
转自:https://www.cnblogs.com/massquantity/p/10054496.html
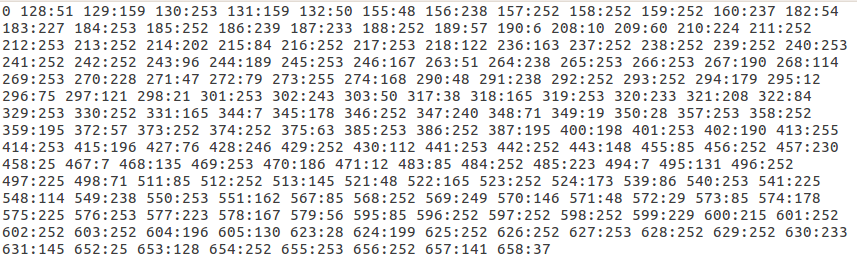
Spark MLlib 的官方例子里面提供的数据大部分是 libsvm 格式的。这其实是一种非常蛋疼的文件格式,和常见的二维表格形式相去甚远,下图是里面的一个例子:
完整代码
libsvm 文件的基本格式如下:
<label> <index1>:<value1> <index2>:<value2>…
label 为类别标识,index 为特征序号,value 为特征取值。如上图中第一行中 0 为标签,128:51 表示第 128 个特征取值为 51 。
Spark 固然提供了读取 libsvm 文件的API,然而如果想把这些数据放到别的库 (比如scikit-learn) 中使用,就不得不面临一个格式转换的问题了。由于 CSV 文件是广大人民群众喜闻乐见的文件格式,因此分别用 Python 和Java 写一个程序来进行转换。我在网上查阅了一下,基本上全是 csv 转 libsvm,很少有 libsvm 转 csv 的,唯一的一个是 phraug库中的libsvm2csv.py。但这个实现有两个缺点: 一个是需要事先指定维度; 另一个是像上图中的特征序号是 128 - 658 ,这样转换完之后 0 - 127 维的特征全为 0,就显得多余了,而比较好的做法是将全为 0 的特征列一并去除。下面是基于 Python 的实现:
import sys
import csv
import numpy as np
def empty_table(input_file): # 建立空表格, 维数为原数据集中最大特征维数
max_feature = 0
count = 0
with open(input_file, 'r', newline='') as f:
reader = csv.reader(f, delimiter=" ")
for line in reader:
count += 1
for i in line:
num = int(i.split(":")[0])
if num > max_feature:
max_feature = num
return np.zeros((count, max_feature + 1))
def write(input_file, output_file, table):
with open(input_file, 'r', newline='') as f:
reader = csv.reader(f, delimiter=" ")
for c, line in enumerate(reader):
label = line.pop(0)
table[c, 0] = label
if line[-1].strip() == '':
line.pop(-1)
line = map(lambda x : tuple(x.split(":")), line)
for i, v in line:
i = int(i)
table[c, i] = v
delete_col = []
for col in range(table.shape[1]):
if not any(table[:, col]):
delete_col.append(col)
table = np.delete(table, delete_col, axis=1) # 删除全 0 列
with open(output_file, 'w') as f:
writer = csv.writer(f)
for line in table:
writer.writerow(line)
if __name__ == "__main__":
input_file = sys.argv[1]
output_file = sys.argv[2]
table = empty_table(input_file)
write(input_file, output_file, table)
以下基于 Java 来实现,不得不说 Java 由于没有 Numpy 这类库的存在,写起来要繁琐得多。
import java.io.*;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class LibsvmToCsv {
public static void main(String[] args) throws IOException {
String src = args[0];
String dest = args[1];
double[][] table = EmptyTable(src);
double[][] newcsv = NewCsv(table, src);
write(newcsv, dest);
}
// 建立空表格, 维数为原数据集中最大特征维数
public static double[][] EmptyTable(String src) throws IOException {
int maxFeatures = 0, count = 0;
File f = new File(src);
BufferedReader br = new BufferedReader(new FileReader(f));
String temp = null;
while ((temp = br.readLine()) != null){
count++;
for (String pair : temp.split(" ")){
int num = Integer.parseInt(pair.split(":")[0]);
if (num > maxFeatures){
maxFeatures = num;
}
}
}
double[][] emptyTable = new double[count][maxFeatures + 1];
return emptyTable;
}
public static double[][] NewCsv(double[][] newTable, String src) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(src)));
String temp = null;
int count = 0;
while ((temp = br.readLine()) != null){
String[] array = temp.split(" ");
double label = Integer.parseInt(array[0]);
for (String pair : Arrays.copyOfRange(array, 1, array.length)){
String[] pairs = pair.split(":");
int index = Integer.parseInt(pairs[0]);
double value = Double.parseDouble(pairs[1]);
newTable[count][index] = value;
}
newTable[count][0] = label;
count++;
}
List<Integer> deleteCol = new ArrayList<>(); // 要删除的全 0 列
int deleteColNum = 0;
coll:
for (int col = 0; col < newTable[0].length; col++){
int zeroCount = 0;
for (int row = 0; row < newTable.length; row++){
if (newTable[row][col] != 0.0){
continue coll; // 若有一个值不为 0, 继续判断下一列
} else {
zeroCount++;
}
}
if (zeroCount == newTable.length){
deleteCol.add(col);
deleteColNum++;
}
}
int newColNum = newTable[0].length - deleteColNum;
double[][] newCsv = new double[count][newColNum]; // 新的不带全 0 列的空表格
int newCol = 0;
colll:
for (int col = 0; col < newTable[0].length; col++){
for (int dCol : deleteCol){
if (col == dCol){
continue colll;
}
}
for (int row = 0; row < newTable.length; row++){
newCsv[row][newCol] = newTable[row][col];
}
newCol++;
}
return newCsv;
}
public static void write(double[][] table, String path) throws FileNotFoundException {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(path)));
try{
for (double[] row : table){
int countComma = 0;
for (double c : row){
countComma ++;
bw.write(String.valueOf(c));
if (countComma <= row.length - 1){
bw.append(',');
}
}
bw.flush();
bw.newLine();
}
} catch (IOException e){
e.printStackTrace();
} finally {
try{
if (bw != null){
bw.close();
}
} catch (IOException e){
e.printStackTrace();
}
}
}
}


相关推荐
标题 "将数据转化成libsvm所需要的格式" 描述了如何将原始数据转换为适用于LibSVM(Library for Support Vector Machines)的特定输入格式。LibSVM是一个广泛使用的开源工具,主要用于支持向量机(SVM)的学习和预测...
