
摘要: DataWorks基于MaxCompute作为核心的计算、存储引擎,提供了海量数据的离线加工分析、数据挖掘的能力。通过DataWorks,可对数据进行数据传输、数据转换等相关操作,从不同的数据存储引入数据,对数据进行转化处理,最后将数据提取到其他数据系统。
摘要:DataWorks基于MaxCompute作为核心的计算、存储引擎,提供了海量数据的离线加工分析、数据挖掘的能力。通过DataWorks,可对数据进行数据传输、数据转换等相关操作,从不同的数据存储引入数据,对数据进行转化处理,最后将数据提取到其他数据系统。在本文中,阿里巴巴计算平台产品专家祎休为大家介绍了通过DataWorks进行新增调度资源、调度资源管理、配置不同周期任务依赖等最佳实践。
直播视频回看,戳这里!
分享资料下载,戳这里!
更多精彩内容传送门:大数据计算技术共享计划 — MaxCompute技术公开课第二季
大家在使用MaxCompute的时候更多地是在DataWorks上面实现基于ETL加工、调度、配置以及云上数仓的构建任务。本文将与大家分享DataWorks后台强大调度系统的实现逻辑以及一些具体的实现案例,希望能够对大家在做云上数仓相关工作时有所帮助。
本次分享主要分成3个部分,在第一部分是调度的基本介绍,主要为大家分享DataWorks的基本概念,这部分将帮助大家理解后续的依赖关系。第二部分将与大家分享依赖关系的简介,比如自依赖、跨周期依赖以及版本依赖等,以及这些依赖之间会在后台生成什么样的实例等。最后一部分将与大家分享依赖关系的实战,为大家剖析两个案例,并回顾本次分享的内容。总体上而言,通过本次分享希望能够帮助大家区分DataWorks和MaxCompute的不同点,让大家更好地理解DataWorks的定位是MaxCompute之上云上数仓的开发工具。
一、调度基本介绍
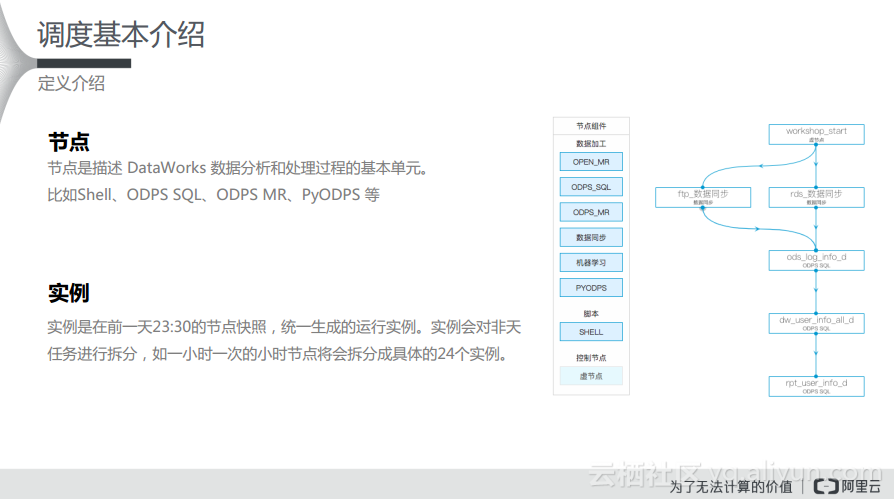
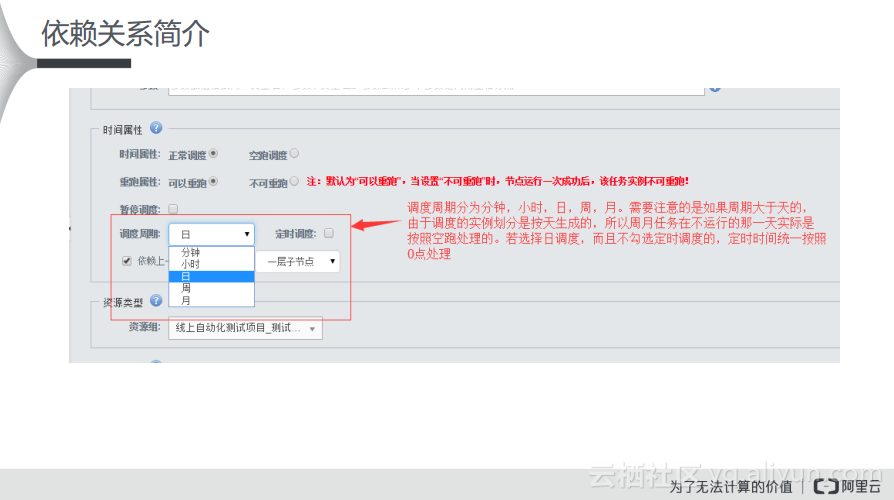
首先需要明确两个概念:节点和实例。如下图左侧所示,节点是描述DataWorks数据分析和处理过程的基本单元,比如Shell、ODPS SQL、ODPS MR、PyODPS等。而在Dataworks后台前一天23:30的节点会生成快照,统一生成的运行实例。对于用户而言,在配置调度上的最大感触就是在23:30分之前提交的调度配置,会在23:30分之后生效,而在23:30分之后配置的一些依赖关系只能够间隔一天再统一地生成实例。实例会对非天任务进行拆分,如一小时一次的小时节点将会拆分成具体的24个实例。
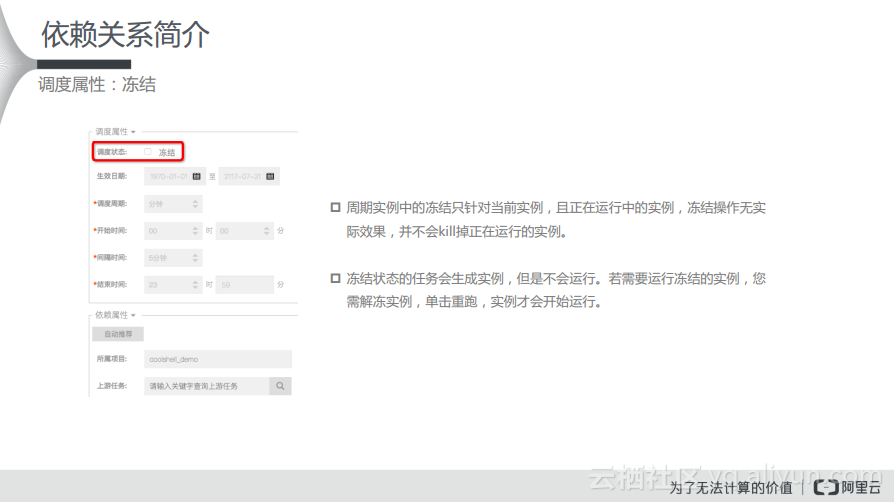
调度属性:冻结
在依赖关系里面,可以通过整体的架构图来看。在WorkFlow里面可以看到,属性里面有一个冻结的概念,周期实例中的冻结只针对当前实例,且正在运行中的实例,冻结操作无实际效果,并不会杀掉正在运行的实例。冻结状态的任务会生成实例,但是不会运行,可以理解为空跑状态。如果需要运行冻结的实例,需要解冻实例,单击重跑,实例才会开始运行。
在公共云上,如果开启了出错机制,那么默认会重试3次,每次间隔2分钟,如果经历了3次重试还是失败,那么就会返回失败状态。
