
Java集合包
java集合的架构。主体内容包括Collection集合和Map类;而Collection集合又可以划分为List(队列)和Set(集合)。
1. List的实现类主要有: LinkedList, ArrayList, Vector, Stack。
(01) LinkedList是双向链表实现的双端队列;它不是线程安全的,只适用于单线程。
(02) ArrayList是数组实现的队列,它是一个动态数组;它也不是线程安全的,只适用于单线程。
(03) Vector是数组实现的矢量队列,它也一个动态数组;不过和ArrayList不同的是,Vector是线程安全的,它支持并发。
(04) Stack是Vector实现的栈;和Vector一样,它也是线程安全的。
2. Set的实现类主要有: HastSet和TreeSet。
(01) HashSet是一个没有重复元素的集合,它通过HashMap实现的;HashSet不是线程安全的,只适用于单线程。
(02) TreeSet也是一个没有重复元素的集合,不过和HashSet不同的是,TreeSet中的元素是有序的;它是通过TreeMap实现的;TreeSet也不是线程安全的,只适用于单线程。
3.Map的实现类主要有: HashMap,WeakHashMap, Hashtable和TreeMap。
(01) HashMap是存储“键-值对”的哈希表;它不是线程安全的,只适用于单线程。
(02) WeakHashMap是也是哈希表;和HashMap不同的是,HashMap的“键”是强引用类型,而WeakHashMap的“键”是弱引用类型,也就是说当WeakHashMap 中的某个键不再正常使用时,会被从WeakHashMap中被自动移除。WeakHashMap也不是线程安全的,只适用于单线程。
(03) Hashtable也是哈希表;和HashMap不同的是,Hashtable是线程安全的,支持并发。
(04) TreeMap也是哈希表,不过TreeMap中的“键-值对”是有序的,它是通过R-B Tree(红黑树)实现的;TreeMap不是线程安全的,只适用于单线程。
为了方便,我们将前面介绍集合类统称为”java集合包“。java集合包大多是“非线程安全的”,虽然可以通过Collections工具类中的方法获取java集合包对应的同步类,但是这些同步类的并发效率并不是很高。为了更好的支持高并发任务,并发大师Doug Lea在JUC(java.util.concurrent)包中添加了java集合包中单线程类的对应的支持高并发的类。例如,ArrayList对应的高并发类是CopyOnWriteArrayList,HashMap对应的高并发类是ConcurrentHashMap,等等。
JUC包在添加”java集合包“对应的高并发类时,为了保持API接口的一致性,使用了”Java集合包“中的框架。例如,CopyOnWriteArrayList实现了“Java集合包”中的List接口,HashMap继承了“java集合包”中的AbstractMap类,等等。得益于“JUC包使用了Java集合包中的类”,如果我们了解了Java集合包中的类的思想之后,理解JUC包中的类也相对容易;理解时,最大的难点是,对JUC包是如何添加对“高并发”的支持的!
