
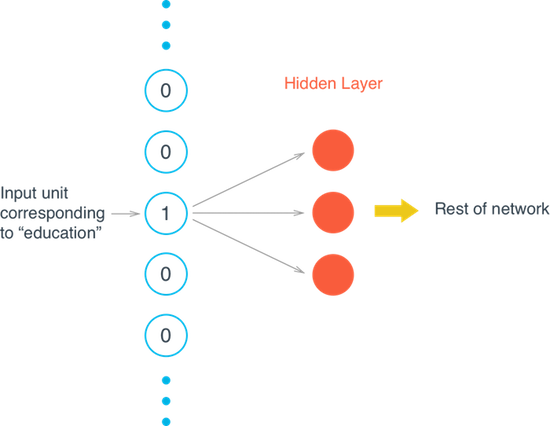
уљєУДБ Word2Vec С╣І Skip-Gram ТеАтъІ
Т│еТўј№╝џТѕЉтЈЉуј░уЪЦС╣јТюЅС║ЏтЁгт╝ЈтюеТЅІТю║уФ»СИЇТўЙуц║№╝їСйєтюеPCуФ»тЈ»С╗ЦТГБтИИТўЙуц║сђѓтљјжЮбуџёТќЄуФаТѕЉС╝џт░йжЄЈућетЏЙуЅЄТѕќУђЁу║»ТќЄТюгТЮЦУАеуц║тЁгт╝Ј№╝їТќ╣СЙ┐ТЅІТю║уФ»жўЁУ»╗сђѓ
тєЎтюеС╣ІтЅЇ
СИЊТаЈу╗ѕС║јућ│У»иТѕљтіЪтЋд№╝їСИЇУ┐Єуј░тюеТГБтюеућ│У»иТћ╣тљЇСИГ№╝їтЈ»УЃйУдЂт«АТаИтЄатцЕсђѓтљјжЮбТѕЉС╝џСИЇт«џТюЪтюеСИЊТаЈСИГТЏ┤Тќ░Тю║тЎетГдС╣атњїТи▒т║дтГдС╣ауџёСИђС║ЏтєЁт«╣№╝їСИ╗УдЂтїЁТІгТю║тЎетГдС╣ауџёТ»ћУхЏС╗БуаЂсђЂТи▒т║дтГдС╣ауџёу«ЌТ│ЋТђЮТЃ│С╗ЦтЈіТи▒т║дтГдС╣ауџёт«ъТѕўС╗БуаЂсђѓућ▒С║јуЏ«тЅЇТѕЉтюетЁгтЈИт«ъС╣аСИГ№╝їТЅђС╗Цт╣│ТЌХСИіуЈГТЌХжЌ┤т░▒У«цуюЪСИіуЈГтЋд№╝їСИІуЈГС╗ЦтљјтњїтЉеТюФТѕЉС╝џТійуЕ║тј╗тєЎУ┐ЎСИфСИЊТаЈ№╝їт»╣С║јУ»ёУ«║тї║уџёжЌ«жбўТѕЉС╣ЪС╝џт░йжЄЈСИђСИђтЏътцЇуџё№╝ЂУ┐ЎТгАуџётѕєС║ФСИ╗УдЂТў»т»╣Word2VecТеАтъІуџёСИцу»ЄУІ▒ТќЄТќЄТАБуџёу┐╗У»ЉсђЂуљєУДБтњїТЋ┤тљѕ№╝їУ┐ЎСИцу»ЄУІ▒ТќЄТќЄТАБжЃйТў»С╗Іу╗ЇWord2VecСИГуџёSkip-GramТеАтъІсђѓСИІСИђу»ЄСИЊТаЈТќЄуФат░єС╝џућеTensorFlowт«ъуј░тЪ║уАђуЅѕWord2Vecуџёskip-gramТеАтъІ№╝їТЅђС╗ЦТюгу»ЄТќЄуФатЁѕтЂџСИђСИфуљєУ«║жЊ║тъФсђѓ
тјЪТќЄУІ▒ТќЄТќЄТАБУ»итЈѓУђЃжЊЙТјЦ№╝џ
-┬аWord2Vec Tutorial - The Skip-Gram Model
-┬аWord2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram)
С╗ђС╣ѕТў»Word2VecтњїEmbeddings№╝Ъ
Word2VecТў»С╗јтцДжЄЈТќЄТюгУ»ГТќЎСИГС╗ЦТЌауЏЉуЮБуџёТќ╣т╝ЈтГдС╣аУ»ГС╣ЅуЪЦУ»єуџёСИђуДЇТеАтъІ№╝їт«ЃУбФтцДжЄЈтю░ућетюеУЄфуёХУ»ГУеђтцёуљє№╝ѕNLP№╝ЅСИГсђѓжѓБС╣ѕт«ЃТў»тдѓСйЋтИ«тіЕТѕЉС╗гтЂџУЄфуёХУ»ГУеђтцёуљєтЉб№╝ЪWord2VecтЁХт«ът░▒Тў»жђџУ┐ЄтГдС╣аТќЄТюгТЮЦућеУ»ЇтљЉжЄЈуџёТќ╣т╝ЈУАетЙЂУ»ЇуџёУ»ГС╣ЅС┐АТЂ»№╝їтЇ│жђџУ┐ЄСИђСИфтхїтЁЦуЕ║жЌ┤Сй┐тЙЌУ»ГС╣ЅСИіуЏИС╝╝уџётЇЋУ»ЇтюеУ»ЦуЕ║жЌ┤тєЁУиЮуд╗тЙѕУ┐ЉсђѓEmbeddingтЁХт«ът░▒Тў»СИђСИфТўат░ё№╝їт░єтЇЋУ»ЇС╗јтјЪтЁѕТЅђт▒ъуџёуЕ║жЌ┤Тўат░ётѕ░Тќ░уџётцџу╗┤уЕ║жЌ┤СИГ№╝їС╣Ът░▒Тў»ТіітјЪтЁѕУ»ЇТЅђтюеуЕ║жЌ┤тхїтЁЦтѕ░СИђСИфТќ░уџёуЕ║жЌ┤СИГтј╗сђѓТѕЉС╗гС╗јуЏ┤УДѓУДњт║дСИіТЮЦуљєУДБСИђСИІ№╝їcatУ┐ЎСИфтЇЋУ»Їтњїkittenт▒ъС║јУ»ГС╣ЅСИітЙѕуЏИУ┐ЉуџёУ»Ї№╝їУђїdogтњїkittenтѕЎСИЇТў»жѓБС╣ѕуЏИУ┐Љ№╝їiphoneУ┐ЎСИфтЇЋУ»ЇтњїkittenуџёУ»ГС╣Ѕт░▒ти«уџёТЏ┤У┐юС║єсђѓжђџУ┐Єт»╣У»ЇТ▒ЄУАеСИГтЇЋУ»ЇУ┐ЏУАїУ┐ЎуДЇТЋ░тђ╝УАеуц║Тќ╣т╝ЈуџётГдС╣а№╝ѕС╣Ът░▒Тў»т░єтЇЋУ»ЇУйгТЇбСИ║У»ЇтљЉжЄЈ№╝Ѕ№╝їУЃйтцЪУ«ЕТѕЉС╗гтЪ║С║јУ┐ЎТаиуџёТЋ░тђ╝У┐ЏУАїтљЉжЄЈтїќуџёТЊЇСйюС╗јУђїтЙЌтѕ░СИђС║ЏТюЅУХБуџёу╗ЊУ«║сђѓТ»ћтдѓУ»┤№╝їтдѓТъюТѕЉС╗гт»╣У»ЇтљЉжЄЈkittenсђЂcatС╗ЦтЈіdogТЅДУАїУ┐ЎТаиуџёТЊЇСйю№╝џkitten - cat + dog№╝їжѓБС╣ѕТюђу╗ѕтЙЌтѕ░уџётхїтЁЦтљЉжЄЈ№╝ѕembedded vector№╝Ѕт░єСИјpuppyУ┐ЎСИфУ»ЇтљЉжЄЈтЇЂтѕєуЏИУ┐Љсђѓ
уггСИђжЃетѕє
ТеАтъІ
Word2VecТеАтъІСИГ№╝їСИ╗УдЂТюЅSkip-GramтњїCBOWСИцуДЇТеАтъІ№╝їС╗јуЏ┤УДѓСИіуљєУДБ№╝їSkip-GramТў»у╗Ўт«џinput wordТЮЦжбёТхІСИіСИІТќЄсђѓУђїCBOWТў»у╗Ўт«џСИіСИІТќЄ№╝їТЮЦжбёТхІinput wordсђѓТюгу»ЄТќЄуФаС╗ЁУ«▓УДБSkip-GramТеАтъІсђѓ
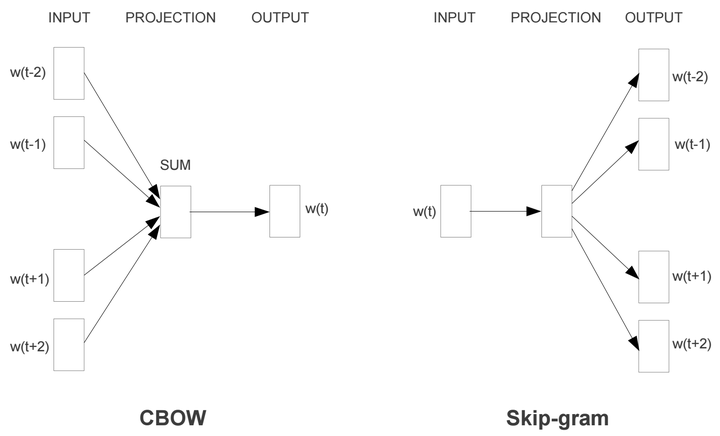
Skip-GramТеАтъІуџётЪ║уАђтйбт╝ЈжЮътИИу«ђтЇЋ№╝їСИ║С║єТЏ┤ТИЁТЦџтю░УДБжЄіТеАтъІ№╝їТѕЉС╗гтЁѕС╗јТюђСИђУѕгуџётЪ║уАђТеАтъІТЮЦуюІWord2Vec№╝ѕСИІТќЄСИГТЅђТюЅуџёWord2VecжЃйТў»ТїЄSkip-GramТеАтъІ№╝Ѕсђѓ
Word2VecТеАтъІт«ъжЎЁСИітѕєСИ║С║єСИцСИфжЃетѕє№╝їуггСИђжЃетѕєСИ║т╗║уФІТеАтъІ№╝їуггС║їжЃетѕєТў»жђџУ┐ЄТеАтъІУјитЈќтхїтЁЦУ»ЇтљЉжЄЈсђѓWord2VecуџёТЋ┤СИфт╗║ТеАУ┐ЄуеІт«ъжЎЁСИіСИјУЄфу╝ќуаЂтЎе№╝ѕauto-encoder№╝ЅуџёТђЮТЃ│тЙѕуЏИС╝╝№╝їтЇ│тЁѕтЪ║С║јУ«Гу╗ЃТЋ░ТЇ«Тъёт╗║СИђСИфуЦъу╗ЈуйЉу╗ю№╝їтйЊУ┐ЎСИфТеАтъІУ«Гу╗ЃтЦйС╗Цтљј№╝їТѕЉС╗гт╣ХСИЇС╝џућеУ┐ЎСИфУ«Гу╗ЃтЦйуџёТеАтъІтцёуљєТќ░уџёС╗╗тіА№╝їТѕЉС╗гуюЪТГБжюђУдЂуџёТў»У┐ЎСИфТеАтъІжђџУ┐ЄУ«Гу╗ЃТЋ░ТЇ«ТЅђтГдтЙЌуџётЈѓТЋ░№╝їСЙІтдѓжџљт▒ѓуџёТЮЃжЄЇуЪЕжўхРђћРђћтљјжЮбТѕЉС╗гт░єС╝џуюІтѕ░У┐ЎС║ЏТЮЃжЄЇтюеWord2VecСИГт«ъжЎЁСИіт░▒Тў»ТѕЉС╗гУ»ЋтЏЙтј╗тГдС╣ауџёРђюword vectorsРђЮсђѓтЪ║С║јУ«Гу╗ЃТЋ░ТЇ«т╗║ТеАуџёУ┐ЄуеІ№╝їТѕЉС╗гу╗Ўт«ЃСИђСИфтљЇтГЌтЈФРђюFake TaskРђЮ№╝їТёЈтЉ│уЮђт╗║ТеАт╣ХСИЇТў»ТѕЉС╗гТюђу╗ѕуџёуЏ«уџёсђѓ
