
应用场景
hdfs中可能保存大量小文件(当然不产生小文件是最佳实践),这样会把namenode的namespace搞的很大。namespace保存着hdfs文件的inode信息,文件越多需要的namenode内存越大,但内存毕竟是有限的(这个是目前hadoop的硬伤)。
下面图片展示了,har文档的结构。har文件是通过mapreduce生成的,job结束后源文件不会删除。
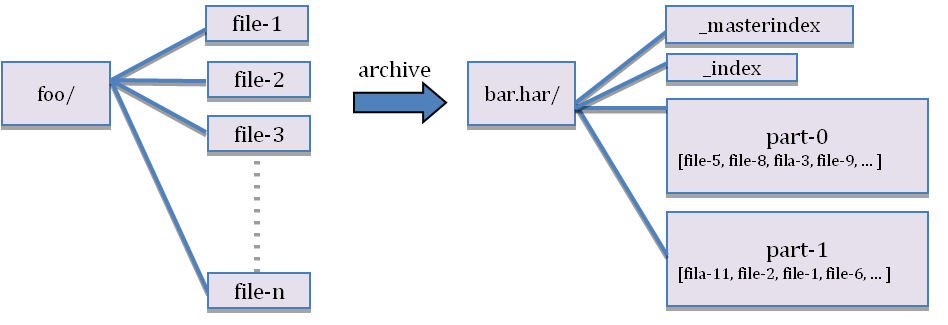
hdfs并不擅长存储小文件,因为每个文件最少占用一个block,每个block的元数据都会在namenode节点占用内存,如果存在这样大量的小文件,它们会吃掉namenode节点的大量内存。
hadoop Archives可以有效的处理以上问题,他可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件,并且可以做为mapreduce任务的输入。
3)、优缺点分析
Hadoop archive 唯一的优势可能就是将众多的小文件打包成一个har 文件了,那这个文件就会按照dfs.block.size 的大小进行分块,因为hdfs为每个块的元数据大小大约为150个字节,如果众多小文件的存在(什么是小文件内,就是小于dfs.block.size 大小的文件,这样每个文件就是一个block)占用大量的namenode 堆内存空间,打成har 文件可以大大降低namenode 守护节点的内存压力。但对于MapReduce 来说起不到任何作用,因为har文件就相当一个目录,仍然不能讲小文件合并到一个split中去,一个小文件一个split ,任然是低效的,这里要说一点<<hadoop 权威指南 中文版>>对这个翻译有问题,上面说可以分配到一个split中去,但是低效的。
删除与恢复:
hdfs文件被归档后,系统不会自动删除源文件,需要手动删除。
hadoop fs -rmr /user/hadoop/xxx/201310/*.*.* 正则表达式来删除的,大家根据自己的需求删除原始文件有人说了,我删了,归档文件存在,源文件不在了,如果要恢复怎么办,其实这也很简单,直接从har 文件中 cp出来就可以了。
hadoop fs -cp /user/xxx/201310/201310.har/* /user/hadoop/xxx/201310/
说明:
hadoop archive -archiveName test_save_foo.har -p /foo/bar a/b/c e/f/g /user/outputdir/以上是将/foo/bar文件夹下面的a/b/c和e/f/g两个目录的内容压缩归档到/user/outputdir/文件夹下,并且源文件不会被更改或者删除。注意,路径a/b/c 和e/f/g都是/foo/bar 的子文件夹
以下写法是错误的。
hadoop archive -archiveName test_save_foo.har -p /foo/bar/a/b/c /foo/bar/e/f/g /user/outputdir/ 报错如下:
source path /foo/bar/a/b/c is not relative to /foo/bar/e/f/g
命令说明:
1)、单个src文件夹
hadoop archive -archiveName test_save_foo.har -p /foo/bar/ 419 /user/outputdir/ 2)、多个src文件夹
hadoop archive -archiveName test_save_foo.har -p /foo/bar/ 419 510 /user/outputdir/ 3)、不指定src path,直接归档parent path(本例为“ /foo/bar/20120116/ ”, “ /user/outputdir ”仍然为输出path),这招是从源码里翻出来的。
hadoop archive -archiveName test_save_foo.har -p /foo/bar/ /user/outputdir/ hadoop archive -archiveName combine.har -p /foo/bar/2011 1[0-2] /user/outputdir/
案例:
1)、将要归档的的hdfs存储目录:
[yz@hai-hadoop06-prd-yz new]$ hadoop dfs -ls /hai_yz/hive/class_room/pomelo_chat_mes/
DEPRECATED: Useof this script toexecute hdfs command is deprecated.
