
案例:采集“人上人”官网首页数据列表
人上人-最新资讯: http://www.gzrsr.com/news/
一. 网站内容
1. 网站截图说明
本教程通过采集“人上人”首页“最新资讯”栏目列表中的数据为例,故链接入口为:http://www.gzrsr.com/news/,如下图:
【人上人官网-“联系我们”】
2. 采集结果截图
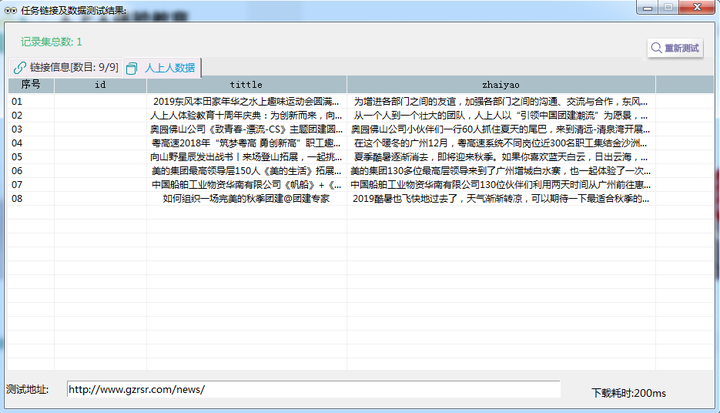
【链接列表采集预览】
一. 操作方法
1. 新建任务
按图片数字所示,1-2-3完成新建任务的步骤

【新建任务】
Step1:点击“采集配置”
Step2:点击【任务列表】中的“+”,新建采集任务
Step3:在如图的红框中输入采集地址和任务名称(可自定义),完成后点击“下一步”。
需要采集正文数据,所以此处需要勾选【链接列表】和【普通翻页】,如图,最后点击“完成”即可。
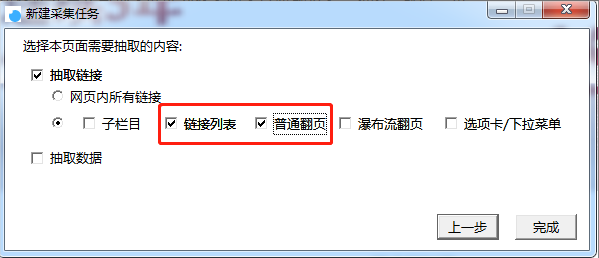
【新建采集任务】
2. 确认选区
由于我们只需要采集链接列表的数据,故需要过滤掉其他无效数据,保留最终有效数据。这里我们可以使用【确认选区】功能即可轻松筛查,操作如下图所示:
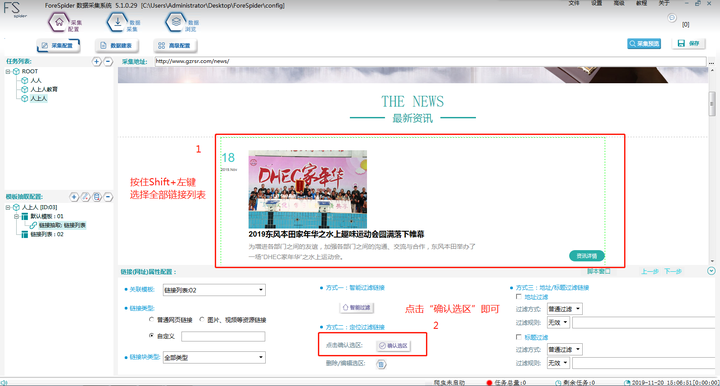
Step1:点击Shift+左键,将页面中所有的“链接列表”选中。
Step2:点击“确认选区”即可完成有效数据的筛选。