СИіжЮбТЈљтѕ░уџёУ┐ЎуДЇТќ╣Т│Ћт«ъжЎЁСИіС╝џтюеТЌауЏЉуЮБуЅ╣тЙЂтГдС╣а№╝ѕunsupervised feature learning№╝ЅСИГУДЂтѕ░№╝їТюђтИИУДЂуџёт░▒Тў»УЄфу╝ќуаЂтЎе№╝ѕauto-encoder№╝Ѕ№╝џжђџУ┐Єтюежџљт▒ѓт░єУЙЊтЁЦУ┐ЏУАїу╝ќуаЂтјІу╝Е№╝їу╗ДУђїтюеУЙЊтЄ║т▒ѓт░єТЋ░ТЇ«УДБуаЂТЂбтцЇтѕЮтДІуіХТђЂ№╝їУ«Гу╗Ѓт«їТѕљтљј№╝їТѕЉС╗гС╝џт░єУЙЊтЄ║т▒ѓРђюуаЇТјЅРђЮ№╝їС╗ЁС┐ЮуЋЎжџљт▒ѓсђѓ
The Fake Task
ТѕЉС╗гтюеСИіжЮбТЈљтѕ░№╝їУ«Гу╗ЃТеАтъІуџёуюЪТГБуЏ«уџёТў»УјитЙЌТеАтъІтЪ║С║јУ«Гу╗ЃТЋ░ТЇ«тГдтЙЌуџёжџљт▒ѓТЮЃжЄЇсђѓСИ║С║єтЙЌтѕ░У┐ЎС║ЏТЮЃжЄЇ№╝їТѕЉС╗гждќтЁѕУдЂТъёт╗║СИђСИфт«їТЋ┤уџёуЦъу╗ЈуйЉу╗юСйюСИ║ТѕЉС╗гуџёРђюFake TaskРђЮ№╝їтљјжЮбтєЇУ┐ћтЏъТЮЦуюІжђџУ┐ЄРђюFake TaskРђЮТѕЉС╗гтдѓСйЋжЌ┤ТјЦтю░тЙЌтѕ░У┐ЎС║ЏУ»ЇтљЉжЄЈсђѓ
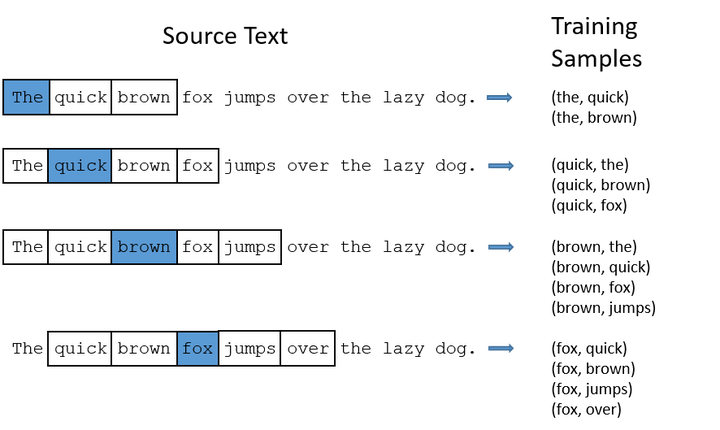
ТјЦСИІТЮЦТѕЉС╗гТЮЦуюІуюІтдѓСйЋУ«Гу╗ЃТѕЉС╗гуџёуЦъу╗ЈуйЉу╗юсђѓтЂЄтдѓТѕЉС╗гТюЅСИђСИфтЈЦтГљРђюThe dog barked at the mailmanРђЮсђѓ
- ждќтЁѕТѕЉС╗гжђЅтЈЦтГљСИГжЌ┤уџёСИђСИфУ»ЇСйюСИ║ТѕЉС╗гуџёУЙЊтЁЦУ»Ї№╝їСЙІтдѓТѕЉС╗гжђЅтЈќРђюdogРђЮСйюСИ║input word№╝Џ
- ТюЅС║єinput wordС╗Цтљј№╝їТѕЉС╗гтєЇт«џС╣ЅСИђСИфтЈФтЂџskip_windowуџётЈѓТЋ░№╝їт«ЃС╗БУАеуЮђТѕЉС╗гС╗јтйЊтЅЇinput wordуџёСИђСЙД№╝ѕтидУЙ╣ТѕќтЈ│УЙ╣№╝ЅжђЅтЈќУ»ЇуџёТЋ░жЄЈсђѓтдѓТъюТѕЉС╗гУ«Йуй«
№╝їжѓБС╣ѕТѕЉС╗гТюђу╗ѕУјитЙЌуфЌтЈБСИГуџёУ»Ї№╝ѕтїЁТІгinput wordтюетєЁ№╝Ѕт░▒Тў»['The', 'dog'№╝ї'barked', 'at']сђѓ
сђѓтЈдСИђСИфтЈѓТЋ░тЈФnum_skips№╝їт«ЃС╗БУАеуЮђТѕЉС╗гС╗јТЋ┤СИфуфЌтЈБСИГжђЅтЈќтцџт░ЉСИфСИЇтљїуџёУ»ЇСйюСИ║ТѕЉС╗гуџёoutput word№╝їтйЊ
ТЌХ№╝їТѕЉС╗гт░єС╝џтЙЌтѕ░СИцу╗ё┬а(input word, output word)┬атйбт╝ЈуџёУ«Гу╗ЃТЋ░ТЇ«№╝їтЇ│┬а('dog', 'barked')№╝ї('dog', 'the')сђѓ
- уЦъу╗ЈуйЉу╗ютЪ║С║јУ┐ЎС║ЏУ«Гу╗ЃТЋ░ТЇ«т░єС╝џУЙЊтЄ║СИђСИфТдѓујЄтѕєтИЃ№╝їУ┐ЎСИфТдѓујЄС╗БУАеуЮђТѕЉС╗гуџёУ»ЇтЁИСИГуџёТ»ЈСИфУ»ЇТў»output wordуџётЈ»УЃйТђДсђѓУ┐ЎтЈЦУ»ЮТюЅуѓ╣у╗Ћ№╝їТѕЉС╗гТЮЦуюІСИфТаЌтГљсђѓуггС║їТГЦСИГТѕЉС╗гтюеУ«Йуй«skip_windowтњїnum_skips=2уџёТЃЁтєхСИІУјитЙЌС║єСИцу╗ёУ«Гу╗ЃТЋ░ТЇ«сђѓтЂЄтдѓТѕЉС╗гтЁѕТІ┐СИђу╗ёТЋ░ТЇ«┬а('dog', 'barked')┬аТЮЦУ«Гу╗ЃуЦъу╗ЈуйЉу╗ю№╝їжѓБС╣ѕТеАтъІжђџУ┐ЄтГдС╣аУ┐ЎСИфУ«Гу╗ЃТаиТюг№╝їС╝џтЉіУ»ЅТѕЉС╗гУ»ЇТ▒ЄУАеСИГТ»ЈСИфтЇЋУ»ЇТў»РђюbarkedРђЮуџёТдѓујЄтцДт░Јсђѓ
ТѕЉС╗гт░єжђџУ┐Єу╗ЎуЦъу╗ЈуйЉу╗юУЙЊтЁЦТќЄТюгСИГТѕљт»╣уџётЇЋУ»ЇТЮЦУ«Гу╗Ѓт«Ѓт«їТѕљСИіжЮбТЅђУ»┤уџёТдѓујЄУ«Ау«ЌсђѓСИІжЮбуџётЏЙСИГу╗ЎтЄ║С║єСИђС║ЏТѕЉС╗гуџёУ«Гу╗ЃТаиТюгуџёСЙІтГљсђѓТѕЉС╗гжђЅт«џтЈЦтГљРђюThe quick brown fox jumps over lazy dogРђЮ№╝їУ«Йт«џТѕЉС╗гуџёуфЌтЈБтцДт░ЈСИ║2№╝ѕ
ТѕЉС╗гуџёТеАтъІт░єС╝џС╗јТ»Јт»╣тЇЋУ»ЇтЄ║уј░уџёТгАТЋ░СИГС╣атЙЌу╗ЪУ«Ау╗ЊТъюсђѓСЙІтдѓ№╝їТѕЉС╗гуџёуЦъу╗ЈуйЉу╗ютЈ»УЃйС╝џтЙЌтѕ░ТЏ┤тцџу▒╗С╝╝№╝ѕРђюSovietРђю№╝їРђЮUnionРђю№╝ЅУ┐ЎТаиуџёУ«Гу╗ЃТаиТюгт»╣№╝їУђїт»╣С║ј№╝ѕРђЮSovietРђю№╝їРђЮSasquatchРђю№╝ЅУ┐ЎТаиуџёу╗ётљѕтЇ┤уюІтѕ░уџётЙѕт░ЉсђѓтЏаТГц№╝їтйЊТѕЉС╗гуџёТеАтъІт«їТѕљУ«Гу╗Ѓтљј№╝їу╗Ўт«џСИђСИфтЇЋУ»ЇРђЮSovietРђюСйюСИ║УЙЊтЁЦ№╝їУЙЊтЄ║уџёу╗ЊТъюСИГРђЮUnionРђюТѕќУђЁРђЮRussiaРђюУдЂТ»ћРђЮSasquatchРђюУбФУхІС║ѕТЏ┤жФўуџёТдѓујЄсђѓ
ТеАтъІу╗єУіѓ
ТѕЉС╗гтдѓСйЋТЮЦУАеуц║У┐ЎС║ЏтЇЋУ»ЇтЉб№╝Ъ
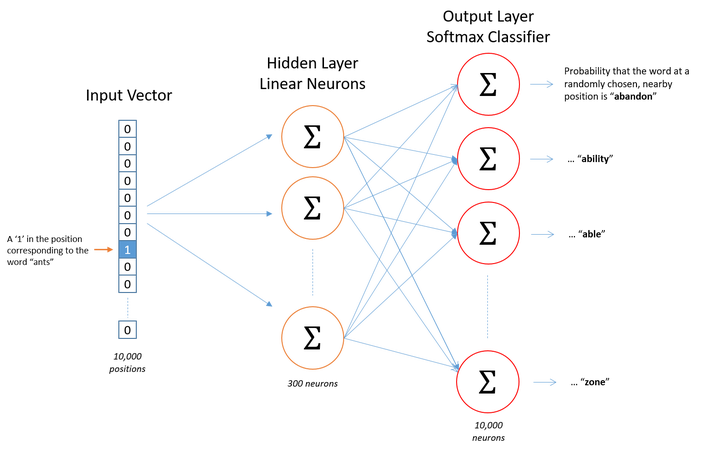
