еӨ§ж¶ӣеӯҰй•ҝ
- жөҸи§Ҳ: 119149 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
**дҪңиҖ…пјҡиӮ–ејәпјҲTalkingData иө„ж·ұе·ҘзЁӢеёҲпјү**
дёҖгҖҒиғҢжҷҜдёҺз—ӣзӮ№
-------
еңЁ 2017 е№ҙдёҠеҚҠе№ҙд»ҘеүҚпјҢTalkingData зҡ„ App Analytics е’Ң Game Analytics дёӨдёӘдә§е“ҒпјҢжөҒејҸжЎҶжһ¶дҪҝз”Ёзҡ„жҳҜиҮӘз ”зҡ„ td-etl-frameworkгҖӮиҜҘжЎҶжһ¶йҷҚдҪҺдәҶејҖеҸ‘жөҒејҸд»»еҠЎзҡ„еӨҚжқӮеәҰпјҢеҜ№дәҺдёҚеҗҢзҡ„д»»еҠЎеҸӘйңҖиҰҒе®һзҺ°дёҖдёӘ changer й“ҫеҚіеҸҜпјҢ并且ж”ҜжҢҒж°ҙе№іжү©еұ•пјҢжҖ§иғҪе°ҡеҸҜпјҢжӣҫз»ҸеҸҜд»Ҙж»Ўи¶ідёҡеҠЎйңҖжұӮгҖӮ
дҪҶжҳҜеҲ°дәҶ 2016 е№ҙеә•е’Ң 2017 е№ҙдёҠеҚҠе№ҙпјҢеҸ‘зҺ°иҝҷдёӘжЎҶжһ¶еӯҳеңЁд»ҘдёӢйҮҚиҰҒеұҖйҷҗпјҡ
1. **жҖ§иғҪйҡҗжӮЈ**пјҡApp Analytics-etl-adaptor е’Ң Game Analytics-etl-adaptor иҝҷдёӨдёӘжЁЎеқ—зӣёз»§еңЁиҠӮеҒҮж—ҘеҮәзҺ°дәҶдёҘйҮҚзҡ„жҖ§иғҪй—®йўҳпјҲFull-GC)пјҢеҜјиҮҙжҢҮж Ү计算延иҝҹгҖӮ
2. **жЎҶжһ¶зҡ„е®№й”ҷжңәеҲ¶дёҚи¶і**пјҡдҫқиө–дәҺдҝқеӯҳеңЁ Kafka жҲ– ZK дёҠзҡ„ offsetпјҢжңҖеӨҡеҸӘиғҪиҫҫеҲ° at-least-onceпјҢиҖҢйңҖиҰҒдҫқиө–е…¶д»–жңҚеҠЎдёҺеӯҳеӮЁжүҚиғҪе®һзҺ° exactly-onceпјҢ并且дјҡдә§з”ҹејӮеёёеҜјиҮҙйҮҚеҗҜдёўж•°гҖӮ
3. **жЎҶжһ¶зҡ„иЎЁиҫҫиғҪеҠӣдёҚи¶і**: дёҚиғҪе®Ңж•ҙзҡ„иЎЁиҫҫ DAG еӣҫпјҢеҜ№дәҺеӨҚжқӮзҡ„жөҒејҸеӨ„зҗҶй—®йўҳйңҖиҰҒиӢҘе№Ідҫқиө–иҜҘжЎҶжһ¶зҡ„иӢҘе№ІдёӘжңҚеҠЎз»„еҗҲеңЁдёҖиө·жүҚиғҪи§ЈеҶій—®йўҳгҖӮ
TalkingData иҝҷдёӨж¬ҫдә§е“Ғдё»иҰҒдёәеҗ„зұ»з§»еҠЁз«Ҝ App е’ҢжёёжҲҸжҸҗдҫӣж•°жҚ®еҲҶжһҗжңҚеҠЎпјҢйҡҸзқҖиҝ‘еҮ е№ҙдёҡеҠЎйҮҸдёҚж–ӯжү©еӨ§пјҢйңҖиҰҒйҖүжӢ©дёҖдёӘжҖ§иғҪжӣҙејәгҖҒеҠҹиғҪжӣҙе®Ңе–„зҡ„жөҒејҸеј•ж“ҺжқҘйҖҗжӯҘеҚҮзә§жҲ‘们зҡ„жөҒејҸжңҚеҠЎгҖӮи°ғз ”д»Һ 2016 е№ҙеә•ејҖе§ӢпјҢдё»иҰҒжҳҜд»Һ FlinkгҖҒHeronгҖҒSpark streaming дёӯдҪңйҖүжӢ©гҖӮ
жңҖз»ҲпјҢжҲ‘们йҖүжӢ©дәҶ FlinkпјҢдё»иҰҒеҹәдәҺд»ҘдёӢеҮ зӮ№иҖғиҷ‘пјҡ
1. Flink зҡ„е®№й”ҷжңәеҲ¶е®Ңе–„пјҢж”ҜжҢҒ Exactly-onceгҖӮ
2. Flink е·Із»ҸйӣҶжҲҗдәҶиҫғдё°еҜҢзҡ„ streaming operatorпјҢиҮӘе®ҡд№ү operator д№ҹиҫғдёәж–№дҫҝпјҢ并且еҸҜд»ҘзӣҙжҺҘи°ғз”Ё API е®ҢжҲҗ stream зҡ„ split е’Ң joinпјҢеҸҜд»Ҙе®Ңж•ҙзҡ„иЎЁиҫҫ DAG еӣҫгҖӮ
3. Flink иҮӘдё»е®һзҺ°еҶ…еӯҳз®ЎзҗҶиҖҢдёҚе®Ңе…Ёдҫқиө–дәҺ JVMпјҢеҸҜд»ҘеңЁдёҖе®ҡзЁӢеәҰдёҠйҒҝе…ҚеҪ“еүҚзҡ„ etl-framework зҡ„йғЁеҲҶжңҚеҠЎзҡ„ Full-GC й—®йўҳгҖӮ
4. Flink зҡ„ window жңәеҲ¶еҸҜд»Ҙи§ЈеҶіGAдёӯзұ»дјјдәҺеҚ•ж—ҘжёёжҲҸж—¶й•ҝжёёжҲҸж¬Ўж•°еҲҶеёғзӯүж—¶й—ҙж®өеҶ…жҹҗдёӘжҢҮж Үзҡ„еҲҶеёғзұ»й—®йўҳгҖӮ
5. Flink зҡ„зҗҶеҝөеңЁеҪ“ж—¶зҡ„жөҒејҸжЎҶжһ¶дёӯжңҖдёәи¶…еүҚ: е°Ҷжү№еҪ“дҪңжөҒзҡ„зү№дҫӢпјҢжңҖз»Ҳе®һзҺ°жү№жөҒз»ҹдёҖгҖӮ
дәҢгҖҒжј”иҝӣи·Ҝзәҝ
------
### 1\. standalone-cluster пјҲ1.1.3->1.1.5->1.3.2пјү
жҲ‘们жңҖејҖе§ӢжҳҜд»Ҙ standalone cluster зҡ„жЁЎејҸйғЁзҪІгҖӮд»Һ 2017 е№ҙдёҠеҚҠе№ҙејҖе§ӢпјҢжҲ‘们йҖҗжӯҘжҠҠ Game Analytics дёӯдёҖдәӣе°ҸжөҒйҮҸзҡ„ etl-job иҝҒ移еҲ° FlinkпјҢеҲ° 4 жңҲд»Ҫж—¶пјҢе·Із»Ҹе°Ҷдә§е“ҒжҺҘ收еҗ„зүҲжң¬ SDK ж•°жҚ®зҡ„ etl-job е®Ңе…ЁиҝҒ移иҮі FlinkпјҢ并ж•ҙеҗҲжҲҗдәҶдёҖдёӘ jobгҖӮеҪўжҲҗдәҶеҰӮдёӢзҡ„ж•°жҚ®жөҒе’Ң stream graphпјҡ
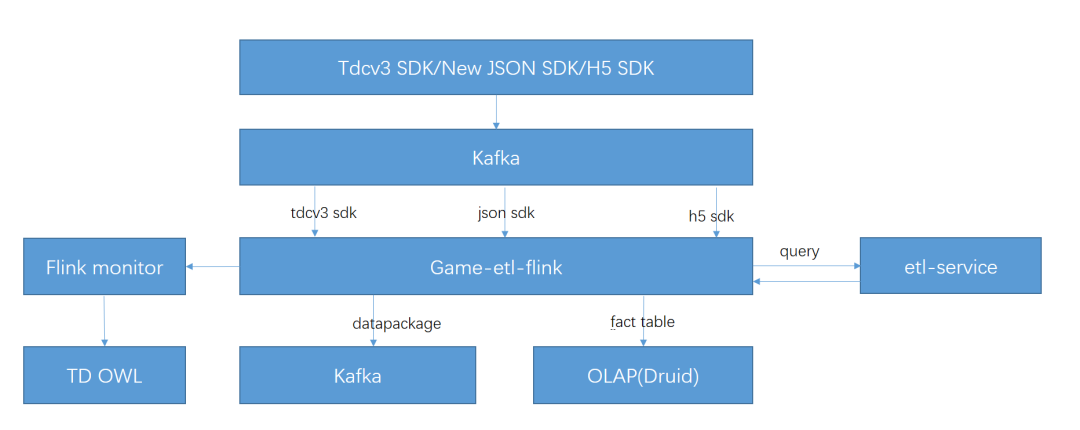
еӣҫ1. Game Analytics-etl-adaptor иҝҒ移иҮі Flink еҗҺзҡ„ж•°жҚ®жөҒеӣҫ
еӣҫ2. Game Analytics-etl зҡ„ stream graph
еңЁдёҠйқўзҡ„ж•°жҚ®жөҒеӣҫдёӯпјҢflink-job йҖҡиҝҮ Dubbo жқҘи°ғз”Ё etl-serviceпјҢд»ҺиҖҢе°Ҷи®ҝй—®еӨ–йғЁеӯҳеӮЁзҡ„йҖ»иҫ‘йғҪжҠҪиұЎеҲ°дәҶ etl-service дёӯпјҢflink-job еҲҷдёҚйңҖиҖғиҷ‘еӨҚжқӮзҡ„и®ҝеӯҳйҖ»иҫ‘д»ҘеҸҠеңЁ job дёӯиҮӘе»ә CacheпјҢиҝҷж ·ж—ўе®ҢжҲҗдәҶжңҚеҠЎзҡ„е…ұз”ЁпјҢеҸҲеҮҸиҪ»дәҶ job иҮӘиә«зҡ„ GC еҺӢеҠӣгҖӮ
жӯӨеӨ–жҲ‘们иҮӘжһ„е»әдәҶдёҖдёӘ monitor жңҚеҠЎпјҢеӣ дёәеҪ“ж—¶зҡ„ 1.1.3 зүҲжң¬зҡ„ Flink еҸҜжҸҗдҫӣзҡ„зӣ‘жҺ§ metric е°‘пјҢиҖҢдё”з”ұдәҺе…¶ Kafka-connector дҪҝз”Ёзҡ„жҳҜ Kafka08 зҡ„дҪҺйҳ¶ APIпјҢKafka зҡ„ж¶Ҳиҙ№ offset 并没жңүжҸҗдәӨзҡ„ ZK дёҠпјҢеӣ жӯӨжҲ‘们йңҖиҰҒжһ„е»әдёҖдёӘ monitor жқҘзӣ‘жҺ§ Flink зҡ„ job зҡ„жҙ»жҖ§гҖҒзһ¬ж—¶йҖҹеәҰгҖҒж¶Ҳиҙ№ж·Өз§Ҝзӯү metricпјҢ并жҺҘе…Ҙе…¬еҸё owl е®ҢжҲҗзӣ‘жҺ§е‘ҠиӯҰгҖӮ
иҝҷж—¶еҖҷпјҢFlink зҡ„ standalone cluster е·Із»ҸжүҝжҺҘдәҶжқҘиҮӘ Game Analytics зҡ„жүҖжңүжөҒйҮҸпјҢж—ҘеқҮеӨ„зҗҶж¶ҲжҒҜзәҰ 10 дәҝжқЎпјҢжҖ»еҗһеҗҗйҮҸиҫҫеҲ° 12 TB жҜҸж—ҘгҖӮеҲ°дәҶжҡ‘еҒҮзҡ„ж—¶еҖҷпјҢж—ҘеқҮж—Ҙеҝ—йҮҸдёҠеҚҮеҲ°дәҶ 18 дәҝжқЎжҜҸеӨ©пјҢеҗһеҗҗйҮҸиҫҫеҲ°дәҶзәҰ 20 TB жҜҸж—ҘпјҢTPS еі°еҖјдёә 3 дёҮгҖӮ
еңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢжҲ‘们еҸҲйҒҮеҲ°дәҶ Flink зҡ„ job ж¶Ҳиҙ№дёҚеқҮиЎЎгҖҒеңЁ standalone cluster дёҠ job зҡ„ deploy дёҚеқҮиЎЎзӯүй—®йўҳпјҢиҖҢйҖ жҲҗзәҝдёҠж¶Ҳиҙ№ж·Өз§ҜпјҢд»ҘеҸҠйӣҶзҫӨж— ж•…иҮӘеҠЁйҮҚеҗҜиҖҢиҮӘеҠЁйҮҚеҗҜеҗҺ job ж— жі•жҲҗеҠҹйҮҚеҗҜгҖӮпјҲжҲ‘们е°ҶеңЁз¬¬дёүз« дёӯиҜҰз»Ҷд»Ӣз»Қиҝҷдәӣй—®йўҳдёӯзҡ„е…ёеһӢиЎЁзҺ°еҸҠеҪ“ж—¶зҡ„и§ЈеҶіж–№жЎҲгҖӮпјү
з»ҸиҝҮдёҖдёӘжҡ‘еҒҮеҗҺпјҢжҲ‘们и®Өдёә Flink з»ҸеҸ—дәҶиҖғйӘҢпјҢеӣ жӯӨејҖе§Ӣе°Ҷ App Analytics зҡ„ etl-job д№ҹиҝҒ移еҲ° Flink дёҠгҖӮеҪўжҲҗдәҶеҰӮдёӢзҡ„ж•°жҚ®жөҒеӣҫпјҡ
еӣҫ3. App Analytics-etl-adaptor зҡ„ж ҮеҮҶ SDK еӨ„зҗҶе·ҘдҪңиҝҒ移еҲ° Flink еҗҺзҡ„ж•°жҚ®жөҒеӣҫ
еӣҫ4. App Analytics-etl-flink job зҡ„ stream graph
2017 е№ҙ 3 жңҲејҖе§ӢжңүеӨ§йҮҸз”ЁжҲ·ејҖе§ӢиҝҒ移иҮіз»ҹдёҖзҡ„ JSON SDKпјҢж–°зүҲ SDK зҡ„ Kafka topic зҡ„еі°еҖјжөҒйҮҸд»Һе№ҙдёӯзҡ„ 8 K/s дёҠж¶ЁиҮідәҶе№ҙеә•зҡ„ 3 W/sгҖӮжӯӨж—¶пјҢж•ҙдёӘ Flink standalone cluster дёҠдёҖе…ұйғЁзҪІдәҶдёӨж¬ҫдә§е“Ғзҡ„ 4 дёӘ jobпјҢж—ҘеқҮеҗһеҗҗйҮҸиҫҫеҲ°дәҶ 35 TBгҖӮ
иҝҷж—¶йҒҮеҲ°дәҶдёӨдёӘйқһеёёдёҘйҮҚзҡ„й—®йўҳпјҡ
* еҗҢдёҖдёӘ standalone cluster дёӯзҡ„ job зӣёдә’жҠўеҚ иө„жәҗпјҢиҖҢ standalone cluster зҡ„жЁЎејҸд»…д»…еҸӘиғҪйҖҡиҝҮ task slot еңЁ task manager зҡ„е ҶеҶ…еҶ…еӯҳдёҠеҒҡеҲ°иө„жәҗйҡ”зҰ»гҖӮеҗҢж—¶з”ұдәҺеүҚж–ҮжҸҗеҲ°иҝҮзҡ„ Flink еңЁ standalone cluster дёӯ deploy job зҡ„ж–№ејҸжң¬жқҘе°ұдјҡйҖ жҲҗиө„жәҗеҲҶй…ҚдёҚеқҮиЎЎпјҢд»ҺиҖҢдјҡеҜјиҮҙ App Analytics зәҝжөҒйҮҸеӨ§ж—¶иҖҢеј•иө·Game Analytics зәҝж·Өз§Ҝзҡ„й—®йўҳгҖӮ
* жҲ‘们зҡ„ source operator зҡ„并иЎҢеәҰзӯүеҗҢдәҺжүҖж¶Ҳиҙ№ Kafka topic зҡ„ partition ж•°йҮҸпјҢиҖҢдёӯй—ҙеҒҡ etl зҡ„ operator зҡ„并иЎҢеәҰеҫҖеҫҖдјҡиҝңеӨ§дәҺ Kafka зҡ„ partition ж•°йҮҸгҖӮеӣ жӯӨжңҖеҗҺзҡ„ job graph дёҚеҸҜиғҪе®Ңе…Ёиў«й“ҫжҲҗдёҖжқЎ operator chainпјҢoperator д№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“еҝ…йЎ»йҖҡиҝҮ Flink зҡ„ network buffer зҡ„з”іиҜ·е’ҢйҮҠж”ҫпјҢиҖҢ 1.1.x зүҲжң¬зҡ„ network buffer еңЁж•°жҚ®йҮҸеӨ§зҡ„ж—¶еҖҷеҫҲе®№жҳ“еңЁе…¶з”іиҜ·е’ҢйҮҠж”ҫж—¶йҖ жҲҗжӯ»й”ҒпјҢиҖҢеҜјиҮҙ Flink жҳҺжҳҺжңүи®ёеӨҡж¶ҲжҒҜиҰҒеӨ„зҗҶпјҢдҪҶжҳҜеӨ§йғЁеҲҶзәҝзЁӢеӨ„дәҺ waiting зҡ„зҠ¶жҖҒеҜјиҮҙдёҡеҠЎзҡ„еӨ§йҮҸ延иҝҹгҖӮ
иҝҷдәӣй—®йўҳйҖјиҝ«зқҖжҲ‘们дёҚеҫ—дёҚе°ҶдёӨж¬ҫдә§е“Ғзҡ„ job жӢҶеҲҶеҲ°дёӨдёӘ standalone cluster дёӯпјҢ并еҜ№ Flink еҒҡдёҖж¬ЎиҫғеӨ§зҡ„зүҲжң¬еҚҮзә§пјҢд»Һ 1.1.3пјҲдёӯй—ҙиҝҮеәҰеҲ° 1.1.5пјүеҚҮзә§жҲҗ 1.3.2гҖӮжңҖз»ҲеҚҮзә§иҮі 1.3.2 еңЁ 18 е№ҙзҡ„ Q1 е®ҢжҲҗпјҢ1.3.2 зүҲжң¬еј•е…ҘдәҶеўһйҮҸејҸзҡ„ checkpoint жҸҗдәӨ并且еңЁжҖ§иғҪе’ҢзЁіе®ҡжҖ§дёҠжҜ” 1.1.x зүҲжң¬еҒҡдәҶе·ЁеӨ§зҡ„ж”№иҝӣгҖӮеҚҮзә§д№ӢеҗҺпјҢFlink йӣҶзҫӨеҹәжң¬зЁіе®ҡпјҢе°Ҫз®Ўиҝҳжңүж¶Ҳиҙ№дёҚеқҮеҢҖзӯүй—®йўҳпјҢдҪҶжҳҜеҹәжң¬еҸҜд»ҘеңЁдёҡеҠЎйҮҸеўһеҠ ж—¶йҖҡиҝҮжү©е®№жңәеҷЁжқҘи§ЈеҶігҖӮ
### 2\. Flink on yarn (1.7.1)
еӣ дёә standalone cluster зҡ„иө„жәҗйҡ”зҰ»еҒҡзҡ„并дёҚдјҳз§ҖпјҢиҖҢдё”иҝҳжңү deploy job дёҚеқҮиЎЎзӯүй—®йўҳпјҢеҠ дёҠзӨҫеҢәдёҠдҪҝз”Ё Flink on yarn е·Із»ҸйқһеёёжҲҗзҶҹпјҢеӣ жӯӨжҲ‘们еңЁ 18 е№ҙзҡ„ Q4 е°ұејҖе§Ӣи®ЎеҲ’е°Ҷ Flink зҡ„ standalone cluster иҝҒ移иҮі Flink on yarn дёҠпјҢ并且 Flink еңЁжңҖиҝ‘зҡ„зүҲжң¬дёӯеҜ№дәҺ batch зҡ„жҸҗеҚҮиҫғеӨҡпјҢжҲ‘们иҝҳ规еҲ’йҖҗжӯҘдҪҝз”Ё Flink жқҘйҖҗжӯҘжӣҝжҚўзҺ°еңЁзҡ„жү№еӨ„зҗҶеј•ж“ҺгҖӮ