JUC中的集合类
下面,我们先了解JUC包中集合类的框架;为了方便讲诉,我将JUC包中的集合类划分为3部分来进行说明。
1. List和Set
JUC集合包中的List和Set实现类包括: CopyOnWriteArrayList, CopyOnWriteArraySet和ConcurrentSkipListSet。ConcurrentSkipListSet稍后在说明Map时再说明,CopyOnWriteArrayList 和 CopyOnWriteArraySet的框架如下图所示:
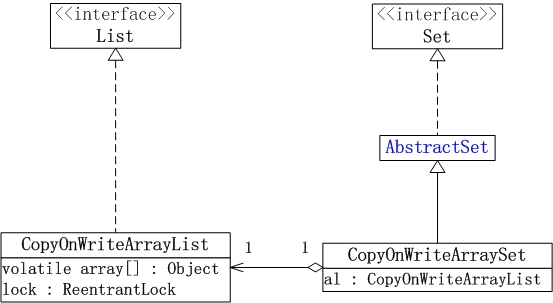
(01) CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口。CopyOnWriteArrayList是支持高并发的。
(02) CopyOnWriteArraySet相当于线程安全的HashSet,它继承于AbstractSet类。CopyOnWriteArraySet内部包含一个CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。
2. Map
JUC集合包中Map的实现类包括: ConcurrentHashMap和ConcurrentSkipListMap。它们的框架如下图所示:

(01) ConcurrentHashMap是线程安全的哈希表(相当于线程安全的HashMap);它继承于AbstractMap类,并且实现ConcurrentMap接口。ConcurrentHashMap是通过“锁分段”来实现的,它支持并发。
(02) ConcurrentSkipListMap是线程安全的有序的哈希表(相当于线程安全的TreeMap); 它继承于AbstractMap类,并且实现ConcurrentNavigableMap接口。ConcurrentSkipListMap是通过“跳表”来实现的,它支持并发。
(03) ConcurrentSkipListSet是线程安全的有序的集合(相当于线程安全的TreeSet);它继承于AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,它也支持并发。
3. Queue
JUC集合包中Queue的实现类包括: ArrayBlockingQueue, LinkedBlockingQueue, LinkedBlockingDeque, ConcurrentLinkedQueue和ConcurrentLinkedDeque。它们的框架如下图所示:
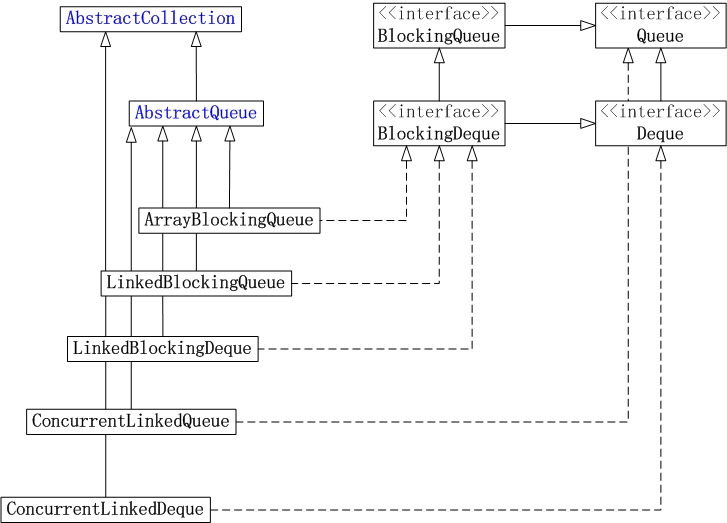
(01) ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列。
(02) LinkedBlockingQueue是单向链表实现的(指定大小)阻塞队列,该队列按 FIFO(先进先出)排序元素。
(03) LinkedBlockingDeque是双向链表实现的(指定大小)双向并发阻塞队列,该阻塞队列同时支持FIFO和FILO两种操作方式。
(04) ConcurrentLinkedQueue是单向链表实现的无界队列,该队列按 FIFO(先进先出)排序元素。
(05) ConcurrentLinkedDeque是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
CopyOnWriteArrayList介绍
它相当于线程安全的ArrayList。和ArrayList一样,它是个可变数组;但是和ArrayList不同的时,它具有以下特性:
1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
CopyOnWriteArrayList原理和数据结构
CopyOnWriteArrayList的数据结构,如下图所示:
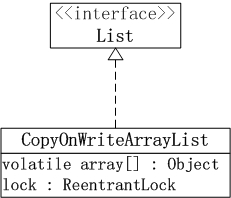
说明:
1. CopyOnWriteArrayList实现了List接口,因此它是一个队列。
2. CopyOnWriteArrayList包含了成员lock。每一个CopyOnWriteArrayList都和一个互斥锁lock绑定,通过lock,实现了对CopyOnWriteArrayList的互斥访问。
3. CopyOnWriteArrayList包含了成员array数组,这说明CopyOnWriteArrayList本质上通过数组实现的。
下面从“动态数组”和“线程安全”两个方面进一步对CopyOnWriteArrayList的原理进行说明。
1. CopyOnWriteArrayList的“动态数组”机制 -- 它内部有个“volatile数组”(array)来保持数据。在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile数组”。这就是它叫做CopyOnWriteArrayList的原因!CopyOnWriteArrayList就是通过这种方式实现的动态数组;不过正由于它在“添加/修改/删除”数据时,都会新建数组,所以涉及到修改数据的操作,CopyOnWriteArrayList效率很
低;但是单单只是进行遍历查找的话,效率比较高。
