАВ
еЕЈдљУжР≠еїЇињЗз®ЛжИСињЩйЗМе∞±дЄНеЬ®иµШињ∞пЉМжЬЙдЄНжЗВзЪДеПѓдї•зІБдњ°жИЦиАЕеЕ≥ж≥®еЕђдЉЧеПЈзХЩи®АйЧЃжИСгАВ
3.1.2 zipkinеРѓеК®
zipkinзЪДеРѓеК®еСљдї§е∞±жѓФиЊГи∞ЬдЇЖгАВ
жЬАзЃАеНХзЪДеРѓеК®еСљдї§дЄЇпЉЪnohup java -jar zipkin.jar >zipkin.out 2>&1 &пЉМињЩжЧґпЉМжИСдїђдљњзФ®зЪДжШѓzipkinзЪДIn-MemoryпЉМеРЂдєЙжШѓжЙАжЬЙзЪДжХ∞жНЃйГљдњЭе≠ШеЬ®еЖЕе≠ШдЄ≠пЉМдЄАжЧ¶йЗНеРѓжХ∞жНЃе∞ЖеЕ®йГ®жЄЕз©ЇпЉМињЩиВѓеЃЪдЄНжШѓжИСдїђжГ≥и¶БзЪДпЉМжИСдїђжЫіжГ≥жХ∞жНЃеПѓдї•дњЭе≠ШеЬ®з£БзЫШдЄ≠пЉМеσ俕襀жКљеПЦеИ∞е§ІжХ∞жНЃеє≥еП∞дЄКпЉМжЦєдЊњжИСдїђеРОзї≠зЪДзЫЄеЕ≥жАІиГљгАБжЬНеК°зКґжАБеИЖжЮРгАБеЃЮжЧґжК•и≠¶з≠ЙеКЯиГљгАВ
ињЩйЗМжИСжККдљњзФ®mysqlзЪДеРѓеК®иѓ≠еП•еИЖдЇЂеЗЇжЭ•пЉМжЬЙеЕ≥ESзЪДеРѓеК®иѓ≠еП•еЯЇжЬђзЫЄеРМпЉЪ
 
STORAGE_TYPE=mysql MYSQL_DB=zipkin MYSQL_USER=name MYSQL_PASS=password MYSQL_HOST=172.19.237.44 MYSQL_TCP_PORT=3306 MYSQL_USE_SSL=false nohup java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=localhost --zipkin.collector.rabbitmq.username=username --zipkin.collector.rabbitmq.password=password --logging.level.zipkin2=DEBUG >zipkin.out 2>&1 &
 
 
-
ж≥®жДПпЉЪ¬†еЫ†дЄЇйУЊиЈѓињљиЄ™зЪДжХ∞жНЃдЄКжК•йЗПжШѓйЭЮеЄЄе§ІзЪДпЉМе¶ВжЮЬдЄКжК•жХ∞жНЃзЫіжО•дљњзФ®httpиѓЈж±ВзЪДжЦєеЉПжО®йАБеИ∞zipkinдЄ≠пЉМеЊИжЬЙеПѓиГљдЉЪжККzipkinжЬНеК°жИЦиАЕжХ∞жНЃеЇУеЖ≤еі©жОЙпЉМжЙАдї•жИСеЬ®ињЩйЗМеҐЮеК†дЇЖrabbitmqзЪДзЫЄеЕ≥йЕНзљЃпЉМдЄКжК•жХ∞жНЃеЕИжО®йАБиЗ≥rabbitmqдЄ≠пЉМеЖНзФ±rabbitmqиЃ≤жХ∞жНЃжО®йАБиЗ≥zipkinжЬНеК°пЉМињЩж†ЈиЊЊеИ∞дЄАдЄ™иѓЈж±ВеЙКе≥∞е°Ђи∞ЈзЪДдљЬзФ®гАВ
-
жЬЙеЕ≥zipkinзЪДеРѓеК®еСљдї§еПѓдї•йЕНзљЃзЪДеПВжХ∞еПѓдї•зЬЛињЩйЗМпЉЪhttps://github.com/apache/incubator-zipkin/tree/master/zipkin-server
-
жЬЙеЕ≥zipkinйЕНзљЃmysqlеЯЇз°АеїЇи°®иѓ≠еП•еПѓдї•зЬЛињЩйЗМпЉЪhttps://github.com/apache/incubator-zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
-
