
在开始分析算法原理之前,简单说明下rsync的增量传输功能。
假设待传输文件为A,如果目标路径下没有文件A,则rsync会直接传输文件A,如果目标路径下已存在文件A,则发送端视情况决定是否要传输文件A。rsync默认使用"quick check"算法,它会比较源文件和目标文件(如果存在)的文件大小和修改时间mtime,如果两端文件的大小或mtime不同,则发送端会传输该文件,否则将忽略该文件。
如果"quick check"算法决定了要传输文件A,它不会传输整个文件A,而是只传源文件A和目标文件A所不同的部分,这才是真正的增量传输。
也就是说,rsync的增量传输体现在两个方面:文件级的增量传输和数据块级别的增量传输。文件级别的增量传输是指源主机上有,但目标主机上没有将直接传输该文件,数据块级别的增量传输是指只传输两文件所不同的那一部分数据。但从本质上来说,文件级别的增量传输是数据块级别增量传输的特殊情况。通读本文后,很容易理解这一点。
1.1 需要解决的问题
假设主机α上有文件A,主机β上有文件B(实际上这两文件是同名文件,此处为了区分所以命名为A和B),现在要让B文件和A文件保持同步。
最简单的方法是将A文件直接拷贝到β主机上。但如果文件A很大,且B和A是相似的(意味着两文件实际内容只有少部分不同),拷贝整个文件A可能会消耗不少时间。如果可以拷贝A和B不同的那一小部分,则传输过程会很快。rsync增量传输算法就充分利用了文件的相似性,解决了远程增量拷贝的问题。
假设文件A的内容为"123xxabc def",文件B的内容为"123abcdefg"。A与B相比,相同的数据部分有123/abc/def,A中多出的内容为xx和一个空格,但文件B比文件A多出了数据g。最终的目标是让B和A的内容完全相同。
如果采用rsync增量传输算法,α主机将只传输文件A中的xx和空格数据给β主机,对于那些相同内容123/abc/def,β主机会直接从B文件中拷贝。根据这两个来源的数据,β主机就能组建成一个文件A的副本,最后将此副本文件重命名并覆盖掉B文件就保证了同步。
虽然看上去过程很简单,但其中有很多细节需要去深究。例如,α主机如何知道A文件中哪些部分和B文件不同,β主机接收了α主机发送的A、B不同部分的数据,如何组建文件A的副本。
1.2 rsync增量传输算法原理
假设执行的rsync命令是将A文件推到β主机上使得B文件和A文件保持同步,即主机α是源主机,是数据的发送端(sender),β是目标主机,是数据的接收端(receiver)。在保证B文件和A文件同步时,大致有以下6个过程:
(1).α主机告诉β主机文件A待传输。
(2).β主机收到信息后,将文件B划分为一系列大小固定的数据块(建议大小在500-1000字节之间),并以chunk号码对数据块进行编号,同时还会记录数据块的起始偏移地址以及数据块长度。显然最后一个数据块的大小可能更小。
对于文件B的内容"123abcdefg"来说,假设划分的数据块大小为3字节,则根据字符数划分成了以下几个数据块:
count=4 n=3 rem=1 这表示划分了4个数据块,数据块大小为3字节,剩余1字节给了最后一个数据块 chunk[0]:offset=0 len=3 该数据块对应的内容为123 chunk[1]:offset=3 len=3 该数据块对应的内容为abc chunk[2]:offset=6 len=3 该数据块对应的内容为def chunk[3]:offset=9 len=1 该数据块对应的内容为g
当然,实际信息中肯定是不会包括文件内容的。
(3).β主机对文件B的每个数据块根据其内容都计算两个校验码:32位的弱滚动校验码(rolling checksum)和128位的MD4强校验码(现在版本的rsync使用的已经是128位的MD5强校验码)。并将文件B计算出的所有rolling checksum和强校验码跟随在对应数据块chunk[N]后形成校验码集合,然后发送给主机α。
也就是说,校验码集合的内容大致如下:其中sum1为rolling checksum,sum2为强校验码。
