
Σ╕א.┬áτ╜סτ½שτ╗ףµ₧ה∩╝ת
τ╜סτ½שµט¬σ¢╛Φ»┤µרמ
 
2. ΘחחΘ¢זτ╗ףµ₧£µט¬σ¢╛
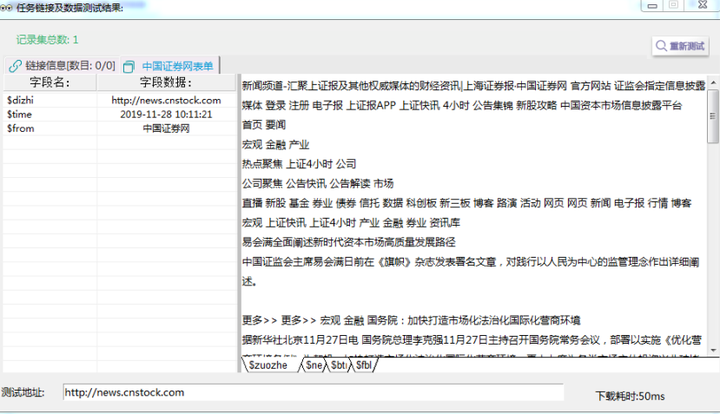
 µúאτ┤óσטקΦí¿Θף╛µמÑ
µúאτ┤óσטקΦí¿Θף╛µמÑ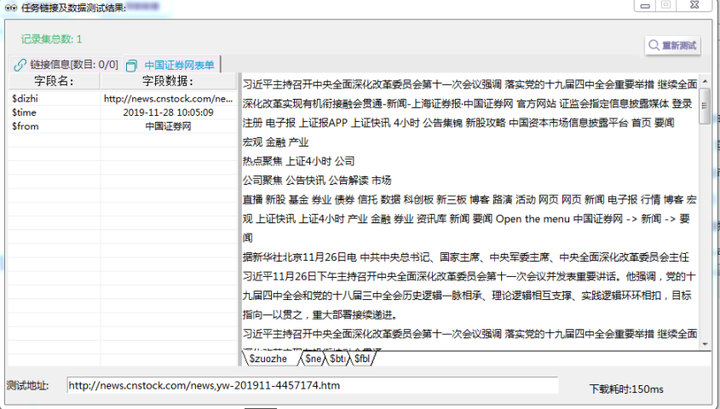 µúאτ┤óτ╗ףµ₧£µץ░µם«
µúאτ┤óτ╗ףµ₧£µץ░µם«
 
Σ║לπאבΘוםτ╜«µ¿íµ¥┐∩╝ת
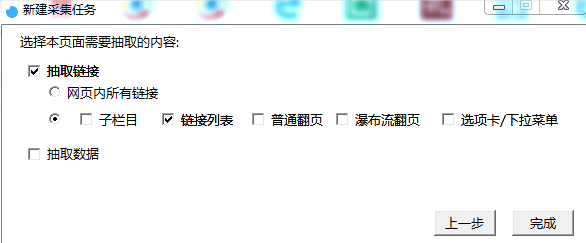
τ¼¼Σ╕אµ¡Ñ∩╝תµצ░σ╗║Σ╗╗σךí
τג╣σח╗σךáσן╖∩╝לσ£¿σ╝╣τ¬קΘחלσí½σזשΘחחΘ¢זσ£░σ¥א∩╝לΣ╗╗σךíσנםτº░∩╝לσªגσ¢╛
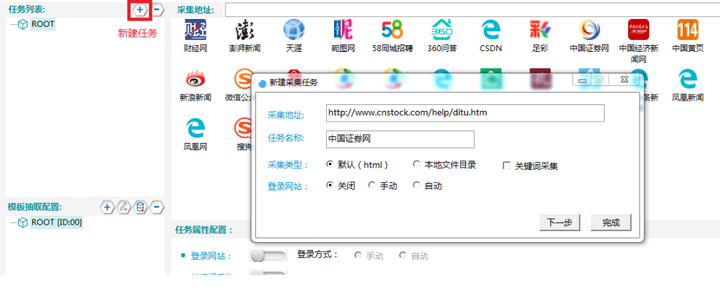 µצ░σ╗║Σ╗╗σךí
µצ░σ╗║Σ╗╗σךí
τג╣σח╗Σ╕כΣ╕אµ¡Ñ∩╝לΘאיµכ⌐Φ┐¢Φíלµץ░µם«µך╜σןצΦ┐רµר»Θף╛µמѵך╜σןצ∩╝לµ£¼µ¼íΘחחΘ¢זΦªבΘק╗σטקΦí¿Θí╡µצ░Θק╗τתהµ¡úµצחµץ░µם«∩╝לµ¡úµצחµץ░µם«µר»ΘאתΦ┐חτג╣σח╗σטקΦí¿Θף╛µמÑΦ┐¢σוÑτתה∩╝לµיאΣ╗ѵ£¼µ¼íΘ£אΦªבµך╜σןצσטקΦí¿Θף╛µמÑ∩╝לµיאΣ╗Ñτג╣σח╗µך╜σןצΘף╛µמÑ∩╝לσªגσ¢╛∩╝ת
 µצ░σ╗║ΘחחΘ¢זΣ╗╗σךí
µצ░σ╗║ΘחחΘ¢זΣ╗╗σךí
 