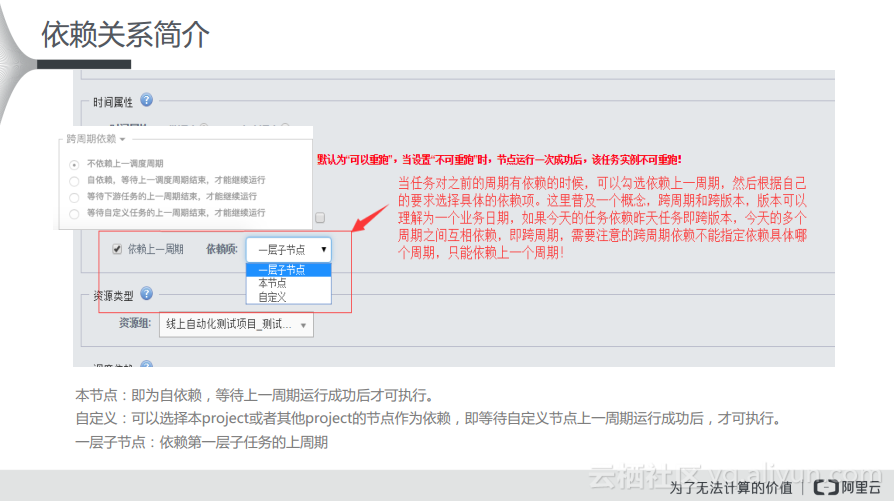
如下图所示,大家可以在DataWorks运维中心里面看到每天生成的运行实例的图。这与开发面板不太一样,如果存在实现的上下游依赖关系,那么就是正常的依赖关系,而有虚线的就是跨周期或者自依赖的关系。从这些可以判断,一些用户配置了自依赖,如果发现今天的任务没有跑起来,就需要去追溯昨天的任务是否运行正常,如果昨天的任务也没有正常运行就需要继续向上追溯。
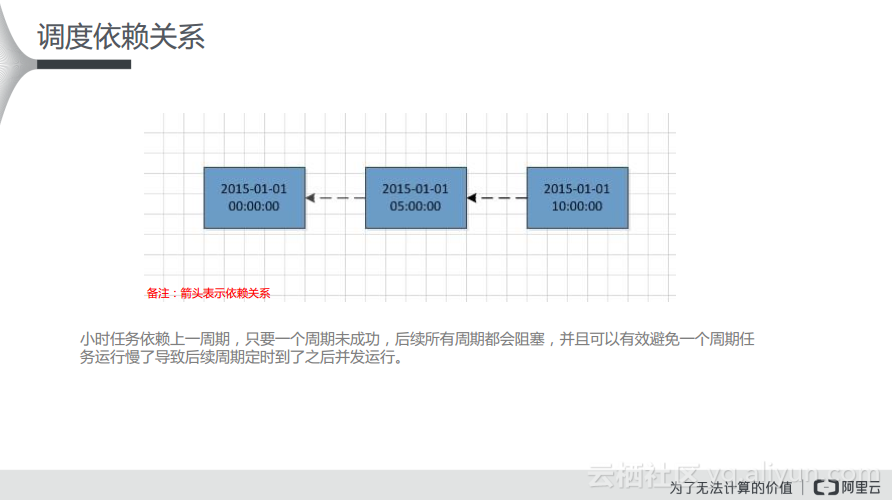
调度依赖关系
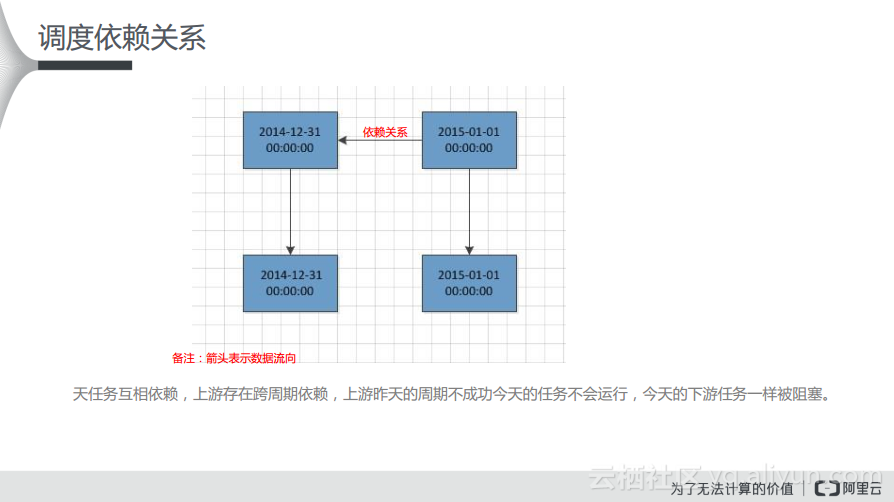
如下所示的整页图里面是天任务的相互依赖,箭头表示的数据流向。如果根据下图将箭头反方向调整就可以理解成依赖关系,也就是下游会依赖上游。现在箭头则表示数据的流向,假设现在有两个天调度的任务,两个都是凌晨开始运行的,那么当上游任务成功运行了,下游才会运行起来,而且如果上游任务没有运行完成,下游任务即使定时时间到了也无法运行。
在下图中可以看出,天任务可以相互依赖,上游存在跨周期依赖。如果下游任务想要成功执行,就需要上游任务成功运行作为前提。下图中可以看出,2014年和2015年的两个实例分别存在相互依赖关系,上游的任务会依赖上一周期的一层子节点,如果上游昨天的任务未成功运行,那么就会阻塞昨天的任务和今天的下游任务。
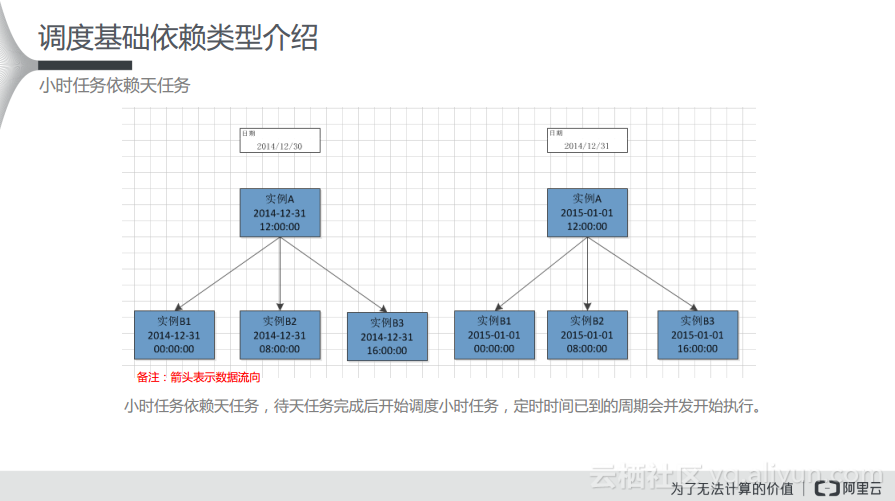
(1) 小时任务依赖天任务
从下图中可以看出,是小时任务依赖天任务。在左侧中是2014年12月31日的情况,实例B1、B2和B3都会依赖实例A,实例A是12点运行,而实例B1、B2以及B3都是小时任务,所以需要依赖天任务,需要等待天任务完成之后才能运行。而当定时的时间到了,这些任务才会并发地执行,在这里就是上游实例A成功运行了,下游的B1、B2和B3才能同时并发地执行。
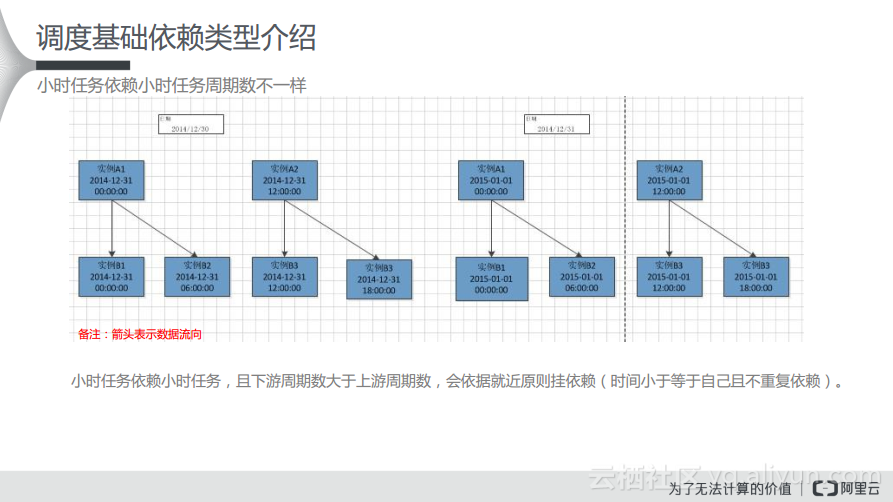
实例A是实例B1、B2和B3的下游节点,也就是说实例A依赖于上游的几个小时任务节点。这样一来,天任务就需要等待小时任务的所有周期都完成了才能去调度这样的天任务,所以如果按照每8个小时跑一个小时任务,这样就能够拆分成3个实例,只有当这些小时实例都成功运行之后,下游的天任务才能在时间已经到了的情况下运行起来。
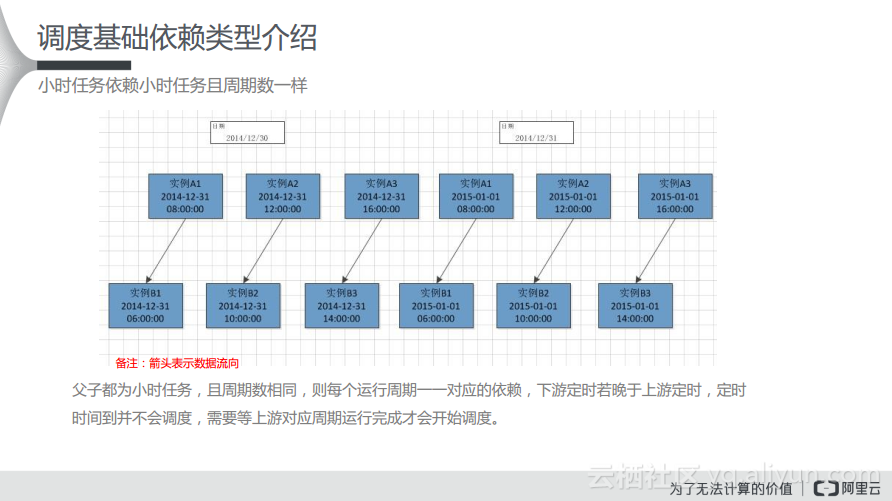
比如上游节点是小时任务,下游的节点也是小时任务,当这两个小时任务都是按照每几个小时生成时,其生成的实例数是一样的,在这种情况下可以理解为父子节点都是小时任务,同时其周期数也是一样的。而每一个运行的实例都会形成一个一一对应的关系。当然,若下游的定时晚于上游的定时,在下游定时时间到了的时候也不能调度,需要等待上游对应的周期完成之后才能开始调度。
在这种情况下,可能上游按照12个小时运行一次,那么一天可能会生成两个实例,下游则可能每天按照6个小时,那么这个时候可能生成6个实例。其实,可以从图中看出其是如何依赖的关系,小时任务依赖小时任务,如果其周期数不同,如果下游周期数大于上有的周期数,则会依据就近原则挂依赖,也就是时间小于或者等于自己且不重复的依赖。