chunk[0] sum1=3ef2c827 sum2=3efa923f8f2e7 chunk[1] sum1=57ac2aaf sum2=aef2dedba2314 chunk[2] sum1=92d7edb4 sum2=a6sd6a9d67a12 chunk[3] sum1=afe74939 sum2=90a12dfe7485c
需要注意,不同内容的数据块计算出的rolling checksum是有可能相同的,但是概率非常小。
(4).当α主机接收到文件B的校验码集合后,α主机将对此校验码集合中的每个rolling checksum计算16位长度的hash值,并将每216个hash值按照hash顺序放入一个hash table中,hash表中的每一个hash条目都指向校验码集合中它所对应的rolling checksum的chunk号码,然后对校验码集合根据hash值进行排序,这样排序后的校验码集合中的顺序就能和hash表中的顺序对应起来。
所以,hash表和排序后的校验码集合对应关系大致如下:假设hash表中的hash值是根据首个字符按照[0-9a-f]的顺序进行排序的。
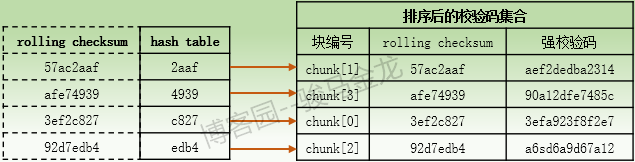
同样需要注意,不同rolling checksum计算出的hash值也是有可能会相同的,概率也比较小,但比rolling checksum出现重复的概率要大一些。
(5).随后主机α将对文件A进行处理。处理的过程是从第1个字节开始取相同大小的数据块,并计算它的校验码和校验码集合中的校验码进行匹配。如果能匹配上校验码集合中的某个数据块条目,则表示该数据块和文件B中数据块相同,它不需要传输,于是主机α直接跳转到该数据块的结尾偏移地址,从此偏移处继续取数据块进行匹配。如果不能匹配校验码集合中的数据块条目,则表示该数据块是非匹配数据块,它需要传输给主机β,于是主机α将跳转到下一个字节,从此字节处继续取数据块进行匹配。注意,匹配成功时跳过的是整个匹配数据块,匹配不成功时跳过的仅是一个字节。可以结合下一小节的示例来理解。
上面说的数据块匹配只是一种描述,具体的匹配行为需要进行细化。rsync算法将数据块匹配过程分为3个层次的搜索匹配过程。
首先,主机α会对取得的数据块根据它的内容计算出它的rolling checksum,再根据此rolling checksum计算出hash值。
然后,将此hash值去和hash表中的hash条目进行匹配,这是第一层次的搜索匹配过程,它比较的是hash值。如果在hash表中能找到匹配项,则表示该数据块存在潜在相同的可能性,于是进入第二层次的搜索匹配。
第二层次的搜索匹配是比较rolling checksum。由于第一层次的hash值匹配到了结果,所以将搜索校验码集合中与此hash值对应的rolling checksum。由于校验码集合是按照hash值排序过的,所以它的顺序和hash表中的顺序一致,也就是说只需从此hash值对应的rolling chcksum开始向下扫描即可。扫描过程中,如果A文件数据块的rolling checksum能匹配某项,则表示该数据块存在潜在相同的可能性,于是停止扫描,并进入第三层次的搜索匹配以作最终的确定。或者如果没有扫描到匹配项,则说明该数据块是非匹配块,也将停止扫描,这说明rolling checksum不同,但根据它计算的hash值却发生了小概率重复事件。
第三层次的搜索匹配是比较强校验码。此时将对A文件的数据块新计算一个强校验码(在第三层次之前,只对A文件的数据块计算了rolling checksum和它的hash值),并将此强校验码与校验码集合中对应强校验码匹配,如果能匹配则说明数据块是完全相同的,不能匹配则说明数据块是不同的,然后开始取下一个数据块进行处理。