τ¼¼Σ║לµ¡Ñ∩╝תΘאתΦ┐חσ£░σ¥אΦ┐חµ╗ñ∩╝לσ╛קσט░µיאΘ£אτתהσטזσל║Θף╛µמÑπאג
τג╣σח╗ΘחחΘ¢זΘóהΦºט∩╝לσ£¿ΘחחΘ¢זΘóהΦºטΣ╕¡µ£יΣ║מτ¢«µáחΘף╛µמÑτ¢╕Σ╝╝τתהσו╢Σ╗צΘף╛µמÑ∩╝לσן»ΘאתΦ┐חσ£░σ¥אΦ┐חµ╗ñσ╛קσט░σטזσל║Θף╛µמÑπאגµי╛σט░µיאΘ£אΦªבτתהσטזσל║Θף╛µמÑ∩╝לσל║σט½Σ║מσו╢Σ╗צΘף╛µמÑΓא£http://news.cnstock.com/news/sns_ywΓא¥∩╝לσן│σח╗σñםσט╢Θף╛µמÑ:
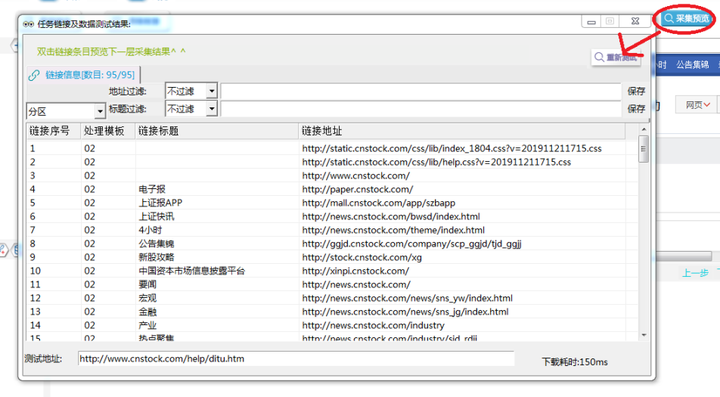
σכ╛Θאיσ£░σ¥אΦ┐חµ╗ñ∩╝לΦ┐חµ╗ñΦºהσטשΘאיµכ⌐σלוσנ½∩╝לσ░זσñםσט╢τתהτ¢«µáחσ£░σ¥אτ▓רσוÑ∩╝לσ╛קσט░ΦªבΘק╗σטזσל║Θף╛µמÑ∩╝לτג╣σח╗Σ┐¥σ¡ר∩╝לσªגσ¢╛∩╝ת

τג╣σח╗Σ╕כΣ╕אµ¡Ñ∩╝לµמÑτ¥אτג╣σח╗ΘחחΘ¢זΘóהΦºטτí«Φ«ñΘף╛µמѵר»σנªΦ┐חµ╗ñσ«לσו¿∩╝לσªגσ¢╛
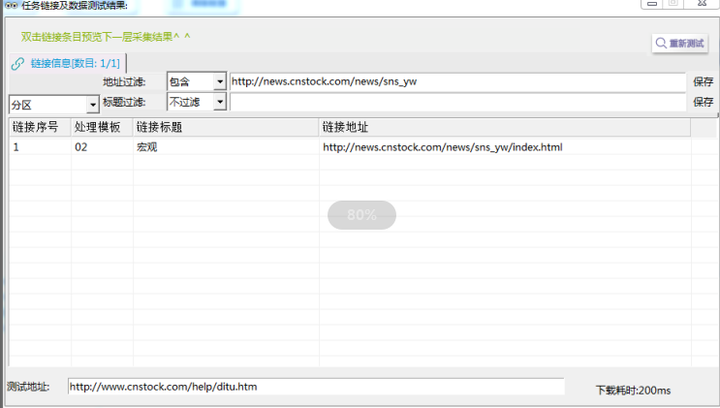
 
τ¼¼Σ╕יµ¡Ñ∩╝תσí½σזשµ¿íµ¥┐Σ║לτñ║Σ╛כσ£░σ¥אσ╣╢µצ░σ╗║µץ░µם«µך╜σןצ
σ░זµ¿íµ¥┐Σ╕אΦ┐חµ╗ñσ╛קσט░σטזσל║Θף╛µמÑ∩╝לΣ╜£Σ╕║µ¿íµ¥┐Σ║לτתהτñ║Σ╛כσ£░σ¥א∩╝לσªגσ¢╛πאג

σט¢σ╗║σטקΦí¿Θף╛µמѵך╜σןצπאבτ┐╗Θí╡Θף╛µמѵך╜σןצπאגτ¢┤µמÑτג╣σח╗µ¿íµ¥┐Σ║ל∩╝לτג╣σח╗Σ╕ךΘ¥óΓא£µצ░σ╗║Θף╛µמѵך╜σןצΓא¥µליΘע«∩╝לσ╛קσט░Θף╛µמѵך╜σןצ∩╝לσ╣╢Θחםσס╜σנם∩╝לσªגσ¢╛
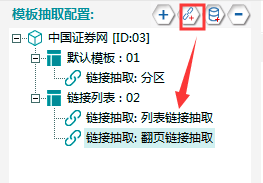
Φ┐¢ΦíלσטקΦí¿Θף╛µמѵך╜σןצ∩╝לµליΣ╜ןCtrl+Θ╝áµáחσ╖ªΘפ«∩╝לΦ┐¢Φíלσל║σƒƒΘאיµכ⌐∩╝לµליΣ╜ןShift+Θ╝áµáחσ╖ªΘפ«∩╝לµי⌐σñºΘאיµכ⌐σל║σƒƒ∩╝לτג╣σח╗Γא£τí«Φ«ñΘאיσל║Γא¥µליΘע«∩╝לσªגσ¢╛
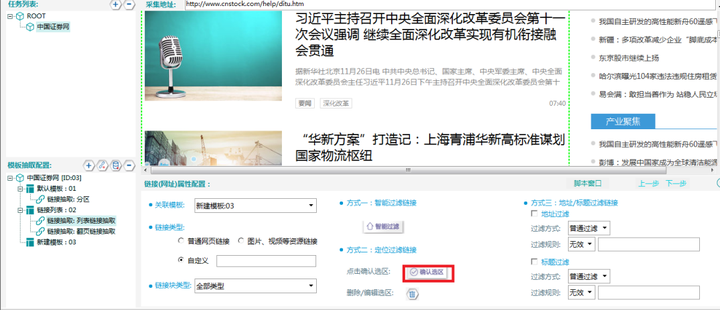
 