еӣҫ5. Flink on yarn cluster 规еҲ’
еҰӮеӣҫ 5пјҢжңӘжқҘзҡ„ Flink on yarn cluster е°ҶеҸҜд»Ҙе®ҢжҲҗжөҒејҸи®Ўз®—е’Ңжү№еӨ„зҗҶи®Ўз®—пјҢйӣҶзҫӨзҡ„дҪҝз”ЁиҖ…еҸҜд»ҘйҖҡиҝҮдёҖдёӘжһ„е»ә service жқҘе®ҢжҲҗ stream/batch job зҡ„жһ„е»әгҖҒдјҳеҢ–е’ҢжҸҗдәӨпјҢjob жҸҗдәӨеҗҺпјҢж №жҚ®дҪҝз”ЁиҖ…жүҖеңЁзҡ„дёҡеҠЎеӣўйҳҹеҸҠжңҚеҠЎе®ўжҲ·зҡ„дёҡеҠЎйҮҸеҲҶеҸ‘еҲ°дёҚеҗҢзҡ„ yarn йҳҹеҲ—дёӯпјҢжӯӨеӨ–пјҢйӣҶзҫӨйңҖиҰҒдёҖдёӘе®Ңе–„зҡ„зӣ‘жҺ§зі»з»ҹпјҢйҮҮйӣҶз”ЁжҲ·зҡ„жҸҗдәӨи®°еҪ•гҖҒеҗ„дёӘйҳҹеҲ—зҡ„жөҒйҮҸеҸҠиҙҹиҪҪгҖҒеҗ„дёӘ job зҡ„иҝҗиЎҢж—¶жҢҮж ҮзӯүзӯүпјҢ并жҺҘе…Ҙе…¬еҸёзҡ„ OWLгҖӮ
д»Һ 19 е№ҙзҡ„ Q1 ејҖе§ӢпјҢжҲ‘们е°Ҷ App Analytics зҡ„йғЁеҲҶ stream job иҝҒ移еҲ°дәҶ Flink on yarn 1.7 дёӯпјҢеҸҲеңЁ 19 е№ҙ Q2 еүҚе®ҢжҲҗдәҶ App Analytics жүҖжңүеӨ„зҗҶз»ҹдёҖ JSON SDK зҡ„жөҒд»»еҠЎиҝҒ移гҖӮеҪ“еүҚзҡ„ Flink on yarn йӣҶзҫӨзҡ„еі°еҖјеӨ„зҗҶзҡ„ж¶ҲжҒҜйҮҸиҫҫеҲ° 30 W/sпјҢж—ҘеқҮж—Ҙеҝ—еҗһеҗҗйҮҸиҫҫзәҰеҲ° 50 дәҝжқЎпјҢзәҰ 60 TBгҖӮеңЁ Flink иҝҒ移еҲ° on yarn д№ӢеҗҺпјҢеӣ дёәзүҲжң¬зҡ„еҚҮзә§жҖ§иғҪжңүжүҖжҸҗеҚҮпјҢдё” job д№Ӣй—ҙзҡ„иө„жәҗйҡ”зҰ»зЎ®е®һдјҳдәҺ standalone clusterгҖӮиҝҒ移еҗҺжҲ‘们дҪҝз”Ё Prometheus+Grafana зҡ„зӣ‘жҺ§ж–№жЎҲпјҢзӣ‘жҺ§жӣҙж–№дҫҝе’Ңзӣҙи§ӮгҖӮ
жҲ‘们е°ҶеңЁеҗҺз»ӯе°Ҷ Game Analytics зҡ„ Flink job е’Ңж—Ҙеҝ—еҜјеҮәзҡ„ job д№ҹиҝҒ移иҮіиҜҘ on yarn йӣҶзҫӨпјҢйў„и®ЎеҸҜд»ҘиҠӮзәҰ 1/4 зҡ„жңәеҷЁиө„жәҗгҖӮ
дёүгҖҒйҮҚзӮ№й—®йўҳзҡ„жҸҸиҝ°дёҺи§ЈеҶі
------------
еңЁ Flink е®һи·өзҡ„иҝҮзЁӢдёӯпјҢжҲ‘们дёҖи·ҜдёҠйҒҮеҲ°дәҶдёҚе°‘еқ‘пјҢжҲ‘们жҢ‘еҮәе…¶дёӯеҮ дёӘйҮҚзӮ№еқ‘еҒҡз®ҖиҰҒи®Іи§ЈгҖӮ
### 1\. е°‘з”ЁйқҷжҖҒеҸҳйҮҸеҸҠ job cancel ж—¶еҗҲзҗҶйҮҠж”ҫиө„жәҗ
еңЁжҲ‘们е®һзҺ° Flink зҡ„ operator зҡ„ function ж—¶пјҢдёҖиҲ¬йғҪеҸҜд»Ҙ继жүҝ AbstractRichFunctionпјҢе…¶е·ІжҸҗдҫӣз”ҹе‘Ҫе‘Ёжңҹж–№жі• open()/close()пјҢжүҖд»Ҙ operator дҫқиө–зҡ„иө„жәҗзҡ„еҲқе§ӢеҢ–е’ҢйҮҠж”ҫеә”иҜҘйҖҡиҝҮйҮҚеҶҷиҝҷдәӣж–№жі•жү§иЎҢгҖӮеҪ“жҲ‘们еҲқе§ӢеҢ–дёҖдәӣиө„жәҗпјҢеҰӮ spring contextгҖҒdubbo config ж—¶пјҢеә”иҜҘе°ҪеҸҜиғҪдҪҝз”ЁеҚ•дҫӢеҜ№иұЎжҢҒжңүиҝҷдәӣиө„жәҗдё”пјҲеңЁдёҖдёӘ TaskManager дёӯпјүеҸӘеҲқе§ӢеҢ– 1 ж¬ЎпјҢеҗҢж ·зҡ„пјҢжҲ‘们еңЁ close ж–№жі•дёӯеә”еҪ“пјҲеңЁдёҖдёӘ TaskManager дёӯпјүеҸӘйҮҠж”ҫдёҖж¬ЎгҖӮ
static зҡ„еҸҳйҮҸеә”иҜҘж…ҺйҮҚдҪҝз”ЁпјҢеҗҰеҲҷеҫҲе®№жҳ“еј•иө· job cancel иҖҢзӣёеә”зҡ„иө„жәҗжІЎжңүйҮҠж”ҫиҝӣиҖҢеҜјиҮҙ job йҮҚеҗҜйҒҮеҲ°й—®йўҳгҖӮ规йҒҝ static еҸҳйҮҸжқҘеҲқе§ӢеҢ–еҸҜд»ҘдҪҝз”Ё org.apache.flink.configuration.ConfigurationпјҲ1.3пјүжҲ–иҖ… org.apache.flink.api.java.utils.ParameterToolпјҲ1.7пјүжқҘдҝқеӯҳжҲ‘们зҡ„иө„жәҗй…ҚзҪ®пјҢ然еҗҺйҖҡиҝҮ ExecutionEnvironment жқҘеӯҳж”ҫпјҲJobжҸҗдәӨж—¶пјүе’ҢиҺ·еҸ–иҝҷдәӣй…ҚзҪ®пјҲJobиҝҗиЎҢж—¶пјүгҖӮ
**зӨәдҫӢд»Јз Ғпјҡ**
Flink 1.3 и®ҫзҪ®еҸҠжіЁеҶҢй…ҚзҪ®:
```
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration parameters = new Configuration();
parameters.setString("zkConnects", zkConnects);
parameters.setBoolean("debug", debug);
env.getConfig().setGlobalJobParameters(parameters);
```

иҺ·еҸ–й…ҚзҪ®пјҲеңЁ operator зҡ„ open ж–№жі•дёӯпјүгҖӮ
```
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ExecutionConfig.GlobalJobParameters globalParams = getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
Configuration globConf = (Configuration) globalParams;
debug = globConf.getBoolean("debug", false);
String zks = globConf.getString("zkConnects", "");
//.. do more ..
}
```

Flink 1.7 и®ҫзҪ®еҸҠжіЁеҶҢй…ҚзҪ®:
```
ParameterTool parameters = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(parameters);
```

иҺ·еҸ–й…ҚзҪ®:
```
public static final class Tokenizer extends RichFlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
ParameterTool parameters = (ParameterTool)
getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
parameters.getRequired("input");
// .. do more ..
```