libsvm要求的数据格式转换工具,excel宏文件,可以把 *.xls文件转换成libsvm的数据格式,方便快捷,本人已使用过!
本篇文章主要介绍了libSVM的数据格式转换方法以及如何使用`FormatDatalibsvm`工具将.xls文件转换为libSVM可读取的格式,并简要提及了.csv和.txt文件的转换方法。 ##### .xls格式转换为libSVM格式 1. **下载工具** ...
在科学实验中,所得到的数据(例如使用示波器)往往是Excel数据文件(csv格式)。由于libsvm支持的数据格式是有固定规范的(采用[分类标示 序号:值 …]的形式)。用户若想将一些波形数据导入到libsvm工具中分析运算,则...
描述中提到的“libsvm的文件格式转换器”暗示了这个MATLAB程序的主要功能是将数据从MATLAB或其他格式转化为LIBSVM能识别的格式。LIBSVM通常接受两个文件:特征文件(数据集)和模型文件(训练结果)。特征文件通常是...
接下来,加载数据集,如CSV文件,并将其转换为DataFrame: ```python data = pd.read_csv('your_dataset.csv') X = data.drop('target', axis=1) # 特征数据 y = data['target'] # 目标变量(类别) ``` 对特征...
【作品名称】:基于 Python 的机器学习分析恶意加密...将数据集的csv文件转为libsvm格式,方便读入模型。 脚本去除了不合规则的数据行,并且将时间字符串转换为了时间戳格式。 使用方法 python3 csv2libsvm.py inp
文件都需要转换为 libsvm 格式。 这涉及根据工具的要求将 X 转换为稀疏向量,以正确的格式将其写出,然后再读回。 参考线代码中的 31 - 34。 d) svmtrain - 在代码中使用了两次,最初是为了选择最佳的 C 和 gamma 值...
将数据集的csv文件转为libsvm格式,方便读入模型。 脚本去除了不合规则的数据行,并且将时间字符串转换为了时间戳格式。 使用方法 ```bash python3 csv2libsvm.py input_file output_file 79 其中79是label的列号...
- 如何将数据转换为LIBSVM所需的格式。 - 如何选择和调整SVM的参数以优化模型性能。 - 如何使用不同的核函数,如线性、多项式、高斯(RBF)等。 - 如何处理不平衡数据集。 - 如何进行交叉验证来评估模型的泛化能力。...
2. 然后,需要将CSV文件转换为Arff文件。可以使用Weka的Explorer界面打开CSV文件,并将其保存为Arff文件。注意,如果有训练集和测试集,需要将训练集的Arff文件的标签头复制到测试集的Arff文件中。 3. 使用Java代码...
3.22 svm算法实现工具result 结果feature2libsvm.csv 符合libsvm格式的输入文件features.pickle 抽取特征的结果features.vec.csv 特征数值化后的结果grid.out 参数优化结果grid.png 参数优化结果model.txt 模型test....
3. **读取数据**:在C++代码中,我们需要编写函数来读取数据文件,解析特征和标签,并将其转换为libsvm格式的数据结构。 4. **参数设置**:SVM的性能很大程度上取决于参数的选择,比如惩罚系数C、核函数类型(如...
每个类别都有30个训练样本和300个测试样本,存储为CSV格式。 在处理这些数据时,使用了LibSVM,这是一个由台湾大学林智仁教授团队开发的SVM工具包。LibSVM简化了SVM的实现,提供了预编译的二进制文件和源代码,支持...
1. **数据导入**:数据通常以CSV或其他格式存储,代码会读取这些数据,并将其转换为适合SVM的格式,如二维数组。 2. **数据预处理**:包括标准化或归一化,将特征缩放到相同的尺度,以及可能的缺失值处理。 3. **...
Spark MLlib支持多种数据格式,如LibSVM、CSV、JSON等。假设你有一个名为`data.csv`的CSV文件,包含特征和标签,你可以这样读取数据: ```python df = spark.read.format("csv").option("header", "true").option(...
1. **数据准备**:将原始数据转换为JSVM可接受的格式,通常是以逗号分隔值(CSV)或LibSVM格式。 2. **加载数据**:使用JSVM提供的API加载训练数据集。 3. **选择核函数**:根据数据的特性选择合适的核函数。 4. **...
XGBoost支持多种数据格式,包括CSV、libsvm等。在实际应用中,你需要了解如何加载数据、处理缺失值、转换类别变量(如独热编码)以及归一化数值特征,确保数据的质量和一致性。 2. **构建模型**:XGBoost的模型构建...
此外,本书还介绍了如何从CSV或文本文件中加载数据,以及如何使用Scikit-learn生成样本数据。 #### 七、数据清洗 **Data Munging**:数据清洗是数据科学工作流程中非常重要的一步,涉及对原始数据进行清理、转换和...