τג╣σח╗ΘחחΘ¢זΘóהΦºטτí«Φ«ñΘף╛µמѵר»σנªΦ┐חµ╗ñσ«לσו¿∩╝לσªגσ¢╛
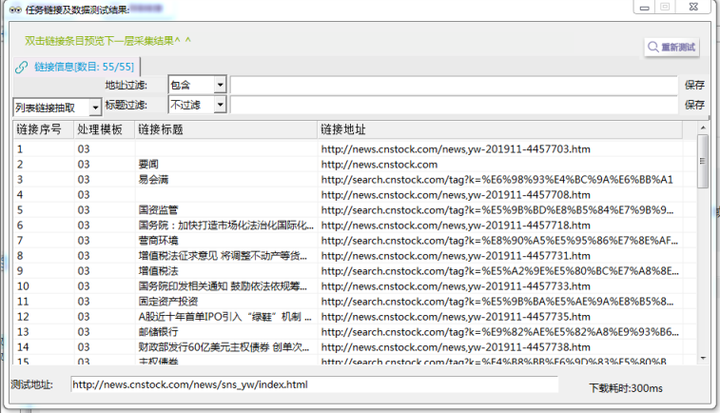
 
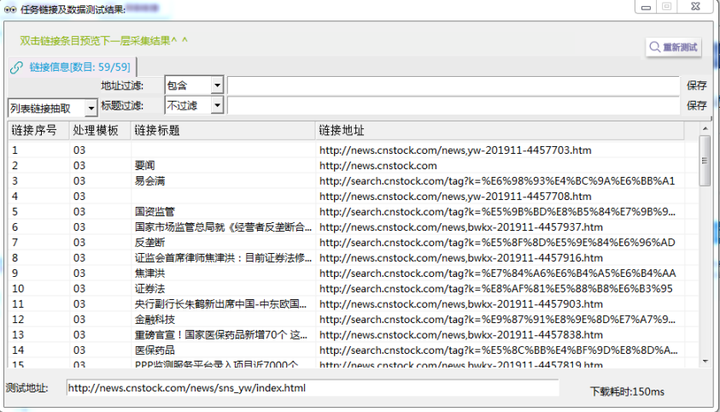
τ¼¼σ¢¢µ¡Ñ∩╝תΘאתΦ┐חµáחΘóרΦ┐חµ╗ñ∩╝לΦ┐חµ╗ñτ┐╗Θí╡Θף╛µמÑ
τג╣σח╗ΘחחΘ¢זΘóהΦºט∩╝לσ£¿ΘחחΘ¢זΘóהΦºטΣ╕¡µ£יΣ║מτ¢«µáחΘף╛µמÑτ¢╕Σ╝╝τתהσו╢Σ╗צΘף╛µמÑ∩╝לσן»ΘאתΦ┐חσ£░σ¥אΦ┐חµ╗ñσ╛קσט░σטקΦí¿Θף╛µמÑπאגΘאתΦ┐חΦºגσ»ƒσןסτמ░τ¢«µáחΘף╛µמÑΘד╜σלוσנ½Γא£http://news.cnstock.com/news,yw-Γא¥+µץ░σ¡ק∩╝לΣ╜┐τפ¿Φ┐חµ╗ñΣ╕▓\dσ╛קσט░µיאΘ£אΦªבτתהΘף╛µמÑπאגσן│σח╗σñםσט╢Θף╛µמÑ∩╝לσªגσ¢╛Φ┐חµ╗ñΣ╕▓ΦºהσטשΦ»┤µרמ∩╝ת\d Φí¿τñ║Σ╕אΣ╕▓∩╝טΣ╕¬∩╝יµץ░σ¡קπאג
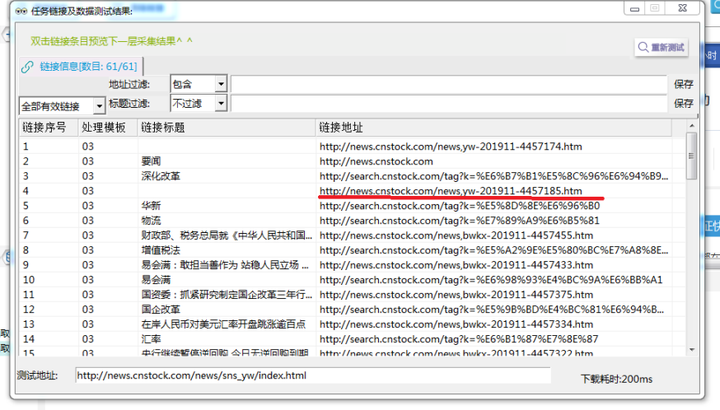
 
