е§ІжґЫе≠¶йХњ
- жµПиІИ: 121718 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еМЧдЇђ
-

з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2020-02 ( 1)
- 2020-01 ( 45)
- 2019-12 ( 61)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
дЄАжЦЗеЄ¶дљ†дЇЖиІ£ Flink Forward жЯПжЮЧзЂЩеЕ®йГ®йЗНзВєеЖЕеЃє
**дљЬиАЕпЉЪжЭ®еЕЛзЙєпЉИй≤Бе∞ЉпЉЙ**
еЙНи®А
==
2019.10.7~9еПЈпЉМйЪПзЭА70еС®еєіеЫљеЇЖжіїеК®зЪДй°ЇеИ©йЧ≠еєХпЉМFlink Forward дєЯзЕІдЊЛеЬ®дїЦдїђзЪДеПСжЇРеЬ∞жЯПжЮЧдЄЊеКЮдЇЖзђђдЇФе±Ке§ІдЉЪгАВиЩљзДґињШж≤°жЬЙжЛњеИ∞еЕЈдљУзЪДжХ∞жНЃпЉМдЄНињЗдїОеЯєиЃ≠йЧ®з•®еЈ≤зїПеЬ®дЉЪеЙНйФАеФЃдЄАз©ЇзЪДињЩж†ЈзЪДзО∞и±°жЭ•зЬЛпЉМFlink Forward е§ІдЉЪињШжШѓзїІзї≠дњЭжМБдЇЖдЄАдЄ™иЙѓе•љзЪДеКње§ігАВжЬђе±Ке§ІдЉЪдЄНзЃ°жШѓдїОеПВдЉЪдЇЇжХ∞дЄКпЉМжПРдЇ§зЪДиЃЃйҐШпЉМдї•еПКеПВеК†зЪДеЕђеПЄжХ∞йЗПжЭ•зЬЛйГљзїІзї≠еИЫдЇЖдЄАдЄ™жЦ∞йЂШгАВељУзДґпЉМињЩи¶БеОїжОЙеОїеєі Flink Forward еМЧдЇђзЂЩзЪДжХ∞жНЃ ;-)гАВйШњйЗМеЈіеЈіињЩжђ°еЕ±жіЊеЗЇдЇЖеМЕжЛђзђФиАЕеЬ®еЖЕзЪД3еРНиЃ≤еЄИпЉМжАїеЕ±еПВеК†дЇЖ4еЬЇеИЖдЇЂеТМ2дЄ™йЧЃз≠ФзОѓиКВгАВеЬ®ињЩйЗМпЉМжИСдЉЪж†єжНЃиЗ™еЈ±еПВдЄОзЪДиЃЃйҐШзїЩе§ІеЃґеБЪдЄАдЄЛињЩжђ°дЉЪиЃЃжХідљУзЪДдЄАдЄ™дїЛзїНеТМдЄ™дЇЇеЬ®ињЩжђ°еПВдЉЪињЗз®ЛйЗМйЭҐзЪДжДЯеПЧеТМжАЭиАГпЉМеЄМжЬЫеѓєжДЯеЕіиґ£зЪДеРМе≠¶жЬЙжЙАеЄЃеК©гАВ
Keynote
=======
еЕИиѓіиѓіињЩ䪧姩зЪД KeynoteгАВзђђдЄА姩зЪДеЉАеЬЇ Keynote ињШжШѓзїІзї≠зФ±з§ЊеМЇдЄАеУ• Stephan Ewen жЭ•зїЩеЗЇгАВдїЦеЕИжАїзїУдЇЖдЄАдЄЛ Flink й°єзЫЃзЫЃеЙНзЪДдЄАдЇЫзКґжАБпЉМеМЕжЛђпЉЪ
* Flink еЬ®8жЬИдїљзЪД Github star жХ∞иґЕињЗдЇЖ1дЄЗ
* еЬ®жЙАжЬЙ Apache й°єзЫЃдЄ≠пЉМFlink жОТеЬ®йВЃдїґеИЧи°®жіїиЈГеЇ¶зЪД Top 3пЉМеєґдЄФињЩдЄ™жХ∞е≠ЧеЬ®жО•дЄЛжЭ•еЊИжЬЙеПѓиГљињШдЉЪеПШе∞П
* 8жЬИдїљеПСеЄГзЪД 1.9.0 зЙИжЬђжШѓ Flink зЫЃеЙНдЄЇж≠ҐеПСеЄГзЪДеКЯиГљжЬАе§ЪпЉМдњЃжФєйЗПжЬАе§ІзЪДдЄАдЄ™зЙИжЬђ
ињЩеЉ†еЫЊзЙЗеЊИе•љзЪДж¶ВжЛђдЇЖ Flink еЬ®ињЗеОїе§ІеНКеєіжЙАдЊІйЗНзЪДеЈ•дљЬпЉЪ

еѓєдЇО Flink жЬ™жЭ•зЪДдЄАдЄ™еПѓиГљзЪДжЦєеРСпЉМStephan зїІзї≠и°®иЊЊдЇЖдїЦеѓє Application ињЩзІНеБПеЬ®зЇњжЬНеК°зЪДеЬЇжЩѓзЪДеЕіиґ£гАВдїЦеЕИжШѓе∞ЖжИСдїђеє≥жЧґжЙАиѓізЪДжЙєе§ДзРЖеТМжµБиЃ°зЃЧжАїзїУдЄЇ Data ProcessingпЉМеРМжЧґе∞ЖжґИжБѓй©±еК®еТМжХ∞жНЃеЇУдєЛз±їзЪДеЇФзФ®жАїзїУдЄЇ ApplicationsпЉМиАМ Stream Processing е∞±жШѓињЮжО•ињЩдЄ§зІНзЬЛиµЈжЭ•жИ™зДґдЄНеРМзЪДеЬЇжЩѓзЪДж°•жҐБгАВжИСеЬ®дЄАеЉАеІЛеРђеИ∞ињЩдЄ™зЪДжЧґеАЩдєЯжЬЙзВєдЄАе§ійЫЊж∞іпЉМдЄНжШОе∞±йЗМзЪДжДЯиІЙпЉМзїПињЗињЩеdž姩僺ињЩдЄ™йЧЃйҐШзЪДжАЭиАГпЉМжЬЙдЇЖдЄАдЇЫиЗ™еЈ±зЪДзРЖиІ£пЉМжИСе∞ЖеЬ®жЦЗжЬЂе±ХеЉАињЫи°МиІ£йЗКгАВжПРеИ∞ ApplicationпЉМе∞±дЄНеЊЧдЄНжПРзО∞еЬ®еЊИжµБи°МзЪД FaaSпЉИFunction as a ServiceпЉЙгАВеЬ®ињЩдЄ™йҐЖеЯЯпЉМStephan иІЙеЊЧе§ІеЃґйГљењљиІЖдЇЖ State еЬ®ињЩйЗМйЭҐзЪДйЗНи¶БжАІгАВжѓФе¶ВдЄАдЄ™еЕЄеЮЛзЪД Application еЬЇжЩѓпЉМдЄАиИђйГљдЉЪеЕЈе§Здї•дЄЛињЩдЇЫзЙєзВєпЉЪ
* жХідЄ™ Application дЉЪжЬЙдЄАдЄ™жИЦиАЕе§ЪдЄ™еЕ•еП£пЉМиЃ°зЃЧйАїиЊСзФ±жґИжБѓжЭ•й©±еК®
* еЕЈдљУзЪДдЄЪеК°йАїиЊС襀жЛЖеИЖжИРз≤ТеЇ¶иЊГе∞ПзЪДеЗ†дЄ™еНХеЕГпЉМжѓПдЄ™йАїиЊСеНХеЕГдљњзФ®дЄАдЄ™ Function жЭ•жЙІи°МеЕЈдљУзЪДйАїиЊС
* Function дєЛйЧідЉЪдЇТзЫЄи∞ГзФ®пЉМдЄАиИђжЭ•иѓіжИСдїђдєЯдЉЪе∞ЖињЩдЇЫи∞ГзФ®иЃЊиЃ°дЄЇеЉВж≠•зЪДж®°еЉП
* жѓПдЄ™ Function зЪДиЃ°зЃЧйАїиЊСеПѓиГљдЉЪйЬАи¶БдЄАдЇЫзКґжАБпЉМжѓФе¶ВеПѓдї•дљњзФ®жХ∞жНЃеЇУдљЬдЄЇзКґжАБзЪДе≠ШеВ®
* еЬ®еЃМжХізЪДиЃ°зЃЧйАїиЊСеЃМжИРдєЛеРОпЉМжИСдїђдЉЪйАЪињЗдЄАдЄ™зїЯдЄАзЪДеЗЇеП£ињФеЫЮе§ДзРЖзЪДзКґжАБ
еЬ®ињЩдЄ™еЬЇжЩѓйЗМпЉМжИСдїђзЬЛеИ∞дЇЖиЗ≥е∞СдЄЙзВєйЬАж±ВпЉЪ
* иЃ°зЃЧйАїиЊСзФ±жґИжБѓй©±еК®
* иЃ°зЃЧйАїиЊСеТМдЇТзЫЄи∞ГзФ®зЪДеЕ≥з≥їењЕй°їеПѓдї•жѓФиЊГзБµжіїзЪДињЫи°МзїДзїЗ
* иЃ°зЃЧйАїиЊСйЬАи¶БзКґжАБзЪДжФѓжМБпЉМеєґдЄФеЬ®жЯРдЇЫжГЕеЖµдЄЛпЉМйЬАи¶БдњЭиѓБ exactly once зЪДе§ДзРЖиѓ≠дєЙ
ињЩйЗМйЭҐе±ЮзђђдЄЙзВєжЬАйЪЊеБЪгАВе§ІеЃґеПѓдї•жГ≥и±°дЄАдЄЛпЉМеБЗе¶ВзО∞еЬ®жИСдїђзЪД Application и¶Бе§ДзРЖз±їдЉЉзФµеХЖеЬЇжЩѓдЄЛеНХињЩж†ЈзЪДињЗз®ЛпЉМеРМжЧґжИСдїђдЊЭиµЦжХ∞жНЃеЇУдљЬдЄЇињЩдЄ™еЇФзФ®зЪДзКґжАБе≠ШеВ®гАВжИСдїђжЬЙдЄАдЄ™дЄУйЧ®зЪДеЇУе≠ШзЃ°зРЖйАїиЊСеТМдЄАдЄ™дЄЛеНХйАїиЊСгАВеЬ®дЄАдЄ™еЃМжХізЪДиі≠дє∞йАїиЊСйЗМпЉМжИСдїђйЬАи¶БеЕИи∞ГзФ®еЇУе≠ШзЃ°зРЖж®°еЭЧпЉМж£АжЯ•дЄЛиѓ•еХЖеУБжШѓеР¶жЬЙеЇУе≠ШпЉМзДґеРОе∞Жиѓ•еХЖеУБзЪДеЇУе≠ШдїОжХ∞жНЃеЇУйЗМеЗПеОї1гАВињЩдЄАж≠•жИРеКЯдєЛеРОпЉМжИСдїђзЪДжЬНеК°еЖНзїІзї≠и∞ГзФ®дЄЛеНХйАїиЊСпЉМеЬ®жХ∞жНЃеЇУйЗМйЭҐзФЯжИРдЄАдЄ™жЦ∞зЪДиЃҐеНХгАВеЬ®дЄАеИЗйГљж≠£еЄЄзЪДжЧґеАЩпЉМињЩж†ЈзЪДйАїиЊСињШжШѓжѓФиЊГзЃАеНХзЪДпЉМдљЖдЄАжЧ¶жЬЙйФЩиѓѓеЗЇзО∞е∞±дЉЪзЫЄељУйЇїзГ¶гАВжѓФе¶ВжИСдїђеЈ≤зїПе∞ЖеЇУе≠ШеЗПжОЙпЉМдљЖжШѓеЬ®зФЯжИРиЃҐеНХзЪДињЗз®ЛдЄ≠еПСзФЯдЇЖйФЩиѓѓпЉМињЩж†ЈжИСдїђињШеЊЧжГ≥еКЮж≥ХиЃ©еЇУе≠ШињЫи°МеЫЮжїЪгАВдЄАжЧ¶з±їдЉЉзЪДдЄЪеК°йАїиЊСеНХеЕГеПШе§ЪдєЛеРОпЉМдљ†зЪДеЇФзФ®дї£з†Бе∞ЖеПШеЊЧеЉВеЄЄе§НжЭВгАВињЩдЄ™йЧЃйҐШе∞±жШѓеЕЄеЮЛзЪД end-to-end exactly onceпЉМжИСдїђеЄМжЬЫдЄАдЄ™йФЩзїЉе§НжЭВзЪДиЃ°зЃЧжµБз®ЛпЉМи¶БдєИеЕ®йГ®дЄАиµЈжИРеКЯпЉМи¶БдєИеЕ®йî姱賕пЉМе∞±ељУеЃГеЃМеЕ®ж≤°еПСзФЯињЗдЄАж†ЈгАВ
дЄЇдЇЖиІ£еЖ≥ињЩж†ЈзЪДйЧЃйҐШпЉМзїУеРИ Flink зЫЃеЙНзЪДдЄАдЇЫзІѓзіѓпЉМStephan жО®еЗЇдЇЖдЄАдЄ™еЕ®жЦ∞зЪДй°єзЫЃпЉЪ[statefun.io](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fstatefun.io%2F)пЉМеН≥ Stateful FunctionsгАВйАЪињЗзїУеРИ Stateful Stream Processing еТМ FaaSпЉМжЭ•жПРдЊЫдЄАзІНеЕ®жЦ∞зЪДзЉЦеЖЩ Stateful Application зЪДжЦєеЉПгАВ
еЕЈдљУзЪДеЃЮзО∞йАїиЊСпЉМжИСе∞±дЄНеЖНињЗе§ЪдїЛзїНпЉМе§ІеЃґеПѓдї•иЗ™и°МеИ∞еЃШзљСињЫи°МжЯ•зЬЛеТМе≠¶дє†гАВ
### Cloudera
Stephan зїЩзЪДзђђдЄАдЄ™ Keynote ињШжШѓжѓФиЊГзЪДеБПжКАжЬѓеМЦпЉМињЩдєЯзђ¶еРИдїЦзЪДдЄ™дЇЇй£Ож†ЉгАВеЬ®дєЛеРОзЪДеМЕжЛђзђђдЇМ姩зЪДжЙАжЬЙ KeynoteпЉМеЯЇжЬђдЄКйГљжШѓзЯ•еРНзЪДе§ІеЕђеПЄжЭ•зїЩ Flink зЂЩеП∞дЇЖгАВеЕИдїО Cloudera иѓіиµЈпЉМдїЦдїђи°®з§ЇзО∞еЬ®еЈ≤зїПжФґеИ∞дЇЖиґКжЭ•иґКе§ЪзЪДеЃҐжИЈзВєеРНи¶Б Flink зЪДжГЕеЖµпЉМеЫ†ж≠§е∞±вАЭй°ЇеЇФж∞СжДПвАЬеЬ®дїЦдїђзЪДжХ∞жНЃеє≥еП∞йЗМеК†еЕ•дЇЖ Flink зЪДжФѓжМБгАВиГљеЬ®ињЩзІНеХЖдЄЪеЉАжЇРиљѓдїґжПРдЊЫеХЖдЄ≠еН†жНЃдЄАеЄ≠дєЛеЬ∞пЉМеЯЇжЬђдєЯзЃЧжШѓж†ЗењЧеЬ® Flink еЈ≤зїПињЫеЕ•дЇЖдЄАдЄ™жѓФиЊГжИРзЖЯзЪДйШґжЃµгАВеП¶е§ЦпЉМCloudera жШѓзО©еЉАжЇРзЪДиАБе§ІеУ•зЇІеИЂдЇЇзЙ©дЇЖпЉМељУзДґдЄНдЉЪеП™жШѓзЃАеНХзЪДжПРдЊЫ Flink иљѓдїґињЩдєИзЃАеНХгАВдїЦдїђеЬ®дЉЪдЄКеЃ£еЄГдЇЖдїЦдїђеЈ≤зїПзїДеїЇдЇЖдЄАжФѓзФ±дЄ§еРН Flink PMC еЄ¶йШЯзЪДеЈ•з®ЛеЫҐйШЯпЉМеєґдЄФжЙУзЃЧеРОзї≠еЬ® Flink з§ЊеМЇдєЯжКХеЕ•жЫіе§ЪзЪДиµДжЇРпЉМињЩжЧ†зЦСжШѓзїЩ Flink з§ЊеМЇзЪДзєБиН£еПИж≥®еЕ•дЇЖдЄАиВ°жЦ∞й≤ЬеПИеЉЇе§ІзЪДеКЫйЗПгАВ

### AWS
AWS еЬ®зђђдЇМ姩зЩїеЬЇпЉМзФ±дїЦдїђдЄїзЃ° EMRгАБAthenaгАБDocumentDBдї•еПКеМЇеЭЧйУЊзЪДиАБе§І Rahul зїЩеЗЇгАВдїЦеЕИжШѓеЫЮй°ЊдЇЖдЄАдЄЛжµБиЃ°зЃЧзЫЄеЕ≥зЪДдЇІеУБеЬ® AWS зЪДеПСе±ХеОЖз®ЛпЉЪ
дїОеЫЊдЄ≠еПѓдї•зЬЛеЗЇпЉМдїЦдїђжЧ©еЬ®2016еєі Flink еі≠йЬ≤е§іиІТзЪДжЧґеАЩе∞±еЈ≤зїПе∞Ж Flink еК†еЕ•еИ∞дЇЖдїЦдїђзЪД EMR ељУдЄ≠гАВзЫЄжѓФ Cloudera зЪДеРОзЯ•еРОиІЙпЉМAWS еЬ®ињЩжЦєйЭҐжЮЬзДґе∞±иАБж±ЯжєЦдЇЖиЃЄе§ЪгАВдї§дЇЇеН∞и±°жЈ±еИїзЪДжШѓпЉМAWS ињЩеЗ†еєіеЫізїХжµБиЃ°зЃЧдЇІеУБзЪДеПСе±ХпЉМдЄАзЫіжЬЙдЄАдЄ™жЄЕжЩ∞зЪДдЄїзЇњпЉМйВ£е∞±жШѓйТИеѓєдЄНеРМдљУйЗПзЪДеЃҐжИЈжО®еЗЇжЫіеК†йАВеРИдїЦдїђзЪДдЇІеУБеТМиІ£еЖ≥жЦєж°ИгАВдїЦдїђеЊИе•љзЪДжАїзїУдЇЖдЄНеРМдљУйЗПзЪДеЃҐжИЈеѓєдЇІеУБзЪДйЬАж±ВзЪДдЄНеРМпЉИзЫЄдњ°ињЩдЄНдїЕдїЕеП™жШѓйТИеѓєжµБиЃ°зЃЧпЉМйТИеѓєеЕґдїЦзЪДдЇІеУБдєЯжШѓеЉВжЫ≤еРМеЈ•пЉЙпЉЪ

жѓФе¶ВдїЦдїђеПСзО∞дЇЖе§ІйЗПзЪДеЃҐжИЈжЬЙжЧґеАЩдљњзФ®жµБиЃ°зЃЧж°ЖжЮґеП™жШѓзЃАеНХзЪДиІ£еЖ≥дЄАдЄ™жХ∞жНЃиљђе≠ШзЪДйЧЃйҐШпЉМжѓФе¶ВзЃАеНХзЪДжККжХ∞жНЃдїО Kinesis Data StreamпЉИињЩдЄ™еЕґеЃЮжШѓдїЦдїђзЪДдЄАдЄ™жґИжБѓйШЯеИЧжЬНеК°пЉМеЕЙзЬЛеРНе≠ЧеЃєжШУжЬЙзВєиѓѓеѓЉпЉЙиљђе≠ШеИ∞ S3 дЄКпЉМжИЦиАЕжККжХ∞жНЃеПСеИ∞ Redshift жИЦиАЕ ElasticsearchгАВйТИеѓєињЩзІНеЬЇжЩѓпЉМдїЦдїђе∞±еЉАеПСдЇЖдЄУйЧ®зЪД Kinesis Data Firehose дЇІеУБпЉМиЃ©зФ®жИЈдЄНйЬАи¶БеЖЩдї£з†Бе∞±иГље§ЯеЃМжИРињЩж†ЈзЪДеЈ•дљЬгАВеП¶е§ЦпЉМдЄАдЇЫеЕЈе§ЗдЄАдЇЫеЉАеПСиГљеКЫзЪДеЃҐжИЈпЉМдЉЪеЖЩдЄАдЇЫдї£з†БжИЦиАЕ SQL жЭ•еѓєжХ∞жНЃињЫи°Ме§ДзРЖеТМеИЖжЮРгАВйТИеѓєињЩзІНеЬЇжЩѓпЉМдїЦдїђжПРдЊЫдЇЖ Kinesis Data Analytics жЬНеК°гАВ
еП¶е§ЦиЃ©дЇЇеН∞и±°жЈ±еИїзЪДдЄАзВєжШѓпЉМAWS зЪДеРДдЄ™дЇІеУБдєЛйЧізЪДеНПеРМеБЪзЪДйЭЮеЄЄе•љпЉИжИСеЬ®еРОжЭ•ињШеПВеК†дЇЖдЄАдЄ™ AWS Kinesis дЇІеУБзЪДжЉФз§ЇеИЖдЇЂпЉМеЕґдЄ≠жґЙеПКеИ∞дЄНе∞СдЇІеУБдєЛйЧізЪДеНПи∞ГеТМжЙУйАЪпЉМиЃ©дЇЇеН∞и±°жЈ±еИїпЉЙгАВжѓПдЄ™дЇІеУБдЄУж≥®иІ£еЖ≥дЄАйГ®еИЖзЪДйЧЃйҐШпЉМдЇІеУБеТМдЇІеУБдєЛйЧіеЬ®еКЯиГљдЄКдЄНиГљиѓіеЃМеЕ®ж≤°жЬЙйЗНеП†зЪДеЬ∞жЦєпЉМдљЖеЯЇжЬђдЄКињШжШѓйЭЮеЄЄеЕЛеИґгАВжЉФиЃ≤дЄ≠еИЖдЇЂзЪДжѓПдЄ™зЬЯеЃЮзЪДзФ®жИЈеЬЇжЩѓпЉМеЯЇжЬђйГљжґЙеПКдЇЖ3-5дЄ™дї•дЄКзЪДдЇІеУБдЇТзЫЄзЪДеНПеРМгАВеѓєеЃҐжИЈйЬАж±ВзЪДз≤ЊеЗЖжККжП°пЉМдї•еПКдЇІеУБзЪДеНПеРМзЂЩдљНз≤Њз°ЃиІ£еЖ≥зФ®жИЈйЧЃйҐШпЉМињЩдЄ§зВєйЭЮеЄЄеАЉеЊЧжИСдїђеОїе≠¶дє†гАВ
жЙѓзЪДжЬЙзВєињЬдЇЖпЉМеЫЮеИ∞ Flink дЄКжЭ•гАВRahul жЬАеРОжАїзїУдЇЖдЄАдЄЛ Flink жШѓдїЦдїђзЫЃеЙНзЬЛеИ∞зЪДдЉЪеОїжґИжБѓйШЯеИЧйЗМжґИиієжХ∞жНЃзЪДдЇІеУБдЄ≠еҐЮйХњжЬАењЂзЪДз≥їзїЯпЉМдљЖдїОзїЭеѓєдљУйЗПдЄКжЭ•зЬЛињШжШѓеБПе∞ПгАВињЩдєЯеЯЇжЬђзђ¶еРИ Flink зЫЃеЙНзЪДдЄАдЄ™зКґжАБпЉМзГ≠еЇ¶йЂШпЉМеҐЮйХњдєЯеЊИењЂпЉМдљЖжШѓзїЭеѓєдљУйЗПињШеБПе∞ПпЉМдЄНињЗињЩдєЯйҐДз§ЇзЭАжГ≥и±°зЪДз©ЇйЧіињШжѓФиЊГе§ІгАВ
### Google
Google еЬ® AWS дєЛеРОеЗЇеЬЇпЉМзФ± Reven еТМ Sergei еЄ¶жЭ•пЉИеЙНиАЕдєЯжШѓгАКStreaming SystemsгАЛдЄАдє¶зЪДдљЬиАЕдєЛдЄАпЉМзїИдЇОиІБеИ∞зЬЯдЇЇдЇЖпЉЙгАВињЩдЄ™ Talk жХідљУдЄКжЭ•иЃ≤еТМ Flink ж≤°жЬЙ姙姲зЪДеЕ≥з≥їпЉМеИЖдЇЂзЪДжШѓ Google ињЩдЇЫеєіеЬ®жµБиЃ°зЃЧзЫЄеЕ≥з≥їзїЯзЪДз†ФеПСињЗз®ЛдЄ≠еЊЧеИ∞зЪДзїПй™МгАВеТМ AWS зЫЄжѓФпЉМдЄ§еЃґеЕђеПЄзЪДзЙєиЙ≤дєЯжШѓзЫЄељУй≤ЬжШОгАВAWS еИЖдЇЂзЪДйГљжШѓеѓєеЃҐжИЈйЬАж±ВеТМдЇІеУБзЪДжАїзїУпЉМиАМ Google иѓізЪДеЯЇжЬђдЄКйГљжШѓзЇѓжКАжЬѓдЄКзЪДзїПй™МжФґиОЈгАВеРђдЇЖдєЛеРОдєЯз°ЃеЃЮжФґиОЈиЙѓе§ЪпЉМдЄНињЗзФ±дЇОзѓЗеєЕйЧЃйҐШе∞±дЄНеЬ®ињЩеЕЈдљУе±ХеЉАдЇЖгАВдЇЇеЃґдєЯеЈ≤зїПеЗЖе§Зе•љдЄАжЃµжАїзїУиЃ©жИСдїђеПѓдї•жЙУеМЕеЄ¶иµ∞пЉЪ

