е§ІжґЫе≠¶йХњ
- жµПиІИ: 120304 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еМЧдЇђ
-

з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
AIеК†жМБзЪДйШњйЗМдЇСй£Ю姩姲жХ∞жНЃеє≥еП∞жКАжЬѓжП≠зІШ
иѓіеИ∞йШњйЗМеЈіеЈіе§ІжХ∞жНЃпЉМдЄНеЊЧдЄНжПРеИ∞зЪДжШѓ10еєіеЙНзОЛеЭЪеНЪе£ЂзОЗйҐЖеїЇжЮДзЪДй£Ю姩姲жХ∞жНЃеє≥еП∞пЉМеНБеєіз£®дЄАеЙСпЉМдїК姩й£Ю姩姲жХ∞жНЃеє≥еП∞еЈ≤жШѓйШњйЗМеЈіеЈі10еєіе§Іеє≥еП∞еїЇиЃЊжЬАдљ≥еЃЮиЈµзЪДзїУжЩґпЉМжШѓйШњйЗМе§ІжХ∞жНЃзФЯдЇІзЪДеЯЇзЯ≥гАВй£Ю姩姲жХ∞жНЃеє≥еП∞еЬ®йШњйЗМеЈіеЈійЫЖеЫҐеЖЕжѓП姩жЬЙжХ∞дЄЗеРНжХ∞жНЃеТМзЃЧж≥ХеЉАеПСеЈ•з®ЛеЄИеЬ®дљњзФ®пЉМжЙњиљљдЇЖйШњйЗМ99%зЪДжХ∞жНЃдЄЪеК°жЮДеїЇгАВеРМжЧґдєЯеЈ≤зїПеєњж≥ЫеЇФзФ®дЇОеЯОеЄВе§ІиДСгАБжХ∞е≠ЧжФњеЇЬгАБзФµеКЫгАБйЗСиЮНгАБжЦ∞йЫґеФЃгАБжЩЇиГљеИґйА†гАБжЩЇжЕІеЖЬдЄЪз≠ЙеРДйҐЖеЯЯзЪДе§ІжХ∞жНЃеїЇиЃЊгАВ

еЬ®2015еєізЪДжЧґеАЩпЉМжИСдїђеЉАеІЛеЕ≥ж≥®еИ∞жХ∞жНЃзЪДжµЈйЗПеҐЮйХњеѓєз≥їзїЯеЄ¶жЭ•дЇЖиґКжЭ•иґКйЂШзЪДи¶Бж±ВпЉМйЪПзЭАжЈ±еЇ¶е≠¶дє†зЪДйЬАж±ВеҐЮйХњпЉМжХ∞жНЃеТМжХ∞жНЃеѓєеЇФзЪДе§ДзРЖиГљеКЫжШѓеИґзЇ¶дЇЇеЈ•жЩЇиГљеПСе±ХзЪДеЕ≥йФЃйЧЃйҐШпЉМжИСдїђеЬ®зїЩеЃҐжИЈиБКеИ∞дЄАдЄ™жСЖеЬ®жѓПдЄ™CIO/CTOйЭҐеЙНзЪДзО∞еЃЮйЧЃйҐШвАФвАФе¶ВжЮЬжХ∞жНЃеҐЮйХњ10еАНпЉМеЇФиѓ•жАОдєИеКЮпЉЯеЫЊдЄ≠жХ∞е≠Че§ІеЃґзЬЛеЊЧйЭЮеЄЄжЄЕжЩ∞пЉМйЭЮеЄЄзЃАеНХзЪДжЛНзЂЛжЈШз≥їзїЯиГМеРОжШѓPBзЪДжХ∞жНЃеЬ®еБЪжФѓжТСпЉМйШњйЗМе∞ПиЬЬеЃҐжЬНз≥їзїЯжЬЙ20дЄ™PBпЉМе§ІеЃґжѓП姩еЬ®жЈШеЃЭдЄКжЧ•еЄЄдљњзФ®зЪДдЄ™жАІеМЦжО®иНРз≥їзїЯпЉМеРОеП∞и¶БиґЕињЗ100дЄ™PBзЪДжХ∞жНЃжЭ•жФѓжТСеРОеП∞зЪДеЖ≥з≠ЦпЉМ10еАНеИ∞100еАНзЪДжХ∞жНЃеҐЮйХњжШѓйЭЮеЄЄеЄЄиІБзЪДгАВдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМ10еАНзЪДжХ∞жНЃеҐЮйХњйАЪеЄЄжДПеС≥зЭАдїАдєИйЧЃйҐШпЉЯ
зђђдЄАпЉМжДПеС≥зЭА10еАНжИРжЬђзЪДеҐЮйХњпЉМе¶ВжЮЬиАГиЩСеИ∞еҐЮйХњдЄНжШѓеЭЗеМАзЪДпЉМдЉЪжЬЙж≥Ґе≥∞еТМж≥Ґи∞ЈпЉМеПѓиГљйЬАи¶Б30еАНеЉєжАІи¶Бж±ВпЉЫзђђдЇМпЉМеЃЮйЩЕдЄКеЫ†дЄЇдЇЇеЈ•жЩЇиГљзЪДеЕіиµЈпЉМдЇМзїізїУжЮДжАІзЪДеЕ≥з≥їеЮЛжХ∞жНЃжМБзї≠жАІеҐЮйХњзЪДеРМжЧґпЉМеЄ¶жЭ•зЪДжШѓйЭЮзїУжЮДеМЦжХ∞жНЃпЉМињЩзІНжМБзї≠зЪДжХ∞жНЃеҐЮйХњйЗМйЭҐпЉМдЄАеНКзЪДеҐЮйХњжЭ•иЗ™дЇОињЩзІНйЭЮзїУжЮДеМЦжХ∞жНЃпЉМжИСдїђйЩ§дЇЖиГље§Яе§ДзРЖе•љињЩзІНдЇМзїізЪДжХ∞жНЃеМЦдєЛеРОпЉМжИСдїђе¶ВдљХжЭ•еБЪе•ље§ЪзІНжХ∞жНЃиЮНеРИзЪДиЃ°зЃЧпЉЯзђђдЄЙпЉМйШњйЗМжЬЙдЄАдЄ™еЇЮе§ІзЪДдЄ≠еП∞еЫҐйШЯпЉМе¶ВжЮЬиѓіжИСдїђзЪДжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжИСдїђзЪДеЫҐйШЯжШѓдЄНжШѓеҐЮйХњдЇЖ10еАНпЉЯе¶ВжЮЬиѓіжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжХ∞жНЃзЪДеЕ≥з≥їе§НжЭВеЇ¶дєЯиґЕињЗдЇЖ10еАНпЉМйВ£дєИдЇЇеЈ•зЪДжИРжЬђжШѓдЄНжШѓдєЯиґЕињЗдЇЖ10еАНдї•дЄКпЉМжИСдїђзЪДй£Ю姩еє≥еП∞еЬ®2015еєіеРОе∞±жШѓеЫізїХињЩдЄЙдЄ™еЕ≥йФЃжАІзЪДйЧЃйҐШжЭ•еБЪеЈ•дљЬзЪДгАВ
еОЯеИЫжКАжЬѓдЉШеМЦ + з≥їзїЯиЮНеРИ
=============
ељУйШњйЗМеЈіеЈізЪДе§ІжХ∞жНЃиµ∞ињЗ10дЄЗеП∞иІДж®°зЪДжЧґеАЩпЉМжИСдїђеЈ≤зїПиµ∞еЕ•еИ∞жКАжЬѓзЪДжЧ†дЇЇеМЇпЉМињЩж†ЈзЪДжМСжИШзїЭе§Іе§ЪжХ∞еЕђеПЄдЄНдЄАеЃЪиГљйБЗеИ∞пЉМдљЖжШѓеѓєдЇОйШњйЗМеЈіеЈіињЩж†ЈзЪДдљУйЗПжЭ•иЃ≤пЉМињЩдЄ™жМСжИШжШѓдЄАзЫіжСЖеЬ®жИСдїђйЭҐеЙНзЪДгАВ
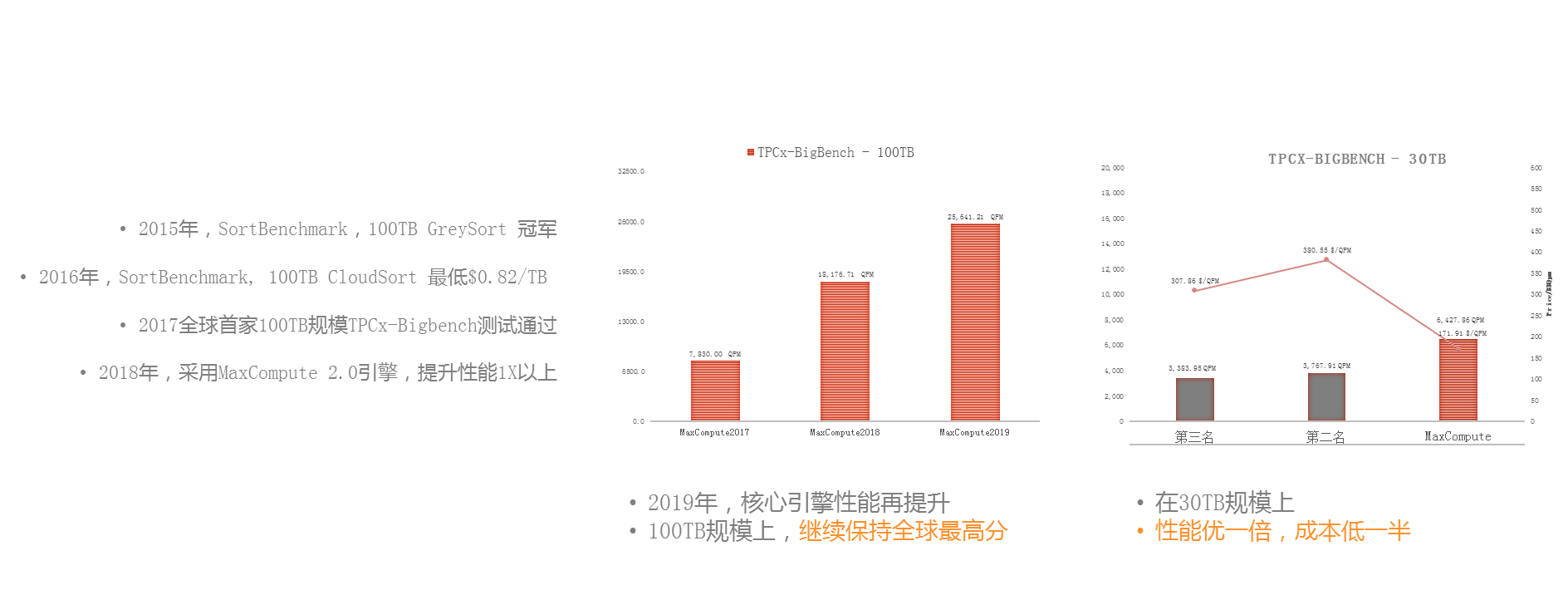
е§ІеЃґеПѓдї•зЬЛеИ∞пЉМ2015еєізЪДжЧґеАЩпЉМжИСдїђжХідЄ™зЪДдљУз≥їеїЇзЂЛиµЈжЭ•дєЛеРОпЉМе∞±еЉАеІЛеБЪеРДзІНеРДж†ЈзЪДBenchmarkпЉМжѓФе¶В2015еєі100TBзЪДSortingпЉМ2016еєіжИСдїђеБЪCloudSortпЉМеОїзЬЛжАІдїЈжѓФпЉМ2017еєіжИСдїђйАЙжЛ©дЇЖBigbenchгАВе¶ВеЫЊжШѓжИСдїђжЬАжЦ∞еПСеЄГзЪДжХ∞жНЃпЉМеЬ®2017гАБ2018еТМ2019еєіпЉМжѓПеєійГљжЬЙдЄАеАНзЪДжАІиГљжПРеНЗпЉМеРМжЧґжИСдїђеЬ®30TBзЪДиІДж®°дЄКжѓФзђђдЇМеРНзЪДдЇІеУБжЬЙдЄАеАНзЪДжАІиГљеҐЮйХњпЉМеєґдЄФжЬЙдЄАеНКзЪДжИРжЬђиКВзЬБпЉМињЩжШѓжИСдїђзЪДиЃ°зЃЧеКЫжМБзї≠дЄКеНЗзЪДдЉШеМЦиґЛеКњгАВ
йВ£дєИпЉМиЃ°зЃЧеКЫжМБзї≠еНЗзЇІжШѓе¶ВдљХеБЪеИ∞зЪДпЉЯе¶ВеЫЊжШѓжИСдїђзїПеЄЄзФ®еИ∞зЪДз≥їзїЯеНЗзЇІзЪДдЄЙиІТзРЖиЃЇпЉМжЬАеЇХе±ВзЪДиЃ°зЃЧж®°еЮЛжШѓйЂШжХИзЪДзЃЧе≠Ре±ВеТМе≠ШеВ®е±ВпЉМињЩжШѓйЭЮеЄЄеЇХе±ВзЪДеЯЇз°АдЉШеМЦпЉМеЊАдЄКйЭҐи¶БжЙЊеИ∞жЬАдЉШзЪДжЙІи°МиЃ°еИТпЉМдєЯе∞±жШѓзЃЧе≠РзїДеРИпЉМеЖНеЊАдЄКжШѓжЦ∞зЪДжЦєеРСпЉМеН≥жАОдєИеБЪеИ∞еК®жАБи∞ГжХідЄОиЗ™е≠¶дє†зЪДи∞ГдЉШгАВ
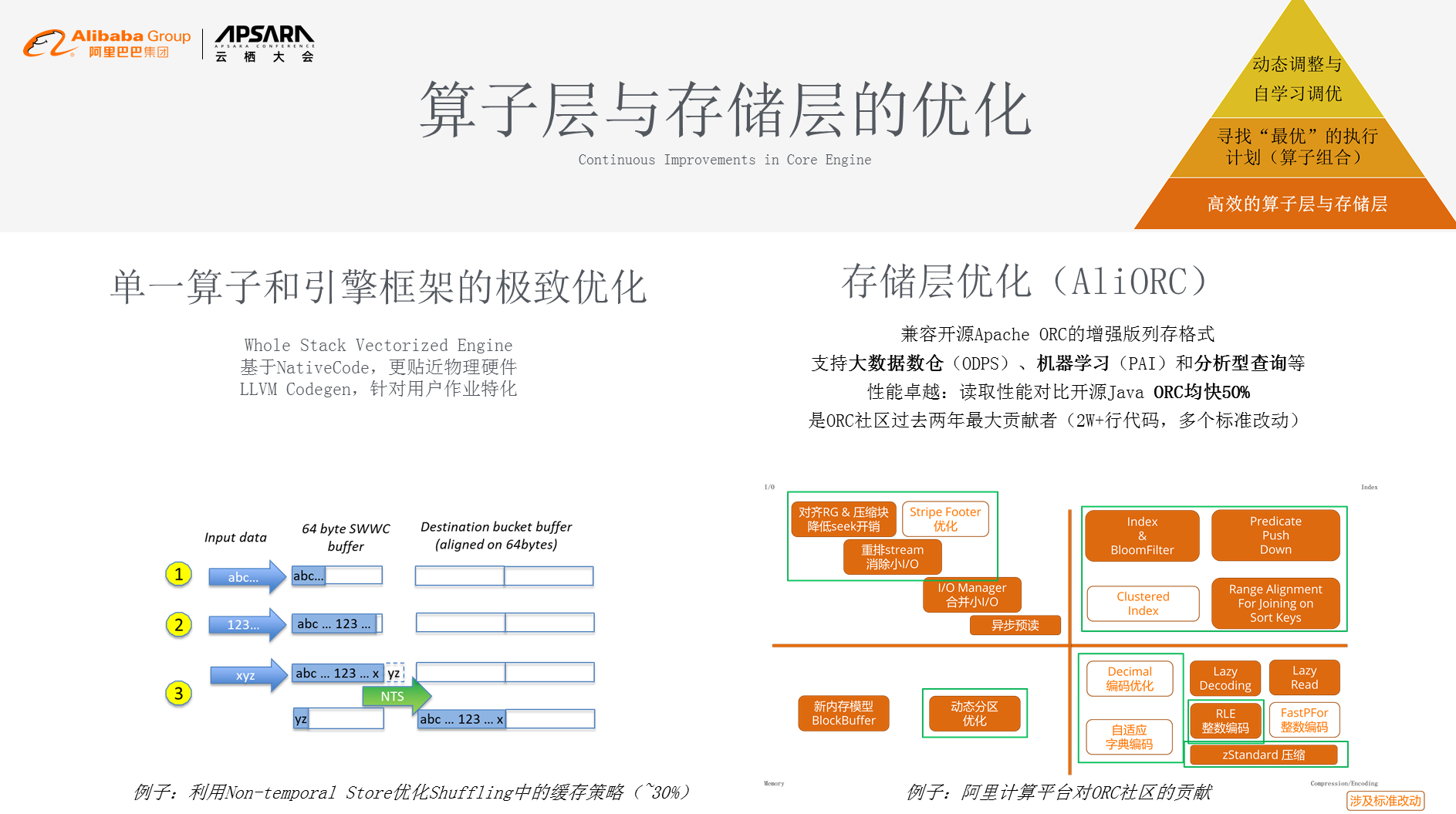
жИСдїђеЕИжЭ•зЬЛеНХдЄАзЃЧе≠РеТМеЉХжУОж°ЖжЮґзЪДжЮБиЗідЉШеМЦпЉМжИСдїђзФ®зЪДжШѓжѓФиЊГйЪЊеЖЩйЪЊзїіжК§зЪДж°ЖжЮґпЉМдљЖжШѓеЫ†дЄЇеЃГжѓФиЊГиііињСзЙ©зРЖз°ђдїґпЉМжЙАдї•еЄ¶жЭ•дЇЖжЫіжЮБиЗізЪДжАІиГљињљж±ВгАВеѓєдЇОеЊИе§Ъз≥їзїЯжЭ•иѓіеПѓиГљ5%зЪДжАІиГљжПРеНЗеєґдЄНеЕ≥йФЃпЉМдљЖеѓєдЇОй£Ю姩жКАжЬѓеє≥еП∞жЭ•иЃ≤пЉМ5%зЪДжАІиГљжПРеНЗе∞±жШѓ5еНГеП∞зЪДиІДж®°пЉМе§Іж¶Ве∞±жШѓ2пљЮ3дЇњзЪДжИРжЬђгАВе¶ВеЫЊеБЪдЇЖдЄАдЄ™зЃАеНХзЪДе∞ПдЊЛе≠РеБЪеНХдЄАзЃЧе≠РзЪДжЮБиЗідЉШеМЦпЉМеЬ®shuffleе≠РеЬЇжЩѓдЄ≠пЉМеИ©зФ®Non-temporal StoreдЉШеМЦshufflingдЄ≠зЪДзЉУе≠Шз≠ЦзХ•пЉМеЬ®ињЩж†ЈзЪДз≠ЦзХ•дЄКжЬЙ30%зЪДжАІиГљжПРеНЗгАВ
йЩ§дЇЖиЃ°зЃЧж®°еЭЧпЉМеЃГињШжЬЙе≠ШеВ®ж®°еЭЧпЉМе≠ШеВ®еИЖдЄЇ4дЄ™и±°йЩРгАВдЄАеЫЫи±°йЩРжШѓе≠ШеВ®жХ∞жНЃжЬђиЇЂзЪДеОЛзЉ©иГљеКЫпЉМжХ∞жНЃеҐЮйХњжЬАзЫіжО•зЪДжИРжЬђе∞±жШѓе≠ШеВ®жИРжЬђзЪДдЄКеНЗпЉМжИСдїђжАОдєИеБЪжЫіе•љзЪДеОЛзЉ©еТМзЉЦз†Бдї•еПКindexingпЉЯињЩжШѓдЄАеЫЫи±°йЩРеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉЫдЇМдЄЙи±°йЩРжШѓеЬ®жАІиГљиКВзЬБдЄКеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉМжИСдїђе≠ШеВ®е±ВеЕґеЃЮжШѓеЯЇдЇОеЉАжЇРORCзЪДж†ЗеЗЖпЉМжИСдїђеЬ®дЄКйЭҐеБЪдЇЖйЭЮеЄЄе§ЪзЪДжФєињЫеТМдЉШеМЦпЉМеЕґдЄ≠зЩљж°ЖйЗМйЭҐйГљжЬЙйЭЮеЄЄе§ЪзЪДж†ЗеЗЖжФєеК®пЉМжИСдїђиѓїеПЦжАІиГљеѓєжѓФеЉАжЇРJava ORC еЭЗењЂ 50%пЉМжИСдїђжШѓORCз§ЊеМЇињЗеОїдЄ§еєіжЬАе§Іиі°зМЃиАЕпЉМиі°зМЃдЇЖ2W+и°Мдї£з†БпЉМињЩжШѓжИСдїђеЬ®зЃЧе≠Ре±ВеТМе≠ШеВ®е±ВзЪДдЉШеМЦпЉМињЩжШѓжЬАеЇХе±ВзЪДжЮґжЮДгАВ

