测试环境虚拟机
CPU:2核
RAM:2G
Kafka Topic为1分区,1副本
Kafka生产者端发送延迟优化
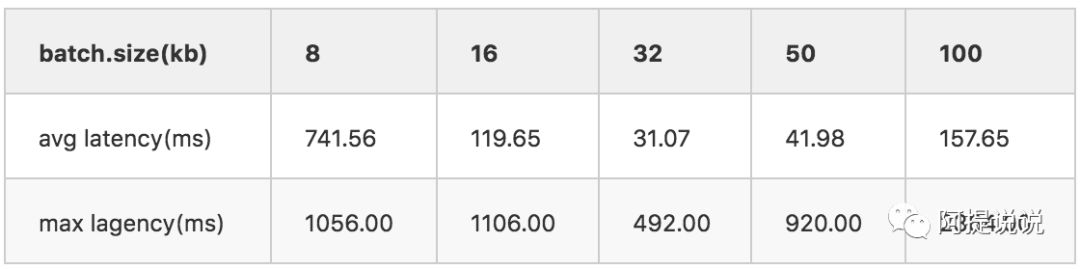
batch.size
batch.size 单位为字节,为了方便这里都表示为kb
默认配置,batch.size=16kb
[root@10 kafka_2.11-2.2.0]# ./bin/kafka-producer-perf-test.sh --producer.config config/me.properties --topic first --record-size 1024 --num-records 1000000 --throughput 50000
249892 records sent, 49978.4 records/sec (48.81 MB/sec), 153.6 ms avg latency, 537.0 ms max latency.
250193 records sent, 50038.6 records/sec (48.87 MB/sec), 1.4 ms avg latency, 12.0 ms max latency.
211747 records sent, 42349.4 records/sec (41.36 MB/sec), 194.3 ms avg latency, 1106.0 ms max latency.
1000000 records sent, 49972.515117 records/sec (48.80 MB/sec), 119.65 ms avg latency, 1106.00 ms max latency, 2 ms 50th, 488 ms 95th, 1043 ms 99th, 1102 ms 99.9th.
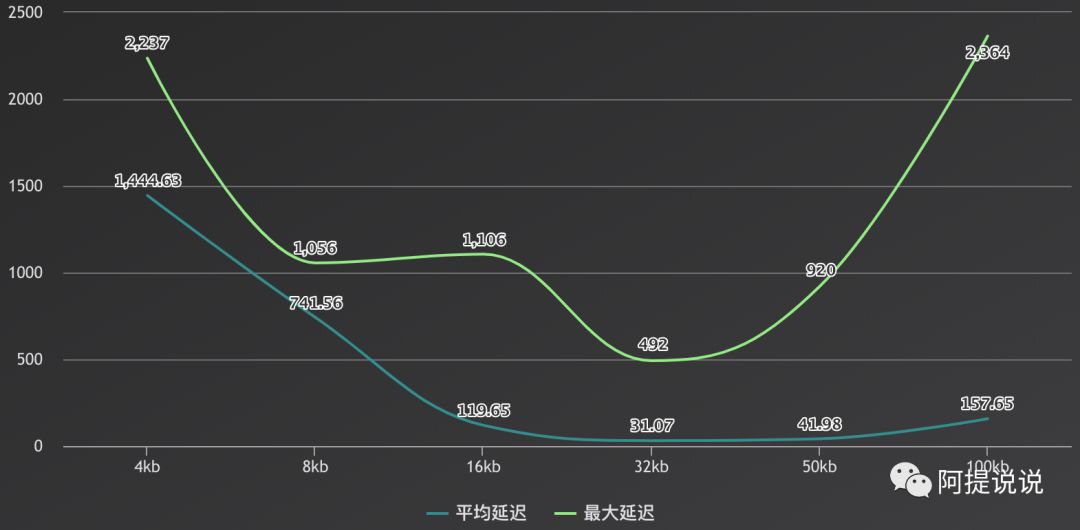
结果显示平均延迟有456.94 ms,最高延迟5308.00 ms
现在我要降低最高延迟数,batch.size的意思是ProducerBatch的内存区域充满后,消息就会被立即发送,那我们把值改小看看
batch.size=8kb
[root@10 kafka_2.11-2.2.0]# ./bin/kafka-producer-perf-test.sh --producer.config config/me.properties --topic first --record-size 1024 --num-records 1000000 --throughput 50000
148553 records sent, 29710.6 records/sec (29.01 MB/sec), 812.4 ms avg latency, 1032.0 ms max latency.