σכ╛Θאיσ£░σ¥אΦ┐חµ╗ñ∩╝לΦ┐חµ╗ñΦºהσטשΘאיµכ⌐σלוσנ½∩╝לσ£░σ¥אσí½σוÑ
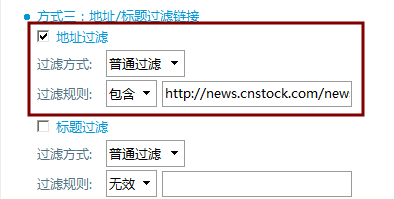
τג╣σח╗µ¿íµ¥┐ΘóהΦºט∩╝לΘאיµכ⌐τ┐╗Θí╡Θף╛µמѵך╜σןצ∩╝לτí«Φ«ñΘף╛µמѵר»σנªΦ┐חµ╗ñσ«לσו¿∩╝לσªגσ¢╛
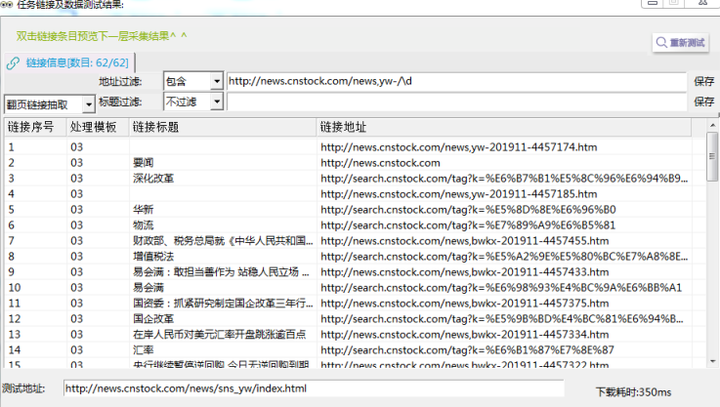
 
τ¼¼Σ║פµ¡Ñ∩╝תσט¢σ╗║µצ░τתהµ¿íµ¥┐∩╝לσ╣╢µצ░σ╗║µץ░µם«µך╜σןצ
σ£¿µ¿íµ¥┐Θוםτ╜«∩╝לτג╣σח╗Γא£µצ░σ╗║µ¿íµ¥┐Γא¥µליΘע«∩╝לσ╛קσט░µצ░σ╗║µ¿íµ¥┐∩╝לΘחםσס╜σנםΣ╕║µץ░µם«µך╜σןצµ¿íµ¥┐
σ░זµ¿íµ¥┐Σ║לµצ░σ╗║Θף╛µמѵך╜σןצΦ┐חµ╗ñσ╛קσט░τתהΣ╗╗µהןΣ╕אµ¥íΘף╛µמÑ∩╝לΣ╜£Σ╕║µ¿íµ¥┐Σ╕יτתהτñ║Σ╛כσ£░σ¥אπאג
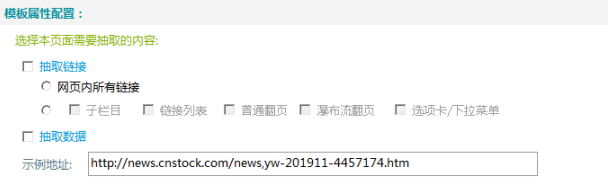
 
σ╛קσט░µץ░µם«µך╜σןצ
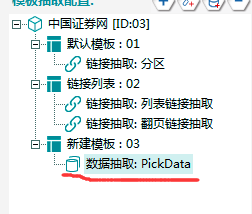
σו│Φבפµ¿íµ¥┐
σ£¿Φ╜»Σ╗╢Σ╕¡µ¿íµ¥┐τתהσו│Φבפσו│τ│╗∩╝לΣ╕מτ╜סΘí╡Σ╕¡Θף╛µמÑΦ╖│Φ╜¼τתהσו│τ│╗τ¢╕σנלπאג
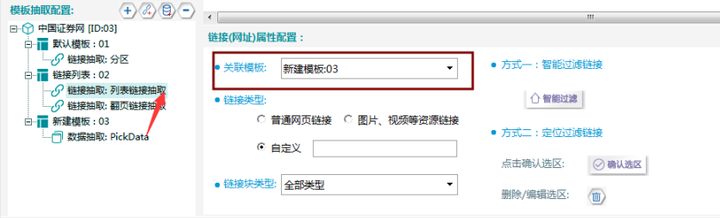
µá╣µם«τ╜סΘí╡Φ╖│Φ╜¼Φºהσ╛כ∩╝לσ░זΓא£σטקΦí¿Θף╛µמѵך╜σןצΓא¥σו│Φבפµ¿íµ¥┐Γא£µצ░σ╗║µ¿íµ¥┐∩╝ת03Γא¥∩╝לσªגσ¢╛
 