дљЖжШѓдїОеП¶е§ЦдЄАдЄ™е±ВйЭҐдЄКжЭ•иЃ≤пЉМеНХдЄАзЪДзЃЧе≠РеТМйГ®еИЖзЪДзЃЧе≠РзїДеРИеЊИйЪЊжї°иґ≥йГ®еИЖзЪДеЬЇжЩѓйЬАж±ВпЉМжЙАдї•жИСдїђе∞±жПРеИ∞зБµжіїзЪДзЃЧе≠РзїДеРИгАВдЄЊеЗ†дЄ™жХ∞е≠ЧпЉМжИСдїђеЬ®JoinдЄКжЬЙ4зІНж®°еЉПпЉМжЬЙ3зІНShufflingж®°еЉПжПРдЊЫпЉМжЬЙ3зІНдљЬдЄЪињРи°Мж®°еЉПпЉМжЬЙе§ЪзІНз°ђдїґжФѓжМБеТМе§ЪзІНе≠ШеВ®дїЛиі®жФѓжМБгАВеЫЊеП≥жШѓжАОж†ЈеОїеК®жАБеИ§еИЂJoinж®°еЉПпЉМдљњеЊЧињРзЃЧжХИзОЗжЫійЂШгАВйАЪињЗињЩзІНеК®жАБзЪДзЃЧе≠РзїДеРИпЉМжШѓжИСдїђдЉШеМЦзЪДзђђдЇМдЄ™зїіеЇ¶гАВ
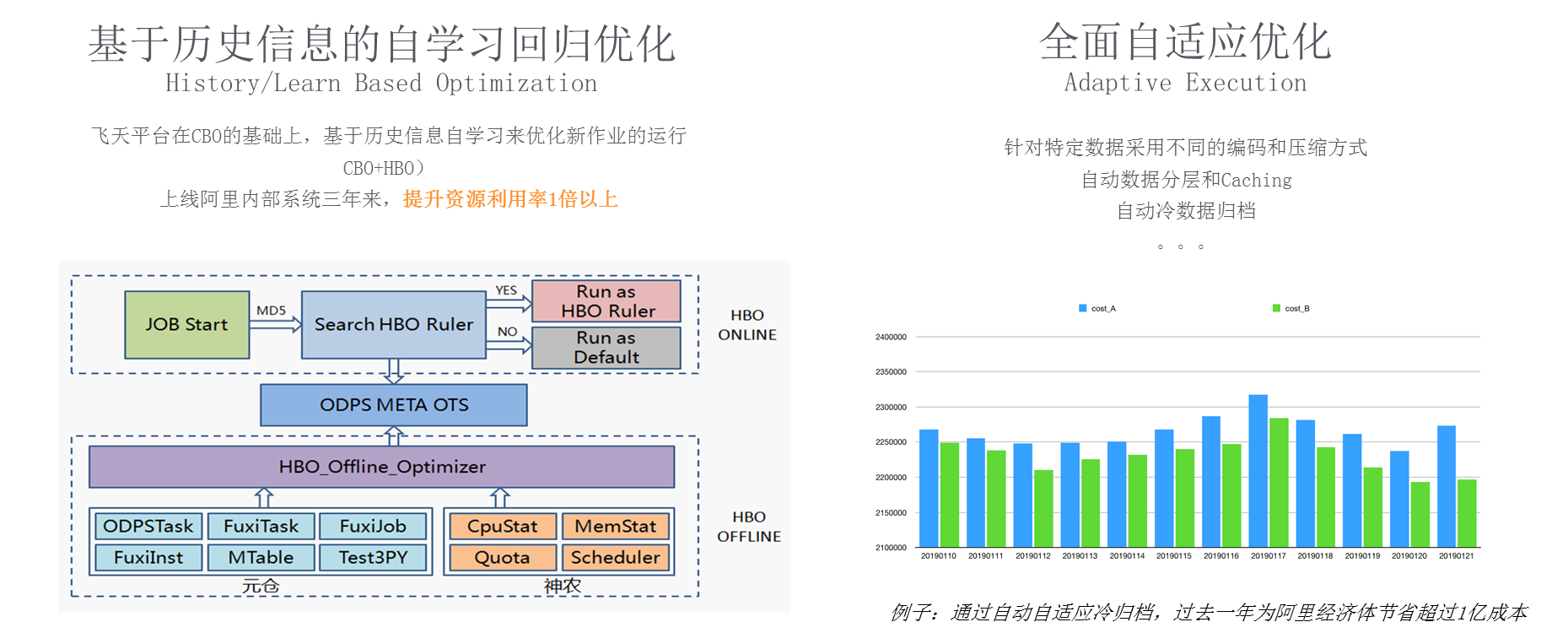
дїОеЉХжУОдЉШеМЦеИ∞иЗ™е≠¶дє†и∞ГдЉШжШѓжИСдїђеЬ®жЬАињС1еєіе§ЪзЪДжЧґйЧійЗМиК±з≤ЊеКЫжѓФиЊГе§ЪзЪДпЉМжИСдїђеЬ®иАГиЩСе¶ВдљХзФ®дЇЇеЈ•жЩЇиГљеПКиЗ™е≠¶дє†жКАжЬѓжЭ•еБЪе§ІжХ∞жНЃз≥їзїЯпЉМе§ІеЃґеПѓдї•жГ≥и±°е≠¶й™СиЗ™и°Миљ¶пЉМеИЪеЉАеІЛй™СеЊЧдЄНе•љпЉМйАЯеЇ¶жѓФиЊГжЕҐзФЪиЗ≥жЬЙзЪДжЧґеАЩдЉЪжСФеАТпЉМйАЪињЗжЕҐжЕҐзЪДе≠¶дє†пЉМдЇЇзЪДиГљеКЫдЉЪиґКжЭ•иґКе•љгАВеѓєдЇОдЄАдЄ™з≥їзїЯиАМи®АпЉМжИСдїђжШѓеР¶еПѓдї•зФ®еРМж†ЈзЪДжЦєеЉПжЭ•еБЪпЉЯељУдЄАдЄ™еЕ®жЦ∞зЪДдљЬдЄЪжПРдЇ§еИ∞ињЩдЄ™з≥їзїЯжЧґпЉМз≥їзїЯеѓєдљЬдЄЪзЪДдЉШеМЦжШѓжѓФиЊГдњЭеЃИзЪДпЉМжѓФе¶Вз®НеЊЃе§ЪзїЩдЄАзВєиµДжЇРпЉМйВ£дєИжИСйАЙжЛ©зЪДжЙІи°МиЃ°еИТдЉЪзЫЄеѓєжѓФиЊГдњЭеЃИдЄАзВєпЉМдљњеЊЧиЗ≥е∞СиГље§ЯиЈСињЗеОїпЉМељУиЈСињЗдєЛеРОе∞±иГље§ЯжРЬйЫЖеИ∞дњ°жБѓеТМзїПй™МпЉМйАЪињЗињЩдЇЫзїПй™МеЖНеПНеУЇеОїдЉШеМЦжХ∞жНЃпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™еЯЇдЇОеОЖеП≤дњ°жБѓзЪДиЗ™е≠¶дє†еЫЮељТдЉШеМЦпЉМеЇХе±ВжШѓе¶ВеЫЊзЪДжЮґжЮДеЫЊпЉМжИСдїђжККеОЖеП≤дњ°жБѓжФЊеЬ®OFFLINE systemеОїеБЪеРДзІНеРДж†ЈзЪДзїЯиЃ°еИЖжЮРпЉМељУдљЬдЄЪжЭ•дЇЖдєЛеРОжИСдїђжККињЩдЇЫдњ°жБѓеПНеУЇеИ∞з≥їзїЯдєЛдЄ≠еОїпЉМиЃ©з≥їзїЯињЫи°МиЗ™е≠¶дє†гАВйАЪеЄЄжГЕеЖµдЄЛпЉМдЄАдЄ™зЫЄдЉЉзЪДдљЬдЄЪе§Іж¶ВиЈСдЇЖ3еИ∞4жђ°зЪДжЧґеАЩпЉМињЫеЕ•еИ∞дЄАдЄ™зЫЄеѓєжѓФиЊГдЉШзЪДињЗз®ЛпЉМдЉШжМЗзЪДжШѓдљЬдЄЪињРи°МжЧґйЧіеТМз≥їзїЯиµДжЇРиКВзЬБгАВињЩе•Чз≥їзїЯе§Іж¶ВеЬ®йШњйЗМеЖЕйГ®3еєіеЙНдЄКзЇњзЪДпЉМжИСдїђйАЪињЗињЩж†ЈзЪДз≥їзїЯжККйШњйЗМзЪДж∞ідљНзЇњдїО40%жПРеНЗеИ∞70%дї•дЄКгАВ
еП¶е§ЦеЫЊдЄ≠еП≥дЊІдєЯжШѓдЄАдЄ™иЗ™е≠¶дє†зЪДдЊЛе≠РпЉМжИСдїђжАОдєИеМЇеИЖзГ≠жХ∞жНЃеТМеЖЈжХ∞жНЃпЉМдєЛеЙНеПѓдї•иЃ©зФ®жИЈиЗ™еЈ±еОїsetпЉМеПѓдї•зФ®дЄАдЄ™жЩЃйАЪзЪДconfigurationеОїйЕНзљЃпЉМеРОжЭ•еПСзО∞жИСдїђйЗЗзФ®еК®жАБзЪДж†єжНЃдљЬдЄЪжЦєеЉПжЭ•еБЪпЉМжХИжЮЬдЉЪжЫіе•љпЉМињЩдЄ™жКАжЬѓжШѓеОїеєідЄКзЇњзЪДпЉМеОїеєідЄЇйШњйЗМиКВзЇ¶дЇЖ1дЇњ+дЇЇж∞СеЄБгАВдїОдї•дЄКеЗ†дЄ™дЊЛе≠РдЄКжЭ•иЃ≤еЉХжУОе±ВйЭҐеТМе≠ШеВ®е±ВйЭҐеБЪзЪДжЮБиЗіжАІиГљдЉШеМЦпЉМжАІиГљдЉШеМЦеПИеЄ¶жЭ•дЇЖзФ®жИЈжИРжЬђзЪДйЩНдљОпЉМеЬ®2019еєі9жЬИ1еПЈпЉМй£Ю姩姲жХ∞жНЃеє≥еП∞зЪДжХідљУе≠ШеВ®жИРжЬђйЩНдљОдЇЖ30%пЉМеРМжЧґжИСдїђеПСеЄГдЇЖеЯЇдЇОеОЯзФЯиЃ°зЃЧзЪДжЦ∞иІДж†ЉпЉМеПѓдї•еЃЮзО∞жЬАйЂШ70%зЪДжИРжЬђиКВзЬБгАВ
дї•дЄКйГљжШѓеЬ®еЉХжУОе±ВйЭҐзЪДдЉШеМЦпЉМйЪПзЭАAIзЪДжЩЃжГ†дЉШеМЦпЉМAIзЪДеЉАеПСдЇЇеСШдЉЪиґКжЭ•иґКе§ЪпЉМзФЪиЗ≥еЊИе§ЪдЇЇйГљдЄН姙еЕЈе§Здї£з†БзЪДиГљеКЫпЉМйШњйЗМеЖЕйГ®жЬЙ10дЄЗеРНеСШеЈ•пЉМжѓП姩жЬЙиґЕињЗ1дЄЗдЄ™еСШеЈ•еЬ®й£Ю姩姲жХ∞жНЃеє≥еП∞дЄКеБЪеЉАеПСпЉМдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМдЄНдїЕз≥їзїЯзЪДдЉШеМЦжШѓйЗНи¶БзЪДпЉМеє≥еП∞еТМеЉАеПСеє≥еП∞зЪДдЉШеМЦдєЯжШѓйЭЮеЄЄеЕ≥йФЃзЪДгАВ
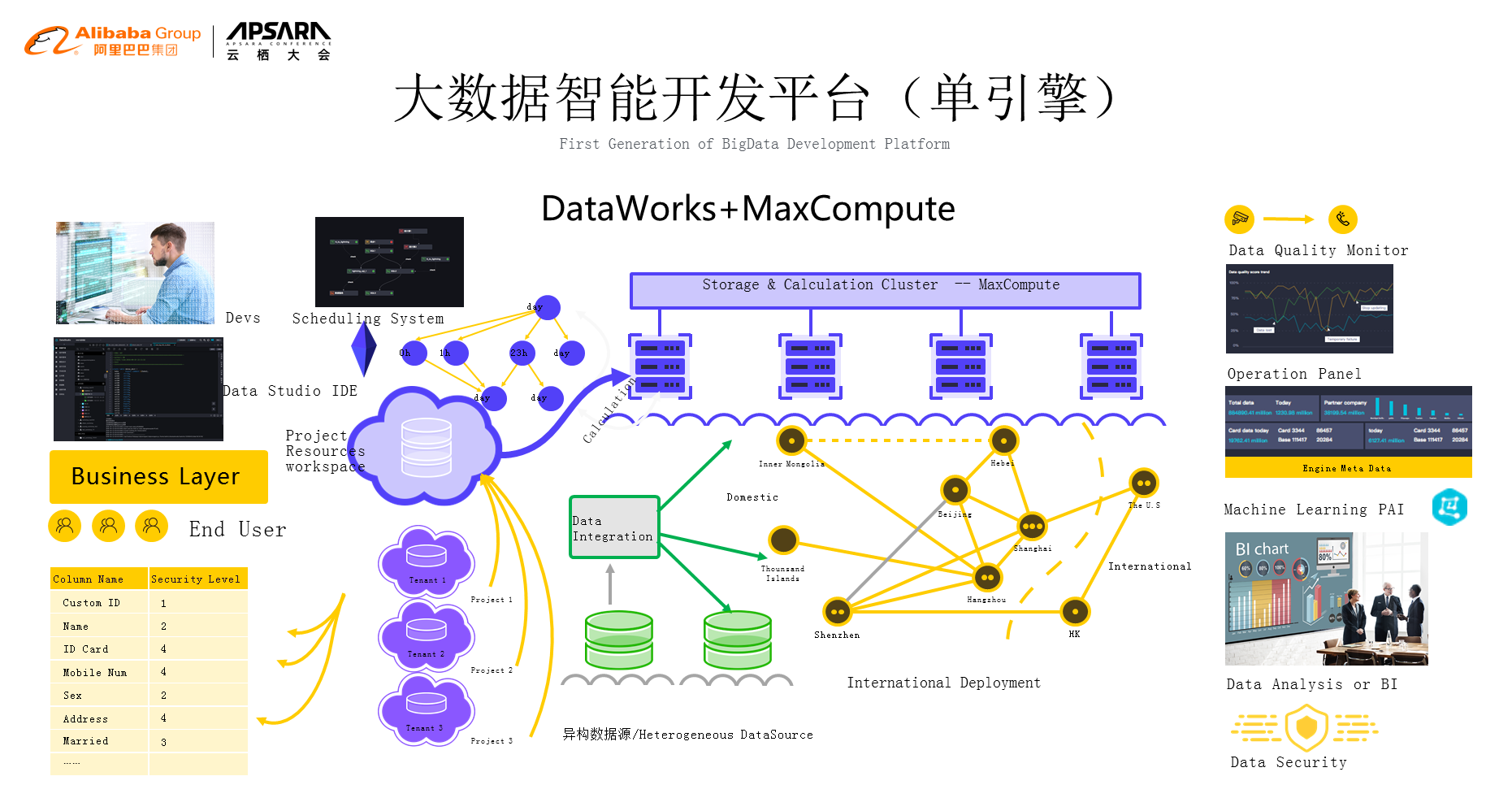
иЃ°зЃЧеЉХжУОеѓєе§ІеЃґжЭ•иѓізЬЛдЄНиІБжСЄдЄНзЭАпЉМжИСдїђи¶БеОїзФ®еЃГиВѓеЃЪеЄМжЬЫзФ®жЬАзЃАеНХзЪДжЦєеЉПпЉМеЕИжЭ•зЬЛдЄАдЄЛMaxcomputeиЃ°зЃЧеЉХжУОгАВй¶ЦеЕИжИСдїђйЬАи¶БжЬЙзФ®жИЈпЉМзФ®жИЈжАОдєИжЭ•дљњзФ®пЉЯйЬАи¶БиµДжЇРйЪФз¶їпЉМдєЯе∞±жШѓиѓіжѓПдЄ™зФ®жИЈеЬ®з≥їзїЯдЄКйЭҐдљњзФ®зЪДжЧґеАЩдЉЪеѓєеЇФзЭАиі¶еПЈпЉМиі¶еПЈдЉЪеѓєеЇФзЭАжЭГйЩРпЉМињЩж†Је∞±жККжХіе•ЧдЄЬи•њдЄ≤иБФиµЈжЭ•гАВдїК姩жИСзЪДзФ®жИЈжАОдєИзФ®пЉЯзФ®еУ™дЇЫйГ®еИЖпЉЯињЩжШѓзђђдЄАйГ®еИЖгАВзђђдЇМйГ®еИЖжШѓеЉАеПСпЉМеЉАеПСжЬЙIDEпЉМIDEзФ®жЭ•еЖЩдї£з†БпЉМеЖЩеЃМдї£з†БдєЛеРОжПРдЇ§пЉМжПРдЇ§дєЛеРОе≠ШеЬ®дЄАдЄ™и∞ГеЇ¶зЪДйЧЃйҐШпЉМињЩдєИе§ЪзЪДиµДжЇРдїїеК°й°ЇеЇПжШѓдїАдєИпЉЯи∞БеЕИи∞БеРОпЉМеЗЇдЇЖйЧЃйҐШи¶БдЄНи¶БдЄ≠жЦ≠пЉМињЩдЇЫйГљзФ±и∞ГеЇ¶з≥їзїЯжЭ•зЃ°пЉМжИСдїђзЪДињЩдЇЫдїїеК°е∞±жЬЙеПѓиГљеЬ®дЄНеРМзЪДеЬ∞жЦєжЭ•ињРи°МпЉМеПѓдї•йАЪињЗжХ∞жНЃйЫЖжИРжККеЃГжЛЙеИ∞дЄНеРМзЪДеМЇеЯЯпЉМиЃ©ињЩдЇЫжХ∞жНЃиГље§ЯеЬ®жХідЄ™зЪДеє≥еП∞дЄКиЈСиµЈжЭ•пЉМжИСдїђжЙАжЬЙзЪДдїїеК°иЈСиµЈжЭ•дєЛеРОжИСдїђйЬАи¶БжЬЙдЄАдЄ™зЫСжОІпЉМеРМжЧґжИСдїђзЪДoperationдєЯйЬАи¶БиЗ™еК®еМЦгАБињРзїіеМЦпЉМеЖНеЊАдЄЛжИСдїђдЉЪињЫи°МжХ∞жНЃзЪДеИЖжЮРжИЦиАЕBIжК•и°®дєЛз±їзЪДпЉМжИСдїђдєЯдЄНиГље§ЯењШиЃ∞machine learningдєЯжШѓеЬ®жИСдїђзЪДеє≥еП∞дЄКйЫЖжИРиµЈжЭ•зЪДгАВжЬАеРОпЉМжЬАйЗНи¶БзЪДе∞±жШѓжХ∞жНЃеЃЙеЕ®пЉМињЩдЄАеЭЧжХідЄ™дЄЬи•њжЮДиµЈдЄАдЄ™е§ІжХ∞жНЃеЉХжУОзЪДе§Цж≤њ+е§ІжХ∞жНЃеЉХжУОжЬђиЇЂпЉМињЩдЄАе•ЧжИСдїђзІ∞дєЛдЄЇеНХеЉХжУОзЪДеЃМе§Зе§ІжХ∞жНЃз≥їзїЯпЉМињЩдЄАе•Чз≥їзїЯжИСдїђеЬ®2017еєізЪДжЧґеАЩе∞±еЕЈе§ЗдЇЖгАВ

