ه¤§و¶›ه¦é•؟
- وµڈ览: 121881 و¬،
- و€§هˆ«:

- و¥è‡ھ: هŒ—ن؛¬
-

社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
背و™¯ن»‹ç»چ
====
**é¥؟ن؛†ن¹ˆç›‘وژ§ç³»ç»ںEMonitor**ï¼ڑوک¯ن¸€و¬¾وœچهٹ،ن؛ژé¥؟ن؛†ن¹ˆو‰€وœ‰وٹ€وœ¯éƒ¨é—¨çڑ„ن¸€ç«™ه¼ڈ监وژ§ç³»ç»ں,覆盖ن؛†ç³»ç»ں监وژ§م€په®¹ه™¨ç›‘وژ§م€پ网络监وژ§م€پن¸é—´ن»¶ç›‘وژ§م€پن¸ڑهٹ،监وژ§م€پوژ¥ه…¥ه±‚监وژ§ن»¥هڈٹه‰چ端监وژ§çڑ„و•°وچ®هکه‚¨ن¸ژوں¥è¯¢م€‚و¯ڈو—¥ه¤„çگ†و€»و•°وچ®é‡ڈè؟‘PB,و¯ڈو—¥ه†™ه…¥وŒ‡و ‡و•°وچ®é‡ڈ百T,و¯ڈو—¥وŒ‡و ‡وں¥è¯¢é‡ڈه‡ هچƒن¸‡ï¼Œé…چç½®ه›¾è،¨ن¸ھو•°ن¸ٹن¸‡ï¼Œçœ‹و؟ن¸ھو•°ن¸ٹهچƒم€‚
**CAT**ï¼ڑوک¯هں؛ن؛ژJava ه¼€هڈ‘çڑ„ه®و—¶ه؛”用监وژ§ه¹³هڈ°ï¼Œن¸؛ç¾ژه›¢ç‚¹è¯„وڈگن¾›ن؛†ه…¨é¢çڑ„ه®و—¶ç›‘وژ§ه‘ٹè¦وœچهٹ،
وœ¬و–‡é€ڑè؟‡ه¯¹و¯”هˆ†وگن¸‹2者و‰€هپڑçڑ„ن؛‹وƒ…ن¸؛ه¥‘وœ؛讨è®؛监وژ§ç³»ç»ںوˆ–许该وœ‰çڑ„é¢è²Œï¼Œن»¥هڈٹوµ…è°ˆن¸‹ç›‘وژ§ç³»ç»ںهڈ‘ه±•çڑ„هگ„ن¸ھéک¶و®µ
CATهپڑçڑ„ن؛‹وƒ…(ه¼€و؛گ版)
============
首ه…ˆè¦په¼؛è°ƒçڑ„وک¯è؟™é‡Œوˆ‘ن»¬هڈھ能و‹؟هˆ°[githubن¸ٹه¼€و؛گ版CAT](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Fdianping%2Fcat)çڑ„وœ€و–°ç‰ˆ3.0.0,و‰€ن»¥وک¯هں؛ن؛ژو¤è؟›è،Œه¯¹و¯”
وژ¥ن¸‹و¥è¯´è¯´CATهپڑن؛†ه“ھن؛›ن؛‹وƒ…ï¼ں
### 1 وٹ½è±،ه‡؛监وژ§و¨،ه‹
وٹ½è±،ه‡؛Transactionم€پEventم€پHeartbeatم€پMetric 4ç§چ监وژ§و¨،ه‹م€‚
* Transactionï¼ڑ用و¥è®°ه½•ن¸€و®µن»£ç پçڑ„و‰§è،Œو—¶é—´ه’Œو¬،و•°
* Eventï¼ڑ用و¥è®°ه½•ن¸€ن»¶ن؛‹هڈ‘ç”ںçڑ„و¬،و•°
* Heartbeatï¼ڑè،¨ç¤؛程ه؛ڈه†…ه®ڑوœںن؛§ç”ںçڑ„ç»ںè®،ن؟،وپ¯, ه¦‚CPUهˆ©ç”¨çژ‡
* Metricï¼ڑ用ن؛ژè®°ه½•ن¸ڑهٹ،وŒ‡و ‡ï¼Œهڈ¯ن»¥è®°ه½•و¬،و•°ه’Œو€»ه’Œ
é’ˆه¯¹Transactionه’ŒEvent都ه›؛ه®ڑن؛†2ن¸ھç»´ه؛¦ï¼Œtypeه’Œname,ه¹¶ن¸”é’ˆه¯¹typeه’Œnameè؟›è،Œهˆ†é’ںç؛§èپڑهگˆوˆگوٹ¥è،¨ه¹¶ه±•ç¤؛و›²ç؛؟م€‚
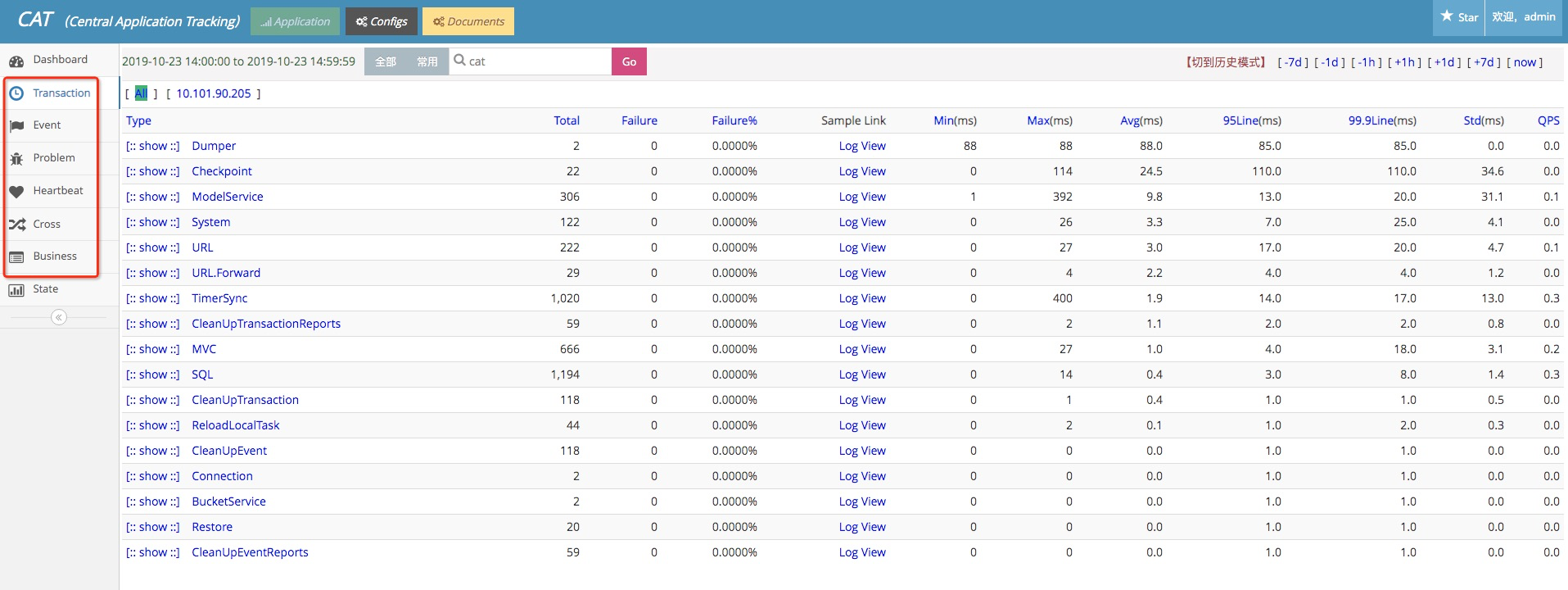
### 2 采و ·é“¾è·¯
é’ˆه¯¹ن¸ٹè؟°Transactionم€پEventçڑ„typeه’Œnameهˆ†هˆ«وœ‰ه¯¹ه؛”çڑ„هˆ†é’ںç؛§çڑ„采و ·é“¾è·¯
### 3 è‡ھه®ڑن¹‰çڑ„Metricو‰“点
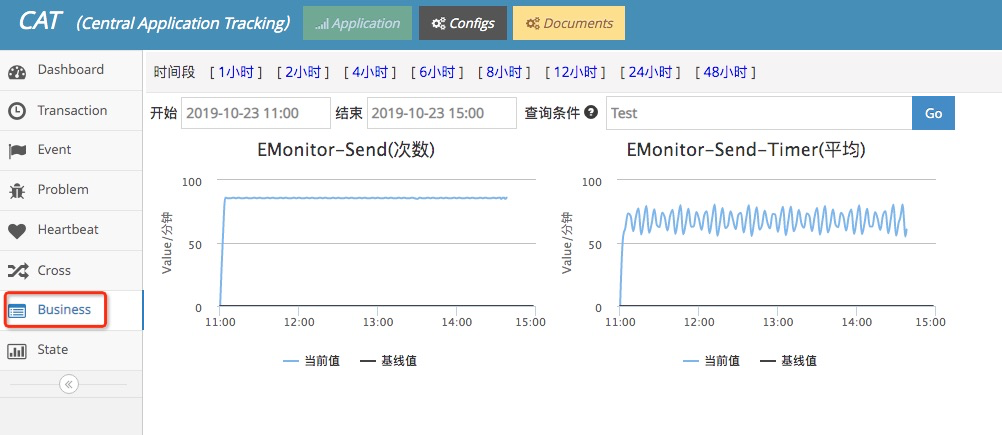
ç›®ه‰چو”¯وŒپCounterه’ŒTimerç±»ه‹çڑ„و‰“点,و”¯وŒپtag,هچ•وœ؛ه†…هچ•ن¸ھMetricçڑ„tag组هگˆو•°é™گهˆ¶1000م€‚
ه¹¶ن¸”وœ‰ç®€هچ•çڑ„监وژ§çœ‹و؟,ه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ
### 4 ن¸ژه…¶ن»–组ن»¶é›†وˆگ
و¯”ه¦‚ه’ŒMybatis集وˆگ,هœ¨ه®¢وˆ·ç«¯ه¼€هگ¯ç›¸ه…³çڑ„sqlو‰§è،Œç»ںè®،,ه¹¶ه°†è¯¥ç»ںè®،هˆ’هˆ†هˆ°Transactionç»ںè®،看و؟ن¸çڑ„type=SQLçڑ„ن¸€و ڈن¸‹
### 5 ه‘ٹè¦
هڈ¯ن»¥é’ˆه¯¹ن¸ٹè؟°çڑ„Transactionم€پEventç‰هپڑن¸€ن؛›ç®€هچ•çڑ„éکˆه€¼ه‘ٹè¦
é¥؟ن؛†ن¹ˆEMonitorه’ŒCATçڑ„ه¯¹و¯”
==================
é¥؟ن؛†ن¹ˆEMonitorه€ں鉴ن؛†CATçڑ„相ه…³و€وƒ³ï¼ŒهگŒو—¶هڈˆè؟›è،Œن؛†و”¹è؟›م€‚
### 1 ه¼•ه…¥Transactionم€پEventçڑ„و¦‚ه؟µ
é’ˆه¯¹Transactionه’ŒEvent都ه›؛ه®ڑن؛†2ن¸ھç»´ه؛¦ï¼Œtypeه’Œname,ن¸چهگŒهœ°و–¹هœ¨ن؛ژèپڑهگˆç”¨وˆ·هڈ‘è؟‡و¥çڑ„و•°وچ®
CATçڑ„و¶و„ه›¾ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
CATçڑ„و¶ˆè´¹وœ؛需è¦پهپڑه¦‚ن¸‹2ن»¶ن؛‹وƒ…ï¼ڑ
* ه¯¹Transactionم€پEventç‰و¶ˆوپ¯و¨،ه‹وŒ‰ç…§typeه’Œnameè؟›è،Œه½“ه‰چه°ڈو—¶çڑ„èپڑهگˆï¼Œهژ†هڈ²ه°ڈو—¶çڑ„èپڑهگˆو•°وچ®ه†™ه…¥هˆ°mysqlن¸
* ه°†é“¾è·¯و•°وچ®ه†™ه…¥هˆ°وœ¬هœ°و–‡ن»¶وˆ–者è؟œç¨‹HDFSن¸ٹ
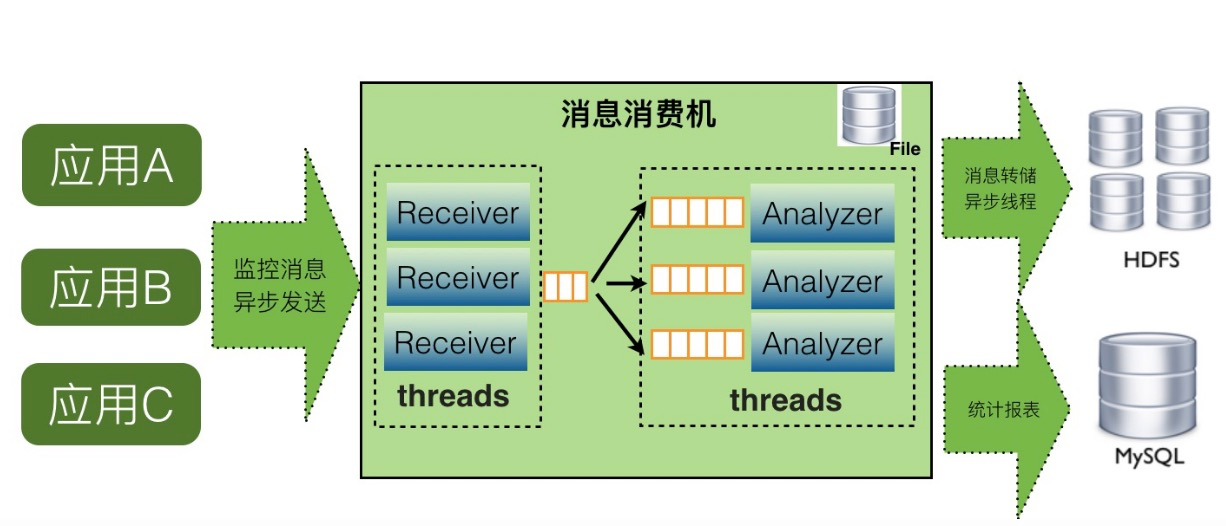
EMonitorçڑ„و¶و„ه›¾ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
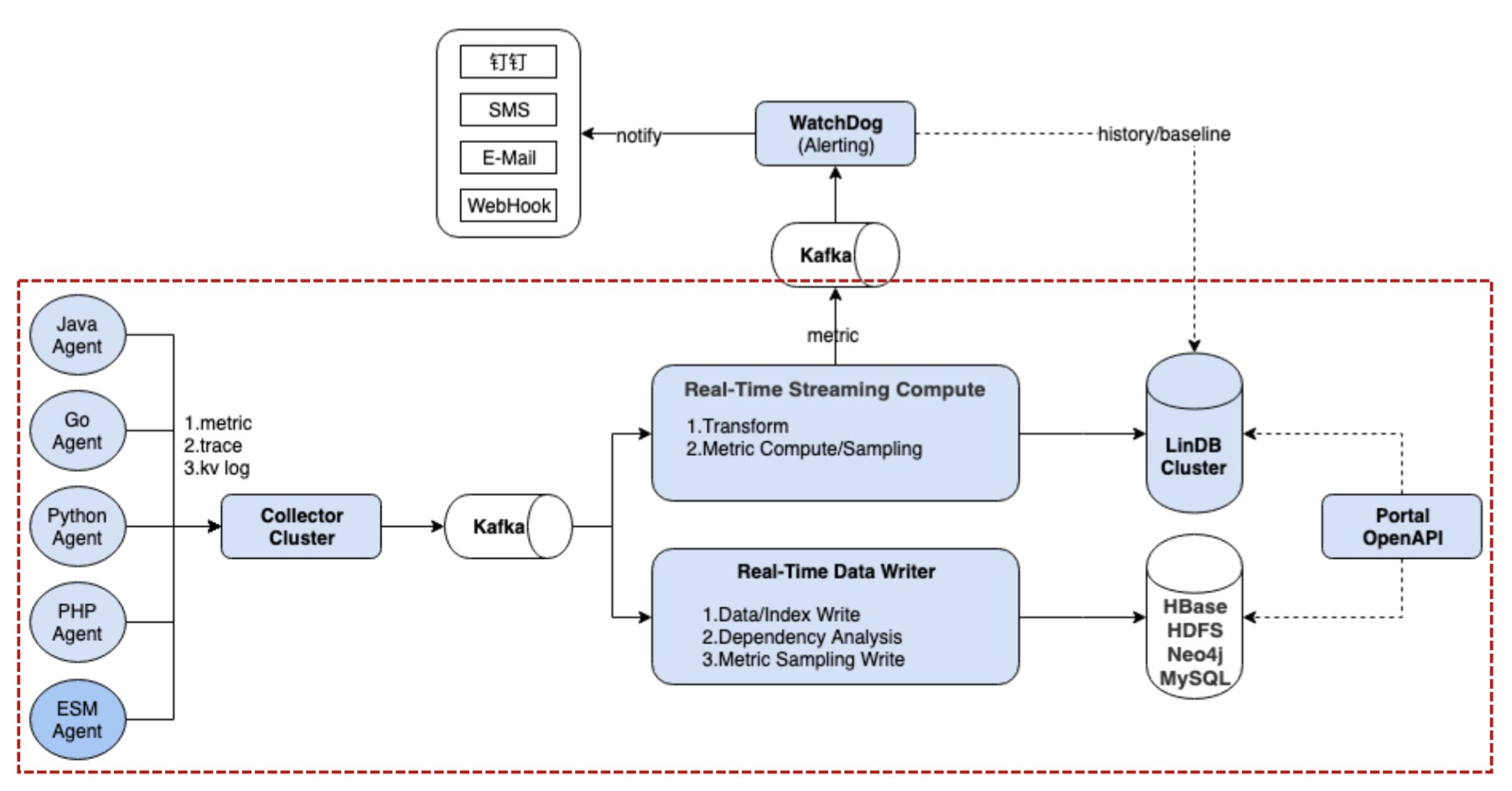
EMonitorهˆ†2è·¯ه¯¹و•°وچ®è؟›è،Œéڑ”离ه¤„çگ†ï¼ڑ
* Real-Time Streaming Computeï¼ڑه¯¹ç”¨وˆ·هڈ‘è؟‡و¥çڑ„链路ن¸çڑ„Transactionم€پEventç‰ç›‘وژ§و¨،ه‹è½¬هڈکوˆگوŒ‡و ‡و•°وچ®ه¹¶è؟›è،Œ10sçڑ„预èپڑهگˆï¼ŒهگŒو—¶ن¹ںه¯¹ç”¨وˆ·هڈ‘è؟‡و¥çڑ„Metricو•°وچ®è؟›è،Œ10s预èپڑهگˆم€‚وœ€هگژه°†10s预èپڑهگˆçڑ„و•°وچ®ه†™ه…¥هˆ°[LinDBو—¶ه؛ڈو•°وچ®ه؛“](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Flindb%2Flindb)(ه·²ه¼€و؛گ,وœ‰ه…´è¶£çڑ„هڈ¯ن»¥ه…³و³¨starن¸‹ï¼‰ن¸ï¼Œن»¥هڈٹkafkaن¸ï¼Œè®©ه‘ٹè¦و¨،ه—watchdogهژ»و¶ˆè´¹kafkaهپڑه®و—¶ه‘ٹè¦
* Real-Time Data Writerï¼ڑه¯¹ç”¨وˆ·هڈ‘è؟‡و¥çڑ„链路و•°وچ®و„ه»؛链路索ه¼•م€پهگ‘HDFSه’ŒHBaseه†™ه…¥ç´¢ه¼•ه’Œé“¾è·¯و•°وچ®ï¼ŒهگŒو—¶ن¼ڑو„ه»؛ه؛”用ن¹‹é—´çڑ„ن¾èµ–ه…³ç³»ï¼Œه°†ن¾èµ–ه…³ç³»ه†™ه…¥هˆ°Neo4jن¸
و‰€ن»¥EMonitorه’ŒCATçڑ„ن¸€ن¸ھه¾ˆه¤§ن¸چهگŒç‚¹ه°±هœ¨ن؛ژه¯¹وŒ‡و ‡çڑ„ه¤„çگ†ن¸ٹ,EMonitorن؛¤ç»™ن¸“ن¸ڑçڑ„و—¶ه؛ڈو•°وچ®ه؛“و¥هپڑ,而CATè‡ھه·±هپڑèپڑهگˆه°±وک¾ه¾—هٹں能éه¸¸هڈ—é™گ,ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
* CATهڈھ能و•´ه°ڈو—¶çڑ„وں¥çœ‹typeه’Œnameو•°وچ®ï¼Œن¸چ能跨ه°ڈو—¶ï¼Œهچ³ن¸چ能وں¥çœ‹ن»»و„ڈ2ن¸ھو—¶é—´ن¹‹é—´çڑ„وٹ¥è،¨و•°وچ®ï¼ŒEMonitorو²،وœ‰و¤é™گهˆ¶
* CATو²،و³•وں¥çœ‹و‰€وœ‰typeو±‡و€»هگژçڑ„ه“چه؛”و—¶é—´ه’ŒQPS,EMonitorهڈ¯ن»¥çپµو´»çڑ„è‡ھ由组هگˆtypeه’Œnameè؟›è،Œèپڑهگˆ
* CATçڑ„typeه’Œnameوٹ¥è،¨وک¯هˆ†é’ںç؛§çڑ„,EMonitorوک¯10sç؛§هˆ«çڑ„
* CATçڑ„typeه’Œnameو²،能ه’Œهژ†هڈ²وٹ¥è،¨و›²ç؛؟ç›´وژ¥ه¯¹و¯”,EMonitorهڈ¯ن»¥ه¯¹و¯”هژ†هڈ²وٹ¥è،¨و›²ç؛؟,و›´ه®¹وک“هڈ‘çژ°é—®é¢ک
