作者:向师富 转自:阿里巴巴数据中台官网[https://dp.alibaba.com](https://dp.alibaba.com/)
**概述**
数据抽取是指从源数据抽取所需要的数据, 是构建数据中台的第一步。 数据源一般是关系型数据库,近几年,随着移动互联网的蓬勃发展,出现了其他类型的数据源,典型的如网站浏览日期、APP浏览日志、IoT设备日志
从技术实现方式来讲,从关系型数据库获取数据,可以细分为全量抽取、增量抽取2种方式,两种方法分别适用于不用的业务场景
**增量抽取**
* 时间戳方式
用时间戳方式抽取增量数据很常见,业务系统在源表上新增一个时间戳字段,创建、修改表记录时,同时修改时间戳字段的值。 抽取任务运行时,进行全表扫描,通过比较抽取任务的业务时间、时间戳字段来决定抽取哪些数据。
此种数据同步方式,在准确率方面有两个弊端:
1、只能获取最新的状态,无法捕获过程变更信息,比如电商购物场景,如果客户下单后很快支付,隔天抽取增量数据时,只能获取最新的支付状态,下单时的状态有可能已经丢失。针对此种问题,需要根据业务需求来综合判定是否需要回溯状态。
2、会丢失已经被delete的记录。如果在业务系统中,将记录物理删除。也就无法进行增量抽取。一般情况下,要求业务系统不删除记录,只对记录进行打标。
业务系统维护时间戳
如果使用了Oracle、DB2等传统关系型数据库,需要业务系统维护时间戳字段,业务系统在更新业务数据时,在代码中更新时间戳字段。此种方法很常见,不过由于需要编码实现,工作量会变大,有可能会出现漏变更的情形
触发器维护时间戳
典型的关系型数据库,都支持触发器。当数据库记录有变更时,调用特定的函数,更新时间戳字段。典型的样例如下:
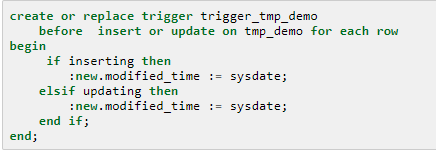
数据库维护时间戳
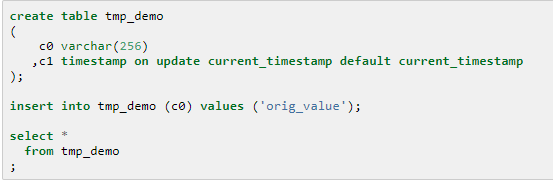
MySQL可以自动实现变更字段的维护,一定程度上减轻了开发工作量。 具体的实现样例如下:
创建记录
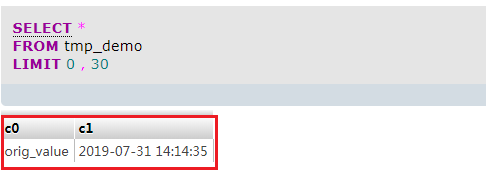
最终的结果如下:
更新记录
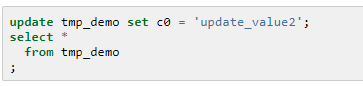
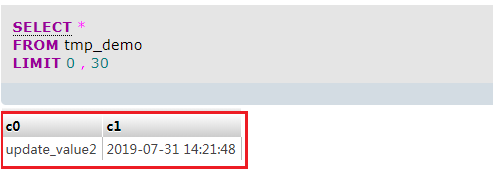
最终的结果如下,数据库自动变更了时间戳字段:
* 分析MySQL binlog日志
近几年,随着互联网的蓬勃发展,互联网公司一般使用MySQL作为主数据库,由于是开源数据库,很多公司都做了定制化开发。 其中一个很大的功能点是通过订阅MySQL binlog日志,实现了读写分离、主备实时同步,典型的示意图如下:
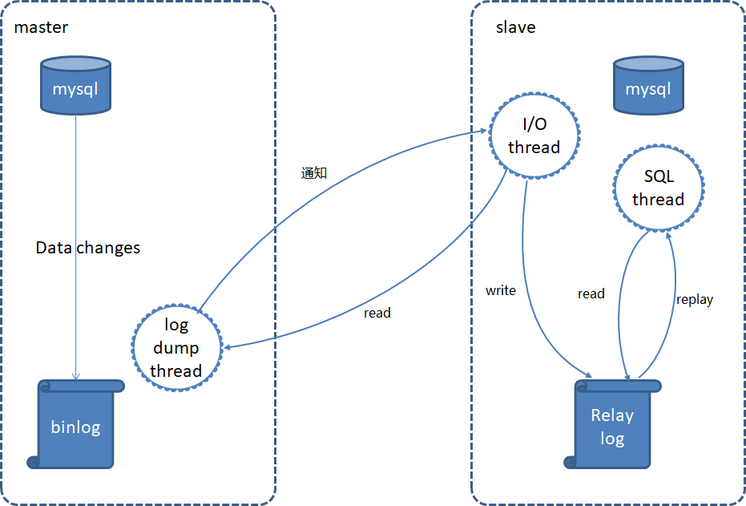
解析binlog日志,给数据同步带来了新的方法,将解析之后结果发送到Hive/MaxCompute等大数据平台,实现秒级延时的数据同步。
解析binlog日志增量同步方式技术很先进,有3个非常大的优点:
1.数据延时小。在阿里巴巴双11场景,在巨大的数据量之下,可以做到秒级延时;
2.不丢失数据,可以捕获数据delete的情形;
3.对业务表无额外要求,可以缺少时间戳字段;
当然,这种同步方式也有些缺点:
1.技术门槛很高。一般公司的技术储备不够,不足以自行完成整个系统搭建。目前国内也仅限于头部的互联网公司、大型的国企、央企。不过随着云计算的快速发展,在阿里云上开放了工具、服务,可以直接实现实时同步,经典的组合是MySQL、DTS、Datahub、MaxCompute;
2.资源成本比较高,要求有一个系统实时接收业务库的binlog日志,一直处于运行状态,占用资源较多
3.业务表中需要有主键,以便进行数据排序
* 分析Oracle Redo Log日志
Oracle是功能非常强大的数据库,通过Oracle GoldenGate实时解析Redo Log日志,并将解析后的结果发布到指定的系统
**全量抽取**
全量抽取是将数据源中的表或视图的数据原封不动的从数据库中抽取出来,并写入到Hive、MaxCompute等大数据平台中,有点类似于业务库之间的数据迁移。
全量同步比较简单,常用于小数据量的离线同步场景。不过这种同步方法,也有两个弊端,与增量离线同步一模一样:
1.只能获取最新的状态
2.会丢失已经被delete的记录
**业务库表同步策略**
* 同步架构图
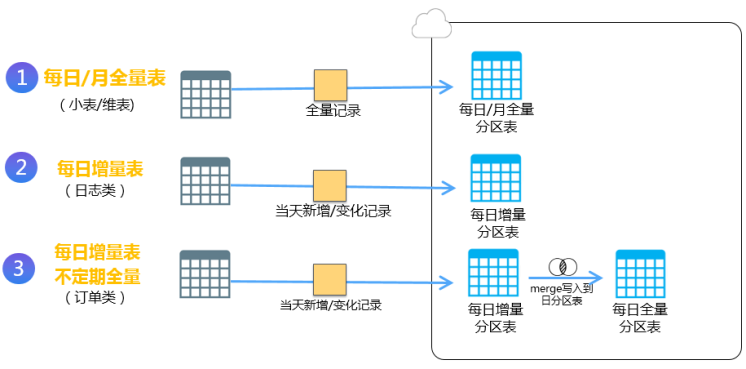
从业务视角,可以将离线数据表同步细分为4个场景,总体架构图表如下:
原则上,在数据上云这个环节,建议只进行数据镜像同步。不进行业务相关的数据转换工作。从ETL策略转变为ELT,出发点有3个:
1.机器成本。在库外进行转换,需要额外的机器,带来新的成本;
2.沟通成本。 业务系统的开发人员,也是数据中台的用户,这些技术人员对原始的业务库表很熟悉,如果进行了额外的转换,他们需要额外的学习其他工具、产品;
3.执行效率。库外的转换机器性能,一般会低于MaxCompute、Hadoop集群,增加了执行时间;
同步过程中,建议全表所有字段上云,减少后期变更成本
* 小数据量表
来源数据每日全量更新,采用数据库直连方式全量抽取,写入每日/每月全量分区表。
* 日志型表
原始日志增量抽取到每日增量表,按天增量存储。因为日志数据表现为只会有新增不会有修改的情况,因此不需要保存全量表。
* 大数据量表
数据库直连方式通过业务时间戳抽取增量数据到今日增量分区表,再将今日增量分区表merge前一日全量分区表,写入今日全量分区表。
* 小时/分钟增量表/不定期全量
来源数据更新频率较高,达到分钟/小时级别,从源数据库通过时间戳抽取增量数据到小时/分钟增量分区表,将N个小时/分钟增量分区表merge入每日增量分区表,再将今日增量分区表merge前一日全量分区表,写入今日全量分区表。
更多内容详见阿里巴巴数据中台官网 [https://dp.alibaba.com](https://dp.alibaba.com/)
阿里巴巴数据中台团队,致力于输出阿里云数据智能的最佳实践,助力每个企业建设自己的数据中台,进而共同实现新时代下的智能商业!