2. CopyOnWriteArrayList的“线程安全”机制 -- 是通过volatile和互斥锁来实现的。(01) CopyOnWriteArrayList是通过“volatile数组”来保存数据的。一个线程读取volatile数组时,总能看到其它线程对该volatile变量最后的写入;就这样,通过volatile提供了“读取到的数据总是最新的”这个机制的
保证。(02) CopyOnWriteArrayList通过互斥锁来保护数据。在“添加/修改/删除”数据时,会先“获取互斥锁”,再修改完毕之后,先将数据更新到“volatile数组”中,然后再“释放互斥锁”;这样,就达到了保护数据的目的。
CopyOnWriteArraySet介绍
它是线程安全的无序的集合,可以将它理解成线程安全的HashSet。有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet;但是,HashSet是通过“散列表(HashMap)”实现的,而CopyOnWriteArraySet则是通过“动态数组(CopyOnWriteArrayList)”实现的,并不是散列表。
和CopyOnWriteArrayList类似,CopyOnWriteArraySet具有以下特性:
1. 它最适合于具有以下特征的应用程序:Set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等 操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
CopyOnWriteArraySet原理和数据结构
CopyOnWriteArraySet的数据结构,如下图所示:

说明:
1. CopyOnWriteArraySet继承于AbstractSet,这就意味着它是一个集合。
2. CopyOnWriteArraySet包含CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。而CopyOnWriteArrayList本质是个动态数组队列,
所以CopyOnWriteArraySet相当于通过通过动态数组实现的“集合”! CopyOnWriteArrayList中允许有重复的元素;但是,CopyOnWriteArraySet是一个集合,所以它不能有重复集合。因此,CopyOnWriteArrayList额外提供了addIfAbsent()和addAllAbsent()这两个添加元素的API,通过这些API来添加元素时,只有当元素不存在时才执行添加操作!
至于CopyOnWriteArraySet的“线程安全”机制,和CopyOnWriteArrayList一样,是通过volatile和互斥锁来实现的。
ConcurrentHashMap介绍
ConcurrentHashMap是线程安全的哈希表。HashMap, Hashtable, ConcurrentHashMap之间的关联如下:
HashMap是非线程安全的哈希表,常用于单线程程序中。
Hashtable是线程安全的哈希表,它是通过synchronized来保证线程安全的;即,多线程通过同一个“对象的同步锁”来实现并发控制。Hashtable在线程竞争激烈时,效率比较低(此时建议使用ConcurrentHashMap)!因为当一个线程访问Hashtable的同步方法时,其它线程就访问Hashtable的同步方法时,可能会进入阻塞状态。
ConcurrentHashMap是线程安全的哈希表,它是通过“锁分段”来保证线程安全的。ConcurrentHashMap将哈希表分成许多片段(Segment),每一个片段除了保存哈希表之外,本质上也是一个“可重入的互斥锁”(ReentrantLock)。多线程对同一个片段的访问,是互斥的;但是,对于不同片段的访问,却是可以同步进行的。
ConcurrentHashMap原理和数据结构
要想搞清ConcurrentHashMap,必须先弄清楚它的数据结构:
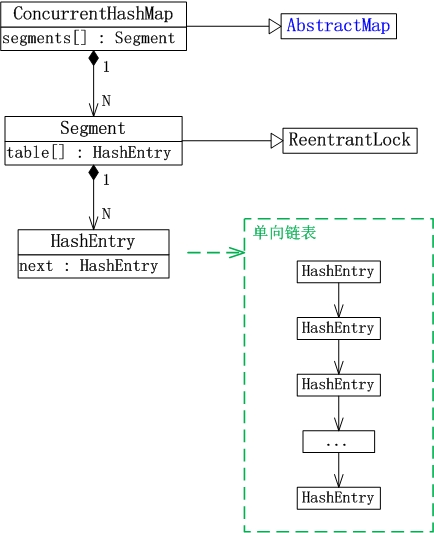
(01) ConcurrentHashMap继承于AbstractMap抽象类。
(02) Segment是ConcurrentHashMap中的内部类,它就是ConcurrentHashMap中的“锁分段”对应的存储结构。ConcurrentHashMap与Segment是组合关系,1个ConcurrentHashMap对象包含若干个Segment对象。在代码中,这表现为ConcurrentHashMap类中存在“Segment数组”成员。
(03) Segment类继承于ReentrantLock类,所以Segment本质上是一个可重入的互斥锁。
(04) HashEntry也是ConcurrentHashMap的内部类,是单向链表节点,存储着key-value键值对。Segment与HashEntry是组合关系,Segment类中存在“HashEntry数组”成员,“HashEntry数组”中的每个HashEntry就是一个单向链表。
对于多线程访问对一个“哈希表对象”竞争资源,Hashtable是通过一把锁来控制并发;而ConcurrentHashMap则是将哈希表分成许多片段,对于每一个片段分别通过一个互斥锁来控制并发。ConcurrentHashMap对并发的控制更加细腻,它也更加适应于高并发场景!