* CATçڑ„typeه’Œnameهˆ—è،¨é¦–é،µه±•ç¤؛ن؛†ن¸€ه †و•°ه—,و— و³•ç«‹هچ³èژ·هڈ–ن¸€ن؛›ç›´è§‚ن؟،وپ¯ï¼Œو¯”ه¦‚ç»™ه‡؛ن؛†ه“چه؛”و—¶é—´TP99 100msè؟™ن¸ھهˆ°ه؛•وک¯ه¥½è؟کوک¯هڈ,EMonitorوœ‰ه½“ه‰چو›²ç؛؟ه’Œهژ†هڈ²و›²ç؛؟,相ه¯¹و¥è¯´هڈ¯ن»¥ç›´وژ¥هˆ¤و–هˆ°ه؛•okن¸چok
* CATçڑ„TP99م€پTP999هں؛ن؛ژهچ•وœ؛ه†…وںگن¸ھه°ڈو—¶ه†…çڑ„وٹ¥è،¨وک¯ه‡†ç،®çڑ„,除و¤ن¹‹ه¤–ه¤ڑوœ؛وˆ–者ه¤ڑن¸ھه°ڈو—¶çڑ„èپڑهگˆTP99م€پTP999وک¯ç”¨هٹ وƒه¹³ه‡و¥è®،ç®—çڑ„,ه‡†ç،®و€§وœ‰ه¾…وڈگé«ک
ن½†وک¯CATن¹ںوœ‰è‡ھه·±çڑ„ن¼کهٹ؟ï¼ڑ
* CATهگ«وœ‰TP999م€پTP9999ç؛؟(ن½†وک¯ه‡†ç،®و€§è؟کوœ‰ن؛›é—®é¢ک),EMonitorهڈھ能细هˆ°TP99
* CATçڑ„typeه’Œnameهڈ¯ن»¥وŒ‰ç…§وœ؛ه™¨ç»´ه؛¦è؟›è،Œè؟‡و»¤ï¼ŒEMonitorو²،وœ‰هپڑهˆ°è؟™ن¹ˆç»†ç²’ه؛¦
### 2 采و ·é“¾è·¯
ç›®ه‰چCATه’ŒEMonitor都هڈ¯ن»¥é€ڑè؟‡typeه’Œnameو¥è؟‡و»¤é‡‡و ·é“¾è·¯ï¼Œن¸چهگŒç‚¹هœ¨ن؛ژ
* CATçڑ„采و ·é“¾è·¯وک¯هˆ†é’ںç؛§هˆ«çڑ„,EMonitorوک¯10sç؛§هˆ«çڑ„
* é’ˆه¯¹وںگن¸€ن¸ھtypeه’Œname,CATç›®ه‰چو— و³•è½»و¾و‰¾وƒ³è¦پçڑ„链路,EMonitorهڈ¯ن»¥è½»و¾çڑ„و‰¾هˆ°وںگن¸ھو—¶هˆ»وˆ–者说وںگو®µو—¶é—´ه†…ه“چه؛”و—¶é—´وƒ³è¦پçڑ„链路(目ه‰چه·²ç»ڈ申请ن¸“هˆ©ï¼‰
EMonitorçڑ„链路ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
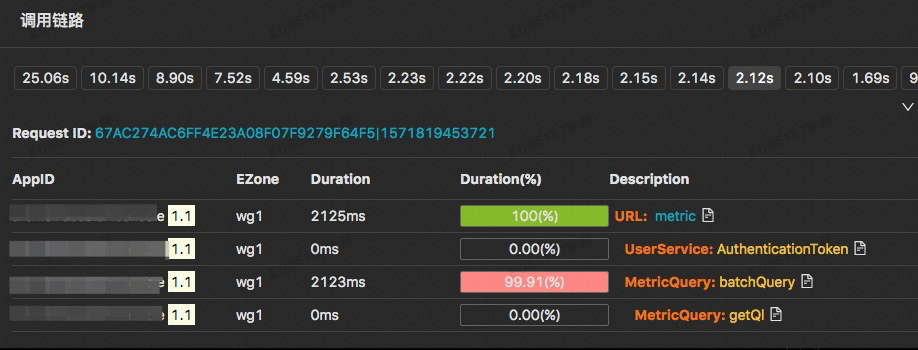
* è؟™ه¼ ه›¾وک¯وںگن¸ھ10sو—¶هˆ»م€پوںگن¸ھtypeه’Œnameè؟‡و»¤و،ن»¶ن¸‹çڑ„采و ·é“¾è·¯
* 第ن¸€è،Œوک¯è؟™10sه†…çڑ„采و ·é“¾è·¯ï¼ŒوŒ‰ç…§ه“چه؛”و—¶é—´è؟›è،Œن؛†وژ’ه؛ڈ
* هڈ¯ن»¥éڑڈو„ڈ点ه‡»وںگن¸ھه“چه؛”و—¶é—´و¥وں¥çœ‹ه¯¹ه؛”çڑ„链路详وƒ…
### 3آ è‡ھه®ڑن¹‰çڑ„Metricو‰“点
EMonitorو”¯وŒپCounterم€پTimerم€پHistogramم€پPayloadم€پGaugeç‰ç‰ه¤ڑç§چه½¢ه¼ڈçڑ„و‰“点و–¹ه¼ڈ,ه¹¶ن¸”و”¯وŒپtag
* Counterï¼ڑè®،و•°ç´¯هٹ ç±»ه‹
* Timerï¼ڑهڈ¯ن»¥è®°ه½•ن¸€و®µن»£ç پçڑ„耗و—¶ï¼ŒهŒ…هگ«و‰§è،Œو¬،و•°م€پ耗و—¶وœ€ه¤§ه€¼م€پوœ€ه°ڈه€¼م€په¹³ه‡ه€¼
* Histogramï¼ڑهŒ…هگ«Timerçڑ„و‰€وœ‰ن¸œè¥؟,هگŒو—¶و”¯وŒپè®،ç®—TP99ç؛؟,ن»¥هڈٹه…¶ن»–ن»»و„ڈTPç؛؟(ن»ژ0هˆ°100)
* Payloadï¼ڑهڈ¯ن»¥è®°ه½•ن¸€ن¸ھو•°وچ®هŒ…çڑ„ه¤§ه°ڈ,هŒ…هگ«و•°وچ®هŒ…ن¸ھو•°م€پهŒ…çڑ„وœ€ه¤§ه€¼م€پوœ€ه°ڈه€¼م€په¹³ه‡ه€¼
* Gaugeï¼ڑوµ‹é‡ڈه€¼ï¼Œن¸€èˆ¬ç”¨ن؛ژè،،é‡ڈéکںهˆ—ه¤§ه°ڈم€پè؟وژ¥و•°م€پCPUم€په†…هکç‰ç‰
ن¹ںه°±وک¯ن»»و„ڈMetricو‰“点都هڈ¯ن»¥وµپç»ڈEMonitorè؟›è،Œه¤„çگ†ن؛†ه¹¶è¾“é€پهˆ°LinDBو—¶ه؛ڈو•°وچ®ه؛“ن¸م€‚至و¤ï¼ŒEMonitorه°±هڈ¯ن»¥ه°†ن»»ن½•ç›‘وژ§وŒ‡و ‡ç»ںن¸€هœ¨ن¸€èµ·ن؛†ï¼Œو¯”ه¦‚وœ؛ه™¨ç›‘وژ§éƒ½هڈ¯ن»¥é€ڑè؟‡EMonitorو¥ن؟هکن؛†ï¼Œè؟™ن¸؛ن¸€ç«™ه¼ڈ监وژ§ç³»ç»ںه¥ ه®ڑن؛†هں؛ç،€
#### è‡ھه®ڑن¹‰Metric看و؟
CATهڈھوœ‰ن¸€ن¸ھ简وک“çڑ„Metric看و؟
EMonitoré’ˆه¯¹Metricه¼€هڈ‘ن؛†ن¸€ه¥—هڈ¯ن»¥هھ²ç¾ژGrafanaçڑ„وŒ‡و ‡çœ‹و؟,相و¯”Grafanaçڑ„ن¼کهٹ؟ï¼ڑ
* وœ‰ن¸€ه¥—ç±»ن¼¼SQLçڑ„éه¸¸ç®€هچ•çڑ„é…چç½®وŒ‡و ‡çڑ„و–¹ه¼ڈ
* è·ںه…¬هڈ¸ن؛؛ه‘ک组织و¶و„集وˆگ,و›´هٹ ن¼کé›…çڑ„وƒé™گوژ§هˆ¶ï¼Œن¸چهگŒçڑ„部门هڈ¯ن»¥ه»؛ه±ن؛ژè‡ھه·±çڑ„看و؟
* وŒ‡و ‡ه’Œçœ‹و؟çڑ„و”¶è—ڈ,ه½“و؛گوŒ‡و ‡وˆ–看و؟و”¹هٹ¨هگژ,و— 需و”¶è—ڈن؛؛ه‘که†چو”¹هٹ¨
* alphaم€پbetaم€پprodن¸چهگŒçژ¯ه¢ƒن¹‹é—´çڑ„ن¸€é”®هگŒو¥وŒ‡و ‡ه’Œçœ‹و؟,و— 需é…چç½®ه¤ڑو¬،
* PC端ه’Œç§»هٹ¨ç«¯çڑ„هگŒو¥وں¥çœ‹وŒ‡و ‡ه’Œçœ‹و؟
ç±»SQLçڑ„é…چç½®وں¥è¯¢وŒ‡و ‡و–¹ه¼ڈه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
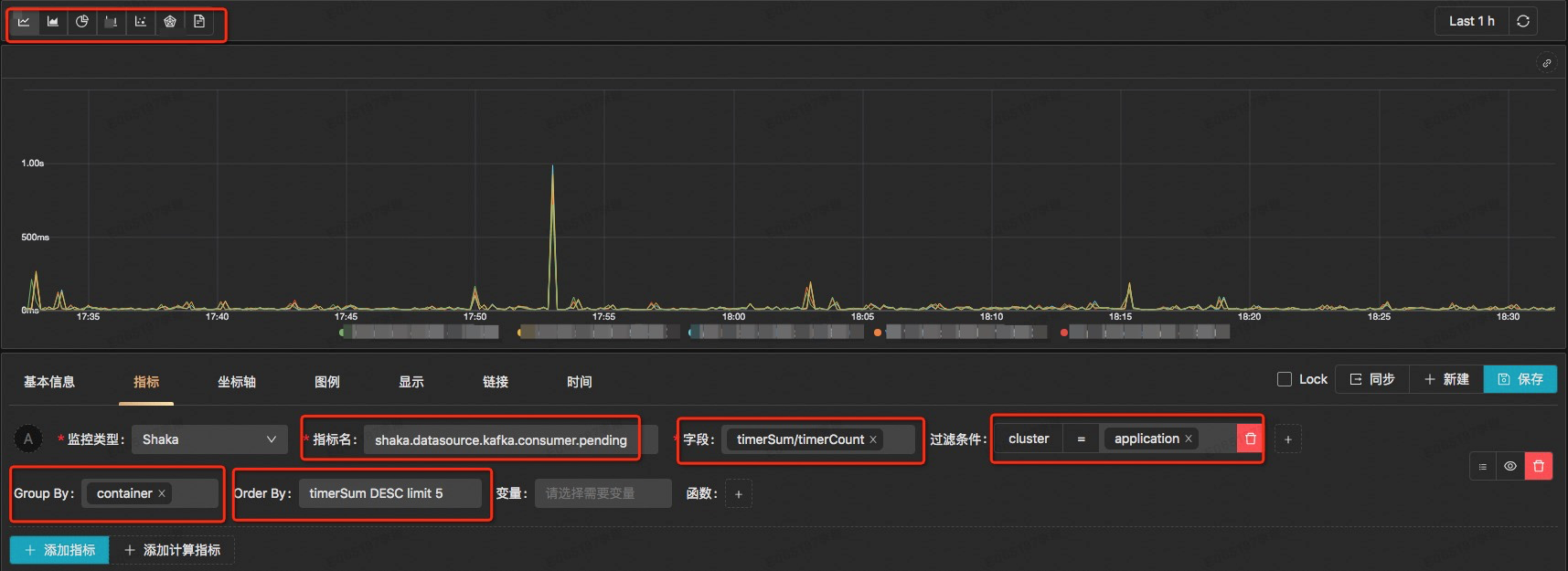
* هڈ¯ن»¥é…چç½®ه›¾è،¨çڑ„ه±•çژ°ه½¢ه¼ڈ
* هڈ¯ن»¥é…چç½®è¦پوں¥è¯¢çڑ„ه—و®µن»¥هڈٹه—و®µن¹‹é—´çڑ„هٹ ه‡ڈن¹ک除ç‰ن¸°ه¯Œçڑ„è،¨è¾¾ه¼ڈ
* هڈ¯ن»¥é…چç½®ه¤ڑن¸ھن»»و„ڈtagçڑ„è؟‡و»¤و،ن»¶
* هڈ¯ن»¥é…چç½®group byن»¥هڈٹorder by
看و؟و•´ن½“ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
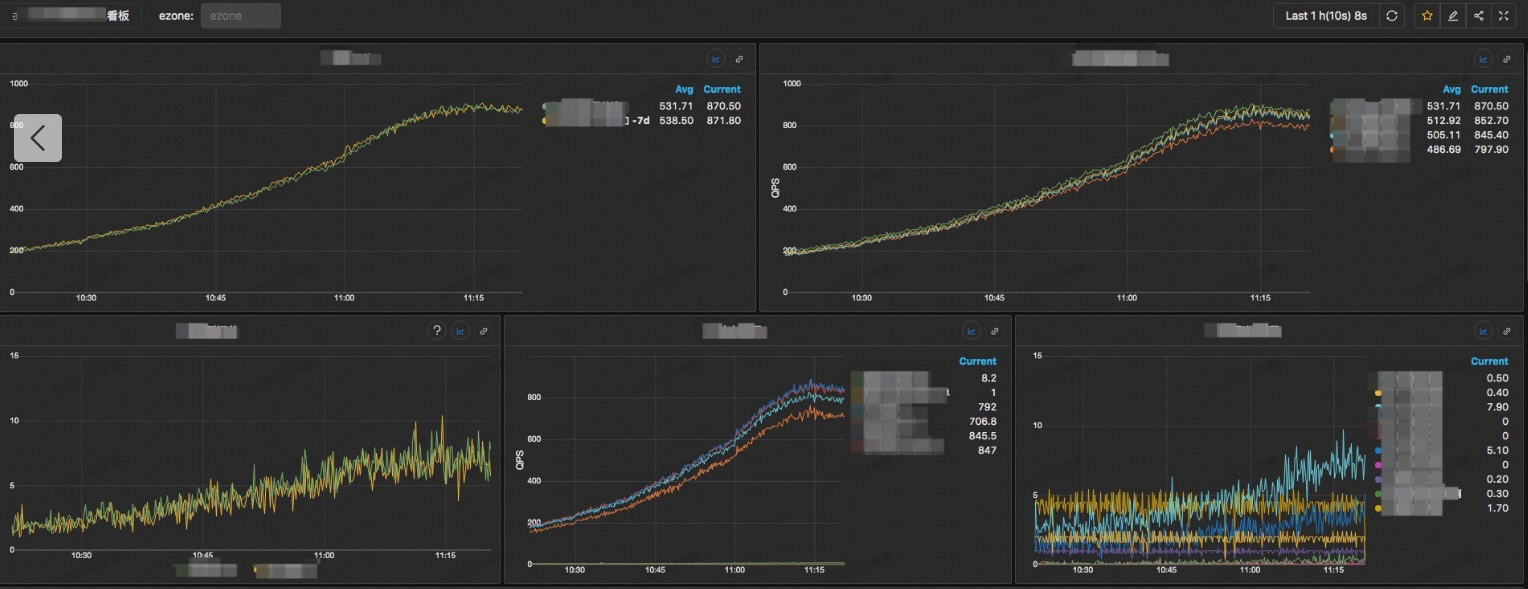
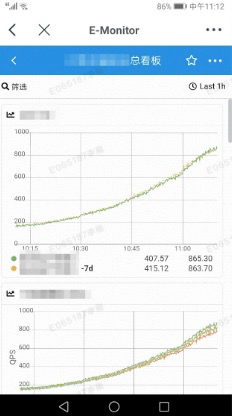
移هٹ¨ç«¯وک¾ç¤؛ه¦‚ن¸‹ï¼ڑ
### 4 ن¸ژه…¶ن»–组ن»¶é›†وˆگ
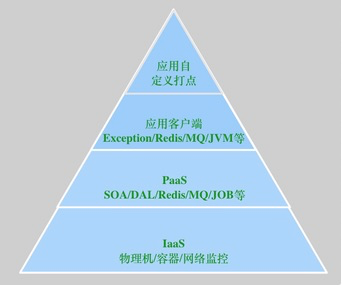
ç›®ه‰چEMonitorه·²ç»ڈو‰“é€ڑن؛†IaaSه±‚م€پPaaSه±‚م€په؛”用ه±‚çڑ„و‰€وœ‰é“¾è·¯ه’ŒوŒ‡و ‡çڑ„监وژ§ï¼Œه†چن¹ںن¸چ用هœ¨ه¤ڑن¸ھ监وژ§ç³»ç»ںن¸هˆ‡وچ¢و¥هˆ‡وچ¢هژ»ن؛†ï¼Œه¦‚ن¸‹و‰€ç¤؛
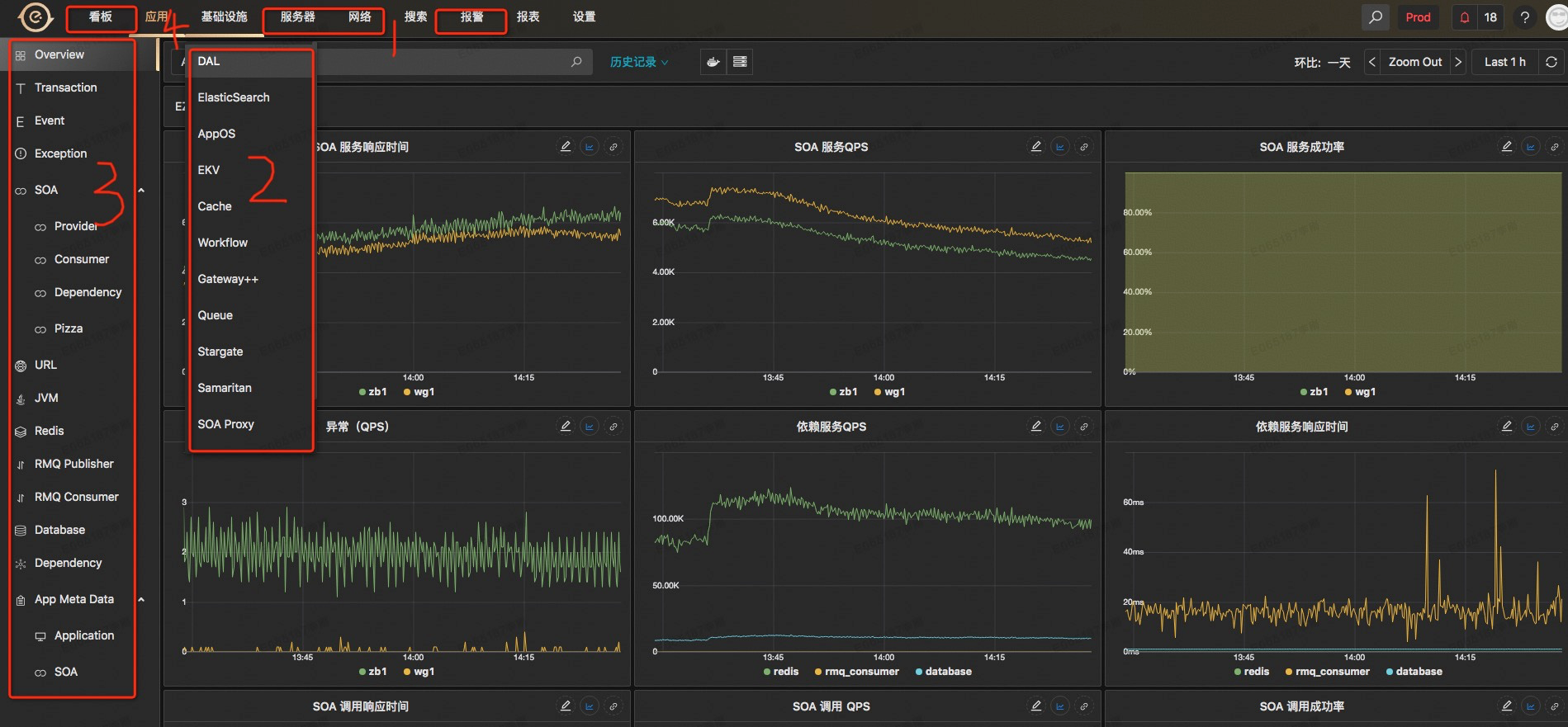
* 1 IaaSه±‚物çگ†وœ؛م€پوœ؛وˆ؟网络ن؛¤وچ¢وœ؛ç‰çڑ„监وژ§وŒ‡و ‡
* 2 PaaSه±‚ن¸é—´ن»¶وœچهٹ،端çڑ„监وژ§وŒ‡و ‡
* 3 ه؛”用ه±‚SOAم€پExceptionم€پJVMم€پMQç‰ه®¢وˆ·ç«¯çڑ„相ه…³وŒ‡و ‡
* 4 ه؛”用ه±‚è‡ھه®ڑن¹‰çڑ„监وژ§وŒ‡و ‡
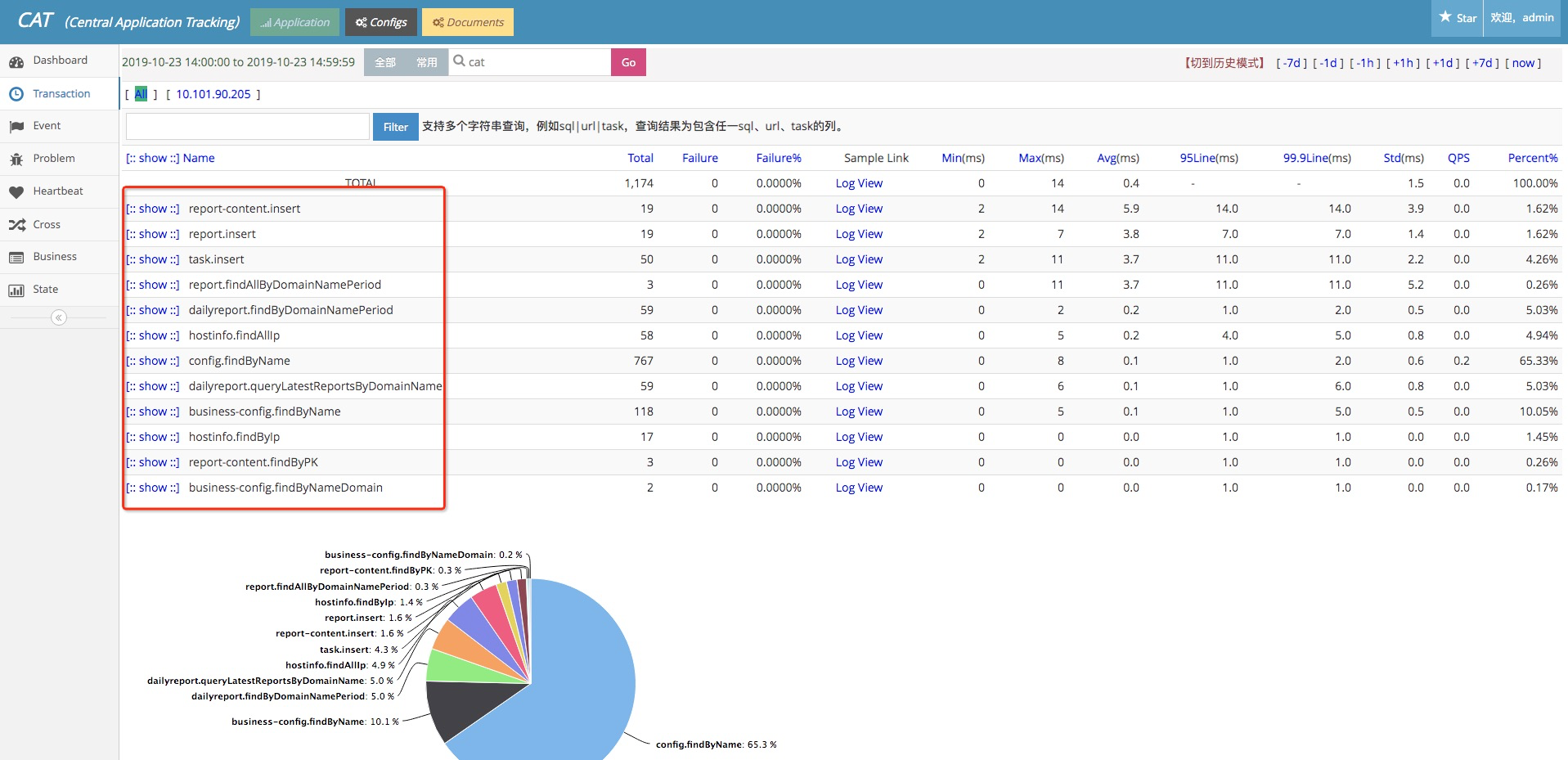
ن»¥و‰“é€ڑé¥؟ن؛†ن¹ˆهˆ†ه؛“هˆ†è،¨ن¸é—´ن»¶DALن¸؛ن¾‹ï¼ڑ
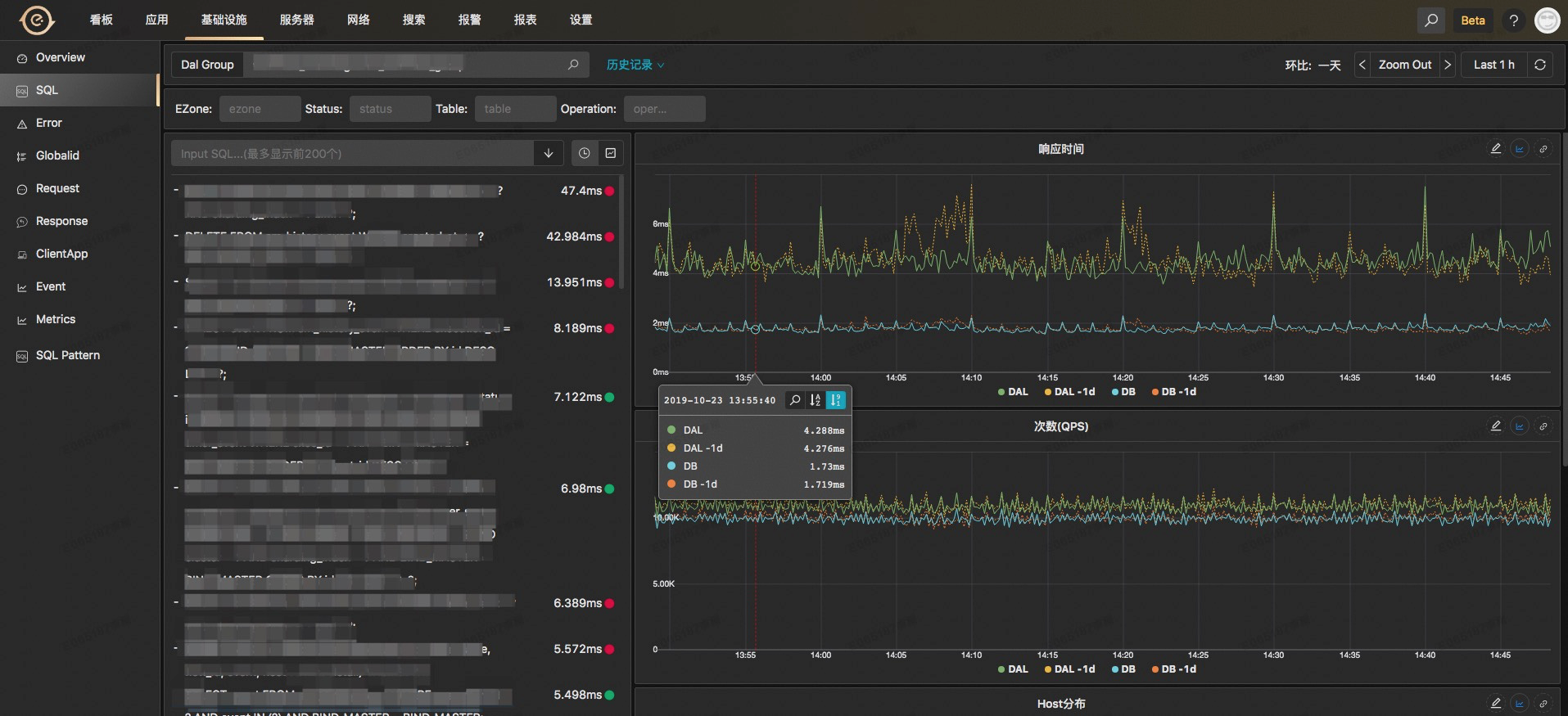
* هڈ¯ن»¥و ¹وچ®وœ؛وˆ؟م€پو‰§è،Œçٹ¶و€پم€پè،¨م€پو“چن½œç±»ه‹ï¼ˆو¯”ه¦‚Insertم€پUpdateم€پSelectç‰ï¼‰è؟›è،Œè؟‡و»¤وں¥çœ‹
* ه·¦è¾¹هˆ—è،¨ç»™ه‡؛و¯ڈو،SQLçڑ„و‰§è،Œçڑ„ه¹³ه‡è€—و—¶
* هڈ³è¾¹2ن¸ھه›¾è،¨ç»™ه‡؛该و،SQLهœ¨DALن¸é—´ن»¶ه±‚é¢م€پDBه±‚é¢çڑ„耗و—¶ن»¥هڈٹ调用QPS
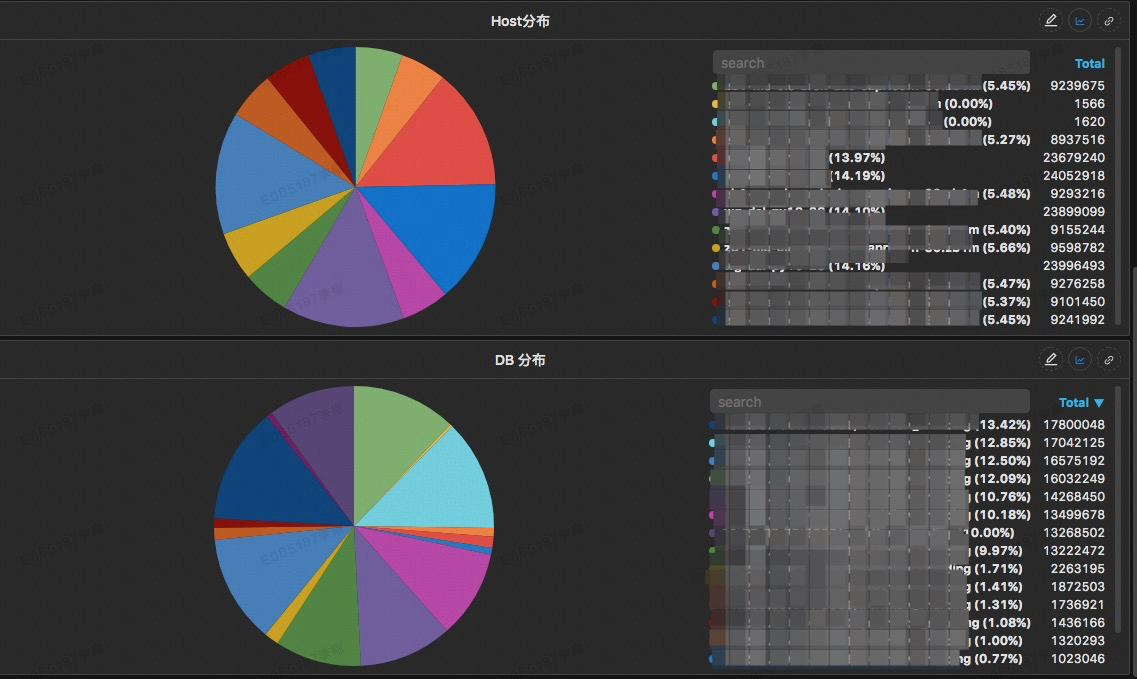
* هڈ¯ن»¥ç»™ه‡؛该SQLو‰“هœ¨هگژ端DALن¸é—´م€پDBن¸ٹçڑ„هˆ†ه¸ƒوƒ…ه†µï¼Œهڈ¯ن»¥ç”¨ن؛ژوژ’وں¥وک¯هگ¦هکهœ¨ن¸€ن؛›çƒç‚¹çڑ„وƒ…ه†µ
* è؟کوœ‰ن¸€ن؛›SQLوں¥è¯¢ç»“وœçڑ„و•°وچ®هŒ…ه¤§ه°ڈçڑ„و›²ç؛؟م€پSQL被DALé™گوµپçڑ„وƒ…ه†µç‰ç‰
* هڈ¯ن»¥وں¥çœ‹ن»»ن½•و—¶é—´ç‚¹ن¸ٹ该SQLçڑ„调用链路ن؟،وپ¯