### 2\. NetworkBuffer еҸҠ operator chain
еҰӮеүҚж–ҮжүҖиҝ°пјҢеҪ“ Flink зҡ„ job зҡ„дёҠдёӢжёё TaskпјҲзҡ„ subTaskпјүеҲҶеёғеңЁдёҚеҗҢзҡ„ TaskManager иҠӮзӮ№дёҠж—¶пјҲд№ҹе°ұжҳҜдёҠдёӢжёё operator жІЎжңү chained еңЁдёҖиө·пјҢдё”зӣёеҜ№еә”зҡ„ subTask еҲҶеёғеңЁдәҶдёҚеҗҢзҡ„ TaskManager иҠӮзӮ№дёҠпјүпјҢе°ұйңҖиҰҒеңЁ operator зҡ„ж•°жҚ®дј йҖ’ж—¶з”іиҜ·е’ҢйҮҠж”ҫ network buffer 并йҖҡиҝҮзҪ‘з»ң I/O дј йҖ’ж•°жҚ®гҖӮ
е…¶иҝҮзЁӢз®Җиҝ°еҰӮдёӢпјҡдёҠжёёзҡ„ operator дә§з”ҹзҡ„з»“жһңдјҡйҖҡиҝҮ RecordWriter еәҸеҲ—еҢ–пјҢ然еҗҺз”іиҜ· BufferPool дёӯзҡ„ Buffer 并е°ҶеәҸеҲ—еҢ–еҗҺзҡ„з»“жһңеҶҷе…Ҙ BufferпјҢжӯӨеҗҺ Buffer дјҡиў«еҠ е…Ҙ ResultPartition зҡ„ ResultSubPartition дёӯгҖӮResultSubPartition дёӯзҡ„ Buffer дјҡйҖҡиҝҮ Netty дј иҫ“иҮідёӢдёҖзә§зҡ„ operator зҡ„ InputGate зҡ„ InputChannel дёӯпјҢеҗҢж ·зҡ„пјҢBuffer иҝӣе…Ҙ InputChannel еүҚеҗҢж ·йңҖиҰҒеҲ°дёӢдёҖзә§ operator жүҖеңЁзҡ„ TaskManager зҡ„ BufferPool з”іиҜ·пјҢRecordReader иҜ»еҸ– Buffer 并е°Ҷе…¶дёӯзҡ„ж•°жҚ®еҸҚеәҸеҲ—еҢ–гҖӮBufferPool жҳҜжңүйҷҗзҡ„пјҢеңЁ BufferPool дёәз©әж—¶ RecordWriter / RecordReader жүҖеңЁзҡ„зәҝзЁӢдјҡеңЁз”іиҜ· Buffer зҡ„иҝҮзЁӢдёӯзӯүеҫ…дёҖж®өж—¶й—ҙпјҢе…·дҪ“еҺҹзҗҶеҸҜд»ҘеҸӮиҖғ:\[1\], \[2\]гҖӮ
з®ҖиҰҒжҲӘеӣҫеҰӮдёӢпјҡ
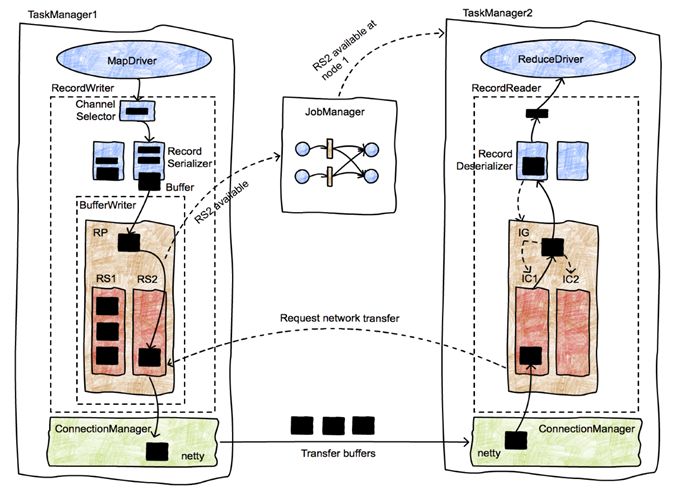
еӣҫ6. Flink зҡ„зҪ‘з»ңж Ҳ, е…¶дёӯ RP дёә ResultPartitionгҖҒRS дёә ResultSubPartitionгҖҒIG дёә InputGateгҖҒIC дёә inputChannel
еңЁдҪҝз”Ё Flink 1.1.x е’Ң 1.3.x зүҲжң¬ж—¶пјҢеҰӮжһңжҲ‘们зҡ„ network buffer зҡ„ж•°йҮҸй…ҚзҪ®зҡ„дёҚе……и¶ідё”ж•°жҚ®зҡ„еҗһеҗҗйҮҸеҸҳеӨ§зҡ„ж—¶еҖҷпјҢе°ұдјҡйҒҮеҲ°еҰӮдёӢзҺ°иұЎпјҡ
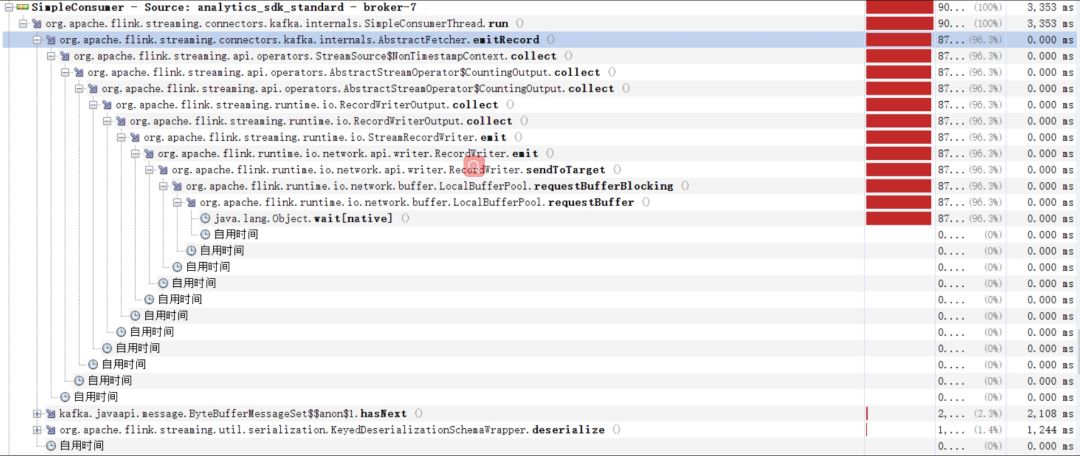
еӣҫ7. дёҠжёё operator йҳ»еЎһеңЁиҺ·еҸ– network buffer зҡ„ requestBuffer() ж–№жі•дёӯ
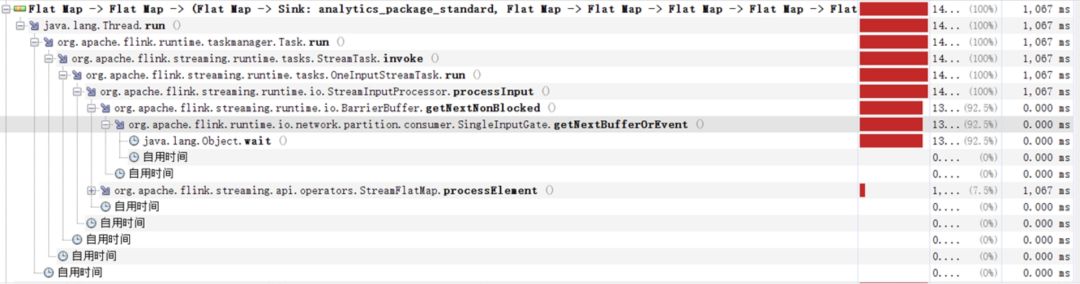
еӣҫ8. дёӢжёёзҡ„ operator йҳ»еЎһеңЁзӯүеҫ…ж–°ж•°жҚ®иҫ“е…Ҙ
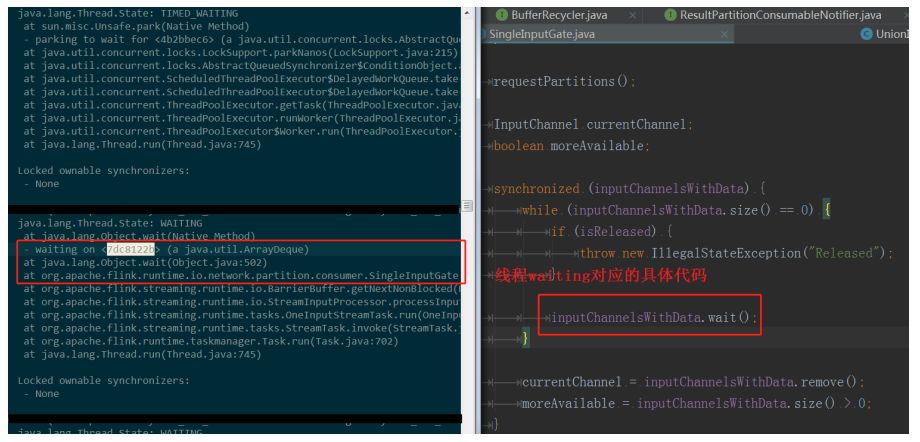
еӣҫ9. дёӢжёёзҡ„ operator йҳ»еЎһеңЁзӯүеҫ…ж–°ж•°жҚ®иҫ“е…Ҙ
жҲ‘们зҡ„е·ҘдҪңзәҝзЁӢпјҲRecordWriter е’Ң RecordReader жүҖеңЁзҡ„зәҝзЁӢпјүзҡ„еӨ§йғЁеҲҶж—¶й—ҙйғҪиҠұеңЁдәҶеҗ‘ BufferPool з”іиҜ· Buffer дёҠпјҢиҝҷж—¶еҖҷ CPU зҡ„дҪҝз”ЁзҺҮдјҡеү§зғҲзҡ„жҠ–еҠЁпјҢдҪҝеҫ— Job зҡ„ж¶Ҳиҙ№йҖҹеәҰдёӢйҷҚпјҢеңЁ 1.1.x зүҲжң¬дёӯз”ҡиҮідјҡйҳ»еЎһеҫҲй•ҝзҡ„дёҖж®өж—¶й—ҙпјҢи§ҰеҸ‘ж•ҙдёӘ job зҡ„иғҢеҺӢпјҢд»ҺиҖҢйҖ жҲҗиҫғдёҘйҮҚзҡ„дёҡеҠЎе»¶иҝҹгҖӮ
иҝҷж—¶еҖҷпјҢжҲ‘们е°ұйңҖиҰҒйҖҡиҝҮдёҠдёӢжёё operator зҡ„并иЎҢеәҰжқҘи®Ўз®— ResultPartition е’Ң InputGate дёӯжүҖйңҖиҰҒзҡ„ buffer зҡ„дёӘж•°пјҢд»Ҙй…ҚзҪ®е……и¶ізҡ„ taskmanager.network.numberOfBuffersгҖӮ
еӣҫ10. дёҚеҗҢзҡ„ network buffer еҜ№ CPU дҪҝз”ЁзҺҮзҡ„еҪұе“Қ
еҪ“й…ҚзҪ®дәҶе……и¶ізҡ„ network buffer ж•°ж—¶пјҢCPU жҠ–еҠЁеҸҜд»ҘеҮҸе°‘пјҢJob ж¶Ҳиҙ№йҖҹеәҰжңүжүҖжҸҗй«ҳгҖӮ
еңЁ Flink 1.5 д№ӢеҗҺпјҢеңЁе…¶ network stack дёӯеј•е…ҘдәҶеҹәдәҺдҝЎз”ЁеәҰзҡ„жөҒйҮҸдј иҫ“жҺ§еҲ¶пјҲcredit-based flow controlпјүжңәеҲ¶\[2\]пјҢиҜҘжңәеҲ¶еӨ§йҷҗеәҰзҡ„йҒҝе…ҚдәҶеңЁеҗ‘ BufferPool з”іиҜ· Buffer зҡ„йҳ»еЎһзҺ°иұЎпјҢжҲ‘们еҲқжӯҘжөӢиҜ• 1.7 зҡ„ network stack зҡ„жҖ§иғҪзЎ®е®һжҜ” 1.3 иҰҒй«ҳгҖӮ
дҪҶиҝҷжҜ•з«ҹиҝҳдёҚжҳҜжңҖдјҳзҡ„жғ…еҶөпјҢеӣ дёәеҰӮжһңеҖҹеҠ© network buffer жқҘе®ҢжҲҗдёҠдёӢжёёзҡ„ operator зҡ„ж•°жҚ®дј йҖ’дёҚеҸҜд»ҘйҒҝе…Қзҡ„иҰҒз»ҸиҝҮеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–зҡ„иҝҮзЁӢпјҢиҖҢдё”дҝЎз”ЁеәҰзҡ„дҝЎжҒҜдј йҖ’жңүдёҖе®ҡзҡ„延иҝҹжҖ§е’ҢејҖй”ҖпјҢиҖҢиҝҷдёӘиҝҮзЁӢеҸҜд»ҘйҖҡиҝҮе°ҶдёҠдёӢжёёзҡ„ operator й“ҫжҲҗдёҖжқЎ operator chain иҖҢйҒҝе…ҚгҖӮ
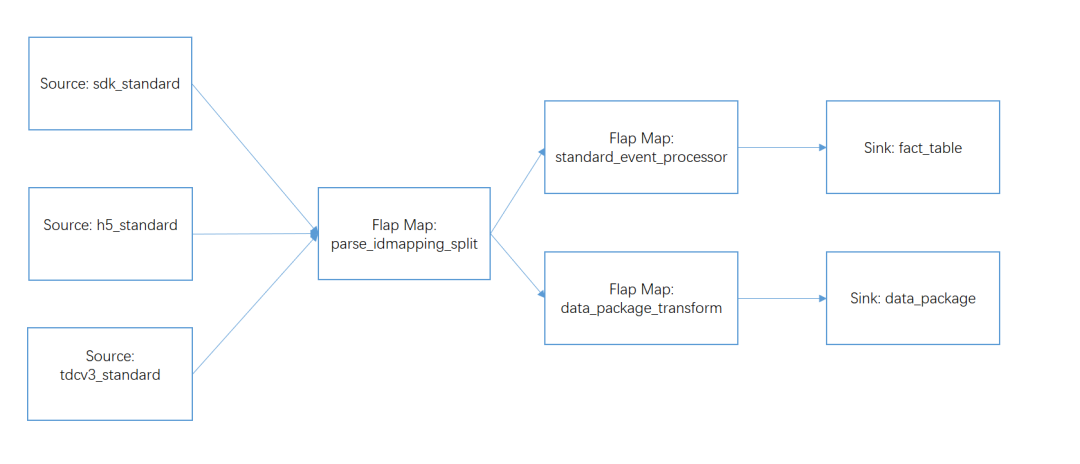
еӣ жӯӨжҲ‘们еңЁжһ„е»әжҲ‘们жөҒд»»еҠЎзҡ„жү§иЎҢеӣҫж—¶пјҢеә”иҜҘе°ҪеҸҜиғҪеӨҡзҡ„и®© operator йғҪ chain еңЁдёҖиө·пјҢеңЁ Kafka иө„жәҗе…Ғи®ёзҡ„жғ…еҶөдёӢеҸҜд»Ҙжү©еӨ§ Kafka зҡ„ partition иҖҢдҪҝеҫ— source operator е’ҢеҗҺ继зҡ„ operator й“ҫеңЁдёҖиө·пјҢдҪҶд№ҹдёҚиғҪдёҖе‘іжү©еӨ§ Kafka topic зҡ„ partitionпјҢеә”ж №жҚ®дёҡеҠЎйҮҸе’ҢжңәеҷЁиө„жәҗеҒҡеҘҪеҸ–иҲҚгҖӮжӣҙиҜҰз»Ҷзҡ„е…ідәҺ operator зҡ„ training е’Ң task slot зҡ„и°ғдјҳеҸҜд»ҘеҸӮиҖғ: \[4\]гҖӮ
### 3\. Flink дёӯжүҖйҖүз”ЁеәҸеҲ—еҢ–еҷЁзҡ„е»әи®®
еңЁдёҠдёҖиҠӮдёӯжҲ‘们зҹҘйҒ“пјҢFlink зҡ„еҲҶеёғеңЁдёҚеҗҢиҠӮзӮ№дёҠзҡ„ Task зҡ„ж•°жҚ®дј иҫ“еҝ…йЎ»з»ҸиҝҮеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–пјҢеӣ жӯӨеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–д№ҹжҳҜеҪұе“Қ Flink жҖ§иғҪзҡ„дёҖдёӘйҮҚиҰҒеӣ зҙ гҖӮFlink иҮӘжңүдёҖеҘ—зұ»еһӢдҪ“зі»пјҢеҚі Flink жңүиҮӘе·ұзҡ„зұ»еһӢжҸҸиҝ°зұ»пјҲTypeInformationпјүгҖӮFlink еёҢжңӣиғҪеӨҹжҺҢжҸЎе°ҪеҸҜиғҪеӨҡзҡ„иҝӣеҮә operator зҡ„ж•°жҚ®зұ»еһӢдҝЎжҒҜпјҢ并дҪҝз”Ё TypeInformation жқҘжҸҸиҝ°пјҢиҝҷж ·еҒҡдё»иҰҒжңүд»ҘдёӢ 2 дёӘеҺҹеӣ пјҡ
* зұ»еһӢдҝЎжҒҜзҹҘйҒ“зҡ„и¶ҠеӨҡпјҢFlink еҸҜд»ҘйҖүеҸ–жӣҙеҘҪзҡ„еәҸеҲ—еҢ–ж–№ејҸпјҢ并дҪҝеҫ— Flink еҜ№еҶ…еӯҳзҡ„дҪҝз”ЁжӣҙеҠ й«ҳж•Ҳпјӣ
* TypeInformation еҶ…йғЁе°ҒиЈ…дәҶиҮӘе·ұзҡ„еәҸеҲ—еҢ–еҷЁпјҢеҸҜйҖҡиҝҮ createSerializer() иҺ·еҸ–пјҢиҝҷж ·еҸҜд»Ҙи®©з”ЁжҲ·дёҚеҶҚж“ҚеҝғеәҸеҲ—еҢ–жЎҶжһ¶зҡ„дҪҝз”ЁпјҲдҫӢеҰӮеҰӮдҪ•е°Ҷ他们иҮӘе®ҡд№үзҡ„зұ»еһӢжіЁеҶҢеҲ°еәҸеҲ—еҢ–жЎҶжһ¶дёӯпјҢе°Ҫз®Ўз”ЁжҲ·зҡ„е®ҡеҲ¶еҢ–е’ҢжіЁеҶҢеҸҜд»ҘжҸҗй«ҳжҖ§иғҪпјүгҖӮ
жҖ»дҪ“дёҠжқҘиҜҙпјҢFlink жҺЁиҚҗжҲ‘们еңЁ operator й—ҙдј йҖ’зҡ„ж•°жҚ®жҳҜ POJOs зұ»еһӢпјҢеҜ№дәҺ POJOs зұ»еһӢпјҢFlink й»ҳи®ӨдјҡдҪҝз”Ё Flink иҮӘиә«зҡ„ PojoSerializer иҝӣиЎҢеәҸеҲ—еҢ–пјҢиҖҢеҜ№дәҺ Flink ж— жі•иҮӘе·ұжҸҸиҝ°жҲ–жҺЁж–ӯзҡ„ж•°жҚ®зұ»еһӢпјҢFlink дјҡе°Ҷе…¶иҜҶеҲ«дёә GenericTypeпјҢ并дҪҝз”Ё Kryo иҝӣиЎҢеәҸеҲ—еҢ–гҖӮFlink еңЁеӨ„зҗҶ POJOs ж—¶жӣҙй«ҳж•ҲпјҢжӯӨеӨ– POJOs зұ»еһӢдјҡдҪҝеҫ— stream зҡ„ grouping/joining/aggregating зӯүж“ҚдҪңеҸҳеҫ—з®ҖеҚ•пјҢеӣ дёәеҸҜд»ҘдҪҝз”ЁеҰӮ: dataSet.keyBy("username") иҝҷж ·зҡ„ж–№ејҸзӣҙжҺҘж“ҚдҪңж•°жҚ®жөҒдёӯзҡ„ж•°жҚ®еӯ—ж®өгҖӮ
йҷӨжӯӨд№ӢеӨ–пјҢжҲ‘们иҝҳеҸҜд»ҘеҒҡиҝӣдёҖжӯҘзҡ„дјҳеҢ–пјҡ
* жҳҫзӨәи°ғз”Ё returns ж–№жі•пјҢд»ҺиҖҢи§ҰеҸ‘ Flink зҡ„ Type Hintпјҡ
```
dataStream.flatMap(new MyOperator()).returns(MyClass.class)
```

returns ж–№жі•жңҖз»Ҳдјҡи°ғз”Ё TypeExtractor.createTypeInfo(typeClass) пјҢз”Ёд»Ҙжһ„е»әжҲ‘们иҮӘе®ҡд№үзҡ„зұ»еһӢзҡ„ TypeInformationгҖӮcreateTypeInfo ж–№жі•еңЁжһ„е»ә TypeInformation ж—¶пјҢеҰӮжһңжҲ‘们зҡ„зұ»еһӢж»Ўи¶і POJOs зҡ„规еҲҷжҲ– Flink дёӯе…¶д»–зҡ„еҹәжң¬зұ»еһӢзҡ„规еҲҷпјҢдјҡе°ҪеҸҜиғҪзҡ„е°ҶжҲ‘们зҡ„зұ»еһӢвҖңзҝ»иҜ‘вҖқжҲҗ Flink зҶҹзҹҘзҡ„зұ»еһӢеҰӮ POJOs зұ»еһӢжҲ–е…¶д»–еҹәжң¬зұ»еһӢпјҢдҫҝдәҺ Flink иҮӘиЎҢдҪҝз”Ёжӣҙй«ҳж•Ҳзҡ„еәҸеҲ—еҢ–ж–№ејҸгҖӮ
```
//org.apache.flink.api.java.typeutils.PojoTypeInfo
@Override
@PublicEvolving
@SuppressWarnings("unchecked")
public TypeSerializer<T> createSerializer(ExecutionConfig config) {
if (config.isForceKryoEnabled()) {
return new KryoSerializer<>(getTypeClass(), config);
}
if (config.isForceAvroEnabled()) {
return AvroUtils.getAvroUtils().createAvroSerializer(getTypeClass());
}
return createPojoSerializer(config);
}
```

еҜ№дәҺ Flink ж— жі•вҖңзҝ»иҜ‘вҖқзҡ„зұ»еһӢпјҢеҲҷиҝ”еӣһ GenericTypeInfoпјҢ并дҪҝз”Ё Kryo еәҸеҲ—еҢ–пјҡ
```
//org.apache.flink.api.java.typeutils.TypeExtractor
@SuppressWarnings({ "unchecked", "rawtypes" })
private <OUT,IN1,IN2> TypeInformation<OUT> privateGetForClass(Class<OUT> clazz, ArrayList<Type> typeHierarchy,
ParameterizedType parameterizedType, TypeInformation<IN1> in1Type, TypeInformation<IN2> in2Type) {
checkNotNull(clazz);
// е°қиҜ•е°Ҷ clazzиҪ¬жҚўдёә PrimitiveArrayTypeInfo, BasicArrayTypeInfo, ObjectArrayTypeInfo
// BasicTypeInfo, PojoTypeInfo зӯүпјҢе…·дҪ“жәҗз Ғе·ІзңҒз•Ҙ
//...
//еҰӮжһңдёҠиҝ°е°қиҜ•дёҚжҲҗеҠҹ , еҲҷreturn a generic type
return new GenericTypeInfo<OUT>(clazz);
}
```