ConcurrentSkipListMap介绍
ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景。
ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表。但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。
关于跳表(Skip List),它是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
ConcurrentSkipListMap原理和数据结构
ConcurrentSkipListMap的数据结构,如下图所示:

说明:
先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
情况1:链表中查找“32”节点
路径如下图1-02所示:
![]()
需要4步(红色部分表示路径)。
情况2:跳表中查找“32”节点
路径如下图1-03所示:

忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。
下面说说Java中ConcurrentSkipListMap的数据结构。
(01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。
(02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。
(03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。
ConcurrentSkipListSet介绍
ConcurrentSkipListSet是线程安全的有序的集合,适用于高并发的场景。
ConcurrentSkipListSet和TreeSet,它们虽然都是有序的集合。但是,第一,它们的线程安全机制不同,TreeSet是非线程安全的,而ConcurrentSkipListSet是线程安全的。第二,ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,而TreeSet是通过TreeMap实现的。
ConcurrentSkipListSet原理和数据结构
ConcurrentSkipListSet的数据结构,如下图所示:

说明:
(01) ConcurrentSkipListSet继承于AbstractSet。因此,它本质上是一个集合。
(02) ConcurrentSkipListSet实现了NavigableSet接口。因此,ConcurrentSkipListSet是一个有序的集合。
(03) ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。它包含一个ConcurrentNavigableMap对象m,而m对象实际上是ConcurrentNavigableMap的实现类ConcurrentSkipListMap的实例。ConcurrentSkipListMap中的元素是key-value键值对;而ConcurrentSkipListSet是集合,它只用到了ConcurrentSkipListMap中的key!
ArrayBlockingQueue介绍
ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列。
线程安全是指,ArrayBlockingQueue内部通过“互斥锁”保护竞争资源,实现了多线程对竞争资源的互斥访问。而有界,则是指ArrayBlockingQueue对应的数组是有界限的。 阻塞队列,是指多线程访问竞争资源时,当竞争资源已被某线程获取时,其它要获取该资源的线程需要阻塞等待;而且,ArrayBlockingQueue是按 FIFO(先进先出)原则对元素进行排序,元素都是从尾部插入到队列,从头部开始返回。
注意:ArrayBlockingQueue不同于ConcurrentLinkedQueue,ArrayBlockingQueue是数组实现的,并且是有界限的;而ConcurrentLinkedQueue是链表实现的,是无界限的。
ArrayBlockingQueue原理和数据结构
ArrayBlockingQueue的数据结构,如下图所示:

说明:
1. ArrayBlockingQueue继承于AbstractQueue,并且它实现了BlockingQueue接口。
2. ArrayBlockingQueue内部是通过Object[]数组保存数据的,也就是说ArrayBlockingQueue本质上是通过数组实现的。ArrayBlockingQueue的大小,即数组的容量是创建ArrayBlockingQueue时指定的。