2018еєізЪДжЧґеАЩжИСдїђеБЪдїАдєИпЉЯ2018еєіжИСдїђеЬ®еНХеЉХжУОзЪДеЯЇз°АдЄКеѓєжО•еИ∞е§ЪеЉХжУОпЉМжИСдїђжХідЄ™еЉАеПСйУЊиЈѓи¶БиЃ©еЃГйЧ≠зОѓеМЦпЉМжХ∞жНЃйЫЖжИРеПѓдї•жККжХ∞жНЃеЬ®дЄНеРМзЪДжХ∞жНЃжЇРдєЛйЧіињЫи°МжЛЦеК®пЉМжИСдїђжККжХ∞жНЃеЉАеПСеЃМдєЛеРОпЉМдЉ†зїЯзЪДжЦєеЉПжШѓеЖНзФ®жХ∞жНЃеЉХжУОжККеЃГжЛЦиµ∞пЉМиАМжИСдїђеБЪзЪДдЇЛжГЕжШѓеЄМжЬЫињЩдЄ™жХ∞жНЃжШѓдЇСдЄКзЪДжЬНеК°пЉМињЩдЄ™жЬНеК°иГље§ЯзЫіжО•еѓєзФ®жИЈжПРдЊЫжГ≥и¶БзЪДжХ∞жНЃпЉМиАМдЄНйЬАи¶БжККжХ∞жНЃжХідЄ™жЛЦиµ∞пЉМеЫ†дЄЇжХ∞жНЃеЬ®дЉ†иЊУињЗз®ЛдЄ≠жЬЙе≠ШеВ®зЪДжґИиАЧгАБзљСзїЬзЪДжґИиАЧеТМдЄАиЗіжАІжґИиАЧпЉМжЙАжЬЙзЪДињЩдЇЫдЄЬи•њйГљеЬ®жґИиАЧзФ®жИЈзЪДжИРжЬђпЉМжИСдїђеЄМжЬЫйАЪињЗжХ∞жНЃжЬНеК°иЃ©зФ®жИЈжЛњеИ∞дїЦжГ≥и¶БзЪДдЄЬи•њгАВеЖНеЊАдЄЛпЉМе¶ВжЮЬжХ∞жНЃжЬНеК°дєЛдЄКињШжЬЙиЗ™еЃЪдєЙзЪДеЇФзФ®пЉМзФ®жИЈињШйЬАи¶БеОїеїЇдЄАдЄ™жЬЇжИњпЉМжР≠дЄАдЄ™webжЬНеК°пЉМзДґеРОжККжХ∞жНЃжЛњињЗжЭ•пЉМињЩж†ЈдєЯеЊИйЇїзГ¶пЉМжЙАдї•жИСдїђжПРдЊЫдЄАдЄ™жЙШзЃ°зЪДwebеЇФзФ®зЪДдЇСдЄКеЉАеПСеє≥еП∞пЉМиГље§ЯиЃ©зФ®жИЈзЫіжО•зЬЛеИ∞жЙАжЬЙзЪДжХ∞жНЃжЬНеК°пЉМеЬ®ињЩдЄ™жЦєеРСдЄКжЭ•иѓіпЉМжИСдїђе∞±еПѓдї•жЮДеїЇдїїжДПзЪДжХ∞жНЃжЩЇиГљиІ£еЖ≥жЦєж°ИгАВ
еИ∞2019еєіпЉМжИСдїђдЉЪжККзРЖењµеЖНжЛУе±ХдЄАе±ВпЉМй¶ЦеЕИеѓєдЇОзФ®жИЈжЭ•иѓіжШѓзФ®жИЈдЇ§дЇТе±ВпЉМдљЖжШѓзФ®жИЈзЪДдЇ§дЇТе±ВдЄНдїЕдїЕжШѓеЉАеПСпЉМжЙАдї•жИСдїђдЉЪжККзФ®жИЈеИЖжИРдЄ§з±їпЉМдЄАйГ®еИЖеПЂеБЪжХ∞жНЃзЪДзФЯдЇІиАЕпЉМдєЯе∞±жШѓеЖЩдїїеК°гАБеЖЩи∞ГеЇ¶гАБињРзїіз≠ЙпЉМињЩдЇЫжШѓжХ∞жНЃзЪДзФЯдЇІиАЕпЉМжХ∞жНЃзЪДзФЯдЇІиАЕеБЪе•љзЪДдЄЬи•њзїЩи∞БеСҐпЉЯзїЩжХ∞жНЃзЪДжґИиієиАЕпЉМжИСдїђзЪДжХ∞жНЃеИЖжХ£еЬ®еРДдЄ™еЬ∞жЦєпЉМжЙАжЬЙзЪДдЄЬи•њйГљдЉЪеЬ®ж≤їзРЖзЪДдЇ§дЇТе±ВеѓєжХ∞жНЃзЪДжґИиієиАЕжПРдЊЫжЬНеК°пЉМињЩж†ЈжИСдїђе∞±еЬ®дЄАдЄ™жЦ∞зЪДиІТеЇ¶жЭ•иѓ†йЗКй£Ю姩姲жХ∞жНЃеє≥еП∞гАВйЩ§дЇЖеЉХжУОе≠ШеВ®дї•е§ЦпЉМжИСдїђжЬЙеЕ®еЯЯзЪДжХ∞жНЃйЫЖжИРињЫи°МжЛЙеК®пЉМзїЯдЄАзЪДи∞ГеЇ¶еПѓдї•еЬ®дЄНеРМзЪДеЉХжУОдєЛйЧіжЭ•еИЗжНҐеНПеРМеЈ•дљЬпЉМеРМжЧґжИСдїђжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМеЬ®ињЩдєЛдЄКжИСдїђеѓєжХ∞жНЃзЪДзФЯдЇІиАЕеТМжХ∞жНЃзЪДжґИиієиАЕдєЯйГљињЫи°МдЇЖзЫЄеЇФзЪДжФѓжМБпЉМйВ£дєИињЩдЄ™жХідљУе∞±жШѓеЕ®еЯЯзЪДе§ІжХ∞жНЃеє≥еП∞дЇІеУБжЮґжЮДгАВ
дЇСеОЯзФЯеє≥еП∞еИ∞еЕ®еЯЯдЇСжХ∞дїУ
===========
жИСдїђжХідЄ™еє≥еП∞йГљжШѓдЇСеОЯзФЯзЪДпЉМдЇСеОЯзФЯжЬЙеУ™дЇЫжКАжЬѓеСҐпЉЯ
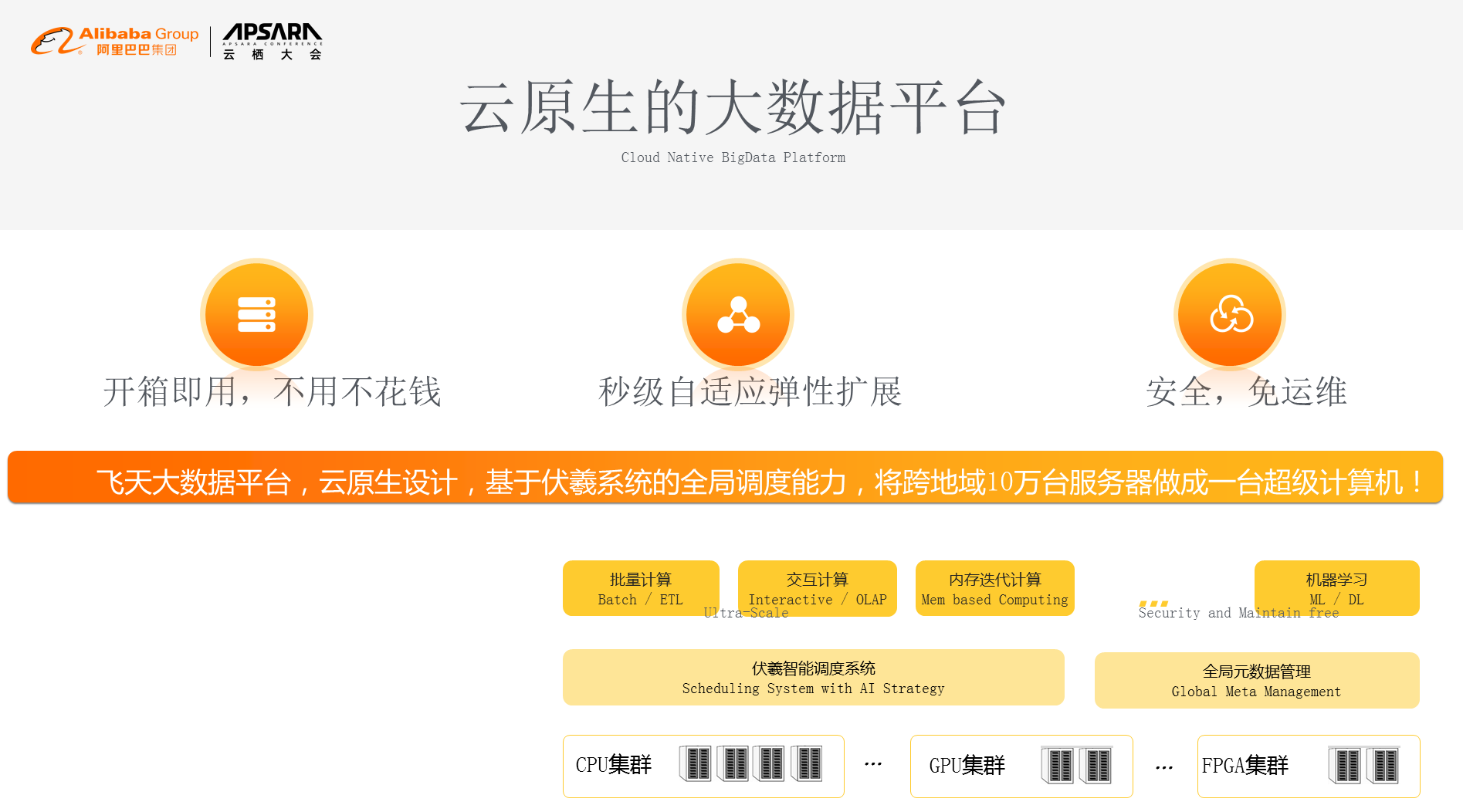
й£Ю姩姲жХ∞жНЃеє≥еП∞еЬ®10еєіеЙНе∞±еЭЪжМБдЇСеОЯзФЯзЪДжХ∞жНЃпЉМдЇСеОЯзФЯжДПеС≥зЭАдЄЙдїґдЇЛжГЕпЉМзђђдЄАеЉАзЃ±еН≥зФ®гАБдЄНзФ®дЄНиК±йТ±пЉМињЩдЄ™еТМдЉ†зїЯзЪДдє∞з°ђдїґжЦєеЉПжЬЙйЭЮеЄЄе§ІзЪДдЄНеРМпЉЫзђђдЇМжИСдїђеЕЈе§ЗдЇЖзІТзЇІиЗ™йАВеЇФзЪДеЉєжАІжЙ©е±ХпЉМзФ®е§Ъе∞Сдє∞е§Ъе∞СпЉЫзђђдЄЙеЫ†дЄЇжШѓдЇСдЄКзЪДж°ЖжЮґпЉМжИСдїђеЊИе§ЪињРзїіеТМеЃЙеЕ®зЪДдЄЬи•њзФ±дЇСиЗ™еК®жЭ•еЃМжИРдЇЖпЉМжЙАдї•жШѓеЃЙеЕ®еЕНињРзїізЪДгАВдїОз≥їзїЯжЮґжЮДдЄКиЃ≤пЉМй£Ю姩姲жХ∞жНЃеМЕжЛђдЉ†зїЯзЪДCPUгАБGPUйЫЖзЊ§пЉМдї•еПКеє≥е§іеУ•иКѓзЙЗйЫЖзЊ§пЉМеЖНеЊАдЄКжШѓжИСдїђзЪДдЉПзЊ≤жЩЇиГљи∞ГеЇ¶з≥їзїЯеТМеЕГжХ∞жНЃз≥їзїЯпЉМеЖНеЊАдЄКжИСдїђжПРдЊЫдЇЖе§ЪзІНиЃ°зЃЧиГљеКЫпЉМжИСдїђжЬАйЗНи¶БзЪДзЫЃж†Зе∞±жШѓйАЪињЗдЇСеОЯзФЯиЃЊиЃ°жКК10дЄЗеП∞еЬ®зЙ©зРЖдЄКеИЖеЄГеЬ®дЄНеРМеЬ∞еЯЯзЪДжЬНеК°еЩ®иЃ©зФ®жИЈиІЙеЊЧеГПдЄАеП∞иЃ°зЃЧжЬЇгАВжИСдїђдїК姩еЈ≤зїПиЊЊеИ∞дЇЖ10еєіеЙНзЪДиЃЊиЃ°и¶Бж±ВпЉМеЕЈе§ЗдЇЖжЫіеЉЇзЪДжЬНеК°жЙ©е±ХиГљеКЫпЉМиГље§ЯжФѓжТС5еИ∞10еєізЪДжХ∞жНЃињЫж≠•зЪДеПСе±ХгАВ
жИСдїђеЕЕеИЖеИ©зФ®дЇСеОЯзФЯиЃЊиЃ°зЪДзРЖењµпЉМжФѓжМБе§ІжХ∞жНЃеТМжЬЇеЩ®е≠¶дє†зЪДењЂйАЯе§ІиІДж®°еЉєжАІиіЯиљљйЬАж±ВгАВжИСдїђжФѓжТС0пљЮ100еАНзЪДеЉєжАІжЙ©еЃєиГљеКЫпЉМеОїеєіеЉАеІЛпЉМеПМеНБдЄА60%зЪДжХ∞жНЃе§ДзРЖйЗПжЭ•иЗ™дЇОе§ІжХ∞жНЃеє≥еП∞зЪДе§ДзРЖиГљеКЫпЉМељУеПМ11еЈЕе≥∞жЭ•зЪДжЧґеАЩпЉМжИСдїђжККе§ІжХ∞жНЃзЪДиµДжЇРеЉєеЫЮжЭ•иЃ©зїЩеЬ®зЇњз≥їзїЯеОїе§ДзРЖйЧЃйҐШгАВдїОеП¶е§ЦдЄАдЄ™иІТеЇ¶жЭ•иЃ≤пЉМжИСдїђеЕЈе§ЗеЉєжАІиГљеКЫпЉМзЫЄжѓФзЙ©зРЖзЪДIDCж®°еЉПпЉМжИСдїђжЬЙ80%жИРжЬђзЪДиКВзЬБпЉМжМЙдљЬдЄЪзЪДиЃ°иієж®°еЉПпЉМжИСдїђжПРдЊЫзІТзЇІеЉєжАІдЉЄзЉ©зЪДеРМжЧґпЉМдЄНдљњзФ®дЄНжФґиієгАВзЫЄжѓФиЗ™еїЇIDCпЉМзїЉеРИжИРжЬђеП™жЬЙ1/5гАВйЩ§дЇЖеЭЪжМБеОЯзФЯдєЛе§ЦпЉМжИСдїђжЬАињСеПСзО∞пЉМйЪПзЭАдЇЇеЈ•жЩЇиГљзЪДеПСе±ХпЉМиѓ≠йЯ≥иІЖеЫЊзЪДжХ∞жНЃиґКжЭ•иґКе§ЪдЇЖпЉМе§ДзРЖзЪДиГљеКЫе∞±и¶БеК†еЉЇпЉМжИСдїђи¶БдїОдЇМзїізЪДе§ІжХ∞жНЃеє≥еП∞еПШжИРеЕ®еЯЯзЪДжХ∞жНЃеє≥еП∞гАВ
е¶ВеЫЊжЙАз§ЇпЉМдЄЪзХМжЬЙдЄАдЄ™жѓФиЊГзБЂзЪДж¶ВењµеПЂжХ∞жНЃжєЦпЉМжИСдїђи¶БжККеЃҐжИЈе§ЪзІНе§Ъж†ЈзЪДжХ∞жНЃжЛњеИ∞дЄАиµЈжЭ•ињЫи°МзїЯдЄАзЪДжߕ胥еТМзЃ°зРЖгАВдљЖжШѓеѓєдЇОзЬЯж≠£зЪДдЉБдЄЪзЇІжЬНеК°еЃЮиЈµпЉМжИСдїђзЬЛеИ∞дЄАдЇЫйЧЃйҐШпЉМй¶ЦеЕИжХ∞жНЃзЪДжЭ•жЇРеѓєдЇОеЃҐжИЈжЭ•иѓіжШѓдЄНеПѓжОІзЪДпЉМдєЯжШѓе§ЪзІНе§Ъж†ЈзЪДпЉМиАМдЄФеЊИе§Із®ЛеЇ¶дЄКж≤°жЬЙеКЮж≥ХжККжЙАжЬЙзЪДжХ∞жНЃзїЯдЄАзФ®дЄАзІНз≥їзїЯеТМеЉХжУОжЭ•зЃ°зРЖиµЈжЭ•пЉМеЬ®ињЩзІНжГЕеЖµдЄЛжИСдїђйЬАи¶БжЫіе§ІзЪДиГљеКЫжШѓдїАдєИеСҐпЉЯжИСдїђдїК姩йАЪињЗдЄНеРМзЪДжХ∞жНЃжЇРпЉМеПѓдї•ињЫи°МзїЯдЄАзЪДиЃ°зЃЧеТМзїЯдЄАзЪДжߕ胥еТМеИЖжЮРпЉМзїЯдЄАзЪДзЃ°зРЖпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™жЫіжЦ∞зЪДж¶ВењµеПЂйАїиЊСжХ∞жНЃжєЦпЉМеѓєдЇОзФ®жИЈжЭ•иѓіпЉМдЄНйЬАи¶БжККдїЦзЪДжХ∞жНЃињЫи°МзЙ©зРЖдЄКзЪДжРђињБпЉМдљЖжШѓжИСдїђдЄАж†ЈиГље§ЯињЫи°МиБФйВ¶иЃ°зЃЧеТМжߕ胥пЉМињЩе∞±жШѓжИСдїђиЃ≤зЪДйАїиЊСжХ∞жНЃжєЦзЪДж†ЄењГзРЖењµгАВ
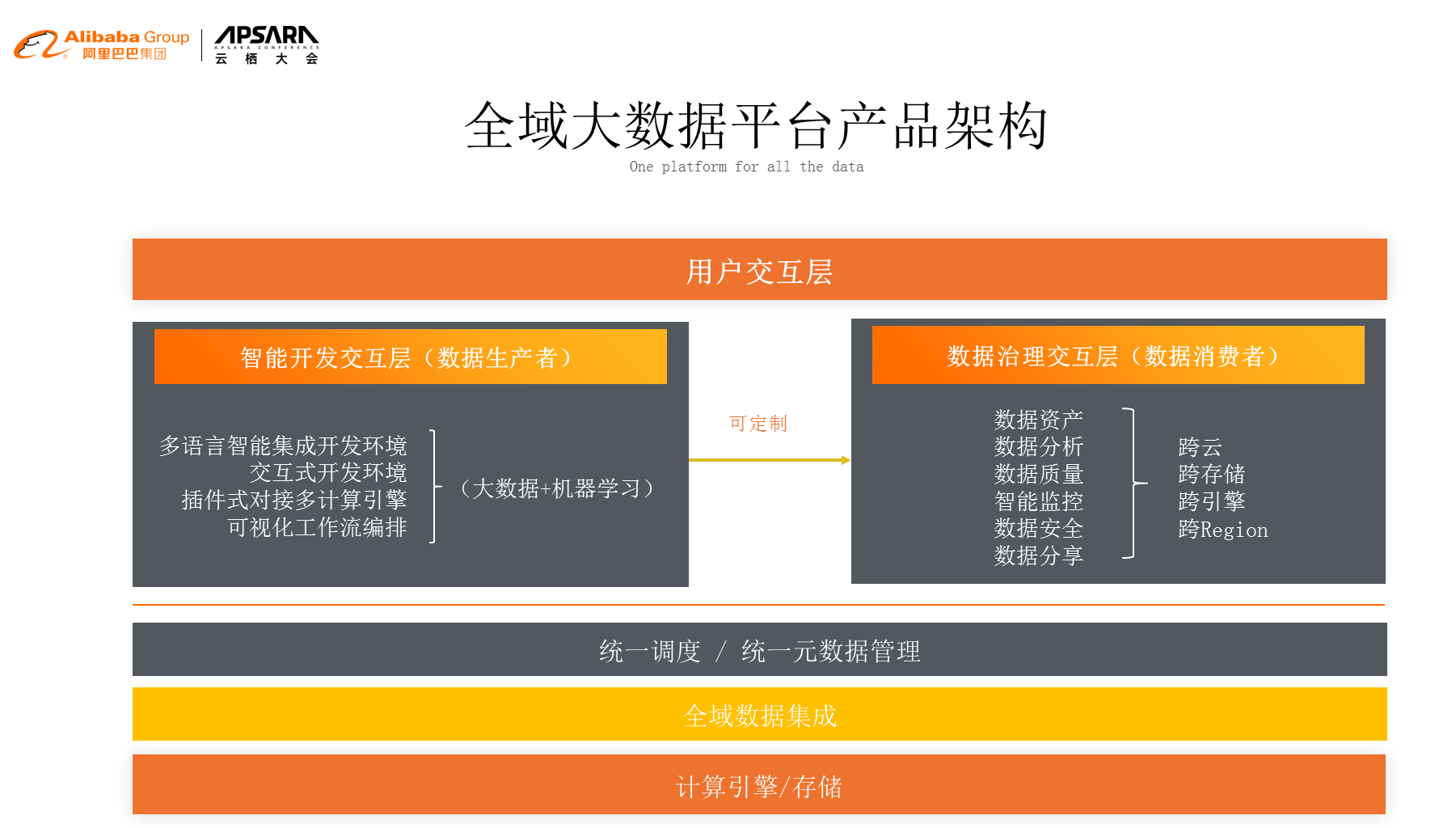
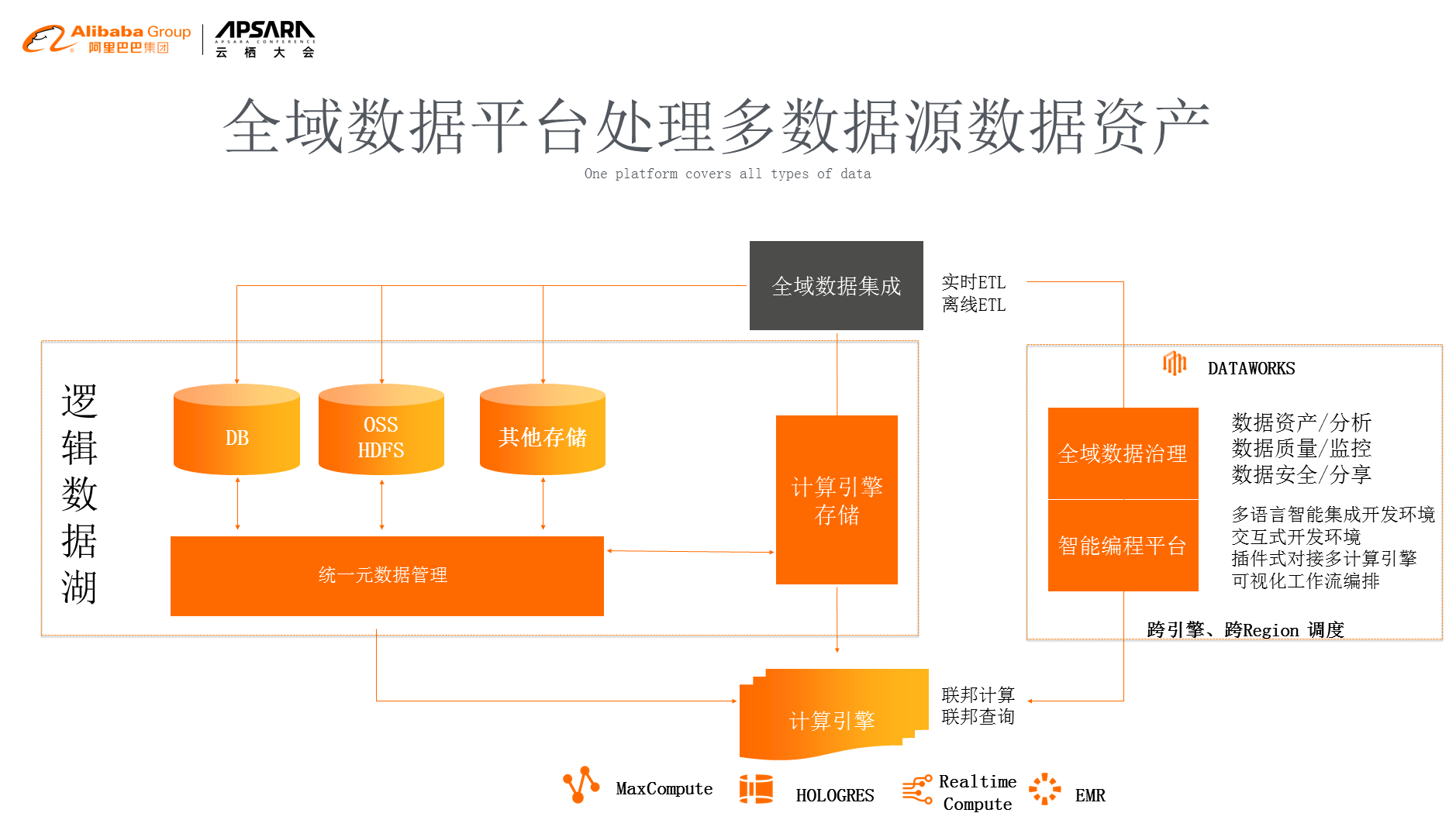
дЄЇдЇЖжФѓжТСињЩдїґдЇЛжГЕпЉМжИСдїђдЉЪжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖз≥їзїЯеТМи∞ГеЇ¶з≥їзїЯпЉМиГље§ЯиЃ©дЄНеРМзЪДиЃ°зЃЧеЉХжУОеНПеРМиµЈжЭ•еЈ•дљЬпЉМжЬАеРОжККжЙАжЬЙзЪДеЈ•дљЬж±ЗиБЪеИ∞еЕ®еЯЯжХ∞жНЃж≤їзРЖдЄКйЭҐпЉМеєґдЄФжПРдЊЫзїЩжХ∞жНЃеЉАеПСиАЕдЄАдЄ™зЉЦз®Леє≥еП∞пЉМиЃ©дїЦиГље§ЯзЫіжО•зЪДдЇІзФЯжХ∞жНЃпЉМжИЦиАЕжШѓеОїеЃЪеИґиЗ™еЈ±зЪДеЇФзФ®гАВйВ£дєИпЉМйАЪињЗињЩж†ЈзЪДжЦєеЉПпЉМжИСдїђжККеОЯжЭ•зЪДеНХзїіеЇ¶е§ІжХ∞жНЃеє≥еП∞еОїеБЪе§ІжХ∞жНЃе§ДзРЖпЉМжЛУе±ХеИ∞дЄАдЄ™еЕ®еЯЯзЪДжХ∞жНЃж≤їзРЖпЉМињЩдЄ™жХ∞жНЃеЕґеЃЮеПѓдї•еМЕеРЂзЃАеНХзЪДе§ІжХ∞жНЃзЪДпЉМдєЯеПѓдї•еМЕеРЂжХ∞жНЃеЇУзЪДпЉМзФЪиЗ≥жШѓдЄАдЇЫOSSзЪДfileпЉМињЩдЇЫжИСдїђеЬ®жХідЄ™зЪДеє≥еП∞йЗМйЭҐйГљдЉЪеК†дї•е§ДзРЖгАВ
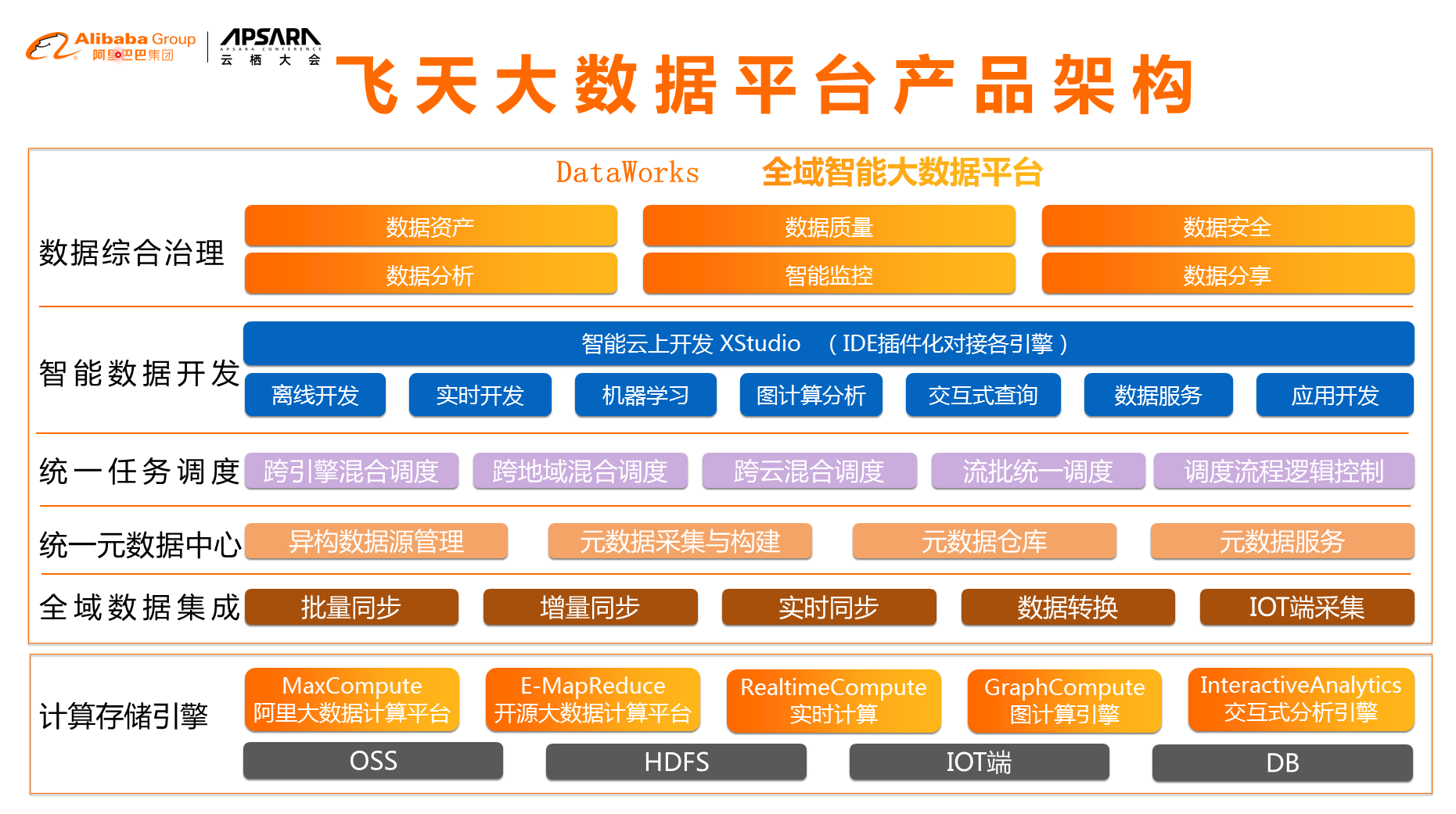
е¶ВеЫЊдЄЇй£Ю姩姲жХ∞жНЃзЪДдЇІеУБжЮґжЮДпЉМдЄЛйЭҐжШѓе≠ШеВ®иЃ°зЃЧеЉХжУОпЉМеПѓдї•зЬЛеИ∞жИСдїђйЩ§дЇЖиЃ°зЃЧеЉХжУОиЗ™еЄ¶зЪДе≠ШеВ®дєЛе§ЦињШжЬЙеЕґеЃГеЉАжФЊзЪДOSSпЉМињШжЬЙIOTзЂѓйЗЗйЫЖзЪДжХ∞жНЃеТМжХ∞жНЃеЇУзЪДжХ∞жНЃпЉМжЙАжЬЙжХ∞жНЃињЫи°МеЕ®еЯЯжХ∞жНЃйЫЖжИРпЉМйЫЖжИРеРОињЫи°МзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМзїЯдЄАзЪДжЈЈеРИдїїеК°и∞ГеЇ¶пЉМеЖНеЊАдЄКжШѓеЉАеПСе±ВеТМжХ∞жНЃзїЉеРИж≤їзРЖе±ВпЉМйАЪињЗињЩзІНжЦєеЉПпЉМжИСдїђзЂЛдљУеМЦзЪДжККжХідЄ™е§ІжХ∞жНЃеЬИиµЈжЭ•зЃ°зРЖгАВ
е§ІжХ∞жНЃдЄОAI еПМзФЯз≥їзїЯ
===========
жПРеИ∞дЇЖе§ІжХ∞жНЃжИСдїђиВѓеЃЪдЉЪжГ≥еИ∞AIпЉМAIеТМе§ІжХ∞жНЃжШѓеПМзФЯзЪДпЉМеѓєдЇОAIжЭ•иѓіеЃГжШѓйЬАи¶Бе§ІжХ∞жНЃжЭ•empowerзЪДпЉМдєЯе∞±иѓіbigdata for AIгАВдЄЛйЭҐеПѓдї•йАЪињЗдЄАдЄ™demoжЭ•зЬЛжИСдїђжАОдєИжЭ•еБЪињЩдїґдЇЛжГЕгАВеѓєдЇОAIзЪДеЉАеПСеЈ•з®ЛеЄИжЭ•иѓіпЉМдїЦдїђжѓФиЊГеЄЄзФ®зЪДжЦєеЉПжШѓзФ®дЇ§дЇТеЉПзЪДnotebookжЭ•ињЫи°МAIзЪДеЉАеПСпЉМеЫ†дЄЇеЃГжѓФиЊГзЫіиІВпЉМдљЖжШѓе¶ВдљХжККе§ІжХ∞жНЃдєЯињЫи°МдЇ§дЇТеЉПеЉАеПСпЉМеєґдЄФеТМAIжЭ•зїСеЃЪпЉМдЄЛйЭҐжЭ•зЬЛдЄАдЄЛињЩдЄ™зЃАеНХзЪДдЊЛе≠РгАВ
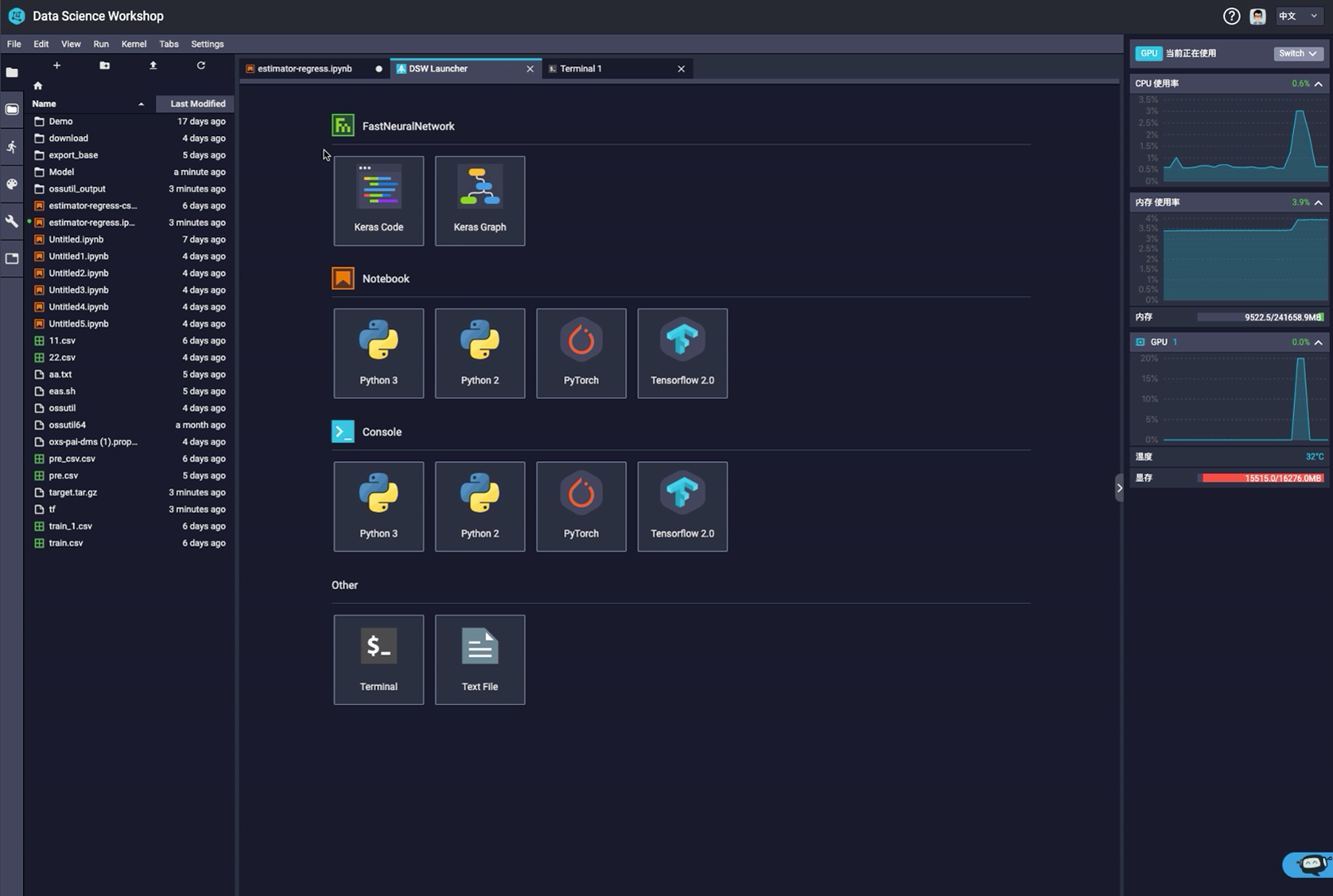
е¶ВеЫЊжШѓжИСдїђDSWзЪДеє≥еП∞пЉМжИСдїђеПѓдї•зЫіжО•зЪДзФ®дЄАдЄ™magicеСљдї§пЉМconnectеИ∞зО∞е≠ШзЪДmaxcomputeйЫЖзЊ§пЉМеєґдЄФйАЙжЛ©projectеРОпЉМеПѓдї•зЫіжО•иЊУеЕ•sqlиѓ≠еП•пЉМињЩдЇЫйГљжШѓжЩЇиГљзЪДгАВзДґеРОжИСдїђеОїжЙІи°МпЉМзїУжЮЬеЗЇжЭ•дєЛеРОжИСдїђеПѓдї•еѓєfeatureињЫи°МзЫЄеЇФзЪДеИЖжЮРпЉМеМЕжЛђеПѓдї•еОїжФєеПШињЩдЇЫfeatureзЪДж®™зЇµеЭРж†ЗеБЪеЗЇдЄНеРМзЪДchartsпЉМеРМжЧґжИСдїђзФЪиЗ≥еПѓдї•жККзФЯжИРзЪДзїУжЮЬзЫіжО•webеИ∞excelжЦєеЉПињЫи°МзЉЦиЊСеТМе§ДзРЖпЉМе§ДзРЖеЃМдєЛеРОжИСдїђеЖНжККжХ∞жНЃжЛЙеЫЮжЭ•пЉМдєЯеПѓдї•еИЗжНҐеИ∞GPUжИЦиАЕCPUињЫи°МжЈ±еЇ¶е≠¶дє†еТМиЃ≠зїГпЉМиЃ≠зїГеЃМдЇЖдєЛеРОпЉМжИСдїђдЉЪжККжХідЄ™зЪДдї£з†БеПШжИРдЄАдЄ™ж®°еЮЛпЉМжИСдїђдЉЪжККињЩдЄ™ж®°еЮЛеѓЉеЕ•еИ∞дЄАдЄ™зЫЄеЇФзЪДеЬ∞жЦєдєЛеРОжПРдЊЫдЄАдЄ™WebжЬНеК°пЉМињЩдЄ™жЬНеК°дєЯе∞±жШѓжИСдїђзЪДеЬ®зЇњжО®зРЖжЬНеК°гАВжХіе•ЧжµБз®ЛеБЪеЃМдєЛеРОпЉМзФЪиЗ≥жИСдїђеПѓдї•еЖНжО•жХ∞жНЃеЇФзФ®пЉМеПѓдї•еЬ®жЙШзЃ°зЪДWEBдЄКжЮДеїЇпЉМињЩе∞±жШѓе§ІжХ∞жНЃеє≥еП∞зїЩAIжПРдЊЫжХ∞жНЃеТМзЃЧеКЫгАВ