ждќтЁѕ№╝їТѕЉС╗гжЃйуЪЦжЂЊуЦъу╗ЈуйЉу╗ютЈфУЃйТјЦтЈЌТЋ░тђ╝УЙЊтЁЦ№╝їТѕЉС╗гСИЇтЈ»УЃйТііСИђСИфтЇЋУ»ЇтГЌугдСИ▓СйюСИ║УЙЊтЁЦ№╝їтЏаТГцТѕЉС╗гтЙЌТЃ│СИфтіъТ│ЋТЮЦУАеуц║У┐ЎС║ЏтЇЋУ»ЇсђѓТюђтИИућеуџётіъТ│Ћт░▒Тў»тЪ║С║јУ«Гу╗ЃТќЄТАБТЮЦТъёт╗║ТѕЉС╗гУЄфти▒уџёУ»ЇТ▒ЄУАе№╝ѕvocabulary№╝ЅтєЇт»╣тЇЋУ»ЇУ┐ЏУАїone-hotу╝ќуаЂсђѓ
тЂЄУ«ЙС╗јТѕЉС╗гуџёУ«Гу╗ЃТќЄТАБСИГТійтЈќтЄ║10000СИфтћ»СИђСИЇжЄЇтцЇуџётЇЋУ»Їу╗ёТѕљУ»ЇТ▒ЄУАесђѓТѕЉС╗гт»╣У┐Ў10000СИфтЇЋУ»ЇУ┐ЏУАїone-hotу╝ќуаЂ№╝їтЙЌтѕ░уџёТ»ЈСИфтЇЋУ»ЇжЃйТў»СИђСИф10000у╗┤уџётљЉжЄЈ№╝їтљЉжЄЈТ»ЈСИфу╗┤т║дуџётђ╝тЈфТюЅ0ТѕќУђЁ1№╝їтЂЄтдѓтЇЋУ»ЇantsтюеУ»ЇТ▒ЄУАеСИГуџётЄ║уј░СйЇуй«СИ║угг3СИф№╝їжѓБС╣ѕantsуџётљЉжЄЈт░▒Тў»СИђСИфуггСИЅу╗┤т║дтЈќтђ╝СИ║1№╝їтЁХС╗ќу╗┤жЃйСИ║0уџё10000у╗┤уџётљЉжЄЈ№╝ѕ№╝Ѕсђѓ
У┐ўТў»СИіжЮбуџёСЙІтГљ№╝їРђюThe dog barked at the mailmanРђЮ№╝їжѓБС╣ѕТѕЉС╗гтЪ║С║јУ┐ЎСИфтЈЦтГљ№╝їтЈ»С╗ЦТъёт╗║СИђСИфтцДт░ЈСИ║5уџёУ»ЇТ▒ЄУАе№╝ѕт┐йуЋЦтцДт░ЈтєЎтњїТаЄуѓ╣угдтЈи№╝Ѕ№╝џ("the", "dog", "barked", "at", "mailman")№╝їТѕЉС╗гт»╣У┐ЎСИфУ»ЇТ▒ЄУАеуџётЇЋУ»ЇУ┐ЏУАїу╝ќтЈи0-4сђѓжѓБС╣ѕРђЮdogРђют░▒тЈ»С╗ЦУбФУАеуц║СИ║СИђСИф5у╗┤тљЉжЄЈ[0, 1, 0, 0, 0]сђѓ
ТеАтъІуџёУЙЊтЁЦтдѓТъюСИ║СИђСИф10000у╗┤уџётљЉжЄЈ№╝їжѓБС╣ѕУЙЊтЄ║С╣ЪТў»СИђСИф10000у╗┤т║д№╝ѕУ»ЇТ▒ЄУАеуџётцДт░Ј№╝ЅуџётљЉжЄЈ№╝їт«ЃтїЁтљФС║є10000СИфТдѓујЄ№╝їТ»ЈСИђСИфТдѓујЄС╗БУАеуЮђтйЊтЅЇУ»ЇТў»УЙЊтЁЦТаиТюгСИГoutput wordуџёТдѓујЄтцДт░Јсђѓ
СИІтЏЙТў»ТѕЉС╗гуЦъу╗ЈуйЉу╗юуџёу╗ЊТъё№╝џ
 жџљт▒ѓТ▓АТюЅСй┐ућеС╗╗СйЋТ┐ђТ┤╗тЄйТЋ░№╝їСйєТў»УЙЊтЄ║т▒ѓСй┐ућеС║єsotfmaxсђѓ
жџљт▒ѓТ▓АТюЅСй┐ућеС╗╗СйЋТ┐ђТ┤╗тЄйТЋ░№╝їСйєТў»УЙЊтЄ║т▒ѓСй┐ућеС║єsotfmaxсђѓТѕЉС╗гтЪ║С║јТѕљт»╣уџётЇЋУ»ЇТЮЦт»╣уЦъу╗ЈуйЉу╗юУ┐ЏУАїУ«Гу╗Ѓ№╝їУ«Гу╗ЃТаиТюгТў» ( input word, output word ) У┐ЎТаиуџётЇЋУ»Їт»╣№╝їinput wordтњїoutput wordжЃйТў»one-hotу╝ќуаЂуџётљЉжЄЈсђѓТюђу╗ѕТеАтъІуџёУЙЊтЄ║Тў»СИђСИфТдѓујЄтѕєтИЃсђѓ
жџљт▒ѓ
У»┤т«їтЇЋУ»Їуџёу╝ќуаЂтњїУ«Гу╗ЃТаиТюгуџёжђЅтЈќ№╝їТѕЉС╗гТЮЦуюІСИІТѕЉС╗гуџёжџљт▒ѓсђѓтдѓТъюТѕЉС╗гуј░тюеТЃ│уће300СИфуЅ╣тЙЂТЮЦУАеуц║СИђСИфтЇЋУ»Ї№╝ѕтЇ│Т»ЈСИфУ»ЇтЈ»С╗ЦУбФУАеуц║СИ║300у╗┤уџётљЉжЄЈ№╝ЅсђѓжѓБС╣ѕжџљт▒ѓуџёТЮЃжЄЇуЪЕжўхт║ћУ»ЦСИ║10000УАї№╝ї300тѕЌ№╝ѕжџљт▒ѓТюЅ300СИфу╗Њуѓ╣№╝Ѕсђѓ
┬а
GoogleтюеТюђТќ░тЈЉтИЃуџётЪ║С║јGoogle newsТЋ░ТЇ«жЏєУ«Гу╗ЃуџёТеАтъІСИГСй┐ућеуџёт░▒Тў»300СИфуЅ╣тЙЂуџёУ»ЇтљЉжЄЈсђѓУ»ЇтљЉжЄЈуџёу╗┤т║дТў»СИђСИфтЈ»С╗ЦУ░ЃУіѓуџёУХЁтЈѓТЋ░№╝ѕтюеPythonуџёgensimтїЁСИГт░ЂУБЁуџёWord2VecТјЦтЈБж╗ўУ«цуџёУ»ЇтљЉжЄЈтцДт░ЈСИ║100№╝ї window_sizeСИ║5№╝Ѕсђѓ
уюІСИІжЮбуџётЏЙуЅЄ№╝їтидтЈ│СИцт╝атЏЙтѕєтѕФС╗јСИЇтљїУДњт║дС╗БУАеС║єУЙЊтЁЦт▒ѓ-жџљт▒ѓуџёТЮЃжЄЇуЪЕжўхсђѓтидтЏЙСИГТ»ЈСИђтѕЌС╗БУАеСИђСИф10000у╗┤уџёУ»ЇтљЉжЄЈтњїжџљт▒ѓтЇЋСИфуЦъу╗ЈтЁЃУ┐ъТјЦуџёТЮЃжЄЇтљЉжЄЈсђѓС╗јтЈ│УЙ╣уџётЏЙТЮЦуюІ№╝їТ»ЈСИђУАїт«ъжЎЁСИіС╗БУАеС║єТ»ЈСИфтЇЋУ»ЇуџёУ»ЇтљЉжЄЈсђѓ
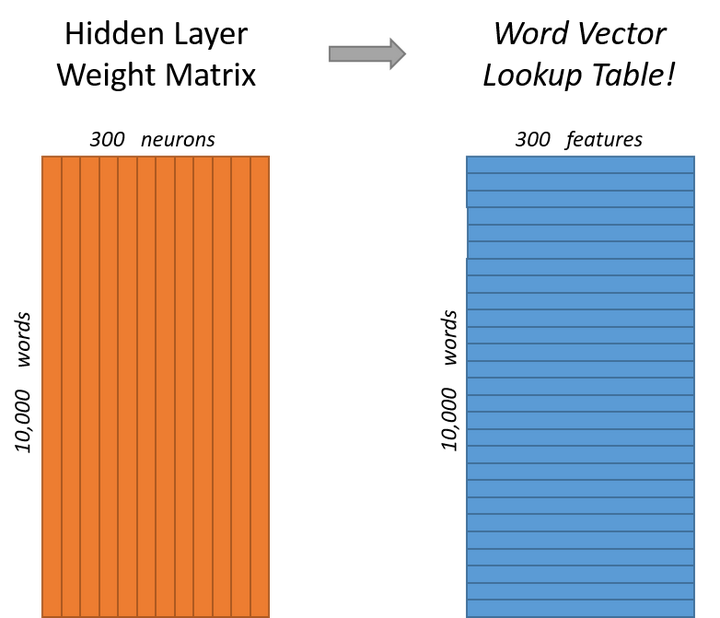
ТЅђС╗ЦТѕЉС╗гТюђу╗ѕуџёуЏ«ТаЄт░▒Тў»тГдС╣аУ┐ЎСИфжџљт▒ѓуџёТЮЃжЄЇуЪЕжўхсђѓ
┬а
ТѕЉС╗гуј░тюетЏъТЮЦТјЦуЮђжђџУ┐ЄТеАтъІуџёт«џС╣ЅТЮЦУ«Гу╗ЃТѕЉС╗гуџёУ┐ЎСИфТеАтъІсђѓ
СИіжЮбТѕЉС╗гТЈљтѕ░№╝їinput wordтњїoutput wordжЃйС╝џУбФТѕЉС╗гУ┐ЏУАїone-hotу╝ќуаЂсђѓС╗ћу╗єТЃ│СИђСИІ№╝їТѕЉС╗гуџёУЙЊтЁЦУбФone-hotу╝ќуаЂС╗ЦтљјтцДтцџТЋ░у╗┤т║дСИіжЃйТў»0№╝ѕт«ъжЎЁСИіС╗ЁТюЅСИђСИфСйЇуй«СИ║1№╝Ѕ№╝їТЅђС╗ЦУ┐ЎСИфтљЉжЄЈуЏИтйЊуеђуќЈ№╝їжѓБС╣ѕС╝џжђаТѕљС╗ђС╣ѕу╗ЊТъютЉбсђѓтдѓТъюТѕЉС╗гт░єСИђСИф1 x 10000уџётљЉжЄЈтњї10000 x 300уџёуЪЕжўхуЏИС╣ў№╝їт«ЃС╝џТХѕУђЌуЏИтйЊтцДуџёУ«Ау«ЌУхёТ║љ№╝їСИ║С║єжФўТЋѕУ«Ау«Ќ№╝їт«ЃС╗ЁС╗ЁС╝џжђЅТІЕуЪЕжўхСИГт»╣т║ћуџётљЉжЄЈСИГу╗┤т║дтђ╝СИ║1уџёу┤бт╝ЋУАї№╝ѕУ┐ЎтЈЦУ»ЮтЙѕу╗Ћ№╝Ѕ№╝їуюІтЏЙт░▒ТўјуЎйсђѓ

ТѕЉС╗гТЮЦуюІСИђСИІСИітЏЙСИГуџёуЪЕжўхУ┐љу«Ќ№╝їтидУЙ╣тѕєтѕФТў»1 x 5тњї5 x 3уџёуЪЕжўх№╝їу╗ЊТъют║ћУ»ЦТў»1 x 3уџёуЪЕжўх№╝їТїЅуЁДуЪЕжўхС╣ўТ│ЋуџёУДётѕЎ№╝їу╗ЊТъюуџёуггСИђУАїуггСИђтѕЌтЁЃу┤аСИ║