ه†چن»¥و‰“é€ڑé¥؟ن؛†ن¹ˆSOAوœچهٹ،ن¸؛ن¾‹ï¼ڑ
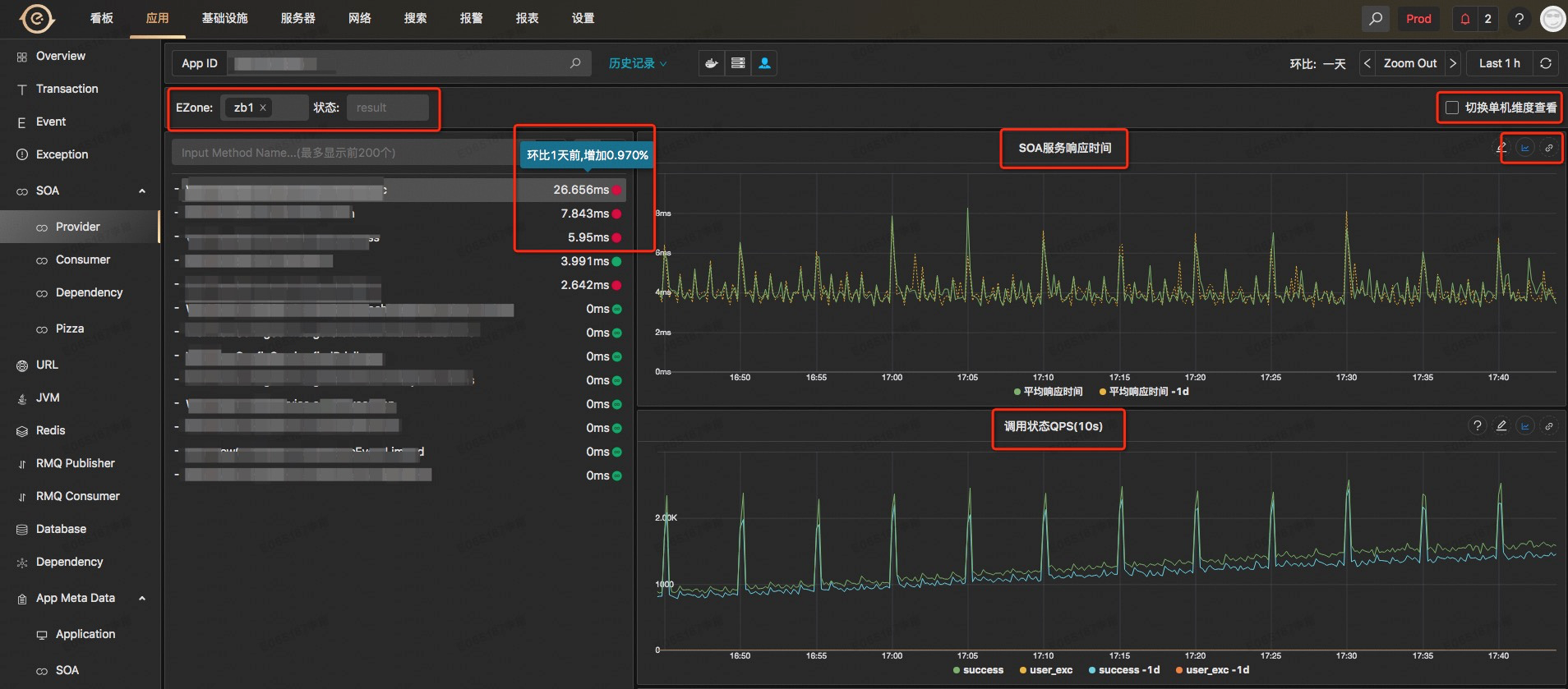
* هڈ¯ن»¥و ¹وچ®وœ؛وˆ؟ه’Œçٹ¶و€پن؟،وپ¯è؟›è،Œè؟‡و»¤
* ه·¦è¾¹ن¸€و ڈهˆ—ه‡؛该ه؛”用وڈگن¾›çڑ„SOAوœچهٹ،وژ¥هڈ£ï¼ŒهگŒو—¶ç»™ه‡؛ه¹³ه‡ه“چه؛”و—¶é—´ن»¥هڈٹه’Œوک¨ه¤©çڑ„ه¯¹و¯”وƒ…ه†µ
* هڈ³è¾¹çڑ„2ن¸ھه›¾è،¨هˆ†هˆ«ç»™ه‡؛ن؛†ه¯¹ه؛”وœچهٹ،وژ¥هڈ£çڑ„وœچهٹ،ه“چه؛”و—¶é—´ه’ŒQPSن»¥هڈٹه’Œوک¨ه¤©çڑ„ه¯¹و¯”وƒ…ه†µï¼ŒهگŒو—¶هڈ¯ن»¥هˆ‡وچ¢ه¹³ه‡ه“چه؛”و—¶é—´هˆ°TP99وˆ–者ه…¶ن»–TPه€¼ï¼ŒهگŒو—¶é…چوœ‰هڈ¯ن»¥ه؟«é€ںه¯¹ç›¸ه…³و›²ç؛؟و·»هٹ ه‘ٹè¦çڑ„跳转链وژ¥
* هڈ¯ن»¥هˆ‡وچ¢هˆ°هچ•وœ؛ç»´ه؛¦و¥وں¥çœ‹و¯ڈهڈ°وœ؛ه™¨è¯¥SOAوژ¥هڈ£çڑ„ه“چه؛”و—¶é—´ه’ŒQPS,用و¥ه®ڑن½چوںگهڈ°وœ؛ه™¨çڑ„é—®é¢ک
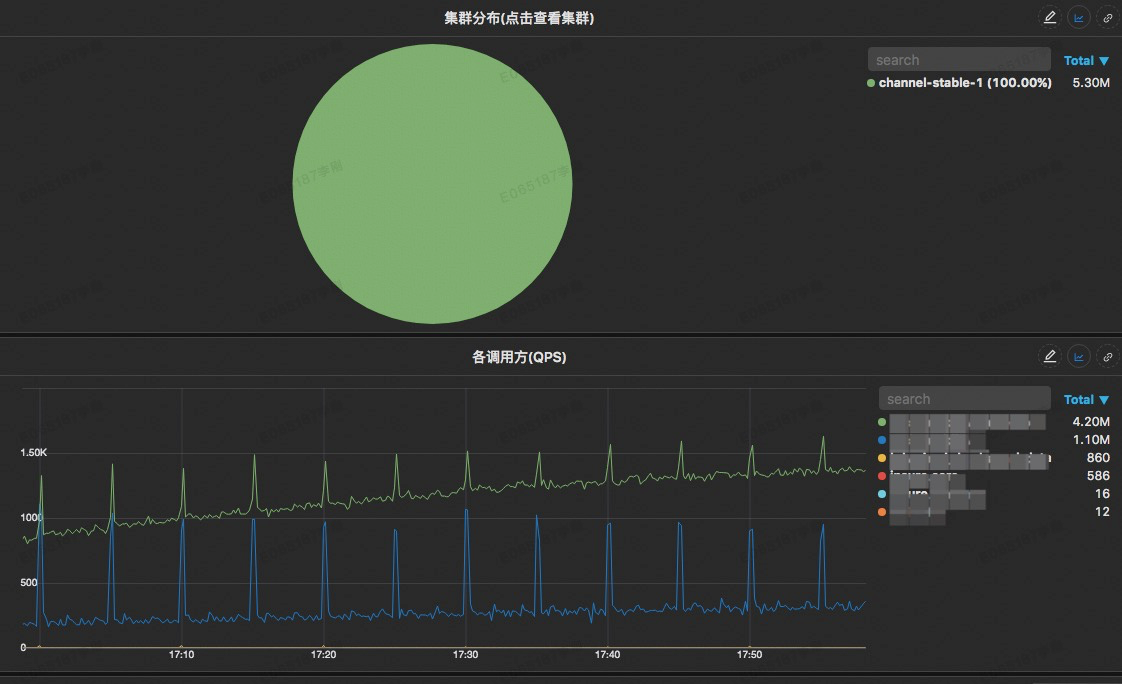
* هڈ¯ن»¥ç»™ه‡؛该SOAوژ¥هڈ£è°ƒç”¨هœ¨ن¸چهگŒé›†ç¾¤çڑ„هˆ†ه¸ƒهچ و¯”
* هڈ¯ن»¥ç»™ه‡؛该SOAوژ¥هڈ£çڑ„و‰€وœ‰è°ƒç”¨و–¹ن»¥هڈٹن»–ن»¬çڑ„QPS
* هڈ¯ن»¥وں¥çœ‹ن»»ن½•و—¶é—´ç‚¹ن¸ٹ该SOAوژ¥هڈ£çڑ„调用链路ن؟،وپ¯
### 5 ه‘ٹè¦
هڈ¯ن»¥é’ˆه¯¹و‰€وœ‰çڑ„监وژ§وŒ‡و ‡é…چç½®ه¦‚ن¸‹ه‘ٹè¦و–¹ه¼ڈï¼ڑ
* éکˆه€¼ï¼ڑ简هچ•çڑ„éکˆه€¼ه‘ٹè¦ï¼Œé€‚用ن؛ژCPUم€په†…هکç‰
* هگŒçژ¯و¯”ï¼ڑن¸ژè؟‡هژ»هگŒوœںو¯”较çڑ„ه‘ٹè¦
* 趋هٹ؟ï¼ڑ适هگˆن؛ژ相ه¯¹ه¹³و»‘è؟ç»çڑ„و— 需éکˆه€¼çڑ„و™؛能ه‘ٹè¦
* ه…¶ن»–ه‘ٹè¦ه½¢ه¼ڈ
وµ…谈监وژ§ç³»ç»ںçڑ„هڈ‘ه±•è¶‹هٹ؟
===========
### 1 و—¥ه؟—监وژ§éک¶و®µ
وœ¬éک¶و®µه®çژ°و–¹ه¼ڈï¼ڑ程ه؛ڈو‰“و—¥ه؟—,ن½؟用ELKو¥هکه‚¨ه’Œوں¥è¯¢ç¨‹ه؛ڈçڑ„è؟گè،Œو—¥ه؟—,ELKن¹ں能简هچ•وک¾ç¤؛وŒ‡و ‡و›²ç؛؟
وژ’éڑœè؟‡ç¨‹ï¼ڑن¸€و—¦وœ‰é—®é¢ک,هˆ™هژ»ELKن¸وگœç´¢هڈ¯èƒ½çڑ„ه¼‚ه¸¸و—¥ه؟—و¥è؟›è،Œهˆ†وگوژ’éڑœ
### 2 链路监وژ§éک¶و®µ
ن¸ٹن¸€ن¸ھéک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑELKهڈھوک¯هں؛ن؛ژن¸€è،Œن¸€è،Œو—¥ه؟—è؟›è،Œèپڑهگˆوˆ–者وگœç´¢هˆ†وگ,و—¥ه؟—ن¹‹é—´و²،وœ‰ن¸ٹن¸‹و–‡ه…³èپ”م€‚ه¾ˆéڑ¾çں¥éپ“ن¸€و¬،请و±‚耗و—¶è¾ƒé•؟究ç«ں耗و—¶هœ¨ه“ھن¸ھéک¶و®µ
وœ¬éک¶و®µه®çژ°و–¹ه¼ڈï¼ڑCATو¨ھç©؛ه‡؛ن¸–,é€ڑè؟‡ه»؛و¨،وٹ½è±،ه‡؛Transactionم€پMetricç‰ç›‘وژ§و¨،ه‹ï¼Œه°†é“¾è·¯هˆ†وگه’Œç®€هچ•çڑ„وٹ¥è،¨ه¸¦ه…¥ن؛†ه¤§ه®¶çڑ„视é‡ژ
ه‘ٹè¦و–¹ه¼ڈï¼ڑé’ˆه¯¹وٹ¥è،¨هڈ¯ن»¥è؟›è،Œéکˆه€¼ç›‘وژ§
وژ’éڑœè؟‡ç¨‹ï¼ڑن¸€و—¦وœ‰ه‘ٹè¦ï¼Œهڈ¯ن»¥é€ڑè؟‡ç‚¹ه‡»وٹ¥è،¨و¥è¯¦ç»†ه®ڑن½چهˆ°وک¯ه“ھن¸ھtypeوˆ–nameوœ‰ن¸€ه®ڑé—®é¢ک,é،؛ن¾؟و‰¾هˆ°ه¯¹ه؛”çڑ„链路,وں¥çœ‹è¯¦ç»†çڑ„ن؟،وپ¯
### 3آ وŒ‡و ‡ç›‘وژ§éک¶و®µ
ن¸ٹن¸€éک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑCATه¯¹è‡ھه®ڑن¹‰وŒ‡و ‡و”¯وŒپçڑ„و¯”较ه¼±ï¼Œن¹ںو— و³•ه®çژ°وˆ–者ه±•çژ°و›´هٹ ه¤ڑو ·çڑ„وں¥è¯¢èپڑهگˆéœ€و±‚
وœ¬éک¶و®µçڑ„ه®çژ°و–¹ه¼ڈï¼ڑو”¯وŒپن¸°ه¯Œçڑ„MetricوŒ‡و ‡ï¼Œه°†é“¾è·¯ن¸ٹçڑ„ن¸€ن؛›وٹ¥è،¨و•°وچ®ن¹ںهڈ¯ن»¥هˆ’هˆ†هˆ°وŒ‡و ‡ن¸ï¼Œن؛¤ç»™ن¸“ن¸ڑçڑ„و—¶ه؛ڈو•°وچ®ه؛“و¥هپڑوŒ‡و ‡çڑ„هکه‚¨ه’Œوں¥è¯¢ï¼Œه¯¹وژ¥وˆ–者è‡ھç ”ن¸°ه¯Œçڑ„وŒ‡و ‡çœ‹و؟ه¦‚Grafana
ه‘ٹè¦و–¹ه¼ڈï¼ڑé’ˆه¯¹وŒ‡و ‡è؟›è،Œو›´هٹ ن¸°ه¯Œçڑ„ه‘ٹè¦ç–ç•¥
وژ’éڑœè؟‡ç¨‹ï¼ڑن¸€و—¦وœ‰ه‘ٹè¦ï¼Œهڈ¯èƒ½éœ€è¦پهˆ°هگ„ن¸ھç³»ç»ںن¸ٹوں¥çœ‹وŒ‡و ‡çœ‹و؟,粗略ه®ڑن½چو ¹ه› ,ه†چ结هگˆé“¾è·¯و€»ه’Œهˆ†وگ
### 4 ه¹³هڈ°و‰“é€ڑو•´هگˆéک¶و®µ
ن¸ٹن¸€éک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑç³»ç»ں监وژ§م€پن¸é—´ن»¶ه’Œن¸ڑهٹ،监وژ§م€پ部هˆ†ن¸ڑهٹ،监وژ§م€پ链路监وژ§ن¸ژوŒ‡و ‡ç›‘وژ§éƒ½هگ„وگن¸€ه¥—و•°وچ®و”¶é›†م€پ预ه¤„çگ†م€پهکه‚¨م€پوں¥è¯¢م€په±•çژ°م€په‘ٹè¦وµپ程,هگ„ن¸ھç³»ç»ںه¤„çگ†و•°وچ®و ¼ه¼ڈم€پن½؟用و–¹ه¼ڈن¸چç»ںن¸€
وœ¬éک¶و®µçڑ„ه®çژ°و–¹ه¼ڈï¼ڑو‰“é€ڑن»ژç³»ç»ںه±‚é¢م€په®¹ه™¨ه±‚é¢م€پن¸é—´ن»¶ه±‚é¢م€پن¸ڑهٹ،ه±‚é¢ç‰ç‰çڑ„هڈ¯èƒ½çڑ„链路ه’ŒوŒ‡و ‡ç›‘وژ§ï¼Œç»ںن¸€و•°وچ®çڑ„ه¤„çگ†وµپ程,هگŒو—¶و•´هگˆهڈ‘ه¸ƒم€پهڈکو›´م€په‘ٹè¦ن¸ژ监وژ§و›²ç؛؟结هگˆï¼Œوˆگن¸؛ن¸€ç«™ه¼ڈ监وژ§ه¹³هڈ°
ه‘ٹè¦و–¹ه¼ڈï¼ڑهڈ¯ن»¥ç»ںن¸€çڑ„é’ˆه¯¹هگ„ن¸ھه±‚é¢çڑ„监وژ§و•°وچ®هپڑç»ںن¸€هŒ–çڑ„ه‘ٹè¦
وژ’éڑœè؟‡ç¨‹ï¼ڑهڈھ需è¦پهœ¨ن¸€ن¸ھ监وژ§ç³»ç»ںن¸ه°±هڈ¯ن»¥وں¥çœ‹هˆ°و‰€وœ‰çڑ„监وژ§و›²ç؛؟ه’Œé“¾è·¯ن؟،وپ¯
ç›®ه‰چوˆ‘ن»¬EMonitorه·²ه®Œوˆگè؟™ن¸ھéک¶و®µï¼Œه°†ه…¬هڈ¸ن¹‹ه‰چهکهœ¨ه·²ن¹…çڑ„3ه¥—独立çڑ„监وژ§ç³»ç»ںç»ںن¸€و•´هگˆوˆگçژ°ه¦‚ن»ٹçڑ„ن¸€ه¥—监وژ§ç³»ç»ں
### 5آ و·±ه؛¦هˆ†وگéک¶و®µ
ن¸ٹن¸€éک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑ
* 用وˆ·è™½ç„¶هڈ¯ن»¥هœ¨ن¸€ن¸ھç³»ç»ںن¸çœ‹هˆ°و‰€وœ‰هگ„ن¸ھه±‚é¢çڑ„监وژ§و•°وچ®ن؛†ï¼Œن½†وک¯و¯ڈو¬،وژ’éڑœو—¶ن»چ然è¦پèٹ±ه¾ˆه¤ڑçڑ„و—¶é—´هژ»وں¥çœ‹هگ„ن¸ھه±‚é¢وک¯هگ¦وœ‰é—®é¢ک,ن¸€و—¦و¼ڈ看ن¸€é،¹هڈ¯èƒ½ه°±é”™è؟‡ن؛†é—®é¢کو‰€هœ¨çڑ„و ¹ه›
* و²،وœ‰و•´ن¸ھن¸ڑهٹ،çڑ„ه…¨ه±€ç›‘وژ§è§†è§’,都هپœç•™هœ¨هگ„è‡ھه؛”用çڑ„角ه؛¦
و€»ن¹‹ï¼ڑن¹‹ه‰چçڑ„éک¶و®µéƒ½وک¯هژ»هپڑن¸€ن¸ھ监وژ§ه¹³هڈ°ï¼Œç”¨وˆ·وں¥è¯¢ن»€ن¹ˆوŒ‡و ‡ه°±ه±•ç¤؛相ه؛”çڑ„و•°وچ®ï¼Œç›‘وژ§ه¹³هڈ°ه¹¶ن¸چهژ»ه…³ه؟ƒç”¨وˆ·و‰€هکه‚¨و•°وچ®çڑ„ه†…ه®¹م€‚çژ°هœ¨ه‘¢ه°±éœ€è¦پ转هڈکو€è·¯ï¼Œç›‘وژ§ه¹³هڈ°éœ€è¦پن¸»هٹ¨هژ»ه¸®ç”¨وˆ·هˆ†وگ里é¢و‰€هکه‚¨çڑ„و•°وچ®ه†…ه®¹
وœ¬éک¶و®µçڑ„ه®çژ°و–¹ه¼ڈï¼ڑو‰€è¦پهپڑçڑ„ه°±وک¯وٹٹه¸®ç”¨وˆ·هˆ†وگçڑ„è؟‡ç¨‹وٹ½è±،ه‡؛و¥ï¼Œن¸؛用وˆ·و„ه»؛ه؛”用ه¤§ç›که’Œن¸ڑهٹ،ه¤§ç›ک,ن»¥هڈٹن¸؛ه¤§ç›کهپڑ相ه…³çڑ„و ¹ه› هˆ†وگم€‚