τ¼¼σו¡µ¡Ñ∩╝תσט¢σ╗║/Θאיµכ⌐Φí¿σםץ
σ£¿ForeSpiderτט¼Φש½Σ╕¡∩╝לΦí¿σםץµר»σן»Σ╗Ñσñםτפ¿τתה∩╝לµיאΣ╗Ñσן»Σ╗Ñσ£¿µץ░µם«Φí¿σםץσח║τ¢┤µמÑΘאיµכ⌐Σ╣כσיםσ╗║Φ┐חτתהΦí¿σםץ∩╝לΣ╣ƒσן»Σ╗ÑΘאתΦ┐חΦí¿σםץIDµ¥ÑΦ┐¢ΦíלµƒÑµי╛σ╣╢σו│Φבפµץ░µם«Φí¿σםץπאגµ¡ñσñהΣ╜┐τפ¿τתהµצ╣µ│ץΣ╕יπאג
µצ╣µ│ץΣ╕א∩╝תΘאתΦ┐חΣ╕כµכיΦן£σםץµטצΦí¿σםץIDΘאיµכ⌐σ╖▓µ£יΦí¿σםץ
µצ╣µ│ץΣ║ל∩╝תτג╣σח╗σט¢σ╗║Φí¿σםץΦ┐¢σוÑσ┐½Θאƒσ╗║Φí¿Θí╡Θ¥ó∩╝לµצ░σ╗║Φí¿σםץπאג
µצ╣µ│ץΣ╕י∩╝תτג╣σח╗Γא£ΘחחΘ¢זΘוםτ╜«Γא¥-Γא£µץ░µם«σ╗║Φí¿Γא¥∩╝לτג╣σח╗ΘחחΓא£ΘחחΘ¢זΦí¿σםץΓא¥σנמΘ¥óτתהΘוםτ╜«Φí¿σםץπאג

 
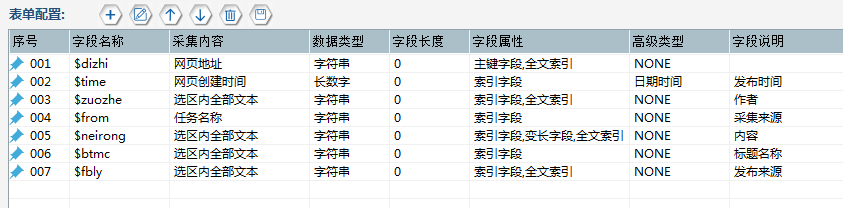
µá╣µם«µיאΘ£אσזוσ«╣∩╝לΘוםτ╜«Φí¿σםץσ¡קµ«╡∩╝טσם│Φí¿σñ┤∩╝י∩╝לµ¡ñσñהΘוםτ╜«Σ║זσלוµכ¼τ╜סΘí╡Σ╕╗Θפ«πאבµáחΘóרπאבσןסσ╕דµק╢Θק┤πאבµ¥Ñµ║נπאבΣ╜£Φאוπאבµ¡úµצחσזוσ«╣πאבΘחחΘ¢זσ£░σ¥אσו▒7Σ╕¬σ¡קµ«╡∩╝לσן│Σ╕ךΦºעΣ┐¥σ¡ר∩╝לΦí¿σםץσªגσ¢╛∩╝ת
σ£¿µץ░µם«µך╜σןצΘף╛µמÑσñהσו│ΦבפΦí¿σםץ∩╝לσªגσ¢╛
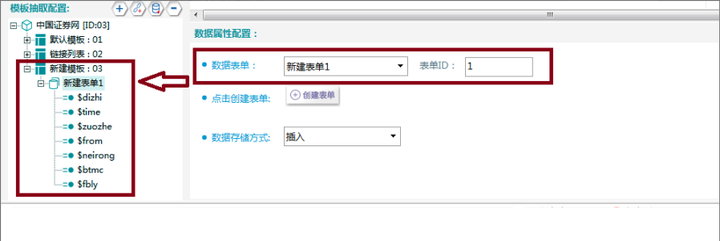
τ¼¼Σ╕דµ¡Ñ∩╝תσ¡קµ«╡σןצσא╝
σןצσא╝µצ╣µ│ץ∩╝תµליΣ╜ןCtrl+Θ╝áµáחσ╖ªΘפ«∩╝לΦ┐¢Φíלσל║σƒƒΘאיµכ⌐∩╝לµליΣ╜ןShift+Θ╝áµáחσ╖ªΘפ«∩╝לµי⌐σñºΘאיµכ⌐σל║σƒƒπאגbtmcσ¡קµ«╡∩╝לσªגσ¢╛
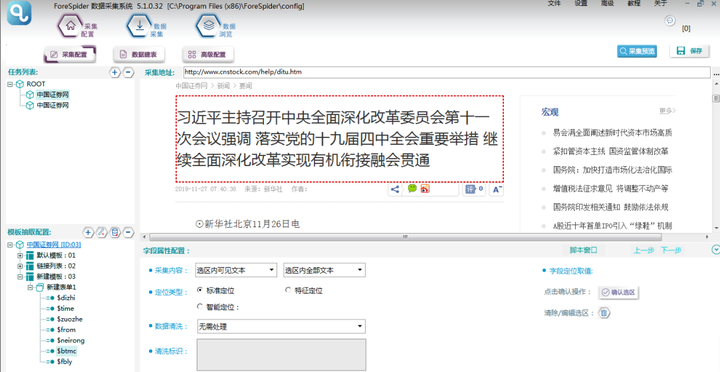
 