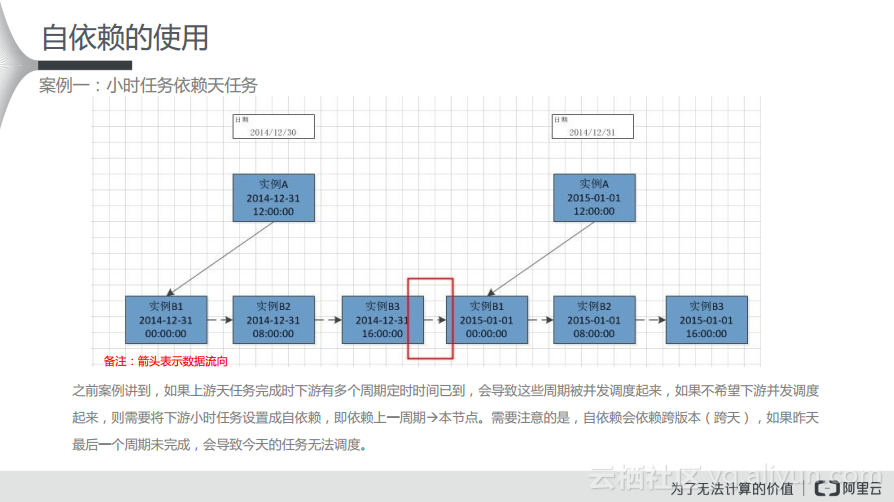
案例1:小时任务依赖天任务
在如下图所示的任务依赖中,箭头表示了数据的流向。之前案例也讲到,如果上游天任务完成时下游有多个周期定时时间已到,会导致这些周期被并发调度起来,如果不希望下游并发调度起来,则需要将下游小时任务设置成自依赖,即依赖上一周期,也就是本节点,这样形成一个自依赖。需要注意的是,自依赖会依赖跨版本(跨天),如果昨天最后一个周期未完成,会导致今天的任务无法调度。如下图所示,实例A属于天任务,而下游实例B则是每8小时执行一次的小时任务,实例B之间则会有一些虚线的依赖关系。比如实例A在12点运行成功了,那么实例B在运行的时候需要先去判断实例A的状态与自己的定时时间,生成完之后才会依次执行B2、B3,而当出现了跨天的情况,比如执行到B4的时候,需要去判断昨天最后一个实例的状态。
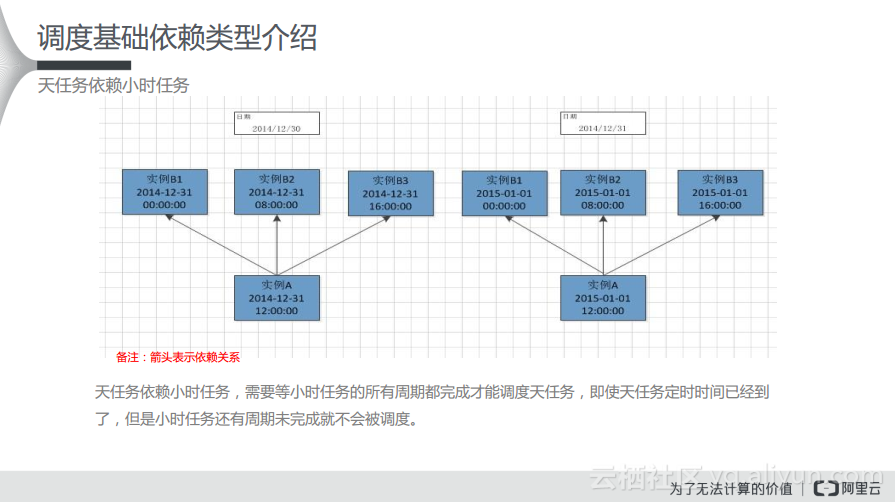
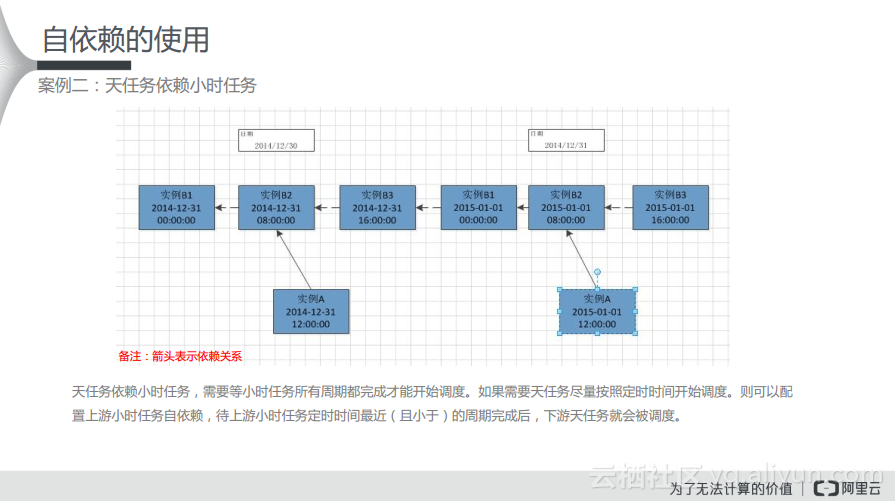
在下图里面,箭头表示依赖关系。如果天任务依赖小时任务,需要等待小时任务的所有周期都完成了才能开始调度。比如在上游按照每小时运行一次的数据,等所有数据都落入到对应的分区之后,再按照一定的数据汇总24小时的数据。如果需要天任务尽量按照定时时间开始调度。则可以配置上游小时任务自依赖,待上游小时任务定时时间最近(且小于)的周期完成后,下游天任务就会被调度。
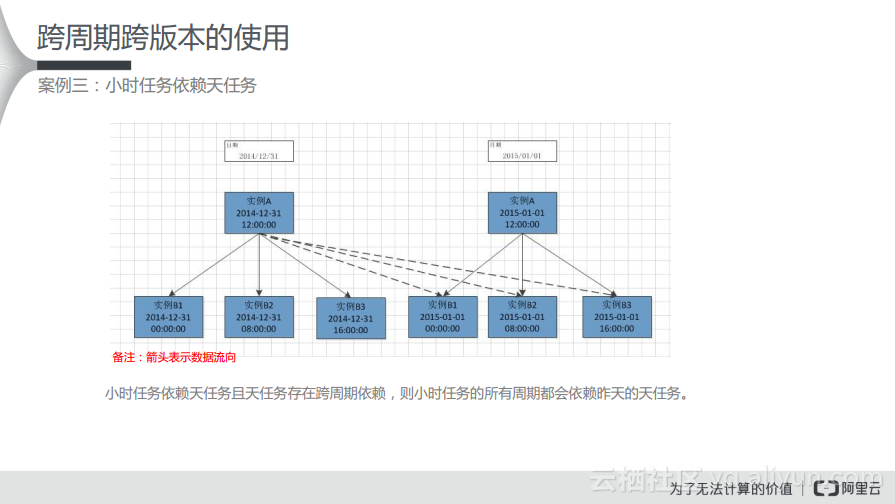
小时任务依赖天任务且天任务存在跨周期依赖,则小时任务的所有周期都会依赖昨天的天任务。
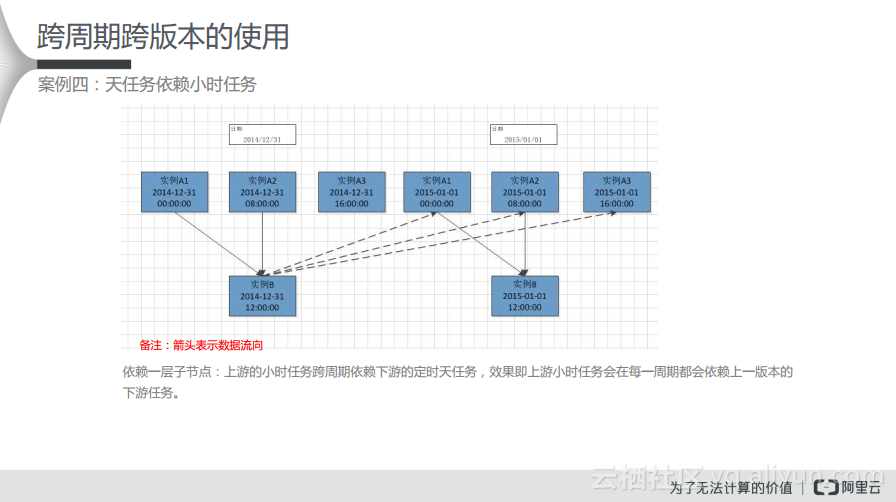
对于这样的情况需要配置依赖一层子节点,比如上游的小时任务跨周期依赖下游的定时天任务,效果即上游小时任务会在每一周期都会依赖上一版本的下游任务。
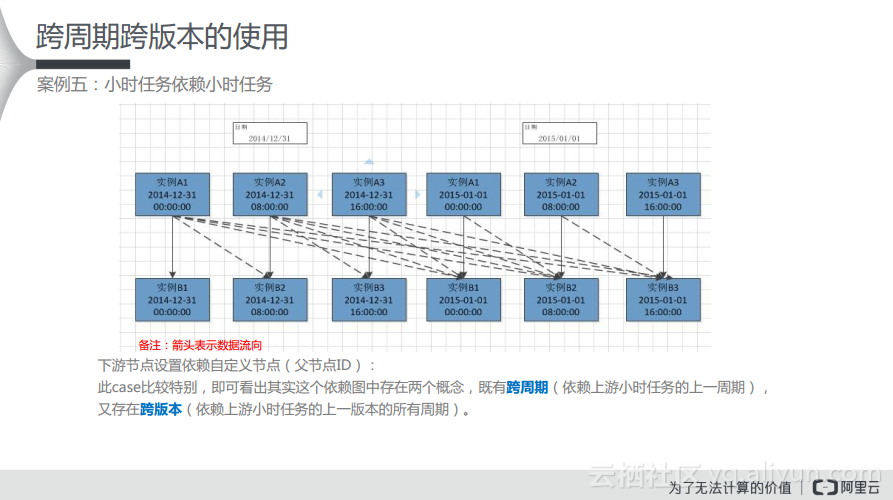
这种情况比较复杂,图中的实线表示依赖关系,虚线则表示自依赖关系。为了实现这样的依赖关系,需要在下游节点设置依赖自定义节点(父节点ID)。在这个case比较特别,即可看出其实这个依赖图中存在两个概念,既有跨周期(依赖上游小时任务的上一周期),又存在跨版本(依赖上游小时任务的上一版本的所有周期)。
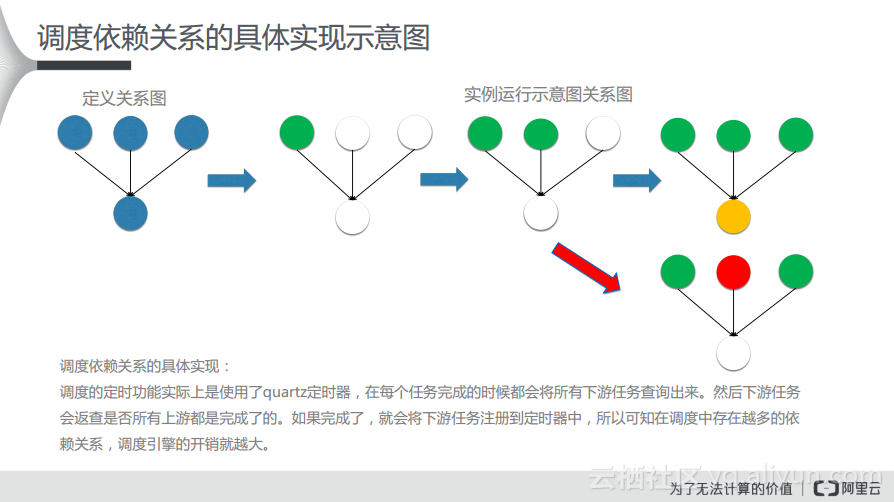
首先对于定义关系图而言,上游三个节点,下游一个节点这样的情况而言,在每天23:30分会生成一个节点快照,生成一个可运行的实例。当实例运行的时候,会依次运行上游的各个节点,当各个节点全部运行成功了之后,下游节点就会判断是否已经到了自己能够执行的时间,如果符合执行条件就会去执行。而如果上游任何一个节点执行失败了,就会导致下游节点一直处于等待状态。
(1) 针对跨周期跨版本依赖的优化
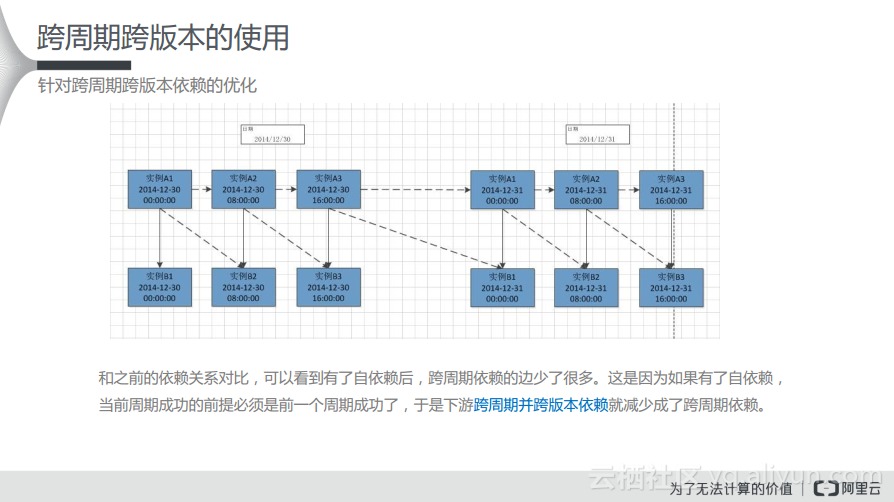