* ه؛”用ه¤§ç›کï¼ڑه°±وک¯ن¸؛ه½“ه‰چه؛”用و„ه»؛ن¸ٹن¸‹و¸¸ه؛”用ن¾èµ–çڑ„监وژ§م€په½“ه‰چه؛”用و‰€ه…³èپ”çڑ„وœ؛ه™¨ç›‘وژ§م€پredisم€پMQم€پdatabaseç‰ç‰ç›‘وژ§ï¼Œهڈ¯ن»¥و—¶هˆ»ن¸؛ه؛”用هپڑن½“و£€ï¼Œو¥ن¸»هٹ¨وڑ´éœ²ه‡؛é—®é¢ک,而ن¸چوک¯ç‰ç”¨وˆ·هژ»ن¸€ن¸ھن¸ھوں¥وŒ‡و ‡è€Œهگژهڈ‘çژ°é—®é¢ک
* ن¸ڑهٹ،ه¤§ç›کï¼ڑه°±وک¯و ¹وچ®ن¸ڑهٹ،و¥و¢³çگ†وˆ–者هˆ©ç”¨é“¾è·¯و¥è‡ھهٹ¨ç”ںن؛§ه¤§ç›ک,该ه¤§ç›کهڈ¯ن»¥ه؟«é€ںه‘ٹ诉用وˆ·وک¯ه“ھن؛›ن¸ڑهٹ،çژ¯èٹ‚ه‡؛çڑ„é—®é¢ک
و ¹ه› هˆ†وگï¼ڑن¸€ن¸ھه¤§ç›کوœ‰ه¾ˆه¤ڑçڑ„çژ¯èٹ‚,و¯ڈن¸ھçژ¯èٹ‚绑ه®ڑوœ‰ه¾ˆه¤ڑçڑ„وŒ‡و ‡ï¼Œو¯ڈو¬،وںگن¸ھه‘ٹè¦ه‡؛و¥وœ‰هڈ¯èƒ½éœ€è¦پ详细çڑ„هˆ†وگن¸‹و¯ڈن¸ھçژ¯èٹ‚çڑ„وŒ‡و ‡ï¼Œو¯”ه¦‚و¶ˆè´¹kafkaçڑ„ه»¶è؟ںن¸ٹهچ‡ï¼Œوœ‰هگ„ç§چهگ„و ·çڑ„هژںه› 都هڈ¯èƒ½ه¯¼è‡´ï¼Œو¯ڈو¬،ه‘ٹè¦وژ’وں¥éƒ½éœ€è¦په°†هˆ†وگوµپ程ه†چه…¨éƒ¨ن؛؛ن¸؛هˆ†وگوژ’وں¥ن¸‹ï¼Œéه¸¸ç´¯ï¼Œو‰€ن»¥éœ€è¦په°†ه®ڑن½چو ¹ه› çڑ„è؟‡ç¨‹é€ڑè؟‡ه»؛و¨،وٹ½è±،ن¸‹ï¼Œو¥è؟›è،Œç»ںن¸€è§£ه†³
趋هٹ؟وٹ¥è،¨هˆ†وگï¼ڑن¸»هٹ¨ه¸®ç”¨وˆ·هڈ‘çژ°ن¸€ن؛›é€گو¸گوپ¶هŒ–çڑ„é—®é¢ک点,و¯”ه¦‚用وˆ·هڈ‘ه¸ƒن¹‹هگژ,وژ¥هڈ£è€—و—¶ه¢هٹ ,ه¾ˆهڈ¯èƒ½ç”¨وˆ·و²،وœ‰هڈ‘çژ°ï¼Œè™½ç„¶ه½“ه‰چو²،وœ‰é—®é¢ک,ن½†وک¯ه¾ˆوœ‰هڈ¯èƒ½هœ¨وکژه¤©çڑ„é«که³°وœںه°±ن¼ڑوڑ´éœ²é—®é¢ک,è؟™ن؛›éƒ½وک¯ه·²ç»ڈه®ه®هœ¨هœ¨هڈ‘ç”ںçڑ„ن؛‹و•…
è¦پوƒ³هپڑن¸»هٹ¨هˆ†وگ,è؟کو·±ه؛¦ن¾èµ–وŒ‡و ‡ن¸‹é’»هˆ†وگ,هچ³وںگن¸ھوŒ‡و ‡è°ƒç”¨é‡ڈن¸‹é™چن؛†ï¼Œèƒ½ن¸»هٹ¨هˆ†وگه‡؛وک¯ه“ھن؛›tagç»´ه؛¦ç»„هگˆه¯¼è‡´çڑ„ن¸‹é™چ,è؟™وک¯ن¸ٹè؟°ه¾ˆه¤ڑو™؛能هˆ†وگçڑ„هں؛ç،€ï¼Œè؟™ن¸€ه—ن¹ںن¸چ简هچ•
ه‘ٹè¦و–¹ه¼ڈï¼ڑهڈ¯ن»¥ç»ںن¸€çڑ„é’ˆه¯¹هگ„ن¸ھه±‚é¢çڑ„监وژ§و•°وچ®هپڑç»ںن¸€هŒ–çڑ„ه‘ٹè¦
وژ’éڑœè؟‡ç¨‹ï¼ڑNOCو ¹وچ®ن¸ڑهٹ،وŒ‡و ‡وˆ–者ن¸ڑهٹ،ه¤§ç›که؟«é€ںه¾—çں¥وک¯ه“ھن؛›ن¸ڑهٹ،وˆ–者ه؛”用ه‡؛ه…ˆن؛†é—®é¢ک,ه؛”用çڑ„owneré€ڑè؟‡ه؛”用ه¤§ç›کçڑ„ن½“و£€ه¾—çں¥ç›¸ه…³çڑ„هڈکهٹ¨ن؟،وپ¯ï¼Œو¯”ه¦‚وک¯redisو³¢هٹ¨م€پdatabaseو³¢هٹ¨م€پن¸ٹن¸‹و¸¸ه؛”用çڑ„وںگن¸ھو–¹و³•و³¢هٹ¨ç‰ç‰ï¼Œو¥è¾¾هˆ°ه؟«é€ںه®ڑن½چé—®é¢کç›®çڑ„,وˆ–者é€ڑè؟‡ه¯¹ه¤§ç›کو‰§è،Œو ¹ه› هˆ†وگو¥ه®ڑن½چهˆ°و ¹ه›
ه†چè°ˆLoggingم€پTracingم€پMetrics
=========================
ه¸¸è§پن¸€ه¼ 3者ه…³ç³»çڑ„ه›¾
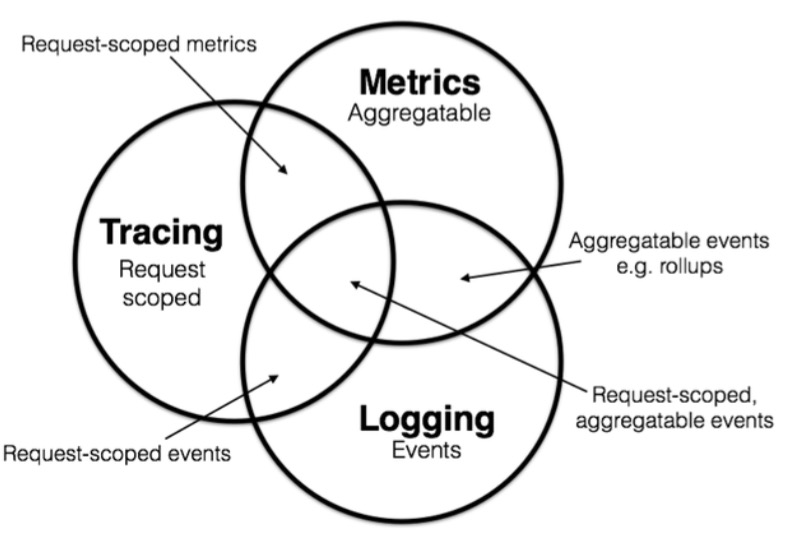
ن¸‰è€…çڑ„ç،®éƒ½ن¸چهڈ¯وˆ–ç¼؛,相辅相وˆگ,ن½†وک¯وˆ‘وƒ³è¯´ن»¥ن¸‹ه‡ 点ï¼ڑ
* ن¸‰è€…هœ¨ç›‘وژ§وژ’éڑœن¸çڑ„و‰€هچ و¯”ن¾‹هچ´ه¤§ن¸چن¸€و ·ï¼ڑMetricsهچ وچ®ه¤§ه¤´ï¼ŒTracingو¬،ن¹‹ï¼ŒLoggingوœ€هگژ
* Tracingهگ«وœ‰é‡چè¦پçڑ„ه؛”用ن¹‹é—´çڑ„ن¾èµ–ن؟،وپ¯ï¼ŒMetricsوœ‰و›´ه¤ڑçڑ„هڈ¯و·±ه؛¦هˆ†وگه’ŒوŒ–وژکçڑ„ç©؛间,و‰€ن»¥وœھو¥ه؟…然وک¯هœ¨Metricsن¸ٹه¤§هپڑو–‡ç« ,ه†چ结هگˆTracingن¸çڑ„ه؛”用ن¾èµ–و¥هپڑو›´و·±ه؛¦ه…¨ه±€هˆ†وگ,هچ³Metricsه’ŒTracingن¸¤è€…结هگˆهڈ‘وŒ¥ه‡؛و›´ه¤ڑçڑ„هڈ¯èƒ½و€§
هڈ‚考链وژ¥ï¼ڑ
CATï¼ڑ[https://github.com/dianping/cat](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Fdianping%2Fcat)
و·±ه؛¦ه‰–وگه¼€و؛گهˆ†ه¸ƒه¼ڈ监وژ§CATï¼ڑ[https://tech.meituan.com/2018/11/01/cat-in-depth-java-application-monitoring.html](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Ftech.meituan.com%2F2018%2F11%2F01%2Fcat-in-depth-java-application-monitoring.html)
**ن½œè€…ن؟،وپ¯ï¼ڑ**وژهˆڑ,网هگچن¹’ن¹“ç‹‚é”,é¥؟ن؛†ن¹ˆç›‘وژ§ç»„ç ”هڈ‘ن¸“ه®¶ï¼Œé¥؟ن؛†ن¹ˆه†…部و—¶ه؛ڈو•°وچ®ه؛“LinDBé،¹ç›®è´ںè´£ن؛؛,目ه‰چ致هٹ›ن؛ژ监وژ§çڑ„و™؛能هˆ†وگ领هںںم€‚
[هژںو–‡é“¾وژ¥](https://yq.aliyun.com/articles/724601?utm_content=g_1000084812)
وœ¬و–‡ن¸؛ن؛‘و –社هŒ؛هژںهˆ›ه†…ه®¹ï¼Œوœھç»ڈه…پ许ن¸چه¾—转载
====
**é¥؟ن؛†ن¹ˆç›‘وژ§ç³»ç»ںEMonitor**ï¼ڑوک¯ن¸€و¬¾وœچهٹ،ن؛ژé¥؟ن؛†ن¹ˆو‰€وœ‰وٹ€وœ¯éƒ¨é—¨çڑ„ن¸€ç«™ه¼ڈ监وژ§ç³»ç»ں,覆盖ن؛†ç³»ç»ں监وژ§م€په®¹ه™¨ç›‘وژ§م€پ网络监وژ§م€پن¸é—´ن»¶ç›‘وژ§م€پن¸ڑهٹ،监وژ§م€پوژ¥ه…¥ه±‚监وژ§ن»¥هڈٹه‰چ端监وژ§çڑ„و•°وچ®هکه‚¨ن¸ژوں¥è¯¢م€‚و¯ڈو—¥ه¤„çگ†و€»و•°وچ®é‡ڈè؟‘PB,و¯ڈو—¥ه†™ه…¥وŒ‡و ‡و•°وچ®é‡ڈ百T,و¯ڈو—¥وŒ‡و ‡وں¥è¯¢é‡ڈه‡ هچƒن¸‡ï¼Œé…چç½®ه›¾è،¨ن¸ھو•°ن¸ٹن¸‡ï¼Œçœ‹و؟ن¸ھو•°ن¸ٹهچƒم€‚
**CAT**ï¼ڑوک¯هں؛ن؛ژJava ه¼€هڈ‘çڑ„ه®و—¶ه؛”用监وژ§ه¹³هڈ°ï¼Œن¸؛ç¾ژه›¢ç‚¹è¯„وڈگن¾›ن؛†ه…¨é¢çڑ„ه®و—¶ç›‘وژ§ه‘ٹè¦وœچهٹ،
وœ¬و–‡é€ڑè؟‡ه¯¹و¯”هˆ†وگن¸‹2者و‰€هپڑçڑ„ن؛‹وƒ…ن¸؛ه¥‘وœ؛讨è®؛监وژ§ç³»ç»ںوˆ–许该وœ‰çڑ„é¢è²Œï¼Œن»¥هڈٹوµ…è°ˆن¸‹ç›‘وژ§ç³»ç»ںهڈ‘ه±•çڑ„هگ„ن¸ھéک¶و®µ
CATهپڑçڑ„ن؛‹وƒ…(ه¼€و؛گ版)
============
首ه…ˆè¦په¼؛è°ƒçڑ„وک¯è؟™é‡Œوˆ‘ن»¬هڈھ能و‹؟هˆ°[githubن¸ٹه¼€و؛گ版CAT](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Fdianping%2Fcat)çڑ„وœ€و–°ç‰ˆ3.0.0,و‰€ن»¥وک¯هں؛ن؛ژو¤è؟›è،Œه¯¹و¯”
وژ¥ن¸‹و¥è¯´è¯´CATهپڑن؛†ه“ھن؛›ن؛‹وƒ…ï¼ں
### 1 وٹ½è±،ه‡؛监وژ§و¨،ه‹
وٹ½è±،ه‡؛Transactionم€پEventم€پHeartbeatم€پMetric 4ç§چ监وژ§و¨،ه‹م€‚
* Transactionï¼ڑ用و¥è®°ه½•ن¸€و®µن»£ç پçڑ„و‰§è،Œو—¶é—´ه’Œو¬،و•°
* Eventï¼ڑ用و¥è®°ه½•ن¸€ن»¶ن؛‹هڈ‘ç”ںçڑ„و¬،و•°
* Heartbeatï¼ڑè،¨ç¤؛程ه؛ڈه†…ه®ڑوœںن؛§ç”ںçڑ„ç»ںè®،ن؟،وپ¯, ه¦‚CPUهˆ©ç”¨çژ‡
* Metricï¼ڑ用ن؛ژè®°ه½•ن¸ڑهٹ،وŒ‡و ‡ï¼Œهڈ¯ن»¥è®°ه½•و¬،و•°ه’Œو€»ه’Œ
é’ˆه¯¹Transactionه’ŒEvent都ه›؛ه®ڑن؛†2ن¸ھç»´ه؛¦ï¼Œtypeه’Œname,ه¹¶ن¸”é’ˆه¯¹typeه’Œnameè؟›è،Œهˆ†é’ںç؛§èپڑهگˆوˆگوٹ¥è،¨ه¹¶ه±•ç¤؛و›²ç؛؟م€‚