┬а
СИ║С║єТюЅТЋѕтю░У┐ЏУАїУ«Ау«Ќ№╝їУ┐ЎуДЇуеђуќЈуіХТђЂСИІСИЇС╝џУ┐ЏУАїуЪЕжўхС╣ўТ│ЋУ«Ау«Ќ№╝їтЈ»С╗ЦуюІтѕ░уЪЕжўхуџёУ«Ау«Ќуџёу╗ЊТъют«ъжЎЁСИіТў»уЪЕжўхт»╣т║ћуџётљЉжЄЈСИГтђ╝СИ║1уџёу┤бт╝Ћ№╝їСИіжЮбуџёСЙІтГљСИГ№╝їтидУЙ╣тљЉжЄЈСИГтЈќтђ╝СИ║1уџёт»╣т║ћу╗┤т║дСИ║3№╝ѕСИІТаЄС╗ј0т╝ђтДІ№╝Ѕ№╝їжѓБС╣ѕУ«Ау«Ќу╗ЊТъют░▒Тў»уЪЕжўхуџёугг3УАї№╝ѕСИІТаЄС╗ј0т╝ђтДІ№╝ЅРђћРђћ [10, 12, 19]№╝їУ┐ЎТаиТеАтъІСИГуџёжџљт▒ѓТЮЃжЄЇуЪЕжўхСЙ┐ТѕљС║єСИђСИфРђЮТЪЦТЅЙУАеРђю№╝ѕlookup table№╝Ѕ№╝їУ┐ЏУАїуЪЕжўхУ«Ау«ЌТЌХ№╝їуЏ┤ТјЦтј╗ТЪЦУЙЊтЁЦтљЉжЄЈСИГтЈќтђ╝СИ║1уџёу╗┤т║дСИІт»╣т║ћуџёжѓБС║ЏТЮЃжЄЇтђ╝сђѓжџљт▒ѓуџёУЙЊтЄ║т░▒Тў»Т»ЈСИфУЙЊтЁЦтЇЋУ»ЇуџёРђютхїтЁЦУ»ЇтљЉжЄЈРђЮсђѓ
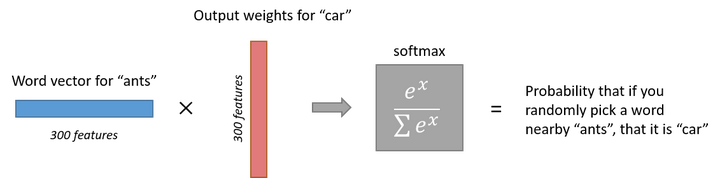
УЙЊтЄ║т▒ѓ
у╗ЈУ┐ЄуЦъу╗ЈуйЉу╗южџљт▒ѓуџёУ«Ау«Ќ№╝їantsУ┐ЎСИфУ»ЇС╝џС╗јСИђСИф1 x 10000уџётљЉжЄЈтЈўТѕљ1 x 300уџётљЉжЄЈ№╝їтєЇУбФУЙЊтЁЦтѕ░УЙЊтЄ║т▒ѓсђѓУЙЊтЄ║т▒ѓТў»СИђСИфsoftmaxтЏътйњтѕєу▒╗тЎе№╝їт«ЃуџёТ»ЈСИфу╗Њуѓ╣т░єС╝џУЙЊтЄ║СИђСИф0-1С╣ІжЌ┤уџётђ╝№╝ѕТдѓујЄ№╝Ѕ№╝їУ┐ЎС║ЏТЅђТюЅУЙЊтЄ║т▒ѓуЦъу╗ЈтЁЃу╗Њуѓ╣уџёТдѓујЄС╣ІтњїСИ║1сђѓ
СИІжЮбТў»СИђСИфСЙІтГљ№╝їУ«Гу╗ЃТаиТюгСИ║ (input word: РђюantsРђЮ№╝ї output word: РђюcarРђЮ) уџёУ«Ау«Ќуц║ТёЈтЏЙсђѓ
уЏ┤УДЅСИіуџёуљєУДБ
СИІжЮбТѕЉС╗гт░єжђџУ┐ЄуЏ┤УДЅТЮЦУ┐ЏУАїСИђС║ЏТђЮУђЃсђѓ
тдѓТъюСИцСИфСИЇтљїуџётЇЋУ»ЇТюЅуЮђжЮътИИуЏИС╝╝уџёРђюСИіСИІТќЄРђЮ№╝ѕС╣Ът░▒Тў»уфЌтЈБтЇЋУ»ЇтЙѕуЏИС╝╝№╝їТ»ћтдѓРђюKitty climbed the treeРђЮтњїРђюCat climbed the treeРђЮ№╝Ѕ№╝їжѓБС╣ѕжђџУ┐ЄТѕЉС╗гуџёТеАтъІУ«Гу╗Ѓ№╝їУ┐ЎСИцСИфтЇЋУ»ЇуџётхїтЁЦтљЉжЄЈт░єжЮътИИуЏИС╝╝сђѓ
┬а
жѓБС╣ѕСИцСИфтЇЋУ»ЇТІЦТюЅуЏИС╝╝уџёРђюСИіСИІТќЄРђЮтѕ░т║ЋТў»С╗ђС╣ѕтљФС╣ЅтЉб№╝ЪТ»ћтдѓт»╣С║јтљїС╣ЅУ»ЇРђюintelligentРђЮтњїРђюsmartРђЮ№╝їТѕЉС╗гУДЅтЙЌУ┐ЎСИцСИфтЇЋУ»Їт║ћУ»ЦТІЦТюЅуЏИтљїуџёРђюСИіСИІТќЄРђЮсђѓУђїСЙІтдѓРђЮengineРђютњїРђЮtransmissionРђюУ┐ЎТаиуЏИтЁ│уџёУ»ЇУ»Г№╝їтЈ»УЃйС╣ЪТІЦТюЅуЮђуЏИС╝╝уџёСИіСИІТќЄсђѓ
т«ъжЎЁСИі№╝їУ┐ЎуДЇТќ╣Т│Ћт«ъжЎЁСИіС╣ЪтЈ»С╗ЦтИ«тіЕСйаУ┐ЏУАїУ»Їт╣▓тїќ№╝ѕstemming№╝Ѕ№╝їСЙІтдѓ№╝їуЦъу╗ЈуйЉу╗ют»╣РђЮantРђютњїРђЮantsРђЮСИцСИфтЇЋУ»ЇС╝џС╣атЙЌуЏИС╝╝уџёУ»ЇтљЉжЄЈсђѓ
У»Їт╣▓тїќ№╝ѕstemming№╝Ѕт░▒Тў»тј╗жЎцУ»Їу╝ђтЙЌтѕ░У»ЇТа╣уџёУ┐ЄуеІсђѓ
---уггСИђжЃетѕєСИјуггС║їжЃетѕєтѕєтЅ▓у║┐---
уггС║їжЃетѕє
уггСИђжЃетѕєТѕЉС╗гС║єУДБskip-gramуџёУЙЊтЁЦт▒ѓсђЂжџљт▒ѓсђЂУЙЊтЄ║т▒ѓсђѓтюеуггС║їжЃетѕє№╝їС╝џу╗Ду╗ГТи▒тЁЦУ«▓тдѓСйЋтюеskip-gramТеАтъІСИіУ┐ЏУАїжФўТЋѕуџёУ«Гу╗Ѓсђѓ
тюеуггСИђжЃетѕєУ«▓УДБт«їТѕљтљј№╝їТѕЉС╗гС╝џтЈЉуј░Word2VecТеАтъІТў»СИђСИфУХЁу║ДтцДуџёуЦъу╗ЈуйЉу╗ю№╝ѕТЮЃжЄЇуЪЕжўхУДёТеАжЮътИИтцД№╝Ѕсђѓ
СИЙСИфТаЌтГљ№╝їТѕЉС╗гТІЦТюЅ10000СИфтЇЋУ»ЇуџёУ»ЇТ▒ЄУАе№╝їТѕЉС╗гтдѓТъюТЃ│тхїтЁЦ300у╗┤уџёУ»ЇтљЉжЄЈ№╝їжѓБС╣ѕТѕЉС╗гуџёУЙЊтЁЦ-жџљт▒ѓТЮЃжЄЇуЪЕжўхтњїжџљт▒ѓ-УЙЊтЄ║т▒ѓуџёТЮЃжЄЇуЪЕжўхжЃйС╝џТюЅ 10000 x 300 = 300СИЄСИфТЮЃжЄЇ№╝їтюетдѓТГцт║ътцДуџёуЦъу╗ЈуйЉу╗юСИГУ┐ЏУАїТб»т║дСИІжЎЇТў»уЏИтйЊТЁбуџёсђѓТЏ┤у│Ъу│ЋуџёТў»№╝їСйажюђУдЂтцДжЄЈуџёУ«Гу╗ЃТЋ░ТЇ«ТЮЦУ░ЃТЋ┤У┐ЎС║ЏТЮЃжЄЇт╣ХСИћжЂ┐тЁЇУ┐ЄТІЪтљѕсђѓуЎЙСИЄТЋ░жЄЈу║ДуџёТЮЃжЄЇуЪЕжўхтњїС║┐СИЄТЋ░жЄЈу║ДуџёУ«Гу╗ЃТаиТюгТёЈтЉ│уЮђУ«Гу╗ЃУ┐ЎСИфТеАтъІт░єС╝џТў»СИфуЂЙжџЙ№╝ѕтцфтЄХТ«ІС║є№╝Ѕсђѓ
Word2VecуџёСйюУђЁтюет«ЃуџёуггС║їу»ЄУ«║ТќЄСИГт╝║У░ЃС║єУ┐ЎС║ЏжЌ«жбў№╝їСИІжЮбТў»СйюУђЁтюеуггС║їу»ЄУ«║ТќЄСИГуџёСИЅСИфтѕЏТќ░№╝џ
- т░єтИИУДЂуџётЇЋУ»Їу╗ётљѕ№╝ѕword pairs№╝ЅТѕќУђЁУ»Їу╗ёСйюСИ║тЇЋСИфРђюwordsРђЮТЮЦтцёуљєсђѓ
- т»╣жФўжбЉТгАтЇЋУ»ЇУ┐ЏУАїТійТаиТЮЦтЄЈт░ЉУ«Гу╗ЃТаиТюгуџёСИфТЋ░сђѓ