дЄїиЃЃз®Л
===
зФ±дЇОеИЖиЇЂдєПжЬѓпЉМеЬ®дЄїиЃЃз®ЛдЄ≠жИСеП™жМСйАЙдЇЖдЄАдЇЫдЄ™дЇЇжѓФиЊГжДЯеЕіиґ£жИЦиАЕжШѓдЄНжАОдєИдЇЖиІ£зЪДйҐЖеЯЯињЫи°МиІВжС©еТМе≠¶дє†гАВдљЖдЄЇдЇЖжХізѓЗжК•еСКзЪДеЃМжХіжАІпЉМжИСињШжШѓе∞љйЗПзЪДзЃАеНХдїЛзїНдЄАдЄЛеЕґдїЦжИСж≤°жЬЙеПВдЄОдљЖжШѓињШзЃЧзЖЯжВЙзЪДиЃЃйҐШгАВеРОзї≠дЄїеКЮжЦєдєЯдЉЪе∞ЖжЙАжЬЙзЪДиІЖйҐСеТМ PPT дЄКдЉ†еИ∞зљСдЄКдЊЫе§ІеЃґињЫи°МжЯ•зЬЛгАВжО•дЄЛжЭ•жИСе∞±жККиЃЃйҐШжМЙзЕІдЄ™дЇЇзРЖиІ£еИЖжИРеЗ†дЄ™дЄНеРМзЪДз±їеИЂпЉМеИЖеИЂжКЫз†ЦеЉХзОЙдЄАдЄЛгАВе§ІеЃґе¶ВжЮЬеѓєеЕґдЄ≠зЪДжЯРдЇЫиЃЃйҐШзЪДзїЖиКВзЙєеИЂжДЯеЕіиґ£зЪДпЉМеПѓдї•еЖНеОїдїФзїЖжЯ•зЬЛиІЖйҐСеТМ PPTгАВ
еє≥еП∞еМЦеЃЮиЈµ
-----
еЯЇдЇО Flink жЮДеїЇжХ∞жНЃеє≥еП∞еПѓдї•зЃЧеЊЧдЄКжЬАзГ≠йЧ®зЪДдЄАдЄ™иЃЃйҐШжЦєеРСдЇЖгАВињЩеЗ†еєійШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯдЄАзЫідЄНйБЧдљЩеКЫзЪДеРСз§ЊеМЇжО®еєњеЯЇдЇО SQL жЮДеїЇжХ∞жНЃе§ДзРЖеє≥еП∞зЪДзїПй™МпЉМзЫЃеЙНзЬЛиµЈжЭ•е§ІеЃґдєЯеЯЇжЬђдЄКиЃ§еРМдЇЖињЩдЄ™жЦєеРСпЉМдєЯзЇЈзЇЈзЪДеЉАеІЛдЄКдЇЖзФЯдЇІгАВдЄНињЗж†єжНЃеЕЈдљУзЪДеЬЇжЩѓпЉМдљЬдЄЪйЗПзЪДиІДж®°з≠ЙзЙєзВєпЉМдєЯжЬЙдЄАдЇЫеЕђеПЄдЉЪйАЙжЛ©дљњзФ®жЫіеК†еЇХе±ВеТМжЫіеК†зБµжіїзЪД DataStream API жЭ•жЮДеїЇжХ∞жНЃеє≥еП∞пЉМжИЦиАЕдЄ§иАЕйГљжПРдЊЫгАВињЩдєЯзђ¶еРИжИСдїђдЄАеЉАеІЛзЪДеИ§жЦ≠пЉМSQL иГљиІ£еЖ≥е§Іе§ЪжХ∞йЧЃйҐШпЉМдљЖдЄНжШѓеЕ®йГ®гАВеЬ®дЄАдЇЫзБµжіїзЪДеЬЇжЩѓдЄЛпЉМDataStream иГљжЫіжЦєдЊњеТМйЂШжХИзЪДиІ£еЖ≥зФ®жИЈзЪДйЧЃйҐШгАВ
#### иЃЃйҐШ1пЉЪгАКWriting a interactive SQL engine and interface for executing SQL against running streams using FlinkгАЛ
ињЩдЄ™еИЖдЇЂжЭ•иЗ™зЊОеЫљзЪДдЄАеЃґеРНеПЂ eventador зЪДеИЫдЄЪеЕђеПЄпЉМдєЯжШѓжЬђжђ°е§ІдЉЪзЪДиµЮеК©еХЖдєЛдЄАгАВжХідЄ™еИЖдЇЂе§ІйГ®еИЖињШжШѓдїЦдїђдЇІеУБжЮґжЮДеТМеКЯиГљзЪДдїЛзїНпЉМеЯЇжЬђдЄКеТМжИСдїђдї•еПКеЕґдїЦеЕђеПЄзЪДеє≥еП∞жЮґжЮДз±їдЉЉгАВжѓФиЊГжЬЙжДПжАЭзЪДжШѓпЉМдїЦдїђдєЯеПСзО∞дЇЖеЬ®еє≥еП∞еМЦзЪДеЃЮиЈµињЗз®ЛдЄ≠пЉМзФ®жИЈжШѓеРМжЧґйЬАи¶Б SQL ињЩзІНйЂШйШґ API дї•еПКжЫіеК†зБµжіїеТМеБПеЇХе±ВзВєзЪД DataStream APIпЉМеєґдЄФињЩдЄ§иАЕзЪДжѓФдЊЛжШѓ8пЉЪ2еЉАгАВ

ињШжЬЙдЄАдЄ™жѓФиЊГжЬЙжДПжАЭзЪДеКЯиГљжШѓпЉМдїЦдїђеЬ® SQL дЄКжПРдЊЫдЇЖ JavaScript зЪД UDF жФѓжМБпЉМеєґдЄФеЬ®дїЦдїђзЪДзФ®жИЈдєЛйЧійЭЮеЄЄеПЧ搥ињОгАВеЬ® SQL дЄКпЉМжМБзї≠зЪДйЩНдљОдљњзФ®йЧ®жІЫз°ЃеЃЮжШѓдЄАдЄ™жѓФиЊГйЭ†и∞±зЪДиЈѓе≠РпЉМеТМжИСдїђжГ≥жПРдЊЫ Python UDF жФѓжМБдєЯжШѓеЯЇдЇОеРМж†ЈзЪДеЗЇеПСзВєгАВ
#### иЃЃйҐШ2пЉЪгАКBuilding a Self-Service Streaming Platform at PinterestгАЛ
Pinterest зЃЧжШѓ Flink з§ЊеМЇзЪДжЦ∞йЭҐе≠ФпЉМињЩжђ°жШѓдїЦдїђзђђдЄАжђ°еЬ® Flink зЪДе§ІдЉЪдЄКеИЖдЇЂдїЦдїђзЪДзїПй™МгАВдїЦдїђдЄїи¶БзЪДеЇФзФ®еЬЇжЩѓдЄїи¶БжШѓеЫізїХеєњеСКжЭ•е±ХеЉАпЉМдљњзФ® Flink жЭ•зїЩеєњеСКдЄїдїђеЃЮжЧґеПНй¶ИеєњеСКзЪДжХИжЮЬгАВињЩдєЯзЃЧзЪДдЄКжШѓ Flink зЫЄељУзїПеЕЄзЪДдЄАдЄ™дљњзФ®еЬЇжЩѓдЇЖгАВиЗ≥дЇОдЄЇдїАдєИињЩдєИжЩЪжЙНзФ® FlinkпЉМдїЦдїђдЄКжЭ•е∞±ињЫи°МдЇЖиѓіжШОгАВдїЦдїђиК±дЇЖжѓФиЊГе§ІзЪДеКЯе§ЂеОїеѓєжѓФ Spark StreamingпЉМFlink дї•еПК Kafka Stream ињЩ3дЄ™еЉХжУОпЉМжЭГи°°еЖНдЄЙдєЛеРОжЙНйАЙжЛ©дЇЖ FlinkпЉМдєЯзЃЧжШѓжѓФиЊГи∞®жЕОеТМењГзїЖдЇЖгАВеРМжЧґдїЦдїђзЪДиАБзЪДдЄЪеК°еЯЇжЬђдЄКйГљжШѓдљњзФ® Spark иЈСжЙєе§ДзРЖдљЬдЄЪпЉМеЬ®еИЗжНҐжИРжµБдєЛеРОпЉМдєЯжШѓйЬАи¶БжЛњеЗЇзВєеЃЮеЃЮеЬ®еЬ®зЪДжИРзї©жЙНжЬЙеПѓиГљеЬ®еЕђеПЄеЖЕе§ІиІДж®°жО®еєњгАВ
жО•зЭАпЉМдїЦдїђдєЯеИЖдЇЂдЇЖдЄ§дЄ™еЬ®еє≥еП∞еМЦеЃЮиЈµињЗз®ЛдЄ≠е°ЂзЪДеЭСгАВзђђдЄАдЄ™жШѓжЧ•ењЧзЪДжЯ•зЬЛпЉМе∞§еЕґжШѓељУжЙАжЬЙзЪДдљЬдЄЪиЈСеЬ® YARN дЄКзЪДжЧґеАЩпЉМељУдљЬдЄЪзїУжЭЯеРОжАОдєИжЯ•зЬЛдљЬдЄЪињРи°МжЧґзЪДжЧ•ењЧжШѓдЄАдЄ™жѓФиЊГе§ізЦЉзЪДйЧЃйҐШгАВзђђдЇМдЄ™жШѓ BackfillingпЉМеЬ®жЦ∞зЪДдљЬдЄЪдЄКзЇњжИЦиАЕдљЬдЄЪйАїиЊСйЬАи¶БеПШжЫізЪДжЧґеАЩпЉМдїЦдїђеЄМжЬЫеЕИињљдЄАйГ®еИЖе≠ШеЬ® S3 дЄКзЪДеОЖеП≤жХ∞жНЃпЉМзДґеРОеЬ®еЯЇжЬђињљеЃМзЪДжЧґеАЩеИЗжНҐеИ∞ Kafka ињЩж†ЈзЪДжґИжБѓйШЯеИЧдЄКзїІзї≠ињЫи°Ме§ДзРЖгАВињЩдЄ™ Backfilling жШѓ Flink жµБжЙєдЄАдљУжЬАзїПеЕЄзЪДеЬЇжЩѓпЉМиАМдЄФзЬЛиµЈжЭ•з°ЃеЃЮжШѓдЄ™еЊИжЩЃйБНзЪДеИЪйЬАгАВе¶ВжЮЬж≤°иЃ∞йФЩзЪДиѓЭпЉМињЩжђ°е§ІдЉЪе∞±жЬЙ 3 дЄ™иЃЃйҐШжПРеИ∞дЇЖињЩжЦєйЭҐзЪДйЧЃйҐШпЉМдї•еПКдїЦдїђзЪДиІ£ж≥ХгАВиІ£ж≥ХеРДжЬЙеНГзІЛпЉМдЄНињЗе¶ВжЮЬ Flink еЬ®еЉХжУОдЄКиГље§ЯзЫіжО•еЖЕзљЃжФѓжМБдЇЖињЩж†ЈзЪДеЬЇжЩѓзЪДиѓЭпЉМзЫЄдњ°дљУй™МдЉЪе•љдЄНе∞СпЉИињЩдєЯжБ∞жБ∞жШѓ Flink жО•дЄЛеОїдЄАдЄ™жѓФиЊГйЗНи¶БзЪДжЦєеРСдєЛдЄАпЉЙгАВ
#### еЕґдїЦиЃЃйҐШжО®иНР
* гАКStream SQL with Flink @ YelpгАЛпЉЪYelp еЈ≤зїПзЃЧжШѓ Flink зЪДиАБзЙМзО©еЃґдЇЖпЉМеЬ®ињЩдЄ™еИЖдЇЂйЗМдїЦдїђжАїзїУдЇЖдїЦдїђзЫЃеЙНзЪДжµБиЃ°зЃЧеЬЇжЩѓпЉМдї•еПКдїЦдїђзЪДеє≥еП∞зЪДеБЪж≥ХгАВжИСеЫ†дЄЇжЧґйЧіеЖ≤з™БзЪДеОЯеЫ†ж≤°жЬЙеРђеИ∞ињЩдЄ™еИЖдЇЂпЉМдЄНињЗдїОеЕґдїЦжЄ†йБУеЊЧеИ∞зЪДеПНй¶ИзЬЛиµЈжЭ•дїЦдїђеЇФиѓ•жШѓе±ЮдЇОзО©зЪДжѓФиЊГжЇЬзЪДгАВжО®иНРе§ІеЃґеЬ®иІЖйҐСеТМ PPT дЄКзЇњеРОиІВжС©е≠¶дє†дЄАдЄЛгАВ
* гАКFlink for Everyone: Self-Service Data Analytics with StreamPipesгАЛпЉЪдЄАиИђжЭ•иѓіпЉМеє≥еП∞еМЦеїЇиЃЊйГљжШѓеЕђеПЄеЖЕйГ®й°єзЫЃпЉМеЊИе∞СињЫи°МеЉАжЇРгАВињЩдЄ™еПЂеБЪ FZI зЪДйЭЮзЫИеИ©жЬЇжЮДиЈ≥еЗЇжЭ•ељУдЇЖдЄАжККйЫЈйФЛпЉМжПРдЊЫдЇЖдЄАе•ЧеЃМеЕ®еЉАжЇРзЪДеє≥еП∞еМЦеЈ•з®ЛеЃЮзО∞пЉЪ[streampipes](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fwww.streampipes.org%2F)гАВиЗ™еЄ¶дЄАжХіе•ЧжЙШжЛЙжЛљзЪДдљЬдЄЪжЮДеїЇжµБз®ЛпЉМиАМдЄФзЬЛиµЈжЭ•зХМйЭҐдєЯзЫЄељУзЪДдЄНйФЩпЉМжЬЙйЬАи¶БзЪДеРМе≠¶еПѓдї•еПВиАГдЄАдЄЛгАВ
* гАКDynamically Generated Flink Jobs at ScaleгАЛпЉЪињЩжШѓйЂШзЫЫеИЖдЇЂзЪДеЯЇдЇО Flink зЪДеє≥еП∞еЃЮиЈµпЉМжФѓжМБдЄА姩ињРи°М 12 дЄЗзЪДдљЬдЄЪгАВеЬ®йУґи°МеТМйЗСиЮНдЄЪзЪД IT еРМе≠¶дїђеПѓдї•еПВиАГдЄЛгАВ
зѓЗеєЕжЬЙйЩРпЉМињШжЬЙеЕґдїЦзЫЄеЕ≥зЪДиЃЃйҐШе∞±дЄНдЄАдЄАеИЧеЗЇдЇЖгАВжАїдљУжЭ•иѓіпЉМеЯЇдЇО Flink жЮДеїЇжХ∞жНЃеє≥еП∞еЈ≤зїПжШѓдЄАдЄ™зЫЄељУжИРзЖЯзЪДеЃЮиЈµпЉМеРДи°МеРДдЄЪйГљжЬЙжИРеКЯзЪДж°ИдЊЛињЫи°МеПВиАГгАВињШж≤°жЬЙдЄКиљ¶зЪДеРМе≠¶дїђпЉМдљ†дїђињШеЬ®з≠ЙдїАдєИпЉЯ
еЇФзФ®еЬЇжЩѓз±ї
-----
йЩ§дЇЖдЄКйЭҐзЪДеє≥еП∞еМЦеЃЮиЈµпЉМдљњзФ® Flink иІ£еЖ≥жЯРдЇЫеЇФзФ®еЬЇжЩѓзЪДеЕЈдљУйЧЃйҐШдєЯжШѓињЩжђ°еИЖдЇЂдЄ≠дЄАдЄ™жѓФиЊГзГ≠йЧ®зЪДжЦєеРСгАВињЩдЇЫзФ®жИЈеЊАеЊАиЗ™еЈ±зЉЦеЖЩе∞СйЗПдљЬдЄЪпЉМжЭ•иІ£еЖ≥дїЦдїђзЪДеЃЮйЩЕйЧЃйҐШгАВжИЦиАЕе∞±еє≤иДЖжШѓеє≥еП∞зЪДдљњзФ®жЦєпЉМжЭ•еИЖдЇЂе¶ВдљХдљњзФ®еє≥еП∞жЭ•иІ£еЖ≥жЫіиііињСзїИзЂѓзФ®жИЈзЪДйЧЃйҐШгАВињЩдєЯжШѓ Flink иГље§ЯзЬЯж≠£еИЫйА†еЃЮйЩЕдЄЪеК°дїЈеАЉзЪДеЬ∞жЦєпЉМжЬђжГ≥е§ЪеРђеЗ†дЄ™пЉМеПѓжЧ†е•ИиАБжШѓжЧґйЧіеЖ≤з™БгАВ
#### иЃЃйҐШ1пЉЪгАКMaking Sense of Streaming Sensor Data: How Uber Detects On-trip Car CrashesгАЛ
ињЩжШѓ Uber еИЖдЇЂзЪДдЄАдЄ™иДСжіЮжѓФиЊГе§ІзЪДеЇФзФ®еЬЇжЩѓпЉМдїЦдїђдљњзФ® Flink жЭ•еЃЮжЧґеИ§жЦ≠дєШеЃҐжШѓдЄНжШѓеПСзФЯдЇЖиљ¶з•ЄгАВеТМ Pinterest дЄАж†ЈпЉМеЬ®ињЩдЄ™дЄЪеК°еЬЇжЩѓдЄЛпЉМUber дєЯжШѓдЄЇдЇЖжЧґжХИжАІиАМдїО Spark ињБзІїеИ∞дЇЖ FlinkгАВдїЦдїђдїЛзїНдЇЖдїЦдїђе¶ВдљХдЊЭиµЦдЄ§й°єжЬАйЗНи¶БзЪДжХ∞жНЃпЉИGPSдњ°жБѓеТМжЙЛжЬЇеК†йАЯдњ°жБѓпЉЙпЉМеЖНе•ЧзФ®жЬЇеЩ®е≠¶дє†ж®°еЮЛпЉМжЭ•еЃЮжЧґзЪДеИ§жЦ≠дєШеЃҐжШѓеР¶еПСзФЯдЇЖиљ¶з•ЄгАВ
еРОзї≠дєЯжПРеИ∞дЇЖдїЦдїђеЄМжЬЫеЕ±дЇЂињЩдЄ™дЄЪеК°дЄКжФґйЫЖзЪДжХ∞жНЃпЉМдї•еПКеЬ®ињЩдЄ™жХ∞жНЃзЪДеЯЇз°АдЄКзФЯжИРзЪДдЄАдЇЫзЙєеЊБпЉМеЬ®еЕґдїЦзЪДеЫҐйШЯињЫи°МжО®еєњпЉИжАОдєИжДЯиІЙжЦєеРСеПИи¶БиљђеИ∞еє≥еП∞еМЦдЇЖ-\_-!пЉЙ