е§ІжХ∞жНЃеТМAIжШѓеПМзФЯз≥їзїЯпЉМAIжШѓдЄАдЄ™еЈ•еЕЈе±ВпЉМеПѓдї•дЉШеМЦжЙАжЬЙзЪДдЇЛжГЕгАВжИСдїђеЄМжЬЫй£Ю姩зЪДе§ІжХ∞жНЃеє≥еП∞иГље§ЯиµЛиГљзїЩAIгАВжИСдїђеЬ®жЬАеЉАеІЛзЪДжЧґеАЩеЄМжЬЫbuildдЄАдЄ™еПѓзФ®зЪДз≥їзїЯпЉМиГље§ЯйЭҐдЄіеПМ11зЪДеЉєжАІиіЯиљљдїНзДґжШѓеПѓзФ®зЪДгАВйАЪињЗињЩдЇЫеєізЪДеК™еКЫпЉМжИСдїђињљж±ВжЮБиЗізЪДжАІиГљпЉМжИСдїђиГље§ЯжЙУз†іжХ∞жНЃзЪДеҐЮйХњеТМжИРжЬђеҐЮйХњзЪДзЇњжАІеЕ≥з≥їпЉМжИСдїђдєЯеЄМжЬЫеЃГжШѓдЄАдЄ™жЩЇиГљзЪДпЉМжИСдїђеЄМжЬЫжЫіе§ЪзЪДжХ∞жНЃеЉАеПСеЈ•з®ЛеЄИжЭ•жФѓжМБеЃГпЉМжИСдїђйЬАи¶БжЫіе§НжЭВзЪДдЇЇеКЫжКХеЕ•жЭ•зРЖиІ£дїЦпЉМжИСдїђеЄМжЬЫжЬЙжЫіеЉЇзЪДе§ІжХ∞жНЃжЭ•дЉШеМЦе§ІжХ∞жНЃз≥їзїЯгАВ