之所以要额外计算hash值并放入hash表,是因为比较rolling checksum的性能不及hash值比较,且通过hash搜索的算法性能非常高。由于hash值重复的概率足够小,所以对绝大多数内容不同的数据块都能直接通过第一层次搜索的hash值比较出来,即使发生了小概率hash值重复事件,还能迅速定位并比较更小概率重复的rolling checksum。即使不同内容计算的rolling checksum也可能出现重复,但它的重复概率比hash值重复概率更小,所以通过这两个层次的搜索就能比较出几乎所有不同的数据块。假设不同内容的数据块的rolling checksum还是出现了小概率重复,它将进行第三层次的强校验码比较,它采用的是MD4(现在是MD5),这种算法具有"雪崩效应",只要一点点不同,结果都是天翻地覆的不同,所以在现实使用过程中,完全可以假设它能做最终的比较。
数据块大小会影响rsync算法的性能。如果数据块大小太小,则数据块的数量就太多,需要计算和匹配的数据块校验码就太多,性能就差,而且出现hash值重复、rolling checksum重复的可能性也增大;如果数据块大小太大,则可能会出现很多数据块都无法匹配的情况,导致这些数据块都被传输,降低了增量传输的优势。所以划分合适的数据块大小是非常重要的,默认情况下,rsync会根据文件大小自动判断数据块大小,但rsync命令的"-B"(或"--block-size")选项支持手动指定大小,如果手动指定,官方建议大小在500-1000字节之间。
(6).当α主机发现是匹配数据块时,将只发送这个匹配块的附加信息给β主机。同时,如果两个匹配数据块之间有非匹配数据,则还会发送这些非匹配数据。当β主机陆陆续续收到这些数据后,会创建一个临时文件,并通过这些数据重组这个临时文件,使其内容和A文件相同。临时文件重组完成后,修改该临时文件的属性信息(如权限、所有者、mtime等),然后重命名该临时文件替换掉B文件,这样B文件就和A文件保持了同步。
1.3 通过示例分析rsync算法
前面说了这么多理论,可能已经看的云里雾里,下面通过A和B文件的示例来详细分析上一小节中的增量传输算法原理,由于上一小节中的过程(1)-(4),已经给出了示例,所以下面将继续分析过程(5)和过程(6)。
先看文件B(内容为"123abcdefg")排序后的校验码集合以及hash表。
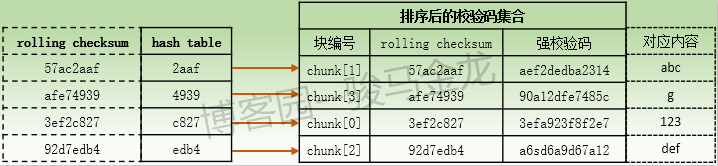
当主机α开始处理文件A时,对于文件A的内容"123xxabc def"来说,从第一个字节开始取大小相同的数据块,所以取得的第一个数据块的内容是"123",由于和文件B的chunk[0]内容完全相同,所以α主机对此数据块计算出的rolling checksum值肯定是"3ef2e827",对应的hash值为"e827"。于是α主机将此hash值去匹配hash表,匹配过程中发现指向chunk[0]的hash值能匹配上,于是进入第二层次的rolling checksum比较,也即从此hash值指向的chunk[0]的条目处开始向下扫描。扫描过程中发现扫描的第一条信息(即chunk[0]对应的条目)的rollign checksum就能匹配上,所以扫描终止,于是进入第三层次的搜索匹配,这时α主机将对"123"这个数据块新计算一个强校验码,与校验码集合中chunk[0]对应的强校验码做比较,最终发现能匹配上,于是确定了文件A中的"123"数据块是匹配数据块,不需要传输给β主机。
虽然匹配数据块不用传输,但匹配的相关信息需要立即传输给β主机,否则β主机不知道如何重组文件A的副本。匹配块需要传输的信息包括:匹配的是B文件中的chunk[0]数据块,在文件A中偏移该数据块的起始偏移地址为第1个字节,长度为3字节。
数据块"123"的匹配信息传输完成后,α主机将取第二个数据块进行处理。本来应该是从第2个字节开始取数据块的,但由于数据块"123"中3个字节完全匹配成功,所以可以直接跳过整个数据块"123",即从第4个字节开始取数据块,所以α主机取得的第2个数据块内容为"xxa"。同样,需要计算它的rolling checksum和hash值,并搜索匹配hash表中的hash条目,发现没有任何一条hash值可以匹配上,于是立即确定该数据块是非匹配数据块。