#### еЕґдїЦиЃЃйҐШжО®иНР
* гАКAirbus makes more of the sky with FlinkгАЛпЉЪз©ЇеЃҐеЕђеПЄдїЛзїНдЇЖдїЦдїђе¶ВдљХдљњзФ® AzureгАБFlink жЭ•ињЫи°Мй£Юи°МжХ∞жНЃзЪДеИЖжЮРпЉМжЧ®еЬ®жПРдЊЫжЫіе•љзЪДй£Юи°МдљУй™МгАВ
* гАКIntelligent Log Analysis and Real-time Anomaly Detection @ SalesforceгАЛпЉЪSalesforce дїЛзїНдЇЖдїЦдїђдљњзФ® Flink зїУеРИжЬЇеЩ®е≠¶дє†ж®°еЮЛжЭ•иІ£еЖ≥еЃЮжЧґжЧ•ењЧеИЖжЮРпЉМеєґдЄФеЃЮжЧґжОҐжµЛдЄАдЇЫеЉВеЄЄжГЕеЖµжѓФе¶ВеЕ≥йФЃжЬНеК°жАІиГљдЄЛйЩНз≠ЙгАВ
* гАКLarge Scale Real Time Ad Invalid Traffic Detection with FlinkгАЛпЉЪCriteo ињЩеЃґж≥ХеЫљзЪДеєњеСКеЕђеПЄдїЛзїНдЇЖеєњеСКеЬЇжЩѓдЄЛињЫи°МеЃЮжЧґзЪДеЉВеЄЄжµБйЗПжОҐжµЛгАВ
* гАКEnabling Machine Learning with Apache FlinkгАЛпЉЪLyft еИЖдЇЂдЇЖдїЦдїђе¶ВдљХеЯЇдЇО Flink жЮДеїЇдЇЖжЬЇеЩ®е≠¶дє†зЪДеє≥еП∞жЭ•иІ£еЖ≥е§ЪзІНе§Ъж†ЈзЪДдЄЪеК°йЧЃйҐШгАВ
зЃАеНХжАїзїУдЄАдЄЛпЉМеЬ®еБПеЇФзФ®еЬЇжЩѓзЪДжЦєеРСдЄКпЉМеЈ≤зїПиґКжЭ•иґКе§ЪзЪДзЬЛеИ∞дЇЖ Flink еТМжЬЇеЩ®е≠¶дє†зїУеРИдљњзФ®зЪДж°ИдЊЛгАВеЯЇжЬђдЄКпЉМдЄАдЇЫз®НеЊЃе§НжЭВзВєзЪДйЧЃйҐШеЊИйЪЊйАЪињЗиІДеИЩйАїиЊСпЉМжИЦиАЕ SQL жЭ•ињЫи°МзЃАеНХзЪДеИ§еЃЪгАВињЩзІНжГЕеЖµдЄЛпЉМжЬЇеЩ®е≠¶дє†е∞±иГље§ЯжіЊдЄКжѓФиЊГе§ІзЪДзФ®еЬЇгАВзЫЃеЙНзЬЛжЭ•пЉМе§ІеЃґињШжШѓжЫіе§ЪзЪДеЕИдљњзФ®еЕґдїЦеЉХжУОиЃ≠зїГе•љж®°еЮЛпЉМзДґеРОиЃ© Flink еК†иљљж®°еЮЛдєЛеРОињЫи°МйҐДжµЛжУНдљЬгАВдљЖжШѓињЗз®ЛдЄ≠дєЯдЉЪзҐ∞еИ∞з±їдЉЉдЄ§дЄ™еЉХжУОеѓєж†ЈжЬђзЪДе§ДзРЖйАїиЊСдЄНеРМз≠ЙйЧЃйҐШиАМељ±еУНжЬАзїИзЪДжХИжЮЬгАВињЩдєЯзЃЧжШѓ Flink дїКеРОзЪДдЄАдЄ™жЬЇдЉЪпЉМе¶ВжЮЬ Flink еЬ®жЫіеК†еБПеРСжЙєе§ДзРЖзЪДж®°еЮЛиЃ≠зїГдЄКиГљжПРдЊЫжѓФиЊГе•љзЪДжФѓжМБпЉМйВ£дєИзФ®жИЈеЃМеЕ®еПѓдї•дљњзФ®еРМдЄАдЄ™еЉХжУОжЭ•ињЫи°МиѓЄе¶ВзФ®жЬђжЛЉжО•пЉМж®°еЮЛиЃ≠зїГдї•еПКеЃЮжЧґйҐДжµЛињЩдЄАжХіе•ЧжµБз®ЛгАВжХідЄ™зЪДеЉАеПСдљУй™МеМЕжЛђеЃЮйЩЕдЄКзЇњжХИжЮЬзЫЄдњ°йГљдЉЪжЬЙиЊГе§ІзЪДжПРеНЗпЉМиЃ©жИСдїђжЛ≠зЫЃдї•еЊЕ Flink еЬ®ињЩжЦєйЭҐзЪДеК®дљЬгАВ
зФЯдЇІеЃЮиЈµ
----
ињЩйГ®еИЖдЄїи¶БжШѓзФЯдЇІеЃЮиЈµзЪДзїПй™МеИЖдЇЂпЉМеЊИдЄНе•љжДПжАЭзЪДжШѓпЉМзЫЄеЕ≥зЪДиЃЃйҐШжИСдЄАдЄ™йГљж≤°жЬЙеПВдЄОгАВжИСж†єжНЃиЃЃйҐШзЪДзЃАдїЛзЃАеНХеБЪдЄ™дїЛзїНпЉМжДЯеЕіиґ£зЪДеРМе≠¶еПѓдї•иЗ™и°МжЯ•зЬЛзЫЄеЕ≥иµДжЦЩгАВ
* гАКApache Flink Worst PracticesгАЛпЉЪе§ІеЃґеПѓиГљйГљеРђињЗдЄНе∞С Best PracticesпЉМињЩдЄ™еИЖдЇЂеПНеЕґйБУиАМи°МдєЛпЉМдЄУйЧ®дїЛзїНеРДзІНдљњзФ® Flink зЪДжЬАеЈЃеІњеКњпЉМеЯЇжЬђдЄКзЃЧжШѓеИЖдЇЂеРДзІНиЄ©еЭСжИЦиАЕиЄ©йЫЈзЪДеЬ∞жЦєпЉМиЃ©еРђдЉЧиГље§ЯйБњеЉАгАВ
* гАКHow to configure your streaming jobs like a proгАЛпЉЪCloudera еЯЇдЇОињЩдЇЫеєідїЦдїђеЬ®жХ∞зЩЊдЄ™жµБиЃ°зЃЧдљЬдЄЪдЄКжАїзїУдЄЛжЭ•зЪДи∞ГеПВзїПй™МгАВйТИеѓєдЄНеРМз±їеЮЛзЪДдљЬдЄЪпЉМеУ™дЇЫеПВжХ∞жѓФиЊГеЕ≥йФЃгАВ
* гАКRunning Flink in production: The good, the bad and the in-betweenгАЛпЉЪLyft еИЖдЇЂзЪДдїЦдїђињРзїі Flink зЪДзїПй™МпЉМжЬЙеУ™дЇЫ Flink еБЪзЪДжѓФиЊГе•љзЪДеЬ∞жЦєпЉМдєЯеМЕжЛђеУ™дЇЫ Flink зО∞еЬ®еБЪзЪДдЄНе§Яе•љзЪДеЬ∞жЦєгАВиЃ©е§ІеЃґеѓєињРзїі Flink зФЯдЇІдљЬдЄЪжЬЙжЫіеЕ®йЭҐзЪДиЃ§зЯ•гАВ
* гАКIntrospection of the Flink in productionгАЛпЉЪCriteo еИЖдЇЂзЪДжХЩе§ІеЃґе¶ВдљХиІВжµЛ Flink дљЬдЄЪжШѓеР¶ж≠£еЄЄзЪДзїПй™МпЉМдї•еПКељУдљЬдЄЪеЗЇйЧЃйҐШжЧґпЉМе¶ВдљХжЬАењЂзЪДеЃЪдљН root causeгАВ
* гАКKubernetes + Operator + PaaSTA = Flink @ YelpгАЛпЉЪељУе§ІйГ®еИЖдЇЇињШжШѓеЯЇдЇО Yarn жЭ•ињРи°М FlinkзЪДжЧґеАЩпЉМYelp ињЩдЄ™жЈ±еЇ¶зО©еЃґеЈ≤зДґиµ∞еИ∞дЇЖе§ІеЃґеЙНйЭҐгАВињЩдєЯжШѓжИСеЬ®ињЩжђ°е§ІдЉЪдЄ≠зЬЛеИ∞зЪДеФѓдЄАдљњзФ® Flink + K8S дЄКзЇњзЪДзїДеРИгАВ
иЩљзДґдЄАдЄ™иЃЃйҐШдєЯж≤°еРђпЉМдљЖжШѓдєЯдїОеИЂзЪДиЃЃйҐШдЄ≠йЫґйЫґжШЯжШЯзЪДеРђеИ∞дЄАдЇЫе§ІеЃґеЕ≥дЇО Flink зФЯдЇІзЪДиѓЭйҐШпЉМеЕґдЄ≠жѓФиЊГз™БеЗЇзЪДжШѓ Flink еТМ Kubernetes зЪДзїУеРИйЧЃйҐШгАВK8S зЪДзБЂзГ≠пЉМиЃ©е§ІеЃґйГљжЬЙзІНдЄНиє≠дЄАдЄЛзГ≠еЇ¶е∞±иРљдЉНдЇЖзЪДжГ≥ж≥ХгАВдЄНе∞СеЕђеПЄйГљжЬЙжЬЭзЭАињЩдЄ™жЦєеРСињЫи°Ме∞ЭиѓХеТМжΥ糥зЪДжДПжДњгАВеЕґдЄ≠е∞±е±Ю Yelp иµ∞зЪДжЬАењЂпЉМеЈ≤зїПжЛњињЩе•ЧжЮґжЮДдЄКзЇњдЇЖгАВдЄ™дЇЇиІЙеЊЧ Flink еТМ K8S зЪДзїУеРИињШжШѓзЫЄељУйЭ†и∞±зЪДпЉМеПѓдї•иІ£йФБжЫіе§Ъ Application еТМеЬ®зЇњжЬНеК°зЫЄеЕ≥зЪДеІњеКњгАВељУзДґпЉМйШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯеЬ®ињЩжЦєйЭҐдєЯж≤°жЬЙиРљдЉНпЉМжИСдїђдєЯеЈ≤зїПеТМйШњйЗМдЇС K8S еРИдљЬдЇЖзЫЄељУйХњдЄАжЃµжЧґйЧіпЉМжЬАињСдєЯжО®еЗЇдЇЖеЯЇдЇО K8S еЃєеЩ®еМЦзЪДеЕ®жЦ∞дЄАдї£еЃЮжЧґиЃ°зЃЧдЇІеУБ ververica platformгАВ
з†Фз©ґеЮЛй°єзЫЃ
-----
еЙНйЭҐзЪДиЃЃйҐШеЯЇжЬђйГљжШѓдЄАдЇЫеЈ•з®ЛеМЦзЪДеЃЮиЈµпЉМињЩжђ°е§ІдЉЪињШжЬЙдЄНе∞Сз†Фз©ґеЮЛзЪДй°єзЫЃеРЄеЉХдЇЖжИСзЪДеЕіиґ£гАВзФЯжАБзЪДзєБиН£еПСе±ХпЉМйЩ§дЇЖжЬЙеРДе§ІеЕђеПЄзЪДеЃЮиЈµдєЛе§ЦпЉМеБПзРЖиЃЇеМЦзЪДз†Фз©ґеЮЛй°єзЫЃдєЯдЄНеПѓзЉЇе∞СгАВеРђиѓіињЩжђ°е§ІдЉЪжФґеИ∞дЇЖдЄНе∞Сз†Фз©ґеЮЛзЪДиЃЃйҐШпЉМдљЖзФ±дЇОиЃЃйҐШжХ∞йЗПжЬЙйЩРпЉМеП™дїОйЗМйЭҐжМСйАЙдЇЖдЄАйГ®еИЖгАВ
#### иЃЃйҐШ1пЉЪгАКSelf-managed and automatically reconfigurable stream processingгАЛ
ињЩжШѓиЛПйїОдЄЦиБФйВ¶зРЖеЈ•е≠¶йЩҐзЪДдЄАеРНеНЪе£ЂеРОеЄ¶жЭ•зЪДиЗ™еК®йЕНзљЃжµБиЃ°зЃЧдљЬдЄЪзЪДдЄАдЄ™з†Фз©ґеЮЛй°єзЫЃгАВдїЦдїђзЪДз†Фз©ґжЦєеРСдЄїи¶БйЫЖдЄ≠еЬ®е¶ВдљХиЃ©жµБиЃ°зЃЧдљЬдЄЪиГље§ЯиЗ™ж≤їпЉМдЄНйЬАи¶БдЇЇдЄЇеє≤йҐДиАМиГље§ЯиЗ™еК®зЪДи∞ГжХіеИ∞жЬАдљ≥зЪДзКґжАБгАВињЩеТМ Google еЬ® keynote йЗМзЪДеИЖдЇЂдЄНи∞ЛиАМеРИпЉМйГљжШѓеЄМжЬЫз≥їзїЯжЬђиЇЂеЕЈе§Зиґ≥е§ЯеЉЇзЪДеК®жАБи∞ГжХіиГљеКЫгАВињЩдЄ™еИЖдЇЂдЄїи¶БжЬЙдЄ§йГ®еИЖеЖЕеЃєпЉМзђђдЄАйГ®еИЖжШѓжПРеЗЇдЇЖдЄАзІНжЦ∞зЪДжАІиГљзУґйҐИеИЖжЮРзРЖиЃЇгАВдЄАиИђжЭ•иѓіпЉМељУжИСдїђжГ≥и¶БдЉШеМЦдЄАдЄ™жµБиЃ°зЃЧдљЬдЄЪзЪДеРЮеРРеТМеїґињЯжЧґпЉМжИСдїђеЊАеЊАйЗЗзФ®жѓФиЊГдЉ†зїЯзЪДиІВжµЛ CPU зГ≠зВєзЪДжЦєеЉПпЉМжЙЊеИ∞дљЬдЄЪдЄ≠жЬАиАЧ CPU зЪДйГ®еИЖзДґеРОињЫи°МдЉШеМЦгАВдљЖеЊАеЊАжИСдїђењљзХ•дЇЖдЄАдЄ™дЇЛеЃЮжШѓпЉМељ±еУНз≥їзїЯ latency жИЦиАЕеРЮеРРеЊАеЊАињШжЬЙеРДзІНз≠ЙеЊЕзЪДжУНдљЬпЉМжѓФе¶ВзЃЧе≠РеЬ®з≠ЙеЊЕжХ∞жНЃињЫи°Ме§ДзРЖз≠ЙгАВе¶ВжЮЬжИСдїђеНХзЛђдЉШеМЦ cpu зГ≠зВєпЉМдЉШеМЦеЃМдєЛеРОеПѓиГљеП™дЉЪиЃ©з≥їзїЯеЕґеЃГеЬ∞жЦєз≠ЙеЊЕзЪДжЧґйЧіеПШйХњпЉМеєґдЄНиГљзЬЯж≠£еЄ¶жЭ•еїґињЯзЪДдЄЛйЩНеТМеРЮеРРзЪДдЄКеНЗгАВжЙАдї•дїЦдїђеЕИжПРеЗЇдЇЖдЄАзІНвАЭеЕ≥йФЃиЈѓеЊДвАЬзЪДзРЖиЃЇпЉМеЬ®еИ§жЦ≠жАІиГљзУґйҐИжЧґжШѓдї•йУЊиЈѓдЄЇеНХеЕГињЫи°МеИ§жЦ≠еТМжµЛйЗПгАВеП™жЬЙзЬЯж≠£зЪДйЩНдљОжХіжЭ°еЕ≥йФЃиЈѓеЊДзЪДиАЧжЧґпЉМжЙНиГљжЬЙжЬЙжХИзЪДйЩНдљОдљЬдЄЪзЪДеїґињЯгАВ
зђђдЇМдЄ™йГ®еИЖжШѓдїЛзїНдЇЖдЄАзІНжЦ∞зЪДдљЬдЄЪиЗ™еК®жЙ©зЉ©еЃєжЬЇеИґпЉМеєґдЄФеТМеЊЃиљѓзЪД Dhalion ињЫи°МдЇЖеѓєжѓФгАВињЩдЄ™еБЪж≥ХзЪДзЙєиЙ≤еЬ®дЇОпЉМеЕґдїЦз±їдЉЉзЪДз≥їзїЯжАїжШѓеѓєдЄАдЄ™зЃЧе≠РеНХзЛђеБЪеЖ≥з≠ЦпЉМиАМдїЦдїђдЉЪжЫіе§ЪзЪДжККе§ЪдЄ™зЃЧе≠РињЫи°МеРМжЧґиАГиЩСгАВеЬ®жЙ©зЉ©еЃєзЪДжЧґеАЩиЃ©е§ЪдЄ™зЃЧе≠РеРМжЧґжУНдљЬпЉМеЗПе∞СжФґжХЫжЙАйЬАи¶БзЪДеК®дљЬжђ°жХ∞гАВ
жµБиЃ°зЃЧдїїеК°зЪДиЗ™ж≤їеМЦдєЯжШѓжИСдЄ™дЇЇйЭЮеЄЄжДЯеЕіиґ£зЪДдЄАдЄ™жЦєеРСпЉМдєЯзЬЛеИ∞дЄНе∞Сз†Фз©ґеЮЛзЪДй°єзЫЃеТМиЃЇжЦЗеЬ®йШРињ∞ињЩжЦєйЭҐзЪДеЈ•дљЬпЉМдљЖжЪВжЧґињШжЬ™иІБеИ∞еЈ•дЄЪзХМеѓєжѓФжЬЙжѓФиЊГжЈ±еЕ•зЪДеИЖдЇЂпЉИAWS зЪД kinesis жЬНеК°еЕЈе§ЗеК®жАБжЙ©зЉ©еЃєиГљеКЫпЉМдљЖзФ±дЇОзЉЇдєПзїЖиКВдїЛзїНдЄНз°ЃеЃЪжШѓеР¶иґ≥е§ЯйАЪзФ®дї•еПКжШѓеР¶иГље§ЯеЇФеѓєжѓФиЊГе§НжЭВзЪДеЬЇжЩѓпЉЙгАВйШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯжЧ©еЬ®дЄАеєіеЙНе∞±еРѓеК®дЇЖз±їдЉЉзЪДй°єзЫЃпЉМеЬ®ињЩжЦєеРСдЄКињЫи°МдЇЖе∞ЭиѓХеТМжΥ糥гАВйЭҐеѓєеЖЕйГ®е§ІйЗПзЪДдЄЪеК°еЬЇжЩѓеТМйЬАж±ВпЉМеК†дЄКзЫЃеЙНеРДзІНеЙНж≤њзЪДз†Фз©ґпЉМзЫЄдњ°дЄНињЬзЪДе∞ЖжЭ•еПѓдї•жЬЙжЙАз™Бз†ігАВ
#### еЕґдїЦиЃЃйҐШжО®иНР
* гАКMoving on from RocksDB to something FASTERгАЛпЉЪињЩдєЯжШѓиЛПйїОдЄЦиБФйВ¶зРЖеЈ•еЄ¶жЭ•зЪДеЕ≥дЇОзКґжАБе≠ШеВ®зЫЄеЕ≥зЪДз†Фз©ґпЉМеѓїжЙЊжѓФ RocksDB жЫіењЂзЪДиІ£еЖ≥жЦєж°ИгАВеЬ® Statebackend дЄКпЉМйШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯдєЯжЬЙжЙАеЄГе±АпЉМжИСдїђж≠£еЬ®жΥ糥дЄАзІНеЃМеЕ®еЯЇдЇО Java зЪДе≠ШеВ®еЉХжУОгАВ
* гАКScotty: Efficient Window Aggregation with General Stream SlicingгАЛпЉЪдїЛзїНдЇЖдЄАзІНдљњзФ®еИЗзЙЗжЭ•жПРеНЗз™ЧеП£иБЪеРИжАІиГљзЪДжЦєж≥ХгАВ
жЈ±еЇ¶жКАжЬѓеЙЦжЮР
------
ињЩдЄ™йГ®еИЖдЄїи¶БдїЛзїНзЪДйГљжШѓ Flink еЬ®ињЗеОї1-2дЄ™зЙИжЬђеЖЕеБЪзЪДдЄАдЇЫе§ІзЪД feature еТМйЗНжЮДгАВзФ±дЇОжЬђдЇЇе∞±жШѓ Flink зЪДеЉАеПСиАЕпЉМеѓєињЩдЇЫеЈ•дљЬйГљжѓФиЊГзЖЯжВЙпЉМеЫ†ж≠§е∞±ж≤°жЬЙйАЙжЛ©еОїеРђињЩдЇЫеИЖдЇЂгАВеАЯзФ® Stephan еЬ® Keynote дЄ≠зЪДдЄ§еЉ†еЫЊпЉМеЯЇжЬђеБЪдЇЖжѓФиЊГе•љзЪДж¶ВжЛђгАВ
жЬЙеРМе≠¶еѓєеЕґдЄ≠дЄ™еИЂзЪДжКАжЬѓзВєжДЯеЕіиґ£зЪДиѓЭпЉМеЯЇжЬђйГљиГље§ЯжЙЊеИ∞еѓєеЇФзЪДиЃЃйҐШпЉМеЬ®ињЩйЗМжИСе∞±дЄНе±ХеЉАдЄАдЄАдїЛзїНдЇЖгАВ
жАїзїУеТМжДЯжГ≥
=====
ињЩеЗ†еєійЪПзЭАйШњйЗМеЈіеЈіжМБзї≠еѓє Flink зЪДе§ІеКЫжКХиµДпЉМFlink зЪДжИРзЖЯеЇ¶еТМжіїиЈГеЇ¶еЭЗжЬЙдЇЖиі®зЪДй£ЮиЈГгАВз§ЊеМЇзФЯжАБдєЯиґКеПСзЪДзєБиН£пЉМеМЕжЛђ cloudera еТМ AWS йГљеЈ≤зїПеЉАеІЛзІѓжЮБзЪДжЛ•жК± FlinkпЉМдєЯеЊЧеИ∞дЇЖдЄНйФЩзЪДжИРжЮЬгАВеРДе§ІеЕђеПЄзЪДиЃЃйҐШдєЯдїОжЧ©еєізЪДжК±зЭАе∞Эй≤ЬзЪДжАБеЇ¶е∞ЭиѓХ FlinkпЉМиљђеПШжИРдЇЖжЭ•еИЖдЇЂдљњзФ® Flink е§ІиІДж®°дЄКзЇњеРОзЪДдЄАдЇЫжИРжЮЬеТМзїПй™МжХЩиЃ≠гАВеЬ®ж≠§еЯЇз°АдєЛдЄКпЉМйАРжЄРдЇЖ嚥жИРдЇЖеЯЇдЇО Flink зЪДеє≥еП∞еМЦеЃЮиЈµгАБзїУеРИжЬЇеЩ®е≠¶дє†ињЫи°МеЕЈдљУдЄЪеК°зЪДйЧЃйҐШиІ£еЖ≥еТМдЄАдЇЫжѓФиЊГжЦ∞йҐЦзЪДжΥ糥з†Фз©ґеЮЛй°єзЫЃз≠ЙжЦєеРСпЉМиЃ©жХідЄ™зФЯжАБзЪДеПСе±ХжЫіеК†зЪДеЃМжХіеТМе£ЃеЃЮгАВдЄНдїЕе¶Вж≠§пЉМFlink дєЯеЬ®зІѓжЮБзЪДжΥ糥дЄАдЇЫжЦ∞зЪДзГ≠йЧ®жЦєеРСпЉМжѓФе¶ВеТМ K8S зЪДзїУеРИпЉМеТМеЬ®зЇњжЬНеК°еЬЇжЩѓзЪДзїУеРИз≠Йз≠ЙпЉМдљУзО∞дЇЖињЩдЄ™зФЯжАБзЪДеЉЇе§ІзФЯеСљеКЫгАВ
дЄНињЗељТж†єзїУеЇХпЉМFlink еИ∞еЇХињШжШѓдЄАдЄ™е§ІжХ∞жНЃиЃ°зЃЧеЉХжУОпЉМеЕґеЃЧжЧ®ињШжШѓеЄМжЬЫеОїиІ£еЖ≥е§ІжХ∞жНЃиЃ°зЃЧињЩдЄ™йЧЃйҐШгАВеЬ®жЦЗзЂ†зЪДдЄАеЉАе§іпЉМжИСдєЯжПРеИ∞дЇЖеЬ®зЬЛеИ∞ Flink ињЫеЖЫ Application еТМ FaaS зЪДжЦєеРСжЧґпЉМдЄАдЄ™зЦСйЧЃдЄАзЫіеЬ®жИСзЪДењГе§іиР¶зїХпЉЪFlink еИ∞еЇХжШѓжАОдєИж†ЈзЪДдЄАдЄ™иЃ°зЃЧеЉХжУОпЉМеЃГз©ґзЂЯжШѓи¶БиІ£еЖ≥дїАдєИж†ЈзЪДйЧЃйҐШпЉЯе¶ВжЮЬж≤°жЬЙдЄАдЄ™еЊИжЄЕжЩ∞зЪДдЄїзЇњеТМйХњињЬиЃ§иѓЖпЉМеЬ®еЉХжУОзЪДеПСе±ХињЗз®ЛдЄ≠еЊИеЃєжШУе∞±дЉЪиµ∞еБПпЉМжЬАзїИеѓЉиdz姱賕гАВ
е§ІйГ®еИЖдЇЇеПѓиГљињШеБЬзХЩеЬ® Flink жШѓдЄАдЄ™жИРзЖЯзЪДеЃЮжЧґиЃ°зЃЧеЉХжУОзЪДиЃ§зЯ•пЉМдљЖ Flink дїОиѓЮзФЯзЪДзђђдЄА姩赣е∞±жГ≥зЭАи¶БиІ£еЖ≥жЙєе§ДзРЖзЪДйЧЃйҐШгАВеН≥дЊњзО∞еЬ® Flink еЈ≤зїПйАРжЄРе°Ђи°•дЇЖжЙєе§ДзРЖињЩдЄ™еЭСпЉМдљЖеПИжЬЭзЭА Application ињЩж†ЈзЪДеЬ®зЇњжЬНеК°еЬЇжЩѓеПСиµЈдЇЖжΥ糥гАВдєНдЄАзЬЛпЉМFlink е•љеГПдїАдєИйЧЃйҐШйГљжГ≥иІ£пЉМдїАдєИжЦєеРСйГљжГ≥жПТдЄАиДЪпЉМзЬЯзЪДжШѓињЩж†ЈеРЧпЉЯ
еЄ¶зЭАињЩж†ЈзЪДзЦСйЧЃеПВеК†еЃМдЇЖжХідЄ™е§ІдЉЪпЉМеПИйҐЭе§ЦжАЭиАГдЇЖеdž姩пЉМжИСеЉАеІЛжЬЙдЇЖдЄАдЇЫжЦ∞зЪДиЃ§иѓЖеТМиІБиІ£гАВжГ≥и¶БеЫЮз≠Ф Flink еИ∞еЇХжШѓжАОдєИж†ЈзЪДдЄАдЄ™иЃ°зЃЧеЉХжУОпЉМеЃГз©ґзЂЯжГ≥иІ£еЖ≥дїАдєИж†ЈзЪДйЧЃйҐШињЩдЄ™зЦСйЧЃпЉМжИСдїђеЊЧдїОжХ∞жНЃжЬђиЇЂеЉАеІЛзЬЛиµЈгАВжѓХзЂЯпЉМдЄАдЄ™иЃ°зЃЧеЉХжУОжЙАи¶Бе§ДзРЖзЪДеѓєи±°пЉМе∞±жШѓжХ∞жНЃжЬђиЇЂгАВ
зђђдЄАдЄ™йЧЃйҐШжШѓпЉМжИСдїђйЬАи¶Бе§ДзРЖзЪДжХ∞жНЃйГљжШѓдїОеУ™йЗМжЭ•зЪДпЉЯеѓєе§ІйГ®еИЖеЕђеПЄеТМдЉБдЄЪжЭ•иѓіпЉМжХ∞жНЃеПѓиГљжЭ•иЗ™еРДзІНжЙЛжЬЇAPPпЉМIoTиЃЊе§ЗпЉМеЬ®зЇњжЬНеК°зЪДжЧ•ењЧпЉМзФ®жИЈзЪДжߕ胥з≠Йз≠ЙгАВиЩљзДґжХ∞жНЃзЪДжЭ•жЇРеТМзІНз±їеРДдЄНзЫЄеРМпЉМдљЖжЬЙдЄАдЄ™зЙєзВєеПѓиГљжШѓе§ІйГ®еИЖжГЕеЖµдЄЛйГљеЕЈе§ЗзЪДпЉЪ**жХ∞жНЃжАїжШѓеЃЮжЧґзЪДдЄНжЦ≠дЇІзФЯ**гАВ
жИСдїђеПѓдї•дљњзФ®жµБпЉИStreamпЉЙжИЦиАЕжЧ•ењЧпЉИLogпЉЙињЩж†ЈзЪДж¶ВењµжЭ•ж®°жЛЯжКљи±°жЙАйЬАи¶Бе§ДзРЖзЪДжХ∞жНЃпЉМињЩдєЯжШѓзО∞еЬ®дЄАзІНжѓФиЊГжµБи°МзЪДжКљи±°жЦєеЉПпЉМJay Kreps е§Із•ЮжЧ©еєіе∞±еЬ®дЄНйБЧдљЩеКЫзЪДжО®еєњињЩж†ЈзЪДжЦєеЉПпЉМжДЯеЕіиґ£зЪДеРМе≠¶еПѓдї•иѓїдЄАдЄЛињЩзѓЗеНЪжЦЗпЉЪ
[гАКThe Log: What every software engineer should know about real-time data's unifying abstractionгАЛ](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fengineering.linkedin.com%2Fdistributed-systems%2Flog-what-every-software-engineer-should-know-about-real-time-datas-unifying)гАВ
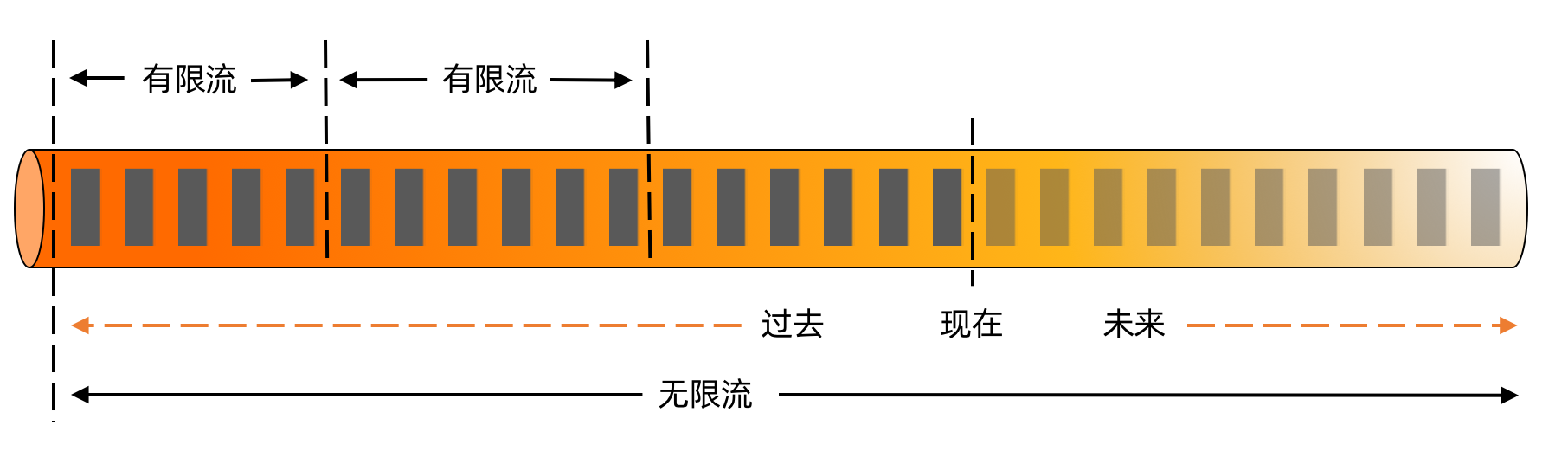
еЬ®ињЩйЗМеЕИиІ£з≠ФдЄАдЄЛеЄЄиІБзЪДеЗ†дЄ™зЦСжГСпЉМеЫ†дЄЇињЩдЄ™зЬЛиµЈжЭ•еТМе§ІеЃґеє≥жЧґжО•иІ¶еИ∞зЪДжХ∞жНЃжѓФиЊГдЄНдЄАж†ЈгАВеЄЄиІБзЪДйЧЃйҐШдЉЪжЬЙпЉЪ
* жИСеє≥жЧґзЪДжО•иІ¶зЪДжХ∞жНЃйГље≠ШеЬ®DatabaseйЗМпЉМзЬЛиµЈжЭ•ињЩдЄ™дЄНдЄАж†ЈеХКпЉЯDatabase еПѓдї•зРЖиІ£жИРдЄЇе∞ЖињЩдЇЫ Stream зЙ©еМЦеРОзЪДдЇІзЙ©пЉМдЄАиИђжШѓдЄЇдЇЖеРОзї≠зЪДйҐСзєБиЃњйЧЃеПѓдї•жЫіењЂгАВиАМдЄФе§ІйГ®еИЖ Database з≥їзїЯзЪДеЃЮзО∞йЗМпЉМеЕґеЃЮдєЯжШѓзФ®зЪД Log жЭ•е≠ШеВ®жЙАжЬЙзЪДеҐЮеИ†жФєи°МдЄЇгАВ
* жИСеє≥жЧґжО•иІ¶зЪДжХ∞жНЃйГљжФЊеЬ®жХ∞дїУйЗМпЉМжМЙзŲ姩еБЪдЇЖеИЖеМЇгАВињЩзІНжГЕеЖµеПѓдї•еЖНеЊАжХ∞жНЃзЪДжЇРе§іжГ≥дЄАдЄЛпЉМжХ∞жНЃеИЪдЇІзФЯзЪДжЧґеАЩдЄНдЉЪзЫіжО•еИ∞дљ†зЪДжХ∞дїУпЉМдЄАиИђдєЯжШѓйЬАи¶БзїПињЗдЄАдЄ™ ETL ињЗз®ЛгАВдЄАиИђзЪДжХ∞дїУеПѓдї•зРЖиІ£жИРе∞ЖињЗеОїзЪДдЄАжЃµжЃµжЬЙйЩРжµБпЉМиљђе≠ШжИРдЇЖжЫійЂШжХИзЪДж†ЉеЉПгАВ
ељУжИСдїђдљњзФ®ињЩж†ЈзЪДжЦєеЉПжЭ•жКљи±°жХ∞жНЃдєЛеРОпЉМжИСдїђе∞±еПѓдї•иАГиЩСжИСдїђдЉЪеЬ®ињЩж†ЈзЪДжХ∞жНЃдЄКеБЪдїАдєИж†Јз±їеЮЛзЪДиЃ°зЃЧдЇЖгАВеЕИдїОжЬЙйЩРжµБеЉАеІЛпЉЪ
* еѓєињЗеОїзЪДдЄАйГ®еИЖжХ∞жНЃеБЪдЄАдЄЛзЃАеНХзЪДжЄЕжіЧеТМе§ДзРЖпЉМињЩеЯЇжЬђдЄКе∞±жШѓе§ІйГ®еИЖзїПеЕЄзЪДжЙєе§ДзРЖ ETL дљЬдЄЪ
* еѓєињЗеОїзЪДдЄАйГ®еИЖжХ∞жНЃеБЪдЄАдЇЫз®НеЊЃе§НжЭВзВєзЪДеЕ≥иБФеТМеИЖжЮРпЉМињЩзЃЧжШѓжѓФ ETL з®НеЊЃе§НжЭВзВєзЪДжЙєе§ДзРЖдљЬдЄЪ
* еѓєињЗеОїзЪДдЄАйГ®еИЖжХ∞жНЃињЫи°МжЈ±еЇ¶зЪДжМЦжОШдїОиАМдЇІзФЯжЫіжЈ±зЪДжіЮеѓЯпЉМињЩжШѓжЬЇеЩ®е≠¶дє†иЃ≠зїГж®°еЮЛзЪДеЬЇжЩѓ
еѓєдЇОжЧ†йЩРжµБжЭ•иѓіпЉМжИСдїђйЬАи¶БжЧґеИїжґИиієжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃпЉМйВ£дєИеПѓиГљдЇІзФЯзЪДиЃ°зЃЧз±їеЮЛдЉЪжЬЙпЉЪ
* еТМжЙєе§ДзРЖз±їдЉЉзЪД ETL еТМеИЖжЮРеЮЛзЪДжХ∞жНЃе§ДзРЖеЬЇжЩѓпЉМеП™дЄНињЗиЃ°зЃЧеПСзФЯеЬ®жЬАжЦ∞еЃЮжЧґдЇІзФЯзЪДжХ∞жНЃдЄК
* еѓєдЇОжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃињЫи°МзЙєеЊБеИЖжЮРеТМжМЦжОШпЉМињЩжШѓжЬЇеЩ®е≠¶дє†еЃЮжЧґиЃ≠зїГж®°еЮЛзЪДеЬЇжЩѓ
* е∞ЖжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃж†ЈжЬђеМЦпЉМзДґеРОе•ЧзФ®жЬЇеЩ®е≠¶дє†ж®°еЮЛињЫи°МеИ§еЃЪпЉМињЩжШѓеЕЄеЮЛзЪДеЃЮжЧґйҐДжµЛеЬЇжЩѓ
* ж†єжНЃжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃпЉМиІ¶еПСдЄАз≥їеИЧеРОеП∞дЄЪеК°йАїиЊСпЉМињЩе∞±жШѓеЕЄеЮЛзЪД Application жИЦиАЕеЬ®зЇњжЬНеК°еЬЇжЩѓ
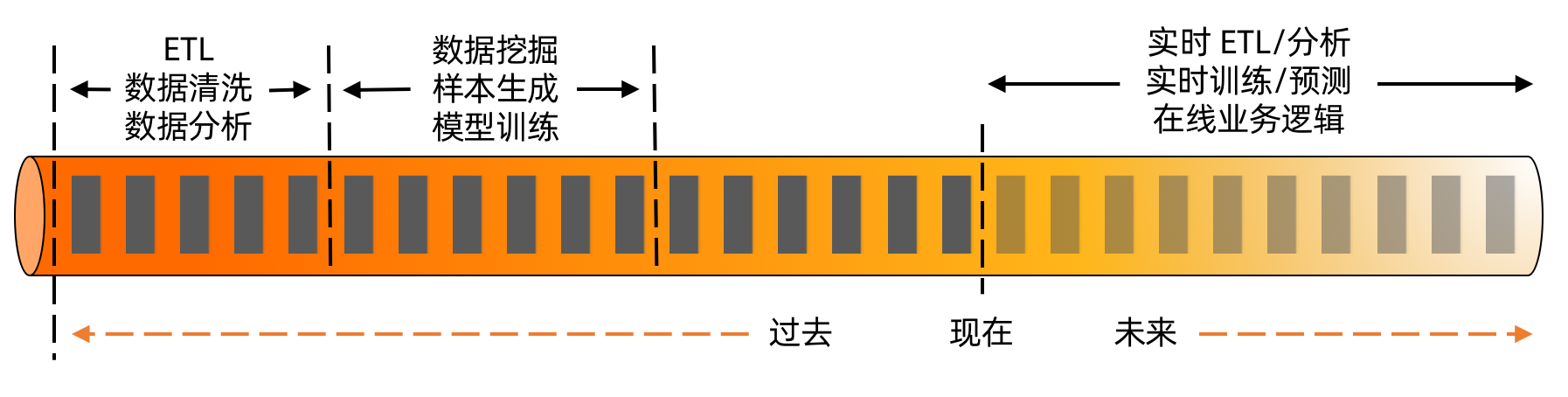
зЙєеИЂеАЉеЊЧж≥®жДПзЪДжШѓпЉМжЬЙйЩРжµБзЪДиЃ°зЃЧеТМжЧ†йЩРжµБзЪДиЃ°зЃЧеєґдЄНжШѓеЃМеЕ®зЛђзЂЛе≠ШеЬ®зЪДпЉМжЬЙжЧґеАЩжИСдїђзЪДиЃ°зЃЧйЬАи¶БеЬ®дЄ§иАЕдєЛйЧіињЫи°МеИЗжНҐпЉМжѓФе¶ВињЩдЇЫеЬЇжЩѓпЉЪ
* еЕИе∞ЖжЙАжЬЙзЪДеОЖеП≤жХ∞жНЃињЫи°Ме§ДзРЖпЉМзДґеРОеЉАеІЛеЃЮжЧґжґИиієжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃгАВжѓФе¶ВиѓізїЯиЃ°зЪДеЬЇжЩѓпЉМељУзїЯиЃ°еП£еЊДеПШеМЦдєЛеРОпЉМжИСдїђеЄМжЬЫеЕИжККжЙАжЬЙеОЖеП≤жХ∞жНЃйЗНжЦ∞зїЯиЃ°дЄАйБНпЉМзДґеРОеЖНжО•дЄКжЬАжЦ∞зЪДжХ∞жНЃињЫи°МеЃЮжЧґзїЯиЃ°гАВ
* жИСдїђеЕИж†єжНЃеОЖеП≤жХ∞жНЃињЫи°Мж†ЈжЬђзФЯжИРзДґеРОиЃ≠зїГж®°еЮЛпЉМзДґеРОеЖНжґИиієжЬАжЦ∞зЪДжХ∞жНЃпЉМе∞ЖеЕґиљђеМЦдЄЇж†ЈжЬђеРОеЉАеІЛеБЪеЃЮжЧґзЪДйҐДжµЛеТМеИ§еЃЪгАВињЩдєЯжШѓжЬЇеЩ®е≠¶дє†дЄ≠еЊИеЕЄеЮЛзЪДеБЪж≥ХпЉМеЕ≥йФЃзВєеЬ®дЇОйЬАи¶БдњЭиѓБиЃ≠зїГж®°еЮЛжЧґзЪДж†ЈжЬђйАїиЊСеТМеЃЮжЧґеИ§еЃЪжЧґзЪДж†ЈжЬђйАїиЊСйЬАи¶БдњЭжМБдЄАиЗігАВ
еП¶е§ЦпЉМжИСдїђдєЯеПѓдї•е∞ЭиѓХдїОиЃ°зЃЧзЪДеїґињЯзЪДиІТеЇ¶еѓєињЩдЇЫзєБе§ЪзЪДиЃ°зЃЧж®°еЉПињЫи°Ме§ІиЗізЪДеИЖз±їпЉЪ