3. ArrayBlockingQueue与ReentrantLock是组合关系,ArrayBlockingQueue中包含一个ReentrantLock对象(lock)。ReentrantLock是可重入的互斥锁,ArrayBlockingQueue就是根据该互斥锁实现“多线程对竞争资源的互斥访问”。而且,ReentrantLock分为公平锁和非公平锁,关于具体使用公平锁还是非公平锁,在创建ArrayBlockingQueue时可以指定;而且,ArrayBlockingQueue默认会使用非公平锁。
4. ArrayBlockingQueue与Condition是组合关系,ArrayBlockingQueue中包含两个Condition对象(notEmpty和notFull)。而且,Condition又依赖于ArrayBlockingQueue而存在,通过Condition可以实现对ArrayBlockingQueue的更精确的访问 -- (01)若某线程(线程A)要取数据时,数组正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向数组中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。(02)若某线程(线程H)要插入数据时,数组已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。
LinkedBlockingQueue介绍
LinkedBlockingQueue是一个单向链表实现的阻塞队列。该队列按 FIFO(先进先出)排序元素,新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
此外,LinkedBlockingQueue还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。
LinkedBlockingQueue原理和数据结构
LinkedBlockingQueue的数据结构,如下图所示:
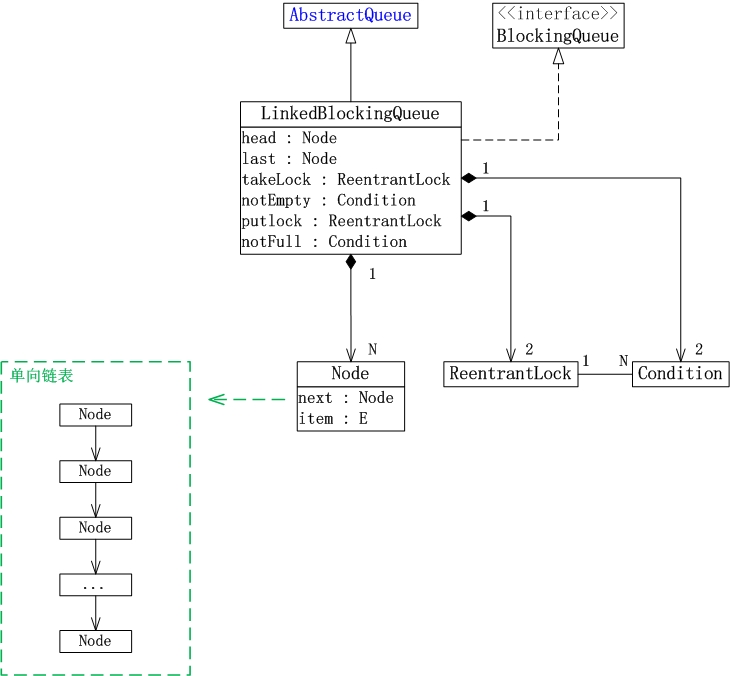
说明:
1. LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。
2. LinkedBlockingQueue实现了BlockingQueue接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
3. LinkedBlockingQueue是通过单链表实现的。
(01) head是链表的表头。取出数据时,都是从表头head处插入。
(02) last是链表的表尾。新增数据时,都是从表尾last处插入。
(03) count是链表的实际大小,即当前链表中包含的节点个数。
(04) capacity是列表的容量,它是在创建链表时指定的。
(05) putLock是插入锁,takeLock是取出锁;notEmpty是“非空条件”,notFull是“未满条件”。通过它们对链表进行并发控制。
LinkedBlockingQueue在实现“多线程对竞争资源的互斥访问”时,对于“插入”和“取出(删除)”操作分别使用了不同的锁。对于插入操作,通过“插入锁putLock”进行同步;对于取出操作,通过“取出锁takeLock”进行同步。
此外,插入锁putLock和“非满条件notFull”相关联,取出锁takeLock和“非空条件notEmpty”相关联。通过notFull和notEmpty更细腻的控制锁。
-- 若某线程(线程A)要取出数据时,队列正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向队列中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。 此外,线程A在执行取操作前,会获取takeLock,在取操作执行完毕再释放takeLock。
-- 若某线程(线程H)要插入数据时,队列已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 此外,线程H在执行插入操作前,会获取putLock,在插入操作执行完毕才释放putLock。
LinkedBlockingDeque介绍
LinkedBlockingDeque是双向链表实现的双向并发阻塞队列。该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除);并且,该阻塞队列是支持线程安全。
此外,LinkedBlockingDeque还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。