此时α主机将继续向前取A文件中的第三个数据块进行处理。由于第二个数据块没有匹配上,所以取第三个数据块时只跳过了一个字节的长度,即从第5个字节开始取,取得的数据块内容为"xab"。经过一番计算和匹配,发现这个数据块和第二个数据块一样是无法匹配的数据块。于是继续向前跳过一个字节,即从第6个字节开始取第四个数据块,这次取得的数据块内容为"abc",这个数据块是匹配数据块,所以和第一个数据块的处理方式是一样的,唯一不同的是第一个数据块到第四个数据块,中间两个数据块是非匹配数据块,于是在确定第四个数据块是匹配数据块后,会将中间的非匹配内容(即123xxabc中间的xx)逐字节发送给β主机。
(前文说过,hash值和rolling checksum是有小概率发生重复,出现重复时匹配如何进行?见本小节的尾部)
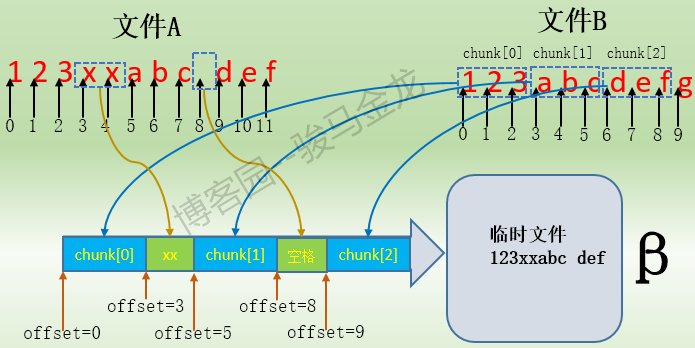
依此方式处理完A中所有数据块,最终有3个匹配数据块chunk[0]、chunk[1]和chunk[2],以及2段非匹配数据"xx"和" "。这样β主机就收到了匹配数据块的匹配信息以及逐字节的非匹配纯数据,这些数据是β主机重组文件A副本的关键信息。它的大致内容如下:
chunk[0] of size 3 at 0 offset=0 data receive 2 at 3 chunk[1] of size 3 at 3 offset=5 data receive 1 at 8 chunk[2] of size 3 at 6 offset=9
为了说明这段信息,首先看文件A和文件B的内容,并标出它们的偏移地址。
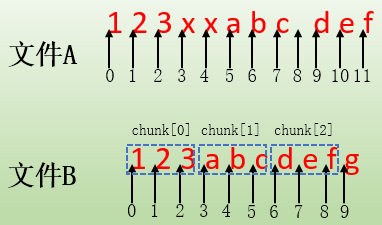
对于"chunk[0] of size 3 at 0 offset=0",这一段表示这是一个匹配数据块,匹配的是文件B中的chunk[0],数据块大小为3字节,关键词at表示这个匹配块在文件B中的起始偏移地址为0,关键词offset表示这个匹配块在文件A中起始偏移地址也为0,它也可以认为是重组临时文件中的偏移。也就是说,在β主机重组文件时,将从文件B的"at 0"偏移处拷贝长度为3字节的chunk[0]对应的数据块,并将这个数据块内容写入到临时文件中的offset=0偏移处,这样临时文件中就有了第一段数据"123"。
对于"data receive 2 at 3",这一段表示这是接收的纯数据信息,不是匹配数据块。2表示接收的数据字节数,"at 3"表示在临时文件的起始偏移3处写入这两个字节的数据。这样临时文件就有了包含了数据"123xx"。
对于"chunk[1] of size 3 at 3 offset=5",这一段表示是匹配数据块,表示从文件B的起始偏移地址at=3处拷贝长度为3字节的chunk[1]对应的数据块,并将此数据块内容写入在临时文件的起始偏移offset=5处,这样临时文件就有了"123xxabc"。
对于"data receive 1 at 8",这一说明接收了纯数据信息,表示将接收到的1个字节的数据写入到临时文件的起始偏移地址8处,所以临时文件中就有了"123xxabc "。
最后一段"chunk[2] of size 3 at 6 offset=9",表示从文件B的起始偏移地址at=6处拷贝长度为3字节的chunk[2]对应的数据块,并将此数据块内容写入到临时文件的起始偏移offset=9处,这样临时文件就包含了"123xxabc def"。到此为止,临时文件就重组结束了,它的内容和α主机上A文件的内容是完全一致的,然后只需将此临时文件的属性修改一番,并重命名替换掉文件B即可,这样就将文件B和文件A进行了同步。
整个过程如下图:
需要注意的是,α主机不是搜索完所有数据块之后才将相关数据发送给β主机的,而是每搜索出一个匹配数据块,就会立即将匹配块的相关信息以及当前匹配块和上一个匹配块中间的非匹配数据发送给β主机,并开始处理下一个数据块,当β主机每收到一段数据后会立即将将其重组到临时文件中。因此,α主机和β主机都尽量做到了不浪费任何资源。
1.3.1 hash值和rolling checksum重复时的匹配过程
在上面的示例分析中,没有涉及hash值重复和rolling checksum重复的情况,但它们有可能会重复,虽然重复后的匹配过程是一样的,但可能不那么容易理解。
