
转自:https://blog.csdn.net/andyzhaojianhui/article/details/76167965
一.collection
Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库。Solr是以Lucene为基础实现的文本检索应用服务。
SolrCloud是Solr4.0版本开发出的具有开创意义的基于Solr和Zookeeper的分布式搜索方案,或者可以说,SolrCloud是Solr的一种部署方式。Solr可以以多种方式部署,例如单机方式,多机Master-Slaver方式,这些方式部署的Solr不具有SolrCloud的特色功能。
看下面的图例:

特色
SolrCloud有几个特色功能:
-
集中式的配置信息
使用ZK进行集中配置。启动时可以指定把Solr的相关配置文件上传Zookeeper,多机器共用。这些ZK中的配置不会再拿到本地缓存,Solr直接读取ZK中的配置信息。配置文件的变动,所有机器都可以感知到。
另外,Solr的一些任务也是通过ZK作为媒介发布的。目的是为了容错。接收到任务,但在执行任务时崩溃的机器,在重启后,或者集群选出候选者时,可以再次执行这个未完成的任务。
-
自动容错
SolrCloud对索引分片,并对每个分片创建多个Replication。每个Replication都可以对外提供服务。一个Replication挂掉不会影响索引服务。
更强大的是,它还能自动的在其它机器上帮你把失败机器上的索引Replication重建并投入使用。
-
近实时搜索
立即推送式的replication(也支持慢推送)。可以在秒内检索到新加入索引。
-
查询时自动负载均衡
SolrCloud索引的多个Replication可以分布在多台机器上,均衡查询压力。如果查询压力大,可以通过扩展机器,增加Replication来减缓。
-
自动分发的索引和索引分片
发送文档到任何节点,它都会转发到正确节点。
-
事务日志
事务日志确保更新无丢失,即使文档没有索引到磁盘。
其它值得一提的功能有:
-
索引存储在HDFS上
索引的大小通常在G和几十G,上百G的很少,这样的功能或许很难实用。但是,如果你有上亿数据来建索引的话,也是可以考虑一下的。我觉得这个功能最大的好处或许就是和下面这个“通过MR批量创建索引”联合实用。
-
通过MR批量创建索引
有了这个功能,你还担心创建索引慢吗?
-
强大的RESTful API
通常你能想到的管理功能,都可以通过此API方式调用。这样写一些维护和管理脚本就方便多了。
-
优秀的管理界面
主要信息一目了然;可以清晰的以图形化方式看到SolrCloud的部署分布;当然还有不可或缺的Debug功能。
概念
-
Collection:在SolrCloud集群中逻辑意义上的完整的索引。它常常被划分为一个或多个Shard,它们使用相同的Config Set。如果Shard数超过一个,它就是分布式索引,SolrCloud让你通过Collection名称引用它,而不需要关心分布式检索时需要使用的和Shard相关参数。
-
Config Set: Solr Core提供服务必须的一组配置文件。每个config set有一个名字。最小需要包括solrconfig.xml (SolrConfigXml)和schema.xml (SchemaXml),除此之外,依据这两个文件的配置内容,可能还需要包含其它文件。它存储在Zookeeper中。Config sets可以重新上传或者使用upconfig命令更新,使用Solr的启动参数bootstrap_confdir指定可以初始化或更新它。
-
Core: 也就是Solr Core,一个Solr中包含一个或者多个Solr Core,每个Solr Core可以独立提供索引和查询功能,每个Solr Core对应一个索引或者Collection的Shard,Solr Core的提出是为了增加管理灵活性和共用资源。在SolrCloud中有个不同点是它使用的配置是在Zookeeper中的,传统的Solr core的配置文件是在磁盘上的配置目录中。
-
Leader: 赢得选举的Shard replicas。每个Shard有多个Replicas,这几个Replicas需要选举来确定一个Leader。选举可以发生在任何时间,但是通常他们仅在某个Solr实例发生故障时才会触发。当索引documents时,SolrCloud会传递它们到此Shard对应的leader,leader再分发它们到全部Shard的replicas。
-