еИЧдЄЊдЇЖињЩдєИе§ЪдЊЛе≠РеТМеЬЇжЩѓдєЛеРОпЉМе§ІеЃґеЇФиѓ•дєЯеЈЃдЄНе§ЪиГљйҐЖжВЯеИ∞еЕґдЄ≠зЪДйБУзРЖдЇЖгАВељУжИСдїђеЯЇдЇО Stream жЭ•жКљи±°жЙАжЬЙзЪДжХ∞жНЃдєЛеРОпЉМеЬ®жХ∞жНЃдєЛдЄКеЉХеПСзЪДиЃ°зЃЧж®°еЉПжШѓзЫЄељУзЪДе§Ъж†ЈеМЦзЪДгАВж≠£е¶В Stephan дЄАеЉАеІЛеЬ® keynote дЄ≠жПРеИ∞зЪДпЉМдЉ†зїЯзЪД Data Processing еТМжґИжБѓй©±еК®зЪД Application еЬЇжЩѓпЉМйГљдЄНиґ≥дї•и¶ЖзЫЦжЙАжЬЙзЪДиЃ°зЃЧж®°еЮЛгАВжЙАжЬЙиЃ°зЃЧж®°еЮЛзЪДжЬђиі®жШѓ Stream ProcessingпЉМеП™дЄНињЗжЬЙжЧґеАЩжИСдїђйЬАи¶БеОїе§ДзРЖжЬЙйЩРзЪДжХ∞жНЃпЉМжЬЙжЧґеАЩжИСдїђеПИйЬАи¶БеОїе§ДзРЖжЬАжЦ∞зЪДеЃЮжЧґжХ∞жНЃгАВFlink зЪДжДњжЩѓе∞±жШѓжИРдЄЇдЄАдЄ™йАЪзФ®зЪД Stream Processing еЉХжУОпЉМеєґи¶ЖзЫЦеЯЇдЇОињЩдЄ™иМГеЉПзЪДжЙАжЬЙеПѓиГљзЪДжѓФиЊГеЕЈдљУзЪДиЃ°зЃЧеЬЇжЩѓгАВињЩж†ЈдЄАжЭ•ељУзФ®жИЈжЬЙдЄНеРМзЪДиЃ°зЃЧйЬАж±ВжЧґпЉМдЄНйЬАи¶БйАЙжЛ©е§ЪдЄ™дЄНеРМзЪДз≥їзїЯпЉИжѓФе¶ВзїПеЕЄзЪД lambda жЮґжЮДпЉМжИСдїђйЬАи¶БйАЙжЛ©дЄАдЄ™дЄУйЧ®зЪДжЙєе§ДзРЖеЉХжУОеТМдЄУйЧ®зЪДжµБиЃ°зЃЧеЉХжУОпЉЙгАВеРМжЧґељУжИСдїђйЬАи¶БеЬ®дЄНеРМзЪДиЃ°зЃЧж®°еЉПйЧіињЫи°МеИЗжНҐзЪДжЧґеАЩпЉИжѓФе¶ВеЕИе§ДзРЖеОЖеП≤жХ∞жНЃеЖНжО•дЄКеЃЮжЧґжХ∞жНЃпЉЙпЉМдљњзФ®зЫЄеРМзЪДиЃ°зЃЧеЉХжУОдєЯжЬЙеИ©дЇОжИСдїђдњЭиѓБи°МдЄЇзЪДзїЯдЄАгАВ
[еОЯжЦЗйУЊжО•](https://yq.aliyun.com/articles/721993)
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ
еЙНи®А
==
2019.10.7~9еПЈпЉМйЪПзЭА70еС®еєіеЫљеЇЖжіїеК®зЪДй°ЇеИ©йЧ≠еєХпЉМFlink Forward дєЯзЕІдЊЛеЬ®дїЦдїђзЪДеПСжЇРеЬ∞жЯПжЮЧдЄЊеКЮдЇЖзђђдЇФе±Ке§ІдЉЪгАВиЩљзДґињШж≤°жЬЙжЛњеИ∞еЕЈдљУзЪДжХ∞жНЃпЉМдЄНињЗдїОеЯєиЃ≠йЧ®з•®еЈ≤зїПеЬ®дЉЪеЙНйФАеФЃдЄАз©ЇзЪДињЩж†ЈзЪДзО∞и±°жЭ•зЬЛпЉМFlink Forward е§ІдЉЪињШжШѓзїІзї≠дњЭжМБдЇЖдЄАдЄ™иЙѓе•љзЪДеКње§ігАВжЬђе±Ке§ІдЉЪдЄНзЃ°жШѓдїОеПВдЉЪдЇЇжХ∞дЄКпЉМжПРдЇ§зЪДиЃЃйҐШпЉМдї•еПКеПВеК†зЪДеЕђеПЄжХ∞йЗПжЭ•зЬЛйГљзїІзї≠еИЫдЇЖдЄАдЄ™жЦ∞йЂШгАВељУзДґпЉМињЩи¶БеОїжОЙеОїеєі Flink Forward еМЧдЇђзЂЩзЪДжХ∞жНЃ ;-)гАВйШњйЗМеЈіеЈіињЩжђ°еЕ±жіЊеЗЇдЇЖеМЕжЛђзђФиАЕеЬ®еЖЕзЪД3еРНиЃ≤еЄИпЉМжАїеЕ±еПВеК†дЇЖ4еЬЇеИЖдЇЂеТМ2дЄ™йЧЃз≠ФзОѓиКВгАВеЬ®ињЩйЗМпЉМжИСдЉЪж†єжНЃиЗ™еЈ±еПВдЄОзЪДиЃЃйҐШзїЩе§ІеЃґеБЪдЄАдЄЛињЩжђ°дЉЪиЃЃжХідљУзЪДдЄАдЄ™дїЛзїНеТМдЄ™дЇЇеЬ®ињЩжђ°еПВдЉЪињЗз®ЛйЗМйЭҐзЪДжДЯеПЧеТМжАЭиАГпЉМеЄМжЬЫеѓєжДЯеЕіиґ£зЪДеРМе≠¶жЬЙжЙАеЄЃеК©гАВ
Keynote
=======
еЕИиѓіиѓіињЩ䪧姩зЪД KeynoteгАВзђђдЄА姩зЪДеЉАеЬЇ Keynote ињШжШѓзїІзї≠зФ±з§ЊеМЇдЄАеУ• Stephan Ewen жЭ•зїЩеЗЇгАВдїЦеЕИжАїзїУдЇЖдЄАдЄЛ Flink й°єзЫЃзЫЃеЙНзЪДдЄАдЇЫзКґжАБпЉМеМЕжЛђпЉЪ
* Flink еЬ®8жЬИдїљзЪД Github star жХ∞иґЕињЗдЇЖ1дЄЗ
* еЬ®жЙАжЬЙ Apache й°єзЫЃдЄ≠пЉМFlink жОТеЬ®йВЃдїґеИЧи°®жіїиЈГеЇ¶зЪД Top 3пЉМеєґдЄФињЩдЄ™жХ∞е≠ЧеЬ®жО•дЄЛжЭ•еЊИжЬЙеПѓиГљињШдЉЪеПШе∞П
* 8жЬИдїљеПСеЄГзЪД 1.9.0 зЙИжЬђжШѓ Flink зЫЃеЙНдЄЇж≠ҐеПСеЄГзЪДеКЯиГљжЬАе§ЪпЉМдњЃжФєйЗПжЬАе§ІзЪДдЄАдЄ™зЙИжЬђ
ињЩеЉ†еЫЊзЙЗеЊИе•љзЪДж¶ВжЛђдЇЖ Flink еЬ®ињЗеОїе§ІеНКеєіжЙАдЊІйЗНзЪДеЈ•дљЬпЉЪ