LinkedBlockingDeque原理和数据结构
LinkedBlockingDeque的数据结构,如下图所示:

说明:
1. LinkedBlockingDeque继承于AbstractQueue,它本质上是一个支持FIFO和FILO的双向的队列。
2. LinkedBlockingDeque实现了BlockingDeque接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
3. LinkedBlockingDeque是通过双向链表实现的。
3.1 first是双向链表的表头。
3.2 last是双向链表的表尾。
3.3 count是LinkedBlockingDeque的实际大小,即双向链表中当前节点个数。
3.4 capacity是LinkedBlockingDeque的容量,它是在创建LinkedBlockingDeque时指定的。
3.5 lock是控制对LinkedBlockingDeque的互斥锁,当多个线程竞争同时访问LinkedBlockingDeque时,某线程获取到了互斥锁lock,其它线程则需要阻塞等待,直到该线程释放lock,其它线程才有机会获取lock从而获取cpu执行权。
3.6 notEmpty和notFull分别是“非空条件”和“未满条件”。通过它们能够更加细腻进行并发控制。
-- 若某线程(线程A)要取出数据时,队列正好为空,则该线程会执行notEmpty.await()进行等待;当其它某个线程(线程B)向队列中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。此时,线程A会被唤醒从而得以继续运行。 此外,线程A在执行取操作前,会获取takeLock,在取操作执行完毕再释放takeLock。
-- 若某线程(线程H)要插入数据时,队列已满,则该线程会它执行notFull.await()进行等待;当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。此时,线程H就会被唤醒从而得以继续运行。 此外,线程H在执行插入操作前,会获取putLock,在插入操作执行完毕才释放putLock。
ConcurrentLinkedQueue介绍
ConcurrentLinkedQueue是线程安全的队列,它适用于“高并发”的场景。
它是一个基于链接节点的无界线程安全队列,按照 FIFO(先进先出)原则对元素进行排序。队列元素中不可以放置null元素(内部实现的特殊节点除外)。
ConcurrentLinkedQueue原理和数据结构
ConcurrentLinkedQueue的数据结构,如下图所示:

说明:
1. ConcurrentLinkedQueue继承于AbstractQueue。
2. ConcurrentLinkedQueue内部是通过链表来实现的。它同时包含链表的头节点head和尾节点tail。ConcurrentLinkedQueue按照 FIFO(先进先出)原则对元素进行排序。元素都是从尾部插入到链表,从头部开始返回。
3. ConcurrentLinkedQueue的链表Node中的next的类型是volatile,而且链表数据item的类型也是volatile。关于volatile,我们知道它的语义包含:“即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入”。ConcurrentLinkedQueue就是通过volatile来实现多线程对竞争资源的互斥访问的。



相关推荐
### Java多线程与并发(14-26)-JUC集合-CopyOnWriteArrayList详解 #### 一、概述 `CopyOnWriteArrayList`是一种线程安全的集合类,它是`ArrayList`的一种特殊版本,主要通过复制底层数组的方式来保证线程安全性。...
### Java多线程与并发(15-26)-JUC集合-ConcurrentLinkedQueue详解 #### 一、ConcurrentLinkedQueue概述 `ConcurrentLinkedQueue`是Java实用工具包(J.U.C)中的一个高性能线程安全队列,主要用于解决多线程环境下...
【Java 多线程与并发】并发集合类`ConcurrentHashMap`是Java程序设计中一个重要的工具,尤其在高并发场景下,它提供了高效的线程安全。`ConcurrentHashMap`在JDK 1.7和1.8中有着显著的区别。 在JDK 1.7中,`...
理解`BlockingQueue`和`BlockingDeque`的关键在于它们的阻塞特性,这使得它们在多线程环境中的使用既高效又安全。面试时,可能会被问到如何使用它们实现生产者-消费者模型,或者如何在并发环境下解决数据同步问题,...