* жіЁеҶҢ subtypes: йҖҡиҝҮ StreamExecutionEnvironment жҲ– ExecutionEnvironment зҡ„е®һдҫӢзҡ„ registerType(clazz) ж–№жі•жіЁеҶҢжҲ‘们зҡ„ж•°жҚ®зұ»еҸҠе…¶еӯҗзұ»гҖҒе…¶еӯ—ж®өзҡ„зұ»еһӢгҖӮеҰӮжһң Flink еҜ№зұ»еһӢзҹҘйҒ“зҡ„и¶ҠеӨҡпјҢжҖ§иғҪдјҡжӣҙеҘҪ
пјӣ
* еҰӮжһңиҝҳжғіеҒҡиҝӣдёҖжӯҘзҡ„дјҳеҢ–пјҢFlink иҝҳе…Ғи®ёз”ЁжҲ·жіЁеҶҢиҮӘе·ұе®ҡеҲ¶зҡ„еәҸеҲ—еҢ–еҷЁпјҢжүӢеҠЁеҲӣе»әиҮӘе·ұзұ»еһӢзҡ„ TypeInformationпјҢе…·дҪ“еҸҜд»ҘеҸӮиҖғ Flink е®ҳзҪ‘пјҡ\[3\]пјӣ
еңЁжҲ‘们зҡ„е®һи·өдёӯпјҢжңҖеҲқдёәдәҶжү©еұ•жҖ§пјҢеңЁ operator д№Ӣй—ҙдј йҖ’зҡ„ж•°жҚ®дёә JsonNodeпјҢдҪҶжҳҜжҲ‘们еҸ‘зҺ°жҖ§иғҪиҫҫдёҚеҲ°йў„жңҹпјҢеӣ жӯӨе°Ҷ JsonNode ж”№жҲҗдәҶз¬ҰеҗҲ POJOs 规иҢғзҡ„зұ»еһӢпјҢеңЁ 1.1.x зҡ„ Flink зүҲжң¬дёҠзӣҙжҺҘиҺ·еҫ—дәҶи¶…иҝҮ 30% зҡ„жҖ§иғҪжҸҗеҚҮгҖӮеңЁжҲ‘们и°ғз”ЁдәҶ Flink зҡ„ Type Hint е’Ң env.getConfig().enableForceAvro() еҗҺпјҢжҖ§иғҪеҫ—еҲ°иҝӣдёҖжӯҘжҸҗеҚҮгҖӮиҝҷдәӣж–№жі•дёҖзӣҙжІҝз”ЁеҲ°дәҶ 1.3.x зүҲжң¬гҖӮ
еңЁеҚҮзә§иҮі 1.7.x ж—¶пјҢеҰӮжһңдҪҝз”Ё env.getConfig().enableForceAvro() иҝҷдёӘй…ҚзҪ®пјҢжҲ‘们зҡ„д»Јз Ғдјҡеј•иө·ж ЎйӘҢз©әеӯ—ж®өзҡ„ејӮеёёгҖӮеӣ жӯӨжҲ‘们еҸ–ж¶ҲдәҶиҝҷдёӘй…ҚзҪ®пјҢ并е°қиҜ•дҪҝз”Ё Kyro иҝӣиЎҢеәҸеҲ—еҢ–пјҢ并且注еҶҢжҲ‘们зҡ„зұ»еһӢзҡ„жүҖжңүеӯҗзұ»еҲ° Flink зҡ„ ExecutionEnvironment дёӯпјҢзӣ®еүҚзңӢжҖ§иғҪе°ҡеҸҜпјҢ并дјҳдәҺж—§зүҲжң¬дҪҝз”Ё Avro зҡ„жҖ§иғҪгҖӮдҪҶжҳҜжңҖдҪіе®һи·өиҝҳйңҖиҰҒз»ҸиҝҮжҜ”иҫғе’ҢеҺӢжөӢ KryoSerializerAvroUtils.getAvroUtils().createAvroSerializerPojoSerializer жүҚиғҪжҖ»з»“еҮәжқҘпјҢеӨ§е®¶иҝҳжҳҜеә”иҜҘж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎеңәжҷҜе’Ңж•°жҚ®зұ»еһӢжқҘеҗҲзҗҶжҢ‘йҖүйҖӮеҗҲиҮӘе·ұзҡ„ serializerгҖӮ
### 4\. Standalone жЁЎејҸдёӢ job зҡ„ deploy дёҺиө„жәҗйҡ”зҰ»е…ұдә«
з»“еҗҲжҲ‘们д№ӢеүҚзҡ„дҪҝз”Ёз»ҸйӘҢпјҢFlink зҡ„ standalone cluster еңЁеҸ‘еёғе…·дҪ“зҡ„ job ж—¶пјҢдјҡжңүдёҖе®ҡзҡ„йҡҸжңәжҖ§гҖӮдёҫдёӘдҫӢеӯҗпјҢеҰӮжһңеҪ“еүҚйӣҶзҫӨжҖ»е…ұжңү 2 еҸ° 8 ж ёзҡ„жңәеҷЁз”Ёд»ҘйғЁзҪІ TaskManagerпјҢжҜҸеҸ°жңәеҷЁдёҠдёҖдёӘ TaskManager е®һдҫӢпјҢжҜҸдёӘ TaskManager зҡ„ TaskSlot дёә 8пјҢиҖҢжҲ‘们зҡ„ job зҡ„并иЎҢеәҰдёә 12пјҢйӮЈд№Ҳе°ұжңүеҸҜиғҪдјҡеҮәзҺ°дёӢеӣҫзҡ„зҺ°иұЎпјҡ
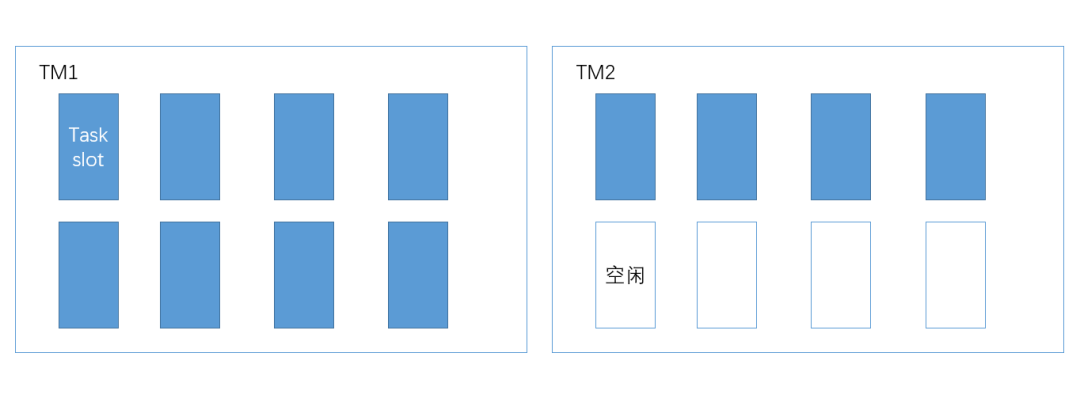
第дёҖдёӘ TaskManager зҡ„ slot е…Ёиў«еҚ ж»ЎпјҢиҖҢ第дәҢдёӘ TaskManager еҸӘдҪҝз”ЁдәҶдёҖеҚҠзҡ„иө„жәҗпјҒиө„жәҗдёҘйҮҚдёҚе№іиЎЎпјҢйҡҸзқҖ job еӨ„зҗҶзҡ„жөҒйҮҸеҠ еӨ§пјҢдёҖе®ҡдјҡйҖ жҲҗ TM1 дёҠзҡ„ task ж¶Ҳиҙ№йҖҹеәҰж…ўпјҢиҖҢ TM2 дёҠзҡ„ task ж¶Ҳиҙ№йҖҹеәҰиҝңй«ҳдәҺ TM1 зҡ„ task зҡ„жғ…еҶөгҖӮеҒҮи®ҫдёҡеҠЎйҮҸзҡ„еўһй•ҝиҝ«дҪҝжҲ‘们дёҚеҫ—дёҚжү©еӨ§ job зҡ„并иЎҢеәҰдёә 24пјҢ并且жү©е®№2еҸ°жҖ§иғҪжӣҙй«ҳзҡ„жңәеҷЁпјҲ12ж ёпјүпјҢеңЁж–°зҡ„жңәеҷЁдёҠпјҢжҲ‘们еҲҶеҲ«йғЁзҪІ slot ж•°дёә 12 зҡ„ TaskManagerгҖӮз»ҸиҝҮжү©е®№еҗҺпјҢйӣҶзҫӨзҡ„ TaskSlot зҡ„еҚ з”ЁеҸҜиғҪдјҡеҪўжҲҗдёӢеӣҫ:
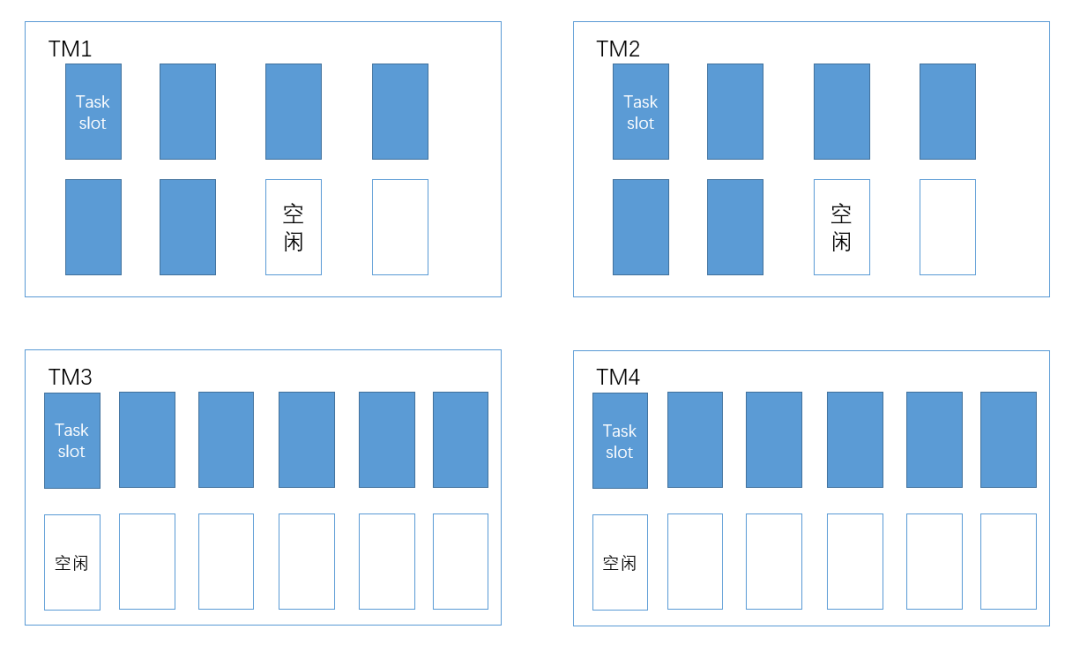
ж–°жү©е®№зҡ„й…ҚзҪ®й«ҳзҡ„жңәеҷЁе№¶жІЎжңүеҺ»жүҝжӢ…жӣҙеӨҡзҡ„ TaskпјҢиҖҒжңәеҷЁзҡ„иҙҹжӢ…д»Қ然жҜ”иҫғдёҘйҮҚпјҢиө„жәҗжң¬иҙЁдёҠиҝҳжҳҜдёҚеқҮеҢҖпјҒ
йҷӨдәҶ standalone cluster жЁЎејҸдёӢ job зҡ„еҸ‘еёғзӯ–з•ҘйҖ жҲҗдёҚеқҮиЎЎзҡ„жғ…еҶөеӨ–пјҢиҝҳжңүиө„жәҗйҡ”зҰ»е·®зҡ„й—®йўҳгҖӮеӣ дёәжҲ‘们еңЁдёҖдёӘ cluster дёӯеҫҖеҫҖдјҡйғЁзҪІдёҚжӯўдёҖдёӘ jobпјҢиҖҢиҝҷдәӣ job еңЁжҜҸеҸ°жңәеҷЁдёҠйғҪе…ұз”Ё JVMпјҢиҮӘ然дјҡйҖ жҲҗиө„жәҗзҡ„з«һдәүгҖӮиө·еҲқпјҢжҲ‘们дёәдәҶи§ЈеҶіиҝҷдәӣй—®йўҳпјҢйҮҮз”ЁдәҶеҰӮдёӢзҡ„и§ЈеҶіж–№жі•:
1. е°Ҷ TaskManager зҡ„зІ’еәҰеҸҳе°ҸпјҢеҚідёҖеҸ°жңәеҷЁйғЁзҪІеӨҡдёӘе®һдҫӢпјҢжҜҸдёӘе®һдҫӢжҢҒжңүзҡ„ slot ж•°иҫғе°‘пјӣ
2. е°ҶеӨ§зҡ„дёҡеҠЎ job йҡ”зҰ»еҲ°дёҚеҗҢзҡ„йӣҶзҫӨдёҠгҖӮ
иҝҷдәӣи§ЈеҶіж–№жі•еўһеҠ дәҶе®һдҫӢж•°е’ҢйӣҶзҫӨж•°пјҢиҝӣиҖҢеўһеҠ дәҶз»ҙжҠӨжҲҗжң¬гҖӮеӣ жӯӨжҲ‘们еҶіе®ҡиҰҒиҝҒ移еҲ° on yarn дёҠпјҢзӣ®еүҚзңӢ Flink on yarn зҡ„иө„жәҗеҲҶй…Қе’Ңиө„жәҗйҡ”зҰ»зЎ®е®һжҜ” standalone жЁЎејҸиҰҒдјҳз§ҖдёҖдәӣгҖӮ
еӣӣгҖҒжҖ»з»“дёҺеұ•жңӣ
-------
Flink еңЁ 2016 е№ҙж—¶д»…дёәжҳҹжҳҹд№ӢзҒ«пјҢиҖҢеҸӘз”ЁзҹӯзҹӯдёӨе№ҙзҡ„ж—¶й—ҙе°ұжҲҗй•ҝдёәдәҶеҪ“еүҚжңҖдёәзӮҷжүӢеҸҜзғӯзҡ„жөҒеӨ„зҗҶе№іеҸ°пјҢиҖҢдё”еӨ§жңүз»ҹдёҖжү№дёҺжөҒд№ӢеҠҝгҖӮз»ҸиҝҮдёӨе№ҙзҡ„е®һи·өпјҢFlink е·Із»ҸиҜҒжҳҺдәҶе®ғиғҪеӨҹжүҝжҺҘ TalkingData зҡ„ App Analytics е’Ң Game Analytics дёӨдёӘдә§е“Ғзҡ„жөҒеӨ„зҗҶйңҖжұӮгҖӮжҺҘдёӢжқҘжҲ‘们дјҡе°ҶжӣҙеӨҚжқӮзҡ„дёҡеҠЎе’Ңжү№еӨ„зҗҶиҝҒ移еҲ° Flink дёҠпјҢе®ҢжҲҗйӣҶзҫӨйғЁзҪІе’ҢжҠҖжңҜж Ҳзҡ„з»ҹдёҖпјҢжңҖз»Ҳе®һзҺ°еӣҫ 5 дёӯ Flink on yarn cluster зҡ„规еҲ’пјҢд»Ҙжӣҙе°‘зҡ„жҲҗжң¬жқҘж”Ҝж’‘жӣҙеӨ§зҡ„дёҡеҠЎйҮҸгҖӮ
[еҺҹж–Үй“ҫжҺҘ](https://yq.aliyun.com/articles/726224?utm_content=g_1000087748)
жң¬ж–Үдёәдә‘ж –зӨҫеҢәеҺҹеҲӣеҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
дёҖгҖҒиғҢжҷҜдёҺз—ӣзӮ№
-------
еңЁ 2017 е№ҙдёҠеҚҠе№ҙд»ҘеүҚпјҢTalkingData зҡ„ App Analytics е’Ң Game Analytics дёӨдёӘдә§е“ҒпјҢжөҒејҸжЎҶжһ¶дҪҝз”Ёзҡ„жҳҜиҮӘз ”зҡ„ td-etl-frameworkгҖӮиҜҘжЎҶжһ¶йҷҚдҪҺдәҶејҖеҸ‘жөҒејҸд»»еҠЎзҡ„еӨҚжқӮеәҰпјҢеҜ№дәҺдёҚеҗҢзҡ„д»»еҠЎеҸӘйңҖиҰҒе®һзҺ°дёҖдёӘ changer й“ҫеҚіеҸҜпјҢ并且ж”ҜжҢҒж°ҙе№іжү©еұ•пјҢжҖ§иғҪе°ҡеҸҜпјҢжӣҫз»ҸеҸҜд»Ҙж»Ўи¶ідёҡеҠЎйңҖжұӮгҖӮ
дҪҶжҳҜеҲ°дәҶ 2016 е№ҙеә•е’Ң 2017 е№ҙдёҠеҚҠе№ҙпјҢеҸ‘зҺ°иҝҷдёӘжЎҶжһ¶еӯҳеңЁд»ҘдёӢйҮҚиҰҒеұҖйҷҗпјҡ
1. **жҖ§иғҪйҡҗжӮЈ**пјҡApp Analytics-etl-adaptor е’Ң Game Analytics-etl-adaptor иҝҷдёӨдёӘжЁЎеқ—зӣёз»§еңЁиҠӮеҒҮж—ҘеҮәзҺ°дәҶдёҘйҮҚзҡ„жҖ§иғҪй—®йўҳпјҲFull-GC)пјҢеҜјиҮҙжҢҮж Ү计算延иҝҹгҖӮ
2. **жЎҶжһ¶зҡ„е®№й”ҷжңәеҲ¶дёҚи¶і**пјҡдҫқиө–дәҺдҝқеӯҳеңЁ Kafka жҲ– ZK дёҠзҡ„ offsetпјҢжңҖеӨҡеҸӘиғҪиҫҫеҲ° at-least-onceпјҢиҖҢйңҖиҰҒдҫқиө–е…¶д»–жңҚеҠЎдёҺеӯҳеӮЁжүҚиғҪе®һзҺ° exactly-onceпјҢ并且дјҡдә§з”ҹејӮеёёеҜјиҮҙйҮҚеҗҜдёўж•°гҖӮ
3. **жЎҶжһ¶зҡ„иЎЁиҫҫиғҪеҠӣдёҚи¶і**: дёҚиғҪе®Ңж•ҙзҡ„иЎЁиҫҫ DAG еӣҫпјҢеҜ№дәҺеӨҚжқӮзҡ„жөҒејҸеӨ„зҗҶй—®йўҳйңҖиҰҒиӢҘе№Ідҫқиө–иҜҘжЎҶжһ¶зҡ„иӢҘе№ІдёӘжңҚеҠЎз»„еҗҲеңЁдёҖиө·жүҚиғҪи§ЈеҶій—®йўҳгҖӮ
TalkingData иҝҷдёӨж¬ҫдә§е“Ғдё»иҰҒдёәеҗ„зұ»з§»еҠЁз«Ҝ App е’ҢжёёжҲҸжҸҗдҫӣж•°жҚ®еҲҶжһҗжңҚеҠЎпјҢйҡҸзқҖиҝ‘еҮ е№ҙдёҡеҠЎйҮҸдёҚж–ӯжү©еӨ§пјҢйңҖиҰҒйҖүжӢ©дёҖдёӘжҖ§иғҪжӣҙејәгҖҒеҠҹиғҪжӣҙе®Ңе–„зҡ„жөҒејҸеј•ж“ҺжқҘйҖҗжӯҘеҚҮзә§жҲ‘们зҡ„жөҒејҸжңҚеҠЎгҖӮи°ғз ”д»Һ 2016 е№ҙеә•ејҖе§ӢпјҢдё»иҰҒжҳҜд»Һ FlinkгҖҒHeronгҖҒSpark streaming дёӯдҪңйҖүжӢ©гҖӮ
жңҖз»ҲпјҢжҲ‘们йҖүжӢ©дәҶ FlinkпјҢдё»иҰҒеҹәдәҺд»ҘдёӢеҮ зӮ№иҖғиҷ‘пјҡ
1. Flink зҡ„е®№й”ҷжңәеҲ¶е®Ңе–„пјҢж”ҜжҢҒ Exactly-onceгҖӮ
2. Flink е·Із»ҸйӣҶжҲҗдәҶиҫғдё°еҜҢзҡ„ streaming operatorпјҢиҮӘе®ҡд№ү operator д№ҹиҫғдёәж–№дҫҝпјҢ并且еҸҜд»ҘзӣҙжҺҘи°ғз”Ё API е®ҢжҲҗ stream зҡ„ split е’Ң joinпјҢеҸҜд»Ҙе®Ңж•ҙзҡ„иЎЁиҫҫ DAG еӣҫгҖӮ
3. Flink иҮӘдё»е®һзҺ°еҶ…еӯҳз®ЎзҗҶиҖҢдёҚе®Ңе…Ёдҫқиө–дәҺ JVMпјҢеҸҜд»ҘеңЁдёҖе®ҡзЁӢеәҰдёҠйҒҝе…ҚеҪ“еүҚзҡ„ etl-framework зҡ„йғЁеҲҶжңҚеҠЎзҡ„ Full-GC й—®йўҳгҖӮ
4. Flink зҡ„ window жңәеҲ¶еҸҜд»Ҙи§ЈеҶіGAдёӯзұ»дјјдәҺеҚ•ж—ҘжёёжҲҸж—¶й•ҝжёёжҲҸж¬Ўж•°еҲҶеёғзӯүж—¶й—ҙж®өеҶ…жҹҗдёӘжҢҮж Үзҡ„еҲҶеёғзұ»й—®йўҳгҖӮ
5. Flink зҡ„зҗҶеҝөеңЁеҪ“ж—¶зҡ„жөҒејҸжЎҶжһ¶дёӯжңҖдёәи¶…еүҚ: е°Ҷжү№еҪ“дҪңжөҒзҡ„зү№дҫӢпјҢжңҖз»Ҳе®һзҺ°жү№жөҒз»ҹдёҖгҖӮ
дәҢгҖҒжј”иҝӣи·Ҝзәҝ
------
### 1\. standalone-cluster пјҲ1.1.3->1.1.5->1.3.2пјү
жҲ‘们жңҖејҖе§ӢжҳҜд»Ҙ standalone cluster зҡ„жЁЎејҸйғЁзҪІгҖӮд»Һ 2017 е№ҙдёҠеҚҠе№ҙејҖе§ӢпјҢжҲ‘们йҖҗжӯҘжҠҠ Game Analytics дёӯдёҖдәӣе°ҸжөҒйҮҸзҡ„ etl-job иҝҒ移еҲ° FlinkпјҢеҲ° 4 жңҲд»Ҫж—¶пјҢе·Із»Ҹе°Ҷдә§е“ҒжҺҘ收еҗ„зүҲжң¬ SDK ж•°жҚ®зҡ„ etl-job е®Ңе…ЁиҝҒ移иҮі FlinkпјҢ并ж•ҙеҗҲжҲҗдәҶдёҖдёӘ jobгҖӮеҪўжҲҗдәҶеҰӮдёӢзҡ„ж•°жҚ®жөҒе’Ң stream graphпјҡ