和之前的依赖关系对比,可以看到有了自依赖后,跨周期依赖的边少了很多。这是因为如果有了自依赖,当前周期成功的前提必须是前一个周期成功了,于是下游跨周期并跨版本依赖就减少成了跨周期依赖。
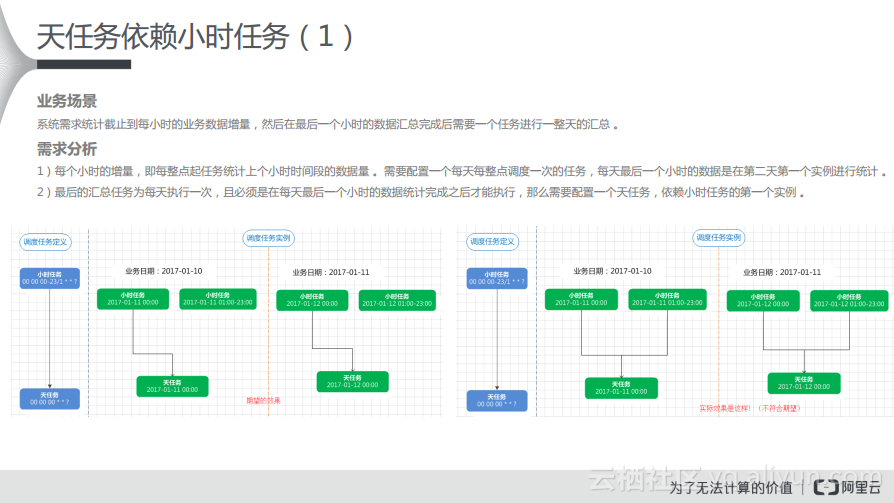
在天任务依赖小时任务的场景下,系统需求统计截止到每小时的业务数据增量,然后在最后一个小时的数据汇总完成后,需要一个任务进行一整天的汇总。对于这样的场景进行需求分析得到以下两点:
1)每个小时的增量,即每整点起任务统计上个小时时间段的数据量。需要配置一个每天每整点调度一次的任务,每天最后一个小时的数据是在第二天第一个实例进行统计。
2)最后的汇总任务为每天执行一次,且必须是在每天最后一个小时的数据统计完成之后才能执行,那么需要配置一个天任务,依赖小时任务的第一个实例。
如下图中左侧所示,可能期望的结果就是在调度任务的定义时,上游是小时任务,每个小时运行一次,下游是天任务,每天凌晨开始运行,就形成了这样的依赖关系。而对于绿色的图而言,对应的任务实例的状况,只有当每天最后一个小时任务处理完成之后,才会去处理天任务。而当真正按照这种依赖关系进行配置,直接挂靠这种依赖关系,在调度系统中会生成右侧所示的实例,但是这是不符合预期的。
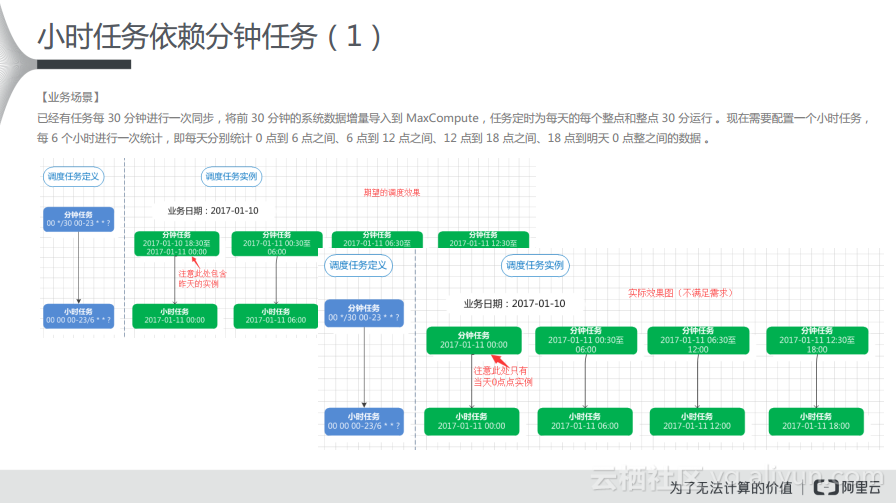
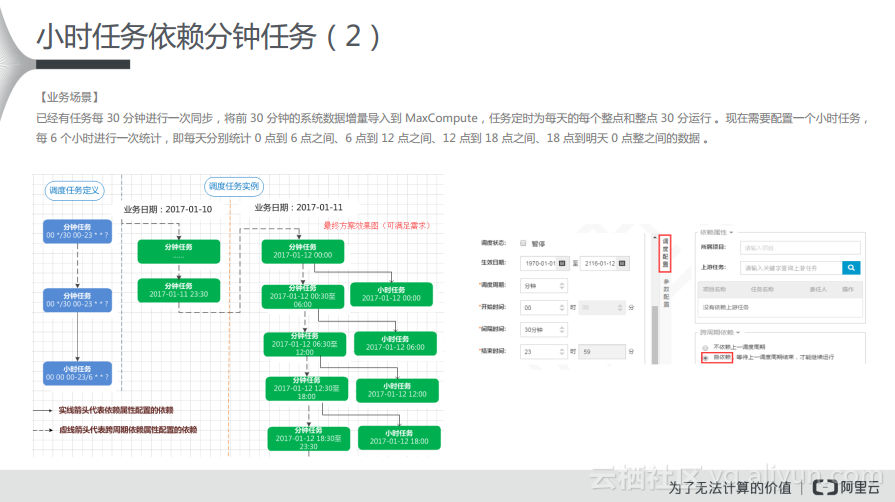
对于小时任务依赖分钟任务而言,有这样的一种业务场景:已经有任务每30分钟进行一次同步,将前30分钟的系统数据增量导入到MaxCompute,任务定时为每天的每个整点和整点30分运行。现在需要配置一个小时任务,每6个小时进行一次统计,即每天分别统计0点到6点之间、6点到12点之间、12点到18点之间、18点到明天0点整之间的数据。从分析来看,我们期望的效果就是如下图中左侧所示,上游的分钟任务,每隔30分钟调度一次,下游是小时任务,每隔6个小时调度一次,那么对应的实例里面就会产生对应的依赖关系。
直播视频回看,戳这里!
分享资料下载,戳这里!
更多精彩内容传送门:大数据计算技术共享计划 — MaxCompute技术公开课第二季
以下内容根据演讲视频及PPT整理而成。
大家在使用MaxCompute的时候更多地是在DataWorks上面实现基于ETL加工、调度、配置以及云上数仓的构建任务。本文将与大家分享DataWorks后台强大调度系统的实现逻辑以及一些具体的实现案例,希望能够对大家在做云上数仓相关工作时有所帮助。
本次分享主要分成3个部分,在第一部分是调度的基本介绍,主要为大家分享DataWorks的基本概念,这部分将帮助大家理解后续的依赖关系。第二部分将与大家分享依赖关系的简介,比如自依赖、跨周期依赖以及版本依赖等,以及这些依赖之间会在后台生成什么样的实例等。最后一部分将与大家分享依赖关系的实战,为大家剖析两个案例,并回顾本次分享的内容。总体上而言,通过本次分享希望能够帮助大家区分DataWorks和MaxCompute的不同点,让大家更好地理解DataWorks的定位是MaxCompute之上云上数仓的开发工具。
一、调度基本介绍