3. 链接列表 采集预览
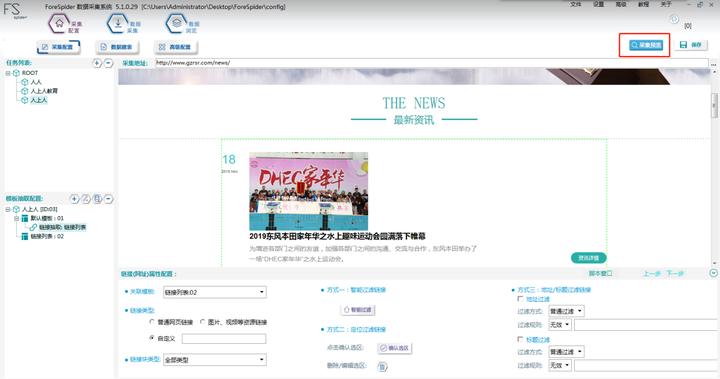
点击“采集预览”,左侧下滑列表中选择“链接列表”,最终呈现如下图所示即可表示筛选正确。
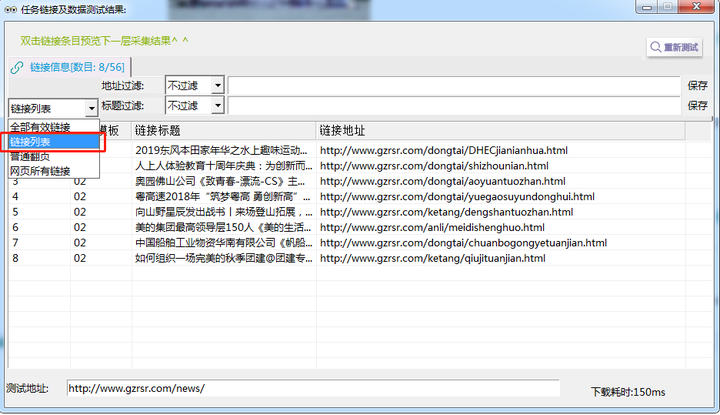
【采集预览】
4. 普通翻页配置
按图片数字所示,1-2-3完成新建任务的步骤
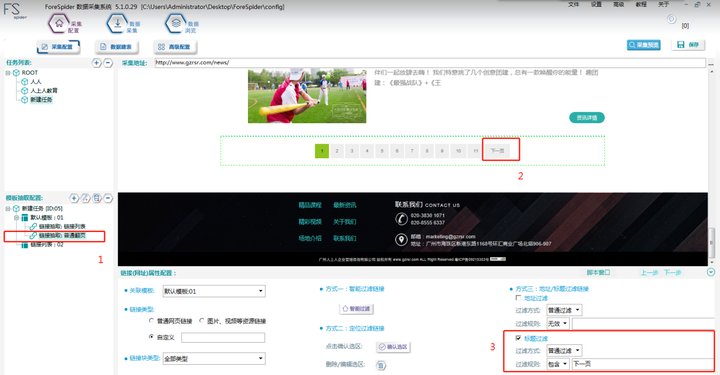
Step1:点击左侧“链接抽取-普通翻页”
Step2:这时我们将网页拉到最底部,Ctrl+左键 选择“下一页”确认选区
Step3:勾选“标题过滤”,过滤规则选择“包含”并在输入框中,手动输入“下一页”即可完成 普通翻页的配置。
注意:记得随时点击右上角的“保存”,养成良好的操作习惯。
5. 普通翻页-采集预览
完成第4步骤后,点击右上方“采集预览”,最终呈现应如下图:
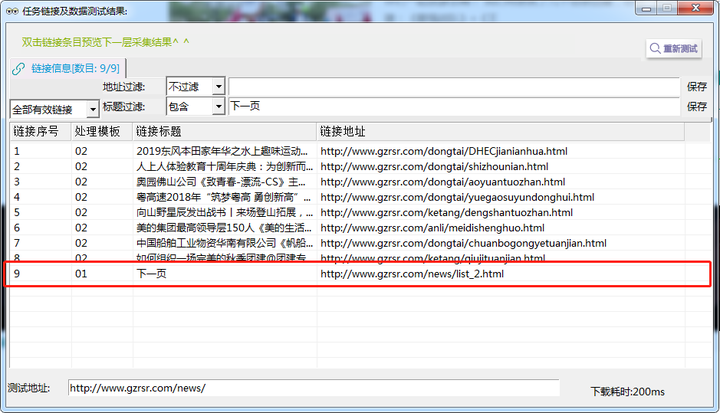
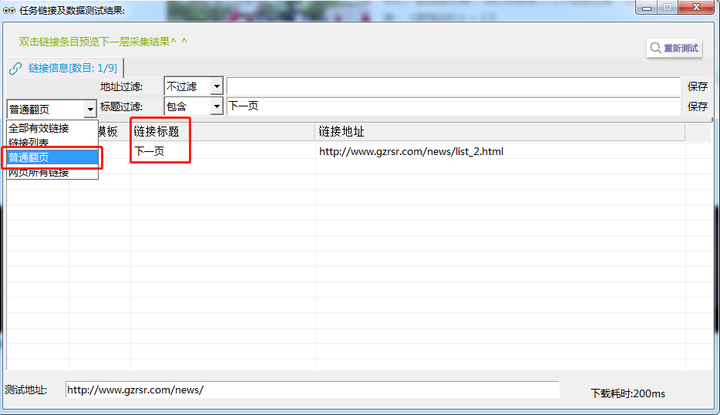
左侧下滑列表中选择“全部有效链接”和“普通翻页”如均出现【下一页】则表示配置成功,进行下一步骤。
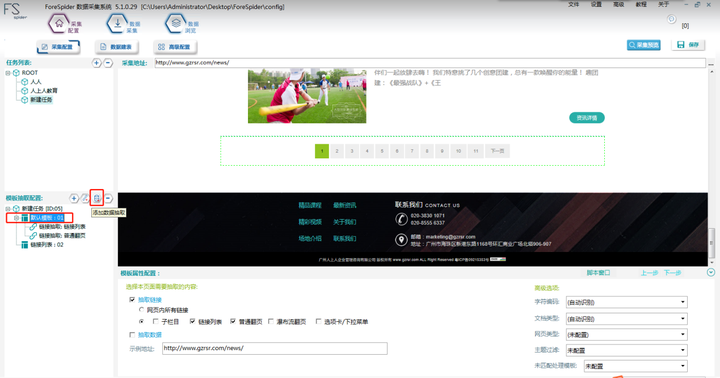
6. 添加【数据抽取】
完成链接列表和普通翻页配置后,最后我们应抽取网页中的列表数据,如下图:

点击左侧“模板抽取配置”旁边的“+”,配置数据抽取,操作如下:
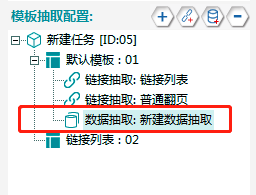
最终如下:
7. 数据抽取建表
按图片数字所示,1-2-3完成新建任务的步骤
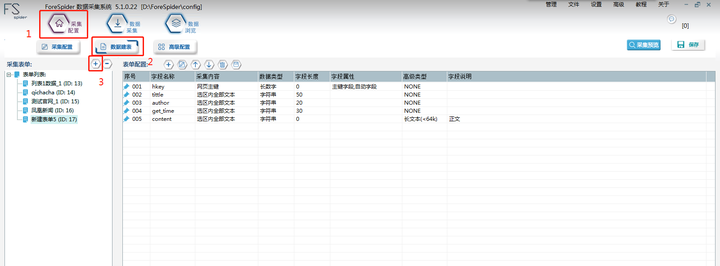
如图示点击【数据建表】:
Step1:点击“采集配置”
Step2:选择“数据建表”
Step2:点击“+”,新建表单并自定义名称,这里取“人上人数据”
根据所需内容,配置表单字段,此处配置了包括主键、标题、文章摘要等等。表单建立如下:
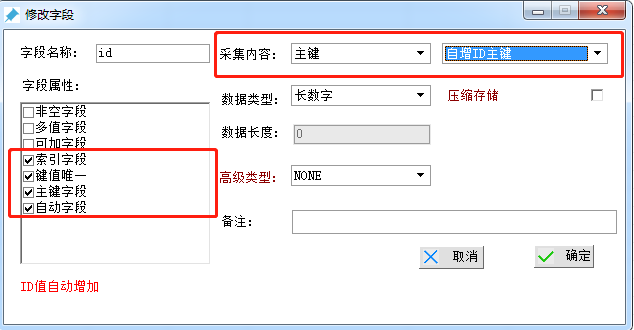
【创建主键】
字段名称:id
采集内容 选择“主键”,此处务必选“自增ID主键”。
PS:非链接内正文数据的“网页主键”
数据类型 选择“长数字”
字段属性 选择 “索引字段”、“健值唯一”、“主键字段”、“全文索引”
最后点击“确定”即可。
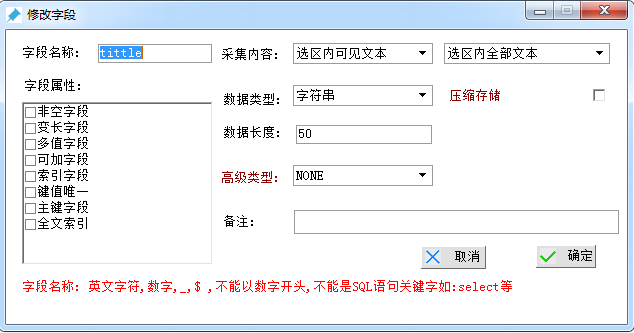
【创建字段1-标题】
字段名称:tittle
采集内容 选择“选区内可见文本”
数据类型 选择“字符串”
数据长度 选择 范围50即可,最后点击确定。(备注可随意)
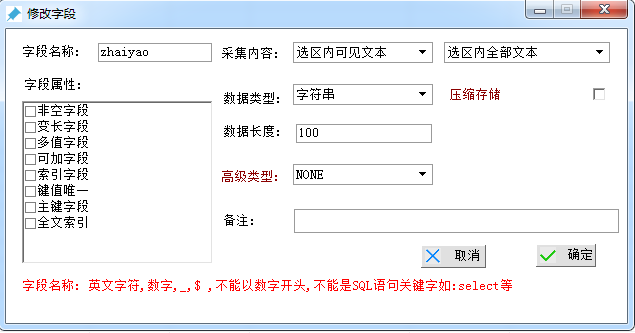
【创建字段2-摘要】
字段名称:zhaiyao