еѓєдЇО Flink жЬ™жЭ•зЪДдЄАдЄ™еПѓиГљзЪДжЦєеРСпЉМStephan зїІзї≠и°®иЊЊдЇЖдїЦеѓє Application ињЩзІНеБПеЬ®зЇњжЬНеК°зЪДеЬЇжЩѓзЪДеЕіиґ£гАВдїЦеЕИжШѓе∞ЖжИСдїђеє≥жЧґжЙАиѓізЪДжЙєе§ДзРЖеТМжµБиЃ°зЃЧжАїзїУдЄЇ Data ProcessingпЉМеРМжЧґе∞ЖжґИжБѓй©±еК®еТМжХ∞жНЃеЇУдєЛз±їзЪДеЇФзФ®жАїзїУдЄЇ ApplicationsпЉМиАМ Stream Processing е∞±жШѓињЮжО•ињЩдЄ§зІНзЬЛиµЈжЭ•жИ™зДґдЄНеРМзЪДеЬЇжЩѓзЪДж°•жҐБгАВжИСеЬ®дЄАеЉАеІЛеРђеИ∞ињЩдЄ™зЪДжЧґеАЩдєЯжЬЙзВєдЄАе§ійЫЊж∞іпЉМдЄНжШОе∞±йЗМзЪДжДЯиІЙпЉМзїПињЗињЩеdž姩僺ињЩдЄ™йЧЃйҐШзЪДжАЭиАГпЉМжЬЙдЇЖдЄАдЇЫиЗ™еЈ±зЪДзРЖиІ£пЉМжИСе∞ЖеЬ®жЦЗжЬЂе±ХеЉАињЫи°МиІ£йЗКгАВжПРеИ∞ ApplicationпЉМе∞±дЄНеЊЧдЄНжПРзО∞еЬ®еЊИжµБи°МзЪД FaaSпЉИFunction as a ServiceпЉЙгАВеЬ®ињЩдЄ™йҐЖеЯЯпЉМStephan иІЙеЊЧе§ІеЃґйГљењљиІЖдЇЖ State еЬ®ињЩйЗМйЭҐзЪДйЗНи¶БжАІгАВжѓФе¶ВдЄАдЄ™еЕЄеЮЛзЪД Application еЬЇжЩѓпЉМдЄАиИђйГљдЉЪеЕЈе§Здї•дЄЛињЩдЇЫзЙєзВєпЉЪ
* жХідЄ™ Application дЉЪжЬЙдЄАдЄ™жИЦиАЕе§ЪдЄ™еЕ•еП£пЉМиЃ°зЃЧйАїиЊСзФ±жґИжБѓжЭ•й©±еК®
* еЕЈдљУзЪДдЄЪеК°йАїиЊС襀жЛЖеИЖжИРз≤ТеЇ¶иЊГе∞ПзЪДеЗ†дЄ™еНХеЕГпЉМжѓПдЄ™йАїиЊСеНХеЕГдљњзФ®дЄАдЄ™ Function жЭ•жЙІи°МеЕЈдљУзЪДйАїиЊС
* Function дєЛйЧідЉЪдЇТзЫЄи∞ГзФ®пЉМдЄАиИђжЭ•иѓіжИСдїђдєЯдЉЪе∞ЖињЩдЇЫи∞ГзФ®иЃЊиЃ°дЄЇеЉВж≠•зЪДж®°еЉП
* жѓПдЄ™ Function зЪДиЃ°зЃЧйАїиЊСеПѓиГљдЉЪйЬАи¶БдЄАдЇЫзКґжАБпЉМжѓФе¶ВеПѓдї•дљњзФ®жХ∞жНЃеЇУдљЬдЄЇзКґжАБзЪДе≠ШеВ®
* еЬ®еЃМжХізЪДиЃ°зЃЧйАїиЊСеЃМжИРдєЛеРОпЉМжИСдїђдЉЪйАЪињЗдЄАдЄ™зїЯдЄАзЪДеЗЇеП£ињФеЫЮе§ДзРЖзЪДзКґжАБ
еЬ®ињЩдЄ™еЬЇжЩѓйЗМпЉМжИСдїђзЬЛеИ∞дЇЖиЗ≥е∞СдЄЙзВєйЬАж±ВпЉЪ
* иЃ°зЃЧйАїиЊСзФ±жґИжБѓй©±еК®
* иЃ°зЃЧйАїиЊСеТМдЇТзЫЄи∞ГзФ®зЪДеЕ≥з≥їењЕй°їеПѓдї•жѓФиЊГзБµжіїзЪДињЫи°МзїДзїЗ
* иЃ°зЃЧйАїиЊСйЬАи¶БзКґжАБзЪДжФѓжМБпЉМеєґдЄФеЬ®жЯРдЇЫжГЕеЖµдЄЛпЉМйЬАи¶БдњЭиѓБ exactly once зЪДе§ДзРЖиѓ≠дєЙ
ињЩйЗМйЭҐе±ЮзђђдЄЙзВєжЬАйЪЊеБЪгАВе§ІеЃґеПѓдї•жГ≥и±°дЄАдЄЛпЉМеБЗе¶ВзО∞еЬ®жИСдїђзЪД Application и¶Бе§ДзРЖз±їдЉЉзФµеХЖеЬЇжЩѓдЄЛеНХињЩж†ЈзЪДињЗз®ЛпЉМеРМжЧґжИСдїђдЊЭиµЦжХ∞жНЃеЇУдљЬдЄЇињЩдЄ™еЇФзФ®зЪДзКґжАБе≠ШеВ®гАВжИСдїђжЬЙдЄАдЄ™дЄУйЧ®зЪДеЇУе≠ШзЃ°зРЖйАїиЊСеТМдЄАдЄ™дЄЛеНХйАїиЊСгАВеЬ®дЄАдЄ™еЃМжХізЪДиі≠дє∞йАїиЊСйЗМпЉМжИСдїђйЬАи¶БеЕИи∞ГзФ®еЇУе≠ШзЃ°зРЖж®°еЭЧпЉМж£АжЯ•дЄЛиѓ•еХЖеУБжШѓеР¶жЬЙеЇУе≠ШпЉМзДґеРОе∞Жиѓ•еХЖеУБзЪДеЇУе≠ШдїОжХ∞жНЃеЇУйЗМеЗПеОї1гАВињЩдЄАж≠•жИРеКЯдєЛеРОпЉМжИСдїђзЪДжЬНеК°еЖНзїІзї≠и∞ГзФ®дЄЛеНХйАїиЊСпЉМеЬ®жХ∞жНЃеЇУйЗМйЭҐзФЯжИРдЄАдЄ™жЦ∞зЪДиЃҐеНХгАВеЬ®дЄАеИЗйГљж≠£еЄЄзЪДжЧґеАЩпЉМињЩж†ЈзЪДйАїиЊСињШжШѓжѓФиЊГзЃАеНХзЪДпЉМдљЖдЄАжЧ¶жЬЙйФЩиѓѓеЗЇзО∞е∞±дЉЪзЫЄељУйЇїзГ¶гАВжѓФе¶ВжИСдїђеЈ≤зїПе∞ЖеЇУе≠ШеЗПжОЙпЉМдљЖжШѓеЬ®зФЯжИРиЃҐеНХзЪДињЗз®ЛдЄ≠еПСзФЯдЇЖйФЩиѓѓпЉМињЩж†ЈжИСдїђињШеЊЧжГ≥еКЮж≥ХиЃ©еЇУе≠ШињЫи°МеЫЮжїЪгАВдЄАжЧ¶з±їдЉЉзЪДдЄЪеК°йАїиЊСеНХеЕГеПШе§ЪдєЛеРОпЉМдљ†зЪДеЇФзФ®дї£з†Бе∞ЖеПШеЊЧеЉВеЄЄе§НжЭВгАВињЩдЄ™йЧЃйҐШе∞±жШѓеЕЄеЮЛзЪД end-to-end exactly onceпЉМжИСдїђеЄМжЬЫдЄАдЄ™йФЩзїЉе§НжЭВзЪДиЃ°зЃЧжµБз®ЛпЉМи¶БдєИеЕ®йГ®дЄАиµЈжИРеКЯпЉМи¶БдєИеЕ®йî姱賕пЉМе∞±ељУеЃГеЃМеЕ®ж≤°еПСзФЯињЗдЄАж†ЈгАВ
дЄЇдЇЖиІ£еЖ≥ињЩж†ЈзЪДйЧЃйҐШпЉМзїУеРИ Flink зЫЃеЙНзЪДдЄАдЇЫзІѓзіѓпЉМStephan жО®еЗЇдЇЖдЄАдЄ™еЕ®жЦ∞зЪДй°єзЫЃпЉЪ[statefun.io](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fstatefun.io%2F)пЉМеН≥ Stateful FunctionsгАВйАЪињЗзїУеРИ Stateful Stream Processing еТМ FaaSпЉМжЭ•жПРдЊЫдЄАзІНеЕ®жЦ∞зЪДзЉЦеЖЩ Stateful Application зЪДжЦєеЉПгАВ

еЕЈдљУзЪДеЃЮзО∞йАїиЊСпЉМжИСе∞±дЄНеЖНињЗе§ЪдїЛзїНпЉМе§ІеЃґеПѓдї•иЗ™и°МеИ∞еЃШзљСињЫи°МжЯ•зЬЛеТМе≠¶дє†гАВ
### Cloudera
Stephan зїЩзЪДзђђдЄАдЄ™ Keynote ињШжШѓжѓФиЊГзЪДеБПжКАжЬѓеМЦпЉМињЩдєЯзђ¶еРИдїЦзЪДдЄ™дЇЇй£Ож†ЉгАВеЬ®дєЛеРОзЪДеМЕжЛђзђђдЇМ姩зЪДжЙАжЬЙ KeynoteпЉМеЯЇжЬђдЄКйГљжШѓзЯ•еРНзЪДе§ІеЕђеПЄжЭ•зїЩ Flink зЂЩеП∞дЇЖгАВеЕИдїО Cloudera иѓіиµЈпЉМдїЦдїђи°®з§ЇзО∞еЬ®еЈ≤зїПжФґеИ∞дЇЖиґКжЭ•иґКе§ЪзЪДеЃҐжИЈзВєеРНи¶Б Flink зЪДжГЕеЖµпЉМеЫ†ж≠§е∞±вАЭй°ЇеЇФж∞СжДПвАЬеЬ®дїЦдїђзЪДжХ∞жНЃеє≥еП∞йЗМеК†еЕ•дЇЖ Flink зЪДжФѓжМБгАВиГљеЬ®ињЩзІНеХЖдЄЪеЉАжЇРиљѓдїґжПРдЊЫеХЖдЄ≠еН†жНЃдЄАеЄ≠дєЛеЬ∞пЉМеЯЇжЬђдєЯзЃЧжШѓж†ЗењЧеЬ® Flink еЈ≤зїПињЫеЕ•дЇЖдЄАдЄ™жѓФиЊГжИРзЖЯзЪДйШґжЃµгАВеП¶е§ЦпЉМCloudera жШѓзО©еЉАжЇРзЪДиАБе§ІеУ•зЇІеИЂдЇЇзЙ©дЇЖпЉМељУзДґдЄНдЉЪеП™жШѓзЃАеНХзЪДжПРдЊЫ Flink иљѓдїґињЩдєИзЃАеНХгАВдїЦдїђеЬ®дЉЪдЄКеЃ£еЄГдЇЖдїЦдїђеЈ≤зїПзїДеїЇдЇЖдЄАжФѓзФ±дЄ§еРН Flink PMC еЄ¶йШЯзЪДеЈ•з®ЛеЫҐйШЯпЉМеєґдЄФжЙУзЃЧеРОзї≠еЬ® Flink з§ЊеМЇдєЯжКХеЕ•жЫіе§ЪзЪДиµДжЇРпЉМињЩжЧ†зЦСжШѓзїЩ Flink з§ЊеМЇзЪДзєБиН£еПИж≥®еЕ•дЇЖдЄАиВ°жЦ∞й≤ЬеПИеЉЇе§ІзЪДеКЫйЗПгАВ

### AWS
AWS еЬ®зђђдЇМ姩зЩїеЬЇпЉМзФ±дїЦдїђдЄїзЃ° EMRгАБAthenaгАБDocumentDBдї•еПКеМЇеЭЧйУЊзЪДиАБе§І Rahul зїЩеЗЇгАВдїЦеЕИжШѓеЫЮй°ЊдЇЖдЄАдЄЛжµБиЃ°зЃЧзЫЄеЕ≥зЪДдЇІеУБеЬ® AWS зЪДеПСе±ХеОЖз®ЛпЉЪ

дїОеЫЊдЄ≠еПѓдї•зЬЛеЗЇпЉМдїЦдїђжЧ©еЬ®2016еєі Flink еі≠йЬ≤е§іиІТзЪДжЧґеАЩе∞±еЈ≤зїПе∞Ж Flink еК†еЕ•еИ∞дЇЖдїЦдїђзЪД EMR ељУдЄ≠гАВзЫЄжѓФ Cloudera зЪДеРОзЯ•еРОиІЙпЉМAWS еЬ®ињЩжЦєйЭҐжЮЬзДґе∞±иАБж±ЯжєЦдЇЖиЃЄе§ЪгАВдї§дЇЇеН∞и±°жЈ±еИїзЪДжШѓпЉМAWS ињЩеЗ†еєіеЫізїХжµБиЃ°зЃЧдЇІеУБзЪДеПСе±ХпЉМдЄАзЫіжЬЙдЄАдЄ™жЄЕжЩ∞зЪДдЄїзЇњпЉМйВ£е∞±жШѓйТИеѓєдЄНеРМдљУйЗПзЪДеЃҐжИЈжО®еЗЇжЫіеК†йАВеРИдїЦдїђзЪДдЇІеУБеТМиІ£еЖ≥жЦєж°ИгАВдїЦдїђеЊИе•љзЪДжАїзїУдЇЖдЄНеРМдљУйЗПзЪДеЃҐжИЈеѓєдЇІеУБзЪДйЬАж±ВзЪДдЄНеРМпЉИзЫЄдњ°ињЩдЄНдїЕдїЕеП™жШѓйТИеѓєжµБиЃ°зЃЧпЉМйТИеѓєеЕґдїЦзЪДдЇІеУБдєЯжШѓеЉВжЫ≤еРМеЈ•пЉЙпЉЪ

жѓФе¶ВдїЦдїђеПСзО∞дЇЖе§ІйЗПзЪДеЃҐжИЈжЬЙжЧґеАЩдљњзФ®жµБиЃ°зЃЧж°ЖжЮґеП™жШѓзЃАеНХзЪДиІ£еЖ≥дЄАдЄ™жХ∞жНЃиљђе≠ШзЪДйЧЃйҐШпЉМжѓФе¶ВзЃАеНХзЪДжККжХ∞жНЃдїО Kinesis Data StreamпЉИињЩдЄ™еЕґеЃЮжШѓдїЦдїђзЪДдЄАдЄ™жґИжБѓйШЯеИЧжЬНеК°пЉМеЕЙзЬЛеРНе≠ЧеЃєжШУжЬЙзВєиѓѓеѓЉпЉЙиљђе≠ШеИ∞ S3 дЄКпЉМжИЦиАЕжККжХ∞жНЃеПСеИ∞ Redshift жИЦиАЕ ElasticsearchгАВйТИеѓєињЩзІНеЬЇжЩѓпЉМдїЦдїђе∞±еЉАеПСдЇЖдЄУйЧ®зЪД Kinesis Data Firehose дЇІеУБпЉМиЃ©зФ®жИЈдЄНйЬАи¶БеЖЩдї£з†Бе∞±иГље§ЯеЃМжИРињЩж†ЈзЪДеЈ•дљЬгАВеП¶е§ЦпЉМдЄАдЇЫеЕЈе§ЗдЄАдЇЫеЉАеПСиГљеКЫзЪДеЃҐжИЈпЉМдЉЪеЖЩдЄАдЇЫдї£з†БжИЦиАЕ SQL жЭ•еѓєжХ∞жНЃињЫи°Ме§ДзРЖеТМеИЖжЮРгАВйТИеѓєињЩзІНеЬЇжЩѓпЉМдїЦдїђжПРдЊЫдЇЖ Kinesis Data Analytics жЬНеК°гАВ
еП¶е§ЦиЃ©дЇЇеН∞и±°жЈ±еИїзЪДдЄАзВєжШѓпЉМAWS зЪДеРДдЄ™дЇІеУБдєЛйЧізЪДеНПеРМеБЪзЪДйЭЮеЄЄе•љпЉИжИСеЬ®еРОжЭ•ињШеПВеК†дЇЖдЄАдЄ™ AWS Kinesis дЇІеУБзЪДжЉФз§ЇеИЖдЇЂпЉМеЕґдЄ≠жґЙеПКеИ∞дЄНе∞СдЇІеУБдєЛйЧізЪДеНПи∞ГеТМжЙУйАЪпЉМиЃ©дЇЇеН∞и±°жЈ±еИїпЉЙгАВжѓПдЄ™дЇІеУБдЄУж≥®иІ£еЖ≥дЄАйГ®еИЖзЪДйЧЃйҐШпЉМдЇІеУБеТМдЇІеУБдєЛйЧіеЬ®еКЯиГљдЄКдЄНиГљиѓіеЃМеЕ®ж≤°жЬЙйЗНеП†зЪДеЬ∞жЦєпЉМдљЖеЯЇжЬђдЄКињШжШѓйЭЮеЄЄеЕЛеИґгАВжЉФиЃ≤дЄ≠еИЖдЇЂзЪДжѓПдЄ™зЬЯеЃЮзЪДзФ®жИЈеЬЇжЩѓпЉМеЯЇжЬђйГљжґЙеПКдЇЖ3-5дЄ™дї•дЄКзЪДдЇІеУБдЇТзЫЄзЪДеНПеРМгАВеѓєеЃҐжИЈйЬАж±ВзЪДз≤ЊеЗЖжККжП°пЉМдї•еПКдЇІеУБзЪДеНПеРМзЂЩдљНз≤Њз°ЃиІ£еЖ≥зФ®жИЈйЧЃйҐШпЉМињЩдЄ§зВєйЭЮеЄЄеАЉеЊЧжИСдїђеОїе≠¶дє†гАВ
жЙѓзЪДжЬЙзВєињЬдЇЖпЉМеЫЮеИ∞ Flink дЄКжЭ•гАВRahul жЬАеРОжАїзїУдЇЖдЄАдЄЛ Flink жШѓдїЦдїђзЫЃеЙНзЬЛеИ∞зЪДдЉЪеОїжґИжБѓйШЯеИЧйЗМжґИиієжХ∞жНЃзЪДдЇІеУБдЄ≠еҐЮйХњжЬАењЂзЪДз≥їзїЯпЉМдљЖдїОзїЭеѓєдљУйЗПдЄКжЭ•зЬЛињШжШѓеБПе∞ПгАВињЩдєЯеЯЇжЬђзђ¶еРИ Flink зЫЃеЙНзЪДдЄАдЄ™зКґжАБпЉМзГ≠еЇ¶йЂШпЉМеҐЮйХњдєЯеЊИењЂпЉМдљЖжШѓзїЭеѓєдљУйЗПињШеБПе∞ПпЉМдЄНињЗињЩдєЯйҐДз§ЇзЭАжГ≥и±°зЪДз©ЇйЧіињШжѓФиЊГе§ІгАВ
Google еЬ® AWS дєЛеРОеЗЇеЬЇпЉМзФ± Reven еТМ Sergei еЄ¶жЭ•пЉИеЙНиАЕдєЯжШѓгАКStreaming SystemsгАЛдЄАдє¶зЪДдљЬиАЕдєЛдЄАпЉМзїИдЇОиІБеИ∞зЬЯдЇЇдЇЖпЉЙгАВињЩдЄ™ Talk жХідљУдЄКжЭ•иЃ≤еТМ Flink ж≤°жЬЙ姙姲зЪДеЕ≥з≥їпЉМеИЖдЇЂзЪДжШѓ Google ињЩдЇЫеєіеЬ®жµБиЃ°зЃЧзЫЄеЕ≥з≥їзїЯзЪДз†ФеПСињЗз®ЛдЄ≠еЊЧеИ∞зЪДзїПй™МгАВеТМ AWS зЫЄжѓФпЉМдЄ§еЃґеЕђеПЄзЪДзЙєиЙ≤дєЯжШѓзЫЄељУй≤ЬжШОгАВAWS еИЖдЇЂзЪДйГљжШѓеѓєеЃҐжИЈйЬАж±ВеТМдЇІеУБзЪДжАїзїУпЉМиАМ Google иѓізЪДеЯЇжЬђдЄКйГљжШѓзЇѓжКАжЬѓдЄКзЪДзїПй™МжФґиОЈгАВеРђдЇЖдєЛеРОдєЯз°ЃеЃЮжФґиОЈиЙѓе§ЪпЉМдЄНињЗзФ±дЇОзѓЗеєЕйЧЃйҐШе∞±дЄНеЬ®ињЩеЕЈдљУе±ХеЉАдЇЖгАВдЇЇеЃґдєЯеЈ≤зїПеЗЖе§Зе•љдЄАжЃµжАїзїУиЃ©жИСдїђеПѓдї•жЙУеМЕеЄ¶иµ∞пЉЪ

дЄїиЃЃз®Л
===
зФ±дЇОеИЖиЇЂдєПжЬѓпЉМеЬ®дЄїиЃЃз®ЛдЄ≠жИСеП™жМСйАЙдЇЖдЄАдЇЫдЄ™дЇЇжѓФиЊГжДЯеЕіиґ£жИЦиАЕжШѓдЄНжАОдєИдЇЖиІ£зЪДйҐЖеЯЯињЫи°МиІВжС©еТМе≠¶дє†гАВдљЖдЄЇдЇЖжХізѓЗжК•еСКзЪДеЃМжХіжАІпЉМжИСињШжШѓе∞љйЗПзЪДзЃАеНХдїЛзїНдЄАдЄЛеЕґдїЦжИСж≤°жЬЙеПВдЄОдљЖжШѓињШзЃЧзЖЯжВЙзЪДиЃЃйҐШгАВеРОзї≠дЄїеКЮжЦєдєЯдЉЪе∞ЖжЙАжЬЙзЪДиІЖйҐСеТМ PPT дЄКдЉ†еИ∞зљСдЄКдЊЫе§ІеЃґињЫи°МжЯ•зЬЛгАВжО•дЄЛжЭ•жИСе∞±жККиЃЃйҐШжМЙзЕІдЄ™дЇЇзРЖиІ£еИЖжИРеЗ†дЄ™дЄНеРМзЪДз±їеИЂпЉМеИЖеИЂжКЫз†ЦеЉХзОЙдЄАдЄЛгАВе§ІеЃґе¶ВжЮЬеѓєеЕґдЄ≠зЪДжЯРдЇЫиЃЃйҐШзЪДзїЖиКВзЙєеИЂжДЯеЕіиґ£зЪДпЉМеПѓдї•еЖНеОїдїФзїЖжЯ•зЬЛиІЖйҐСеТМ PPTгАВ
еє≥еП∞еМЦеЃЮиЈµ
-----
еЯЇдЇО Flink жЮДеїЇжХ∞жНЃеє≥еП∞еПѓдї•зЃЧеЊЧдЄКжЬАзГ≠йЧ®зЪДдЄАдЄ™иЃЃйҐШжЦєеРСдЇЖгАВињЩеЗ†еєійШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯдЄАзЫідЄНйБЧдљЩеКЫзЪДеРСз§ЊеМЇжО®еєњеЯЇдЇО SQL жЮДеїЇжХ∞жНЃе§ДзРЖеє≥еП∞зЪДзїПй™МпЉМзЫЃеЙНзЬЛиµЈжЭ•е§ІеЃґдєЯеЯЇжЬђдЄКиЃ§еРМдЇЖињЩдЄ™жЦєеРСпЉМдєЯзЇЈзЇЈзЪДеЉАеІЛдЄКдЇЖзФЯдЇІгАВдЄНињЗж†єжНЃеЕЈдљУзЪДеЬЇжЩѓпЉМдљЬдЄЪйЗПзЪДиІДж®°з≠ЙзЙєзВєпЉМдєЯжЬЙдЄАдЇЫеЕђеПЄдЉЪйАЙжЛ©дљњзФ®жЫіеК†еЇХе±ВеТМжЫіеК†зБµжіїзЪД DataStream API жЭ•жЮДеїЇжХ∞жНЃеє≥еП∞пЉМжИЦиАЕдЄ§иАЕйГљжПРдЊЫгАВињЩдєЯзђ¶еРИжИСдїђдЄАеЉАеІЛзЪДеИ§жЦ≠пЉМSQL иГљиІ£еЖ≥е§Іе§ЪжХ∞йЧЃйҐШпЉМдљЖдЄНжШѓеЕ®йГ®гАВеЬ®дЄАдЇЫзБµжіїзЪДеЬЇжЩѓдЄЛпЉМDataStream иГљжЫіжЦєдЊњеТМйЂШжХИзЪДиІ£еЖ≥зФ®жИЈзЪДйЧЃйҐШгАВ
#### иЃЃйҐШ1пЉЪгАКWriting a interactive SQL engine and interface for executing SQL against running streams using FlinkгАЛ
ињЩдЄ™еИЖдЇЂжЭ•иЗ™зЊОеЫљзЪДдЄАеЃґеРНеПЂ eventador зЪДеИЫдЄЪеЕђеПЄпЉМдєЯжШѓжЬђжђ°е§ІдЉЪзЪДиµЮеК©еХЖдєЛдЄАгАВжХідЄ™еИЖдЇЂе§ІйГ®еИЖињШжШѓдїЦдїђдЇІеУБжЮґжЮДеТМеКЯиГљзЪДдїЛзїНпЉМеЯЇжЬђдЄКеТМжИСдїђдї•еПКеЕґдїЦеЕђеПЄзЪДеє≥еП∞жЮґжЮДз±їдЉЉгАВжѓФиЊГжЬЙжДПжАЭзЪДжШѓпЉМдїЦдїђдєЯеПСзО∞дЇЖеЬ®еє≥еП∞еМЦзЪДеЃЮиЈµињЗз®ЛдЄ≠пЉМзФ®жИЈжШѓеРМжЧґйЬАи¶Б SQL ињЩзІНйЂШйШґ API дї•еПКжЫіеК†зБµжіїеТМеБПеЇХе±ВзВєзЪД DataStream APIпЉМеєґдЄФињЩдЄ§иАЕзЪДжѓФдЊЛжШѓ8пЉЪ2еЉАгАВ