жИСдїђжПРеЗЇдЄАдЄ™ж¶ВењµеПЂAuto Data WarehouseпЉМжИСдїђеЄМжЬЫйАЪињЗжЩЇиГљеМЦзЪДжЦєеЉПжККе§ІжХ∞жНЃеБЪеЊЧжЫіиБ™жШОгАВжХідљУдЄКеПѓдї•еИЖжИР3дЄ™йШґжЃµпЉЪ
* зђђдЄАйШґжЃµжШѓиЃ°зЃЧе±ВйЭҐеТМжХИзОЗе±ВйЭҐпЉМжИСдїђе∞ЭиѓХеѓїжЙЊиЃ°зЃЧзЪДзђђдЄАе±ВеОЯзРЖпЉМжИСдїђеОїжЙЊзЩЊдЄЗеИ∞еНГдЄЗзЇІеИЂйЗМйЭҐзЪДеУ™дЇЫдљЬдЄЪжШѓзЫЄдЉЉзЪДпЉМеЫ†ж≠§еПѓдї•еРИеєґпЉМйАЪињЗињЩзІНжЦєеЉПжЭ•иКВзЬБжИРжЬђпЉМињШжЬЙељУдљ†жЬЙеНГдЄЗзЇІеИЂзЪДи°®дєЛеРОпЉМз©ґзЂЯеУ™дЇЫ谮忯糥еЉХеЕ®е±АжШѓжЬАдЉШзЪДпЉМдї•еПКжИСдїђжАОдєИеОїеБЪеЖЈзГ≠зЪДжХ∞жНЃеИЖе±ВеТМеБЪиЗ™йАВеЇФзЉЦз†БгАВ
* зђђдЇМйШґжЃµжШѓиµДжЇРиІДеИТпЉМAIеТМAuto Data WarehouseеПѓдї•еЄЃеК©жИСдїђеБЪжЫіе•љзЪДиµДжЇРдЉШеМЦпЉМеМЕжЛђжИСдїђжЬЙ3зІНзЪДжЙІи°МдљЬдЄЪж®°еЉПпЉМеУ™дЄАзІНж®°еЉПжЫіе•љпЉМжШѓеПѓдї•йАЪињЗе≠¶дє†зЪДжЦєеЉПе≠¶еЗЇжЭ•зЪДпЉМињШжЬЙеМЕжЛђдљЬдЄЪзЪДињРи°МйҐДжµЛеТМиЗ™еК®йҐДжК•и≠¶пЉМињЩе•Чз≥їзїЯдњЭиѓБдЇЖе§ІеЃґзЬЛеЊЧеИ∞жИЦиАЕзЬЛдЄНеИ∞зЪДйШњйЗМеЕ≥йФЃдљЬдЄЪзЪДж†ЄењГпЉМжѓФе¶ВжѓПињЗдЄАжЃµжЧґйЧіе§ІеЃґдЉЪеИЈдЄАдЄЛиКЭйЇїдњ°зФ®еИЖпЉМжѓП姩жЧ©дЄКдєЭзВєйШњйЗМзЪДеХЖжИЈз≥їзїЯдЉЪеТМдЄЛжЄЄз≥їзїЯеБЪзїУзЃЧпЉМеТМе§Ѓи°МеБЪзїУзЃЧпЉМињЩдЇЫеЯЇзЇњжШѓзФ±еНГзЩЊдЄ™дљЬдЄЪзїДжИРзЪДдЄАжЭ°зЇњпЉМдїОжѓП姩жЧ©дЄКеЗМжЩ®еЉАеІЛињРи°МеИ∞жЧ©дЄКеЕЂзВєиЈСеЃМпЉМз≥їзїЯеЫ†дЄЇеРДзІНеРДж†ЈзЪДеОЯеЫ†дЉЪеЗЇзО∞еРДзІНзЪДзКґеЖµпЉМеПѓиГљдЄ™еИЂзЪДжЬЇеЩ®дЉЪеЃХжЬЇгАВжИСдїђеБЪдЇЖдЄАдЄ™иЗ™еК®йҐДжµЛз≥їзїЯпЉМеОїйҐДжµЛињЩдЄ™з≥їзїЯжШѓеР¶иГље§ЯеЬ®еЕ≥йФЃжЧґйЧізВєдЄКеЃМжИРпЉМе¶ВжЮЬдЄНиГље§ЯеЃМжИРпЉМдЉЪжККжЫіе§ЪзЪДиµДжЇРеК†ињЫжЭ•пЉМдњЭиѓБеЕ≥йФЃдљЬдЄЪзЪДеЃМжИРгАВињЩдЇЫз≥їзїЯдњЭиѓБдЇЖжИСдїђе§ІеЃґжЧ•еЄЄзЬЛдЄНиІБзЪДеЕ≥йФЃжХ∞жНЃзЪДжµБиљђпЉМдї•еПКеПМеНБдЄАз≠ЙйЗНи¶БзЪДиµДжЇРеЉєжАІгАВ
* зђђдЄЙйШґжЃµжШѓжЩЇиГљеїЇж®°пЉМељУжХ∞жНЃињЫжЭ•дєЛеРОеТМйЗМйЭҐеЈ≤жЬЙзЪДжХ∞жНЃз©ґзЂЯжЬЙе§Ъе∞СзЪДйЗНеП†пЉЯињЩдЇЫжХ∞жНЃжЬЙе§Ъе∞СзЪДеЕ≥иБФпЉЯељУжХ∞жНЃжШѓеЗ†зЩЊеЉ†и°®жЧґпЉМжРЮDBAжЙЛеЈ•зЪДжЦєеЉПеПѓдї•и∞ГдЉШзЪДпЉМзО∞еЬ®йШњйЗМеЖЕйГ®зЪДз≥їзїЯжЬЙиґЕињЗеНГдЄЗзЇІеИЂзЪДи°®пЉМжИСдїђжЬЙйЭЮеЄЄе•љзЪДеЉАеПСдЇЇеСШзРЖиІ£и°®йЗМйЭҐеЃМеЕ®зЪДйАїиЊСеЕ≥з≥їгАВињЩдЇЫиЗ™еК®и∞ГдЉШеТМиЗ™еК®еїЇж®°иГље§ЯеЄЃеК©жИСдїђеЬ®ињЩдЇЫжЦєйЭҐеБЪдЄАдЇЫиЊЕеК©жАІзЪДеЈ•дљЬгАВ
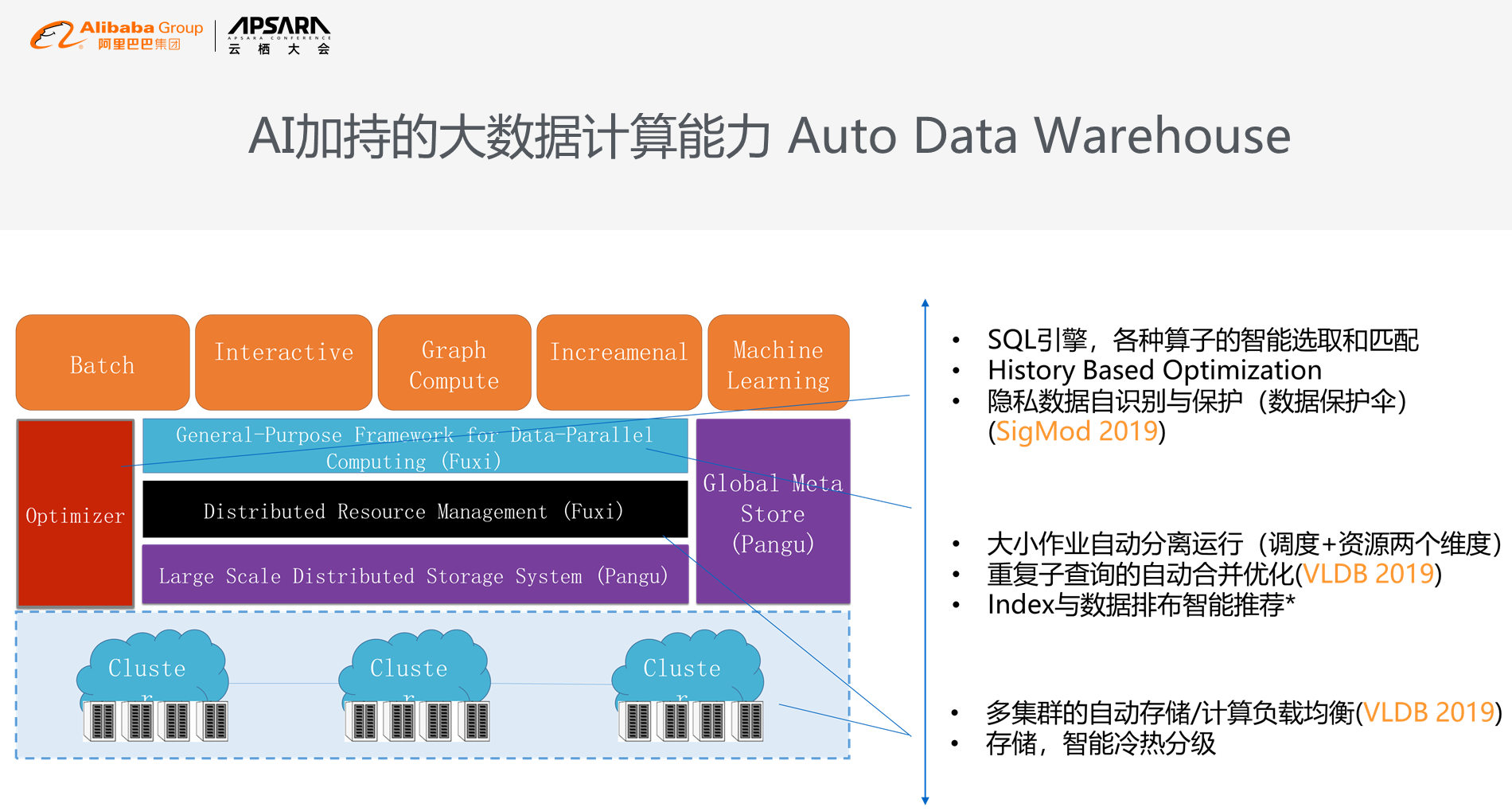
ињЩжШѓAuto Data Warehouseз≥їзїЯжЮґжЮДеЫЊпЉМдїОе§ЪйЫЖзЊ§зЪДиіЯиљљеЭЗи°°еИ∞иЗ™еК®еЖЈе≠ШпЉМеИ∞дЄ≠йЧізЪДйЪР嚥дљЬдЄЪдЉШеМЦпЉМеЖНеИ∞дЄКе±ВзЪДйЪРзІБжХ∞жНЃиЗ™еК®иѓЖеИЂпЉМињЩжШѓжИСдїђеТМиЪВиЪБдЄАиµЈеЉАеПСзЪДжКАжЬѓпЉМељУйЪРзІБзЪДжХ∞жНЃиЗ™еК®жШЊз§ЇеИ∞е±ПеєХдЄКжЭ•пЉМз≥їзїЯдЉЪиЗ™еК®ж£АжµЛеєґжЙУз†БгАВжИСдїђеЕґдЄ≠зЪДдЄЙй°єжКАжЬѓпЉМеМЕжЛђиЗ™еК®йЪРзІБдњЭжК§пЉМеМЕжЛђйЗНе§Не≠Ржߕ胥иЗ™еК®еРИеєґдЉШеМЦпЉМеМЕжЛђе§ЪйЫЖзЊ§зЪДиЗ™еК®еЃєзБЊпЉМжИСдїђжЬЙ3зѓЗpaperеПСи°®пЉМе§ІеЃґжЬЙеЕіиґ£зЪДиѓЭеПѓдї•еОїзљСзЂЩдЄКиѓїдЄАдЄЛзЫЄеЕ≥зЪДиЃЇжЦЗгАВ
[еОЯжЦЗйУЊжО•](https://yq.aliyun.com/articles/723228?utm_content=g_1000085633)
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ

еЬ®2015еєізЪДжЧґеАЩпЉМжИСдїђеЉАеІЛеЕ≥ж≥®еИ∞жХ∞жНЃзЪДжµЈйЗПеҐЮйХњеѓєз≥їзїЯеЄ¶жЭ•дЇЖиґКжЭ•иґКйЂШзЪДи¶Бж±ВпЉМйЪПзЭАжЈ±еЇ¶е≠¶дє†зЪДйЬАж±ВеҐЮйХњпЉМжХ∞жНЃеТМжХ∞жНЃеѓєеЇФзЪДе§ДзРЖиГљеКЫжШѓеИґзЇ¶дЇЇеЈ•жЩЇиГљеПСе±ХзЪДеЕ≥йФЃйЧЃйҐШпЉМжИСдїђеЬ®зїЩеЃҐжИЈиБКеИ∞дЄАдЄ™жСЖеЬ®жѓПдЄ™CIO/CTOйЭҐеЙНзЪДзО∞еЃЮйЧЃйҐШвАФвАФе¶ВжЮЬжХ∞жНЃеҐЮйХњ10еАНпЉМеЇФиѓ•жАОдєИеКЮпЉЯеЫЊдЄ≠жХ∞е≠Че§ІеЃґзЬЛеЊЧйЭЮеЄЄжЄЕжЩ∞пЉМйЭЮеЄЄзЃАеНХзЪДжЛНзЂЛжЈШз≥їзїЯиГМеРОжШѓPBзЪДжХ∞жНЃеЬ®еБЪжФѓжТСпЉМйШњйЗМе∞ПиЬЬеЃҐжЬНз≥їзїЯжЬЙ20дЄ™PBпЉМе§ІеЃґжѓП姩еЬ®жЈШеЃЭдЄКжЧ•еЄЄдљњзФ®зЪДдЄ™жАІеМЦжО®иНРз≥їзїЯпЉМеРОеП∞и¶БиґЕињЗ100дЄ™PBзЪДжХ∞жНЃжЭ•жФѓжТСеРОеП∞зЪДеЖ≥з≠ЦпЉМ10еАНеИ∞100еАНзЪДжХ∞жНЃеҐЮйХњжШѓйЭЮеЄЄеЄЄиІБзЪДгАВдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМ10еАНзЪДжХ∞жНЃеҐЮйХњйАЪеЄЄжДПеС≥зЭАдїАдєИйЧЃйҐШпЉЯ
зђђдЄАпЉМжДПеС≥зЭА10еАНжИРжЬђзЪДеҐЮйХњпЉМе¶ВжЮЬиАГиЩСеИ∞еҐЮйХњдЄНжШѓеЭЗеМАзЪДпЉМдЉЪжЬЙж≥Ґе≥∞еТМж≥Ґи∞ЈпЉМеПѓиГљйЬАи¶Б30еАНеЉєжАІи¶Бж±ВпЉЫзђђдЇМпЉМеЃЮйЩЕдЄКеЫ†дЄЇдЇЇеЈ•жЩЇиГљзЪДеЕіиµЈпЉМдЇМзїізїУжЮДжАІзЪДеЕ≥з≥їеЮЛжХ∞жНЃжМБзї≠жАІеҐЮйХњзЪДеРМжЧґпЉМеЄ¶жЭ•зЪДжШѓйЭЮзїУжЮДеМЦжХ∞жНЃпЉМињЩзІНжМБзї≠зЪДжХ∞жНЃеҐЮйХњйЗМйЭҐпЉМдЄАеНКзЪДеҐЮйХњжЭ•иЗ™дЇОињЩзІНйЭЮзїУжЮДеМЦжХ∞жНЃпЉМжИСдїђйЩ§дЇЖиГље§Яе§ДзРЖе•љињЩзІНдЇМзїізЪДжХ∞жНЃеМЦдєЛеРОпЉМжИСдїђе¶ВдљХжЭ•еБЪе•ље§ЪзІНжХ∞жНЃиЮНеРИзЪДиЃ°зЃЧпЉЯзђђдЄЙпЉМйШњйЗМжЬЙдЄАдЄ™еЇЮе§ІзЪДдЄ≠еП∞еЫҐйШЯпЉМе¶ВжЮЬиѓіжИСдїђзЪДжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжИСдїђзЪДеЫҐйШЯжШѓдЄНжШѓеҐЮйХњдЇЖ10еАНпЉЯе¶ВжЮЬиѓіжХ∞жНЃеҐЮйХњдЇЖ10еАНпЉМжХ∞жНЃзЪДеЕ≥з≥їе§НжЭВеЇ¶дєЯиґЕињЗдЇЖ10еАНпЉМйВ£дєИдЇЇеЈ•зЪДжИРжЬђжШѓдЄНжШѓдєЯиґЕињЗдЇЖ10еАНдї•дЄКпЉМжИСдїђзЪДй£Ю姩еє≥еП∞еЬ®2015еєіеРОе∞±жШѓеЫізїХињЩдЄЙдЄ™еЕ≥йФЃжАІзЪДйЧЃйҐШжЭ•еБЪеЈ•дљЬзЪДгАВ
еОЯеИЫжКАжЬѓдЉШеМЦ + з≥їзїЯиЮНеРИ
=============
ељУйШњйЗМеЈіеЈізЪДе§ІжХ∞жНЃиµ∞ињЗ10дЄЗеП∞иІДж®°зЪДжЧґеАЩпЉМжИСдїђеЈ≤зїПиµ∞еЕ•еИ∞жКАжЬѓзЪДжЧ†дЇЇеМЇпЉМињЩж†ЈзЪДжМСжИШзїЭе§Іе§ЪжХ∞еЕђеПЄдЄНдЄАеЃЪиГљйБЗеИ∞пЉМдљЖжШѓеѓєдЇОйШњйЗМеЈіеЈіињЩж†ЈзЪДдљУйЗПжЭ•иЃ≤пЉМињЩдЄ™жМСжИШжШѓдЄАзЫіжСЖеЬ®жИСдїђйЭҐеЙНзЪДгАВ

е§ІеЃґеПѓдї•зЬЛеИ∞пЉМ2015еєізЪДжЧґеАЩпЉМжИСдїђжХідЄ™зЪДдљУз≥їеїЇзЂЛиµЈжЭ•дєЛеРОпЉМе∞±еЉАеІЛеБЪеРДзІНеРДж†ЈзЪДBenchmarkпЉМжѓФе¶В2015еєі100TBзЪДSortingпЉМ2016еєіжИСдїђеБЪCloudSortпЉМеОїзЬЛжАІдїЈжѓФпЉМ2017еєіжИСдїђйАЙжЛ©дЇЖBigbenchгАВе¶ВеЫЊжШѓжИСдїђжЬАжЦ∞еПСеЄГзЪДжХ∞жНЃпЉМеЬ®2017гАБ2018еТМ2019еєіпЉМжѓПеєійГљжЬЙдЄАеАНзЪДжАІиГљжПРеНЗпЉМеРМжЧґжИСдїђеЬ®30TBзЪДиІДж®°дЄКжѓФзђђдЇМеРНзЪДдЇІеУБжЬЙдЄАеАНзЪДжАІиГљеҐЮйХњпЉМеєґдЄФжЬЙдЄАеНКзЪДжИРжЬђиКВзЬБпЉМињЩжШѓжИСдїђзЪДиЃ°зЃЧеКЫжМБзї≠дЄКеНЗзЪДдЉШеМЦиґЛеКњгАВ

йВ£дєИпЉМиЃ°зЃЧеКЫжМБзї≠еНЗзЇІжШѓе¶ВдљХеБЪеИ∞зЪДпЉЯе¶ВеЫЊжШѓжИСдїђзїПеЄЄзФ®еИ∞зЪДз≥їзїЯеНЗзЇІзЪДдЄЙиІТзРЖиЃЇпЉМжЬАеЇХе±ВзЪДиЃ°зЃЧж®°еЮЛжШѓйЂШжХИзЪДзЃЧе≠Ре±ВеТМе≠ШеВ®е±ВпЉМињЩжШѓйЭЮеЄЄеЇХе±ВзЪДеЯЇз°АдЉШеМЦпЉМеЊАдЄКйЭҐи¶БжЙЊеИ∞жЬАдЉШзЪДжЙІи°МиЃ°еИТпЉМдєЯе∞±жШѓзЃЧе≠РзїДеРИпЉМеЖНеЊАдЄКжШѓжЦ∞зЪДжЦєеРСпЉМеН≥жАОдєИеБЪеИ∞еК®жАБи∞ГжХідЄОиЗ™е≠¶дє†зЪДи∞ГдЉШгАВ