еӣҫ1. Game Analytics-etl-adaptor иҝҒ移иҮі Flink еҗҺзҡ„ж•°жҚ®жөҒеӣҫ

еӣҫ2. Game Analytics-etl зҡ„ stream graph
еңЁдёҠйқўзҡ„ж•°жҚ®жөҒеӣҫдёӯпјҢflink-job йҖҡиҝҮ Dubbo жқҘи°ғз”Ё etl-serviceпјҢд»ҺиҖҢе°Ҷи®ҝй—®еӨ–йғЁеӯҳеӮЁзҡ„йҖ»иҫ‘йғҪжҠҪиұЎеҲ°дәҶ etl-service дёӯпјҢflink-job еҲҷдёҚйңҖиҖғиҷ‘еӨҚжқӮзҡ„и®ҝеӯҳйҖ»иҫ‘д»ҘеҸҠеңЁ job дёӯиҮӘе»ә CacheпјҢиҝҷж ·ж—ўе®ҢжҲҗдәҶжңҚеҠЎзҡ„е…ұз”ЁпјҢеҸҲеҮҸиҪ»дәҶ job иҮӘиә«зҡ„ GC еҺӢеҠӣгҖӮ
жӯӨеӨ–жҲ‘们иҮӘжһ„е»әдәҶдёҖдёӘ monitor жңҚеҠЎпјҢеӣ дёәеҪ“ж—¶зҡ„ 1.1.3 зүҲжң¬зҡ„ Flink еҸҜжҸҗдҫӣзҡ„зӣ‘жҺ§ metric е°‘пјҢиҖҢдё”з”ұдәҺе…¶ Kafka-connector дҪҝз”Ёзҡ„жҳҜ Kafka08 зҡ„дҪҺйҳ¶ APIпјҢKafka зҡ„ж¶Ҳиҙ№ offset 并没жңүжҸҗдәӨзҡ„ ZK дёҠпјҢеӣ жӯӨжҲ‘们йңҖиҰҒжһ„е»әдёҖдёӘ monitor жқҘзӣ‘жҺ§ Flink зҡ„ job зҡ„жҙ»жҖ§гҖҒзһ¬ж—¶йҖҹеәҰгҖҒж¶Ҳиҙ№ж·Өз§Ҝзӯү metricпјҢ并жҺҘе…Ҙе…¬еҸё owl е®ҢжҲҗзӣ‘жҺ§е‘ҠиӯҰгҖӮ
иҝҷж—¶еҖҷпјҢFlink зҡ„ standalone cluster е·Із»ҸжүҝжҺҘдәҶжқҘиҮӘ Game Analytics зҡ„жүҖжңүжөҒйҮҸпјҢж—ҘеқҮеӨ„зҗҶж¶ҲжҒҜзәҰ 10 дәҝжқЎпјҢжҖ»еҗһеҗҗйҮҸиҫҫеҲ° 12 TB жҜҸж—ҘгҖӮеҲ°дәҶжҡ‘еҒҮзҡ„ж—¶еҖҷпјҢж—ҘеқҮж—Ҙеҝ—йҮҸдёҠеҚҮеҲ°дәҶ 18 дәҝжқЎжҜҸеӨ©пјҢеҗһеҗҗйҮҸиҫҫеҲ°дәҶзәҰ 20 TB жҜҸж—ҘпјҢTPS еі°еҖјдёә 3 дёҮгҖӮ
еңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢжҲ‘们еҸҲйҒҮеҲ°дәҶ Flink зҡ„ job ж¶Ҳиҙ№дёҚеқҮиЎЎгҖҒеңЁ standalone cluster дёҠ job зҡ„ deploy дёҚеқҮиЎЎзӯүй—®йўҳпјҢиҖҢйҖ жҲҗзәҝдёҠж¶Ҳиҙ№ж·Өз§ҜпјҢд»ҘеҸҠйӣҶзҫӨж— ж•…иҮӘеҠЁйҮҚеҗҜиҖҢиҮӘеҠЁйҮҚеҗҜеҗҺ job ж— жі•жҲҗеҠҹйҮҚеҗҜгҖӮпјҲжҲ‘们е°ҶеңЁз¬¬дёүз« дёӯиҜҰз»Ҷд»Ӣз»Қиҝҷдәӣй—®йўҳдёӯзҡ„е…ёеһӢиЎЁзҺ°еҸҠеҪ“ж—¶зҡ„и§ЈеҶіж–№жЎҲгҖӮпјү
з»ҸиҝҮдёҖдёӘжҡ‘еҒҮеҗҺпјҢжҲ‘们и®Өдёә Flink з»ҸеҸ—дәҶиҖғйӘҢпјҢеӣ жӯӨејҖе§Ӣе°Ҷ App Analytics зҡ„ etl-job д№ҹиҝҒ移еҲ° Flink дёҠгҖӮеҪўжҲҗдәҶеҰӮдёӢзҡ„ж•°жҚ®жөҒеӣҫпјҡ

еӣҫ3. App Analytics-etl-adaptor зҡ„ж ҮеҮҶ SDK еӨ„зҗҶе·ҘдҪңиҝҒ移еҲ° Flink еҗҺзҡ„ж•°жҚ®жөҒеӣҫ

еӣҫ4. App Analytics-etl-flink job зҡ„ stream graph
2017 е№ҙ 3 жңҲејҖе§ӢжңүеӨ§йҮҸз”ЁжҲ·ејҖе§ӢиҝҒ移иҮіз»ҹдёҖзҡ„ JSON SDKпјҢж–°зүҲ SDK зҡ„ Kafka topic зҡ„еі°еҖјжөҒйҮҸд»Һе№ҙдёӯзҡ„ 8 K/s дёҠж¶ЁиҮідәҶе№ҙеә•зҡ„ 3 W/sгҖӮжӯӨж—¶пјҢж•ҙдёӘ Flink standalone cluster дёҠдёҖе…ұйғЁзҪІдәҶдёӨж¬ҫдә§е“Ғзҡ„ 4 дёӘ jobпјҢж—ҘеқҮеҗһеҗҗйҮҸиҫҫеҲ°дәҶ 35 TBгҖӮ
иҝҷж—¶йҒҮеҲ°дәҶдёӨдёӘйқһеёёдёҘйҮҚзҡ„й—®йўҳпјҡ
* еҗҢдёҖдёӘ standalone cluster дёӯзҡ„ job зӣёдә’жҠўеҚ иө„жәҗпјҢиҖҢ standalone cluster зҡ„жЁЎејҸд»…д»…еҸӘиғҪйҖҡиҝҮ task slot еңЁ task manager зҡ„е ҶеҶ…еҶ…еӯҳдёҠеҒҡеҲ°иө„жәҗйҡ”зҰ»гҖӮеҗҢж—¶з”ұдәҺеүҚж–ҮжҸҗеҲ°иҝҮзҡ„ Flink еңЁ standalone cluster дёӯ deploy job зҡ„ж–№ејҸжң¬жқҘе°ұдјҡйҖ жҲҗиө„жәҗеҲҶй…ҚдёҚеқҮиЎЎпјҢд»ҺиҖҢдјҡеҜјиҮҙ App Analytics зәҝжөҒйҮҸеӨ§ж—¶иҖҢеј•иө·Game Analytics зәҝж·Өз§Ҝзҡ„й—®йўҳгҖӮ
* жҲ‘们зҡ„ source operator зҡ„并иЎҢеәҰзӯүеҗҢдәҺжүҖж¶Ҳиҙ№ Kafka topic зҡ„ partition ж•°йҮҸпјҢиҖҢдёӯй—ҙеҒҡ etl зҡ„ operator зҡ„并иЎҢеәҰеҫҖеҫҖдјҡиҝңеӨ§дәҺ Kafka зҡ„ partition ж•°йҮҸгҖӮеӣ жӯӨжңҖеҗҺзҡ„ job graph дёҚеҸҜиғҪе®Ңе…Ёиў«й“ҫжҲҗдёҖжқЎ operator chainпјҢoperator д№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“еҝ…йЎ»йҖҡиҝҮ Flink зҡ„ network buffer зҡ„з”іиҜ·е’ҢйҮҠж”ҫпјҢиҖҢ 1.1.x зүҲжң¬зҡ„ network buffer еңЁж•°жҚ®йҮҸеӨ§зҡ„ж—¶еҖҷеҫҲе®№жҳ“еңЁе…¶з”іиҜ·е’ҢйҮҠж”ҫж—¶йҖ жҲҗжӯ»й”ҒпјҢиҖҢеҜјиҮҙ Flink жҳҺжҳҺжңүи®ёеӨҡж¶ҲжҒҜиҰҒеӨ„зҗҶпјҢдҪҶжҳҜеӨ§йғЁеҲҶзәҝзЁӢеӨ„дәҺ waiting зҡ„зҠ¶жҖҒеҜјиҮҙдёҡеҠЎзҡ„еӨ§йҮҸ延иҝҹгҖӮ
иҝҷдәӣй—®йўҳйҖјиҝ«зқҖжҲ‘们дёҚеҫ—дёҚе°ҶдёӨж¬ҫдә§е“Ғзҡ„ job жӢҶеҲҶеҲ°дёӨдёӘ standalone cluster дёӯпјҢ并еҜ№ Flink еҒҡдёҖж¬ЎиҫғеӨ§зҡ„зүҲжң¬еҚҮзә§пјҢд»Һ 1.1.3пјҲдёӯй—ҙиҝҮеәҰеҲ° 1.1.5пјүеҚҮзә§жҲҗ 1.3.2гҖӮжңҖз»ҲеҚҮзә§иҮі 1.3.2 еңЁ 18 е№ҙзҡ„ Q1 е®ҢжҲҗпјҢ1.3.2 зүҲжң¬еј•е…ҘдәҶеўһйҮҸејҸзҡ„ checkpoint жҸҗдәӨ并且еңЁжҖ§иғҪе’ҢзЁіе®ҡжҖ§дёҠжҜ” 1.1.x зүҲжң¬еҒҡдәҶе·ЁеӨ§зҡ„ж”№иҝӣгҖӮеҚҮзә§д№ӢеҗҺпјҢFlink йӣҶзҫӨеҹәжң¬зЁіе®ҡпјҢе°Ҫз®Ўиҝҳжңүж¶Ҳиҙ№дёҚеқҮеҢҖзӯүй—®йўҳпјҢдҪҶжҳҜеҹәжң¬еҸҜд»ҘеңЁдёҡеҠЎйҮҸеўһеҠ ж—¶йҖҡиҝҮжү©е®№жңәеҷЁжқҘи§ЈеҶігҖӮ
### 2\. Flink on yarn (1.7.1)
еӣ дёә standalone cluster зҡ„иө„жәҗйҡ”зҰ»еҒҡзҡ„并дёҚдјҳз§ҖпјҢиҖҢдё”иҝҳжңү deploy job дёҚеқҮиЎЎзӯүй—®йўҳпјҢеҠ дёҠзӨҫеҢәдёҠдҪҝз”Ё Flink on yarn е·Із»ҸйқһеёёжҲҗзҶҹпјҢеӣ жӯӨжҲ‘们еңЁ 18 е№ҙзҡ„ Q4 е°ұејҖе§Ӣи®ЎеҲ’е°Ҷ Flink зҡ„ standalone cluster иҝҒ移иҮі Flink on yarn дёҠпјҢ并且 Flink еңЁжңҖиҝ‘зҡ„зүҲжң¬дёӯеҜ№дәҺ batch зҡ„жҸҗеҚҮиҫғеӨҡпјҢжҲ‘们иҝҳ规еҲ’йҖҗжӯҘдҪҝз”Ё Flink жқҘйҖҗжӯҘжӣҝжҚўзҺ°еңЁзҡ„жү№еӨ„зҗҶеј•ж“ҺгҖӮ