ињШжЬЙдЄАдЄ™жѓФиЊГжЬЙжДПжАЭзЪДеКЯиГљжШѓпЉМдїЦдїђеЬ® SQL дЄКжПРдЊЫдЇЖ JavaScript зЪД UDF жФѓжМБпЉМеєґдЄФеЬ®дїЦдїђзЪДзФ®жИЈдєЛйЧійЭЮеЄЄеПЧ搥ињОгАВеЬ® SQL дЄКпЉМжМБзї≠зЪДйЩНдљОдљњзФ®йЧ®жІЫз°ЃеЃЮжШѓдЄАдЄ™жѓФиЊГйЭ†и∞±зЪДиЈѓе≠РпЉМеТМжИСдїђжГ≥жПРдЊЫ Python UDF жФѓжМБдєЯжШѓеЯЇдЇОеРМж†ЈзЪДеЗЇеПСзВєгАВ

#### иЃЃйҐШ2пЉЪгАКBuilding a Self-Service Streaming Platform at PinterestгАЛ
Pinterest зЃЧжШѓ Flink з§ЊеМЇзЪДжЦ∞йЭҐе≠ФпЉМињЩжђ°жШѓдїЦдїђзђђдЄАжђ°еЬ® Flink зЪДе§ІдЉЪдЄКеИЖдЇЂдїЦдїђзЪДзїПй™МгАВдїЦдїђдЄїи¶БзЪДеЇФзФ®еЬЇжЩѓдЄїи¶БжШѓеЫізїХеєњеСКжЭ•е±ХеЉАпЉМдљњзФ® Flink жЭ•зїЩеєњеСКдЄїдїђеЃЮжЧґеПНй¶ИеєњеСКзЪДжХИжЮЬгАВињЩдєЯзЃЧзЪДдЄКжШѓ Flink зЫЄељУзїПеЕЄзЪДдЄАдЄ™дљњзФ®еЬЇжЩѓдЇЖгАВиЗ≥дЇОдЄЇдїАдєИињЩдєИжЩЪжЙНзФ® FlinkпЉМдїЦдїђдЄКжЭ•е∞±ињЫи°МдЇЖиѓіжШОгАВдїЦдїђиК±дЇЖжѓФиЊГе§ІзЪДеКЯе§ЂеОїеѓєжѓФ Spark StreamingпЉМFlink дї•еПК Kafka Stream ињЩ3дЄ™еЉХжУОпЉМжЭГи°°еЖНдЄЙдєЛеРОжЙНйАЙжЛ©дЇЖ FlinkпЉМдєЯзЃЧжШѓжѓФиЊГи∞®жЕОеТМењГзїЖдЇЖгАВеРМжЧґдїЦдїђзЪДиАБзЪДдЄЪеК°еЯЇжЬђдЄКйГљжШѓдљњзФ® Spark иЈСжЙєе§ДзРЖдљЬдЄЪпЉМеЬ®еИЗжНҐжИРжµБдєЛеРОпЉМдєЯжШѓйЬАи¶БжЛњеЗЇзВєеЃЮеЃЮеЬ®еЬ®зЪДжИРзї©жЙНжЬЙеПѓиГљеЬ®еЕђеПЄеЖЕе§ІиІДж®°жО®еєњгАВ

жО•зЭАпЉМдїЦдїђдєЯеИЖдЇЂдЇЖдЄ§дЄ™еЬ®еє≥еП∞еМЦеЃЮиЈµињЗз®ЛдЄ≠е°ЂзЪДеЭСгАВзђђдЄАдЄ™жШѓжЧ•ењЧзЪДжЯ•зЬЛпЉМе∞§еЕґжШѓељУжЙАжЬЙзЪДдљЬдЄЪиЈСеЬ® YARN дЄКзЪДжЧґеАЩпЉМељУдљЬдЄЪзїУжЭЯеРОжАОдєИжЯ•зЬЛдљЬдЄЪињРи°МжЧґзЪДжЧ•ењЧжШѓдЄАдЄ™жѓФиЊГе§ізЦЉзЪДйЧЃйҐШгАВзђђдЇМдЄ™жШѓ BackfillingпЉМеЬ®жЦ∞зЪДдљЬдЄЪдЄКзЇњжИЦиАЕдљЬдЄЪйАїиЊСйЬАи¶БеПШжЫізЪДжЧґеАЩпЉМдїЦдїђеЄМжЬЫеЕИињљдЄАйГ®еИЖе≠ШеЬ® S3 дЄКзЪДеОЖеП≤жХ∞жНЃпЉМзДґеРОеЬ®еЯЇжЬђињљеЃМзЪДжЧґеАЩеИЗжНҐеИ∞ Kafka ињЩж†ЈзЪДжґИжБѓйШЯеИЧдЄКзїІзї≠ињЫи°Ме§ДзРЖгАВињЩдЄ™ Backfilling жШѓ Flink жµБжЙєдЄАдљУжЬАзїПеЕЄзЪДеЬЇжЩѓпЉМиАМдЄФзЬЛиµЈжЭ•з°ЃеЃЮжШѓдЄ™еЊИжЩЃйБНзЪДеИЪйЬАгАВе¶ВжЮЬж≤°иЃ∞йФЩзЪДиѓЭпЉМињЩжђ°е§ІдЉЪе∞±жЬЙ 3 дЄ™иЃЃйҐШжПРеИ∞дЇЖињЩжЦєйЭҐзЪДйЧЃйҐШпЉМдї•еПКдїЦдїђзЪДиІ£ж≥ХгАВиІ£ж≥ХеРДжЬЙеНГзІЛпЉМдЄНињЗе¶ВжЮЬ Flink еЬ®еЉХжУОдЄКиГље§ЯзЫіжО•еЖЕзљЃжФѓжМБдЇЖињЩж†ЈзЪДеЬЇжЩѓзЪДиѓЭпЉМзЫЄдњ°дљУй™МдЉЪе•љдЄНе∞СпЉИињЩдєЯжБ∞жБ∞жШѓ Flink жО•дЄЛеОїдЄАдЄ™жѓФиЊГйЗНи¶БзЪДжЦєеРСдєЛдЄАпЉЙгАВ

#### еЕґдїЦиЃЃйҐШжО®иНР
* гАКStream SQL with Flink @ YelpгАЛпЉЪYelp еЈ≤зїПзЃЧжШѓ Flink зЪДиАБзЙМзО©еЃґдЇЖпЉМеЬ®ињЩдЄ™еИЖдЇЂйЗМдїЦдїђжАїзїУдЇЖдїЦдїђзЫЃеЙНзЪДжµБиЃ°зЃЧеЬЇжЩѓпЉМдї•еПКдїЦдїђзЪДеє≥еП∞зЪДеБЪж≥ХгАВжИСеЫ†дЄЇжЧґйЧіеЖ≤з™БзЪДеОЯеЫ†ж≤°жЬЙеРђеИ∞ињЩдЄ™еИЖдЇЂпЉМдЄНињЗдїОеЕґдїЦжЄ†йБУеЊЧеИ∞зЪДеПНй¶ИзЬЛиµЈжЭ•дїЦдїђеЇФиѓ•жШѓе±ЮдЇОзО©зЪДжѓФиЊГжЇЬзЪДгАВжО®иНРе§ІеЃґеЬ®иІЖйҐСеТМ PPT дЄКзЇњеРОиІВжС©е≠¶дє†дЄАдЄЛгАВ
* гАКFlink for Everyone: Self-Service Data Analytics with StreamPipesгАЛпЉЪдЄАиИђжЭ•иѓіпЉМеє≥еП∞еМЦеїЇиЃЊйГљжШѓеЕђеПЄеЖЕйГ®й°єзЫЃпЉМеЊИе∞СињЫи°МеЉАжЇРгАВињЩдЄ™еПЂеБЪ FZI зЪДйЭЮзЫИеИ©жЬЇжЮДиЈ≥еЗЇжЭ•ељУдЇЖдЄАжККйЫЈйФЛпЉМжПРдЊЫдЇЖдЄАе•ЧеЃМеЕ®еЉАжЇРзЪДеє≥еП∞еМЦеЈ•з®ЛеЃЮзО∞пЉЪ[streampipes](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fwww.streampipes.org%2F)гАВиЗ™еЄ¶дЄАжХіе•ЧжЙШжЛЙжЛљзЪДдљЬдЄЪжЮДеїЇжµБз®ЛпЉМиАМдЄФзЬЛиµЈжЭ•зХМйЭҐдєЯзЫЄељУзЪДдЄНйФЩпЉМжЬЙйЬАи¶БзЪДеРМе≠¶еПѓдї•еПВиАГдЄАдЄЛгАВ
* гАКDynamically Generated Flink Jobs at ScaleгАЛпЉЪињЩжШѓйЂШзЫЫеИЖдЇЂзЪДеЯЇдЇО Flink зЪДеє≥еП∞еЃЮиЈµпЉМжФѓжМБдЄА姩ињРи°М 12 дЄЗзЪДдљЬдЄЪгАВеЬ®йУґи°МеТМйЗСиЮНдЄЪзЪД IT еРМе≠¶дїђеПѓдї•еПВиАГдЄЛгАВ
зѓЗеєЕжЬЙйЩРпЉМињШжЬЙеЕґдїЦзЫЄеЕ≥зЪДиЃЃйҐШе∞±дЄНдЄАдЄАеИЧеЗЇдЇЖгАВжАїдљУжЭ•иѓіпЉМеЯЇдЇО Flink жЮДеїЇжХ∞жНЃеє≥еП∞еЈ≤зїПжШѓдЄАдЄ™зЫЄељУжИРзЖЯзЪДеЃЮиЈµпЉМеРДи°МеРДдЄЪйГљжЬЙжИРеКЯзЪДж°ИдЊЛињЫи°МеПВиАГгАВињШж≤°жЬЙдЄКиљ¶зЪДеРМе≠¶дїђпЉМдљ†дїђињШеЬ®з≠ЙдїАдєИпЉЯ
еЇФзФ®еЬЇжЩѓз±ї
-----
йЩ§дЇЖдЄКйЭҐзЪДеє≥еП∞еМЦеЃЮиЈµпЉМдљњзФ® Flink иІ£еЖ≥жЯРдЇЫеЇФзФ®еЬЇжЩѓзЪДеЕЈдљУйЧЃйҐШдєЯжШѓињЩжђ°еИЖдЇЂдЄ≠дЄАдЄ™жѓФиЊГзГ≠йЧ®зЪДжЦєеРСгАВињЩдЇЫзФ®жИЈеЊАеЊАиЗ™еЈ±зЉЦеЖЩе∞СйЗПдљЬдЄЪпЉМжЭ•иІ£еЖ≥дїЦдїђзЪДеЃЮйЩЕйЧЃйҐШгАВжИЦиАЕе∞±еє≤иДЖжШѓеє≥еП∞зЪДдљњзФ®жЦєпЉМжЭ•еИЖдЇЂе¶ВдљХдљњзФ®еє≥еП∞жЭ•иІ£еЖ≥жЫіиііињСзїИзЂѓзФ®жИЈзЪДйЧЃйҐШгАВињЩдєЯжШѓ Flink иГље§ЯзЬЯж≠£еИЫйА†еЃЮйЩЕдЄЪеК°дїЈеАЉзЪДеЬ∞жЦєпЉМжЬђжГ≥е§ЪеРђеЗ†дЄ™пЉМеПѓжЧ†е•ИиАБжШѓжЧґйЧіеЖ≤з™БгАВ
#### иЃЃйҐШ1пЉЪгАКMaking Sense of Streaming Sensor Data: How Uber Detects On-trip Car CrashesгАЛ
ињЩжШѓ Uber еИЖдЇЂзЪДдЄАдЄ™иДСжіЮжѓФиЊГе§ІзЪДеЇФзФ®еЬЇжЩѓпЉМдїЦдїђдљњзФ® Flink жЭ•еЃЮжЧґеИ§жЦ≠дєШеЃҐжШѓдЄНжШѓеПСзФЯдЇЖиљ¶з•ЄгАВеТМ Pinterest дЄАж†ЈпЉМеЬ®ињЩдЄ™дЄЪеК°еЬЇжЩѓдЄЛпЉМUber дєЯжШѓдЄЇдЇЖжЧґжХИжАІиАМдїО Spark ињБзІїеИ∞дЇЖ FlinkгАВдїЦдїђдїЛзїНдЇЖдїЦдїђе¶ВдљХдЊЭиµЦдЄ§й°єжЬАйЗНи¶БзЪДжХ∞жНЃпЉИGPSдњ°жБѓеТМжЙЛжЬЇеК†йАЯдњ°жБѓпЉЙпЉМеЖНе•ЧзФ®жЬЇеЩ®е≠¶дє†ж®°еЮЛпЉМжЭ•еЃЮжЧґзЪДеИ§жЦ≠дєШеЃҐжШѓеР¶еПСзФЯдЇЖиљ¶з•ЄгАВ

еРОзї≠дєЯжПРеИ∞дЇЖдїЦдїђеЄМжЬЫеЕ±дЇЂињЩдЄ™дЄЪеК°дЄКжФґйЫЖзЪДжХ∞жНЃпЉМдї•еПКеЬ®ињЩдЄ™жХ∞жНЃзЪДеЯЇз°АдЄКзФЯжИРзЪДдЄАдЇЫзЙєеЊБпЉМеЬ®еЕґдїЦзЪДеЫҐйШЯињЫи°МжО®еєњпЉИжАОдєИжДЯиІЙжЦєеРСеПИи¶БиљђеИ∞еє≥еП∞еМЦдЇЖ-\_-!пЉЙ

#### еЕґдїЦиЃЃйҐШжО®иНР
* гАКAirbus makes more of the sky with FlinkгАЛпЉЪз©ЇеЃҐеЕђеПЄдїЛзїНдЇЖдїЦдїђе¶ВдљХдљњзФ® AzureгАБFlink жЭ•ињЫи°Мй£Юи°МжХ∞жНЃзЪДеИЖжЮРпЉМжЧ®еЬ®жПРдЊЫжЫіе•љзЪДй£Юи°МдљУй™МгАВ
* гАКIntelligent Log Analysis and Real-time Anomaly Detection @ SalesforceгАЛпЉЪSalesforce дїЛзїНдЇЖдїЦдїђдљњзФ® Flink зїУеРИжЬЇеЩ®е≠¶дє†ж®°еЮЛжЭ•иІ£еЖ≥еЃЮжЧґжЧ•ењЧеИЖжЮРпЉМеєґдЄФеЃЮжЧґжОҐжµЛдЄАдЇЫеЉВеЄЄжГЕеЖµжѓФе¶ВеЕ≥йФЃжЬНеК°жАІиГљдЄЛйЩНз≠ЙгАВ
* гАКLarge Scale Real Time Ad Invalid Traffic Detection with FlinkгАЛпЉЪCriteo ињЩеЃґж≥ХеЫљзЪДеєњеСКеЕђеПЄдїЛзїНдЇЖеєњеСКеЬЇжЩѓдЄЛињЫи°МеЃЮжЧґзЪДеЉВеЄЄжµБйЗПжОҐжµЛгАВ
* гАКEnabling Machine Learning with Apache FlinkгАЛпЉЪLyft еИЖдЇЂдЇЖдїЦдїђе¶ВдљХеЯЇдЇО Flink жЮДеїЇдЇЖжЬЇеЩ®е≠¶дє†зЪДеє≥еП∞жЭ•иІ£еЖ≥е§ЪзІНе§Ъж†ЈзЪДдЄЪеК°йЧЃйҐШгАВ
зЃАеНХжАїзїУдЄАдЄЛпЉМеЬ®еБПеЇФзФ®еЬЇжЩѓзЪДжЦєеРСдЄКпЉМеЈ≤зїПиґКжЭ•иґКе§ЪзЪДзЬЛеИ∞дЇЖ Flink еТМжЬЇеЩ®е≠¶дє†зїУеРИдљњзФ®зЪДж°ИдЊЛгАВеЯЇжЬђдЄКпЉМдЄАдЇЫз®НеЊЃе§НжЭВзВєзЪДйЧЃйҐШеЊИйЪЊйАЪињЗиІДеИЩйАїиЊСпЉМжИЦиАЕ SQL жЭ•ињЫи°МзЃАеНХзЪДеИ§еЃЪгАВињЩзІНжГЕеЖµдЄЛпЉМжЬЇеЩ®е≠¶дє†е∞±иГље§ЯжіЊдЄКжѓФиЊГе§ІзЪДзФ®еЬЇгАВзЫЃеЙНзЬЛжЭ•пЉМе§ІеЃґињШжШѓжЫіе§ЪзЪДеЕИдљњзФ®еЕґдїЦеЉХжУОиЃ≠зїГе•љж®°еЮЛпЉМзДґеРОиЃ© Flink еК†иљљж®°еЮЛдєЛеРОињЫи°МйҐДжµЛжУНдљЬгАВдљЖжШѓињЗз®ЛдЄ≠дєЯдЉЪзҐ∞еИ∞з±їдЉЉдЄ§дЄ™еЉХжУОеѓєж†ЈжЬђзЪДе§ДзРЖйАїиЊСдЄНеРМз≠ЙйЧЃйҐШиАМељ±еУНжЬАзїИзЪДжХИжЮЬгАВињЩдєЯзЃЧжШѓ Flink дїКеРОзЪДдЄАдЄ™жЬЇдЉЪпЉМе¶ВжЮЬ Flink еЬ®жЫіеК†еБПеРСжЙєе§ДзРЖзЪДж®°еЮЛиЃ≠зїГдЄКиГљжПРдЊЫжѓФиЊГе•љзЪДжФѓжМБпЉМйВ£дєИзФ®жИЈеЃМеЕ®еПѓдї•дљњзФ®еРМдЄАдЄ™еЉХжУОжЭ•ињЫи°МиѓЄе¶ВзФ®жЬђжЛЉжО•пЉМж®°еЮЛиЃ≠зїГдї•еПКеЃЮжЧґйҐДжµЛињЩдЄАжХіе•ЧжµБз®ЛгАВжХідЄ™зЪДеЉАеПСдљУй™МеМЕжЛђеЃЮйЩЕдЄКзЇњжХИжЮЬзЫЄдњ°йГљдЉЪжЬЙиЊГе§ІзЪДжПРеНЗпЉМиЃ©жИСдїђжЛ≠зЫЃдї•еЊЕ Flink еЬ®ињЩжЦєйЭҐзЪДеК®дљЬгАВ
зФЯдЇІеЃЮиЈµ
----
ињЩйГ®еИЖдЄїи¶БжШѓзФЯдЇІеЃЮиЈµзЪДзїПй™МеИЖдЇЂпЉМеЊИдЄНе•љжДПжАЭзЪДжШѓпЉМзЫЄеЕ≥зЪДиЃЃйҐШжИСдЄАдЄ™йГљж≤°жЬЙеПВдЄОгАВжИСж†єжНЃиЃЃйҐШзЪДзЃАдїЛзЃАеНХеБЪдЄ™дїЛзїНпЉМжДЯеЕіиґ£зЪДеРМе≠¶еПѓдї•иЗ™и°МжЯ•зЬЛзЫЄеЕ≥иµДжЦЩгАВ
* гАКApache Flink Worst PracticesгАЛпЉЪе§ІеЃґеПѓиГљйГљеРђињЗдЄНе∞С Best PracticesпЉМињЩдЄ™еИЖдЇЂеПНеЕґйБУиАМи°МдєЛпЉМдЄУйЧ®дїЛзїНеРДзІНдљњзФ® Flink зЪДжЬАеЈЃеІњеКњпЉМеЯЇжЬђдЄКзЃЧжШѓеИЖдЇЂеРДзІНиЄ©еЭСжИЦиАЕиЄ©йЫЈзЪДеЬ∞жЦєпЉМиЃ©еРђдЉЧиГље§ЯйБњеЉАгАВ
* гАКHow to configure your streaming jobs like a proгАЛпЉЪCloudera еЯЇдЇОињЩдЇЫеєідїЦдїђеЬ®жХ∞зЩЊдЄ™жµБиЃ°зЃЧдљЬдЄЪдЄКжАїзїУдЄЛжЭ•зЪДи∞ГеПВзїПй™МгАВйТИеѓєдЄНеРМз±їеЮЛзЪДдљЬдЄЪпЉМеУ™дЇЫеПВжХ∞жѓФиЊГеЕ≥йФЃгАВ
* гАКRunning Flink in production: The good, the bad and the in-betweenгАЛпЉЪLyft еИЖдЇЂзЪДдїЦдїђињРзїі Flink зЪДзїПй™МпЉМжЬЙеУ™дЇЫ Flink еБЪзЪДжѓФиЊГе•љзЪДеЬ∞жЦєпЉМдєЯеМЕжЛђеУ™дЇЫ Flink зО∞еЬ®еБЪзЪДдЄНе§Яе•љзЪДеЬ∞жЦєгАВиЃ©е§ІеЃґеѓєињРзїі Flink зФЯдЇІдљЬдЄЪжЬЙжЫіеЕ®йЭҐзЪДиЃ§зЯ•гАВ
* гАКIntrospection of the Flink in productionгАЛпЉЪCriteo еИЖдЇЂзЪДжХЩе§ІеЃґе¶ВдљХиІВжµЛ Flink дљЬдЄЪжШѓеР¶ж≠£еЄЄзЪДзїПй™МпЉМдї•еПКељУдљЬдЄЪеЗЇйЧЃйҐШжЧґпЉМе¶ВдљХжЬАењЂзЪДеЃЪдљН root causeгАВ
* гАКKubernetes + Operator + PaaSTA = Flink @ YelpгАЛпЉЪељУе§ІйГ®еИЖдЇЇињШжШѓеЯЇдЇО Yarn жЭ•ињРи°М FlinkзЪДжЧґеАЩпЉМYelp ињЩдЄ™жЈ±еЇ¶зО©еЃґеЈ≤зДґиµ∞еИ∞дЇЖе§ІеЃґеЙНйЭҐгАВињЩдєЯжШѓжИСеЬ®ињЩжђ°е§ІдЉЪдЄ≠зЬЛеИ∞зЪДеФѓдЄАдљњзФ® Flink + K8S дЄКзЇњзЪДзїДеРИгАВ
иЩљзДґдЄАдЄ™иЃЃйҐШдєЯж≤°еРђпЉМдљЖжШѓдєЯдїОеИЂзЪДиЃЃйҐШдЄ≠йЫґйЫґжШЯжШЯзЪДеРђеИ∞дЄАдЇЫе§ІеЃґеЕ≥дЇО Flink зФЯдЇІзЪДиѓЭйҐШпЉМеЕґдЄ≠жѓФиЊГз™БеЗЇзЪДжШѓ Flink еТМ Kubernetes зЪДзїУеРИйЧЃйҐШгАВK8S зЪДзБЂзГ≠пЉМиЃ©е§ІеЃґйГљжЬЙзІНдЄНиє≠дЄАдЄЛзГ≠еЇ¶е∞±иРљдЉНдЇЖзЪДжГ≥ж≥ХгАВдЄНе∞СеЕђеПЄйГљжЬЙжЬЭзЭАињЩдЄ™жЦєеРСињЫи°Ме∞ЭиѓХеТМжΥ糥зЪДжДПжДњгАВеЕґдЄ≠е∞±е±Ю Yelp иµ∞зЪДжЬАењЂпЉМеЈ≤зїПжЛњињЩе•ЧжЮґжЮДдЄКзЇњдЇЖгАВдЄ™дЇЇиІЙеЊЧ Flink еТМ K8S зЪДзїУеРИињШжШѓзЫЄељУйЭ†и∞±зЪДпЉМеПѓдї•иІ£йФБжЫіе§Ъ Application еТМеЬ®зЇњжЬНеК°зЫЄеЕ≥зЪДеІњеКњгАВељУзДґпЉМйШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯеЬ®ињЩжЦєйЭҐдєЯж≤°жЬЙиРљдЉНпЉМжИСдїђдєЯеЈ≤зїПеТМйШњйЗМдЇС K8S еРИдљЬдЇЖзЫЄељУйХњдЄАжЃµжЧґйЧіпЉМжЬАињСдєЯжО®еЗЇдЇЖеЯЇдЇО K8S еЃєеЩ®еМЦзЪДеЕ®жЦ∞дЄАдї£еЃЮжЧґиЃ°зЃЧдЇІеУБ ververica platformгАВ
з†Фз©ґеЮЛй°єзЫЃ
-----
еЙНйЭҐзЪДиЃЃйҐШеЯЇжЬђйГљжШѓдЄАдЇЫеЈ•з®ЛеМЦзЪДеЃЮиЈµпЉМињЩжђ°е§ІдЉЪињШжЬЙдЄНе∞Сз†Фз©ґеЮЛзЪДй°єзЫЃеРЄеЉХдЇЖжИСзЪДеЕіиґ£гАВзФЯжАБзЪДзєБиН£еПСе±ХпЉМйЩ§дЇЖжЬЙеРДе§ІеЕђеПЄзЪДеЃЮиЈµдєЛе§ЦпЉМеБПзРЖиЃЇеМЦзЪДз†Фз©ґеЮЛй°єзЫЃдєЯдЄНеПѓзЉЇе∞СгАВеРђиѓіињЩжђ°е§ІдЉЪжФґеИ∞дЇЖдЄНе∞Сз†Фз©ґеЮЛзЪДиЃЃйҐШпЉМдљЖзФ±дЇОиЃЃйҐШжХ∞йЗПжЬЙйЩРпЉМеП™дїОйЗМйЭҐжМСйАЙдЇЖдЄАйГ®еИЖгАВ
#### иЃЃйҐШ1пЉЪгАКSelf-managed and automatically reconfigurable stream processingгАЛ
ињЩжШѓиЛПйїОдЄЦиБФйВ¶зРЖеЈ•е≠¶йЩҐзЪДдЄАеРНеНЪе£ЂеРОеЄ¶жЭ•зЪДиЗ™еК®йЕНзљЃжµБиЃ°зЃЧдљЬдЄЪзЪДдЄАдЄ™з†Фз©ґеЮЛй°єзЫЃгАВдїЦдїђзЪДз†Фз©ґжЦєеРСдЄїи¶БйЫЖдЄ≠еЬ®е¶ВдљХиЃ©жµБиЃ°зЃЧдљЬдЄЪиГље§ЯиЗ™ж≤їпЉМдЄНйЬАи¶БдЇЇдЄЇеє≤йҐДиАМиГље§ЯиЗ™еК®зЪДи∞ГжХіеИ∞жЬАдљ≥зЪДзКґжАБгАВињЩеТМ Google еЬ® keynote йЗМзЪДеИЖдЇЂдЄНи∞ЛиАМеРИпЉМйГљжШѓеЄМжЬЫз≥їзїЯжЬђиЇЂеЕЈе§Зиґ≥е§ЯеЉЇзЪДеК®жАБи∞ГжХіиГљеКЫгАВињЩдЄ™еИЖдЇЂдЄїи¶БжЬЙдЄ§йГ®еИЖеЖЕеЃєпЉМзђђдЄАйГ®еИЖжШѓжПРеЗЇдЇЖдЄАзІНжЦ∞зЪДжАІиГљзУґйҐИеИЖжЮРзРЖиЃЇгАВдЄАиИђжЭ•иѓіпЉМељУжИСдїђжГ≥и¶БдЉШеМЦдЄАдЄ™жµБиЃ°зЃЧдљЬдЄЪзЪДеРЮеРРеТМеїґињЯжЧґпЉМжИСдїђеЊАеЊАйЗЗзФ®жѓФиЊГдЉ†зїЯзЪДиІВжµЛ CPU зГ≠зВєзЪДжЦєеЉПпЉМжЙЊеИ∞дљЬдЄЪдЄ≠жЬАиАЧ CPU зЪДйГ®еИЖзДґеРОињЫи°МдЉШеМЦгАВдљЖеЊАеЊАжИСдїђењљзХ•дЇЖдЄАдЄ™дЇЛеЃЮжШѓпЉМељ±еУНз≥їзїЯ latency жИЦиАЕеРЮеРРеЊАеЊАињШжЬЙеРДзІНз≠ЙеЊЕзЪДжУНдљЬпЉМжѓФе¶ВзЃЧе≠РеЬ®з≠ЙеЊЕжХ∞жНЃињЫи°Ме§ДзРЖз≠ЙгАВе¶ВжЮЬжИСдїђеНХзЛђдЉШеМЦ cpu зГ≠зВєпЉМдЉШеМЦеЃМдєЛеРОеПѓиГљеП™дЉЪиЃ©з≥їзїЯеЕґеЃГеЬ∞жЦєз≠ЙеЊЕзЪДжЧґйЧіеПШйХњпЉМеєґдЄНиГљзЬЯж≠£еЄ¶жЭ•еїґињЯзЪДдЄЛйЩНеТМеРЮеРРзЪДдЄКеНЗгАВжЙАдї•дїЦдїђеЕИжПРеЗЇдЇЖдЄАзІНвАЭеЕ≥йФЃиЈѓеЊДвАЬзЪДзРЖиЃЇпЉМеЬ®еИ§жЦ≠жАІиГљзУґйҐИжЧґжШѓдї•йУЊиЈѓдЄЇеНХеЕГињЫи°МеИ§жЦ≠еТМжµЛйЗПгАВеП™жЬЙзЬЯж≠£зЪДйЩНдљОжХіжЭ°еЕ≥йФЃиЈѓеЊДзЪДиАЧжЧґпЉМжЙНиГљжЬЙжЬЙжХИзЪДйЩНдљОдљЬдЄЪзЪДеїґињЯгАВ