жЬЙеЕ≥zipkinжЬђиЇЂйЕНзљЃжЦЗдїґеПѓдї•зЬЛињЩйЗМпЉЪhttps://github.com/apache/incubator-zipkin/blob/master/zipkin-server/src/main/resources/zipkin-server-shared.yml
иЗ≥ж≠§пЉМzipkinжЬНеК°еЇФиѓ•еЈ≤зїПжР≠еїЇеєґеЃМжИРпЉМзО∞еЬ®жИСдїђеПѓдї•иЃњйЧЃдЄАдЄЛйїШиЃ§зЂѓеП£пЉМзЬЛдЄАдЄЛzipkin-uiеЕЈдљУйХњдїАдєИж†Је≠РдЇЖгАВ
 
 
3.2 Spring Cloud Sleuth дљњзФ®
жИСдїђеЕИе∞ЖдЄКдЄАзѓЗзФ®еИ∞зЪДzuul-simpleгАБEurekaеТМproducer copyеИ∞жЬђзѓЗжЦЗзЂ†дљњзФ®зЪДжЦЗдїґе§єдЄ≠гАВ
3.2.1 еҐЮеК†дЊЭиµЦпЉЪ
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency>
¬†еЬ®zuul-simpleеТМproducerдЄ§дЄ™й°єзЫЃдЄ≠еҐЮеК†sleuthеТМrabbitmqзЪДдЊЭиµЦгАВ
3.2.2 йЕНзљЃжЦЗдїґ
еҐЮеК†жЬЙеЕ≥rabbitmqеТМsleuthзЪДйЕНзљЃпЉМињЩйЗМжИСдїЕзїЩеЗЇzuulзЪДйЕНзљЃжЦЗдїґпЉМproducerзЪДйЕНзљЃеРМзРЖгАВ
 
server:
port: 8080
spring:
application:
name: spring-cloud-zuul
rabbitmq:
host: host
port: port
username: username
password: password
sleuth:
sampler:
probability: 1.0
zuul:
FormBodyWrapperFilter:
pre:
disable: true