还是看B文件排序后的校验码集合。
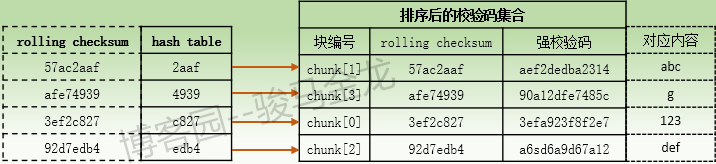
当文件A处理数据块时,假设处理的是第2个数据块,它是非匹配数据块,对此数据块会计算rolling checksum和hash值。假设此数据块的hash值从hash表中匹配成功,例如匹配到了上图中"4939"这个值,于是会将此第二个数据块的rolling checksum与hash值"4939"所指向的chunk[3]的rolling checksum作比较,hash值重复且rolling checksum重复的可能性几乎趋近于0,所以就能确定此数据块是非匹配数据块。
考虑一种极端情况,假如文件B比较大,划分的数据块数量也比较多,那么B文件自身包含的数据块的rolling checksum就有可能会出现重复事件,且hash值也可能会出现重复事件。
例如chunk[0]和chunk[3]的rolling checksum不同,但根据rolling checksum计算的hash值却相同,此时hash表和校验码集合的对应关系大致如下:
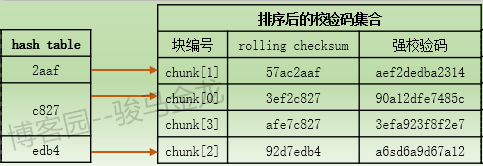
如果文件A中正好有数据块的hash值能匹配到"c827",于是准备比较rolling checksum,此时将从hash值"c827"指向的chunk[0]向下扫描校验码集合。当扫描过程中发现数据块的rolling checksum正好能匹配到某个rolling checksum,如chunk[0]或chunk[3]对应的rolling checksum,则扫描终止,并进入第三层次的搜索匹配。如果向下扫描的过程中发现直到chunk[2]都没有找到能匹配的rolling checksum,则扫描终止,因为chunk[2]的hash值和数据块的hash值已经不同,最终确定该数据块是非匹配数据块,于是α主机继续向前处理下一个数据块。
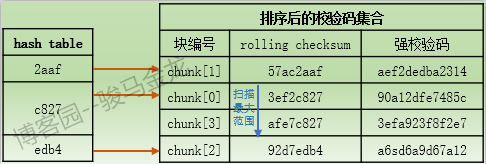
假如文件B中数据块的rolling checksum出现了重复(这只说明一件事,你太幸运),将只能通过强校验码来匹配。
1.4 rsync工作流程分析
上面已经把rsync增量传输的核心分析过了,下面将分析rsync对增量传输算法的实现方式以及rsync传输的整个过程。在这之前,有必要先解释下rsync传输过程中涉及的client/server、sender、receiver、generator等相关概念。
1.4.1 几个进程和术语
rsync有3种工作方式。一是本地传输方式,二是使用远程shell连接方式,三是使用网络套接字连接rsync daemon模式。
使用远程shell如ssh连接方式时,本地敲下rsync命令后,将请求和远程主机建立远程shell连接如ssh连接,连接建立成功后,在远程主机上将fork远程shell进程调用远程rsync程序,并将rsync所需的选项通过远程shell命令如ssh传递给远程rsync。这样两端就都启动了rsync,之后它们将通过管道的方式(即使它们之间是本地和远程的关系)进行通信。
使用网络套接字连接rsync daemon时,当通过网络套接字和远程已运行好的rsync建立连接时,rsync daemon进程会创建一个子进程来响应该连接并负责后续该连接的所有通信。这样两端也都启动了连接所需的rsync,此后通信方式是通过网络套接字来完成的。
本地传输其实是一种特殊的工作方式,首先rsync命令执行时,会有一个rsync进程,然后根据此进程fork另一个rsync进程作为连接的对端,连接建立之后,后续所有的通信将采用管道的方式。
无论使用何种连接方式,发起连接的一端被称为client,也即执行rsync命令的一段,连接的另一端称为server端。注意,server端不代表rsync daemon端。server端在rsync中是一个通用术语,是相对client端而言的,只要不是client端,都属于server端,它可以是本地端,也可以是远程shell的对端,还可以是远程rsync daemon端,这和大多数daemon类服务的server端不同。