- т»╣С╝ўтїќуЏ«ТаЄжЄЄућеРђюnegative samplingРђЮТќ╣Т│Ћ№╝їУ┐ЎТаиТ»ЈСИфУ«Гу╗ЃТаиТюгуџёУ«Гу╗ЃтЈфС╝џТЏ┤Тќ░СИђт░ЈжЃетѕєуџёТеАтъІТЮЃжЄЇ№╝їС╗јУђїжЎЇСйјУ«Ау«ЌУ┤ЪТІЁсђѓ
Word pairs and "phases"
У«║ТќЄуџёСйюУђЁТїЄтЄ║№╝їСИђС║ЏтЇЋУ»Їу╗ётљѕ№╝ѕТѕќУђЁУ»Їу╗ё№╝ЅуџётљФС╣ЅтњїТІєт╝ђС╗ЦтљјтЁиТюЅт«їтЁеСИЇтљїуџёТёЈС╣ЅсђѓТ»ћтдѓРђюBoston GlobeРђЮТў»СИђуДЇТіЦтѕіуџётљЇтГЌ№╝їУђїтЇЋуІгуџёРђюBostonРђЮтњїРђюGlobeРђЮУ┐ЎТаитЇЋСИфуџётЇЋУ»ЇтЇ┤УАеУЙЙСИЇтЄ║У┐ЎТаиуџётљФС╣ЅсђѓтЏаТГц№╝їтюеТќЄуФаСИГтЈфУдЂтЄ║уј░РђюBoston GlobeРђЮ№╝їТѕЉС╗гт░▒т║ћУ»ЦТііт«ЃСйюСИ║СИђСИфтЇЋуІгуџёУ»ЇТЮЦућЪТѕљтЁХУ»ЇтљЉжЄЈ№╝їУђїСИЇТў»т░єтЁХТІєт╝ђсђѓтљїТаиуџёСЙІтГљУ┐ўТюЅРђюNew YorkРђЮ№╝їРђюUnited StatedРђЮуГЅсђѓ
тюеGoogleтЈЉтИЃуџёТеАтъІСИГ№╝їт«ЃТюгУ║ФуџёУ«Гу╗ЃТаиТюгСИГТюЅТЮЦУЄфGoogle NewsТЋ░ТЇ«жЏєСИГуџё1000С║┐уџётЇЋУ»Ї№╝їСйєТў»жЎцС║єтЇЋСИфтЇЋУ»ЇС╗Цтцќ№╝їтЇЋУ»Їу╗ётљѕ№╝ѕТѕќУ»Їу╗ё№╝ЅтЈѕТюЅ3уЎЙСИЄС╣Ітцџсђѓ
тдѓТъюСйат»╣ТеАтъІуџёУ»ЇТ▒ЄУАеТёЪтЁ┤УХБ№╝їтЈ»С╗Цуѓ╣тЄ╗У┐ЎжЄї№╝їСйаУ┐ўтЈ»С╗ЦуЏ┤ТјЦТхЈУДѕУ┐ЎСИфУ»ЇТ▒ЄУАесђѓ
тдѓТъюТЃ│С║єУДБУ┐ЎСИфТеАтъІтдѓСйЋУ┐ЏУАїТќЄТАБСИГуџёУ»Їу╗ёТійтЈќ№╝їтЈ»С╗ЦуюІУ«║ТќЄСИГРђюLearning PhrasesРђЮУ┐ЎСИђуФа№╝їт»╣т║ћуџёС╗БуаЂword2phrase.cУбФтЈЉтИЃтюеУ┐ЎжЄїсђѓ
т»╣жФўжбЉУ»ЇТійТаи
тюеуггСИђжЃетѕєуџёУ«▓УДБСИГ№╝їТѕЉС╗гт▒Ћуц║С║єУ«Гу╗ЃТаиТюгТў»тдѓСйЋС╗јтјЪтДІТќЄТАБСИГућЪТѕљтЄ║ТЮЦуџё№╝їУ┐ЎжЄїТѕЉтєЇжЄЇтцЇСИђТгАсђѓТѕЉС╗гуџётјЪтДІТќЄТюгСИ║РђюThe quick brown fox jumps over the laze dogРђЮ№╝їтдѓТъюТѕЉСй┐ућетцДт░ЈСИ║2уџёуфЌтЈБ№╝їжѓБС╣ѕТѕЉС╗гтЈ»С╗ЦтЙЌтѕ░тЏЙСИГт▒Ћуц║уџёжѓБС║ЏУ«Гу╗ЃТаиТюгсђѓ
СйєТў»т»╣С║јРђюtheРђЮУ┐ЎуДЇтИИућежФўжбЉтЇЋУ»Ї№╝їУ┐ЎТаиуџётцёуљєТќ╣т╝ЈС╝џтГўтюеСИІжЮбСИцСИфжЌ«жбў№╝џ
- тйЊТѕЉС╗гтЙЌтѕ░Тѕљт»╣уџётЇЋУ»ЇУ«Гу╗ЃТаиТюгТЌХ№╝ї("fox", "the") У┐ЎТаиуџёУ«Гу╗ЃТаиТюгт╣ХСИЇС╝џу╗ЎТѕЉС╗гТЈљСЙЏтЁ│С║јРђюfoxРђЮТЏ┤тцџуџёУ»ГС╣ЅС┐АТЂ»№╝їтЏаСИ║РђюtheРђЮтюеТ»ЈСИфтЇЋУ»ЇуџёСИіСИІТќЄСИГтЄаС╣јжЃйС╝џтЄ║уј░сђѓ
- ућ▒С║јтюеТќЄТюгСИГРђюtheРђЮУ┐ЎТаиуџётИИућеУ»ЇтЄ║уј░ТдѓујЄтЙѕтцД№╝їтЏаТГцТѕЉС╗гт░єС╝џТюЅтцДжЄЈуџё№╝ѕРђЮtheРђю№╝ї...№╝ЅУ┐ЎТаиуџёУ«Гу╗ЃТаиТюг№╝їУђїУ┐ЎС║ЏТаиТюгТЋ░жЄЈУ┐юУ┐юУХЁУ┐ЄС║єТѕЉС╗гтГдС╣аРђюtheРђЮУ┐ЎСИфУ»ЇтљЉжЄЈТЅђжюђуџёУ«Гу╗ЃТаиТюгТЋ░сђѓ
тдѓТъюТѕЉС╗гУ«Йуй«уфЌтЈБтцДт░Ј
- ућ▒С║јТѕЉС╗гтѕажЎцС║єТќЄТюгСИГТЅђТюЅуџёРђюtheРђЮ№╝їжѓБС╣ѕтюеТѕЉС╗гуџёУ«Гу╗ЃТаиТюгСИГ№╝їРђюtheРђЮУ┐ЎСИфУ»ЇТ░ИУ┐юС╣ЪСИЇС╝џтЄ║уј░тюеТѕЉС╗гуџёСИіСИІТќЄуфЌтЈБСИГсђѓ
- тйЊРђюtheРђЮСйюСИ║input wordТЌХ№╝їТѕЉС╗гуџёУ«Гу╗ЃТаиТюгТЋ░УЄ│т░ЉС╝џтЄЈт░Љ10СИфсђѓ
У┐ЎтЈЦУ»Ют║ћУ»ЦУ┐ЎС╣ѕуљєУДБ№╝їтЂЄтдѓТѕЉС╗гуџёТќЄТюгСИГС╗ЁтЄ║уј░С║єСИђСИфРђюtheРђЮ№╝їжѓБС╣ѕтйЊУ┐ЎСИфРђюtheРђЮСйюСИ║input wordТЌХ№╝їТѕЉС╗гУ«Йуй«span=10№╝їТГцТЌХС╝џтЙЌтѕ░10СИфУ«Гу╗ЃТаиТюг ("the", ...) №╝їтдѓТъютѕаТјЅУ┐ЎСИфРђюtheРђЮ№╝їТѕЉС╗гт░▒С╝џтЄЈт░Љ10СИфУ«Гу╗ЃТаиТюгсђѓт«ъжЎЁСИГТѕЉС╗гуџёТќЄТюгСИГСИЇТГбСИђСИфРђюtheРђЮ№╝їтЏаТГцтйЊРђюtheРђЮСйюСИ║input wordуџёТЌХтђЎ№╝їУЄ│т░ЉС╝џтЄЈт░Љ10СИфУ«Гу╗ЃТаиТюгсђѓСИіжЮбТЈљтѕ░уџёУ┐ЎСИцСИфтй▒тЊЇу╗ЊТъют«ъжЎЁСИіт░▒тИ«тіЕТѕЉС╗гУДБтє│С║єжФўжбЉУ»ЇтИдТЮЦуџёжЌ«жбўсђѓ
ТійТаиујЄ
word2vecуџёCУ»ГУеђС╗БуаЂт«ъуј░С║єСИђСИфУ«Ау«ЌтюеУ»ЇТ▒ЄУАеСИГС┐ЮуЋЎТЪљСИфУ»ЇТдѓујЄуџётЁгт╝Јсђѓ
тюеС╗БуаЂСИГУ┐ўТюЅСИђСИфтЈѓТЋ░тЈФРђюsampleРђЮ№╝їУ┐ЎСИфтЈѓТЋ░С╗БУАеСИђСИфжўѕтђ╝№╝їж╗ўУ«цтђ╝СИ║0.001№╝ѕтюеgensimтїЁСИГуџёWord2Vecу▒╗У»┤ТўјСИГ№╝їУ┐ЎСИфтЈѓТЋ░ж╗ўУ«цСИ║0.001№╝їТќЄТАБСИГт»╣У┐ЎСИфтЈѓТЋ░уџёУДБжЄіСИ║Рђю threshold┬аfor configuring which higher-frequency words are randomly downsampledРђЮ№╝ЅсђѓУ┐ЎСИфтђ╝УХіт░ЈТёЈтЉ│уЮђУ┐ЎСИфтЇЋУ»ЇУбФС┐ЮуЋЎСИІТЮЦуџёТдѓујЄУХіт░Ј№╝ѕтЇ│ТюЅУХітцДуџёТдѓујЄУбФТѕЉС╗гтѕажЎц№╝Ѕсђѓ