首先需要明确两个概念:节点和实例。如下图左侧所示,节点是描述DataWorks数据分析和处理过程的基本单元,比如Shell、ODPS SQL、ODPS MR、PyODPS等。而在Dataworks后台前一天23:30的节点会生成快照,统一生成的运行实例。对于用户而言,在配置调度上的最大感触就是在23:30分之前提交的调度配置,会在23:30分之后生效,而在23:30分之后配置的一些依赖关系只能够间隔一天再统一地生成实例。实例会对非天任务进行拆分,如一小时一次的小时节点将会拆分成具体的24个实例。

调度属性:冻结
在依赖关系里面,可以通过整体的架构图来看。在WorkFlow里面可以看到,属性里面有一个冻结的概念,周期实例中的冻结只针对当前实例,且正在运行中的实例,冻结操作无实际效果,并不会杀掉正在运行的实例。冻结状态的任务会生成实例,但是不会运行,可以理解为空跑状态。如果需要运行冻结的实例,需要解冻实例,单击重跑,实例才会开始运行。
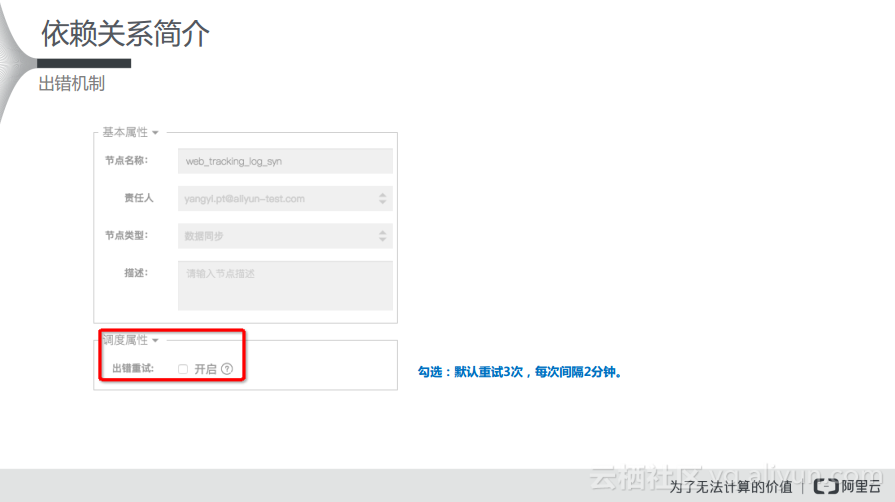
在公共云上,如果开启了出错机制,那么默认会重试3次,每次间隔2分钟,如果经历了3次重试还是失败,那么就会返回失败状态。
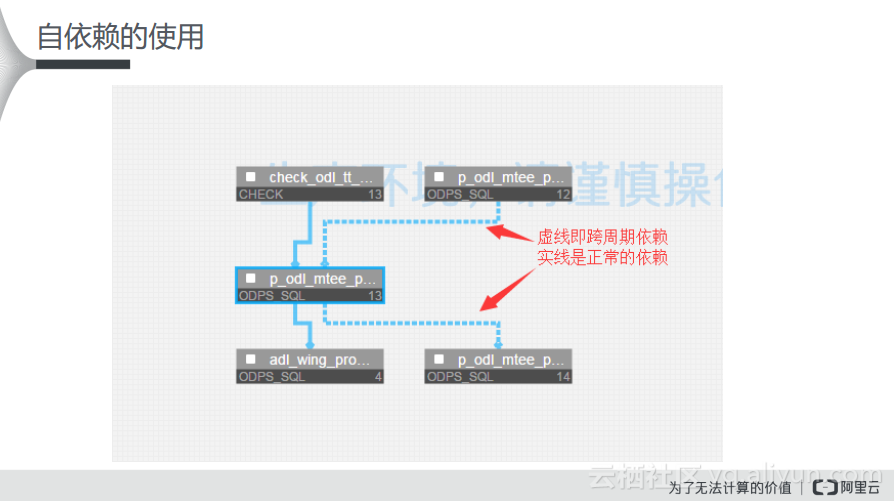
如下图所示,大家可以在DataWorks运维中心里面看到每天生成的运行实例的图。这与开发面板不太一样,如果存在实现的上下游依赖关系,那么就是正常的依赖关系,而有虚线的就是跨周期或者自依赖的关系。从这些可以判断,一些用户配置了自依赖,如果发现今天的任务没有跑起来,就需要去追溯昨天的任务是否运行正常,如果昨天的任务也没有正常运行就需要继续向上追溯。
调度依赖关系
如下所示的整页图里面是天任务的相互依赖,箭头表示的数据流向。如果根据下图将箭头反方向调整就可以理解成依赖关系,也就是下游会依赖上游。现在箭头则表示数据的流向,假设现在有两个天调度的任务,两个都是凌晨开始运行的,那么当上游任务成功运行了,下游才会运行起来,而且如果上游任务没有运行完成,下游任务即使定时时间到了也无法运行。
在下图中可以看出,天任务可以相互依赖,上游存在跨周期依赖。如果下游任务想要成功执行,就需要上游任务成功运行作为前提。下图中可以看出,2014年和2015年的两个实例分别存在相互依赖关系,上游的任务会依赖上一周期的一层子节点,如果上游昨天的任务未成功运行,那么就会阻塞昨天的任务和今天的下游任务。
(1) 小时任务依赖天任务
从下图中可以看出,是小时任务依赖天任务。在左侧中是2014年12月31日的情况,实例B1、B2和B3都会依赖实例A,实例A是12点运行,而实例B1、B2以及B3都是小时任务,所以需要依赖天任务,需要等待天任务完成之后才能运行。而当定时的时间到了,这些任务才会并发地执行,在这里就是上游实例A成功运行了,下游的B1、B2和B3才能同时并发地执行。
实例A是实例B1、B2和B3的下游节点,也就是说实例A依赖于上游的几个小时任务节点。这样一来,天任务就需要等待小时任务的所有周期都完成了才能去调度这样的天任务,所以如果按照每8个小时跑一个小时任务,这样就能够拆分成3个实例,只有当这些小时实例都成功运行之后,下游的天任务才能在时间已经到了的情况下运行起来。