Replica: Shard的一个拷贝。每个Replica存在于Solr的一个Core中。一个命名为“test”的collection以numShards=1创建,并且指定replicationFactor设置为2,这会产生2个replicas,也就是对应会有2个Core,每个在不同的机器或者Solr实例。一个会被命名为test_shard1_replica1,另一个命名为test_shard1_replica2。它们中的一个会被选举为Leader。
-
Shard: Collection的逻辑分片。每个Shard被化成一个或者多个replicas,通过选举确定哪个是Leader。
-
Zookeeper: Zookeeper提供分布式锁功能,对SolrCloud是必须的。它处理Leader选举。Solr可以以内嵌的Zookeeper运行,但是建议用独立的,并且最好有3个以上的主机。
架构
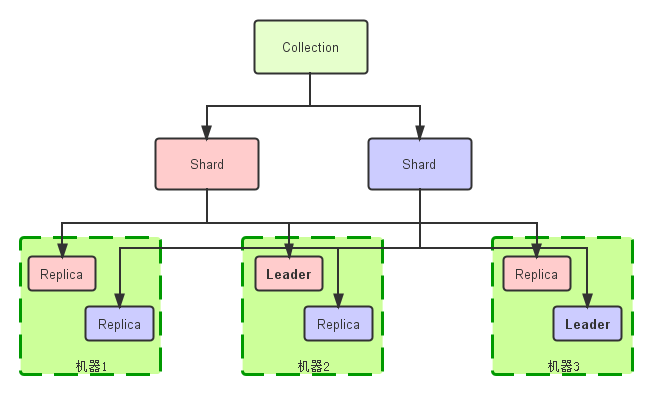
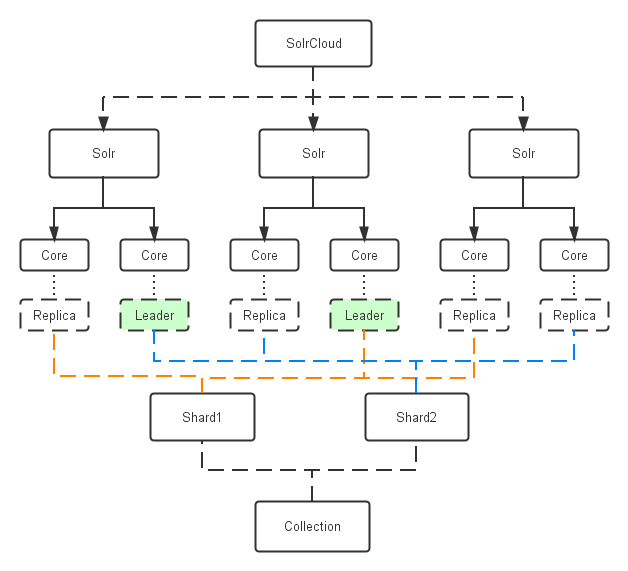



入门
安装配置
前提,你需要先安装好Java,6.0+。 假设我们有5台机器要安装Solr。
-
安装外部zookeeper
Solr默认是用内置的Zookeeper,为了方便管理和维护,建议使用外部Zookeeper。
123456789101112wget http : //apache.dataguru.cn/zookeeper/zookeeper-3.4.3/zookeeper-3.4.3.tar.gztar - zxvf zookeeper - 3.4.3.tar.gzJava的程序解压后就可以运行,不需要安装。修改或者创建配置文件 $ ZOOKEEPER_HOME / conf / zoo . cfg,内容如下:# 注意修改为你的真实路径dataDir = / home / hadoop / zookeeper - 3.4.3 / dataclientPort = 2181# 编号从1开始,solr1-3每个是一台主机,共3个server . 1 = solr1 : 2888 : 3888server . 2 = solr2 : 2888 : 3888server . 3 = solr3 : 2888 : 3888在3台机器上都同样安装。
另外,还需要在$dataDir中配置myid,zookeeper是以此文件确定本机身份。
12345# 注意每台机器上的不一样echo "1" > myid #在solr1上echo "2" > myid #在solr2上echo "3" > myid #在solr3上启动, 需要在3台机器上分别启动
1234$ ZOOKEEPER_HOME / bin / zkServer . sh start# 查看状态,确认启动成功$ ZOOKEEPER_HOME / bin / zkServer . sh status -
Solr安装下载
在5台机上做同样操作
12345678910wget http : //apache.mirrors.pair.com/lucene/solr/4.5.0/solr-4.5.0.tgztar - xzf solr - 4.5.0.tgzcd solr - 4.5.0cp - r example node1cdo node1# 第一条solr机器java - Dbootstrap_confdir = . / solr / collection1 / conf - Dcollection . configName = myconf - DnumShards = 2 - DzkHost = solr1 : 2181 , solr2 : 2181 , solr3 : 2181 - jar start . jar# 其它solr机器java - DzkHost = solr1 : 2181 , solr2 : 2181 , solr3 : 2181 - jar start . jar启动成功后,你可以通过浏览器8983看到solr的Web页面。
-
索引
123cd $ SOLR_HOME / node1 / exampledocsjava - Durl = http : //solr1:8983/solr/collection1/update -jar post.jar ipod_video.xml -
检索
你可以在web界面选定一个Core,然后查询。solr有查询语法文档。
-
如果要想把数据写到HDFS
