集合类结构
Java中的集合包含多种数据结构,如链表、队列、哈希表等。从类的继承结构来说,可以分为两大类,一类是继承自Collection接口,这类集合包含List、Set和Queue等集合类。另一类是继承自Map接口,这主要包含了哈希表相关的集合类。下面我们看一下这两大类的继承结构图:
1、List、Set和Queue
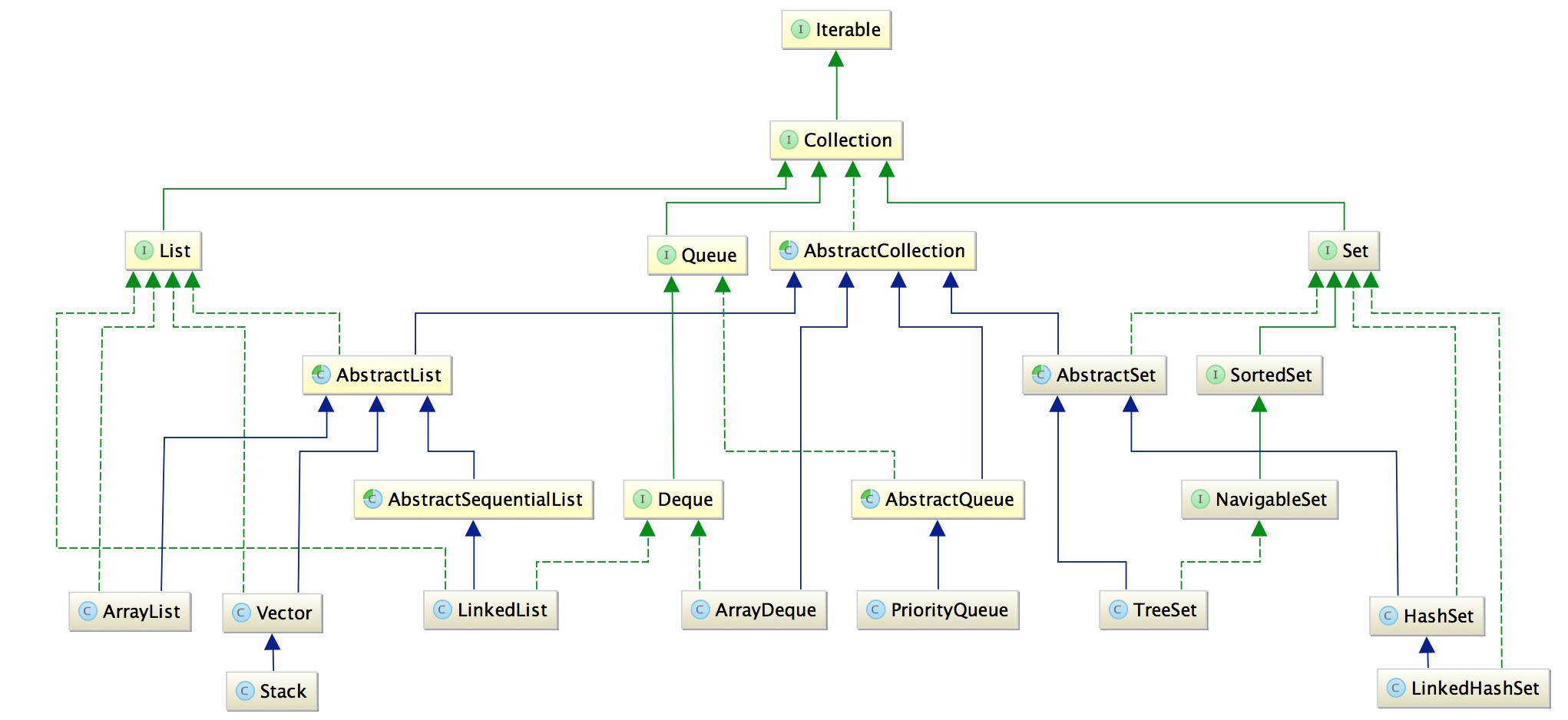
图中的绿色的虚线代表实现,绿色实线代表接口之间的继承,蓝色实线代表类之间的继承。
(1)List:我们用的比较多List包括ArrayList和LinkedList,这两者的区别也很明显,从其名称上就可以看出。ArrayList的底层的通过数组实现,所以其随机访问的速度比较快,但是对于需要频繁的增删的情况,效率就比较低了。而对于LinkedList,底层通过链表来实现,所以增删操作比较容易完成,但是对于随机访问的效率比较低。
我们先看下两者的插入效率:

1 package com.paddx.test.collection;
2
3 import java.util.ArrayList;
4 import java.util.LinkedList;
5
6 public class ListTest {
7 public static void main(String[] args) {
8 for(int i=0;i<10000;i++){
9
10 }
11 long start = System.currentTimeMillis();
12
13 LinkedList<Integer> linkedList = new LinkedList<Integer>();
14 for(int i=0;i<100000;i++){
15 linkedList.add(0,i);
16 }
17
18 long end = System.currentTimeMillis();
19 System.out.println(end - start);
20
21 ArrayList<Integer> arrayList = new ArrayList<Integer>();
22 for(int i=0;i<100000;i++){
23 arrayList.add(0,i);
24 }
25
26 System.out.println(System.currentTimeMillis() - end);
27 }
28 }
下面是本地执行的结果:
?
可以看出,在这种情况下,LinkedList的插入效率远远高于ArrayList,当然这是一种比较极端的情况。我们再来比较一下两者随机访问的效率:
1 package com.paddx.test.collection;
2
3 import java.util.ArrayList;
4 import java.util.LinkedList;
5 import java.util.Random;
6
7 public class ListTest {
8 public static void main(String[] args) {
9
10 Random random = new Random();
11
12 for(int i=0;i<10000;i++){
13
14 }
15 LinkedList<Integer> linkedList = new LinkedList<Integer>();
16 for(int i=0;i<100000;i++){
17 linkedList.add(i);
18 }
19
20 ArrayList<Integer> arrayList = new ArrayList<Integer>();
21 for(int i=0;i<100000;i++){
22 arrayList.add(i);
23 }
24
25 long start = System.currentTimeMillis();
26
27
28 for(int i=0;i<100000;i++){