比如上游节点是小时任务,下游的节点也是小时任务,当这两个小时任务都是按照每几个小时生成时,其生成的实例数是一样的,在这种情况下可以理解为父子节点都是小时任务,同时其周期数也是一样的。而每一个运行的实例都会形成一个一一对应的关系。当然,若下游的定时晚于上游的定时,在下游定时时间到了的时候也不能调度,需要等待上游对应的周期完成之后才能开始调度。
在这种情况下,可能上游按照12个小时运行一次,那么一天可能会生成两个实例,下游则可能每天按照6个小时,那么这个时候可能生成6个实例。其实,可以从图中看出其是如何依赖的关系,小时任务依赖小时任务,如果其周期数不同,如果下游周期数大于上有的周期数,则会依据就近原则挂依赖,也就是时间小于或者等于自己且不重复的依赖。
案例1:小时任务依赖天任务
在如下图所示的任务依赖中,箭头表示了数据的流向。之前案例也讲到,如果上游天任务完成时下游有多个周期定时时间已到,会导致这些周期被并发调度起来,如果不希望下游并发调度起来,则需要将下游小时任务设置成自依赖,即依赖上一周期,也就是本节点,这样形成一个自依赖。需要注意的是,自依赖会依赖跨版本(跨天),如果昨天最后一个周期未完成,会导致今天的任务无法调度。如下图所示,实例A属于天任务,而下游实例B则是每8小时执行一次的小时任务,实例B之间则会有一些虚线的依赖关系。比如实例A在12点运行成功了,那么实例B在运行的时候需要先去判断实例A的状态与自己的定时时间,生成完之后才会依次执行B2、B3,而当出现了跨天的情况,比如执行到B4的时候,需要去判断昨天最后一个实例的状态。
在下图里面,箭头表示依赖关系。如果天任务依赖小时任务,需要等待小时任务的所有周期都完成了才能开始调度。比如在上游按照每小时运行一次的数据,等所有数据都落入到对应的分区之后,再按照一定的数据汇总24小时的数据。如果需要天任务尽量按照定时时间开始调度。则可以配置上游小时任务自依赖,待上游小时任务定时时间最近(且小于)的周期完成后,下游天任务就会被调度。
小时任务依赖天任务且天任务存在跨周期依赖,则小时任务的所有周期都会依赖昨天的天任务。
对于这样的情况需要配置依赖一层子节点,比如上游的小时任务跨周期依赖下游的定时天任务,效果即上游小时任务会在每一周期都会依赖上一版本的下游任务。
这种情况比较复杂,图中的实线表示依赖关系,虚线则表示自依赖关系。为了实现这样的依赖关系,需要在下游节点设置依赖自定义节点(父节点ID)。在这个case比较特别,即可看出其实这个依赖图中存在两个概念,既有跨周期(依赖上游小时任务的上一周期),又存在跨版本(依赖上游小时任务的上一版本的所有周期)。
首先对于定义关系图而言,上游三个节点,下游一个节点这样的情况而言,在每天23:30分会生成一个节点快照,生成一个可运行的实例。当实例运行的时候,会依次运行上游的各个节点,当各个节点全部运行成功了之后,下游节点就会判断是否已经到了自己能够执行的时间,如果符合执行条件就会去执行。而如果上游任何一个节点执行失败了,就会导致下游节点一直处于等待状态。
(1) 针对跨周期跨版本依赖的优化
和之前的依赖关系对比,可以看到有了自依赖后,跨周期依赖的边少了很多。这是因为如果有了自依赖,当前周期成功的前提必须是前一个周期成功了,于是下游跨周期并跨版本依赖就减少成了跨周期依赖。