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
¬†ж≥®пЉЪspring.sleuth.sampler.probabilityзЪДеРЂдєЙжШѓйУЊиЈѓињљиЄ™йЗЗж†ЈзОЗпЉМйїШиЃ§жШѓ0.1пЉМжИСињЩйЗМдЄЇдЇЖжЦєдЊњжµЛиѓХпЉМе∞ЖеЕґжФєжИР1.0пЉМжДПжАЭжШѓзЩЊеИЖдєЛзЩЊйЗЗж†ЈгАВ
 
3.2.3 жµЛиѓХ
ињЩйЗМжИСдїђдЊЭжђ°еРѓеК®EurekaгАБproducerеТМzuul-simpleгАВ
жЙУеЉАжµПиІИеЩ®пЉМиЃњйЧЃжµЛиѓХињЮжО•пЉЪhttp://localhost:8080/spring-cloud-producer/hello?name=spring&token=123
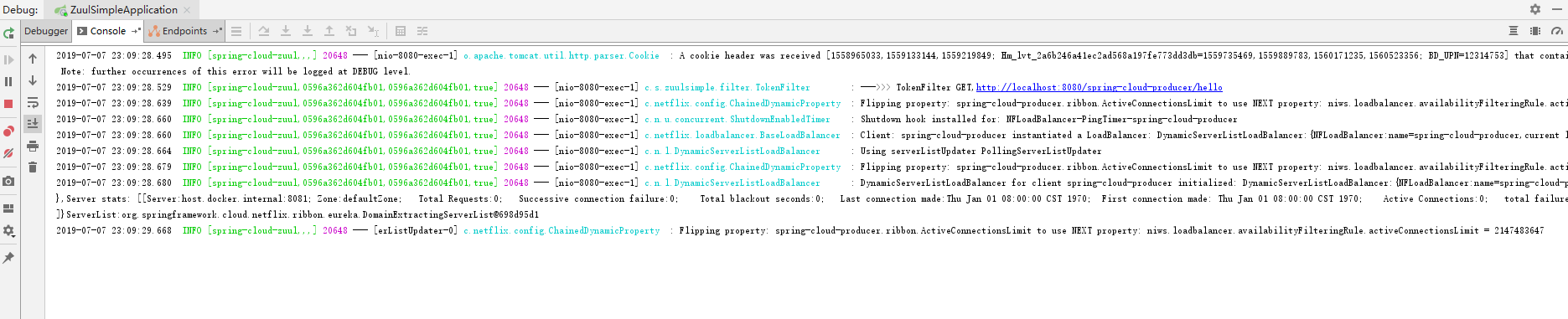
ињЩжЧґжИСдїђеЕИзЬЛzuulзЪДжЧ•ењЧпЉМе¶ВдЄЛеЫЊпЉЪ
 
 
-
2019-07-07 23:09:28.529 INFO [spring-cloud-zuul,0596a362d604fb01,0596a362d604fb01,true] 20648 --- [nio-8080-exec-1] c.s.zuulsimple.filter.TokenFilter 
- ж≥®пЉЪињЩйЗМзЪД0596a362d604fb01е∞±жШѓињЩдЄ™иѓЈж±ВзЪДtraceIDпЉМ0596a362d604fb01жШѓspanIDгАВ
жИСдїђжЙУеЉАzipkin-uiзЪДзХМйЭҐпЉМе¶ВдЄЛеЫЊпЉЪ
 
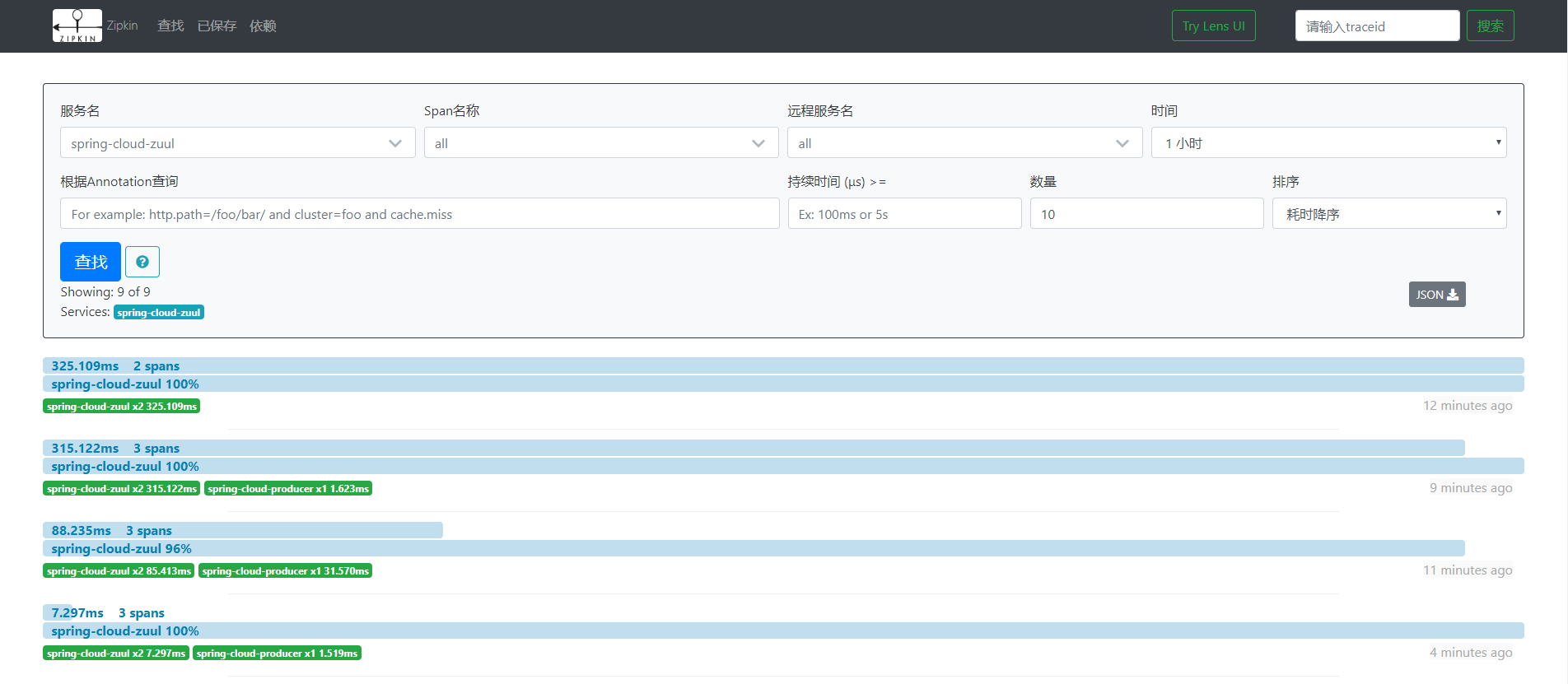
 