rsync的client和server端的概念存活周期很短,当client端和server端都启动好rsync进程并建立好了rsync连接(管道、网络套接字)后,将使用sender端和receiver端来代替client端和server端的概念。sender端为文件发送端,receiver端为文件接收端。
当两端的rsync连接建立后,sender端的rsync进程称为sender进程,该进程负责sender端所有的工作。receiver端的rsync进程称为receiver进程,负责接收sender端发送的数据,以及完成文件重组的工作。receiver端还有一个核心进程——generator进程,该进程负责在receiver端执行"--delete"动作、比较文件大小和mtime以决定文件是否跳过、对每个文件划分数据块、计算校验码以及生成校验码集合,然后将校验码集合发送给sender端。
rsync的整个传输过程由这3个进程完成,它们是高度流水线化的,generator进程的输出结果作为sender端的输入,sender端的输出结果作为recevier端的输入。即:
generator进程-->sender进程-->receiver进程
虽然这3个进程是流水线式的,但不意味着它们存在数据等待的延迟,它们是完全独立、并行工作的。generator计算出一个文件的校验码集合发送给sender,会立即计算下一个文件的校验码集合,而sender进程一收到generator的校验码集合会立即开始处理该文件,处理文件时每遇到一个匹配块都会立即将这部分相关数据发送给receiver进程,然后立即处理下一个数据块,而receiver进程收到sender发送的数据后,会立即开始重组工作。也就是说,只要进程被创建了,这3个进程之间是不会互相等待的。
另外,流水线方式也不意味着进程之间不会通信,只是说rsync传输过程的主要工作流程是流水线式的。例如receiver进程收到文件列表后就将文件列表交给generator进程。
1.4.2 rsync整个工作流程
假设在α主机上执行rsync命令,将一大堆文件推送到β主机上。
1.首先client和server建立rsync通信的连接,远程shell连接方式建立的是管道,连接rsync daemon时建立的是网络套接字。
2.rsync连接建立后,sender端的sender进程根据rsync命令行中给出的源文件收集待同步文件,将这些文件放入文件列表(file list)中并传输给β主机。在创建文件列表的过程中,有几点需要说明:
(1).创建文件列表时,会先按照目录进行排序,然后对排序后的文件列表中的文件进行编号,以后将直接使用文件编号来引用文件。
(2).文件列表中还包含文件的一些属性信息,包括:权限mode,文件大小len,所有者和所属组uid/gid,最近修改时间mtime等,当然,有些信息是需要指定选项后才附带的,例如不指定"-o"和"-g"选项将不包含uid/gid,指定"--checksum"公还将包含文件级的checksum值。
(3).发送文件列表时不是收集完成后一次性发送的,而是按照顺序收集一个目录就发送一个目录,同理receiver接收时也是一个目录一个目录接收的,且接收到的文件列表是已经排过序的。
(4).如果rsync命令中指定了exclude或hide规则,则被这些规则筛选出的文件会在文件列表中标记为hide(exclude规则的本质也是hide)。带有hide标志的文件对receiver是不可见的,所以receiver端会认为sender端没有这些被hide的文件。
3.receiver端从一开始接收到文件列表中的内容后,立即根据receiver进程fork出generator进程。generator进程将根据文件列表扫描本地目录树,如果目标路径下文件已存在,则此文件称为basis file。
generator的工作总体上分为3步:
(1).如果rsync命令中指定了"--delete"选项,则首先在β主机上执行删除动作,删除源路径下没有,但目标路径下有的文件。
(2).然后根据file list中的文件顺序,逐个与本地对应文件的文件大小和mtime做比较。如果发现本地文件的大小或mtime与file list中的相同,则表示该文件不需要传输,将直接跳过该文件。
(3).如果发现本地文件的大小或mtime不同,则表示该文件是需要传输的文件,generator将立即对此文件划分数据块并编号,并对每个数据块计算弱滚动校验码(rolling checksum)和强校验码,并将这些校验码跟随数据块编号组合在一起形成校验码集合,然后将此文件的编号和校验码集合一起发送给sender端。发送完毕后开始处理file list中的下一个文件。
需要注意,α主机上有而β主机上没有的文件,generator会将文件列表中的此文件的校验码设置为空发送给sender。如果指定了"--whole-file"选项,则generator会将file list中的所有文件的校验码都设置为空,这样将使得rsync强制采用全量传输功能,而不再使用增量传输功能。
从下面的步骤4开始,这些步骤在前文分析rsync算法原理时已经给出了非常详细的解释,所以此处仅概括性地描述,如有不解之处,请翻到前文查看相关内容。
4.sender进程收到generator发送的数据,会读取文件编号和校验码集合。然后根据校验码集合中的弱滚动校验码(rolling checksum)计算hash值,并将hash值放入hash表中,且对校验码集合按照hash值进行排序,这样校验码集合和hash表的顺序就能完全相同。
5.sender进程对校验码集合排序完成后,根据读取到的文件编号处理本地对应的文件。处理的目的是找出能匹配的数据块(即内容完全相同的数据块)以及非匹配的数据。每当找到匹配的数据块时,都将立即发送一些匹配信息给receiver进程。当发送完文件的所有数据后,sender进程还将对此文件生成一个文件级的whole-file校验码给receiver。
6.receiver进程接收到sender发送的指令和数据后,立即在目标路径下创建一个临时文件,并按照接收到的数据和指令重组该临时文件,目的是使该文件和α主机上的文件完全一致。重组过程中,能匹配的数据块将从basis file中copy并写入到临时文件,非匹配的数据则是接收自sender端。
7.临时文件重组完成后,将对此临时文件生成文件级的校验码,并与sender端发送的whole-file校验码比较,如果能匹配成功则表示此临时文件和源文件是完全相同的,也就表示临时文件重组成功,如果校验码匹配失败,则表示重组过程中可能出错,将完全从头开始处理此源文件。
8.当临时文件重组成功后,receiver进程将修改该临时文件的属性信息,包括权限、所有者、所属组、mtime等。最后将此文件重命名并覆盖掉目标路径下已存在的文件(即basis file)。至此,文件同步完成。
1.5 根据执行过程分析rsync工作流程
为了更直观地感受上文所解释的rsync算法原理和工作流程,下面将给出两个rsync执行过程的示例,并分析工作流程,一个是全量传输的示例,一个是增量传输的示例。
要查看rsync的执行过程,执行在rsync命令行中加上"-vvvv"选项即可。
1.5.1 全量传输执行过程分析
要执行的命令为:
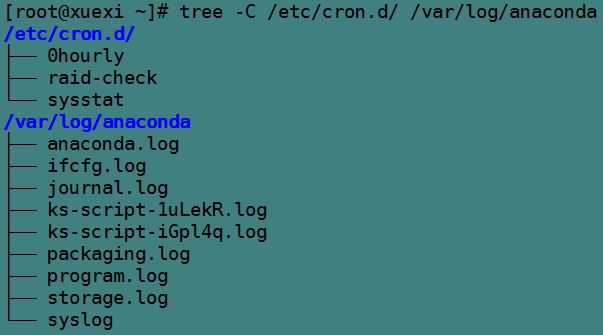
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp
目的是将/etc/cron.d目录、/var/log/anaconda目录和/etc/issue文件传输到172.16.10.5主机上的/tmp目录下,由于/tmp目录下不存在这些文件,所以整个过程是全量传输的过程。但其本质仍然是采用增量传输的算法,只不过generator发送的校验码集合全为空而已。
以下是/etc/cron.d目录和/var/log/anaconda目录的层次结构。
1.6 从工作原理分析rsync的适用场景
(1).rsync两端耗费计算机的什么资源比较严重?