Instead use the hdfs command for it.
Found2 items
drwxr-xr-x - simth_yz supergroup 02017-11-2716:45 /hai_yz/hive/class_room/pomelo_chat_mes/2017-11-26
drwxr-xr-x - simth_yz supergroup 02017-11-2811:46 /hai_yz/hive/class_room/pomelo_chat_mes/2017-11-27
[yz@hai-hadoop06-prd-yz new]$ hadoop dfs -ls /hai_yz/hive/class_room/frontend_dot
DEPRECATED: Useof this script toexecute hdfs command is deprecated.
Instead use the hdfs command for it.
Found1 items
drwxr-xr-x - work supergroup 02018-01-1118:52 /hai_yz/hive/class_room/frontend_dot/2018-01-10
[yaoyingzhe@haibian-hadoop06-prd-yz weike_chat_new]$
2)、进行归档压缩命令:
[yz@hai-hadoop06-prd-yz new]$ hadoop archive -archiveName test.har -p /hai_yz/hive/class_room/ frontend_dot pomelo_chat_mes /haibi/yz/test
3)、查看压缩文件的组成结构:
[yaoyingzhe@haibian-hadoop06-prd-yz weike_chat_new]$ hadoop dfs -ls /haibi/yz/test/test.har
DEPRECATED: Useof this script toexecute hdfs command is deprecated.
Instead use the hdfs command for it.
Found4 items
-rw-r--r-- 3 simth_yz supergroup 0 2018-01-25 11:13 /haibi/yz/test/test.har/_SUCCESS
-rw-r--r-- 5 simth_yz supergroup 3105 2018-01-25 11:13 /haibi/yz/test/test.har/_index
-rw-r--r-- 5 simth_yz supergroup 24 2018-01-25 11:13 /haibi/yz/test/test.har/_masterindex
-rw-r--r-- 3 simth_yz supergroup 18743845 2018-01-25 11:13 /haibi/yz/test/test.har/part-0
[yaoyingzhe@haibian-hadoop06-prd-yz weike_chat_new]$
4)、使用hdfs文件系统查看har文件目录内容
[yz@hai-hadoop06-prd-yz new]$ hadoop dfs -ls har:///haibi/yz/test/test.har/*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Found 1 items
drwxr-xr-x - simth_yz supergroup 0 2018-01-11 18:52 har:///haibi/yz/test/test.har/frontend_dot/2018-01-10
Found 2 items
drwxr-xr-x - simth_yz supergroup 0 2017-11-27 16:45 har:///haibi/yz/test/test.har/pomelo_chat_mes/2017-11-26
drwxr-xr-x - simth_yz supergroup 0 2017-11-28 11:46 har:///haibi/yz/test/test.har/pomelo_chat_mes/2017-11-27
5)、使用hdfs文件系统查看har文件具体的内容
[yz@hai-hadoop06-prd-yz new]$ hadoop dfs -cat har:///haibi/yz/test/test.har/*/*/*
案例:



相关推荐
1. **概述**:Hadoop Archives (HAR) 把多个小文件打包成一个大文件,这个大文件实际上是一个由多个小文件组成的归档文件。这种归档文件可以像普通HDFS文件一样被访问,用户可以通过指定路径透明地读取原文件内容。 ...
