
写在前面
前两天想爬知乎,发现用selenium模拟登录时出现了问题——点击登录按钮没反应。。。
无论是用webdirver模拟点击,还是自己手动点击,都无法跳转到首页。
后来发现大概是知乎识别出selenium了。把我们给反爬了。
解决办法
解决办法就是——用webdirver接管我们自己打开的浏览器,然后再进行登录操作。
具体的接管方法,这篇文章已经说得非常清楚了:https://www.cnblogs.com/HJkoma/p/9936434.html
具体步骤
在环境变量中PATH里将chrome的路径添加进去:
打开控制面板,点击“高级系统设置”
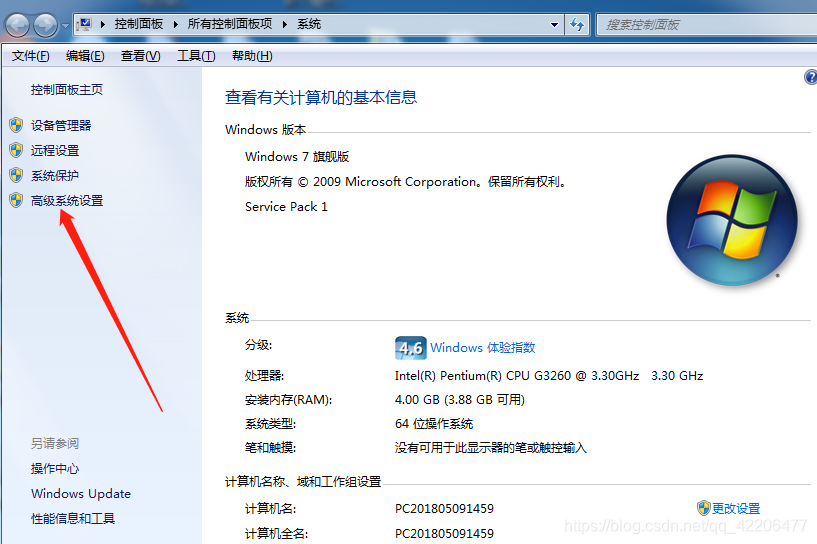
进入系统属性,点击下方“环境变量”
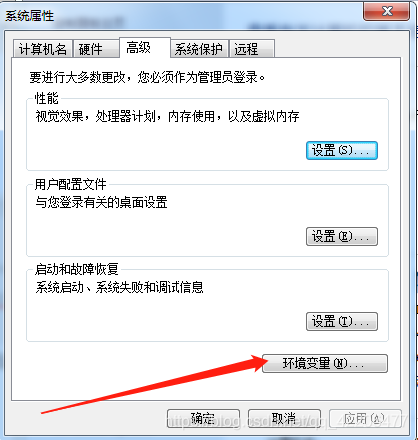
找到Path,点击“编辑”
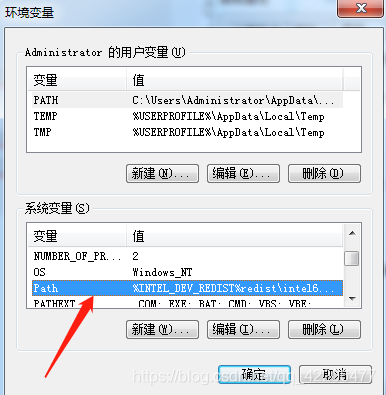
在变量值中添加配置路径 C:\Program Files (x86)\Google\Chrome\Application(注意要与前面的路径用分号隔开)
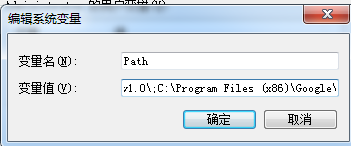
一路点“确定”就ok了
在cmd中运行命令:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\selenum\AutomationProfile"

这时,会打开一个浏览器。
然后我们回到pycharm,运行模拟登录知乎的代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(executable_path = 'D:\Documents\Downloads\chromedriver_win32\chromedriver.exe', options=chrome_options)
browser.get("https://www.zhihu.com/signin")
browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys("用户名")
import time
time.sleep(3)
browser.find_element_by_css_selector(".SignFlow-password input").send_keys("密码")
browser.find_element_by_css_selector(
".Button.SignFlow-submitButton").click()
发现登录成功了!