195468 records sent, 39093.6 records/sec (38.18 MB/sec), 735.9 ms avg latency, 907.0 ms max latency.
189700 records sent, 37940.0 records/sec (37.05 MB/sec), 763.4 ms avg latency, 1053.0 ms max latency.
208418 records sent, 41683.6 records/sec (40.71 MB/sec), 689.7 ms avg latency, 923.0 ms max latency.
196504 records sent, 39300.8 records/sec (38.38 MB/sec), 718.1 ms avg latency, 1056.0 ms max latency.
1000000 records sent, 37608.123355 records/sec (36.73 MB/sec), 741.56 ms avg latency, 1056.00 ms max latency, 725 ms 50th, 937 ms 95th, 1029 ms 99th, 1051 ms 99.9th.
但经过测试发现,延迟反而很高,连设定的50000吞吐量都达不到,原因应该是这样:batch.size小了,消息很快就会充满,这样消息就会被立即发送的服务端,但这样的话发送的次数就变多了,但由于网络原因是不可控的,有时候网络发生抖动就会造成较高的延迟
那就改大看看。
batch.size=32kb
[root@10 kafka_2.11-2.2.0]# ./bin/kafka-producer-perf-test.sh --producer.config config/me.properties --topic first --record-size 1024 --num-records 1000000 --throughput 50000
249852 records sent, 49970.4 records/sec (48.80 MB/sec), 88.8 ms avg latency, 492.0 ms max latency.
250143 records sent, 50028.6 records/sec (48.86 MB/sec), 1.2 ms avg latency, 15.0 ms max latency.
250007 records sent, 49991.4 records/sec (48.82 MB/sec), 1.2 ms avg latency, 17.0 ms max latency.
1000000 records sent, 49952.545082 records/sec (48.78 MB/sec), 31.07 ms avg latency, 492.00 ms max latency, 1 ms 50th, 305 ms 95th, 440 ms 99th, 486 ms 99.9th.
测试后,平均延迟,最高延迟都降下来很多,而且比默认值延迟都要小很多,那再改大延迟还会降低吗
batch.size=50kb
[root@10 kafka_2.11-2.2.0]# ./bin/kafka-producer-perf-test.sh --producer.config config/me.properties --topic first --record-size 1024 --num-records 1000000 --throughput 50000
249902 records sent, 49970.4 records/sec (48.80 MB/sec), 27.3 ms avg latency, 219.0 ms max latency.
250200 records sent, 50030.0 records/sec (48.86 MB/sec), 1.2 ms avg latency, 8.0 ms max latency.
250098 records sent, 50019.6 records/sec (48.85 MB/sec), 18.6 ms avg latency, 288.0 ms max latency.
242327 records sent, 48407.3 records/sec (47.27 MB/sec), 121.3 ms avg latency, 920.0 ms max latency.
1000000 records sent, 49823.127896 records/sec (48.66 MB/sec), 41.98 ms avg latency, 920.00 ms max latency, 1 ms 50th, 221 ms 95th, 792 ms 99th, 910 ms 99.9th.