Java-JUC-多线程进阶resources是 Java 并发编程的高级课程,涵盖了 Java 中的并发编程概念、线程安全、锁机制、集合类、线程池、函数式接口、Stream流式计算等多个方面。 什么是JUC JUC(Java Utilities for ...
"Java 多线程与并发(7-26)-JUC - 类汇总和学习指南" Java 多线程与并发是 Java 编程语言中的一部分,用于处理多线程和并发编程。Java 提供了一个名为 JUC(Java Utilities for Concurrency)的框架,用于帮助开发者...
JUC中的原子引用集合类如AtomicReference、AtomicIntegerArray等,它们通过原子操作保证了在多线程环境下的线程安全性。但是,这些集合类并不总是安全的,例如在迭代时,它们不能防止其他线程的并发修改。 #### 锁 ...
Java并发编程是Java Util Concurrency(JUC)库的核心内容,它为多线程环境提供了高效、安全且灵活的工具和API。JUC是Java 5及后续版本引入的一个重要特性,极大地提升了Java在多处理器和高并发环境下的性能表现。 ...
高并发与多线程 Stargazers over time 线程 线程的创建和启动 线程的sleep、yield、join 线程的状态 代码在 部分。 synchronized关键字(悲观锁) synchronized(Object) 不能用String常量、Integer、Long。 锁住的是...
4. **并发问题**:尽管HashMap在单线程环境下表现优秀,但在多线程环境下可能存在安全问题,因为它不是线程安全的。在Java 7中,如果多个线程同时修改HashMap,可能会导致数据不一致。对于并发需求,可以使用`...
这个集合提供了一系列高效、线程安全的类和接口,用于简化多线程环境下的编程任务。本资源"JUC代码收集,java高并发多线程学习"显然是一个专注于探讨和学习JUC库的资料包。 JUC库包含多个子包,如`concurrent`, `...
Java多线程是Java编程中的一个关键领域,尤其在面试中常常被重点考察。这份"【面试资料】-(机构内训资料)Java多线程面试59题(含答案)_"的压缩文件包含了59个关于Java多线程的面试问题及解答,可以帮助我们深入...
Java并发编程是Java开发中的重要领域,而Java并发工具包(Java Concurrency Utility,简称JUC)则是Java标准库提供的一套强大而丰富的工具,它极大地简化了多线程环境下的编程工作。JUC主要包含在`java.util....
Java Util Concurrent(JUC)是Java并发编程的核心库,提供了丰富的工具和接口,使得开发者能够高效、安全地处理多线程环境中的并发问题。以下将详细介绍JUC中的关键概念和特性。 1. **线程池**:JUC通过Executor...
该教程旨在帮助学习者掌握Java多线程编程的核心技术和高级特性,通过一系列实践案例加深对JUC包中各类工具的理解与运用。 #### JUC核心概念详解 1. **线程安全与同步机制** - **锁(Lock)**: 锁是实现线程同步的...
JUC提供了一系列的原子变量类,如AtomicInteger、AtomicLong等,它们实现了在无同步的情况下进行原子操作,确保在多线程环境下数据的一致性。这些类通过CAS(Compare and Swap)算法实现,能够在高并发场景下高效地...
JavaCommon 是一个涵盖Java基础知识和进阶特性的项目,它主要关注Java编程语言的基础用法、集合框架、多线程处理以及Java并发工具集(JUC)。该项目还深入解析了从JDK 5到JDK 8各版本的重要特性,为开发者提供了丰富...
3. **多线程** - **线程创建**:通过实现Runnable接口或继承Thread类创建线程。 - **线程同步**:synchronized关键字、wait()、notify()和notifyAll()方法,以及Lock接口和ReentrantLock类的应用。 - **线程池**...
2. **并发集合类(Concurrent Collections)**:JUC库提供了一系列线程安全的集合类,例如ConcurrentHashMap、ConcurrentLinkedQueue等,这些类在多线程环境下可以保证数据的一致性和完整性,避免竞态条件。...