жИСдїђеЕИжЭ•зЬЛеНХдЄАзЃЧе≠РеТМеЉХжУОж°ЖжЮґзЪДжЮБиЗідЉШеМЦпЉМжИСдїђзФ®зЪДжШѓжѓФиЊГйЪЊеЖЩйЪЊзїіжК§зЪДж°ЖжЮґпЉМдљЖжШѓеЫ†дЄЇеЃГжѓФиЊГиііињСзЙ©зРЖз°ђдїґпЉМжЙАдї•еЄ¶жЭ•дЇЖжЫіжЮБиЗізЪДжАІиГљињљж±ВгАВеѓєдЇОеЊИе§Ъз≥їзїЯжЭ•иѓіеПѓиГљ5%зЪДжАІиГљжПРеНЗеєґдЄНеЕ≥йФЃпЉМдљЖеѓєдЇОй£Ю姩жКАжЬѓеє≥еП∞жЭ•иЃ≤пЉМ5%зЪДжАІиГљжПРеНЗе∞±жШѓ5еНГеП∞зЪДиІДж®°пЉМе§Іж¶Ве∞±жШѓ2пљЮ3дЇњзЪДжИРжЬђгАВе¶ВеЫЊеБЪдЇЖдЄАдЄ™зЃАеНХзЪДе∞ПдЊЛе≠РеБЪеНХдЄАзЃЧе≠РзЪДжЮБиЗідЉШеМЦпЉМеЬ®shuffleе≠РеЬЇжЩѓдЄ≠пЉМеИ©зФ®Non-temporal StoreдЉШеМЦshufflingдЄ≠зЪДзЉУе≠Шз≠ЦзХ•пЉМеЬ®ињЩж†ЈзЪДз≠ЦзХ•дЄКжЬЙ30%зЪДжАІиГљжПРеНЗгАВ
йЩ§дЇЖиЃ°зЃЧж®°еЭЧпЉМеЃГињШжЬЙе≠ШеВ®ж®°еЭЧпЉМе≠ШеВ®еИЖдЄЇ4дЄ™и±°йЩРгАВдЄАеЫЫи±°йЩРжШѓе≠ШеВ®жХ∞жНЃжЬђиЇЂзЪДеОЛзЉ©иГљеКЫпЉМжХ∞жНЃеҐЮйХњжЬАзЫіжО•зЪДжИРжЬђе∞±жШѓе≠ШеВ®жИРжЬђзЪДдЄКеНЗпЉМжИСдїђжАОдєИеБЪжЫіе•љзЪДеОЛзЉ©еТМзЉЦз†Бдї•еПКindexingпЉЯињЩжШѓдЄАеЫЫи±°йЩРеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉЫдЇМдЄЙи±°йЩРжШѓеЬ®жАІиГљиКВзЬБдЄКеБЪзЪДзЫЄеЕ≥еЈ•дљЬпЉМжИСдїђе≠ШеВ®е±ВеЕґеЃЮжШѓеЯЇдЇОеЉАжЇРORCзЪДж†ЗеЗЖпЉМжИСдїђеЬ®дЄКйЭҐеБЪдЇЖйЭЮеЄЄе§ЪзЪДжФєињЫеТМдЉШеМЦпЉМеЕґдЄ≠зЩљж°ЖйЗМйЭҐйГљжЬЙйЭЮеЄЄе§ЪзЪДж†ЗеЗЖжФєеК®пЉМжИСдїђиѓїеПЦжАІиГљеѓєжѓФеЉАжЇРJava ORC еЭЗењЂ 50%пЉМжИСдїђжШѓORCз§ЊеМЇињЗеОїдЄ§еєіжЬАе§Іиі°зМЃиАЕпЉМиі°зМЃдЇЖ2W+и°Мдї£з†БпЉМињЩжШѓжИСдїђеЬ®зЃЧе≠Ре±ВеТМе≠ШеВ®е±ВзЪДдЉШеМЦпЉМињЩжШѓжЬАеЇХе±ВзЪДжЮґжЮДгАВ

дљЖжШѓдїОеП¶е§ЦдЄАдЄ™е±ВйЭҐдЄКжЭ•иЃ≤пЉМеНХдЄАзЪДзЃЧе≠РеТМйГ®еИЖзЪДзЃЧе≠РзїДеРИеЊИйЪЊжї°иґ≥йГ®еИЖзЪДеЬЇжЩѓйЬАж±ВпЉМжЙАдї•жИСдїђе∞±жПРеИ∞зБµжіїзЪДзЃЧе≠РзїДеРИгАВдЄЊеЗ†дЄ™жХ∞е≠ЧпЉМжИСдїђеЬ®JoinдЄКжЬЙ4зІНж®°еЉПпЉМжЬЙ3зІНShufflingж®°еЉПжПРдЊЫпЉМжЬЙ3зІНдљЬдЄЪињРи°Мж®°еЉПпЉМжЬЙе§ЪзІНз°ђдїґжФѓжМБеТМе§ЪзІНе≠ШеВ®дїЛиі®жФѓжМБгАВеЫЊеП≥жШѓжАОж†ЈеОїеК®жАБеИ§еИЂJoinж®°еЉПпЉМдљњеЊЧињРзЃЧжХИзОЗжЫійЂШгАВйАЪињЗињЩзІНеК®жАБзЪДзЃЧе≠РзїДеРИпЉМжШѓжИСдїђдЉШеМЦзЪДзђђдЇМдЄ™зїіеЇ¶гАВ

дїОеЉХжУОдЉШеМЦеИ∞иЗ™е≠¶дє†и∞ГдЉШжШѓжИСдїђеЬ®жЬАињС1еєіе§ЪзЪДжЧґйЧійЗМиК±з≤ЊеКЫжѓФиЊГе§ЪзЪДпЉМжИСдїђеЬ®иАГиЩСе¶ВдљХзФ®дЇЇеЈ•жЩЇиГљеПКиЗ™е≠¶дє†жКАжЬѓжЭ•еБЪе§ІжХ∞жНЃз≥їзїЯпЉМе§ІеЃґеПѓдї•жГ≥и±°е≠¶й™СиЗ™и°Миљ¶пЉМеИЪеЉАеІЛй™СеЊЧдЄНе•љпЉМйАЯеЇ¶жѓФиЊГжЕҐзФЪиЗ≥жЬЙзЪДжЧґеАЩдЉЪжСФеАТпЉМйАЪињЗжЕҐжЕҐзЪДе≠¶дє†пЉМдЇЇзЪДиГљеКЫдЉЪиґКжЭ•иґКе•љгАВеѓєдЇОдЄАдЄ™з≥їзїЯиАМи®АпЉМжИСдїђжШѓеР¶еПѓдї•зФ®еРМж†ЈзЪДжЦєеЉПжЭ•еБЪпЉЯељУдЄАдЄ™еЕ®жЦ∞зЪДдљЬдЄЪжПРдЇ§еИ∞ињЩдЄ™з≥їзїЯжЧґпЉМз≥їзїЯеѓєдљЬдЄЪзЪДдЉШеМЦжШѓжѓФиЊГдњЭеЃИзЪДпЉМжѓФе¶Вз®НеЊЃе§ЪзїЩдЄАзВєиµДжЇРпЉМйВ£дєИжИСйАЙжЛ©зЪДжЙІи°МиЃ°еИТдЉЪзЫЄеѓєжѓФиЊГдњЭеЃИдЄАзВєпЉМдљњеЊЧиЗ≥е∞СиГље§ЯиЈСињЗеОїпЉМељУиЈСињЗдєЛеРОе∞±иГље§ЯжРЬйЫЖеИ∞дњ°жБѓеТМзїПй™МпЉМйАЪињЗињЩдЇЫзїПй™МеЖНеПНеУЇеОїдЉШеМЦжХ∞жНЃпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™еЯЇдЇОеОЖеП≤дњ°жБѓзЪДиЗ™е≠¶дє†еЫЮељТдЉШеМЦпЉМеЇХе±ВжШѓе¶ВеЫЊзЪДжЮґжЮДеЫЊпЉМжИСдїђжККеОЖеП≤дњ°жБѓжФЊеЬ®OFFLINE systemеОїеБЪеРДзІНеРДж†ЈзЪДзїЯиЃ°еИЖжЮРпЉМељУдљЬдЄЪжЭ•дЇЖдєЛеРОжИСдїђжККињЩдЇЫдњ°жБѓеПНеУЇеИ∞з≥їзїЯдєЛдЄ≠еОїпЉМиЃ©з≥їзїЯињЫи°МиЗ™е≠¶дє†гАВйАЪеЄЄжГЕеЖµдЄЛпЉМдЄАдЄ™зЫЄдЉЉзЪДдљЬдЄЪе§Іж¶ВиЈСдЇЖ3еИ∞4жђ°зЪДжЧґеАЩпЉМињЫеЕ•еИ∞дЄАдЄ™зЫЄеѓєжѓФиЊГдЉШзЪДињЗз®ЛпЉМдЉШжМЗзЪДжШѓдљЬдЄЪињРи°МжЧґйЧіеТМз≥їзїЯиµДжЇРиКВзЬБгАВињЩе•Чз≥їзїЯе§Іж¶ВеЬ®йШњйЗМеЖЕйГ®3еєіеЙНдЄКзЇњзЪДпЉМжИСдїђйАЪињЗињЩж†ЈзЪДз≥їзїЯжККйШњйЗМзЪДж∞ідљНзЇњдїО40%жПРеНЗеИ∞70%дї•дЄКгАВ
еП¶е§ЦеЫЊдЄ≠еП≥дЊІдєЯжШѓдЄАдЄ™иЗ™е≠¶дє†зЪДдЊЛе≠РпЉМжИСдїђжАОдєИеМЇеИЖзГ≠жХ∞жНЃеТМеЖЈжХ∞жНЃпЉМдєЛеЙНеПѓдї•иЃ©зФ®жИЈиЗ™еЈ±еОїsetпЉМеПѓдї•зФ®дЄАдЄ™жЩЃйАЪзЪДconfigurationеОїйЕНзљЃпЉМеРОжЭ•еПСзО∞жИСдїђйЗЗзФ®еК®жАБзЪДж†єжНЃдљЬдЄЪжЦєеЉПжЭ•еБЪпЉМжХИжЮЬдЉЪжЫіе•љпЉМињЩдЄ™жКАжЬѓжШѓеОїеєідЄКзЇњзЪДпЉМеОїеєідЄЇйШњйЗМиКВзЇ¶дЇЖ1дЇњ+дЇЇж∞СеЄБгАВдїОдї•дЄКеЗ†дЄ™дЊЛе≠РдЄКжЭ•иЃ≤еЉХжУОе±ВйЭҐеТМе≠ШеВ®е±ВйЭҐеБЪзЪДжЮБиЗіжАІиГљдЉШеМЦпЉМжАІиГљдЉШеМЦеПИеЄ¶жЭ•дЇЖзФ®жИЈжИРжЬђзЪДйЩНдљОпЉМеЬ®2019еєі9жЬИ1еПЈпЉМй£Ю姩姲жХ∞жНЃеє≥еП∞зЪДжХідљУе≠ШеВ®жИРжЬђйЩНдљОдЇЖ30%пЉМеРМжЧґжИСдїђеПСеЄГдЇЖеЯЇдЇОеОЯзФЯиЃ°зЃЧзЪДжЦ∞иІДж†ЉпЉМеПѓдї•еЃЮзО∞жЬАйЂШ70%зЪДжИРжЬђиКВзЬБгАВ
дї•дЄКйГљжШѓеЬ®еЉХжУОе±ВйЭҐзЪДдЉШеМЦпЉМйЪПзЭАAIзЪДжЩЃжГ†дЉШеМЦпЉМAIзЪДеЉАеПСдЇЇеСШдЉЪиґКжЭ•иґКе§ЪпЉМзФЪиЗ≥еЊИе§ЪдЇЇйГљдЄН姙еЕЈе§Здї£з†БзЪДиГљеКЫпЉМйШњйЗМеЖЕйГ®жЬЙ10дЄЗеРНеСШеЈ•пЉМжѓП姩жЬЙиґЕињЗ1дЄЗдЄ™еСШеЈ•еЬ®й£Ю姩姲жХ∞жНЃеє≥еП∞дЄКеБЪеЉАеПСпЉМдїОињЩдЄ™иІТеЇ¶дЄКжЭ•иЃ≤пЉМдЄНдїЕз≥їзїЯзЪДдЉШеМЦжШѓйЗНи¶БзЪДпЉМеє≥еП∞еТМеЉАеПСеє≥еП∞зЪДдЉШеМЦдєЯжШѓйЭЮеЄЄеЕ≥йФЃзЪДгАВ

иЃ°зЃЧеЉХжУОеѓєе§ІеЃґжЭ•иѓізЬЛдЄНиІБжСЄдЄНзЭАпЉМжИСдїђи¶БеОїзФ®еЃГиВѓеЃЪеЄМжЬЫзФ®жЬАзЃАеНХзЪДжЦєеЉПпЉМеЕИжЭ•зЬЛдЄАдЄЛMaxcomputeиЃ°зЃЧеЉХжУОгАВй¶ЦеЕИжИСдїђйЬАи¶БжЬЙзФ®жИЈпЉМзФ®жИЈжАОдєИжЭ•дљњзФ®пЉЯйЬАи¶БиµДжЇРйЪФз¶їпЉМдєЯе∞±жШѓиѓіжѓПдЄ™зФ®жИЈеЬ®з≥їзїЯдЄКйЭҐдљњзФ®зЪДжЧґеАЩдЉЪеѓєеЇФзЭАиі¶еПЈпЉМиі¶еПЈдЉЪеѓєеЇФзЭАжЭГйЩРпЉМињЩж†Је∞±жККжХіе•ЧдЄЬи•њдЄ≤иБФиµЈжЭ•гАВдїК姩жИСзЪДзФ®жИЈжАОдєИзФ®пЉЯзФ®еУ™дЇЫйГ®еИЖпЉЯињЩжШѓзђђдЄАйГ®еИЖгАВзђђдЇМйГ®еИЖжШѓеЉАеПСпЉМеЉАеПСжЬЙIDEпЉМIDEзФ®жЭ•еЖЩдї£з†БпЉМеЖЩеЃМдї£з†БдєЛеРОжПРдЇ§пЉМжПРдЇ§дєЛеРОе≠ШеЬ®дЄАдЄ™и∞ГеЇ¶зЪДйЧЃйҐШпЉМињЩдєИе§ЪзЪДиµДжЇРдїїеК°й°ЇеЇПжШѓдїАдєИпЉЯи∞БеЕИи∞БеРОпЉМеЗЇдЇЖйЧЃйҐШи¶БдЄНи¶БдЄ≠жЦ≠пЉМињЩдЇЫйГљзФ±и∞ГеЇ¶з≥їзїЯжЭ•зЃ°пЉМжИСдїђзЪДињЩдЇЫдїїеК°е∞±жЬЙеПѓиГљеЬ®дЄНеРМзЪДеЬ∞жЦєжЭ•ињРи°МпЉМеПѓдї•йАЪињЗжХ∞жНЃйЫЖжИРжККеЃГжЛЙеИ∞дЄНеРМзЪДеМЇеЯЯпЉМиЃ©ињЩдЇЫжХ∞жНЃиГље§ЯеЬ®жХідЄ™зЪДеє≥еП∞дЄКиЈСиµЈжЭ•пЉМжИСдїђжЙАжЬЙзЪДдїїеК°иЈСиµЈжЭ•дєЛеРОжИСдїђйЬАи¶БжЬЙдЄАдЄ™зЫСжОІпЉМеРМжЧґжИСдїђзЪДoperationдєЯйЬАи¶БиЗ™еК®еМЦгАБињРзїіеМЦпЉМеЖНеЊАдЄЛжИСдїђдЉЪињЫи°МжХ∞жНЃзЪДеИЖжЮРжИЦиАЕBIжК•и°®дєЛз±їзЪДпЉМжИСдїђдєЯдЄНиГље§ЯењШиЃ∞machine learningдєЯжШѓеЬ®жИСдїђзЪДеє≥еП∞дЄКйЫЖжИРиµЈжЭ•зЪДгАВжЬАеРОпЉМжЬАйЗНи¶БзЪДе∞±жШѓжХ∞жНЃеЃЙеЕ®пЉМињЩдЄАеЭЧжХідЄ™дЄЬи•њжЮДиµЈдЄАдЄ™е§ІжХ∞жНЃеЉХжУОзЪДе§Цж≤њ+е§ІжХ∞жНЃеЉХжУОжЬђиЇЂпЉМињЩдЄАе•ЧжИСдїђзІ∞дєЛдЄЇеНХеЉХжУОзЪДеЃМе§Зе§ІжХ∞жНЃз≥їзїЯпЉМињЩдЄАе•Чз≥їзїЯжИСдїђеЬ®2017еєізЪДжЧґеАЩе∞±еЕЈе§ЗдЇЖгАВ

2018еєізЪДжЧґеАЩжИСдїђеБЪдїАдєИпЉЯ2018еєіжИСдїђеЬ®еНХеЉХжУОзЪДеЯЇз°АдЄКеѓєжО•еИ∞е§ЪеЉХжУОпЉМжИСдїђжХідЄ™еЉАеПСйУЊиЈѓи¶БиЃ©еЃГйЧ≠зОѓеМЦпЉМжХ∞жНЃйЫЖжИРеПѓдї•жККжХ∞жНЃеЬ®дЄНеРМзЪДжХ∞жНЃжЇРдєЛйЧіињЫи°МжЛЦеК®пЉМжИСдїђжККжХ∞жНЃеЉАеПСеЃМдєЛеРОпЉМдЉ†зїЯзЪДжЦєеЉПжШѓеЖНзФ®жХ∞жНЃеЉХжУОжККеЃГжЛЦиµ∞пЉМиАМжИСдїђеБЪзЪДдЇЛжГЕжШѓеЄМжЬЫињЩдЄ™жХ∞жНЃжШѓдЇСдЄКзЪДжЬНеК°пЉМињЩдЄ™жЬНеК°иГље§ЯзЫіжО•еѓєзФ®жИЈжПРдЊЫжГ≥и¶БзЪДжХ∞жНЃпЉМиАМдЄНйЬАи¶БжККжХ∞жНЃжХідЄ™жЛЦиµ∞пЉМеЫ†дЄЇжХ∞жНЃеЬ®дЉ†иЊУињЗз®ЛдЄ≠жЬЙе≠ШеВ®зЪДжґИиАЧгАБзљСзїЬзЪДжґИиАЧеТМдЄАиЗіжАІжґИиАЧпЉМжЙАжЬЙзЪДињЩдЇЫдЄЬи•њйГљеЬ®жґИиАЧзФ®жИЈзЪДжИРжЬђпЉМжИСдїђеЄМжЬЫйАЪињЗжХ∞жНЃжЬНеК°иЃ©зФ®жИЈжЛњеИ∞дїЦжГ≥и¶БзЪДдЄЬи•њгАВеЖНеЊАдЄЛпЉМе¶ВжЮЬжХ∞жНЃжЬНеК°дєЛдЄКињШжЬЙиЗ™еЃЪдєЙзЪДеЇФзФ®пЉМзФ®жИЈињШйЬАи¶БеОїеїЇдЄАдЄ™жЬЇжИњпЉМжР≠дЄАдЄ™webжЬНеК°пЉМзДґеРОжККжХ∞жНЃжЛњињЗжЭ•пЉМињЩж†ЈдєЯеЊИйЇїзГ¶пЉМжЙАдї•жИСдїђжПРдЊЫдЄАдЄ™жЙШзЃ°зЪДwebеЇФзФ®зЪДдЇСдЄКеЉАеПСеє≥еП∞пЉМиГље§ЯиЃ©зФ®жИЈзЫіжО•зЬЛеИ∞жЙАжЬЙзЪДжХ∞жНЃжЬНеК°пЉМеЬ®ињЩдЄ™жЦєеРСдЄКжЭ•иѓіпЉМжИСдїђе∞±еПѓдї•жЮДеїЇдїїжДПзЪДжХ∞жНЃжЩЇиГљиІ£еЖ≥жЦєж°ИгАВ