ињЩйЗМжИСдїђеПѓдї•зЬЛеИ∞ињЩдЄ™иѓЈж±ВзЪДжХідљУиАЧжЧґпЉМзВєеЗїињЩдЄ™иѓЈж±ВпЉМеПѓдї•ињЫеЕ•еИ∞иѓ¶жГЕй°µйЭҐпЉМжЯ•зЬЛжѓПдЄ™жЬНеК°зЪДиАЧжЧґпЉЪ
 
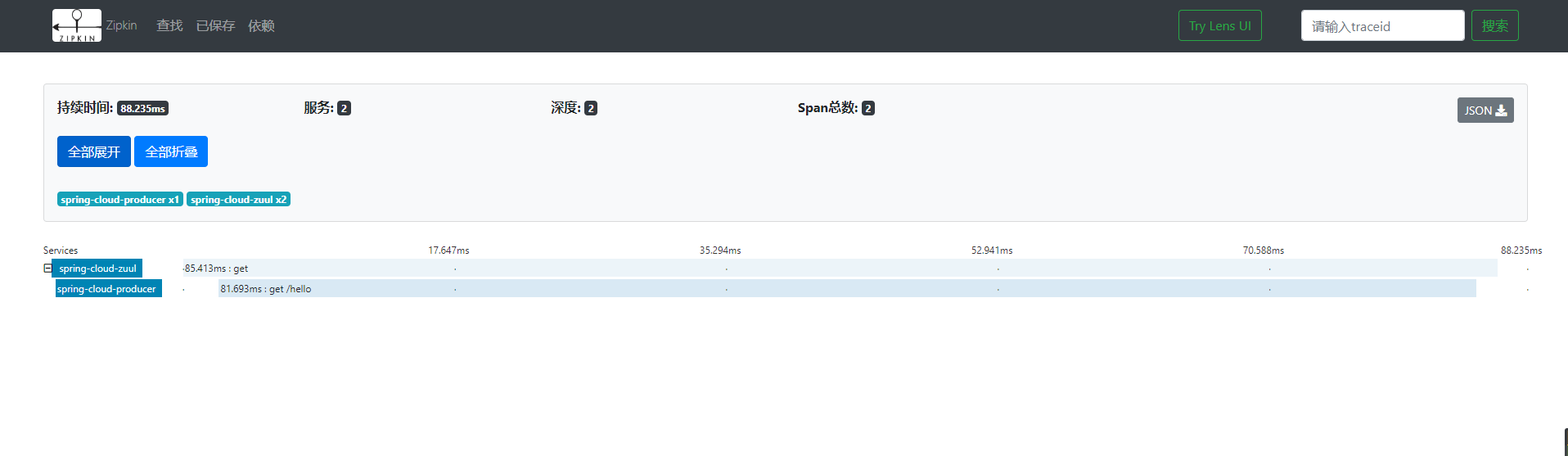
 
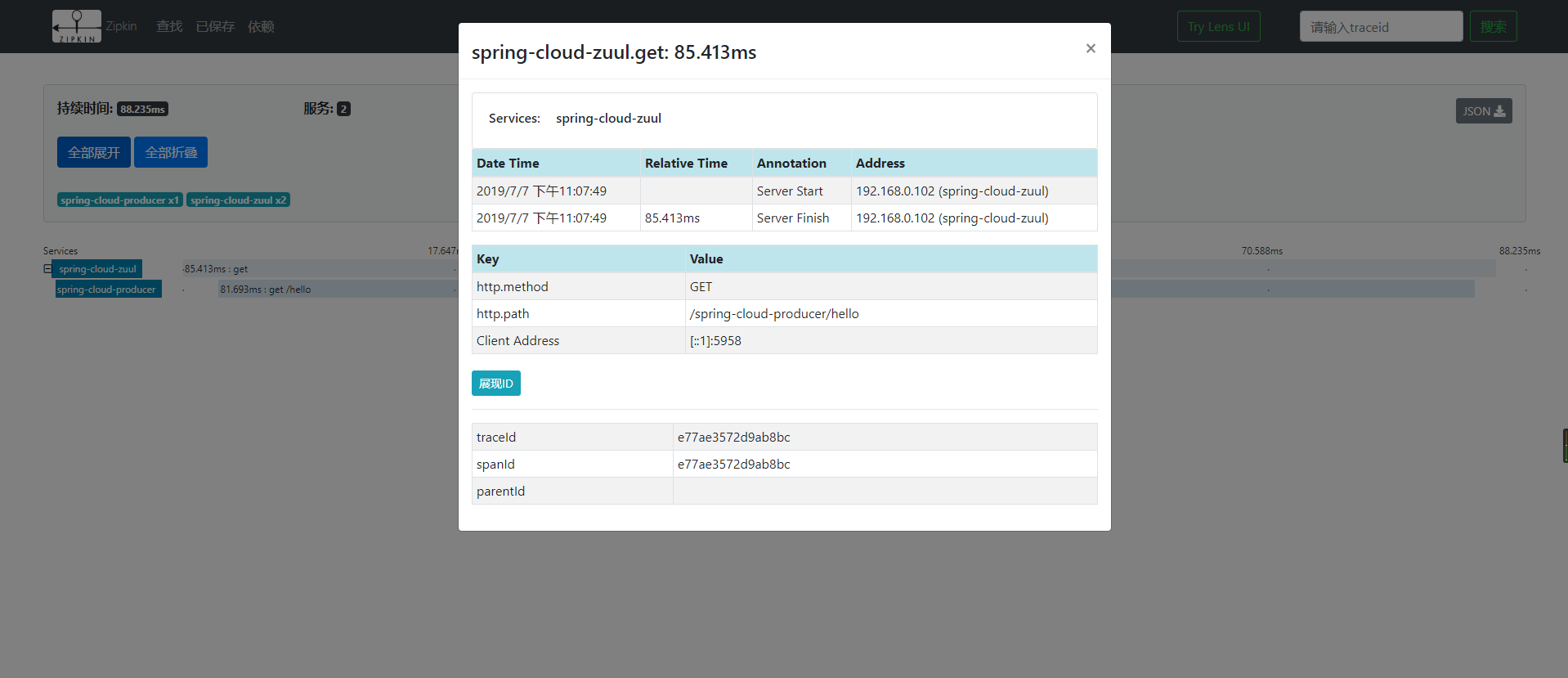
зВєеЗїеѓєеЇФзЪДжЬНеК°пЉМжИСдїђеПѓдї•зЬЛеИ∞зЫЄеЇФзЪДиЃњйЧЃжЧґйЧіпЉМhttpиѓЈж±Вз±їеЮЛгАБиЈѓеЊДгАБIPгАБtranceIDгАБspanIdз≠ЙеЖЕеЃєпЉМе¶ВдЄЛеЫЊпЉЪ
 
 



зЫЄеЕ≥жО®иНР
жАїзїУжЭ•иѓіпЉМSpring Cloud Sleuth+RabbitMQ+ZipkinзЪДзїУеРИжПРдЊЫдЇЖдЄАе•ЧеЉЇе§ІзЪДиІ£еЖ≥жЦєж°ИпЉМеЄЃеК©жИСдїђеЬ®еЊЃжЬНеК°зОѓеҐГдЄ≠еЃЮзО∞еИЖеЄГеЉПйУЊиЈѓињљиЄ™гАВйАЪињЗињЩдЄ™Demoз®ЛеЇПпЉМжИСдїђеПѓдї•е≠¶дє†е¶ВдљХйЕНзљЃеТМдљњзФ®ињЩдЇЫеЈ•еЕЈпЉМдї•дЊњжЫіе•љеЬ∞зРЖиІ£еТМи∞ГиѓХжИСдїђзЪД...
Spring Cloud Sleuth еТМ Zipkin жШѓдЄ§дЄ™йЭЮеЄЄжµБи°МзЪДеЈ•еЕЈпЉМзФ®дЇОеЃЮзО∞еЊЃжЬНеК°жЮґжЮДдЄ≠зЪДйУЊиЈѓињљиЄ™гАВжЬђзѓЗе∞Жиѓ¶зїЖдїЛзїНињЩдЄ§дЄ™зїДдїґдї•еПКе¶ВдљХеЬ®WindowsзОѓеҐГдЄЛињЫи°МеИЭж≠•дљњзФ®гАВ **Spring Cloud Sleuth** Spring Cloud Sleuth жШѓдЄАдЄ™...