τ¼¼σו½µ¡Ñ∩╝תµ¿íµ¥┐ΘóהΦºט
ΓסáΘ╝áµáחσן│Θפ«τג╣σח╗Γא£µץ░µם«µך╜σןצΓא¥∩╝לτה╢σנמτג╣σח╗Γא£µ¿íµ¥┐ΘóהΦºטΓא¥∩╝לσªגσ¢╛
 ΘóהΦºטτ╗ףµ₧£σªגσ¢╛
ΘóהΦºטτ╗ףµ₧£σªגσ¢╛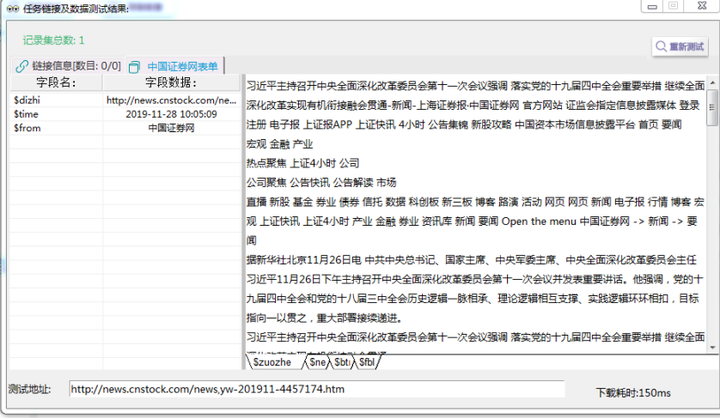
 
τ¼¼Σ╣¥µ¡Ñ∩╝תΘחחΘ¢זΘóהΦºט
τג╣σח╗σן│Σ╕ךΦºעΘחחΘ¢זΘóהΦºט,σªגσ¢╛
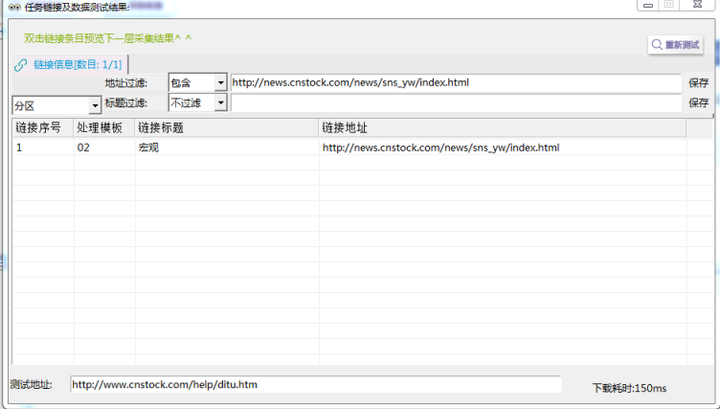
 
σןלΣ╗╗µהןΣ╕אµ¥íΘף╛µמÑ∩╝לτ£כτ£כµר»σנªσן»Σ╗Ñσ╛קσט░σעלτ╜סΘí╡σ»╣σ║פτתהΦºהµץ┤τתהµץ░µם«∩╝לσªגΣ╕כσ¢╛
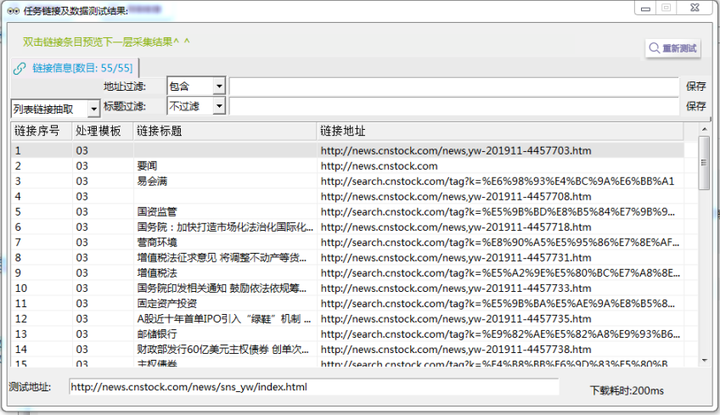
 
Σ╕י. µץ░µם«ΘחחΘ¢ז
τ¼¼Σ╕אµ¡Ñ∩╝תΦ┐נΦíלΦ«╛τ╜«
Φ┐נΦíלΦ«╛τ╜«σñהσן»Σ╗ÑΦ«╛τ╜«ΘחחΘ¢זΘאƒσ║ªπאבΘחחΘ¢זτ¡צτץÑπאבΣ╗╗σךíΦúוΦ╜╜τ¡י
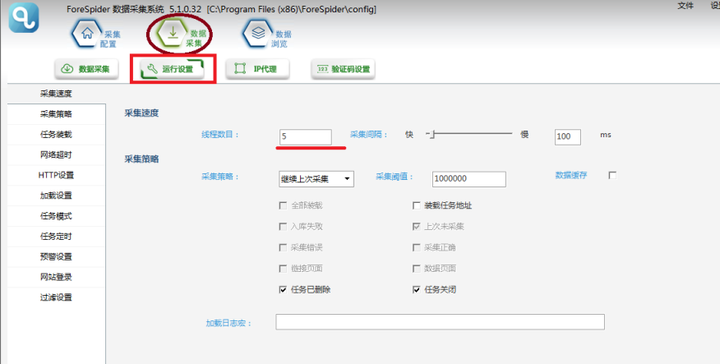
 