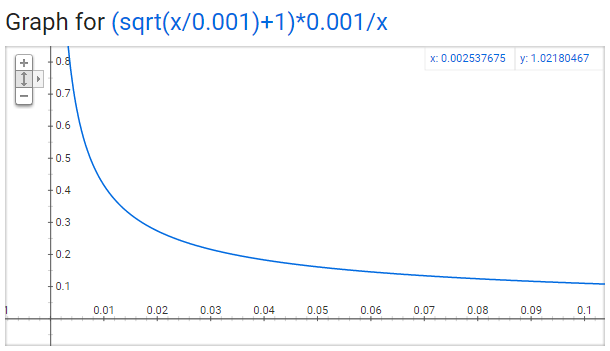
тЏЙСИГxУй┤С╗БУАеуЮђ
С╗јУ┐ЎСИфтЏЙСИГ№╝їТѕЉС╗гтЈ»С╗ЦуюІтѕ░№╝їжџЈуЮђтЇЋУ»ЇтЄ║уј░жбЉујЄуџётбъжФў№╝їт«ЃУбФжЄЄТаиС┐ЮуЋЎуџёТдѓујЄУХіТЮЦУХіт░Ј№╝їТѕЉС╗гУ┐ўтЈ»С╗ЦуюІтѕ░СИђС║ЏТюЅУХБуџёу╗ЊУ«║№╝џ
- тйЊ
ТЌХ№╝ї
сђѓтйЊтЇЋУ»ЇтюеУ»ГТќЎСИГтЄ║уј░уџёжбЉујЄт░ЈС║ј0.0026ТЌХ№╝їт«ЃТў»100%УбФС┐ЮуЋЎуџё№╝їУ┐ЎТёЈтЉ│уЮђтЈфТюЅжѓБС║ЏтюеУ»ГТќЎСИГтЄ║уј░жбЉујЄУХЁУ┐Є0.26%уџётЇЋУ»ЇТЅЇС╝џУбФжЄЄТаисђѓ
- тйЊ
ТЌХ№╝ї
№╝їТёЈтЉ│уЮђУ┐ЎСИђжЃетѕєуџётЇЋУ»ЇТюЅ50%уџёТдѓујЄУбФС┐ЮуЋЎсђѓ
- тйЊ
ТЌХ№╝ї
№╝їТёЈтЉ│уЮђУ┐ЎжЃетѕєтЇЋУ»ЇС╗Ц3.3%уџёТдѓујЄУбФС┐ЮуЋЎсђѓ
тдѓТъюСйатј╗уюІжѓБу»ЄУ«║ТќЄуџёУ»Ю№╝їСйаС╝џтЈЉуј░СйюУђЁтюеУ«║ТќЄСИГт»╣тЄйТЋ░тЁгт╝Јуџёт«џС╣ЅтњїтюеCУ»ГУеђС╗БуаЂуџёт«ъуј░СИіТюЅСИђС║Џти«тѕФ№╝їСйєТѕЉУ«цСИ║CУ»ГУеђС╗БуаЂуџётЁгт╝Јт«ъуј░Тў»ТЏ┤ТЮЃтеЂуџёСИђСИфуЅѕТюгсђѓ
У┤ЪжЄЄТаи№╝ѕnegative sampling№╝Ѕ
У«Гу╗ЃСИђСИфуЦъу╗ЈуйЉу╗юТёЈтЉ│уЮђУдЂУЙЊтЁЦУ«Гу╗ЃТаиТюгт╣ХСИћСИЇТќГУ░ЃТЋ┤уЦъу╗ЈтЁЃуџёТЮЃжЄЇ№╝їС╗јУђїСИЇТќГТЈљжФўт»╣уЏ«ТаЄуџётЄєуА«жбёТхІсђѓТ»ЈтйЊуЦъу╗ЈуйЉу╗юу╗ЈУ┐ЄСИђСИфУ«Гу╗ЃТаиТюгуџёУ«Гу╗Ѓ№╝їт«ЃуџёТЮЃжЄЇт░▒С╝џУ┐ЏУАїСИђТгАУ░ЃТЋ┤сђѓ
ТГБтдѓТѕЉС╗гСИіжЮбТЅђУ«еУ«║уџё№╝їvocabularyуџётцДт░Јтє│т«џС║єТѕЉС╗гуџёSkip-GramуЦъу╗ЈуйЉу╗ют░єС╝џТІЦТюЅтцДУДёТеАуџёТЮЃжЄЇуЪЕжўх№╝їТЅђТюЅуџёУ┐ЎС║ЏТЮЃжЄЇжюђУдЂжђџУ┐ЄТѕЉС╗гТЋ░С╗ЦС║┐У«АуџёУ«Гу╗ЃТаиТюгТЮЦУ┐ЏУАїУ░ЃТЋ┤№╝їУ┐ЎТў»жЮътИИТХѕУђЌУ«Ау«ЌУхёТ║љуџё№╝їт╣ХСИћт«ъжЎЁСИГУ«Гу╗ЃУхиТЮЦС╝џжЮътИИТЁбсђѓ
У┤ЪжЄЄТаи№╝ѕnegative sampling№╝ЅУДБтє│С║єУ┐ЎСИфжЌ«жбў№╝їт«ЃТў»ућеТЮЦТЈљжФўУ«Гу╗ЃжђЪт║дт╣ХСИћТћ╣тќёТЅђтЙЌтѕ░У»ЇтљЉжЄЈуџёУ┤ежЄЈуџёСИђуДЇТќ╣Т│ЋсђѓСИЇтљїС║јтјЪТюгТ»ЈСИфУ«Гу╗ЃТаиТюгТЏ┤Тќ░ТЅђТюЅуџёТЮЃжЄЇ№╝їУ┤ЪжЄЄТаиТ»ЈТгАУ«ЕСИђСИфУ«Гу╗ЃТаиТюгС╗ЁС╗ЁТЏ┤Тќ░СИђт░ЈжЃетѕєуџёТЮЃжЄЇ№╝їУ┐ЎТаит░▒С╝џжЎЇСйјТб»т║дСИІжЎЇУ┐ЄуеІСИГуџёУ«Ау«ЌжЄЈсђѓ
тйЊТѕЉС╗гућеУ«Гу╗ЃТаиТюг ( input word: "fox"№╝їoutput word: "quick") ТЮЦУ«Гу╗ЃТѕЉС╗гуџёуЦъу╗ЈуйЉу╗юТЌХ№╝їРђю foxРђЮтњїРђюquickРђЮжЃйТў»у╗ЈУ┐Єone-hotу╝ќуаЂуџёсђѓтдѓТъюТѕЉС╗гуџёvocabularyтцДт░ЈСИ║10000ТЌХ№╝їтюеУЙЊтЄ║т▒ѓ№╝їТѕЉС╗гТюЪТюЏт»╣т║ћРђюquickРђЮтЇЋУ»ЇуџёжѓБСИфуЦъу╗ЈтЁЃу╗Њуѓ╣УЙЊтЄ║1№╝їтЁХСйЎ9999СИфжЃйт║ћУ»ЦУЙЊтЄ║0сђѓтюеУ┐ЎжЄї№╝їУ┐Ў9999СИфТѕЉС╗гТюЪТюЏУЙЊтЄ║СИ║0уџёуЦъу╗ЈтЁЃу╗Њуѓ╣ТЅђт»╣т║ћуџётЇЋУ»ЇТѕЉС╗гуД░СИ║РђюnegativeРђЮ wordсђѓ
тйЊСй┐ућеУ┤ЪжЄЄТаиТЌХ№╝їТѕЉС╗гт░єжџЈТю║жђЅТІЕСИђт░ЈжЃетѕєуџёnegative words№╝ѕТ»ћтдѓжђЅ5СИфnegative words№╝ЅТЮЦТЏ┤Тќ░т»╣т║ћуџёТЮЃжЄЇсђѓТѕЉС╗гС╣ЪС╝џт»╣ТѕЉС╗гуџёРђюpositiveРђЮ wordУ┐ЏУАїТЮЃжЄЇТЏ┤Тќ░№╝ѕтюеТѕЉС╗гСИіжЮбуџёСЙІтГљСИГ№╝їУ┐ЎСИфтЇЋУ»ЇТїЄуџёТў»РђЮquickРђю№╝Ѕсђѓ
тюеУ«║ТќЄСИГ№╝їСйюУђЁТїЄтЄ║ТїЄтЄ║т»╣С║јт░ЈУДёТеАТЋ░ТЇ«жЏє№╝їжђЅТІЕ5-20СИфnegative wordsС╝џТ»ћУЙЃтЦй№╝їт»╣С║јтцДУДёТеАТЋ░ТЇ«жЏєтЈ»С╗ЦС╗ЁжђЅТІЕ2-5СИфnegative wordsсђѓтЏът┐єСИђСИІТѕЉС╗гуџёжџљт▒ѓ-УЙЊтЄ║т▒ѓТІЦТюЅ300 x 10000уџёТЮЃжЄЇуЪЕжўхсђѓтдѓТъюСй┐ућеС║єУ┤ЪжЄЄТаиуџёТќ╣Т│ЋТѕЉС╗гС╗ЁС╗Ётј╗ТЏ┤Тќ░ТѕЉС╗гуџёpositive word-РђюquickРђЮуџётњїТѕЉС╗гжђЅТІЕуџётЁХС╗ќ5СИфnegative wordsуџёу╗Њуѓ╣т»╣т║ћуџёТЮЃжЄЇ№╝їтЁ▒У«А6СИфУЙЊтЄ║уЦъу╗ЈтЁЃ№╝їуЏИтйЊС║јТ»ЈТгАтЈфТЏ┤Тќ░
тдѓСйЋжђЅТІЕnegative words
ТѕЉС╗гСй┐ућеРђюСИђтЁЃТеАтъІтѕєтИЃ№╝ѕunigram distribution№╝ЅРђЮТЮЦжђЅТІЕРђюnegative wordsРђЮсђѓ
УдЂТ│еТёЈуџёСИђуѓ╣Тў»№╝їСИђСИфтЇЋУ»ЇУбФжђЅСйюnegative sampleуџёТдѓујЄУиЪт«ЃтЄ║уј░уџёжбЉТгАТюЅтЁ│№╝їтЄ║уј░жбЉТгАУХіжФўуџётЇЋУ»ЇУХіт«╣ТўЊУбФжђЅСйюnegative wordsсђѓ
тюеword2vecуџёCУ»ГУеђт«ъуј░СИГ№╝їСйатЈ»С╗ЦуюІтѕ░т»╣С║јУ┐ЎСИфТдѓујЄуџёт«ъуј░тЁгт╝ЈсђѓТ»ЈСИфтЇЋУ»ЇУбФжђЅСИ║Рђюnegative wordsРђЮуџёТдѓујЄУ«Ау«ЌтЁгт╝ЈСИјтЁХтЄ║уј░уџёжбЉТгАТюЅтЁ│сђѓ
