
说明:SpringCloud系列笔者自学系列,学习来源是周立的博客 http://www.itmuch.com/ 。而此处转载其博客只是为了方便自己以后的学习。
本篇来源 http://www.itmuch.com/spring-cloud/finchley-12/
至此,我们已实现服务发现、负载均衡,同时,使用Feign也实现了良好的远程调用——我们的代码是可读、可维护的。理论上,我们现在已经能构建一个不错的分布式应用了,但微服务之间是通过网络通信的,网络可能出问题;微服务本身也不可能100%可用。
如何提升应用的可用性呢?这是我们必须考虑的问题——
举个例子:某大型系统中,服务A调用服务B,某个时刻,微服务B突然崩溃了。微服务A中,依然有大量请求在请求B,如果没有任何措施,微服务A很可能很快就会被拖死——因为在Java中,一次请求往往对应着一个线程,如果不做任何措施,那意味着微服务A请求B的线程要等Feign Client/RestTemplate超时才会释放(这个时间一般非常长,长达几十秒),于是就会有大量的线程被阻塞,而线程又对应着计算资源(CPU/内存),于是乎,大量的资源被浪费,并且越积越多,最终服务器终于没有资源给微服务A浪费了,微服务A也挂了。
因此,在大型应用中,微服务之间的容错必不可少,下面来讨论如何实现微服务的容错。
应用容错三板斧
超时机制
超时机制你懂的,配置一下超时时间,例如1秒——每次请求在1秒内必须返回,否则到点就把线程掐死,释放资源!
思路:一旦超时,就释放资源。由于释放资源速度较快,应用就不会那么容易被拖死。
舱壁模式
有兴趣的可以先了解一下船舱构造——一般来说,现代的轮船都会分很多舱室,舱室之间用钢板焊死,彼此隔离。这样即使有某个/某些船舱进水,也不会影响其他舱室,浮力够,船不会沉。
软件世界里的仓壁模式可以这样理解:M类使用线程池1,N类使用线程池2,彼此的线程池不同,并且为每个类分配的线程池较小,例如coreSize=10。举个例子:M类调用B服务,N类调用C服务,如果M类和N类使用相同的线程池,那么如果B服务挂了,M类调用B服务的接口并发又很高,你又没有任何保护措施,你的服务就很可能被M类拖死。而如果M类有自己的线程池,N类也有自己的线程池,如果B服务挂了,M类顶多是将自己的线程池占满,不会影响N类的线程池——于是N类依然能正常工作,
思路:不把鸡蛋放在一个篮子里。你有你的线程池,我有我的线程池,你的线程池满了和我没关系,你挂了也和我没关系。
断路器
现实世界的断路器大家肯定都很了解,每个人家里都会有断路器。断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路被烧毁。
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。
跳闸一段时间后(例如15秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的“自我修复“。
TIPS:
断路器的提出人也是Martin Fowler,”微服务“这个名词被广泛了解,也和他有密不可分的关系。Martin Fowler的博客:http://www.martinfowler.com 。
断路器状态转换可如下图所示:
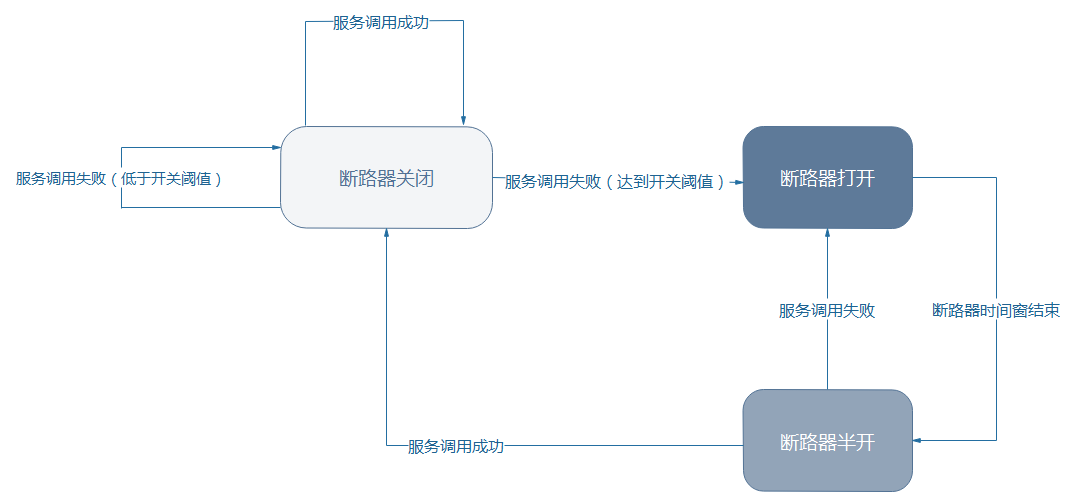
本文较短,但相信已经用通俗的语言讲解了常见的几种容错机制——目前Spring Cloud生态中,支持的断路器有:Hystrix、Resilience4J、Alibaba Sentinel,虽然彼此实现有较大差异,但本质原理是相通的。
本节是断路器的基石,在理解原理后,你会发现用不同的实现只是使用的依赖和注解不大一样而已。
下一节,将着重讲解如何使用Hystrix实现微服务的容错。
相关文章
- 跟我学Spring Cloud(Finchley版)-13-通用方式使用Hystrix
- 跟我学Spring Cloud(Finchley版)-14-Feign使用Hystrix
- 跟我学Spring Cloud(Finchley版)-15-Hystrix监控详解
- Spring Cloud中,如何解决Feign/Ribbon第一次请求失败的问题?