HAR文件通过MapReduce任务将小文件打包成一个大的归档文件,从而减少NameNode的内存负担。客户端可以像访问普通文件一样访问HAR文件,但读取效率较低,因为需要额外的索引查找步骤。尽管HAR文件可以作为MapReduce...
Hadoop Archives DistCp GridMix Rumen Scheduler Load Simulator Reference Release Notes API docs Common CHANGES.txt HDFS CHANGES.txt MapReduce CHANGES.txt YARN CHANGES.txt Metrics ...
9. **org.apache.hadoop.tools**: 包含了一些实用工具,比如`HadoopArchives`用于创建Hadoop存档(HAR),`DistCp`用于大规模文件复制,还有`FsShell`提供了命令行工具,如`hadoop fs`,用于执行HDFS操作。...
- **定义**:Hadoop Archives(HAR文件)是一种在Hadoop 0.18.0版本中引入的技术,旨在通过减少HDFS中文件的数量来减轻Namenode的内存负担。 - **创建过程**:通过运行MapReduce任务,将多个小文件打包成一个HAR文件...
比如,通过Hadoop Archives保持HDFS集群平衡,使用distcp工具进行数据的并行复制,以及维护数据完整性的方法。这些内容对于操作和维护Hadoop集群的管理员来说具有很高的参考价值。 综上所述,本章节涉及了Hadoop的...
文章目录OverviewHow to Create an ArchiveHow to Look Up ...一个 Hadoop archive 对应一个文件系统目录。 Hadoop archive 的扩展名是 *.har。Hadoop archive 包含元数据(形式是 _index 和 _masterindx)和数据(p
本文档为Apache官方Hadoop 1.1.0中文文档 文档目录: 1.概述 2.快速入门 3.集群搭建 4.HDFS构架设计 5.HDFS使用指南 6.HDFS权限指南 ...14.Hadoop Archives 15.Hadoop On Demand 另附带 Hadoop API
* -archives <逗号分隔的 archive 列表>:指定要被解压到计算节点上的档案文件的逗号分割的列表。只适用于 job。 Hadoop 命令手册提供了详细的命令参考指南,帮助用户熟悉 Hadoop 命令,让云计算更上一步。
- `-archives <逗号分隔的archive列表>`: 指定要解压到计算节点的归档文件列表。 #### 用户命令 ##### archive 用于创建Hadoop存档文件,其格式通常为`.har`。通过这种方式,可以将多个文件打包成一个单一的归档...
此外,书中还介绍了Hadoop Archives,它是Hadoop用来对文件进行高效打包的技术,适用于存储大量的小文件。 最后,Hadoop权威指南(第三版)还涉及了Hadoop的配置和环境搭建,包括如何在本地运行MapReduce任务以及...
启动Hadoop集群之前,需要格式化HDFS文件系统。 **步骤七:启动Hadoop集群** 使用`sbin/start-dfs.sh`等脚本命令启动Hadoop集群。 ### 暴力卸载流程 当需要彻底清除Hadoop及其相关组件时,可以采取暴力卸载的方式...
[INFO] Apache Hadoop Archives ............................ SUCCESS [2.099s] [INFO] Apache Hadoop Rumen ............................... SUCCESS [6.924s] [INFO] Apache Hadoop Gridmix ......................
[INFO] Apache Hadoop Archives ............................ SUCCESS [2.099s] [INFO] Apache Hadoop Rumen ............................... SUCCESS [6.924s] [INFO] Apache Hadoop Gridmix ......................
它通过分布式文件系统(HDFS)来存储数据,并利用MapReduce编程模型来处理这些数据。对于希望深入了解Hadoop的技术人员来说,获取高质量的学习资源至关重要。本文将详细介绍一系列Hadoop学习资料及其来源,帮助读者...