еӣҫ5. Flink on yarn cluster 规еҲ’
еҰӮеӣҫ 5пјҢжңӘжқҘзҡ„ Flink on yarn cluster е°ҶеҸҜд»Ҙе®ҢжҲҗжөҒејҸи®Ўз®—е’Ңжү№еӨ„зҗҶи®Ўз®—пјҢйӣҶзҫӨзҡ„дҪҝз”ЁиҖ…еҸҜд»ҘйҖҡиҝҮдёҖдёӘжһ„е»ә service жқҘе®ҢжҲҗ stream/batch job зҡ„жһ„е»әгҖҒдјҳеҢ–е’ҢжҸҗдәӨпјҢjob жҸҗдәӨеҗҺпјҢж №жҚ®дҪҝз”ЁиҖ…жүҖеңЁзҡ„дёҡеҠЎеӣўйҳҹеҸҠжңҚеҠЎе®ўжҲ·зҡ„дёҡеҠЎйҮҸеҲҶеҸ‘еҲ°дёҚеҗҢзҡ„ yarn йҳҹеҲ—дёӯпјҢжӯӨеӨ–пјҢйӣҶзҫӨйңҖиҰҒдёҖдёӘе®Ңе–„зҡ„зӣ‘жҺ§зі»з»ҹпјҢйҮҮйӣҶз”ЁжҲ·зҡ„жҸҗдәӨи®°еҪ•гҖҒеҗ„дёӘйҳҹеҲ—зҡ„жөҒйҮҸеҸҠиҙҹиҪҪгҖҒеҗ„дёӘ job зҡ„иҝҗиЎҢж—¶жҢҮж ҮзӯүзӯүпјҢ并жҺҘе…Ҙе…¬еҸёзҡ„ OWLгҖӮ
д»Һ 19 е№ҙзҡ„ Q1 ејҖе§ӢпјҢжҲ‘们е°Ҷ App Analytics зҡ„йғЁеҲҶ stream job иҝҒ移еҲ°дәҶ Flink on yarn 1.7 дёӯпјҢеҸҲеңЁ 19 е№ҙ Q2 еүҚе®ҢжҲҗдәҶ App Analytics жүҖжңүеӨ„зҗҶз»ҹдёҖ JSON SDK зҡ„жөҒд»»еҠЎиҝҒ移гҖӮеҪ“еүҚзҡ„ Flink on yarn йӣҶзҫӨзҡ„еі°еҖјеӨ„зҗҶзҡ„ж¶ҲжҒҜйҮҸиҫҫеҲ° 30 W/sпјҢж—ҘеқҮж—Ҙеҝ—еҗһеҗҗйҮҸиҫҫзәҰеҲ° 50 дәҝжқЎпјҢзәҰ 60 TBгҖӮеңЁ Flink иҝҒ移еҲ° on yarn д№ӢеҗҺпјҢеӣ дёәзүҲжң¬зҡ„еҚҮзә§жҖ§иғҪжңүжүҖжҸҗеҚҮпјҢдё” job д№Ӣй—ҙзҡ„иө„жәҗйҡ”зҰ»зЎ®е®һдјҳдәҺ standalone clusterгҖӮиҝҒ移еҗҺжҲ‘们дҪҝз”Ё Prometheus+Grafana зҡ„зӣ‘жҺ§ж–№жЎҲпјҢзӣ‘жҺ§жӣҙж–№дҫҝе’Ңзӣҙи§ӮгҖӮ
жҲ‘们е°ҶеңЁеҗҺз»ӯе°Ҷ Game Analytics зҡ„ Flink job е’Ңж—Ҙеҝ—еҜјеҮәзҡ„ job д№ҹиҝҒ移иҮіиҜҘ on yarn йӣҶзҫӨпјҢйў„и®ЎеҸҜд»ҘиҠӮзәҰ 1/4 зҡ„жңәеҷЁиө„жәҗгҖӮ
дёүгҖҒйҮҚзӮ№й—®йўҳзҡ„жҸҸиҝ°дёҺи§ЈеҶі
------------
еңЁ Flink е®һи·өзҡ„иҝҮзЁӢдёӯпјҢжҲ‘们дёҖи·ҜдёҠйҒҮеҲ°дәҶдёҚе°‘еқ‘пјҢжҲ‘们жҢ‘еҮәе…¶дёӯеҮ дёӘйҮҚзӮ№еқ‘еҒҡз®ҖиҰҒи®Іи§ЈгҖӮ
### 1\. е°‘з”ЁйқҷжҖҒеҸҳйҮҸеҸҠ job cancel ж—¶еҗҲзҗҶйҮҠж”ҫиө„жәҗ
еңЁжҲ‘们е®һзҺ° Flink зҡ„ operator зҡ„ function ж—¶пјҢдёҖиҲ¬йғҪеҸҜд»Ҙ继жүҝ AbstractRichFunctionпјҢе…¶е·ІжҸҗдҫӣз”ҹе‘Ҫе‘Ёжңҹж–№жі• open()/close()пјҢжүҖд»Ҙ operator дҫқиө–зҡ„иө„жәҗзҡ„еҲқе§ӢеҢ–е’ҢйҮҠж”ҫеә”иҜҘйҖҡиҝҮйҮҚеҶҷиҝҷдәӣж–№жі•жү§иЎҢгҖӮеҪ“жҲ‘们еҲқе§ӢеҢ–дёҖдәӣиө„жәҗпјҢеҰӮ spring contextгҖҒdubbo config ж—¶пјҢеә”иҜҘе°ҪеҸҜиғҪдҪҝз”ЁеҚ•дҫӢеҜ№иұЎжҢҒжңүиҝҷдәӣиө„жәҗдё”пјҲеңЁдёҖдёӘ TaskManager дёӯпјүеҸӘеҲқе§ӢеҢ– 1 ж¬ЎпјҢеҗҢж ·зҡ„пјҢжҲ‘们еңЁ close ж–№жі•дёӯеә”еҪ“пјҲеңЁдёҖдёӘ TaskManager дёӯпјүеҸӘйҮҠж”ҫдёҖж¬ЎгҖӮ
static зҡ„еҸҳйҮҸеә”иҜҘж…ҺйҮҚдҪҝз”ЁпјҢеҗҰеҲҷеҫҲе®№жҳ“еј•иө· job cancel иҖҢзӣёеә”зҡ„иө„жәҗжІЎжңүйҮҠж”ҫиҝӣиҖҢеҜјиҮҙ job йҮҚеҗҜйҒҮеҲ°й—®йўҳгҖӮ规йҒҝ static еҸҳйҮҸжқҘеҲқе§ӢеҢ–еҸҜд»ҘдҪҝз”Ё org.apache.flink.configuration.ConfigurationпјҲ1.3пјүжҲ–иҖ… org.apache.flink.api.java.utils.ParameterToolпјҲ1.7пјүжқҘдҝқеӯҳжҲ‘们зҡ„иө„жәҗй…ҚзҪ®пјҢ然еҗҺйҖҡиҝҮ ExecutionEnvironment жқҘеӯҳж”ҫпјҲJobжҸҗдәӨж—¶пјүе’ҢиҺ·еҸ–иҝҷдәӣй…ҚзҪ®пјҲJobиҝҗиЎҢж—¶пјүгҖӮ
**зӨәдҫӢд»Јз Ғпјҡ**
Flink 1.3 и®ҫзҪ®еҸҠжіЁеҶҢй…ҚзҪ®:
```
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration parameters = new Configuration();
parameters.setString("zkConnects", zkConnects);
parameters.setBoolean("debug", debug);
env.getConfig().setGlobalJobParameters(parameters);
```

иҺ·еҸ–й…ҚзҪ®пјҲеңЁ operator зҡ„ open ж–№жі•дёӯпјүгҖӮ
```
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ExecutionConfig.GlobalJobParameters globalParams = getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
Configuration globConf = (Configuration) globalParams;
debug = globConf.getBoolean("debug", false);
String zks = globConf.getString("zkConnects", "");
//.. do more ..
}
```

Flink 1.7 и®ҫзҪ®еҸҠжіЁеҶҢй…ҚзҪ®:
```
ParameterTool parameters = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(parameters);
```

иҺ·еҸ–й…ҚзҪ®:
```
public static final class Tokenizer extends RichFlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
ParameterTool parameters = (ParameterTool)
getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
parameters.getRequired("input");
// .. do more ..
```

### 2\. NetworkBuffer еҸҠ operator chain
еҰӮеүҚж–ҮжүҖиҝ°пјҢеҪ“ Flink зҡ„ job зҡ„дёҠдёӢжёё TaskпјҲзҡ„ subTaskпјүеҲҶеёғеңЁдёҚеҗҢзҡ„ TaskManager иҠӮзӮ№дёҠж—¶пјҲд№ҹе°ұжҳҜдёҠдёӢжёё operator жІЎжңү chained еңЁдёҖиө·пјҢдё”зӣёеҜ№еә”зҡ„ subTask еҲҶеёғеңЁдәҶдёҚеҗҢзҡ„ TaskManager иҠӮзӮ№дёҠпјүпјҢе°ұйңҖиҰҒеңЁ operator зҡ„ж•°жҚ®дј йҖ’ж—¶з”іиҜ·е’ҢйҮҠж”ҫ network buffer 并йҖҡиҝҮзҪ‘з»ң I/O дј йҖ’ж•°жҚ®гҖӮ
е…¶иҝҮзЁӢз®Җиҝ°еҰӮдёӢпјҡдёҠжёёзҡ„ operator дә§з”ҹзҡ„з»“жһңдјҡйҖҡиҝҮ RecordWriter еәҸеҲ—еҢ–пјҢ然еҗҺз”іиҜ· BufferPool дёӯзҡ„ Buffer 并е°ҶеәҸеҲ—еҢ–еҗҺзҡ„з»“жһңеҶҷе…Ҙ BufferпјҢжӯӨеҗҺ Buffer дјҡиў«еҠ е…Ҙ ResultPartition зҡ„ ResultSubPartition дёӯгҖӮResultSubPartition дёӯзҡ„ Buffer дјҡйҖҡиҝҮ Netty дј иҫ“иҮідёӢдёҖзә§зҡ„ operator зҡ„ InputGate зҡ„ InputChannel дёӯпјҢеҗҢж ·зҡ„пјҢBuffer иҝӣе…Ҙ InputChannel еүҚеҗҢж ·йңҖиҰҒеҲ°дёӢдёҖзә§ operator жүҖеңЁзҡ„ TaskManager зҡ„ BufferPool з”іиҜ·пјҢRecordReader иҜ»еҸ– Buffer 并е°Ҷе…¶дёӯзҡ„ж•°жҚ®еҸҚеәҸеҲ—еҢ–гҖӮBufferPool жҳҜжңүйҷҗзҡ„пјҢеңЁ BufferPool дёәз©әж—¶ RecordWriter / RecordReader жүҖеңЁзҡ„зәҝзЁӢдјҡеңЁз”іиҜ· Buffer зҡ„иҝҮзЁӢдёӯзӯүеҫ…дёҖж®өж—¶й—ҙпјҢе…·дҪ“еҺҹзҗҶеҸҜд»ҘеҸӮиҖғ:\[1\], \[2\]гҖӮ
з®ҖиҰҒжҲӘеӣҫеҰӮдёӢпјҡ

еӣҫ6. Flink зҡ„зҪ‘з»ңж Ҳ, е…¶дёӯ RP дёә ResultPartitionгҖҒRS дёә ResultSubPartitionгҖҒIG дёә InputGateгҖҒIC дёә inputChannel
еңЁдҪҝз”Ё Flink 1.1.x е’Ң 1.3.x зүҲжң¬ж—¶пјҢеҰӮжһңжҲ‘们зҡ„ network buffer зҡ„ж•°йҮҸй…ҚзҪ®зҡ„дёҚе……и¶ідё”ж•°жҚ®зҡ„еҗһеҗҗйҮҸеҸҳеӨ§зҡ„ж—¶еҖҷпјҢе°ұдјҡйҒҮеҲ°еҰӮдёӢзҺ°иұЎпјҡ

еӣҫ7. дёҠжёё operator йҳ»еЎһеңЁиҺ·еҸ– network buffer зҡ„ requestBuffer() ж–№жі•дёӯ

еӣҫ8. дёӢжёёзҡ„ operator йҳ»еЎһеңЁзӯүеҫ…ж–°ж•°жҚ®иҫ“е…Ҙ

еӣҫ9. дёӢжёёзҡ„ operator йҳ»еЎһеңЁзӯүеҫ…ж–°ж•°жҚ®иҫ“е…Ҙ
жҲ‘们зҡ„е·ҘдҪңзәҝзЁӢпјҲRecordWriter е’Ң RecordReader жүҖеңЁзҡ„зәҝзЁӢпјүзҡ„еӨ§йғЁеҲҶж—¶й—ҙйғҪиҠұеңЁдәҶеҗ‘ BufferPool з”іиҜ· Buffer дёҠпјҢиҝҷж—¶еҖҷ CPU зҡ„дҪҝз”ЁзҺҮдјҡеү§зғҲзҡ„жҠ–еҠЁпјҢдҪҝеҫ— Job зҡ„ж¶Ҳиҙ№йҖҹеәҰдёӢйҷҚпјҢеңЁ 1.1.x зүҲжң¬дёӯз”ҡиҮідјҡйҳ»еЎһеҫҲй•ҝзҡ„дёҖж®өж—¶й—ҙпјҢи§ҰеҸ‘ж•ҙдёӘ job зҡ„иғҢеҺӢпјҢд»ҺиҖҢйҖ жҲҗиҫғдёҘйҮҚзҡ„дёҡеҠЎе»¶иҝҹгҖӮ
иҝҷж—¶еҖҷпјҢжҲ‘们е°ұйңҖиҰҒйҖҡиҝҮдёҠдёӢжёё operator зҡ„并иЎҢеәҰжқҘи®Ўз®— ResultPartition е’Ң InputGate дёӯжүҖйңҖиҰҒзҡ„ buffer зҡ„дёӘж•°пјҢд»Ҙй…ҚзҪ®е……и¶ізҡ„ taskmanager.network.numberOfBuffersгҖӮ

еӣҫ10. дёҚеҗҢзҡ„ network buffer еҜ№ CPU дҪҝз”ЁзҺҮзҡ„еҪұе“Қ
еҪ“й…ҚзҪ®дәҶе……и¶ізҡ„ network buffer ж•°ж—¶пјҢCPU жҠ–еҠЁеҸҜд»ҘеҮҸе°‘пјҢJob ж¶Ҳиҙ№йҖҹеәҰжңүжүҖжҸҗй«ҳгҖӮ
еңЁ Flink 1.5 д№ӢеҗҺпјҢеңЁе…¶ network stack дёӯеј•е…ҘдәҶеҹәдәҺдҝЎз”ЁеәҰзҡ„жөҒйҮҸдј иҫ“жҺ§еҲ¶пјҲcredit-based flow controlпјүжңәеҲ¶\[2\]пјҢиҜҘжңәеҲ¶еӨ§йҷҗеәҰзҡ„йҒҝе…ҚдәҶеңЁеҗ‘ BufferPool з”іиҜ· Buffer зҡ„йҳ»еЎһзҺ°иұЎпјҢжҲ‘们еҲқжӯҘжөӢиҜ• 1.7 зҡ„ network stack зҡ„жҖ§иғҪзЎ®е®һжҜ” 1.3 иҰҒй«ҳгҖӮ
дҪҶиҝҷжҜ•з«ҹиҝҳдёҚжҳҜжңҖдјҳзҡ„жғ…еҶөпјҢеӣ дёәеҰӮжһңеҖҹеҠ© network buffer жқҘе®ҢжҲҗдёҠдёӢжёёзҡ„ operator зҡ„ж•°жҚ®дј йҖ’дёҚеҸҜд»ҘйҒҝе…Қзҡ„иҰҒз»ҸиҝҮеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–зҡ„иҝҮзЁӢпјҢиҖҢдё”дҝЎз”ЁеәҰзҡ„дҝЎжҒҜдј йҖ’жңүдёҖе®ҡзҡ„延иҝҹжҖ§е’ҢејҖй”ҖпјҢиҖҢиҝҷдёӘиҝҮзЁӢеҸҜд»ҘйҖҡиҝҮе°ҶдёҠдёӢжёёзҡ„ operator й“ҫжҲҗдёҖжқЎ operator chain иҖҢйҒҝе…ҚгҖӮ
еӣ жӯӨжҲ‘们еңЁжһ„е»әжҲ‘们жөҒд»»еҠЎзҡ„жү§иЎҢеӣҫж—¶пјҢеә”иҜҘе°ҪеҸҜиғҪеӨҡзҡ„и®© operator йғҪ chain еңЁдёҖиө·пјҢеңЁ Kafka иө„жәҗе…Ғи®ёзҡ„жғ…еҶөдёӢеҸҜд»Ҙжү©еӨ§ Kafka зҡ„ partition иҖҢдҪҝеҫ— source operator е’ҢеҗҺ继зҡ„ operator й“ҫеңЁдёҖиө·пјҢдҪҶд№ҹдёҚиғҪдёҖе‘іжү©еӨ§ Kafka topic зҡ„ partitionпјҢеә”ж №жҚ®дёҡеҠЎйҮҸе’ҢжңәеҷЁиө„жәҗеҒҡеҘҪеҸ–иҲҚгҖӮжӣҙиҜҰз»Ҷзҡ„е…ідәҺ operator зҡ„ training е’Ң task slot зҡ„и°ғдјҳеҸҜд»ҘеҸӮиҖғ: \[4\]гҖӮ
### 3\. Flink дёӯжүҖйҖүз”ЁеәҸеҲ—еҢ–еҷЁзҡ„е»әи®®
еңЁдёҠдёҖиҠӮдёӯжҲ‘们зҹҘйҒ“пјҢFlink зҡ„еҲҶеёғеңЁдёҚеҗҢиҠӮзӮ№дёҠзҡ„ Task зҡ„ж•°жҚ®дј иҫ“еҝ…йЎ»з»ҸиҝҮеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–пјҢеӣ жӯӨеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–д№ҹжҳҜеҪұе“Қ Flink жҖ§иғҪзҡ„дёҖдёӘйҮҚиҰҒеӣ зҙ гҖӮFlink иҮӘжңүдёҖеҘ—зұ»еһӢдҪ“зі»пјҢеҚі Flink жңүиҮӘе·ұзҡ„зұ»еһӢжҸҸиҝ°зұ»пјҲTypeInformationпјүгҖӮFlink еёҢжңӣиғҪеӨҹжҺҢжҸЎе°ҪеҸҜиғҪеӨҡзҡ„иҝӣеҮә operator зҡ„ж•°жҚ®зұ»еһӢдҝЎжҒҜпјҢ并дҪҝз”Ё TypeInformation жқҘжҸҸиҝ°пјҢиҝҷж ·еҒҡдё»иҰҒжңүд»ҘдёӢ 2 дёӘеҺҹеӣ пјҡ
* зұ»еһӢдҝЎжҒҜзҹҘйҒ“зҡ„и¶ҠеӨҡпјҢFlink еҸҜд»ҘйҖүеҸ–жӣҙеҘҪзҡ„еәҸеҲ—еҢ–ж–№ејҸпјҢ并дҪҝеҫ— Flink еҜ№еҶ…еӯҳзҡ„дҪҝз”ЁжӣҙеҠ й«ҳж•Ҳпјӣ
* TypeInformation еҶ…йғЁе°ҒиЈ…дәҶиҮӘе·ұзҡ„еәҸеҲ—еҢ–еҷЁпјҢеҸҜйҖҡиҝҮ createSerializer() иҺ·еҸ–пјҢиҝҷж ·еҸҜд»Ҙи®©з”ЁжҲ·дёҚеҶҚж“ҚеҝғеәҸеҲ—еҢ–жЎҶжһ¶зҡ„дҪҝз”ЁпјҲдҫӢеҰӮеҰӮдҪ•е°Ҷ他们иҮӘе®ҡд№үзҡ„зұ»еһӢжіЁеҶҢеҲ°еәҸеҲ—еҢ–жЎҶжһ¶дёӯпјҢе°Ҫз®Ўз”ЁжҲ·зҡ„е®ҡеҲ¶еҢ–е’ҢжіЁеҶҢеҸҜд»ҘжҸҗй«ҳжҖ§иғҪпјүгҖӮ
жҖ»дҪ“дёҠжқҘиҜҙпјҢFlink жҺЁиҚҗжҲ‘们еңЁ operator й—ҙдј йҖ’зҡ„ж•°жҚ®жҳҜ POJOs зұ»еһӢпјҢеҜ№дәҺ POJOs зұ»еһӢпјҢFlink й»ҳи®ӨдјҡдҪҝз”Ё Flink иҮӘиә«зҡ„ PojoSerializer иҝӣиЎҢеәҸеҲ—еҢ–пјҢиҖҢеҜ№дәҺ Flink ж— жі•иҮӘе·ұжҸҸиҝ°жҲ–жҺЁж–ӯзҡ„ж•°жҚ®зұ»еһӢпјҢFlink дјҡе°Ҷе…¶иҜҶеҲ«дёә GenericTypeпјҢ并дҪҝз”Ё Kryo иҝӣиЎҢеәҸеҲ—еҢ–гҖӮFlink еңЁеӨ„зҗҶ POJOs ж—¶жӣҙй«ҳж•ҲпјҢжӯӨеӨ– POJOs зұ»еһӢдјҡдҪҝеҫ— stream зҡ„ grouping/joining/aggregating зӯүж“ҚдҪңеҸҳеҫ—з®ҖеҚ•пјҢеӣ дёәеҸҜд»ҘдҪҝз”ЁеҰӮ: dataSet.keyBy("username") иҝҷж ·зҡ„ж–№ејҸзӣҙжҺҘж“ҚдҪңж•°жҚ®жөҒдёӯзҡ„ж•°жҚ®еӯ—ж®өгҖӮ
йҷӨжӯӨд№ӢеӨ–пјҢжҲ‘们иҝҳеҸҜд»ҘеҒҡиҝӣдёҖжӯҘзҡ„дјҳеҢ–пјҡ
* жҳҫзӨәи°ғз”Ё returns ж–№жі•пјҢд»ҺиҖҢи§ҰеҸ‘ Flink зҡ„ Type Hintпјҡ
```
dataStream.flatMap(new MyOperator()).returns(MyClass.class)
```