Spring Cloud SleuthпЉЪеИЖеЄГеЉПиѓЈж±ВйУЊиЈѓиЈЯиЄ™ Spring Cloud Sleuth жШѓдЄАзІНеИЖеЄГеЉПз≥їзїЯдЄ≠иЈЯиЄ™жЬНеК°йЧіи∞ГзФ®зЪДеЈ•еЕЈпЉМеЃГеПѓдї•зЫіиІВеЬ∞е±Хз§ЇеЗЇдЄАжђ°иѓЈж±ВзЪДи∞ГзФ®ињЗз®ЛгАВеЬ®е§ІеЮЛеИЖеЄГеЉПз≥їзїЯдЄ≠пЉМжЬНеК°дєЛйЧізЪДи∞ГзФ®еЕ≥з≥їйЭЮеЄЄе§НжЭВпЉМдљњзФ® Spring ...
Spring Cloud еИЖеЄГеЉПжХіеРИ Zipkin зЪДйУЊиЈѓиЈЯиЄ™иѓ¶иІ£ зЯ•иѓЖзВє1пЉЪдЄЇдїАдєИдљњзФ® ZipkinпЉЯ еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠пЉМжЬНеК°дєЛйЧізЪДи∞ГзФ®еЕ≥з≥їйЭЮеЄЄе§НжЭВпЉМеѓЉиЗіжЧ•ењЧжЯ•жЙЊеТМи∞ГзФ®еЕ≥з≥їињљиЄ™еПШеЊЧеЫ∞йЪЊгАВZipkin еПѓдї•иІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМеЃГеПѓдї•е∞ЖйУЊиЈѓи∞ГзФ®...
йАЪињЗйЫЖжИРSpring Cloud SleuthеТМZipkinпЉМжИСдїђеПѓдї•еЬ®Spring BootеЇФзФ®дЄ≠еЃЮзО∞еИЖеЄГеЉПињљиЄ™пЉМињЩеѓєдЇОи∞ГиѓХеТМзЫСжОІеЊЃжЬНеК°жЮґжЮДдЄ≠зЪДеЇФзФ®иЗ≥еЕ≥йЗНи¶БгАВеРМжЧґпЉМйАЪињЗеЬ®Vue.jsеЙНзЂѓйЫЖжИРињљиЄ™дњ°жБѓпЉМеПѓдї•еЃЮзО∞зЂѓеИ∞зЂѓзЪДеЕ®йУЊиЈѓињљиЄ™гАВињЩзІНжЦєж≥ХдЄНдїЕ...
- [springcloud(еНБдЇМ)пЉЪдљњзФ®Spring Cloud SleuthеТМZipkinињЫи°МеИЖеЄГеЉПйУЊиЈѓиЈЯиЄ™](http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html) - [springcloud(еНБдЄЙ)пЉЪSpring Cloud Consul ...
Spring Cloud Sleuth жШѓдЄАдЄ™зФ®дЇОеИЖеЄГеЉПз≥їзїЯиЈЯиЄ™зЪДеЈ•еЕЈпЉМеЃГжШѓеЯЇдЇО Zipkin зЪДпЉМеПѓдї•жЦєдЊњеЬ∞йЫЖжИРеИ∞еЯЇдЇО Spring Boot еТМ Spring Cloud зЪДеЊЃжЬНеК°жЮґжЮДдЄ≠гАВйАЪињЗ SleuthпЉМжИСдїђеПѓдї•иљїжЭЊеЬ∞жФґйЫЖеТМеИЖжЮРжЬНеК°йЧізЪДи∞ГзФ®йУЊиЈѓжХ∞жНЃпЉМдїОиАМ...
Spring Cloud Zipkin жШѓдЄАдЄ™жµБи°МзЪДйУЊиЈѓињљиЄ™еЈ•еЕЈпЉМеЃГдЄО Spring Boot еТМ Spring Cloud зїУеРИдљњзФ®пЉМеПѓдї•иљїжЭЊеЬ∞еЬ®еЊЃжЬНеК°жЮґжЮДдЄ≠еЃЮзО∞еИЖеЄГеЉПз≥їзїЯзЪДеПѓиІВжµЛжАІгАВжЬђжХЩз®Ле∞ЖдїЛзїНе¶ВдљХжХіеРИ Spring Cloud дЄО Zipkin жЭ•еЃЮзО∞йУЊиЈѓињљиЄ™пЉМ...