зђђдЇМдЄ™йГ®еИЖжШѓдїЛзїНдЇЖдЄАзІНжЦ∞зЪДдљЬдЄЪиЗ™еК®жЙ©зЉ©еЃєжЬЇеИґпЉМеєґдЄФеТМеЊЃиљѓзЪД Dhalion ињЫи°МдЇЖеѓєжѓФгАВињЩдЄ™еБЪж≥ХзЪДзЙєиЙ≤еЬ®дЇОпЉМеЕґдїЦз±їдЉЉзЪДз≥їзїЯжАїжШѓеѓєдЄАдЄ™зЃЧе≠РеНХзЛђеБЪеЖ≥з≠ЦпЉМиАМдїЦдїђдЉЪжЫіе§ЪзЪДжККе§ЪдЄ™зЃЧе≠РињЫи°МеРМжЧґиАГиЩСгАВеЬ®жЙ©зЉ©еЃєзЪДжЧґеАЩиЃ©е§ЪдЄ™зЃЧе≠РеРМжЧґжУНдљЬпЉМеЗПе∞СжФґжХЫжЙАйЬАи¶БзЪДеК®дљЬжђ°жХ∞гАВ

жµБиЃ°зЃЧдїїеК°зЪДиЗ™ж≤їеМЦдєЯжШѓжИСдЄ™дЇЇйЭЮеЄЄжДЯеЕіиґ£зЪДдЄАдЄ™жЦєеРСпЉМдєЯзЬЛеИ∞дЄНе∞Сз†Фз©ґеЮЛзЪДй°єзЫЃеТМиЃЇжЦЗеЬ®йШРињ∞ињЩжЦєйЭҐзЪДеЈ•дљЬпЉМдљЖжЪВжЧґињШжЬ™иІБеИ∞еЈ•дЄЪзХМеѓєжѓФжЬЙжѓФиЊГжЈ±еЕ•зЪДеИЖдЇЂпЉИAWS зЪД kinesis жЬНеК°еЕЈе§ЗеК®жАБжЙ©зЉ©еЃєиГљеКЫпЉМдљЖзФ±дЇОзЉЇдєПзїЖиКВдїЛзїНдЄНз°ЃеЃЪжШѓеР¶иґ≥е§ЯйАЪзФ®дї•еПКжШѓеР¶иГље§ЯеЇФеѓєжѓФиЊГе§НжЭВзЪДеЬЇжЩѓпЉЙгАВйШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯжЧ©еЬ®дЄАеєіеЙНе∞±еРѓеК®дЇЖз±їдЉЉзЪДй°єзЫЃпЉМеЬ®ињЩжЦєеРСдЄКињЫи°МдЇЖе∞ЭиѓХеТМжΥ糥гАВйЭҐеѓєеЖЕйГ®е§ІйЗПзЪДдЄЪеК°еЬЇжЩѓеТМйЬАж±ВпЉМеК†дЄКзЫЃеЙНеРДзІНеЙНж≤њзЪДз†Фз©ґпЉМзЫЄдњ°дЄНињЬзЪДе∞ЖжЭ•еПѓдї•жЬЙжЙАз™Бз†ігАВ
#### еЕґдїЦиЃЃйҐШжО®иНР
* гАКMoving on from RocksDB to something FASTERгАЛпЉЪињЩдєЯжШѓиЛПйїОдЄЦиБФйВ¶зРЖеЈ•еЄ¶жЭ•зЪДеЕ≥дЇОзКґжАБе≠ШеВ®зЫЄеЕ≥зЪДз†Фз©ґпЉМеѓїжЙЊжѓФ RocksDB жЫіењЂзЪДиІ£еЖ≥жЦєж°ИгАВеЬ® Statebackend дЄКпЉМйШњйЗМеЈіеЈіеЃЮжЧґиЃ°зЃЧеЫҐйШЯдєЯжЬЙжЙАеЄГе±АпЉМжИСдїђж≠£еЬ®жΥ糥дЄАзІНеЃМеЕ®еЯЇдЇО Java зЪДе≠ШеВ®еЉХжУОгАВ
* гАКScotty: Efficient Window Aggregation with General Stream SlicingгАЛпЉЪдїЛзїНдЇЖдЄАзІНдљњзФ®еИЗзЙЗжЭ•жПРеНЗз™ЧеП£иБЪеРИжАІиГљзЪДжЦєж≥ХгАВ
жЈ±еЇ¶жКАжЬѓеЙЦжЮР
------
ињЩдЄ™йГ®еИЖдЄїи¶БдїЛзїНзЪДйГљжШѓ Flink еЬ®ињЗеОї1-2дЄ™зЙИжЬђеЖЕеБЪзЪДдЄАдЇЫе§ІзЪД feature еТМйЗНжЮДгАВзФ±дЇОжЬђдЇЇе∞±жШѓ Flink зЪДеЉАеПСиАЕпЉМеѓєињЩдЇЫеЈ•дљЬйГљжѓФиЊГзЖЯжВЙпЉМеЫ†ж≠§е∞±ж≤°жЬЙйАЙжЛ©еОїеРђињЩдЇЫеИЖдЇЂгАВеАЯзФ® Stephan еЬ® Keynote дЄ≠зЪДдЄ§еЉ†еЫЊпЉМеЯЇжЬђеБЪдЇЖжѓФиЊГе•љзЪДж¶ВжЛђгАВ


жЬЙеРМе≠¶еѓєеЕґдЄ≠дЄ™еИЂзЪДжКАжЬѓзВєжДЯеЕіиґ£зЪДиѓЭпЉМеЯЇжЬђйГљиГље§ЯжЙЊеИ∞еѓєеЇФзЪДиЃЃйҐШпЉМеЬ®ињЩйЗМжИСе∞±дЄНе±ХеЉАдЄАдЄАдїЛзїНдЇЖгАВ
жАїзїУеТМжДЯжГ≥
=====
ињЩеЗ†еєійЪПзЭАйШњйЗМеЈіеЈіжМБзї≠еѓє Flink зЪДе§ІеКЫжКХиµДпЉМFlink зЪДжИРзЖЯеЇ¶еТМжіїиЈГеЇ¶еЭЗжЬЙдЇЖиі®зЪДй£ЮиЈГгАВз§ЊеМЇзФЯжАБдєЯиґКеПСзЪДзєБиН£пЉМеМЕжЛђ cloudera еТМ AWS йГљеЈ≤зїПеЉАеІЛзІѓжЮБзЪДжЛ•жК± FlinkпЉМдєЯеЊЧеИ∞дЇЖдЄНйФЩзЪДжИРжЮЬгАВеРДе§ІеЕђеПЄзЪДиЃЃйҐШдєЯдїОжЧ©еєізЪДжК±зЭАе∞Эй≤ЬзЪДжАБеЇ¶е∞ЭиѓХ FlinkпЉМиљђеПШжИРдЇЖжЭ•еИЖдЇЂдљњзФ® Flink е§ІиІДж®°дЄКзЇњеРОзЪДдЄАдЇЫжИРжЮЬеТМзїПй™МжХЩиЃ≠гАВеЬ®ж≠§еЯЇз°АдєЛдЄКпЉМйАРжЄРдЇЖ嚥жИРдЇЖеЯЇдЇО Flink зЪДеє≥еП∞еМЦеЃЮиЈµгАБзїУеРИжЬЇеЩ®е≠¶дє†ињЫи°МеЕЈдљУдЄЪеК°зЪДйЧЃйҐШиІ£еЖ≥еТМдЄАдЇЫжѓФиЊГжЦ∞йҐЦзЪДжΥ糥з†Фз©ґеЮЛй°єзЫЃз≠ЙжЦєеРСпЉМиЃ©жХідЄ™зФЯжАБзЪДеПСе±ХжЫіеК†зЪДеЃМжХіеТМе£ЃеЃЮгАВдЄНдїЕе¶Вж≠§пЉМFlink дєЯеЬ®зІѓжЮБзЪДжΥ糥дЄАдЇЫжЦ∞зЪДзГ≠йЧ®жЦєеРСпЉМжѓФе¶ВеТМ K8S зЪДзїУеРИпЉМеТМеЬ®зЇњжЬНеК°еЬЇжЩѓзЪДзїУеРИз≠Йз≠ЙпЉМдљУзО∞дЇЖињЩдЄ™зФЯжАБзЪДеЉЇе§ІзФЯеСљеКЫгАВ
дЄНињЗељТж†єзїУеЇХпЉМFlink еИ∞еЇХињШжШѓдЄАдЄ™е§ІжХ∞жНЃиЃ°зЃЧеЉХжУОпЉМеЕґеЃЧжЧ®ињШжШѓеЄМжЬЫеОїиІ£еЖ≥е§ІжХ∞жНЃиЃ°зЃЧињЩдЄ™йЧЃйҐШгАВеЬ®жЦЗзЂ†зЪДдЄАеЉАе§іпЉМжИСдєЯжПРеИ∞дЇЖеЬ®зЬЛеИ∞ Flink ињЫеЖЫ Application еТМ FaaS зЪДжЦєеРСжЧґпЉМдЄАдЄ™зЦСйЧЃдЄАзЫіеЬ®жИСзЪДењГе§іиР¶зїХпЉЪFlink еИ∞еЇХжШѓжАОдєИж†ЈзЪДдЄАдЄ™иЃ°зЃЧеЉХжУОпЉМеЃГз©ґзЂЯжШѓи¶БиІ£еЖ≥дїАдєИж†ЈзЪДйЧЃйҐШпЉЯе¶ВжЮЬж≤°жЬЙдЄАдЄ™еЊИжЄЕжЩ∞зЪДдЄїзЇњеТМйХњињЬиЃ§иѓЖпЉМеЬ®еЉХжУОзЪДеПСе±ХињЗз®ЛдЄ≠еЊИеЃєжШУе∞±дЉЪиµ∞еБПпЉМжЬАзїИеѓЉиdz姱賕гАВ
е§ІйГ®еИЖдЇЇеПѓиГљињШеБЬзХЩеЬ® Flink жШѓдЄАдЄ™жИРзЖЯзЪДеЃЮжЧґиЃ°зЃЧеЉХжУОзЪДиЃ§зЯ•пЉМдљЖ Flink дїОиѓЮзФЯзЪДзђђдЄА姩赣е∞±жГ≥зЭАи¶БиІ£еЖ≥жЙєе§ДзРЖзЪДйЧЃйҐШгАВеН≥дЊњзО∞еЬ® Flink еЈ≤зїПйАРжЄРе°Ђи°•дЇЖжЙєе§ДзРЖињЩдЄ™еЭСпЉМдљЖеПИжЬЭзЭА Application ињЩж†ЈзЪДеЬ®зЇњжЬНеК°еЬЇжЩѓеПСиµЈдЇЖжΥ糥гАВдєНдЄАзЬЛпЉМFlink е•љеГПдїАдєИйЧЃйҐШйГљжГ≥иІ£пЉМдїАдєИжЦєеРСйГљжГ≥жПТдЄАиДЪпЉМзЬЯзЪДжШѓињЩж†ЈеРЧпЉЯ
еЄ¶зЭАињЩж†ЈзЪДзЦСйЧЃеПВеК†еЃМдЇЖжХідЄ™е§ІдЉЪпЉМеПИйҐЭе§ЦжАЭиАГдЇЖеdž姩пЉМжИСеЉАеІЛжЬЙдЇЖдЄАдЇЫжЦ∞зЪДиЃ§иѓЖеТМиІБиІ£гАВжГ≥и¶БеЫЮз≠Ф Flink еИ∞еЇХжШѓжАОдєИж†ЈзЪДдЄАдЄ™иЃ°зЃЧеЉХжУОпЉМеЃГз©ґзЂЯжГ≥иІ£еЖ≥дїАдєИж†ЈзЪДйЧЃйҐШињЩдЄ™зЦСйЧЃпЉМжИСдїђеЊЧдїОжХ∞жНЃжЬђиЇЂеЉАеІЛзЬЛиµЈгАВжѓХзЂЯпЉМдЄАдЄ™иЃ°зЃЧеЉХжУОжЙАи¶Бе§ДзРЖзЪДеѓєи±°пЉМе∞±жШѓжХ∞жНЃжЬђиЇЂгАВ
зђђдЄАдЄ™йЧЃйҐШжШѓпЉМжИСдїђйЬАи¶Бе§ДзРЖзЪДжХ∞жНЃйГљжШѓдїОеУ™йЗМжЭ•зЪДпЉЯеѓєе§ІйГ®еИЖеЕђеПЄеТМдЉБдЄЪжЭ•иѓіпЉМжХ∞жНЃеПѓиГљжЭ•иЗ™еРДзІНжЙЛжЬЇAPPпЉМIoTиЃЊе§ЗпЉМеЬ®зЇњжЬНеК°зЪДжЧ•ењЧпЉМзФ®жИЈзЪДжߕ胥з≠Йз≠ЙгАВиЩљзДґжХ∞жНЃзЪДжЭ•жЇРеТМзІНз±їеРДдЄНзЫЄеРМпЉМдљЖжЬЙдЄАдЄ™зЙєзВєеПѓиГљжШѓе§ІйГ®еИЖжГЕеЖµдЄЛйГљеЕЈе§ЗзЪДпЉЪ**жХ∞жНЃжАїжШѓеЃЮжЧґзЪДдЄНжЦ≠дЇІзФЯ**гАВ
жИСдїђеПѓдї•дљњзФ®жµБпЉИStreamпЉЙжИЦиАЕжЧ•ењЧпЉИLogпЉЙињЩж†ЈзЪДж¶ВењµжЭ•ж®°жЛЯжКљи±°жЙАйЬАи¶Бе§ДзРЖзЪДжХ∞жНЃпЉМињЩдєЯжШѓзО∞еЬ®дЄАзІНжѓФиЊГжµБи°МзЪДжКљи±°жЦєеЉПпЉМJay Kreps е§Із•ЮжЧ©еєіе∞±еЬ®дЄНйБЧдљЩеКЫзЪДжО®еєњињЩж†ЈзЪДжЦєеЉПпЉМжДЯеЕіиґ£зЪДеРМе≠¶еПѓдї•иѓїдЄАдЄЛињЩзѓЗеНЪжЦЗпЉЪ
[гАКThe Log: What every software engineer should know about real-time data's unifying abstractionгАЛ](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fengineering.linkedin.com%2Fdistributed-systems%2Flog-what-every-software-engineer-should-know-about-real-time-datas-unifying)гАВ