С╗БуаЂСИГуџётЁгт╝Јт«ъуј░тдѓСИІ№╝џ
Т»ЈСИфтЇЋУ»ЇУбФУхІС║ѕСИђСИфТЮЃжЄЇ№╝їтЇ│
тЁгт╝ЈСИГт╝ђ3/4уџёТа╣тЈит«їтЁеТў»тЪ║С║ју╗Јжфїуџё№╝їУ«║ТќЄСИГТЈљтѕ░У┐ЎСИфтЁгт╝ЈуџёТЋѕТъюУдЂТ»ћтЁХт«ЃтЁгт╝ЈТЏ┤тіатЄ║УЅ▓сђѓСйатЈ»С╗ЦтюеgoogleуџёТљюу┤бТаЈСИГУЙЊтЁЦРђюplot y = x^(3/4) and y = xРђЮ№╝їуёХтљјуюІтѕ░У┐ЎСИцт╣ЁтЏЙ№╝ѕтдѓСИІтЏЙ№╝Ѕ№╝їС╗ћу╗єУДѓт»Ъxтюе[0,1]тї║жЌ┤тєЁТЌХyуџётЈќтђ╝№╝ї
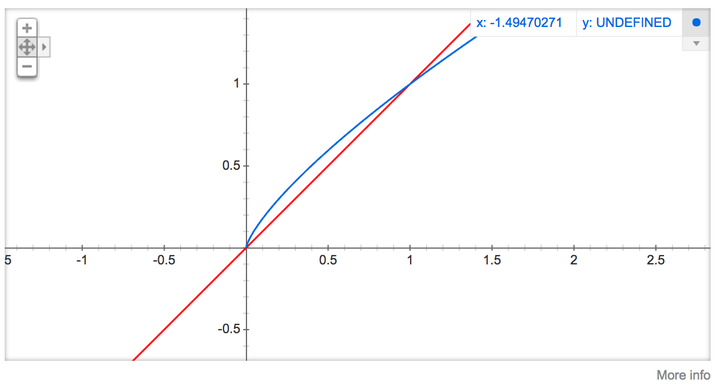
У┤ЪжЄЄТаиуџёCУ»ГУеђт«ъуј░жЮътИИуџёТюЅУХБсђѓunigram tableТюЅСИђСИфтїЁтљФС║єСИђС║┐СИфтЁЃу┤ауџёТЋ░у╗ё№╝їУ┐ЎСИфТЋ░у╗ёТў»ућ▒У»ЇТ▒ЄУАеСИГТ»ЈСИфтЇЋУ»Їуџёу┤бт╝ЋтЈитАФтЁЁуџё№╝їт╣ХСИћУ┐ЎСИфТЋ░у╗ёСИГТюЅжЄЇтцЇ№╝їС╣Ът░▒Тў»У»┤ТюЅС║ЏтЇЋУ»ЇС╝џтЄ║уј░тцџТгАсђѓжѓБС╣ѕТ»ЈСИфтЇЋУ»Їуџёу┤бт╝ЋтюеУ┐ЎСИфТЋ░у╗ёСИГтЄ║уј░уџёТгАТЋ░У»ЦтдѓСйЋтє│т«џтЉб№╝їТюЅтЁгт╝Ј
ТюЅС║єУ┐Ўт╝аУАеС╗Цтљј№╝їТ»ЈТгАтј╗ТѕЉС╗гУ┐ЏУАїУ┤ЪжЄЄТаиТЌХ№╝їтЈфжюђУдЂтюе0-1С║┐УїЃтЏ┤тєЁућЪТѕљСИђСИфжџЈТю║ТЋ░№╝їуёХтљјжђЅТІЕУАеСИГу┤бт╝ЋтЈиСИ║У┐ЎСИфжџЈТю║ТЋ░уџёжѓБСИфтЇЋУ»ЇСйюСИ║ТѕЉС╗гуџёnegative wordтЇ│тЈ»сђѓСИђСИфтЇЋУ»ЇуџёУ┤ЪжЄЄТаиТдѓујЄУХітцД№╝їжѓБС╣ѕт«ЃтюеУ┐ЎСИфУАеСИГтЄ║уј░уџёТгАТЋ░т░▒УХітцџ№╝їт«ЃУбФжђЅСИГуџёТдѓујЄт░▒УХітцДсђѓ
тѕ░уЏ«тЅЇСИ║ТГб№╝їWord2VecСИГуџёSkip-GramТеАтъІт░▒У«▓т«їС║є№╝їт»╣С║јжЄїжЮбтЁиСйЊуџёТЋ░тГдтЁгт╝ЈТјет»╝у╗єУіѓУ┐ЎжЄїт╣ХТ▓АТюЅТи▒тЁЦсђѓУ┐Ўу»ЄТќЄуФатЈфТў»т»╣С║јт«ъуј░у╗єУіѓСИіуџёСИђС║ЏТђЮТЃ│У┐ЏУАїС║єжўљУ┐░сђѓ
тЁХС╗ќУхёТќЎ
тдѓТъюТЃ│С║єУДБТЏ┤тцџуџёт«ъуј░у╗єУіѓ№╝їтЈ»С╗Цтј╗ТЪЦуюІCУ»ГУеђуџёт«ъуј░Т║љуаЂсђѓ
тЁХС╗ќWord2VecТЋЎуеІУ»итЈѓУђЃУ┐ЎжЄїсђѓ
СИІСИђу»ЄТќЄуФат░єС╝џС╗Іу╗ЇтдѓСйЋућеTensorFlowт«ъуј░СИђСИфWord2VecСИГуџёSkip-GramТеАтъІсђѓ



уЏИтЁ│ТјеУЇљ
Skip-GramТеАтъІТў»Word2VecуџёСИцуДЇСИ╗УдЂт«ъуј░Тќ╣т╝ЈС╣ІСИђ№╝їтЈдСИђуДЇТў»CBOW№╝ѕContinuous Bag of Words№╝ЅсђѓSkip-GramТеАтъІуџёТаИт┐ЃТђЮТЃ│Тў»жђџУ┐ЄтйЊтЅЇУ»ЇТЮЦжбёТхІСИіСИІТќЄУ»Ї№╝їС╗јУђїтГдС╣аУ»ЇтљЉжЄЈсђѓ тюеSkip-GramТеАтъІСИГ№╝їУ«Гу╗ЃуџёуЏ«ТаЄТў»ТюђтцДтїќу╗Ўт«џ...
Word2VecС╣ІSkip-GramТеАтъІжђџУ┐ЄжбёТхІСИіСИІТќЄУ»ЇуџёТќ╣т╝Ј№╝їТюЅТЋѕтю░ТЇЋТЇЅтѕ░С║єУ»ЇУ»ГС╣ІжЌ┤уџёУ»ГС╣ЅУЂћу│╗№╝їСИ║тљју╗ГуџёУЄфуёХУ»ГУеђтцёуљєС╗╗тіАТЈљСЙЏС║єт╝║тцДуџёТћ»ТїЂсђѓтЁХУЃїтљјуџёТЋ░тГдтјЪуљєтњїУ«Гу╗ЃУ┐ЄуеІСИЇС╗ЁСйЊуј░С║єТи▒т║дтГдС╣ауџёт╝║тцДУЃйтіЏ№╝їС╣ЪСИ║уљєУДБУЄфуёХУ»ГУеђтцёуљє...
Skip-GramТеАтъІТў»word2vecуџёСИцуДЇТќ╣Т│ЋС╣ІСИђ№╝їтЈдСИђуДЇТў»Continuous Bag of Words№╝ѕCBOW№╝ЅсђѓТГцжА╣уЏ«тЈ»УЃйТЈљСЙЏС║єСИђСИфу«ђтїќуЅѕуџёт«ъуј░№╝їСЙ┐С║јтѕЮтГдУђЁуљєУДБтњїт║ћућесђѓ **ТЈЈУ┐░тѕєТъљ№╝џ** ТЈЈУ┐░ТЈљтѕ░№╝їУ»ЦжА╣уЏ«тїЁТІгСИђСИфТЋ░ТЇ«жЏє№╝їУ»ЦТЋ░ТЇ«жЏєТў»С╗ј...
сђљWord2vecСИјSkip-GramТеАтъІсђЉWord2vecТў»ућ▒У░иТГїуаћуЕХтЉўтюе2013т╣┤ТЈљтЄ║уџёСИђуДЇућеС║јтГдС╣аУ»ЇтљЉжЄЈуџёжФўТЋѕТќ╣Т│Ћ№╝їт«ЃУЃйтцЪТЇЋТЇЅтѕ░У»ЇСИјУ»ЇС╣ІжЌ┤уџёСИіСИІТќЄтЁ│у│╗№╝їС╗јУђїтюеУЄфуёХУ»ГУеђтцёуљєСИГУАеуј░тЄ║т╝║тцДуџёУ»ГС╣ЅУАеуц║УЃйтіЏсђѓSkip-GramТў»Word2vecСИГуџёСИц...
Skip-GramТеАтъІТў»Word2Vecу«ЌТ│ЋСИГуџёСИцуДЇСИ╗УдЂТеАтъІС╣ІСИђ№╝ѕтЈдСИђуДЇСИ║CBOWТеАтъІ№╝Ѕ№╝їтЁХуЏ«ТаЄТў»С╗ју╗Ўт«џуџёуЏ«ТаЄУ»ЇжбёТхІСИіСИІТќЄУ»ЇсђѓТюгТќЄт░єжЄЇуѓ╣С╗Іу╗ЇSkip-GramТеАтъІуџётЪ║Тюгу╗ЊТъёсђЂУ«Гу╗ЃУ┐ЄуеІС╗ЦтЈітдѓСйЋС╗јСИГТЈљтЈќУ»ЇтљЉжЄЈсђѓ #### Word2Vecу«ђС╗І ...
2. **Тъёт╗║skip-gramТеАтъІ**№╝џskip-gramуџёТаИт┐ЃТђЮТЃ│Тў»№╝їт»╣С║јСИђСИфСИГт┐ЃУ»Ї№╝ѕtarget word№╝Ѕ№╝їТѕЉС╗гт░ЮУ»ЋжбёТхІтЁХСИіСИІТќЄСИГуџётЇЋУ»ЇсђѓТеАтъІу╗ЊТъёжђџтИИтїЁТІгСИцСИфжЃетѕє№╝џУЙЊтЁЦт▒ѓ№╝ѕInput Layer№╝ЅтњїУЙЊтЄ║т▒ѓ№╝ѕOutput Layer№╝ЅсђѓУЙЊтЁЦт▒ѓТјЦТћХтйЊтЅЇУ»Ї...