жѓХдЄЪиЃЊиЃ°еЯЇдЇОSpringCloudеЊЃжЬНеК°еИЖеЄГеЉПйУЊиЈѓињљиЄ™з≥їзїЯжЇРз†Б ињљиЄ™еЃЮзО∞ дљњзФ®zipkin+sleuthеЃЮзО∞ ињЩдЄ™жШѓжѓФиЊГжИРзЖЯзЪДеИЖеЄГеЉПйУЊиЈѓињљиЄ™еЃЮзО∞жЦєж°И жЛ¶жИ™еЩ®иЗ™еЃЪдєЙеЃЮзО∞ еЯЇдЇОGoogle Dapper иЃЇжЦЗпЉМињЫи°МиЗ™еЃЪдєЙеЃЮзО∞гАВ еОЯзРЖпЉЪ traceId пЉЪ...
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХеЬ®Spring Bootй°єзЫЃдЄ≠йЫЖжИРSpring Cloud SleuthеТМZipkinпЉМдї•еПКињЩдЄ§дЄ™зїДдїґе¶ВдљХеНПеРМеЈ•дљЬпЉМеЃЮзО∞еЉЇе§ІзЪДеИЖеЄГеЉПињљиЄ™еКЯиГљгАВ й¶ЦеЕИпЉМSpring Cloud SleuthйАЪињЗAOPпЉИйЭҐеРСеИЗйЭҐзЉЦз®ЛпЉЙжКАжЬѓпЉМиЗ™еК®еЬ∞еЬ®еЊЃжЬНеК°йЧізЪД...
Spring Cloud SleuthжШѓSpring CloudзФЯжАБз≥їзїЯзЪДдЄАйГ®еИЖпЉМеЃГеЃЮзО∞дЇЖеИЖеЄГеЉПињљиЄ™зЪДж†ЗеЗЖвАФвАФOpenTracingеТМZipkinгАВйАЪињЗйЫЖжИРSleuthпЉМеЉАеПСиАЕеПѓдї•еЬ®дЄНдњЃжФєдї£з†БзЪДжГЕеЖµдЄЛпЉМиљїжЭЊеЬ∞еЬ®еЊЃжЬНеК°жЮґжЮДдЄ≠еЃЮзО∞иѓЈж±ВзЪДеЕ®йУЊиЈѓињљиЄ™гАВ дЇМгАБж†ЄењГ...
Spring Cloud Sleuth еТМ Zipkin жШѓдЄ§дЄ™еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠зФ®дЇОиЈЯиЄ™еЊЃжЬНеК°дєЛйЧіи∞ГзФ®зЪДйЗНи¶БеЈ•еЕЈгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХдљњзФ®еЃГдїђжЭ•жПРеНЗз≥їзїЯзЪДеПѓзЫСжОІжАІеТМжХЕйЪЬжОТжЯ•иГљеКЫгАВ й¶ЦеЕИпЉМSpring Cloud Sleuth жШѓдЄАдЄ™йЫЖжИРеЬ® Spring Boot ...
жЬђй°єзЫЃ"microservices-latency-analysis"дЄУж≥®дЇОдљњзФ®Spring Cloud SleuthеТМZipkinжЭ•еИЖжЮРSpring BootеЇФзФ®з®ЛеЇПдЄ≠зЪДеїґињЯпЉМеЄЃеК©еЉАеПСиАЕдЉШеМЦеЊЃжЬНеК°жАІиГљгАВ **Spring Boot** Spring BootжШѓеЯЇдЇОSpringж°ЖжЮґзЪДењЂйАЯеЉАеПСеЈ•еЕЈпЉМеЃГ...
еЬ®Spring CloudдљУз≥їдЄ≠пЉМйУЊиЈѓиЈЯиЄ™зЪДеЃЮзО∞дЄАиИђдЊЭиµЦдЇОSpring Cloud SleuthдЄОZipkinгАВSpring Cloud Sleuthз±їдЉЉдЇОдЄАдЄ™дЄ≠йЧідїґпЉМеПѓдї•еЬ®еЊЃжЬНеК°и∞ГзФ®ињЗз®ЛдЄ≠пЉМе∞ЖжѓПдЄ™жЬНеК°зЪДи∞ГзФ®иЃ∞ељХдЄЛжЭ•гАВеЃГдЉЪеЬ®жЧ•ењЧдЄ≠жЈїеК†дЄАдЇЫзЙєжЬЙзЪДж†Зз≠ЊпЉМе¶В...