### 2 采و ·é“¾è·¯
é’ˆه¯¹ن¸ٹè؟°Transactionم€پEventçڑ„typeه’Œnameهˆ†هˆ«وœ‰ه¯¹ه؛”çڑ„هˆ†é’ںç؛§çڑ„采و ·é“¾è·¯

### 3 è‡ھه®ڑن¹‰çڑ„Metricو‰“点
ç›®ه‰چو”¯وŒپCounterه’ŒTimerç±»ه‹çڑ„و‰“点,و”¯وŒپtag,هچ•وœ؛ه†…هچ•ن¸ھMetricçڑ„tag组هگˆو•°é™گهˆ¶1000م€‚
ه¹¶ن¸”وœ‰ç®€هچ•çڑ„监وژ§çœ‹و؟,ه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ

### 4 ن¸ژه…¶ن»–组ن»¶é›†وˆگ
و¯”ه¦‚ه’ŒMybatis集وˆگ,هœ¨ه®¢وˆ·ç«¯ه¼€هگ¯ç›¸ه…³çڑ„sqlو‰§è،Œç»ںè®،,ه¹¶ه°†è¯¥ç»ںè®،هˆ’هˆ†هˆ°Transactionç»ںè®،看و؟ن¸çڑ„type=SQLçڑ„ن¸€و ڈن¸‹

### 5 ه‘ٹè¦
هڈ¯ن»¥é’ˆه¯¹ن¸ٹè؟°çڑ„Transactionم€پEventç‰هپڑن¸€ن؛›ç®€هچ•çڑ„éکˆه€¼ه‘ٹè¦
é¥؟ن؛†ن¹ˆEMonitorه’ŒCATçڑ„ه¯¹و¯”
==================
é¥؟ن؛†ن¹ˆEMonitorه€ں鉴ن؛†CATçڑ„相ه…³و€وƒ³ï¼ŒهگŒو—¶هڈˆè؟›è،Œن؛†و”¹è؟›م€‚
### 1 ه¼•ه…¥Transactionم€پEventçڑ„و¦‚ه؟µ
é’ˆه¯¹Transactionه’ŒEvent都ه›؛ه®ڑن؛†2ن¸ھç»´ه؛¦ï¼Œtypeه’Œname,ن¸چهگŒهœ°و–¹هœ¨ن؛ژèپڑهگˆç”¨وˆ·هڈ‘è؟‡و¥çڑ„و•°وچ®
CATçڑ„و¶و„ه›¾ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ

CATçڑ„و¶ˆè´¹وœ؛需è¦پهپڑه¦‚ن¸‹2ن»¶ن؛‹وƒ…ï¼ڑ
* ه¯¹Transactionم€پEventç‰و¶ˆوپ¯و¨،ه‹وŒ‰ç…§typeه’Œnameè؟›è،Œه½“ه‰چه°ڈو—¶çڑ„èپڑهگˆï¼Œهژ†هڈ²ه°ڈو—¶çڑ„èپڑهگˆو•°وچ®ه†™ه…¥هˆ°mysqlن¸
* ه°†é“¾è·¯و•°وچ®ه†™ه…¥هˆ°وœ¬هœ°و–‡ن»¶وˆ–者è؟œç¨‹HDFSن¸ٹ
EMonitorçڑ„و¶و„ه›¾ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ

EMonitorهˆ†2è·¯ه¯¹و•°وچ®è؟›è،Œéڑ”离ه¤„çگ†ï¼ڑ
* Real-Time Streaming Computeï¼ڑه¯¹ç”¨وˆ·هڈ‘è؟‡و¥çڑ„链路ن¸çڑ„Transactionم€پEventç‰ç›‘وژ§و¨،ه‹è½¬هڈکوˆگوŒ‡و ‡و•°وچ®ه¹¶è؟›è،Œ10sçڑ„预èپڑهگˆï¼ŒهگŒو—¶ن¹ںه¯¹ç”¨وˆ·هڈ‘è؟‡و¥çڑ„Metricو•°وچ®è؟›è،Œ10s预èپڑهگˆم€‚وœ€هگژه°†10s预èپڑهگˆçڑ„و•°وچ®ه†™ه…¥هˆ°[LinDBو—¶ه؛ڈو•°وچ®ه؛“](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Flindb%2Flindb)(ه·²ه¼€و؛گ,وœ‰ه…´è¶£çڑ„هڈ¯ن»¥ه…³و³¨starن¸‹ï¼‰ن¸ï¼Œن»¥هڈٹkafkaن¸ï¼Œè®©ه‘ٹè¦و¨،ه—watchdogهژ»و¶ˆè´¹kafkaهپڑه®و—¶ه‘ٹè¦
* Real-Time Data Writerï¼ڑه¯¹ç”¨وˆ·هڈ‘è؟‡و¥çڑ„链路و•°وچ®و„ه»؛链路索ه¼•م€پهگ‘HDFSه’ŒHBaseه†™ه…¥ç´¢ه¼•ه’Œé“¾è·¯و•°وچ®ï¼ŒهگŒو—¶ن¼ڑو„ه»؛ه؛”用ن¹‹é—´çڑ„ن¾èµ–ه…³ç³»ï¼Œه°†ن¾èµ–ه…³ç³»ه†™ه…¥هˆ°Neo4jن¸
و‰€ن»¥EMonitorه’ŒCATçڑ„ن¸€ن¸ھه¾ˆه¤§ن¸چهگŒç‚¹ه°±هœ¨ن؛ژه¯¹وŒ‡و ‡çڑ„ه¤„çگ†ن¸ٹ,EMonitorن؛¤ç»™ن¸“ن¸ڑçڑ„و—¶ه؛ڈو•°وچ®ه؛“و¥هپڑ,而CATè‡ھه·±هپڑèپڑهگˆه°±وک¾ه¾—هٹں能éه¸¸هڈ—é™گ,ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
* CATهڈھ能و•´ه°ڈو—¶çڑ„وں¥çœ‹typeه’Œnameو•°وچ®ï¼Œن¸چ能跨ه°ڈو—¶ï¼Œهچ³ن¸چ能وں¥çœ‹ن»»و„ڈ2ن¸ھو—¶é—´ن¹‹é—´çڑ„وٹ¥è،¨و•°وچ®ï¼ŒEMonitorو²،وœ‰و¤é™گهˆ¶
* CATو²،و³•وں¥çœ‹و‰€وœ‰typeو±‡و€»هگژçڑ„ه“چه؛”و—¶é—´ه’ŒQPS,EMonitorهڈ¯ن»¥çپµو´»çڑ„è‡ھ由组هگˆtypeه’Œnameè؟›è،Œèپڑهگˆ
* CATçڑ„typeه’Œnameوٹ¥è،¨وک¯هˆ†é’ںç؛§çڑ„,EMonitorوک¯10sç؛§هˆ«çڑ„
* CATçڑ„typeه’Œnameو²،能ه’Œهژ†هڈ²وٹ¥è،¨و›²ç؛؟ç›´وژ¥ه¯¹و¯”,EMonitorهڈ¯ن»¥ه¯¹و¯”هژ†هڈ²وٹ¥è،¨و›²ç؛؟,و›´ه®¹وک“هڈ‘çژ°é—®é¢ک
* CATçڑ„typeه’Œnameهˆ—è،¨é¦–é،µه±•ç¤؛ن؛†ن¸€ه †و•°ه—,و— و³•ç«‹هچ³èژ·هڈ–ن¸€ن؛›ç›´è§‚ن؟،وپ¯ï¼Œو¯”ه¦‚ç»™ه‡؛ن؛†ه“چه؛”و—¶é—´TP99 100msè؟™ن¸ھهˆ°ه؛•وک¯ه¥½è؟کوک¯هڈ,EMonitorوœ‰ه½“ه‰چو›²ç؛؟ه’Œهژ†هڈ²و›²ç؛؟,相ه¯¹و¥è¯´هڈ¯ن»¥ç›´وژ¥هˆ¤و–هˆ°ه؛•okن¸چok
* CATçڑ„TP99م€پTP999هں؛ن؛ژهچ•وœ؛ه†…وںگن¸ھه°ڈو—¶ه†…çڑ„وٹ¥è،¨وک¯ه‡†ç،®çڑ„,除و¤ن¹‹ه¤–ه¤ڑوœ؛وˆ–者ه¤ڑن¸ھه°ڈو—¶çڑ„èپڑهگˆTP99م€پTP999وک¯ç”¨هٹ وƒه¹³ه‡و¥è®،ç®—çڑ„,ه‡†ç،®و€§وœ‰ه¾…وڈگé«ک
ن½†وک¯CATن¹ںوœ‰è‡ھه·±çڑ„ن¼کهٹ؟ï¼ڑ
* CATهگ«وœ‰TP999م€پTP9999ç؛؟(ن½†وک¯ه‡†ç،®و€§è؟کوœ‰ن؛›é—®é¢ک),EMonitorهڈھ能细هˆ°TP99
* CATçڑ„typeه’Œnameهڈ¯ن»¥وŒ‰ç…§وœ؛ه™¨ç»´ه؛¦è؟›è،Œè؟‡و»¤ï¼ŒEMonitorو²،وœ‰هپڑهˆ°è؟™ن¹ˆç»†ç²’ه؛¦
### 2 采و ·é“¾è·¯
ç›®ه‰چCATه’ŒEMonitor都هڈ¯ن»¥é€ڑè؟‡typeه’Œnameو¥è؟‡و»¤é‡‡و ·é“¾è·¯ï¼Œن¸چهگŒç‚¹هœ¨ن؛ژ
* CATçڑ„采و ·é“¾è·¯وک¯هˆ†é’ںç؛§هˆ«çڑ„,EMonitorوک¯10sç؛§هˆ«çڑ„
* é’ˆه¯¹وںگن¸€ن¸ھtypeه’Œname,CATç›®ه‰چو— و³•è½»و¾و‰¾وƒ³è¦پçڑ„链路,EMonitorهڈ¯ن»¥è½»و¾çڑ„و‰¾هˆ°وںگن¸ھو—¶هˆ»وˆ–者说وںگو®µو—¶é—´ه†…ه“چه؛”و—¶é—´وƒ³è¦پçڑ„链路(目ه‰چه·²ç»ڈ申请ن¸“هˆ©ï¼‰
EMonitorçڑ„链路ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ

* è؟™ه¼ ه›¾وک¯وںگن¸ھ10sو—¶هˆ»م€پوںگن¸ھtypeه’Œnameè؟‡و»¤و،ن»¶ن¸‹çڑ„采و ·é“¾è·¯
* 第ن¸€è،Œوک¯è؟™10sه†…çڑ„采و ·é“¾è·¯ï¼ŒوŒ‰ç…§ه“چه؛”و—¶é—´è؟›è،Œن؛†وژ’ه؛ڈ
* هڈ¯ن»¥éڑڈو„ڈ点ه‡»وںگن¸ھه“چه؛”و—¶é—´و¥وں¥çœ‹ه¯¹ه؛”çڑ„链路详وƒ…
### 3آ è‡ھه®ڑن¹‰çڑ„Metricو‰“点
EMonitorو”¯وŒپCounterم€پTimerم€پHistogramم€پPayloadم€پGaugeç‰ç‰ه¤ڑç§چه½¢ه¼ڈçڑ„و‰“点و–¹ه¼ڈ,ه¹¶ن¸”و”¯وŒپtag
* Counterï¼ڑè®،و•°ç´¯هٹ ç±»ه‹
* Timerï¼ڑهڈ¯ن»¥è®°ه½•ن¸€و®µن»£ç پçڑ„耗و—¶ï¼ŒهŒ…هگ«و‰§è،Œو¬،و•°م€پ耗و—¶وœ€ه¤§ه€¼م€پوœ€ه°ڈه€¼م€په¹³ه‡ه€¼
* Histogramï¼ڑهŒ…هگ«Timerçڑ„و‰€وœ‰ن¸œè¥؟,هگŒو—¶و”¯وŒپè®،ç®—TP99ç؛؟,ن»¥هڈٹه…¶ن»–ن»»و„ڈTPç؛؟(ن»ژ0هˆ°100)
* Payloadï¼ڑهڈ¯ن»¥è®°ه½•ن¸€ن¸ھو•°وچ®هŒ…çڑ„ه¤§ه°ڈ,هŒ…هگ«و•°وچ®هŒ…ن¸ھو•°م€پهŒ…çڑ„وœ€ه¤§ه€¼م€پوœ€ه°ڈه€¼م€په¹³ه‡ه€¼
* Gaugeï¼ڑوµ‹é‡ڈه€¼ï¼Œن¸€èˆ¬ç”¨ن؛ژè،،é‡ڈéکںهˆ—ه¤§ه°ڈم€پè؟وژ¥و•°م€پCPUم€په†…هکç‰ç‰
ن¹ںه°±وک¯ن»»و„ڈMetricو‰“点都هڈ¯ن»¥وµپç»ڈEMonitorè؟›è،Œه¤„çگ†ن؛†ه¹¶è¾“é€پهˆ°LinDBو—¶ه؛ڈو•°وچ®ه؛“ن¸م€‚至و¤ï¼ŒEMonitorه°±هڈ¯ن»¥ه°†ن»»ن½•ç›‘وژ§وŒ‡و ‡ç»ںن¸€هœ¨ن¸€èµ·ن؛†ï¼Œو¯”ه¦‚وœ؛ه™¨ç›‘وژ§éƒ½هڈ¯ن»¥é€ڑè؟‡EMonitorو¥ن؟هکن؛†ï¼Œè؟™ن¸؛ن¸€ç«™ه¼ڈ监وژ§ç³»ç»ںه¥ ه®ڑن؛†هں؛ç،€
#### è‡ھه®ڑن¹‰Metric看و؟
CATهڈھوœ‰ن¸€ن¸ھ简وک“çڑ„Metric看و؟
EMonitoré’ˆه¯¹Metricه¼€هڈ‘ن؛†ن¸€ه¥—هڈ¯ن»¥هھ²ç¾ژGrafanaçڑ„وŒ‡و ‡çœ‹و؟,相و¯”Grafanaçڑ„ن¼کهٹ؟ï¼ڑ
* وœ‰ن¸€ه¥—ç±»ن¼¼SQLçڑ„éه¸¸ç®€هچ•çڑ„é…چç½®وŒ‡و ‡çڑ„و–¹ه¼ڈ
* è·ںه…¬هڈ¸ن؛؛ه‘ک组织و¶و„集وˆگ,و›´هٹ ن¼کé›…çڑ„وƒé™گوژ§هˆ¶ï¼Œن¸چهگŒçڑ„部门هڈ¯ن»¥ه»؛ه±ن؛ژè‡ھه·±çڑ„看و؟
* وŒ‡و ‡ه’Œçœ‹و؟çڑ„و”¶è—ڈ,ه½“و؛گوŒ‡و ‡وˆ–看و؟و”¹هٹ¨هگژ,و— 需و”¶è—ڈن؛؛ه‘که†چو”¹هٹ¨
* alphaم€پbetaم€پprodن¸چهگŒçژ¯ه¢ƒن¹‹é—´çڑ„ن¸€é”®هگŒو¥وŒ‡و ‡ه’Œçœ‹و؟,و— 需é…چç½®ه¤ڑو¬،
* PC端ه’Œç§»هٹ¨ç«¯çڑ„هگŒو¥وں¥çœ‹وŒ‡و ‡ه’Œçœ‹و؟
ç±»SQLçڑ„é…چç½®وں¥è¯¢وŒ‡و ‡و–¹ه¼ڈه¦‚ن¸‹و‰€ç¤؛ï¼ڑ

* هڈ¯ن»¥é…چç½®ه›¾è،¨çڑ„ه±•çژ°ه½¢ه¼ڈ
* هڈ¯ن»¥é…چç½®è¦پوں¥è¯¢çڑ„ه—و®µن»¥هڈٹه—و®µن¹‹é—´çڑ„هٹ ه‡ڈن¹ک除ç‰ن¸°ه¯Œçڑ„è،¨è¾¾ه¼ڈ
* هڈ¯ن»¥é…چç½®ه¤ڑن¸ھن»»و„ڈtagçڑ„è؟‡و»¤و،ن»¶
* هڈ¯ن»¥é…چç½®group byن»¥هڈٹorder by
看و؟و•´ن½“ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ

移هٹ¨ç«¯وک¾ç¤؛ه¦‚ن¸‹ï¼ڑ

### 4 ن¸ژه…¶ن»–组ن»¶é›†وˆگ

ç›®ه‰چEMonitorه·²ç»ڈو‰“é€ڑن؛†IaaSه±‚م€پPaaSه±‚م€په؛”用ه±‚çڑ„و‰€وœ‰é“¾è·¯ه’ŒوŒ‡و ‡çڑ„监وژ§ï¼Œه†چن¹ںن¸چ用هœ¨ه¤ڑن¸ھ监وژ§ç³»ç»ںن¸هˆ‡وچ¢و¥هˆ‡وچ¢هژ»ن؛†ï¼Œه¦‚ن¸‹و‰€ç¤؛

* 1 IaaSه±‚物çگ†وœ؛م€پوœ؛وˆ؟网络ن؛¤وچ¢وœ؛ç‰çڑ„监وژ§وŒ‡و ‡
* 2 PaaSه±‚ن¸é—´ن»¶وœچهٹ،端çڑ„监وژ§وŒ‡و ‡
* 3 ه؛”用ه±‚SOAم€پExceptionم€پJVMم€پMQç‰ه®¢وˆ·ç«¯çڑ„相ه…³وŒ‡و ‡
* 4 ه؛”用ه±‚è‡ھه®ڑن¹‰çڑ„监وژ§وŒ‡و ‡
ن»¥و‰“é€ڑé¥؟ن؛†ن¹ˆهˆ†ه؛“هˆ†è،¨ن¸é—´ن»¶DALن¸؛ن¾‹ï¼ڑ


* هڈ¯ن»¥و ¹وچ®وœ؛وˆ؟م€پو‰§è،Œçٹ¶و€پم€پè،¨م€پو“چن½œç±»ه‹ï¼ˆو¯”ه¦‚Insertم€پUpdateم€پSelectç‰ï¼‰è؟›è،Œè؟‡و»¤وں¥çœ‹
* ه·¦è¾¹هˆ—è،¨ç»™ه‡؛و¯ڈو،SQLçڑ„و‰§è،Œçڑ„ه¹³ه‡è€—و—¶
* هڈ³è¾¹2ن¸ھه›¾è،¨ç»™ه‡؛该و،SQLهœ¨DALن¸é—´ن»¶ه±‚é¢م€پDBه±‚é¢çڑ„耗و—¶ن»¥هڈٹ调用QPS
* هڈ¯ن»¥ç»™ه‡؛该SQLو‰“هœ¨هگژ端DALن¸é—´م€پDBن¸ٹçڑ„هˆ†ه¸ƒوƒ…ه†µï¼Œهڈ¯ن»¥ç”¨ن؛ژوژ’وں¥وک¯هگ¦هکهœ¨ن¸€ن؛›çƒç‚¹çڑ„وƒ…ه†µ
* è؟کوœ‰ن¸€ن؛›SQLوں¥è¯¢ç»“وœçڑ„و•°وچ®هŒ…ه¤§ه°ڈçڑ„و›²ç؛؟م€پSQL被DALé™گوµپçڑ„وƒ…ه†µç‰ç‰
* هڈ¯ن»¥وں¥çœ‹ن»»ن½•و—¶é—´ç‚¹ن¸ٹ该SQLçڑ„调用链路ن؟،وپ¯
ه†چن»¥و‰“é€ڑé¥؟ن؛†ن¹ˆSOAوœچهٹ،ن¸؛ن¾‹ï¼ڑ