如上测试在不同的机器上结果会有不同,但总体的变化曲线是一样的,成U型变化
batch.size代码实现
Kafka客户端有一个RecordAccumulator类,叫做消息记录池,内部有一个BufferPool内存区域
RecordAccumulator(LogContext logContext,
int batchSize,
CompressionType compression,
int lingerMs,
long retryBackoffMs,
int deliveryTimeoutMs,
Metrics metrics,
String metricGrpName,
Time time,
ApiVersions apiVersions,
TransactionManager transactionManager,
BufferPool bufferPool)
当该判断为true,消息就会被发送
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
PS: 6.27号 2:30

max.in.flight.requests.per.connection
该参数可以在一个connection中发送多个请求,叫作一个flight,这样可以减少开销,但是如果产生错误,可能会造成数据的发送顺序改变,默认5
在batch.size=100kb的基础上,增加该参数值到10,看看效果
[root@10 kafka_2.11-2.2.0]# ./bin/kafka-producer-perf-test.sh --producer.config config/me.properties --topic two --record-size 1024 --num-records 1000000 --throughput 50000
249902 records sent, 49960.4 records/sec (48.79 MB/sec), 16.1 ms avg latency, 185.0 ms max latency.
250148 records sent, 50019.6 records/sec (48.85 MB/sec), 1.3 ms avg latency, 14.0 ms max latency.
239585 records sent, 47917.0 records/sec (46.79 MB/sec), 6.4 ms avg latency, 226.0 ms max latency.
1000000 records sent, 49960.031974 records/sec (48.79 MB/sec), 9.83 ms avg latency, 226.00 ms max latency, 1 ms 50th, 83 ms 95th, 182 ms 99th, 219 ms 99.9th.
多次测试结果延迟都比原来降低了10倍多,效果还是很明显的
但物极必反,如果你再调大后,效果就不明显了,最终延迟反而变高,这个batch.size道理是一样的
compression.type
指定消息的压缩方式,默认不压缩
在原来batch.size=100kb,max.in.flight.requests.per.connection=10的基础上,设置compression.type=gzip 看看延迟是否还可以降低
[root@10 kafka_2.11-2.2.0]# ./bin/kafka-producer-perf-test.sh --producer.config config/me.properties --topic two --record-size 1024 --num-records 1000000 --throughput 50000
249785 records sent, 49957.0 records/sec (48.79 MB/sec), 2.5 ms avg latency, 199.0 ms max latency.
250091 records sent, 50008.2 records/sec (48.84 MB/sec), 1.9 ms avg latency, 17.0 ms max latency.
250123 records sent, 50024.6 records/sec (48.85 MB/sec), 1.5 ms avg latency, 18.0 ms max latency.
1000000 records sent, 49960.031974 records/sec (48.79 MB/sec), 1.89 ms avg latency, 199.00 ms max latency, 2 ms 50th, 4 ms 95th, 6 ms 99th, 18 ms 99.9th.
测试结果发现延迟又降低了,是不是感觉很强大
分享到:




相关推荐
标题中的"Kafka生产者消费者插件 steps.zip"指的是在Kettle 8.2版本中使用的,与Kafka交互的特定插件。这个插件允许Kettle作业或转换发送和接收消息到Kafka集群,从而实现数据的实时流动。 描述中提到,该插件适用...
`simple-kafka-producer-pool` 是一个基于 Java 开发的库,用于管理 Kafka 生产者的集合,以提高效率和性能。这个库的设计目标是为应用程序提供一个简单的方法来创建和管理多个 Kafka 生产者的实例,形成一个池,...
消息积压通常由生产者发送速度过快或消费者处理过慢引起,解决方法包括快速转发到其他topic或改进消费端程序。 延时队列和消息回溯是Kafka的两个高级特性,可用于处理特定时间后的消息消费和重新消费之前的消息。
它不是将我们的销售端点直接打入数据库,而是将销售数据推送到Kafka,从而充当“生产者”。 我们启动了一个“消费者”,它将从Kafka中获取数据并将其推入数据库。 使用说明 本演示假定您已经安装了docker和docker-...
4. **生产者API**:学习如何使用Java或Scala等语言的Kafka生产者API,发送消息到Kafka主题,包括批量生产和异步生产等模式。 5. **消费者API**:研究消费者端的编程,理解消费者组的概念,以及如何进行并行消费和...