阿里巴巴数据中台解决方案,核心产品:
Dataphin,以阿里巴巴大数据核心方法论OneData为内核驱动,提供一站式数据构建与管理能力;
Quick BI,集阿里巴巴数据分析经验沉淀,提供一站式数据分析与展现能力;
Quick Audience,集阿里巴巴消费者洞察及营销经验,提供一站式人群圈选、洞察及营销投放能力,连接阿里巴巴商业,实现用户增长。
[原文链接](https://yq.aliyun.com/articles/721965?utm_content=g_1000085051)
本文为云栖社区原创内容,未经允许不得转载。
分享到:





相关推荐
内容概要:本文详细介绍了LabVIEW控件的设计与实现,尤其是一些由经验丰富的老工程师精心打造的控件。LabVIEW是一款图形化编程语言,广泛应用于数据采集、仪器控制和工业自动化领域。文中通过具体实例展示了如何利用LabVIEW创建美观且功能强大的控件,如滑动条、波形图、金属质感旋钮、动态波形图表以及智能选项卡等。作者强调了LabVIEW控件在灵活性和美观度方面的优势,并分享了许多实用的技术细节和优化方法。 适合人群:具有一定编程基础并希望深入了解LabVIEW控件设计的开发者和技术爱好者。 使用场景及目标:适用于需要进行高效的数据展示和交互设计的应用场景,如工业控制系统、实验室设备操作界面等。目标是帮助用户掌握LabVIEW控件的高级特性,提高开发效率和用户体验。 其他说明:文章不仅提供了具体的代码示例,还探讨了控件美学背后的设计理念和技术实现,鼓励读者探索更多可能性。
Delphi 12.3控件之unidac_10.4.0_d27pro.exe
11.盛趣自闭面(还是自己太菜).txt
58面经面试过程和题目.txt
电大操作系统课后习题解答
人工智能技术与应用演讲【61页PPT】
chromedriver-mac-arm64-135.0.7049.41.zip
内容概要:本文详细介绍了QPSK(四相移键控)调制方法及其在瑞利信道和高斯白噪声信道下的误码率(BER)性能分析。首先展示了QPSK星座图的绘制方法,接着构建了一个简化的QPSK发射机模型,用于将二进制比特流映射到相应的星座点。随后,分别实现了两种信道模型:高斯白噪声信道(AWGN)和瑞利信道,并解释了它们的工作原理以及如何向传输信号添加噪声。文中还提供了详细的误码率测试脚本,通过大量随机比特进行仿真,最终得到了不同信噪比条件下的误码率曲线。此外,作者还讨论了QPSK与其他调制方式如BPSK、16QAM之间的性能差异,强调了频谱效率与抗噪能力之间的权衡关系。 适合人群:对无线通信系统感兴趣的科研人员、研究生以及从事通信工程领域的工程师。 使用场景及目标:①帮助读者理解QPSK的基本原理及其在不同信道环境中的行为特性;②提供实用的Python代码片段,便于快速搭建仿真环境并验证理论结果;③探讨各种调制方式的选择依据,指导实际应用中的优化决策。 其他说明:文中多次提到‘骚操作’,意指一些巧妙但非传统的编程技巧,有助于提高代码执行效率或简化复杂度。同时提醒读者注意仿真过程中可能出现的问题,如
新建 Microsoft Word 文档 (9).docx
计算机科学与技术- 软件开发工具 培训资料
bitcount统计每个元素中设置的位数 B = bitcount(A) Counts the number '1' bits in each element B = bitcount(A, bitValue) "bitValue" = 1 = default = counts the occurance of '1' if bitValue = 0; counts the number '0' The total bits to verify is [8,16,32,or 64] based on the maximal value of A B = bitcount(A, bitValue, maxBits) the total # of bits to examine
MOM生产运营管理平台解决方案【35页PPT】
deli-数码录音电话机-HCD6238(28)P-TSD-使用说明书
Java项目基于ssm框架的课程设计,包含LW+ppt
Delphi 12.3控件之Tsilang 7.5.0.0 D12.7z
ios+UIButton分类+UIButton+UIButton图片文字位置
项目已获导师指导并通过的高分毕业设计项目,可作为课程设计和期末大作业,下载即用无需修改,项目完整确保可以运行。 该系统功能完善、界面美观、操作简单、功能齐全、管理便捷,具有很高的实际应用价值。 项目都经过严格调试,确保可以运行!可以放心下载
Java项目基于ssm框架的课程设计,包含LW+ppt
Delphi 12.3控件之TextEditorPro64.7z
尝试给OpenHarmony4.0增加可以在动态库中使用的日志模块 文章使用的资源,防止gitee资源丢失