* هڈ¯ن»¥و ¹وچ®وœ؛وˆ؟ه’Œçٹ¶و€پن؟،وپ¯è؟›è،Œè؟‡و»¤
* ه·¦è¾¹ن¸€و ڈهˆ—ه‡؛该ه؛”用وڈگن¾›çڑ„SOAوœچهٹ،وژ¥هڈ£ï¼ŒهگŒو—¶ç»™ه‡؛ه¹³ه‡ه“چه؛”و—¶é—´ن»¥هڈٹه’Œوک¨ه¤©çڑ„ه¯¹و¯”وƒ…ه†µ
* هڈ³è¾¹çڑ„2ن¸ھه›¾è،¨هˆ†هˆ«ç»™ه‡؛ن؛†ه¯¹ه؛”وœچهٹ،وژ¥هڈ£çڑ„وœچهٹ،ه“چه؛”و—¶é—´ه’ŒQPSن»¥هڈٹه’Œوک¨ه¤©çڑ„ه¯¹و¯”وƒ…ه†µï¼ŒهگŒو—¶هڈ¯ن»¥هˆ‡وچ¢ه¹³ه‡ه“چه؛”و—¶é—´هˆ°TP99وˆ–者ه…¶ن»–TPه€¼ï¼ŒهگŒو—¶é…چوœ‰هڈ¯ن»¥ه؟«é€ںه¯¹ç›¸ه…³و›²ç؛؟و·»هٹ ه‘ٹè¦çڑ„跳转链وژ¥
* هڈ¯ن»¥هˆ‡وچ¢هˆ°هچ•وœ؛ç»´ه؛¦و¥وں¥çœ‹و¯ڈهڈ°وœ؛ه™¨è¯¥SOAوژ¥هڈ£çڑ„ه“چه؛”و—¶é—´ه’ŒQPS,用و¥ه®ڑن½چوںگهڈ°وœ؛ه™¨çڑ„é—®é¢ک
* هڈ¯ن»¥ç»™ه‡؛该SOAوژ¥هڈ£è°ƒç”¨هœ¨ن¸چهگŒé›†ç¾¤çڑ„هˆ†ه¸ƒهچ و¯”
* هڈ¯ن»¥ç»™ه‡؛该SOAوژ¥هڈ£çڑ„و‰€وœ‰è°ƒç”¨و–¹ن»¥هڈٹن»–ن»¬çڑ„QPS
* هڈ¯ن»¥وں¥çœ‹ن»»ن½•و—¶é—´ç‚¹ن¸ٹ该SOAوژ¥هڈ£çڑ„调用链路ن؟،وپ¯
### 5 ه‘ٹè¦
هڈ¯ن»¥é’ˆه¯¹و‰€وœ‰çڑ„监وژ§وŒ‡و ‡é…چç½®ه¦‚ن¸‹ه‘ٹè¦و–¹ه¼ڈï¼ڑ
* éکˆه€¼ï¼ڑ简هچ•çڑ„éکˆه€¼ه‘ٹè¦ï¼Œé€‚用ن؛ژCPUم€په†…هکç‰
* هگŒçژ¯و¯”ï¼ڑن¸ژè؟‡هژ»هگŒوœںو¯”较çڑ„ه‘ٹè¦
* 趋هٹ؟ï¼ڑ适هگˆن؛ژ相ه¯¹ه¹³و»‘è؟ç»çڑ„و— 需éکˆه€¼çڑ„و™؛能ه‘ٹè¦
* ه…¶ن»–ه‘ٹè¦ه½¢ه¼ڈ
وµ…谈监وژ§ç³»ç»ںçڑ„هڈ‘ه±•è¶‹هٹ؟
===========
### 1 و—¥ه؟—监وژ§éک¶و®µ
وœ¬éک¶و®µه®çژ°و–¹ه¼ڈï¼ڑ程ه؛ڈو‰“و—¥ه؟—,ن½؟用ELKو¥هکه‚¨ه’Œوں¥è¯¢ç¨‹ه؛ڈçڑ„è؟گè،Œو—¥ه؟—,ELKن¹ں能简هچ•وک¾ç¤؛وŒ‡و ‡و›²ç؛؟
وژ’éڑœè؟‡ç¨‹ï¼ڑن¸€و—¦وœ‰é—®é¢ک,هˆ™هژ»ELKن¸وگœç´¢هڈ¯èƒ½çڑ„ه¼‚ه¸¸و—¥ه؟—و¥è؟›è،Œهˆ†وگوژ’éڑœ
### 2 链路监وژ§éک¶و®µ
ن¸ٹن¸€ن¸ھéک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑELKهڈھوک¯هں؛ن؛ژن¸€è،Œن¸€è،Œو—¥ه؟—è؟›è،Œèپڑهگˆوˆ–者وگœç´¢هˆ†وگ,و—¥ه؟—ن¹‹é—´و²،وœ‰ن¸ٹن¸‹و–‡ه…³èپ”م€‚ه¾ˆéڑ¾çں¥éپ“ن¸€و¬،请و±‚耗و—¶è¾ƒé•؟究ç«ں耗و—¶هœ¨ه“ھن¸ھéک¶و®µ
وœ¬éک¶و®µه®çژ°و–¹ه¼ڈï¼ڑCATو¨ھç©؛ه‡؛ن¸–,é€ڑè؟‡ه»؛و¨،وٹ½è±،ه‡؛Transactionم€پMetricç‰ç›‘وژ§و¨،ه‹ï¼Œه°†é“¾è·¯هˆ†وگه’Œç®€هچ•çڑ„وٹ¥è،¨ه¸¦ه…¥ن؛†ه¤§ه®¶çڑ„视é‡ژ
ه‘ٹè¦و–¹ه¼ڈï¼ڑé’ˆه¯¹وٹ¥è،¨هڈ¯ن»¥è؟›è،Œéکˆه€¼ç›‘وژ§
وژ’éڑœè؟‡ç¨‹ï¼ڑن¸€و—¦وœ‰ه‘ٹè¦ï¼Œهڈ¯ن»¥é€ڑè؟‡ç‚¹ه‡»وٹ¥è،¨و¥è¯¦ç»†ه®ڑن½چهˆ°وک¯ه“ھن¸ھtypeوˆ–nameوœ‰ن¸€ه®ڑé—®é¢ک,é،؛ن¾؟و‰¾هˆ°ه¯¹ه؛”çڑ„链路,وں¥çœ‹è¯¦ç»†çڑ„ن؟،وپ¯
### 3آ وŒ‡و ‡ç›‘وژ§éک¶و®µ
ن¸ٹن¸€éک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑCATه¯¹è‡ھه®ڑن¹‰وŒ‡و ‡و”¯وŒپçڑ„و¯”较ه¼±ï¼Œن¹ںو— و³•ه®çژ°وˆ–者ه±•çژ°و›´هٹ ه¤ڑو ·çڑ„وں¥è¯¢èپڑهگˆéœ€و±‚
وœ¬éک¶و®µçڑ„ه®çژ°و–¹ه¼ڈï¼ڑو”¯وŒپن¸°ه¯Œçڑ„MetricوŒ‡و ‡ï¼Œه°†é“¾è·¯ن¸ٹçڑ„ن¸€ن؛›وٹ¥è،¨و•°وچ®ن¹ںهڈ¯ن»¥هˆ’هˆ†هˆ°وŒ‡و ‡ن¸ï¼Œن؛¤ç»™ن¸“ن¸ڑçڑ„و—¶ه؛ڈو•°وچ®ه؛“و¥هپڑوŒ‡و ‡çڑ„هکه‚¨ه’Œوں¥è¯¢ï¼Œه¯¹وژ¥وˆ–者è‡ھç ”ن¸°ه¯Œçڑ„وŒ‡و ‡çœ‹و؟ه¦‚Grafana
ه‘ٹè¦و–¹ه¼ڈï¼ڑé’ˆه¯¹وŒ‡و ‡è؟›è،Œو›´هٹ ن¸°ه¯Œçڑ„ه‘ٹè¦ç–ç•¥
وژ’éڑœè؟‡ç¨‹ï¼ڑن¸€و—¦وœ‰ه‘ٹè¦ï¼Œهڈ¯èƒ½éœ€è¦پهˆ°هگ„ن¸ھç³»ç»ںن¸ٹوں¥çœ‹وŒ‡و ‡çœ‹و؟,粗略ه®ڑن½چو ¹ه› ,ه†چ结هگˆé“¾è·¯و€»ه’Œهˆ†وگ
### 4 ه¹³هڈ°و‰“é€ڑو•´هگˆéک¶و®µ
ن¸ٹن¸€éک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑç³»ç»ں监وژ§م€پن¸é—´ن»¶ه’Œن¸ڑهٹ،监وژ§م€پ部هˆ†ن¸ڑهٹ،监وژ§م€پ链路监وژ§ن¸ژوŒ‡و ‡ç›‘وژ§éƒ½هگ„وگن¸€ه¥—و•°وچ®و”¶é›†م€پ预ه¤„çگ†م€پهکه‚¨م€پوں¥è¯¢م€په±•çژ°م€په‘ٹè¦وµپ程,هگ„ن¸ھç³»ç»ںه¤„çگ†و•°وچ®و ¼ه¼ڈم€پن½؟用و–¹ه¼ڈن¸چç»ںن¸€
وœ¬éک¶و®µçڑ„ه®çژ°و–¹ه¼ڈï¼ڑو‰“é€ڑن»ژç³»ç»ںه±‚é¢م€په®¹ه™¨ه±‚é¢م€پن¸é—´ن»¶ه±‚é¢م€پن¸ڑهٹ،ه±‚é¢ç‰ç‰çڑ„هڈ¯èƒ½çڑ„链路ه’ŒوŒ‡و ‡ç›‘وژ§ï¼Œç»ںن¸€و•°وچ®çڑ„ه¤„çگ†وµپ程,هگŒو—¶و•´هگˆهڈ‘ه¸ƒم€پهڈکو›´م€په‘ٹè¦ن¸ژ监وژ§و›²ç؛؟结هگˆï¼Œوˆگن¸؛ن¸€ç«™ه¼ڈ监وژ§ه¹³هڈ°
ه‘ٹè¦و–¹ه¼ڈï¼ڑهڈ¯ن»¥ç»ںن¸€çڑ„é’ˆه¯¹هگ„ن¸ھه±‚é¢çڑ„监وژ§و•°وچ®هپڑç»ںن¸€هŒ–çڑ„ه‘ٹè¦
وژ’éڑœè؟‡ç¨‹ï¼ڑهڈھ需è¦پهœ¨ن¸€ن¸ھ监وژ§ç³»ç»ںن¸ه°±هڈ¯ن»¥وں¥çœ‹هˆ°و‰€وœ‰çڑ„监وژ§و›²ç؛؟ه’Œé“¾è·¯ن؟،وپ¯
ç›®ه‰چوˆ‘ن»¬EMonitorه·²ه®Œوˆگè؟™ن¸ھéک¶و®µï¼Œه°†ه…¬هڈ¸ن¹‹ه‰چهکهœ¨ه·²ن¹…çڑ„3ه¥—独立çڑ„监وژ§ç³»ç»ںç»ںن¸€و•´هگˆوˆگçژ°ه¦‚ن»ٹçڑ„ن¸€ه¥—监وژ§ç³»ç»ں
### 5آ و·±ه؛¦هˆ†وگéک¶و®µ
ن¸ٹن¸€éک¶و®µهکهœ¨çڑ„é—®é¢کï¼ڑ
* 用وˆ·è™½ç„¶هڈ¯ن»¥هœ¨ن¸€ن¸ھç³»ç»ںن¸çœ‹هˆ°و‰€وœ‰هگ„ن¸ھه±‚é¢çڑ„监وژ§و•°وچ®ن؛†ï¼Œن½†وک¯و¯ڈو¬،وژ’éڑœو—¶ن»چ然è¦پèٹ±ه¾ˆه¤ڑçڑ„و—¶é—´هژ»وں¥çœ‹هگ„ن¸ھه±‚é¢وک¯هگ¦وœ‰é—®é¢ک,ن¸€و—¦و¼ڈ看ن¸€é،¹هڈ¯èƒ½ه°±é”™è؟‡ن؛†é—®é¢کو‰€هœ¨çڑ„و ¹ه›
* و²،وœ‰و•´ن¸ھن¸ڑهٹ،çڑ„ه…¨ه±€ç›‘وژ§è§†è§’,都هپœç•™هœ¨هگ„è‡ھه؛”用çڑ„角ه؛¦
و€»ن¹‹ï¼ڑن¹‹ه‰چçڑ„éک¶و®µéƒ½وک¯هژ»هپڑن¸€ن¸ھ监وژ§ه¹³هڈ°ï¼Œç”¨وˆ·وں¥è¯¢ن»€ن¹ˆوŒ‡و ‡ه°±ه±•ç¤؛相ه؛”çڑ„و•°وچ®ï¼Œç›‘وژ§ه¹³هڈ°ه¹¶ن¸چهژ»ه…³ه؟ƒç”¨وˆ·و‰€هکه‚¨و•°وچ®çڑ„ه†…ه®¹م€‚çژ°هœ¨ه‘¢ه°±éœ€è¦پ转هڈکو€è·¯ï¼Œç›‘وژ§ه¹³هڈ°éœ€è¦پن¸»هٹ¨هژ»ه¸®ç”¨وˆ·هˆ†وگ里é¢و‰€هکه‚¨çڑ„و•°وچ®ه†…ه®¹
وœ¬éک¶و®µçڑ„ه®çژ°و–¹ه¼ڈï¼ڑو‰€è¦پهپڑçڑ„ه°±وک¯وٹٹه¸®ç”¨وˆ·هˆ†وگçڑ„è؟‡ç¨‹وٹ½è±،ه‡؛و¥ï¼Œن¸؛用وˆ·و„ه»؛ه؛”用ه¤§ç›که’Œن¸ڑهٹ،ه¤§ç›ک,ن»¥هڈٹن¸؛ه¤§ç›کهپڑ相ه…³çڑ„و ¹ه› هˆ†وگم€‚
* ه؛”用ه¤§ç›کï¼ڑه°±وک¯ن¸؛ه½“ه‰چه؛”用و„ه»؛ن¸ٹن¸‹و¸¸ه؛”用ن¾èµ–çڑ„监وژ§م€په½“ه‰چه؛”用و‰€ه…³èپ”çڑ„وœ؛ه™¨ç›‘وژ§م€پredisم€پMQم€پdatabaseç‰ç‰ç›‘وژ§ï¼Œهڈ¯ن»¥و—¶هˆ»ن¸؛ه؛”用هپڑن½“و£€ï¼Œو¥ن¸»هٹ¨وڑ´éœ²ه‡؛é—®é¢ک,而ن¸چوک¯ç‰ç”¨وˆ·هژ»ن¸€ن¸ھن¸ھوں¥وŒ‡و ‡è€Œهگژهڈ‘çژ°é—®é¢ک
* ن¸ڑهٹ،ه¤§ç›کï¼ڑه°±وک¯و ¹وچ®ن¸ڑهٹ،و¥و¢³çگ†وˆ–者هˆ©ç”¨é“¾è·¯و¥è‡ھهٹ¨ç”ںن؛§ه¤§ç›ک,该ه¤§ç›کهڈ¯ن»¥ه؟«é€ںه‘ٹ诉用وˆ·وک¯ه“ھن؛›ن¸ڑهٹ،çژ¯èٹ‚ه‡؛çڑ„é—®é¢ک
و ¹ه› هˆ†وگï¼ڑن¸€ن¸ھه¤§ç›کوœ‰ه¾ˆه¤ڑçڑ„çژ¯èٹ‚,و¯ڈن¸ھçژ¯èٹ‚绑ه®ڑوœ‰ه¾ˆه¤ڑçڑ„وŒ‡و ‡ï¼Œو¯ڈو¬،وںگن¸ھه‘ٹè¦ه‡؛و¥وœ‰هڈ¯èƒ½éœ€è¦پ详细çڑ„هˆ†وگن¸‹و¯ڈن¸ھçژ¯èٹ‚çڑ„وŒ‡و ‡ï¼Œو¯”ه¦‚و¶ˆè´¹kafkaçڑ„ه»¶è؟ںن¸ٹهچ‡ï¼Œوœ‰هگ„ç§چهگ„و ·çڑ„هژںه› 都هڈ¯èƒ½ه¯¼è‡´ï¼Œو¯ڈو¬،ه‘ٹè¦وژ’وں¥éƒ½éœ€è¦په°†هˆ†وگوµپ程ه†چه…¨éƒ¨ن؛؛ن¸؛هˆ†وگوژ’وں¥ن¸‹ï¼Œéه¸¸ç´¯ï¼Œو‰€ن»¥éœ€è¦په°†ه®ڑن½چو ¹ه› çڑ„è؟‡ç¨‹é€ڑè؟‡ه»؛و¨،وٹ½è±،ن¸‹ï¼Œو¥è؟›è،Œç»ںن¸€è§£ه†³
趋هٹ؟وٹ¥è،¨هˆ†وگï¼ڑن¸»هٹ¨ه¸®ç”¨وˆ·هڈ‘çژ°ن¸€ن؛›é€گو¸گوپ¶هŒ–çڑ„é—®é¢ک点,و¯”ه¦‚用وˆ·هڈ‘ه¸ƒن¹‹هگژ,وژ¥هڈ£è€—و—¶ه¢هٹ ,ه¾ˆهڈ¯èƒ½ç”¨وˆ·و²،وœ‰هڈ‘çژ°ï¼Œè™½ç„¶ه½“ه‰چو²،وœ‰é—®é¢ک,ن½†وک¯ه¾ˆوœ‰هڈ¯èƒ½هœ¨وکژه¤©çڑ„é«که³°وœںه°±ن¼ڑوڑ´éœ²é—®é¢ک,è؟™ن؛›éƒ½وک¯ه·²ç»ڈه®ه®هœ¨هœ¨هڈ‘ç”ںçڑ„ن؛‹و•…
è¦پوƒ³هپڑن¸»هٹ¨هˆ†وگ,è؟کو·±ه؛¦ن¾èµ–وŒ‡و ‡ن¸‹é’»هˆ†وگ,هچ³وںگن¸ھوŒ‡و ‡è°ƒç”¨é‡ڈن¸‹é™چن؛†ï¼Œèƒ½ن¸»هٹ¨هˆ†وگه‡؛وک¯ه“ھن؛›tagç»´ه؛¦ç»„هگˆه¯¼è‡´çڑ„ن¸‹é™چ,è؟™وک¯ن¸ٹè؟°ه¾ˆه¤ڑو™؛能هˆ†وگçڑ„هں؛ç،€ï¼Œè؟™ن¸€ه—ن¹ںن¸چ简هچ•
ه‘ٹè¦و–¹ه¼ڈï¼ڑهڈ¯ن»¥ç»ںن¸€çڑ„é’ˆه¯¹هگ„ن¸ھه±‚é¢çڑ„监وژ§و•°وچ®هپڑç»ںن¸€هŒ–çڑ„ه‘ٹè¦
وژ’éڑœè؟‡ç¨‹ï¼ڑNOCو ¹وچ®ن¸ڑهٹ،وŒ‡و ‡وˆ–者ن¸ڑهٹ،ه¤§ç›که؟«é€ںه¾—çں¥وک¯ه“ھن؛›ن¸ڑهٹ،وˆ–者ه؛”用ه‡؛ه…ˆن؛†é—®é¢ک,ه؛”用çڑ„owneré€ڑè؟‡ه؛”用ه¤§ç›کçڑ„ن½“و£€ه¾—çں¥ç›¸ه…³çڑ„هڈکهٹ¨ن؟،وپ¯ï¼Œو¯”ه¦‚وک¯redisو³¢هٹ¨م€پdatabaseو³¢هٹ¨م€پن¸ٹن¸‹و¸¸ه؛”用çڑ„وںگن¸ھو–¹و³•و³¢هٹ¨ç‰ç‰ï¼Œو¥è¾¾هˆ°ه؟«é€ںه®ڑن½چé—®é¢کç›®çڑ„,وˆ–者é€ڑè؟‡ه¯¹ه¤§ç›کو‰§è،Œو ¹ه› هˆ†وگو¥ه®ڑن½چهˆ°و ¹ه›
ه†چè°ˆLoggingم€پTracingم€پMetrics
=========================
ه¸¸è§پن¸€ه¼ 3者ه…³ç³»çڑ„ه›¾

ن¸‰è€…çڑ„ç،®éƒ½ن¸چهڈ¯وˆ–ç¼؛,相辅相وˆگ,ن½†وک¯وˆ‘وƒ³è¯´ن»¥ن¸‹ه‡ 点ï¼ڑ
* ن¸‰è€…هœ¨ç›‘وژ§وژ’éڑœن¸çڑ„و‰€هچ و¯”ن¾‹هچ´ه¤§ن¸چن¸€و ·ï¼ڑMetricsهچ وچ®ه¤§ه¤´ï¼ŒTracingو¬،ن¹‹ï¼ŒLoggingوœ€هگژ
* Tracingهگ«وœ‰é‡چè¦پçڑ„ه؛”用ن¹‹é—´çڑ„ن¾èµ–ن؟،وپ¯ï¼ŒMetricsوœ‰و›´ه¤ڑçڑ„هڈ¯و·±ه؛¦هˆ†وگه’ŒوŒ–وژکçڑ„ç©؛间,و‰€ن»¥وœھو¥ه؟…然وک¯هœ¨Metricsن¸ٹه¤§هپڑو–‡ç« ,ه†چ结هگˆTracingن¸çڑ„ه؛”用ن¾èµ–و¥هپڑو›´و·±ه؛¦ه…¨ه±€هˆ†وگ,هچ³Metricsه’ŒTracingن¸¤è€…结هگˆهڈ‘وŒ¥ه‡؛و›´ه¤ڑçڑ„هڈ¯èƒ½و€§
هڈ‚考链وژ¥ï¼ڑ
CATï¼ڑ[https://github.com/dianping/cat](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fgithub.com%2Fdianping%2Fcat)
و·±ه؛¦ه‰–وگه¼€و؛گهˆ†ه¸ƒه¼ڈ监وژ§CATï¼ڑ[https://tech.meituan.com/2018/11/01/cat-in-depth-java-application-monitoring.html](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Ftech.meituan.com%2F2018%2F11%2F01%2Fcat-in-depth-java-application-monitoring.html)
**ن½œè€…ن؟،وپ¯ï¼ڑ**وژهˆڑ,网هگچن¹’ن¹“ç‹‚é”,é¥؟ن؛†ن¹ˆç›‘وژ§ç»„ç ”هڈ‘ن¸“ه®¶ï¼Œé¥؟ن؛†ن¹ˆه†…部و—¶ه؛ڈو•°وچ®ه؛“LinDBé،¹ç›®è´ںè´£ن؛؛,目ه‰چ致هٹ›ن؛ژ监وژ§çڑ„و™؛能هˆ†وگ领هںںم€‚
[هژںو–‡é“¾وژ¥](https://yq.aliyun.com/articles/724601?utm_content=g_1000084812)
وœ¬و–‡ن¸؛ن؛‘و –社هŒ؛هژںهˆ›ه†…ه®¹ï¼Œوœھç»ڈه…پ许ن¸چه¾—转载
هˆ†ن؛«هˆ°ï¼ڑ


- 2019-11-12 15:19
- وµڈ览 440
- 评è®؛(0)
- هˆ†ç±»:éوٹ€وœ¯
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