在天任务依赖小时任务的场景下,系统需求统计截止到每小时的业务数据增量,然后在最后一个小时的数据汇总完成后,需要一个任务进行一整天的汇总。对于这样的场景进行需求分析得到以下两点:
1)每个小时的增量,即每整点起任务统计上个小时时间段的数据量。需要配置一个每天每整点调度一次的任务,每天最后一个小时的数据是在第二天第一个实例进行统计。
2)最后的汇总任务为每天执行一次,且必须是在每天最后一个小时的数据统计完成之后才能执行,那么需要配置一个天任务,依赖小时任务的第一个实例。
如下图中左侧所示,可能期望的结果就是在调度任务的定义时,上游是小时任务,每个小时运行一次,下游是天任务,每天凌晨开始运行,就形成了这样的依赖关系。而对于绿色的图而言,对应的任务实例的状况,只有当每天最后一个小时任务处理完成之后,才会去处理天任务。而当真正按照这种依赖关系进行配置,直接挂靠这种依赖关系,在调度系统中会生成右侧所示的实例,但是这是不符合预期的。

对于小时任务依赖分钟任务而言,有这样的一种业务场景:已经有任务每30分钟进行一次同步,将前30分钟的系统数据增量导入到MaxCompute,任务定时为每天的每个整点和整点30分运行。现在需要配置一个小时任务,每6个小时进行一次统计,即每天分别统计0点到6点之间、6点到12点之间、12点到18点之间、18点到明天0点整之间的数据。从分析来看,我们期望的效果就是如下图中左侧所示,上游的分钟任务,每隔30分钟调度一次,下游是小时任务,每隔6个小时调度一次,那么对应的实例里面就会产生对应的依赖关系。
本文为云栖社区原创内容,未经允许不得转载



相关推荐
8月14日MaxCompute直播课件下载。 了解更多MaxCompute产品和技术相关内容,可扫描二维码加入“MaxCompute开发者交流”钉钉群。
### DataWorks调度最佳实践知识点详解 #### DataWorks与MaxCompute简介 - **DataWorks**:阿里云提供的数据研发平台,支持大数据开发、调度、运维、治理等全链路功能,适用于构建云上的数据仓库。 - **MaxCompute**...
"DataWorks调度任务迁移概述" DataWorks调度任务迁移是指将DataWorks工作空间中的调度任务迁移到新的环境中,以便更好地管理和维护这些任务。该技术创新为DataWorks工作空间迁移提供了强大的解决方案。 数据备份是...
根据提供的文件信息,我们可以深入探讨Spring框架中的时间调度配置及其应用。Spring框架为开发者提供了强大的时间任务调度功能,尤其在企业级应用中极为常见。本文将详细介绍如何利用Spring进行时间调度配置,包括...
任务调度、代码审查、日志查看等功能促进了团队间的有效沟通和协作。 7. 实时计算与大数据处理: DataWorks集成了Flink、Spark等实时计算引擎,支持实时数据处理和流计算,满足低延迟数据需求。同时,对于大规模...
《Spring任务调度配置详解:Spring+Quartz的整合应用》 在Java开发中,任务调度是不可或缺的一部分,Spring框架提供了与Quartz集成的能力,使得我们可以方便地管理和执行定时任务。本文将详细介绍如何通过Spring和...