returns ж–№жі•жңҖз»Ҳдјҡи°ғз”Ё TypeExtractor.createTypeInfo(typeClass) пјҢз”Ёд»Ҙжһ„е»әжҲ‘们иҮӘе®ҡд№үзҡ„зұ»еһӢзҡ„ TypeInformationгҖӮcreateTypeInfo ж–№жі•еңЁжһ„е»ә TypeInformation ж—¶пјҢеҰӮжһңжҲ‘们зҡ„зұ»еһӢж»Ўи¶і POJOs зҡ„规еҲҷжҲ– Flink дёӯе…¶д»–зҡ„еҹәжң¬зұ»еһӢзҡ„规еҲҷпјҢдјҡе°ҪеҸҜиғҪзҡ„е°ҶжҲ‘们зҡ„зұ»еһӢвҖңзҝ»иҜ‘вҖқжҲҗ Flink зҶҹзҹҘзҡ„зұ»еһӢеҰӮ POJOs зұ»еһӢжҲ–е…¶д»–еҹәжң¬зұ»еһӢпјҢдҫҝдәҺ Flink иҮӘиЎҢдҪҝз”Ёжӣҙй«ҳж•Ҳзҡ„еәҸеҲ—еҢ–ж–№ејҸгҖӮ
```
//org.apache.flink.api.java.typeutils.PojoTypeInfo
@Override
@PublicEvolving
@SuppressWarnings("unchecked")
public TypeSerializer<T> createSerializer(ExecutionConfig config) {
if (config.isForceKryoEnabled()) {
return new KryoSerializer<>(getTypeClass(), config);
}
if (config.isForceAvroEnabled()) {
return AvroUtils.getAvroUtils().createAvroSerializer(getTypeClass());
}
return createPojoSerializer(config);
}
```

еҜ№дәҺ Flink ж— жі•вҖңзҝ»иҜ‘вҖқзҡ„зұ»еһӢпјҢеҲҷиҝ”еӣһ GenericTypeInfoпјҢ并дҪҝз”Ё Kryo еәҸеҲ—еҢ–пјҡ
```
//org.apache.flink.api.java.typeutils.TypeExtractor
@SuppressWarnings({ "unchecked", "rawtypes" })
private <OUT,IN1,IN2> TypeInformation<OUT> privateGetForClass(Class<OUT> clazz, ArrayList<Type> typeHierarchy,
ParameterizedType parameterizedType, TypeInformation<IN1> in1Type, TypeInformation<IN2> in2Type) {
checkNotNull(clazz);
// е°қиҜ•е°Ҷ clazzиҪ¬жҚўдёә PrimitiveArrayTypeInfo, BasicArrayTypeInfo, ObjectArrayTypeInfo
// BasicTypeInfo, PojoTypeInfo зӯүпјҢе…·дҪ“жәҗз Ғе·ІзңҒз•Ҙ
//...
//еҰӮжһңдёҠиҝ°е°қиҜ•дёҚжҲҗеҠҹ , еҲҷreturn a generic type
return new GenericTypeInfo<OUT>(clazz);
}
```

* жіЁеҶҢ subtypes: йҖҡиҝҮ StreamExecutionEnvironment жҲ– ExecutionEnvironment зҡ„е®һдҫӢзҡ„ registerType(clazz) ж–№жі•жіЁеҶҢжҲ‘们зҡ„ж•°жҚ®зұ»еҸҠе…¶еӯҗзұ»гҖҒе…¶еӯ—ж®өзҡ„зұ»еһӢгҖӮеҰӮжһң Flink еҜ№зұ»еһӢзҹҘйҒ“зҡ„и¶ҠеӨҡпјҢжҖ§иғҪдјҡжӣҙеҘҪ
пјӣ
* еҰӮжһңиҝҳжғіеҒҡиҝӣдёҖжӯҘзҡ„дјҳеҢ–пјҢFlink иҝҳе…Ғи®ёз”ЁжҲ·жіЁеҶҢиҮӘе·ұе®ҡеҲ¶зҡ„еәҸеҲ—еҢ–еҷЁпјҢжүӢеҠЁеҲӣе»әиҮӘе·ұзұ»еһӢзҡ„ TypeInformationпјҢе…·дҪ“еҸҜд»ҘеҸӮиҖғ Flink е®ҳзҪ‘пјҡ\[3\]пјӣ
еңЁжҲ‘们зҡ„е®һи·өдёӯпјҢжңҖеҲқдёәдәҶжү©еұ•жҖ§пјҢеңЁ operator д№Ӣй—ҙдј йҖ’зҡ„ж•°жҚ®дёә JsonNodeпјҢдҪҶжҳҜжҲ‘们еҸ‘зҺ°жҖ§иғҪиҫҫдёҚеҲ°йў„жңҹпјҢеӣ жӯӨе°Ҷ JsonNode ж”№жҲҗдәҶз¬ҰеҗҲ POJOs 规иҢғзҡ„зұ»еһӢпјҢеңЁ 1.1.x зҡ„ Flink зүҲжң¬дёҠзӣҙжҺҘиҺ·еҫ—дәҶи¶…иҝҮ 30% зҡ„жҖ§иғҪжҸҗеҚҮгҖӮеңЁжҲ‘们и°ғз”ЁдәҶ Flink зҡ„ Type Hint е’Ң env.getConfig().enableForceAvro() еҗҺпјҢжҖ§иғҪеҫ—еҲ°иҝӣдёҖжӯҘжҸҗеҚҮгҖӮиҝҷдәӣж–№жі•дёҖзӣҙжІҝз”ЁеҲ°дәҶ 1.3.x зүҲжң¬гҖӮ
еңЁеҚҮзә§иҮі 1.7.x ж—¶пјҢеҰӮжһңдҪҝз”Ё env.getConfig().enableForceAvro() иҝҷдёӘй…ҚзҪ®пјҢжҲ‘们зҡ„д»Јз Ғдјҡеј•иө·ж ЎйӘҢз©әеӯ—ж®өзҡ„ејӮеёёгҖӮеӣ жӯӨжҲ‘们еҸ–ж¶ҲдәҶиҝҷдёӘй…ҚзҪ®пјҢ并е°қиҜ•дҪҝз”Ё Kyro иҝӣиЎҢеәҸеҲ—еҢ–пјҢ并且注еҶҢжҲ‘们зҡ„зұ»еһӢзҡ„жүҖжңүеӯҗзұ»еҲ° Flink зҡ„ ExecutionEnvironment дёӯпјҢзӣ®еүҚзңӢжҖ§иғҪе°ҡеҸҜпјҢ并дјҳдәҺж—§зүҲжң¬дҪҝз”Ё Avro зҡ„жҖ§иғҪгҖӮдҪҶжҳҜжңҖдҪіе®һи·өиҝҳйңҖиҰҒз»ҸиҝҮжҜ”иҫғе’ҢеҺӢжөӢ KryoSerializerAvroUtils.getAvroUtils().createAvroSerializerPojoSerializer жүҚиғҪжҖ»з»“еҮәжқҘпјҢеӨ§е®¶иҝҳжҳҜеә”иҜҘж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎеңәжҷҜе’Ңж•°жҚ®зұ»еһӢжқҘеҗҲзҗҶжҢ‘йҖүйҖӮеҗҲиҮӘе·ұзҡ„ serializerгҖӮ
### 4\. Standalone жЁЎејҸдёӢ job зҡ„ deploy дёҺиө„жәҗйҡ”зҰ»е…ұдә«
з»“еҗҲжҲ‘们д№ӢеүҚзҡ„дҪҝз”Ёз»ҸйӘҢпјҢFlink зҡ„ standalone cluster еңЁеҸ‘еёғе…·дҪ“зҡ„ job ж—¶пјҢдјҡжңүдёҖе®ҡзҡ„йҡҸжңәжҖ§гҖӮдёҫдёӘдҫӢеӯҗпјҢеҰӮжһңеҪ“еүҚйӣҶзҫӨжҖ»е…ұжңү 2 еҸ° 8 ж ёзҡ„жңәеҷЁз”Ёд»ҘйғЁзҪІ TaskManagerпјҢжҜҸеҸ°жңәеҷЁдёҠдёҖдёӘ TaskManager е®һдҫӢпјҢжҜҸдёӘ TaskManager зҡ„ TaskSlot дёә 8пјҢиҖҢжҲ‘们зҡ„ job зҡ„并иЎҢеәҰдёә 12пјҢйӮЈд№Ҳе°ұжңүеҸҜиғҪдјҡеҮәзҺ°дёӢеӣҫзҡ„зҺ°иұЎпјҡ

第дёҖдёӘ TaskManager зҡ„ slot е…Ёиў«еҚ ж»ЎпјҢиҖҢ第дәҢдёӘ TaskManager еҸӘдҪҝз”ЁдәҶдёҖеҚҠзҡ„иө„жәҗпјҒиө„жәҗдёҘйҮҚдёҚе№іиЎЎпјҢйҡҸзқҖ job еӨ„зҗҶзҡ„жөҒйҮҸеҠ еӨ§пјҢдёҖе®ҡдјҡйҖ жҲҗ TM1 дёҠзҡ„ task ж¶Ҳиҙ№йҖҹеәҰж…ўпјҢиҖҢ TM2 дёҠзҡ„ task ж¶Ҳиҙ№йҖҹеәҰиҝңй«ҳдәҺ TM1 зҡ„ task зҡ„жғ…еҶөгҖӮеҒҮи®ҫдёҡеҠЎйҮҸзҡ„еўһй•ҝиҝ«дҪҝжҲ‘们дёҚеҫ—дёҚжү©еӨ§ job зҡ„并иЎҢеәҰдёә 24пјҢ并且жү©е®№2еҸ°жҖ§иғҪжӣҙй«ҳзҡ„жңәеҷЁпјҲ12ж ёпјүпјҢеңЁж–°зҡ„жңәеҷЁдёҠпјҢжҲ‘们еҲҶеҲ«йғЁзҪІ slot ж•°дёә 12 зҡ„ TaskManagerгҖӮз»ҸиҝҮжү©е®№еҗҺпјҢйӣҶзҫӨзҡ„ TaskSlot зҡ„еҚ з”ЁеҸҜиғҪдјҡеҪўжҲҗдёӢеӣҫ:

ж–°жү©е®№зҡ„й…ҚзҪ®й«ҳзҡ„жңәеҷЁе№¶жІЎжңүеҺ»жүҝжӢ…жӣҙеӨҡзҡ„ TaskпјҢиҖҒжңәеҷЁзҡ„иҙҹжӢ…д»Қ然жҜ”иҫғдёҘйҮҚпјҢиө„жәҗжң¬иҙЁдёҠиҝҳжҳҜдёҚеқҮеҢҖпјҒ
йҷӨдәҶ standalone cluster жЁЎејҸдёӢ job зҡ„еҸ‘еёғзӯ–з•ҘйҖ жҲҗдёҚеқҮиЎЎзҡ„жғ…еҶөеӨ–пјҢиҝҳжңүиө„жәҗйҡ”зҰ»е·®зҡ„й—®йўҳгҖӮеӣ дёәжҲ‘们еңЁдёҖдёӘ cluster дёӯеҫҖеҫҖдјҡйғЁзҪІдёҚжӯўдёҖдёӘ jobпјҢиҖҢиҝҷдәӣ job еңЁжҜҸеҸ°жңәеҷЁдёҠйғҪе…ұз”Ё JVMпјҢиҮӘ然дјҡйҖ жҲҗиө„жәҗзҡ„з«һдәүгҖӮиө·еҲқпјҢжҲ‘们дёәдәҶи§ЈеҶіиҝҷдәӣй—®йўҳпјҢйҮҮз”ЁдәҶеҰӮдёӢзҡ„и§ЈеҶіж–№жі•:
1. е°Ҷ TaskManager зҡ„зІ’еәҰеҸҳе°ҸпјҢеҚідёҖеҸ°жңәеҷЁйғЁзҪІеӨҡдёӘе®һдҫӢпјҢжҜҸдёӘе®һдҫӢжҢҒжңүзҡ„ slot ж•°иҫғе°‘пјӣ
2. е°ҶеӨ§зҡ„дёҡеҠЎ job йҡ”зҰ»еҲ°дёҚеҗҢзҡ„йӣҶзҫӨдёҠгҖӮ
иҝҷдәӣи§ЈеҶіж–№жі•еўһеҠ дәҶе®һдҫӢж•°е’ҢйӣҶзҫӨж•°пјҢиҝӣиҖҢеўһеҠ дәҶз»ҙжҠӨжҲҗжң¬гҖӮеӣ жӯӨжҲ‘们еҶіе®ҡиҰҒиҝҒ移еҲ° on yarn дёҠпјҢзӣ®еүҚзңӢ Flink on yarn зҡ„иө„жәҗеҲҶй…Қе’Ңиө„жәҗйҡ”зҰ»зЎ®е®һжҜ” standalone жЁЎејҸиҰҒдјҳз§ҖдёҖдәӣгҖӮ
еӣӣгҖҒжҖ»з»“дёҺеұ•жңӣ
-------
Flink еңЁ 2016 е№ҙж—¶д»…дёәжҳҹжҳҹд№ӢзҒ«пјҢиҖҢеҸӘз”ЁзҹӯзҹӯдёӨе№ҙзҡ„ж—¶й—ҙе°ұжҲҗй•ҝдёәдәҶеҪ“еүҚжңҖдёәзӮҷжүӢеҸҜзғӯзҡ„жөҒеӨ„зҗҶе№іеҸ°пјҢиҖҢдё”еӨ§жңүз»ҹдёҖжү№дёҺжөҒд№ӢеҠҝгҖӮз»ҸиҝҮдёӨе№ҙзҡ„е®һи·өпјҢFlink е·Із»ҸиҜҒжҳҺдәҶе®ғиғҪеӨҹжүҝжҺҘ TalkingData зҡ„ App Analytics е’Ң Game Analytics дёӨдёӘдә§е“Ғзҡ„жөҒеӨ„зҗҶйңҖжұӮгҖӮжҺҘдёӢжқҘжҲ‘们дјҡе°ҶжӣҙеӨҚжқӮзҡ„дёҡеҠЎе’Ңжү№еӨ„зҗҶиҝҒ移еҲ° Flink дёҠпјҢе®ҢжҲҗйӣҶзҫӨйғЁзҪІе’ҢжҠҖжңҜж Ҳзҡ„з»ҹдёҖпјҢжңҖз»Ҳе®һзҺ°еӣҫ 5 дёӯ Flink on yarn cluster зҡ„规еҲ’пјҢд»Ҙжӣҙе°‘зҡ„жҲҗжң¬жқҘж”Ҝж’‘жӣҙеӨ§зҡ„дёҡеҠЎйҮҸгҖӮ
[еҺҹж–Үй“ҫжҺҘ](https://yq.aliyun.com/articles/726224?utm_content=g_1000087748)
жң¬ж–Үдёәдә‘ж –зӨҫеҢәеҺҹеҲӣеҶ…е®№пјҢжңӘз»Ҹе…Ғи®ёдёҚеҫ—иҪ¬иҪҪгҖӮ
еҲҶдә«еҲ°пјҡ