еИ∞2019еєіпЉМжИСдїђдЉЪжККзРЖењµеЖНжЛУе±ХдЄАе±ВпЉМй¶ЦеЕИеѓєдЇОзФ®жИЈжЭ•иѓіжШѓзФ®жИЈдЇ§дЇТе±ВпЉМдљЖжШѓзФ®жИЈзЪДдЇ§дЇТе±ВдЄНдїЕдїЕжШѓеЉАеПСпЉМжЙАдї•жИСдїђдЉЪжККзФ®жИЈеИЖжИРдЄ§з±їпЉМдЄАйГ®еИЖеПЂеБЪжХ∞жНЃзЪДзФЯдЇІиАЕпЉМдєЯе∞±жШѓеЖЩдїїеК°гАБеЖЩи∞ГеЇ¶гАБињРзїіз≠ЙпЉМињЩдЇЫжШѓжХ∞жНЃзЪДзФЯдЇІиАЕпЉМжХ∞жНЃзЪДзФЯдЇІиАЕеБЪе•љзЪДдЄЬи•њзїЩи∞БеСҐпЉЯзїЩжХ∞жНЃзЪДжґИиієиАЕпЉМжИСдїђзЪДжХ∞жНЃеИЖжХ£еЬ®еРДдЄ™еЬ∞жЦєпЉМжЙАжЬЙзЪДдЄЬи•њйГљдЉЪеЬ®ж≤їзРЖзЪДдЇ§дЇТе±ВеѓєжХ∞жНЃзЪДжґИиієиАЕжПРдЊЫжЬНеК°пЉМињЩж†ЈжИСдїђе∞±еЬ®дЄАдЄ™жЦ∞зЪДиІТеЇ¶жЭ•иѓ†йЗКй£Ю姩姲жХ∞жНЃеє≥еП∞гАВйЩ§дЇЖеЉХжУОе≠ШеВ®дї•е§ЦпЉМжИСдїђжЬЙеЕ®еЯЯзЪДжХ∞жНЃйЫЖжИРињЫи°МжЛЙеК®пЉМзїЯдЄАзЪДи∞ГеЇ¶еПѓдї•еЬ®дЄНеРМзЪДеЉХжУОдєЛйЧіжЭ•еИЗжНҐеНПеРМеЈ•дљЬпЉМеРМжЧґжИСдїђжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМеЬ®ињЩдєЛдЄКжИСдїђеѓєжХ∞жНЃзЪДзФЯдЇІиАЕеТМжХ∞жНЃзЪДжґИиієиАЕдєЯйГљињЫи°МдЇЖзЫЄеЇФзЪДжФѓжМБпЉМйВ£дєИињЩдЄ™жХідљУе∞±жШѓеЕ®еЯЯзЪДе§ІжХ∞жНЃеє≥еП∞дЇІеУБжЮґжЮДгАВ
дЇСеОЯзФЯеє≥еП∞еИ∞еЕ®еЯЯдЇСжХ∞дїУ
===========
жИСдїђжХідЄ™еє≥еП∞йГљжШѓдЇСеОЯзФЯзЪДпЉМдЇСеОЯзФЯжЬЙеУ™дЇЫжКАжЬѓеСҐпЉЯ

й£Ю姩姲жХ∞жНЃеє≥еП∞еЬ®10еєіеЙНе∞±еЭЪжМБдЇСеОЯзФЯзЪДжХ∞жНЃпЉМдЇСеОЯзФЯжДПеС≥зЭАдЄЙдїґдЇЛжГЕпЉМзђђдЄАеЉАзЃ±еН≥зФ®гАБдЄНзФ®дЄНиК±йТ±пЉМињЩдЄ™еТМдЉ†зїЯзЪДдє∞з°ђдїґжЦєеЉПжЬЙйЭЮеЄЄе§ІзЪДдЄНеРМпЉЫзђђдЇМжИСдїђеЕЈе§ЗдЇЖзІТзЇІиЗ™йАВеЇФзЪДеЉєжАІжЙ©е±ХпЉМзФ®е§Ъе∞Сдє∞е§Ъе∞СпЉЫзђђдЄЙеЫ†дЄЇжШѓдЇСдЄКзЪДж°ЖжЮґпЉМжИСдїђеЊИе§ЪињРзїіеТМеЃЙеЕ®зЪДдЄЬи•њзФ±дЇСиЗ™еК®жЭ•еЃМжИРдЇЖпЉМжЙАдї•жШѓеЃЙеЕ®еЕНињРзїізЪДгАВдїОз≥їзїЯжЮґжЮДдЄКиЃ≤пЉМй£Ю姩姲жХ∞жНЃеМЕжЛђдЉ†зїЯзЪДCPUгАБGPUйЫЖзЊ§пЉМдї•еПКеє≥е§іеУ•иКѓзЙЗйЫЖзЊ§пЉМеЖНеЊАдЄКжШѓжИСдїђзЪДдЉПзЊ≤жЩЇиГљи∞ГеЇ¶з≥їзїЯеТМеЕГжХ∞жНЃз≥їзїЯпЉМеЖНеЊАдЄКжИСдїђжПРдЊЫдЇЖе§ЪзІНиЃ°зЃЧиГљеКЫпЉМжИСдїђжЬАйЗНи¶БзЪДзЫЃж†Зе∞±жШѓйАЪињЗдЇСеОЯзФЯиЃЊиЃ°жКК10дЄЗеП∞еЬ®зЙ©зРЖдЄКеИЖеЄГеЬ®дЄНеРМеЬ∞еЯЯзЪДжЬНеК°еЩ®иЃ©зФ®жИЈиІЙеЊЧеГПдЄАеП∞иЃ°зЃЧжЬЇгАВжИСдїђдїК姩еЈ≤зїПиЊЊеИ∞дЇЖ10еєіеЙНзЪДиЃЊиЃ°и¶Бж±ВпЉМеЕЈе§ЗдЇЖжЫіеЉЇзЪДжЬНеК°жЙ©е±ХиГљеКЫпЉМиГље§ЯжФѓжТС5еИ∞10еєізЪДжХ∞жНЃињЫж≠•зЪДеПСе±ХгАВ
жИСдїђеЕЕеИЖеИ©зФ®дЇСеОЯзФЯиЃЊиЃ°зЪДзРЖењµпЉМжФѓжМБе§ІжХ∞жНЃеТМжЬЇеЩ®е≠¶дє†зЪДењЂйАЯе§ІиІДж®°еЉєжАІиіЯиљљйЬАж±ВгАВжИСдїђжФѓжТС0пљЮ100еАНзЪДеЉєжАІжЙ©еЃєиГљеКЫпЉМеОїеєіеЉАеІЛпЉМеПМеНБдЄА60%зЪДжХ∞жНЃе§ДзРЖйЗПжЭ•иЗ™дЇОе§ІжХ∞жНЃеє≥еП∞зЪДе§ДзРЖиГљеКЫпЉМељУеПМ11еЈЕе≥∞жЭ•зЪДжЧґеАЩпЉМжИСдїђжККе§ІжХ∞жНЃзЪДиµДжЇРеЉєеЫЮжЭ•иЃ©зїЩеЬ®зЇњз≥їзїЯеОїе§ДзРЖйЧЃйҐШгАВдїОеП¶е§ЦдЄАдЄ™иІТеЇ¶жЭ•иЃ≤пЉМжИСдїђеЕЈе§ЗеЉєжАІиГљеКЫпЉМзЫЄжѓФзЙ©зРЖзЪДIDCж®°еЉПпЉМжИСдїђжЬЙ80%жИРжЬђзЪДиКВзЬБпЉМжМЙдљЬдЄЪзЪДиЃ°иієж®°еЉПпЉМжИСдїђжПРдЊЫзІТзЇІеЉєжАІдЉЄзЉ©зЪДеРМжЧґпЉМдЄНдљњзФ®дЄНжФґиієгАВзЫЄжѓФиЗ™еїЇIDCпЉМзїЉеРИжИРжЬђеП™жЬЙ1/5гАВйЩ§дЇЖеЭЪжМБеОЯзФЯдєЛе§ЦпЉМжИСдїђжЬАињСеПСзО∞пЉМйЪПзЭАдЇЇеЈ•жЩЇиГљзЪДеПСе±ХпЉМиѓ≠йЯ≥иІЖеЫЊзЪДжХ∞жНЃиґКжЭ•иґКе§ЪдЇЖпЉМе§ДзРЖзЪДиГљеКЫе∞±и¶БеК†еЉЇпЉМжИСдїђи¶БдїОдЇМзїізЪДе§ІжХ∞жНЃеє≥еП∞еПШжИРеЕ®еЯЯзЪДжХ∞жНЃеє≥еП∞гАВ

е¶ВеЫЊжЙАз§ЇпЉМдЄЪзХМжЬЙдЄАдЄ™жѓФиЊГзБЂзЪДж¶ВењµеПЂжХ∞жНЃжєЦпЉМжИСдїђи¶БжККеЃҐжИЈе§ЪзІНе§Ъж†ЈзЪДжХ∞жНЃжЛњеИ∞дЄАиµЈжЭ•ињЫи°МзїЯдЄАзЪДжߕ胥еТМзЃ°зРЖгАВдљЖжШѓеѓєдЇОзЬЯж≠£зЪДдЉБдЄЪзЇІжЬНеК°еЃЮиЈµпЉМжИСдїђзЬЛеИ∞дЄАдЇЫйЧЃйҐШпЉМй¶ЦеЕИжХ∞жНЃзЪДжЭ•жЇРеѓєдЇОеЃҐжИЈжЭ•иѓіжШѓдЄНеПѓжОІзЪДпЉМдєЯжШѓе§ЪзІНе§Ъж†ЈзЪДпЉМиАМдЄФеЊИе§Із®ЛеЇ¶дЄКж≤°жЬЙеКЮж≥ХжККжЙАжЬЙзЪДжХ∞жНЃзїЯдЄАзФ®дЄАзІНз≥їзїЯеТМеЉХжУОжЭ•зЃ°зРЖиµЈжЭ•пЉМеЬ®ињЩзІНжГЕеЖµдЄЛжИСдїђйЬАи¶БжЫіе§ІзЪДиГљеКЫжШѓдїАдєИеСҐпЉЯжИСдїђдїК姩йАЪињЗдЄНеРМзЪДжХ∞жНЃжЇРпЉМеПѓдї•ињЫи°МзїЯдЄАзЪДиЃ°зЃЧеТМзїЯдЄАзЪДжߕ胥еТМеИЖжЮРпЉМзїЯдЄАзЪДзЃ°зРЖпЉМжЙАдї•жИСдїђжПРеЗЇдЄАдЄ™жЫіжЦ∞зЪДж¶ВењµеПЂйАїиЊСжХ∞жНЃжєЦпЉМеѓєдЇОзФ®жИЈжЭ•иѓіпЉМдЄНйЬАи¶БжККдїЦзЪДжХ∞жНЃињЫи°МзЙ©зРЖдЄКзЪДжРђињБпЉМдљЖжШѓжИСдїђдЄАж†ЈиГље§ЯињЫи°МиБФйВ¶иЃ°зЃЧеТМжߕ胥пЉМињЩе∞±жШѓжИСдїђиЃ≤зЪДйАїиЊСжХ∞жНЃжєЦзЪДж†ЄењГзРЖењµгАВ
дЄЇдЇЖжФѓжТСињЩдїґдЇЛжГЕпЉМжИСдїђдЉЪжЬЙзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖз≥їзїЯеТМи∞ГеЇ¶з≥їзїЯпЉМиГље§ЯиЃ©дЄНеРМзЪДиЃ°зЃЧеЉХжУОеНПеРМиµЈжЭ•еЈ•дљЬпЉМжЬАеРОжККжЙАжЬЙзЪДеЈ•дљЬж±ЗиБЪеИ∞еЕ®еЯЯжХ∞жНЃж≤їзРЖдЄКйЭҐпЉМеєґдЄФжПРдЊЫзїЩжХ∞жНЃеЉАеПСиАЕдЄАдЄ™зЉЦз®Леє≥еП∞пЉМиЃ©дїЦиГље§ЯзЫіжО•зЪДдЇІзФЯжХ∞жНЃпЉМжИЦиАЕжШѓеОїеЃЪеИґиЗ™еЈ±зЪДеЇФзФ®гАВйВ£дєИпЉМйАЪињЗињЩж†ЈзЪДжЦєеЉПпЉМжИСдїђжККеОЯжЭ•зЪДеНХзїіеЇ¶е§ІжХ∞жНЃеє≥еП∞еОїеБЪе§ІжХ∞жНЃе§ДзРЖпЉМжЛУе±ХеИ∞дЄАдЄ™еЕ®еЯЯзЪДжХ∞жНЃж≤їзРЖпЉМињЩдЄ™жХ∞жНЃеЕґеЃЮеПѓдї•еМЕеРЂзЃАеНХзЪДе§ІжХ∞жНЃзЪДпЉМдєЯеПѓдї•еМЕеРЂжХ∞жНЃеЇУзЪДпЉМзФЪиЗ≥жШѓдЄАдЇЫOSSзЪДfileпЉМињЩдЇЫжИСдїђеЬ®жХідЄ™зЪДеє≥еП∞йЗМйЭҐйГљдЉЪеК†дї•е§ДзРЖгАВ

е¶ВеЫЊдЄЇй£Ю姩姲жХ∞жНЃзЪДдЇІеУБжЮґжЮДпЉМдЄЛйЭҐжШѓе≠ШеВ®иЃ°зЃЧеЉХжУОпЉМеПѓдї•зЬЛеИ∞жИСдїђйЩ§дЇЖиЃ°зЃЧеЉХжУОиЗ™еЄ¶зЪДе≠ШеВ®дєЛе§ЦињШжЬЙеЕґеЃГеЉАжФЊзЪДOSSпЉМињШжЬЙIOTзЂѓйЗЗйЫЖзЪДжХ∞жНЃеТМжХ∞жНЃеЇУзЪДжХ∞жНЃпЉМжЙАжЬЙжХ∞жНЃињЫи°МеЕ®еЯЯжХ∞жНЃйЫЖжИРпЉМйЫЖжИРеРОињЫи°МзїЯдЄАзЪДеЕГжХ∞жНЃзЃ°зРЖпЉМзїЯдЄАзЪДжЈЈеРИдїїеК°и∞ГеЇ¶пЉМеЖНеЊАдЄКжШѓеЉАеПСе±ВеТМжХ∞жНЃзїЉеРИж≤їзРЖе±ВпЉМйАЪињЗињЩзІНжЦєеЉПпЉМжИСдїђзЂЛдљУеМЦзЪДжККжХідЄ™е§ІжХ∞жНЃеЬИиµЈжЭ•зЃ°зРЖгАВ
е§ІжХ∞жНЃдЄОAI еПМзФЯз≥їзїЯ
===========
жПРеИ∞дЇЖе§ІжХ∞жНЃжИСдїђиВѓеЃЪдЉЪжГ≥еИ∞AIпЉМAIеТМе§ІжХ∞жНЃжШѓеПМзФЯзЪДпЉМеѓєдЇОAIжЭ•иѓіеЃГжШѓйЬАи¶Бе§ІжХ∞жНЃжЭ•empowerзЪДпЉМдєЯе∞±иѓіbigdata for AIгАВдЄЛйЭҐеПѓдї•йАЪињЗдЄАдЄ™demoжЭ•зЬЛжИСдїђжАОдєИжЭ•еБЪињЩдїґдЇЛжГЕгАВеѓєдЇОAIзЪДеЉАеПСеЈ•з®ЛеЄИжЭ•иѓіпЉМдїЦдїђжѓФиЊГеЄЄзФ®зЪДжЦєеЉПжШѓзФ®дЇ§дЇТеЉПзЪДnotebookжЭ•ињЫи°МAIзЪДеЉАеПСпЉМеЫ†дЄЇеЃГжѓФиЊГзЫіиІВпЉМдљЖжШѓе¶ВдљХжККе§ІжХ∞жНЃдєЯињЫи°МдЇ§дЇТеЉПеЉАеПСпЉМеєґдЄФеТМAIжЭ•зїСеЃЪпЉМдЄЛйЭҐжЭ•зЬЛдЄАдЄЛињЩдЄ™зЃАеНХзЪДдЊЛе≠РгАВ

е¶ВеЫЊжШѓжИСдїђDSWзЪДеє≥еП∞пЉМжИСдїђеПѓдї•зЫіжО•зЪДзФ®дЄАдЄ™magicеСљдї§пЉМconnectеИ∞зО∞е≠ШзЪДmaxcomputeйЫЖзЊ§пЉМеєґдЄФйАЙжЛ©projectеРОпЉМеПѓдї•зЫіжО•иЊУеЕ•sqlиѓ≠еП•пЉМињЩдЇЫйГљжШѓжЩЇиГљзЪДгАВзДґеРОжИСдїђеОїжЙІи°МпЉМзїУжЮЬеЗЇжЭ•дєЛеРОжИСдїђеПѓдї•еѓєfeatureињЫи°МзЫЄеЇФзЪДеИЖжЮРпЉМеМЕжЛђеПѓдї•еОїжФєеПШињЩдЇЫfeatureзЪДж®™зЇµеЭРж†ЗеБЪеЗЇдЄНеРМзЪДchartsпЉМеРМжЧґжИСдїђзФЪиЗ≥еПѓдї•жККзФЯжИРзЪДзїУжЮЬзЫіжО•webеИ∞excelжЦєеЉПињЫи°МзЉЦиЊСеТМе§ДзРЖпЉМе§ДзРЖеЃМдєЛеРОжИСдїђеЖНжККжХ∞жНЃжЛЙеЫЮжЭ•пЉМдєЯеПѓдї•еИЗжНҐеИ∞GPUжИЦиАЕCPUињЫи°МжЈ±еЇ¶е≠¶дє†еТМиЃ≠зїГпЉМиЃ≠зїГеЃМдЇЖдєЛеРОпЉМжИСдїђдЉЪжККжХідЄ™зЪДдї£з†БеПШжИРдЄАдЄ™ж®°еЮЛпЉМжИСдїђдЉЪжККињЩдЄ™ж®°еЮЛеѓЉеЕ•еИ∞дЄАдЄ™зЫЄеЇФзЪДеЬ∞жЦєдєЛеРОжПРдЊЫдЄАдЄ™WebжЬНеК°пЉМињЩдЄ™жЬНеК°дєЯе∞±жШѓжИСдїђзЪДеЬ®зЇњжО®зРЖжЬНеК°гАВжХіе•ЧжµБз®ЛеБЪеЃМдєЛеРОпЉМзФЪиЗ≥жИСдїђеПѓдї•еЖНжО•жХ∞жНЃеЇФзФ®пЉМеПѓдї•еЬ®жЙШзЃ°зЪДWEBдЄКжЮДеїЇпЉМињЩе∞±жШѓе§ІжХ∞жНЃеє≥еП∞зїЩAIжПРдЊЫжХ∞жНЃеТМзЃЧеКЫгАВ

е§ІжХ∞жНЃеТМAIжШѓеПМзФЯз≥їзїЯпЉМAIжШѓдЄАдЄ™еЈ•еЕЈе±ВпЉМеПѓдї•дЉШеМЦжЙАжЬЙзЪДдЇЛжГЕгАВжИСдїђеЄМжЬЫй£Ю姩зЪДе§ІжХ∞жНЃеє≥еП∞иГље§ЯиµЛиГљзїЩAIгАВжИСдїђеЬ®жЬАеЉАеІЛзЪДжЧґеАЩеЄМжЬЫbuildдЄАдЄ™еПѓзФ®зЪДз≥їзїЯпЉМиГље§ЯйЭҐдЄіеПМ11зЪДеЉєжАІиіЯиљљдїНзДґжШѓеПѓзФ®зЪДгАВйАЪињЗињЩдЇЫеєізЪДеК™еКЫпЉМжИСдїђињљж±ВжЮБиЗізЪДжАІиГљпЉМжИСдїђиГље§ЯжЙУз†іжХ∞жНЃзЪДеҐЮйХњеТМжИРжЬђеҐЮйХњзЪДзЇњжАІеЕ≥з≥їпЉМжИСдїђдєЯеЄМжЬЫеЃГжШѓдЄАдЄ™жЩЇиГљзЪДпЉМжИСдїђеЄМжЬЫжЫіе§ЪзЪДжХ∞жНЃеЉАеПСеЈ•з®ЛеЄИжЭ•жФѓжМБеЃГпЉМжИСдїђйЬАи¶БжЫіе§НжЭВзЪДдЇЇеКЫжКХеЕ•жЭ•зРЖиІ£дїЦпЉМжИСдїђеЄМжЬЫжЬЙжЫіеЉЇзЪДе§ІжХ∞жНЃжЭ•дЉШеМЦе§ІжХ∞жНЃз≥їзїЯгАВ