登录异常次数多了,就会出现验证码。关于知乎的验证码破解欢移步我的这篇博文(还没写好)
结语
这个方法比较笨
但是我目前还没找到别的解决办法
欢迎大家提供其他的解决办法~
今天在网上看到一个思路:http://www.site-digger.com/html/articles/20180821/653.html



相关推荐
【项目资源】: 物联网项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
【项目资源】: 适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
# 基于Python的KMeans和EM算法结合图像分割项目 ## 项目简介 本项目结合KMeans聚类和EM(期望最大化)算法,实现对马赛克图像的精准分割。通过Gabor滤波器提取图像的多维特征,并利用KMeans进行初步聚类,随后使用EM算法优化聚类结果,最终生成高质量的分割图像。 ## 项目的主要特性和功能 1. 图像导入和预处理: 支持导入马赛克图像,并进行灰度化、滤波等预处理操作。 2. 特征提取: 使用Gabor滤波器提取图像的多维特征向量。 3. 聚类分析: 使用KMeans算法对图像进行初步聚类。 利用KMeans的聚类中心初始化EM算法,进一步优化聚类结果。 4. 图像生成和比较: 生成分割后的图像,并与原始图像进行比较,评估分割效果。 5. 数值比较: 通过计算特征向量之间的余弦相似度,量化分割效果的提升。 ## 安装使用步骤 ### 假设用户已经下载了项目的源码文件 1. 环境准备:
HCIP第一次作业:静态路由综合实验
【项目资源】: 单片机项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
内容概要:本文详细介绍了Johnson-SU分布的参数计算与优化过程,涵盖位置参数γ、形状参数δ、尺度参数ξ和伸缩参数λ的计算方法,并实现了相应的Python代码。文中首先导入必要的库并设置随机种子以确保结果的可复现性。接着,分别定义了四个参数的计算函数,其中位置参数γ通过加权平均值计算,形状参数δ基于局部均值和标准差的比值,尺度参数ξ结合峰度和绝对偏差,伸缩参数λ依据偏态系数。此外,还实现了Johnson-SU分布的概率密度函数(PDF),并使用负对数似然函数作为目标函数,采用L-BFGS-B算法进行参数优化。最后,通过弹性网络的贝叶斯优化展示了另一种参数优化方法。; 适合人群:具有Python编程基础,对统计学和机器学习有一定了解的研究人员或工程师。; 使用场景及目标:①需要对复杂数据分布进行建模和拟合的场景;②希望通过优化算法提升模型性能的研究项目;③学习如何实现和应用先进的统计分布及优化技术。; 阅读建议:由于涉及较多数学公式和编程实现,建议读者在阅读时结合相关数学知识,同时动手实践代码,以便更好地理解和掌握Johnson-SU分布及其优化方法。
TSP问题的3种智能优化方法求解(研究生课程《智能优化算法》结课大作业).zip
【项目资源】: 物联网项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
【项目资源】: 单片机项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
自动发布Java项目(Tomcat)Shell脚本
# 基于webpack和Vue的前端项目构建方案 ## 项目简介 本项目是基于webpack和Vue构建的前端项目方案,借助webpack强大的打包能力以及Vue的开发特性,可用于快速搭建现代化的前端应用。项目不仅完成了基本的webpack与Vue的集成配置,还在构建速度优化和代码规范性方面做了诸多配置。 ## 项目的主要特性和功能 1. 打包功能运用webpack进行模块打包,支持将scss转换为css,借助babel实现语法转换。 2. Vue开发支持集成Vue框架,能使用Vue单文件组件的开发模式。 3. 构建优化采用threadloader实现多进程打包,cacheloader缓存资源,极大提高构建速度开启热更新功能,开发更高效。 4. 错误处理与优化提供不同环境下的错误映射配置,便于定位错误利用webpackbundleanalyzer分析打包体积。
Hands-On Large Language Models - Jay Alammar 袋鼠书 《动手学大语言模型》PDF
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
# 基于Arduino Feather M0和Raspberry Pi的传感器数据采集与监控系统 ## 项目简介 本项目是一个基于Arduino Feather M0和Raspberry Pi的传感器数据采集与监控系统。系统通过Arduino Feather M0采集传感器数据,并通过WiFi将数据传输到Raspberry Pi。Raspberry Pi运行BalenaOS,集成了MySQL、PHP、NGINX、Apache和Grafana等工具,用于数据的存储、处理和可视化。项目适用于环境监测、物联网设备监控等场景。 ## 项目的主要特性和功能 1. 传感器数据采集使用Arduino Feather M0和AM2315传感器采集温度和湿度数据。 2. WiFi数据传输Arduino Feather M0通过WiFi将采集到的数据传输到Raspberry Pi。
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
【项目资源】: 适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
【项目资源】: 物联网项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
# 基于Arduino的WiFi按钮项目 ## 一、项目简介 本项目是一个基于ESP8266芯片的Arduino项目,主要实现WiFi连接、电压检测、LED灯控制以及向服务器发送POST请求等功能。通过简单的按钮操作,可以实现与服务器通信并获取相关信息,同时能检测电池电压并提示用户。 ## 二、项目的主要特性和功能 1. WiFi连接项目能够自动连接到指定的WiFi网络。 2. 电压检测通过ADC(模数转换器)检测电池电压,并在电压低于阈值时发出警告。 3. LED灯控制通过控制LED灯的亮灭来提示用户不同的状态信息(如连接成功、电压低等)。 4. 服务器通信项目可以向指定的服务器发送POST请求并处理返回的HTTP响应。 ## 三、安装使用步骤 1. 环境准备确保已安装Arduino IDE和ESP8266插件。 2. 下载源码下载项目的源码文件并解压。 3. 打开项目在Arduino IDE中打开解压后的main.cpp文件。
该资源为scipy-0.10.1-cp26-cp26mu-manylinux1_x86_64.whl,欢迎下载使用哦!
计算机毕业设计;计算机毕设;Java毕业设计;小程序毕业设计;企业、旅游、党建、学校、人事、酒店、民宿、预约、考试、外卖、点餐、外贸、宠物、图书、销售、商城、就业、助农、仓储、交易、美食、博客、婚庆、二手、养老、医院、医疗、药品、招聘、考勤、宿舍、物流、租赁、公益等