在$SOLR_HOME/node1/solr/collection1/conf/solrconfig.xml 增加
1234567891011121314< directoryFactory name = "DirectoryFactory" class = "solr.HdfsDirectoryFactory" >< str name = "solr.hdfs.home" > hdfs : //mycluster/solr</str>< bool name = "solr.hdfs.blockcache.enabled" > true < / bool >< int name = "solr.hdfs.blockcache.slab.count" > 1 < / int >< bool name = "solr.hdfs.blockcache.direct.memory.allocation" > true < / bool >< int name = "solr.hdfs.blockcache.blocksperbank" > 16384 < / int >< bool name = "solr.hdfs.blockcache.read.enabled" > true < / bool >< bool name = "solr.hdfs.blockcache.write.enabled" > true < / bool >< bool name = "solr.hdfs.nrtcachingdirectory.enable" > true < / bool >< int name = "solr.hdfs.nrtcachingdirectory.maxmergesizemb" > 16 < / int >< int name = "solr.hdfs.nrtcachingdirectory.maxcachedmb" > 192 < / int >< str name = "solr.hdfs.confdir" > $ { user . home } / local / hadoop / etc / hadoop < / int >< / directoryFactory >重新启动
12java - Dsolr . directoryFactory = HdfsDirectoryFactory - Dsolr . lock . type = hdfs - Dsolr . data . dir = hdfs : //mycluster/solr -Dsolr.updatelog=hdfs://mycluster/solrlog -jar start.jar可以增加如下参数设定直接内存大小,优化Hdfs读写速度。
12- XX : MaxDirectMemorySize = 1g
其它
-
NRT 近实时搜索
Solr的建索引数据是要在提交时写入磁盘的,这是硬提交,确保即便是停电也不会丢失数据;为了提供更实时的检索能力,Solr设定了一种软提交方式。
软提交(soft commit):仅把数据提交到内存,index可见,此时没有写入到磁盘索引文件中。
一个通常的用法是:每1-10分钟自动触发硬提交,每秒钟自动触发软提交。
-
RealTime Get 实时获取
允许通过唯一键查找任何文档的最新版本数据,并且不需要重新打开searcher。这个主要用于把Solr作为NoSQL数据存储服务,而不仅仅是搜索引擎。
Realtime Get当前依赖事务日志,默认是开启的。另外,即便是Soft Commit或者commitwithin,get也能得到真实数据。 注:commitwithin是一种数据提交特性,不是立刻,而是要求在一定时间内提交数据



相关推荐
每个 shard 中应该由 2 台以上设备组成,设备组称为 Replicaset。Replicaset 中有一台设备为主,其它为从。当主服务器宕机后,会自动重启将一台从服务器切换为主服务。 MongoDB shard 是一种强大的数据存储解决方案...
在大型分布式系统中,为了实现高可用性和水平扩展,MongoDB提供了两种关键特性:副本集(Replica Sets)和分片(Sharding)。这篇博客将探讨如何搭建MongoDB的副本集和分片集群。 首先,我们来理解一下MongoDB的...
每个Core对应一个索引或Collection的一个Shard,其配置信息来自Zookeeper。 4. **Leader**:在每个Shard中,当选的Replica作为Leader,负责接收和分发索引操作,确保数据的一致性。 5. **Replica**:Shard的备份,多...