жИСдїђжПРеЗЇдЄАдЄ™ж¶ВењµеПЂAuto Data WarehouseпЉМжИСдїђеЄМжЬЫйАЪињЗжЩЇиГљеМЦзЪДжЦєеЉПжККе§ІжХ∞жНЃеБЪеЊЧжЫіиБ™жШОгАВжХідљУдЄКеПѓдї•еИЖжИР3дЄ™йШґжЃµпЉЪ
* зђђдЄАйШґжЃµжШѓиЃ°зЃЧе±ВйЭҐеТМжХИзОЗе±ВйЭҐпЉМжИСдїђе∞ЭиѓХеѓїжЙЊиЃ°зЃЧзЪДзђђдЄАе±ВеОЯзРЖпЉМжИСдїђеОїжЙЊзЩЊдЄЗеИ∞еНГдЄЗзЇІеИЂйЗМйЭҐзЪДеУ™дЇЫдљЬдЄЪжШѓзЫЄдЉЉзЪДпЉМеЫ†ж≠§еПѓдї•еРИеєґпЉМйАЪињЗињЩзІНжЦєеЉПжЭ•иКВзЬБжИРжЬђпЉМињШжЬЙељУдљ†жЬЙеНГдЄЗзЇІеИЂзЪДи°®дєЛеРОпЉМз©ґзЂЯеУ™дЇЫ谮忯糥еЉХеЕ®е±АжШѓжЬАдЉШзЪДпЉМдї•еПКжИСдїђжАОдєИеОїеБЪеЖЈзГ≠зЪДжХ∞жНЃеИЖе±ВеТМеБЪиЗ™йАВеЇФзЉЦз†БгАВ
* зђђдЇМйШґжЃµжШѓиµДжЇРиІДеИТпЉМAIеТМAuto Data WarehouseеПѓдї•еЄЃеК©жИСдїђеБЪжЫіе•љзЪДиµДжЇРдЉШеМЦпЉМеМЕжЛђжИСдїђжЬЙ3зІНзЪДжЙІи°МдљЬдЄЪж®°еЉПпЉМеУ™дЄАзІНж®°еЉПжЫіе•љпЉМжШѓеПѓдї•йАЪињЗе≠¶дє†зЪДжЦєеЉПе≠¶еЗЇжЭ•зЪДпЉМињШжЬЙеМЕжЛђдљЬдЄЪзЪДињРи°МйҐДжµЛеТМиЗ™еК®йҐДжК•и≠¶пЉМињЩе•Чз≥їзїЯдњЭиѓБдЇЖе§ІеЃґзЬЛеЊЧеИ∞жИЦиАЕзЬЛдЄНеИ∞зЪДйШњйЗМеЕ≥йФЃдљЬдЄЪзЪДж†ЄењГпЉМжѓФе¶ВжѓПињЗдЄАжЃµжЧґйЧіе§ІеЃґдЉЪеИЈдЄАдЄЛиКЭйЇїдњ°зФ®еИЖпЉМжѓП姩жЧ©дЄКдєЭзВєйШњйЗМзЪДеХЖжИЈз≥їзїЯдЉЪеТМдЄЛжЄЄз≥їзїЯеБЪзїУзЃЧпЉМеТМе§Ѓи°МеБЪзїУзЃЧпЉМињЩдЇЫеЯЇзЇњжШѓзФ±еНГзЩЊдЄ™дљЬдЄЪзїДжИРзЪДдЄАжЭ°зЇњпЉМдїОжѓП姩жЧ©дЄКеЗМжЩ®еЉАеІЛињРи°МеИ∞жЧ©дЄКеЕЂзВєиЈСеЃМпЉМз≥їзїЯеЫ†дЄЇеРДзІНеРДж†ЈзЪДеОЯеЫ†дЉЪеЗЇзО∞еРДзІНзЪДзКґеЖµпЉМеПѓиГљдЄ™еИЂзЪДжЬЇеЩ®дЉЪеЃХжЬЇгАВжИСдїђеБЪдЇЖдЄАдЄ™иЗ™еК®йҐДжµЛз≥їзїЯпЉМеОїйҐДжµЛињЩдЄ™з≥їзїЯжШѓеР¶иГље§ЯеЬ®еЕ≥йФЃжЧґйЧізВєдЄКеЃМжИРпЉМе¶ВжЮЬдЄНиГље§ЯеЃМжИРпЉМдЉЪжККжЫіе§ЪзЪДиµДжЇРеК†ињЫжЭ•пЉМдњЭиѓБеЕ≥йФЃдљЬдЄЪзЪДеЃМжИРгАВињЩдЇЫз≥їзїЯдњЭиѓБдЇЖжИСдїђе§ІеЃґжЧ•еЄЄзЬЛдЄНиІБзЪДеЕ≥йФЃжХ∞жНЃзЪДжµБиљђпЉМдї•еПКеПМеНБдЄАз≠ЙйЗНи¶БзЪДиµДжЇРеЉєжАІгАВ
* зђђдЄЙйШґжЃµжШѓжЩЇиГљеїЇж®°пЉМељУжХ∞жНЃињЫжЭ•дєЛеРОеТМйЗМйЭҐеЈ≤жЬЙзЪДжХ∞жНЃз©ґзЂЯжЬЙе§Ъе∞СзЪДйЗНеП†пЉЯињЩдЇЫжХ∞жНЃжЬЙе§Ъе∞СзЪДеЕ≥иБФпЉЯељУжХ∞жНЃжШѓеЗ†зЩЊеЉ†и°®жЧґпЉМжРЮDBAжЙЛеЈ•зЪДжЦєеЉПеПѓдї•и∞ГдЉШзЪДпЉМзО∞еЬ®йШњйЗМеЖЕйГ®зЪДз≥їзїЯжЬЙиґЕињЗеНГдЄЗзЇІеИЂзЪДи°®пЉМжИСдїђжЬЙйЭЮеЄЄе•љзЪДеЉАеПСдЇЇеСШзРЖиІ£и°®йЗМйЭҐеЃМеЕ®зЪДйАїиЊСеЕ≥з≥їгАВињЩдЇЫиЗ™еК®и∞ГдЉШеТМиЗ™еК®еїЇж®°иГље§ЯеЄЃеК©жИСдїђеЬ®ињЩдЇЫжЦєйЭҐеБЪдЄАдЇЫиЊЕеК©жАІзЪДеЈ•дљЬгАВ

ињЩжШѓAuto Data Warehouseз≥їзїЯжЮґжЮДеЫЊпЉМдїОе§ЪйЫЖзЊ§зЪДиіЯиљљеЭЗи°°еИ∞иЗ™еК®еЖЈе≠ШпЉМеИ∞дЄ≠йЧізЪДйЪР嚥дљЬдЄЪдЉШеМЦпЉМеЖНеИ∞дЄКе±ВзЪДйЪРзІБжХ∞жНЃиЗ™еК®иѓЖеИЂпЉМињЩжШѓжИСдїђеТМиЪВиЪБдЄАиµЈеЉАеПСзЪДжКАжЬѓпЉМељУйЪРзІБзЪДжХ∞жНЃиЗ™еК®жШЊз§ЇеИ∞е±ПеєХдЄКжЭ•пЉМз≥їзїЯдЉЪиЗ™еК®ж£АжµЛеєґжЙУз†БгАВжИСдїђеЕґдЄ≠зЪДдЄЙй°єжКАжЬѓпЉМеМЕжЛђиЗ™еК®йЪРзІБдњЭжК§пЉМеМЕжЛђйЗНе§Не≠Ржߕ胥иЗ™еК®еРИеєґдЉШеМЦпЉМеМЕжЛђе§ЪйЫЖзЊ§зЪДиЗ™еК®еЃєзБЊпЉМжИСдїђжЬЙ3зѓЗpaperеПСи°®пЉМе§ІеЃґжЬЙеЕіиґ£зЪДиѓЭеПѓдї•еОїзљСзЂЩдЄКиѓїдЄАдЄЛзЫЄеЕ≥зЪДиЃЇжЦЗгАВ
[еОЯжЦЗйУЊжО•](https://yq.aliyun.com/articles/723228?utm_content=g_1000085633)
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ
еИЖдЇЂеИ∞пЉЪ


- 2019-11-06 14:59
- жµПиІИ 273
- иѓДиЃЇ(0)
- еИЖз±ї:йЭЮжКАжЬѓ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
еЬ®2019еєідЇСж†Це§ІдЉЪзЪДе§ІжХ∞жНЃ&AIдЄУеЬЇдЄКпЉМйШњйЗМдЇСжЩЇиГљиЃ°зЃЧеє≥еП∞дЇЛдЄЪйГ®зЪДз†Фз©ґеСШеЕ≥жґЫеПКиµДжЈ±дЄУеЃґеЊРжЩЯжЈ±еЕ•иІ£жЮРдЇЖгАКAIеК†жМБзЪДйШњйЗМдЇСй£Ю姩姲жХ∞жНЃеє≥еП∞жКАжЬѓжП≠зІШгАЛзЪДдЄїйҐШжЉФиЃ≤гАВжЬђйГ®еИЖдЄїи¶БеИЖдЄЇдЄЙдЄ™йЗНзВєйГ®еИЖињЫи°МйШРињ∞пЉЪ 1. **еОЯеИЫжКАжЬѓ...
йТИеѓєињЩдЇЫйЧЃйҐШпЉМйШњйЗМдЇСй£Ю姩姲жХ∞жНЃеє≥еП∞йЗЗеПЦдЇЖеМЕжЛђеОЯеИЫжКАжЬѓдЉШеМЦдЄОз≥їзїЯиЮНеРИгАБдїОдЇСеОЯзФЯе§ІжХ∞жНЃеє≥еП∞еИ∞еЕ®еЯЯдЇСжХ∞дїУзЪДиљђеПШпЉМдї•еПКе§ІжХ∞жНЃдЄОAIеПМзФЯз≥їзїЯзЪДжЮДеїЇз≠ЙжО™жЦљгАВ й£Ю姩姲жХ∞жНЃеє≥еП∞зЪДеОЯеИЫжКАжЬѓдЉШеМЦеТМз≥їзїЯиЮНеРИйГ®еИЖдљУзО∞еЬ®йАЪињЗе§І...
йШњйЗМдЇСзЪДй£Ю姩姲жХ∞жНЃеє≥еП∞дљЬдЄЇиѓ•йҐЖеЯЯзЪДдљЉдљЉиАЕпЉМжПРдЊЫдЇЖдЄАз≥їеИЧзЪДдЇІеУБдљУз≥їеТМйАЪзФ®жКАжЬѓжЦєж°ИпЉМеЄЃеК©еЃҐжИЈдїОжХ∞жНЃдЄ≠иОЈеПЦдїЈеАЉгАВ й£Ю姩姲жХ∞жНЃеє≥еП∞дЇІеУБдљУз≥їзЪДеЖЕеЃєжґµзЫЦдЇЖдЄАз≥їеИЧзЪДе§ІжХ∞жНЃдЇІеУБеТМжЬНеК°пЉМдЊЛе¶ВMaxComputeгАБDataWorksгАБPAIз≠Й...
йШњйЗМе§ІжХ∞жНЃеє≥еП∞еПСе±ХеОЖеП≤пЉЪдїОжЧ©жЬЯзЪДдЇС楃1пЉИеЯЇдЇОHadoopпЉЙеИ∞дЇС楃2пЉИй£Ю姩姲жХ∞жНЃеє≥еП∞пЉЙпЉМеЖНеИ∞MaxCompute+DataWorksзЪДеЕ®йЭҐиЗ™з†ФеТМиљђеРСпЉМдї•еПКињСеєіжЭ•зЪДй£Ю姩姲жХ∞жНЃеТМй£Ю姩AIдЇІеУБзЪДйЫЖжИРпЉМе±ХзО∞дЇЖйШњйЗМдЇСе§ІжХ∞жНЃеє≥еП∞зЪДжЉФеПШеТМжКАжЬѓињЫж≠•...
йШњйЗМдЇСеЬ®е§ІжХ∞жНЃдЄОдЇЇеЈ•жЩЇиГљйҐЖеЯЯзЪДеЃЮиЈµеТМеИЫжЦ∞жШѓељУеЙНжКАжЬѓеПСе±ХзЪДй£ОеРСж†ЗгАВеЬ®IDCзЪДе§ІжХ∞жНЃиґЛеКњиІ£иѓїдЄ≠пЉМеПѓдї•зЬЛеИ∞дЉБдЄЪж≠£йЭҐдЄізЭАе§ІжХ∞жНЃиљђеЮЛзЪДжМСжИШпЉМйЬАи¶БйАЪињЗжЈ±еЕ•еИЖжЮРйЧЃйҐШеєґжЙЊеИ∞з†іе±АдєЛз≠ЦпЉМжО®еК®жХ∞жЩЇеИЫжЦ∞俕赥еЊЧеЄВеЬЇзЂЮдЇЙдЉШеКњгАВдЉБдЄЪ...
AIе§ІжХ∞жНЃеє≥еП∞жЮґжЮДеЫЊжШѓжМЗеЯЇдЇОArtificial IntelligenceпЉИдЇЇеЈ•жЩЇиГљпЉЙеТМе§ІжХ∞жНЃжКАжЬѓзЪДеє≥еП∞жЮґжЮДеЫЊпЉМиѓ•жЮґжЮДеЫЊжЧ®еЬ®е∞ЖAIжКАжЬѓеТМе§ІжХ∞жНЃжКАжЬѓзїУеРИиµЈжЭ•пЉМеЃЮзО∞жХ∞жНЃй©±еК®зЪДжЩЇиГљеЖ≥з≠ЦгАВ дїОжЮґжЮДеЫЊдЄ≠еПѓдї•зЬЛеИ∞пЉМAIе§ІжХ∞жНЃеє≥еП∞жЮґжЮДеЫЊдЄїи¶Б...
6. **жЬЇеЩ®е≠¶дє†дЄОдЇЇеЈ•жЩЇиГљ**пЉЪйШњйЗМеЈіеЈізЪДе§ІжХ∞жНЃеє≥еП∞дєЯжШѓеЕґAIжКАжЬѓеПСе±ХзЪДеЯЇз°АпЉМдє¶дЄ≠дЉЪиЃ≤ињ∞е¶ВдљХеИ©зФ®е§ІжХ∞жНЃињЫи°МжЬЇеЩ®е≠¶дє†иЃ≠зїГпЉМеЃЮзО∞жЩЇиГљжО®иНРгАБй£ОйЩ©жОІеИґгАБеЃҐжИЈжЬНеК°з≠ЙдЄЪеК°еЬЇжЩѓзЪДиЗ™еК®еМЦеТМжЩЇиГљеМЦгАВ 7. **е§ІжХ∞жНЃеЃЮжИШж°ИдЊЛ**пЉЪ...
AI+жЩЇжЕІе∞ПеМЇе§ІжХ∞жНЃеє≥еП∞еїЇиЃЊжЦєж°И дЇЇеЈ•жЩЇиГљ+жЩЇжЕІе∞ПеМЇе§ІжХ∞жНЃеє≥еП∞еїЇиЃЊжЦєж°И
"йШњйЗМдЇСдЄУжЬЙдЇСдЉБдЄЪзЙИV3.8.1еЉАеПСжМЗеНЧ-е§ІжХ∞жНЃеТМдЇЇеЈ•жЩЇиГљеРИйЫЖ" жЬђиµДжЇРжСШи¶Бдњ°жБѓе∞ЖеѓєйШњйЗМдЇСдЄУжЬЙдЇСдЉБдЄЪзЙИV3.8.1еЉАеПСжМЗеНЧ-е§ІжХ∞жНЃеТМдЇЇеЈ•жЩЇиГљеРИйЫЖињЫи°Миѓ¶зїЖзЪДзЯ•иѓЖзВєжАїзїУгАВ дЄАгАБж≥ХеЊЛе£∞жШО йШњйЗМдЇСж≥ХеЊЛе£∞жШОжШОз°ЃдЇЖзФ®жИЈеЬ®йШЕиѓїжИЦ...
йШњйЗМдЇСдљЬдЄЇеЕ®зРГйҐЖеЕИзЪДжХ∞жНЃжЩЇиГљзІСжКАеЕђеПЄпЉМеЕґе§ІжХ∞жНЃдЇІеУБдЄОиІ£еЖ≥жЦєж°ИеЬ®дЄЪзХМжЬЙзЭАеєњж≥ЫзЪДељ±еУНеКЫгАВињЩдЇЫдЇІеУБеТМжЬНеК°жЧ®еЬ®еЄЃеК©дЉБдЄЪзЃ°зРЖеТМеИЖжЮРжµЈйЗПжХ∞жНЃпЉМжПРеНЗдЄЪеК°жХИзОЗпЉМй©±еК®жХ∞е≠ЧеМЦиљђеЮЛгАВдї•дЄЛе∞Жиѓ¶зїЖжОҐиЃ®йШњйЗМдЇСеЬ®е§ІжХ∞жНЃйҐЖеЯЯзЪДж†ЄењГ...
жЬђжЦЗйАЪињЗеИЖжЮРељУеЙНдЄїжµБзЪДе§ІжХ∞жНЃеХЖзФ®еТМеЉАжЇРеє≥еП∞зЪДзЙєзВєпЉМйЗНзВєжОҐиЃ®дЇЖе¶ВдљХдї•йШњйЗМдЇСе§ІжХ∞жНЃеє≥еП∞дЄЇж†ЄењГжЮДеїЇвАЬжХ∞жНЃжМЦжОШвАЭиѓЊз®ЛзЪДеЃЮй™МжХЩе≠¶дљУз≥їпЉМжПРеЗЇдЇЖзЇњдЄЛзЉЦз®ЛдЄОзЇњдЄКжУНдљЬзЫЄзїУеРИгАБзРЖиЃЇзЃЧж≥ХеЃЮзО∞дЄОеХЖдЄЪеЇФзФ®еЃЮиЈµзЫЄдЇТеН∞иѓБзЪДжХЩе≠¶жЦєж≥Х...
йШњйЗМеЈіеЈізЪДе§ІжХ∞жНЃеЃЮжИШжАїзїУпЉМmaxcomputeпЉМhadoopз≠ЙгАВжЈ±еЇ¶еЙЦжЮРжЈШеЃЭгАБйЂШеЊЈгАБеПЛзЫЯ+гАБ1688гАБдЉШйЕЈгАБйШњйЗМе¶Ие¶ИгАБйШњйЗМељ±дЄЪе§ІжХ∞жНЃеЃЮжИШеЬЇжЩѓпЉМ2020дЄНеЃєйФЩињЗзЪДдЉБдЄЪе§ІжХ∞жНЃеЃЮжИШжЙЛеЖМ
йШњйЗМеПМеНБдЄАе§ІжХ∞жНЃиЃ°зЃЧеє≥еП∞жШѓйШњйЗМеЈіеЈійЫЖеЫҐеЬ®жѓПеєіеПМеНБдЄАиі≠зЙ©зЛВ搥иКВжЬЯйЧіпЉМдЄЇе§ДзРЖжµЈйЗПдЇ§жШУжХ∞жНЃиАМжЮДеїЇзЪДдЄАдЄ™еЉЇе§ІгАБйЂШжХИгАБеПѓйЭ†зЪДиЃ°зЃЧеє≥еП∞гАВињЩдЄ™еє≥еП∞зЪДж†ЄењГзЫЃж†ЗжШѓеЃЮжЧґе§ДзРЖгАБеИЖжЮРеТМйҐДжµЛдЄЪеК°жХ∞жНЃпЉМз°ЃдњЭиі≠зЙ©иКВжЬЯйЧізЪДз≥їзїЯз®≥еЃЪ...
жЩЇиГљдЇІдЄЪеЫ≠еМЇе§ІжХ∞жНЃеє≥еП∞й°єзЫЃеїЇиЃЊжЦєж°ИжШѓжМЗеЯЇдЇОе§ІжХ∞жНЃжКАжЬѓеТМдЇСиЃ°зЃЧжКАжЬѓзЪДжЩЇжЕІеЫ≠еМЇдњ°жБѓеМЦеїЇиЃЊй°єзЫЃгАВиѓ•й°єзЫЃзЪДзЫЃзЪДжШѓдЄЇдЇЖжПРйЂШеЫ≠еМЇзЪДдњ°жБѓеМЦж∞іеє≥пЉМжПРйЂШдЉБдЄЪзЪДзЂЮдЇЙеКЫеТМеИЫжЦ∞иГљеКЫгАВ еїЇиЃЊиГМжЩѓпЉЪ йЪПзЭАзїПжµОзЪДеПСе±ХеТМеЯОеЄВеМЦзЪДињЫз®Л...
AI+жЩЇжЕІз§ЊеМЇе§ІжХ∞жНЃеє≥еП∞еїЇиЃЊжЦєж°И AI+жЩЇжЕІе∞ПеМЇе§ІжХ∞жНЃеє≥еП∞еїЇиЃЊжЦєж°И
йШњйЗМдЇСиЃ°зЃЧдЄОе§ІжХ∞жНЃжКАжЬѓжШѓељУеЙНжХ∞е≠ЧеМЦиљђеЮЛзЪДеЕ≥йФЃй©±еК®еКЫпЉМеЃГдїђеЕ±еРМжЮДеїЇдЇЖжЦ∞жЧґдї£зЪДеЯЇз°АиЃЊжЦљпЉМжФєеПШдЇЖдЉБдЄЪзЪДињРиР•ж®°еЉПеТМеИЫжЦ∞иГљеКЫгАВдЇСиЃ°зЃЧдљЬдЄЇжЦ∞еЯЇз°АиЃЊжЦљзЪДж†ЄењГпЉМдї•еЕґеЉєжАІгАБеПѓжЙ©е±ХжАІеТМйЂШжХИжАІпЉМж≠£еЬ®йАРж≠•жЫњдї£дЉ†зїЯзЪДITжЮґжЮДпЉМ...