29 int j = random.nextInt(i+1);
30 int k = linkedList.get(j);
31 }
32
33 long end = System.currentTimeMillis();
34 System.out.println(end - start);
35
36 for(int i=0;i<100000;i++){
37 int j = random.nextInt(i+1);
38 int k = arrayList.get(j);
39 }
40
41 System.out.println(System.currentTimeMillis() - end);
42 }
43 }
下面是我本机执行的结果:
?
很明显可以看出,ArrayList的随机访问效率比LinkedList高出好几个数量级。通过这两段代码,我们应该能够比较清楚的知道LinkedList和ArrayList的区别和适应的场景。至于Vector,它是ArrayList的线程安全版本,而Stack则对应栈数据结构,这两者用的比较少,这里就不举例了。
(2)Queue:一般可以直接使用LinkedList完成,从上述类图也可以看出,LinkedList继承自Deque,所以LinkedList具有双端队列的功能。PriorityQueue的特点是为每个元素提供一个优先级,优先级高的元素会优先出队列。
(3)Set:Set与List的主要区别是Set是不允许元素重复的,而List则可以允许元素重复的。判断元素的重复需要根据对象的hash方法和equals方法来决定。这也是我们通常要为集合中的元素类重写hashCode方法和equals方法的原因。我们还是通过一个例子来看一下Set和List的区别,以及hashcode方法和equals方法的作用:
package com.paddx.test.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Set;
public class SetTest {
public static void main(String[] args) {
Person p1 = new Person("lxp",10);
Person p2 = new Person("lxp",10);
Person p3 = new Person("lxp",20);
ArrayList<Person> list = new ArrayList<Person>();
list.add(p1);
System.out.println("---------");
list.add(p2);
System.out.println("---------");
list.add(p3);
System.out.println("List size=" + list.size());
System.out.println("----分割线-----");
Set<Person> set = new HashSet<Person>();
set.add(p1);
System.out.println("---------");
set.add(p2);
System.out.println("---------");
set.add(p3);
System.out.println("Set size="+set.size());
}
static class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
System.out.println("Call equals();name="+name);
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return name.equals(person.name);
}
@Override
public int hashCode() {
System.out.println("Call hashCode(),age="+age);
return age;
}
}
}
上述代码的执行结果如下:
?