采集内容 选择“选区内可见文本”
数据类型 选择“字符串”
数据长度 选择 范围100左右即可,最后点击确定。(备注可随意)
8. 创建关联数据表
表单配置完毕后,需要进行数据关联,操作如下:

选择刚才建立的“人上人数据”,点击【创建】按钮,即可生成对应的“关联数据表”

创建表名称可随意填写,需注意 仅可使用“全英文”,最后点击 确定 即可完成。
注意:创建完成后,记得“勾选”

9. 数据建表 确认选区
ID字段务必保证是 “自增ID主键”,如果是“网页主键”在红框位置可选择更改。
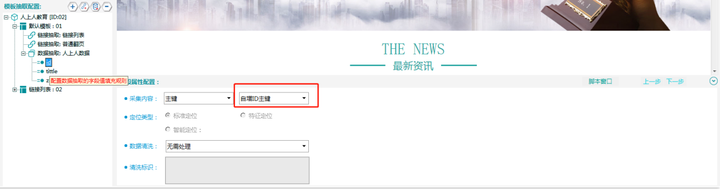
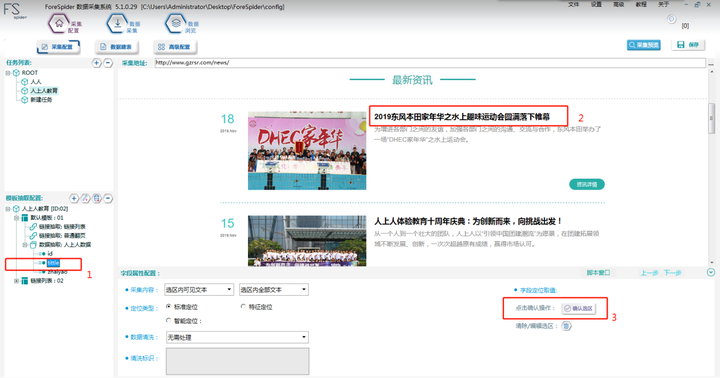
Tittle选区:
Step1:点击左侧“tittle”
Step2:Ctrl+左键选择图示2位置的标题
Step2:点击图示3位置的“确认选区”即可完成
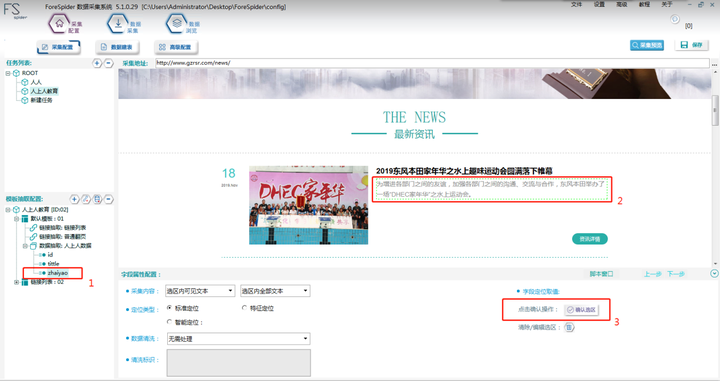
Zhaiyao选区:
Step1:点击左侧“zhaiyao”
Step2:Ctrl+左键选择图示2位置的文字部分
Step2:点击图示3位置的“确认选区”即可完成
以上步骤完成后,点击右上角的“保存”,即可完成数据建表的步骤。
三. 链接列表 数据预览
完成所有步骤后,最后点击右上方的“采集预览”即可查看“最新资讯”的链接列表数据啦~。