在分布式数据库领域,Shard是一个重要的概念,它涉及到数据库的水平扩展,通过数据分片来解决单个数据库性能瓶颈的问题。本文将深入探讨Shard-源码,揭示其背后的设计思想和技术实现,帮助读者理解如何在实际项目中...
在Android开发中,"android shard分享"涉及到的是应用内实现社交分享功能的技术。"shard"在这里可能是"shared"的误拼,指的是共享或分享。ShareSDK是为Android开发者提供的一种便捷的社交分享解决方案,它整合了众多...
SolrCloud是Solr的分布式解决方案,它引入了新的概念和机制,如Collection、Shard和Replica,以及对Zookeeper的依赖,以实现分布式索引和搜索。SolrCloud能自动处理索引的分片、复制和负载均衡,同时提供故障切换和...
Shard Replica可以配置0-N个只读的Replica,Replica会自动同步并回放主Shard的WAL(write ahead log),从而构建mem table,Replica不flush数据,也不做compaction,而是直接复用主Shard的存算分离数据。 在...
- **定义**:Shard是Collection的逻辑分片,用于水平分割数据,每个Shard内部可以包含一个或多个副本(Replica),其中至少有一个是Leader Replica。 - **作用**:实现数据的负载均衡,提高系统的整体性能。 #### 3...
分片的关键在于分片键(shard key),它决定了数据如何被分配到不同的分片上。MongoDB使用配置服务器(Config Servers)来跟踪分片信息,并使用路由服务器(Mongos)来管理客户端请求和分片间的路由。 在本文中,...
在大型分布式系统中,为了实现水平扩展和数据冗余,MongoDB提供了分片(Sharding)和复制集(Replica Set)的功能。本文将深入探讨如何使用这两种技术来设置MongoDB集群。 **一、MongoDB分片** 1. **分片概念**: ...
MySQL 分库分表查询工具——Shard 在大型的互联网应用中,数据库的性能瓶颈往往成为系统扩展性的关键因素。为了应对高并发、大数据量的挑战,MySQL 数据库的分库分表策略被广泛采用。分库是将数据分散到多个独立的...
碎片Shard 是一种加密工具,可让您将文件拆分为“分片”,因此只有将一定数量的分片重新组合在一起才能恢复原始文件。 警告: Shard 是实验性软件,其安全性尚未得到验证。 请不要依赖 Shard 来获取重要文件。截图...
假设存在一个SolrCloud集群,它包括三个Shard(shard-1、shard-2、shard-3),每个Shard由三个Core组成,其中一个是Leader Core,另外两个是Replica Core。Leader Core是由ZooKeeper选举产生的,并且ZooKeeper还负责...
3. 配置 Replica Sets:配置每个 Shard 的 Replica Sets,例如 Shard1 的 Replica Sets 由 Server1、Server2 和 Server3 组成。 4. 初始化 Replica Set:使用 mongo 连接到其中一个 Mongod 实例,执行 `rs.initiate`...
本资源摘要信息涵盖了Elasticsearch的基础知识、核心概念、安装、启动、使用案例、分布式架构、Shard和Replica机制、分布式原理、容错机制、Document核心元数据等 contenu,为reader提供了一个系统的Elasticsearch...
1. 在 3 台机器上分别运行一个 mongod 实例(称为 mongod shard11,mongod shard12,mongod shard13),组织 Replica Set1,作为 Cluster 的 Shard1。 2. 在 3 台机器上分别运行一个 mongod 实例(称为 mongod shard...
SolrCloud通过引入诸如Shard、Collection等概念实现了高性能、高可用性和可扩展性的搜索解决方案。此外,Solr5.x在独立模式和云模式下的应用方式也为不同规模的应用场景提供了更多的选择。最后,部署过程中可能会...
在Unity3D游戏引擎中,"Polygon_unity3d_多边形shard_"这个主题主要涉及到了如何创建和操作多边形图形。多边形是3D图形的基础元素,通常用于构建复杂的3D模型。在Unity3D中,我们可以使用各种技术来生成和编辑多边形...
"shard解包工具"是一款专门针对iOS平台设计的解包和封包工具,它为开发者和逆向工程师提供了一种高效、便捷的方式来探索和理解应用程序的内部结构。这款工具的强大之处在于它能够帮助我们查看并分析二进制资源、处理...