| ---------
---------
List size=3
----分割线-----
Call hashCode(),age=10
---------
Call hashCode(),age=10
Call equals();name=lxp
---------
Call hashCode(),age=20
Set size=2
|
从结果看出,元素加入List的时候,不执行额外的操作,并且可以重复。而加入Set之前需要先执行hashCode方法,如果返回的值在集合中已存在,则要继续执行equals方法,如果equals方法返回的结果也为真,则证明该元素已经存在,会将新的元素覆盖老的元素,如果返回hashCode值不同,则直接加入集合。这里记住一点,对于集合中元素,hashCode值不同的元素一定不相等,但是不相等的元素,hashCode值可能相同。
HashSet和LinkedHashSet的区别在于后者可以保证元素插入集合的元素顺序与输出顺序保持一致。而TresSet的区别在于其排序是按照Comparator来进行排序的,默认情况下按照字符的自然顺序进行升序排列。
(4)Iterable:从这个图里面可以看到Collection类继承自Iterable,该接口的作用是提供元素遍历的功能,也就是说所有的集合类(除Map相关的类)都提供元素遍历的功能。Iterable里面包含了Iterator的迭代器,其源码如下,大家如果熟悉迭代器模式的话,应该很容易理解。
1 public interface Iterator<E> {
2
3 boolean hasNext();
4
5 E next();
6
7 void remove();
8 }
2、Map:
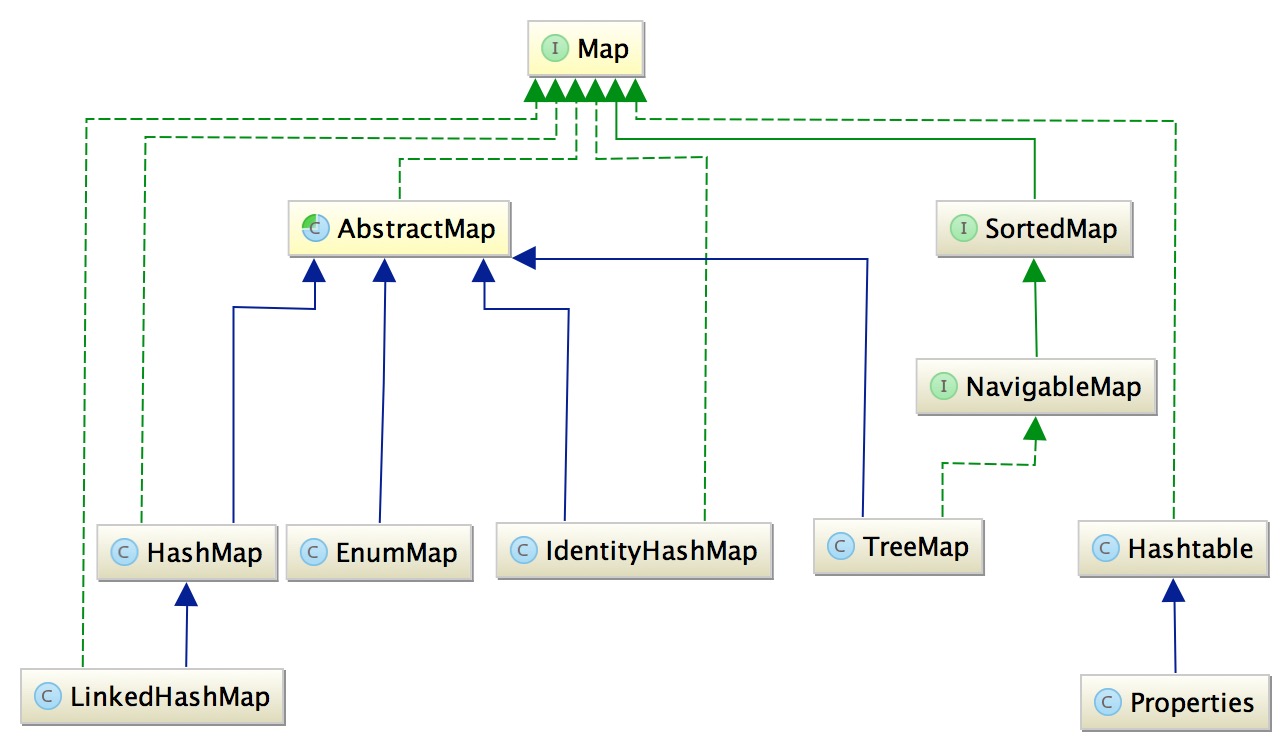
Map类型的集合最大的优点在于其查找效率比较高,理想情况下可以实现O(1)的时间复杂度。Map中最常用的是HashMap,LinkedHashMap与HashMap的区别在于前者能够保证插入集合的元素顺序与输出顺序一致。这两者与TreeMap的区别在于TreeMap是根据键值进行排序的,当然其底层的实现也有本质的区别,如HashMap底层是一个哈希表,而TreeMap的底层数据结构是一棵树。我们现在看下TreeMap与LinkedHashMap的区别:
package com.paddx.test.collection;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
public class MapTest {
public static void main(String[] args) {
Map<String,String> treeMap = new TreeMap<String,String>();
Map<String,String> linkedMap = new LinkedHashMap<String, String>();