Spring Cloud Sleuth жШѓдЄАдЄ™еЉЇе§ІзЪДеЈ•еЕЈпЉМеЃГйЫЖжИРдЇЖеИЖеЄГеЉПз≥їзїЯзЪДжЧ•ењЧиЈЯиЄ™пЉМжПРдЊЫдЇЖеЕ®йУЊиЈѓињљиЄ™зЪДиГљеКЫгАВеЬ®еЊЃжЬНеК°жЮґжЮДдЄ≠пЉМзРЖиІ£иѓЈж±ВеЬ®дЄНеРМжЬНеК°дєЛйЧізЪДжµБиљђињЗз®ЛеПШеЊЧе∞§дЄЇе§НжЭВпЉМSleuth ж≠£жШѓдЄЇдЇЖиІ£еЖ≥ињЩдЄАйЧЃйҐШиАМиЃЊиЃ°зЪДгАВеЃГдЄО ...
Spring Cloud Sleuth жШѓSpring CloudзФЯжАБдЄЛзЪДдЄАдЄ™е≠Рй°єзЫЃпЉМеЃГдЄОZipkinгАБHTraceз≠ЙжЬНеК°ињљиЄ™з≥їзїЯйЫЖжИРпЉМеЄЃеК©жИСдїђжФґйЫЖеТМеПѓиІЖеМЦеЊЃжЬНеК°йЧізЪДи∞ГзФ®йУЊиЈѓгАВSleuth иЗ™еК®дЄЇжИСдїђзЪДеЊЃжЬНеК°иѓЈж±ВжЈїеК†зЛђзЙєзЪДиЈЯиЄ™IDпЉМдљњеЊЧжИСдїђеПѓдї•ињљиЄ™еИ∞...
Spring Cloud SleuthйЗЗзФ®дЇЖDapperеТМlog-basedињљиЄ™зЪДж¶ВењµпЉМеєґдЄОZipkinеТМHTraceзЪДжУНдљЬжО•еП£ињЫи°МдЇЖе∞Би£ЕгАВDapperжШѓGoogleеПСеЄГзЪДдЄАзѓЗеЕ≥дЇОеИЖеЄГеЉПз≥їзїЯињљиЄ™зЪДиЃЇжЦЗпЉМlog-basedињљиЄ™еИЩжШѓйАЪињЗжЧ•ењЧзЪДжЦєеЉПиЃ∞ељХеТМеИЖжЮРеИЖеЄГеЉПз≥їзїЯзЪД...
Spring Cloud Sleuth жШѓдЄАжђЊйТИеѓєеЊЃжЬНеК°жЮґжЮДдЄ≠зЪДжЬНеК°йУЊиЈѓињљиЄ™еЈ•еЕЈпЉМдЄїи¶БзФ®дЇОиІ£еЖ≥еИЖеЄГеЉПз≥їзїЯдЄ≠жЬНеК°и∞ГзФ®йУЊиЈѓзЪДињљиЄ™йЧЃйҐШгАВйАЪињЗеЉХеЕ•SleuthпЉМеЉАеПСиАЕеПѓдї•еЬ®еЊЃжЬНеК°йЧіињЫи°МињљиЄ™пЉМдїОиАМжЫіеК†жЄЕжЩ∞еЬ∞дЇЖиІ£иѓЈж±ВеЬ®еРДдЄ™жЬНеК°йЧізЪДжµБиљђжГЕеЖµ...
SpringCloudж†ЄењГзїДдїґSleuthйУЊиЈѓињљиЄ™ SpringCloudж†ЄењГзїДдїґZipkinеИЖеЄГеЉПињљиЄ™з≥їзїЯ SpringCloudж†ЄењГзїДдїґStreamжґИжБѓжµБе§ДзРЖ SpringCloudж†ЄењГзїДдїґKafkaжґИжБѓдЄ≠йЧідїґйЫЖжИР SpringCloudж†ЄењГзїДдїґGatewayжЦ∞дЄАдї£APIзљСеЕ≥ SpringCloud...
еЬ®SpringCloudй°єзЫЃдЄ≠пЉМжИСдїђйЬАи¶БеЬ®pom.xmlжЦЗдїґдЄ≠еЉХеЕ•Spring Cloud SleuthеТМSpring Cloud ZipkinзЪДзЫЄеЕ≥дЊЭиµЦгАВињЩж†ЈпЉМSleuthдЉЪиЗ™еК®еЬ®жѓПдЄ™жЬНеК°зЪДи∞ГзФ®дЄ≠жПТеЕ•иЈЯиЄ™IDеТМиЈ®еЇ¶IDпЉМиАМZipkinеИЩиіЯиі£жФґйЫЖињЩдЇЫжХ∞жНЃеєґе≠ШеВ®гАВ ```xml...