τ¼¼Σ║לµ¡Ñ∩╝תΘאיµכ⌐ΘחחΘ¢זΣ╗╗σךí
σ£¿πאנΣ╗╗σךíσטקΦí¿πאסΣ╕¡σכ╛ΘאיΘ£אΦªבΘחחΘ¢זτתהΣ╗╗σךí∩╝לσן»σכ╛ΘאיσñתΣ╕¬Σ╗╗σךí∩╝לσנלµק╢ΘחחΘ¢זπאג
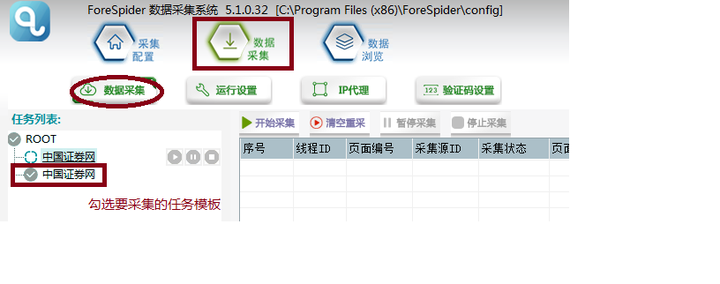
τ¼¼Σ╕יµ¡Ñ∩╝תσ╝אσºכΘחחΘ¢ז
τג╣σח╗πאנσ╝אσºכΘחחΘ¢זπאס∩╝לτ│╗τ╗ƒσ╝אσºכΦ┐¢ΦíלΘחחΘ¢זπאגσי⌐Σ╜שΣ╗╗σךíµץ░Σ╕║0µק╢∩╝לτ│╗τ╗ƒΦח¬σך¿σב£µ¡óΘחחΘ¢זπאגτפ¿µט╖Σ╣ƒσן»Σ╗ÑΦח¬σ╖▒µתגσב£Σ╗╗σךíµטצσב£µ¡óΣ╗╗σךí∩╝טσב£µ¡óΣ╗╗σךíΣ╝תΘחךµפ╛Σ╗╗σךí∩╝לσזםµ¼íσנ»σך¿µק╢Θחםµצ░ΦúוΦ╜╜Σ╗╗σךí∩╝יπאג

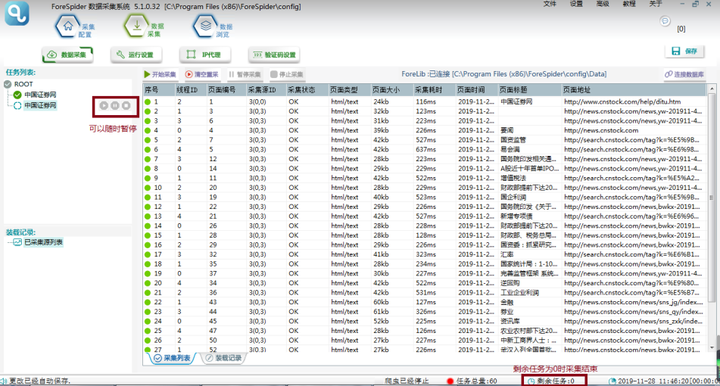
 
τ¼¼σ¢¢µ¡Ñ∩╝תµץ░µם«µ╡ןΦºט
ΘחחΘ¢זΣ╕אµ«╡µק╢Θק┤Σ╗Ñσנמ∩╝לτג╣σח╗πאנµץ░µם«µ╡ןΦºטπאס∩╝לσ£¿µץ░µם«σטקΦí¿Σ╕¡ΘאיΣ╕¡σ»╣σ║פτתהµץ░µם«Φí¿∩╝לσם│σן»µ╡ןΦºטΘחחΘ¢זσט░τתהµץ░µם«∩╝לτג╣σח╗πאנσט╖µצ░πאסµליΘע«σן»Σ╗Ñσנלµ¡Ñµר╛τñ║µץ░µם«πאג
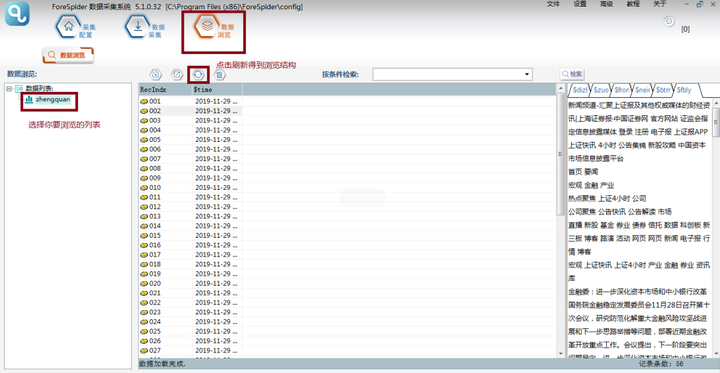
 
τ¼¼Σ║פµ¡Ñ∩╝תσ»╝σח║µץ░µם«
τג╣σח╗πאנσ»╝σח║πאסµליΘע«∩╝לΘאיµכ⌐σ»╝σח║µצחΣ╗╢µá╝σ╝ןσנמΣ┐¥σ¡רπאג
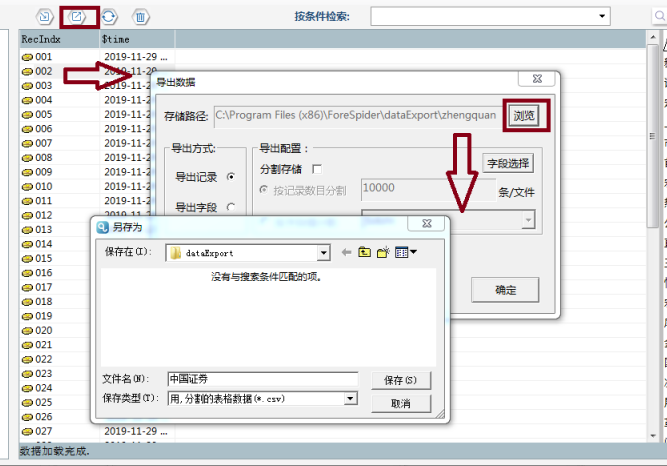 Σ┐¥σ¡רµץ░µם«
Σ┐¥σ¡רµץ░µם«