treeMap.put("b",null);
treeMap.put("c",null);
treeMap.put("a",null);
for (Iterator<String> iter = treeMap.keySet().iterator();iter.hasNext();){
System.out.println("TreeMap="+iter.next());
}
System.out.println("----------分割线---------");
linkedMap.put("b",null);
linkedMap.put("c",null);
linkedMap.put("a",null);
for (Iterator<String> iter = linkedMap.keySet().iterator();iter.hasNext();){
System.out.println("LinkedHashMap="+iter.next());
}
}
}
运行上述代码,执行结果如下:
?
| TreeMap=a
TreeMap=b
TreeMap=c
----------分割线---------
LinkedHashMap=b
LinkedHashMap=c
LinkedHashMap=a
|
从运行结果可以很明显的看出这TreeMap和LinkedHashMap的区别,前者是按字符串排序进行输出的,而后者是根据插入顺序进行输出的。细心的读者可以发现,HashMap与TreeMap的区别,与之前提到的HashSet与TreeSet的区别是一致的,在后续进行源码分析的时候,我们可以看到HashSet和TreeSet本质上分别是通过HashMap和TreeMap来实现的,所以它们的区别自然也是相同的。HashTable现在已经很少使用了,与HashMap的主要区别是HashTable是线程安全的,不过由于其效率比较低,所以通常使用HashMap,在多线程环境下,通常用CurrentHashMap来代替。
三、总结
本文只是从整体上介绍了Java集合框架及其继承关系。除了上述类,集合还提供Collections和Arrays两个工具类,此外,集合中排序跟Comparable和Comparator紧密相关。在之后的文章中将对上述提的类在JDK中实现源码进行详细分析。




相关推荐
本文将深入探讨Java集合的整体结构,主要包括两大类:继承自`Collection`接口的集合和继承自`Map`接口的集合。 一、Collection接口及其子接口 1. `List`接口:`List`是`Collection`的一个子接口,它代表了一组有序...
在Java集合框架中,Map接口的实现类广泛用于存储键值对数据结构。主要实现类包括HashMap、Hashtable、LinkedHashMap和TreeMap。 1. HashMap:它利用键的hashCode值存储数据,根据键快速定位到值。由于使用了哈希表...