从前文中已经知道,rsync的sender端因为要多次计算、多次比较各种校验码而对cpu的消耗很高,receiver端因为要从basis file中复制数据而对io的消耗很高。但这只是rsync增量传输时的情况,如果是全量传输(如第一次同步,或显式使用了全量传输选项"--whole-file"),那么sender端不用计算、比较校验码,receiver端不用copy basis file,这和scp消耗的资源是一样的。
(2).rsync不适合对数据库文件进行实时同步。
像数据库文件这样的大文件,且是频繁访问的文件,如果使用rsync实时同步,sender端要计算、比较的数据块校验码非常多,cpu会长期居高不下,从而影响数据库提供服务的性能。另一方面,receiver端每次都要从巨大的basis file(一般提供服务的数据库文件至少都几十G)中复制大部分相同的数据块重组新文件,这几乎相当于直接cp了一个文件,它一定无法扛住巨大的io压力,再好的机器也扛不住。
所以,对频繁改变的单个大文件只适合用rsync偶尔同步一次,也就是备份的功能,它不适合实时同步。像数据库文件,要实时同步应该使用数据库自带的replication功能。
(3).可以使用rsync对大量小文件进行实时同步。
由于rsync是增量同步,所以对于receiver端已经存在的和sender端相同的文件,sender端是不会发送的,这样就使得sender端和receiver端都只需要处理少量的文件,由于文件小,所以无论是sender端的cpu还是receiver端的io都不是问题。
但是,rsync的实时同步功能是借助工具来实现的,如inotify+rsync,sersync,所以这些工具要设置合理,否则实时同步一样效率低下,不过这不是rsync导致的效率低,而是这些工具配置的问题。
本文原创地址在博客园:https://www.cnblogs.com/f-ck-need-u/p/7226781.html



相关推荐
**Rsync技术详解** Rsync是一款强大的文件同步和备份工具,广泛应用于Linux和Unix系统,同时也存在Windows版本的实现,如cwRsync。...通过理解Rsync的工作原理和使用方法,可以极大地提高文件管理和备份的效率。
《inotify+rsync实时远程同步技术详解》 在现代的IT环境中,数据同步是至关重要的任务,特别是在分布式...在实际操作中,理解这两个工具的工作原理,并根据具体场景进行适当配置和优化,是确保系统高效运行的关键。
由于其采用的Rsync算法只需传输源文件和目标文件之间的差异部分,大大减少了同步所需的时间,使得Rsync成为一款备受欢迎的数据同步工具。它最初设计用来取代rcp这一命令,其维护工作目前由***负责。 Rsync不仅可以...
gSync是一个基于rsync算法的库,专为Go语言设计,用于高效地进行文件和目录的增量同步。rsync算法以其高效的数据传输能力而闻名,它能够在本地或远程服务器之间只传输文件的差异部分,从而大大减少了网络带宽的使用...
3. **自定义解决方案**:开发者也可以自行实现增量更新,例如使用开源库如DiffUtil或Rsync算法,根据应用需求定制更新流程。 三、关键技术 1. **文件差分算法**:如Rsync、Diff、Patch等算法用于找出文件或数据的...
* 采用 kafka 作消息队列,支持 NSSP 数据实时写入,并通过 kafka Consumer Group 支持数据实时分析和离线存储。 * 实时分析:基于 spark streaming,实时批量从 kafka 消费数据并将分析后结果按业务类型写入 hbase ...
通过阅读源码,开发者可以深入理解数据存储的工作原理,优化性能,或者定制化以满足特定需求。例如,在分布式存储系统中,源码分析可能涉及到数据分布策略、复制机制、故障恢复算法等。 其次,工具在存储管理中起着...
项目可能采用了诸如RSync或Git等工具的算法,通过哈希值比较来确定文件是否发生变化。如果文件内容相同,则跳过;如果不同,则记录其差异,并打包到更新文件中。 3. 更新包生成: 一旦确定了变动文件,UpdateApk会...
1.3 Nginx的模块与工作原理 1.4 Nginx的安装与配置 1.4.1 下载与安装Nginx 1.4.2 Nginx配置文件的结构 1.4.3 配置与调试Nginx 1.4.4 Nginx的启动、关闭和平滑重启 1.5 Nginx常用配置实例 1.5.1 虚拟...
随着大数据时代的到来,如何高效地处理和分析海量数据成为了一个重要的课题。Apache Mahout作为一款基于Hadoop的机器学习库,为解决这一问题提供了强大的工具和支持。本文将详细介绍Mahout的相关知识,并通过其背景...
"mirror-sync:预先同步脚本" 是一个使用TypeScript编写的工具,主要用于自动化镜像同步操作。TypeScript是JavaScript的一个超集,它提供...通过阅读和分析项目源代码,你可以进一步掌握这个工具的工作原理和实际应用。
- **流程控制**: 如何使用条件语句和循环控制程序流程。 - **函数**: 在shell脚本中定义和使用函数。 **6.10 shell编程进阶 (Chapter 36: Shell Programming for the Initiated)** - **高级特性**: shell脚本中的...
《ProGit》这本书不仅涵盖了Git的基本概念和使用方法,还深入探讨了Git的工作原理及其在实际项目中的应用策略。通过阅读本书,读者不仅可以学会如何使用Git进行版本控制,还能了解如何高效地利用Git进行团队协作。...
《Pro Git》这本书是学习Git的绝佳资源,不仅适合新手入门,也适合有经验的用户深入了解Git的工作原理。 ##### 1.1 关于版本控制 - **本地版本控制系统**:早期的版本控制系统多为本地存储,如RCS或CVS,它们将...