- Spring Cloud Alibaba迁移指南2:一行代码从Hystrix迁移到Sentinel



相关推荐
【若依SpringCloud微服务版-傻瓜式教程模式】是一个面向初学者的教程,旨在帮助没有微服务架构经验的人快速上手搭建基于Spring Cloud的若依(RuoYi)微服务系统。若依是一个开源的Java管理框架,集成了Vue前端和Spring...
SpringCloud 核心技术初识微服务解决方案 SpringCloud 是一个基于 Java 语言的微服务架构解决方案,由 Netflix 公司开发,旨在帮助开发者快速构建可靠的微服务系统。 SpringCloud 的核心技术包括服务注册、服务...
SpringCloud Finchley三版本(M2-RELEASE-SR2)微服务实战源码项目是一个涵盖了多个微服务组件的综合性实战案例。该项目依托于Spring Cloud的Finchley M2-RELEASE-SR2版本,专注于微服务架构的开发与部署。Spring ...
spring cloud的pom文件,解决maven无法导入依赖的问题,spring-cloud-dependencies-Finchley.SR2.pom文件
黑马程序员-SpringCloud-学习笔记01-认识微服务
在接下来的内容中,我将详细描述标题《Spring Cloud Finchley.SR1-Spring Cloud 手册-Spring Cloud 文档》与《Spring Cloud 2.x手册-Spring Cloud 2.x 文档》以及标签“springCloud spring 微服务”中涉及的知识点。...
黑马程序员-SpringCloud-学习笔记-02-微服务拆分及远程调用
在分布式系统中,Spring Cloud是实现微服务架构的重要工具,而Spring Cloud Netflix Eureka则是Spring Cloud生态中的服务发现组件。本项目"springcloud-Netflix-eureka demo"提供了一个基于Spring Boot搭建的基础...
本文档将详细解读Spring-cloud-alibaba微服务工程模板的相关知识点。 Spring Cloud Alibaba是一套完整的微服务解决方案,它不仅提供了服务发现与注册、配置管理、消息驱动、负载均衡、断路器、数据网关等微服务基础...
SpringCloud是中国Java开发者中最受欢迎的微服务框架之一,它提供了构建分布式系统所需的众多工具和服务,如服务发现、负载均衡、断路器、API网关、配置中心等。本压缩包"springcloud-learning-master.zip"是一个...
<artifactId>spring-cloud-starter-stream-rabbit ``` 在 `application.properties` 文件中,我们可以添加以下配置: ```properties spring.rabbitmq.host=47.92.108.148 spring.rabbitmq.port=6672 spring....
良心demo,可以再学习的过程中参考一下,官网的教程是真的需要好好琢磨的,这个可以作为辅助参考,demo采用的版本均为最新版本:springcloud2.0-Finchley.SR1版本,大神提醒我一句学习springcloud不要想的太复杂,...
SpringCloud是中国Java开发者广泛采用的微服务框架,它基于Spring Boot进行快速构建分布式系统中的配置管理、服务发现、断路器、智能路由、微代理、控制总线等核心功能。本压缩包“springcloud-learning-master.zip...
《Spring Cloud Netflix Zuul:一个已经闭源的API网关组件》 在现代微服务架构中,API网关起着至关重要的角色,它作为一个统一的入口,负责路由、安全、监控等多种职责。Spring Cloud Netflix Zuul就是这样一款组件...
Spring Cloud Stream 是一个构建消息驱动微服务的框架,它通过定义消息通道抽象,简化了消息中间件的使用。而RocketMQ是一个开源的消息中间件,它具有高吞吐量、高可用性以及分布式系统的特性。当我们将Spring Cloud...
在IT行业中,微服务架构已经成为了现代应用程序开发的主流方式,Spring Cloud Alibaba是其中的一款强大框架,它提供了众多用于构建分布式系统的工具。本资源“Java-spring cloud alibaba 微服务单点登录及组件配置...
《Spring Cloud 2021在mall-swarm微服务商城系统中的应用详解》 随着互联网技术的飞速发展,微服务架构已经成为构建大型分布式系统的主流选择。mall-swarm便是一套基于Spring Cloud 2021实现的微服务商城系统,它...
《Spring Cloud实战详解:基于spring-cloud-examples-master的深度解析》 在当今的软件开发领域,微服务架构已经成为主流趋势,而Spring Cloud作为Java生态中的微服务治理框架,深受开发者们的喜爱。本篇文章将深入...
SpringCloud作为微服务架构中的热门框架,因其强大的服务治理功能和易用性,被广大开发者广泛采用。本资源“SpringCloud-Learning-master.zip”是程序猿DD关于SpringCloud的学习资料,包含了源码及截至2018年11月10...
最新基于SpringCloud-微服务系统设计方案-精选版整理版.pdf最新基于SpringCloud-微服务系统设计方案-精选版整理版.pdf最新基于SpringCloud-微服务系统设计方案-精选版整理版.pdf最新基于SpringCloud-微服务系统设计...