тюеУ«Гу╗ЃУ┐ЄуеІСИГ№╝їword2vecС╝џжђџУ┐ЄСИцуДЇСИ╗УдЂуџёУ«Гу╗ЃТќ╣Т│ЋС╣ІСИђУ┐ЏУАїтГдС╣а№╝џCBOWТѕќskip-gramсђѓCBOWТў»С╗јСИіСИІТќЄУ»ЇжбёТхІуЏ«ТаЄУ»Ї№╝їУђїskip-gramтѕЎТў»С╗јуЏ«ТаЄУ»ЇжбёТхІСИіСИІТќЄУ»ЇсђѓУ┐ЎСИцуДЇТќ╣Т│ЋтљёТюЅС╝ўтіБ№╝їCBOWтюеТЋѕујЄСИіТЏ┤жФў№╝їskip-gramтѕЎтюеТЇЋУјижЋ┐...
2. **Тъёт╗║skip-gramТеАтъІ**№╝џТа╣ТЇ«skip-gramТеАтъІуџёт«џС╣Ѕ№╝їТѕЉС╗гСИ║Т»ЈСИфтЇЋУ»ЇућЪТѕљУ«Гу╗ЃТаиТюг№╝їтЇ│тйЊтЅЇУ»ЇтњїтЁХСИіСИІТќЄуфЌтЈБтєЁуџёУ»Їт»╣сђѓуфЌтЈБтцДт░ЈтЈ»С╗ЦТа╣ТЇ«ТЋ░ТЇ«жЏєуџёуЅ╣ТђДУ░ЃТЋ┤сђѓ 3. **У«Гу╗ЃТеАтъІ**№╝џСй┐ућежџЈТю║Тб»т║дСИІжЎЇ№╝ѕSGD№╝ЅТѕќтЁХС╗ќС╝ўтїќтЎе...
Сй┐ућеPytorchУ»ГУеђ№╝їтЪ║С║јуЪЕжўхУ┐љу«Ќ№╝їт«ъуј░word2vecСИГуџёCBOWтњїSkip-gramТеАтъІ№╝їт«ъуј░Negative Sampling тњї Hierarchical SoftmaxСИцуДЇтйбт╝Јсђѓ 2сђЂт«ъжфїуј»тбЃ№╝џ СИфС║║угћУ«░Тюг/Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz 1.80GHz...
Word2VEC_java-master Тў»СИђСИфтЪ║С║јJavaт«ъуј░уџёWord2VecТеАтъІ№╝їт«ЃТў»УЄфуёХУ»ГУеђтцёуљєжбєтЪЪСИГСИђСИфжЄЇУдЂуџётиЦтЁи№╝їућеС║јтГдС╣атЇЋУ»ЇуџётѕєтИЃт╝ЈУАеуц║сђѓWord2VecТў»ућ▒GoogleуџёTomas MikolovуГЅС║║ТЈљтЄ║уџёСИђуДЇТи▒т║дтГдС╣аТќ╣Т│Ћ№╝їт«ЃУЃйтцЪт░єтЇЋУ»ЇУйгТЇбСИ║...
сђіСй┐ућеNumPyт«ъуј░Word2vec№╝џТЅІТііТЅІТЋЎуеІсђІ ...жђџУ┐ЄС╗ЦСИіТГЦжфц№╝їТѕЉС╗гтЈ»С╗ЦтѕЕућеNumPyт«ъуј░Word2vecТеАтъІ№╝їуљєУДБтЁХУЃїтљјуџёТЋ░тГдтјЪуљєС╗ЦтЈітюет«ъжЎЁТЊЇСйюСИГуџёт║ћућесђѓУ┐ЎуДЇт«ъУихСИЇС╗ЁтЈ»С╗ЦТЈљтЇЄу╝ќуеІТіђУЃй№╝їУ┐ўУЃйтіаТи▒т»╣УЄфуёХУ»ГУеђтцёуљєТеАтъІуџёуљєУДБсђѓ
Word2VecТў»Googleтюе2013т╣┤ТјетЄ║уџёСИђуДЇУЄфуёХУ»ГУеђтцёуљє...уљєУДБWord2VecТеАтъІт»╣С║јТи▒тЁЦтГдС╣аNLPжбєтЪЪУЄ│тЁ│жЄЇУдЂ№╝їт«ЃСИ║тљју╗ГуџёТи▒т║дтГдС╣аТеАтъІ№╝їтдѓTransformerсђЂBERTуГЅТЈљСЙЏС║єтЪ║уАђсђѓтљїТЌХ№╝їWord2VecуџёС╝ўтїќТіђТю»С╣ЪтюетЁХС╗ќжбєтЪЪтЙЌтѕ░С║єт╣┐Т│Џт║ћућесђѓ
1. **Skip-gramТеАтъІ**№╝џУ┐ЎТў»Word2vecуџёСИцуДЇСИ╗УдЂТќ╣Т│ЋС╣ІСИђ№╝їт«ЃуџёуЏ«ТаЄТў»жбёТхІСИђСИфУ»ЇуџёСИіСИІТќЄУ»Ї№╝їжђџУ┐ЄтЈЇтљЉС╝аТњГТЮЦТЏ┤Тќ░У»ЇтљЉжЄЈсђѓтюеУ┐ЎСИфТеАтъІСИГ№╝їТ»ЈСИфУ»ЇжЃйС╝џУбФТўат░ётѕ░СИђСИфжФўу╗┤уЕ║жЌ┤СИГуџётљЉжЄЈ№╝їСй┐тЙЌУ»ГС╣ЅуЏИС╝╝уџёУ»ЇтюеуЕ║жЌ┤СИГУиЮуд╗УЙЃУ┐Љсђѓ...
- **Skip-gramТеАтъІ**№╝џСИјCBOWуЏИтЈЇ№╝їSkip-gramт░ЮУ»ЋжбёТхІуЏ«ТаЄтЇЋУ»ЇуџёСИіСИІТќЄтЇЋУ»Їсђѓт«Ѓт░єуЏ«ТаЄтЇЋУ»ЇуџётљЉжЄЈУЙЊтЁЦтѕ░уЦъу╗ЈуйЉу╗ю№╝їуёХтљјжбёТхІтЁХтЉетЏ┤уџётЇЋУ»Їсђѓ 2. **У»ЇтљЉжЄЈ№╝ѕWord Embeddings№╝Ѕ** - У»ЇтљЉжЄЈТў»Word2VecуџёСИ╗УдЂС║ДуЅЕ№╝їт«Ѓт░є...
тюеword2vecуџёт«ъуј░СИГ№╝їтдѓGoogleуџёт╝ђТ║љт║Њ`gensim`№╝їућеТѕитЈ»С╗ЦжђЅТІЕCBOWТѕќSkip-GramТеАтъІ№╝їт╣ХтЈ»С╗ЦУ░ЃТЋ┤тЈѓТЋ░№╝їтдѓСИіСИІТќЄуфЌтЈБтцДт░ЈсђЂУ┐ГС╗БТгАТЋ░сђЂтГдС╣аујЄуГЅ№╝їС╗Цжђѓт║ћСИЇтљїуџёт║ћућетю║ТЎ»тњїжюђТ▒ѓсђѓТђ╗уџёТЮЦУ»┤№╝їCBOWтњїSkip-GramжЃйТў»т╝║тцДуџётиЦтЁи...
сђіТи▒тЁЦУДБТъљword2vec№╝џТъёт╗║У»ГС╣ЅуЕ║жЌ┤уџёуЦъу╗ЈуйЉу╗юТеАтъІсђІ тюеУЄфуёХУ»ГУеђтцёуљє№╝ѕNLP№╝ЅжбєтЪЪ№╝їword2vecТў»..."word2vec-master"жА╣уЏ«ТЈљСЙЏС║єСИђСИфТи▒тЁЦуљєУДБт╣Хт«ъУихУ┐ЎСИђТіђТю»уџёт╣│тЈ░№╝їт»╣С║јтГдС╣атњїт║ћућеword2vecуџёућеТѕиТЮЦУ»┤№╝їТў»СИђСИфт«ЮУ┤хуџёУхёТ║љсђѓ
word2vecТеАтъІСИ╗УдЂтїЁтљФСИцуДЇу«ЌТ│Ћ№╝џContinuous Bag of Words (CBOW) тњї Skip-GramсђѓCBOWжђџУ┐ЄСИіСИІТќЄжбёТхІСИГт┐ЃУ»Ї№╝їSkip-GramтѕЎуЏИтЈЇ№╝їжђџУ┐ЄСИГт┐ЃУ»ЇжбёТхІСИіСИІТќЄсђѓУ┐ЎСИцуДЇТќ╣Т│ЋжЃйтюеуЦъу╗ЈуйЉу╗юТъХТъёСИІУ┐љУАї№╝їжђџУ┐ЄтЈЇтљЉС╝аТњГС╝ўтїќТеАтъІтЈѓТЋ░...
Word2Vec тњї DNA2Vec С╗Іу╗Ї Word2Vec Тў»СИђуДЇтИИУДЂуџёУ»ЇтхїтЁЦу«ЌТ│Ћ№╝їТЌетюет░єУ»ЇУ»ГУйгТЇбСИ║тљЉжЄЈтйбт╝Ј№╝їС╗ЦСЙ┐С║јcapture У»ГС╣ЅС┐АТЂ»сђѓWord2Vec уџёТаИт┐ЃТђЮТЃ│Тў»Сй┐ућеСИђСИфУ»ЇуџёСИіСИІТќЄТЮЦтѕ╗ућ╗У┐ЎСИфУ»Їсђѓт«ЃТюЅСИцуДЇСИ╗УдЂуџёТеАтъІ№╝џCBOW тњї Skip-Gram...
GensimТЈљСЙЏС║єУ«Гу╗ЃWord2VecТеАтъІуџётіЪУЃй№╝їтЈ»С╗ЦУ«Йуй«СИЇтљїуџётЈѓТЋ░№╝їтдѓТеАтъІу▒╗тъІ№╝ѕCBOWТѕќSkip-gram№╝ЅсђЂуфЌтЈБтцДт░ЈсђЂТюђт░ЈУ»ЇжбЉсђЂУ┐ГС╗БТгАТЋ░уГЅ№╝їС╗Цжђѓт║ћСИЇтљїуџёС╗╗тіАжюђТ▒ѓсђѓУ«Гу╗ЃУ┐ЄуеІСИГ№╝їТеАтъІС╝џтГдС╣аТ»ЈСИфУ»ЇтюеСИіСИІТќЄСИГуџётѕєтИЃ№╝їС╗јУђїтЙЌтѕ░У»Ї...
уЏИТ»ћС║јCBOW№╝їSkip-gramТеАтъІуџёТђЮУи»уЏИтЈЇ№╝їт«Ѓт░ЮУ»ЋжбёТхІУ»ЇуџёСИіСИІТќЄУ»Ї№╝їу╗Ўт«џуџёТў»СИГт┐ЃУ»ЇсђѓУ┐ЎуДЇТќ╣Т│ЋУ«ЕТеАтъІУЃйТЏ┤тЦйтю░ТЇЋТЇЅтѕ░У»ЇТ▒ЄуџётЁет▒ђСЙЮУхќтЁ│у│╗№╝їт░цтЁХт»╣уеђТюЅУ»ЇуџёУАеуц║ТЏ┤СИ║ТюЅТЋѕсђѓ 3. MikolovуџётЏЏу»Єу╗ЈтЁИУ«║ТќЄ№╝џ - "Efficient ...