相ه…³وژ¨èچگ
وœ¬و–‡ن¸»è¦په¯¹و¯”ن؛†é¥؟ن؛†ن¹ˆçڑ„EMonitorه’Œç¾ژه›¢ç‚¹è¯„çڑ„CATن¸¤ن¸ھ监وژ§ç³»ç»ںم€‚ م€گCAT简ن»‹م€‘ CAT(Cat-Client Application Trace)وک¯ن¸€و¬¾ç”±ç¾ژه›¢ç‚¹è¯„ه¼€هڈ‘çڑ„ه®و—¶ه؛”用监وژ§ه¹³هڈ°ï¼Œن¸»è¦پهٹں能هŒ…و‹¬ن؛‹هٹ،(Transaction)م€پن؛‹ن»¶ï¼ˆEvent)م€پ...
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ç”¨ن؛ژو™؛能车ç«èµ›ه¾®ç¼©ç”µç£پ组çڑ„و— ç؛؟ه……电LCC-Sن»؟çœںو¨،ه‹م€‚该و¨،ه‹é‡‡ç”¨Simulinkوگه»؛,ن¸»è¦پé’ˆه¯¹48V输ه…¥م€پ1000W输ه‡؛çڑ„و— ç؛؟ه……电系ç»ںè؟›è،Œن»؟çœںم€‚و–‡ن¸ن¸چن»…وڈگن¾›ن؛†ه…·ن½“çڑ„è°گوŒ¯هڈ‚و•°ï¼ˆه¦‚L1=35uH,C1=62nF,C2=72nF),è؟کهˆ†ن؛«ن؛†è°ƒو•´و»هŒ؛و—¶é—´م€پ耦هگˆç³»و•°م€پè´ںè½½çھپهڈکوµ‹è¯•ç‰ه®è·µç»ڈéھŒم€‚و¤ه¤–,ن½œè€…ه¼؛è°ƒن؛†ه®é™…ه؛”用ن¸çڑ„و³¨و„ڈن؛‹é،¹ï¼Œه¦‚ه…ƒن»¶é€‰ه‹م€پو•£çƒè®¾è®،ن»¥هڈٹن»؟çœںن¸ژçژ°ه®ه·®ه¼‚çڑ„ه¤„çگ†و–¹و³•م€‚ 适هگˆن؛؛群ï¼ڑهڈ‚ن¸ژو™؛能车ç«èµ›çڑ„ه¦ç”ںه’Œوٹ€وœ¯çˆ±ه¥½è€…,ه°¤ه…¶وک¯ه¯¹و— ç؛؟ه……电وٹ€وœ¯ه’Œç”µهٹ›ç”µهگو„ںه…´è¶£çڑ„读者م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑâ‘ ه¸®هٹ©هڈ‚èµ›éکںن¼چه؟«é€ںه»؛ç«‹é«کو•ˆçڑ„و— ç؛؟ه……电系ç»ںن»؟çœںو¨،ه‹ï¼›â‘،وŒ‡ه¯¼ه®é™…ç،¬ن»¶وگه»؛è؟‡ç¨‹ن¸هڈ‚و•°çڑ„选و‹©ه’Œن¼کهŒ–;③وڈگé«کç³»ç»ںو•ˆçژ‡ï¼Œç،®ن؟هœ¨و¯”èµ›ن¸çڑ„هڈ¯é و€§ه’Œو€§èƒ½م€‚ ه…¶ن»–说وکژï¼ڑوœ¬و–‡وڈگن¾›çڑ„و¨،ه‹ه·²هœ¨Matlab 2023bن¸éھŒè¯پهڈ¯è،Œï¼Œه»؛è®®ن½؟用者و ¹وچ®ه®é™…وƒ…ه†µè°ƒو•´هڈ‚و•°ï¼Œه¹¶ه…³و³¨ن»؟çœںن¸ژه®é™…ه؛”用ن¹‹é—´çڑ„ه·®ه¼‚م€‚
هں؛ن؛ژspringboot+vueçڑ„è€ƒç ”èµ„è®¯ه¹³هڈ°ç®،çگ†ç³»ç»ںï¼ڑه‰چ端 vue2م€پelement-ui,هگژ端 mavenم€پspringmvcم€پspringم€پmybatis;角色هˆ†ن¸؛ç®،çگ†ه‘کم€په¦ç”ں;集وˆگè€ƒç ”èµ„è®¯م€پوٹ¥è€ƒوŒ‡هچ—م€پ资و–™ن؟،وپ¯م€په®¢وœچç‰هٹں能ن؛ژن¸€ن½“çڑ„ç³»ç»ںم€‚ ## çژ¯ه¢ƒ-239 - <b>IntelliJ IDEA 2021.3</b> - <b>Mysql 5.7.26</b> - <b>Node 14.14.0</b> - <b>JDK 1.8</b>
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه°†وŒ¯هٹ¨ن؟،هڈ·è½¬هŒ–ن¸؛ن؛Œç»´ه›¾هƒڈه¹¶هˆ©ç”¨Transformerè؟›è،Œè½´و‰؟و•…éڑœè¯ٹو–çڑ„و–¹و³•م€‚首ه…ˆï¼Œé€ڑè؟‡و ¼و‹‰ه§†è§’هœ؛(GADF)م€په°ڈو³¢هڈکوچ¢ï¼ˆDWT)ه’Œçںو—¶ه‚…ç«‹هڈ¶هڈکوچ¢ï¼ˆSTFT)ه°†ن¸€ç»´وŒ¯هٹ¨ن؟،هڈ·è½¬وچ¢ن¸؛ن؛Œç»´ه›¾هƒڈم€‚然هگژ,و„ه»؛ن؛†ن¸€ن¸ھهں؛ن؛ژTransformerçڑ„视觉و¨،ه‹ï¼Œç”¨ن؛ژوچ•وچ‰ه›¾هƒڈçڑ„ه…¨ه±€ç‰¹ه¾پم€‚ه®éھŒç»“وœوک¾ç¤؛,该و–¹و³•هœ¨ه‡¯و–¯è¥؟ه‚¨ه¤§ه¦è½´و‰؟و•°وچ®é›†ن¸ٹè¾¾هˆ°ن؛†98.7%çڑ„ه‡†ç،®çژ‡ï¼Œه°¤ه…¶هœ¨ن½ژن؟،ه™ھو¯”çژ¯ه¢ƒن¸‹çڑ„è،¨çژ°ن¼کن؛ژن¼ ç»ںو–¹و³•م€‚و¤ه¤–,و–‡ن¸وڈگن¾›ن؛†è¯¦ç»†çڑ„ن»£ç په®çژ°ه’Œو•°وچ®é¢„ه¤„çگ†و¥éھ¤ï¼Œن»¥هڈٹن¸€ن؛›ه®ç”¨çڑ„è®ç»ƒوٹ€ه·§م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹وœ؛و¢°و•…éڑœè¯ٹو–çڑ„ç ”ç©¶ن؛؛ه‘که’Œوٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯ه¯¹و·±ه؛¦ه¦ن¹ ه؛”用ن؛ژه·¥ن¸ڑ设ه¤‡ç›‘وµ‹و„ںه…´è¶£çڑ„读者م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژه·¥ن¸ڑçژ¯ه¢ƒن¸وœ؛و¢°è®¾ه¤‡çڑ„و•…éڑœé¢„وµ‹ن¸ژهپ¥ه؛·ç®،çگ†م€‚ن¸»è¦پç›®و ‡وک¯وڈگé«کو•…éڑœو£€وµ‹çڑ„ه‡†ç،®و€§ï¼Œç‰¹هˆ«وک¯هœ¨ه¤چو‚ه·¥ه†µه’Œن½ژن؟،ه™ھو¯”وƒ…ه†µن¸‹ï¼Œه¸®هٹ©ç»´وٹ¤ه›¢éکںهڈٹو—¶هڈ‘çژ°و½œهœ¨é—®é¢ک,é™چن½ژç»´ن؟®وˆگوœ¬م€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگهˆ°çڑ„و‰€وœ‰ن»£ç په’Œé¢„è®ç»ƒو¨،ه‹ه‡ه·²ه¼€و؛گ,هڈ¯ن¾›ç ”究ه’Œو•™ه¦ن½؟用م€‚هگŒو—¶ï¼Œن½œè€…هˆ†ن؛«ن؛†ن¸€ن؛›ه®è·µç»ڈéھŒï¼Œه¦‚و•°وچ®ه¢ه¼؛ç–ç•¥çڑ„选و‹©ه’Œن؟،هڈ·هژ»ه™ھو–¹و³•çڑ„ه؛”用,وœ‰هٹ©ن؛ژ读者و›´ه¥½هœ°çگ†è§£ه’Œه¤چçژ°ه®éھŒç»“وœم€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡و،£وک¯م€ٹهچ،ç پ网-25ç§چACM输ه…¥è¾“ه‡؛و€»ç»“و¨،و؟.pdfم€‹ï¼Œç”±ç¨‹ه؛ڈه‘کCarlç¼–ه†™ï¼Œو—¨هœ¨ه¸®هٹ©è¯»è€…وژŒوڈ،ACMç«èµ›ن¸ه¸¸è§پçڑ„25ç§چ输ه…¥è¾“ه‡؛و–¹ه¼ڈم€‚و–‡و،£è¯¦ç»†ن»‹ç»چن؛†ه¤ڑç§چ编程è¯è¨€ï¼ˆه¦‚C++م€پJavaم€پPythonم€پGoم€پJavaScriptç‰ï¼‰çڑ„ه®çژ°و–¹و³•ï¼Œو¶µç›–ن؛†ن»ژ简هچ•çڑ„A+Bé—®é¢کهˆ°ه¤چو‚çڑ„链è،¨و“چن½œم€پن؛Œهڈ‰و ‘éپچهژ†ç‰هگ„ç±»ه…¸ه‹é¢کç›®م€‚و¯ڈç§چ输ه…¥è¾“ه‡؛و–¹ه¼ڈه‡é…چوœ‰ç›¸ه؛”çڑ„练ن¹ é¢ک,ه¸®هٹ©è¯»è€…é€ڑè؟‡ه®é™…و“چن½œهٹ و·±çگ†è§£م€‚و¤ه¤–,و–‡و،£ن¸چن»…وڈگن¾›ن»£ç پو¨،و؟,è؟که¼؛è°ƒن؛†ه¯¹é—®é¢کçڑ„هˆ†وگه’Œè§£ه†³و€è·¯م€‚ 适هگˆن؛؛群ï¼ڑه…·ه¤‡ن¸€ه®ڑ编程هں؛ç،€ï¼Œه°¤ه…¶وک¯ه‡†ه¤‡هڈ‚هٹ ACMç«èµ›وˆ–ن»ژن؛‹ç®—و³•ç›¸ه…³ه·¥ن½œçڑ„ه¼€هڈ‘者م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑâ‘ ه¸®هٹ©è¯»è€…ه؟«é€ںوژŒوڈ،ACMç«èµ›ن¸ه¸¸è§پçڑ„输ه…¥è¾“ه‡؛و ¼ه¼ڈï¼›â‘،وڈگé«ک编程و•ˆçژ‡ï¼Œه‡ڈه°‘هœ¨ç¬”试ه’Œé¢è¯•ن¸ه› 输ه…¥è¾“ه‡؛ه¤„çگ†ن¸چه½“而وµھè´¹çڑ„و—¶é—´ï¼›â‘¢é€ڑè؟‡ç»ƒن¹ é¢که·©ه›؛و‰€ه¦çں¥è¯†ï¼Œوڈگهچ‡è§£ه†³ه®é™…é—®é¢کçڑ„能هٹ›م€‚ éک…读ه»؛è®®ï¼ڑç”±ن؛ژو–‡و،£ن¾§é‡چن؛ژ输ه…¥è¾“ه‡؛و¨،و؟çڑ„و€»ç»“,ه»؛议读者هœ¨ه¦ن¹ è؟‡ç¨‹ن¸ç»“هگˆه…·ن½“çڑ„编程è¯è¨€ç‰¹و€§è؟›è،Œه®è·µï¼Œه¹¶ه°è¯•ه®Œوˆگوڈگن¾›çڑ„练ن¹ é¢ک,ن»¥هٹ و·±ه¯¹و¨،و؟çڑ„çگ†è§£ه’Œه؛”用م€‚هگŒو—¶ï¼Œو³¨و„ڈن¸چهگŒè¯è¨€ن¹‹é—´çڑ„è¯و³•ه·®ه¼‚,çپµو´»è؟گ用و‰€ه¦çں¥è¯†م€‚
هں؛ن؛ژspringbootçڑ„هپ¥è؛«ن¸ه؟ƒن¼ڑه‘کç®،çگ†ç³»ç»ںï¼ڑه‰چ端 jspم€پjquery,هگژ端 mavenم€پspringmvcم€پspringم€پmybatis;角色هˆ†ن¸؛ç®،çگ†ه‘کم€پ用وˆ·ï¼›é›†وˆگن¼ڑه‘کهچ،م€پ留言و؟م€په…¬ه‘ٹم€پç»ںè®،وٹ¥è،¨ç‰هٹں能ن؛ژن¸€ن½“çڑ„ç³»ç»ںم€‚ ## هٹں能ن»‹ç»چ ### ه®¢وˆ· - هں؛وœ¬هٹں能ï¼ڑç™»ه½•ï¼Œé€€ه‡؛,ن¸ھن؛؛资و–™وں¥çœ‹ن¸ژن؟®و”¹ï¼Œه¯†ç پن؟®و”¹ - وˆ‘çڑ„ن¼ڑه‘کهچ،ï¼ڑن¼ڑه‘کهچ،وں¥è¯¢ï¼Œè¯¦وƒ… - ه……ه€¼ن؟،وپ¯ï¼ڑه……ه€¼ن؟،وپ¯çڑ„هˆ—è،¨وں¥è¯¢ï¼Œه¤ڑو،ن»¶وگœç´¢وں¥è¯¢ï¼Œè¯¦وƒ… - وˆ‘çڑ„و¶ˆè´¹è®°ه½•ï¼ڑو¶ˆè´¹è®°ه½•وں¥è¯¢ï¼Œه¤ڑو،ن»¶وگœç´¢وں¥è¯¢ï¼Œè¯¦وƒ… ### ç®،çگ†ه‘ک - è´¦هڈ·ç®،çگ†ï¼ڑç®،çگ†ه‘کè´¦هڈ·ن؟،وپ¯çڑ„ه¢هˆ و”¹وں¥ï¼Œه¯†ç پن؟®و”¹ - ه…¬ه‘ٹç®،çگ†ï¼ڑه…¬ه‘ٹن؟،وپ¯çڑ„ه¢هˆ و”¹وں¥ - ه®¢وˆ·ç®،çگ†ï¼ڑه®¢وˆ·ن؟،وپ¯çڑ„ه¢هˆ و”¹وں¥ - ن¼ڑه‘کهچ،ç®،çگ†ï¼ڑن¼ڑه‘کهچ،ن؟،وپ¯çڑ„ه¢هˆ و”¹وں¥ï¼Œه¤ڑو،ن»¶وگœç´¢وں¥è¯¢ï¼Œن¼ڑه‘کهچ،ه……ه€¼ - 留言و؟ç®،çگ†ï¼ڑ留言و؟ن؟،وپ¯çڑ„هˆ—è،¨وں¥è¯¢ï¼Œç•™è¨€ه›ه¤چ - ç»ںè®،وٹ¥è،¨ç®،çگ†ï¼ڑو¶ˆè´¹ن؟،وپ¯çڑ„وں¥è¯¢ç»ںè®،,ه……ه€¼ن؟،وپ¯çڑ„وں¥è¯¢ç»ںè®، ## çژ¯ه¢ƒ - <b>IntelliJ IDEA 2021.3</b> - <b>Mysql 5.7.26</b> - <b>Tomcat 7.0.73</b> - <b>JDK 1.8</b>
هں؛ن؛ژspringbootçڑ„و•™è‚²ن؛’هٹ©ç®،çگ†ç³»ç»ںï¼ڑه‰چ端 htmlم€پjquery,هگژ端 mavenم€پspringmvcم€پspringم€پmybatis;角色هˆ†ن¸؛ç®،çگ†ه‘کم€پ用وˆ·ï¼›é›†وˆگن؛¤وµپهٹ¨و€پم€پوˆ‘çڑ„ه¹³هڈ°م€پوˆ‘çڑ„ه¥½هڈ‹م€پن؛’هٹ©è¯„è®؛م€پو•™è‚²ن؛’هٹ©ç‰هٹں能ن؛ژن¸€ن½“çڑ„ç³»ç»ںم€‚ ## çژ¯ه¢ƒ-236 - <b>IntelliJ IDEA 2021.3</b> - <b>Mysql 5.7.26</b> - <b>JDK 1.8</b>
multisim
و‰‹ç»که½©è™¹ه°ڈه¤ھéک³ه¹¼ه„؟و•™ه¦è¯¾ن»¶و¨،و؟
SH3201و•°وچ®و‰‹ه†Œه’Œن»£ç پ.tar ن؛§ه“پ简ن»‹ SH3201وک¯ن¸€و¬¾ه…è½´IMU(Inertial measurement unit)وƒ¯و€§وµ‹é‡ڈهچ•ه…ƒم€‚SH3201ه†…部集وˆگن¸‰è½´é™€è؛ن»ھن»¥هڈٹن¸‰è½´هٹ é€ںه؛¦è®،,ه°؛ه¯¸ه°ڈ,هٹں耗ن½ژ,适用ن؛ژو¶ˆè´¹ç”µهگه¸‚هœ؛ه؛”用,能وڈگن¾›é«کç²¾ه؛¦çڑ„ه®و—¶è§’é€ںه؛¦ن¸ژç؛؟هٹ é€ںه؛¦و•°وچ®م€‚SH3201ه…·وœ‰ه‡؛色çڑ„و¸©ه؛¦ç¨³ه®ڑو€§ï¼Œهœ¨-40℃هˆ°85℃çڑ„ه·¥ن½œèŒƒه›´ه†…能ن؟وŒپé«کهˆ†è¾¨çژ‡م€‚ ه°پ装ه½¢ه¼ڈه’Œه°؛ه¯¸ â—ڈ ه°پ装ï¼ڑ14 Pins LGA â—ڈ ه°؛ه¯¸ï¼ڑ2.5أ—3.0أ—1.0mmآ³
و•°وچ®é›†ن»‹ç»چï¼ڑè‡ھهٹ¨é©¾é©¶ه¤ڑç±»ن؛¤é€ڑç›®و ‡و£€وµ‹و•°وچ®é›† ن¸€م€پهں؛ç،€ن؟،وپ¯ و•°وچ®é›†هگچ称ï¼ڑè‡ھهٹ¨é©¾é©¶ه¤ڑç±»ن؛¤é€ڑç›®و ‡و£€وµ‹و•°وچ®é›† ه›¾ç‰‡و•°é‡ڈï¼ڑ - è®ç»ƒé›†ï¼ڑ2,868ه¼ ه›¾ç‰‡ - éھŒè¯پ集ï¼ڑ30ه¼ ه›¾ç‰‡ - وµ‹è¯•é›†ï¼ڑ301ه¼ ه›¾ç‰‡ هˆ†ç±»ç±»هˆ«ï¼ڑ - Bikes(è‡ھè،Œè½¦ï¼‰ï¼ڑن؛¤é€ڑهœ؛و™¯ن¸ه¸¸è§پéوœ؛هٹ¨è½¦ç±»ه‹ - Bus(ه…¬ن؛¤è½¦ï¼‰ï¼ڑه¤§ه‹ه…¬ه…±ن؛¤é€ڑه·¥ه…· - Car(و±½è½¦ï¼‰ï¼ڑن¸»وµپوœ؛هٹ¨è½¦è¾†ç±»ه‹ - Crosswalk(ن؛؛è،Œو¨ھéپ“)ï¼ڑéپ“è·¯ه®‰ه…¨و ‡è¯† - Fire hydrant(و¶ˆéک²و “)ï¼ڑهںژه¸‚هں؛ç،€è®¾و–½ç»„ن»¶ و ‡و³¨و ¼ه¼ڈï¼ڑ YOLOو ¼ه¼ڈ,هŒ…هگ«ç›®و ‡و£€وµ‹و‰€éœ€çڑ„边界و،†هگو ‡هڈٹç±»هˆ«و ‡ç¾ï¼Œو”¯وŒپن¸»وµپو·±ه؛¦ه¦ن¹ و،†و¶م€‚ و•°وچ®و¥و؛گï¼ڑçœںه®éپ“è·¯هœ؛و™¯é‡‡é›†ï¼Œو¶µç›–ه¤ڑو ·ن؛¤é€ڑçژ¯ه¢ƒم€‚ ن؛Œم€پ适用هœ؛و™¯ è‡ھهٹ¨é©¾é©¶و„ںçں¥ç³»ç»ںه¼€هڈ‘ï¼ڑ 用ن؛ژè®ç»ƒè½¦è¾†çژ¯ه¢ƒو„ںçں¥و¨،ه‹ï¼Œç²¾ه‡†è¯†هˆ«éپ“è·¯هڈ‚ن¸ژ者(车辆م€پè،Œن؛؛)هڈٹه…³é”®هں؛ç،€è®¾و–½ï¼ˆن؛؛è،Œéپ“م€پو¶ˆéک²و “)م€‚ و™؛能ن؛¤é€ڑ监وژ§ç³»ç»ںï¼ڑ و”¯وŒپه¼€هڈ‘ه®و—¶ن؛¤é€ڑوµپé‡ڈهˆ†وگç³»ç»ں,识هˆ«è½¦è¾†ç±»ه‹هڈٹéپ“è·¯ه®‰ه…¨و ‡è¯†م€‚ éپ“è·¯ه®‰ه…¨ç ”究ï¼ڑ ن¸؛ن؛¤هڈ‰è·¯هڈ£ه®‰ه…¨هˆ†وگم€پهں؛ç،€è®¾و–½ه¸ƒه±€ن¼کهŒ–وڈگن¾›و•°وچ®و”¯و’‘م€‚ AIç®—و³•هں؛ه‡†وµ‹è¯•ï¼ڑ 适用ن؛ژç›®و ‡و£€وµ‹و¨،ه‹و€§èƒ½éھŒè¯پ,覆盖ه¸¸è§پن؛¤é€ڑç›®و ‡ç±»هˆ«م€‚ ن¸‰م€پو•°وچ®é›†ن¼کهٹ؟ هœ؛و™¯è¦†ç›–ه…¨é¢ï¼ڑ هŒ…هگ«5ç±»ه…³é”®ن؛¤é€ڑè¦پç´ ï¼Œè¦†ç›–è½¦è¾†م€پè،Œن؛؛设و–½هڈٹه¸‚و”؟设ه¤‡ï¼Œو»،足ه¤چو‚هœ؛و™¯ه»؛و¨،需و±‚م€‚ و ‡و³¨è´¨é‡ڈهڈ¯é ï¼ڑ ن¸“ن¸ڑه›¢éکںو ‡و³¨ï¼Œن¸¥و ¼è´¨و£€وµپ程ç،®ن؟边界و،†ه®ڑن½چç²¾ه‡†ï¼Œç±»هˆ«و ‡و³¨ه‡†ç،®م€‚ ن»»هٹ،适é…چو€§ه¼؛ï¼ڑ هژںç”ںYOLOو ¼ه¼ڈو”¯وŒپن¸»وµپو£€وµ‹و،†و¶ï¼ˆYOLOv5/v7/v8ç‰ï¼‰ï¼Œهچ³وڈ’هچ³ç”¨م€‚ ه؛”用و½œهٹ›çھپه‡؛ï¼ڑ و•°وچ®و¥و؛گن؛ژçœںه®éپ“è·¯هœ؛و™¯ï¼Œهڈ¯ç›´وژ¥ه؛”用ن؛ژL2-L4ç؛§è‡ھهٹ¨é©¾é©¶ç³»ç»ںه¼€هڈ‘,ه…·ه¤‡ه¼؛ه·¥ç¨‹èگ½هœ°ن»·ه€¼م€‚