### Java宝典:数组与集合的神秘面纱——从新手到高手的进阶之路 #### 数据结构,编程的灵魂 在程序设计的世界里,数据结构扮演着至关重要的角色。它不仅决定了程序的性能,还直接影响了代码的可读性和可维护性。...
本文旨在为读者提供关于Java集合框架的概览性介绍,帮助理解其整体架构与设计理念。对于希望深入掌握特定接口或类使用方法的学习者,建议查阅官方提供的Java API文档。 #### 一、概述 数据结构在软件开发中扮演着...
1. **数组**:数组是最基本的数据结构,它包含相同类型的元素集合。在Java中,我们可以通过声明数组变量来创建数组,例如`int[] arr = new int[10];`,这将创建一个包含10个整数的数组。 2. **链表**:链表由一系列...
数据结构可以分为四类基本结构:集合结构、线性结构、树型结构、图状结构或网状结构。 三、数据结构的表示方法 数据结构在计算机中有两种不同的表示方法:顺序存储结构和链式存储结构。顺序存储结构用数据元素在...
本文提出了一种新的教学方法,通过数据结构和简化的内存模型来帮助学生更好地理解Java集合框架。 首先,教学方法的基础是数据结构理论。数据结构是一门研究数据组织、存储、操作的学科。在教学中,教师需要先回顾...
最后,实验16是项目实训,这通常是将前面所学知识综合应用到一个实际的物流信息管理系统项目中,以提升学生对Java编程的整体理解和应用能力。在这个过程中,学生会遇到类的继承、多态、接口、集合框架、线程同步等...
5. **逻辑结构**:数据之间的相互关系,通常分为以下四类基本结构: - **集合结构**:数据元素除了同属于一种类型外,别无其它关系。 - **线性结构**:数据元素之间存在一对一的关系。 - **树型结构**:数据元素...
"Java集合框架面试题" Java 集合框架是 Java 语言中的一组预定义类和接口的集合,用于存储和操作数据。下面是 Java 集合框架的知识点总结: 1. Java 集合类主要有两大分支:Collection 接口和 Map 接口。...
### Java集合类总结 #### 一、概述 Java集合类框架是Java标准库的一个重要组成部分,主要用于存储和...通过本文的介绍,希望能帮助读者建立起对Java集合框架的整体认知,并能在实际开发中更加灵活地运用这些集合类。
在Java编程语言中,数组是一种基本的数据结构,用于存储固定大小的同类型元素集合。数组倒置,也就是将数组中的元素顺序反转,是常见的编程练习,有助于理解和掌握数组操作。这个压缩包“Java数组倒置.zip”很可能...
2. **集合**:Java集合框架是用于存储对象的容器,包括ArrayList、LinkedList、HashSet、HashMap等。ArrayList基于动态数组,适合随机访问;LinkedList适合频繁进行插入和删除操作;HashSet不允许有重复元素,不保证...
1. **数据结构**:可能使用数组或集合框架(如ArrayList、LinkedList)来存储学生对象。 2. **面向对象编程**:定义学生类,包括私有化属性和公共方法。 3. **输入/输出流**:可能使用`Scanner`类从控制台读取用户...
Java中的数据结构如ArrayList或LinkedList可以用来存储商品信息,而Entity类则用于封装商品属性。同时,可能还会使用到Set集合来避免重复的商品,以及HashMap来快速查找商品。 2. **库存控制**:库存管理涉及商品的...
2. 查找速度:通过使用高效的哈希算法和数据结构,Koloboke在查找操作上比标准的Java集合更快。这对于需要频繁进行查找操作的应用来说,可以大大提高运行效率。 3. 并发性能:虽然Koloboke的主要优化目标不是并发,...
【JAVA魔板游戏课程设计报告】是一...总结来说,这个课程设计涵盖了JAVA GUI编程、面向对象设计、数据结构(如二维数组表示魔板)、文件I/O操作、图形处理以及游戏逻辑等多个方面的知识,旨在锻炼学生的综合编程能力。