еЬ®ињЩйЗМеЕИиІ£з≠ФдЄАдЄЛеЄЄиІБзЪДеЗ†дЄ™зЦСжГСпЉМеЫ†дЄЇињЩдЄ™зЬЛиµЈжЭ•еТМе§ІеЃґеє≥жЧґжО•иІ¶еИ∞зЪДжХ∞жНЃжѓФиЊГдЄНдЄАж†ЈгАВеЄЄиІБзЪДйЧЃйҐШдЉЪжЬЙпЉЪ
* жИСеє≥жЧґзЪДжО•иІ¶зЪДжХ∞жНЃйГље≠ШеЬ®DatabaseйЗМпЉМзЬЛиµЈжЭ•ињЩдЄ™дЄНдЄАж†ЈеХКпЉЯDatabase еПѓдї•зРЖиІ£жИРдЄЇе∞ЖињЩдЇЫ Stream зЙ©еМЦеРОзЪДдЇІзЙ©пЉМдЄАиИђжШѓдЄЇдЇЖеРОзї≠зЪДйҐСзєБиЃњйЧЃеПѓдї•жЫіењЂгАВиАМдЄФе§ІйГ®еИЖ Database з≥їзїЯзЪДеЃЮзО∞йЗМпЉМеЕґеЃЮдєЯжШѓзФ®зЪД Log жЭ•е≠ШеВ®жЙАжЬЙзЪДеҐЮеИ†жФєи°МдЄЇгАВ
* жИСеє≥жЧґжО•иІ¶зЪДжХ∞жНЃйГљжФЊеЬ®жХ∞дїУйЗМпЉМжМЙзŲ姩еБЪдЇЖеИЖеМЇгАВињЩзІНжГЕеЖµеПѓдї•еЖНеЊАжХ∞жНЃзЪДжЇРе§іжГ≥дЄАдЄЛпЉМжХ∞жНЃеИЪдЇІзФЯзЪДжЧґеАЩдЄНдЉЪзЫіжО•еИ∞дљ†зЪДжХ∞дїУпЉМдЄАиИђдєЯжШѓйЬАи¶БзїПињЗдЄАдЄ™ ETL ињЗз®ЛгАВдЄАиИђзЪДжХ∞дїУеПѓдї•зРЖиІ£жИРе∞ЖињЗеОїзЪДдЄАжЃµжЃµжЬЙйЩРжµБпЉМиљђе≠ШжИРдЇЖжЫійЂШжХИзЪДж†ЉеЉПгАВ
ељУжИСдїђдљњзФ®ињЩж†ЈзЪДжЦєеЉПжЭ•жКљи±°жХ∞жНЃдєЛеРОпЉМжИСдїђе∞±еПѓдї•иАГиЩСжИСдїђдЉЪеЬ®ињЩж†ЈзЪДжХ∞жНЃдЄКеБЪдїАдєИж†Јз±їеЮЛзЪДиЃ°зЃЧдЇЖгАВеЕИдїОжЬЙйЩРжµБеЉАеІЛпЉЪ
* еѓєињЗеОїзЪДдЄАйГ®еИЖжХ∞жНЃеБЪдЄАдЄЛзЃАеНХзЪДжЄЕжіЧеТМе§ДзРЖпЉМињЩеЯЇжЬђдЄКе∞±жШѓе§ІйГ®еИЖзїПеЕЄзЪДжЙєе§ДзРЖ ETL дљЬдЄЪ
* еѓєињЗеОїзЪДдЄАйГ®еИЖжХ∞жНЃеБЪдЄАдЇЫз®НеЊЃе§НжЭВзВєзЪДеЕ≥иБФеТМеИЖжЮРпЉМињЩзЃЧжШѓжѓФ ETL з®НеЊЃе§НжЭВзВєзЪДжЙєе§ДзРЖдљЬдЄЪ
* еѓєињЗеОїзЪДдЄАйГ®еИЖжХ∞жНЃињЫи°МжЈ±еЇ¶зЪДжМЦжОШдїОиАМдЇІзФЯжЫіжЈ±зЪДжіЮеѓЯпЉМињЩжШѓжЬЇеЩ®е≠¶дє†иЃ≠зїГж®°еЮЛзЪДеЬЇжЩѓ
еѓєдЇОжЧ†йЩРжµБжЭ•иѓіпЉМжИСдїђйЬАи¶БжЧґеИїжґИиієжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃпЉМйВ£дєИеПѓиГљдЇІзФЯзЪДиЃ°зЃЧз±їеЮЛдЉЪжЬЙпЉЪ
* еТМжЙєе§ДзРЖз±їдЉЉзЪД ETL еТМеИЖжЮРеЮЛзЪДжХ∞жНЃе§ДзРЖеЬЇжЩѓпЉМеП™дЄНињЗиЃ°зЃЧеПСзФЯеЬ®жЬАжЦ∞еЃЮжЧґдЇІзФЯзЪДжХ∞жНЃдЄК
* еѓєдЇОжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃињЫи°МзЙєеЊБеИЖжЮРеТМжМЦжОШпЉМињЩжШѓжЬЇеЩ®е≠¶дє†еЃЮжЧґиЃ≠зїГж®°еЮЛзЪДеЬЇжЩѓ
* е∞ЖжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃж†ЈжЬђеМЦпЉМзДґеРОе•ЧзФ®жЬЇеЩ®е≠¶дє†ж®°еЮЛињЫи°МеИ§еЃЪпЉМињЩжШѓеЕЄеЮЛзЪДеЃЮжЧґйҐДжµЛеЬЇжЩѓ
* ж†єжНЃжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃпЉМиІ¶еПСдЄАз≥їеИЧеРОеП∞дЄЪеК°йАїиЊСпЉМињЩе∞±жШѓеЕЄеЮЛзЪД Application жИЦиАЕеЬ®зЇњжЬНеК°еЬЇжЩѓ

зЙєеИЂеАЉеЊЧж≥®жДПзЪДжШѓпЉМжЬЙйЩРжµБзЪДиЃ°зЃЧеТМжЧ†йЩРжµБзЪДиЃ°зЃЧеєґдЄНжШѓеЃМеЕ®зЛђзЂЛе≠ШеЬ®зЪДпЉМжЬЙжЧґеАЩжИСдїђзЪДиЃ°зЃЧйЬАи¶БеЬ®дЄ§иАЕдєЛйЧіињЫи°МеИЗжНҐпЉМжѓФе¶ВињЩдЇЫеЬЇжЩѓпЉЪ
* еЕИе∞ЖжЙАжЬЙзЪДеОЖеП≤жХ∞жНЃињЫи°Ме§ДзРЖпЉМзДґеРОеЉАеІЛеЃЮжЧґжґИиієжЬАжЦ∞дЇІзФЯзЪДжХ∞жНЃгАВжѓФе¶ВиѓізїЯиЃ°зЪДеЬЇжЩѓпЉМељУзїЯиЃ°еП£еЊДеПШеМЦдєЛеРОпЉМжИСдїђеЄМжЬЫеЕИжККжЙАжЬЙеОЖеП≤жХ∞жНЃйЗНжЦ∞зїЯиЃ°дЄАйБНпЉМзДґеРОеЖНжО•дЄКжЬАжЦ∞зЪДжХ∞жНЃињЫи°МеЃЮжЧґзїЯиЃ°гАВ
* жИСдїђеЕИж†єжНЃеОЖеП≤жХ∞жНЃињЫи°Мж†ЈжЬђзФЯжИРзДґеРОиЃ≠зїГж®°еЮЛпЉМзДґеРОеЖНжґИиієжЬАжЦ∞зЪДжХ∞жНЃпЉМе∞ЖеЕґиљђеМЦдЄЇж†ЈжЬђеРОеЉАеІЛеБЪеЃЮжЧґзЪДйҐДжµЛеТМеИ§еЃЪгАВињЩдєЯжШѓжЬЇеЩ®е≠¶дє†дЄ≠еЊИеЕЄеЮЛзЪДеБЪж≥ХпЉМеЕ≥йФЃзВєеЬ®дЇОйЬАи¶БдњЭиѓБиЃ≠зїГж®°еЮЛжЧґзЪДж†ЈжЬђйАїиЊСеТМеЃЮжЧґеИ§еЃЪжЧґзЪДж†ЈжЬђйАїиЊСйЬАи¶БдњЭжМБдЄАиЗігАВ
еП¶е§ЦпЉМжИСдїђдєЯеПѓдї•е∞ЭиѓХдїОиЃ°зЃЧзЪДеїґињЯзЪДиІТеЇ¶еѓєињЩдЇЫзєБе§ЪзЪДиЃ°зЃЧж®°еЉПињЫи°Ме§ІиЗізЪДеИЖз±їпЉЪ

еИЧдЄЊдЇЖињЩдєИе§ЪдЊЛе≠РеТМеЬЇжЩѓдєЛеРОпЉМе§ІеЃґеЇФиѓ•дєЯеЈЃдЄНе§ЪиГљйҐЖжВЯеИ∞еЕґдЄ≠зЪДйБУзРЖдЇЖгАВељУжИСдїђеЯЇдЇО Stream жЭ•жКљи±°жЙАжЬЙзЪДжХ∞жНЃдєЛеРОпЉМеЬ®жХ∞жНЃдєЛдЄКеЉХеПСзЪДиЃ°зЃЧж®°еЉПжШѓзЫЄељУзЪДе§Ъж†ЈеМЦзЪДгАВж≠£е¶В Stephan дЄАеЉАеІЛеЬ® keynote дЄ≠жПРеИ∞зЪДпЉМдЉ†зїЯзЪД Data Processing еТМжґИжБѓй©±еК®зЪД Application еЬЇжЩѓпЉМйГљдЄНиґ≥дї•и¶ЖзЫЦжЙАжЬЙзЪДиЃ°зЃЧж®°еЮЛгАВжЙАжЬЙиЃ°зЃЧж®°еЮЛзЪДжЬђиі®жШѓ Stream ProcessingпЉМеП™дЄНињЗжЬЙжЧґеАЩжИСдїђйЬАи¶БеОїе§ДзРЖжЬЙйЩРзЪДжХ∞жНЃпЉМжЬЙжЧґеАЩжИСдїђеПИйЬАи¶БеОїе§ДзРЖжЬАжЦ∞зЪДеЃЮжЧґжХ∞жНЃгАВFlink зЪДжДњжЩѓе∞±жШѓжИРдЄЇдЄАдЄ™йАЪзФ®зЪД Stream Processing еЉХжУОпЉМеєґи¶ЖзЫЦеЯЇдЇОињЩдЄ™иМГеЉПзЪДжЙАжЬЙеПѓиГљзЪДжѓФиЊГеЕЈдљУзЪДиЃ°зЃЧеЬЇжЩѓгАВињЩж†ЈдЄАжЭ•ељУзФ®жИЈжЬЙдЄНеРМзЪДиЃ°зЃЧйЬАж±ВжЧґпЉМдЄНйЬАи¶БйАЙжЛ©е§ЪдЄ™дЄНеРМзЪДз≥їзїЯпЉИжѓФе¶ВзїПеЕЄзЪД lambda жЮґжЮДпЉМжИСдїђйЬАи¶БйАЙжЛ©дЄАдЄ™дЄУйЧ®зЪДжЙєе§ДзРЖеЉХжУОеТМдЄУйЧ®зЪДжµБиЃ°зЃЧеЉХжУОпЉЙгАВеРМжЧґељУжИСдїђйЬАи¶БеЬ®дЄНеРМзЪДиЃ°зЃЧж®°еЉПйЧіињЫи°МеИЗжНҐзЪДжЧґеАЩпЉИжѓФе¶ВеЕИе§ДзРЖеОЖеП≤жХ∞жНЃеЖНжО•дЄКеЃЮжЧґжХ∞жНЃпЉЙпЉМдљњзФ®зЫЄеРМзЪДиЃ°зЃЧеЉХжУОдєЯжЬЙеИ©дЇОжИСдїђдњЭиѓБи°МдЄЇзЪДзїЯдЄАгАВ
[еОЯжЦЗйУЊжО•](https://yq.aliyun.com/articles/721993)
жЬђжЦЗдЄЇдЇСж†Цз§ЊеМЇеОЯеИЫеЖЕеЃєпЉМжЬ™зїПеЕБиЃЄдЄНеЊЧиљђиљљгАВ
еИЖдЇЂеИ∞пЉЪ


- 2019-11-01 15:09
- жµПиІИ 442
- иѓДиЃЇ(0)
- еИЖз±ї:йЭЮжКАжЬѓ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
йАЪињЗFlink Forward 2018зЪДиµДжЦЩпЉМиѓїиАЕдЄНдїЕеПѓдї•жЈ±еЕ•дЇЖиІ£FlinkзЪДзРЖиЃЇзЯ•иѓЖпЉМињШиГљиОЈеЊЧиЃЄе§ЪеЃЮйЩЕжУНдљЬзЪДзїПй™МеТМжКАеЈІпЉМеѓєдЇОеЄМжЬЫеЬ®е§ІжХ∞жНЃйҐЖеЯЯжЈ±еМЦFlinkжКАжЬѓеЇФзФ®зЪДдЄУдЄЪдЇЇе£ЂжЭ•иѓіпЉМжЧ†зЦСжШѓдЄАдїљеЃЭиіµзЪДе≠¶дє†иµДжЇРгАВ
**ж†ЗйҐШдЄОжППињ∞иІ£жЮРпЉЪ** ...жАїзїУпЉМ"Flink Forward China 2018.12.23 PPT"еМЕеРЂзЪДиµДжЦЩеПѓиГљдЉЪжґµзЫЦдЄКињ∞зЪДFlinkжКАжЬѓзїЖиКВпЉМжЈ±еЕ•иЃ≤иІ£FlinkзЪДжЬАжЦ∞еПСе±ХгАБеЃЮжИШж°ИдЊЛеТМжЬАдљ≥еЃЮиЈµпЉМеѓєдЇОдЇЖиІ£еТМжОМжП°FlinkињЩдЄАеЉЇе§ІзЪДжµБе§ДзРЖж°ЖжЮґйЭЮеЄЄжЬЙеЄЃеК©гАВ
дЇМгАБжµБжЙєдЄАдљУпЉЪйЗНзВєиЃ®иЃЇжµБжЙєдЄАдљУжЮґжЮДеЬ®дЄНеРМдЄЪеК°еЬЇжЩѓдЄ≠зЪДеЃЮиЈµж°ИдЊЛеТМжФґзЫКпЉМеИЖжЮРеЬ®иРљеЬ∞жµБжЙєдЄАдљУињЗз®ЛдЄ≠йБЗеИ∞зЪДзЧЫзВєдЄОжАЭиАГгАВ дЄЙгАБData+AI иЮНеРИпЉЪиБЪзД¶еЃЮжЧґе§ІжХ∞жНЃе§ДзРЖдЄОдЇЇеЈ•жЩЇиГљзЪДеЙНж≤њиЮНеРИпЉМжОҐиЃ®е¶ВдљХеИ©зФ® Flink еК©еКЫ AI е§І...
Flink Forward Asia 2021PPTеРИйЫЖпЉИ79дїљпЉЙгАВ йАЪињЗе§ІдЉЪеПѓдї•дЇЖиІ£еИ∞еЫљеЖЕе§ЦдЄАзЇњеОВеХЖеЫізїХ Flink зФЯжАБзЪДзФЯдЇІеЃЮиЈµзїПй™МгАВ еЈ•еХЖйУґи°МеЃЮжЧґе§ІжХ∞жНЃеє≥еП∞еїЇиЃЊеОЖз®ЛеПКе±ХжЬЫ еЃЮжЧґиЃ°зЃЧзЪДеПСе±ХдЄОе±ХжЬЫ жЈ±еЇ¶иІ£жЮРFlinkзїЖз≤ТеЇ¶иµДжЇРзЃ°зРЖ зЊОеЫҐ...
гАРж†ЗйҐШгАС"Flink Forward China 2018 PPT" жґµзЫЦдЇЖ2018еєіFlink Forward Chinaе§ІдЉЪзЪДдЄїи¶БжЉФиЃ≤еТМжКАжЬѓеИЖдЇЂеЖЕеЃєгАВињЩеЬЇе§ІдЉЪжШѓдЄ≠еЫљFlinkеЉАеПСиАЕеТМжКАжЬѓзИ±е•љиАЕзЪДдЄАжђ°зЫЫдЉЪпЉМиБЪзД¶дЇОApache FlinkеЃЮжЧґиЃ°зЃЧж°ЖжЮґзЪДжЬАжЦ∞еПСе±ХгАБжЬАдљ≥еЃЮиЈµ...
гАКFlink Forward Asia 2019пЉЪе§ІжХ∞жНЃжµБе§ДзРЖзЪДжЈ±еЇ¶жΥ糥гАЛ Flink Forward Asia 2019 жШѓдЄАеЬЇиБЪзД¶дЇОApache FlinkжКАжЬѓзЪДзЫЫдЉЪпЉМж±ЗйЫЖдЇЖеЕ®зРГй°ґе∞ЦзЪДFlinkдЄУеЃґеТМеЉАеПСиАЕпЉМеЕ±еРМжОҐиЃ®ињЩдЄАеИЖеЄГеЉПжµБе§ДзРЖж°ЖжЮґзЪДжЬАжЦ∞ињЫе±ХдЄОеЇФзФ®еЃЮиЈµгАВињЩ...
еЬ®2018еєі9жЬИ3жЧ•иЗ≥5жЧ•пЉМеЕ®зРГе§ІжХ∞жНЃйҐЖеЯЯзЪДзД¶зВєиБЪйЫЖеЬ®еЊЈеЫљжЯПжЮЧпЉМдЄЊеКЮдЇЖзЫЫе§ІзЪДFlink Forward 2018е§ІдЉЪгАВињЩеЬЇдЉЪиЃЃжШѓApache Flinkз§ЊеМЇзЪДйЗНи¶БжіїеК®пЉМеРЄеЉХдЇЖдЉЧе§ЪеЉАеПСиАЕгАБжХ∞жНЃзІСе≠¶еЃґеТМжКАжЬѓзИ±е•љиАЕеПВдЄОпЉМеЕ±еРМжОҐиЃ®FlinkињЩдЄАеЉАжЇРжµБ...
Flink Forward Asia 2019 PPT , FFA 2019 PPT гАВ1. дЄїдЉЪеЬЇ 2. Apache Flink ж†ЄењГжКАжЬѓ 3. еЉАжЇРе§ІжХ∞жНЃзФЯжАБ 4. дЉБдЄЪеЃЮиЈµ 5. дЇЇеЈ•жЩЇиГљ 6. еЃЮжЧґжХ∞дїУ
"Flink Forward China 2018вАФвАФеЬ®зЇњжЬЇеЩ®е≠¶дє†еє≥еП∞еТМзЃЧж≥Х" Flink Forward China 2018жШѓйШњйЗМдЇСдЄЊеКЮзЪДдЄАеЬЇе§ІеЮЛжКАжЬѓе≥∞дЉЪпЉМжЬђжђ°е≥∞дЉЪиБЪзД¶еЬ®зЇњжЬЇеЩ®е≠¶дє†еє≥еП∞еТМзЃЧж≥ХпЉМжЧ®еЬ®иЃ®иЃЇеЬ®зЇњжЬЇеЩ®е≠¶дє†еЬ® IoTгАБSmart FactoryгАБSmart ...
ж†ЗйҐШжПРеПКзЪДжШѓвАЬ2021 Flink Forward Asia е§ІдЉЪиµДжЦЩж±ЗжАївАЭпЉМињЩи°®жШОињЩжШѓдЄАдЄ™еЕ≥дЇОApache FlinkжКАжЬѓзЪДе§ІеЮЛдЉЪиЃЃжіїеК®пЉМFlink Forward AsiaжШѓеЕ®зРГиМГеЫіеЖЕиБЪзД¶дЇОFlinkжКАжЬѓзЪДйЗНи¶БеєіеЇ¶зЫЫдЉЪгАВ2021еєізЪДе§ІдЉЪзЙєеИЂж±ЗйЫЖдЇЖ79дїљиµДжЦЩпЉМ...
Flink Next, Beyond Stream Processing-Flink Forward Asia 2021
"Flink Forward China 2018вАФвАФRedefining Computation" Apache FlinkжШѓдЄАзІНеЉАжЇРзЪДеИЖеЄГеЉПжµБе§ДзРЖеЉХжУОпЉМиГље§ЯеЃЮжЧґе§ДзРЖе§ІйЗПжХ∞жНЃжµБгАВFlink Forward China 2018жШѓйШњйЗМдЇСзїДзїЗзЪДдЄАжђ°дЉЪиЃЃпЉМжЧ®еЬ®жО®еК®FlinkеЬ®дЄ≠еЫљзЪДеЇФзФ®еТМеПСе±Х...
жО•зЭАпЉМжИСдїђеПѓдї•дЇЖиІ£еИ∞Flink SQLзЪДеЈ•дљЬжµБз®ЛеТМйЫЖзЊ§йГ®зљ≤ж®°еЉПгАВFlinkжФѓжМБе§ЪзІНйГ®зљ≤ж®°еЉПпЉМеМЕжЛђApplicationж®°еЉПгАБPerJobж®°еЉПеТМSessionж®°еЉПгАВApplicationж®°еЉПдЄЛпЉМTableEnvironmentеЬ®дљЬдЄЪжПРдЇ§еРОйААеЗЇпЉЫPerJobж®°еЉПдЄЛпЉМ...
иЕЊиЃѓжЦ∞йЧїеЯЇдЇОFlink+PipeLineж®°еЉПзЪДеЃЮиЈµдЄОеЇФзФ®-Flink Forward Asia 2021
ж†ЗйҐШгАКFLINK SQL еЬ®ењЂжЙЛзЪДжЙ©е±ХеТМеЃЮиЈµ-Flink Forward Asia 2021гАЛеТМжППињ∞гАКFLINK SQL еЬ®ењЂжЙЛзЪДжЙ©е±ХеТМеЃЮиЈµ-Flink Forward Asia 2021гАЛжЙАжґЙеПКзЪДзЯ•иѓЖзВєдЄїи¶БйЫЖдЄ≠еЬ®еѓєApache FlinkеПКеЕґSQLжО•еП£еЬ®ењЂжЙЛеє≥еП∞зЪДеЇФзФ®еТМжЙ©е±ХеЃЮиЈµгАВ...
гАКиЧПзїПйШБ-Flink Forward China 2018вАФвАФдЇСдЄКиЃ°зЃЧжЩЃжГ†зІСжКА.pdfгАЛињЩзѓЗжЦЗж°£дЄїи¶БжОҐиЃ®дЇЖйШњйЗМдЇСеЬ®FlinkжКАжЬѓдЄКзЪДеЇФзФ®еТМеПСе±ХпЉМдї•еПКдЇСиЃ°зЃЧе¶ВдљХжО®еК®зІСжКАжЩЃжГ†еМЦгАВFlinkжШѓдЄАдЄ™еЉАжЇРзЪДжµБе§ДзРЖж°ЖжЮґпЉМеЃГеЬ®е§ІжХ∞жНЃе§ДзРЖйҐЖеЯЯжЙЃжЉФзЭАйЗНи¶БзЪД...
еЬ®дЇђдЄЬзЪДжРЬ糥жО®иНРз≥їзїЯдЄ≠пЉМAlinkеТМTensorflow on FlinkзЪДеЇФзФ®жЙЃжЉФдЇЖеЕ≥йФЃиІТиЙ≤пЉМдї•жї°иґ≥йЂШжЧґжХИжАІеТМйЂШжХИжАІиГљзЪДйЬАж±ВгАВAlinkжШѓдЄАдЄ™еЯЇдЇОFlinkзЪДжЬЇеЩ®е≠¶дє†ж°ЖжЮґпЉМеЃГжЧ®еЬ®дЄЇеЃЮжЧґеТМжЙєйЗПжХ∞жНЃе§ДзРЖжПРдЊЫзїЯдЄАзЪДиІ£еЖ≥жЦєж°ИгАВиАМTensorflow ...
FlinkеЉХжУОеЬ®ењЂжЙЛзЪДжЈ±еЇ¶дЉШеМЦдЄОзФЯдЇІеЃЮиЈµпЉМдЄїи¶БжґЙеПКењЂжЙЛеЖЕйГ®дљњзФ®Apache FlinkзЪДеОЖз®ЛгАБзО∞зКґгАБдЉШеМЦжО™жЦљдї•еПКеѓєжЬ™жЭ•зЪДеПСе±ХиІДеИТгАВжЬђзѓЗжЦЗж°£зФ±ењЂжЙЛжКАжЬѓдЄУеЃґеИШеїЇеИЪињЫи°МеИЖдЇЂпЉМеЕґдЄ≠жґµзЫЦдЇЖFlinkеЬ®ењЂжЙЛеЖЕйГ®зЪДеЃЮиЈµеТМдЉШеМЦзЪДе§ЪдЄ™еЕ≥йФЃзВє...
гАРFlinkеЬ®жШУиљ¶иРљеЬ∞еЇФзФ®дЄОеЃЮиЈµгАС жШУиљ¶еЕђеПЄдљЬдЄЇдЄАеЃґдЄУж≥®дЇОж±љиљ¶и°МдЄЪзЪДдЇТиБФзљСдЉБдЄЪпЉМеЕґжХ∞жНЃеє≥еП∞еЬ®ињСеєіжЭ•йАРжЄРйЗЗзФ®Apache FlinkдљЬдЄЇеЃЮжЧґиЃ°зЃЧзЪДж†ЄењГеЉХжУОпЉМеЃЮзО∞дЇЖжµБе§ДзРЖдЄОжЙєе§ДзРЖзЪДдЄАдљУеМЦпЉМжПРеНЗдЇЖжХ∞жНЃе§ДзРЖзЪДжХИзОЗеТМеЗЖз°ЃжАІгАВ...