ن¸€ن¸ھوپé€ں,ه¤ڑهٹں能çڑ„ه“”ه“©ه“”ه“©وژ¨é€پوœ؛ه™¨ن؛؛
هں؛ن؛ژjsp+servletçڑ„وœ؛票预订هگژهڈ°ç®،çگ†ç³»ç»ںï¼ڑه‰چ端 jspم€پjquery,هگژ端 servletم€پjdbc,角色هˆ†ن¸؛ç®،çگ†ه‘کم€پ用وˆ·ï¼›é›†وˆگèˆھçڈن؟،وپ¯وں¥è¯¢ï¼Œهœ¨ç؛؟订票,订هچ•وں¥è¯¢ç‰هٹں能ن؛ژن¸€ن½“çڑ„ç³»ç»ںم€‚ ## هٹں能ن»‹ç»چ ### ç®،çگ†ه‘ک - èˆھçڈن؟،وپ¯ç®،çگ†ï¼ڑèˆھçڈن؟،وپ¯هˆ—è،¨وں¥è¯¢ï¼Œèˆھçڈو·»هٹ - 订هچ•ن؟،وپ¯ç®،çگ†ï¼ڑ用وˆ·هœ¨ه‰چهڈ°وµڈ览èˆھçڈن؟،وپ¯ï¼Œè®¢ç¥¨ن¸‹هچ•هگژ,ç®،çگ†ه‘کهڈ¯ن»¥هœ¨هگژهڈ°وں¥è¯¢ç”¨وˆ·ن¸‹هچ•ن؟،وپ¯ - 用وˆ·ن؟،وپ¯ç®،çگ†ï¼ڑ用وˆ·ن؟،وپ¯ç”±ه®¢وˆ·è‡ھه·±هœ¨ه‰چهڈ°و³¨ه†Œï¼Œç®،çگ†ه‘کهڈ¯ن»¥وں¥çœ‹ه’Œهˆ 除用وˆ· - 留言评è®؛ç®،çگ†ï¼ڑ用وˆ·هœ¨ه‰چهڈ°é’ˆه¯¹èˆھçڈن؟،وپ¯وˆ–订票وœچهٹ،è؟›è،Œè¯„è®؛,هگژهڈ°وں¥çœ‹è¯„è®؛ه’Œهˆ 除 ### 用وˆ· - هں؛وœ¬هٹں能ï¼ڑç™»ه½•ï¼Œو³¨ه†Œï¼Œé€€ه‡؛ - 网站首é،µï¼ڑè½®و’ه›¾ï¼Œèˆھçڈوگœç´¢ï¼Œèˆھçڈهˆ—è،¨ن؟،وپ¯ه±•ç¤؛ - 订票ï¼ڑèˆھçڈ详وƒ…,هœ¨ç؛؟订票,ه،«ه†™ن¹کوœ؛ن؛؛ه’Œèپ”ç³»ن؛؛ن؟،وپ¯ï¼Œé€€و”¹ç¾è¯´وکژ,وڈگن؛¤è®¢هچ• - 用وˆ·ن¸ه؟ƒï¼ڑن¸ھن؛؛资و–™وں¥è¯¢ن¸ژن؟®و”¹ï¼Œè®¢هچ•هˆ—è،¨وں¥è¯¢ - 留言ï¼ڑ留言هˆ—è،¨وں¥çœ‹ï¼Œهڈ‘è،¨ç•™è¨€è¯„è®؛ ## çژ¯ه¢ƒ - <b>IntelliJ IDEA 2021.3</b> - <b>Mysql 5.7.26</b> - <b>Tomcat 7.0.73</b> - <b>JDK 1.8</b>
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†هˆ©ç”¨COMSOLè؟›è،Œوµ·ه؛•و°”ن½“و°´هگˆç‰©و²‰ç§¯ç‰©ن¸و±½و¶²ن¸¤ç›¸وµپهٹ¨çڑ„و•°ه€¼و¨،و‹ںم€‚首ه…ˆï¼Œو–‡ç« 解é‡ٹن؛†و¨،ه‹çڑ„هں؛وœ¬و¶و„,هŒ…و‹¬ه¤ڑه”ن»‹è´¨وµپه’Œç›¸هœ؛و³•è؟½è¸ھو°”و¶²ç•Œé¢ï¼Œه¹¶ه±•ç¤؛ن؛†ه…³é”®çڑ„هپڈه¾®هˆ†و–¹ç¨‹م€‚وژ¥ç€ï¼Œè®¨è®؛ن؛†ç½‘و ¼هˆ’هˆ†م€پو°´هگˆç‰©ç›¸هڈکçڑ„能é‡ڈو–¹ç¨‹و؛گé،¹è®¾ç½®ن»¥هڈٹé‡چè¦پهڈ‚و•°ه¦‚هگ„هگ‘ه¼‚و€§ç³»و•°çڑ„و£ç،®é…چç½®م€‚و¤ه¤–,و–‡ن¸ه¼؛è°ƒن؛†و¨،ه‹éھŒè¯پو¥éھ¤ï¼Œه¦‚网و ¼و”¶و•›و€§وµ‹è¯•م€پو—¶é—´و¥é•؟و•ڈو„ںو€§هˆ†وگه’Œç‰©è´¨ه®ˆوپ’و£€وں¥م€‚وœ€هگژ,هˆ†ن؛«ن؛†ن¸€ن؛›ه®é™…ه·¥ç¨‹ه؛”用çڑ„ç»ڈéھŒï¼Œه¦‚ه¤„çگ†éه‡è´¨ه‚¨ه±‚ه’Œç›¸هڈکو½œçƒçڑ„ه½±ه“چم€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹هœ°è´¨ه·¥ç¨‹م€پçں³و²¹ه‹کوژ¢م€پçژ¯ه¢ƒç§‘ه¦ç‰é¢†هںںç ”ç©¶çڑ„ن¸“ن¸ڑن؛؛ه£«ه’Œوٹ€وœ¯ن؛؛ه‘کم€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پو·±ه…¥çگ†è§£ه’Œو¨،و‹ںوµ·ه؛•و°”ن½“و°´هگˆç‰©و²‰ç§¯ç‰©ن¸ه¤چو‚物çگ†çژ°è±،çڑ„ç ”ç©¶ن؛؛ه‘کم€‚ن¸»è¦پç›®و ‡وک¯ه¸®هٹ©ç”¨وˆ·وژŒوڈ،COMSOLهœ¨è؟™ن¸€é¢†هںںçڑ„ه…·ن½“ه؛”用و–¹و³•ï¼Œوڈگé«کو•°ه€¼و¨،و‹ںçڑ„ه‡†ç،®و€§م€‚ ه…¶ن»–说وکژï¼ڑو–‡ç« ن¸چن»…وڈگن¾›ن؛†è¯¦ç»†çڑ„و•°ه¦و¨،ه‹ه’Œç¼–程ن»£ç پ片و®µï¼Œè؟کهˆ†ن؛«ن؛†è®¸ه¤ڑه®è·µç»ڈéھŒï¼Œوœ‰هٹ©ن؛ژ读者éپ؟ه¼€ه¸¸è§پé™·éک±ه¹¶ن¼کهŒ–è®،ç®—و•ˆçژ‡م€‚
Screenshot_2025_0421_055352.png
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•ن½؟用Abaqusè؟›è،Œو··ه‡هœںو”¶ç¼©ه»؛و¨،ن¸ژهˆ†وگم€‚首ه…ˆè®²è§£ن؛†و··ه‡هœںو”¶ç¼©çڑ„هں؛وœ¬و¦‚ه؟µهڈٹه…¶é‡چè¦پو€§ï¼Œوژ¥ç€é€گو¥ن»‹ç»چوگو–™ه®ڑن¹‰م€پو”¶ç¼©و¨،ه‹é€‰و‹©م€پو”¶ç¼©ه؛”هڈکè®،ç®—و–¹و³•ï¼ˆهŒ…و‹¬UMATهگ程ه؛ڈه’Œçƒè†¨èƒ€و¨،و‹ں)م€پهˆ†وگو¥é…چç½®م€پ边界و،ن»¶è®¾ç½®م€پهگژه¤„çگ†éھŒè¯پç‰هگ„ن¸ھçژ¯èٹ‚çڑ„ه…·ن½“و“چن½œو¥éھ¤ه’Œوٹ€وœ¯ç»†èٹ‚م€‚و–‡ن¸è؟کوڈگن¾›ن؛†ه¤ڑن¸ھه®ç”¨çڑ„Pythonè„ڑوœ¬ه’Œ.inpو–‡ن»¶و¨،و؟,ه¸®هٹ©ç”¨وˆ·و›´ه¥½هœ°çگ†è§£ه’Œه؛”用相ه…³çں¥è¯†ç‚¹م€‚و¤ه¤–,ن½œè€…هˆ†ن؛«ن؛†è®¸ه¤ڑه®وˆکç»ڈéھŒه’Œه¸¸è§پ错误规éپ؟وٹ€ه·§ï¼Œç،®ن؟و¨،ه‹çڑ„稳ه®ڑو€§ه’Œه‡†ç،®و€§م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹هœںوœ¨ه·¥ç¨‹ن»؟çœںهˆ†وگçڑ„ن¸“ن¸ڑن؛؛ه£«ï¼Œه°¤ه…¶وک¯وœ‰ن¸€ه®ڑAbaqusن½؟用ç»ڈéھŒçڑ„ç ”ç©¶ن؛؛ه‘که’Œه·¥ç¨‹ه¸ˆم€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦پè؟›è،Œو··ه‡هœں结و„é•؟وœںو€§èƒ½é¢„وµ‹م€پ裂ç¼هڈ‘ه±•و¨،و‹ںç‰ه¤چو‚ه·¥ç¨‹é—®é¢کçڑ„ç ”ç©¶ن؛؛ه‘کم€‚é€ڑè؟‡وژŒوڈ،وœ¬و–‡وڈگن¾›çڑ„وٹ€وœ¯ه’Œو–¹و³•ï¼Œèƒ½ه¤ںوڈگé«کن»؟çœںو¨،ه‹çڑ„ç²¾ه؛¦ï¼Œه‡ڈه°‘ن¸ژه®é™…وµ‹é‡ڈ结وœن¹‹é—´çڑ„هپڈه·®م€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگهˆ°çڑ„و‰€وœ‰ن»£ç پ片و®µه’Œو“چن½œوŒ‡هچ—ه‡هں؛ن؛ژوœ€و–°ç‰ˆوœ¬çڑ„Abaqus软ن»¶ه¹³هڈ°م€‚ه»؛议读者结هگˆه®کو–¹و–‡و،£ه’Œه…¶ن»–هœ¨ç؛؟资و؛گè؟›ن¸€و¥ه¦ن¹ ه’Œوژ¢ç´¢م€‚
ه‰چ端هˆ†وگ-2023071100789s
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†هˆ©ç”¨و”¹è؟›çڑ„ç²’هگ群算و³•ï¼ˆPSO)ن¼کهŒ–هڈکهˆ†و¨،و€پهˆ†è§£ï¼ˆVMD)هڈ‚و•°çڑ„و–¹و³•م€‚首ه…ˆوŒ‡ه‡؛ن؛†ن¼ ç»ںPSOهکهœ¨çڑ„ه±€é™گو€§ï¼Œهچ³ه®¹وک“é™·ه…¥ه±€éƒ¨وœ€ن¼ک解م€‚وژ¥ç€وڈگه‡؛ن؛†و”¹è؟›وژھو–½ï¼ŒهŒ…و‹¬هٹ¨و€پè°ƒو•´وƒ¯و€§وƒé‡چه’Œه¦ن¹ ه› هگ,ن½؟ه¾—ç®—و³•èƒ½ه¤ںهœ¨ه‰چوœںè؟›è،Œه¹؟و³›çڑ„ه…¨ه±€وگœç´¢ï¼Œهœ¨هگژوœںè؟›è،Œç²¾ç،®çڑ„ه±€éƒ¨وگœç´¢م€‚و–‡ن¸è؟کوڈگن¾›ن؛†ه…·ن½“çڑ„Matlabن»£ç په®çژ°ï¼Œو¶µç›–ن؛†و•°وچ®é¢„ه¤„çگ†م€پç²’هگهˆه§‹هŒ–م€پ适ه؛”ه؛¦ه‡½و•°é€‰و‹©ç‰و–¹é¢çڑ„ه†…ه®¹م€‚ه®éھŒç»“وœوک¾ç¤؛,و”¹è؟›هگژçڑ„PSOهœ¨ن¼کهŒ–VMDهڈ‚و•°و–¹é¢è،¨çژ°ن¼که¼‚,ه°½ç®،و”¶و•›é€ںه؛¦ç¨چو…¢ï¼Œن½†èƒ½ه¤ںèژ·ه¾—و›´ن½ژçڑ„适ه؛”ه؛¦ه€¼ï¼Œن»ژ而وڈگé«کهˆ†è§£è´¨é‡ڈم€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹ن؟،هڈ·ه¤„çگ†ç ”究çڑ„وٹ€وœ¯ن؛؛ه‘ک,ه°¤ه…¶وک¯é‚£ن؛›ه¯¹VMDهˆ†è§£وœ‰ن¸€ه®ڑن؛†è§£ه¹¶ه¸Œوœ›è؟›ن¸€و¥وڈگهچ‡ه…¶و€§èƒ½çڑ„ç ”ç©¶è€…م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژ需è¦په¯¹ن¸€ç»´و—¶ه؛ڈو•°وچ®è؟›è،Œé«کè´¨é‡ڈهˆ†è§£çڑ„ه؛”用هœ؛هگˆï¼Œه¦‚ç”ں物هŒ»ه¦ن؟،هڈ·ه¤„çگ†م€پو•…éڑœè¯ٹو–ç‰é¢†هںںم€‚ç›®و ‡وک¯é€ڑè؟‡ن¼کهŒ–VMDçڑ„هˆ†è§£ه±‚و•°Kه’Œوƒ©ç½ڑه› هگخ±ï¼Œè¾¾هˆ°و›´ه¥½çڑ„ن؟،هڈ·هˆ†ç¦»و•ˆوœم€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگهˆ°çڑ„و‰€وœ‰ن»£ç په‡هں؛ن؛ژMatlab 2018aهڈٹن»¥ن¸ٹ版وœ¬ç¼–ه†™ï¼Œه»؛è®®ن½؟用و›´é«ک版وœ¬ن»¥ç،®ن؟ه…¼ه®¹و€§ه’Œو•ˆçژ‡م€‚هگŒو—¶ï¼Œه¯¹ن؛ژهˆه¦è€…而言,هڈ¯ن»¥ه…ˆه°è¯•وڈگن¾›çڑ„ç¤؛ن¾‹و•°وچ®è؟›è،Œç»ƒن¹ م€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†هœ¨PLECSن»؟çœںçژ¯ه¢ƒن¸ه¤چçژ°IEEEé،¶هˆٹè®؛و–‡ن¸وڈگه‡؛çڑ„DAB(هڈŒوœ‰و؛گو،¥ï¼‰هڈکوچ¢ه™¨ه³°ه€¼ç”µوµپه‰چ馈وژ§هˆ¶ç–ç•¥çڑ„è؟‡ç¨‹م€‚و–‡ç« 首ه…ˆç®€è؟°ن؛†DABهڈکوچ¢ه™¨çڑ„هں؛وœ¬ç»“و„هڈٹه…¶ه؛”用هœ؛و™¯ï¼Œوژ¥ç€و·±ه…¥وژ¢è®¨ن؛†ه³°ه€¼ç”µوµپه‰چ馈وژ§هˆ¶ç–ç•¥çڑ„ه·¥ن½œهژںçگ†ï¼ŒهŒ…و‹¬ه®و—¶و£€وµ‹هژں边电وµپه³°ه€¼ه¹¶هڈچ馈هˆ°وژ§هˆ¶çژ¯èٹ‚ن»¥و”¹ه–„هڈکوچ¢ه™¨هٹ¨و€پو€§èƒ½çڑ„و–¹و³•م€‚و–‡ن¸ه±•ç¤؛ن؛†ه…·ن½“çڑ„MATLAB-PLECSèپ”هگˆن»؟çœںه®çژ°و¥éھ¤ï¼Œو¶µç›–ن؛†هڈ‚و•°è®¾ه®ڑم€پن¸»ه¾ھçژ¯é€»è¾‘م€پهچ ç©؛و¯”è®،ç®—ç‰و–¹é¢çڑ„ه†…ه®¹م€‚و¤ه¤–,ن½œè€…هˆ†ن؛«ن؛†هœ¨ن»؟çœںè؟‡ç¨‹ن¸éپ‡هˆ°çڑ„é—®é¢کهڈٹ解ه†³و–¹و،ˆï¼Œه¦‚هڈ‚و•°و•´ه®ڑم€پç،¬ن»¶ç»†èٹ‚ه¤„çگ†ç‰ï¼Œه¹¶é€ڑè؟‡ن»؟çœںو³¢ه½¢ه¯¹و¯”éھŒè¯پن؛†è¯¥وژ§هˆ¶ç–ç•¥çڑ„وœ‰و•ˆو€§م€‚ 适هگˆن؛؛群ï¼ڑن»ژن؛‹ç”µهٹ›ç”µهگ领هںںç ”ç©¶çڑ„وٹ€وœ¯ن؛؛ه‘کم€پç ”ç©¶ç”ںهڈٹن»¥ن¸ٹه¦هژ†çڑ„ه¦ç”ں,ه°¤ه…¶وک¯ه¯¹DABهڈکوچ¢ه™¨هڈٹه³°ه€¼ç”µوµپه‰چ馈وژ§هˆ¶ç–ç•¥و„ںه…´è¶£çڑ„读者م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژه¸Œوœ›و·±ه…¥ن؛†è§£DABهڈکوچ¢ه™¨ه·¥ن½œهژںçگ†هڈٹه…¶ه…ˆè؟›وژ§هˆ¶ç–ç•¥çڑ„ç ”ç©¶ن؛؛ه‘که’Œوٹ€وœ¯ه¼€هڈ‘者م€‚ç›®و ‡وک¯وژŒوڈ،ه¦‚ن½•هˆ©ç”¨PLECSه’ŒMATLABè؟›è،Œه¤چو‚电هٹ›ç”µهگç³»ç»ںçڑ„ن»؟çœںه’Œن¼کهŒ–,وڈگé«کهڈکوچ¢ه™¨çڑ„هٹ¨و€په“چه؛”é€ںه؛¦ه’Œç¨³ه®ڑو€§م€‚ ه…¶ن»–说وکژï¼ڑو–‡ç« ن¸چن»…وڈگن¾›ن؛†è¯¦ç»†çڑ„çگ†è®؛解é‡ٹه’Œوٹ€وœ¯ه®çژ°è·¯ه¾„,è؟کهˆ†ن؛«ن؛†è®¸ه¤ڑه®ç”¨ç»ڈéھŒه’Œوٹ€ه·§ï¼Œوœ‰هٹ©ن؛ژ读者و›´ه¥½هœ°çگ†è§£ه’Œه؛”用و‰€ه¦çں¥è¯†م€‚
ه†…ه®¹و¦‚è¦پï¼ڑوœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†ه¦‚ن½•ن½؟用NSGA-IIIç®—و³•ç»“هگˆOptunaه؛“è؟›è،Œéڑڈوœ؛و£®و—و¨،ه‹çڑ„ه¤ڑç›®و ‡ن¼کهŒ–م€‚首ه…ˆه®ڑن¹‰ن؛†ن¸€ن¸ھç›®و ‡ه‡½و•°ï¼Œè¯¥ه‡½و•°و—¨هœ¨وœ€ه°ڈهŒ–ن؛¤هڈ‰éھŒè¯پ误ه·®ه’Œوµ‹è¯•é›†è¯¯ه·®م€‚وژ¥ç€ï¼Œé€ڑè؟‡Optunaهˆ›ه»؛ç ”ç©¶ه¯¹è±،ه¹¶و‰§è،Œن¼کهŒ–و“چن½œï¼Œهœ¨و¤è؟‡ç¨‹ن¸ï¼ŒNSGA-IIIç®—و³•ç”¨ن؛ژه¯»و‰¾ه¸•ç´¯و‰که‰چو²؟ن¸ٹçڑ„وœ€ن½³è§£م€‚ن¼کهŒ–ه®Œوˆگهگژ,ن½œè€…ه±•ç¤؛ن؛†ه¤ڑç§چهڈ¯è§†هŒ–و‰‹و®µï¼Œه¦‚3Dو›²é¢ه›¾م€پçƒهٹ›ه›¾ن»¥هڈٹ预وµ‹ه¯¹و¯”ه›¾ï¼Œه¸®هٹ©çگ†è§£هڈ‚و•°é—´çڑ„ه…³ç³»هڈٹه…¶ه¯¹و¨،ه‹و€§èƒ½çڑ„ه½±ه“چم€‚و¤ه¤–,è؟کوژ¢è®¨ن؛†ن¸€ن؛›ه®ç”¨وٹ€ه·§ï¼Œن¾‹ه¦‚è°ƒو•´é‡‡و ·èŒƒه›´م€پç§چ群规و¨،ç‰م€‚ 适用ن؛؛群ï¼ڑç†ںو‚‰وœ؛ه™¨ه¦ن¹ هں؛وœ¬و¦‚ه؟µه’Œوٹ€وœ¯و ˆçڑ„ç ”ç©¶ن؛؛ه‘کوˆ–ه·¥ç¨‹ه¸ˆï¼Œç‰¹هˆ«وک¯ه¯¹éڑڈوœ؛و£®و—و¨،ه‹وœ‰و·±ه…¥ç ”究ه…´è¶£çڑ„ن؛؛ه£«م€‚ ن½؟用هœ؛و™¯هڈٹç›®و ‡ï¼ڑ适用ن؛ژه¸Œوœ›وڈگé«کéڑڈوœ؛و£®و—و¨،ه‹و€§èƒ½ï¼ŒهگŒو—¶وژŒوڈ،ه¤ڑç›®و ‡ن¼کهŒ–çگ†è®؛çڑ„ه؛”用هœ؛و™¯م€‚ن¸»è¦پç›®و ‡وک¯é€ڑè؟‡هگˆçگ†çڑ„هڈ‚و•°é…چç½®ن½؟و¨،ه‹è¾¾هˆ°و›´ه¥½çڑ„و³›هŒ–能هٹ›ه’Œو›´é«کçڑ„و•ˆçژ‡م€‚ ه…¶ن»–说وکژï¼ڑو–‡ن¸وڈگن¾›ن؛†ه®Œو•´çڑ„ن»£ç پ片و®µï¼Œن¾؟ن؛ژ读者ه¤چçژ°ه®éھŒç»“وœم€‚ه¼؛è°ƒن؛†è°ƒهڈ‚è؟‡ç¨‹ن¸éœ€è¦پو³¨و„ڈçڑ„é—®é¢ک,ه¦‚éپ؟ه…چè؟‡ه؛¦و‰©ه±•وگœç´¢ç©؛é—´م€پهگˆçگ†è®¾ه®ڑç§چ群规و¨،ç‰م€‚