- 2019-11-15 15:22
- жөҸи§Ҳ 427
- иҜ„и®ә(0)
- еҲҶзұ»:йқһжҠҖжңҜ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
Apache Pulsar е’Ң Apache Flink жҳҜдёӨдёӘеңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹдёӯе№ҝжіӣеә”з”Ёзҡ„ејҖжәҗйЎ№зӣ®гҖӮApache Pulsar жҳҜдёҖдёӘе…Ҳиҝӣзҡ„гҖҒеҲҶеёғејҸзҡ„ж¶ҲжҒҜдј йҖ’зі»з»ҹпјҢиҖҢ Apache Flink жҳҜдёҖдёӘејәеӨ§зҡ„жөҒеӨ„зҗҶе’Ңжү№еӨ„зҗҶеј•ж“ҺгҖӮиҝҷзҜҮж–ҮжЎЈи®Ёи®әдәҶеҰӮдҪ•з»“еҗҲиҝҷдёӨдёӘ...
гҖҗJStormеҲ°Apache Flinkзҡ„иҝҒ移е®һи·өгҖ‘ еңЁе®һж—¶ж•°д»“йўҶеҹҹпјҢеӯ—иҠӮи·іеҠЁе…¬еҸёд»ҺJStormиҝҒ移еҲ°Apache Flinkзҡ„еҶізӯ–иғҢеҗҺжңүзқҖдёҖзі»еҲ—зҡ„еҺҹеӣ е’ҢжҢ‘жҲҳгҖӮJStormеңЁеӯ—иҠӮи·іеҠЁзҡ„дёҡеҠЎжһ¶жһ„дёӯжү®жј”дәҶйҮҚиҰҒи§’иүІпјҢзү№еҲ«жҳҜеңЁе№ҝе‘ҠгҖҒABжөӢиҜ•гҖҒжҺЁйҖҒд»ҘеҸҠ...
Apache FlinkжҳҜдёҖдёӘејәеӨ§зҡ„ејҖжәҗжөҒеӨ„зҗҶжЎҶжһ¶пјҢдё»иҰҒз”ЁдәҺе®һж—¶ж•°жҚ®еӨ„зҗҶе’Ңжү№еӨ„зҗҶгҖӮFlinkзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜй«ҳж•ҲгҖҒдҪҺ延иҝҹең°еӨ„зҗҶж— з•Ңе’Ңжңүз•Ңж•°жҚ®жөҒгҖӮеңЁv1.9зүҲжң¬дёӯпјҢе®ғжҸҗдҫӣдәҶдёҖзі»еҲ—зҡ„еҠҹиғҪе’ҢдјҳеҢ–пјҢдҪҝе…¶еңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹжӣҙеҠ жҲҗзҶҹе’ҢеҸҜйқ ...
еӯ—иҠӮи·іеҠЁ Jstorm еҲ° Apache Flink зҡ„иҝҒ移е®һи·ө...............................................20 Apache Flink еңЁзҫҺеӣўзҡ„е®һи·өдёҺеә”з”Ё ....................................................................32 ...
жҖ»д№ӢпјҢApache Flink 1.9дёҺHiveзҡ„е…је®№жҖ§жҳҜеӨ§ж•°жҚ®з”ҹжҖҒзі»з»ҹдёӯзҡ„дёҖдёӘйҮҚиҰҒйҮҢзЁӢзў‘пјҢе®ғдҪҝеҫ—з”ЁжҲ·иғҪеӨҹеңЁз»ҹдёҖзҡ„е№іеҸ°дёҠе®ҢжҲҗе®һж—¶е’ҢзҰ»зәҝж•°жҚ®еҲҶжһҗпјҢжҸҗеҚҮдәҶж•ҙдҪ“зҡ„ж•°жҚ®еӨ„зҗҶиғҪеҠӣгҖӮеҗҢж—¶пјҢFlinkдёҚж–ӯжј”иҝӣзҡ„зү№жҖ§пјҢеҰӮдјҳеҢ–зҡ„SQLж”ҜжҢҒе’Ңеўһејәзҡ„...
жң¬ж–Үдё»иҰҒи®°еҪ•дёҖдәӣе…ідәҺFlink... stormжҳҜеҹәдәҺжөҒи®Ўз®—зҡ„, дҪҶжҳҜд№ҹеҸҜд»ҘжЁЎжӢҹжү№еӨ„зҗҶ, spark streamingд№ҹеҸҜд»ҘиҝӣиЎҢеҫ®жү№еӨ„зҗҶ, иҷҪиҜҙеңЁжҖ§иғҪ延иҝҹдёҠеӨ„дәҺдәҡз§’зә§еҲ«, дҪҶд№ҹдёҚи¶ід»ҘиҜҙжҳҺFlinkеҙӣиө·еҰӮжӯӨиҝ…йҖҹ(жҜ•з«ҹд»ҺsparkиҝҒ移еҲ°FlinkжҳҜиҰҒжҲҗжң¬зҡ„).
Apache FlinkжҳҜдёҖдёӘејҖжәҗзҡ„жөҒеӨ„зҗҶжЎҶжһ¶пјҢдё»иҰҒз”ЁдәҺеӨ„зҗҶж— з•Ңе’Ңжңүз•Ңж•°жҚ®жөҒгҖӮе…¶ж ёеҝғжҳҜжөҒеӨ„зҗҶеј•ж“ҺпјҢжҸҗдҫӣдәҶж•°жҚ®жөҒеӨ„зҗҶе’ҢдәӢ件时й—ҙеӨ„зҗҶзҡ„иғҪеҠӣгҖӮдёәдәҶзЎ®дҝқеңЁеҲҶеёғејҸзі»з»ҹдёӯзҡ„й«ҳеҸҜз”ЁжҖ§пјҲHAпјүпјҢеҚіеңЁйҒҮеҲ°ж•…йҡңж—¶д»ҚиғҪжҸҗдҫӣдёҚй—ҙж–ӯзҡ„жңҚеҠЎпјҢ...
Apache Flink жҳҜдёҖж¬ҫејҖжәҗжөҒеӨ„зҗҶжЎҶжһ¶пјҢз”ЁдәҺеӨ„зҗҶе’ҢеҲҶжһҗж•°жҚ®жөҒгҖӮе®ғе…·жңүй«ҳеәҰзҡ„дјёзј©жҖ§гҖҒй«ҳжҖ§иғҪе’ҢдәӢ件时й—ҙеӨ„зҗҶиғҪеҠӣгҖӮFlink йҖӮеҗҲиҝӣиЎҢе®һж—¶ж•°жҚ®еҲҶжһҗпјҢеҗҢж—¶д№ҹж”ҜжҢҒеӨҚжқӮдәӢ件еӨ„зҗҶе’Ңжү№йҮҸж•°жҚ®еӨ„зҗҶгҖӮе®ғзҡ„зү№зӮ№еҢ…жӢ¬еӨ„зҗҶж— з•Ңе’Ңжңүз•Ңж•°жҚ®...
ж Үйўҳдёӯзҡ„вҖңflinkзЁӢеәҸпјҢstormд»Јз Ғзҡ„иҝҒ移вҖқжҢҮзҡ„жҳҜеңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹдёӯпјҢе°ҶеҹәдәҺApache Stormзҡ„еә”з”ЁзЁӢеәҸиҪ¬жҚўдёәдҪҝз”ЁApache FlinkиҝӣиЎҢжү§иЎҢзҡ„иҝҮзЁӢгҖӮиҝҷйҖҡеёёжҳҜеӣ дёәFlinkжҸҗдҫӣдәҶжӣҙејәзҡ„жҖ§иғҪгҖҒжӣҙдҪҺзҡ„延иҝҹд»ҘеҸҠжӣҙдё°еҜҢзҡ„еҠҹиғҪпјҢдҪҝеҫ—е®ғ...
Apache Flink зҡ„еұ•жңӣеҢ…жӢ¬е°Ҹж—¶зә§ ETLгҖҒе®һж—¶еҢ–зҡ„иҜүжұӮгҖҒзҰ»зәҝеҲ°е®һж—¶зҡ„е№іж»‘иҝҒ移зӯүгҖӮ дә”гҖҒFlink SQL зј–зЁӢзӨәдҫӢ Flink SQL зј–зЁӢзӨәдҫӢеҢ…жӢ¬дҪҝз”Ё Flink SQL иҝӣиЎҢж•°жҚ®еӨ„зҗҶе’ҢеҲҶжһҗзҡ„зӨәдҫӢд»Јз ҒгҖӮзӨәдҫӢд»Јз ҒеҢ…жӢ¬иҝһжҺҘ KafkaгҖҒжіЁеҶҢиЎЁж ј...
1. DataStream APIпјҡFlinkзҡ„дё»иҰҒзј–зЁӢжҺҘеҸЈд№ӢдёҖпјҢз”ЁдәҺеӨ„зҗҶж— з•Ңе’Ңжңүз•Ңж•°жҚ®жөҒгҖӮDataStream APIж”ҜжҢҒдәӢ件时й—ҙгҖҒеӨ„зҗҶж—¶й—ҙе’Ңзі»з»ҹж—¶й—ҙпјҢжҸҗдҫӣдәҶдё°еҜҢзҡ„з®—еӯҗиҝӣиЎҢж•°жҚ®иҪ¬жҚўгҖӮ 2. JobManagerдёҺTaskManagerпјҡFlinkзҡ„еҲҶеёғејҸжһ¶жһ„еҢ…еҗ«...
Apache FlinkжҳҜдёҖдёӘејҖжәҗзҡ„жөҒеӨ„зҗҶжЎҶжһ¶пјҢз”ұеҫ·еӣҪжҹҸжһ—е·ҘдёҡеӨ§еӯҰзҡ„дёҖзҫӨеҚҡеЈ«з”ҹе’Ңз ”з©¶з”ҹеҸ‘иө·пјҢжңҖеҲқеҗҚдёәStratosphereпјҢ2014е№ҙејҖжәҗ并жӣҙеҗҚдёәFlinkгҖӮFlinkд»Ҙе…¶еңЁжөҒеӨ„зҗҶж–№йқўзҡ„й«ҳжҖ§иғҪе’ҢеҸҜйқ жҖ§иҺ·еҫ—дәҶеҝ«йҖҹеҸ‘еұ•пјҢжҲҗдёәеӨ§ж•°жҚ®е’ҢHadoop...
Apache FlinkпјҢдҪңдёәдёҡз•Ңе…¬и®Өзҡ„йЎ¶зә§жөҒи®Ўз®—еј•ж“ҺпјҢе…¶и®Ўз®—иғҪеҠӣдёҚд»…йҷҗдәҺжөҒеӨ„зҗҶгҖӮе®һйҷ…дёҠпјҢApache Flinkиў«е®ҡдҪҚдёәдёҖдёӘеӨҡеҠҹиғҪзҡ„еӨ§ж•°жҚ®еј•ж“ҺпјҢйӣҶжҲҗдәҶжөҒеӨ„зҗҶгҖҒжү№еӨ„зҗҶд»ҘеҸҠжңәеҷЁеӯҰд№ зӯүеӨҡз§Қи®Ўз®—еҠҹиғҪгҖӮ еңЁжң¬еҗҲйӣҶдёӯпјҢжӮЁе°Ҷж·ұе…ҘдәҶи§Јд»ҘдёӢ...
жҖ»з»“жқҘиҜҙпјҢApache Flink 1.14.2жҳҜдёҖдёӘеҠҹиғҪејәеӨ§гҖҒжҖ§иғҪдјҳи¶Ҡзҡ„жөҒеӨ„зҗҶе’Ңжү№еӨ„зҗҶжЎҶжһ¶пјҢе…¶дё°еҜҢзҡ„APIгҖҒејәеӨ§зҡ„е®№й”ҷжңәеҲ¶д»ҘеҸҠеҜ№еӨҡз§ҚзҺҜеўғзҡ„йҖӮй…ҚпјҢдҪҝе…¶жҲҗдёәеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹзҡ„йҰ–йҖүе·Ҙе…·д№ӢдёҖгҖӮж— и®әжҳҜе®һж—¶жөҒж•°жҚ®зҡ„еӨ„зҗҶпјҢиҝҳжҳҜзҰ»зәҝжү№еӨ„зҗҶ...
- **е…¶д»–дјҳеҢ–**пјҡдә¬дёңиҝҳиҝӣиЎҢдәҶHDFSе°Ҹж–Ү件еҗҲ并гҖҒйҷҚдҪҺRPCи°ғз”ЁгҖҒжң¬ең°ж–Ү件系з»ҹиҜ»еҶҷдјҳеҢ–д»ҘеҸҠZKзӯүеӨҡж–№йқўзҡ„жҖ§иғҪжҸҗеҚҮе’ҢзЁіе®ҡжҖ§еўһејәжҺӘж–ҪпјҢиҝӣдёҖжӯҘжҸҗй«ҳдәҶFlinkеңЁе®һйҷ…дёҡеҠЎдёӯзҡ„еә”з”Ёж•ҲжһңгҖӮ з»јдёҠжүҖиҝ°пјҢApache FlinkеңЁдә¬дёңзҡ„еә”з”Ё...
Apache FlinkжҳҜдёҖдёӘжөҒиЎҢзҡ„ејҖжәҗжөҒеӨ„зҗҶе’Ңжү№еӨ„зҗҶжЎҶжһ¶пјҢдё»иҰҒз”ЁдәҺе®һж—¶ж•°жҚ®еӨ„зҗҶе’ҢеҲҶжһҗгҖӮеңЁиҝҷдёӘеңәжҷҜдёӯпјҢжҲ‘们关注зҡ„жҳҜFlinkзҡ„1.15.0зүҲжң¬пјҢе®ғзү№еҲ«й’ҲеҜ№Scala 2.12иҝӣиЎҢдәҶзј–иҜ‘пјҢиҝҷж„Ҹе‘ізқҖе®ғдёҺиҝҷдёӘзү№е®ҡзҡ„ScalaзүҲжң¬е…је®№гҖӮFlink ...
иҝҷе°Ҷеё®еҠ©д»–们жӣҙеҘҪең°зҗҶи§Је’Ңеә”з”ЁApache Flink SQLпјҢи§ЈеҶіе®һйҷ…йЎ№зӣ®дёӯзҡ„й—®йўҳпјҢ并жҸҗеҚҮж•°жҚ®еҲҶжһҗе’ҢеӨ„зҗҶиғҪеҠӣгҖӮ жҖ»зҡ„жқҘиҜҙпјҢApache Flink SQL CookbookжҳҜдёҖдёӘж·ұе…ҘеӯҰд№ Flink SQLзҡ„е®қиҙөиө„жәҗпјҢе®ғжҸҗдҫӣзҡ„зӨәдҫӢиҰҶзӣ–дәҶд»ҺеҹәзЎҖеҲ°й«ҳзә§зҡ„...
Apache FlinkдҪңдёәдёҖдёӘејәеӨ§зҡ„ејҖжәҗжөҒеӨ„зҗҶжЎҶжһ¶пјҢжҸҗдҫӣдәҶдё°еҜҢзҡ„иҝһжҺҘеҷЁжқҘе®һзҺ°еҗ„з§Қж•°жҚ®жәҗдёҺж•°жҚ®жҺҘ收方д№Ӣй—ҙзҡ„ж•°жҚ®иҝҒ移гҖӮжң¬иҜқйўҳе°ҶиҜҰз»Ҷи®Іи§ЈеҰӮдҪ•еҲ©з”ЁFlinkзҡ„SQL Server Change Data Capture (CDC) иҝһжҺҘеҷЁзүҲжң¬2.3.0пјҢе°ҶSQL ...
еңЁITиЎҢдёҡдёӯпјҢеӨ§ж•°жҚ®еӨ„зҗҶе’ҢеҲҶжһҗжҳҜиҮіе…ійҮҚиҰҒзҡ„зҺҜиҠӮпјҢиҖҢCloudera Data Hub (CDH) е’Ң Apache Flink жҳҜдёӨдёӘеңЁиҜҘйўҶеҹҹе№ҝжіӣдҪҝз”Ёзҡ„ејҖжәҗе·Ҙе…·гҖӮCDH жҳҜдёҖдёӘе…Ёйқўзҡ„еӨ§ж•°жҚ®е№іеҸ°пјҢйӣҶжҲҗдәҶеӨҡдёӘејҖжәҗйЎ№зӣ®пјҢеҰӮ HadoopгҖҒSparkгҖҒHive зӯүпјҢ...
Apache FlinkжҳҜдёҖдёӘејҖжәҗзҡ„жөҒеӨ„зҗҶжЎҶжһ¶пјҢз”ЁдәҺеңЁй«ҳеәҰеҲҶеёғејҸзҡ„зі»з»ҹдёӯиҝӣиЎҢй«ҳжҖ§иғҪгҖҒй«ҳеҸҜйқ жҖ§зҡ„е®һж—¶ж•°жҚ®еӨ„зҗҶгҖӮFlink-1.7зүҲжң¬жҳҜиҜҘжЎҶжһ¶зҡ„дёҖдёӘзЁіе®ҡзүҲжң¬пјҢж–ҮжЎЈеҜ№е®ғзҡ„еҗ„дёӘ组件гҖҒAPIгҖҒд»ҘеҸҠиҝҗиЎҢж—¶зҺҜеўғзӯүиҝӣиЎҢдәҶиҜҰз»Ҷзҡ„д»Ӣз»ҚгҖӮ 1. **...