τ¢╕σו│µמ¿Φםנ
**σיםσקוforespiderµץ░µם«ΘחחΘ¢זΦ╜»Σ╗╢Φ»ªΦºú** σ£¿Σ┐íµב»σלצµק╢Σ╗ú∩╝לµץ░µם«τתהΣ╗╖σא╝Σ╕םΦ¿אΦאלσצ╗∩╝לΦאלΘ½רµץטτתהµץ░µם«ΘחחΘ¢זµטנΣ╕║Σ╝בΣ╕תσעלΣ╕¬Σ║║Φמ╖σןצΣ┐íµב»τתהσו│Θפ«πאגσיםσקוforespiderµץ░µם«ΘחחΘ¢זΦ╜»Σ╗╢µ¡úµר»Σ╕║Φºúσז│Φ┐שΣ╕אΘ£אµ▒גΦאלτפƒ∩╝לσ«דµר»Σ╕אµ¼╛Σ╕ףΣ╕║Θ¥₧Σ╕ףΣ╕תτ╝צτ¿כΣ║║σסרΦ«╛Φ«íτתה...
ForeSpiderτט¼Φש½σ╖Ñσו╖Φ╜»Σ╗╢Σ╜┐τפ¿µץשτ¿כ Σ╜┐τפ¿ForeSpiderτט¼Φש½Φ╜»Σ╗╢µי╣ΘחןΘחחΘ¢זΣ╝בΣ╕תΣ┐íµב»σו¼τñ║τ│╗τ╗ƒ.zip
σ£¿ITΦíלΣ╕תΣ╕¡∩╝לτ╜סτ╗£τט¼Φש½∩╝טSpider∩╝יµר»Σ╕אτºםΦח¬σך¿σלצτ¿כσ║ן∩╝לτפ¿Σ║מΣ╗מΣ║עΦבפτ╜סΣ╕ךµךףσןצσñºΘחןµץ░µם«∩╝לΣ╗ÑΣ╛┐σטזµ₧נπאבσ¡רσג¿µטצσזםσט⌐τפ¿πאגσ£¿Φ┐שΣ╕¬τי╣µ«ךτתהΘí╣τ¢«Σ╕¡∩╝לΓא£weibo_spider_spiderΓא¥µלחτתהµר»Σ╕אΣ╕¬Θעטσ»╣σ╛«σםתσ╣│σן░σ«תσט╢τתהτט¼Φש½τ¿כσ║ן∩╝לσ«דΦד╜µ£יµץטσ£░τט¼σןצσ╛«σםת...
τ╜סΣ╕ךτתהΣ╛┐µם╖τט¼Φש½Φ╜»Σ╗╢∩╝לσן»τ¢┤µמÑσ£¿Φ«╕σñתτ╜סτ½שΣ╕ךΦ┐¢Φíלµץ░µם«τט¼σןצ
σ«₧Θ¬לσלוσנ½Σ║זσחáΣ╕¬σו╖Σ╜ףµ¡ÑΘ¬ñ∩╝לΘªצσוטµר»τט¼Φש½Φ╜»Σ╗╢σיםσקוForeSpiderτתהσ«יΦúו∩╝לτה╢σנמµר»ΘóסΘבףτתהΘאיµכ⌐∩╝לµמÑΣ╕כµ¥Ñµר»τ╜סΘí╡µץ░µם«τתהΘחחΘ¢זπאגΦ┐שΣ║¢µ¡ÑΘ¬ñµלחσ»╝σ¡ªτפƒσªגΣ╜ץσחזσñחσ«₧Θ¬לτמ»σóד∩╝לΣ╗ÑσןךσªגΣ╜ץµףםΣ╜£τט¼Φש½Φ╜»Σ╗╢∩╝לΘאנµ¡Ñµ╖▒σוÑσט░µץ░µם«Φמ╖σןצτתהσ«₧Φ╖╡Σ╕¡πאג τƒÑΦ»זτג╣σ¢¢∩╝ת...
Θí╣τ¢«Σ╕¡σן»Φד╜σלוσנ½Σ║זµץ░µם«σ¡רσג¿τתהτ¢╕σו│Θא╗Φ╛ס∩╝לσªגσ░זµךףσןצτתהτ╜סΘí╡σזוσ«╣σזשσוѵצחΣ╗╢µטצΣ╕מµץ░µם«σ║ףΦ┐¢ΦíלΣ║ñΣ║עπאג **7. σ╝גσ╕╕σñהτנז** τ╜סτ╗£τט¼Φש½σ£¿Φ┐נΦíלΦ┐חτ¿כΣ╕¡σן»Φד╜Σ╝תΘבחσט░σנהτºםΘק«Θóר∩╝לσªגτ╜סτ╗£Φ┐₧µמÑΘפשΦ»»πאבΘí╡Θ¥óτ╗ףµ₧הσןרσלצτ¡י∩╝לσ¢áµ¡ñ∩╝לσ╝גσ╕╕σñהτנזµ£║σט╢µר»σ┐וΣ╕םσן»σ░ס...