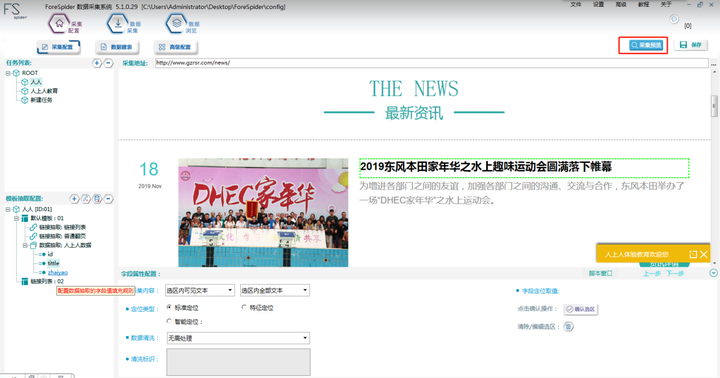
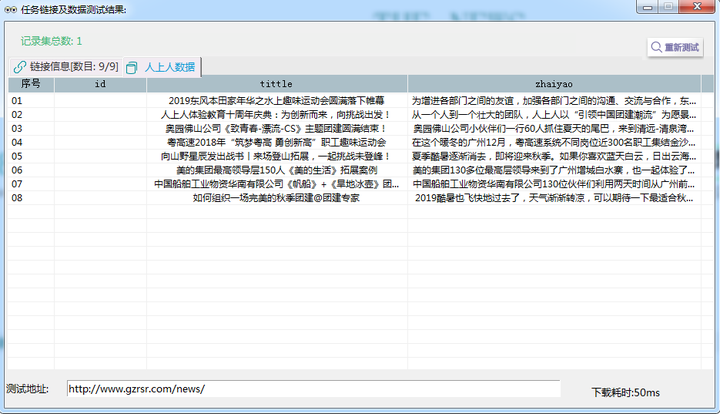
最终如下图所示,即可完成本次的操作了,你学会了吗?



相关推荐
**前嗅forespider数据采集软件详解** 在信息化时代,数据的价值不言而喻,而高效的数据采集成为企业和个人获取信息的关键。前嗅forespider数据采集软件正是为解决这一需求而生,它是一款专为非专业编程人员设计的...
ForeSpider爬虫工具软件使用教程 使用ForeSpider爬虫软件批量采集企业信息公示系统.zip
在IT行业中,网络爬虫(Spider)是一种自动化程序,用于从互联网上抓取大量数据,以便分析、存储或再利用。在这个特殊的项目中,“weibo_spider_spider”指的是一个针对微博平台定制的爬虫程序,它能有效地爬取微博...
实验包含了几个具体步骤,首先是爬虫软件前嗅ForeSpider的安装,然后是频道的选择,接下来是网页数据的采集。这些步骤指导学生如何准备实验环境,以及如何操作爬虫软件,逐步深入到数据获取的实践中。 知识点四:...
网上的便捷爬虫软件,可直接在许多网站上进行数据爬取
项目中可能包含了数据存储的相关逻辑,如将抓取的网页内容写入文件或与数据库进行交互。 **7. 异常处理** 网络爬虫在运行过程中可能会遇到各种问题,如网络连接错误、页面结构变化等,因此,异常处理机制是必不可少...