**企业级调度器LVS实战详解** Linux Virtual Server(LVS)是Linux内核中集成的一种负载均衡技术,由章文卓博士在1998年开发,旨在为大型网络服务提供高可用性和高性能的解决方案。LVS通过将流量分发到多个服务器,...
为了解决这一问题,可以采取多个IO调度配置的方法。 在描述的场景中,力控系统需要同时处理Anco PLC(通过TCP/IP连接的4个设备)、Siemens PLC(通过MPI方式连接的4个设备)以及OPTO22模块(通过串口方式连接的5个...
"shizi.rar_K._shizi_任务调度_最佳调度算法"这个压缩包文件标题和描述涉及的核心概念是任务调度和最佳调度算法,特别是针对K个可并行工作的机器的情况。我们来详细探讨这些知识点。 首先,任务调度(Task ...
2018重庆云栖大会与重庆智博会强强联合,继续以...在重庆云栖大会期间,嘉宾曾福华做了《百T级CDN智能流量调度系统的实战分享》的主题分享,对智能化离线资源规划、重新认识LDNS、精准实时流量控制等内容展开了讨论
最佳调度问题
曙光作业管理-调度系统安装配置手册 本文将以应用于实际案例(南航理学院、复旦大学物理系、宁波气象局)中的作业调度系统为例,简单介绍一下免费开源又好用的Torque+Maui如何在曙光服务器上进行安装和配置,以及...
最佳调度问题的回溯算法实现:有n个任务由k个可并行工作的机器完成。完成任务i需要的时间为Ti。找出完成这n个任务的最佳调度,使得完成全部任务的时间最少。用文件导入每个任务所需要的时间Ti。(至少10个任务)使用...
光热电站考虑N-K安全约束的风电、光伏电力系统优化调度模型研究与实践(仿真测试表现良好),光热电站下的风电-光伏电力系统N-k安全优化调度策略与实战案例解析:弃风弃光问题及调度策略对比,含风电-光伏-光热电站...
基于两阶段鲁棒优化算法的多微网联合调度与容量配置:考虑环境效益与固定储能的综合优化,MATLAB代码:基于两阶段鲁棒优化算法的多微网联合调度及容量配置 关键词:多微网 优化调度 容量配置 两阶段鲁棒 仿真平台:...
同时,理解Quartz的API和配置文件是关键,这将帮助你更有效地利用这个强大的调度框架。 总之,Quartz为Java开发者提供了一个灵活且功能强大的任务调度解决方案,它能够适应各种复杂的需求。通过深入了解并实践...
Matlab在综合能源系统优化调度中的实战:涵盖热电厂、储能、风电光伏等机组的Cplex求解方案,Matlab,风光火储网综合能源系统优化调度。 包括热电厂热电机组(11台,电出力上下限受热出力的影响)、热电厂纯凝机组(4台...
"基于MATLAB优化策略的光储电站经济性与调度模式相关储能容量最佳配置解析",MATLAB代码:多种调度模式下的光储电站经济性最优储能容量配置分析 关键词:光储电站 优化配置 经济性分析 参考文档:《多种调度模式下的...
MILP)算法,以全生命周期内经济成本最低为优化目标,考虑物料及能量平衡约束,实现典型周内各设备功率的最优逐时调度优化,并得到最佳综合能源系统中碳捕集+电 制氢+甲烧化+氢存储+CO2存储的容量配置结果。...
spring中的任务调度器配置方法 spring中的任务调度器配置方法 spring中的任务调度器配置方法