- 生产者配置包括设置Bootstrap Servers(Kafka集群地址),键值编码器,acks配置(决定何时确认消息已被接收)等。 - 生产者负责将消息序列化,并将其发送到适当的分区。 6. **Kafka 消费者**: - 消费者从...
2. **Producers**:Kafka生产者的源码展示了如何将消息发送到服务器,包括分区策略的实现,如轮询、哈希等,以及幂等性和事务支持。 3. **Brokers**:Kafka服务器端的实现,包括如何存储和检索消息,以及如何处理...
1. **发布/订阅模型**:Kafka采用发布/订阅模型,生产者发布消息到主题(Topic),消费者则订阅这些主题以获取消息。 2. **分区与副本**:每个主题都可以被划分为多个分区(Partition),每个分区都有一个主副本和...
默认情况下,Kafka生产者使用轮询(Round Robin)策略将消息均匀地分发到所有分区。然而,有时我们希望消息能被发送到特定的分区,这可以通过设置消息的键(Key)来实现。生产者可以基于消息键的哈希值决定其所属的...
生产者配置通常包括设置bootstrap servers(Kafka集群的地址),key and value serializers(键值序列化方式),以及其他的性能优化参数,如batch size和linger time。在`application.properties`或`application.yml...
3. 生产者(Producer):生产者负责将数据发布到 Kafka 的主题中。你可以通过编程接口,如 Java 或 Scala API,创建生产者并向指定主题发送消息。 4. 消费者(Consumer):消费者从 Kafka 主题中读取数据。Kafka ...
- **Kafka Client**:提供生产者和消费者的API,用于与Kafka服务器进行交互。 - **Zookeeper**:Kafka依赖Zookeeper进行集群管理和协调。 - **Schema Registry**:用于处理Avro等序列化格式,管理消息的schema。 ...
acks=0时,生产者不等待任何确认,最快速但最易丢消息。适用于对数据完整性要求不高的场景。 - acks=1时,生产者只需等待leader确认,但如果follower未备份,仍可能导致消息丢失。 - acks=-1或all,需要所有副本...
消费者端,Kafka 提供了 `KafkaConsumer` 类,它支持多线程消费、分区分配策略以及自动和手动提交偏移量。`subscribe` 和 `assign` 方法分别用于基于主题订阅和直接指定分区进行消费。Kafka 还支持消费者组,同一组...
2. **接收信息**:消费者端,我们可以创建Consumer实例,订阅主题并使用poll()方法来获取新消息。消费者同样需要配置bootstrap servers、group id、offset管理策略等。 3. **创建Topic**:创建Topic是通过Kafka的...
检查JStorm UI以验证拓扑是否正常运行,同时观察Kafka的生产者和消费者端数据流动情况。 8. **监控与优化**:在实际部署中,需要关注性能指标,如处理速度、内存使用和错误率。根据需求调整JStorm和Kafka的配置,...
总结来说,通过增加 topic 分片、调整消费者数量、定制生产者的分发策略,以及理解并利用 Kafka 的消费者-分片模型,我们可以显著提高一个老系统的 Kafka 消费者服务的性能。在面对类似问题时,关键是深入理解业务...
Kafka 的生产者API进行了改进,允许批量发送消息,降低了网络通信的开销。同时,消费者端也有了性能提升,通过使用更有效的位图索引来定位消息偏移量,减少了磁盘I/O。 Kafka 0.8.1 还引入了命令行工具,使得管理和...
3. 生产者(Producer):生产者是向Kafka发布消息的应用程序,它们负责将数据写入主题的各个分区。 4. 消费者(Consumer):消费者从Kafka中读取数据,可以是单个应用程序实例或消费者组内的多个实例,实现负载均衡...
1. **生产者(Producer)**:负责将消息发送到Kafka的服务器端,通常使用`KafkaProducer`类来实现。 2. **消费者(Consumer)**:从Kafka获取消息,可以使用`KafkaConsumer`类来实现。消费者可以订阅一个或多个主题...